
Теперь обсудим типы данных Delphi, которые программист использует при написании программы. Любая программа на Delphi может содержать данные многих типов:
- целые и дробные числа,
- символы,
- строки символов,
- логические величины.
Целый тип Delphi
Библиотека языка Delphi включает в себя 7 целых типов данных: Shortint, Smallint, Longint, Int64, Byte, Word, Longword, характеристики которых приведены в таблице ниже.

Вещественный тип Delphi
Кроме того, в поддержку языка Delphi входят 6 различных вещественных типов (Real68, Single, Double, Extended, Comp, Currency), которые отличаются друг от друга, прежде всего, по диапазону допустимых значений, по количеству значащих цифр, по количеству байт, которые необходимы для хранения некоторых данных в памяти ПК (характеристики вещественных типов приведены ниже). Также в состав библиотеки языка Delphi входит и наиболее универсальный вещественный тип — тип Real, эквивалентный Double.

Символьный тип Delphi
Кроме числовых типов, язык Delphi располагает двумя символьными типами:
Тип Ansichar — символы c кодировкой ANSI, им ставятся в соответствие числа от 0 до 255;
Тип Widechar — символы с кодировкой Unicode, им ставятся в соответствие числа от 0 до 65 535.
Строковый тип Delphi
Строковый тип в Delphi обозначается идентификатором string. В языке Delphi представлены три строковых типа:
Тип Shortstring — присущ статически размещаемым в памяти ПК строкам, длина которых изменяется в диапазоне от 0 до 255 символов;
Тип Longstring — этим типом обладают динамически размещаемые в памяти ПК строки с длиной, ограниченной лишь объемом свободной памяти;
Тип WideString — тип данных, использующийся для того, чтобы держать необходимую последовательность Интернациональный символов, подобно целым предложениям. Всякий символ строки, имеющей тип WideString, представляет собой Unicode-символ. В отличие от типа Shortstring, тип WideString является указателем, который ссылается на переменные.
Логический тип Delphi
Логический тип соответствует переменным, которые могут принять лишь одно из двух значений: true, false. В языке Delphi логические величины обладают типом Boolean. Вам были представлены основные типы данных Delphi. Движемся дальше.
Похожие записи:
Contents
- 1 Ordinal Types
- 1.1 Integer Types
- 1.1.1 Platform-Dependent Integer Types
- 1.1.2 Platform-Independent Integer Types
- 1.2 Character Types
- 1.3 Boolean Types
- 1.4 Enumerated Types
- 1.4.1 Enumerated Types with Explicitly Assigned Ordinality
- 1.4.2 Scoped Enumerations
- 1.5 Subrange Types
- 1.1 Integer Types
- 2 Real Types
- 3 See Also
Go Up to Data Types, Variables, and Constants Index
Simple types — which include ordinal types and real types — define ordered sets of values.
Ordinal Types
Ordinal types include integer, character, Boolean, enumerated, and subrange types. An ordinal type defines an ordered set of values in which each value except the first has a unique predecessor and each value except the last has a unique successor. Further, each value has an ordinality, which determines the ordering of the type. In most cases, if a value has ordinality n, its predecessor has ordinality n-1 and its successor has ordinality n+1.
For integer types, the ordinality of a value is the value itself. Subrange types maintain the ordinalities of their base types. For other ordinal types, by default the first value has ordinality 0, the next value has ordinality 1, and so forth. The declaration of an enumerated type can explicitly override this default.
Several predefined functions operate on ordinal values and type identifiers. The most important of them are summarized below.
| Function | Parameter | Return value | Remarks |
|---|---|---|---|
|
Ord |
Ordinal expression |
Ordinality of expression’s value |
Does not take Int64 arguments. |
|
Pred |
Ordinal expression |
Predecessor of expression’s value |
|
|
Succ |
Ordinal expression |
Successor of expression’s value |
|
|
High |
Ordinal type identifier or variable of ordinal type |
Highest value in type |
Also operates on short-string types and arrays. |
|
Low |
Ordinal type identifier or variable of ordinal type |
Lowest value in type |
Also operates on short-string types and arrays. |
For example, High(Byte) returns 255 because the highest value of type Byte is 255, and Succ(2) returns 3 because 3 is the successor of 2.
The standard procedures Inc and Dec increment and decrement the value of an ordinal variable. For example, Inc(I) is equivalent to I := Succ(I) and, if I is an integer variable, to I := I + 1.
Integer Types
An integer type represents a subset of the integral numbers.
Integer types can be platform-dependent and platform-independent.
Platform-Dependent Integer Types
The platform-dependent integer types are transformed to fit the bit size of the current compiler platform. The platform-dependent integer types are
NativeInt, NativeUInt, LongInt, and LongWord. Using these types whenever possible, since they result in the best performance for the underlying CPU and operating system, is desirable. The following table illustrates their ranges and storage formats for the Delphi compiler.
Platform-dependent integer types
| Type | Platform | Range | Format | Alias |
|---|---|---|---|---|
|
NativeInt |
32-bit platforms |
|
Signed 32-bit |
Integer |
| 64-bit platforms |
|
Signed 64-bit |
Int64 |
|
|
NativeUInt |
32-bit platforms |
|
Unsigned 32-bit |
Cardinal |
| 64-bit platforms |
|
Unsigned 64-bit | UInt64 | |
|
LongInt |
32-bit platforms and 64-bit Windows platforms |
|
Signed 32-bit |
Integer |
| 64-bit POSIX platforms include iOS and Linux |
|
Signed 64-bit | Int64 | |
|
LongWord |
32-bit platforms and 64-bit Windows platforms |
|
Unsigned 32-bit |
Cardinal |
| 64-bit POSIX platforms include iOS and Linux |
|
Unsigned 64-bit |
UInt64 |
Note: 32-bit platforms include 32-bit Windows, 32-bit macOS, 32-bit iOS, iOS Simulator and Android.
Platform-Independent Integer Types
Platform-independent integer types always have the same size, regardless of what platform you use. Platform-independent integer types include ShortInt, SmallInt, LongInt, Integer, Int64, Byte, Word, LongWord, Cardinal, and UInt64.
Platform-independent integer types
| Type | Range | Format | Alias |
|---|---|---|---|
|
ShortInt |
|
Signed 8-bit |
Int8 |
|
SmallInt |
|
Signed 16-bit |
Int16 |
|
FixedInt |
|
Signed 32-bit |
Int32 |
|
Integer |
|
Signed 32-bit |
Int32 |
|
Int64 |
|
Signed 64-bit |
|
|
Byte |
|
Unsigned 8-bit |
UInt8 |
|
Word |
|
Unsigned 16-bit |
UInt16 |
|
FixedUInt |
|
Unsigned 32-bit |
UInt32 |
|
Cardinal |
|
Unsigned 32-bit |
UInt32 |
|
UInt64 |
|
Unsigned 64-bit |
In general, arithmetic operations on integers return a value of type Integer, which is equivalent to the 32-bit LongInt. Operations return a value of type Int64 only when performed on one or more Int64 operands. Therefore, the following code produces incorrect results:
var I: Integer; J: Int64; ... I := High(Integer); J := I + 1;
To get an Int64 return value in this situation, cast I as Int64:
... J := Int64(I) + 1;
For more information, see Arithmetic Operators.
Note: Some standard routines that take integer arguments truncate Int64 values to 32 bits. However, the High, Low, Succ, Pred, Inc, Dec, IntToStr, and IntToHex routines fully support Int64 arguments. Also, the Round, Trunc, StrToInt64, and StrToInt64Def functions return Int64 values. A few routines cannot take Int64 values at all.
When you increment the last value or decrement the first value of an integer type, the result wraps around the beginning or end of the range. For example, the ShortInt type has the range -128..127; hence, after execution of the code:
var I: Shortint; ... I := High(Shortint); I := I + 1;
the value of I is -128. If compiler range-checking is enabled, however, this code generates a runtime error.
Character Types
The character types are Char, AnsiChar, WideChar, UCS2Char, and UCS4Char:
- Char in the current implementation is equivalent to WideChar, since now the default string type is UnicodeString. Because the implementation of Char can change in future releases, it is a good idea to use the standard function SizeOf rather than a hard-coded constant when writing programs that may need to handle characters of different sizes.
- AnsiChar values are byte-sized (8-bit) characters ordered according to the locale character set, which is possibly multibyte.
- WideChar characters use more than one byte to represent every character. In the current implementations, WideChar is word-sized (16-bit) characters ordered according to the Unicode character set (note that it could be longer in future implementations). The first 256 Unicode characters correspond to the ANSI characters.
- UCS2Char is an alias for WideChar.
- UCS4Char is used for working with 4–byte Unicode characters.
A string constant of length 1, such as ‘A’, can denote a character value. The predefined function Chr returns the character value for any integer in the range of WideChar; for example, Chr(65) returns the letter A.
AnsiChar and WideChar values, like integers, wrap around when decremented or incremented past the beginning or end of their range (unless range-checking is enabled). For example, after execution of the code:
var Letter: AnsiChar; I: Integer; begin Letter := High(Letter); for I := 1 to 66 do Inc(Letter); end;
Letter has the value A (ASCII 65).
Boolean Types
The 4 predefined Boolean types are Boolean, ByteBool, WordBool, and LongBool. Boolean is the preferred type. The others exist to provide compatibility with other languages and operating system libraries.
A Boolean variable occupies one byte of memory, a ByteBool variable also occupies one byte, a WordBool variable occupies 2 bytes (one word), and a LongBool variable occupies 4 bytes (2 words).
Boolean values are denoted by the predefined constants True and False. The following relationships hold:
| Boolean | ByteBool, WordBool, LongBool |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A value of type ByteBool, LongBool, or WordBool is considered True when its ordinality is nonzero. If such a value appears in a context where a Boolean is expected, the compiler automatically converts any value of nonzero ordinality to True.
The previous remarks refer to the ordinality of Boolean values, not to the values themselves. In Delphi, Boolean expressions cannot be equated with integers or reals. Hence, if X is an integer variable, the statement:
if X then ...;
generates a compilation error. Casting the variable to a Boolean type is unreliable, but each of the following alternatives will work.
if X <> 0 then ...; { use an expression that returns a Boolean value }
...
var OK: Boolean; { use a Boolean variable }
...
if X <> 0 then
OK := True;
if OK then ...;
Enumerated Types
An enumerated type defines an ordered set of values by simply listing identifiers that denote these values. The values have no inherent meaning. To declare an enumerated type, use the syntax:
type typeName = (val1, ...,valn)
where typeName and each val are valid identifiers. For example, the declaration:
type Suit = (Club, Diamond, Heart, Spade);
defines an enumerated type called Suit, whose possible values are Club, Diamond, Heart, and Spade, where Ord(Club) returns 0, Ord(Diamond) returns 1, and so on.
When you declare an enumerated type, you are declaring each val to be a constant of type typeName. If the val identifiers are used for another purpose within the same scope, naming conflicts occur. For example, suppose you declare the type:
type TSound = (Click, Clack, Clock)
Unfortunately, Click is also the name of a method defined for TControl and all of the objects in VCL that descend from it. So if you are writing an application and you create an event handler like:
procedure TForm1.DBGridEnter(Sender: TObject);
var
Thing: TSound;
begin
...
Thing := Click;
end;
you will get a compilation error; the compiler interprets Click within the scope of the procedure as a reference to a Click method of a TForm. You can work around this by qualifying the identifier; thus, if TSound is declared in MyUnit, you would use:
Thing := MyUnit.Click;
A better solution, however, is to choose constant names that are not likely to conflict with other identifiers. Examples:
type TSound = (tsClick, tsClack, tsClock); TMyColor = (mcRed, mcBlue, mcGreen, mcYellow, mcOrange); Answer = (ansYes, ansNo, ansMaybe)
You can use the (val1, ..., valn) construction directly in variable declarations, as if it were a type name:
var MyCard: (Club, Diamond, Heart, Spade);
But if you declare MyCard this way, you cannot declare another variable within the same scope using these constant identifiers. Thus:
var Card1: (Club, Diamond, Heart, Spade); var Card2: (Club, Diamond, Heart, Spade);
generates a compilation error. But:
var Card1, Card2: (Club, Diamond, Heart, Spade);
compiles cleanly, as does:
type Suit = (Club, Diamond, Heart, Spade); var Card1: Suit; Card2: Suit;
Enumerated Types with Explicitly Assigned Ordinality
By default, the ordinalities of enumerated values start from 0 and follow the sequence in which their identifiers are listed in the type declaration. You can override this by explicitly assigning ordinalities to some or all of the values in the declaration. To assign an ordinality to a value, follow its identifier with = constantExpression, where constantExpression is a constant expression that evaluates to an integer. For example:
type Size = (Small = 5, Medium = 10, Large = Small + Medium);
defines a type called Size whose possible values include Small, Medium, and Large, where Ord(Small) returns 5, Ord(Medium) returns 10, and Ord(Large) returns 15.
An enumerated type is, in effect, a subrange whose lowest and highest values correspond to the lowest and highest ordinalities of the constants in the declaration. In the previous example, the Size type has 11 possible values whose ordinalities range from 5 to 15. (Hence the type array[Size] of Char represents an array of 11 characters.) Only three of these values have names, but the others are accessible through typecasts and through routines such as Pred, Succ, Inc, and Dec. In the following example, «anonymous» values in the range of Size are assigned to the variable X.
var X: Size; begin X := Small; // Ord(X) = 5 X := Size(6); // Ord(X) = 6 Inc(X); // Ord(X) = 7
Any value that is not explicitly assigned an ordinality has the ordinality one greater than that of the previous value in the list. If the first value is not assigned an ordinality, its ordinality is 0. Hence, given the declaration:
type SomeEnum = (e1, e2, e3 = 1);
SomeEnum has only two possible values: Ord(e1) returns 0, Ord(e2) returns 1, and Ord(e3) also returns 1; because e2 and e3 have the same ordinality, they represent the same value.
Enumerated constants without a specific value have RTTI:
type SomeEnum = (e1, e2, e3);
whereas enumerated constants with a specific value, such as the following, do not have RTTI:
type SomeEnum = (e1 = 1, e2 = 2, e3 = 3);
Scoped Enumerations
You can use scoped enumerations in Delphi code if you enable the {$SCOPEDENUMS ON} compiler directive.
The {$SCOPEDENUMS ON or OFF} compiler directive enables or disables the use of scoped enumerations in Delphi code. {$SCOPEDENUMS ON} defines that enumerations are scoped. {$SCOPEDENUMS ON} affects declarations of enumeration types until the nearest {$SCOPEDENUMS OFF} directive. The identifiers of the enumeration introduced in enumeration types declared after the {$SCOPEDENUMS ON} directive are not added to the global scope. To use a scoped enumeration identifier, you should qualify it with the name of the enumeration type introducing this identifier.
For instance, let us define the following unit in the Unit1.pas file
unit Unit1; interface // {$SCOPEDENUMS ON} // clear comment from this directive type TMyEnum = (First, Second, Third); implementation end.
and the following program using this unit
program Project1; {$APPTYPE CONSOLE} uses SysUtils, Unit1 in 'Unit1.pas'; var // First: Integer; // clear comment from this variable Value: TMyEnum; begin try Value := First; // Value := TMyEnum.First; // Value := unit1.First; except on E:Exception do Writeln(E.Classname, ': ', E.Message); end; end.
Now we can investigate effects of the {$SCOPEDENUMS} compiler directive on the scopes in which the First, Second, and Third identifiers, defined in the TMyEnum enumeration, are visible.
First, Run (F9) on this code. The code runs successfully. This means that the First identifier, used in the
Value := First;
variable, is the global scope identifier introduced in the
TMyEnum = (First, Second, Third);
enumeration type.
Now clear comment from the
{$SCOPEDENUMS ON}
compiler directive in the unit1 unit. This directive enforces the TMyEnum enumeration to be scoped. Execute Run. The E2003 Undeclared identifier ‘First’ error is generated on the
Value := First;
line. It informs that the {$SCOPEDENUMS ON} compiler directive prevents
the First identifier, introduced in the scoped TMyEnum enumeration, to be added to the global scope.
To use identifiers introduced in scoped enumerations, prefix a reference to an enumeration’s element with its type name. For example, clear comment in the second
Value := TMyEnum.First;
version of the Value variable (and comment the first version of Value). Execute Run. The program runs successfully. This means that the First identifier is known in the TMyEnum scope.
Now comment the
// {$SCOPEDENUMS ON}
compiler directive in unit1. Then clear comment from the declaration of the First variable
First: Integer;
and again use the
Value := First;
variable. Now the code in the program Project1 looks like this:
var First: Integer; Value: TMyEnum; begin try Value := First;
Execute Run. The
First: Integer;
line causes the E2010 Incompatible types — ‘TMyEnum’ and ‘Integer’ error. This means that the naming conflict occurs between the global scope First identifier introduced in the TMyEnum enumeration and the First variable. You can work around this conflict by qualifying the First identifier with the unit1 unit in which it is defined. For this, comment again the first version of Value variable and clear comment from the third one:
Value := unit1.First;
Execute Run. The program runs successfully. That is, now the First identifier can be qualified with the unit1 unit scope. But what happens if we again enable the
{$SCOPEDENUMS ON}
compiler directive in unit1. The compiler generates the E2003 Undeclared identifier ‘First’ error on the
Value := unit1.First;
line. This means that {$SCOPEDENUMS ON} prevents adding the First enumeration’s identifier in the unit1 scope. Now the First identifier is added only in the TMyEnum enumeration’s scope. To check this, let us again use the
Value := TMyEnum.First;
version of the Value variable. Execute Run and the code succeeds.
Subrange Types
A subrange type represents a subset of the values in another ordinal type (called the base type). Any construction of the form Low..High, where Low and High are constant expressions of the same ordinal type and Low is less than High, identifies a subrange type that includes all values between Low and High. For example, if you declare the enumerated type:
type TColors = (Red, Blue, Green, Yellow, Orange, Purple, White, Black);
you can then define a subrange type like:
type TMyColors = Green..White;
Here TMyColors includes the values Green, Yellow, Orange, Purple, and White.
You can use numeric constants and characters (string constants of length 1) to define subrange types:
type SomeNumbers = -128..127; Caps = 'A'..'Z';
When you use numeric or character constants to define a subrange, the base type is the smallest integer or character type that contains the specified range.
The LowerBound..UpperBound construction itself functions as a type name, so you can use it directly in variable declarations. For example:
var SomeNum: 1..500;
declares an integer variable whose value can be anywhere in the range from 1 through 500.
The ordinality of each value in a subrange is preserved from the base type. (In the first example, if Color is a variable that holds the value Green, Ord(Color) returns 2 regardless of whether Color is of type TColors or TMyColors.) Values do not wrap around the beginning or end of a subrange, even if the base is an integer or character type; incrementing or decrementing past the boundary of a subrange simply converts the value to the base type. Hence, while:
type Percentile = 0..99; var I: Percentile; ... I := 100;
produces an error, the following code:
... I := 99; Inc(I);
assigns the value 100 to I (unless compiler range-checking is enabled).
The use of constant expressions in subrange definitions introduces a syntactic difficulty. In any type declaration, when the first meaningful character after = is a left parenthesis, the compiler assumes that an enumerated type is being defined. Hence the code:
const X = 50; Y = 10; type Scale = (X - Y) * 2..(X + Y) * 2;
produces an error. Work around this problem by rewriting the type declaration to avoid the leading parenthesis:
type Scale = 2 * (X - Y)..(X + Y) * 2;
Real Types
A real type defines a set of numbers that can be represented with the floating-point notation. The table below gives the ranges and storage formats for the real types on 64-bit and 32-bit platforms.
Real types
| Type | Platform | Approximate Positive Range | Significant decimal digits | Size in bytes |
|---|---|---|---|---|
| Real48 | all | 2.94e-39 .. 1.70e+38
|
11-12 | 6 |
| Single | all | 1.18e-38 .. 3.40e+38
|
7-8 | 4 |
| Double | all | 2.23e-308 .. 1.79e+308
|
15-16 | 8 |
| Real | all | 2.23e-308 .. 1.79e+308
|
15-16 | 8 |
| Extended | 32bit Intel Windows | 3.37e-4932 .. 1.18e+4932
|
10-20 | 10 |
| 64-bit Intel Linux 32-bit Intel macOS 32-bit Intel iOS Simulator |
3.37e-4932 .. 1.18e+4932
|
10-20 | 16 | |
| other platforms | 2.23e-308 .. 1.79e+308
|
15-16 | 8 | |
| Comp | all | -9223372036854775808.. 9223372036854775807(-263.. 263-1)
|
10-20 | 8 |
| Currency | all | -922337203685477.5808.. 922337203685477.5807(-(263+1)/10000.. 263/10000)
|
10-20 | 8 |
The following remarks apply to real types:
- Real is equivalent to Double, in the current implementation.
- Real48 is maintained for backward compatibility. Since its storage format is not native to the Intel processor architecture, it results in slower performance than other floating-point types.
- The 6-byte Real48 type was called Real in earlier versions of Object Pascal. If you are recompiling code that uses the older, 6-byte Real type in Delphi, you may want to change it to Real48. You can also use the
{$REALCOMPATIBILITY ON}compiler directive to turn Real back into the 6-byte type.
- Extended offers greater precision on 32-bit platforms than other real types.
- On 64-bit platforms Extended is an alias for a Double; that is, the size of the Extended data type is 8 bytes. Thus you have less precision using an Extended on 64-bit platforms compared to 32-bit platforms, where Extended is 10 bytes. Therefore, if your applications use the Extended data type and you rely on precision for floating-point operations, this size difference might affect your data. Be careful using Extended if you are creating data files to share across platforms. For more information, see The Extended Data Type Is 2 Bytes Smaller on 64-bit Windows Systems.
- The Comp (computational) type is native to the Intel processor architecture and represents a 64-bit integer. It is classified as a real, however, because it does not behave like an ordinal type. (For example, you cannot increment or decrement a Comp value.) Comp is maintained for backward compatibility only. Use the Int64 type for better performance.
- Currency is a fixed-point data type that minimizes rounding errors in monetary calculations. It is stored as a scaled 64-bit integer with the 4 least significant digits implicitly representing decimal places. When mixed with other real types in assignments and expressions, Currency values are automatically divided or multiplied by 10000.
See Also
- Delphi Data Types for API Integration
- About Data Types (Delphi)
- String Types (Delphi)
- Structured Types (Delphi)
- Pointers and Pointer Types (Delphi)
- Procedural Types (Delphi)
- Variant Types (Delphi)
- Type Compatibility and Identity (Delphi)
- Data Types, Variables, and Constants Index (Delphi)
- Variables (Delphi)
- Declared Constants
- Internal Data Formats (Delphi)
- 64-bit Windows Data Types Compared to 32-bit Windows Data Types
- About Floating-Point Arithmetic
- Floating-Point Comparison Routines
- Floating-Point Rounding Routines
- Floating-Point Number Control Routines
- Delphi Intrinsic Routines
Delphi Pascal supports several extensions to the standard Pascal data types. Like any Pascal language, Delphi supports enumerations, sets, arrays, integer and enumerated subranges, records, and variant records. If you are accustomed to C or C++, make sure you understand these standard Pascal types, because they can save you time and headache. The differences include the following:
- Instead of bit masks, sets are usually easier to read.
- You can use pointers instead of arrays, but arrays are easier and offer bounds-checking.
- Records are the equivalent of structures, and variant records are like unions.
8 Chapter 1 — Delphi Pascal
Integer Types
The basic integer type is Integer. The Integer type represents the natural size of an integer, given the operating system and platform. Currently, Integer represents a 32-bit integer, but you must not rely on that. The future undoubtedly holds a 64-bit operating system running on 64-bit hardware, and calling for a 64-bit Integer type. To help cope with future changes, Delphi defines some types whose size depends on the natural integer size and other types whose sizes are fixed for all future versions of Delphi. Table 1-2 lists the standard integer types. The types marked with natural size might change in future versions of Delphi, which means the range will also change. The other types will always have the size and range shown.
|
Type |
Size |
Range in Delphi 5 |
|
Integer |
natural |
-2,147,483,648 .. 2,147,483,647 |
|
Cardinal |
natural |
0 .. 4,294,967,295 |
|
Shortlnt |
8 bits |
-128 .. 127 |
|
Byte |
8 bits |
0 .. 255 |
|
Smalllnt |
16 bits |
-32,768 .. 32,767 |
|
Word |
16 bits |
0 .. 65,535 |
|
Longlnt |
32 bits |
-2,147,483,648 .. 2,147,483,647 |
|
LongWord |
32 bits |
0 .. 4,294,967,295 |
|
Int64 |
64 bits |
-9,223,372,036,854,775,808 .. 9,223,372,036,854,775,807 |
Real Types
Delphi has several floating-point types. The basic types are Single, Double, and Extended Single and Double correspond to the standard sizes for the IEEE-754 standard, which is the basis for floating-point hardware on Intel platforms and in Windows. Extended is the Intel extended precision format, which conforms to the minimum requirements of the IEEE-754 standard for extended double precision. Delphi defines the standard Pascal Real type as a synonym for Double. See the descriptions of each type in Chapter 5 for details about representation.
The floating-point hardware uses the full precision of the Extended type for its computations, but that doesn’t mean you should use Extended to store numbers. Extended takes up 10 bytes, but the Double type is only 8 bytes and is more efficient to move into and out of the floating-point unit. In most cases, you will get better performance and adequate precision by using Double.
Errors in floating-point arithmetic, such as dividing by zero, result in runtime errors. Most Delphi applications use the SysUtils unit, which maps runtime errors into exceptions, so you will usually receive a floating-point exception for such errors. Read more about exceptions and errors in «Exception Handling,» later in this chapter.
The floating-point types also have representations for infinity and not-a-number (NaN). These special values don’t arise normally unless you set the floating-point control word. You can read more about infinity and NaN in the IEEE-754 standard, which is available for purchase from the IEEE. Read about the floating-point control word in Intel’s architecture manuals, especially the Pentium Developer’s Manual, volume 3, Architecture and Programming Manual. Intel’s manuals are available online at http://developer.intel.com/design/processor/
Delphi also has a fixed-point type, Currency This type represents numbers with four decimal places in the range -922,337,203,685,477 5808 to 922,337,203,685,477. 5807, which is enough to store the gross income for the entire planet, accurate to a hundredth of a cent. The Currency type employs the floating-point processor, using 64 bits of precision in two’s complement form. Because Currency is a floating-point type, you cannot use any integer operators (such as bit shifting or masking).
The floating-point unit (FPU) can perform calculations in single-precision, double-precision, or extended-precision mode. Delphi sets the FPU to extended precision, which provides full support for the Extended and Currency types. Some Windows API functions, however, change the FPU to double precision. At double precision, the FPU maintains only 53 bits of precision instead of 64.
When the FPU uses double precision, you have no reason to use Extended values, which is another reason to use Double for most computations. A bigger problem is the Currency type. You can try to track down exactly which functions change the FPU control word and reset the precision to extended precision after the errant functions return. (See the Set8087CW function in Chapter 5 ) Another solution is to use the Int64 type instead of Currency, and implement your own fixed-point scaling in the manner shown in Example 1-6.
Example 1-6: Using Int64 to Store Currency Values resourcestring slnvalidCurrency = ‘Invalid Currency string: »%s»’; const
Currency64Decimals =4; // number of fixed decimal places Currency64Scale = 10000; // 10**Decimal64Decimals type
Currency64 = type Int64;
function Currency64ToString(Value: Currency64): string; begin
Result := Format(‘%d%s%.4d’, [Value div Currency64Scale, DecimalSeparator, Abs(Value mod Currency64Scale)]);
end;
10 Chapter 1 — Delphi Pascal
Example 1-6: Using Int64 to Store Currency Values (continued)
function StringToCurrency64(const Str: string): Currency64; var
Code: Integer; Fraction: Integer;
FractionString: string[Currency64Decimals]; I: Integer; begin
// Convert the integer part and scale by Currency64Scale
Result := Result * Currency64Scale;
if Code = 0 then
- integer part only in Str Exit else if Str[Code] = DecimalSeparator then begin
- The user might specify more or fewer than 4 decimal points, // but at most 4 places are meaningful. FractionString := Copy(Str, Code+1, Currency64Deciraals); // Pad missing digits with zeros.
for I := Length(FractionString)+1 to Currency64Decimals do
FractionString[I] := ‘0’; SetLength(FractionString, Currency64Decimals);
// Convert the fractional part and add it to the result. Val(FractionString, Fraction, Code); if Code = 0 then begin if Result < 0 then
Result := Result — Fraction else
// The string is not a valid currency string (signed, fixed point // number).
raise EConvertError.CreateFmt(sInvalidCurrency, [Str]); end;
Arrays
In additional to standard Pascal arrays, Delphi defines several extensions for use in special circumstances. Dynamic arrays are arrays whose size can change at runtime. Open arrays are array parameters that can accept any size array as actual arguments. A special case of open arrays lets you pass an array of heterogeneous types as an argument to a routine. Delphi does not support conformant arrays, as found in ISO standard Pascal, but open arrays offer the same functionality
Dynamic arrays
A dynamic array is an array whose size is determined at runtime. You can make a dynamic array grow or shrink while the program runs. Declare a dynamic array without an index type. The index is always an integer, and always starts at zero. At runtime you can change the size of a dynamic array with the SetLength procedure. Assignment of a dynamic array assigns a reference to the same array Unlike strings, dynamic arrays do not use copy-on-write, so changing an element of a dynamic array affects all references to that array Delphi manages dynamic arrays using reference counting so when an array goes out of scope, its memory is automatically freed. Example 1-7 shows how to declare and use a dynamic array
Example 1- 7/ Using a Dynamic Array var
I: Integer;
Data: array of Double; // Dynamic array storing Double values F: TextFile; // Read data from this file
Value: Double; begin
while not Eof(F) do begin
ReadLn(F, Value);
// Inefficient, but simple way to grow a dynamic array. In a real // program, you should increase the array size in larger chunks, // not one element at a time. SetLength(Data, Length(Data) + 1); Data[Length(Data)] := Value; end;
CloseFile(F); end;
Delphi checks array indices to make sure they are in bounds. (Assuming you have not disabled range checks; see the $R directive in Chapter 8.) Empty dynamic arrays are an exception. Delphi represents an empty dynamic array as a nil pointer. If you attempt to access an element of an empty dynamic array, Delphi dereferences the nil pointer, resulting in an access violation, not a range check error.
Open arrays
You can declare a parameter to a function or procedure as an open array. When calling the routine, you can pass any size array (with the same base type) as an argument. The routine should use the Low and High functions to determine the bounds of the array (Delphi always uses zero as the lower bound, but the Low and High, functions tell the maintainer of your code exactly what the code is
12 Chapter 1 — Delphi Pascal doing. Hard-coding 0 is less clear.) Be sure to declare the parameter as const if the routine does not need to modify the array, or as var if the routine modifies the array contents.
The declaration for an open array argument looks like the declaration for a dynamic array, which can cause some confusion. When used as a parameter, an array declaration without an index type is an open array When used to declare a local or global variable, a field in a class, or a new type, an array declaration without an index means a dynamic array.
You can pass a dynamic array to a routine that declares its argument as an open array, and the routine can access the elements of the dynamic array, but cannot change the array’s size. Because open arrays and dynamic arrays are declared identically, the- only way to declare a parameter as a dynamic array is to declare a new type identifier for the dynamic array type, as shown below procedure CantGrow(var Data: array of integer); begin
// Data is an open array, so it cannot change size, end;
type
TArrayOflnteger = array of integer; // dynamic array type procedure Grow (var Data: TArrayOflnteger); begin
// Data is a dynamic array, so it can change size. SetLength(Data, Length(Data) + 1); end;
You can pass a dynamic array to the CantGrow procedure, but the array is passed as an open array, not as a dynamic array The procedure can access or change the elements of the array, but it cannot change the size of the array
If you must call a Delphi function from another language, you can pass an open array argument as a pointer to the first element of the array and the array length minus one as a separate 32-bit integer argument. In other words, the lower bound for the array index is always zero, and the second parameter is the upper bound.
You can also create an open array argument by enclosing a series of values in square brackets. The open array expression can be used only as an open array argument, so you cannot assign such a value to an array-type variable. You cannot use this construct for a var open array. Creating an open array on the fly is a convenient shortcut, avoiding the need to declare a const array:
The Slice function is another way to pass an array to a function or procedure. Slice lets you pass part of an array to a routine. Chapter 5 describes Slice in detail.
Type variant open arrays
Another kind of open array parameter is the type variant open array, or array of const. A variant open array lets you pass a heterogeneous array, that is, an array where each element of the array can have a different type. For each array element,
Delphi creates a TVarRec record, which stores the element’s type and value. The array of TVarRec records is passed to the routine as a const open array The routine can examine the type of each element of the array by checking the VType member of each TVarRec record. Type variant open arrays give you a way to pass a variable size argument list to a routine in a type-safe manner.
TVarRec is a variant record similar to a Variant, but implemented differently Unlike a Variant, you can pass an object reference using TVarRec. Chapter 6, System Constants, lists all the types that TVarRec supports. Example 1-8 shows a simple example of a routine that converts a type variant open array to a string.
Example 1-8: Converting Type Variant Data to a String function AsString(const Args: array of const): string; var
I: Integer; S: String; begin
for I := Low(Args) to High(Args) do begin case Args[I].VType of vtAnsiString:
S := PChar(Args[I].VAnsiString); vtBoolean:
if Args[I].VBoolean then
S := Args[I].VClass.ClassName; vtCurrency:
S := FloatToStr(Args[I].VCurrencyA); vtExtended:
S := FloatToStr(Args[I] ,VExtendedA); Vtlnt64:
S := IntToStr(Args[I].VInt64A); vtlnteger:
S := IntToStr(Args[I].VInteger); vtlnterface:
S := Args[I].VObject.ClassName; VtPChar:
S := Format(‘%p’, [Args[I].VPointer]); vtPWideChar:
S := Args[I].VFWideChar; vtString:
14 Chapter 1 — Delphi Pascal
Example 1-8: Converting Type Variant Data to a String (continued)
vtVariant:
S := Args[I].VWideChar; vtWideString:
S := WideString(Args[I].VWideString); else raise Exception.CreateFmt(‘Unsupported VType=%d’,
end;
Strings
Delphi has four kinds of strings: short, long, wide, and zero-terminated. A short string is a counted array of characters, with up to 255 characters in the string. Short strings are not used much in Delphi programs, but if you know a string will have fewer than 255 characters, short strings incur less overhead than long strings.
Long strings can be any size, and the size can change at runtime. Delphi uses a copy-on-write system to minimize copying when you pass strings as arguments to routines or assign them to variables. Delphi maintains a reference count to free the memory for a string automatically when the string is no longer used.
Wide strings are also dynamically allocated and managed, but they do not use reference counting. When you assign a wide string to a WideString variable, Delphi copies the entire string.
Delphi checks string references the same way it checks dynamic array references, that is, Delphi checks subscripts to see if they are in range, but an empty long or wide string is represented by a nil pointer. Testing the bounds of an empty long or wide string, therefore, results in an access violation instead of a range check error.
A zero-terminated string is an array of characters, indexed by an integer starting from zero. The string does not store a size, but uses a zero-valued character to mark the end of the string. The Windows API uses zero-terminated strings, but you should not use them for other purposes. Without an explicit size, you lose the benefit of bounds checking, and performance suffers because some operations require two passes over the string contents or must process the string contents more slowly, always checking for the terminating zero value. Delphi will also treat a pointer to such an array as a string.
For your convenience, Delphi stores a zero value at the end of long and wide strings, so you can easily cast a long string to the type PAnsiChar, PChar, or PWideChar to obtain a pointer to a zero-terminated string. Delphi’s PChar type is the equivalent of char* in C or C++
String literals
You can write a string literal in the standard Pascal way, or use a pound sign (#) followed by an integer to specify a character by value, or use a caret (A) followed by a letter to specify a control character. You can mix any kind of string to form a single literal, for example:
‘Normal string: ‘#13#10’Next line (after CR-LF),AI’That was a »TAB»’
The caret (A) character toggles the sixth bit ($40) of the character’s value, which changes an upper case letter to its control character equivalent. If the character is lowercase, the caret clears the fifth and sixth bits ($60). This means you can apply the caret to nonalphabetic characters. For example, is the same as ‘ r1 because ‘ 2’ has the ordinal value $32, and toggling the $40 bit makes it $72, which is the ordinal value for ‘ r’. Delphi applies the same rules to every character, so you can use the caret before a space, tab, or return, with the result that your code will be completely unreadable.
Mixing string types
You can freely mix all different kinds of strings, and Delphi does its best to make sense out of what you are trying to do. You can concatenate different kinds of strings, and Delphi will narrow a wide string or widen a narrow string as needed. To pass a string to a function that expects a PChar parameter, just cast a long string to PChar. A short string does not automatically have a zero byte at the end, so you need to make a temporary copy, append a #0 byte, and take the address of the first character to get a PChar value.
Unicode and multibyte strings
Delphi supports Unicode with its WideChar, WideString and FWideChar types. All the usual string operations work for wide strings and narrow (long or short) strings. You can assign a narrow string to a WideString variable, and Delphi automatically converts the string to Unicode. When you assign a wide string to a long (narrow) string, Delphi uses the ANSI code page to map Unicode characters to multibyte characters.
A multibyte string is a string where a single character might occupy more than one byte. (The Windows term for a multibyte character set is double-byte character set.) Some national languages (e.g., Japanese and Chinese) use character sets that are much larger than the 256 characters in the ANSI character set. Multibyte character sets use one or two bytes to represent a character, allowing many more characters to be represented. In a multibyte string, a byte can be a single character, a lead byte (that is, the first byte of a multibyte character), or a trailing byte (the second byte of a multibyte character). Whenever you examine a string one character at a time, you should make sure that you test for multibyte characters because the character that looks like, say, the letter «A» might actually be the trailing byte of an entirely different character.
Ironically, some of Delphi’s string handling functions do not handle multibyte strings correctly Instead, the SysUtils unit has numerous string functions that work correctly with multibyte strings. Handling multibyte strings is especially impor-
16 Chapter 1 — Delphi Pascal tant for filenames, and the SysUtils unit has special functions for working with multibyte characters in filenames. See Appendix B, The SysUtils Unit, for details.
Windows NT and Windows 2000 support narrow and wide versions of most API functions. Delphi defaults to the narrow versions, but you can call the wide functions just as easily For example, you can call CreateFileW to create a file with a Unicode filename, or you can call CreateFileA to create a file with an ANSI filename. CreateFile is the same as CreateFileA. Delphi’s VCL uses the narrow versions of the Windows controls, to maintain compatibility with all versions of Windows. (Windows 95 and 98 do not support most Unicode controls.)
Boolean Types
Delphi has the usual Pascal Boolean type, but it also has several other types that make it easier to work with the Windows API. Numerous API and other functions written in C or C++ return values that are Boolean in nature, but are documented as returning an integer. In C and C++, any non-zero value is considered True, so Delphi defines the LongBool, WordBool, and ByteBool values with the same semantics.
For example, if you must call a function that was written in C, and the function returns a Boolean result as a short integer, you can declare the function with the WordBool return type and call the function as you would any other Boolean-type function in Pascal:
function SomeCFunc: WordBool; external «TheCDll.dll’;
if SomeCFunc then …
It doesn’t matter what numeric value SomeCFunc actually returns; Delphi will treat zero as False and any other value as True. You can use any of the C-like logical types the same way you would the native Delphi Boolean type. The semantics are identical. For pure Delphi code, you should always use Boolean.
Variants
Delphi supports OLE variant types, which makes it easy to write an OLE automation client or server. You can use Variants in any other situation where you want a variable whose type can change at runtime. A Variant can be an array, a string, a number, or even an IDispatch interface. You can use the Variant type or the OleVariant type. The difference is that an OleVariant takes only COM-compat-ible types, in particular, all strings are converted to wide strings. Unless the distinction is important, this book uses the term Variant to refer to both types.
A Variant variable is always initialized to Unassigned. You can assign almost any kind of value to the variable, and it will keep track of the type and value. To learn the type of a Variant, call the VarType function. Chapter 6 lists the values that VarType can return. You can also access Delphi’s low-level implementation of Variants by casting a Variant to the TVarData record type. Chapter 5 describes TVarData in detail.
When you use a Variant in an expression, Delphi automatically converts the other value in the expression to a Variant and returns a Variant result. You can assign that result to a statically typed variable, provided the Variant’s type is compatible with the destination variable.
The most common use for Variants is to write an OLE automation client. You can assign an IDispatch interface to a Variant variable, and use that variable to call functions the interface declares. The compiler does not know about these functions, so the function calls are not checked for correctness until runtime. For example, you can create an OLE client to print the version of Microsoft Word installed on your system, as shown in the following code. Delphi doesn’t know anything about the Version property or any other method or property of the Word OLE client. Instead, Delphi compiles your property and method references into calls to the IDispatch interface. You lose the benefit of compile-time checks, but you gain the flexibility of runtime binding. (If you want to keep the benefits of type safety, you will need a type library from the vendor of the OLE automation server. Use the IDE’s type library editor to extract the COM interfaces the server’s type library defines. This is not part of the Delphi language, so the details are not covered in this book.)
WordApp: Variant; begin try
WordApp := Create01e0bject(‘Word.Application’); Writeljn (WordApp.Version) ; except
WriteLnl’Word is not installed’); end; end;
Pointers
Pointers are not as important in Delphi as they are in C or C++ Delphi has real arrays, so there is no need to simulate arrays using pointers. Delphi objects use their own syntax, so there is no need to use pointers to refer to objects. Pascal also has true pass-by-reference parameters. The most common use for pointers is interfacing to C and C++ code, including the Windows API.
C and C++ programmers will be glad that Delphi’s rules for using pointers are more C-like than Pascal-like. In particular, type checking is considerably looser for pointers than for other types. (But see the $T and $TypedAddress directives, in Chapter 8, which tighten up the loose rules.)
The type Pointer is a generic pointer type, equivalent to void* in C or C++ When you assign a pointer to a variable of type Pointer, or assign a Pointer-type expression to a pointer variable, you do not need to use a type cast. To take the address of a variable or routine, use Addr or @ (equivalent to & in C or C++). When using a pointer to access an element of a record or array, you can omit the dereference operator (A). Delphi can tell that the reference uses a pointer, and supplies the A operator automatically
You can perform arithmetic on pointers in a slightly more restricted manner than you can in C or C++. Use the Inc or Dec statements to advance or retreat a pointer value by a certain number of base type elements. The actual pointer value
18 Chapter 1 — Delphi Pascal changes according to the size of the pointer’s base type. For example, incrementing a pointer to an Integer advances the pointer by 4 bytes:
IntPtr: AInteger; begin
Inc(IntPtr); // Make IntPtr point to the next Integer, 4 bytes later Inc(IntPtr, 3); // Increase IntPtr by 12 bytes = 3 * SizeOf(Integer)
Programs that interface directly with the Windows API often need to work with pointers explicitly For example, if you need to create a logical palette, the type definition of TLogPalette requires dynamic memory allocation and pointer manipulation, using a common C hack of declaring an array of one element. In order to use TLogPalette in Delphi, you have to write your Delphi code using C-like style, as shown in Example 1-9.
Example 1-9: Using a Pointer to Create a Palette
// Create a gray-scale palette with NumColors entries in it. type
TNumColors = 1..256; function MakeGrayPalette (NumColors: TNumColors) : HPalette; var
Palette: PLogPalette; // pointer to a TLogPalette record
I: TNumColors; Gray: Byte; begin
- TLogPalette has a palette array of one element. To allocate // memory for the entire palette, add the size of NumColors-1 // palette entries. GetMem(Palette, SizeOf(TLogPalette) +
- NumColors-1)*SizeOf(TPaletteEntry));
//In standard Pascal, you must write PaletteA.palVersion, // but Delphi dereferences the pointer automatically. Palette.palVersion := $300; Palette.palNumEntries := NumColors;
for I := 1 to NumColors do begin
- Use a linear scale for simplicity, even though a logarithmic // scale gives better results. Gray := I * 255 div NumColors;
- Turn off range checking to access palette entries past the first. {$R-}
Palette.palPalEntry[I-l].peRed := Gray; Palette.palPalEntry[I-l].peGreen := Gray; Palette.palPalEntry[I-l].peBlue := Gray; Palette.palPalEntry[1-1] .peFlags := 0;
Example 1-9: Using a Pointer to Create a Palette (continued)
II Delphi does not dereference pointers automatically when used // alone, as in the following case: Result := CreatePalette(Palette»); finally
FreeMem(Palette); end; end;
Function and Method Pointers
Delphi lets you take the address of a function, procedure, or method, and use that address to call the routine. For the sake of simplicity, all three kinds of pointers are called procedure pointers.
A procedure pointer has a type that specifies a function’s return type, the arguments, and whether the pointer is a method pointer or a plain procedure pointer. Source code is easier to read if you declare a procedure type and then declare a variable of that type, for example:
type
TProcedureType = procedure(Arg: Integer); TFunctionType = function(Arg: Integer): string; var
Proc: TProcedureType; Func: TFunctionType; begin
Proc := SomeProcedure;
Proc(42); // Call Proc as though it were an ordinary procedure
Usually, you can assign a procedure to a procedure variable directly. Delphi can tell from context that you are not calling the procedure, but are assigning its address. (A strange consequence of this simple rule is that a function of no arguments whose return type is a function cannot be called in the usual Pascal manner. Without any arguments, Delphi thinks you are trying to take the function’s address. Instead, call the function with empty parentheses—the same way C calls functions with no arguments.)
You can also use the @ or Addr operators to get the address of a routine. The explicit use of @ or Addr provides a clue to the person who must read and maintain your software.
Use a nil pointer for procedure pointers the same way you would for any other pointer. A common way to test a procedure variable for a nil pointer is with the Assigned function:
if Assigned(Proc) then Proc(42);
Type Declarations
Delphi follows the basic rules of type compatibility that ordinary Pascal follows for arithmetic, parameter passing, and so on. Type declarations have one new trick, though, to support the IDE. If a type declaration begins with the type keyword,
20 Chapter 1 — Delphi Pascal
Delphi creates separate runtime type information for that type, and treats the new type as a distinct type for var and out parameters. If the type declaration is just a synonym for another type, Delphi does not ordinarily create separate Ri ll for the type synonym. With the extra type keyword, though, separate RTTI tables let the IDE distinguish between the two types. You can read more about RTTI in Chapter 3-
Continue reading here: Variables and Constants
Was this article helpful?
Работа со строками и символами
Обработка текста — одна из часто встречающихся задач программирования. Если требуется обработать какие-либо текстовые данные, то без знаний того материала, что будет изложен ниже, просто не обойтись. Особенно, если данные сформированы не лично вами, а какой-либо сторонней программой или другим человеком.
Символы
Символ — это одна единица текста. Это буква, цифра, какой-либо знак. Кодовая таблица символов состоит из 256 позиций, т.е. каждый символ имеет свой уникальный код от 0 до 255. Символ с некоторым кодом N записывают так: #N. Прямо так символы и указываются в коде программы. Так как код символа представляет собой число не более 255, то очевидно, что в памяти символ занимает 1 байт. Как известно, менее байта размерности нет. Точнее, она есть — это бит, но работать с битами в программе мы не можем: байт — минимальная единица. Просмотреть таблицу символов и их коды можно с помощью стандартной утилиты «Таблица символов», входящей в Windows (ярлык расположен в меню Пуск — Программы — Стандартные — Служебные). Но совсем скоро мы и сами напишем нечто подобное.
Строки
Строка, она же текст — это набор символов, любая их последовательность. Соответственно, один символ — это тоже строка, тоже текст. Текстовая строка имеет определённую длину. Длина строки — это количество символов, которые она содержит. Если один символ занимает 1 байт, то строка из N символов занимает соответственно N байт.
Есть и другие кодовые таблицы, в которых 1 символ представлен не одним байтом, а двумя. Это Юникод (Unicode). В таблице Юникода есть символы всех языков мира. К сожалению, работа с Юникодом довольно затруднена и его поддержка пока что носит лишь локальный характер. Delphi не предоставляет возможностей для работы с Юникодом. Программная часть есть, но вот визуальные элементы — формы, кнопки и т.д. не умеют отображать текст в формате Юникода. Будем надеяться, в ближайшем будущем такая поддержка появится. 2 байта также называют словом (word). Отсюда и название соответствующего числового типа данных — Word (число, занимающее в памяти 2 байта, значения от 0 до 65535). Количество «ячеек» в таблице Юникода составляет 65536 и этого вполне достаточно для хранения всех языков мира. Если вы решили, что «1 байт — 256 значений, значит 2 байта — 2*256 = 512 значений», советую вспомнить двоичную систему и принцип хранения данных в компьютере.
Типы данных
Перейдём непосредственно к программированию. Для работы с символами и строками существуют соответствующие типы данных:
· Char — один символ (т.е. 1 байт);
· String — строка символов, текст (N байт).
Официально строки вмещают лишь 255 символов, однако в Delphi в строку можно записать гораздо больше. Для хранения больших текстов и текстов со специальными символами существуют специальные типы данных AnsiString и WideString (последний, кстати, двухбайтовый, т.е. для Юникода).
Для задания текстовых значений в Pascal используются одинарные кавычки (не двойные!). Т.е. когда вы хотите присвоить строковой переменной какое-либо значение, следует сделать это так:
s:=’text’;
Символы указываются аналогично, только в кавычках присутствует один-единственный символ.
Если вы хотите жёстко ограничить длину текста, хранимого в строковой переменной, можно сделать это следующим образом:
В скобках указывается максимальная длина строки.
Операции со строками
Основной операцией со строками является сложение. Подобно числам, строки можно складывать. И если в числах стулья с апельсинами складывать нельзя, то в строках — можно. Сложение строк — это просто их объединение. Пример:
var s: string;
...
s:='123'+'456';
//s = "123456"
Поскольку каждая строка — это последовательность символов, каждый символ имеет свой порядковый номер. В Pascal нумерация символов в строках начинается с 1. Т.е. в строке «ABC» символ «A» — первый, «B» — второй и т.д.
Порядковый номер символа в строке придуман не случайно, ведь именно по этим номерам, индексам, осуществляются действия над строками. Получить любой символ из строки можно указанием его номера в квадратных скобках рядом с именем переменной. Например:
var s: string; c: char;
...
s:='Hello!';
c:=s[2];
//c = "e"
Чуть позже, когда мы будем изучать массивы, станет понятно, что строка — это массив символов. Отсюда следует и форма обращения к отдельным символам.
Обработка строк
Перейдём к функциям и процедурам обработки строк.
Длину строки можно узнать с помощью функции Length(). Функция принимает единственный параметр — строку, а возвращает её длину. Пример:
var Str: String; L: Integer;
{ ... }
Str:='Hello!';
L:=Length(Str);
//L = 6
Нахождение подстроки в строке
Неотъемлемой задачей является нахождение подстроки в строке. Т.е. задача формулируется так: есть строка S1. Определить, начиная с какой позиции в неё входит строка S2. Без выполнения этой операции ни одну обработку представить невозможно.
Итак, для такого нахождения существует функция Pos(). Функция принимает два параметра: первый — подстроку, которую нужно найти, второй — строку, в которой нужно выполнить поиск. Поиск осуществляется с учётом регистра символов. Если функция нашла вхождение подстроки в строку, возвращается номер позиции её первого вхождения. Если вхождение не найдено, функция даёт результат 0. Пример:
var Str1, Str2: String; P: Integer;
{ ... }
Str1:='Hi! How do you do?';
Str2:='do';
P:=Pos(Str2, Str1);
//P = 9
Удаление части строки
Удалить часть строки можно процедурой Delete(). Следует обратить внимание, что это именно процедура, а не функция — она производит действия непосредственно над той переменной, которая ей передана. Итак, первый параметр — переменная строкового типа, из которой удаляется фрагмент (именно переменная! конкретное значение не задаётся, т.к. процедура не возвращает результат), второй параметр — номер символа, начиная с которого нужно удалить фрагмент, третий параметр — количество символов для удаления. Пример:
var Str1: String;
{ ... }
Str1:='Hello, world!';
Delete(Str1, 6, 7);
// Str1 = "Hello!"
Следует отметить, что если длина удаляемого фрагмента окажется больше количества символов в строке, начиная с указанной позиции (т.е. «вылезем за край»), функция нормально отработает. Поэтому, если нужно удалить фрагмент из строки с какого-то символа до конца, не нужно вычислять количество этих символов. Лучшим способом будет задать длину самой этой строки.
Вот пример. Допустим, требуется найти в строке первую букву «a» и удалить следующую за ней часть строки. Сделаем следующим образом: позицию буквы в строке найдём функцией Pos(), а фрагмент удалим функцией Delete().
var Str: String;
{ ... }
Str:='This is a test.';
Delete(Str,Pos('a',Str),Length(Str));
Попробуем подставить значения и посмотреть, что передаётся функции Delete. Первая буква «a» в строке стоит на позиции 9. Длина всей строки — 15 символов. Значит вызов функции происходит такой: Delete(Str,9,15). Видно, что от буквы «a» до конца строки всего 7 символов… Но функция сделает своё дело, не смотря на эту разницу. Результатом, конечно, будет строка «This is «. Данный пример одновременно показал и комбинирование нескольких функций.
Копирование (извлечение) части строки
Ещё одной важной задачей является копирование части строки. Например, извлечение из текста отдельных слов. Выделить фрагмент строки можно удалением лишних частей, но этот способ неудобен. Функция Copy() позволяет скопировать из строки указанную часть. Функция принимает 3 параметра: текст (строку), откуда копировать, номер символа, начиная с которого скопировать и количество символов для копирования. Результатом работы функции и будет фрагмент строки.
Пример: пусть требуется выделить из предложения первое слово (слова разделены пробелом). На форме разместим Edit1 (TEdit), в который будет введено предложение. Операцию будет выполнять по нажатию на кнопку. Имеем:
procedure TForm1.Button1Click(Sender: TObject);
var s,word: string;
begin
s:=Edit1.Text;
word:=Copy(s,1,Pos(' ',s)-1);
ShowMessage('Первое слово: '+word);
end;
В данном случае из строки копируется фрагмент от начала до первого пробела. Число символов берётся на единицу меньше, т.к. в противном случае пробел также будет скопирован.
Вставка подстроки в строку
Если требуется в имеющуюся строку вставить другую строку, можно использовать процедуру Insert(). Первый параметр — строка для вставки, второй — переменная, содержащая строку, куда нужно вставить, третий — позиция (номер символа), начиная с которого будет вставлена строка. Пример:
procedure TForm2.Button1Click(Sender: TObject);
var S: String;
begin
S:='1234567890';
Insert('000',S,3);
ShowMessage(S)
end;
В данном случае результатом будет строка «1200034567890».
Пример «посерьёзнее»
Примеры, приведённые выше, лишь демонстрируют принцип работы со строками с помощью функций Length(), Pos(), Delete() и Copy(). Теперь решим задачу посложнее, которая потребует комбинированного применения этих функций.
Задача: текст, введённый в поле Memo, разбить на слова и вывести их в ListBox по одному на строке. Слова отделяются друг от друга пробелами, точками, запятыми, восклицательными и вопросительными знаками. Помимо этого вывести общее количество слов в тексте и самое длинное из этих слов.
Вот уж да… Задача вовсе не простая. Во-первых, вы сразу должны догадаться, что нужно использовать циклы. Без них никак, ведь мы не знаем, какой текст будет передан программе для обработки. Во-вторых, слова отделяются разными символами — это создаёт дополнительные трудности. Что ж, пойдём по порядку.
Интерфейс: Memo1 (TMemo), Button1 (TButton), ListBox1 (TListBox), Label1, Label2 (TLabel).
Сначала перенесём введённый текст в переменную. Для того, чтобы разом взять весь текст из Memo, обратимся к свойству Lines.Text:
procedure TForm1.Button1Click(Sender: TObject);
var Text: string;
begin
Text:=Memo1.Lines.Text;
end;
Теперь перейдём к обработке. Первое, что нужно сделать — разобраться с символами-разделителями. Дело в том, что такие символы могут запросто идти подряд, ведь после запятых, точек и других знаков ставится пробел. Обойти эту трудность можно таким простым способом: все разделяющие символы заменим на какой-то один, например на запятую. Для этого пройдём все символы и сделаем необходимые замены. Чтобы определить, является ли символ разделителем, запишем все разделители в отдельную строковую переменную (константу), а затем будем искать в этой строке каждый символ функцией Pos(). Все эти замены будут производиться в переменной, чтобы оригинальный текст в Memo (т.е. на экране) не был затронут. Тем не менее, для проверки промежуточных результатов работы имеет смысл выводить обработанный текст куда-либо. Например, в другое поле Memo. Чтобы пройти все символы, воспользуемся циклом FOR, где переменная пройдёт порядковые номера всех символов, т.е. от 1 до длины строки текста:
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
Memo2.Text:=Text;
end;
Теперь нужно устранить помехи. Во-первых, первый символ не должен быть разделителем, т.е. если первый символ — запятая, его нужно удалить. Далее, если подряд идут несколько запятых, их нужно заменить на одну. И наконец, чтобы корректно обработать весь текст, последним символом должна быть запятая.
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
if Text[Length(Text)] <> ',' then
Text:=Text+',';
Здесь замена произведена следующим образом: организован цикл, в котором одна из запятых удаляется, но происходит это до тех пор, пока в тексте есть две идущие подряд запятые.
Ну вот, теперь в тексте не осталось ничего лишнего — только слова, разделённые запятыми. Сначала добьёмся того, чтобы программа извлекла из текста первое слово. Для этого найдём первую запятую, скопируем слово от начала текста до этой запятой, после чего удалим это слово из текста вместе с запятой. Удаление делается для того, чтобы далее можно было, проделав ту же самую операцию, вырезать следующее слово.
var Word: string;
{...}
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
Теперь в переменной Word у нас слово из текста, а в переменной Text вся остальная часть текста. Вырезанное слово теперь добавляем в ListBox, вызывая ListBox.Items.Add(строка_для_добавления).
Теперь нам нужно организовать такой цикл, который позволил бы вырезать из текста все слова, а не только первое. В данном случае подойдёт скорее REPEAT, чем WHILE. В качестве условия следует указать Length(Text) = 0, т.е. завершить цикл тогда, когда текст станет пустым, т.е. когда мы вырежем из него все слова.
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
Итак, на данный момент имеем:
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text,Word: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
end;
Если вы сейчас запустите программу, то увидите, что всё отлично работает. За исключением одного момента — в ListBox в конце появились какие-то пустые строки… Возникает вопрос: откуда же они взялись? Об этом вы узнаете в следующем разделе урока, а пока давайте реализуем требуемое до конца.
Количество слов в тексте определить очень просто — не нужно заново ничего писать. Т.к. слова у нас занесены в ListBox, достаточно просто узнать, сколько там строк — ListBox.Items.Count.
Label1.Caption:='Количество слов в тексте: '+IntToStr(ListBox1.Items.Count);
Теперь нужно найти самое длинное из всех слов. Алгоритм нахождения максимального числа таков: принимаем в качестве максимального первое из чисел. Затем проверяем все остальные числа таким образом: если число больше того, которое сейчас записано как максимальное, делаем максимальным это число. В нашем случае нужно искать максимальную длину слова. Для этого можно добавить код в цикл вырезания слов из текста или произвести поиск после добавления всех слов в ListBox. Сделаем вторым способом: организуем цикл по строкам ListBox. Следует отметить, что строки нумеруются с нуля, а не с единицы! В отдельной переменной будем хранить самое длинное слово. Казалось бы, нужно ведь ещё хранить максимальную длину слова, чтобы было с чем сравнивать… Но не нужно заводить для этого отдельную переменную, ведь мы всегда можем узнать длину слова функцией Length(). Итак, предположим, что первое слово самое длинное…
var LongestWord: string;
{...}
LongestWord:=ListBox1.Items[0];
for i := 1 to ListBox1.Items.Count-1 do
if Length(ListBox1.Items[i]) > Length(LongestWord) then
LongestWord:=ListBox1.Items[i];
Label2.Caption:='Самое длинное слово: '+LongestWord+' ('+IntToStr(Length(LongestWord))+' букв)';
Почему цикл до ListBox.Items.Count-1, а не просто до Count, разберитесь самостоятельно 
Вот теперь всё готово!
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text,Word,LongestWord: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
Text:=AnsiReplaceText(Text,Chr(13),'');
Text:=AnsiReplaceText(Text,Chr(10),'');
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
Label1.Caption:='Количество слов в тексте: '+IntToStr(ListBox1.Items.Count);
LongestWord:=ListBox1.Items[0];
for i := 1 to ListBox1.Items.Count-1 do
if Length(ListBox1.Items[i]) > Length(LongestWord) then
LongestWord:=ListBox1.Items[i];
Label2.Caption:='Самое длинное слово: '+LongestWord+' ('+IntToStr(Length(LongestWord))+' букв)';
end;
Работа с символами
Собственно, работа с символами сводится к использованию двух основных функций — Ord() и Chr(). С ними мы уже встречались. Функция Ord() возвращает код указанного символа, а функция Chr() — наоборот, возвращает символ с указанным кодом.
Помните «Таблицу символов»? Давайте сделаем её сами!
Вывод осуществим в TStringGrid. Этот компонент представляет собой таблицу, где в каждой ячейке записано текстовое значение. Компонент расположен на вкладке Additional (по умолчанию следует прямо за Standard). Перво-наперво настроим нашу табличку. Нам нужны всего две колонки: в одной будем отображать код символа, а в другой — сам символ. Количество колонок задаётся в свойстве с логичным названием ColCount. Устанавливаем его равным 2. По умолчанию у StringGrid задан один фиксированный столбец и одна фиксированная строка (они отображаются серым цветом). Столбец нам не нужен, а вот строка очень кстати, поэтому ставим FixedCols = 0, а FixedRows оставляем = 1.
Заполнение осуществим прямо при запуске программы, т.е. не будем ставить никаких кнопок. Итак, создаём обработчик события OnCreate() формы.
Количество символов в кодовой таблице 256, плюс заголовок — итого 257. Зададим число строк программно (хотя можно задать и в Инспекторе Объекта):
procedure TForm1.FormCreate(Sender: TObject);
begin
StringGrid1.RowCount:=257;
end;
Вывод делается крайне просто — с помощью цикла. Просто проходим числа от 0 до 255 и выводим соответствующий символ. Также выводим надписи в заголовок. Доступ к ячейкам StringGrid осуществляется с помощью свойства Cells: Cells[номер_столбца,номер_строки]. В квадратных скобках указываются номера столбца и строки (начинаются с нуля). Значения текстовые.
procedure TForm1.FormCreate(Sender: TObject);
var
i: Integer;
begin
StringGrid1.RowCount:=257;
StringGrid1.Cells[0,0]:='Код';
StringGrid1.Cells[1,0]:='Символ';
for i := 0 to 255 do
begin
StringGrid1.Cells[0,i+1]:=IntToStr(i);
StringGrid1.Cells[1,i+1]:=Chr(i);
end;
end;
Запускаем, смотрим.
Специальные символы
Если вы внимательно посмотрите на нашу таблицу, то увидите, что многие символы отображаются в виде квадратиков. Нет, это не значки. Так отображаются символы, не имеющие визуального отображения. Т.е. символ, например, с кодом 13 существует, но он невидим. Эти символы используются в дополнительных целях. К примеру, символ #0 (т.е. символ с кодом 0) часто применяется для указания отсутствия символа. Существуют также строки, называемые null-terminated — это строки, заканчивающиеся символом #0. Такие строки используются в языке Си.
По кодам можно опознавать нажатия клавиш. К примеру, клавиша Enter имеет код 13, Escape — 27, пробел — 32, Tab — 9 и т.д.
Давайте добавим в нашу программу возможность узнать код любой клавиши. Для этого обработаем событие формы OnKeyPress(). Чтобы этот механизм работал, необходимо установить у формы KeyPreview = True.
procedure TForm1.FormKeyPress(Sender: TObject; var Key: Char);
begin
ShowMessage('Код нажатой клавиши: '+IntToStr(Ord(Key)));
end;
Здесь мы выводим окошко с текстом. У события есть переменная Key, в которой хранится символ, соответствующий нажатой клавише. С помощью функции Ord() узнаём код этого символа, а затем функцией IntToStr() преобразуем это число в строку.
Пример «посерьёзнее» — продолжение
Вернёмся к нашему примеру. Пришло время выяснить, откуда в ListBox берутся пустые строки. Дело в том, что они не совсем пустые. Да, визуально они пусты, но на самом деле в каждой из них по 2 специальных символа. Это символы с кодами 13 и 10 (т.е. строка #13#10). В Windows такая последовательность этих двух не визуальных символов означает конец текущей строки и начало новой строки. Т.е. в любом файле и вообще где угодно переносы строк — это два символа. А весь текст, соответственно, остаётся непрерывной последовательностью символов. Эти символы можно (и даже нужно) использовать в случаях, когда требуется вставить перенос строки.
Доведём нашу программу по поиску слов до логического конца. Итак, чтобы избавиться от пустых строк, нам нужно удалить из текста символы #13 и #10. Сделать это можно с помощью цикла, по аналогии с тем, как мы делали замену двух запятых на одну:
while Pos(Chr(13),Text) > 0 do
Delete(Text,Pos(Chr(13),Text),1);
while Pos(Chr(10),Text) > 0 do
Delete(Text,Pos(Chr(10),Text),1);
Ну вот — теперь программа полностью работоспособна!
Дополнительные функции для работы со строками — модуль StrUtils
Дополнительный модуль StrUtils.pas содержит дополнительные функции для работы со строками. Среди этих функций множество полезных. Вот краткое описание часто используемых функций:
PosEx(подстрока, строка, отступ) — функция, аналогичная функции Pos(), но выполняющая поиск с указанной позиции (т.е. с отступом от начала строки). К примеру, если вы хотите найти в строке второй пробел, а не первый, без этой функции вам не обойтись. Чтобы сделать поиск второго пробела вручную, нужно предварительно вырезать часть из исходной строки.
AnsiReplaceStr, AnsiReplaceText (строка, текст_1, текст_2) — функции выполняют замену в строке строка строки текст_1 на текст_2. Функции отличаются только тем, что первая ведёт замену с учётом регистра символов, а вторая — без него.
В нашей программе можно использовать эти функции для вырезания из строки символов #13 и #10 — для этого в качестве текста для замены следует указать пустую строку. Вот решение в одну строку кода:
Text:=AnsiReplaceText(AnsiReplaceText(Text,Chr(13),''),Chr(10),'');
DupeString(строка, число_повторений) — формирует строку, состоящую из строки строка путём повторения её заданное количество раз.
ReverseString(строка) — инвертирует строку («123» -> «321»).
Также следует упомянуть у функциях преобразования регистра.
UpperCase(строка) — преобразует строку в верхний регистр; LowerCase(строка) — преобразует строку в нижний регистр.
Для преобразования отдельных символов следует использовать эти же функции.
Подробную информацию о каждой функции можно получить, введя её название в любом месте редактора кода, установив курсор на это название (или выделив его) и нажав F1.
Скриншоты программ, описанных в статье
|
Программа извлечения слов из текста |
Таблица символов |
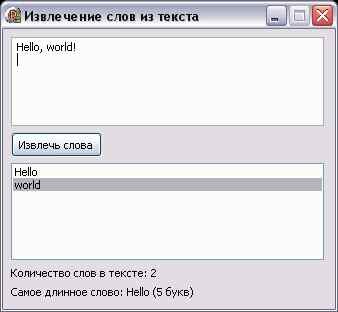

Заключение
Длинный получился урок. Итак, сегодня мы познакомились со строками и символами и научились с ними работать. Изученные приёмы используются практически повсеместно. Не бойтесь экспериментировать — самостоятельно повышайте свой уровень навыков программирования!