
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
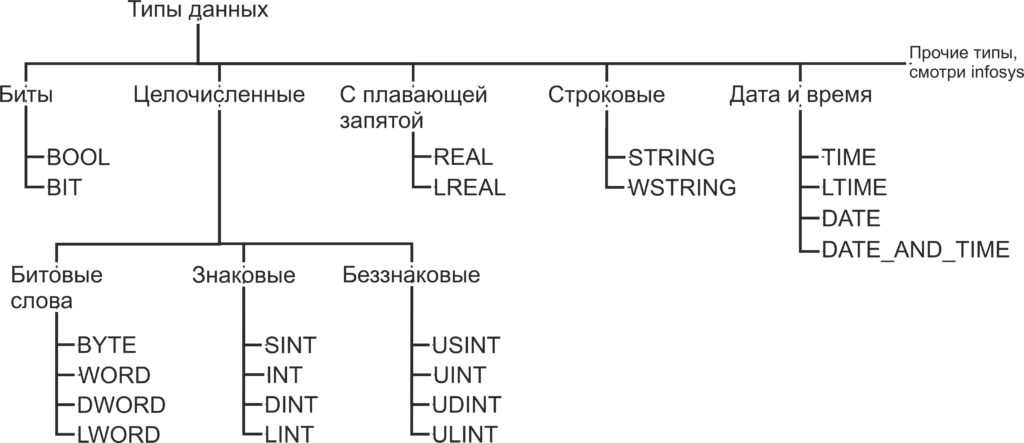
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
Целые числа
Данные каким-либо образом необходимо представлять в памяти компьютера. Существует множество различных типов данных, простых и довольно сложных, имеющих большое число компонентов и свойств. Однако, для компьютера необходимо использовать некий унифицированный способ представления данных, некоторые элементарные составляющие, с помощью которых можно представить данные абсолютно любых типов. Этими составляющими являются числа, а вернее, цифры, из которых они состоят. С помощью цифр можно закодировать практически любую дискретную информацию. Поэтому такая информация часто называется цифровой (в отличие от аналоговой, непрерывной).
Первым делом необходимо выбрать систему счисления, наиболее подходящую для применения в конкретных устройствах. Для электронных устройств самой простой реализацией является двоичная система: есть ток — нет тока, или малый уровень тока — большой уровень тока. Хотя наиболее эффективной являлась бы троичная система. Наверное, выбор двоичной системы связан еще и с использование перфокарт, в которых она проявляется в виде наличия или отсутствия отверстия. Отсюда в качестве цифр для представления информации используются 0 и 1.
Таким образом данные в компьютере представляются в виде потока нулей и единиц. Один разряд этого потока называется битом. Однако в таком виде неудобно оперировать с данными вручную. Стандартом стало разделение всего потока на равные последовательные группы из 8 битов — байты или октеты. Далее несколько байтов могут составлять слово. Здесь следует разделять машинное слово и слово как тип данных. В первом случае его разрядность обычно равна разрядности процессора, т.к. машинное слово является наиболее эффективным элементом для его работы. В случае, когда слово трактуется как тип данных (word), его разрядность всегда равна 16 битам (два последовательных байта). Также как типы данных существую двойные слова (double word, dword, 32 бита), четверные слова (quad word, qword, 64 бита) и т.п.
Теперь мы вплотную подошли к представлению целых чисел в памяти. Т.к. у нас есть байты и различные слова, то можно создать целочисленные типы данных, которые будут соответствовать этим элементарным элементам: byte (8 бит), word (16 бит), dword (32 бита), qword (64 бита) и т.д. При этом любое число этих типов имеет обычное двоичное представление, дополненное нулями до соответствующей размерности. Можно заметить, что число меньшей размерности можно легко представить в виде числа большей размерности, дополнив его нулями, однако в обратном случае это не верно. Поэтому для представления числа большей размерности необходимо использовать несколько чисел меньшей размерности. Например:
- qword (64 бита) можно представить в виде 2 dword (32 бита) или 4 word (16 бит) или 8 byte (8 бит);
- dword (32 бита) можно представить в виде 2 word (16 бит) или 4 byte (8 бит);
- word (16 бит) можно представить в виде 2 byte (8 бит);
Если A — число, B1..Bk — части числа, N — разрядность числа, M — разрядность части, N = k*M, то:
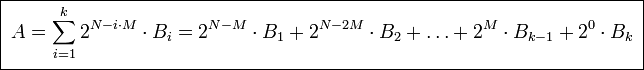
Например:
- A = F1E2D3C4B5A69788 (qword)
- A = 232 * F1E2D3C4 (dword) + 20 * B5A69788 (dword)
- A = 248 * F1E2 (word) + 232 * D3C4 (word) + 216 * B5A6 (word) + 20 * 9788 (word)
- A = 256 * F1 (byte) + 248 * E2 (byte) + … + 28 * 97 (byte) + 20 * 88 (byte)
Существуют понятия младшая часть (low) и старшая часть (hi) числа. Старшая часть входит в число с коэффициентом 2N-M, а младшая с коэффициентом 20. Например:
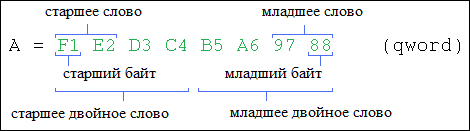
Байты числа можно хранить в памяти в различном порядке. В настоящее время используются два способа расположения: в прямом порядке байт и в обратном порядке байт. В первом случае старший байт записывается в начале, затем последовательно записываются остальные байты, вплоть до младшего. Такой способ используется в процессорах Motorola и SPARC. Во втором случае, наоборот, сначала записывает младший байт, а затем последовательно остальные байты, вплоть до старшего. Такой способ используется в процессорах архитектуры x86 и x64. Далее приведен пример:

Используя подобные целочисленные типы можно представить большое количество неотрицательных чисел: от 0 до 2N-1, где N — разрядность типа. Однако, целочисленный тип подразумевает представление также и отрицательных чисел. Можно ввести отдельные типы для отрицательных чисел от -2N до -1, но тогда такие типы потеряют универсальность хранить и неотрицательные, и отрицательные числа. Поэтому для определения знака числа можно выделить один бит из двоичного представления. По соглашению, это старший бит. Остальная часть числа называется мантиссой.
Если старший бит равен нулю, то мантисса есть обычное представление числа от 0 до 2N-1-1. Если же старший бит равен 1, то число является отрицательным и мантисса представляет собой так называемый дополнительный код числа. Поясним на примере:
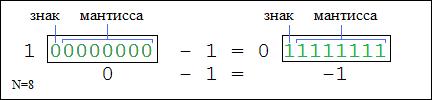
Как видно из рисунка, дополнительный код равен разнице между числом 2N-1 и модулем исходного отрицательного числа (127 (1111111) = 128 (10000000) — |-1| (0000001)). Из этого вытекает, что сумма основного и дополнительного кода одного и того же числа равна 2N-1.
Из вышеописанного получается, что можно использовать только целочисленные типы со знаком для описания чисел. Однако существует множество сущностей, которые не требуют отрицательных значений, а значит, место под знак можно включить в представление неотрицательного числа, удвоив количество различных неотрицательных значений. Как результат, в современных компьютерах используются как типы со знаком или знаковые типы, так и типы без знака или беззнаковые типы.
В итоге можно составить таблицу наиболее используемых целочисленных типов данных:
| Общее название | Название в Pascal | Название в C++ | Описание | Диапазон значений |
| unsigned byte | byte | unsigned char | беззнаковый 8 бит | 0..255 |
| signed byte | shortint | char | знаковый 8 бит | -128..127 |
| unsigned word | word | unsigned short | беззнаковый 16 бит | 0..65535 |
| signed word | smallint | short | знаковый 16 бит | -32768..32767 |
| unsigned double word | cardinal | unsigned int | беззнаковый 32 бита | 0..232-1 |
| signed double word | integer | int | знаковый 32 бита | -231..231-1 |
| unsigned quad word | uint64 | unsigned long long unsigned __int64_t (VC++) |
беззнаковый 64 бита | 0..264-1 |
| signed quad word | int64 | long long __int64_t (VC++) |
знаковый 64 бита | -263..263-1 |
В VC ++ 6.0 BYTE, WORD, DWORD — это целое число без знака, которое определено в WINDEF.h
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned long DWORD;Другими словами, BYTE — это тип без знака, WORD — беззнаковый короткий тип, а DWORD — беззнаковый длинный тип.
В VC ++ 6.0 1 байт символа, short — 2 байта, int и long — 4 байта, поэтому можно считать, что переменные, определяемые BYTE, WORD, DWORD, — это 1 раздел, 2 байта, 4 слова. Раздел.
То есть: BYTE = unsigned char, WORD = unsigned short, DWORD = unsigned long
DWORD обычно используется для сохранения адреса или сохранения указателя
Разница между словом и словом
Определение WORD и DWORD в основном для: 1. Легко трансплантировать; 2. Более строгая проверка типов
WORD фиксируется на 2 байта, DWORD фиксируется на 4 байта
Int, с разными операционными системами, имеет разное количество байтов, в 32-битной операционной системе — 4 байта, в 16-битной операционной системе — 2 байта
В операции сериализации, поскольку сериализация хранится в соответствии с потоком байтов, чтобы гарантировать, что она не будет выровнена, необходимо использовать тип данных с четким числом байтов.
Прежде
чем переходить к непосредственно
изучению МЭК-языков,
необходимо познакомиться с общими
элементами этих
языков. Общие элементы служат единым
фундаментом, позволяющим
объединить многоязычные компоненты в
одном проекте.
В главе будут рассмотрены данные, с
которыми способен работать
стандартный ПЛК, форматы их представления
и наиболее общие
приемы и тонкости работы с ними.
Типы данных
Тип
данных переменной определяет род
информации, диапазон представления и
множество допустимых операций. Языки
МЭК
используют идеологию строгой проверки
типов данных. Это означает,
что любую переменную можно использовать
только после
ее объявления. Присваивать значение
одной переменной другой
можно, только если они обе одного типа.
Допускается также присваивание
значения переменной совместимого типа,
имеющей более
широкое множество допустимых значений.
В этом случае происходит
неявное преобразование типа без
потерь. Неявные преобразования
типов данных с потерями запрещены. Так,
например,
логическую переменную, способную
принимать только два
значения (логические 0 и 1), можно присвоить
переменной типа
SINT
(-128…+127), но не наоборот.
При
трансляции программы все подобные
попытки отслеживаются и считаются
грубыми ошибками. Если же это действительно
необходимо,
то выполнить присваивание с потерями
возможно, но
только при помощи специальных операторов.
Операторы преобразования
в МЭК выполняют также и более сложные
операции, например
преобразование числа или календарной
даты в текстовую
строку, и наоборот.
Наибольшее
разнообразие типов данных в стандарте
предусмотрено
для представления целых
чисел. Смысл
применения широкого
спектра целочисленных переменных
заключается в первую
очередь в оптимизации кода программы.
Скорость вычислений
зависит от того, как микропроцессор
оперирует с переменными
данного типа. Так, вполне очевидно, что
16-разрядный процессор
выполняет сложение двух 16-разрядных
значений одной командой.
Сложение же двух значений 32-разрядных
переменных
— это подпрограмма из нескольких команд.
Дополнительные
задержки могут образовываться за счет
мультиплексирования
шины данных, связывающих процессор и
память,
особенностей микросхем памяти и т. д. В
общем случае, меньшие
по диапазону представляемых значений
типы переменных требуют меньше памяти,
меньше кода, и вычисления с их участием
выполняются значительно быстрее.
Типы
данных МЭК разделяются на две категории
— элементарные и составные. Элементарные
или
базовые
типы являются
основой для построения составных типов.
К составным
типам
относятся
перечисления, массивы, структуры, массивы
структур
и т. д.
Элементарные
типы данных
Целочисленные
типы
Целочисленные
переменные отличаются
различным диапазоном
сохраняемых данных и, естественно,
различными требованиями
к памяти. Подробно данные характеристики
представлены в следующей
таблице.
|
Тип |
Нижний предел |
Верхний предел |
Размер,
в |
|
BYTE |
8 |
1 |
|
|
WORD |
16 |
2 |
|
|
DWORD |
32 |
4 |
|
|
LWORD |
64 |
8 |
|
|
SINT |
-128 |
127 |
1 |
|
INT |
-32768 |
32767 |
2 |
|
DINT |
-231-1 |
231-1 |
4 |
|
LINT |
-263-1 |
263-1 |
8 |
|
USINT |
0 |
255 |
1 |
|
Тип |
Нижний |
Верхний предел |
|
UINT |
0 |
65535 |
|
UDINT |
0 |
232-1 |
|
ULINT |
0 |
264-1 |
Нижний
предел диапазона целых без знака 0,
верхний предел определяется
как (2n)
— 1, где n
— число разрядов числа. Для чисел
со знаком нижний предел —(2n-1),
верхний
предел (2n-1).
Наименования
целых типов данных образуются с
применением
префиксов, выражающих отношение размера
к 16-разрядным словам:
S
(short
*1/2) короткое, D
(double
*2) двойное, L
(long
*4) длинное.
Префикс U
(unsigned)
указывает на представление целых
без знака.
Переменные
типов BYTE,
WORD,
DWORD
и LWORD
определяются
стандартом как битовые строки ANY_BIT.
Говорить
о диапазоне значений чисел для этих
переменных вообще некорректно. Они
представляют строки из 8, 16 и 32 бит,
соответственно.
Помимо обращения с такими переменными
как к единым целым,
их можно использовать побитно.
Целые
числа могут быть представлены в двоичной,
восьмеричной,
десятичной или шестнадцатеричной
системе счисления. Числовые
константы, отличные от десятичных,
требуют указания основания
системы счисления перед знаком «#».
Например:
2#0100_1110
8#116
16#4E78
Для
обозначения шестнадцатеричных цифр от
10 до 15 используются
латинские буквы от А до F.
Символ
подчеркивания «_» не влияет на значение
и используется
исключительно для улучшения зрительного
восприятия числа.
Например: 10_000, 16#01_88. Подчеркивание можно
применять
только между цифрами или в конце числа.
Два или более подчеркивания
подряд применять нельзя.
Логический тип
Два значении False
и True.
Начальная инициализация – ложь.
По
определению BOOL
—
это строка из одного бита, но из соображений
эффективности кода при автоматическом
распределении
памяти транслятором под битовую
переменную выделяется, как
правило, 1 байт памяти целиком. Переменные
типа BOOL,
связанные
с дискретными входами-выходами или
определенные с прямым битовым адресом,
действительно физически представлены
одним битом.
Действительные
типы
Переменные
действительного типа REAL
представляют действительные
числа в диапазоне ±10±38.
Из 32 бит, занимаемых числом, мантисса
занимает 23 бита. В результате точность
представления
приблизительно составляет 6 — 7 десятичных
цифр.
Длинный
действительный формат LREAL
занимает
64 бита. Число
содержит 52-битовую мантиссу. Точность
представления приблизительно
составляет 15 — 16 десятичных цифр.
Диапазон чисел
длинного действительного ±10±307.
Числа
с плавающей запятой, записываются в
формате с точкой:
14.0, -120.2, 0.33_ или в экспоненциальной форме:
-1.2Е10, 3.1е7.
Интервал времени
Переменные
типа TIME
используются для выражения интервалов
времени. В
отличие от времени суток (TIME_OF_DAY)
временной
интервал не ограничен максимальным
значением в 24
часа.
Числа,
выражающие временной интервал, должны
начинаться с
ключевого слова TIME#
или в сокращенной форме Т#. В общем случае
представление времени составляется из
полей дней (d),
часов
(h),
минут (m),
секунд (s)
и миллисекунд (ms).
Порядок представления
должен быть именно такой, хотя ненужные
элементы можно опускать. Для лучшего
зрительного восприятия поля допускается
разделять символом подчеркивания.
Например:
VAR
TIME1:
TIME:=
T#10h_14m_5s;
END_VAR
Старший
элемент может превышать верхнюю границу
диапазона представления. Так, если
в представлении присутствуют дни или
часы, то секунды не могут превышать
значения 59. Если секунды
стоят первыми, то их значение может быть
и большим. Смысл
этого правила состоит в том, что если
вы хотите выражать интервал,
например, исключительно в секундах —
пожалуйста. Но
если вы задействуете минуты, то для
единообразия представления, секунды
обязаны соблюдать принятые «правила
субординации».
Младший
элемент можно представить в виде
десятичной дроби:
TIME1:=
T#1.2S; (*равносильно
Т#1s200ms*)
Время суток и
дата
Типы
переменных, выражающие время дня или
дату, представляются
в соответствии с ISO
8601.
|
Тип |
Короткое |
Начальное значение |
|
DATE |
D |
1 |
|
TIME_OF_DAY |
TOD |
00:00 |
|
DAT |
DT |
00:00 |
Дата
записывается в формате «год» — «месяц»
— «число». Время
записывается в формате «часы»: «минуты»:
«секунды».«сотые».
Дата определяется ключевым словом DATE#
(сокращенно D#),
время дня TIME_OF_DAY#
(сокращенно TOD#),
дата и время
DATE
AND
TIME#
(сокращенно DT#).
DATE#2002-01-31
или
D#2002-01-31 TIME_OF_DAY#16:03:15.47
или
TOD#16:03:15.47
DATE_AND_TIME#2002-01-31-16:03:15.47
или
DT#2002-01-31-16:03:15.47
Все
три типа данных физически занимают 4
байта (DWORD).
Тип
TOD
содержит время суток в миллисекундах
начиная с 0 часов. Типы DATE
и DT
содержат время в секундах начиная с 0
часов
1 января 1970 года.
Строки
Тип
строковых
переменных STRING
определяет
переменные, содержащие текстовую
информацию. Размер строки задается при
объявлении.
Например, объявление строки strl,
вмещающей до 20
символов, и str2
— до 60 символов:
VAR
str1:
STRING(20); str2:
STRING(60):= ‘Тест’;
END_VAR
Если
начальное значение не задано, то при
инициализации будет
создана пустая строка.
Количество
необходимой памяти определяется заданным
при объявлении
размером строки. Для типа STRING
каждый
символ занимает
1 байт (WSTRING
2
байта). Строковые константы задаются
между одинарных кавычек:
str1
:= ‘Полет нормальный’;
При
необходимости помещения в строку кода,
не имеющего печатного
отображения, используется знак ($) и
следующий за ним
код из двух цифр в шестнадцатеричной
системе счисления. Для
распространенных управляющих терминальных
кодов можно
применить следующие сокращения:
$$
$’
$L
или $l
для LF
$N
для CR
$T
для Tab
Иерархия
элементарных типов
Приведенная
ниже иерархия
элементарных типов применяется
исключительно для удобства описания
программ. Каждое наименование ANY_…
объединяет некоторое множество типов.
Так, при
описании любой битовой операций удобнее
указать, что она применима
для ANY_BIT,
чем перечислять всякий раз допустимые
элементарные типы. Применять ANY_
при
объявлении переменных,
конечно, нельзя.
|
ANY |
ANY_NUM |
ANY_INT |
SINT, |
|
ANY_REAL |
REAL, |
||
|
ANY_BIT |
BOOL, |
||
|
STRING |
|||
|
TIME |
|||
|
ANY_DATE |
DATE, TIME_OF_DAY, DATE_AND_TIME |
Пользовательские
типы данных
Описание
пользовательских
типов данных (кроме
массивов) должно
выполняться на уровне проекта (в CoDeSys
на вкладке «Типы
данных» — «Организатор Объектов»).
Объявление типа всегда
начинается с ключевого слова TYPE
и
заканчивается строкой END
TYPE.
Массивы
Массивы
представляют
собой множество однотипных элементов
с произвольным доступом. Массивы могут
быть многомерными.
Размерность массива и диапазоны индексов
задаются при объявлении
(см. пример задания трехмерного массива):
<Имя
массива>: ARRAY
[<li1…lh1>,
<li2…lh2>,
<li3…lh3>]
OF
<mun
элемента>;
где
,
li1,
li2,
li3
указывают нижние пределы индексов; lh1,
lh2
и lh3
— верхние пределы. Индексы должны быть
целого типа и только
положительные, отрицательные индексы
использовать нельзя.
Примеры объявления
массивов:
XYbass: ARRAY
[1..10,1..20] OF
INT;
TxtMsg: ARRAY
[0..10] OF STRING(32);
Massl: ARRAY
[1..6] OF SINT := 1,1,2,2,2,2;
Mass2: ARRAY
[1..6] OF
SINT
:= 1,1,4(2);
Два
нижних примера показывают, как можно
выполнить элементов
массива при объявлении. Оба примера
создают
одинаковые массивы. В первом примере
все начальные значения приведены
через запятую. Во втором примере
присутствует сокращение N(a,b,c..),
которое означает — повторить
последовательность а, b,
с.. N раз. Многомерные массивы
инициализируются построчно:
Mass2d:
ARRAY
[1..2,1..4] OF
SINT
:= 1,2,3,4,5,6,7,8;
Для
доступа к элементам массива применяется
следующий синтаксис:
<Имя_массива>[Индекс1,Индекс2,ИндексЗ]
Для
двухмерного массива используются два
индекса. Для одномерного,
очевидно, достаточно одного. Например:
XYbass[2,12]
:= 1;
i
:= STR_TO_INT(TxtMsg[4]);
Если
это не принципиально, используйте в
массивах нумерацию с
0. В этом случае вычисление физического
адреса элемента при исполнении
проще. В результате код получается
несколько короче.
Структуры
Структуры
предназначены
для создания новых типов данных на
основе элементов разных базовых типов.
С переменной типа структура
можно обращаться как с единым элементом,
передавать в
качестве параметра, создавать указатели,
копировать и т. д.
В
отличие от массивов структура действительно
вводит новый тип данных. Это означает,
что до применения конкретной переменной
нужно выполнить как минимум два
объявления. Сначала нужно
описать структуру. Описание структуры
происходит глобально,
на уровне проекта. Описанная структура
получает идентификатор
(имя
структуры). Но это еще не переменная,
это новый тип
данных. Теперь, используя новый
идентификатор, нужно объявить
одну или сколько угодно переменных,
точно так же, как
и для базовых типов. Только теперь
переменная нового типа получает
«телесную оболочку» или, иными словами,
конкретное место
в памяти данных.
Объявление
структуры должно
начинаться с ключевого слова STRUCT
и заканчиваться END_STRUCT.
Синтаксис объявления выглядит
так:
TYPE
<Имя_структуры>:
STRUCT
<Объявление
переменной 1>
• • •
<Объявление
переменной п>
END_STRUCT
END_TYPE
Пример
объявления структуры по имени Trolley:
TYPE Trolley: STRUCT
Start: TIME;
Distance: INT;
Load,
On: BOOL;
Articl: STRING(16);
END_STRUCT
END_TYPE
Объявление
в программе переменной Telegal
типа Trolley
и начальная
инициализация структуры выглядит так:
Telegal:
Trolley
:= (Articl:=’Пустой’);
При
начальной инициализации не обязательно
задавать значения для всех элементов.
Элементы, не имеющие явно указанных
начальных
значений, по умолчанию получат нулевые
значения.
Для доступа к
элементам структуры используется
следующий синтаксис:
<Имя__переменной>.<Имя_элемента>
Например:
Telegal.On
:= True;
Структуры
могут включать другие структуры, массивы
и сами образовывать
массивы. Пример объявления и инициализации
массива
структур:
TrolleySet:
ARRAY[0..2]
OF
Trolley
:= (Articl
:= ‘Т1’), (Articl
:= ‘Т2’), (Articl
:= ‘ТЗ’); TrolleySet[i].On
:= TRUE;
Если
структура содержит вложенную структуру,
то доступ к элементам
вложенной структуры осуществляется с
применением составного имени, содержащего
две точки:
train.wagon[5].
weight;
(*wagon[]
вложенный массив структур*)
Поскольку
физический размер элементов структуры
известен транслятору
заранее, обращение к элементу структуры
не дает каких-либо накладных расходов
в сравнении с простой переменной.
Транслятор имеет возможность рассчитать
абсолютные адре-
са
элементов при компиляции. Естественно,
это не относится к массивам структур.
Чтобы не иметь проблем при использовании
нескольких
различных переменных одной структуры,
применять прямые
адреса в структуре нельзя.
Перечисления
Перечисление
позволяет
определить несколько последовательных
значений переменной и присвоить им
наименования. Перечисление
— это удобный инструмент, позволяющий
ограничить множество
значений переменной и усилить контроль
при трансляции.
Как и структура, перечисление создает
новый тип данных,
определение которого выполняется на
уровне проекта:
TYPE
<Имя
перечисления>:
(<Элемент
0>, < Элемент 1>, … <
Элемент
п>);
END_TYPE
Объявленная
позднее переменная типа <Имя
перечисления> может
принимать только перечисленные значения.
При инициализации переменная получает
первое из списка значение. Если числовые
значения элементов перечисления не
указаны явно, им присваиваются
последовательно возрастающие числа
начиная с 0. Фактически элемент перечисления
— это число типа INT
с ограниченным набором значений.
Если необходимо, значения элементам
можно присвоить явно при объявлении
типа перечисления. Например:
TYPE
TEMPO:
(Adagio
:= 1,
Andante
:= 2,
Allegro
:= 4);
END_TYPE
Идентификаторы
элементов перечисления используются
в программе
как значения переменной:
VAR
LiftTemp:
TEMPO:= Allegro;
END_VAR
Если
в разные перечисления включены элементы
с одинаковыми именами, возникает
неоднозначность. Для решения этой
проблемы
применяется префикс, содержащий
перечисление: TEMPO#Adagio.
В CoDeSys
все наименования элементов перечисления
обязаны быть уникальными.
Ограничение
диапазона
Тип
переменных с ограниченным
диапазоном значений позволяет
определить допустимое множество значений
переменной. Объявление
типа переменной с ограниченным диапазоном
должно происходить
непосредственно между ключевыми словами
TYPE
и END_TYPE:
TYPE
<Имя>
:
<Целый
тип> (от ..до)
END_TYPE
Например:
TYPE
DAC10:
INT(0..16#3FF);
END_TYPE
Применение
переменной с ограничением диапазона
покажем на
примере:
VAR
dac: DAC10;
END_VAR
dac:= 2000;
При
попытке трансляции данного примера
возникает законная ошибка:
‘Error:
Type mismatch: Cannot convert ‘2000’ to INT(0.
.1023)’.
Псевдонимы типов
Проблема
выбора подходящего типа данных не всегда
решается легко. Допустим, вы работаете
с температурой, замеренной 16-разрядным
АЦП. Может ли быть температура только
выше нуля
или когда-либо потребуется работать в
отрицательной области,
еще не совсем очевидно. В одном случае
нужно использовать тип
переменных UINT,
а в другом — INT.
Здесь удобно определить
новый тип данных:
TYPE
TEMPERATURA:
UINT;
END
TYPE
Далее
везде в программе вы используете тип
TEMPERATURA
при
объявлении переменных. Если вдруг
понадобится изменить тип
температуры на INT,
то это легко и быстро можно будет сделать
в одном месте.
Аналогичные
псевдонимы
типов удобно
создавать для любых
часто используемых в программе типов.
Например, для массивов
или других типов, имеющих длинное и
невыразительное
определение.
Переменные
Каждая
переменная
обязательно
имеет наименование и тип. Сущность
переменной может быть различной.
Переменная может представлять
вход или выход ПЛК, данные в оперативной
или энергонезависимой памяти. Далее мы
рассмотрим правила объявления
и некоторые практические сложности и
тонкости, возникающие при работе с
переменными.
Идентификаторы
Имя
переменной (ее
идентификатор) должно быть составлено
из
печатных символов и цифр. Цифру нельзя
ставить на первое место. Пробелы в
наименовании использовать нельзя.
Вместо них
обычно
применяется символ подчеркивания.
Символ подчеркивания
является значимым. Так имена ‘Varl’,
‘Var_l’
и ‘_Varl’
являются
различными. Два подчеркивания подряд
использовать нельзя.
Регистр букв не учитывается. Так ‘VAR1’
и ‘Varl’
одно и то значение.
Как минимум, 6 первых знаков идентификатора
являются значимыми
для всех систем программирования.
Аналогичные
требования относятся и к любым
идентификаторам
МЭК-программ (компоненты, метки, типы и
т. д.).
Распределение
памяти переменных
Контроллер
с точки зрения МЭК программы имеет
несколько областей
памяти, имеющих разное назначение.
-
Область входов
ПЛК. -
Область выходов
ПЛК. -
Область прямо
адресуемой памяти. -
Оперативная память
пользователя (ОЗУ).
Аппаратные
ресурсы ПЛК присутствуют в МЭК-проектах
в неявной форме. Размещение переменной
в одной из трех первых областей
приводит к ее связи с определенной
аппаратурой — входами,
выходами или переменными системы
исполнения (диагностика
модулей, настройка параметров ядра и
т. д.). Распределение переменных
в этих областях определяется изготовителем
ПЛК. Привязка
к конкретным адресам задается при помощи
прямой адресации.
Для обеспечения переносимости программного
обеспечения прямые
адреса нужно использовать только в
разделе объявлений. В языках программирования
стандарта не предусмотрено операций
прямого чтения входов-выходов. Эту
работу выполняет система исполнения.
При необходимости для низкоуровневого
обращения
изготовителем ПЛК поставляются
специальные библиотеки.
Объявление
переменной без префикса AT
физически означает выделение
ей определенной памяти в области ОЗУ.
Распределение доступной
памяти ОЗУ транслятор осуществляет
автоматически.
Переменные
принято разделять на глобальные и
локальные по области
видимости. Глобальные
переменные определяются
на Уровне
ресурсов проекта (VAR_GLOBAL)
и доступны для всех программных
компонентов проекта. Локальные
переменные описываются
при объявлении компонента и доступны
только внутри него. Описание любого
программного компонента содержит, как
минимум, один раздел объявления
локальных переменных VAR,
переменных
интерфейса VAR_INPUT,
VAR_OUTPUT,
VAR_IN_OUT
и
внешних глобальных переменных VAR_EXTERNAL
(см.
подробнее
«Компоненты организации программ»).
Наименования
разделов объявления переменных могут
содержать дополнительные ключевые
слова, уточняющие способ применения.
|
Ключевое |
Применение |
|
RETAIN |
Переменные |
|
CONSTANT |
Константы, |
Прямая адресация
Для
создания прямо
адресуемой переменной
используется следующее
объявление:
имя
переменной АТ%
прямой
адрес тип;
Прямой адрес
начинается с буквы, определяющей область
памяти:
|
Символ |
Область |
|
I |
Область |
|
Q |
Область |
|
M |
Прямо |
Далее следует
символ, определяющий тип прямого адреса:
|
Символ |
Область |
|
нет |
Бит |
|
X |
Бит _ |
|
В |
Байт |
|
W |
Слово |
|
D |
Двойное |
|
L |
Длинное |
Завершает
прямой адрес число — составной
иерархический адрес, поля которого
разделены точкой. В простейшем случае
используется
два поля адреса: номер элемента и номер
бита.
В конце
объявления, как и для автоматически
размещаемых переменных,
необходимо указать тип переменной. При
указании адреса
одного бита тип переменной может быть
только BOOL.
В
прямом адресе указывается именно номер
элемента. Это коренным
образом отличается от физических адресов
микропроцессора.
Если прямой адрес определяет байт, то
номер элемента — это
номер байта. Если прямой адрес определяет
слово, то номер элемента
— это номер слова, и, естественно, один
элемент занимает два байта. Так,
следующие два объявления адресуют один
и тот
же байт:
a1 AT%QB5 BYTE;
a2 AT%QW2 WORD;
a1:=5;
a2.0:=8;
В
каждой области памяти адресация элементов
начинается с нуля.
Физическое размещение прямо адресуемых
областей в ОЗУ определяется
конфигурацией контроллера. Очевидно,
что сопоставление идентификаторов
переменных прямым адресам является
делом, требующим большой аккуратности.
Поэтому для сложных
модульных контроллеров применяются
специальные фирменные
конфигураторы, подключаемые к оболочке
комплекса программирования
и позволяющие графически «собрать» ПЛК
и определить
все необходимые интерфейсные переменные.
Входы
ПЛК — это переменные с прямыми адресами
в области
I.
Они доступны в прикладных программах
только по чтению, Выходы Q
— только по записи. Переменные в области
М доступны
по записи и чтению.
В
области памяти М размещают обычно
переменные, которые нельзя
однозначно отнести к входам или выходам.
Это могут быть
диагностические ресурсы модулей,
параметры системы исполнения
и т. д.
Прямые
адреса можно использовать в программах
непосредственно:
IF
%IW4
> 1 THEN
(*3начение входа
IW4*)
Тем
не менее все же желательно компактно
сосредоточить в проекте
все аппаратно-зависимые моменты.
Обратите
внимание, что прямая адресация позволяет
разместить
несколько разнотипных переменных в
одной и той же памяти.
Например, специально для быстрого
обнуления 16-дискретных выходов
(BOOL)
можно использовать переменную типа
WORD.
Или, например, совместить переменную
STRING
и несколько переменных
типа BYTE,
что даст возможность организовать
форматирование
вывода без применения строковых функций.
Поскольку
физическое распределение адресов
известно на этапе трансляции,
компилятор формирует максимально
компактный код для таких
объединений, чего не удается достичь
при работе с элементами
массива, где требуется динамическая
адресация.

Синтаксис
прямых или МЭК адресов выглядит следующим
образом:
каждый адрес начинается с
символа %,
с последующим префиксом области.
Префикс
I
указывает на область входов, Q
— область выходов и M
— область маркеров.
Далее следует
идентификатор размера: X
или ничего – один бит, B
обозначает байт (8 бит), W
— это 16 разрядное слово и D
— это двойное слово (32 бита). Завершают
адрес цифры, указывающие последовательные
адреса в заданной области, начиная с
0.
Например:
%IW215 — это 216-тое слово
в области входов.
%QX1.1 — это 2-й бит 2-го
слова в области выходов.
%MD48 — это 49-е
двойное слово в области маркеров.
Поразрядная
адресация
В
стандарте предусмотрена удобная форма
работы с отдельными битами переменных
типа битовых строк — поразрядная
адресация.
Необходимый
бит указывается через точку после
идентификатора.
Аналогичным образом можно использовать
отдельные биты прямо адресуемой памяти.
Младшему биту соответствует нулевой
номер. Поразрядная нумерация не должна
превышать границы
соответствующего типа числа.
VAR
a: WORD;
bStop AT %IX64.3:
BOOL;
END_VAR
a:=0;
a.3:=
1; (*или
а.З := TRUE;
— результат 2#0000_1000*)
a.18:=
TRUE; (*ошибка,
в WORD
не может быть бит а.18*)
IF
a.15
THEN
… (*а
меньше нуля?*)
Преобразования
типов
Преобразование
типов происходит
при присваивании значения
переменной одного типа переменной
другого типа. Преобразование
меняет физическое представление значения
в памяти данных,
но не должно изменять само значение.
Если это невозможно,
то преобразование приводит к частичной
потере данных. Но
в таком случае транслятор требует явного
указания необходимости
выполнения такой операции.
Рассмотрим
сначала работу с целыми числами. Пусть,
например,
объявлена переменная siVar
типа короткое целое (SINT
8 бит) и переменная iVar
типа целое (INT
16 бит). Допустим
siVar
= 100, a
iVar
= 1000. Выражение iVar
:= siVar
является
вполне допустимым, поскольку числа типа
SINT
являются подмножеством
INT
(iVar
примет значение 100). Здесь преобразование
типа будет выполнено транслятором
автоматически, без каких-либо дополнительных
указаний. Обратное присваивание siVar:=
iVar
приведет к переполнению и потере данных.
Заставить
транслятор выполнить преобразование
с вероятной потерей
данных можно только в явной форме при
помощи специального
оператора siVar
:= INT_TO_SINT(iVar).
Результат равен 24 (в шестнадцатеричной
форме 1000 это 1б#ОЗЕ8 и только младший его
байт перейдет в SINT,
значение 16#Е8 соответствует десятичному
числу 24).
Аналогичная
ситуация возникает при работе с
действительными
числами длинного LREAL
и короткого REAL
типов.
Операторы
явного преобразования базовых МЭК-типов
образу-к>т свои наименования из двух
частей. Вначале указывается «исходный
тип», затем «_ТО _» и «тип результата*.
Например:
(*
Результат 16#АА*) (*120*)
i
:= REAL_TO_INT(2.7); (*Результат
3*)
i
:= TRUNC(2.7); (*Результат
2*)
t
:= STRING_TO_TIME(‘T#216ms’); (*РезультатТ#216ms*)
Операция
TRUNC
выполняет отбрасывание дробной части
в отличие
от преобразования REAL__TO_INT,
выполняющего округление.
Обратите
внимание, что операции преобразования
допустимы для
любых комбинаций базовых типов, а не
только для совместимых
типов (например, дату в строку). Так,
преобразования <…>_TO_STRING
фактически заменяют оператор PRINT,
распространенный
в языках общего применения.
В
конкретной реализации отдельные
преобразования могут не поддерживаться
или иметь определенные особенности, в
первую очередь это относится к
преобразованиям строк в другие типы и
обратно.
Поэтому мы не будем здесь приводить
подробные описания
всех возможных преобразований. При
необходимости используйте
руководство по применению системы
программирования или
оперативную справку.
Венгерская запись
При
наличии строгой типизации данных очень
полезной оказывается
возможность узнавать тип переменной
по ее наименованию
непосредственно в тексте программ. В
этом случае некорректное
применение переменных бросается в глаза
и позволяет избежать
многих сложно локализуемых ошибок.
Для
этого может использоваться специальная
запись имен переменных.
Впервые такая запись имен была предложена
Чарльзом
Симони (Charles
Simonyi)
и обоснована в его докторской диссертации.
Возможно, потому что Симони родился в
Будапеште и образованные
по его системе наименования причудливы
(на первый
взгляд), как венгерский язык, за его
методикой записи закрепилось
название «венгерская запись». В настоящее
время Симони
является ведущим инженером Microsoft,
а венгерская запись
стала общепризнанной при программировании
под Windows.
Идея
венгерской записи заключается в
прибавлении к идентификаторам коротких
префиксов, определяющих тип и некоторые
другие
важные характеристики переменной.
Префиксы принято записывать
строчными буквами, а имя переменной с
заглавной буквы.
Поскольку венгерская запись «работает»
для любых типизированных языков,
имеет смысл применить ее и при
программировании
ПЛК.
Для
базовых типов МЭК можно предложить
следующие префиксы
типов.
|
Префикс |
Тип |
|
b |
BOOL |
|
by |
BYTE, |
|
si |
SINT |
|
w |
WORD, |
|
i |
INT |
|
dw |
DWORD, |
|
di |
DINT |
|
r |
REAL |
|
Ir |
LREAL |
|
st |
STRING |
|
t |
TIME |
|
td |
TIME_OF_DAY |
|
d |
DATE |
|
dt |
DATE_AND_TIME |
Примеры обозначений:
bStop: BOOL;
bySet: BYTE;
wSize UINT;
«Венгерские»
имена сами говорят о корректности их
применения.
Очевидно, следующее выражение является
бессмысленным; bStop
:= wSize
* 2; а выражение bStop
:= wSize
> 2; вполне допустимым.
Уточнить
назначение переменной можно добавлением
еще одного
символа перед префиксом типа:
|
Префикс |
Назначение |
переменной |
|
а |
Составной |
массив |
|
п |
Индекс |
|
|
с |
Счетчик |
Для
временных переменных можно вообще не
утруждать себя
придумыванием имен, а использовать
только префиксы. Например:
aiSample:
ARRAY
[1..32]
OF
INT;
ci: INT;
FOR ci := 1 TO 32 DO
(*без
комментариев*)
siSample[ci]
:= -1; END_FOR
К
сожалению, некоторые из предложенных
префиксов совпадают
с зарезервированными словами (BY,
AT,
D,
DT,
N,
ST).
При использовании
их в качестве временных переменных вы
можете добавить
порядковый номер или букву алфавита.
Например:
ЬуА,
ЬуВ, byl,
Ьу2: ‘BYTE;
Структуры
и функциональные блоки образуют имена
экземпляров
с включением полного или сокращенного
наименования типа.
Например, tpUpDelay:
TP;
Символ
подчеркивания удобно использовать для
индикаций способа
обращения к переменной. Подчеркивание
в начале имени указывает
— только чтение. Идентификаторы
переменных, соответствующих
входами ПЛК, начинаются символом
подчеркивания.
Подчеркивание в конце имени указывает
— только запись. Идентификаторы выходов
заканчиваются символом подчеркивания.
Например, Jylnpl,
byOut2_.
Если
система обозначений хорошо продумана,
то ее применение
не вызывает сложности. Единый подход к
наименованию очень
здорово облегчает чтение программы и
позволяет отказаться от излишних
комментариев. Уникальные префиксы
удобны не только
для базовых типов, но и для широко
используемых в проекте собственных
типов данных и функциональных блоков.
Стандарт
МЭК не содержит рекомендаций по
составлению имен переменных
и компонентов программы. Никакого
стандартного набора
префиксов венгерской записи также нет.
Вы можете использовать
вышеописанную систему или разработать
свою собственную. Главное,
чтобы принятая система была понятна
всем программистам
— участникам проекта.
Описанные
правила образования венгерских имен
применяются в приведенных ниже
примерах. В простых случаях, когда тип
переменной
не имеет значения или очевиден, венгерская
запись не
используется.
Формат
BCD
Двоично-кодированный
десятичный формат представления BCD
(binary
coded
decimal)
представляет собой числа в позиционной
десятичной системе, где каждая цифра
числа занимает 4 бита.
Например, десятичное число 81 будет
представлено в виде 2#1000_0001.
Арифметические
операции с BCD-числами
требуют применения специального
математического аппарата, малоэффективны
в сравнении с обычным двоичным
представлением. Но, с другой
стороны, BCD
оказывается очень удобным при организации
клавиатурного ввода и индикации.
Например, функции вывода
числа на принтер или даже на сегментный
индикатор получаются тривиальными
(одна одномерная таблица на 10 констант).
Для
хранения чисел в формате BCD
стандарт МЭК предлагает использовать
переменные типов ANY_BIT
(кроме BOOL,
конечно).
Арифметика BCD-вычислений
обычно не поддерживается в стандартном
комплекте библиотек систем программирования
ПЛК.
В библиотеке утилит CoDeSys
реализованы две простые Функции
BCD
преобразования: BCD_TO_INT
и INT_TO_BCD.
К.Р.3
One of the first things that is going to strike many first-time programmers of the Win32 API is that there are tons and tons of old data types to deal with. Sometimes, just keeping all the correct data types in order can be more difficult than writing a nice program. This page will talk a little bit about some of the data types that a programmer will come in contact with.
Hungarian Notation[edit | edit source]
First, let’s make a quick note about the naming convention used for some data types, and some variables. The Win32 API uses the so-called «Hungarian Notation» for naming variables. Hungarian Notation requires that a variable be prefixed with an abbreviation of its data type, so that when you are reading the code, you know exactly what type of variable it is. The reason this practice is done in the Win32 API is because there are many different data types, making it difficult to keep them all straight. Also, there are a number of different data types that are essentially defined the same way, and therefore some compilers will not pick up on errors when they are used incorrectly. As we discuss each data type, we will also note the common prefixes for that data type.
Putting the letter «P» in front of a data type, or «p» in front of a variable usually indicates that the variable is a pointer. The letters «LP» or the prefix «lp» stands for «Long Pointer», which is exactly the same as a regular pointer on 32 bit machines. LP data objects are simply legacy objects that were carried over from Windows 3.1 or earlier, when pointers and long pointers needed to be differentiated. On modern 32-bit systems, these prefixes can be used interchangeably.
LPVOID[edit | edit source]
LPVOID data types are defined as being a «pointer to a void object». This may seem strange to some people, but the ANSI-C standard allows for generic pointers to be defined as «void*» types. This means that LPVOID pointers can be used to point to any type of object, without creating a compiler error. However, the burden is on the programmer to keep track of what type of object is being pointed to.
Also, some Win32 API functions may have arguments labeled as «LPVOID lpReserved». These reserved data members should never be used in your program, because they either depend on functionality that hasn’t yet been implemented by Microsoft, or else they are only used in certain applications. If you see a function with an «LPVOID lpReserved» argument, you must always pass a NULL value for that parameter — some functions will fail if you do not do so.
LPVOID objects frequently do not have prefixes, although it is relatively common to prefix an LPVOID variable with the letter «p», as it is a pointer.
DWORD, WORD, BYTE[edit | edit source]
These data types are defined to be a specific length, regardless of the target platform. There is a certain amount of additional complexity in the header files to achieve this, but the result is code that is very well standardized, and very portable to different hardware platforms and different compilers.
DWORDs (Double WORDs), the most commonly occurring of these data types, are defined always to be unsigned 32-bit quantities. On any machine, be it 16, 32, or 64 bits, a DWORD is always 32 bits long. Because of this strict definition, DWORDS are very common and popular on 32-bit machines, but are less common on 16-bit and 64-bit machines.
WORDs (Single WORDs) are defined strictly as unsigned 16-bit values, regardless of what machine you are programming on. BYTEs are defined strictly as being unsigned 8-bit values. QWORDs (Quad WORDs), although rare, are defined as being unsigned 64-bit quantities. Putting a «P» in front of any of these identifiers indicates that the variable is a pointer. putting two «P»s in front indicates it’s a pointer to a pointer. These variables may be unprefixed, or they may use any of the prefixes common with DWORDs. Because of the differences in compilers, the definition of these data types may be different, but typically these definitions are used:
#include <stdint.h>
typedef uint8_t BYTE; typedef uint16_t WORD; typedef uint32_t DWORD; typedef uint64_t QWORD;
Notice that these definitions are not the same in all compilers. It is a known issue that the GNU GCC compiler uses the long and short specifiers differently from the Microsoft C Compiler. For this reason, the windows header files typically will use conditional declarations for these data types, depending on the compiler being used. In this way, code can be more portable.
As usual, we can define pointers to these types as:
#include <stdint.h>
typedef uint8_t * PBYTE; typedef uint16_t * PWORD; typedef uint32_t * PDWORD; typedef uint64_t * PQWORD;
typedef uint8_t ** PPBYTE; typedef uint16_t ** PPWORD; typedef uint32_t ** PPDWORD; typedef uint64_t ** PPQWORD;
DWORD variables are typically prefixed with «dw». Likewise, we have the following prefixes:
| Data Type | Prefix |
|---|---|
| BYTE | «b» |
| WORD | «w» |
| DWORD | «dw» |
| QWORD | «qw» |
LONG, INT, SHORT, CHAR[edit | edit source]
These types are not defined to a specific length. It is left to the host machine to determine exactly how many bits each of these types has.
- Types
typedef long LONG; typedef unsigned long ULONG; typedef int INT; typedef unsigned int UINT; typedef short SHORT; typedef unsigned short USHORT; typedef char CHAR; typedef unsigned char UCHAR;
- LONG notation
- LONG variables are typically prefixed with an «l» (lower-case L).
- UINT notation
- UINT variables are typically prefixed with an «i» or a «ui» to indicate that it is an integer, and that it is unsigned.
- CHAR, UCHAR notation
- These variables are usually prefixed with a «c» or a «uc» respectively.
If the size of the variable doesn’t matter, you can use some of these integer types. However, if you want to exactly specify the size of a variable, so that it has a certain number of bits, use the BYTE, WORD, DWORD, or QWORD identifiers, because their lengths are platform-independent and never change.
STR, LPSTR[edit | edit source]
STR data types are string data types, with storage already allocated. This data type is less common than the LPSTR. STR data types are used when the string is supposed to be treated as an immediate array, and not as a simple character pointer. The variable name prefix for a STR data type is «sz» because it’s a zero-terminated string (ends with a null character).
Most programmers will not define a variable as a STR, opting instead to define it as a character array, because defining it as an array allows the size of the array to be set explicitly. Also, creating a large string on the stack can cause greatly undesirable stack-overflow problems.
LPSTR stands for «Long Pointer to a STR», and is essentially defined as such:
#define STR * LPSTR;
LPSTR can be used exactly like other string objects, except that LPSTR is explicitly defined as being ASCII, not unicode, and this definition will hold on all platforms. LPSTR variables will usually be prefixed with the letters «lpsz» to denote a «Long Pointer to a String that is Zero-terminated». The «sz» part of the prefix is important, because some strings in the Windows world (especially when talking about the DDK) are not zero-terminated. LPSTR data types, and variables prefixed with the «lpsz» prefix can all be used seamlessly with the standard library <string.h> functions.
TCHAR[edit | edit source]
TCHAR data types, as will be explained in the section on Unicode, are generic character data types. TCHAR can hold either standard 1-byte ASCII characters, or wide 2-byte Unicode characters. Because this data type is defined by a macro and is not set in stone, only character data should be used with this type. TCHAR is defined in a manner similar to the following (although it may be different for different compilers):
#ifdef UNICODE #define TCHAR WORD #else #define TCHAR BYTE #endif
TSTR, LPTSTR[edit | edit source]
Strings of TCHARs are typically referred to as TSTR data types. More commonly, they are defined as LPTSTR types as such:
#define TCHAR * LPTSTR
These strings can be either UNICODE or ASCII, depending on the status of the UNICODE macro. LPTSTR data types are long pointers to generic strings, and may contain either ASCII strings or Unicode strings, depending on the environment being used. LPTSTR data types are also prefixed with the letters «lpsz».
HANDLE[edit | edit source]
HANDLE data types are some of the most important data objects in Win32 programming, and also some of the hardest for new programmers to understand. Inside the kernel, Windows maintains a table of all the different objects that the kernel is responsible for. Windows, buttons, icons, mouse pointers, menus, and so on, all get an entry in the table, and each entry is assigned a unique address known as a HANDLE. If you want to pick a particular entry out of that table, you need to give Windows the HANDLE value, and Windows will return the corresponding table entry.
HANDLEs are defined as void pointers (void*). They are used as unique identifiers to each Windows object in our program such as a button, a window an icon, etc. Specifically their definition follows:
typedef PVOID HANDLE;
and
typedef void *PVOID;
In other words HANDLE = void*.
HANDLEs are generally prefixed with an «h». Handles are unsigned integers that Windows uses internally to keep track of objects in memory. Windows moves objects like memory blocks in memory to make room, if the object is moved in memory, the handles table is updated.
Below are a few special handles that are worth discussing:
HWND[edit | edit source]
HWND data types are «Handles to a Window», and are used to keep track of the various objects that appear on the screen. To communicate with a particular window, you need to have a copy of the window’s handle. HWND variables are usually prefixed with the letters «hwnd», just so the programmer knows they are important.
Canonically, main windows are defined as:
HWND hwnd;
Child windows are defined as:
HWND hwndChild1, hwndChild2...
and Dialog Box handles are defined as:
HWND hDlg;
Although you are free to name these variables whatever you want in your own program, readability and compatibility suffer when an idiosyncratic naming scheme is chosen — or worse, no scheme at all.
HINSTANCE[edit | edit source]
HINSTANCE variables are handles to a program instance. Each program gets a single instance variable, and this is important so that the kernel can communicate with the program. If you want to create a new window, for instance, you need to pass your program’s HINSTANCE variable to the kernel, so that the kernel knows what program instance the new window belongs to. If you want to communicate with another program, it is frequently very useful to have a copy of that program’s instance handle. HINSTANCE variables are usually prefixed with an «h», and furthermore, since there is frequently only one HINSTANCE variable in a program, it is canonical to declare that variable as such:
HINSTANCE hInstance;
It is usually a benefit to make this HINSTANCE variable a global value, so that all your functions can access it when needed.
[edit | edit source]
If your program has a drop-down menu available (as most visual Windows programs do), that menu will have an HMENU handle associated with it. To display the menu, or to alter its contents, you need to have access to this HMENU handle. HMENU handles are frequently prefixed with simply an «h».
WPARAM, LPARAM[edit | edit source]
In the earlier days of Microsoft Windows, parameters were passed to a window in one of two formats: WORD-length (16-bit) parameters, and LONG-length (32-bit) parameters. These parameter types were defined as being WPARAM (16-bit) and LPARAM (32-bit). However, in modern 32-bit systems, WPARAM and LPARAM are both 32 bits long. The names however have not changed, for legacy reasons.
WPARAM and LPARAM variables are generic function parameters, and are frequently type-cast to other data types including pointers and DWORDs.
Next Chapter[edit | edit source]
- Unicode