
I need to create a word list from a text file. The list is going to be used in a hangman code and needs to exclude the following from the list:
- duplicate words
- words containing less than 5 letters
- words that contain ‘xx’ as a substring
- words that contain upper case letters
the word list then needs to be output into file so that every word appears on its own line.
The program also needs to output the number of words in the final list.
This is what I have, but it’s not working properly.
def MakeWordList():
infile=open(('possible.rtf'),'r')
whole = infile.readlines()
infile.close()
L=[]
for line in whole:
word= line.split(' ')
if word not in L:
L.append(word)
if len(word) in range(5,100):
L.append(word)
if not word.endswith('xx'):
L.append(word)
if word == word.lower():
L.append(word)
print L
MakeWordList()
asked Apr 9, 2013 at 1:05
![]()
2
You’re appending the word many times with this code,
You arn’t actually filtering out the words at all, just adding them a different number of timed depending on how many if‘s they pass.
you should combine all the if‘s:
if word not in L and len(word) >= 5 and not 'xx' in word and word.islower():
L.append(word)
Or if you want it more readable you can split them:
if word not in L and len(word) >= 5:
if not 'xx' in word and word.islower():
L.append(word)
But don’t append after each one.
answered Apr 9, 2013 at 1:10
![]()
SerdalisSerdalis
10.2k2 gold badges38 silver badges58 bronze badges
4
Think about it: in your nested if-statements, ANY word that is not already in the list will make it through on your first line. Then if it is 5 or more characters, it will get added again (I bet), and again, etc. You need to rethink your logic in the if statements.
answered Apr 9, 2013 at 1:16
![]()
mrKelleymrKelley
3,3152 gold badges20 silver badges28 bronze badges
Improved code:
def MakeWordList():
with open('possible.rtf','r') as f:
data = f.read()
return set([word for word in data if len(word) >= 5 and word.islower() and not 'xx' in word])
set(_iterable_) returns a set-type object that has no duplicates (all set items must be unique). [word for word...] is a list comprehension which is a shorter way of creating simple lists. You can iterate over every word in ‘data’ (this assumes each word is on a separate line). if len(word) >= 5 and word.islower() and not 'xx' in word accomplishes the final three requirements (must be more than 5 letters, have only lowercase letters, and cannot contain ‘xx’).
answered Apr 9, 2013 at 1:46
![]()
Rushy PanchalRushy Panchal
16.8k16 gold badges60 silver badges92 bronze badges
List Of English Words
A text file containing over 466k English words.
While searching for a list of english words (for an auto-complete tutorial)
I found: https://stackoverflow.com/questions/2213607/how-to-get-english-language-word-database which refers to https://www.infochimps.com/datasets/word-list-350000-simple-english-words-excel-readable (archived).
No idea why infochimps put the word list inside an excel (.xls) file.
I pulled out the words into a simple new-line-delimited text file.
Which is more useful when building apps or importing into databases etc.
Copyright still belongs to them.
Files you may be interested in:
- words.txt contains all words.
- words_alpha.txt contains only [[:alpha:]] words (words that only have letters, no numbers or symbols). If you want a quick solution choose this.
- words_dictionary.json contains all the words from words_alpha.txt as json format.
If you are using Python, you can easily load this file and use it as a dictionary for faster performance. All the words are assigned with 1 in the dictionary.
See read_english_dictionary.py for example usage.
sed -e 's/[^[:alpha:]]/ /g' text_to_analize.txt | tr 'n' " " | tr -s " " | tr " " 'n'| tr 'A-Z' 'a-z' | sort | uniq -c | sort -nr | nl
This command makes the following:
- Substitute all non alphanumeric characters with a blank space.
- All line breaks are converted to spaces also.
- Reduces all multiple blank spaces to one blank space
- All spaces are now converted to line breaks. Each word in a line.
- Translates all words to lower case to avoid ‘Hello’ and ‘hello’ to be different words
- Sorts de text
- Counts and remove the equal lines
- Sorts reverse in order to count the most frequent words
- Add a line number to each word in order to know the word posotion in the whole
For example if I want to analize the first Linus Torvald message:
From: torvalds@klaava.Helsinki.FI (Linus Benedict Torvalds)
Newsgroups: comp.os.minix Subject: What would you like to see most in
minix? Summary: small poll for my new operating system Message-ID:
<1991Aug25.205708.9541@klaava.Helsinki.FI> Date: 25 Aug 91 20:57:08
GMT Organization: University of HelsinkiHello everybody out there using minix –
I’m doing a (free) operating system (just a hobby, won’t be big and
professional like gnu) for 386(486) AT clones. This has been brewing
since april, and is starting to get ready. I’d like any feedback on
things people like/dislike in minix, as my OS resembles it somewhat
(same physical layout of the file-system (due to practical reasons)
among other things).I’ve currently ported bash(1.08) and gcc(1.40), and things seem to
work. This implies that I’ll get something practical within a few
months, and I’d like to know what features most people would want. Any
suggestions are welcome, but I won’t promise I’ll implement them 🙂Linus (torvalds@kruuna.helsinki.fi)
PS. Yes – it’s free of any minix code, and it has a multi-threaded fs.
It is NOT protable (uses 386 task switching etc), and it probably
never will support anything other than AT-harddisks, as that’s all I
have :-(.
I create a file named linus.txt, I paste the content and then I write in the console:
sed -e 's/[^[:alpha:]]/ /g' linus.txt | tr 'n' " " | tr -s " " | tr " " 'n'| tr 'A-Z' 'a-z' | sort | uniq -c | sort -nr | nl
The out put would be:
1 7 i
2 5 to
3 5 like
4 5 it
5 5 and
6 4 minix
7 4 a
8 3 torvalds
9 3 of
10 3 helsinki
11 3 fi
12 3 any
13 2 would
14 2 won
15 2 what
16 ...
If you want to visualize only the first 20 words:
sed -e 's/[^[:alpha:]]/ /g' text_to_analize.txt | tr 'n' " " | tr -s " " | tr " " 'n'| tr 'A-Z' 'a-z' | sort | uniq -c | sort -nr | nl | head -n 20
It’s important to note that the command tr ‘A-Z’ ‘a-z’ doesn’t suport UTF-8 yet, so that in foreign languages the word APRÈS would be translated as aprÈs.
I need to create a word list from a text file. The list is going to be used in a hangman code and needs to exclude the following from the list:
- duplicate words
- words containing less than 5 letters
- words that contain ‘xx’ as a substring
- words that contain upper case letters
the word list then needs to be output into file so that every word appears on its own line.
The program also needs to output the number of words in the final list.
This is what I have, but it’s not working properly.
def MakeWordList():
infile=open(('possible.rtf'),'r')
whole = infile.readlines()
infile.close()
L=[]
for line in whole:
word= line.split(' ')
if word not in L:
L.append(word)
if len(word) in range(5,100):
L.append(word)
if not word.endswith('xx'):
L.append(word)
if word == word.lower():
L.append(word)
print L
MakeWordList()
3 Answers
You’re appending the word many times with this code,
You arn’t actually filtering out the words at all, just adding them a different number of timed depending on how many if‘s they pass.
you should combine all the if‘s:
if word not in L and len(word) >= 5 and not 'xx' in word and word.islower():
L.append(word)
Or if you want it more readable you can split them:
if word not in L and len(word) >= 5:
if not 'xx' in word and word.islower():
L.append(word)
But don’t append after each one.
Think about it: in your nested if-statements, ANY word that is not already in the list will make it through on your first line. Then if it is 5 or more characters, it will get added again (I bet), and again, etc. You need to rethink your logic in the if statements.
Improved code:
def MakeWordList():
with open('possible.rtf','r') as f:
data = f.read()
return set([word for word in data if len(word) >= 5 and word.islower() and not 'xx' in word])
set(_iterable_) returns a set-type object that has no duplicates (all set items must be unique). [word for word...] is a list comprehension which is a shorter way of creating simple lists. You can iterate over every word in ‘data’ (this assumes each word is on a separate line). if len(word) >= 5 and word.islower() and not 'xx' in word accomplishes the final three requirements (must be more than 5 letters, have only lowercase letters, and cannot contain ‘xx’).
Главная : Расширения файлов : .wordlist File
Тип файлаDesktop Poet Word List File
.WORDLIST вариант №
Список слов, используемый Desktop Poet, программа «fridge poetry», которая позволяет пользователям создавать стихи, упорядочивая слова на рабочем столе; содержит набор слов, а также определения для временных слов (например, времен глагола, сингулярных и множественных времен); также сохраняет название списка слов, язык, автор и информацию об авторских правах.
Больше информации
Файлы списка слов могут использоваться для хранения коллекций слов на разных языках. Несколько стандартных файлов списка слов включены в программное обеспечение Desktop Poet. Другие словарные списки могут быть загружены и добавлены в программное обеспечение.
Файлы WORDLIST хранятся в текстовом формате и включают теги, которые делят разные разделы файла.
ПРИМЕЧАНИЕ. Desktop Poet больше не разрабатывается.
Программы, которые открывают WORDLIST файлы
О WORDLIST файлах
Наша цель — помочь вам понять за что отвечает файл с расширением * .wordlist и как его открыть.
Тип файла Desktop Poet Word List File, описания программ для Mac, Windows, Linux, Android и iOS, перечисленные
на этой странице, были индивидуально исследованы и проверены командой FileExt. Мы стремимся к 100-процентной точности и публикуем только информацию о форматах файлов, которые мы тестировали и проверяли.
Just Want a List of Words? ❓
If you only care about the list of words in this repo, 📝
that’s great; use them and have an awesome day! 🎉

Want More? 🚀
For the minuscule minority of people who want more, this issue is for you! 🙌

Brief History / Context
A few years ago I needed a list of English Words for a work project. 👨💻
Went searching and didn’t find a ready-made list of English Words … 🔍 🤷♂️
But found this StackOverflow Question and Answer:
https://stackoverflow.com/questions/2213607/how-to-get-english-language-word-database
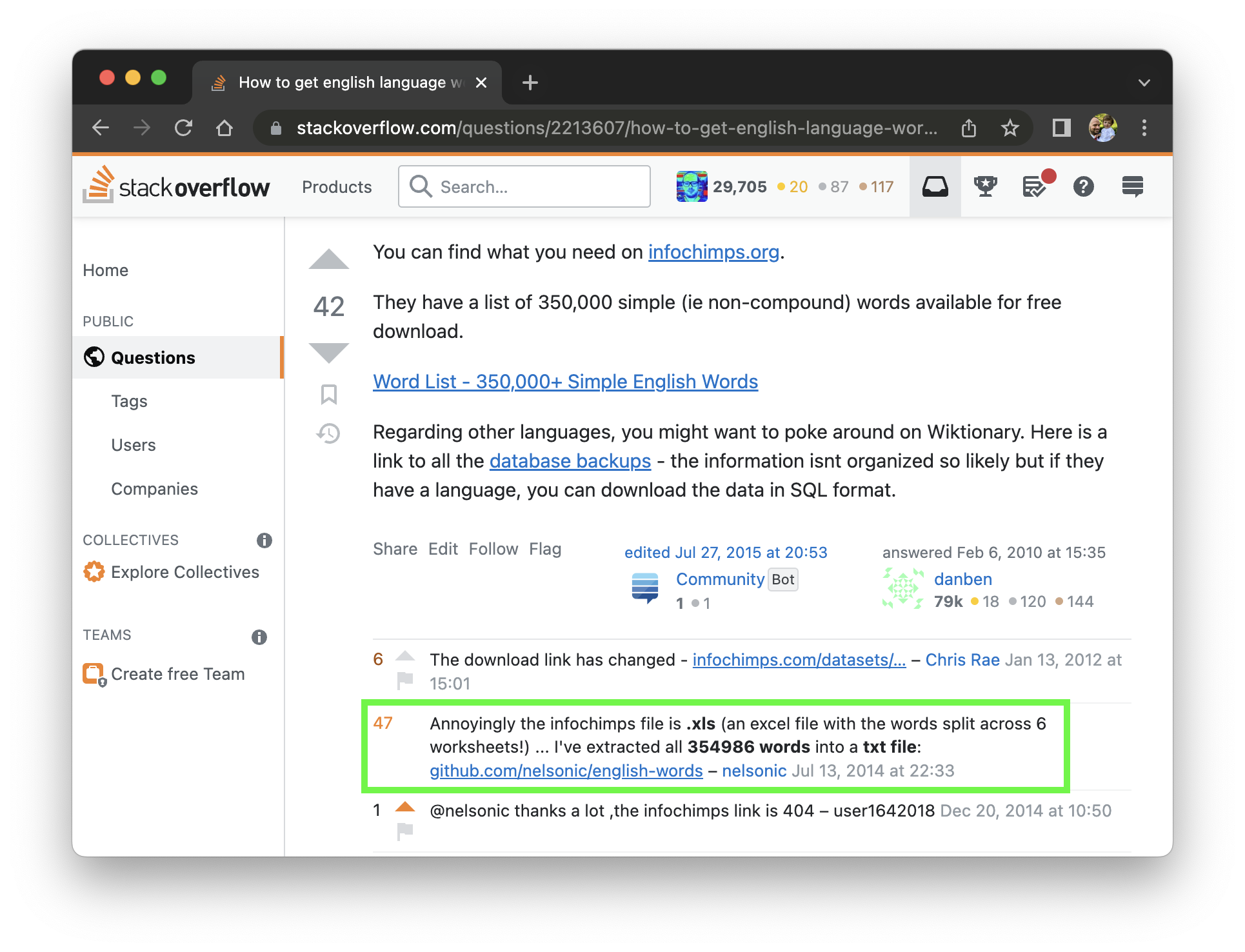
Extracted the words from the Excel file that was on InfoChimps (now 404) and dumped them in a .txt file.
Put it on GitHub and linked to it in a comment on SO and didn’t give it anymore thought. 👌
Sadly, the work project that used the words was closed source for a company that got acquired and the App was shut down. 😢 The folly of working on closed source things is that you often have nothing to show for your years of your life! 💭
Meanwhile many thousands of people have downloaded the word list and the repo has 8.3k ⭐ 🤯
The mini [Open Source] demo project I created: nelsonic/autocomplete ➡️ wordsy.herokuapp.com …

will soon be taken offline by Heroku’s Bean-counters 🙄
I outlined what I wanted to do in autocomplete#tasks but it’s very incomplete …
so this issue will give a muuuuch better roadmap of what we’re doing. 🤞
What challenge are we solving? 🤔
The original purpose of this repo will 100% be maintained. ✅
What we are doing is enhancing the repo with a showcase App that allows people to:
With that in mind, this is the plan:
- High quality list of English words in an easy to extract file/format e.g.
.txt,.jsonand.zip - Instructions for how to use the words in various programming languages;
codeexamples.
- [ ]
JavaScript/TypeScript - [ ]
Python - [ ]
Elixir - [ ]
Dart - [ ]
Rust - [ ] Invite contributions from the community for
codeexamples from more programming languages [but NOT frameworks]
Make it clear that we really don’t want aReactsample because we don’t want to encourage anyone to use it.
- Clarity on the Process for updating the words list both adding, correcting and removing [invalid] words.
- Automate the creation of the
.zipfile so that we don’t have people attempting to submit Pull Requests with Zip Files.
We’re never going to accept a PR with a zip file. It’s an easy attack vector for a malicious auto-executable.
Read more: https://github.com/snyk/zip-slip-vulnerability
It’s not that we don’t «trust» people … but we know that not everyone on GitHub has good intentions.
Crime pays otherwise there wouldn’t be any crims … And cyber-crime pays big BTCs! So let’s just avoid it. 👌
- Allow anyone to lookup words with auto-completion and to make suggestions via Web App/UI. That will invite way more people including non-technical people who don’t know how to use GitHub to help maintain+improve the list of words.
Todo
- [ ] Review the existing/open PRs and try to merge them: https://github.com/dwyl/english-words/issues/155
- [ ] Create
PhoenixApp 🆕 … Note: waiting forPhoenix v1.7to do this to minimise time wasted with updates … ⏳ - [ ] Re-create basic features from nelsonic/autocomplete:
- [ ] Use
PostgreSQLfor simplicity. - [ ] If we notice too much query latency, we can switch to
SQLiteorETSfor speed:
- [ ] Use
- [ ] Load the current English Words List into the DB
- [ ] Determine/decide what other metadata we want to store for each word. 💭
- [ ] Discuss any other features we want to have. (please comment!) 💬
enhancement help wanted T1d chore epic technical priority-2 discuss
- Remove From My Forums
-
Question
-
How can i take a text file with one word on each line of the file and add each line in the text file as an item in a List<string>?
Answers
-
An easy way to do this would just be:
List<string> lines = System.IO.File.ReadLines(filePath).ToList();
(Note that this requires .NET 4)
Reed Copsey, Jr. — http://reedcopsey.com
If a post answers your question, please click «Mark As Answer» on that post and «Mark as Helpful«.-
Proposed as answer by
Friday, June 8, 2012 1:53 AM
-
Marked as answer by
Lisa Zhu
Wednesday, June 13, 2012 1:18 AM
-
Proposed as answer by
-
string filePath = this.textBox1.Text; List<string> linesList = new List<string>(); string [] fileContent = System.IO.File.ReadAllLines(filePath); linesList.AddRange(fileContent);
Regards,
Ahmed Ibrahim
SQL Server Setup Team
This posting is provided «AS IS» with no warranties, and confers no rights. Please remember to click
«Mark as Answer» and «Vote as Helpful»
on posts that help you.
This can be beneficial to other community members reading the thread.-
Proposed as answer by
Chris Holly
Friday, June 8, 2012 4:02 PM -
Marked as answer by
Lisa Zhu
Wednesday, June 13, 2012 1:18 AM
-
Proposed as answer by
-
Here is your answer for a fast way to add strings from a file to a List<> collection:
Read all lines in file
In the second example of «this C# tutorial shows how to use StreamReader to read text files».
Dan Randolph
-
Marked as answer by
Lisa Zhu
Wednesday, June 13, 2012 1:18 AM
-
Marked as answer by
-
Use the StreamReader object:
http://msdn.microsoft.com/en-us/library/system.io.streamreader.aspxIt would be a little bit changed. Pseudo-code:
- Create the List to hold the strings ( List<string> blah = new List<string>() )
- Create the streamReader object and open the connection to the file ( using StreamReader x = new StreamReader(«C:\fakepath.txt») )
- While the streamReader.EndOfFile property is not false, keep reading lines and add it to the list
Give it a small whirl and if you need sample code let me know
-
Marked as answer by
Lisa Zhu
Wednesday, June 13, 2012 1:18 AM
-
How about this?
var query = File.ReadAllLines(somePathVariable)
mylist = query.toList();
Not sure if it works.
JP Cowboy Coders Unite!
-
Edited by
Mr. Javaman II
Thursday, June 7, 2012 11:24 PM -
Marked as answer by
Lisa Zhu
Wednesday, June 13, 2012 1:18 AM
-
Edited by
The wordlist program that reads a text file and makes an alphabetical list of all the words in that file. The list of words is output to another file. Improve the program so that it also keeps track of the number of times that each word occurs in the file. Write two lists to the output file. The first list contains the words in alphabetical order.The number of times that the word occurred in the file should be listed along with the word. Then write a second list to the output file in which the words are sorted according to the number of times that they occurredin the files. The word that occurred most often should be listed first.
Code for Word list program that reads a text file and makes an alphabetical list of all the words in that file. The list of words is output to another file in Java
import java.io.*; class cntwords { publicstaticvoid main(String args[]) throws IOException { try { FileReader fr = new FileReader("data.txt"); BufferedReader br = new BufferedReader(fr); String str; while((str = br.readLine()) != null) countwords(str); fr.close(); } catch(FileNotFoundException e) { System.out.println("File Not Found"); } catch(IOException e) { System.out.println("Exception : " + e); } } staticvoid countwords(String st) { int len,i,totwords=1,j=-1,k=0,freqarr[],temp; int cnt=0,flag=0; len = st.length(); char ch[]; String starr[],st1[]; for(i=0;i<len-1;i++) { if(st.charAt(i) != ' ' && st.charAt(i+1) == ' ') totwords++; } starr = new String[totwords+1]; freqarr = newint[totwords]; st1 = new String[totwords]; for(i=0;i<len-1;i++) { if(st.charAt(i) != ' ' && st.charAt(i+1) == ' ') { ch = newchar[(i+1) - j]; st.getChars(j+1,i+1,ch,0); starr[k++] = new String(ch); j = i+1; } } ch = newchar[(i+1) - j]; st.getChars(j+1,i+1,ch,0); starr[k] = new String(ch); k=0; for(i=0;i<totwords;i++) { temp = 1; flag = 0; for(j=i+1;j<=totwords;j++) { if(starr[i].equals(starr[j])) temp++; } freqarr[k] = temp; for(cnt=0;cnt<k;cnt++) { if(starr[i].equals(st1[cnt])) flag = 1; } if(flag == 0) st1[k++] = starr[i]; } for(i=0;i<k;i++) System.out.println(st1[i] + "has count : " + freqarr[i]); writedata(st1,freqarr,k); } staticvoid writedata(String arr[],int intarr[],int len) { try { FileOutputStream fos = new FileOutputStream("res.txt"); FileOutputStream fos1 = new FileOutputStream("res1.txt"); DataOutputStream dos = new DataOutputStream(fos); int i,j,val; String temp; for(i=0;i<len;i++) { dos.writeChars(arr[i]); dos.writeChars(Integer.toString(intarr[i])); dos.writeChar(' '); } fos.close(); dos = new DataOutputStream(fos1); for(i=0;i<len;i++) { for(j=i+1;j<len;j++) { if(intarr[i] < intarr[j]) { val = intarr[j]; intarr[j] = intarr[i]; intarr[i] = val; temp = arr[j]; arr[j] = arr[i]; arr[i] = temp; } } } for(i=0;i<len;i++) { dos.writeChars(arr[i]); dos.writeChars(Integer.toString(intarr[i])); dos.writeChar(' '); } fos1.close(); } catch(IOException e) { System.out.println("Exception : " + e); } } }