
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» — «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа.
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:
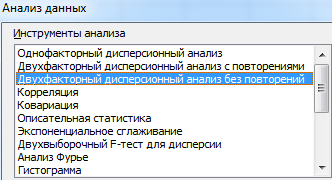
- Открываем диалоговое окно нашего аналитического инструмента. В раскрывшемся списке выбираем «Однофакторный дисперсионный анализ» и нажимаем ОК.
- В поле «Входной интервал» ввести ссылку на диапазон ячеек, содержащихся во всех столбцах таблицы.
- «Группирование» назначить по столбцам.
- «Параметры вывода» — новый рабочий лист. Если нужно указать выходной диапазон на имеющемся листе, то переключатель ставим в положение «Выходной интервал» и ссылаемся на левую верхнюю ячейку диапазона для выводимых данных. Размеры определятся автоматически.
- Результаты анализа выводятся на отдельный лист (в нашем примере).
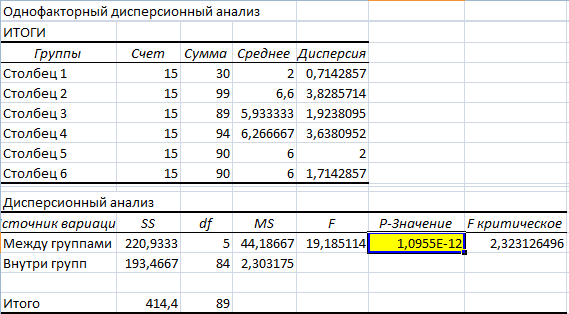
Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.
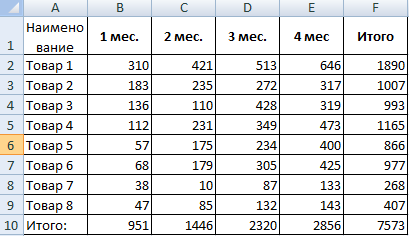
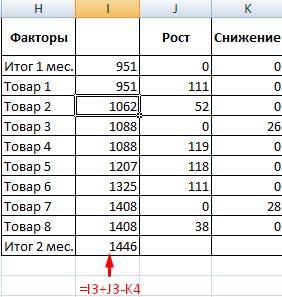
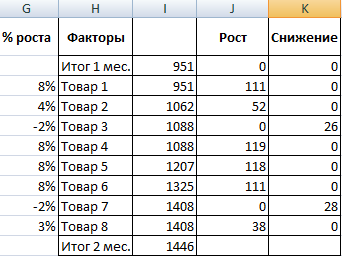
- Посмотрим, за счет, каких наименований произошел основной рост по итогам второго месяца. Если продажи какого-то товара выросли, положительная дельта – в столбец «Рост». Отрицательная – «Снижение». Формула в Excel для «роста»: =ЕСЛИ((C2-B2)>0;C2-B2;0), где С2-В2 – разница между 2 и 1 месяцем. Формула для «снижения»: =ЕСЛИ(J3=0;B2-C2;0), где J3 – ссылка на ячейку слева («Рост»). Во втором столбце – сумма предыдущего значения и предыдущего роста за вычетом текущего снижения.
- Рассчитаем процент роста по каждому наименованию товара. Формула: =ЕСЛИ(J3/$I$11=0;-K3/$I$11;J3/$I$11). Где J3/$I$11 – отношение «роста» к итогу за 2 месяц, ;-K3/$I$11 – отношение «снижения» к итогу за 2 месяц.
- Выделяем область данных для построения диаграммы. Переходим на вкладку «Вставка» — «Гистограмма».
- Поработаем с подписями и цветами. Уберем накопительный итог через «Формат ряда данных» — «Заливка» («Нет заливки»). С помощью данного инструментария меняем цвет для «снижения» и «роста».
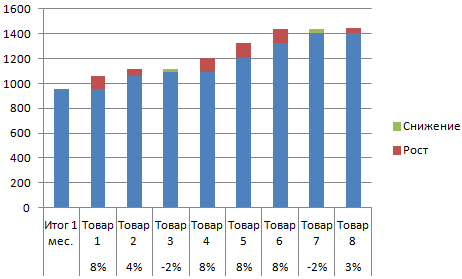
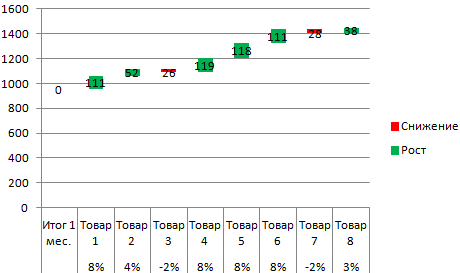
Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.
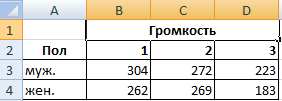
- Переходим на вкладку «Данные» — «Анализ данных» Выбираем из списка «Двухфакторный дисперсионный анализ без повторений».
- Заполняем поля. В диапазон должны войти только числовые значения.
- Результат анализа выводится на новый лист (как было задано).
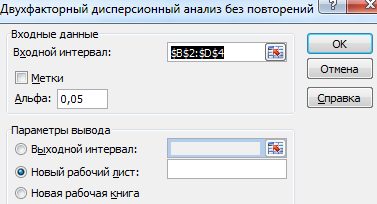
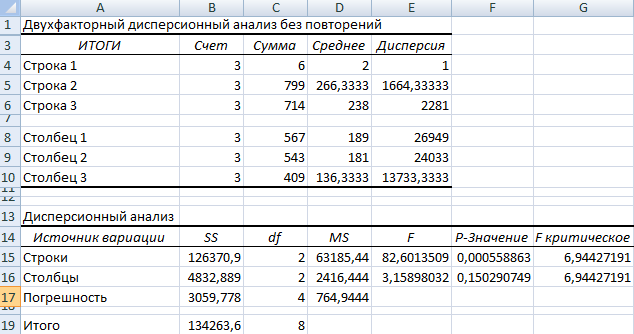
Та как F-статистики (столбец «F») для фактора «Пол» больше критического уровня F-распределения (столбец «F-критическое»), данный фактор имеет влияние на анализируемый параметр (время реакции на звук).
Скачать пример факторного и дисперсионного анализа
скачать факторный анализ отклонений
скачать пример 2
Для фактора «Громкость»: 3,16 < 6,94. Следовательно, данный фактор не влияет на время ответа.
Для примера также прилагаем факторный анализ отклонений в маржинальном доходе.
Авторы: Гончар-Зайкин П.П., к.б.н.; Чертов В.Г., к.э.н.
Полный текст на сайте http://www.sniish.ru/proposal_desc.php?id=8
Нами разработан пакет программ AgCStat в виде надстройки Excel.
В настоящее время пакет включает 12 программ плюс лист с примерами подготовки данных для анализа:
- получение табличных значений критериев Фишера и Стьюдента;
- восстановление выпавших данных
- вычисление статистик выборки;
- однофакторный дисперсионный анализ полевых опытов по Б.А. Доспехову;
- двухфакторный дисперсионный анализ полевых опытов по Б.А. Доспехову;
- двухфакторный дисперсионный анализ неравномерного комплекса по Н.А. Плохинскому;
- трехфакторный дисперсионный анализ равномерного комплекса (оригинальный алгоритм авторов);
- одно, двух и трех факторный анализ качественных признаков по Н.А. Плохинскому;
- парная корреляция и регрессия с полным статистическим анализом результатов;
- оценка разности средних по критерию Стьюдента.
1. Скачать с сайта разработчиков
2. Скачать с нашего сайта
3. Если первые две ссылки не работают, Вы можете скачать Эксель файл AgCStat
Анализируя список программ пакета, специалист может заметить, что некоторые программы дублируют программы стандартного Пакета анализа и даже встроенные функций. Это вызвано рядом причин.
Во-первых, неискушенному пользователю все же удобнее иметь все в одном пакете, освоить который значительно проще, чем работу со встроенными функциями.
Во-вторых, в версиях Excel младше Excel 2002 ряд функций либо отсутствуют, либо они не доступны, как, например, функции GetFisher и GetStudent – выдающих табличные значения критериев.
В-третьих, и, может быть самое главное, — это типизация. При просмотре «Примеров подготовки данных» видно, что все таблицы данных для анализов выполняются по одному типу, тогда как в стандартном Пакете анализа таблица данных для однофакторного комплекса строится по одному типу, а для двухфакторного — совсем по другому, понять который совсем не просто. По одному же типу построены и все диалоговые окна надстройки AgCSTAT (строка в меню Сервис – CXSTAT). Вся терминология, используемая в пакете, полностью соответствует терминологии принятой в отечественной литературе.
При разработке программ входящих в пакет нами использовались исключительно отечественные разработки, причем предпочтение оказывалось алгоритмам, которые в аграрных научных учреждениях приняты как стандартные.
Дадим некоторые пояснения по пакету программ.
Восстановление выпавших данных. Выбраковка делянки полевого опыта – обычное дело. Причины самые разные от градобоя до воровства и потравы. Узнать количество пропавшего в принципе нельзя, но вычислить величину, которая не нарушая статистических характеристик комплекса, восстановит его ортогональность для проведения некоторого формального анализа можно [3, 6]. Прием восстановления выпавшего данного применяется и тогда, когда некоторое данное резко отличается от соседних, однако пользоваться этим приемом следует с большой осторожностью и в купе с другими видами анализов о принадлежности данного к выборке.
Напомним, что алгоритмы Б.А. Доспехова привязаны к схеме закладки полевого опыта и повторения рассматриваются как фактор. В связи с этим, обратим внимание на то, что если в диалоговом окне «Однофакторный дисперсионный анализ по Доспехову» установить опцию «Опыт в вегетационных сосудах …», т.е. перейти к общей схеме дисперсионного анализа, то мы получим результаты, совпадающие как с результатами «по Плохинскому», так и однофакторного дисперсионного анализа пакета «Анализ данных».
В доступной нам литературе, мы не нашли четкого алгоритма трехфакторного дис-персионного анализа для количественных признаков (равномерного комплекса), но, поскольку необходимость в нем высока, разработали его сами, опираясь на алгоритмы Н.А. Плохинского [5].
Анализ опытов, связанных с изучением устойчивости растений к вредителям и болезням, а также для оценки эффективности различных химических препаратов, влияющих на устойчивость, очень часто проводится с использованием качественных признаков (больной – здоровый, заражен – не заражен и т. д.). В нашем пакете одно диалоговое окно позволяет выполнить дисперсионный анализ качественных признаков по одно, двух и трехфакторной схеме.
Программа для расчета корреляции и регрессии при парных взаимодействиях построена так, что выдает результаты регрессионного и корреляционного анализов в один прием вместе с оценкой их статистической достоверности.
Иногда исследователя интересует всего лишь величина разности средних двух выборок и ее достоверность. Эту задачу решает последняя в списке программа. Достаточно указать диапазоны, в которых находятся выборки, диапазоны могут быть как смежными, так и несмежными и даже располагаться на разных листах книги Excel.
Для установки книги надстройки на ПК достаточно иметь дискету с двумя файлами:AgCStat.xla и SetUp.exe. Вы запускаете файл SetUp.exe, а все остальное делается в автоматическом режиме. По завершению установки в списке надстроек Excel (меню Сервис — Надстройки, окно Надстройки) появится новая строка: “Agcstat”. Для начала работы с надстройкой ее нужно активизировать, установкой флажка.
Теперь в меню Сервис видим команду СХSТАТ, щелкаем по ней мышкой и на экране монитора появится диалоговое окно с перечнем программ пакета. До начала работы, советуем просмотреть примеры подготовки данных (первая строка списка). Дополнительной информации для работы с пакетом не потребуется.
Важные примечания от администратора vniioh.ru:
- Надстройка также работает в последних версиях Excel (2007 и 2010) 32-битных. Для единовременного использования надстройки необходимо распаковать архив agstat.zip в любую папку, запустить файл , подтвердить разрешение на включение макросов, и согласиться на установку надстройки. После этого на ленте справа появится вкладка «Надстройки», а в ней CXSTAT.
- Для постоянного включения надстройки нужно скопировать файл AgCStat.xla в папку:для Excel 2007 — C:Program FilesMicrosoft OfficeOffice12Library;
для Excel 2010 — C:Program FilesMicrosoft OfficeOffice14LibraryОткрыть окно свойств папки Library и снять флажок «Только чтение». Проверить атрибуты файла AgcStat.xla флажек «Только чтение» — должен быть снят.Запустите Excel от имени администратора. Нажмите вкладку Файл (для 2007 нажать на кружок) -> пункт Параметры -> Надстройки — внизу Управление (выбрать надстройки Excel) и нажмите Перейти -> отметить галочкой Agcstat и нажмите OK - Если у вас возникают ошибки в работе с программой (например ошибка 6 или 9), попробуйте для расчета создать новый файл рабочей книги, и скопируйте туда чистые числовые данные (через Специальную вставку — Вставка только значения). Ошибка должна исчезнуть. Замечено, что надстройка выдаёт ошибку когда данные отформатированы или к ним применено цветовое или условное форматирование. Программа 100% РАБОЧАЯ.
- UPD/ На 64-битных версиях Office 2010 и Office 365 (2013) запустить не удалось.
Использованная литература
- Эрмантраут Э.Р., Гудзъ В.П. Статистический анализ результатов агрономических ис-следований в прикладной программе «EXCEL-2000». //Материалы международной научно-практической конференции «современные проблемы опытного дела», том 2, СПб, 2000, стр.13-134.
- Лапач С.Н., Чубенко А.В., Бабич П.Н. Статистические методы в медико-биологических исследованиях с использованием Excel. Киев «МОРИОН», 2000, 320 с.
- Доспехов Б.А. Методика полевого опыта. 1-5 изд. М., 1965 — 1985
- Лакин Г.Ф. Биометрия. М., Изд. «Высшая школа», 1990, 352с.
- Плохинский Н.А. Биометрия. М., Изд. МГУ, 1970, 368с.
- Снедекор Д.У. Статистические методы в применении к исследованиям в сельском хозяйстве и биологии. М., 1961
- Фишер Р.Э. Статистические методы для исследователей. М., 1958
- Митропольский А.К. Техника статистических вычислений. М., 1971.
- Уэллс Э., Хешбаргер С. Microsoft Excel 97: разработка приложений / Пер. с анг. –СПб., БХВ-Санкт-Петербург, 1998, 624с.
При использовании вышеизложенных материалов необходимо ссылаться на авторов.
Данный материал опубликован в:
Сборнике «Рациональное природопользование и сельскохозяйственное производство в южных регионах Российской Федерации» М. «Современные тетради», 2003, с.559-564 П.П. Гончар-Зайкин, В.Г. Чертов.
Примечание
3. В пакете анализа программы MS Excel не
существует инструмента многофакторного
дисперсионного анализа с повторениями
или без повторений. Но зато в рамках
многофакторного регрессионного анализа
(инструмент анализа «Регрессия») [4] для
оценки достоверности получаемой
регрессионной модели производится
многофакторный дисперсионный анализ.
Нашей задачей является освоение данного
многофакторного анализа, что позволит
в дальнейшем правильно интерпретировать
результаты многофакторного регрессионного
анализа.
5.1. Открыть файл
MS
Excel
«многофакторный дисперсионный анализ»,
представляющий собой результаты контроля
пяти технологических факторов xi
(h, k, μ, Pb, Si) и отклика (y)
в 142 точках реально проводившегося
эксперимента.
5.2. Исключить из
142 точек 2 точки случайным образом с
помощью инструмента анализа «Выборка»
аналогично тому, как это делалось ранее,
см. п. 2.1.2.2.
5.3.
Сформировать таблицу исходных данных
из 140 оставшихся точек.
5.4. Открыть инструмент
анализа «Регрессия» (рис. 5).

Рис. 5. Опции
инструмента анализа «Регрессия»
5.5. Ввести данные
входных интервалов x
и y
для выбранных 140 точек с «метками»
(наименованиями столбцов) и нажать ОК,
получив в итоге три таблицы результатов
для принятого по умолчанию «Уровня
надёжности» (доверительной вероятности)
β
= 95
%.
5.6. Сравнить
полученную таблицу «Дисперсионный
анализ» с приведённым в табл. 9 результатом
дисперсионного анализа, выполненным
для всех исходных 142 точек, по величине
характеристик, обусловленных двумя
различными источниками вариации:
– регрессией
(действием пяти рассматриваемых факторов,
«Регрессия»);
– действием всех
остальных случайных и неучитываемых
факторов, «Остаток».
Сравнить следующие
характеристики:
– число степеней
свободы (df);
– полные составляющие
дисперсии (SS) и составляющие дисперсии,
приходящиеся на одну степень свободы
(MS);
– расчётную
величину фактора Фишера (F) и F-значение
уровня значимости «Значимость F».
Таблица 9
Итоги дисперсионного
анализа влияния
пяти технологических факторов
на
характеристику качества
y,
полученного для
142 наблюдений,
производимого
с использованием
инструмента анализа «Регрессия»
|
Источник вариации |
df |
SS |
MS |
F |
Значимость |
|
Регрессия |
5 |
93,8 |
18,8 |
18 |
1,08E-13 |
|
Остаток |
136 |
141,5 |
1,041 |
||
|
Итого |
141 |
235,3 |
Примечание
4:
А. Здесь рассчитываются
параметры вариации не по отдельным
факторам, как это делалось выше, а по
всем варьируемым и контролируемым
факторам вместе («Регрессия»), а также
по всем остальным случайным и неучитываемым
факторам («Остаток»).
Б. Вместо критического
(табличного) значения F-критерия (см.
выше) в многофакторном дисперсионном
анализе рассчитывается не менее удобное
F-значение уровня значимости, соответствующее
вычисленному значению F («Значимость
F»).
5.7. Сделать заключение
о достоверности получаемой регрессионной
модели. С этой целью следует сравнить
по величине «Значимость F» с принятым
в данной отрасли уровнем значимости α
= 0,05.
Примечание
5:
А.
Напомним, что уровень
значимости α
определяется из «Уровня
надёжности» β,
см. рис. 5, при преобразовании формулы
(1):
α
=
(100% –
β)/100.
(2)
Б.
Если «Значимость
F» < α,
можно говорить о достаточно высокой
достоверности (более 95%) получаемой
регрессионной модели. (Можно повысить
«Уровень
надёжности», см. рис. 5, например, до β
= 99 % и проверить, удовлетворяет ли
регрессионная
модель этому ещё более высокому «Уровню
надёжности»).
В.
В противном случае достоверность
получаемой регрессионной модели меньше
95 %, следовательно, целесообразно
попытаться её улучшить (повысить) за
счёт:
– изменения набора
рассматриваемых факторов,
– использования
взамен линейной зависимости от всех
действующих факторов более сложной
зависимости от одного, нескольких или
всех факторов. Можно рекомендовать для
этой цели специализированные статистические
программы, например, STATISTICA.
(В рамках MS
Excel
многофакторный нелинейный регрессионный
и, соответственно, дисперсионный анализы
не производятся).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
17 авг. 2022 г.
читать 3 мин
Двухфакторный дисперсионный анализ («дисперсионный анализ») используется для определения того, существует ли статистически значимое различие между средними значениями трех или более независимых групп, разделенных на два фактора.
В этом руководстве объясняется, как выполнить двусторонний дисперсионный анализ в Excel.
Пример. Двухфакторный дисперсионный анализ в Excel
Ботаник хочет знать, влияет ли на рост растений воздействие солнечного света и частота полива. Она сажает 40 семян и дает им расти в течение двух месяцев при различных условиях солнечного света и частоты полива. Через два месяца она записывает высоту каждого растения. Результаты показаны ниже:
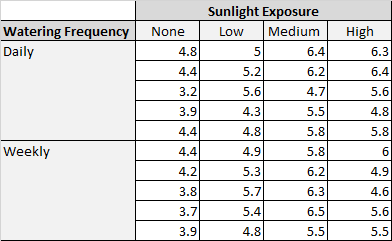
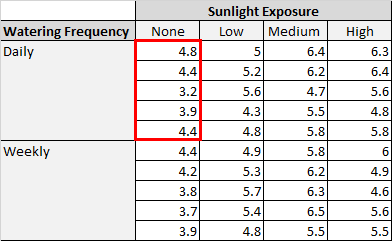
В таблице выше мы видим, что в каждой комбинации условий выращивалось по пять растений. Например, было пять растений, выращенных с ежедневным поливом и без солнечного света, и их высота через два месяца составила 4,8 дюйма, 4,4 дюйма, 3,2 дюйма, 3,9 дюйма и 4,4 дюйма:
Мы можем использовать следующие шаги для выполнения двустороннего анализа этих данных:
Шаг 1: Выберите пакет инструментов анализа данных.
На вкладке « Данные » нажмите « Анализ данных» :

Если вы не видите этот вариант, вам нужно сначала загрузить бесплатный пакет инструментов для анализа данных .
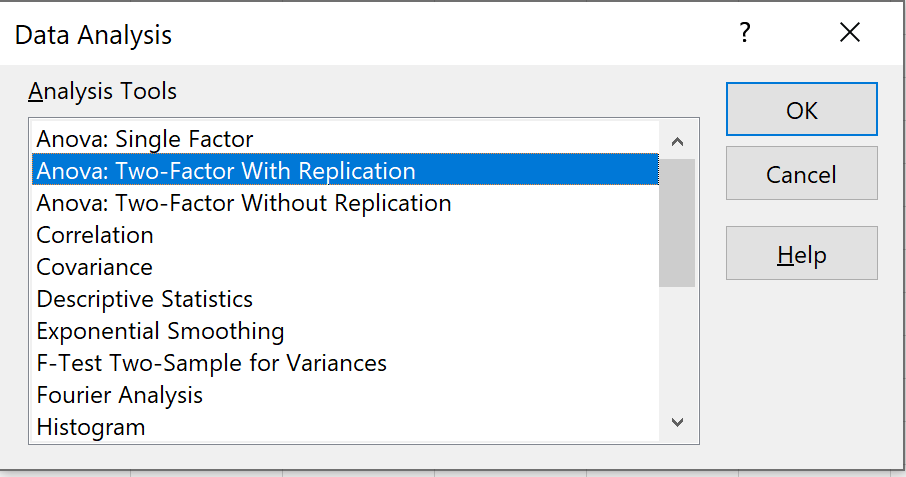
2. Выберите Anova: двухфакторный с репликацией
Выберите вариант с надписью Anova: Two-Factor With Replication , затем нажмите OK .
В этом контексте «повторение» означает наличие нескольких наблюдений в каждой группе. Например, было несколько растений, которые выращивались без воздействия солнечного света и ежедневного полива. Если бы вместо этого мы выращивали только одно растение в каждой комбинации условий, мы бы использовали «без повторения», но размер нашей выборки был бы намного меньше.
3. Введите необходимые значения.
Далее заполните следующие значения:
- Диапазон ввода: выберите диапазон ячеек, в котором находятся наши данные, включая заголовки.
- Рядов на образец: введите «5», поскольку в каждом образце 5 растений.
- Альфа: выберите уровень значимости для использования. Мы выберем 0,05.
- Выходной диапазон: выберите ячейку, в которой должны появиться выходные данные двухфакторного дисперсионного анализа. Мы выберем ячейку $G$4.
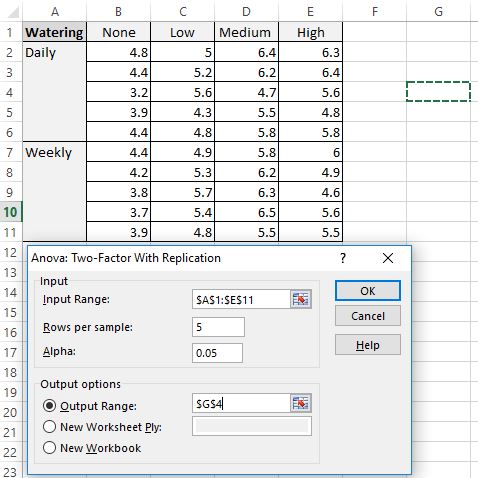
Шаг 4: Интерпретируйте вывод.
Как только мы нажмем OK , появятся результаты двухфакторного дисперсионного анализа:
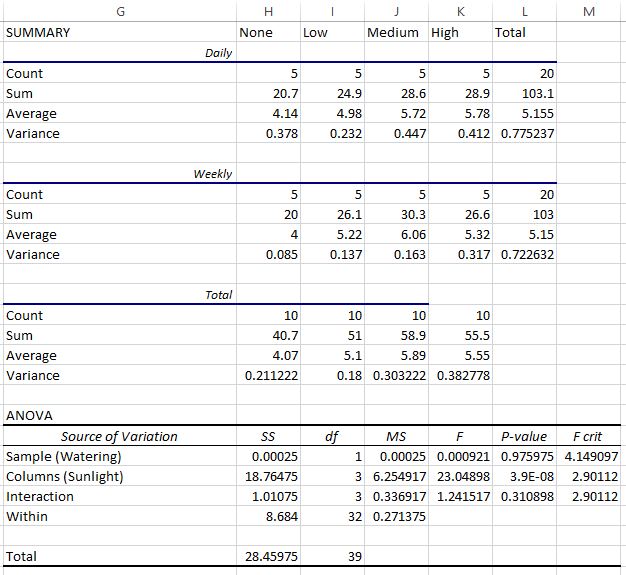
Первые три таблицы показывают сводную статистику для каждой группы. Например:
- Средняя высота растений, которые ежедневно поливали, но не освещали солнечным светом, составляла 4,14 дюйма.
- Средняя высота растений, которые поливали еженедельно и получали мало солнечного света, составляла 5,22 дюйма.
- Средняя высота всех ежедневно поливаемых растений составляла 5,115 дюйма.
- Средняя высота всех растений, которые поливали еженедельно, составляла 5,15 дюйма.
- Средняя высота всех растений, получавших много солнечного света, составляла 5,55 дюйма.
И так далее.
В последней таблице показан результат двухфакторного дисперсионного анализа. Мы можем наблюдать следующее:
- Значение p для взаимодействия между частотой полива и воздействием солнечного света составило 0,310898.Это не является статистически значимым при уровне альфа 0,05.
- Значение p для частоты полива составило 0,975975.Это не является статистически значимым при уровне альфа 0,05.
- Значение p для воздействия солнечного света составило 3,9E-8 (0,000000039).Это статистически значимо при уровне альфа 0,05.
Эти результаты показывают, что воздействие солнечного света является единственным фактором, статистически значимо влияющим на высоту растений. А поскольку эффекта взаимодействия нет, эффект воздействия солнечного света одинаков для каждого уровня частоты полива. То есть, поливают ли растение ежедневно или еженедельно, это не влияет на то, как воздействие солнечного света влияет на растение.
 If you thought there were a lot of functions and features already packed in to Excel, you may be surprised that there are even more available. Both Microsoft and third party developers publish additional tools, called add-ins, that are typically used for specialized number crunching in various fields.
If you thought there were a lot of functions and features already packed in to Excel, you may be surprised that there are even more available. Both Microsoft and third party developers publish additional tools, called add-ins, that are typically used for specialized number crunching in various fields.
If you are working on statistical analysis and, more specifically, undertaking a variation analysis, there is a tool available through add-ins that should help make the process much easier. Regardless of how complex the research you are working with, the ANOVA tool is simple and user friendly. Here we will briefly take a look at the tool and walk through the steps involved in using it.
If you are interested in learning more about Excel’s advanced analytical capabilities, you might be interested in an online advanced Excel course.
Understanding ANOVA in Excel
The ANOVA function in Excel is the analytical tool used for variance analysis. A form of hypothesis testing, it will determine whether two or more factors have the same mean. Currently, it has three different variations depending on the test you want to perform: Single factor, two-factor with replication and two factor without replication.
Single-factor: This offers a test on data of two or more samples. With it, you can test the hypothesis that each of the samples is drawn from the same underlying probability distribution against the hypothesis that the underlying probability distribution is not the same.
If you are working with only two samples, note that Excel gives you an alternative called T-Test, which is built in to its regular set of functions. If you would like to understand how this and other standard functions operate in Excel, you can take an online course in advanced Excel.
two-factor with replication: when you have two factors on which the variance depends and you are collecting multiple data points for a specified condition, you will want to use this option.
two-factor without replication: When variance depends on two factors and you are collecting a single dat point for a specified condition, you will use this test.
This tutorial assumes that you are familiar with these statistical concepts and will focus on explaining how to use Excel to help you run the tests. If, however, you need to brush up on concepts in statistics, you can take an online introduction to statistics that should serve as a refresher.
Enable the Analysis Toolpak
The ANOVA function is part of an add-in for Excel, so if you haven’t already, you will need to enable the Excel Analysis Toolpak before you can use it. In addition to ANOVA, this add-in for Excel will give you access to a number of helpful tools for running statistical analysis in your workbooks. If you would like to dive in and understand the power of Excel for working with statistics, you can take a course on Excel’s statistical functions.
Here are instructions for enabling the toolpak in Excel 2010. Depending on the version you are using, the method may vary slightly. So if this does not work for you, you should be able to search for another method or find it on Office.com
1. Go to the file menu
2. Select Options
3. From the options menu, select add-ins from the left column
4. At the bottom of the menu, you will see a label that says “Manage:” followed by a drop-down box. Make sure Excel add-ins is selected from that drop-down and click Go.

5. Another menu will appear, showing you the available add-ins. Check the box next to Analysis Toolpak, and click OK
If the Analysis toolpak is not listed, click browse to locate it. If the program tells you it isn’t installed, click Yes to install it.
You should now have the Analysis Toolpak enabled. To verify, click on the data tab from the main ribbon. You should see a data analysis option on the right. If you click on that Anova should be among the first options available.
Running ANOVA
Now that you have the Analysis toolpak enabled, you have what you need to complete the test.
Running the ANOVA function
To start with the Anova function, open the workbook containing the data you want to run the test on. Then, follow these steps:
1. click in a cell on your spreadsheet where your output will begin. The results, of course, will cover a range of cells.
2. Click on the Data tab from the main ribbon and select data analysis, which should be in the analysis menu on the right.
3. Select the appropriate Anova test from the options in the Data Analysis menu.
4. The function’s menu will pop up. Start by putting in the range containing the data to be analyzed. If you click the button to the right of the text box (containing a red arrow) you can select your cell range by clicking and dragging.

5. Select the number of rows each sample contains.
6. Specify the alpha (the default 0.05 represents a 95% confidence interval.
7. Specify the output range. Again, you can click the button to the right of the text box to click and drag. All you really need to consider here is where the first cell of the results will be located. You do not need to indicate the exact number of rows and columns for the result. Note that the output will be contained in a range of 7 columns by 30 rows.
You now have your result. All that’s left is interpreting it! If you are a little bit fuzzy on what the numbers mean, don’t worry, you have resources available to help out. In fact you can take an online course that includes a walkthrough of ANOVA and its results.
Hopefully, your test has run smoothly and produced a useable outcome.