
I want to get the most recent word entered by the user from the UITextView.
The user can enter a word anywhere in the UITextView, in the middle or in the end or in the beginning. I would consider it a word when the user finishes typing it and presses a space and does any corrections using the «Suggestions from the UIMenuController«.
Example: User types in «kimd» in the UITextView somewhere in the middle of text, he gets a popup for autocorrection «kind» which he does. After he does that, I want to capture «kind» and use it in my application.
I searched a lot on the internet but found solutions that talk about when the user enters text in the end. I also tried detecting a space and then doing a backward search until another space after some text is found, so that i can qualify it as a word. But I think there may be better ways to do this.
I have read somewhere that iOS caches the recent text that we enter in a text field or text view. If I can pop off the top one , that’s all I want. I just need handle to that object.
I would really appreciate the help.
Note: The user can enter text anywhere in UItextview. I need the most recent entered word
Thanks.
Комп_Оратор)
![]()
8839 / 4558 / 614
Регистрация: 04.12.2011
Сообщений: 13,601
Записей в блоге: 16
14.11.2012, 20:33
11
![]()
Сообщение от Kuzia domovenok

Я тут задумался и понял, что был не прав насчёт «указатель на позицию последнего слова в тексте». Если мы в функции мы найдём, что посл.слово начинается с 7го символа, то согласно моему ответу должны будем сделать word=text+7; и выйти из функции. Но это не верно, т.к. значение переданного аргумента не изменится после выхода из функции. Нужно именно что возвращать копию последнего слова в тексте делать strncpy(word, text+7, n); и выйти из функции.
Думаю можно выяснить длину (*text) потом установить word на конец text пройти цикл while декрементируя word пока не встретим «непробел» и потом еще один цикл пока не встретим пробел. Инкриментируем до break и в этом случае. И всё. И в обоих случаях совмещаем проверку с проверкой на валидность (вдруг строка из пробелов или одного слова) ")
Добавлено через 2 часа 3 минуты
Строго прототипу не получается. Просто решается если передать указатель на указатель.
| C++ | ||
|
Добавлено через 1 час 26 минут
Вот так в соответствии с прототипом. Прав Kuzia domovenok копию и нужно присвоить.
| C++ | ||
|
Добавлено через 10 минут
Думаю можно выяснить длину (*text) потом установить word на конец text пройти цикл while декрементируя word пока не встретим «непробел» и потом еще один цикл пока не встретим пробел. Инкриментируем до break и в этом случае. И всё. И в обоих случаях совмещаем проверку с проверкой на валидность (вдруг строка из пробелов или одного слова)
Добавлено через 2 часа 3 минуты
Строго прототипу не получается. Просто решается если передать указатель на указатель.
| C++ | ||
|
Добавлено через 1 час 26 минут
Вот так в соответствии с прототипом. Прав Kuzia domovenok копию и нужно присвоить.
| C++ | ||
|
0
Looking at the code, it seems like you are reinventing the wheel.
See the answer of @Josiah for some alternatives to use the standard library.
Assuming this ain’t possible for some reason, lets say its implemented badly, I would improve some smaller things.
Before giving some improvements, make sure to measure!
Is this code only used once? Does it only take 1% of the time? Is the example code the only use? Than don’t spend time on this!
Add preconditions
Currently your function accepts an empty string.
When this is encountered, you always get an error message.
If you somewhere want to handle this differently, it should be checked twice.
Or in case you know it can’t be empty, it still is checked when not needed.
Instead, you could write:
assert(!str.empty() && "An empty string should not be passed");
If your specific example, you’ll have to write the check in the main function. However, in that case, you could use an alternative way of handling it. For example:
std::string str;
do
{
std::cout << "Enter string :n";
std::getline(std::cin, str);
} while (str.empty());
Memory allocations
std::string can have short string optimization. Although, for large strings, this might allocate memory. If you append character by character, this might reallocate.
To prevent this reallocation, you can reserve the string:
last_word.reserve(str.size() + 1 /*Null terminator*/);
The code above would be wonderful for a vector, when you have at least 1 element. However, as we have short string optimization, this might allocate, while the result won’t require it.
last_word.reserve(len — j); // To be verified with null terminator.
If really performance critical, you might want to check the implementation of the standard library as they are allowed to reserve more characters than you pass. So, they can add 1 for the null terminator. (libstdc++ and MSVC do so, I read)
Output argument
In order to not recreate a string, you can manipulate the original string.
With the erase method, you can (in bulk) remove all previous characters at once.
This will work when you don’t need that argument any more, however, this might add unwanted overhead if you do or don’t have a std::string instance.
string_view
std::string_view was added in a recent c++ version, this will behave as a string, although, doesn’t store the content in it.
Returning a string_view might prevent copying over the characters into the std::string. Same can be said for the input argument.
Warning: This is error prone in case you work with temporaries.
Нужно найти самое часто встречающееся слово в тексте. Текст должен содержать не более 1000 символов. Вывод должен быть в UPPER CASE (верхний регистр). Написать функцию void mostRecent(char *text,char *word).
Параметр char *word должен возвращать самое часто встречающееся слово, например:
ВВОД: Can you can the can with can?
Вывод: CAN
// test.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
using namespace std;
void mostRecent(char *, char *); // прототип функции поиска часто встречающегося слова
int main(int argc, char* argv[])
{
setlocale(LC_ALL, "rus"); // установка локалии
cout << "Введите текст:n";
const int buff_size = 1001; // максимальное количество вводимых символов + позиция под ''
char buff_text[buff_size]; // символьный массив, который хранит введённый текст
char word [30]; // строка, в которй будет храниться искомое слово
mostRecent(gets(buff_text), word); // вызов функции поиска часто встречающегося слова
for (int counter = 0; counter < strlen(word); counter++)
word[counter] = toupper(word[counter]); // преобразование символов слова в верхний регистр
cout << "Cамое часто встречающееся слово в тексте: " << word << endl;
system("pause");
return 0;
}
void mostRecent(char * text, char *word) // функция поиска часто встречающегося слова
{
int words_counter = 0; // количество слов в тексте
char *arrayPtr[1000]; //массив указателей на строки, в которых будут храниться слова из текста
arrayPtr[0] = strtok(text, " "); // нулевому указателю присваеваем первое слово
// подсчёт количества слов во введённом тексте
while (arrayPtr[words_counter] != NULL) // пока в тексте есть слова
{
words_counter++; // инкремент счётчика слов
arrayPtr [words_counter] = strtok(NULL, " "); // очередное слово сохраняем в массиве
}
bool first_iter = true, // флаг определяющий этап первой итерации
go = false;
int max_number1 = 0, // количество слов
max_number2 = 0, // количество слов
max_word = 0, // индекс самого часто встречающегося слова
flag = 0; // флаг, подсчёта двух итераций
int index1, index2;
for (int counter1 = 0; counter1 < (words_counter - 1) ; counter1++) // перебор слов, начиная с первого и заканчивая предпоследним
{
flag++; // инкремент итераций
for (int counter2 = counter1 + 1; counter2 < words_counter; counter2++) // перебор слов, начиная со второго и заканчивая предпоследним
{
if (strcmp(arrayPtr [counter1], arrayPtr [counter2] ) == 0) // сравниваем два слова
if ( first_iter) // если первая итерация (то есть сюда заходим один раз)
{
max_number1++; // инкремент переменной, подсчитывающей количество одинаковых слов
first_iter = false; // меняем условие оператора if
index1 = counter1;
}
else
{
max_number2++; // инкремент переменной, подсчитывающей количество одинаковых слов
index2 = counter1;
}
}
if (flag == 2 || go) // если прошли две итерации, или поэлементный проход разрешён
{
if (max_number1 >= max_number2) // если количество первого слова больше количества второго слова
{
max_word = index1; // присваиваем индекс самого часто повторяющегося слова
}
else { max_word = index2; max_number1 = max_number2; } // присваиваем индекс самого часто повторяющегося слова и количество появления второго слова присваиваем переменной max_number1
flag = 0; // обнуляем счётчик итераций
go = true; // разрешить поэлементный проход
}
max_number2 = 0; // обнуляем накопленное количество появления второго слова
}
strcpy(word, arrayPtr[max_word]); // возвращаем результат поиска самого часто встречающегося слова
}
Вводим текст в программу, причём количество символов не может быть больше 1000. В случае, если будет введено больше 1000 символов, в символьном массиве buff_text[1000] сохранятся только 1000 символов. Для искомого слова объявлен символьный массив word [30], таким образом максимальная длинна слова не должна превышать 29 символов. В строках 19 -20 выполняется преобразование найденного слова в верхний регистр. В функции mostRecent(), сначала массив с текстом разбивается на слова, которые сохраняются в массив указателей на строки arrayPtr[1000]. После чего, методом последовательного перебора слов в массиве указателей, выполняется поиск самого часто встречающегося слова во введённом тексте.
‘MOST RECENT’ is a 10 letter
Phrase
starting with M and ending with T
Crossword answers for MOST RECENT
| Clue | Answer |
|---|---|
|
|
|
|
MOST RECENT (3) |
NTH |
|
MOST RECENT (4) |
LAST |
|
MOST RECENT (6) |
LATEST |
|
MOST RECENT (6) |
NEWEST |
Synonyms, crossword answers and other related words for MOST RECENT
We hope that the following list of synonyms for the word Most recent will help
you to finish your
crossword today. We’ve arranged the synonyms in length order so that they are easier to find.
Most recent 4 letter words
Most recent 5 letter words
Most recent 6 letter words
Most recent 13 letter words
Synonyms for LATEST
2 letter words
3 letter words
4 letter words
Top answers for MOST RECENT crossword clue from newspapers
Thanks for visiting The Crossword Solver «Most recent».
We’ve listed any clues from our database that match your search for «Most recent». There will also be a
list of synonyms for your answer.
The synonyms and answers have been arranged depending on the number of characters so that they’re easy to
find.
If a particular answer is generating a lot of interest on the site today, it may be highlighted in
orange.
If your word «Most recent» has any anagrams, you can find them with our anagram solver or at this
site.
We hope that you find the site useful.
Regards, The Crossword Solver Team
More clues you might be interested in
- acid
- cranium
- discussion
- feel sore
- bootleg
- noble act
- fencer’s foil
- icky residue
- threaded, tied
- an urgent request
- on the outside
- dash
- compete in a race
- slavery
- biblical mount
- saluted
- fatuity
- duct
- unblocks
- itemize
- reddish-brown horse
- oik
- equipment required for a task or sport
- high-pitched cry
- disinclination to move
- slice
- unshaven
- star wars princess
- firing
- very funny
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Python provides inbuilt functions for creating, writing, and reading files. Two types of files can be handled in python, normal text files, and binary files (written in binary language,0s and 1s).
- Text files: In this type of file, Each line of text is terminated with a special character called EOL (End of Line), which is the new line character (‘n’) in python by default.
- Binary files: In this type of file, there is no terminator for a line, and the data is stored after converting it into machine-understandable binary language.
Here we are operating on the .txt file in Python. Through this program, we will find the most repeated word in a file.
Approach:
- We will take the content of the file as input.
- We will save each word in a list after removing spaces and punctuation from the input string.
- Find the frequency of each word.
- Print the word which has a maximum frequency.
Input File:
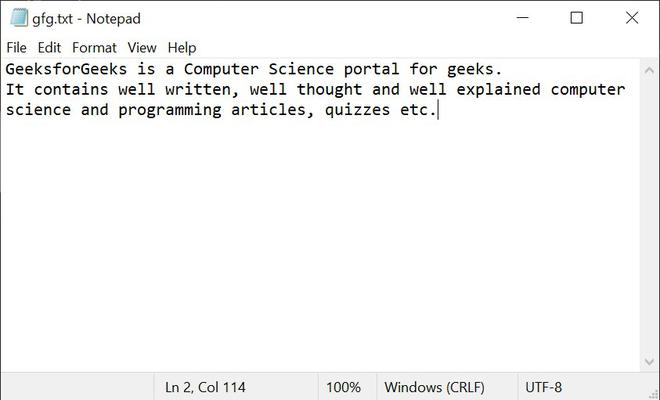
Below is the implementation of the above approach:
Python3
file = open("gfg.txt","r")
frequent_word = ""
frequency = 0
words = []
for line in file:
line_word = line.lower().replace(',','').replace('.','').split(" ");
for w in line_word:
words.append(w);
for i in range(0, len(words)):
count = 1;
for j in range(i+1, len(words)):
if(words[i] == words[j]):
count = count + 1;
if(count > frequency):
frequency = count;
frequent_word = words[i];
print("Most repeated word: " + frequent_word)
print("Frequency: " + str(frequency))
file.close();
Output:
Most repeated word: well Frequency: 3
Like Article
Save Article