
Information is an abstract concept that refers to that which has the power to inform. At the most fundamental level information pertains to the interpretation of that which may be sensed. Any natural process that is not completely random and any observable pattern in any medium can be said to convey some amount of information. Whereas digital signals and other data use discrete signs to convey information, other phenomena and artefacts such as analogue signals, poems, pictures, music or other sounds, and currents convey information in a more continuous form.[1] Information is not knowledge itself, but the meaning that may be derived from a representation through interpretation.[2]
Information is often processed iteratively: Data available at one step are processed into information to be interpreted and processed at the next step. For example, in written text each symbol or letter conveys information relevant to the word it is part of, each word conveys information relevant to the phrase it is part of, each phrase conveys information relevant to the sentence it is part of, and so on until at the final step information is interpreted and becomes knowledge in a given domain. In a digital signal, bits may be interpreted into the symbols, letters, numbers, or structures that convey the information available at the next level up. The key characteristic of information is that it is subject to interpretation and processing.
The concept of information is relevant in various contexts,[3] including those of constraint, communication, control, data, form, education, knowledge, meaning, understanding, mental stimuli, pattern, perception, proposition, representation, and entropy.
The derivation of information from a signal or message may be thought of as the resolution of ambiguity or uncertainty that arises during the interpretation of patterns within the signal or message.[4]
Information may be structured as data. Redundant data can be compressed up to an optimal size, which is the theoretical limit of compression.
The information available through a collection of data may be derived by analysis. For example, data may be collected from a single customer’s order at a restaurant. The information available from many orders may be analyzed, and then becomes knowledge that is put to use when the business subsequently is able to identify the most popular or least popular dish.[5]
Information can be transmitted in time, via data storage, and space, via communication and telecommunication.[6] Information is expressed either as the content of a message or through direct or indirect observation. That which is perceived can be construed as a message in its own right, and in that sense, all information is always conveyed as the content of a message.
Information can be encoded into various forms for transmission and interpretation (for example, information may be encoded into a sequence of signs, or transmitted via a signal). It can also be encrypted for safe storage and communication.
The uncertainty of an event is measured by its probability of occurrence. Uncertainty is inversely proportional to the probability of occurrence. Information theory takes advantage of this by concluding that more uncertain events require more information to resolve their uncertainty. The bit is a typical unit of information. It is ‘that which reduces uncertainty by half’.[7] Other units such as the nat may be used. For example, the information encoded in one «fair» coin flip is log2(2/1) = 1 bit, and in two fair coin flips is log2(4/1) = 2 bits. A 2011 Science article estimates that 97% of technologically stored information was already in digital bits in 2007 and that the year 2002 was the beginning of the digital age for information storage (with digital storage capacity bypassing analogue for the first time).[8]
Etymology[edit]
The English word «information» comes from Middle French enformacion/informacion/information ‘a criminal investigation’ and its etymon, Latin informatiō(n) ‘conception, teaching, creation’.[9]
In English, «information» is an uncountable mass noun.
Information theory[edit]
Information theory is the scientific study of the quantification, storage, and communication of information. The field was fundamentally established by the works of Harry Nyquist and Ralph Hartley in the 1920s, and Claude Shannon in the 1940s. The field is at the intersection of probability theory, statistics, computer science, statistical mechanics, information engineering, and electrical engineering.
A key measure in information theory is entropy. Entropy quantifies the amount of uncertainty involved in the value of a random variable or the outcome of a random process. For example, identifying the outcome of a fair coin flip (with two equally likely outcomes) provides less information (lower entropy) than specifying the outcome from a roll of a die (with six equally likely outcomes). Some other important measures in information theory are mutual information, channel capacity, error exponents, and relative entropy. Important sub-fields of information theory include source coding, algorithmic complexity theory, algorithmic information theory, and information-theoretic security.
There is another opinion regarding the universal definition of information. It lies in the fact that the concept itself has changed along with the change of various historical epochs, and in order to find such a definition, it is necessary to find common features and patterns of this transformation. For example, researchers in the field of information Petrichenko E. A. and Semenova V. G., based on a retrospective analysis of changes in the concept of information, give the following universal definition: «Information is a form of transmission of human experience (knowledge).» In their opinion, the change in the essence of the concept of information occurs after various breakthrough technologies for the transfer of experience (knowledge), i.e. the appearance of writing, the printing press, the first encyclopedias, the telegraph, the development of cybernetics, the creation of a microprocessor, the Internet, smartphones, etc. Each new form of experience transfer is a synthesis of the previous ones. That is why we see such a variety of definitions of information, because, according to the law of dialectics «negation-negation», all previous ideas about information are contained in a «filmed» form and in its modern representation.[10]
Applications of fundamental topics of information theory include source coding/data compression (e.g. for ZIP files), and channel coding/error detection and correction (e.g. for DSL). Its impact has been crucial to the success of the Voyager missions to deep space, the invention of the compact disc, the feasibility of mobile phones and the development of the Internet. The theory has also found applications in other areas, including statistical inference,[11] cryptography, neurobiology,[12] perception,[13] linguistics, the evolution[14] and function[15] of molecular codes (bioinformatics), thermal physics,[16] quantum computing, black holes, information retrieval, intelligence gathering, plagiarism detection,[17] pattern recognition, anomaly detection[18] and even art creation.
As sensory input[edit]
Often information can be viewed as a type of input to an organism or system. Inputs are of two kinds; some inputs are important to the function of the organism (for example, food) or system (energy) by themselves. In his book Sensory Ecology[19] biophysicist David B. Dusenbery called these causal inputs. Other inputs (information) are important only because they are associated with causal inputs and can be used to predict the occurrence of a causal input at a later time (and perhaps another place). Some information is important because of association with other information but eventually there must be a connection to a causal input.
In practice, information is usually carried by weak stimuli that must be detected by specialized sensory systems and amplified by energy inputs before they can be functional to the organism or system. For example, light is mainly (but not only, e.g. plants can grow in the direction of the lightsource) a causal input to plants but for animals it only provides information. The colored light reflected from a flower is too weak for photosynthesis but the visual system of the bee detects it and the bee’s nervous system uses the information to guide the bee to the flower, where the bee often finds nectar or pollen, which are causal inputs, serving a nutritional function.
As representation and complexity[edit]
The cognitive scientist and applied mathematician Ronaldo Vigo argues that information is a concept that requires at least two related entities to make quantitative sense. These are, any dimensionally defined category of objects S, and any of its subsets R. R, in essence, is a representation of S, or, in other words, conveys representational (and hence, conceptual) information about S. Vigo then defines the amount of information that R conveys about S as the rate of change in the complexity of S whenever the objects in R are removed from S. Under «Vigo information», pattern, invariance, complexity, representation, and information—five fundamental constructs of universal science—are unified under a novel mathematical framework.[20][21][22] Among other things, the framework aims to overcome the limitations of Shannon-Weaver information when attempting to characterize and measure subjective information.
As a substitute for task wasted time, energy, and material[edit]
Michael Grieves has proposed that the focus on information should be what it does as opposed to defining what it is. Grieves has proposed [23] that information can be substituted for wasted physical resources, time, energy, and material, for goal oriented tasks. Goal oriented tasks can be divided into two components: the most cost efficient use of physical resources: time, energy and material, and the additional use of physical resources used by the task.This second category is by definition wasted physical resources. Information does not substitute or replace the most cost efficient use of physical resources, but can be used to replace the wasted physical resources. The condition that this occurs under is that the cost of information is less than the cost of the wasted physical resources. Since information is a non-rival good, this can be especially beneficial for repeatable tasks. In manufacturing, the task category of the most cost efficient use of physical resources is called lean manufacturing.
As an influence that leads to transformation[edit]
Information is any type of pattern that influences the formation or transformation of other patterns.[24][25] In this sense, there is no need for a conscious mind to perceive, much less appreciate, the pattern. Consider, for example, DNA. The sequence of nucleotides is a pattern that influences the formation and development of an organism without any need for a conscious mind. One might argue though that for a human to consciously define a pattern, for example a nucleotide, naturally involves conscious information processing.
Systems theory at times seems to refer to information in this sense, assuming information does not necessarily involve any conscious mind, and patterns circulating (due to feedback) in the system can be called information. In other words, it can be said that information in this sense is something potentially perceived as representation, though not created or presented for that purpose. For example, Gregory Bateson defines «information» as a «difference that makes a difference».[26]
If, however, the premise of «influence» implies that information has been perceived by a conscious mind and also interpreted by it, the specific context associated with this interpretation may cause the transformation of the information into knowledge. Complex definitions of both «information» and «knowledge» make such semantic and logical analysis difficult, but the condition of «transformation» is an important point in the study of information as it relates to knowledge, especially in the business discipline of knowledge management. In this practice, tools and processes are used to assist a knowledge worker in performing research and making decisions, including steps such as:
- Review information to effectively derive value and meaning
- Reference metadata if available
- Establish relevant context, often from many possible contexts
- Derive new knowledge from the information
- Make decisions or recommendations from the resulting knowledge
Stewart (2001) argues that transformation of information into knowledge is critical, lying at the core of value creation and competitive advantage for the modern enterprise.
The Danish Dictionary of Information Terms[27] argues that information only provides an answer to a posed question. Whether the answer provides knowledge depends on the informed person. So a generalized definition of the concept should be: «Information» = An answer to a specific question».
When Marshall McLuhan speaks of media and their effects on human cultures, he refers to the structure of artifacts that in turn shape our behaviors and mindsets. Also, pheromones are often said to be «information» in this sense.
Technologically mediated information[edit]
These sections are using measurements of data rather than information, as information cannot be directly measured.
As of 2007[edit]
It is estimated that the world’s technological capacity to store information grew from 2.6 (optimally compressed) exabytes in 1986 – which is the informational equivalent to less than one 730-MB CD-ROM per person (539 MB per person) – to 295 (optimally compressed) exabytes in 2007.[8] This is the informational equivalent of almost 61 CD-ROM per person in 2007.[6]
The world’s combined technological capacity to receive information through one-way broadcast networks was the informational equivalent of 174 newspapers per person per day in 2007.[8]
The world’s combined effective capacity to exchange information through two-way telecommunication networks was the informational equivalent of 6 newspapers per person per day in 2007.[6]
As of 2007, an estimated 90% of all new information is digital, mostly stored on hard drives.[28]
As of 2020[edit]
The total amount of data created, captured, copied, and consumed globally is forecast to increase rapidly, reaching 64.2 zettabytes in 2020. Over the next five years up to 2025, global data creation is projected to grow to more than 180 zettabytes.[29]
As records[edit]
Records are specialized forms of information. Essentially, records are information produced consciously or as by-products of business activities or transactions and retained because of their value. Primarily, their value is as evidence of the activities of the organization but they may also be retained for their informational value. Sound records management[30] ensures that the integrity of records is preserved for as long as they are required.
The international standard on records management, ISO 15489, defines records as «information created, received, and maintained as evidence and information by an organization or person, in pursuance of legal obligations or in the transaction of business».[31] The International Committee on Archives (ICA) Committee on electronic records defined a record as, «recorded information produced or received in the initiation, conduct or completion of an institutional or individual activity and that comprises content, context and structure sufficient to provide evidence of the activity».[32]
Records may be maintained to retain corporate memory of the organization or to meet legal, fiscal or accountability requirements imposed on the organization. Willis expressed the view that sound management of business records and information delivered «…six key requirements for good corporate governance…transparency; accountability; due process; compliance; meeting statutory and common law requirements; and security of personal and corporate information.»[33]
Semiotics[edit]
Michael Buckland has classified «information» in terms of its uses: «information as process», «information as knowledge», and «information as thing».[34]
Beynon-Davies[35][36] explains the multi-faceted concept of information in terms of signs and signal-sign systems. Signs themselves can be considered in terms of four inter-dependent levels, layers or branches of semiotics: pragmatics, semantics, syntax, and empirics. These four layers serve to connect the social world on the one hand with the physical or technical world on the other.
Pragmatics is concerned with the purpose of communication. Pragmatics links the issue of signs with the context within which signs are used. The focus of pragmatics is on the intentions of living agents underlying communicative behaviour. In other words, pragmatics link language to action.
Semantics is concerned with the meaning of a message conveyed in a communicative act. Semantics considers the content of communication. Semantics is the study of the meaning of signs — the association between signs and behaviour. Semantics can be considered as the study of the link between symbols and their referents or concepts – particularly the way that signs relate to human behavior.
Syntax is concerned with the formalism used to represent a message. Syntax as an area studies the form of communication in terms of the logic and grammar of sign systems. Syntax is devoted to the study of the form rather than the content of signs and sign-systems.
Nielsen (2008) discusses the relationship between semiotics and information in relation to dictionaries. He introduces the concept of lexicographic information costs and refers to the effort a user of a dictionary must make to first find, and then understand data so that they can generate information.
Communication normally exists within the context of some social situation. The social situation sets the context for the intentions conveyed (pragmatics) and the form of communication. In a communicative situation intentions are expressed through messages that comprise collections of inter-related signs taken from a language mutually understood by the agents involved in the communication. Mutual understanding implies that agents involved understand the chosen language in terms of its agreed syntax (syntactics) and semantics. The sender codes the message in the language and sends the message as signals along some communication channel (empirics). The chosen communication channel has inherent properties that determine outcomes such as the speed at which communication can take place, and over what distance.
The application of information study[edit]
The information cycle (addressed as a whole or in its distinct components) is of great concern to information technology, information systems, as well as information science. These fields deal with those processes and techniques pertaining to information capture (through sensors) and generation (through computation, formulation or composition), processing (including encoding, encryption, compression, packaging), transmission (including all telecommunication methods), presentation (including visualization / display methods), storage (such as magnetic or optical, including holographic methods), etc.
Information visualization (shortened as InfoVis) depends on the computation and digital representation of data, and assists users in pattern recognition and anomaly detection.
-

Partial map of the Internet, with nodes representing IP addresses
-

Galactic (including dark) matter distribution in a cubic section of the Universe
-
Information embedded in an abstract mathematical object with symmetry breaking nucleus
-

Visual representation of a strange attractor, with converted data of its fractal structure




Information security (shortened as InfoSec) is the ongoing process of exercising due diligence to protect information, and information systems, from unauthorized access, use, disclosure, destruction, modification, disruption or distribution, through algorithms and procedures focused on monitoring and detection, as well as incident response and repair.
Information analysis is the process of inspecting, transforming, and modelling information, by converting raw data into actionable knowledge, in support of the decision-making process.
Information quality (shortened as InfoQ) is the potential of a dataset to achieve a specific (scientific or practical) goal using a given empirical analysis method.
Information communication represents the convergence of informatics, telecommunication and audio-visual media & content.
See also[edit]
- Abstraction
- Accuracy and precision
- Classified information
- Complex adaptive system
- Complex system
- Cybernetics
- Data storage device#Recording media
- Engram
- Exformation
- Free Information Infrastructure
- Freedom of information
- Informatics
- Information and communication technologies
- Information architecture
- Information broker
- Information continuum
- Information ecology
- Information engineering
- Information geometry
- Information inequity
- Information infrastructure
- Information management
- Information metabolism
- Information overload
- Information quality (InfoQ)
- Information science
- Information sensitivity
- Information superhighway
- Information technology
- Information theory
- Information warfare
- Infosphere
- Internet forum
- Lexicographic information cost
- Library science
- Meme
- Philosophy of information
- Propaganda model
- Quantum information
- Receiver operating characteristic
- Satisficing
References[edit]
- ^ John B. Anderson; Rolf Johnnesson (1996). Understanding Information Transmission. Ieee Press. ISBN 9780471711209.
- ^ Hubert P. Yockey (2005). Information Theory, Evolution, and the Origin of Life. Cambridge University Press. p. 7. ISBN 9780511546433.
- ^ Luciano Floridi (2010). Information — A Very Short Introduction. Oxford University Press. ISBN 978-0-19-160954-1.
- ^ Webler, Forrest (25 February 2022). «Measurement in the Age of Information». Information. 13 (3): 111. doi:10.3390/info13030111.
- ^ «What Is The Difference Between Data And Information?». BYJUS. Retrieved 5 August 2021.
- ^ a b c «World_info_capacity_animation». YouTube. 11 June 2011. Archived from the original on 21 December 2021. Retrieved 1 May 2017.
- ^ «DT&SC 4-5: Information Theory Primer, Online Course». youtube.com. University of California. 2015.
- ^ a b c Hilbert, Martin; López, Priscila (2011). «The World’s Technological Capacity to Store, Communicate, and Compute Information». Science. 332 (6025): 60–65. Bibcode:2011Sci…332…60H. doi:10.1126/science.1200970. PMID 21310967. S2CID 206531385. Free access to the article at martinhilbert.net/WorldInfoCapacity.html
- ^ Oxford English Dictionary, Third Edition, 2009, full text
- ^ Semenova, Veronika; Petrichenko, Evgeny (2022). «Information: The History of Notion, Its Present and Future». Izvestiya University. The North Caucasus Region. Series: Social Sciences. 1 (213): 16–26. doi:10.18522/2687-0770-2022-1-16-26. ISSN 2687-0770. S2CID 249796993.
- ^ Burnham, K. P. and Anderson D. R. (2002) Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, Second Edition (Springer Science, New York) ISBN 978-0-387-95364-9.
- ^ F. Rieke; D. Warland; R Ruyter van Steveninck; W Bialek (1997). Spikes: Exploring the Neural Code. The MIT press. ISBN 978-0262681087.
- ^ Delgado-Bonal, Alfonso; Martín-Torres, Javier (3 November 2016). «Human vision is determined based on information theory». Scientific Reports. 6 (1): 36038. Bibcode:2016NatSR…636038D. doi:10.1038/srep36038. ISSN 2045-2322. PMC 5093619. PMID 27808236.
- ^ cf; Huelsenbeck, J. P.; Ronquist, F.; Nielsen, R.; Bollback, J. P. (2001). «Bayesian inference of phylogeny and its impact on evolutionary biology». Science. 294 (5550): 2310–2314. Bibcode:2001Sci…294.2310H. doi:10.1126/science.1065889. PMID 11743192. S2CID 2138288.
- ^ Allikmets, Rando; Wasserman, Wyeth W.; Hutchinson, Amy; Smallwood, Philip; Nathans, Jeremy; Rogan, Peter K. (1998). «Thomas D. Schneider], Michael Dean (1998) Organization of the ABCR gene: analysis of promoter and splice junction sequences». Gene. 215 (1): 111–122. doi:10.1016/s0378-1119(98)00269-8. PMID 9666097.
- ^ Jaynes, E. T. (1957). «Information Theory and Statistical Mechanics». Phys. Rev. 106 (4): 620. Bibcode:1957PhRv..106..620J. doi:10.1103/physrev.106.620.
- ^ Bennett, Charles H.; Li, Ming; Ma, Bin (2003). «Chain Letters and Evolutionary Histories». Scientific American. 288 (6): 76–81. Bibcode:2003SciAm.288f..76B. doi:10.1038/scientificamerican0603-76. PMID 12764940. Archived from the original on 7 October 2007. Retrieved 11 March 2008.
- ^ David R. Anderson (1 November 2003). «Some background on why people in the empirical sciences may want to better understand the information-theoretic methods» (PDF). Archived from the original (PDF) on 23 July 2011. Retrieved 23 June 2010.
- ^ Dusenbery, David B. (1992). Sensory Ecology. New York: W.H. Freeman. ISBN 978-0-7167-2333-2.
- ^ Vigo, R. (2011). «Representational information: a new general notion and measure of information» (PDF). Information Sciences. 181 (21): 4847–59. doi:10.1016/j.ins.2011.05.020.
- ^ Vigo, R. (2013). «Complexity over Uncertainty in Generalized Representational Information Theory (GRIT): A Structure-Sensitive General Theory of Information». Information. 4 (1): 1–30. doi:10.3390/info4010001.
- ^ Vigo, R. (2014). Mathematical Principles of Human Conceptual Behavior: The Structural Nature of Conceptual Representation and Processing. New York and London: Scientific Psychology Series, Routledge. ISBN 978-0415714365.
- ^ Grieves, Michael (2006). Product Lifecycle Management: Driving the Next Generation of Lean Thinking. New York: McGraw Hill. pp. 6–12. ISBN 0-07-145230-3.
- ^ Shannon, Claude E. (1949). The Mathematical Theory of Communication.
- ^ Casagrande, David (1999). «Information as verb: Re-conceptualizing information for cognitive and ecological models» (PDF). Journal of Ecological Anthropology. 3 (1): 4–13. doi:10.5038/2162-4593.3.1.1.
- ^ Bateson, Gregory (1972). Form, Substance, and Difference, in Steps to an Ecology of Mind. University of Chicago Press. pp. 448–66.
- ^ Simonsen, Bo Krantz. «Informationsordbogen — vis begreb». Informationsordbogen.dk. Retrieved 1 May 2017.
- ^ Failure Trends in a Large Disk Drive Population. Eduardo Pinheiro, Wolf-Dietrich Weber and Luiz Andre Barroso
- ^ «Total data volume worldwide 2010-2025». Statista. Retrieved 6 August 2021.
- ^ «What is records management?». Retrieved 29 January 2021.
- ^ ISO 15489
- ^ Committee on Electronic Records (February 1997). «Guide For Managing Electronic Records From An Archival Perspective» (PDF). www.ica.org. International Committee on Archives. p. 22. Retrieved 9 February 2019.
- ^ Willis, Anthony (1 August 2005). «Corporate governance and management of information and records». Records Management Journal. 15 (2): 86–97. doi:10.1108/09565690510614238.
- ^ Buckland, Michael K. (June 1991). «Information as thing». Journal of the American Society for Information Science. 42 (5): 351–360. doi:10.1002/(SICI)1097-4571(199106)42:5<351::AID-ASI5>3.0.CO;2-3.
- ^ Beynon-Davies, P. (2002). Information Systems: an introduction to informatics in Organisations. Basingstoke, UK: Palgrave. ISBN 978-0-333-96390-6.
- ^ Beynon-Davies, P. (2009). Business Information Systems. Basingstoke: Palgrave. ISBN 978-0-230-20368-6.
Further reading[edit]
- Liu, Alan (2004). The Laws of Cool: Knowledge Work and the Culture of Information. University of Chicago Press.
- Bekenstein, Jacob D. (August 2003). «Information in the holographic universe». Scientific American. 289 (2): 58–65. Bibcode:2003SciAm.289b..58B. doi:10.1038/scientificamerican0803-58. PMID 12884539.
- Gleick, James (2011). The Information: A History, a Theory, a Flood. New York, NY: Pantheon.
- Lin, Shu-Kun (2008). «Gibbs Paradox and the Concepts of Information, Symmetry, Similarity and Their Relationship». Entropy. 10 (1): 1–5. arXiv:0803.2571. Bibcode:2008Entrp..10….1L. doi:10.3390/entropy-e10010001. S2CID 41159530.
- Floridi, Luciano (2005). «Is Information Meaningful Data?» (PDF). Philosophy and Phenomenological Research. 70 (2): 351–70. doi:10.1111/j.1933-1592.2005.tb00531.x. hdl:2299/1825. S2CID 5593220.
- Floridi, Luciano (2005). «Semantic Conceptions of Information». In Zalta, Edward N. (ed.). The Stanford Encyclopedia of Philosophy (Winter 2005 ed.). Metaphysics Research Lab, Stanford University.
- Floridi, Luciano (2010). Information: A Very Short Introduction. Oxford: Oxford University Press.
- Logan, Robert K. What is Information? — Propagating Organization in the Biosphere, the Symbolosphere, the Technosphere and the Econosphere. Toronto: DEMO Publishing.
- Machlup, F. and U. Mansfield, The Study of information : interdisciplinary messages. 1983, New York: Wiley. xxii, 743 p. ISBN 9780471887171
- Nielsen, Sandro (2008). «The Effect of Lexicographical Information Costs on Dictionary Making and Use». Lexikos. 18: 170–89.
- Stewart, Thomas (2001). Wealth of Knowledge. New York, NY: Doubleday.
- Young, Paul (1987). The Nature of Information. Westport, Ct: Greenwood Publishing Group. ISBN 978-0-275-92698-4.
- Kenett, Ron S.; Shmueli, Galit (2016). Information Quality: The Potential of Data and Analytics to Generate Knowledge. Chichester, United Kingdom: John Wiley and Sons. doi:10.1002/9781118890622. ISBN 978-1-118-87444-8.
External links[edit]
![]()
Look up information in Wiktionary, the free dictionary.
- Semantic Conceptions of Information Review by Luciano Floridi for the Stanford Encyclopedia of Philosophy
- Principia Cybernetica entry on negentropy
- Fisher Information, a New Paradigm for Science: Introduction, Uncertainty principles, Wave equations, Ideas of Escher, Kant, Plato and Wheeler. This essay is continually revised in the light of ongoing research.
- How Much Information? 2003 an attempt to estimate how much new information is created each year (study was produced by faculty and students at the School of Information Management and Systems at the University of California at Berkeley)
- (in Danish) Informationsordbogen.dk The Danish Dictionary of Information Terms / Informationsordbogen

Wiki User
∙ 8y ago
Best Answer
![]() Copy
Copy
The word contains the word
formation. It also contains the words info, form, for, mat, on, in,
or and at.
Charlene Schinner ∙
Lvl 10
∙ 7mo ago
This answer is:
![]()
Study guides
Add your answer:
![]() Earn +
Earn +
20
pts
Q: What is the word information made up of?
Write your answer…
Submit
Still have questions?
![]()
![]()
Related questions
People also asked
Intro to Information Theory: Claude Shannon, Entropy, Redundancy, Data Compression & Bits
Script:
Summary of Previous Video:
In the previous video I discussed several definitions of information and I mainly concentrated on Gregory Bateson’s definition, which describes information as “a difference that makes a difference”. I modified his definition to information is a “perceived difference that can make a difference” and discussed how information has the potential to be used as the basic currency for describing reality.
Reality is a subjective experience, it is perception, it is qualia. In this way, information represents the connection between the observer and the observed, it encapsulates the link between the subject and the object, the relationship between what we conceptualise as the external world and what it feels like to experience this external world from within.
Therefore, using information to describe reality also embodies the recognition that, in many contexts, it doesn’t make sense anymore to speak of things in themselves, but that all we can possibly describe are perceived distinctions, perceived properties, perceived patterns and regularities in Nature.
Information has the potential to be assigned a meaning and therefore it has the potential to become knowledge. Meaning is subjective so information doesn’t really have objective intrinsic meaning.
Introduction to Information Theory:
Now, you may be wondering what science has to say about all this. How does science currently define information? Has science been able to objectively quantify information? The answer to these questions lies at the heart of Information Theory.
Information Theory is a branch of mathematics and computer science which studies the quantification of information. As you have probably realised by now, the concept of information can be defined in many different ways. Clearly, if we want to quantify information, we need to use definitions which are as objective as possible.
While subjectivity can never be completely removed from the equation (reality is, after all, always perceived and interpreted in a subjective manner) we will now explore a definition of information that is much more technical and objective than the definitions we discussed in the previous video.
This is Claude Shannon, an American mathematician and electronic engineer who is now considered the «Father of Information Theory». While working at Bell Laboratories, he formulated a theory which aimed to quantify the communication of information.
Shannon’s article titled «A Mathematical Theory of Communication», published in 1948, as well as his book «The Mathematical Theory of Communication», co-written with mathematician Warren Weaver and published in 1949, truly revolutionised science.
Shannon’s theory tackled the problem of how to transmit information most efficiently through a given channel as well as many other practical issues such as how to make communication more secure (for instance, how to tackle unauthorised eavesdropping).
Thanks to Shannon’s ideas on signal processing, data compression, as well as data storage and communication, useful applications have been found in many different areas. For instance, lossless data compression is used in ZIP files, while lossy data compression is used in other types of files such as MP3s or JPGs. Other important applications of Information Theory are within the fields of cryptography, thermal physics, neurobiology or quantum computing, to name just a few.
It is important to realise that Shannon’s Theory was created to find ways to optimise the physical encoding of information, to find fundamental limits on signal processing operations. Because of this, Shannon’s definition of information was originally associated with the actual symbols which are used to encode a message (for instance, the letters or words contained in a message), and not intended to relate to the actual interpretation, assigned meaning or importance of the message.
As we have seen in the previous video, information itself does not really have intrinsic objective meaning. What Shannon’s Theory aimed to tackle were practical issues completely unrelated to qualitative properties such as meaningfulness, but more related to the actual encoding used in the transmission of a particular message.
Therefore, what we are dealing with here is a very different definition of information than those we have discussed so far. Shannon defines information as a purely quantitative measure of communication exchanges. As we will see, Shannon’s definition represents a way to measure the amount of information that can potentially be gained when one learns of the outcome of a random process. And it is precisely this probabilistic nature of Shannon’s definition that turns out to be a very useful tool; one that physicists (and other science disciplines) now use in many different areas of research.
Shannon’s information is in fact known as Shannon’s entropy (Legend says that it was the mathematician John von Neumann who suggested that Shannon use this term, instead of information). In general, I will refer to Shannon’s definition as Shannon’s entropy, information entropy or Shannon’s information, to avoid confusion with other definitions of information or with the concept of thermodynamical entropy.
Shannon’s Entropy Formula – Uncertainty – Information Gain & Information Content:
So what is Shannon’s definition then? Well, the amount of information contained in a given message is defined as the negative of a certain sum of probabilities. Don’t worry, we are not going to deal with the actual details of the equation here, but instead I will give you a flavour of what it means. Suppose we have a probabilistic process which has a certain number of possible outcomes, each with a different probability of occurring.
Let’s call the total number of possible outcomes N and the probabilities of each outcome p(1), p(2), p(3), ….., p(N). For instance, let’s say that the probabilistic process we are dealing with is the throw of a coin. In this case, the total number of possible outcomes is 2, so N=2 (that is, heads and tails – let’s call heads 1 and tails 2). The probabilities associated with each of these possible outcomes, assuming a fair coin, is ½. So we have p(1)= ½ and p(2)= ½ (which is the same as saying each possible outcome, heads or tails, has a 50% probability of occurring).
Shannon showed that the entropy (designated by the letter H) is equivalent to the potential information gain once the experimenter learns the outcome of the experiment, and is given by the following formula:
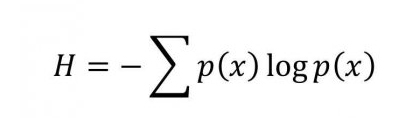
This formula implies that the more entropy a system has, the more information we can potentially gain once we know the outcome of the experiment. Shannon’s entropy can be thought of as a way to quantify the potential reduction in our uncertainty once we have learnt the outcome of the probabilistic process.
Don’t worry if you feel a bit confused right now. I’ll explain the concept of Shannon’s entropy for you in very easy terms. Let’s go back to the coin example:
The coin is fair, so the probability of heads is the same as the probability of tails (that is, ½ each). Let’s consider the event of throwing the coin. Plugging the given probabilities into the equation gives us a Shannon entropy, that is, an information content of one bit, because there are two possible outcomes and each has equal probability. Once we have thrown the coin and we have learnt its outcome, we can say that we have gained one bit of information, or alternatively, we can say that our uncertainty has been reduced by one bit.
Now imagine you have a coin which has two heads. In this case, N=1, that is, there is only one possible outcome. The likelihood of obtaining heads is therefore equal to 1 (a probability equal to 1 means absolute certainty, 100%). Since the uncertainty is zero in this case, Shannon’s entropy is zero, and so is the information content. There is no longer the presence of two different alternatives here. The information we gain after throwing the coin is therefore, zero. Look at it this way: we already knew with certainty what was going to happen in advance, so there is no potential gain in information after learning the outcome.
Another way of describing Shannon’s entropy is to say that it represents the amount of information the experimenter lacks prior to learning the outcome of a probabilistic process.
Hence, according to Shannon’s formula, a message’s entropy is maximised when the occurrence of each of its individual parts is equally probable. What this means is that we will gain the largest amount of Shannon’s information when dealing with systems whose individual possible outcomes are equally likely to occur (for instance, throwing a fair coin or rolling a fair die, both systems having a set of possible outcomes which are all equally likely to occur).
Shannon’s entropy is a measure of the potential reduction in uncertainty in the receiver’s knowledge. We can see the process of gaining information as equivalent to the process of losing uncertainty. You may be wondering what all this has to do with the actual content and encoding of a message, since so far we have only been talking of coins. Here’s another example, which illustrates the usefulness of Shannon’s formula when it comes to written language.
Entropy per Character – Written English Language:
Can we estimate the information entropy of the written English language? Consider starting with one particular letter which is picked at random. Knowing this first letter, you then want to estimate the probability of getting another particular letter after that one, and the probability of getting another letter after that first and second one, and so on. Knowing these probabilities is what we need in order to calculate the information entropy associated with the English text.
If we assume we are dealing with 27 characters (that is, 26 letters plus space), and that all of these characters are equally probable, then we have an information entropy of about 4.8 bits per character. But we know that the characters are not equally probable; for instance, the letter E has the highest frequency of occurrence, while the letter Z has the lowest. This is related to the concept of redundancy, which is nothing more than the number of constraints imposed on the text of the English language: for example, the letter Q is always followed by U, and we also have rules such as «I before E except after C», and so on.
There are various methods for calculating the information entropy of the written English language. For instance, Shannon’s methods – which take into account many factors, including redundancy and contextuality for instance – give the English language text an information entropy of between 0.6 and 1.3 bits per character.
So, if we compare this with the previous result of around 4.8 bits per character, we can see that the constraints imposed by factors such as redundancy have the overall effect of reducing the entropy per character. What this means is that finding the amount of redundancy in a language can help us find the minimum amount of information needed to encode a message. And of course, this leads us to the important concept of data compression.
Data Compression – Redundancy:
In information theory, the redundancy in a message is the number of bits used to encode it minus the number of bits of Shannon’s information contained in the message.
Redundancy in a message is related to the extent to which it is possible to compress it. What lossless data compression does is reduce the number of bits used to encode a message by identifying and eliminating statistical redundancy . Hence:
The more redundancy there is in a message, the more predictability we have à that means less entropy per encoded symbol à hence the higher the compressibility
When we compress data, we extract redundancy. When we compress a message, what we do is encode the same amount of Shannon’s information by using less bits. Hence, we end up having more Shannon’s information per encoded symbol, more Shannon’s information per bit of encoded message. A compressed message is less predictable, since the repeated patterns have been eliminated; the redundancy has been removed.
In fact, Shannon’s entropy represents a lower limit for lossless data compression: the minimum amount of bits that can be used to encode a message without loss. Shannon’s source coding theorem states that a lossless data compression scheme cannot compress messages, on average, to have more than one bit of Shannon’s information per bit of encoded message.
Calculating the redundancy and the information entropy of the English language has therefore many practical applications. For instance, ASCII codes (which are codes that represent text in computers, communications equipment, and other devices that use text) allocate exactly 8 bits per character.
But this is very inefficient when we consider Shannon’s and other similar calculations which, as we have seen, give us an information entropy of around 1 bit per character. Put another way, a smaller amount of bits can be used to store the same text. What this means, is that, in theory, there exists a compression scheme which is 8 times more effective than ASCII.
Let’s use an example to see how lossless data compression works. We will use Huffman coding, an algorithm developed by electrical engineer David Huffman in 1952. Huffman coding is a variable length code which assigns codes using the estimated probability of occurrence of each source symbol. For instance, let’s say we take as symbols all the letters of the English alphabet plus space. Huffman coding assigns codes with varying length depending on the frequency of occurrence of each symbol. Just as with Morse code, the most frequent symbols are assigned the shortest codes and the less frequent symbols are assigned the longest codes.
Let’s take a piece of text written in English, which is long enough so that we can approximate our calculations by using standard frequency tables for the letters of the written English language. The most frequent symbols, such as space and the letter e will be assigned the shortest codes, while the least frequent symbols, such as the letters q and z will be assigned the longest codes. Applying the Huffman algorithm using standard frequency tables, we obtain the Huffman codes given on this table. As you can see, the lengths of the codes vary from 3 to 11 bits, depending on the character.
We are going to use this short passage, from Brave New World, by Aldous Huxley:
“All right then,» said the savage defiantly, I’m claiming the right to be unhappy.»
«Not to mention the right to grow old and ugly and impotent; the right to have syphilis and cancer; the right to have too little to eat, the right to be lousy; the right to live in constant apprehension of what may happen tomorrow; the right to catch typhoid; the right to be tortured by unspeakable pains of every kind.»
There was a long silence.
«I claim them all,» said the Savage at last.”
Excluding punctuation and just counting letters and spaces, we have a total of 462 characters to encode. If we encode this piece of text using ASCII, we will need to use a total of 3,696 bits (8 bits per character). However, if we use Huffman code, we will only need to use a total of 1,883 bits (an average of about 4.1 bits per character).
So we see that by using Huffman encoding instead of ASCII, we can store the same amount of information, but twice as effectively. Although Huffman coding is more efficient, we are still far from reaching the limit given by Shannon’s entropy, which as we saw earlier on, can be approximated to be around 1 bit per character.
By using Huffman’s code, we have managed to extract a certain amount of redundancy, but we are still far from the limit where all the redundancy would have been extracted: that limit is Shannon’s entropy.
There are however many other compression techniques; for instance, there is a technique called arithmetic coding, which can extract a lot more redundancy than Huffman coding, and hence it can create compressed messages where the average number of bits per character is much closer to Shannon’s entropy.
So by using this particular example, we have seen how the concept of Shannon’s entropy, in this case calculated from the probabilities of occurrence associated with the letters belonging to the words of a particular language, has very important applications; data compression being one of them. Summarising:
Shannon’s entropy is a measure of uncertainty, of unpredictability, and also a measure of information content, of potential information gain.
Shannon’s entropy can also represent a lower limit for lossless data compression: the minimum amount of bits that can be used to encode a message without loss.
Also note that with this definition, more information content has nothing to do with its quality. So in this sense, a larger amount of Shannon’s entropy does not necessarily imply a better quality of its content (an example of two subjective concepts which could be linked to quality are meaningfulness or importance).
I will expand on this topic in the following video, when we discuss Norbert Wiener’s ideas.
Shannon’s Bit vs Storage Bit:
Now, there is one point that needs clarifying. In this past section of the video, while discussing concepts such as compression and redundancy, we have actually been talking about different kinds of bits, that is, bits which represent different concepts.
You may recall that in the previous video we defined the bit as a variable which can have two possible values, which we represent by the digits 0 and 1. This is the most popular definition, one that is usually associated with the storage or transmission of encoded data. In this way, one bit is the capacity of a system which can exist in only two states.
In information theory, however, the bit can be defined in a different way. As we have seen, it can be a unit of measurement for Shannon’s information. In this context, one bit is defined as the uncertainty associated with a binary random variable that can be in one of two possible states with equal probability.
Put another way, one Shannon bit is the amount of entropy that is present in the selection of two equally probable options, it is the information that is gained when the value of this variable becomes known. Remember, this is exactly what we showed earlier on when we applied Shannon’s formula to the throw of a fair coin.
Well, it turns out that the first time the word “bit” appeared in a written document was precisely in Shannon’s ground-breaking paper “A mathematical theory of communication“. In it, Shannon clearly states that it was mathematician John Tukey, a fellow Bell Labs researcher, who coined the term “bit”, short for binary digit.
While Tukey’s binary digit is a unit related to the encoding of data, Shannon’s bit is a unit that is related to uncertainty, unpredictability. In one Tukey bit of encoded data there is often less than one bit of Shannon’s information. Why?
Well, Shannon’s entropy is maximised when all possible states are equally likely, and one Shannon bit is defined in relation to a system whose states are equally likely. Therefore, in a binary system, when the two possible states are not equally likely, such as the toss of a biased coin, Shannon’s information is less than 1 bit.
Recall Shannon’s source coding theorem, which states that a lossless data compression scheme cannot compress messages, on average, to have more than one bit of Shannon’s information per bit of encoded message. Well, now you know that these bits are different kinds of bits, in the sense that they represent different concepts. The latter refers to the encoding, storage or transmission of binary data, redundant or not, whereas the former refers to amounts of Shannon’s information, as defined by his entropy equation. An encoded bit of data contains, at most, one bit of Shannon’s information, usually a lot less.
In information theory, therefore, it is important to understand the distinction between encoded binary data and information. In this context, the word information is used in reference to Shannon’s entropy, a much more abstract concept that does not equate with the actual encoding of zeros and ones.
Now, so far we have discussed the important concepts of entropy, uncertainty, information and redundancy… and we have seen how Shannon’s Source Coding Theorem provides us with a theoretical lower bound for data compression. Hopefully you now understand the relationship between entropy, uncertainty reduction, information gain, information content, redundancy and compression.
We have covered the most important theoretical aspects of Information Theory which establish the limits to how efficiently a particular message can be encoded.
But what does Shannon have to say about sending a message not only efficiently but also reliably though a given channel? How does one transmit information reliably in the presence of noise? That is, in the presence of physical disturbances which can introduce random errors in the encoding of a particular message, what are the theoretical limits to detecting and correcting these errors? This leads us to the very important topic of Error-Detection and Correction.
… to be continued 🙂
Coming up in Part 2b:
– Shannon’s Noisy Channel Coding Theorem
– Adding redundancy bits to a message (called parity or check bits) to detect and correct errors
– Error-correcting codes – What are Hamming codes?
– Example using a Hamming code
– What are doubly-even self-dual linear binary error-correcting block codes?
– James Gates discovery: error-correcting codes found buried inside the fundamental equations of physics?
– Little side journey: Cosmological and biological evolution. The Universe as a self-organised system. How does Nature store information? Nature’s use of redundancy and error-correcting codes. Information, the Laws of Physics and unknown organising principles: fixed or evolving? Biology, DNA and information.
References – Further Information:
Wikipedia: Information Theory
Wikipedia: Shannon’s Entropy
Princeton Uni: Shannon’s Entropy
Scrabble Letter Scores
Entropy, Compression & Information Content – Victoria Fossum
Entropy & Information Gain Lecture – Nick Hawes (very good at clarifying difference between individual information of each outcome and the expectation value of information, that is, Shannon’s entropy)
Harvard Uni: Entropy & Redundancy in the English Language
Lecture: Entropy & Data Compression – David MacKay
Documentary: Claude Shannon: Father of the Information Age
Video: Entropy in Compression – Computerphile
Wikipedia: Huffman Coding
Wikipedia: the Bit

Словосочетания
is made up from — составлен из
the rock is made up of — горная порода сложёна
his character is made up of negatives — он средоточие недостатков
a white color is made up of many different wavelengths of light — белый цвет состоит из множества различных длин световых волн
be made up — компенсироваться; складываться; слагаться
be made up of — состоять из; слагаться
she was heavily made up — она была сильно накрашена
parcel was neatly made up — посылка была аккуратно упакована
the parcel was neatly made up — посылка была аккуратно упакована
he was made up to look the part — его загримировали как требовалось для роли
to be made up of several factions — состоять из нескольких фракций
she was made-up to look like Joan of Arc — её загримировали под Жанну д’Арк
Автоматический перевод
составленный
Перевод по словам
be — быть, находиться, должен, тратта
make — марка, изготовление, производство, модель, делаться, делать, производить, совершать
up — вверх, вверху, по, вверх по, поднимать, подъем, успех, повышающийся
Примеры
The book is made up of 20 chapters.
Книга состоит из двадцати глав.
No more argument. My mind is made up.
Хватит спорить, я уже всё решил.
Her audience is made up mostly of young women.
Её аудитория состоит в основном из молодых женщин.
The board of directors is made up of men and women.
В Совете директоров есть мужчины и женщины.
The full computer program is made up of several modules.
Компьютерная программа состоит из нескольких модулей.
Her TV programme is made up of a series of comic sketches.
Её телепрограмма состоит из серии юмористических сценок.
The committee is made up of representatives from every state.
Комитет состоит из представителей каждого штата.
ещё 10 примеров свернуть
Примеры, отмеченные *, могут содержать сленг и разговорные фразы.
Примеры, ожидающие перевода
She was heavily made-up (=wearing a lot of make-up). ![]()
When I heard she was pregnant, I was really made up for her. ![]()
One lucky winner will have the chance to be made up and photographed. ![]()
Для того чтобы добавить вариант перевода, кликните по иконке ☰, напротив примера.
1
a(1)
: knowledge obtained from investigation, study, or instruction
b
: the attribute inherent in and communicated by one of two or more alternative sequences or arrangements of something (such as nucleotides in DNA or binary digits in a computer program) that produce specific effects
c(1)
: a signal or character (as in a communication system or computer) representing data
(2)
: something (such as a message, experimental data, or a picture) which justifies change in a construct (such as a plan or theory) that represents physical or mental experience or another construct
d
: a quantitative measure of the content of information
specifically
: a numerical quantity that measures the uncertainty in the outcome of an experiment to be performed
2
: the communication or reception of knowledge or intelligence
4
: a formal accusation of a crime made by a prosecuting officer as distinguished from an indictment presented by a grand jury

Synonyms
Example Sentences
They’re working to collect information about the early settlers in the region.
The pamphlet provides a lot of information on recent changes to the tax laws.
He gave the police false information about his background.
The conference will give us an opportunity to exchange information with other researchers.
We can’t make a decision until we have more information.
The tests have not yet uncovered any new information.
I don’t like having to reveal personal information when I fill in a job application.
He’s accused of withholding useful information.
I couldn’t remember his number so I had to call information.
See More
Recent Examples on the Web
Historical information about players like Ty Cobb and Al Kaline, all the way to current player Miguel Cabrera, is painted on the walls.
— Evan Petzold, Detroit Free Press, 8 Apr. 2023
Evan Petzold, Detroit Free Press, 8 Apr. 2023
For more information, go to KaoBarandGrill.com.
—Phillip Valys, Sun Sentinel, 8 Apr. 2023
Application error: a client-side exception has occurred (see the browser console for more information).
—Karen Wilkin, wsj.com, 8 Apr. 2023
For more information on the first-class services and offerings aboard the Airbus A380 and the Boeing 777, head to Emirates.com.
—Lydia Mansel, Travel + Leisure, 8 Apr. 2023
For more information on the project, email africatownwelcomecenter@cityofmobile.org.
—Lawrence Specker | , al, 8 Apr. 2023
For more information, go to https://hampsteadmd.gov/.
—Sherry Greenfield, Baltimore Sun, 8 Apr. 2023
For more information, visit noblebb.com.
—Haadiza Ogwude, The Enquirer, 7 Apr. 2023
For more information To support Make-A-Wish Wisconsin, visit www.wish.org/wisconsin/give or call 262 -781-4445.
—Cathy Kozlowicz, Journal Sentinel, 7 Apr. 2023
See More
These examples are programmatically compiled from various online sources to illustrate current usage of the word ‘information.’ Any opinions expressed in the examples do not represent those of Merriam-Webster or its editors. Send us feedback about these examples.
Word History
First Known Use
14th century, in the meaning defined at sense 1a
Time Traveler
The first known use of information was
in the 14th century
Dictionary Entries Near information
Cite this Entry
“Information.” Merriam-Webster.com Dictionary, Merriam-Webster, https://www.merriam-webster.com/dictionary/information. Accessed 14 Apr. 2023.
Share
More from Merriam-Webster on information
Last Updated:
10 Apr 2023
— Updated example sentences
Subscribe to America’s largest dictionary and get thousands more definitions and advanced search—ad free!
Merriam-Webster unabridged