
From Wikipedia, the free encyclopedia

According to surveys,[1][2] the percentage of modern English words derived from each language group are as follows:
| Latin | ≈29% |
| French | ≈29% |
| Germanic | ≈26% |
| Greek | ≈5% |
| Others | ≈10% |
The following are lists of words in the English language that are known as «loanwords» or «borrowings,» which are derived from other languages.
For Old English-derived words, see List of English words of Old English origin.
- English words of African origin
- List of English words of Afrikaans origin
- List of South African English regionalisms
- List of South African slang words
- List of English words from indigenous languages of the Americas
- List of English words of Arabic origin
- List of Arabic star names
- List of English words of Australian Aboriginal origin
- List of English words of Brittonic origin
- Lists of English words of Celtic origin
- List of English words of Chinese origin
- List of English words of Czech origin
- List of English words of Dravidian origin (Kannada, Malayalam, Tamil, Telugu)
- List of English words of Dutch origin
- List of English words of Afrikaans origin
- List of South African slang words
- List of place names of Dutch origin
- Australian places with Dutch names
- List of English words of Etruscan origin
- List of English words of Finnish origin
- List of English words of French origin
- Glossary of ballet, mostly French words
- List of French expressions in English
- List of English words with dual French and Anglo-Saxon variations
- List of pseudo-French words adapted to English
- List of English Latinates of Germanic origin
- List of English words of Gaulish origin
- List of German expressions in English
- List of pseudo-German words adapted to English
- English words of Greek origin (a discussion rather than a list)
- List of Greek morphemes used in English
- List of English words of Hawaiian origin
- List of English words of Hebrew origin
- List of English words of Hindi or Urdu origin
- List of English words of Hungarian origin
- List of English words of Indian origin
- List of English words of Indonesian origin, including from Javanese, Malay (Sumatran) Sundanese, Papuan (West Papua), Balinese, Dayak and other local languages in Indonesia
- List of English words of Irish origin
- List of Irish words used in the English language
- List of English words of Italian origin
- List of Italian musical terms used in English
- List of English words of Japanese origin
- List of English words of Korean origin
- List of Latin words with English derivatives
- List of English words of Malay origin
- List of English words of Māori origin
- List of English words of Niger-Congo origin
- List of English words of Old Norse origin
- List of English words of Persian origin
- List of English words of Philippine origin
- List of English words of Polish origin
- List of English words of Polynesian origin
- List of English words of Portuguese origin
- List of English words of Romani origin
- List of English words of Romanian origin
- List of English words of Russian origin
- List of English words of Sami origin
- List of English words of Sanskrit origin
- List of English words of Scandinavian origin (incl. Danish, Norwegian)
- List of English words of Scots origin
- List of English words of Scottish Gaelic origin
- List of English words of Semitic origin
- List of English words of Spanish origin
- List of English words of Swedish origin
- List of English words of Turkic origin
- List of English words of Ukrainian origin
- List of English words of Welsh origin
- List of English words of Yiddish origin
- List of English words of Zulu origin
See also[edit]
- Anglicisation
- English terms with diacritical marks
- Inkhorn term
- Linguistic purism in English
- List of Germanic and Latinate equivalents in English
- List of Greek and Latin roots in English
- List of proposed etymologies of OK
- List of Latin legal terms
References[edit]
- ^ Finkenstaedt, Thomas; Dieter Wolff (1973). Ordered profusion; studies in dictionaries and the English lexicon. C. Winter. ISBN 3-533-02253-6.
- ^ Joseph M. Williams (1986) [1975]. Origins of the English Language. A social and linguistic history. Free Press. ISBN 0029344700.[page needed]
External links[edit]
- Ancient Egyptian Loan-Words in English
- List of etymologies of English words
We know for a fact that language and culture are intricately intertwined that one influences the other in tremendous, and sometimes amazing, ways. It is this intertwining that makes translations from one language to another extremely difficult. You can only translate words and concepts that exist in both cultures. Cultural subtleties that are not shared by other cultures will often get lost in translation.
This is why other languages will always have words that your language doesn’t and vice versa. Taking English as a reference, New Zealand-based designer Anjana Iyer compiled an amusing list of words that do not have an equivalent in English. She even drew lightheaded illustrations to help us understand what they mean beyond words. Have a glance and let us know what you think.
1. Fernweh (German)

2. Komorebi (Japanese)

3. Tingo (Pascuense)

4. Pochemuchka (Russian)

5. Gökotta (Swedish)

6. Bakku-shan (Japanese)

7. Backpfeifengesicht (German)

8. Aware (Japanese)

9. Tsundoku (Japanese)

10. Shlimazl (Yiddish)
![]()
11. Rire dans sa barbe (French)

12. Waldeinsamkeit (German)

13. Hanyauku (Rukwangali)

14. Gattara (Italian)

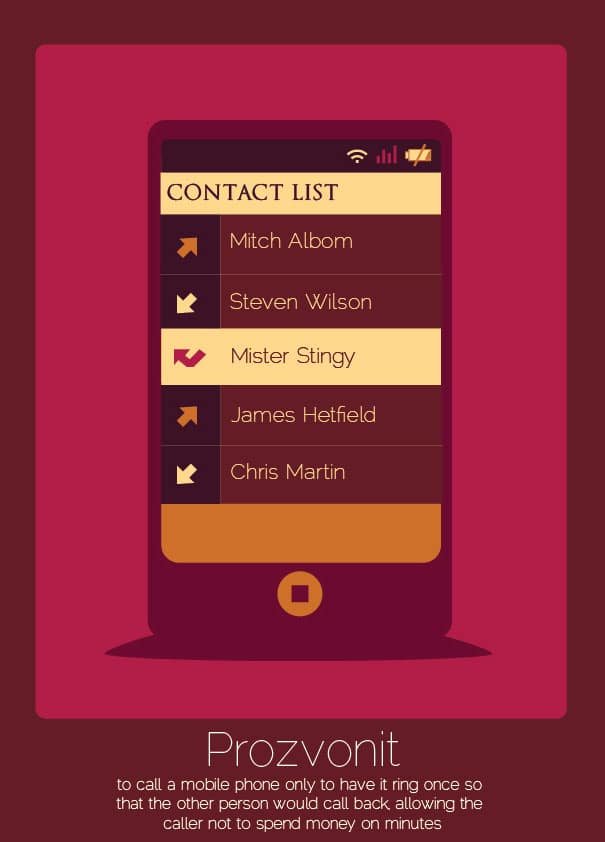
15. Prozvonit (Czech)
16. Iktsuarpok (Inuit)

17. Papakata (Cook Islands Maori)

18. Friolero (Spanish)

19. Schilderwald (German)

20. Utepils (Norwegian)

21. Mamihlapinatapei (Yagan)

22. Culaccino (Italian)

23. Ilunga (Tshiluba)

24. Kyoikumama (Japanese)

25. Age-otori (Japanese)

26. Chai-Pani (Hindi)

27. Won (Korean)

28. Tokka (Finnish)

29. Schadenfreude (German)

30. Wabi-Sabi (Japanese)

You’ve reached the end of the article. Please share it if you think it deserves.
Definition from Wiktionary, the free dictionary
Jump to navigation
Jump to search
Lists of basic words (for learners, etc.)
Pages in category «Basic word lists by language»
The following 200 pages are in this category, out of 266 total.
(previous page) (next page)
A
- Appendix:Achuar word list
- Appendix:Adai word list
- Appendix:Aiwa word list
- Appendix:Akpes word lists
- Appendix:Allentiac word list
- Appendix:Alsea word list
- Appendix:Amdang word list
- Appendix:Amerindian basic vocabulary
- Appendix:Anaang word list
- Appendix:Andaqui word list
- Appendix:Arabic Frequency List from Quran
- Appendix:Arabic Quranic Verbs
- Appendix:Arabic Quranic Verbs/Arabic Quranic Verbs 1-500
- Appendix:Arabic Quranic Verbs/Arabic Quranic Verbs 1001-1475
- Appendix:Arabic Quranic Verbs/Arabic Quranic Verbs 501-1000
- Appendix:Arabic Frequency List from Quran/Arabic Frequency List from Quran 1-1000
- Appendix:Arabic Frequency List from Quran/Arabic Frequency List from Quran 1001-2000
- Appendix:Arabic Frequency List from Quran/Arabic Frequency List from Quran 2001-3000
- Appendix:Arabic Frequency List from Quran/Arabic Frequency List from Quran 3001-3680
- Appendix:Atikum word lists
- Appendix:Axi word list
B
- Appendix:Baenan word list
- Appendix:Bangime word list
- Appendix:Bariba word list
- Appendix:Bayono-Awbono word lists
- Appendix:Beothuk word list
- Appendix:Berta word lists
- Appendix:Betoi word list
- Appendix:Biao Min (Shikou) word list
- Appendix:Biao word list
- Appendix:Bijogo word list
- Appendix:Birri word list
- Appendix:Bora word list
- Appendix:Bouyei comparative vocabulary list
- Appendix:Bulaka River word lists
- Appendix:Burmese basic vocabulary
- Appendix:Burushaski comparative vocabulary list
C
- Appendix:Caddoan word lists
- Appendix:Candoshi word list
- Appendix:Canichana word list
- Appendix:Caraballo word list
- Appendix:Cayuse word list
- Appendix:Chamacoco word list
- Appendix:Chaná word list
- Appendix:Chimariko word list
- Appendix:Chinook word list
- Appendix:Chiquitano word list
- Appendix:Cholón word list
- Appendix:Chono word list
- Appendix:Coahuilteco word list
- Appendix:Comecrudo word list
- Appendix:Coos word list
- Appendix:Cotoname word list
- Appendix:Cuitlatec word list
- Appendix:Culli word list
D
- Appendix:Defaka word list
- Appendix:Dhimalish comparative vocabulary list
- Appendix:Dogon word lists
- Appendix:Dura word list
- Appendix:1000 basic Dutch words
- Appendix:Dzubukua word list
E
- Appendix:Elamite word list
- Appendix:1000 basic English words
- Appendix:Esmeralda word list
- Appendix:Esselen word list
- Appendix:Etruscan word list
F
- Appendix:French basic words
G
- Appendix:Gahri word list
- Appendix:Gamela word list
- Appendix:Goethe-Zertifikat A1/A2
- Appendix:Gong vocabulary lists
- Appendix:Guachi word list
- Appendix:Guamo word list
- Appendix:Guató word lists
- Appendix:Guiqiong word list
- Appendix:Gule word lists
- Appendix:Gumuz word lists
H
- Appendix:Hadza word list
- Appendix:Hattic word list
- Appendix:Highland Chontal word list
- Appendix:Common Hindi words
- Wiktionary:Frequency lists/Hindi 1900
- Appendix:Horpa (Zongke) word list
- Appendix:Huamelultec word list
- Wiktionary:Frequency lists/Hungarian
- Wiktionary:Frequency lists/Hungarian frequency list 1-10000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/1001-2000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/2001-3000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/3001-4000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/4001-5000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/5001-6000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/6001-7000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/7001-8000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/8001-9000
- Wiktionary:Frequency lists/Hungarian webcorpus frequency list/9001-10000
- Appendix:Hupdë word list
- Appendix:Hurro-Urartian word lists
I
- Appendix:1000 basic Ido words
- Appendix:Iquito word list
- Appendix:Irantxe word lists
J
- Appendix:Jalaa word list
- Appendix:1000 Japanese basic words
- Wiktionary:Frequency lists/Japanese/Wikipedia2013
- Wiktionary:Frequency lists/Japanese10001-20000
- Appendix:Jeikó word list
- Appendix:Jiamao vocabulary lists
- Appendix:JLPT
- Appendix:JLPT/N1
- Appendix:JLPT/N2
- Appendix:JLPT/N3
- Appendix:JLPT/N4
- Appendix:JLPT/N5
K
- Appendix:Kaimbé word list
- Appendix:Kamakã word lists
- Appendix:Kambiwá word list
- Appendix:Kamsá word list
- Appendix:Kanoé word list
- Appendix:Kanuri word list
- Appendix:Karankawa word list
- Appendix:Karo word list
- Appendix:Katembri word lists
- Appendix:Kathu word list
- Appendix:Kenaboi word list
- Appendix:Khitan word list
- Appendix:Klamath word list
- Appendix:Kolopom word lists
- Appendix:Basic Korean Vocabulary List
- Appendix:Common Korean words
- Wiktionary:Frequency lists/Korean 5800
- Appendix:Koro word lists
- Appendix:Kujarge word list
- Appendix:Kunama word list
- Appendix:Kusunda word list
- Appendix:Kutenai word list
L
- Appendix:Laha word list
- Appendix:Lalo word list
- Appendix:Leco word lists
- Appendix:Lenca word list
- Appendix:Lower Umpqua word list
M
- Appendix:HSK list of Mandarin words
- Appendix:PSC list of Mandarin words
- Appendix:Mandarin Frequency lists
- Appendix:HSK list of Mandarin words/Beginning Mandarin
- Appendix:HSK list of Mandarin words/Elementary Mandarin
- Appendix:HSK list of Mandarin words/Intermediate Mandarin
- Appendix:HSK list of Mandarin words/Advanced Mandarin
- Appendix:Maratino word list
- Appendix:Massep word list
- Appendix:Matanawi word list
- Appendix:Mato Grosso Arára word lists
- Appendix:Maxakali word lists
- Appendix:Mien (Gongcheng) word list
- Appendix:Mimi of Decorse word list
- Appendix:Mimi of Nachtigal word list
- Appendix:Minkin word list
- Appendix:Mochica word list
- Appendix:Molala word list
- Appendix:Mru word list
- Appendix:Munichi word list
- Appendix:Mura word list
N
- Appendix:Naolan word list
- Appendix:Nara word list
- Appendix:Natchez word list
- Appendix:Natioro word lists
- Appendix:Natú word list
- Appendix:Nesu word list
- Appendix:Nihali word list
O
- Appendix:Oko word list
- Appendix:Old Chinese basic vocabulary
- Appendix:Olukumi word list
- Appendix:Omurano word list
- Appendix:Ongota word list
- Appendix:Oti word list
P
- Appendix:Pa-Hng comparative vocabulary list
- Appendix:Pana word list
- Appendix:Paniai Lakes word lists
- Appendix:Pankararú word lists
- Appendix:Paraguayan Guaraní basic vocabulary
- Appendix:Payagua word lists
- Appendix:Common Persian verbs
- Appendix:Piaroa word list
- Appendix:Pirahã word lists
- Wiktionary:Frequency lists/Polish wordlist
- Wiktionary:Project cleanup of basic English entries/Table
- Appendix:Proto-Mumuye reconstructions
- Appendix:Puinave word list
- Appendix:Puquina word list
- Appendix:Puroik comparative vocabulary list
- Appendix:Puruborá word list
- Appendix:Purépecha word list
- Appendix:Páez word list
Q
- Appendix:Qabiao word list
- Appendix:Quang Lam word list
- Appendix:Quinigua word list
R
- Appendix:Ramanos word list
- Appendix:Rikbaktsa word list
- Appendix:Mantauran Rukai vocabulary list
- Wiktionary:Frequency lists/Russian/1K most used
- Appendix:Russian Frequency lists
(previous page) (next page)
List of Cuss/Obscene/Naughty/Bad/Curse/Swear/Vulgar Words in Various Languages
Profanities list in various lanuages.
List of Cuss Words in English Language
English Cuss Word List
List of Cuss Words in Arabic Language
Arabic Cuss Word List
List of Cuss Words in Czech Language
Czech Cuss Word List
List of Cuss Words in Danish Language
Danish Cuss Word List
List of Cuss Words in German Language
German Cuss Word List
List of Cuss Words in Esperanto Language
Esperanto Cuss Word List
List of Cuss Words in Spanish Language
Spanish Cuss Word List
List of Cuss Words in Persian Language
Persian Cuss Word List
List of Cuss Words in Finnish Language
Finnish Cuss Word List
List of Cuss Words in Filipino Language
Filipino Cuss Word List
List of Cuss Words in French Language
French Cuss Word List
List of Cuss Words in Canadian-French Language
French (CA) Cuss Word List
List of Cuss Words in Hindi Language
Hindi Cuss Word List
List of Cuss Words in Hungarian Language
Hungarian Cuss Word List
List of Cuss Words in Italian Language
Italian Cuss Word List
List of Cuss Words in Japanese Language
Japanese Cuss Word List
List of Cuss Words in Kabyle Language
Kabyle Cuss Word List
List of Cuss Words in Korean Language
Korean Cuss Word List
List of Cuss Words in Dutch Language
Dutch Cuss Word List
List of Cuss Words in Norwegian Language
Norwegian Cuss Word List
List of Cuss Words in Polish Language
Polish Cuss Word List
List of Cuss Words in Portuguese Language
Portuguese Cuss Word List
List of Cuss Words in Russian Language
Russian Cuss Word List
List of Cuss Words in Swedish Language
Swedish Cuss Word List
List of Cuss Words in Thai Language
Thai Cuss Word List
List of Cuss Words in Turkish Language
Turkish Cuss Word List
List of Cuss Words in Chinese Language
Chinese Cuss Word List
List of Cuss Words in Klingon Language
Klingon Cuss Word List
References
https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words
A word list (or lexicon) is a list of a language’s lexicon (generally sorted by frequency of occurrence either by levels or as a ranked list) within some given text corpus, serving the purpose of vocabulary acquisition. A lexicon sorted by frequency «provides a rational basis for making sure that learners get the best return for their vocabulary learning effort» (Nation 1997), but is mainly intended for course writers, not directly for learners. Frequency lists are also made for lexicographical purposes, serving as a sort of checklist to ensure that common words are not left out. Some major pitfalls are the corpus content, the corpus register, and the definition of «word». While word counting is a thousand years old, with still gigantic analysis done by hand in the mid-20th century, natural language electronic processing of large corpora such as movie subtitles (SUBTLEX megastudy) has accelerated the research field.
In computational linguistics, a frequency list is a sorted list of words (word types) together with their frequency, where frequency here usually means the number of occurrences in a given corpus, from which the rank can be derived as the position in the list.
| Type | Occurrences | Rank |
|---|---|---|
| the | 3,789,654 | 1st |
| he | 2,098,762 | 2nd |
| […] | ||
| king | 57,897 | 1,356th |
| boy | 56,975 | 1,357th |
| […] | ||
| stringyfy | 5 | 34,589th |
| […] | ||
| transducionalify | 1 | 123,567th |
MethodologyEdit
FactorsEdit
Nation (Nation 1997) noted the incredible help provided by computing capabilities, making corpus analysis much easier. He cited several key issues which influence the construction of frequency lists:
- corpus representativeness
- word frequency and range
- treatment of word families
- treatment of idioms and fixed expressions
- range of information
- various other criteria
CorporaEdit
Traditional written corpusEdit
Most of currently available studies are based on written text corpus, more easily available and easy to process.
SUBTLEX movementEdit
However, New et al. 2007 proposed to tap into the large number of subtitles available online to analyse large numbers of speeches. Brysbaert & New 2009 made a long critical evaluation of this traditional textual analysis approach, and support a move toward speech analysis and analysis of film subtitles available online. This has recently been followed by a handful of follow-up studies,[1] providing valuable frequency count analysis for various languages. Indeed, the SUBTLEX movement completed in five years full studies for French (New et al. 2007), American English (Brysbaert & New 2009; Brysbaert, New & Keuleers 2012), Dutch (Keuleers & New 2010), Chinese (Cai & Brysbaert 2010), Spanish (Cuetos et al. 2011), Greek (Dimitropoulou et al. 2010), Vietnamese (Pham, Bolger & Baayen 2011), Brazil Portuguese (Tang 2012) and Portugal Portuguese (Soares et al. 2015), Albanian (Avdyli & Cuetos 2013), Polish (Mandera et al. 2014) and Catalan (2019[2]). SUBTLEX-IT (2015) provides raw data only.[1]
Lexical unitEdit
In any case, the basic «word» unit should be defined. For Latin scripts, words are usually one or several characters separated either by spaces or punctuation. But exceptions can arise, such as English «can’t», French «aujourd’hui», or idioms. It may also be preferable to group words of a word family under the representation of its base word. Thus, possible, impossible, possibility are words of the same word family, represented by the base word *possib*. For statistical purpose, all these words are summed up under the base word form *possib*, allowing the ranking of a concept and form occurrence. Moreover, other languages may present specific difficulties. Such is the case of Chinese, which does not use spaces between words, and where a specified chain of several characters can be interpreted as either a phrase of unique-character words, or as a multi-character word.
StatisticsEdit
It seems that Zipf’s law holds for frequency lists drawn from longer texts of any natural language. Frequency lists are a useful tool when building an electronic dictionary, which is a prerequisite for a wide range of applications in computational linguistics.
German linguists define the Häufigkeitsklasse (frequency class) of an item in the list using the base 2 logarithm of the ratio between its frequency and the frequency of the most frequent item. The most common item belongs to frequency class 0 (zero) and any item that is approximately half as frequent belongs in class 1. In the example list above, the misspelled word outragious has a ratio of 76/3789654 and belongs in class 16.
where is the floor function.
Frequency lists, together with semantic networks, are used to identify the least common, specialized terms to be replaced by their hypernyms in a process of semantic compression.
PedagogyEdit
Those lists are not intended to be given directly to students, but rather to serve as a guideline for teachers and textbook authors (Nation 1997). Paul Nation’s modern language teaching summary encourages first to «move from high frequency vocabulary and special purposes [thematic] vocabulary to low frequency vocabulary, then to teach learners strategies to sustain autonomous vocabulary expansion» (Nation 2006).
Effects of words frequencyEdit
Word frequency is known to have various effects (Brysbaert et al. 2011; Rudell 1993). Memorization is positively affected by higher word frequency, likely because the learner is subject to more exposures (Laufer 1997). Lexical access is positively influenced by high word frequency, a phenomenon called word frequency effect (Segui et al.). The effect of word frequency is related to the effect of age-of-acquisition, the age at which the word was learned.
LanguagesEdit
Below is a review of available resources.
EnglishEdit
Word counting dates back to Hellenistic time. Thorndike & Lorge, assisted by their colleagues, counted 18,000,000 running words to provide the first large-scale frequency list in 1944, before modern computers made such projects far easier (Nation 1997).
Traditional listsEdit
These all suffer from their age. In particular, words relating to technology, such as «blog,» which, in 2014, was #7665 in frequency[3] in the Corpus of Contemporary American English,[4] was first attested to in 1999,[5][6][7] and does not appear in any of these three lists.
- The Teachers Word Book of 30,000 words (Thorndike and Lorge, 1944)
The TWB contains 30,000 lemmas or ~13,000 word families (Goulden, Nation and Read, 1990). A corpus of 18 million written words was hand analysed. The size of its source corpus increased its usefulness, but its age, and language changes, have reduced its applicability (Nation 1997).
- The General Service List (West, 1953)
The GSL contains 2,000 headwords divided into two sets of 1,000 words. A corpus of 5 million written words was analyzed in the 1940s. The rate of occurrence (%) for different meanings, and parts of speech, of the headword are provided. Various criteria, other than frequence and range, were carefully applied to the corpus. Thus, despite its age, some errors, and its corpus being entirely written text, it is still an excellent database of word frequency, frequency of meanings, and reduction of noise (Nation 1997). This list was updated in 2013 by Dr. Charles Browne, Dr. Brent Culligan and Joseph Phillips as the New General Service List.
- The American Heritage Word Frequency Book (Carroll, Davies and Richman, 1971)
A corpus of 5 million running words, from written texts used in United States schools (various grades, various subject areas). Its value is in its focus on school teaching materials, and its tagging of words by the frequency of each word, in each of the school grade, and in each of the subject areas (Nation 1997).
- The Brown (Francis and Kucera, 1982) LOB and related corpora
These now contain 1 million words from a written corpus representing different dialects of English. These sources are used to produce frequency lists (Nation 1997).
FrenchEdit
- Traditional datasets
A review has been made by New & Pallier.
An attempt was made in the 1950s–60s with the Français fondamental. It includes the F.F.1 list with 1,500 high-frequency words, completed by a later F.F.2 list with 1,700 mid-frequency words, and the most used syntax rules.[8] It is claimed that 70 grammatical words constitute 50% of the communicatives sentence,[9] while 3,680 words make about 95~98% of coverage.[10] A list of 3,000 frequent words is available.[11]
The French Ministry of the Education also provide a ranked list of the 1,500 most frequent word families, provided by the lexicologue Étienne Brunet.[12] Jean Baudot made a study on the model of the American Brown study, entitled «Fréquences d’utilisation des mots en français écrit contemporain».[13]
More recently, the project Lexique3 provides 142,000 French words, with orthography, phonetic, syllabation, part of speech, gender, number of occurrence in the source corpus, frequency rank, associated lexemes, etc., available under an open license CC-by-sa-4.0.[14]
- Subtlex
This Lexique3 is a continuous study from which originate the Subtlex movement cited above. New et al. 2007 made a completely new counting based on online film subtitles.
SpanishEdit
There have been several studies of Spanish word frequency (Cuetos et al. 2011).[15]
ChineseEdit
Chinese corpora have long been studied from the perspective of frequency lists. The historical way to learn Chinese vocabulary is based on characters frequency (Allanic 2003). American sinologist John DeFrancis mentioned its importance for Chinese as a foreign language learning and teaching in Why Johnny Can’t Read Chinese (DeFrancis 1966). As a frequency toolkit, Da (Da 1998) and the Taiwanese Ministry of Education (TME 1997) provided large databases with frequency ranks for characters and words. The HSK list of 8,848 high and medium frequency words in the People’s Republic of China, and the Republic of China (Taiwan)’s TOP list of about 8,600 common traditional Chinese words are two other lists displaying common Chinese words and characters. Following the SUBTLEX movement, Cai & Brysbaert 2010 recently made a rich study of Chinese word and character frequencies.
OtherEdit
Most frequently used words in different languages based on Wikipedia or combined corpora.[16]
See alsoEdit
- Letter frequency
- Most common words in English
- Long tail
- Google Ngram Viewer – shows changes in word/phrase frequency (and relative frequency) over time
NotesEdit
- ^ a b «Crr » Subtitle Word Frequencies».
- ^ Boada, Roger; Guasch, Marc; Haro, Juan; Demestre, Josep; Ferré, Pilar (1 February 2020). «SUBTLEX-CAT: Subtitle word frequencies and contextual diversity for Catalan». Behavior Research Methods. 52 (1): 360–375. doi:10.3758/s13428-019-01233-1. ISSN 1554-3528. PMID 30895456. S2CID 84843788.
- ^ «Words and phrases: Frequency, genres, collocates, concordances, synonyms, and WordNet».
- ^ «Corpus of Contemporary American English (COCA)».
- ^ «It’s the links, stupid». The Economist. 20 April 2006. Retrieved 2008-06-05.
- ^ Merholz, Peter (1999). «Peterme.com». Internet Archive. Archived from the original on 1999-10-13. Retrieved 2008-06-05.
- ^ Kottke, Jason (26 August 2003). «kottke.org». Retrieved 2008-06-05.
- ^ «Le français fondamental». Archived from the original on 2010-07-04.
- ^ Ouzoulias, André (2004), Comprendre et aider les enfants en difficulté scolaire: Le Vocabulaire fondamental, 70 mots essentiels (PDF), Retz — Citing V.A.C Henmon
- ^ «Generalities».
- ^ «PDF 3000 French words».
- ^ «Maitrise de la langue à l’école: Vocabulaire». Ministère de l’éducation nationale.
- ^ Baudot, J. (1992), Fréquences d’utilisation des mots en français écrit contemporain, Presses de L’Université, ISBN 978-2-7606-1563-2
- ^ «Lexique».
- ^ «Spanish word frequency lists». Vocabularywiki.pbworks.com.
- ^ Most frequently used words in different languages, ezglot
ReferencesEdit
Theoretical conceptsEdit
- Nation, P. (1997), «Vocabulary size, text coverage, and word lists», in Schmitt; McCarthy (eds.), Vocabulary: Description, Acquisition and Pedagogy, Cambridge: Cambridge University Press, pp. 6–19, ISBN 978-0-521-58551-4
- Laufer, B. (1997), «What’s in a word that makes it hard or easy? Some intralexical factors that affect the learning of words.», Vocabulary: Description, Acquisition and Pedagogy, Cambridge: Cambridge University Press, pp. 140–155, ISBN 9780521585514
- Nation, P. (2006), «Language Education — Vocabulary», Encyclopedia of Language & Linguistics, Oxford: 494–499, doi:10.1016/B0-08-044854-2/00678-7, ISBN 9780080448541.
- Brysbaert, Marc; Buchmeier, Matthias; Conrad, Markus; Jacobs, Arthur M.; Bölte, Jens; Böhl, Andrea (2011). «The word frequency effect: a review of recent developments and implications for the choice of frequency estimates in German». Experimental Psychology. 58 (5): 412–424. doi:10.1027/1618-3169/a000123. PMID 21768069. database
- Rudell, A.P. (1993), «Frequency of word usage and perceived word difficulty : Ratings of Kucera and Francis words», Most, vol. 25, pp. 455–463
- Segui, J.; Mehler, Jacques; Frauenfelder, Uli; Morton, John (1982), «The word frequency effect and lexical access», Neuropsychologia, 20 (6): 615–627, doi:10.1016/0028-3932(82)90061-6, PMID 7162585, S2CID 39694258
- Meier, Helmut (1967), Deutsche Sprachstatistik, Hildesheim: Olms (frequency list of German words)
- DeFrancis, John (1966), Why Johnny can’t read Chinese (PDF)
- Allanic, Bernard (2003), The corpus of characters and their pedagogical aspect in ancient and contemporary China (fr: Les corpus de caractères et leur dimension pédagogique dans la Chine ancienne et contemporaine) (These de doctorat), Paris: INALCO
Written texts-based databasesEdit
- Da, Jun (1998), Jun Da: Chinese text computing, retrieved 2010-08-21.
- Taiwan Ministry of Education (1997), 八十六年常用語詞調查報告書, retrieved 2010-08-21.
- New, Boris; Pallier, Christophe, Manuel de Lexique 3 (in French) (3.01 ed.).
- Gimenes, Manuel; New, Boris (2016), «Worldlex: Twitter and blog word frequencies for 66 languages», Behavior Research Methods, 48 (3): 963–972, doi:10.3758/s13428-015-0621-0, ISSN 1554-3528, PMID 26170053.
SUBTLEX movementEdit
- New, B.; Brysbaert, M.; Veronis, J.; Pallier, C. (2007). «SUBTLEX-FR: The use of film subtitles to estimate word frequencies» (PDF). Applied Psycholinguistics. 28 (4): 661. doi:10.1017/s014271640707035x. hdl:1854/LU-599589. S2CID 145366468. Archived from the original (PDF) on 2016-10-24.
- Brysbaert, Marc; New, Boris (2009), «Moving beyond Kucera and Francis: a critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English» (PDF), Behavior Research Methods, 41 (4): 977–990, doi:10.3758/brm.41.4.977, PMID 19897807, S2CID 4792474
- Keuleers, E, M, B.; New, B. (2010), «SUBTLEX—NL: A new measure for Dutch word frequency based on film subtitles», Behavior Research Methods, 42 (3): 643–650, doi:10.3758/brm.42.3.643, PMID 20805586
- Cai, Q.; Brysbaert, M. (2010), «SUBTLEX-CH: Chinese Word and Character Frequencies Based on Film Subtitles», PLOS ONE, 5 (6): 8, Bibcode:2010PLoSO…510729C, doi:10.1371/journal.pone.0010729, PMC 2880003, PMID 20532192
- Cuetos, F.; Glez-nosti, Maria; Barbón, Analía; Brysbaert, Marc (2011), «SUBTLEX-ESP : Spanish word frequencies based on film subtitles» (PDF), Psicológica, 32: 133–143
- Dimitropoulou, M.; Duñabeitia, Jon Andoni; Avilés, Alberto; Corral, José; Carreiras, Manuel (2010), «SUBTLEX-GR: Subtitle-Based Word Frequencies as the Best Estimate of Reading Behavior: The Case of Greek», Frontiers in Psychology, 1 (December): 12, doi:10.3389/fpsyg.2010.00218, PMC 3153823, PMID 21833273
- Pham, H.; Bolger, P.; Baayen, R.H. (2011), «SUBTLEX-VIE : A Measure for Vietnamese Word and Character Frequencies on Film Subtitles», ACOL
- Brysbaert, M.; New, Boris; Keuleers, E. (2012), «SUBTLEX-US : Adding Part of Speech Information to the SUBTLEXus Word Frequencies» (PDF), Behavior Research Methods: 1–22 (databases)
- Mandera, P.; Keuleers, E.; Wodniecka, Z.; Brysbaert, M. (2014). «Subtlex-pl: subtitle-based word frequency estimates for Polish» (PDF). Behav Res Methods. 47 (2): 471–483. doi:10.3758/s13428-014-0489-4. PMID 24942246. S2CID 2334688.
- Tang, K. (2012), «A 61 million word corpus of Brazilian Portuguese film subtitles as a resource for linguistic research», UCL Work Pap Linguist (24): 208–214
- Avdyli, Rrezarta; Cuetos, Fernando (June 2013), «SUBTLEX- AL: Albanian word frequencies based on film subtitles», ILIRIA International Review, 3 (1): 285–292, doi:10.21113/iir.v3i1.112, ISSN 2365-8592
- Soares, Ana Paula; Machado, João; Costa, Ana; Iriarte, Álvaro; Simões, Alberto; de Almeida, José João; Comesaña, Montserrat; Perea, Manuel (April 2015), «On the advantages of word frequency and contextual diversity measures extracted from subtitles: The case of Portuguese», The Quarterly Journal of Experimental Psychology, 68 (4): 680–696, doi:10.1080/17470218.2014.964271, PMID 25263599, S2CID 5376519