
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
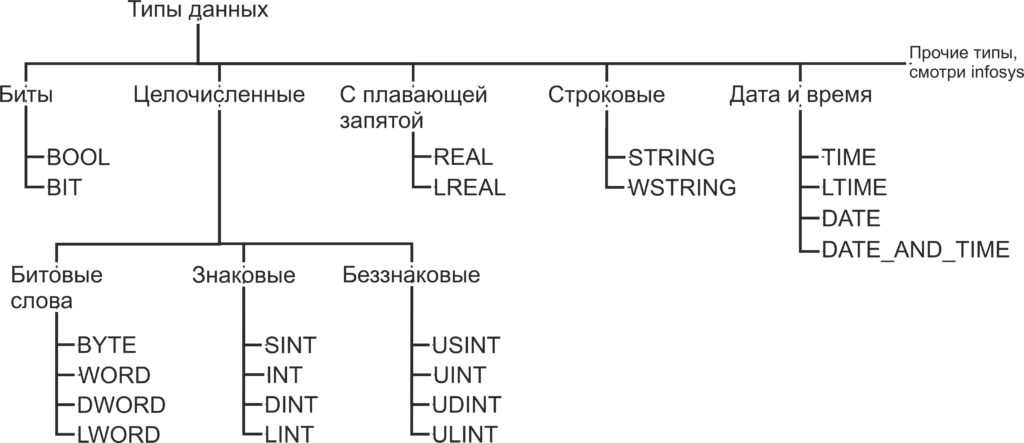
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
stesl писал(а): ↑23 мар 2021, 10:37
Тип Word — это целочисленный беззнаковый тип данных, в два байта. Диапазон 0-65535. Используется везде, где оказывается нужным.
Не путайте Word с UInt (unsigned integer16), он не относится к целочисленным, так как не кодирует числовые значения и не совместим с математическими операциями.
Потому что:
Sergy6661 писал(а): ↑23 мар 2021, 12:54
Вот для упаковки-распаковки битовых переменных и используется в основном.
Но не в основном, а только для этого. Если конечно в конкретном ПЛК не срабатывает неявное преобразование, из-за которого кажется, что Word — это целое число.
Отправлено спустя 21 минуту 7 секунд:
Не, иначе объясню:
Word — это когда ты в 16 бит записал 16 булевых значений, каждый из которых что-то значит в смысле true/false. Например, при управлении сервоприводом или частотником.
Int16, UInt16 — это числа, отдельные биты не представляют интереса (хотя бывают редкие исключения).
Математические операции умеют работать с числами, то есть Add(), Sub(), Mul(), Div() работают с Int16/UInt16, а с Word работает подозрительно, подсвечивает типа «глянь, что за дрянь ты задумал?», но воспринимает как число 0-65535. Извините, правда, зачем вы складываете слово управления частотника с числом -85?
Зато сдвиговые операции и операции со словами типа ANDW(), ORW(), NOT(W), XORW() работают именно со словами и подозрительно с целыми числами.
Это разные типы данных, хотя все они 16 бит.
Любые данные – константы, переменные, значения функций характеризуются в Паскале типом данных.
Определим понятие типа данных. Как уже известно, все объекты программы (переменные, константы и т.д.) должны быть описаны.
Описания информируют транслятор, во-первых, о существовании используемых переменных и других объектов, во-вторых, указывают на свойства этих объектов. Например, описание переменной, значение которой является числом, указывает на свойства чисел. Формально числа могут быть целыми и вещественными (дробными). В Паскале, как и в других языках программирования, числа разделены на два типа: целые (зарезервированное слово integer ) и вещественные (зарезервированное слово real ).
Выделение целых чисел в отдельный тип объясняется тем, что в вычислительной машине целые и вещественные числа представляются по-разному: целое число может быть представлено абсолютно точно, а вещественное – неизбежно с некоторой конечной погрешностью, которая определяется свойствами транслятора.
Например, пусть переменная x имеет тип real и ее значение равно единице: x=1 . Соответствующее значение в памяти компьютера может быть и 0.999999999, и 1.000000001, и 1.000000000 . Но если переменная x будет объявлена как переменная целого типа, то единица в компьютере будет представлена абсолютно точно и переменная x не сможет принимать вещественные (дробные) значения – ведь она была описана как переменная целого типа.
Таким образом, тип данных определяет:
- внутреннее представление данных в памяти компьютера;
- множество значений, которые могут принимать величины этого типа;
- операции, которые могут выполняться над величинами этого типа.
Введение типов данных является одной из базовых концепций языка Паскаль, заключающейся в том, что при выполнении операции присваивания переменной значения выражения, переменная и выражение должны быть одного типа. Такая проверка выполняется компилятором, что значительно упрощает поиск ошибок и приводит к повышению надежности программы.
Множество типов данных языка Турбо Паскаль можно разделить на две группы:
- стандартные (предопределенные) типы;
- типы, определяемые пользователем (пользовательские типы).
К стандартным типам Турбо Паскаль относят:
- целый тип – integer ;
- вещественный тип – real ;
- символьный тип – char ;
- логический тип – boolean ;
- строковый тип – string ;
- указательный тип – pointer ;
- текстовый тип – text .
Пользовательские типы данных представляют собой различные комбинации стандартных типов.
К пользовательским типам относят:
- перечисляемый тип;
- интервальный тип;
- указательный тип;
- структурированные типы;
- процедурный тип.
Замечание. Возможна и другая классификация типов данных, согласно которой типы делятся на простые и сложные.
К простым типам относят: целый тип, вещественный тип, символьный тип, логический тип, перечислимый тип и интервальный тип.
Сложный тип представляет собой различные комбинации простых типов (массивы, записи, множества, файлы и т.д.)
Стандартные типы
Стандартный тип данных определен самим языком Паскаль. При использовании в программе стандартных типов достаточно указать подразделы необходимых типов ( const, var ) и далее описать используемые в программе константы и переменные. Необходимость использования подраздела Type отсутствует.
Например, если в программе используются только переменные:
i,j – integer (целые);
x,y — real (вещественные);
t,s — char (символьные);
a,b – boolean (логические),
то необходим только подраздел переменных – Var . Поэтому в описательной части программы объявления переменных записываются следующим образом:
Var
i,j:integer;
x,y:real;
t,s:char;
a,b:boolean;
Целые типы
Данные этого типа могут принимать только значения целых чисел. В компьютере значения целого типа представляются абсолютно точно. Если переменная отрицательная, то перед ней должен стоять знак «–», если переменная положительная, то знак «+» можно опустить. Данный тип необходим в том случае, когда какую-то величину нельзя представить приближенно – вещественным числом. Например, число людей, животных и т.д.
Примеры записи значений целых чисел: 17, 0, 44789, -4, -127.
Диапазон изменения данных целого типа, определяется пятью стандартными типами целых чисел и представлен в таблице:
| Тип | Диапазон | Размер в байтах |
| Shortint | -128…+128 | 1 |
| Integer | -32768…32767 | 2 |
| Longint | -2147483648…2147483647 | 4 |
| Byte | 0…255 | 1 |
| Word | 0…65535 | 2 |
Последние два типа служат для представления только положительных чисел, а первые три как положительных, так и отрицательных чисел.
В тексте программы или при вводе данных целого типа значения записываются без десятичной точки. Фактические значения переменной не должны превышать допустимых значений того типа ( Shortint, Integer, Longint, Byte, Word ), который был использован при описании переменной. Возможные превышения при вычислениях ни как не контролируются, что приведет к неверной работе программы.
Пример использования переменной целого типа
Vara:integer;
b:word;
c:byte;
Begin
a:=300; {a присвоено значение 300}
b:=300; {b присвоено значение300}
c:=200; {c присвоено значение200}
a:=b+c; {a присвоено значение500}
c:=b; {Ошибка! Переменная c может принимать значения не более 255. Здесь переменной c присваивается значение 500,что вызовет переполнение результата.}
End.
Вещественные типы
Значения вещественных типов в компьютере представляются приближенно. Диапазон изменения данных вещественного типа определяется пятью стандартными типами: вещественный ( Real ), с одинарной точностью ( Single ), двойной точностью ( Double ), с повышенной точностью ( Extended ), сложный ( Comp ) и представлен в таблице:
| Тип | Диапазон | Число значащих цифр | Размер в байтах |
| Real | 2.9E-39…1.7E+38 | 11-12 | 6 |
| Single | 1.5E-45…3.4E+38 | >7-8 | 4 |
| Double | 5E-324…1.7E+308 | 15-16 | 8 |
| Extended | 3.4E-4951…1.1E+4932 | 19-20 | 10 |
| Comp | -2E+63+1…+2E+63-1 | 19-20 | 8 |
Вещественные числа могут быть представлены в двух форматах: с фиксированной и плавающей точкой.
Формат записи числа с фиксированной точкой совпадает с обычной математической записью десятичного числа с дробной частью. Дробная часть отделяется от целой части с помощью точки, например
34.5, -4.0, 77.001, 100.56
Формат записи с плавающей точкой применяется при записи очень больших или очень малых чисел. В этом формате число, стоящее перед символом «E», умножается на число 10 в степени, указанной после символа «E».
| 1E-4 | 1*10-4 |
| 3.4574E+3 | 3.4574*10+3 |
| 4.51E+1 | 4.51*10+1 |
Примеры чисел с плавающей точкой:
| Число | Запись на Паскале |
| 0,0001 | 1E-4 |
| 3457,4 | 34574E-1 |
| 45,1 | 451E-1 |
| 40000 | 4E+4 |
| 124 | 0.124E+3 |
| 124 | 1.24E+2 |
| 124 | 12.4E+1 |
| 124 | 1240E-1 |
| 124 | 12400E-2 |
В таблице с 5 по 9 строку показана запись одного и того же числа 124. Изменяя положение десятичной точки в мантиссе (точка «плывет», отсюда следует название «запись числа с плавающей точкой») и одновременно изменяя величину порядка, можно выбрать наиболее подходящую запись числа.
Пример описания переменных вещественного типа.
Var
x,y,z:real;
Символьный тип
Значениями символьного типа являются символы, которые можно набрать на клавиатуре компьютера. Это позволяет представить в программе текст и производить над ним различные операции: вставлять, удалять отдельные буквы и слова, форматировать и т.д.
Символьный тип обозначается зарезервированным словом Char и предназначен для хранения одного символа. Данные символьного типа в памяти занимают один байт.
Формат объявления символьной переменной:
<имя переменной>: Char;
При определении значения символьной переменной символ записывается в апострофах. Кроме того, задать требуемый символ можно указанием непосредственно его числового значения ASCII-кода. В этом случае необходимо перед числом, обозначающим код ASCII необходимого символа, поставить знак #.
Пример использования переменных символьного типа:
Varc:char; {c – переменная символьного типа}
Begin
c:=’A’; {переменной c присваивается символ ’A’}
c:=#65; {переменной c также присваивается символ A. Его ASCII код равен 65}
c:=’5’; {переменной c присваивается символ 5,
End. здесь 5 это уже не число}
Логический тип
Логический тип данных называют булевским по имени английского математика Джорджа Буля, создателя области математики – математической логики.
Формат объявления переменной логического типа:
<имя переменной>: boolean;
Данные этого типа могут принимать только два значения:
- True – истина;
- False – ложь.
Логические данные широко используются при проверке правильности некоторых условий и при сравнении величин. Результат может оказаться истинным или ложным.
Для сравнения данных предусмотрены следующие операции отношений:
| = | равно | |
| <> | не равно | |
| > | больше | |
| < | меньше | |
| >= | больше или равно | |
| <= | меньше или равно |
Пример использования операций отношения:
отношение 5>3, результат true (истина);
отношение 5=3, результат false (ложь).
Пример использования переменных логического типа.
Vara,b:boolean; {a,b – переменные логического типа}
Begin
a:=Тrue; {переменной a присваивается значение «истина»}
b:=false; {переменной b присваивается значение «ложь»}
End.
Константы
В качестве констант могут использоваться целые, вещественные числа, символы, строки символов, логические константы.
Константу необходимо объявить в описательной части с помощью зарезервированного слова const.
Формат объявления константы
Const <имя константы>= <значение>;
Если в программе используются несколько констант, допускается использование только одного ключевого слова Const, описание каждой константы заканчивается точкой с запятой. Блок констант заканчивается объявлением другого раздела или объявлением блока исполняемых операторов.
Пример:
Const {объявление раздела констант}year=2003; {константа целого типа, т.к. нет в записи десятичной точки}
time=14.05; {константа вещественного типа}
N=24; {константа целого типа, т.к. нет в записи десятичной точки}
P=3.14; {константа вещественного типа}
A=true; {константа логического типа}
str1=’7’; {константа символьного типа}
str2=’A’; {константа символьного типа}
str3=’Turbo’; {константа строкового типа}
Var {объявление раздела переменных}
X,y:integer; {переменные целого типа}
Пользовательские типы
Из совокупности пользовательских типов рассмотрим только
- перечисляемый тип;
- интервальный тип.
Эти два типа нам будут необходимы при изучении массивов.
Перечисляемый тип
Перечисляемый тип данных описывает новые типы данных, значения которых определяет сам программист. Перечисляемый тип задается перечислением тех значений, которые он может получать. Каждое значение именуется некоторым идентификатором и располагается в списке, обрамленном круглыми скобками. Перечисляемый тип относится к типам данных, определяемым пользователем, поэтому объявление этого типа начинается зарезервированным словом TYPE .
Формат перечисляемого типа:
Type
<имя типа>= (константа1, константа2,…, константаN);
где
константа1, константа2,…, константаN – упорядоченный набор значений идентификаторов, рассматриваемых как константы.
Пример описания перечисляемого типа:
Typeball=(one, two, three, four, five);
var
t:ball;
Здесь ball – имя перечисляемого типа; one, two, three, four, five – константы; t – переменная, которая может принимать любое значение констант.
В перечисляемом типе константа является идентификатором, поэтому она не заключается в кавычки и не может быть числом. Таким образом, в перечисляемом типе под константой понимается особый вид констант, которые не могут быть:
- константами числового типа: 1, 2, 3, 4 и т. д;
- константами символьного типа: ‘a’, ‘s’, ‘1’, ‘3’ и т. д.;
- константами строкового типа: ‘first’, ‘second’ и т.д.
Кроме того, к значениям этого типа не применимы арифметические операции и стандартные процедуры ввода и вывода Read, Write .
Пример использования переменных перечисляемого типа:
Typedays = (Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
Var
day: days;
begin
if day = Sunday then writeln(‘Сегодня Воскресенье!’);
End.
Элементы, входящие в определение перечисляемого типа, считаются упорядоченными в той последовательности, в которой они перечисляются. Нумерация начинается с нуля. Поэтому в приведенном примере дни недели имеют следующие порядковые номера

Для программного определения порядкового номера используется функция Ord() .
В нашем примере порядковые номера равны:
Ord(Monday) = 0;
Ord(Saturday) = 5;
Ord(Sunday) = 6.
Интервальный тип
Если какая-то переменная принимает не все значения своего типа, а только значения, содержащиеся в некотором диапазоне, то такой тип данных называется интервальным типом. Часто интервальный тип называют ограниченным типом и типом-диапазоном. Интервальный тип задается границами своих значений:
<минимальное значение>..<максимальное значение>
Здесь:
- два символа «..» рассматриваются как один символ, поэтому между ними недопустимы пробелы;
- левая граница диапазона не должна превышать его правую границу.
Интервальный тип относится к типам данных, определяемых пользователем, поэтому объявление этого типа начинается со служебного слова TYPE .
Пример описания интервального типа:
Typedigit = 1..10;
month = 1..31;
lat = ’A’..’Z’;
Целые числа
Данные каким-либо образом необходимо представлять в памяти компьютера. Существует множество различных типов данных, простых и довольно сложных, имеющих большое число компонентов и свойств. Однако, для компьютера необходимо использовать некий унифицированный способ представления данных, некоторые элементарные составляющие, с помощью которых можно представить данные абсолютно любых типов. Этими составляющими являются числа, а вернее, цифры, из которых они состоят. С помощью цифр можно закодировать практически любую дискретную информацию. Поэтому такая информация часто называется цифровой (в отличие от аналоговой, непрерывной).
Первым делом необходимо выбрать систему счисления, наиболее подходящую для применения в конкретных устройствах. Для электронных устройств самой простой реализацией является двоичная система: есть ток — нет тока, или малый уровень тока — большой уровень тока. Хотя наиболее эффективной являлась бы троичная система. Наверное, выбор двоичной системы связан еще и с использование перфокарт, в которых она проявляется в виде наличия или отсутствия отверстия. Отсюда в качестве цифр для представления информации используются 0 и 1.
Таким образом данные в компьютере представляются в виде потока нулей и единиц. Один разряд этого потока называется битом. Однако в таком виде неудобно оперировать с данными вручную. Стандартом стало разделение всего потока на равные последовательные группы из 8 битов — байты или октеты. Далее несколько байтов могут составлять слово. Здесь следует разделять машинное слово и слово как тип данных. В первом случае его разрядность обычно равна разрядности процессора, т.к. машинное слово является наиболее эффективным элементом для его работы. В случае, когда слово трактуется как тип данных (word), его разрядность всегда равна 16 битам (два последовательных байта). Также как типы данных существую двойные слова (double word, dword, 32 бита), четверные слова (quad word, qword, 64 бита) и т.п.
Теперь мы вплотную подошли к представлению целых чисел в памяти. Т.к. у нас есть байты и различные слова, то можно создать целочисленные типы данных, которые будут соответствовать этим элементарным элементам: byte (8 бит), word (16 бит), dword (32 бита), qword (64 бита) и т.д. При этом любое число этих типов имеет обычное двоичное представление, дополненное нулями до соответствующей размерности. Можно заметить, что число меньшей размерности можно легко представить в виде числа большей размерности, дополнив его нулями, однако в обратном случае это не верно. Поэтому для представления числа большей размерности необходимо использовать несколько чисел меньшей размерности. Например:
- qword (64 бита) можно представить в виде 2 dword (32 бита) или 4 word (16 бит) или 8 byte (8 бит);
- dword (32 бита) можно представить в виде 2 word (16 бит) или 4 byte (8 бит);
- word (16 бит) можно представить в виде 2 byte (8 бит);
Если A — число, B1..Bk — части числа, N — разрядность числа, M — разрядность части, N = k*M, то:
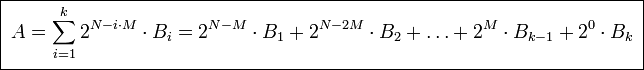
Например:
- A = F1E2D3C4B5A69788 (qword)
- A = 232 * F1E2D3C4 (dword) + 20 * B5A69788 (dword)
- A = 248 * F1E2 (word) + 232 * D3C4 (word) + 216 * B5A6 (word) + 20 * 9788 (word)
- A = 256 * F1 (byte) + 248 * E2 (byte) + … + 28 * 97 (byte) + 20 * 88 (byte)
Существуют понятия младшая часть (low) и старшая часть (hi) числа. Старшая часть входит в число с коэффициентом 2N-M, а младшая с коэффициентом 20. Например:
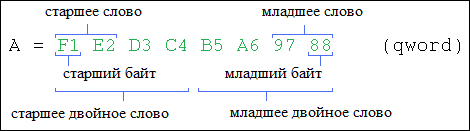
Байты числа можно хранить в памяти в различном порядке. В настоящее время используются два способа расположения: в прямом порядке байт и в обратном порядке байт. В первом случае старший байт записывается в начале, затем последовательно записываются остальные байты, вплоть до младшего. Такой способ используется в процессорах Motorola и SPARC. Во втором случае, наоборот, сначала записывает младший байт, а затем последовательно остальные байты, вплоть до старшего. Такой способ используется в процессорах архитектуры x86 и x64. Далее приведен пример:

Используя подобные целочисленные типы можно представить большое количество неотрицательных чисел: от 0 до 2N-1, где N — разрядность типа. Однако, целочисленный тип подразумевает представление также и отрицательных чисел. Можно ввести отдельные типы для отрицательных чисел от -2N до -1, но тогда такие типы потеряют универсальность хранить и неотрицательные, и отрицательные числа. Поэтому для определения знака числа можно выделить один бит из двоичного представления. По соглашению, это старший бит. Остальная часть числа называется мантиссой.
Если старший бит равен нулю, то мантисса есть обычное представление числа от 0 до 2N-1-1. Если же старший бит равен 1, то число является отрицательным и мантисса представляет собой так называемый дополнительный код числа. Поясним на примере:
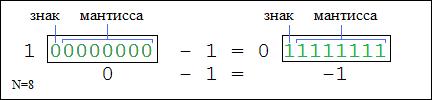
Как видно из рисунка, дополнительный код равен разнице между числом 2N-1 и модулем исходного отрицательного числа (127 (1111111) = 128 (10000000) — |-1| (0000001)). Из этого вытекает, что сумма основного и дополнительного кода одного и того же числа равна 2N-1.
Из вышеописанного получается, что можно использовать только целочисленные типы со знаком для описания чисел. Однако существует множество сущностей, которые не требуют отрицательных значений, а значит, место под знак можно включить в представление неотрицательного числа, удвоив количество различных неотрицательных значений. Как результат, в современных компьютерах используются как типы со знаком или знаковые типы, так и типы без знака или беззнаковые типы.
В итоге можно составить таблицу наиболее используемых целочисленных типов данных:
| Общее название | Название в Pascal | Название в C++ | Описание | Диапазон значений |
| unsigned byte | byte | unsigned char | беззнаковый 8 бит | 0..255 |
| signed byte | shortint | char | знаковый 8 бит | -128..127 |
| unsigned word | word | unsigned short | беззнаковый 16 бит | 0..65535 |
| signed word | smallint | short | знаковый 16 бит | -32768..32767 |
| unsigned double word | cardinal | unsigned int | беззнаковый 32 бита | 0..232-1 |
| signed double word | integer | int | знаковый 32 бита | -231..231-1 |
| unsigned quad word | uint64 | unsigned long long unsigned __int64_t (VC++) |
беззнаковый 64 бита | 0..264-1 |
| signed quad word | int64 | long long __int64_t (VC++) |
знаковый 64 бита | -263..263-1 |