
Обработка естественного языка сейчас не используются разве что в совсем консервативных отраслях. В большинстве технологических решений распознавание и обработка «человеческих» языков давно внедрена: именно поэтому обычный IVR с жестко заданными опциями ответов постепенно уходит в прошлое, чатботы начинают все адекватнее общаться без участия живого оператора, фильтры в почте работают на ура и т.д. Как же происходит распознавание записанной речи, то есть текста? А вернее будет спросить, что лежит в основе соврменных техник распознавания и обработки? На это хорошо отвечает наш сегодняшний адаптированный перевод – под катом вас ждет лонгрид, который закроет пробелы по основам NLP. Приятного чтения!

Что такое Natural Language Processing?
Natural Language Processing (далее – NLP) – обработка естественного языка – подраздел информатики и AI, посвященный тому, как компьютеры анализируют естественные (человеческие) языки. NLP позволяет применять алгоритмы машинного обучения для текста и речи.
Например, мы можем использовать NLP, чтобы создавать системы вроде распознавания речи, обобщения документов, машинного перевода, выявления спама, распознавания именованных сущностей, ответов на вопросы, автокомплита, предиктивного ввода текста и т.д.
Сегодня у многих из нас есть смартфоны с распознаванием речи – в них используется NLP для того, чтобы понимать нашу речь. Также многие люди используют ноутбуки со встроенным в ОС распознаванием речи.
Примеры
Cortana

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.
Siri

Siri это помощник для ОС от Apple: iOS, watchOS, macOS, HomePod и tvOS. Множество функций также работает через голосовое управление: позвонить/написать кому-либо, отправить письмо, установить таймер, сделать фото и т.д.
Gmail

Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ.
Python-библиотека NLTK
NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python. У нее есть легкие в использовании интерфейсы для многих языковых корпусов, а также библиотеки для обработки текстов для классификации, токенизации, стемминга, разметки, фильтрации и семантических рассуждений. Ну и еще это бесплатный опенсорсный проект, который развивается с помощью коммьюнити.
Мы будем использовать этот инструмент, чтобы показать основы NLP. Для всех последующих примеров я предполагаю, что NLTK уже импортирован; сделать это можно командой import nltk
Основы NLP для текста
В этой статье мы рассмотрим темы:
- Токенизация по предложениям.
- Токенизация по словам.
- Лемматизация и стемминг текста.
- Стоп-слова.
- Регулярные выражения.
- Мешок слов.
- TF-IDF.
1. Токенизация по предложениям
Токенизация (иногда – сегментация) по предложениям – это процесс разделения письменного языка на предложения-компоненты. Идея выглядит довольно простой. В английском и некоторых других языках мы можем вычленять предложение каждый раз, когда находим определенный знак пунктуации – точку.
Но даже в английском эта задача нетривиальна, так как точка используется и в сокращениях. Таблица сокращений может сильно помочь во время обработки текста, чтобы избежать неверной расстановки границ предложений. В большинстве случаев для этого используются библиотеки, так что можете особо не переживать о деталях реализации.
Пример:
Возьмем небольшой текст про настольную игру нарды:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Чтобы сделать токенизацию предложений с помощью NLTK, можно воспользоваться методом nltk.sent_tokenize
На выходе мы получим 3 отдельных предложения:
Backgammon is one of the oldest known board games.
Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East.
It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.2. Токенизация по словам
Токенизация (иногда – сегментация) по словам – это процесс разделения предложений на слова-компоненты. В английском и многих других языках, использующих ту или иную версию латинского алфавита, пробел – это неплохой разделитель слов.
Тем не менее, могут возникнуть проблемы, если мы будем использовать только пробел – в английском составные существительные пишутся по-разному и иногда через пробел. И тут вновь нам помогают библиотеки.
Пример:
Давайте возьмем предложения из предыдущего примера и применим к ним метод nltk.word_tokenize
Вывод:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.']
['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.']
['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']3. Лемматизация и стемминг текста
Обычно тексты содержат разные грамматические формы одного и того же слова, а также могут встречаться однокоренные слова. Лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме.
Примеры:
Приведение разных словоформ к одной:
dog, dogs, dog’s, dogs’ => dogТо же самое, но уже применительно к целому предложению:
the boy’s dogs are different sizes => the boy dog be differ sizeЛемматизация и стемминг – это частные случаи нормализации и они отличаются.
Стемминг – это грубый эвристический процесс, который отрезает «лишнее» от корня слов, часто это приводит к потере словообразовательных суффиксов.
Лемматизация – это более тонкий процесс, который использует словарь и морфологический анализ, чтобы в итоге привести слово к его канонической форме – лемме.
Отличие в том, что стеммер (конкретная реализация алгоритма стемминга – прим.переводчика) действует без знания контекста и, соответственно, не понимает разницу между словами, которые имеют разный смысл в зависимости от части речи. Однако у стеммеров есть и свои преимущества: их проще внедрить и они работают быстрее. Плюс, более низкая «аккуратность» может не иметь значения в некоторых случаях.
Примеры:
- Слово good – это лемма для слова better. Стеммер не увидит эту связь, так как здесь нужно сверяться со словарем.
- Слово play – это базовая форма слова playing. Тут справятся и стемминг, и лемматизация.
- Слово meeting может быть как нормальной формой существительного, так и формой глагола to meet, в зависимости от контекста. В отличие от стемминга, лемматизация попробует выбрать правильную лемму, опираясь на контекст.
Теперь, когда мы знаем, в чем разница, давайте рассмотрим пример:
Вывод:
Stemmer: seen
Lemmatizer: see
Stemmer: drove
Lemmatizer: drive4. Стоп-слова

Стоп-слова – это слова, которые выкидываются из текста до/после обработки текста. Когда мы применяем машинное обучение к текстам, такие слова могут добавить много шума, поэтому необходимо избавляться от нерелевантных слов.
Стоп-слова это обычно понимают артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При этом надо понимать, что не существует универсального списка стоп-слов, все зависит от конкретного случая.
В NLTK есть предустановленный список стоп-слов. Перед первым использованием вам понадобится его скачать: nltk.download(“stopwords”). После скачивания можно импортировать пакет stopwords и посмотреть на сами слова:
Вывод:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]Рассмотрим, как можно убрать стоп-слова из предложения:
Вывод:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']Если вы не знакомы с list comprehensions, то можно узнать побольше здесь. Вот другой способ добиться того же результата:
Тем не менее, помните, что list comprehensions быстрее, так как оптимизированы – интерпретатор выявляет предиктивный паттерн во время цикла.
Вы можете спросить, почему мы конвертировали список во множество. Множество это абстрактный тип данных, который может хранить уникальные значения, в неопределенном порядке. Поиск по множеству гораздо быстрее поиска по списку. Для небольшого количества слов это не имеет значения, но если речь про большое количество слов, то строго рекомендуется использовать множества. Если хотите узнать чуть больше про время выполнения разных операций, посмотрите на эту чудесную шпаргалку.
5. Регулярные выражения.

Регулярное выражение (регулярка, regexp, regex) – это последовательность символов, которая определяет шаблон поиска. Например:
- . – любой символ, кроме перевода строки;
- w – один символ;
- d – одна цифра;
- s – один пробел;
- W – один НЕсимвол;
- D – одна НЕцифра;
- S – один НЕпробел;
- [abc] – находит любой из указанных символов match any of a, b, or c;
- [^abc] – находит любой символ, кроме указанных;
- [a-g] – находит символ в промежутке от a до g.
Выдержка из документации Python:
Регулярные выражение используют обратный слеш
()для обозначения специальных форм или чтобы разрешить использование спецсимволов. Это противоречит использованию обратного слеша в Python: например, чтобы буквально обозначить обратный слеш, необходимо написать'\\'в качестве шаблона для поиска, потому что регулярное выражение должно выглядеть как\, где каждый обратный слеш должен быть экранирован.Решение – использовать нотацию raw string для шаблонов поиска; обратные слеши не будут особым образом обрабатываться, если использованы с префиксом
‘r’. Таким образом,r”n”– это строка с двумя символами(‘’ и ‘n’), а“n”– строка с одним символом (перевод строки).
Мы можем использовать регулярки для дополнительного фильтрования нашего текста. Например, можно убрать все символы, которые не являются словами. Во многих случаях пунктуация не нужна и ее легко убрать с помощью регулярок.
Модуль re в Python представляет операции с регулярными выражениями. Мы можем использовать функцию re.sub, чтобы заменить все, что подходит под шаблон поиска, на указанную строку. Вот так можно заменить все НЕслова на пробелы:
Вывод:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing 'Регулярки – это мощный инструмент, с его помощью можно создавать гораздо более сложные шаблоны. Если вы хотите узнать больше о регулярных выражениях, то могу порекомендовать эти 2 веб-приложения: regex, regex101.
6. Мешок слов

Алгоритмы машинного обучения не могут напрямую работать с сырым текстом, поэтому необходимо конвертировать текст в наборы цифр (векторы). Это называется извлечением признаков.
Мешок слов – это популярная и простая техника извлечения признаков, используемая при работе с текстом. Она описывает вхождения каждого слова в текст.
Чтобы использовать модель, нам нужно:
- Определить словарь известных слов (токенов).
- Выбрать степень присутствия известных слов.
Любая информация о порядке или структуре слов игнорируется. Вот почему это называется МЕШКОМ слов. Эта модель пытается понять, встречается ли знакомое слово в документе, но не знает, где именно оно встречается.
Интуиция подсказывает, что схожие документы имеют схожее содержимое. Также, благодаря содержимому, мы можем узнать кое-что о смысле документа.
Пример:
Рассмотрим шаги создания этой модели. Мы используем только 4 предложения, чтобы понять, как работает модель. В реальной жизни вы столкнетесь с бОльшими объемами данных.
1. Загружаем данные

Представим, что это наши данные и мы хотим загрузить их в виде массива:
I like this movie, it's funny.
I hate this movie.
This was awesome! I like it.
Nice one. I love it.Для этого достаточно прочитать файл и разделить по строкам:
Вывод:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']2. Определяем словарь

Соберем все уникальные слова из 4 загруженных предложений, игнорируя регистр, пунктуацию и односимвольные токены. Это и будет наш словарь (известные слова).
Для создания словаря можно использовать класс CountVectorizer из библиотеки sklearn. Переходим к следующему шагу.
3. Создаем векторы документа

Далее, мы должны оценить слова в документе. На этом шаге наша цель – превратить сырой текст в набор цифр. После этого, мы используем эти наборы как входные данные для модели машинного обучения. Простейший метод скоринга – это отметить наличие слов, то есть ставить 1, если есть слово и 0 при его отсутствии.
Теперь мы можем создать мешок слов используя вышеупомянутый класс CountVectorizer.
Вывод:

Это наши предложения. Теперь мы видим, как работает модель «мешок слов».
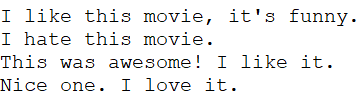
Еще пару слов про мешок слов

Сложность этой модели в том, как определить словарь и как подсчитать вхождение слов.
Когда размер словаря увеличивается, вектор документа тоже растет. В примере выше, длина вектора равна количеству известных слов.
В некоторых случаях, у нас может быть неимоверно большой объем данных и тогда вектор может состоять из тысяч или миллионов элементов. Более того, каждый документ может содержать лишь малую часть слов из словаря.
Как следствие, в векторном представлении будет много нулей. Векторы с большим количеством нулей называются разреженным векторами (sparse vectors), они требуют больше памяти и вычислительных ресурсов.
Однако мы можем уменьшить количество известных слов, когда используем эту модель, чтобы снизить требования к вычислительным ресурсам. Для этого можно использовать те же техники, что мы уже рассматривали до создания мешка слов:
- игнорирование регистра слов;
- игнорирование пунктуации;
- выкидывание стоп-слов;
- приведение слов к их базовым формам (лемматизация и стемминг);
- исправление неправильно написанных слов.
Другой, более сложный способ создания словаря – использовать сгруппированные слова. Это изменит размер словаря и даст мешку слов больше деталей о документе. Такой подход называется «N-грамма».
N-грамма это последовательность каких-либо сущностей (слов, букв, чисел, цифр и т.д.). В контексте языковых корпусов, под N-граммой обычно понимают последовательность слов. Юниграмма это одно слово, биграмма это последовательность двух слов, триграмма – три слова и так далее. Цифра N обозначает, сколько сгруппированных слов входит в N-грамму. В модель попадают не все возможные N-граммы, а только те, что фигурируют в корпусе.
Пример:
Рассмотрим такое предложение:
The office building is open todayВот его биграммы:
- the office
- office building
- building is
- is open
- open today
Как видно, мешок биграмм – это более действенный подход, чем мешок слов.
Оценка (скоринг) слов
Когда создан словарь, следует оценить наличие слов. Мы уже рассматривали простой, бинарный подход (1 – есть слово, 0 – нет слова).
Есть и другие методы:
- Количество. Подсчитывается, сколько раз каждое слово встречается в документе.
- Частотность. Подсчитывается, как часто каждое слово встречается в тексте (по отношению к общему количеству слов).
7. TF-IDF
У частотного скоринга есть проблема: слова с наибольшей частотностью имеют, соответственно, наибольшую оценку. В этих словах может быть не так много информационного выигрыша для модели, как в менее частых словах. Один из способов исправить ситуацию – понижать оценку слова, которое часто встречается во всех схожих документах. Это называется TF-IDF.
TF-IDF (сокращение от term frequency — inverse document frequency) – это статистическая мера для оценки важности слова в документе, который является частью коллекции или корпуса.
Скоринг по TF-IDF растет пропорционально частоте появления слова в документе, но это компенсируется количеством документов, содержащих это слово.
Формула скоринга для слова X в документе Y:
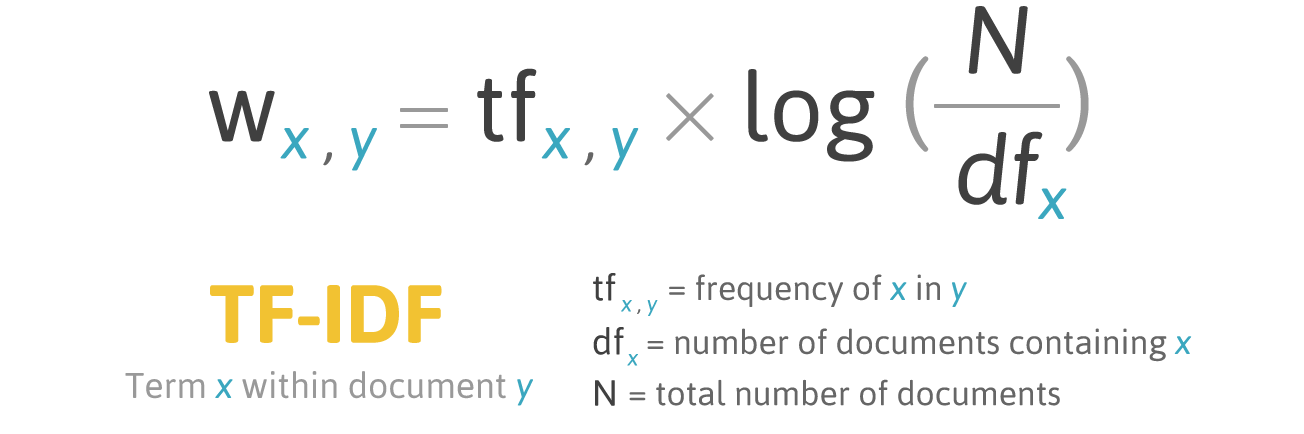
Формула TF-IDF. Источник: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
TF (term frequency — частота слова) – отношение числа вхождений слова к общему числу слов документа.
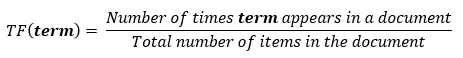
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции.
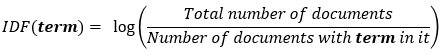
В итоге, вычислить TF-IDF для слова term можно так:

Пример:
Можно использовать класс TfidfVectorizer из библиотеки sklearn, чтобы вычислить TF-IDF. Давайте проделаем это с теми же сообщениями, что мы использовали в примере с мешком слов.
I like this movie, it's funny.
I hate this movie.
This was awesome! I like it.
Nice one. I love it.Код:
Вывод:

Заключение
В этой статье были разобраны основы NLP для текста, а именно:
- NLP позволяет применять алгоритмы машинного обучения для текста и речи;
- NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python;
- токенизация по предложениям – это процесс разделения письменного языка на предложения-компоненты;
- токенизация по словам – это процесс разделения предложений на слова-компоненты;
- лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме;
- стоп-слова – это слова, которые выкидываются из текста до/после обработки текста;
- регулярное выражение (регулярка, regexp, regex) – это последовательность символов, которая определяет шаблон поиска;
- мешок слов – это популярная и простая техника извлечения признаков, используемая при работе с текстом. Она описывает вхождения каждого слова в текст.
Отлично! Теперь, зная основы выделения признаков, вы можете использовать признаки как входные данные для алгоритмов машинного обучения.
Если вы хотите увидеть все описанные концепции в одном большом примере, то вам сюда.
PROFESSIONAL ENGLISH IN USE FOR COMPUTER
12. WORD PROCESSING
|
A |
|
|
A word The great Word |
|
|
|
EXERCISES
|
12.1 |
Match words from the opposite page with these definitions.
|
||||||
|
12.2 |
Label these
|
||||||
|
12.3 |
Complete these statements with
|
||||||
|
|
ANSWER KEY
Goals
- Students will recognize the major types of word processing programs.
- Students will discriminate the types of problems that are best solved
with various types of word processors. - Students will recognize the major tools that are available in word
processor application programs. - Students will use a text editor to create and modify a simple ASCII
text file. - Students will use a high end word processing program to practice
common text formatting problems.
Prereqs
- Comfort with the keyboard and mouse
- Experience with the STAIR process for solving problems
- Familiarity with principles of data encoding
- Familiarity with differences between hardware and software
- Understanding of the attributes of RAM
- Familiarity with operating systems, file names and directories
Discussion
Word processing is one of the most common applications for computers
today. It would be difficult to spend a day in a modern office or
university without coming into contact with a word processing program.
Most people have had some contact with word processing. We shall
examine the concept in some detail, so you will be familiar with a
number of levels of word processing software applications, the types
of tools such programs make available to you, and so you will know
what kinds of problems are best solved with this type of program.
How Word Processors Work
The advantages of word processing programs can best be illustrated by
thinking of some of the disadvantages of typewriters. When we use a
typewriter to create a document, there is a direct connection between
the keys and the paper. As soon as you press a key on the keyboard,
there is an impact on the paper, and the document has been modified.
If you catch a mistake quickly, you can fix it with correction tape or
white-out. If your mistake is more than one character long, it is
much harder to fix. If you want to add a word, move a
paragraph, or change the margins, you have to completely retype the
page. Sometimes this necessitates changes on other pages as well. A
one word change could lead to retyping an entire document.
Word processing is a type of software that focuses on the ability to
handle text. The computer does this by assigning each letter of the
alphabet and each other character on the keyboard a specific numeric
code. These numeric codes are translated into computer machine language,
and stored in the computer’s memory. Because the information is in memory,
it is very easy to change and manipulate. This is the key to the
success of word processing.
Example
Information in memory can be moved very quickly and easily. If we
want to change a word in a document, what happens in the computer is
something like this:
Imagine Darlene has started out her resume with the following word:
REUME
Obviously she has forgotten a letter. If she were using a typewriter,
the page would be trashed, and she would have to start over. Since
this is a word processor, Darlene can manipulate the memory containing
codes for the word «REUME» and add the «S» to it. When she tries, the
following things happen:
She moves her cursor to the spot in the text where she wants the S to
show up. The «cursor» is a special mark on the screen that indicates
at which place in the document the computer is currently focused. In this
case, Darlene wants to put an S between the E and the U. Her word
processor won’t let her put the cursor between two letters (although
some will), so she puts it on the U.
By moving the cursor, Darlene is telling the program to move around in
memory as well. When she place her cursor on the U on the screen, she
is telling the program to point to the corresponding spot in the
computer’s memory. The computer is now concentrating on the memory
cell that contains the code for the character «U».
She checks to be sure she is in insert mode (more on that later),
and she types the letter «S».
When Darlene does this, the computer shifts all the letters one memory
cell to the right, and inserts the code for the S in its proper
place.
Word processors and RAM
It sounds like a lot is happening. That’s true, but computers do all
these things so quickly that it seems instantaneous to us. You don’t
really have to know exactly where the stuff is in memory, or how it
gets moved around. The important thing to understand is that all the
information in your document is stored in some kind of digital
format in the computer’s memory. When you modify a document, you are really
modifying the computer’s memory. A word processing program handles
all the messy memory manipulation, so all you have to do is concentrate
on writing your paper.
RAM (Random Access Memory), where all the action is happening, has
one serious drawback. It only lasts as long as the computer is receiving
electrical power. Obviously this will cause some problems, because you
can’t just carry a computer around to show people your documents.
(Imagine the extension cord!) You also might run into some serious
problems if your computer were suddenly hit by a monsoon or something,
and you lost electrical power. In short, you cannot count on RAM memory
alone.
Word processing programs (as well as almost every type of program) are
designed to allow you to copy your information. Computer scientists
refer to the information your program is using as data. The data in
RAM can easily be duplicated to floppy disks or a hard drive. This is
called saving. Copying the data from RAM to a printer is called
printing. You can also copy data from other places to RAM. Copying the data
from the disk is referred to as loading the data. You might already
know what saving and printing are. We don’t mean to insult you by
telling you again. We just want to illustrate that it all boils down
to copying binary information to and from RAM.
Types of Word Processing Programs
There are many flavors of word processing programs. Different
programs are better for different types of jobs. One common problem
is deciding which program you will use to do a certain type of job.
It is important to know your options.
Text Editors
The simplest programs that do word processing are known as text
editors. These programs are designed to be small, simple, and cheap.
Almost every operating system made has at least one built in text
editor. Most text editors save files in a special format called
ASCII (American Standard Code for Information Interchange — Whew!)
ASCII is a coding convention that almost all computers understand.
Each letter is assigned a numeric value that will fit in eight digits
of binary notation. «a» is 97 in ASCII, and «A» is 65. All the
numeric digits, and most punctuation marks also have numeric values in
ASCII. You certainly don’t need to memorize all the codes, (That’s
the text editor’s job.) but you should recognize the word « ASCII».
The biggest advantage of this scheme is that almost any program
can read and write ASCII text.
Text editors can be wonderful programs. The biggest advantage is the
price. There is probably already one or more installed on your
computer. You can find a number of text editors for free on the
Internet. Text editors are generally very easy to learn. Since they don’t
do a lot of fancy things, they are generally less intimidating than
full fledged word processor packages with all kinds of features.
Finally, text editors are pretty universal. Since they almost all use
the ASCII standard, you can read a text file written on any text
editor with just about any text editor. This is often not the case
when using fancier programs.
The ability to write ASCII text is the biggest benefit of text
editors. ASCII is also the biggest disadvantage of most text editors.
It is a very good way of storing text information, but it has no way
of handling more involved formatting. Text editors generally do not
allow you to do things like change font sizes or styles, spell
checking, or columns. (If you don’t know what those things are, stay
tuned. We will talk about them later in this chapter.)
Text editors aren’t all simple, though. Text editors are actually the
workhorses of the computing world. Most computer programs and web
pages are written with specialized text editors, and these programs
can be quite involved. You won’t need to learn any hard-core text editors
for this class, but you may end up learning one down the road.
If all you want to do is get text written, and you aren’t too
concerned about how fancy it looks, text editors are fine. (In fact,
this book was written entirely in emacs, a unix-based text editor.)
Common text editor programs:
- Windows: Notepad
- Macintosh: SimpleText
- Linux: vi, emacs
- Multi-platform: notepad++, jedit, synedit, many more
Integrated Packages
Frequently these software packages are included when a person buys a
new computer system. An integrated package is a huge program that
contains a word processor, a spreadsheet, a database tool, and other
software applications in the same program. (Don’t worry if you don’t
know what a spreadsheet or a database is. We’ll get there soon
enough!) An integrated application package is kind of like a «Swiss
army knife» of software.
The advantages of an integrated package derive from the fact that all
the applications are part of the same program, and were written by the
same company. It should be relatively easy to use the parts of an
integrated package together. These programs tend to be smaller, older
versions of larger programs, so they might be less complicated to use.
Since they were presumably written together, they should all have the
same general menu structure, and similar commands. (The command to
save a file would be the same set of keystrokes in all the programs,
for example.) Integrated packages are often designed with casual
users in mind. This might make them easier to use than more robust
programs. The word processor built into an integrated package is
probably more powerful than a typical text editor. Integrated
packages are often already installed on new computers, so they might
not cost you any more than the original purchase price of the
computer. The word processor on an integrated package will almost
certainly give you some features you would not expect to find on plain
text editors.
Integrated packages have some disadvantages. With the advent of
graphic user interfaces and modern operating systems, programs have
become more and more standard even if they were written by completely
different companies. Almost every program for Windows uses Alt-F-S to
save, for example. Also, as in the Swiss army knife analogy, the
programmers had to make some compromises in order to make all the
applications fit in one program. A Swiss army knife does contain a
saw, but if you had to cut down a tree, wouldn’t you rather use a real
saw? The programs in an integrated package are usually stripped down
or older versions of the company’s high end software. They certainly
have fewer features, and might be less friendly. Word processing
programs that are part of integrated packages generally have their own
special code for storing text information, although they can usually
read and write ASCII as well. (However, if you choose to save in
ASCII, you cannot save all the special formatting commands).
Common Integrated Packages:
- Microsoft Works
- Lotus Works
- Claris Works
Today the trend is to package all the high-level programs together, so
MS-Office and OpenOffice.org both contain fully-featured Word
Processors, Databases, Spreadsheets, and more.
High-End Word Processors
Word processing programs have evolved a great deal from the early
days of computing. A modern word processing program can do many
things besides simply handling text.
Since the early ’90s, most word processors feature a WYSIWYG
interface. WYSIWYG (pronounced «whizeewig») stands for «What You See
Is What You Get.» This means that the screen will look reasonably
like the printed document. This feature is important because the
real strength of word processors is in the formatting they allow.
Formatting is the manipulation of characters, paragraphs, pages, and
documents. Most of the word processor features we will discuss below
are various ways of formatting the text, or changing the way it looks
on the page. Formatting was possible before WYSIWYG, but it required
more imagination from the writer, because you couldn’t see the effects
of the formatting until you printed out the document.
Modern word processors also are designed to have numerous features for
advanced users. Since a large portion of most people’s computer time
is spent with a word processing program, it is important that these
programs have features to make editing documents easier. Some of the
additional features that one can expect to find on a modern word
processor are spelling and grammar checkers, ability to handle
graphics, tables, and mathematical formulas, and outline editors. The
word processing market is a very competitive one, and the major
software companies are always competing to have the word processor
with the most advanced features available.
Software companies are also interested in making their programs as
easy to learn as possible. With this goal in mind, most word
processors come with tutorial programs, extensive on-line help, and
clear menus.
These full featured word processors sound wonderful, and they are.
You might wonder if they have any drawbacks. Of course they do.
Word processing programs as have been described often cost hundreds of
dollars. The cost seems prohibitive for something that doesn’t even
have a physical presence! Many of the features of full-fledged
word processors are not needed by casual users. Sometimes the sheer
number of unneeded features can be intimidating. Using a full-power
word processor just to write a couple of letters a week is like
killing flies with a chain saw. You simply might not need that much
power to do the job properly. High end word processing programs
almost always save documents in special proprietary codes rather than
as ASCII code. This means the programs can save all the special
formatting that ASCII cannot handle (like font sizes, columns,
graphics, and so on.) It also means that if you write a document in
WordPerfect, you may not be able to read it in Word. Even
different versions of the same program might not be able to read each
other’s documents directly. There are ways you can work around this
problem, but you should know it exists.
High-end Word Processing Packages:
- WordPerfect
- Microsoft Word
- OpenOffice.org Write
Ironically, there is now a trend away from WYSIWYG towards
«semantic markup.» The idea is not to put all the formatting details
in place, but to explain the meaning of the text in the document. The
actual markup of each meaning is defined in a separate document. For
example, here’s the semantic markup of this paragraph:
<p class = "update"> Ironically, there is now a trend away from WYSIWYG towards "semantic markup." The idea is not to put all the formatting details in place, but to explain the meaning of the text in the document. The actual markup of each meaning is defined in a separate document. For example, here's the semantic markup of this paragraph: </p>
In another part of the document I describe how to format «updates»:
.update {
border: 1px black solid;
background-color: #FFFFCC;
padding-left: .5em;
}
It’s completely OK if you don’t understand any of the code. The
important idea is how markup can be separated from meaning.
Desktop Publishing
Another classification of programs you should know about has an
uncertain future. These programs are called desktop publishing
applications. Desktop publishing takes text that has already been
created, and applies powerful formatting features to that text.
Traditionally, applications that allowed the integration of text and
graphics, and allowed the development of style sheets were thought of
as desktop publishing. Such a program makes it easy to create other
kinds of documents rather than just plain pages. With a desktop
publisher, there are already style sheets developed to help you create
pamphlets, cards, signs, and other types of documents that you wouldn’t
be able to create on a typewriter.
The higher end word processing programs give you most of the features
you could want in a desktop publishing program. It is possible to do
many of the same things. Desktop Publishers are still very popular in
certain specialty fields (graphic arts, printing, and publishing,) but
the effects can be duplicated with skillful use of a word processing
program.
Common Desktop Publishing programs:
- Pagemaker
- Microsoft Publisher
Sign / Banner Programs
Another level of desktop publishing that has become very popular is
the advent of specialty printing programs such as «The Print Shop» or
«Print Master +». These programs are designed specifically to help the
user create signs, banners, and greeting cards. They are very easy to
use, and much less expensive than full-feature desktop publishing
applications, but again the effects can be duplicated with a higher
end word processor.
How Do You Choose Which Word Processor You Use?
As always, the critical question is: «What kinds of problems are you
trying to solve?» For most beginners, the lower end word processor
that came with their computer is a fine start. If it does what you
need, and you are happy with it, don’t spend money unnecessarily.
Many people find that if they do a lot of writing, they begin to yearn
for the features of a more powerful word processing program. As you
gain experience, you will find a favorite program and learn its
commands and idiosyncrasies well. You will find if you concentrate on
the concepts, that all word processors of a certain level are pretty
much the same, although the exact layout and command structure may
differ. You will also probably discover if you do a lot of writing
with the computer that you have several programs you use
interchangeably. A skilled computer user often chooses the program to
solve a specific problem much like a golfer chooses a different club
for each type of shot. Sometimes a text editor is sufficient, and
sometimes only the best, most powerful, and most expensive program
will do the job properly. Learning what is best for you is part of
the process.
Layout of Word Processors
Word processing programs of any type usually share the most basic
features. They universally reserve most of the screen for the text
being edited. Most word processing programs also contain a
menu structure with most of the programs commands available in a
hierarchical organization scheme. Many word processors have graphic
toolbars with icons representing the most critical commands. Almost
all such programs have scroll bars or some other mechanism for
allowing the user to move around in large documents. All word
processors also have a cursor, which is usually a small box or line,
which shows the user where in the document she is currently typing.
Commands Available In Most Word Processing Programs:
Different types of word processing programs will have different
commands available. Generally, text editors have the fewest commands.
More complex programs often start with the same types of commands and
add to them. Commands may be available in a number of ways; by
locating them on the menu system, by looking up shortcut keys, or by
pressing an icon on a graphic tool bar. If in doubt, utilize the
on-line help to locate the command you want.
File Handling Commands
Any level of text editor or word processor will have commands to save,
load, and print your text. These commands are so frequent that you
will usually see many ways to invoke them.
- Save Document
-
Allows you to save your document onto some kind of disk.
If you have already saved this document at least once, it will save
the document to the same drive, directory, and file name you used last
time. Saving a document really means making a copy of the codes in
memory that represent the document, and copying those codes onto a
disk file. If you have never given this document a name, a Save
command often acts like a Save As. (see below) You might also look for
a Write command, a picture of a disk, or a Save As command. - Save As…
-
Often you will see this command in addition to a save command. There
is a subtle difference between the two commands. Save As {it always}
asks you for the name and location of your file. Most of the time,
the Save command does not ask for this information. If the Save
command does not know what to call the file (because you have never
saved it before) it will automatically invoke a Save As. The only
time you absolutely must use a Save As is when you want to load a
file, make some changes to it, and save it as a NEW file with a
DIFFERENT name. If you use the Save command, the new changes will be
written on top of the old document. With Save As, you can force the
changed document to be in a new file. This really doesn’t happen very
much. Many people spend their whole lives using nothing but Save. - Load or Open
-
You will almost always see a command that allows you to open or load a
document. These terms usually mean the same thing. You will usually
get some sort of a dialog box asking you for the directory and file
name of a text document, and the program goes to the disk, grabs the
file, and loads it into the editing area of the screen. (Actually, it
loads the file into memory, and then shows a copy of the memory onto
the screen.) -
A print command takes the document and copies it to the printer.
Obviously, for this to work, you must have a printer attached to your
machine. There are occasional variations to this command. You might
get a dialog box that asks you which pages to print, how many copies you
want, which printer you want to use (if more than one is set up on
your computer), and so on. You might also see a Print Preview command
that shows a picture of what the page will look like when printed.
This is especially useful when you are using a program that does not
support WYSIWYG.
Editing Commands and Block Manipulation
There are a number of commands you will find on nearly any word
processor that enable you to manipulate text in special ways.
Frequently you will find these commands on an Edit menu. The editing
commands are based on a concept called block manipulation.
Block manipulation simply means taking a «chunk» of text and marking
it in some way so it can be treated as one unit. Once a block of text
is marked as such, it can be deleted or manipulated easily.
- Marking a Block
-
Many modern programs allow you to mark a block of text with the mouse.
Simply point the mouse at the beginning of the text you want to mark,
hold down the mouse button, and drag to the end of the block. You
will probably see the text you have dragged over change color. Some
programs put highlighted text in inverse video. Many programs also
allow you to select text with the Shift key and the arrow keys in
combination. This is sometimes more precise than the mouse
techniques. Some older programs require you to move the cursor to the
beginning of the text, mark it as the beginning of a block, move to
the end of the text you want to manipulate, and mark it as the end of
the block. Learn how your program does it. It is worth the effort. - Copying a Block
-
You will usually find some kind of command called Copy. It only works
after you have marked a block of text. Copy by itself doesn’t do
anything on the screen, but it is still a very important command.
What it does is to take the block of text and make a copy of it in a
special part of memory called the clipboard (or sometimes the buffer).
The copy command does not change the original text; it just places a
copy of the text in the clipboard. - Cutting a Block
-
Cutting is very similar to copying. You must start by marking a block
of text. When you activate a cut command, the original block will
disappear. It isn’t gone forever, though. A copy of it has been made
in the clipboard. - Pasting a Block
-
The paste command doesn’t make much sense until you have cut or copied
a block of text into the clipboard. The paste command copies the
contents of the clipboard into the document at whatever point the
cursor was sitting when the paste command was activated. - How Block Manipulation Works
-
These commands really need to be used together to be useful. Which
ones you use depend on the kind of problem you are trying to solve.
If you had to write «I will not talk out in class» 100 times, you
might write the phrase once, mark it as a block, copy it, and then
paste it 99 times.
If you have written a document and realize that the last line really
belongs at the beginning of the document, you might mark the line you
want to move as a block, cut the block move the cursor to the
beginning of the document, and activate the paste command.
Formatting Commands
Another set of commands are found less frequently on text editors, but
are common on higher-level word processors. These commands are for
formatting various elements of a document. You may find a format
menu. Many of these commands also are available on toolbars.
Formatting a Character
A character is one letter or other symbol. There are many ways to
format characters in word processing programs. It is possible to make
characters bold, italic, underlined, or perhaps some other attribute.
Not all word processors will do all these things, but most will do
bold, italic, and underline. Often you activate the command by
choosing it from a menu, clicking on a toolbar icon, or activating a
key sequence. Once you have started the command, anything you type
will be typed in that style. When you want to go back to standard
letters, you activate the same command again. Commands that turn off
and on like this are called toggles, because they are reminiscent of
toggle switches. Many word processors allow you to enter the text
without any format, then to select a set of characters as a block
(like you did to copy and paste), then to activate the command.
Experiment with your word processor to see how it works.
Word processors that feature WYSIWYG frequently support the use of
fonts. A font is defined in computing as a combination of a special
character set and type size. In the typewriter world, you were pretty
much stuck with the size and style of letters the typewriter came
with. Some of the later typewriters had the characters on a ball you
could change, but you still had very little control of exactly how the
letters looked. In a modern word processing application, you have a
great deal of control. You can choose different type faces that look
like script, handwriting, Old English, or whatever. After you have
chosen a basic look for your letters, you can choose what size the
letters are.
Fonts are measured by typesetters in points. 72.25 points is
equivalent to an inch. Most standard text is 10 points. A newspaper
headline might be 200 points. You may be able to control other
attributes of each letter, such as its color, a shadow, and other advanced
features.
Formatting Paragraphs}
Most writing is organized into paragraphs. These divisions make a
document easier to read. There are ways you can control how
paragraphs look on the screen. You can control how your program
handles indention. You can often force the computer to indent the
first line of every paragraph automatically. You can also frequently
control the line spacing inside the paragraph, the amount of spacing
between paragraphs, and the justification.
Justification refers to how the text is lined up between the margins.
Most documents created with a typewriter or word processor are
left-justified. That means that the left margin is lined up perfectly, but
the right margin is a little ragged. The computer keeps track of the
right margin for you when you use a word processor, so you don’t have
to press the «Enter» key at the end of every line (in fact you
shouldn’t press «Enter» at the end of every line. The only time you
should press «Enter» is when you want to end a paragraph!) The
automatic process the computer uses to send text to the next line is
called word wrap. If you want to have the right margin line up
cleanly, but let the left one be a little ragged (Maybe as you type
the return address and date of a business letter) you can choose a
right justify command. If you look at books and magazines, you will
see that both the right and left columns are justified. Many word
processors will allow you to justify both margins. This works by
adjusting the amount of space between letters and words so the margins
work out perfectly. The computer does it automatically when you ask
it to do so. Another form of justification is centering. When you
center a line, you tell the program to give it equal left and right
margins, regardless of the length of the line. Centering is useful
for headlines, but is often distracting when used for body text.
The other major element of a document is the page. There are some
page formatting commands you should be able to find in any word
processor as well. You will probably have some way to adjust the
margins of the page. Note that there are top and bottom margins, as
well as left and right margins.
You can also frequently find some kind of header/footer command.
Headers and footers are special areas at the top and bottom,
respectively, of the page. These areas are not used for regular text,
but reserved for special things like a title at the top of every page,
page numbers, and footnotes. You will have to experiment a little
to see how your word processor handles these features, but they are
well worth learning. You will never go back to the old way of writing
footnotes once you have mastered using footers to automate the
process.
One more page formatting command you might find useful is page
orientation. Many word processors allow you to choose how information
is printed on the page. The «up and down» orientation we are used to
seeing on typewritten documents is called portrait mode. (If you
think about painted portraits, they are usually up-and-down rectangles.)
When your document is printed «sideways» it is referred to as landscape
mode. (Landscape paintings are often oriented in this way.)
__________
| ___ | ________________
| /o o | | |
|| L | | | /WWW |
||___/| | | / |
| / | |/ |
|_/_____| |______________|
Portrait Landscape
mode mode
Most of the time you should use portrait mode, but sometimes landscape
mode is appropriate, especially when you are doing something special
like tables, graphics, or fancy desktop publishing.
Commands Found in More Advanced Programs
High-End Formatting Tools
There are a few more elaborate formatting tools generally found
only in the higher end word processors. These tools border on desktop
publishing, and allow you better control of your document. You
probably won’t use them every day, but they are wonderful when you
need them.
- Tables
-
On a typewriter, creating a table required judicious use of the TAB
key and very careful planning. Most advanced word processors allow
you to create tables very easily. You can usually select the number
of rows and columns, change the size and format of rows and columns,
and easily copy and paste specific cells. The table tool is worth
learning. - Columns
-
Sometimes you will want to have a page formatted into two or more
vertical columns. This was quite tedious on a typewriter, but there
is usually some kind of tool to make column creation easier on a
modern word processor. - Lists
-
You will frequently find tools for making lists. Lists can have
automatic numbering (like an outline) or each list item might have a
small icon marking, called a bullet. Most modern word processing
programs have some kind of tool to make list management easier. - Graphics
-
Most high-end word processing programs enable you to incorporate
graphics into text documents with relative ease. Often they
incorporate small painting programs so you can generate your own
graphics as well. To make graphics and text easier to work with, many
word processing programs include frames, which are boxes on the screen
that can hold text and graphics. When you mix text and graphics on a
page, you may want to investigate frames in the on-line help so you can
have more control over how the text and graphics interact.
Composition Tools
Many word processors have other advanced features that help a writer
with the mechanics of writing properly. These tools can be
instrumental in avoiding common writing mistakes.
- Spell Checking
-
A spell checker is a program that looks at a document and compares
each word in the document to an electronic dictionary. If it finds
the word in the dictionary, it moves on to the next word. If it does
not find the word, it stops and asks the user for guidance. Good
spell checkers try to guess what word the user was trying to type and
make suggestions. Even if you are a very good speller, you should get
in the habit of running your materials through a spell checker. It is
a quick and relatively painless way to keep typos from marring your
paper.Keep in mind that spelling checkers are not perfect, and they cannot
catch every mistake. The following poem excerpt points out the
problem:Ode To The Spell Checker I have a spelling checker. It came with my PC. It plane lee marks four my revue, Miss steaks aye can know sea. Eye ran this poem threw it, Your sure reel glad two no. Its vary polished in it's weigh, My checker tooled me sew.(This poem can be found in its entirety at:
http://selma.ucd.ie/~pdurkin/Jokes/spellcheck.html It is attributed
to Jerry Zar, the Dean of the Graduate School, NW Ill. U) - Grammar Checkers
-
There are also tools available on most high end word processors that
will check your grammar for common mistakes. Grammar checkers are
wonderful at catching mechanical problems like incomplete sentences
and subject-verb agreement. Grammar tends to be more subjective
than spelling, so the advice of a grammar checker might or might not
be useful to you. It is worth running to check your mistakes, but it
will never replace the lessons you learned from your English teachers
or a skilled editor. When grammar checkers first came on the market,
a reporter tried testing the Gettysburg Address by Abraham Lincoln.
The program gave the speech extremely poor marks. Many people
consider it to be one of the most beautiful passages of American
English ever. Use a grammar checker if you have one, but also use
your judgment. - Outline Editors
-
These features allow you to organize your thoughts in outline format.
The advantage is that you can choose to see only your main ideas or
headings, and have all the text hidden. This feature allows you to
move the main headings around and all the text associated with the
headings will automatically move appropriately. If you are going to
do term papers or other serious writing, you should investigate this
feature.
Vocabulary/Important Ideas
- Word Processing
-
A type of software that specializes in handling text. Word processing
programs typically contain commands for handling and formatting text
documents. - Insert/Overwrite Modes
-
Most word processors allow you to choose one of these modes. When you
are in {bf insert} mode, any text you type is inserted into the
document at the cursor position. {it Overwrite} mode also types text
at the cursor position, but it writes over the top of existing text,
much like a typewriter with correcting tape. Most experienced word
processor users prefer insert mode for most of their work. - Text Editors
-
A classification of word processing software characterized by its low
cost, ready availability, tendency to work only in ASCII format, and
inability to do high-powered formatting. - ASCII
-
American Standard C}ode for Information
Interchange. A standard convention used to encode text, numbers, and
common punctuation in numeric format so they can be stored in a
computer’s memory. Nearly all computers and programs can work with
some form of ASCII. Text editors are designed especially to work with
ASCII-based documents. - Integrated Packages
-
Programs that contain all the major applications within one «super
application». These programs are useful, but often lack some of the
more advanced features of full-fledged application packages. - WYSIWYG
-
What You See is What You Get.
A capability often found on higher-level word processing
programs. The screen mimics the output of the printer, so the typist
can see pretty much what the final output of the document will be. - Proprietary
-
The term {it proprietary} is frequently used when discussing software to
denote a certain idea that is particular to a specific brand of
software. When a program uses a proprietary scheme to save word
processing documents, for example, other programs may not be able to
read these documents without some kind of translation. - Desktop Publishing
-
A classification of word processing software that concentrates on
incorporation of graphics, powerful formatting, and development of
complex styles including newsletters, signs, and pamphlets. - Style Sheet
-
In desktop publishing, a template that specifies how a certain type of
document will be created. Style sheets are used to define a uniform
look and feel for documents of the same general type. For example, a
company might issue a standard style sheet for intra-corporation
memoranda. Many high-end word processors incorporate this feature.
Sometimes style sheets are referred to as templates. - Scroll Bars
-
Horizontal or vertical bars which indicate the cursor position in a
document. Usually scroll bars can be used with the mouse to
facilitate moving through the document. - Cursor
-
A small mark on the screen, usually a rectangle, underline, or
I-shaped design. The cursor indicates the exact position within the document
(and memory) where any commands and typing will be executed. - Save
-
The Save command saves a document without prompting for the file
name, unless the file has never been saved before. If this is the
case, it invokes a Save As command instead. - Save As
-
This command always prompts for a file name. It is used when
you want to save the changes to file without changing the file already
saved on the disk. - Load (or Open)
-
This command prompts the user for a file name, then loads the document
into the application. -
A print command is used to send a copy of the document to the
printer. - Print Preview
-
This command is especially useful in non-WYSIWYG environments. It
allows you to see a preview of the document exactly as it will be
printed. It is often a good idea to invoke this command before you
print a document, to be sure it will turn out exactly as you plan. - Block Manipulation
-
The process of defining a section of text so it can be copied, pasted,
or otherwise manipulated as one unit. - Copy
-
A copy command takes a block of text and copies it to a memory
buffer without removing the original text. Used to it
duplicate sections of a document. - Cut
-
This command copies a block of text to a memory buffer, and removes
the original text from the document. Used to {it move} sections of a
document. - Paste
-
This command takes the block of text last placed in the buffer by a
cut or copy command, and inserts it into the document at the current
cursor position. - Formatting
-
The process of defining how a document will look. Formatting can
occur at the character level, as well as at the paragraph and page
level. - Character Attributes
-
The special modifications to letters, such as {bf boldface} and {it
italic} - Font
-
The combination of character set and size that defines how an
individual character looks. Most word processing packages allow the
user to choose from many fonts. - Toggle
-
A command is referred to as a {it toggle} if repeated execution of
the command causes something to switch between two modes. Insert
and Overwrite modes are good examples of toggles. Often character
attributes are also considered toggles. - Point
-
A point is a type setter’s measurement of character size. Officially,
there are 72.25 points to an inch. - Justification
-
The way the lines of text are arranged on the page. The usual options
are left-justified, right-justified, centered, and both-justified. - Left-Justified
-
The text is lined up so that the left margin is even. The right
margin will not be even in left-justified text. - Right-Justified
-
The text is lined up so that the left margin is ragged, but the right
margin is even. Often used to line up dates and return addresses on
business letters. - Both-Justified
-
The text is lined up so that both the left and right margins are lined
up, as in a newspaper or magazine. - Centered
-
The text is lined up with an equal distance from the left and right
margins. Usually used in headlines. - Word Wrap
-
A behavior of word processing programs which automatically moves words
too large to fit the current line onto a new line. Eliminates the
need to press «return» at the end of each line. - Headers, Footers
-
Special areas at the top and bottom of word processing documents.
These sections are reserved for information that will appear on {it
each page} of the document. Usually page numbers, document name, or
document author will be in the header/footer area. The footer is
also useful for holding footnotes. - Landscape Mode
-
Documents in this mode print the long part of the page horizontally, as
in a landscape painting. - Portrait Mode
-
Documents in this mode print the long part of the page vertically,
as in a portrait painting. - Table
-
A section of a document organized into rows and columns. Higher-end
word processors often have a number of tools to help make tables
easier to create and manage. - Column
-
Vertical separation of text into two or more sections. Newspapers and
newsletters are often arranged in columns. High-end word processing
programs and desktop publishing programs usually include some tools to
make column manipulation easier. - Spell Checker
-
A feature of higher-end word processing programs that compares each
word in a document to a dictionary of proper spellings. Most spell
checkers «guess» which word the user was trying to type and give the
user some guesses to choose from. - Grammar Checker
-
A feature in word processing programs that checks a document for
common grammatical errors. Grammar checkers can also grade documents
for readability and complexity. Sometimes grammar checkers are
separate programs. - Outline Editors
-
A feature or program that easily enables the user to create and
manipulate outlines. Most of these programs allow you to hide the
body text so you can see and modify the subject headings. The
associated body text is automatically moved with the appropriate heading.
Summary
Word processing programs are a type of software that make
it easier to create and modify text documents. Word Processing
applications are organized into a number of categories according to
their complexity: Simple programs that manipulate ASCII are called
Text Editors. More complex programs that feature formatting commands
are called Word Processors. Some word processors are included in
integrated application packages, which also feature other application
programs. Such packages are convenient, but may not have all the
features of larger programs. Full-featured word processing programs
contain many options for formatting text and documents. They also
might contain special utilities for more complex formatting and
composition. Desktop publishing programs are designed for more
complex formatting, especially the integration of text and graphics.
Most word processing programs contain the same types of commands,
although the exact ways to access these commands may vary. You will
almost always see file handling commands, including commands to Load,
Save, Save As, and Print. Frequently, you will also see commands for block
manipulation, including Copy, Cut, and Paste. More advanced programs
may contain special commands for formatting characters and paragraphs,
as well as other commands to deal with tables, columns, and lists.
The fanciest word processing programs may also contain commands to
assist with composition, such as spelling and grammar checkers and
outline editors.
a)
Read the text about word-processing:
Word-Processing Facilities
Writing letters, memos or
reports are the ways most people use computers. They manipulate
words and text on a screen – primarily to print at some later time
and store for safe keeping. Computers alleviate much of the tedium1
associated with typing, proofing, and manipulating words. Because
computers can store and recall information so readily, documents
need not be retyped from
scratch2
just to make corrections or changes. The real strength of word
processing lies in this ability to store, retrieve and change
information. Typing is still necessary (at least for now) to put the
information into the computer initially, but once in, the need to
retype only applies to new information.
Word processing is more than
just typing, however. Features such as Search and Replace allow
users to find a particular phrase or word no matter where it is in a
body of text. This becomes more useful as the amount of text grows.
Word processors usually
include different ways to view the text. Some include a view that
displays the text with editor’s marks that show hidden characters
or commands (spaces, returns, paragraph endings, applied styles,
etc.). Many word processors include the ability to show exactly how
the
text will appear on paper when printed. This is called WYSIWYG (What
You See Is What You Get, pronounced ‘wizzy-wig’). WYSIWYG shows
bold,
italics,
underline
and other type style characteristics on the screen so that the user
can clearly see what he or she is typing. Another feature is the
correct display of different typefaces and format characteristics
(margins, indents3,
super- and subscripted characters, etc.). This allows the user to
plan the document more accurately and reduces the frustration4
of printing something that doesn’t look right.
Many word processors now have
so many features that they approach the capabilities of layout5
applications for desktop publishing. They can import graphics,
format multiple columns of text, run text around graphics etc.
Two important features
offered by word processors are automatic hyphenation6
and mail merging7.
Automatic hyphenation is the splitting of a word between two lines
so that the text will fit better on page. The word processor
constantly monitors words typed and when it reaches the end of the
line, if a word is too long to fit, it checks that word in a
hyphenation dictionary. The dictionary contains a list of words with
preferred places to split them. If one of these cases fits part of
the word at the end of the line, the word processor splits the word,
adds a hyphen at the end and places the rest of the word on the next
line. This happens extremely fast and gives the text a more polished
and professional look.
mail
merging applications are largely responsible for explosion of
‘personalized mail’. Form letters with designed spaces for names
and addresses are stored as documents with links to lists of names
and addresses of potential buyers or clients. By designating what
information goes into which blank space, a computer can process a
huge amount of correspondence substituting the ‘personal’
information into a form letter. The final document appears to be
typed specifically to the person addressed.
Many of word processors can
also generate tables of numbers or figures, sophisticated indexes
and comprehensive tables of contents.
b)
Complete the sentences with the words from the box:
-
type
style, WYSIWYG, format, indent, font menu,
justification, mail merging
-
_____ stands for ‘What You
See Is What You Get’. It means that your printout will precisely
match what you see on the screen. -
_____ refers to the process
by which the space between the words in a line is divided evenly to
make the text flush with both left and right margins. -
You can change font by
selecting the font name and point size from the _____. -
_____ refers to
distinguished visual characteristic of a typeface; ‘italic’ for
example is a _____ that may be used with a number of typefaces. -
The _____ menu of a word
processor allows you to set margins, page numbers, spaces between
columns and paragraph justifications. -
_____ enables you to combine
two files, one containing names and addresses and the other
containing a standard letter. -
An _____ is the distance
between the beginning of a line and the left margin, or the end of
the line and the right margin. Indented text is usually narrower
than text without it.
c) Match the words with
their definitions:
|
|
d)
Match the words with the types of lettering:
-
bold,
bold italic, italic, lower case, outline, plain text,
shadow, strikethrough, underline, upper case
1.
_____________ Word-Processing
2.
_____________ word-processing
3. _____________
Word-processing
4. _____________
Word—Processing
5. _____________
Word—Processing
6.
_____________
Word—Processing
7. _____________
Word—Processing
8. _____________
Word-Processing
9. _____________
Word—Processing
10. ____________
Word—Processing
e)
Read the text and describe the major features of the word processor:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Word Processing
Andrew Prestage, in Encyclopedia of Information Systems, 2003
I. An Introduction to Word Processing
Word processing is the act of using a computer to transform written, verbal, or recorded information into typewritten or printed form. This chapter will discuss the history of word processing, identify several popular word processing applications, and define the capabilities of word processors.
Of all the computer applications in use, word processing is by far the most common. The ability to perform word processing requires a computer and a special type of computer software called a word processor. A word processor is a program designed to assist with the production of a wide variety of documents, including letters, memoranda, and manuals, rapidly and at relatively low cost. A typical word processor enables the user to create documents, edit them using the keyboard and mouse, store them for later retrieval, and print them to a printer. Common word processing applications include Microsoft Notepad, Microsoft Word, and Corel WordPerfect.
Word processing technology allows human beings to freely and efficiently share ideas, thoughts, feelings, sentiments, facts, and other information in written form. Throughout history, the written word has provided mankind with the ability to transform thoughts into printed words for distribution to hundreds, thousands, or possibly millions of readers around the world. The power of the written word to transcend verbal communications is best exemplified by the ability of writers to share information and express ideas with far larger audiences and the permanency of the written word.
The increasingly large collective body of knowledge is one outcome of the permanency of the written word, including both historical and current works. Powered by decreasing prices, increasing sophistication, and widespread availability of technology, the word processing revolution changed the landscape of communications by giving people hitherto unavailable power to make or break reputations, to win or lose elections, and to inspire or mislead through the printed word.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404001982
Computers and Effective Security Management1
Charles A. Sennewald, Curtis Baillie, in Effective Security Management (Sixth Edition), 2016
Word Processing
Word processing software can easily create, edit, store, and print text documents such as letters, memoranda, forms, employee performance evaluations (such as those in Appendix A), proposals, reports, security surveys (such as those in Appendix B), general security checklists, security manuals, books, articles, press releases, and speeches. A professional-looking document can be easily created and readily updated when necessary.
The length of created documents is limited only by the storage capabilities of the computer, which are enormous. Also, if multiple copies of a working document exist, changes to it should be promptly communicated to all persons who use the document. Specialized software, using network features, can be programmed to automatically route changes to those who need to know about updates.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128027745000241
Globalization
Jennifer DeCamp, in Encyclopedia of Information Systems, 2003
II.D.2.c. Rendering Systems
Special word processing software is usually required to correctly display languages that are substantially different from English, for example:
- 1.
-
Connecting characters, as in Arabic, Persian, Urdu, Hindi, and Hebrew
- 2.
-
Different text direction, as in the right-to-left capability required in Arabic, Persian, Urdu, and Hindi, or the right-to-left and top-to-bottom capability in formal Chinese
- 3.
-
Multiple accents or diacritics, such as in Vietnamese or in fully vowelled Arabic
- 4.
-
Nonlinear text entry, as in Hindi, where a vowel may be typed after the consonant but appears before the consonant.
Alternatives to providing software with appropriate character rendering systems include providing graphic files or elaborate formatting (e.g., backwards typing of Arabic and/or typing of Arabic with hard line breaks). However, graphic files are cumbersome to download and use, are space consuming, and cannot be electronically searched except by metadata. The second option of elaborate formatting often does not look as culturally appropriate as properly rendered text, and usually loses its special formatting when text is added or is upgraded to a new system. It is also difficult and time consuming to produce. Note that Microsoft Word 2000 and Office XP support the above rendering systems; Java 1.4 supports the above rendering systems except for vertical text.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404000800
Text Entry When Movement is Impaired
Shari Trewin, John Arnott, in Text Entry Systems, 2007
15.3.2 Abbreviation Expansion
Popular word processing programs often include abbreviation expansion capabilities. Abbreviations for commonly used text can be defined, allowing a long sequence such as an address to be entered with just a few keystrokes. With a little investment of setup time, those who are able to remember the abbreviations they have defined can find this a useful technique. Abbreviation expansion schemes have also been developed specifically for people with disabilities (Moulton et al., 1999; Vanderheiden, 1984).
Automatic abbreviation expansion at phrase/sentence level has also been investigated: the Compansion (Demasco & McCoy, 1992; McCoy et al., 1998) system was designed to process and expand spontaneous language constructions, using Natural Language Processing to convert groups of uninflected content words automatically into full phrases or sentences. For example, the output sentence “John breaks the window with the hammer” might derive from the user input text “John break window hammer” using such an approach.
With the rise of text messaging on mobile devices such as mobile (cell) phones, abbreviations are increasingly commonplace in text communications. Automatic expansion of many abbreviations may not be necessary, however, depending on the context in which the text is being used. Frequent users of text messaging can learn to recognize a large number of abbreviations without assistance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123735911500152
Case Studies
Brett Shavers, in Placing the Suspect Behind the Keyboard, 2013
Altered evidence and spoliation
Electronic evidence in the form of word processing documents which were submitted by a party in litigation is alleged to have been altered. Altered electronic evidence has become a common claim with the ability to determine the changes becoming more difficult. How do you know if an email has been altered? What about a text document?
Case in Point
Odom v Microsoft and Best Buy, 2006
The Odom v Microsoft and Best Buy litigation primarily focused on Internet access offered to customers in which the customers were automatically billed for Internet service without their consent. One of the most surprising aspects of this case involved the altering of electronic evidence by an attorney for Best Buy. The attorney, Timothy Block, admitted to altering documents prior to producing the documents in discovery to benefit Best Buy.
Investigative Tips: All evidence needs to be validated for authenticity. The weight given in legal hearings depends upon the veracity of the evidence. Many electronic files can be quickly validated through hash comparisons. An example seen in Figure 11.4 shows two files with different file names, yet their hash values are identical. If one file is known to be valid, perhaps an original evidence file, any file matching the hash values would also be a valid and unaltered copy of the original file.

Figure 11.4. Two files with different file names, but having the same hash value, indicating the contents of the files are identical.
Alternatively, Figure 11.5 shows two files with the same file name but having different hash values. If there were a claim that both of these files are the same original files, it would be apparent that one of the files has been modified.

Figure 11.5. Two files with the same file names, but having different hash values, indicating the contents are not identical.
Finding the discrepancies or modifications of an electronic file can only be accomplished if there is a comparison to be made with the original file. Using Figure 11.5 as an example, given that the file having the MD5 hash value of d41d8cd98f00b204e9800998ecf8427e is the original, and where the second file is the alleged altered file, a visual inspection of both files should be able to determine the modifications. However, when only file exists, proving the file to be unaltered is more than problematic, it is virtually impossible.
In this situation of having a single file to verify as original and unaltered evidence, an analysis would only be able to show when the file was modified over time, but the actual modifications won’t be known. Even if the document has “track changed” enabled, which logs changes to a document, that would only capture changes that were tracked, as there may be more untracked and unknown changes.
As a side note to hash values, in Figure 11.5, the hash values are completely different, even though the only difference between the two sample files is a single period added to the text. Any modification, no matter how minor, results in a drastic different hash value.
The importance in validating files in relation to the identification of a suspect that may have altered a file is that the embedded metadata will be a key point of focus and avenue for case leads. As a file is created, copied, modified, and otherwise touched, the file and system metadata will generally be updated.
Having the dates and times of these updates should give rise to you that the updates occurred on some computer system. This may be on one or more computers even if the file existed on a flash drive. At some point, the flash drive was connected to a computer system, where evidence on a system may show link files to the file. Each of these instances of access to the file is an opportunity to create a list of possible suspects having access to those systems in use at each updated metadata fields.
In the Microsoft Windows operating systems, Volume Shadow Copies may provide an examiner with a string of previous versions of a document, in which the modifications between each version can be determined. Although not every change may have been incrementally saved by the Volume Shadow Service, such as if the file was saved to a flash drive, any previous versions that can be found will allow to find some of the modifications made.
Where a single file will determine the outcome of an investigation or have a dramatic effect on the case, the importance of ‘getting it right’ cannot be overstated. Such would be the case of a single file, modified by someone in a business office, where many persons had common access to the evidence file before it was known to be evidence. Finding the suspect that altered the evidence file may be simple if you were at the location close to the time of occurrence. Interviews of the employees would be easier as most would remember their whereabouts in the office within the last few days. Some may be able to tell you exactly where other employees were in the office, even point the suspect out directly.
But what if you are called in a year later? How about 2 or more years later? What would be the odds employees remembering their whereabouts on a Monday in July 2 years earlier? To identify a suspect at this point requires more than a forensic analysis of a computer. It will probably require an investigation into work schedules, lunch schedules, backup tapes, phone call logs, and anything else to place everyone somewhere during the time of the file being altered.
Potentially you may even need to examine the hard drive of a copy machine and maybe place a person at the copy machine based on what was copied at the time the evidence file was being modified. When a company’s livelihood is at stake or a person’s career is at risk, leave no stone unturned. If you can’t place a suspect at the scene, you might be able to place everyone else at a location, and those you can’t place, just made your list of possible suspects.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781597499859000113
When, How, and Why Do We Trust Technology Too Much?
Patricia L. Hardré, in Emotions, Technology, and Behaviors, 2016
Trusting Spelling and Grammar Checkers
We often see evidence that users of word processing systems trust absolutely in spelling and grammar checkers. From errors in business letters and on resumes to uncorrected word usage in academic papers, this nonstrategy emerges as epidemic. It underscores a pattern of implicit trust that if a word is not flagged as incorrect in a word processing system, then it must be not only spelled correctly but also used correctly. The overarching error is trusting the digital checking system too much, while the underlying functional problem is that such software identifies gross errors (such as nonwords) but cannot discriminate finer nuances of language requiring judgment (like real words used incorrectly). Users from average citizens to business executives have become absolutely comfortable with depending on embedded spelling and grammar checkers that are supposed to autofind, trusting the technology so much that they often do not even proofread. Like overtrust of security monitoring, these personal examples are instances of reduced vigilance due to their implicit belief that the technology is functionally flawless, that if the technology has not found an error, then an error must not exist.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128018736000054
Establishing a C&A Program
Laura Taylor, Matthew Shepherd Technical Editor, in FISMA Certification and Accreditation Handbook, 2007
Template Development
Certification Packages consist of a set of documents that all go together and complement one another. A Certification Package is voluminous, and without standardization, it takes an inordinate amount of time to evaluate it to make sure all the right information is included. Therefore, agencies should have templates for all the documents that they require in their Certification Packages. Agencies without templates should work on creating them. If an agency does not have the resources in-house to develop these templates, they should consider outsourcing this initiative to outside consultants.
A template should be developed using the word processing application that is the standard within the agency. All of the relevant sections that the evaluation team will be looking for within each document should be included. Text that will remain constant for a particular document type also should be included. An efficient and effective C&A program will have templates for the following types of C&A documents:
- ▪
-
Categorization and Certification Level Recommendation
- ▪
-
Hardware and Software Inventory
- ▪
-
Self-Assessment
- ▪
-
Security Awareness and Training Plan
- ▪
-
End-User Rules of Behavior
- ▪
-
Incident Response Plan
- ▪
-
Security Test and Evaluation Plan
- ▪
-
Privacy Impact Assessment
- ▪
-
Business Risk Assessment
- ▪
-
Business Impact Assessment
- ▪
-
Contingency Plan
- ▪
-
Configuration Management Plan
- ▪
-
System Risk Assessment
- ▪
-
System Security Plan
- ▪
-
Security Assessment Report
The later chapters in this book will help you understand what should be included in each of these types of documents. Some agencies may possibly require other types of documents as required by their information security program and policies.
Templates should include guidelines for what type of content should be included, and also should have built-in formatting. The templates should be as complete as possible, and any text that should remain consistent and exactly the same in like document types should be included. Though it may seem redundant to have the exact same verbatim text at the beginning of, say, each Business Risk Assessment from a particular agency, each document needs to be able to stand alone and make sense if it is pulled out of the Certification Package for review. Having similar wording in like documents also shows that the packages were developed consistently using the same methodology and criteria.
With established templates in hand, it makes it much easier for the C&A review team to understand what it is that they need to document. Even expert C&A consultants need and appreciate document templates. Finding the right information to include the C&A documents can by itself by extremely difficult without first having to figure out what it is that you are supposed to find—which is why the templates are so very important. It’s often the case that a large complex application is distributed and managed throughout multiple departments or divisions and it can take a long time to figure out not just what questions to ask, but who the right people are who will know the answers.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781597491167500093
Speech Recognition
John-Paul Hosom, in Encyclopedia of Information Systems, 2003
I.B. Capabilities and Limitations of Automatic Speech Recognition
ASR is currently used for dictation into word processing software, or in a “command-and-control” framework in which the computer recognizes and acts on certain key words. Dictation systems are available for general use, as well as for specialized fields such as medicine and law. General dictation systems now cost under $100 and have speaker-dependent word-recognition accuracy from 93% to as high as 98%. Command-and-control systems are more often used over the telephone for automatically dialing telephone numbers or for requesting specific services before (or without) speaking to a human operator. Telephone companies use ASR to allow customers to automatically place calls even from a rotary telephone, and airlines now utilize telephone-based ASR systems to help passengers locate and reclaim lost luggage. Research is currently being conducted on systems that allow the user to interact naturally with an ASR system for goals such as making airline or hotel reservations.
Despite these successes, the performance of ASR is often about an order of magnitude worse than human-level performance, even with superior hardware and long processing delays. For example, recognition of the digits “zero” through “nine” over the telephone has word-level accuracy of about 98% to 99% using ASR, but nearly perfect recognition by humans. Transcription of radio broadcasts by world-class ASR systems has accuracy of less than 87%. This relatively low accuracy of current ASR systems has limited its use; it is not yet possible to reliably and consistently recognize and act on a wide variety of commands from different users.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404001647
Prototyping
Rex Hartson, Pardha Pyla, in The UX Book (Second Edition), 2019
20.7 Software Tools for Making Wireframes
Wireframes can be sketched using any drawing or word processing software package that supports creating and manipulating shapes. While many applications suffice for simple wireframing, we recommend tools designed specifically for this purpose. We use Sketch, a drawing app, to do all the drawing. Craft is a plug-in to Sketch that connects it to InVision, allowing you to export Sketch screen designs to InVision to incorporate hotspots as working links.
In the “Build mode” of InVision, you work on one screen at a time, adding rectangular overlays that are the hotspots. For each hotspot, you specify what other screen you go to when someone clicks on that hotspot in “Preview mode.” You get a nice bonus using InVision: In the “operate” mode, you, or the user, can click anywhere in an open space in the prototype and it highlights all the available links. These tools are available only on Mac computers, but similar tools are available under Windows.
Beyond this discussion, it’s not wise to try to cover software tools for making prototypes in this kind of textbook. The field is changing fast and whatever we could say here would be out of date by the time you read this. Plus, it wouldn’t be fair to the numerous other perfectly good tools that didn’t get cited. To get the latest on software tools for prototyping, it’s better to ask an experienced UX professional or to do your research online.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128053423000205
Design Production
Rex Hartson, Partha S. Pyla, in The UX Book, 2012
9.5.3 How to Build Wireframes?
Wireframes can be built using any drawing or word processing software package that supports creating and manipulating shapes, such as iWork Pages, Keynote, Microsoft PowerPoint, or Word. While such applications suffice for simple wireframing, we recommend tools designed specifically for this purpose, such as OmniGraffle (for Mac), Microsoft Visio (for PC), and Adobe InDesign.
Many tools and templates for making wireframes are used in combination—truly an invent-as-you-go approach serving the specific needs of prototyping. For example, some tools are available to combine the generic-looking placeholders in wireframes with more detailed mockups of some screens or parts of screens. In essence they allow you to add color, graphics, and real fonts, as well as representations of real content, to the wireframe scaffolding structure.
In early stages of design, during ideation and sketching, you started with thinking about the high-level conceptual design. It makes sense to start with that here, too, first by wireframing the design concept and then by going top down to address major parts of the concept. Identify the interaction conceptual design using boxes with labels, as shown in Figure 9-4.
Take each box and start fleshing out the design details. What are the different kinds of interaction needed to support each part of the design, and what kinds of widgets work best in each case? What are the best ways to lay them out? Think about relationships among the widgets and any data that need to go with them. Leverage design patterns, metaphors, and other ideas and concepts from the work domain ontology. Do not spend too much time with exact locations of these widgets or on their alignment yet. Such refinement will come in later iterations after all the key elements of the design are represented.
As you flesh out all the major areas in the design, be mindful of the information architecture on the screen. Make sure the wireframes convey that inherent information architecture. For example, do elements on the screen follow a logical information hierarchy? Are related elements on the screen positioned in such a way that those relationships are evident? Are content areas indented appropriately? Are margins and indents communicating the hierarchy of the content in the screen?
Next it is time to think about sequencing. If you are representing a workflow, start with the “wake-up” state for that workflow. Then make a wireframe representing the next state, for example, to show the result of a user action such as clicking on a button. In Figure 9-6 we showed what happens when a user clicks on the “Related information” expander widget. In Figure 9-7 we showed what happens if the user clicks on the “One-up” view switcher button.
Once you create the key screens to depict the workflow, it is time to review and refine each screen. Start by specifying all the options that go on the screen (even those not related to this workflow). For example, if you have a toolbar, what are all the options that go into that toolbar? What are all the buttons, view switchers, window controllers (e.g., scrollbars), and so on that need to go on the screen? At this time you are looking at scalability of your design. Is the design pattern and layout still working after you add all the widgets that need to go on this screen?
Think of cases when the windows or other container elements such as navigation bars in the design are resized or when different data elements that need to be supported are larger than shown in the wireframe. For example, in Figures 9-5 and 9-6, what must happen if the number of photo collections is greater than what fits in the default size of that container? Should the entire page scroll or should new scrollbars appear on the left-hand navigation bar alone? How about situations where the number of people identified in a collection are large? Should we show the first few (perhaps ones with most number of associated photos) with a “more” option, should we use an independent scrollbar for that pane, or should we scroll the entire page? You may want to make wireframes for such edge cases; remember they are less expensive and easier to do using boxes and lines than in code.
As you iterate your wireframes, refine them further, increasing the fidelity of the deck. Think about proportions, alignments, spacing, and so on for all the widgets. Refine the wording and language aspects of the design. Get the wireframe as close to the envisioned design as possible within the constraints of using boxes and lines.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123852410000099