
I would like to create a «reduced» version of an Excel (xlsx) spreadsheet (i.e. by removing some rows according to some criterion), and I’d like to know if this can be done with openpyxl.
In (pythonish) pseudo-code, what I want to do would look something like:
wb = openpyxl.reader.excel.load_workbook('/path/to/workbook.xlsx')
sh = wb.get_sheet_by_name('someworksheet')
# weed out the rows of sh according to somecriterion
sh.rows[:] = [r for r in sh.rows if somecriterion(r)]
# save the workbook, with the weeded-out sheet
wb.save('/path/to/workbook_reduced.xlsx')
Can something like this be done with openpyxl, and if so, how?
![]()
Drise
4,2845 gold badges40 silver badges66 bronze badges
asked Feb 15, 2013 at 23:18
![]()
2018 update: I was searching how to delete a row today and found that the functionality is added in openpyxl 2.5.0-b2. Just tried and it worked perfectly.
Here’s the link where I found the answer: https://bitbucket.org/openpyxl/openpyxl/issues/964/delete_rows-does-not-work-on-deleting
And here’s the syntax to delete one row:
ws.delete_rows(index, 1)
where:
‘ws’ is the worksheet,
‘index’ is the row number, and
‘1’ is the number of rows to delete.
There’s also the ability to delete columns, but I haven’t tried that.
answered Mar 19, 2018 at 18:41
![]()
jhughsjhughs
3613 silver badges5 bronze badges
4
Internally openpyxl does not seem to have a concept of ‘rows’ it works with cells and keeps track of the dimensions and if you use Worksheet.rows it calculates a 2D array of cells from that. You can mutate the array, but it doesn’t change the Worksheet.
If you want to do this within the Worksheet, you need to copy the values from the old position to the new position, and set the value of the cells that are no longer needed to '' or None and call Worksheet.garbage_collect().
If your dataset is small and of uniform nature (all strings e.g.), you might be better of copying the relevant cell (content) to a new worksheet, remove the old one and set the title of the new one to the title of the just deleted one.
The most elegant thing to do, IMHO, would be to extend Worksheet or a subclass with a delete_rows method. I would implement such a method by changing the coordinates of its Cells in place. But this could break if openpyxl internals change.
![]()
answered Mar 19, 2013 at 7:29
![]()
AnthonAnthon
67k29 gold badges183 silver badges239 bronze badges
2
I have a really large excel file and i need to delete about 20,000 rows, contingent on meeting a simple condition and excel won’t let me delete such a complex range when using a filter. The condition is:
If the first column contains the value, X, then I need to be able to delete the entire row.
I’m trying to automate this using python and xlwt, but am not quite sure where to start. Seeking some code snippits to get me started…
Grateful for any help that’s out there!
asked Apr 12, 2011 at 12:19
![]()
Don’t delete. Just copy what you need.
- read the original file
- open a new file
- iterate over rows of the original file (if the first column of the row does not contain the value X, add this row to the new file)
- close both files
- rename the new file into the original file
answered Apr 12, 2011 at 12:31
![]()
eumiroeumiro
204k34 gold badges297 silver badges261 bronze badges
1
I like using COM objects for this kind of fun:
import win32com.client
from win32com.client import constants
f = r"h:PythonExamplestest.xls"
DELETE_THIS = "X"
exc = win32com.client.gencache.EnsureDispatch("Excel.Application")
exc.Visible = 1
exc.Workbooks.Open(Filename=f)
row = 1
while True:
exc.Range("B%d" % row).Select()
data = exc.ActiveCell.FormulaR1C1
exc.Range("A%d" % row).Select()
condition = exc.ActiveCell.FormulaR1C1
if data == '':
break
elif condition == DELETE_THIS:
exc.Rows("%d:%d" % (row, row)).Select()
exc.Selection.Delete(Shift=constants.xlUp)
else:
row += 1
# Before
#
# a
# b
# X c
# d
# e
# X d
# g
#
# After
#
# a
# b
# d
# e
# g
I usually record snippets of Excel macros and glue them together with Python as I dislike Visual Basic :-D.
answered Apr 12, 2011 at 13:40
![]()
FeniksoFenikso
9,1815 gold badges45 silver badges71 bronze badges
3
![]()
Coding Mash
3,3405 gold badges23 silver badges45 bronze badges
answered Apr 12, 2011 at 12:32
![]()
RajRaj
6983 gold badges9 silver badges21 bronze badges
You can use,
sh.Range(sh.Cells(1,1),sh.Cells(20000,1)).EntireRow.Delete()
will delete rows 1 to 20,000 in an open Excel spreadsheet so,
if sh.Cells(1,1).Value == 'X':
sh.Cells(1,1).EntireRow.Delete()
![]()
SUB0DH
5,0904 gold badges29 silver badges46 bronze badges
answered Jan 25, 2017 at 21:27
![]()
If you just need to delete the data (rather than ‘getting rid of’ the row, i.e. it shifts rows) you can try using my module, PyWorkbooks. You can get the most recent version here:
https://sourceforge.net/projects/pyworkbooks/
There is a pdf tutorial to guide you through how to use it. Happy coding!
answered Apr 12, 2011 at 16:38
![]()
Garrett BergGarrett Berg
2,5851 gold badge22 silver badges20 bronze badges
I have achieved this using Pandas package….
import pandas as pd
#Read from Excel
xl= pd.ExcelFile("test.xls")
#Parsing Excel Sheet to DataFrame
dfs = xl.parse(xl.sheet_names[0])
#Update DataFrame as per requirement
#(Here Removing the row from DataFrame having blank value in "Name" column)
dfs = dfs[dfs['Name'] != '']
#Updating the excel sheet with the updated DataFrame
dfs.to_excel("test.xls",sheet_name='Sheet1',index=False)
![]()
Tomerikoo
17.9k16 gold badges45 silver badges60 bronze badges
answered Jan 6, 2016 at 6:00
![]()
Jd16Jd16
3771 gold badge3 silver badges11 bronze badges
1
Время на прочтение
4 мин
Количество просмотров 199K

По работе пришлось столкнуться с задачей обработки xls файлов средствами python. Немного по гуглив, я натолкнулся на несколько библиотек, с помощью которых можно работать с файлами excel.
Библиотеки:
— xlrd – дает возможность читать файлы Excel
— xlwt – создание и заполнение файлов Excel
— xlutils – набор утилит для расширения возможности предыдущих двух библиотек
— pyExcelerator – также дает возможность работать с файлами Excel, но давно не обновлялась.
Для своей задачи я использовал первые три библиотеки.
Задача была разбита на несколько частей: чтение файла с расширением xls; создание нового и заполнение его; создание копии файла на основе входного файла; удаление необходимых строк в выходном файле.
Чтение входного файла
Эта задача не отличается высокой сложностью. Документация и примеры, идущие в комплекте с xlrd, помогли быстро решить ее.
Пример кода:
import xlrd
rb = xlrd.open_workbook('d:/final.xls',formatting_info=True)
sheet = rb.sheet_by_index(0)
for rownum in range(sheet.nrows):
row = sheet.row_values(rownum)
for c_el in row:
print c_el
Создание нового файла и заполнение его
Эта задача оказалась не сложнее предыдущей. Документация и примеры помогли.
Пример кода:
import xlwt
from datetime import datetimefont0
= xlwt.Font()
font0.name = 'Times New Roman'
font0.colour_index = 2
font0.bold = Truestyle0
= xlwt.XFStyle()
style0.font = font0style1
= xlwt.XFStyle()
style1.num_format_str = 'D-MMM-YY'wb
= xlwt.Workbook()
ws = wb.add_sheet('A Test Sheet')ws
.write(0, 0, 'Test', style0)
ws.write(1, 0, datetime.now(), style1)
ws.write(2, 0, 1)
ws.write(2, 1, 1)
ws.write(2, 2, xlwt.Formula("A3+B3"))wb
.save('example.xls')
Создание копии файла на основе входного файла
Эта задача может решаться двумя путями. Вариант первый: открываем на чтение входной файл, создаем новый файл и по циклу переписываем все данные с одного файла в другой. Такое решение не сложно реализовать, поэтому пример кода выкладывать нет смысла. Вариант второй: воспользоваться библиотекой xlutils. В данной библиотеке есть много чего интересного и полезного, но для нашей задачи будет интересен именно xlutils.copy.
И так, пример кода по созданию файла на основании входного с использованием xlutils.copy:
import xlrd
import xlwt
from xlutils.copy import copyrb
= open_workbook('final.xls',on_demand=True,formatting_info=True)
wb = copy(rb)
wb.save("final_complete.xls")
Вот такой вот небольшой код получился. Для того чтобы он работал, обязательно должен стоять флаг on_demand=True. Благодаря использованию флага formatting_info выходной файл получается с такими же стилями оформления, как и входной. Для моей задачи это оказалась нужная опция.
Удаление строк по заданному условию
Для решения данной задачи было решено использовать фильтр. Один из вариантов — это переписывание из одного файла в другой, исключая те варианты, которые не выполняют заданное условие. Но тут есть одна загвоздка, если необходимо сохранить стиль оформление документа, то этот подход не подойдет (Если конечно вы заранее не знаете стиль оформления и можете задать его программно). Решение поставленной задачи было достигнуто посредством использования xlutils.filter. Задача: оставить в выходном Excel файле только те записи, которые содержатся в передаваемом списке.
Код, который решает данную задачу:
from xlutils.filter import GlobReader,BaseFilter,DirectoryWriter,processmyfile
='final2.xls'
mydir='d:/' class MyFilter(BaseFilter):goodlist
= Nonedef __init__(self,elist):
self.goodlist = goodlist
self.wtw = 0
self.wtc = 0def workbook(self, rdbook, wtbook_name):
self.next.workbook(rdbook, 'filtered_'+wtbook_name) def row(self, rdrowx, wtrowx):
passdef cell(self, rdrowx, rdcolx, wtrowx, wtcolx):
value = self.rdsheet.cell(rdrowx,rdcolx).value
if value in self.goodlist:
self.wtc=self.wtc+1
self.next.row(rdrowx,wtrowx)
else:
return
self.next.cell(rdrowx,rdcolx,self.wtc,wtcolx)
data= """somedata1
somedata2
somedata3
somedata4
somedata5
"""goodlist
= data.split("n")
process(GlobReader(os
.path.join(mydir,myfile)),MyFilter(goodlist),DirectoryWriter(mydir))
Заключение
Используя набор из трех библиотек, поставленные задачи были решены. Было замечено следующее: при наличии во входном Excel файле графических элементов (картинки и т.д) в выходной файл они не переносятся. Возможно изучив эти библиотеки можно будет решить и эту часть задачи.
Ссылки
sourceforge.net/projects/pyexcelerator
www.python-excel.org — на три первых библиотеки.
groups.google.com/group/python-excel — группа, в которой обсуждают использование библиотек xlrd, xlwt и xlutils.
P.S. Думаю было бы неплохо перенести данный пост в тематический блог.
Openpyxl is a Python library to manipulate xlsx/xlsm/xltx/xltm files. With Openpyxl you can create a new Excel file or a sheet and can also be used on an existing Excel file or sheet.
Installation
This module does not come built-in with Python. To install this type the below command in the terminal.
pip3 install openpyxl
In this article, we will discuss how to delete rows in an Excel sheet with openpyxl. You can find the Excel file used for this article here.
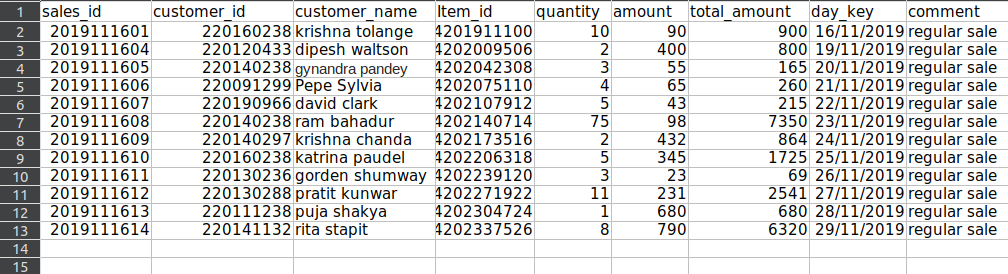
Deleting Empty rows (one or more)
Method 1:
This method removes empty rows but not continues empty rows, because when you delete the first empty row the next row gets its position. So it is not validated. Hence, this problem can be solved by recursive function calls.
Approach:
- Import openpyxl library.
- Load Excel file with openpyxl.
- Then load the sheet from the file.
- Iterate the rows from the sheet that is loaded.
- Pass the row to remove the function.
- Then check for each cell if it is empty if any of the cells non-empty return the function, so only empty rows will exit the for loop without returning.
- Only if all rows are empty, remove statement is executed.
- Finally, save the file to the path.
Python3
import openpyxl
def remove(sheet, row):
for cell in row:
if cell.value != None:
return
sheet.delete_rows(row[0].row, 1)
if __name__ == '__main__':
path = './delete_empty_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['daily sales']
print("Maximum rows before removing:", sheet.max_row)
for row in sheet:
remove(sheet,row)
print("Maximum rows after removing:",sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 14
File after deletion:
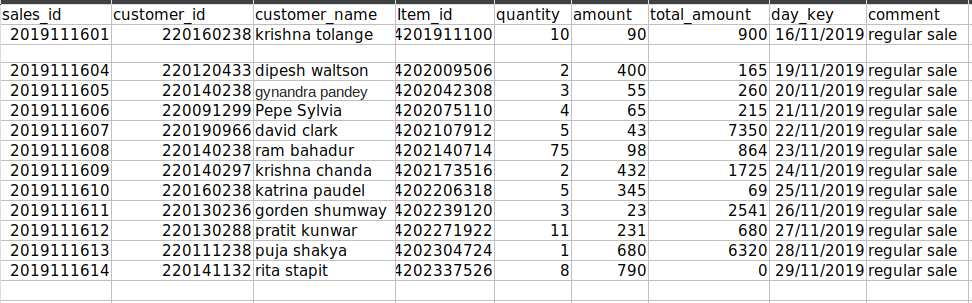
The first method deleted only the first empty row and the second continuous empty row is not deleted.
Method 2:
This method removes empty rows, including continuous empty rows by using the recursive approach. The key point is to pass the modified sheet object as an argument to the recursive function. If there is no empty row function is returned immediately.
Approach:
- Import openpyxl library.
- Load Excel file with openpyxl.
- Then load the sheet from the file.
- Pass the sheet that is loaded to the remove function.
- Iterate the rows with iter_rows().
- If any of the cells in a row is non-empty, any() return false, so it is returned immediately.
- If all cells in a row are empty, then remove the row with delete_rows().
- Then pass the modified sheet object to the remove function, this repeats until the end of the sheet is reached.
- Finally, save the file to the path.
Python3
import openpyxl
def remove(sheet):
for row in sheet.iter_rows():
if not all(cell.value for cell in row):
sheet.delete_rows(row[0].row, 1)
remove(sheet)
return
if __name__ == '__main__':
path = './delete_empty_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['daily sales']
print("Maximum rows before removing:", sheet.max_row)
for row in sheet:
remove(sheet)
print("Maximum rows after removing:",sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 13
File after deletion:
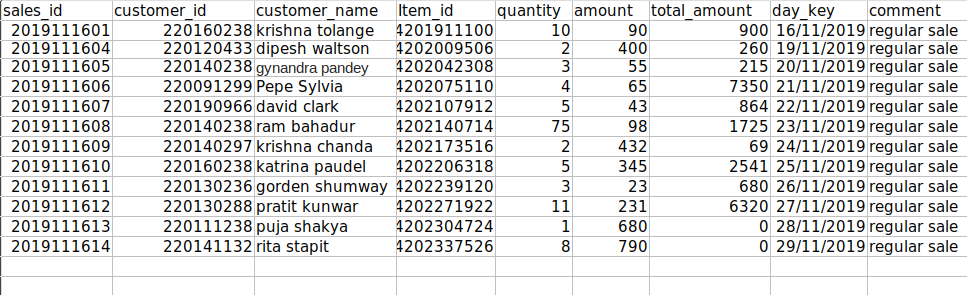
This method deleted both continuous empty rows as expected.
Deleting All rows
Method 1:
In this method, we delete the second row repeatedly until a single row is left(column names).
Approach:
- Import openpyxl library.
- Load the Excel file and the sheet to work with.
- Pass the sheet object to delete function.
- Delete the second row, until there is a single row left.
- Finally, return the function.
Python3
import openpyxl
def delete(sheet):
while(sheet.max_row > 1):
sheet.delete_rows(2)
return
if __name__ == '__main__':
path = './delete_every_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['sheet1']
print("Maximum rows before removing:", sheet.max_row)
delete(sheet)
print("Maximum rows after removing:", sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 1
File after deletion:
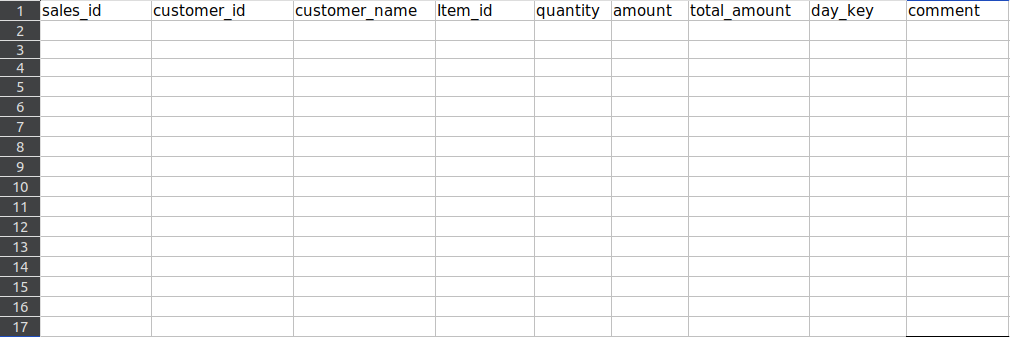
Method 2:
In this method, we use openpyxl sheet method to delete entire rows with a single command.
Approach:
- Import openpyxl library.
- Load the Excel file and the sheet to work with.
- Use delete_rows function to delete all rows except the column names.
- So a single empty row is left over.
Python3
import openpyxl
if __name__ == '__main__':
path = './delete_every_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['sheet1']
print("Maximum rows before removing:", sheet.max_row)
sheet.delete_rows(2, sheet.max_row-1)
print("Maximum rows after removing:", sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 1
File after deletion:
Last Updated on July 14, 2022 by
This tutorial will show you how to use the Python openpyxl library to delete rows or columns from existing Excel files.
Library
To install the openpyxl library, type the following in a command prompt window:
pip install openpyxlSample Dataset
Copy and run the following code to create a sample Excel file to follow the tutorial.
from openpyxl import load_workbook, Workbook
wb = Workbook()
ws = wb.create_sheet('eg')
data = [('id', 'name', 'country'),
(1, 'Trudeau','Canada'),
(2,'Zelenskyy', 'Ukraine'),
(3,'Putin', 'Russia'),
(4,),
(5,'Biden', 'US'),
(6, 'Xi', 'China'),
(7,'Johnson', 'UK'),
(8, 'Castex', 'France'),
(9,),
(10, 'Steinmeier', 'Germany'),
(11, 'Rutte', 'Netherlands'),
(12,'Loong', 'Singapore')]
for row in data:
ws.append(row)
wb.save('names.xlsx')
In openpyxl, we can use delete_rows() and delete_cols() methods from the Worksheet object to remove entire rows and columns. The syntax is straightforward:
- delete_rows(row_id, number_of_rows)
- delete_cols(col_id, number_of_cols)
Delete at Known Position
Since we need to delete from existing Excel files, let’s first read the file content into Python. Then we can use the delete_rows() or delete_cols() to remove rows and columns.
wb2 = load_workbook('names.xlsx')
ws2 = wb2['eg']
for i in ws2.values:
print(i)
('id', 'name', 'country')
(1, 'Trudeau', 'Canada')
(2, 'Zelenskyy', 'Ukraine')
(3, 'Putin', 'Russia')
(4, None, None)
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(9, None, None)
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')
Delete 1 Row or Column
If we want to delete just 1 row, just call delete_rows(n), which will delete the nth row from the top. We can ignore the second argument, which equals 1 by default. Similarly, to delete just 1 column, use delete_cols(n) and skip the second argument.
Delete Multiple Rows or Columns
To delete multiple rows or columns, we’ll need to use both arguments. The following code will delete the 2nd row to the 5th row. It means to delete row 2, plus the 3 rows underneath it, for a total of 4 rows.
ws2.delete_rows(2,4)
for i in ws2.values:
print(i)
('id', 'name', 'country')
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(9, None, None)
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')Similarly, to delete multiple columns we need to use both arguments. The below deletes from column 2 (B), and for a total of 2 columns (B and C).
ws2.delete_cols(2,2)
for i in ws2.values:
print(i)
('id',)
(1,)
(2,)
(3,)
(4,)
(5,)
(6,)
(7,)
(8,)
(9,)
(10,)
(11,)
(12,)Unfortunately, there’s no easy way to delete multiple non-consecutive rows or columns. We have to delete one by one and figure out the new position of the rows/cols after each delete.
Delete Based on Cell Values
Our dataset contains 2 empty rows at id 4 and 9. Let’s say if the empty rows can appear randomly anywhere in a file, then we don’t know the exact location of those rows (or columns) so we can’t use the delete methods directly.

We need to first find where those rows are. Basically, we need to know which rows have empty values.
In the below code, using ws.iter_rows() we can get tuples of Cell objects. Then from those Cell objects, we can access the cell values and row/column positions.
any() returns True if at least one of the elements is not None, and returns False if all elements are None. We can use this function to locate the empty rows.
Of course, don’t forget to save the changes back to the Excel file!
any([1,2,None])
True
any([None,None,None])
False
for row in ws2.iter_rows():
if not any([cell.value for cell in row[1:]]):
ws2.delete_rows(row[0].row)
for i in ws2.values:
print(i)
('id', 'name', 'country')
(1, 'Trudeau', 'Canada')
(2, 'Zelenskyy', 'Ukraine')
(3, 'Putin', 'Russia')
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')
wb.save('names.xlsx)Additional Resources
Python & Excel – Number Format
Python openpyxl – How to Insert Rows, Columns in Excel
Adjust Excel Fonts using Python openpyxl
Write Data to Excel using Python