
Авторы: Гончар-Зайкин П.П., к.б.н.; Чертов В.Г., к.э.н.
Полный текст на сайте http://www.sniish.ru/proposal_desc.php?id=8
Нами разработан пакет программ AgCStat в виде надстройки Excel.
В настоящее время пакет включает 12 программ плюс лист с примерами подготовки данных для анализа:
- получение табличных значений критериев Фишера и Стьюдента;
- восстановление выпавших данных
- вычисление статистик выборки;
- однофакторный дисперсионный анализ полевых опытов по Б.А. Доспехову;
- двухфакторный дисперсионный анализ полевых опытов по Б.А. Доспехову;
- двухфакторный дисперсионный анализ неравномерного комплекса по Н.А. Плохинскому;
- трехфакторный дисперсионный анализ равномерного комплекса (оригинальный алгоритм авторов);
- одно, двух и трех факторный анализ качественных признаков по Н.А. Плохинскому;
- парная корреляция и регрессия с полным статистическим анализом результатов;
- оценка разности средних по критерию Стьюдента.
1. Скачать с сайта разработчиков
2. Скачать с нашего сайта
3. Если первые две ссылки не работают, Вы можете скачать Эксель файл AgCStat
Анализируя список программ пакета, специалист может заметить, что некоторые программы дублируют программы стандартного Пакета анализа и даже встроенные функций. Это вызвано рядом причин.
Во-первых, неискушенному пользователю все же удобнее иметь все в одном пакете, освоить который значительно проще, чем работу со встроенными функциями.
Во-вторых, в версиях Excel младше Excel 2002 ряд функций либо отсутствуют, либо они не доступны, как, например, функции GetFisher и GetStudent – выдающих табличные значения критериев.
В-третьих, и, может быть самое главное, — это типизация. При просмотре «Примеров подготовки данных» видно, что все таблицы данных для анализов выполняются по одному типу, тогда как в стандартном Пакете анализа таблица данных для однофакторного комплекса строится по одному типу, а для двухфакторного — совсем по другому, понять который совсем не просто. По одному же типу построены и все диалоговые окна надстройки AgCSTAT (строка в меню Сервис – CXSTAT). Вся терминология, используемая в пакете, полностью соответствует терминологии принятой в отечественной литературе.
При разработке программ входящих в пакет нами использовались исключительно отечественные разработки, причем предпочтение оказывалось алгоритмам, которые в аграрных научных учреждениях приняты как стандартные.
Дадим некоторые пояснения по пакету программ.
Восстановление выпавших данных. Выбраковка делянки полевого опыта – обычное дело. Причины самые разные от градобоя до воровства и потравы. Узнать количество пропавшего в принципе нельзя, но вычислить величину, которая не нарушая статистических характеристик комплекса, восстановит его ортогональность для проведения некоторого формального анализа можно [3, 6]. Прием восстановления выпавшего данного применяется и тогда, когда некоторое данное резко отличается от соседних, однако пользоваться этим приемом следует с большой осторожностью и в купе с другими видами анализов о принадлежности данного к выборке.
Напомним, что алгоритмы Б.А. Доспехова привязаны к схеме закладки полевого опыта и повторения рассматриваются как фактор. В связи с этим, обратим внимание на то, что если в диалоговом окне «Однофакторный дисперсионный анализ по Доспехову» установить опцию «Опыт в вегетационных сосудах …», т.е. перейти к общей схеме дисперсионного анализа, то мы получим результаты, совпадающие как с результатами «по Плохинскому», так и однофакторного дисперсионного анализа пакета «Анализ данных».
В доступной нам литературе, мы не нашли четкого алгоритма трехфакторного дис-персионного анализа для количественных признаков (равномерного комплекса), но, поскольку необходимость в нем высока, разработали его сами, опираясь на алгоритмы Н.А. Плохинского [5].
Анализ опытов, связанных с изучением устойчивости растений к вредителям и болезням, а также для оценки эффективности различных химических препаратов, влияющих на устойчивость, очень часто проводится с использованием качественных признаков (больной – здоровый, заражен – не заражен и т. д.). В нашем пакете одно диалоговое окно позволяет выполнить дисперсионный анализ качественных признаков по одно, двух и трехфакторной схеме.
Программа для расчета корреляции и регрессии при парных взаимодействиях построена так, что выдает результаты регрессионного и корреляционного анализов в один прием вместе с оценкой их статистической достоверности.
Иногда исследователя интересует всего лишь величина разности средних двух выборок и ее достоверность. Эту задачу решает последняя в списке программа. Достаточно указать диапазоны, в которых находятся выборки, диапазоны могут быть как смежными, так и несмежными и даже располагаться на разных листах книги Excel.
Для установки книги надстройки на ПК достаточно иметь дискету с двумя файлами:AgCStat.xla и SetUp.exe. Вы запускаете файл SetUp.exe, а все остальное делается в автоматическом режиме. По завершению установки в списке надстроек Excel (меню Сервис — Надстройки, окно Надстройки) появится новая строка: “Agcstat”. Для начала работы с надстройкой ее нужно активизировать, установкой флажка.
Теперь в меню Сервис видим команду СХSТАТ, щелкаем по ней мышкой и на экране монитора появится диалоговое окно с перечнем программ пакета. До начала работы, советуем просмотреть примеры подготовки данных (первая строка списка). Дополнительной информации для работы с пакетом не потребуется.
Важные примечания от администратора vniioh.ru:
- Надстройка также работает в последних версиях Excel (2007 и 2010) 32-битных. Для единовременного использования надстройки необходимо распаковать архив agstat.zip в любую папку, запустить файл , подтвердить разрешение на включение макросов, и согласиться на установку надстройки. После этого на ленте справа появится вкладка «Надстройки», а в ней CXSTAT.
- Для постоянного включения надстройки нужно скопировать файл AgCStat.xla в папку:для Excel 2007 — C:Program FilesMicrosoft OfficeOffice12Library;
для Excel 2010 — C:Program FilesMicrosoft OfficeOffice14LibraryОткрыть окно свойств папки Library и снять флажок «Только чтение». Проверить атрибуты файла AgcStat.xla флажек «Только чтение» — должен быть снят.Запустите Excel от имени администратора. Нажмите вкладку Файл (для 2007 нажать на кружок) -> пункт Параметры -> Надстройки — внизу Управление (выбрать надстройки Excel) и нажмите Перейти -> отметить галочкой Agcstat и нажмите OK - Если у вас возникают ошибки в работе с программой (например ошибка 6 или 9), попробуйте для расчета создать новый файл рабочей книги, и скопируйте туда чистые числовые данные (через Специальную вставку — Вставка только значения). Ошибка должна исчезнуть. Замечено, что надстройка выдаёт ошибку когда данные отформатированы или к ним применено цветовое или условное форматирование. Программа 100% РАБОЧАЯ.
- UPD/ На 64-битных версиях Office 2010 и Office 365 (2013) запустить не удалось.
Использованная литература
- Эрмантраут Э.Р., Гудзъ В.П. Статистический анализ результатов агрономических ис-следований в прикладной программе «EXCEL-2000». //Материалы международной научно-практической конференции «современные проблемы опытного дела», том 2, СПб, 2000, стр.13-134.
- Лапач С.Н., Чубенко А.В., Бабич П.Н. Статистические методы в медико-биологических исследованиях с использованием Excel. Киев «МОРИОН», 2000, 320 с.
- Доспехов Б.А. Методика полевого опыта. 1-5 изд. М., 1965 — 1985
- Лакин Г.Ф. Биометрия. М., Изд. «Высшая школа», 1990, 352с.
- Плохинский Н.А. Биометрия. М., Изд. МГУ, 1970, 368с.
- Снедекор Д.У. Статистические методы в применении к исследованиям в сельском хозяйстве и биологии. М., 1961
- Фишер Р.Э. Статистические методы для исследователей. М., 1958
- Митропольский А.К. Техника статистических вычислений. М., 1971.
- Уэллс Э., Хешбаргер С. Microsoft Excel 97: разработка приложений / Пер. с анг. –СПб., БХВ-Санкт-Петербург, 1998, 624с.
При использовании вышеизложенных материалов необходимо ссылаться на авторов.
Данный материал опубликован в:
Сборнике «Рациональное природопользование и сельскохозяйственное производство в южных регионах Российской Федерации» М. «Современные тетради», 2003, с.559-564 П.П. Гончар-Зайкин, В.Г. Чертов.
Представленные
в предыдущем параграфе теоретические
соображения позволяют начинать
планирование трёхфакторного эксперимента
не с план-матрицы, а с подготовки макета
Итоговой таблицытрёхфакторного эксперимента (такой
макет представлен в начале следующего
листа)). На
этом макете в клетках-ячейках показаны
очевидные соотношения, которые на этапе
планирования должны быть введены в них
в виде формул для вычисления итогов.
Такую таблицу, как
и в предыдущем случае, следовало бы
готовить в рамках единой электронной
таблицы совместно с план-матрицей
трёхфакторного эксперимента, который
(план) здесь будет выглядеть существенносложнее, чем при одно- и двухфакторном
экспериментах. Это связано с дополнительной
необходимостью вычисления построчных
промежуточных величин (Сp,Сp2и др.) «нового» фактораС.
Макет
итоговой таблицы трёхфакторного
эксперимента
|
Источник дисперсии |
Математи-ческое ожидание дисперсии |
Итоговая дисперсии |
Кол-во степеней свободы дисперсии |
Выборочная дисперсии |
|
Эксперимент целиком |
σ2 |
(Σ∑) |
Fijp= |
(Σijp):(nmk-1) |
|
Случайные |
σέ2 |
(Σέ) |
fέ – (n+m+ |
(Σέ) nmk – |
|
Фактор |
mnσА2 |
(ΣА)=КЧА–КЧ∑ |
fА=n–1 |
(ΣА):(n–1) |
|
Фактор |
knσB2 |
(ΣB)=КЧB |
fB |
(ΣB):(m |
|
Фактор |
kmσC2 |
(ΣC)=КЧC |
fC |
(ΣC):(k–1) |
|
s |
||||
|
s |
||||
|
s |
Примечания:1.mnk;mn,kn,kmи – объёмы выборок («слоёв» в
кубическом
«хранилище»
откликов) всего и при неизменных уровнях
факторов
А,В, и С,соответственно.
2.
fέlj
= flj– (fА+
fB+
fС)
=mnp
–1–
(n
–1+
m–1+
p
–1)
=
=
nmk
–1–
n
+1–
m+
1–
k+1=
nmk
– (n+
m+
k
–2).
Если при двухфакторном
эксперименте данные всехизмерений (как и при однофакторном)
могли быть размещены в одной «плоской»
(двухмерной) таблице (содержательной
частиПротокола…), наглядным аналогом которой выше была
представленастлаж-этажерка, то
при трёхфакторном эксперименте в
подобную «плоскую» таблицу вместятся
данные, полученные только приодномзначении третьего фактора С.
Наглядным образом
«хранилища»всехданных
трёхфакторного эксперимента может
послужитьскладское помещение,
заполненное целым рядом (kштук) подобных стеллажей-этажерок, на
каждой из которых размещено поnmзначений откликов, измеренных приодном
и том жезначении третьего фактора
С.
Это трёхмерный
образ. Таблица не может быть трёхмерной.
Следовательно, для записи всех данных
трёхфакторного эксперимента потребуютсяk
таблиц. Как каждая такая таблица
может выглядеть, показано ниже, где
приведена таблица откликов, измеренных
принаименьшем значении третьего
фактора С: при значенииc1.
Следовательно,
здесь должны быть предусмотрены (и в
ходе эксперимента – заполнены) ещё n
—1 аналогичных таблиц. В соответствующих
клетках-ячейках этих таблиц по
соответствующим (обоснованным выше и
размещённым в этих ячейках) формулам
автоматически будут вычисляться (на
основе размещаемых в план-матрице
данных измерений) все промежуточные
величины, используемые при обработке
экспериментальных данных и при вычислениях
результатов в соответствующих разделахИтоговой таблицы.
Речь идёт прежде
всего о величинах СК∑,КЧ∑иКЧk,
которые теперь должны считаться, если
не по новым, то по модифицированным под
конкретную ситуацию формулам. В
частности, при трёх факторах они будут
выглядеть:
СК∑
= СКijp=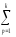
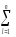
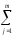 (yijp)2,КЧ∑ =
(yijp)2,КЧ∑ =
КЧijp=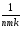 (
(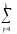
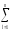
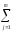 yijp)2и,
yijp)2и,
соответственно:
КЧ1 =КЧА
=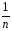
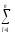
(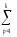
 yljp)2,
yljp)2,
КЧ2=КЧВ =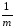
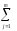 (
(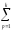
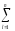 yljp)2
yljp)2
и
КЧ3=КЧС =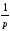
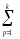
(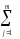
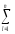 yljp)2.
yljp)2.
Макет первого
фрагмента рабочей электронной таблицы
для сопровождения трёхфакторного
эксперимента повторяют план-матрицу
двухфакторного эксперимента. Здесь –
рабочая электронная таблица,
предусматривающая варьирование уровней
факторов АиВпри удержании
(в ходе такого двухфакторного эксперимента)
фактора С на егопервом(р=1)
уровне. По ней ничего невозможно
вычислить окончательно: ниКЧ∑,
ниКЧА,
ниКЧВ,
ниКЧС и
ниСК∑.
По этой таблице
можно вычислить только одно
(КЧС1=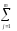
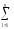 ylj1)слагаемое для последующего вычисленияКЧСпо
ylj1)слагаемое для последующего вычисленияКЧСпо
формуле
КЧС
=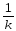
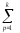 КЧСp=
КЧСp=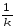
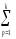 (
(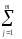
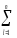 yljp)2
yljp)2
.
Фрагмент
макета рабочей электронной таблицы
для
сопровождения трёхфакторного эксперимента
n
– количество уровней варьирования
фактора А.
m
– количество уровней варьирования
фактора В.
k
– количество уровней варьирования
фактора С.
|
Уровни m |
Уровни а1,а2, n |
Сумма во
|
Полный суммы КЧС1 |
|
b1 b2 ….. bj ….. bm |
Отклики ….yi11…. ….yi21…. ….. ….yij1… … …..yim1… |
Сумма в …. ….. Bj1 …. |
Квадрат в (Bj1)2 |
|
Количество Уровней Фактора n |
Сумма в Аi1= |
Сумма во
|
Сюда ничего |
|
Уровни фактора m |
Квадрат (Al1)2= ( |
Квадрат столбцах |
Квадрат строках |
|
b1 b2 ….. bj ….. bm |
Квадраты ….y2i11…. ….y2i21…. ….. ….y2ij1… ….. ….y2im1… |
Сумма в = |
Сюда ничего |
|
Количество уровней фактора m |
Сумма в
|
Общая
квадратов
|
х3p= значение |


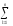 yij1
yij1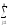
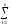 yij1)2
yij1)2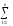 yij1
yij1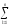 yij1)2
yij1)2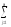
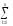
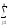 yij1
yij1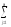 yij1)2
yij1)2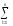 (Ai1)2
(Ai1)2 (Bj1)2
(Bj1)2
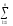 (yij1)2
(yij1)2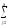 (yij1)2
(yij1)2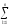
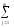 (yij1)2
(yij1)2
Для вычисления
других частичных сумм для КЧСp
при последующих уровнях фактора С
(уровняхcp,
гдер=2,3,4,…k)
потребуются, как сказано выше, ещёk-1
аналогичных фрагментов таблицы.
На первом фрагменте
рабочей таблицы в правую нижнюю ячейку
для сведения заносится первое значение
третьего фактора (х3p=
= х31
с1),
а все данные измерений и промежуточные
результаты их обработки имеетодин
тотже третий индекс, а именноp=1.
В каждом из
последующих точно таких жефрагментов таблицы значение третьего
индекса изменяется на единицу (p=
2,p=3,p=
4,… доp
= k,
а в его правую нижнюю ячейку заносится
соответствующее значение третьего
факторах3p
(х32
с2,
х33
с3,.. …. дох3k

сk).
Второй
фрагмент макета рабочей электронной
таблицы 
для
сопровождения трёхфакторного эксперимента
n
– количество уровней варьирования
фактора А.
m
– количество уровней варьирования
фактора В.
k
– количество уровней варьирования
фактора С.
|
Уровни фактора |
Уровни а1,а2, n |
Сумма во
|
Полный суммы КЧС2 |
|
b1 b2 ….. bj ….. bm |
Отклики ….yl12…. ….yl22…. ….. ….ylj2… ….. …..ylm2… |
Сумма в …. ….. Bj2 …. |
Квадрат в …. ….. (Bj2)2 …. |
|
Количество уровней фактора n |
Сумма в Аl2= |
Сумма во
|
Сюда ничего |
|
Уровни фактора m |
Квадрат
откликов (Al2)2= ( |
Квадрат
откликов столбцах |
Квадрат
откликов строках |
|
b1 b2 ….. bj ….. bm |
Квадраты ….y2l12…. ….y2l22…. ….. ….y2lj2… ….. ….y2lm2… |
Сумма в ….. …..
….. |
Сюда ничего |
|
Количество уровней фактора m |
Сумма в
|
Общая квадратов
|
х3p= значение |

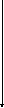

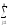
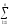 ylj2
ylj2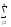
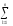 ylj2)2
ylj2)2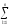 ylj2
ylj2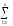 ylj2)2
ylj2)2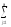
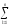
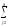 ylj2
ylj2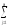 ylj1)2
ylj1)2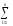 (Al2)2
(Al2)2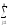 (Bj2)2
(Bj2)2
 (ylj2)2
(ylj2)2 (ylj2)2
(ylj2)2
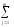 (yij2)2
(yij2)2
Выше представлен
второйтакой фрагмент большой
рабочей таблицы, а ниже – последний.
Таким образом, для
записи данных всехизмерений и
предварительной их автоматической
обработки (повторим ещё раз) следует
«заготовить»kштук очень похожих друг на друга, норазныхфрагментов-сечений общей
«трёхмерной» рабочей таблицы.
Ниже представлен
последний из них.

Последний
фрагмент макета рабочей электронной
таблицы
для
сопровождения трёхфакторного эксперимента
n
– количество уровней варьирования
фактора А.
m
– количество уровней варьирования
фактора В.
k
– количество уровней варьирования
фактора С.
|
Уровни фактора m |
Уровни а1,а2, n |
Сумма во
|
Полный суммы КЧСk |
|
b1 b2 ….. bj ….. bm |
Отклики ….yi1n…. ….yi2n ….. ….yijk ….. …..yimk |
Сумма в …. ….. Bjk …. |
Квадрат в …. ….. (Bjk)2 …. |
|
Количество Уровне фактора — |
Сумма в Аln= |
Сумма во
|
Сюда ничего |
|
Уровни фактора m |
Квадрат (Aln)2= ( |
Квадрат столбцах |
Квадрат строках |
|
b1 b2 ….. bj ….. bm |
Квадраты ….y2i1k…. ….y2i2k…. ….. ….y2ijk… ….. ….y2imk… |
Сумма в ….. …..
….. |
Сюда ничего |
|
Количество уровней фактора – m |
Сумма в
|
Общая
квадратов
|
х3p наибольшее
третьего |

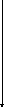

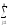
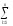 yijk
yijk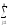
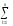 yijk)2
yijk)2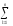 yijk
yijk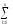 yijk)2
yijk)2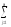
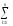
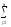 yijk)
yijk)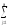 yljk)2
yljk)2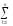 (Alk)2
(Alk)2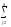 (Bjk)2
(Bjk)2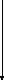
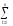 (yijk)2
(yijk)2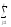 (yijk)2
(yijk)2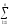
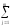 (yljk)2
(yljk)2
Но на этом, однако,
«заготовки» не заканчиваются. Ведь
для того, чтобы «собрать» суммуКЧС
=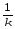
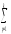 (
(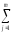
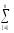 yijp)2
yijp)2
следует где-то предусмотреть
ячейку для размещения
в ней соответствующей формулы, содержащей
ссылки наодноимённыеячейкивсех kфрагментов единой таблицы. Далее
потребуются ячейки и для ещё более
трудного «собирания» промежуточных
величин КЧА
иКЧВ
по формулам
КЧА
=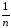
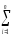 (
(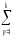
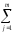 yljp)2
yljp)2
иКЧВ
=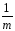
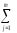 (
(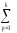
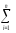 yijp)2.
yijp)2.
Наконец, потребуются
дополнительные ячейки для формул
СК∑
= СКijp=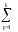
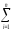
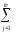 (yijp)2иКЧ∑ =
(yijp)2иКЧ∑ =
КЧljp=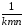 (
(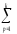
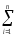
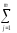 yljp)2, ибо промежуточные величиныСК∑
yljp)2, ибо промежуточные величиныСК∑
= СКljpиКЧ∑ =
КЧljpтоже нужны для «срабатывания»Итоговой таблицы,
в которой должны быть ссылки именно на
эти дополнительные ячейки единой рабочей
электронной таблицы
Выделить в Excel’е
ещё группу ячеек и ввести в них формулы
со ссылками на соответствующие ячейки
каждого из представленных выше похожих
друг на друга фрагментов-сечений
электронной таблицы – дело не хитрое
и этим планирование эксперимента при
проведении трёхфакторного дисперсионного
анализа заканчивается. Выглядит такое
планирование довольно громоздким. Вряд
ли оно применимо практически
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» — «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа.
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:
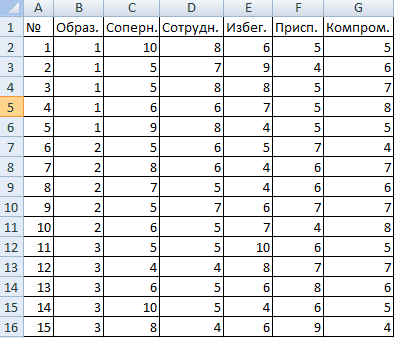
- Открываем диалоговое окно нашего аналитического инструмента. В раскрывшемся списке выбираем «Однофакторный дисперсионный анализ» и нажимаем ОК.
- В поле «Входной интервал» ввести ссылку на диапазон ячеек, содержащихся во всех столбцах таблицы.
- «Группирование» назначить по столбцам.
- «Параметры вывода» — новый рабочий лист. Если нужно указать выходной диапазон на имеющемся листе, то переключатель ставим в положение «Выходной интервал» и ссылаемся на левую верхнюю ячейку диапазона для выводимых данных. Размеры определятся автоматически.
- Результаты анализа выводятся на отдельный лист (в нашем примере).
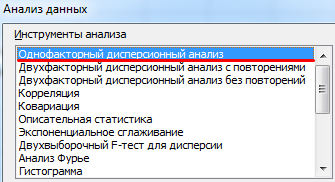
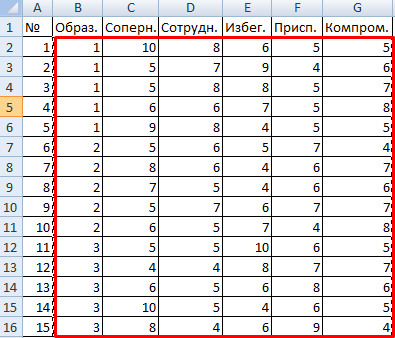
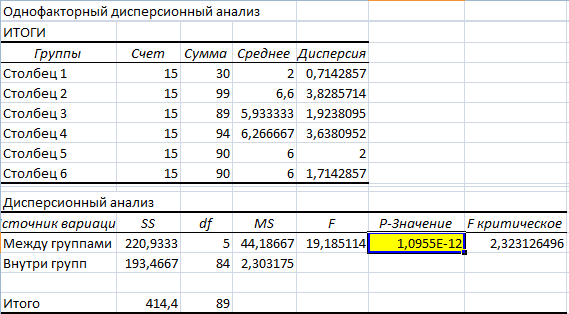
Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.
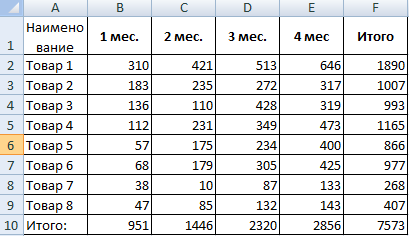
- Посмотрим, за счет, каких наименований произошел основной рост по итогам второго месяца. Если продажи какого-то товара выросли, положительная дельта – в столбец «Рост». Отрицательная – «Снижение». Формула в Excel для «роста»: =ЕСЛИ((C2-B2)>0;C2-B2;0), где С2-В2 – разница между 2 и 1 месяцем. Формула для «снижения»: =ЕСЛИ(J3=0;B2-C2;0), где J3 – ссылка на ячейку слева («Рост»). Во втором столбце – сумма предыдущего значения и предыдущего роста за вычетом текущего снижения.
- Рассчитаем процент роста по каждому наименованию товара. Формула: =ЕСЛИ(J3/$I$11=0;-K3/$I$11;J3/$I$11). Где J3/$I$11 – отношение «роста» к итогу за 2 месяц, ;-K3/$I$11 – отношение «снижения» к итогу за 2 месяц.
- Выделяем область данных для построения диаграммы. Переходим на вкладку «Вставка» — «Гистограмма».
- Поработаем с подписями и цветами. Уберем накопительный итог через «Формат ряда данных» — «Заливка» («Нет заливки»). С помощью данного инструментария меняем цвет для «снижения» и «роста».
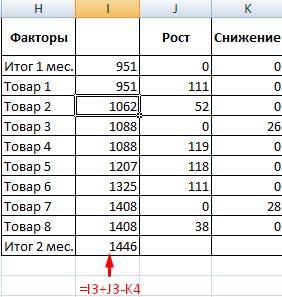
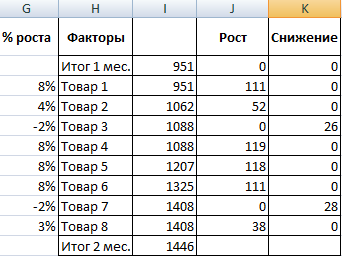
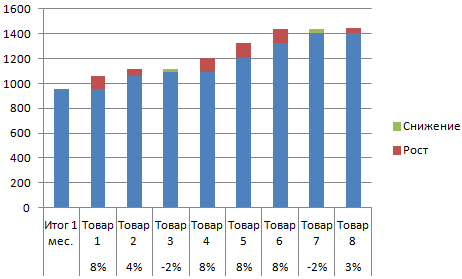
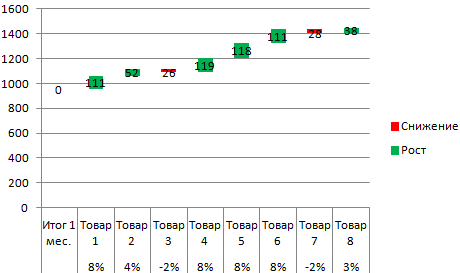
Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.
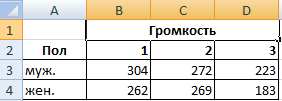
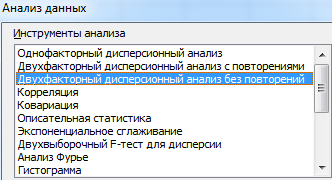
- Переходим на вкладку «Данные» — «Анализ данных» Выбираем из списка «Двухфакторный дисперсионный анализ без повторений».
- Заполняем поля. В диапазон должны войти только числовые значения.
- Результат анализа выводится на новый лист (как было задано).
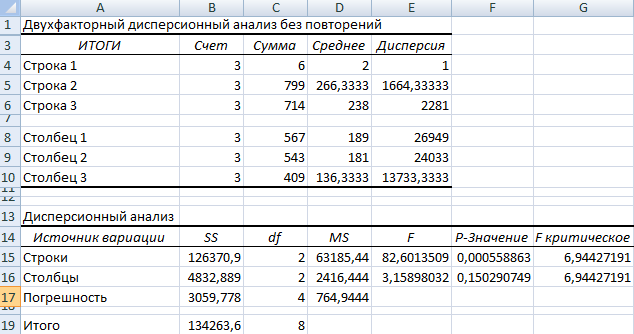
Та как F-статистики (столбец «F») для фактора «Пол» больше критического уровня F-распределения (столбец «F-критическое»), данный фактор имеет влияние на анализируемый параметр (время реакции на звук).
Скачать пример факторного и дисперсионного анализа
скачать факторный анализ отклонений
скачать пример 2
Для фактора «Громкость»: 3,16 < 6,94. Следовательно, данный фактор не влияет на время ответа.
Для примера также прилагаем факторный анализ отклонений в маржинальном доходе.
Ни одна компания не может обойтись без такого аналитического инструмента, как факторный анализ. Не важно, имеет ли бизнес миллионы прибыли или убытки — важно понимать, какие факторы оказали влияние на появления прибыли или убытка. Почему статья называется Факторный анализ простым языком? Почему именно простым?
Например, Википедия определяет факторный анализ как “многомерный метод, применяемый для изучения взаимосвязей между значениями переменных”. Отлично, только что делать, если мы только начинаем постигать азы аналитики в целом и факторного анализа в частности? Именно поэтому в данной статье рассмотрен самый простой пример факторного анализа на примере 3-х магазинов одной сети.
Мы проведем факторный анализ показателей реализации продукции, т.е. товарооборота, валовой прибыли и себестоимости складских запасов в разрезе трех магазинов компании и определим, как каждый из магазина в том или ином случае повлияли на общий результат компании. Таким образом, магазин будет являться фактором, который влияет на общий результат работы компании.
Факторный анализ пример расчета по продажам
Имеем такую таблицу, в которой показаны суммы продаж за 2019 и 2020 годы по трем магазинам сети.
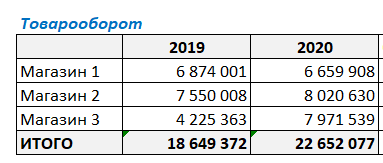
Как видите, товарооборот в 2020 году изменился по отношению к 2019 г. во всех магазинах. У кого-то уменьшился, у кого-то увеличился. И нужно понять, насколько изменение товарооборота конкретного магазина повлияло на общий результат деятельности компании.
Для этого добавим в таблицу следующие столбцы:
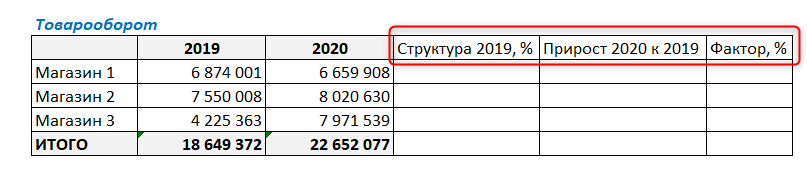
Для начала нашего факторного анализа посчитаем структуру товарооборота в 2019 году. Структура будет показывать долю каждого магазина в суммарных продажах за 2019 год.
Для этого в ячейку Е4 введем следующую формулу:
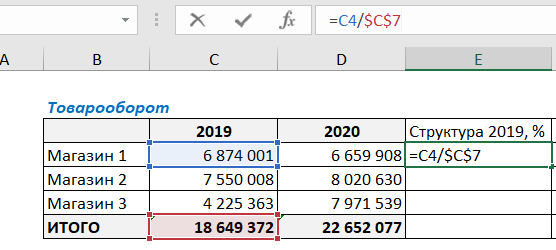
Нужно поделить продажи Магазина 1 на общую сумму продаж. Не забудьте закрепить значение итоговой ячейки C7 в формуле знаками $ ($C$7). Закрепить значение ячейки можно, установив курсор на C7 и нажав клавишу F4 (подробнее об абсолютных и относительных ссылках в *статье*). Это нужно для того, чтобы ссылка на итоговую ячейку не съехала при протягивании формулы вниз.
Для полученного результата выберем процентный формат ячейки и протянем формулу вниз:
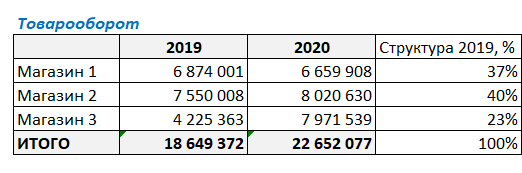
На данном этапе факторного анализа видим, что наибольший вклад в товарооборот компании за 2019 г. внес Магазин 2 — 40%. В итоговой ячейке нужно просуммировать получившиеся проценты, сумма обязательно должна быть равна 100% — это значит, что все посчитано верно.
Далее в ячейке F4 посчитаем прирост продаж 2020 года к 2019. Для этого разделим сумму продаж за 2020 г на сумму за 2019 и отнимем единицу (стандартная формула для расчета изменения показателя).
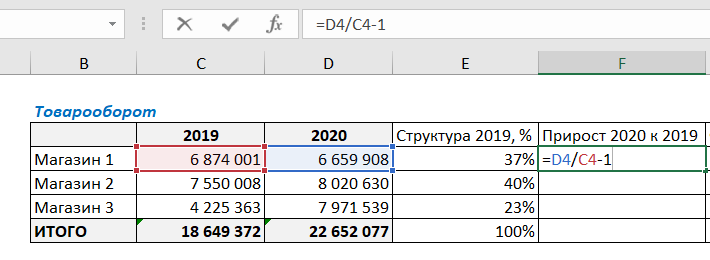
Протянем формулу вниз, захватывая итоговую строку, и увидим, что продажи в 2020 г. в целом по компании выросли на 21% по отношению к предыдущему году. Также видим изменение товарооборота в каждом из магазинов.
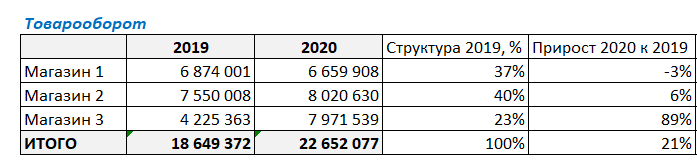
И в завершении данного этапа факторного анализа нужно умножить долю магазина на прирост продаж. Для этого в ячейке G4 напишем следующую формулу:
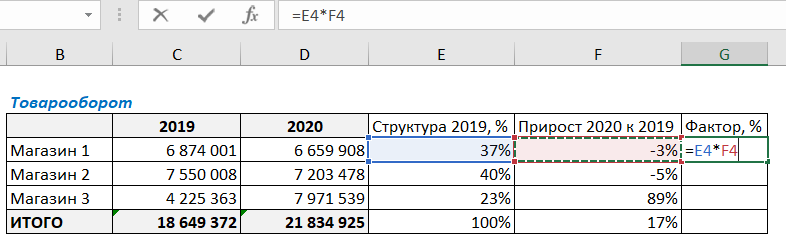
Протянем формулу вниз до итоговой ячейки.
Что же можно увидеть из итоговых результатов факторного анализа по товарообороту?
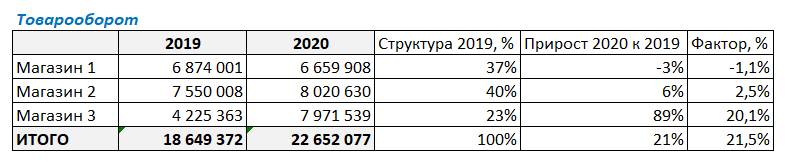
В целом товарооборот, вырос на 21,5% (выведем десятые доли для наглядности). И эти 21,5% складываются из следующих составляющих (факторов):
Фактор “Магазин 1” дал -1,1 % прироста в изменении товарооборота компании (т.е. падение товарооборота, т.к. прирост отрицательный)
Фактор “Магазин 2” для 2,5 % прироста из 21%.
А вот Фактор “Магазин 3” дал 20,1% прироста в составе группы магазинов, и аж 89% по отношению к собственным продажам в предыдущем году.
В итоге:
-1,1% + 2,5% + 20,1% = 21,5%
Таким образом, этот простой пример факторного анализа показывает, что максимальный вклад в прирост товарооборота сделал фактор “Магазин 3”.
Но не будем останавливаться на достигнутом, т.к. нам, во-первых, нужно понять, так ли на самом деле успешен Магазин 3 (ведь конечной целью бизнеса является получение прибыли, а не выручки), а во-вторых, понять, чем можно объяснить такой большой прирост продаж по данному магазину и падение продаж по Магазину 1.
Факторный анализ по операционной прибыли
Что такое операционная прибыль, можно прочитать в статье Что такое прибыль. Виды прибыли
Факторный анализ по операционной прибыли проведем по тем же этапам, что и анализ по продажам. Используем те же дополнительные столбцы и такие же формулы (их можно даже скопировать).
В итоге видим, что Магазин 3, который показывал головокружительный рост выручки, по операционной прибыли уже не такой успешный.
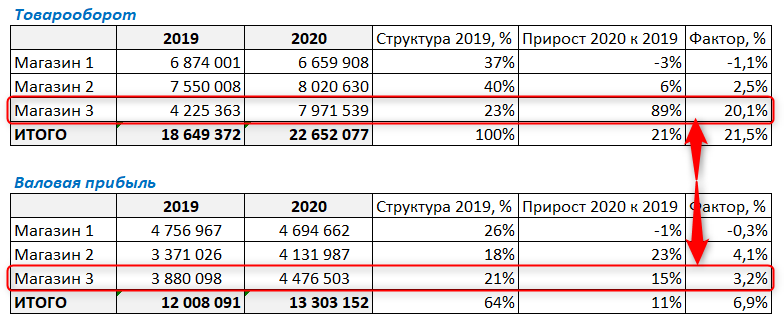
О чем это может говорить? О том, что нужно проводить дополнительный анализ факторов, которые могли повлиять на операционную прибыль. В данном случае в Магазине 3 сильно увеличились издержки (намного сильнее, чем выросла выручка), и при дополнительном анализе нужно понять, какие именно это издержки. Возможно, значительно увеличился штат сотрудников или арендуемая площадь, и т.д.
Магазин 2 показал рост прибыли больше, чем рост выручки. Это может говорить о том, что данный магазин снизил издержки (например, сократился штат сотрудников).
Факторный анализ пример расчета по себестоимости складских запасов
Дополнительно можно провести факторный анализ складских запасов. Это нужно, чтобы понять, за счет чего изменяется выручка.
Проделаем те же шаги, что и на предыдущих двух этапах.
Видим, что у Магазин 3, который показал высокий рост выручки и совсем небольшой рост операционной прибыли, очень сильно выросла сумма складских запасов.
Какой можно сделать предварительный вывод? Например, что Магазин 3, увидев тенденцию к росту продаж, арендовал дополнительную площадь для хранения товарных запасов. А рост выручки хоть и был достаточно высок — но меньше ожидаемого, и в итоге аренда дополнительных площадей для хранения сказалась на прибыли не лучшим образом.
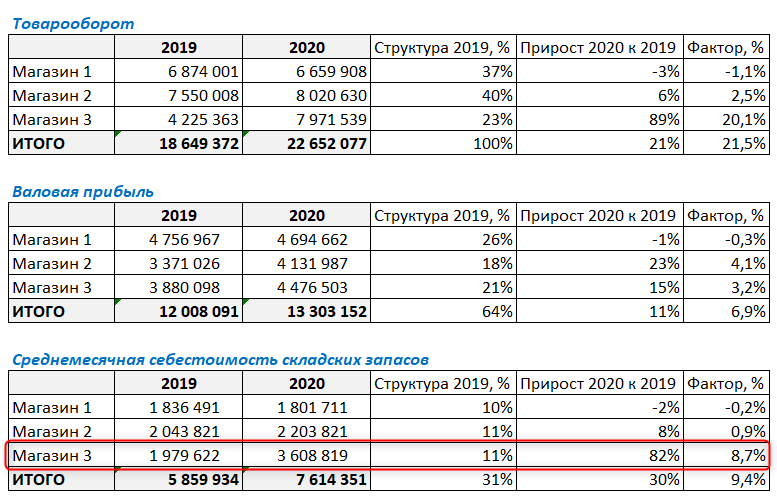
Таким вот нехитрым образом можно провести простой факторный анализ. Конечно, для полноценной аналитики этого может быть недостаточно, нужно учитывать еще множество факторов и составляющих. Но для того, чтобы увидеть общие тенденции, такого простого анализа бывает достаточно.
Более подробно о факторном анализе с примерами расчета можно прочитать в статьях:
Вам может быть интересно: