
1. Introduction
This module describes the typesetting controls of CSS;
that is, the features of CSS that control the translation of
source text to formatted, line-wrapped text.
Various CSS properties provide control over case transformation, white space collapsing, text wrapping, line breaking rules and hyphenation, alignment and justification, spacing,
and indentation.
Further information about the typesetting requirements
of various languages and writing systems around the world
can be found in the Internationalization Working Group’s Language Enablement Index. [TYPOGRAPHY]
1.1. Module Interactions
This module, together with the CSS Text Decoration Module,
replaces and extends the text-level features defined in Cascading Style Sheets Level 2 chapter 16. [CSS-TEXT-DECOR-3] [CSS2]
In addition to the terms defined below,
other terminology and concepts used in this specification are defined
in Cascading Style Sheets Level 2 and the CSS Writing Modes Module. [CSS2] and [CSS-WRITING-MODES-4].
1.2. Value Definitions
This specification follows the CSS property definition conventions from [CSS2] using the value definition syntax from [CSS-VALUES-3].
Value types not defined in this specification are defined in CSS Values & Units [CSS-VALUES-3].
Combination with other CSS modules may expand the definitions of these value types.
In addition to the property-specific values listed in their definitions,
all properties defined in this specification
also accept the CSS-wide keywords as their property value.
For readability they have not been repeated explicitly.
1.3. Languages and Typesetting
Authors should accurately language-tag their content
for the best typographic behavior.
Many typographic effects vary by linguistic context.
Language and writing system conventions can affect
line breaking, hyphenation, justification, glyph selection,
and many other typographic effects. In CSS, language-specific typographic tailorings
are only applied when the content language is known (declared). Therefore,
higher quality typography requires authors to communicate to the UA
the correct linguistic context of the text in the document.
The content language of an element is the (human) language
the element is declared to be in, according to the rules of the document language.
Note that it is possible for the content language of an element
to be unknown—e.g. untagged content,
or content in a document language that does not have a language-tagging facility,
is considered to have an unknown content language.
Note: Authors can declare the content language using the global lang attribute in HTML
or the universal xml:lang attribute in XML.
See the rules for determining the content language of an HTML element in HTML,
and the rules for determining the content language of an XML element in XML 1.0. [HTML] [XML10]
The content language an element is declared to be in
also identifies the specific written form of that language used in that element,
known as the content writing system.
Depending on the document language’s facilities for identifying the content language,
this information can be explicit or implied.
See the normative Appendix F:
Identifying the Content Writing System.
Note: Some languages have more than one writing system tradition;
in other cases a language can be transliterated into a foreign writing system.
Authors should subtag such cases
so that the UA can adapt appropriately.
For example, Korean (ko) can be written in
Hangul (-Hang),
Hanja (-Hani),
or a combination (-Kore).
Historical documents written solely in Hanja
do not use word spaces and
are formatted more like modern Chinese than modern Korean.
In other words, for typographic purposes ko-Hani behaves more like zh-Hant than ko (ko-Kore).
As another example Japanese (ja) is typically written
in a combination (-Japn) of Hiragana (-Hira),
Katakana (-Kana), and Kanji (-Hani).
However, it can also be ”romanized” into Latin (-Latn)
for special purposes like language-learning textbooks,
in which case it should be formatted more like English than Japanese.
As a third example contemporary Mongolian is written in two scripts:
Cyrillic (-Cyrl, officially used in Mongolia)
and Mongolian (-Mong, more common in Inner Mongolia, part of China).
These have very different formatting requirements,
with Cyrillic behaving similar to Latin and Greek,
and Mongolian deriving from both Arabic and Chinese writing conventions.
1.4. Characters and Letters
The basic unit of typesetting is the character.
However, because writing systems are not always as simple as the basic English alphabet,
what a character actually is depends on the context in which the term is used.
For example, in Hangul (the Korean writing system),
each square representation of a syllable
(e.g. 한=Han)
can be considered a character.
However, the square symbol is really composed of multiple letters each representing a phoneme
(e.g. ㅎ=h, ㅏ=a, ㄴ=n)
and these also could each be considered a character.
A basic unit of computer text encoding, for any given encoding,
is also called a character,
and depending on the encoding,
a single encoding character might correspond
to the entire pre-composed syllabic character (e.g. 한),
to the individual phonemic character (e.g. ㅎ),
or to smaller units such as
a base letterform (e.g. ㅇ)
and any combining marks that vary it (e.g. extra strokes that represent aspiration).
In turn, a single encoding character can be represented in the data stream as one or more bytes;
and in programming environments one byte is sometimes also called a character.
Therefore the term character is fairly ambiguous where technical precision is required.
For text layout, we will refer to the typographic character unit as the basic unit of text.
Even within the realm of text layout,
the relevant character unit depends on the operation.
For example, line-breaking and letter-spacing will segment
a sequence of Thai characters that include U+0E33 ำ THAI CHARACTER SARA AM differently;
or the behavior of a conjunct consonant in a script such as Devanagari
may depend on the font in use.
So the typographic character represents a unit of the writing system—such as a Latin alphabetic letter (including its diacritics),
Hangul syllable,
Chinese ideographic character,
Myanmar syllable cluster—that is indivisible with respect to a particular typographic operation
(line-breaking, first-letter effects, tracking, justification, vertical arrangement, etc.).
Unicode Standard Annex #29: Text Segmentation defines a unit called the grapheme cluster which approximates the typographic character. [UAX29] A UA must use the extended grapheme cluster (not legacy grapheme cluster), as defined in UAX29,
as the basis for its typographic character unit.
However, the UA should tailor the definitions
as required by typographic tradition
since the default rules are not always appropriate or ideal—and is expected to tailor them differently
depending on the operation as needed.
Note: The rules for such tailorings are out of scope for CSS.
The following are some examples of typographic character unit tailorings
required by standard typesetting practice:
- In some scripts such as Myanmar or Devanagari,
the typographic character unit for both justification and line-breaking
is an entire syllable,
which can include more than one Unicode grapheme cluster. [UAX29] -
In other scripts such as Thai or Lao,
even though for line-breaking the typographic character matches Unicode’s default grapheme clusters,
for letter-spacing the relevant unit
is less than a Unicode grapheme cluster,
and may require decomposition or other substitutions
before spacing can be inserted. [UAX29]For instance,
to properly letter-space the Thai word คำ (U+0E04 + U+0E33),
the U+0E33 needs to be decomposed into U+0E4D + U+0E32,
and then the extra letter-space inserted before the U+0E32: คํ า.A slightly more complex example is น้ำ (U+0E19 + U+0E49 + U+0E33).
In this case, normal Thai shaping will first decompose the U+0E33 into U+0E4D + U+0E32
and then swap the U+0E4D with the U+0E49, giving U+0E19 + U+0E4D + U+0E49 + U+0E32.
As before the extra letter-space is then inserted before the U+0E32: นํ้ า. - Vertical typesetting can also require tailoring.
For example, when typesetting upright text,
Tibetan tsek and shad marks are kept with the preceding grapheme cluster,
rather than treated as an independent typographic character unit. [CSS-WRITING-MODES-4]
A typographic letter unit (or letter for the purpose of this specification)
is a typographic character unit belonging to one of the Letter or Number general categories.
See Appendix E:
Characters and Properties for how to determine the Unicode properties of a typographic character unit.
The rendering characteristics of a typographic character unit divided
by an element boundary is undefined.
Ideally each component should be rendered
according to the formatting requirements of its respective element’s properties
while maintaining correct shaping and positioning
of the typographic character unit as a whole.
However, depending on the nature of the formatting differences between its parts
and the capabilities of the font technology in use,
this is not always possible.
Therefore such a typographic character unit may be rendered as belonging to either side of the boundary,
or as some approximation of belonging to both.
Authors are forewarned that dividing grapheme clusters or ligatures
by element boundaries may give inconsistent or undesired results.
1.5. Text Processing
CSS is built on Unicode. [UNICODE] UAs that support Unicode must adhere to all normative requirements
of the Unicode Core Standard,
except where explicitly overridden by CSS.
UAs implemented on the basis of a non-Unicode text encoding model are still
expected to fulfill the same text handling requirements
by assuming an appropriate mapping and analogous behavior.
For the purpose of determining adjacency for text processing
(such as white space processing, text transformation, line-breaking, etc.),
and thus in general within this specification,
intervening inline box boundaries and out-of-flow elements
must be ignored.
With respect to text shaping, however, see § 7.3 Shaping Across Element Boundaries.
2. Transforming Text
2.1. Case Transforms: the text-transform property
| Name: | text-transform |
|---|---|
| Value: | none | [capitalize | uppercase | lowercase ] || full-width || full-size-kana |
| Initial: | none |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property transforms text for styling purposes.
It has no effect on the underlying content,
and must not affect the content of a plain text copy & paste operation.
Authors must not rely on text-transform for semantic purposes;
rather the correct casing and semantics should be encoded
in the source document text and markup.
Values have the following meanings:
- none
- No effects.
- capitalize
- Puts the first typographic letter unit of each word, if lowercase, in titlecase;
other characters are unaffected. - uppercase
- Puts all letters in uppercase.
- lowercase
- Puts all letters in lowercase.
- full-width
- Puts all typographic character units in full-width form.
If a character does not have a corresponding full-width form,
it is left as is.
This value is typically used to typeset Latin letters and digits
as if they were ideographic characters. - full-size-kana
- Converts all small Kana characters to the equivalent full-size Kana.
This value is typically used for ruby annotation text,
where authors may want all small Kana to be drawn as large Kana
to compensate for legibility issues at the small font sizes typically used in ruby.
The following example converts the ASCII characters
used in abbreviations in Japanese text to their full-width variants
so that they lay out and line break like ideographs:
abbr:lang(ja) { text-transform: full-width; }
Note: The purpose of text-transform is
to allow for presentational casing transformations
without affecting the semantics of the document.
Note in particular that text-transform casing operations are lossy,
and can distort the meaning of a text.
While accessibility interfaces may wish to convey
the apparent casing of the rendered text to the user,
the transformed text cannot be relied on to accurately represent
the underlying meaning of the document.
In this example,
the first line of text is capitalized as a visual effect.
section > p:first-of-type::first-line {
text-transform: uppercase;
}
This effect cannot be written into the source document
because the position of the line break depends on layout.
But also, the capitalization is not reflecting a semantic distinction
and is not intended to affect the paragraph’s reading;
therefore it belongs in the presentation layer.
In this example,
the ruby annotations,
which are half the size of the main paragraph text,
are transformed to use regular-size kana
in place of small kana.
rt { font-size: 50%; text-transform: full-size-kana; }
:is(h1, h2, h3, h4) rt { text-transform: none; /* unset for large text*/ }
Note that while this makes such letters easier to see at small type sizes,
the transformation distorts the text:
the reader needs to mentally substitute small kana in the appropriate places—not unlike reading a Latin inscription
where all “U”s look like “V”s.
For example, if text-transform: full-size-kana were applied to the following source,
the annotation would read “じゆう” (jiyū), which means “liberty”,
instead of “じゅう” (jū), which means “ten”,
the correct reading and meaning for the annotated “十”.
<ruby>十<rt>じゅう</ruby>
2.1.1. Mapping Rules
For capitalize, what constitutes a “word“ is UA-dependent; [UAX29] is suggested (but not required)
for determining such word boundaries.
Out-of-flow elements and inline element boundaries
must not introduce a text-transform word boundary
and must be ignored when determining such word boundaries.
Note: Authors cannot depend on capitalize to follow
language-specific titlecasing conventions
(such as skipping articles in English).
The UA must use the full case mappings for Unicode characters,
including any conditional casing rules,
as defined in the Default Case Algorithms section of The Unicode Standard. [UNICODE] If (and only if) the content language of the element is,
according to the rules of the document language,
known,
then any appropriate language-specific rules must be applied as well.
These minimally include,
but are not limited to,
the language-specific rules in Unicode’s SpecialCasing.txt.
For example, in Turkish there are two “i”s,
one with a dot—“İ” and “i”—and one without—“I” and “ı”.
Thus the usual case mappings between “I” and “i”
are replaced with a different set of mappings
to their respective dotless/dotted counterparts,
which do not exist in English.
This mapping must only take effect
if the content language is Turkish
written in its modern Latin-based writing system (or another Turkic language that uses Turkish casing rules);
in other languages,
the usual mapping of “I” and “i” is required.
This rule is thus conditionally defined in Unicode’s SpecialCasing.txt file.
The definition of full-width and half-width forms
can be found in Unicode Standard Annex #11: East Asian Width. [UAX11] The mapping to full-width form is defined
by taking code points with the <wide> or the <narrow> tag
in their Decomposition_Mapping in Unicode Standard Annex #44: Unicode Character Database. [UAX44] For the <narrow> tag,
the mapping is from the code point to the decomposition
(minus <narrow> tag),
and for the <wide> tag,
the mapping is from the decomposition
(minus the <wide> tag)
back to the original code point.
The mappings for small Kana to full-size Kana are defined in Appendix G:
Small Kana Mappings.
2.1.2. Order of Operations
When multiple values are specified
and therefore multiple transformations need to be applied,
they are applied in the following order:
- capitalize, uppercase, and lowercase
- full-width
- full-size-kana
Text transformation happens after § 4.1.1 Phase I: Collapsing and Transformation but before § 4.1.2 Phase II: Trimming and Positioning.
This means that full-width only transforms
spaces (U+0020) to U+3000 IDEOGRAPHIC SPACE within preserved white space.
Note: As defined in Appendix A:
Text Processing Order of Operations,
transforming text affects line-breaking and other formatting operations.
3. White Space and Wrapping: the white-space property
| Name: | white-space |
|---|---|
| Value: | normal | pre | nowrap | pre-wrap | break-spaces | pre-line |
| Initial: | normal |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property specifies two things:
- whether and how white space is collapsed
- whether lines may wrap at unforced soft wrap opportunities
Values have the following meanings,
which must be interpreted according to
the White Space Processing and Line Breaking rules:
- normal
- This value directs user agents to collapse sequences of white space into a single character
(or in some cases, no character).
Lines may wrap at allowed soft wrap opportunities,
as determined by the line-breaking rules in effect,
in order to minimize inline-axis overflow. - pre
- This value prevents user agents from collapsing sequences of white space. Segment breaks such as line feeds
are preserved as forced line breaks.
Lines only break at forced line breaks;
content that does not fit within the block container overflows it. - nowrap
- Like normal,
this value collapses white space;
but like pre, it does not allow wrapping. - pre-wrap
- Like pre,
this value preserves white space;
but like normal,
it allows wrapping. - break-spaces
-
The behavior is identical to that of pre-wrap,
except that:- Any sequence of preserved white space or other space separators always takes up space,
including at the end of the line. - A line breaking opportunity exists
after every preserved white space character
and after every other space separator (including between adjacent spaces).
Note: This value does not guarantee
that there will never be any overflow due to white space:
for example, if the line length is so short
that even a single white space character does not fit,
overflow is unavoidable. - Any sequence of preserved white space or other space separators always takes up space,
- pre-line
- Like normal,
this value collapses consecutive white space characters and allows wrapping,
but it preserves segment breaks in the source as forced line breaks.
White space that was not removed or collapsed due to white space processing
is called preserved white space.
Note: In some cases, preserved white space and other space separators can hang when at the end of the line;
this can affect whether they are measured for intrinsic sizing.
The following informative table summarizes the behavior
of various white-space values:
| New Lines | Spaces and Tabs | Text Wrapping | End-of-line spaces | End-of-line other space separators | |
|---|---|---|---|---|---|
| normal | Collapse | Collapse | Wrap | Remove | Hang |
| pre | Preserve | Preserve | No wrap | Preserve | No wrap |
| nowrap | Collapse | Collapse | No wrap | Remove | Hang |
| pre-wrap | Preserve | Preserve | Wrap | Hang | Hang |
| break-spaces | Preserve | Preserve | Wrap | Wrap | Wrap |
| pre-line | Preserve | Collapse | Wrap | Remove | Hang |
See White Space Processing Rules for details on how white space collapses.
See Line Breaking for details on wrapping behavior.
4. White Space Processing & Control Characters
The source text of a document often contains formatting
that is not relevant to the final rendering:
for example, breaking the source into segments (lines) for ease of editing
or adding white space characters such as tabs and spaces to indent the source code.
CSS white space processing allows the author
to control interpretation of such formatting:
to preserve or collapse it away when rendering the document.
White space processing in CSS
(which is controlled with the white-space property)
interprets white space characters only for rendering:
it has no effect on the underlying document data.
Note: Depending on the document language,
segments can be separated by a particular newline sequence
(such as a line feed or CRLF pair),
or delimited by some other mechanism,
such as the SGML RECORD-START and RECORD-END tokens.
For CSS processing,
each document language–defined “segment break” or “newline sequence”—or if none are defined, each line feed (U+000A)—in the text is treated as a segment break,
which is then interpreted for rendering as specified by the white-space property.
In the case of HTML,
each newline sequence is normalized to a single line feed (U+000A)
for representation in the DOM,
so when an HTML document is represented as a DOM tree
each line feed (U+000A)
is treated as a segment break. [HTML] [DOM]
Note: In most common CSS implementations,
HTML does not get styled directly.
Instead, it is processed into a DOM tree,
which is then styled.
Unlike HTML,
the DOM does not give any particular meaning to carriage returns (U+000D),
so they are not treated as segment breaks.
If carriage returns (U+000D) are inserted into the DOM
by means other than HTML parsing,
they then get treated as defined below.
Note: A document parser might
not only normalize any segment breaks,
but also collapse other space characters or
otherwise process white space according to markup rules.
Because CSS processing occurs after the parsing stage,
it is not possible to restore these characters for styling.
Therefore, some of the behavior specified below
can be affected by these limitations and
may be user agent dependent.
Note: Anonymous blocks consisting entirely of collapsible white space are removed from the rendering tree.
Thus any such white space surrounding a block-level element is collapsed away.
See Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification § visuren#anonymous. [CSS2]
Control characters (Unicode category Cc)—other than tabs (U+0009),
line feeds (U+000A),
carriage returns (U+000D)
and sequences that form a segment break—must be rendered as a visible glyph
which the UA must synthesize if the glyphs found in the font are not visible,
and must be otherwise treated as any other character
of the Other Symbols (So) general category and Common script.
The UA may use a glyph provided by a font specifically for the control character,
substitute the glyphs provided for the corresponding symbol in the Control Pictures block,
generate a visual representation of its code point value,
or use some other method to provide an appropriate visible glyph.
As required by Unicode,
unsupported Default_ignorable characters
must be ignored for text rendering. [UNICODE]
Carriage returns (U+000D) are treated identically to spaces (U+0020) in all respects.
Note: For HTML documents,
carriage returns present in the source code
are converted to line feeds at the parsing stage
(see HTML § 13.2.3.5 Preprocessing the input stream and the definition of normalize newlines in Infra and therefore do no appear as U+000D CARRIAGE RETURN to CSS. [HTML] [INFRA])
However, the character is preserved—and the above rule observable—when encoded using an escape sequence (
).
4.1. The White Space Processing Rules
Except where specified otherwise,
white space processing in CSS affects only
the document white space characters: spaces (U+0020), tabs (U+0009), and segment breaks.
Note: The set of characters considered document white space (part of the document content)
and those considered syntactic white space
(part of the CSS syntax)
are not necessarily identical.
However, since both include spaces (U+0020), tabs (U+0009), and line feeds (U+000A)
most authors won’t notice any differences.
Besides space (U+0020)
and no-break space (U+00A0),
Unicode defines a number of additional space separator characters. [UNICODE] In this specification
all characters in the Unicode general category Zs
except space (U+0020)
and no-break space (U+00A0)
are collectively referred to as other space separators.
4.1.1. Phase I: Collapsing and Transformation
For each inline
(including anonymous inlines;
see Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification § visuren#anonymous [CSS2])
within an inline formatting context, white space characters are processed as follows
prior to line breaking and bidi reordering,
ignoring bidi formatting characters (characters with the Bidi_Control property [UAX9])
as if they were not there:
-
If white-space is set to normal, nowrap, or pre-line, white space characters are considered collapsible and are processed by performing the following steps:
- Any sequence of collapsible spaces and tabs immediately preceding or following a segment break is removed.
- Collapsible segment breaks are transformed for rendering
according to the segment break transformation rules. - Every collapsible tab is converted to a collapsible space (U+0020).
- Any collapsible space immediately following another collapsible space—even one outside the boundary of the inline containing that space,
provided both spaces are within the same inline formatting context—is collapsed to have zero advance width.
(It is invisible,
but retains its soft wrap opportunity,
if any.)
- If white-space is set to pre, pre-wrap, or break-spaces,
any sequence of spaces is treated as a sequence of non-breaking spaces.
However, for pre-wrap,
a soft wrap opportunity exists at the end of a sequence of spaces and/or tabs,
while for break-spaces,
a soft wrap opportunity exists after every space and every tab.
The following example illustrates
the interaction of white-space collapsing and bidirectionality.
Consider the following markup fragment, taking special note of spaces (with varied backgrounds and borders for emphasis and identification):
<ltr>A <rtl> B </rtl> C</ltr>where the <ltr> element represents a left-to-right embedding
and the <rtl> element represents a right-to-left embedding.
If the white-space property is set to normal,
the white-space processing model will result in the following:
- The space before the B ( )
will collapse with the space after the A ( ). - The space before the C ( )
will collapse with the space after the B ( ).
This will leave two spaces,
one after the A in the left-to-right embedding level,
and one after the B in the right-to-left embedding level.
The text will then be ordered according to the Unicode bidirectional algorithm,
with the end result being:
A BC
Note that there will be two spaces between A and B,
and none between B and C.
This is best avoided by putting spaces outside the element
instead of just inside the opening and closing tags
and, where practical,
by relying on implicit bidirectionality instead of explicit embedding levels.
4.1.2. Phase II: Trimming and Positioning
Then, the entire block is rendered.
Inlines are laid out,
taking bidi reordering into account,
and wrapping as specified by the white-space property.
As each line is laid out,
- A sequence of collapsible spaces at the beginning of a line
is removed. -
If the tab size is zero, preserved tabs are not rendered.
Otherwise, each preserved tab is rendered
as a horizontal shift that lines up
the start edge of the next glyph with the next tab stop.
If this distance is less than 0.5ch,
then the subsequent tab stop is used instead. Tab stops occur at points
that are multiples of the tab size from the starting content edge
of the preserved tab’s nearest block container ancestor.
The tab size is given by the tab-size property.Note: See the Unicode rules on how tabulation (U+0009) interacts with bidi. [UAX9]
-
A sequence of collapsible spaces at the end of a line is removed,
as well as any trailing U+1680 OGHAM SPACE MARK
whose white-space property is normal, nowrap, or pre-line.Note: Due to Unicode Bidirectional Algorithm rule L1,
a sequence of collapsible spaces located at the end of the line
prior to bidi reordering will also be at the end of the line after reordering. [UAX9] [CSS-WRITING-MODES-4] -
If there remains any sequence of white space, other space separators,
and/or preserved tabs at the end of a line
(after bidi reordering [CSS-WRITING-MODES-4]):- If white-space is set to normal, nowrap,
or pre-line,
the UA must hang this sequence (unconditionally). -
If white-space is set to pre-wrap,
the UA must (unconditionally) hang this sequence,
unless the sequence is followed by a forced line break,
in which case it must conditionally hang the sequence instead.
It may also visually collapse the character advance widths
of any that would otherwise overflow.Note: Hanging the white space rather than collapsing it
allows users to see the space when selecting or editing text. -
If white-space is set to break-spaces, spaces, tabs, and other space separators are treated the same as other visible characters:
they cannot hang nor have their advance width collapsed.Note: Such characters therefore take up space,
and depending on the available space
and applicable line breaking controls
will either overflow or cause the line to wrap.
- If white-space is set to normal, nowrap,
This example shows that conditionally hanging white space
at the end of lines with forced breaks
provides symmetry with the start of the line.
An underline is added to help visualize the spaces.
p {
white-space: pre-wrap;
width: 5ch;
border: solid 1px;
font-family: monospace;
text-align: center;
}
<p> 0 </p>
The sample above would be rendered as follows:
0
Since the final space is before a forced line break
and does not overflow,
it does not hang,
and centering works as expected.
This example illustrates the difference
between hanging spaces at the end of lines without forced breaks,
and conditionally hanging them at the end of lines with forced breaks.
An underline is added to help visualize the spaces.
p {
white-space: pre-wrap;
width: 3ch;
border: solid 1px;
font-family: monospace;
}
<p> 0 0 0 0 </p>
The sample above would be rendered as follows:
0
0 0
0
If p { text-align: right; } was added,
the result would be as follows:
0
0 0
0
As the preserved spaces at the end of lines without a forced break must hang,
they are not considered when placing the rest of the line during text alignment.
When aligning towards the end,
this means any such spaces will overflow,
and will not prevent the rest of the line’s content from being flush with the edge of the line.
On the other hand,
preserved spaces at the end of a line with a forced break conditionally hang.
Since the space at the end of the last line would not overflow in this example,
it does not hang and therefore is considered during text alignment.
In the following example,
there is not enough room on any line to fit the end-of-line spaces,
so they hang on all lines:
the one on the line without a forced break because it must,
as well as the one on the line with a forced break,
because it conditionally hangs and overflows.
An underline is added to help visualize the spaces.
p {
white-space: pre-wrap;
width: 3ch;
border: solid 1px;
font-family: monospace;
}
<p>0 0 0 0 </p>
0 0
0 0
The last line is not wrapped before the last 0 because characters that conditionally hang are not considered
when measuring the line’s contents for fit.
4.1.3. Segment Break Transformation Rules
When white-space is pre, pre-wrap, break-spaces, or pre-line, segment breaks are not collapsible and are instead transformed into a preserved line feed (U+000A).
For other values of white-space, segment breaks are collapsible,
and are collapsed as follows:
- First, any collapsible segment break immediately following another collapsible segment break is removed.
-
Then any remaining segment break is either transformed into a space (U+0020)
or removed
depending on the context before and after the break.
The rules for this operation are UA-defined in this level.Note: The white space processing rules have already
removed any tabs and spaces around the segment break before this context is evaluated.
The purpose of the segment break transformation rules
(and white space collapsing in general)
is to “unbreak” text that has been broken into segments to make the document source code easier to work with.
In languages that use word separators, such as English and Korean,
“unbreaking” a line requires joining the two lines with a space.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
requires maintaining a space in its place.
In languages that have no word separators, such as Chinese,
“unbreaking” a line requires joining the two lines with no intervening space.
這個段落是那麼長, 在一行寫不行。最好 用三行寫。
這個段落是那麼長,在一行寫不行。最好用三行寫。
requires eliminating any intervening white space.
The segment break transformation rules can use adjacent context
to either transform the segment break into a space
or eliminate it entirely.
Note: Historically, HTML and CSS have unconditionally converted segment breaks to spaces,
which has prevented content authored in languages such as Chinese
from being able to break lines within the source.
Thus UA heuristics need to be conservative about where they discard segment breaks even as they strive to improve support for such languages.
4.2. Tab Character Size: the tab-size property
| Name: | tab-size |
|---|---|
| Value: | <number> | <length> |
| Initial: | 8 |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | the specified number or absolute length |
| Canonical order: | n/a |
| Animation type: | by computed value type |
This property determines the tab size used to render preserved tab characters (U+0009).
A <number> represents the measure
as a multiple of the advance width of the space character (U+0020)
of the nearest block container ancestor of the preserved tab,
including its associated letter-spacing and word-spacing.
Negative values are not allowed.
5. Line Breaking and Word Boundaries
When inline-level content is laid out into lines, it is broken across line boxes.
Such a break is called a line break.
When a line is broken due to explicit line-breaking controls
(such as a preserved newline character),
or due to the start or end of a block,
it is a forced line break.
When a line is broken due to content wrapping (i.e. when the UA creates unforced line breaks
in order to fit the content within the measure),
it is a soft wrap break.
The process of breaking inline-level content into lines is called line breaking.
Wrapping is only performed at an allowed break point,
called a soft wrap opportunity.
When wrapping is enabled (see white-space),
the UA must minimize the amount of content overflowing a line
by wrapping the line at a soft wrap opportunity,
if one exists.
In most writing systems,
in the absence of hyphenation a soft wrap opportunity occurs only at word boundaries.
Many such systems use spaces or punctuation to explicitly separate words,
and soft wrap opportunities can be identified by these characters.
Scripts such as Thai, Lao, and Khmer, however,
do not use spaces or punctuation to separate words.
Although the zero width space (U+200B) can be used as an explicit word delimiter
in these scripts,
this practice is not common.
As a result, a lexical resource is needed
to correctly identify soft wrap opportunities in such texts.
In some other writing systems, soft wrap opportunities are based on orthographic syllable boundaries,
not word boundaries.
Some of these systems, such as Javanese and Balinese,
are similar to Thai and Lao in that they
require analysis of the text to find breaking opportunities.
In others such as Chinese (as well as Japanese, Yi, and sometimes also Korean),
each syllable tends to correspond to a single typographic letter unit,
and thus line breaking conventions allow the line to break
anywhere except between certain character combinations.
Additionally the level of strictness in these restrictions
varies with the typesetting style.
While CSS does not fully define where soft wrap opportunities occur,
some controls are provided to distinguish common variations:
- The line-break property allows choosing various levels of “strictness”
for line breaking restrictions. - The word-break property controls what types of letters
are glommed together to form unbreakable “words”,
causing CJK characters to behave like non-CJK text or vice versa. - The hyphens property controls whether automatic hyphenation
is allowed to break words in scripts that hyphenate. - The overflow-wrap property allows the UA to take a break anywhere
in otherwise-unbreakable strings that would otherwise overflow.
Note: Unicode Standard Annex #14: Unicode Line Breaking Algorithm defines a baseline behavior
for line breaking for all scripts in Unicode,
which is expected to be further tailored. [UAX14] More information on line breaking conventions
can be found in Requirements for Japanese Text Layout [JLREQ] and Formatting Rules for Japanese Documents [JIS4051] for Japanese, Requirements for Chinese Text Layout [CLREQ] and General Rules for Punctuation [ZHMARK] for Chinese.
See also the Internationalization Working Group’s Language Enablement Index which includes more information on additional languages. [TYPOGRAPHY] Any guidance on additional appropriate references
would be much appreciated.
5.1. Line Breaking Details
When determining line breaks:
- The interaction of line breaking and bidirectional text is defined by CSS Writing Modes 4 § 2.4 Applying the Bidirectional Reordering Algorithm and the Unicode Bidirectional Algorithm (UAX9§3.4 Reordering Resolved Levels in particular). [CSS-WRITING-MODES-4] [UAX9]
-
Preserved segment breaks, and—regardless of the white-space value—any Unicode character with the the
BKandNLline breaking class,
must be treated as forced line breaks. [UAX14]Note: The bidi implications of such forced line breaks are defined by the Unicode Bidirectional Algorithm. [UAX9]
- Except where explicitly defined otherwise
(e.g. for line-break: anywhere or overflow-wrap: anywhere)
line breaking behavior defined for
theWJ,ZW,GL,
andZWJUnicode line breaking classes
must be honored. [UAX14] - UAs that allow wrapping at punctuation
other than word separators in writing systems that use them should prioritize breakpoints.
(For example, if breaks after slashes are given a lower priority than spaces,
the sequence “check /etc” will never break between the «/» and the «e».)
As long as care is taken to avoid such awkward breaks,
allowing breaks at appropriate punctuation other than word separators is recommended,
as it results in more even-looking margins, particularly in narrow measures.
The UA may use the width of the containing block, the text’s language,
the line-break value,
and other factors in assigning priorities:
CSS does not define prioritization of line breaking opportunities.
Prioritization of word separators is not expected,
however,
if word-break: break-all is specified
(since this value explicitly requests line breaking behavior
not based on breaking at word separators)—and is forbidden under line-break: anywhere. - Out-of-flow elements
and inline element boundaries
do not introduce a forced line break or soft wrap opportunity in the flow. - For Web-compatibility
there is a soft wrap opportunity before and after each replaced element or other atomic inline,
even when adjacent to a character that would normally suppress them,
such as U+00A0 NO-BREAK SPACE. - For soft wrap opportunities created by characters
that disappear at the line break (e.g. U+0020 SPACE),
properties on the box directly containing that character
control the line breaking at that opportunity.
For soft wrap opportunities defined by the boundary between two characters,
the white-space property
on the nearest common ancestor of the two characters
controls breaking;
which elements’ line-break, word-break, and overflow-wrap properties
control the determination of soft wrap opportunities at such boundaries
is undefined in Level 3. - For soft wrap opportunities before the first
or after the last character of a box,
the break occurs immediately before/after the box
(at its margin edge)
rather than breaking the box
between its content edge and the content. - Line breaking in/around Ruby is defined
in CSS Ruby Annotation Layout 1 § 3.4 Breaking Across Lines. [CSS-RUBY-1] -
In order to avoid unexpected overflow,
if the user agent is unable to perform the requisite lexical
or orthographic analysis
for line breaking any content language that requires it—for example due to lacking a dictionary for certain languages—it must assume a soft wrap opportunity between pairs of typographic letter units in that writing system.Note: This provision is not triggered merely when
the UA fails to find a word boundary in a particular text run;
the text run may well be a single unbreakable word.
It applies for example
when a text run is composed of Khmer characters (U+1780 to U+17FF)
if the user agent does not know how to determine
word boundaries in Khmer.
5.2. Breaking Rules for Letters: the word-break property
| Name: | word-break |
|---|---|
| Value: | normal | keep-all | break-all | break-word |
| Initial: | normal |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property specifies soft wrap opportunities between letters,
i.e. where it is “normal” and permissible to break lines of text.
Specifically it controls whether a soft wrap opportunity generally exists
between adjacent typographic letter units,
treating non-letter typographic character units belonging to the NU, AL, AI,
or ID Unicode line breaking classes
as typographic letter units for this purpose (only). [UAX14] It does not affect rules governing the soft wrap opportunities created by white space (as well as by other space separators)
and around punctuation.
(See line-break for controls affecting punctuation and small kana.)
For example,
in some styles of CJK typesetting,
English words are allowed to break between any two letters,
rather than only at spaces or hyphenation points;
this can be enabled with word-break:break-all.

being broken at an arbitrary point in the word.
As another example, Korean has two styles of line-breaking:
between any two Korean syllables (word-break: normal)
or, like English, mainly at spaces (word-break: keep-all).
각 줄의 마지막에 한글이 올 때 줄 나눔 기 준을 “글자” 또는 “어절” 단위로 한다.
각 줄의 마지막에 한글이 올 때 줄 나눔 기준을 “글자” 또는 “어절” 단위로 한다.
Ethiopic similarly has two styles of line-breaking,
either only breaking at word separators (word-break: normal),
or also allowing breaks between letters within a word (word-break: break-all).
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡ በማዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ ወይትጌበሩ፡አሐዱ፡ምስለ፡አሀዱ፡ በመንፈሰ፡እኍና።
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡በማ ዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ወይትጌ በሩ፡አሐዱ፡ምስለ፡አሀዱ፡በመንፈሰ፡እኍና።
Note: To enable additional break opportunities only in the case of overflow,
see overflow-wrap.
Values have the following meanings:
- normal
- Words break according to their customary rules,
as described above.
Korean, which commonly exhibits two different behaviors,
allows breaks between any two consecutive Hangul/Hanja.
For Ethiopic, which also exhibits two different behaviors,
such breaks within words are not allowed. - break-all
-
Breaking is allowed within “words”:
specifically,
in addition to soft wrap opportunities allowed for normal,
any typographic letter units (and any typographic character units resolving to theNU(“numeric”),AL(“alphabetic”),
orSA(“Southeast Asian”)
line breaking classes [UAX14])
are instead treated asID(“ideographic characters”)
for the purpose of line-breaking.
Hyphenation is not applied.Note: This value does not affect
whether there are soft wrap opportunities around punctuation characters.
To allow breaks anywhere, see line-break: anywhere.Note: This option enables the other common behavior for Ethiopic.
It is also often used in a context where
the text consists predominantly of CJK characters
with only short non-CJK excerpts,
and it is desired that the text be better distributed on each line. - keep-all
-
Breaking is forbidden within “words”:
implicit soft wrap opportunities between typographic letter units (or other typographic character units belonging to theNU,AL,AI,
orIDUnicode line breaking classes [UAX14])
are suppressed,
i.e. breaks are prohibited between pairs of such characters
(regardless of line-break settings other than anywhere)
except where opportunities exist due to dictionary-based breaking.
Otherwise this option is equivalent to normal.
In this style, sequences of CJK characters do not break.Note: This is the other common behavior for Korean
(which uses spaces between words),
and is also useful for mixed-script text where CJK snippets are mixed
into another language that uses spaces for separation.
Symbols that line-break the same way as letters of a particular category
are affected the same way as those letters.
Here’s a mixed-script sample text:
这是一些汉字 and some Latin و کمی خط عربی และตัวอย่างการเขียนภาษาไทย በጽሑፍ፡ማራዘሙን፡አንዳንድ፡
The break-points are determined as follows (indicated by ‘·’):
- word-break: normal
-
这·是·一·些·汉·字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
- word-break: break-all
-
这·是·一·些·汉·字·a·n·d·s·o·m·e·L·a·t·i·n·و·ﮐ·ﻤ·ﻰ·ﺧ·ﻁ·ﻋ·ﺮ·ﺑ·ﻰ·แ·ล·ะ·ตั·ว·อ·ย่·า·ง·ก·า·ร·เ·ขี·ย·น·ภ·า·ษ·า·ไ·ท·ย·በ·ጽ·ሑ·ፍ፡·ማ·ራ·ዘ·ሙ·ን፡·አ·ን·ዳ·ን·ድ፡
- word-break: keep-all
-
这是一些汉字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
Japanese is usually typeset allowing line breaks within words.
However, it is sometimes preferred to suppress these wrapping opportunities
and to only allow wrapping at the end of certain sentence fragments.
This is most commonly done in very short pieces of text,
such as headings and table or figure captions.
This can be achieved by marking the allowed wrapping points
with wbr or U+200B ZERO WIDTH SPACE,
and suppressing the other ones using word-break: keep-all.
For instance, the following markup can produce either of the renderings below,
depending on the value of the word-break property:
<h1>窓ぎわの<wbr>トットちゃん</h1>
h1 { word-break: normal }
|
h1 { word-break: keep-all }
|
|
|---|---|---|
| Expected rendering |
窓ぎわのトットちゃ ん |
窓ぎわの トットちゃん |
| Result in your browser | 窓ぎわのトットちゃん | 窓ぎわのトットちゃん |
When shaping scripts such as Arabic
are allowed to break within words due to break-all the characters must still be shaped
as if the word were not broken (see § 5.6 Shaping Across Intra-word Breaks).
For compatibility with legacy content,
the word-break property also supports
a deprecated break-word keyword.
When specified, this has the same effect as word-break: normal and overflow-wrap: anywhere,
regardless of the actual value of the overflow-wrap property.
5.3. Line Breaking Strictness: the line-break property
| Name: | line-break |
|---|---|
| Value: | auto | loose | normal | strict | anywhere |
| Initial: | auto |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property specifies the strictness of line-breaking rules applied
within an element:
especially how wrapping interacts with punctuation and symbols.
Values have the following meanings:
- auto
- The UA determines the set of line-breaking restrictions to use,
and it may vary the restrictions based on the length of the line;
e.g., use a less restrictive set of line-break rules for short lines. - loose
- Breaks text using the least restrictive set of line-breaking
rules. Typically used for short lines, such as in newspapers. - normal
- Breaks text using the most common set of line-breaking rules.
- strict
- Breaks text using the most stringent set of line-breaking rules.
- anywhere
-
There is a soft wrap opportunity around every typographic character unit,
including around any punctuation character
or preserved white spaces,
or in the middle of words,
disregarding any prohibition against line breaks,
even those introduced by characters with theGL,WJ, orZWJline breaking classes
or mandated by the word-break property. [UAX14] The different wrapping opportunities must not be prioritized.
Hyphenation is not applied.Note: This value triggers the line breaking rules typically seen in terminals.
Note: anywhere only allows preserved white spaces at the end of the line
to be wrapped to the next line
when white-space is set to break-spaces,
because in other cases:- preserved white space at the end/start of the line is discarded
(normal, pre-line) - wrapping is forbidden altogether (nowrap, pre)
- the preserved white space hang (pre-wrap).
When it does have an effect on preserved white space,
with white-space: break-spaces,
it allows breaking before the first space of a sequence,
which break-spaces on its own does not. - preserved white space at the end/start of the line is discarded
CSS distinguishes between four levels of strictness
in the rules for text wrapping.
The precise set of rules in effect for each of loose, normal,
and strict is up to the UA
and should follow language conventions.
However, this specification does require that:
-
The following breaks are forbidden in strict line breaking
and allowed in normal and loose:- breaks before Japanese small kana
or the Katakana-Hiragana prolonged sound mark,
i.e. characters
from the Unicode line breaking classCJ. [UAX14]
- breaks before Japanese small kana
-
The following breaks are allowed for normal and loose line breaking
if the writing system is Chinese or Japanese,
and are otherwise forbidden:- breaks before certain CJK hyphen-like characters:
〜 U+301C,
゠ U+30A0
- breaks before certain CJK hyphen-like characters:
-
The following breaks are allowed for loose line breaking
if the preceding character
belongs to the Unicode line breaking classID[UAX14] (including when the preceding character
is treated asIDdue to word-break: break-all),
and are otherwise forbidden:- breaks before hyphens:
‐ U+2010, – U+2013
- breaks before hyphens:
-
The following breaks are forbidden for normal and strict line breaking
and allowed in loose:- breaks before iteration marks:
々 U+3005, 〻 U+303B, ゝ U+309D,
ゞ U+309E, ヽ U+30FD, ヾ U+30FE - breaks between inseparable characters
(such as ‥ U+2025, … U+2026)
i.e. characters from the Unicode line breaking classIN. [UAX14]
- breaks before iteration marks:
-
The following breaks are allowed for loose if the writing system is Chinese or Japanese and are otherwise forbidden:
- breaks before certain centered punctuation marks:
・ U+30FB,
: U+FF1A, ; U+FF1B, ・ U+FF65,
‼ U+203C,
⁇ U+2047, ⁈ U+2048, ⁉ U+2049,
! U+FF01, ? U+FF1F - breaks before suffixes:
Characters with the Unicode line breaking classPO[UAX14] and the East Asian Width property [UAX11]Ambiguous,Fullwidth,
orWide. - breaks after prefixes:
Characters with the Unicode line breaking classPR[UAX14] and the East Asian Width property [UAX11]Ambiguous,Fullwidth,
orWide.
- breaks before certain centered punctuation marks:
Note: The requirements listed above
only create distinctions in CJK text.
In an implementation that matches only the rules above,
and no additional rules, line-break would only affect CJK code points
unless the writing system is tagged as Chinese or Japanese.
Future levels may add additional specific rules
for other writing systems and languages
as their requirements become known.
As UAs can add additional distinctions
between strict/normal/loose modes,
these values can exhibit differences in other writing systems as well.
For example, a UA with sufficiently-advanced Thai language processing ability
could choose to map different levels of strictness in Thai line-breaking
to these keywords,
e.g. disallowing breaks within compound words in strict mode
(e.g. breaking ตัวอย่างการเขียนภาษาไทย as ตัวอย่าง·การเขียน·ภาษาไทย)
while allowing more breaks in loose (ตัวอย่าง·การ·เขียน·ภาษา·ไทย).
Note: The CSSWG recognizes that in a future edition of the specification
finer control over line breaking may be necessary
to satisfy high-end publishing requirements.
5.4. Hyphenation: the hyphens property
Hyphenation is the controlled splitting of words
where they usually would not be allowed to break
to improve the layout of paragraphs,
typically splitting words at syllabic or morphemic boundaries
and visually indicating the split
(usually by inserting a hyphen, U+2010).
In some cases, hyphenation may also alter the spelling of a word.
Regardless, hyphenation is a rendering effect only:
it must have no effect on the underlying document content
or on text selection or searching.
Hyphenation Across Languages
Hyphenation practices vary across languages,
and can involve not just inserting a hyphen before the line break,
but inserting a hyphen after the break (or both),
inserting a different character than U+2010,
or changing the spelling of the word.
| Language | Unbroken | Before | After |
|---|---|---|---|
| English | Unbroken | Un‐ | broken |
| Dutch | cafeetje | café‐ | tje |
| Hungarian | Összeg | Ösz‐ | szeg |
| Mandarin | tú’àn | tú‐ | àn |
| àizēng‐fēnmíng | àizēng‐ | ‐fēnmíng | |
| Uyghur | داميدى | داميـ | دى |
Hyphenation occurs
when the line breaks at a valid hyphenation opportunity,
which is a type of soft wrap opportunity that exists within a word where hyphenation is allowed.
In CSS hyphenation opportunities are controlled
with the hyphens property.
CSS Text Level 3 does not define the exact rules for hyphenation;
however UAs are strongly encouraged
to optimize their choice of break points
and to chose language-appropriate hyphenation points.
Note: The soft wrap opportunity introduced by
the U+002D — HYPHEN-MINUS character
or the U+2010 ‐ HYPHEN character
is not a hyphenation opportunity,
as no visual indication of the split is created when wrapping:
these characters are visible whether the line is wrapped at that point or not.
Hyphenation opportunities are considered when calculating min-content intrinsic sizes.
Note: This allows tables to hyphenate their contents
instead of overflowing their containing block,
which is particularly important in long-word languages like German.
| Name: | hyphens |
|---|---|
| Value: | none | manual | auto |
| Initial: | manual |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property controls whether hyphenation is allowed to create more soft wrap opportunities within a line of text.
Values have the following meanings:
- none
-
Words are not hyphenated,
even if characters inside the word
explicitly define hyphenation opportunities.Note: This does not suppress the existing soft wrap opportunities introduced by always visible characters such as
U+002D — HYPHEN-MINUS
or U+2010 ‐ HYPHEN. - manual
-
Words are only hyphenated where there are characters inside the word
that explicitly suggest hyphenation opportunities.
The UA must use the appropriate language-specific hyphenation character(s)
and should apply any appropriate spelling changes
just as for automatic hyphenation at the same point.In Unicode, U+00AD is a conditional «soft hyphen»
and U+2010 is an unconditional hyphen. Unicode Standard Annex #14 describes the role of soft hyphens in Unicode line breaking. [UAX14] In HTML,
­ represents the soft hyphen character,
which suggests a hyphenation opportunity.ex­ample
- auto
- Words may be broken at hyphenation opportunities determined automatically by a language-appropriate hyphenation resource
in addition to those indicated explicitly by a conditional hyphen.
Automatic hyphenation opportunities elsewhere within a word must be ignored
if the word contains a conditional hyphen
(­ or U+00AD SOFT HYPHEN),
in favor of the conditional hyphen(s).
However, if, even after breaking at such opportunities,
a portion of that word is still too long to fit on one line,
an automatic hyphenation opportunity may be used.
Correct automatic hyphenation requires a hyphenation resource
appropriate to the language of the text being broken.
The UA must therefore only automatically hyphenate text
for which the content language is known
and for which it has an appropriate hyphenation resource.
Authors should correctly tag their content’s language (e.g. using the HTML lang attribute
or XML xml:lang attribute)
in order to obtain correct automatic hyphenation.
The UA may use language-tailored heuristics
to exclude certain words
from automatic hyphenation.
For example, a UA might try to avoid hyphenation in proper nouns
by excluding words matching certain capitalization and punctuation patterns.
Such heuristics are not defined by this specification.
(Note that such heuristics will need to vary by language:
English and German, for example, have very different capitalization conventions.)
For the purpose of the hyphens property,
what constitutes a “word” is UA-dependent.
However, inline element boundaries
and out-of-flow elements
must be ignored when determining word boundaries.
Any glyphs shown due to hyphenation
at a hyphenation opportunity created by a conditional hyphen character
(such as U+00AD SOFT HYPHEN)
are represented by that character
and are styled according to the properties applied to it.
When shaping scripts such as Arabic are allowed to break within words
due to hyphenation,
the characters must still be shaped
as if the word were not broken (see § 5.6 Shaping Across Intra-word Breaks).
For example, if the Uyghur word “داميدى”
were hyphenated, it would appear as ![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + hyphen + line-break + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-joined.png) not as
not as ![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen + line-break + isolated DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-unjoined.png) .
.
5.5. Overflow Wrapping: the overflow-wrap/word-wrap property
| Name: | overflow-wrap, word-wrap |
|---|---|
| Value: | normal | break-word | anywhere |
| Initial: | normal |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property specifies whether the UA may break
at otherwise disallowed points within a line
to prevent overflow,
when an otherwise-unbreakable string is too long to fit within the line box.
It only has an effect when white-space allows wrapping. Possible values:
- normal
- Lines may break only at allowed break points.
However,
the restrictions introduced by word-break: keep-all may be relaxed
to match word-break: normal if there are no otherwise-acceptable break points in the line. - anywhere
- An otherwise unbreakable sequence of characters may be broken at an arbitrary point
if there are no otherwise-acceptable break points in the line.
Shaping characters are still shaped
as if the word were not broken,
and grapheme clusters must stay together as one unit.
No hyphenation character is inserted at the break point. Soft wrap opportunities introduced by anywhere are considered when calculating min-content intrinsic sizes. - break-word
- As for anywhere except that soft wrap opportunities introduced by break-word are not considered
when calculating min-content intrinsic sizes.
For legacy reasons, UAs must treat word-wrap as a legacy name alias of the overflow-wrap property.
5.6. Shaping Across Intra-word Breaks
When shaping scripts such as Arabic wrap at unforced soft wrap opportunities within words
(such as when breaking due to word-break: break-all, line-break: anywhere, overflow-wrap: break-word, overflow-wrap: anywhere,
or when hyphenating)
the characters must still be shaped
(their joining forms chosen)
as if the word were still whole.
For example,
if the word “نوشتن” is broken between the “ش” and “ت”,
the “ش” still takes its initial form (“ﺷ”),
and the “ت” its medial form (“ﺘ”)—forming as in “ﻧﻮﺷ | ﺘﻦ”, not as in “نوش | تن”.
6. Alignment and Justification
Alignment and justification controls
how inline content is distributed within a line box.
6.1. Text Alignment: the text-align shorthand
| Name: | text-align |
|---|---|
| Value: | start | end | left | right | center | justify | match-parent | justify-all |
| Initial: | start |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | see individual properties |
| Computed value: | see individual properties |
| Animation type: | discrete |
| Canonical order: | n/a |
This shorthand property sets the text-align-all and text-align-last properties
and describes how the inline-level content of a block
is aligned along the inline axis
if the content does not completely fill the line box.
Values other than justify-all or match-parent are assigned to text-align-all and reset text-align-last to auto.
Values have the following meanings:
- start
- Inline-level content is aligned
to the start edge of the line box. - end
- Inline-level content is aligned
to the end edge of the line box. - left
- Inline-level content is aligned
to the line-left edge of the line box.
(In vertical writing modes,
this can be either the physical top or bottom,
depending on writing-mode.) [CSS-WRITING-MODES-4] - right
- Inline-level content is aligned
to the line-right edge of the line box.
(In vertical writing modes,
this can be either the physical top or bottom,
depending on writing-mode.) [CSS-WRITING-MODES-4] - center
- Inline-level content is centered within the line box.
- justify
- Text is justified
according to the method specified by the text-justify property,
in order to exactly fill the line box.
Unless otherwise specified by text-align-last,
the last line before a forced break
or the end of the block
is start-aligned. - justify-all
- Sets both text-align-all and text-align-last to justify,
forcing the last line to justify as well. - match-parent
-
This value behaves the same as inherit (computes to its parent’s computed value)
except that an inherited value of start or end is interpreted against the parent’s direction value
and results in a computed value of either left or right.
Computes to start when specified on the root element.When specified on the text-align shorthand,
sets both text-align-all and text-align-last to match-parent.
A block of text
is a stack of line boxes.
This property specifies how the inline-level boxes within each line box
align with respect to the start and end sides of the line box.
Alignment is not with respect to the viewport or containing block.
In the case of justify,
the UA may stretch or shrink any inline boxes
by adjusting their text.
(See text-justify.)
If an element’s white space is not collapsible,
then the UA is not required to adjust its text
for the purpose of justification
and may instead treat the text
as having no justification opportunities.
If the UA chooses to adjust the text,
then it must ensure
that tab stops continue to line up as required by the white space processing rules.
If (after justification, if any)
the inline contents of a line box are too long to fit within it,
then the contents are start-aligned:
any content that doesn’t fit
overflows the line box’s end edge.
See § 8.3 Bidirectionality and Line Boxes for details on how to determine
the start and end edges
of a line box.
6.2. Default Text Alignment: the text-align-all property
| Name: | text-align-all |
|---|---|
| Value: | start | end | left | right | center | justify | match-parent |
| Initial: | start |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | keyword as specified, except for match-parent which computes as defined above |
| Canonical order: | n/a |
| Animation type: | discrete |
This longhand of the text-align shorthand property specifies the inline alignment of all lines of inline content in the block container,
except for last lines
overridden by a non-auto value of text-align-last.
See text-align for a full description of values.
Authors should use the text-align shorthand instead of this property.
6.3. Last Line Alignment: the text-align-last property
| Name: | text-align-last |
|---|---|
| Value: | auto | start | end | left | right | center | justify | match-parent |
| Initial: | auto |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | n/a |
| Animation type: | discrete |
This property describes how the last line of a block or a line
right before a forced line break is aligned.
If auto is specified,
content on the affected line is aligned per text-align-all unless text-align-all is set to justify,
in which case it is start-aligned.
All other values are interpreted as described for text-align.
6.4. Justification Method: the text-justify property
| Name: | text-justify |
|---|---|
| Value: | auto | none | inter-word | inter-character |
| Initial: | auto |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword (except for the distribute legacy value) |
| Canonical order: | n/a |
| Animation type: | discrete |
This property selects the justification method
used when a line’s alignment is set to justify (see text-align).
The property applies to text,
but is inherited from block containers
to the root inline box containing their inline-level contents.
It takes the following values:
- auto
-
The UA determines the justification algorithm to follow,
based on a balance between performance and adequate presentation quality.
Since justification rules vary by writing system and language,
UAs should, where possible,
use a justification algorithm appropriate to the text.For example,
the UA could use by default a justification method
that is a simple universal compromise for all writing systems—such as primarily expanding word separators and between CJK typographic letter units along with secondarily expanding
between Southeast Asian typographic letter units.
Then, in cases where the content language of the paragraph is known,
it could choose a more language-tailored justification behavior
e.g. following the Requirements for Japanese Text Layout for Japanese [JLREQ],
using cursive elongation for Arabic,
using inter-word for German,
etc.
An example of cursively-justified Arabic text,
rendered by Tasmeem.
Like English,
Arabic can be justified by adjusting the spacing between words,
but in most styles
it can also be justified by calligraphically elongating
or compressing the letterforms themselves.
In this example,
the upper text is extended to fill the line
by the use of elongated (kashida) forms and swash forms,
while the bottom line is compressed slightly
by using a stacked combination for the characters between ت and م.
By employing traditional calligraphic techniques,
a typesetter can justify the line while preserving flow and color,
providing a very high quality justification effect.
However, this is by its nature a very script-specific effect.
Mixed-script text with text-justify: auto:
this interpretation uses a universal-compromise justification method,
expanding at spaces as well as between CJK and Southeast Asian letters.
This effectively uses inter-word + inter-ideograph spacing
for lines that have word-separators and/or CJK characters
and falls back to inter-cluster behavior for lines that don’t
or for which the space stretches too far. - none
-
Justification is disabled:
there are no justification opportunities within the text.Mixed-script text with text-justify: none Note: This value is intended for use in user stylesheets
to improve readability or for accessibility purposes. - inter-word
-
Justification adjusts spacing at word separators only
(effectively varying the used word-spacing on the line).
This behavior is typical for languages that separate words using spaces,
like English or Korean.Mixed-script text with text-justify: inter-word - inter-character
-
Justification adjusts spacing
between each pair of adjacent typographic character units (effectively varying the used letter-spacing on the line).
This value is sometimes used in East Asian systems such as Japanese.Mixed-script text with text-justify: inter-character For legacy reasons,
UAs must also support the alternate keyword distribute which must compute to inter-character,
thus having the exact same meaning and behavior.
UAs may treat this as a legacy value alias.

Since optimal justification is language-sensitive,
authors should correctly language-tag their content for the best results.
Note: The guidelines in this level of CSS
do not describe a complete justification algorithm.
They are merely a minimum set of requirements
that a complete algorithm should meet.
Limiting the set of requirements gives UAs some latitude
in choosing a justification algorithm
that meets their needs and desired balance of quality, speed, and complexity.
6.4.1. Expanding and Compressing Text
When justifying text,
the user agent takes the remaining space
between the ends of a line’s contents and the edges of its line box,
and distributes that space throughout its content
so that the contents exactly fill the line box.
The user agent may alternatively distribute negative space,
putting more content on the line
than would otherwise fit under normal spacing conditions.
A justification opportunity is a point
where the justification algorithm may alter spacing within the text.
A justification opportunity can be provided by a single typographic character unit (such as a word separator),
or by the juxtaposition of two typographic character units.
As with controls for soft wrap opportunities,
whether a typographic character unit provides a justification opportunity is controlled by the text-justify value of its parent;
similarly,
whether a justification opportunity exists
between two consecutive typographic character units is determined by the text-justify value of their nearest common ancestor.
Space distributed by justification is in addition to the spacing defined by the letter-spacing or word-spacing properties.
When such additional space is distributed
to a word separator justification opportunity,
it is applied under the same rules as for word-spacing.
Similarly, when space is distributed
to a justification opportunity between two typographic character units,
should be applied under the same rules as for letter-spacing.
A justification algorithm may divide justification opportunities into different priority levels.
All justification opportunities within a given level
are expanded or compressed at the same priority,
regardless of which typographic character units created that opportunity.
For example,
if justification opportunities between two Han characters
and between two Latin letters
are defined to be at the same level
(as they are in the inter-character justification style),
they are not treated differently
because they originate from different typographic character units.
It is not defined in this level
whether or how other factors
(such as font size, letter-spacing, glyph shape, position within the line, etc.)
may influence the distribution of space to justification opportunities within the line.
The UA may enable or break optional ligatures
or use other font features
such as alternate glyphs or glyph compression
to help justify the text under any method.
This behavior is not controlled by this level of CSS.
However,
UAs must not break required ligatures
or otherwise disable features required to correctly shape complex scripts.
If a justification opportunity exists within a line,
and text alignment specifies full justification
(justify)
for that line,
it must be justified.
6.4.2. Handling Symbols and Punctuation
When determining justification opportunities,
a typographic character unit from the Unicode Symbols (S*) and Punctuation (P*) classes
is generally treated the same as a typographic letter unit of the same script
(or, if the character’s script property is Common,
then as a typographic letter unit of the dominant script).
However, by typographic tradition
there may be additional rules controlling the justification of symbols and punctuation.
Therefore, the UA may reassign specific characters
or introduce additional levels of prioritization
to handle justification opportunities involving symbols and punctuation.
For example, there are traditionally no justification opportunities between consecutive
U+2014 — EM DASH,
U+2015 ― HORIZONTAL BAR,
U+2026 … HORIZONTAL ELLIPSIS,
or U+2025 ‥ TWO DOT LEADER
characters [JLREQ];
thus a UA might assign these characters to a “never” prioritization level.
As another example, certain full-width punctuation characters
(such as U+301A [ LEFT WHITE SQUARE BRACKET)
are considered to contain a justification opportunity in Japanese.
The UA might therefore assign these characters to a higher prioritization
level than the opportunities between ideographic characters.
6.4.3. Unexpandable Text
If the inline contents of a line cannot be stretched to the full width of the line box,
then they must be aligned as specified by the text-align-last property.
(If text-align-last is justify,
then they must be aligned as for center.)
6.4.4. Cursive Scripts
Justification must not introduce gaps
between the joined typographic letter units of cursive scripts such as Arabic.
If it is able,
the UA may translate space distributed to justification opportunities within a run of such typographic letter units into some form of cursive elongation for that run.
It otherwise must assume that no justification opportunity exists
between any pair of typographic letter units in cursive script (regardless of whether they join).
The following are examples of unacceptable justification:
![]()
![]()
Some font designs allow for the use of the tatweel character for justification.
A UA that performs tatweel-based justification
must properly handle the rules for its use.
Note that correct insertion of tatweel characters depends on context,
including the letter-combinations involved,
location within the word,
and location of the word within the line.
6.4.5. Minimum Requirements for auto Justification
For auto justification,
this specification does not define
what all of the justification opportunities are,
how they are prioritized,
or when and how multiple levels of justification opportunities interact.
However, it does require that:
-
Unless contraindicated by the typographic traditions
of the content language or adjacent symbols/punctuation,
each of the following provides a justification opportunity:- Word separators
- The boundary between a typographic character unit of any block scripts and any other typographic character unit
- The boundary between a typographic character unit of any clustered scripts and any other typographic character unit
- All letters belonging to all block scripts are treated the same,
and all letters belonging to all clustered scripts are treated the same.
For example, no distinction is made
between the justification opportunity
between a Han letter followed by another Han letter,
vs. the justification opportunity
between a Han letter followed by a Hangul letter.
Further information on text justification can be found in (or submitted to) “Approaches to Full Justification”,
which indexes by writing system and language,
and is maintained by the W3C Internationalization Working Group. [JUSTIFY]
7. Spacing
CSS offers control over text spacing
via the word-spacing and letter-spacing properties,
which specify additional space
around word separators or between typographic character units,
respectively.
7.1. Word Spacing: the word-spacing property
| Name: | word-spacing |
|---|---|
| Value: | normal | <length> |
| Initial: | normal |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | N/A |
| Computed value: | an absolute length |
| Canonical order: | n/a |
| Animation type: | by computed value type |
This property specifies additional spacing
between “words”.
Values are interpreted as defined below:
- normal
- No additional spacing is applied.
Computes to zero. - <length>
- Specifies extra spacing in addition to the intrinsic inter-word spacing
defined by the font.
Additional spacing is applied to each word separator left in the text
after the white space processing rules have been applied,
and should be applied half on each side of the character
unless otherwise dictated by typographic tradition.
Values may be negative, but there may be implementation-dependent limits.
Word-separator characters are typographic character units whose primary purpose and general usage is to separate words.
In Unicode this includes
(but is not exhaustively defined as)
the space (U+0020),
the no-break space (U+00A0),
the Ethiopic word space (U+1361),
the Aegean word separators (U+10100,U+10101),
the Ugaritic word divider (U+1039F),
and the Phoenician word separator (U+1091F). [UNICODE]
Note: Neither punctuation in general,
nor fixed-width spaces (such as U+3000 and U+2000 through U+200A),
are considered word-separator characters,
because even though they frequently happen to separate words,
their primary purpose is not to separate words.
If there are no word-separator characters,
or if a word-separating character has a zero advance width
(such as U+200B ZERO WIDTH SPACE)
then the user agent must not create an additional spacing between words.
7.2. Tracking: the letter-spacing property
| Name: | letter-spacing |
|---|---|
| Value: | normal | <length> |
| Initial: | normal |
| Applies to: | inline boxes and text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | an absolute length |
| Canonical order: | n/a |
| Animation type: | by computed value type |
This property specifies additional spacing
(commonly called tracking)
between adjacent typographic character units.
Letter-spacing is applied after bidi reordering and is in addition to kerning and word-spacing. [CSS-WRITING-MODES-4] [CSS-FONTS-3] Depending on the justification rules in effect,
user agents may further increase or decrease the space
between typographic character units in order to justify text.
Values have the following meanings:
- normal
- No additional spacing is applied. Computes to zero.
- <length>
- Specifies additional spacing
between typographic character units.
Values may be negative,
but there may be implementation-dependent limits.
For legacy reasons,
a computed letter-spacing of zero
yields a resolved value (getComputedStyle() return value)
of normal.
For the purpose of letter-spacing,
each consecutive run of atomic inlines (such as images and inline blocks)
is treated as a single typographic character unit.
Letter-spacing must not be applied at the beginning of a line.
Whether letter-spacing is applied at the end of a line is undefined in this level.
When letter-spacing is not applied at the beginning or end of a line,
text always fits flush with the edge of the block.
p { letter-spacing: 1em; }
<p>abc</p>
a b c
a b c
UAs therefore really should not [RFC6919] append letter spacing to the right or trailing edge of a line:
a b c
Letter spacing between two typographic character units effectively “belongs” to the innermost element
that contains the two typographic character units:
the total letter spacing between two adjacent typographic character units (after bidi reordering)
is specified by and rendered within the innermost element
that contains the boundary
between the two typographic character units.
However, the UA may instead attach letter-spacing at element boundaries
to one or the other typographic character unit using the letter-spacing value pertaining to its containing element.
Note: This secondary behavior is permitted in this level
due to Web-compat concerns.
An inline box is expected to only include
letter spacing between characters completely contained within that element,
thus excluding letter spacing on the right or trailing edge of the element:
p { letter-spacing: 1em; }
<p>a<span>bb</span>c</p>
a b b c
a b b c
Consequently a given value of letter-spacing is expected
to only affect the spacing between characters
completely contained within the element for which it is specified:
p { letter-spacing: 1em; }
span { letter-spacing: 2em; }
<p>a<span>bb</span>c</p>
a b b c
This further implies that applying letter-spacing to
an element containing only a single character
has no effect on the rendered result:
p { letter-spacing: 1em; }
span { letter-spacing: 2em; }
<p>a<span>b</span>c</p>
a b c
Since letter spacing is inserted after RTL reordering,
the letter spacing applied to the inner span below likewise has no effect,
since after reordering the «c» doesn’t end up next to «א»:
p { letter-spacing: 1em; }
span { letter-spacing: 2em; }
<!-- abc followed by Hebrew letters alef (א), bet (ב) and gimel (ג) --> <!-- Reordering will display these in reverse order. --> <p>ab<span>cא</span>בג</p>
a b c א ב ג
Letter spacing ignores invisible zero-width formatting characters
(such as those from the Unicode Cf category).
Spacing must be added as if those characters did not exist in the document.
For example, letter-spacing applied to AB is identical to AB,
regardless of where any element boundaries might fall.
When the effective spacing between two characters is not zero
(due to either justification or a non-zero value of letter-spacing),
user agents should not apply optional ligatures,
i.e. those that are not defined as required
for fundamentally correct glyph shaping.
However, ligatures and other font features
specified via the low-level font-feature-settings property
take precedence over this rule.
See CSS Fonts Module Level 3 § feature-precedence.
For example, if the word “filial” is letter-spaced,
an “fi” ligature should not be used
as it will prevent even spacing of the text.
filial vs filial
Note: In OpenType, required ligatures are expected
to be associated to the rlig feature.
All other ligatures are therefore considered optional.
In some cases, however, UA or platform heuristics
apply additional ligatures in order to handle broken fonts;
this specification does not define or override such exceptional handling.
7.2.1. Cursive Scripts
If it is able,
the UA may apply letter spacing to cursive scripts by translating the total extra space to be distributed to a run of such letters
into some form of cursive elongation
(or compression, for negative tracking values)
for that run
that results in an equivalent total expansion (or compression) of the run.
Otherwise,
if the UA cannot expand text from a cursive script without breaking its cursive connections,
it must not apply spacing
between any pair of that script’s typographic letter units at all
(effectively treating each word as a single typographic letter unit for the purpose of letter-spacing).
Both cases will result in an effective spacing of zero between such letters;
however the former will preserve the sense of stretching out the text.
Note: Proper cursive elongation or compression of a text
can vary depending on the
script,
typeface,
language,
location within a word,
location within a line,
implementation complexity,
font capabilities,
and calligraphic preferences,
and may not be possible in certain cases at all.
It may involve the use of shortening ligatures,
swash variants,
contextual forms,
elongation glyphs such as U+0640 ـ ARABIC TATWEEL,
or other microtypography.
It is outside the scope of CSS to define rules for these effects.
Authors should avoid applying letter-spacing to cursive scripts
unless they are prepared to accept non-interoperable results.
7.3. Shaping Across Element Boundaries
Text shaping must be broken at inline box boundaries
when any of the following are true
for any box whose boundary separates the two typographic character units:
- Any of margin/border/padding separating the two typographic character units in the inline axis
is non-zero. - vertical-align is not baseline.
- The boundary is a bidi isolation boundary.
Text shaping must not be broken across inline box boundaries
when there is no effective change in formatting,
or if the only formatting changes do not affect the glyphs
(as in applying text decoration).
Text shaping should not be broken across inline box boundaries otherwise,
if it is reasonable and possible for that case given the limitations of the font technology.
An example of reasonable and possible shaping across boundaries
is Arabic shaping:
in many systems this is performed by the font engine,
allowing the font to provide variant glyphs
with potentially very sophisticated contextual shaping.
It’s not generally possible to rely on this system across a font change
unless the font engine has an API to provide context,
but it is straightforward and therefore quite reasonable
for an engine to work around this limitation by, for example,
using the zero-width-joiner (U+200D) or zero-width-non-joiner (U+200C)
as appropriate to solicit the correct choice of
initial/medial/final/isolated glyph.
An example of possible but not reasonable shaping across boundaries
is handling a font that is sensitive to 20 characters of context
on either side to choose its glyphs:
passing all the text before and after the string in question,
even through multiple inline boundaries with formatting changes,
is complicated.
The UA could handle such cases,
but is not required to,
as they are not typical or fundamentally required
by any modern writing system.
An example of impossible shaping across boundaries
is a change in font weight partway through the word “and”
in a font where a ligature would replace
all three letters of the word “and”
with an ampersand glyph (“&”).
8. Edge Effects
Edge effects control
the indentation of lines with respect to other lines in the block (text-indent)
and how content is measured at the start and end edges of a line (hanging-punctuation).
8.1. First Line Indentation: the text-indent property
| Name: | text-indent |
|---|---|
| Value: | [ <length-percentage> ] && hanging? && each-line? |
| Initial: | 0 |
| Applies to: | block containers |
| Inherited: | yes |
| Percentages: | refers to block container’s own inline-axis inner size |
| Computed value: | computed <length-percentage> value, plus any specified keywords |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
This property specifies the indentation
applied to lines of inline content in a block.
The indent is treated as a margin
applied to the start edge of the line box.
Unless otherwise specified
by the each-line and/or hanging keywords,
only lines that are the first formatted line of an element are affected. [CSS-PSEUDO-4] For example, the first line of an anonymous block box is only affected
if it is the first child of its parent element.
Values have the following meanings:
- <length>
- Gives the amount of the indent as an absolute length.
- <percentage>
-
Gives the amount of the indent
as a percentage of the block container’s own logical width.Percentages must be treated as 0 for the purpose of calculating intrinsic size contributions,
but are always resolved normally when performing layout.Note: This can lead to the element overflowing.
It is not recommended to use percentage indents and intrinsic sizing together. - each-line
- Indentation affects the first line of each block container
and each line after a forced line break (but not lines after a soft wrap break). - hanging
- Inverts which lines are affected.
If text-align is start and text-indent is 5em in
left-to-right text with no floats present, then first line of text
will start 5em into the block:
Since CSS1 it has been possible to indent the first line of a block element 5em by setting the 'text-indent' property to '5em'.
If we add the hanging keyword,
then the first line will start flush,
but other lines will be indented 5em:
In CSS3 we can instead indent all other
lines of the block element by 5em
by setting the 'text-indent' property
to 'hanging 5em'.
Since the text-indent property only affects the “first formatted line”,
a line after a forced break will not be indented.
For example, in the middle of
this paragraph is an equation,
which is centered:
x + y = z
The first line after the equation
is flush (else it would look like
we started a new paragraph).
However, sometimes (as in poetry or code),
it is appropriate to indent each line
that happens to be long enough to wrap.
In the following example, text-indent is given a value of 3em hanging each-line,
giving the third line of the poem a hanging indent
where it soft-wraps at the block’s right boundary:
In a short line of text There need be no wrapping, But when we go on and on and on and on, Sometimes a soft break Can help us stay on the page.
Note: Since the text-indent property inherits,
when specified on a block element, it will affect descendant
inline-block elements.
For this reason, it is often wise to specify text-indent: 0 on
elements that are specified display: inline-block.
8.2. Hanging Glyphs
When a glyph at the start or end edge of a line hangs,
it is not considered
when measuring the line’s contents for fit, alignment, or justification.
Depending on the line’s alignment/justification, this can
result in the mark being placed outside the line box.
The hanging glyph is also not taken into account
when computing intrinsic sizes (min-content size and max-content size),
and any sizes derived thereof.
(The interaction of this measurement and kerning is currently UA-defined;
the CSSWG welcomes advice on this point.)
A hanging glyph is still enclosed inside its parent inline box
and still participates in text justification:
its character advance is just not measured when determining
how much content fits on the line,
how much the line’s contents need to be expanded or compressed for justification,
or how to position the content within the line box for text alignment.
Effectively, the hanging glyph character advance
is re-interpreted as an additional negative margin
on the affected edge of its parent inline box;
the line is otherwise laid out as usual.
An overflowing hanging glyph should typically be considered ink overflow so as to avoid creating unnecessary scrollbars,
but the UA may treat it as scrollable overflow when the content is editable
or in other circumstances where treating it as scrollable overflow would be useful to the user. [CSS-OVERFLOW-3]
In some cases, a glyph at the end of a line
can conditionally hang:
it hangs only if it does not otherwise fit in the line prior to justification.
It is not considered when measuring the line’s contents for fit;
however, any part of it that does not fit
is considered to hang.
Glyphs that conditionally hang are not taken into account
when computing min-content sizes and any sizes derived thereof,
but they are taken into account for max-content sizes and any sizes derived thereof.
Non-zero inline-axis borders or padding between
a hangable glyph and the edge of the line prevent the glyph from hanging.
For example, a period at the end of an inline box with end padding
does not hang at the end edge of a line.
Multiple adjacent glyphs can hang together,
however specific limits on how many are allowed to hang may be specified
(e.g. at most one punctuation character may hang at each edge of the line).
8.2.1. Hanging Punctuation: the hanging-punctuation property
| Name: | hanging-punctuation |
|---|---|
| Value: | none | [ first || [ force-end | allow-end ] || last ] |
| Initial: | none |
| Applies to: | text |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword(s) |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property determines whether a punctuation mark,
if one is present, hangs and may be placed outside the line box (or in the indent)
at the start or at the end of a line of text.
Note: If there is not sufficient padding on the
block container, hanging-punctuation can trigger overflow.
Values have the following meanings:
- none
- No punctuation character is made to hang.
- first
- An opening bracket or quote at the start
of the first formatted line of an element hangs.
This applies to all characters in the Unicode categories Ps, Pf, Pi
plus the ASCII quote marks U+0027 ‘ APOSTROPHE and U+0022 » QUOTATION MARK. - last
- A closing bracket or quote at the end
of the last formatted line of an element hangs.
This applies to all characters in the Unicode categories Pe, Pf, Pi
plus the ASCII quote marks U+0027 ‘ APOSTROPHE and U+0022 » QUOTATION MARK. - force-end
- A stop or comma at the end of a line hangs.
- allow-end
- A stop or comma at the end of a line conditionally hangs.
At most one punctuation character may hang at each edge of the line.
Stops and commas allowed to hang include:
| U+002C | , | COMMA |
| U+002E | . | FULL STOP |
| U+060C | ، | ARABIC COMMA |
| U+06D4 | ۔ | ARABIC FULL STOP |
| U+3001 | 、 | IDEOGRAPHIC COMMA |
| U+3002 | 。 | IDEOGRAPHIC FULL STOP |
| U+FF0C | , | FULLWIDTH COMMA |
| U+FF0E | . | FULLWIDTH FULL STOP |
| U+FE50 | ﹐ | SMALL COMMA |
| U+FE51 | ﹑ | SMALL IDEOGRAPHIC COMMA |
| U+FE52 | ﹒ | SMALL FULL STOP |
| U+FF61 | 。 | HALFWIDTH IDEOGRAPHIC FULL STOP |
| U+FF64 | 、 | HALFWIDTH IDEOGRAPHIC COMMA |
The UA may include other characters as appropriate.
Note: The CSS Working Group would appreciate if UAs including
other characters would inform the working group of such additions.
The allow-end and force-end are two variations
of hanging punctuation used in East Asia.
The punctuation at the end of the first line for allow-end does not hang, because it fits without hanging.
However, if force-end is used, it is forced to hang.
The justification measures the line without the hanging punctuation.
Therefore when the line is expanded, the punctuation is pushed outside the line.
8.3. Bidirectionality and Line Boxes
The start and end sides of a line box
are determined by the inline base direction of the line box.
Although they usually match,
the inline base direction of a line box is distinct from the inline base direction of the containing block or the bidi paragraph.
The line box’s inline base direction affects text-align-all, text-align-last, text-indent, and hanging-punctuation—i.e. the position and alignment of its contents with respect to its edges.
It does not affect the formatting or ordering of inline content
(which is controlled by the Unicode Bidirectional Algorithm as applied by CSS Writing Modes [UAX9] [CSS-WRITING-MODES-4]).
In most cases, a line box’s inline base direction is given by its containing block’s computed direction.
However,
if its containing block has unicode-bidi: plaintext [CSS-WRITING-MODES-4]:
- If the bidi paragraph to which the line box belongs
(that is, the bidi paragraph for which the line box holds content)
has strong directionality,
the line box’s inline base direction is that direction. - If the line box is empty
(i.e. contains no atomic inlines or
characters other than the newline character, if any)
or otherwise has no strong directionality
(contains only weak or neutral characters),
its inline base direction is taken
from the preceding line box (if any),
or, if this is the first line box in the containing block,
from the direction property of the containing block.
(This can result in an RTL line box whose contents have an LTR base direction.)
In the following example,
assuming the <block> is a start-aligned preformatted block
(display: block; white-space: pre; text-align: start),
every other line is right-aligned:
<block style="unicode-bidi: plaintext"> français فارسی français فارسی français فارسی </block>
Because neutral characters (such as punctuation)
and isolated runs are skipped
when finding the inline base direction of a plaintext bidi paragraph,
the line box in the following example will be left-to-right
(and thus left-aligned given text-align: start),
as dictated by the first strong character, ‘h’:
<para style="display: block; direction: rtl; unicode-bidi:plaintext"> “<quote style="unicode-bidi:plaintext">שלום!</quote>”, he said. </para>
<textarea style="direction: rtl; unicode-bidi:plaintext"> Hello! </textarea>
Because of unicode-bidi: plaintext,
the “Hello!” is typeset LTR
(i.e. with the exclamation mark on the right side)
and left-aligned,
ignoring the containing block’s RTL direction.
This makes the empty line following it LTR as well,
which means that a caret on that line should appear at its left edge.
The empty first line, however, is right-aligned:
having no preceding line,
it assumes the RTL direction of its containing block.
Appendix A:
Text Processing Order of Operations
This appendix is normative.
The following list defines the order of text operations.
(Implementations are not bound to this order as long as the resulting layout is the same.)
- white space processing part I (pre-wrapping)
- text transformation
- text combination [CSS-WRITING-MODES-4]
- text orientation [CSS-WRITING-MODES-4]
-
text wrapping while applying per line:
-
indentation
-
bidirectional reordering [CSS2] / [CSS-WRITING-MODES-4]
-
white space processing part II
-
font/glyph selection and positioning [CSS-FONTS-3]
-
letter-spacing and word-spacing
-
hanging punctuation
-
- justification (which may affect glyph selection and/or text wrapping, looping back into that step)
- text alignment
Appendix B:
Conversion to Plaintext
This appendix is normative for the purpose of plaintext copy-paste operations.
When a CSS-rendered document is converted to a plaintext format,
it is expected that:
- The text-transform property has no effect.
- § 4.1.1 Phase I: Collapsing and Transformation is applied
and any sequence of collapsible white space at the beginning of a block or immediately following a forced line break is removed.
Appendix C:
Default UA Stylesheet
This appendix is informative, and is to help UA developers to implement a default stylesheet for HTML,
but UA developers are free to ignore or modify as appropriate.
/* make option elements align together */
option { text-align: match-parent; }
Appendix D:
Scripts and Spacing
This appendix is normative.
Typographic behavior varies somewhat by language,
but varies drastically by writing system.
This appendix categorizes some common scripts in Unicode 6.0
according to their justification and spacing behavior.
Category descriptions are descriptive, not prescriptive;
the determining factor is the prioritization of justification opportunities.
- block scripts
- CJK and by extension all Wide characters
(see East Asian Width [UAX11]).
The following Unicode scripts are included:
Bopomofo, Han, Hangul, Hiragana, Katakana, and Yi.
Characters of the East Asian Width propertyWideandFullwidthare also included,
butAmbiguouscharacters are included
only if the writing system is Chinese, Korean,
or Japanese. - clustered scripts
- Clustered scripts have discrete units
and break only at word boundaries,
but do not use visible word separators.
They prioritize stretching spaces,
but comfortably admit inter-character spacing for justification.
The clustered scripts include,
but are not limited to,
the following Unicode scripts:
Khmer,
Lao,
Myanmar,
New Tai Lue,
Tai Le,
Tai Tham,
Tai Viet,
Thai - cursive scripts
-
Cursive scripts do not admit gaps
between their letters for either justification or letter-spacing.
The following Unicode scripts are included:
Arabic,
Mandaic,
Mongolian,
N’Ko,
Phags Pa,
SyriacNote: Indic scripts with baseline connectors
(such as Devanagari and Gujarati) are not considered cursive scripts,
and do admit such gaps
between typographic character units.
See Indic Layout Requirements. [ILREQ]
User agents should update this list
as they update their Unicode support
to handle as-yet-unencoded cursive scripts in future versions of Unicode,
and are encouraged to ask the CSSWG to update this spec accordingly.
Appendix E:
Characters and Properties
This appendix is normative.
Unicode defines four code point-level properties
that are referenced in CSS typesetting:
- East Asian width property
- Defined in Unicode Standard Annex #11 [UAX11] and given as the
East_Asian_Widthproperty
in the Unicode Character Database [UAX44]. - general category
- Defined in Unicode Standard Annex #44 [UAX44] and given as the
General_Categoryproperty
in the Unicode Character Database [UAX44]. - script property
- Defined in Unicode Standard Annex #24 [UAX24] and given as the
Scriptproperty
in the Unicode Character Database [UAX44].
(UAs must include any ScriptExtensions.txt assignments in this mapping.) - Vertical Orientation
- Defined in Unicode Standard Annex #50 [UAX50] as the Vertical_Orientation property
in the Unicode Character Database [UAX44].
Unicode defines properties for individual code points,
but sometimes it is necessary to determine the properties
of a typographic character unit.
For the purposes of CSS Text,
the properties of a typographic character unit are given
by the base character of its first grapheme cluster—except in two cases:
- Grapheme clusters formed with an Enclosing Mark
(Me)
of the Common script
are considered to be Other Symbols
(So)
in the Common script.
They are assumed to have the same Unicode properties
as the replacement character (U+FFFD). - Grapheme clusters formed with a Space Separator
(Zs)
as the base
are considered to be Modifier Symbols
(Sk).
They are assumed to have the same East Asian Width property as the base,
but take their other properties
from the first combining character in the sequence.
Appendix F:
Identifying the Content Writing System
This appendix is normative.
While most languages have a preferred writing system,
some have multiple, and
most can also be transcribed into one or more foreign writing systems.
As a common example, most languages have at least one Latin transcription,
and can thus be written in the Latin writing system.
Transcribed texts typically adopt the typographic conventions of the writing system:
for example Japanese “romaji” and Chinese Pinyin use Latin letters and word spaces,
and follow Latin line-breaking and justification practices accordingly.
As another example, historical ideographic Korean
(ko-Hani)
does not use word spaces,
and should therefore be typeset similar to Chinese
rather than modern Korean.
In HTML or any other document language using BCP47 tags for identifying languages to declare the content language,
authors can disambiguate or indicate the use of an atypical writing system
with script subtags. [BCP47] For example, to indicate use of the Latin writing system
for languages which don’t natively use it,
the -Latn script subtag can be added,
e.g. ja-Latn for Japanese romaji.
Other subtags exist for other writing systems,
see ISO’s Code for the Representation of Names of Scripts and the ISO15924 script tag registry. [ISO15924]
Some common/historical examples of using BCP47 tags with script subtags:
zh-Latn- Chinese, written in Latin transcription.
ko-Hani- Korean, written in Hanja (Chinese ideographic characters).
tr-Arab- Turkish, written in Arabic script.
mn-Cyrl- Mongolian, written in Cyrillic.
mn-Mong- Mongolian, written in traditional Mongolian script.
However, BCP47 script subtags are not typically used
(and are in fact discouraged)
for languages strongly associated with a single writing system:
instead that writing system is expected to be implied
when no other is specified. [BCP47] IANA maintains a database of various languages’ most common writing system
via the Suppress-Script field in its language subtag registry for this purpose.
Note: More advice on language tagging can be found in
the Internationalization Working Group’s “Language tags in HTML and XML” and “Choosing a Language Tag”.
When no writing system is explicitly indicated,
UAs should assume the most common writing system
of the declared content language for language-sensitive typographic behaviors
such as line-breaking or justification.
However, UAs must not assume that writing system
if the author has explicitly declared a different one.
If the UA has no language-specific knowledge
of a particular language and writing system combination,
it must use the typographic conventions of the declared writing system
(assuming the conventions of a different language if necessary),
not the conventions of the declared language in an assumed writing system,
which would be inappropriate to the declared writing system.
The full correspondence between languages and their most common writing systems
is out of scope for this document.
However, user agents must assume at least the following:
- If the content language is Chinese and the writing system is unspecified,
or for any content language if the writing system to specified to be one of the Hant, Hans, Hani, Hanb,
or Bopo ISO script codes,
then the writing system is Chinese. - If the content language is Japanese and the writing system is unspecified,
or for any content language if the writing system to specified to be one of the Jpan, Hrkt, Hira,
or Kana ISO script codes,
then the writing system is Japanese. - If the content language is Korean and the writing system is unspecified,
or for any content language if the writing system to specified to be one of the Kore, Hang,
or Jamo ISO script codes,
then the writing system is Korean. -
The writing system is only considered
to be unknown if the content language itself is unknown,
or if it explicitly indicates an unknown writing system.Note: Mere omission of the writing system information
when the content language is declared
means the that the writing system is implied, not unknown.
Appendix G:
Small Kana Mappings
This appendix is normative.
| Small | Full-size |
|---|---|
| ぁ U+3041 | あ U+3042 |
| ぃ U+3043 | い U+3044 |
| ぅ U+3045 | う U+3046 |
| ぇ U+3047 | え U+3048 |
| ぉ U+3049 | お U+304A |
| ゕ U+3095 | か U+304B |
| ゖ U+3096 | け U+3051 |
| っ U+3063 | つ U+3064 |
| ゃ U+3083 | や U+3084 |
| ゅ U+3085 | ゆ U+3086 |
| ょ U+3087 | よ U+3088 |
| ゎ U+308E | わ U+308F |
| ァ U+30A1 | ア U+30A2 |
| ィ U+30A3 | イ U+30A4 |
| ゥ U+30A5 | ウ U+30A6 |
| ェ U+30A7 | エ U+30A8 |
| ォ U+30A9 | オ U+30AA |
| ヵ U+30F5 | カ U+30AB |
| ㇰ U+31F0 | ク U+30AF |
| ヶ U+30F6 | ケ U+30B1 |
| ㇱ U+31F1 | シ U+30B7 |
| ㇲ U+31F2 | ス U+30B9 |
| ッ U+30C3 | ツ U+30C4 |
| ㇳ U+31F3 | ト U+30C8 |
| ㇴ U+31F4 | ヌ U+30CC |
| ㇵ U+31F5 | ハ U+30CF |
| ㇶ U+31F6 | ヒ U+30D2 |
| ㇷ U+31F7 | フ U+30D5 |
| ㇸ U+31F8 | ヘ U+30D8 |
| ㇹ U+31F9 | ホ U+30DB |
| ㇺ U+31FA | ム U+30E0 |
| ャ U+30E3 | ヤ U+30E4 |
| ュ U+30E5 | ユ U+30E6 |
| ョ U+30E7 | ヨ U+30E8 |
| ㇻ U+31FB | ラ U+30E9 |
| ㇼ U+31FC | リ U+30EA |
| ㇽ U+31FD | ル U+30EB |
| ㇾ U+31FE | レ U+30EC |
| ㇿ U+31FF | ロ U+30ED |
| ヮ U+30EE | ワ U+30EF |
| ァ U+FF67 | ア U+FF71 |
| ィ U+FF68 | イ U+FF72 |
| ゥ U+FF69 | ウ U+FF73 |
| ェ U+FF6A | エ U+FF74 |
| ォ U+FF6B | オ U+FF75 |
| ッ U+FF6F | ツ U+FF82 |
| ャ U+FF6C | ヤ U+FF94 |
| ュ U+FF6D | ユ U+FF95 |
| ョ U+FF6E | ヨ U+FF96 |
Privacy Considerations
This specification leaks the user’s installed hyphenation and line-breaking dictionaries.
Security Considerations
This specification introduces no new security considerations.
Acknowledgements
This specification would not have been possible without the help from:
Addison Phillips,
Aharon Lanin,
Alan Stearns,
Ambrose Li,
Arnold Schrijver,
Arye Gittelman,
Ayman Aldahleh,
Ben Errez,
Bert Bos,
Chris Lilley,
Chris Pratley,
Chris Thrasher,
Chris Wilson,
Dave Hyatt,
David Baron,
Emilio Cobos Álvarez,
Eric LeVine,
Etan Wexler,
Frank Tang,
Håkon Wium Lie,
IM Mincheol,
Ian Hickson,
James Clark,
Javier Fernandez,
John Daggett,
Jonathan Kew,
Ken Lunde,
Laurie Anna Edlund,
Marcin Sawicki,
Martin Dürst,
Martin Heijdra,
Masafumi Yabe,
Masayasu Ishikawa,
Michael Jochimsen,
Michel Suignard,
Mike Bemford,
Myles Maxfield,
Nat McCully,
Paul Nelson,
Rahul Sonnad,
Richard Ishida,
Shinyu Murakami,
Stephen Deach,
Steve Zilles,
Takao Suzuki,
Tantek Çelik,
Xidorn Quan,
Yaniv Feinberg.
Changes
Recent Changes
The following normative changes have been made since
the December 2020 Candidate Recommendation.
-
Define that distribute computes to inter-character, rather than merely behave the same;
allow distribute to be implemented as a legacy value alias,
since this is easier for some engines and does not matter for compatibility.
(Issue 6156, Issue 7322) -
Clarify that language-specific hyphenation rules also apply to explicit hyphenation opportunities.
(Issue 5973)Words are only hyphenated where there are characters inside the word
that explicitly suggest hyphenation opportunities.
The UA must use the appropriate language-specific hyphenation character(s)
and should apply any appropriate spelling changes
just as for automatic hyphenation at the same point. -
Define match-parent on the root element to compute to start instead of computing against the principal writing mode.
(Issue 6542) -
Make authoring advice regarding text-transform a normative recommendation.
(Issue 8279)Note: The text-transform property only affects the presentation layer;
correct casing for semantic purposes is expected to be represented
in the source document.Advisement: Authors must not rely on text-transform for semantic purposes;
rather the correct casing and semantics should be encoded
in the source document text and markup.
In addition there have been some minor editorial fixes.
Older Changes
See also earlier list of changes covering the 2020 and 2019 Working Drafts prior to that Candidate Recommendation
and the Disposition of Comments covering all comments between 2013 and 2020.
Conformance requirements are expressed with a combination of
descriptive assertions and RFC 2119 terminology. The key words “MUST”,
“MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”,
“RECOMMENDED”, “MAY”, and “OPTIONAL” in the normative parts of this
document are to be interpreted as described in RFC 2119.
However, for readability, these words do not appear in all uppercase
letters in this specification.
All of the text of this specification is normative except sections
explicitly marked as non-normative, examples, and notes. [RFC2119]
Examples in this specification are introduced with the words “for example”
or are set apart from the normative text with class="example",
like this:
Informative notes begin with the word “Note” and are set apart from the
normative text with class="note", like this:
Note, this is an informative note.
Advisements are normative sections styled to evoke special attention and are
set apart from other normative text with <strong class="advisement">, like
this: UAs MUST provide an accessible alternative.
A style sheet is conformant to this specification
if all of its statements that use syntax defined in this module are valid
according to the generic CSS grammar and the individual grammars of each
feature defined in this module.
A renderer is conformant to this specification
if, in addition to interpreting the style sheet as defined by the
appropriate specifications, it supports all the features defined
by this specification by parsing them correctly
and rendering the document accordingly. However, the inability of a
UA to correctly render a document due to limitations of the device
does not make the UA non-conformant. (For example, a UA is not
required to render color on a monochrome monitor.)
An authoring tool is conformant to this specification
if it writes style sheets that are syntactically correct according to the
generic CSS grammar and the individual grammars of each feature in
this module, and meet all other conformance requirements of style sheets
as described in this module.
So that authors can exploit the forward-compatible parsing rules to
assign fallback values, CSS renderers must treat as invalid (and ignore
as appropriate) any at-rules, properties, property values, keywords,
and other syntactic constructs for which they have no usable level of
support. In particular, user agents must not selectively
ignore unsupported component values and honor supported values in a single
multi-value property declaration: if any value is considered invalid
(as unsupported values must be), CSS requires that the entire declaration
be ignored.
Once a specification reaches the Candidate Recommendation stage,
non-experimental implementations are possible, and implementors should
release an unprefixed implementation of any CR-level feature they
can demonstrate to be correctly implemented according to spec.
To establish and maintain the interoperability of CSS across
implementations, the CSS Working Group requests that non-experimental
CSS renderers submit an implementation report (and, if necessary, the
testcases used for that implementation report) to the W3C before
releasing an unprefixed implementation of any CSS features. Testcases
submitted to W3C are subject to review and correction by the CSS
Working Group.
For this specification to be advanced to Proposed Recommendation,
there must be at least two independent, interoperable implementations
of each feature. Each feature may be implemented by a different set of
products, there is no requirement that all features be implemented by
a single product. For the purposes of this criterion, we define the
following terms:
The specification will remain Candidate Recommendation for at least
six months.
How can text like aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa which exceeds the width of a div (say 200px) be wrapped?
I am open to any kind of solution such as CSS, jQuery, etc.
![]()
trejder
17k27 gold badges123 silver badges215 bronze badges
asked Jul 18, 2009 at 15:56
![]()
Satya KalluriSatya Kalluri
5,1084 gold badges27 silver badges37 bronze badges
Try this:
div {
width: 200px;
word-wrap: break-word;
}
answered Jul 18, 2009 at 16:02
![]()
Alan Haggai AlaviAlan Haggai Alavi
72.2k19 gold badges101 silver badges127 bronze badges
6
On bootstrap 3, make sure the white-space is not set as ‘nowrap’.
div {
width: 200px;
word-break: break-all;
white-space: normal;
}
answered Nov 12, 2013 at 8:39
![]()
2
You can use a soft hyphen like so:
aaaaaaaaaaaaaaa­aaaaaaaaaaaaaaa
This will appear as
aaaaaaaaaaaaaaa-
aaaaaaaaaaaaaaa
if the containing box isn’t big enough, or as
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
if it is.
![]()
Tunaki
131k46 gold badges330 silver badges415 bronze badges
answered Jul 18, 2009 at 16:13
![]()
Kim StebelKim Stebel
41.6k12 gold badges125 silver badges142 bronze badges
7
div {
/* Set a width for element */
word-wrap: break-word
}
The ‘word-wrap‘ solution only works in IE and browsers supporting CSS3.
The best cross browser solution is to use your server side language (php or whatever) to locate long strings and place inside them in regular intervals the html entity
This entity breaks the long words nicely, and works on all browsers.
e.g.
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
![]()
code
5,1204 gold badges16 silver badges37 bronze badges
answered Jul 18, 2009 at 16:14
![]()
Orr SiloniOrr Siloni
1,24010 silver badges20 bronze badges
1
This worked for me
word-wrap: normal;
word-break: break-all;
white-space: normal;
display: block;
height: auto;
margin: 3px auto;
line-height: 1.4;
-webkit-line-clamp: 1;
-webkit-box-orient: vertical;
answered Jun 2, 2016 at 2:04
![]()
AmolAmol
9087 silver badges20 bronze badges
1
The only one that works across IE, Firefox, chrome, safari and opera if there are no spaces in the word (such as a long URL) is:
div{
width: 200px;
word-break: break-all;
}
I found this to be bullet-proof.
![]()
answered Apr 12, 2013 at 13:56
![]()
Kyle DearleKyle Dearle
1291 gold badge2 silver badges9 bronze badges
0
Another option is also using:
div
{
white-space: pre-line;
}
This will set all your div elements in all browsers that support CSS1 (which is pretty much all common browsers as far back as IE 
answered Oct 14, 2014 at 15:59
![]()
1
Cross Browser
.wrap
{
white-space: pre-wrap; /* css-3 */
white-space: -moz-pre-wrap; /* Mozilla, since 1999 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: -o-pre-wrap; /* Opera 7 */
word-wrap: break-word; /* Internet Explorer 5.5+ */
}
![]()
answered Apr 20, 2015 at 9:21
![]()
TimelessTimeless
7,2898 gold badges60 silver badges94 bronze badges
<p style="word-wrap: break-word; word-break: break-all;">
Adsdbjf bfsi hisfsifisfsifs shifhsifsifhis aifoweooweoweweof
</p>
answered Oct 1, 2020 at 20:23
![]()
Manoj AlwisManoj Alwis
1,27911 silver badges24 bronze badges
Example from CSS Tricks:
div {
-ms-word-break: break-all;
/* Be VERY careful with this, breaks normal words wh_erever */
word-break: break-all;
/* Non standard for webkit */
word-break: break-word;
-webkit-hyphens: auto;
-moz-hyphens: auto;
hyphens: auto;
}
More examples here.
answered Feb 4, 2015 at 10:01
![]()
In HTML body try:
<table>
<tr>
<td>
<div style="word-wrap: break-word; width: 800px">
Hello world, how are you? More text here to see if it wraps after a long while of writing and it does on Firefox but I have not tested it on Chrome yet. It also works wonders if you have a medium to long paragraph. Just avoid writing in the CSS file that the words have to break-all, that's a small tip.
</div>
</td>
</tr>
</table>
In CSS body try:
background-size: auto;
table-layout: fixed;
![]()
John Slegers
44.5k22 gold badges201 silver badges169 bronze badges
answered Feb 6, 2016 at 17:06
![]()
Add this CSS to the paragraph.
width:420px;
min-height:15px;
height:auto!important;
color:#666;
padding: 1%;
font-size: 14px;
font-weight: normal;
word-wrap: break-word;
text-align: left;
![]()
TylerH
20.6k64 gold badges76 silver badges97 bronze badges
answered May 23, 2012 at 9:53
![]()
Swapnil GodambeSwapnil Godambe
2,0541 gold badge24 silver badges28 bronze badges
1
Try this
div{
display: block;
display: -webkit-box;
height: 20px;
margin: 3px auto;
font-size: 14px;
line-height: 1.4;
-webkit-line-clamp: 1;
-webkit-box-orient: vertical;
overflow: hidden;
text-overflow: ellipsis;
}the property text-overflow: ellipsis add … and line-clamp show the number of lines.
answered Nov 27, 2014 at 21:10
![]()
I have used bootstrap.
My html code looks like ..
<div class="container mt-3" style="width: 100%;">
<div class="row">
<div class="col-sm-12 wrap-text">
<h6>
text content
</h6>
</div>
</div>
</div>
CSS
.wrap-text {
text-align:justify;
}
![]()
Stephen Rauch♦
47.2k31 gold badges110 silver badges133 bronze badges
answered Sep 18, 2018 at 2:24
![]()
1
you can use this CSS
p {
width: min-content;
min-width: 100%;
}
answered Dec 27, 2019 at 10:22
![]()
Rashid IqbalRashid Iqbal
1,05313 silver badges12 bronze badges
Try this CSS property —
overflow-wrap: anywhere;
answered Jun 9, 2022 at 6:12
![]()
A server side solution that works for me is: $message = wordwrap($message, 50, "<br>", true); where $message is a string variable containing the word/chars to be broken up. 50 is the max length of any given segment, and "<br>" is the text you want to be inserted every (50) chars.
answered Jan 23, 2012 at 7:31
![]()
1
Try this
div {display: inline;}
answered Jul 18, 2018 at 16:58
![]()
try:
overflow-wrap: break-word;
![]()
borchvm
3,48411 gold badges45 silver badges43 bronze badges
answered Jan 29, 2020 at 3:00
![]()
Use word-wrap:break-word attribute along with required width. Mainly, put
the width in pixels, not in percentages.
width: 200px;
word-wrap: break-word;
![]()
JSuar
21.1k4 gold badges43 silver badges82 bronze badges
answered Jan 27, 2011 at 8:36
![]()
1
Text alignment
Easily realign text to components with text alignment classes. For start, end, and center alignment, responsive classes are available that use the same viewport width breakpoints as the grid system.
Start aligned text on all viewport sizes.
Center aligned text on all viewport sizes.
End aligned text on all viewport sizes.
Start aligned text on viewports sized SM (small) or wider.
Start aligned text on viewports sized MD (medium) or wider.
Start aligned text on viewports sized LG (large) or wider.
Start aligned text on viewports sized XL (extra-large) or wider.
<p class="text-start">Start aligned text on all viewport sizes.</p>
<p class="text-center">Center aligned text on all viewport sizes.</p>
<p class="text-end">End aligned text on all viewport sizes.</p>
<p class="text-sm-start">Start aligned text on viewports sized SM (small) or wider.</p>
<p class="text-md-start">Start aligned text on viewports sized MD (medium) or wider.</p>
<p class="text-lg-start">Start aligned text on viewports sized LG (large) or wider.</p>
<p class="text-xl-start">Start aligned text on viewports sized XL (extra-large) or wider.</p>Note that we don’t provide utility classes for justified text. While, aesthetically, justified text might look more appealing, it does make word-spacing more random and therefore harder to read.
Text wrapping and overflow
Wrap text with a .text-wrap class.
<div class="badge bg-primary text-wrap" style="width: 6rem;">
This text should wrap.
</div>Prevent text from wrapping with a .text-nowrap class.
This text should overflow the parent.
<div class="text-nowrap bg-body-secondary border" style="width: 8rem;">
This text should overflow the parent.
</div>Word break
Prevent long strings of text from breaking your components’ layout by using .text-break to set word-wrap: break-word and word-break: break-word. We use word-wrap instead of the more common overflow-wrap for wider browser support, and add the deprecated word-break: break-word to avoid issues with flex containers.
mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm
<p class="text-break">mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm</p>Text transform
Transform text in components with text capitalization classes.
Lowercased text.
Uppercased text.
CapiTaliZed text.
<p class="text-lowercase">Lowercased text.</p>
<p class="text-uppercase">Uppercased text.</p>
<p class="text-capitalize">CapiTaliZed text.</p>Note how .text-capitalize only changes the first letter of each word, leaving the case of any other letters unaffected.
Font size
Quickly change the font-size of text. While our heading classes (e.g., .h1–.h6) apply font-size, font-weight, and line-height, these utilities only apply font-size. Sizing for these utilities matches HTML’s heading elements, so as the number increases, their size decreases.
.fs-1 text
.fs-2 text
.fs-3 text
.fs-4 text
.fs-5 text
.fs-6 text
<p class="fs-1">.fs-1 text</p>
<p class="fs-2">.fs-2 text</p>
<p class="fs-3">.fs-3 text</p>
<p class="fs-4">.fs-4 text</p>
<p class="fs-5">.fs-5 text</p>
<p class="fs-6">.fs-6 text</p>Customize your available font-sizes by modifying the $font-sizes Sass map.
Font weight and italics
Quickly change the font-weight or font-style of text with these utilities. font-style utilities are abbreviated as .fst-* and font-weight utilities are abbreviated as .fw-*.
Bold text.
Bolder weight text (relative to the parent element).
Semibold weight text.
Medium weight text.
Normal weight text.
Light weight text.
Lighter weight text (relative to the parent element).
Italic text.
Text with normal font style
<p class="fw-bold">Bold text.</p>
<p class="fw-bolder">Bolder weight text (relative to the parent element).</p>
<p class="fw-semibold">Semibold weight text.</p>
<p class="fw-medium">Medium weight text.</p>
<p class="fw-normal">Normal weight text.</p>
<p class="fw-light">Light weight text.</p>
<p class="fw-lighter">Lighter weight text (relative to the parent element).</p>
<p class="fst-italic">Italic text.</p>
<p class="fst-normal">Text with normal font style</p>Line height
Change the line height with .lh-* utilities.
This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.
This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.
This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.
This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.
<p class="lh-1">This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.</p>
<p class="lh-sm">This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.</p>
<p class="lh-base">This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.</p>
<p class="lh-lg">This is a long paragraph written to show how the line-height of an element is affected by our utilities. Classes are applied to the element itself or sometimes the parent element. These classes can be customized as needed with our utility API.</p>Monospace
Change a selection to our monospace font stack with .font-monospace.
This is in monospace
<p class="font-monospace">This is in monospace</p>Reset color
Reset a text or link’s color with .text-reset, so that it inherits the color from its parent.
<p class="text-body-secondary">
Muted text with a <a href="#" class="text-reset">reset link</a>.
</p>Text decoration
Decorate text in components with text decoration classes.
<p class="text-decoration-underline">This text has a line underneath it.</p>
<p class="text-decoration-line-through">This text has a line going through it.</p>
<a href="#" class="text-decoration-none">This link has its text decoration removed</a>CSS
Sass variables
Default type and font related Sass variables:
// stylelint-disable value-keyword-case
$font-family-sans-serif: system-ui, -apple-system, "Segoe UI", Roboto, "Helvetica Neue", "Noto Sans", "Liberation Sans", Arial, sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
$font-family-monospace: SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
// stylelint-enable value-keyword-case
$font-family-base: var(--#{$prefix}font-sans-serif);
$font-family-code: var(--#{$prefix}font-monospace);
// $font-size-root affects the value of `rem`, which is used for as well font sizes, paddings, and margins
// $font-size-base affects the font size of the body text
$font-size-root: null;
$font-size-base: 1rem; // Assumes the browser default, typically `16px`
$font-size-sm: $font-size-base * .875;
$font-size-lg: $font-size-base * 1.25;
$font-weight-lighter: lighter;
$font-weight-light: 300;
$font-weight-normal: 400;
$font-weight-medium: 500;
$font-weight-semibold: 600;
$font-weight-bold: 700;
$font-weight-bolder: bolder;
$font-weight-base: $font-weight-normal;
$line-height-base: 1.5;
$line-height-sm: 1.25;
$line-height-lg: 2;
$h1-font-size: $font-size-base * 2.5;
$h2-font-size: $font-size-base * 2;
$h3-font-size: $font-size-base * 1.75;
$h4-font-size: $font-size-base * 1.5;
$h5-font-size: $font-size-base * 1.25;
$h6-font-size: $font-size-base;
Sass maps
Font-size utilities are generated from this map, in combination with our utilities API.
$font-sizes: (
1: $h1-font-size,
2: $h2-font-size,
3: $h3-font-size,
4: $h4-font-size,
5: $h5-font-size,
6: $h6-font-size
);
$theme-colors-text: (
"primary": $primary-text-emphasis,
"secondary": $secondary-text-emphasis,
"success": $success-text-emphasis,
"info": $info-text-emphasis,
"warning": $warning-text-emphasis,
"danger": $danger-text-emphasis,
"light": $light-text-emphasis,
"dark": $dark-text-emphasis,
);
Utilities API
Font and text utilities are declared in our utilities API in scss/_utilities.scss. Learn how to use the utilities API.
"font-family": (
property: font-family,
class: font,
values: (monospace: var(--#{$prefix}font-monospace))
),
"font-size": (
rfs: true,
property: font-size,
class: fs,
values: $font-sizes
),
"font-style": (
property: font-style,
class: fst,
values: italic normal
),
"font-weight": (
property: font-weight,
class: fw,
values: (
lighter: $font-weight-lighter,
light: $font-weight-light,
normal: $font-weight-normal,
medium: $font-weight-medium,
semibold: $font-weight-semibold,
bold: $font-weight-bold,
bolder: $font-weight-bolder
)
),
"line-height": (
property: line-height,
class: lh,
values: (
1: 1,
sm: $line-height-sm,
base: $line-height-base,
lg: $line-height-lg,
)
),
"text-align": (
responsive: true,
property: text-align,
class: text,
values: (
start: left,
end: right,
center: center,
)
),
"text-decoration": (
property: text-decoration,
values: none underline line-through
),
"text-transform": (
property: text-transform,
class: text,
values: lowercase uppercase capitalize
),
"white-space": (
property: white-space,
class: text,
values: (
wrap: normal,
nowrap: nowrap,
)
),
"word-wrap": (
property: word-wrap word-break,
class: text,
values: (break: break-word),
rtl: false
),Выравнивание текста
Легко выравнивайте текст по компонентам с помощью классов выравнивания текста. Для выравнивания влево, вправо и по центру доступны адаптивные классы, которые используют те же контрольные точки по ширине области просмотра, что и система сетки.
Текст с выравниванием по левому краю для всех размеров области просмотра.
Выровненный по центру текст на всех размерах области просмотра.
Текст с выравниванием по правому краю для всех размеров области просмотра.
Выровненный по левому краю текст на размерных области просмотра SM (маленький) или шире.
Выровненный по левому краю текст на размерных области просмотра MD (средний) или шире.
Выровненный по левому краю текст на размерных области просмотра LG (большой) или шире.
Выровненный по левому краю текст на размерных области просмотра XL (очень большой) или шире.
<p class="text-start">Текст с выравниванием по левому краю для всех размеров области просмотра.</p>
<p class="text-center">Выровненный по центру текст на всех размерах области просмотра.</p>
<p class="text-end">Текст с выравниванием по правому краю для всех размеров области просмотра.</p>
<p class="text-sm-start">Выровненный по левому краю текст на размерных области просмотра SM (маленький) или шире.</p>
<p class="text-md-start">Выровненный по левому краю текст на размерных области просмотра MD (средний) или шире.</p>
<p class="text-lg-start">Выровненный по левому краю текст на размерных области просмотра LG (большой) или шире.</p>
<p class="text-xl-start">Выровненный по левому краю текст на размерных области просмотра XL (очень большой) или шире.</p>Обратите внимание, что мы не предоставляем служебные классы для выравнивания текста по всей ширине. Хотя эстетически выровненный по ширине текст может выглядеть более привлекательно, он делает интервалы между словами более случайными и, следовательно, труднее читать.
Перенос текста и переполнение
Оберните текст классом .text-wrap.
Этот текст следует обернуть.
<div class="badge bg-primary text-wrap" style="width: 6rem;">
Этот текст следует обернуть.
</div>Запретить перенос текста с помощью класса .text-nowrap.
Этот текст должен переполнять родительский.
<div class="text-nowrap bd-highlight" style="width: 8rem;">
Этот текст должен переполнять родительский.
</div>Разрыв слова
Предотвратите разрушение макета ваших компонентов длинными строками текста, используя .text-break для установки word-wrap: break-word и word-break: break-word. Мы используем word-wrap вместо более обычного overflow-wrap для более широкой поддержки браузеров и добавляем устаревший word-break: break-word, чтобы избежать проблем с гибкими контейнерами.
mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm
<p class="text-break">mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm</p>
Обратите внимание, что разрыв слов на арабском языке невозможен, который является наиболее часто используемым языком RTL. Поэтому .text-break удаляется из нашего RTL-скомпилированного CSS.
Преобразование текста
Преобразование текста в компонентах с помощью классов капитализации текста.
Текст в нижнем регистре.
Текст в верхнем регистре.
Заглавный текст.
<p class="text-lowercase">Текст в нижнем регистре.</p>
<p class="text-uppercase">Текст в верхнем регистре.</p>
<p class="text-capitalize">Заглавный текст.</p>Обратите внимание, как .text-capitalize изменяет только первую букву каждого слова, не затрагивая регистр любых других букв.
Размер шрифта
Быстро изменить размер шрифта текста font-size. В то время как наши классы заголовков (например, .h1–.h6) применяют font-size, font-weight и line-height, эти утилиты применяют только font-size. Размер этих утилит соответствует элементам заголовка HTML, поэтому по мере увеличения числа их размер уменьшается.
.fs-1 text
.fs-2 text
.fs-3 text
.fs-4 text
.fs-5 text
.fs-6 text
<p class="fs-1">.fs-1 text</p>
<p class="fs-2">.fs-2 text</p>
<p class="fs-3">.fs-3 text</p>
<p class="fs-4">.fs-4 text</p>
<p class="fs-5">.fs-5 text</p>
<p class="fs-6">.fs-6 text</p>Настройте свой доступный font-size, изменив карту Sass $font-sizes.
Толщина шрифта и курсив
С помощью этих утилит можно быстро изменить font-weight или font-style. Утилиты font-style сокращенно обозначаются как .fst-*, а утилиты font-weight сокращаются как .fw-*.
Жирный текст.
Более жирный текст (относительно родительского элемента).
Текст с нормальной толщиной.
Текст с легкой толщиной.
Более легкий текст (относительно родительского элемента).
Курсивный текст.
Текст с обычным шрифтом
<p class="fw-weight-bold">Жирный текст.</p>
<p class="fw-weight-bolder">Более жирный текст (относительно родительского элемента).</p>
<p class="fw-weight-normal">Текст с нормальной толщиной.</p>
<p class="fw-weight-light">Текст с легкой толщиной.</p>
<p class="fw-weight-lighter">Более легкий текст (относительно родительского элемента).</p>
<p class="fst-italic">Курсивный текст.</p>
<p class="fst-normal">Текст с обычным шрифтом</p>Высота линии
Измените высоту строки с помощью утилит .lh-*.
Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.
Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.
Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.
Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.
<p class="lh-1">Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.</p>
<p class="lh-sm">Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.</p>
<p class="lh-base">Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.</p>
<p class="lh-lg">Это длинный абзац, написанный для того, чтобы показать, как наши утилиты влияют на высоту строки элемента. Классы применяются к самому элементу или иногда к родительскому элементу. Эти классы можно настроить по мере необходимости с помощью нашего служебного API.</p>Моноширинный
Измените выделение на наш стек моноширинных шрифтов с помощью .font-monospace.
Это в моноширинном пространстве
<p class="font-monospace">Это в моноширинном пространстве</p>Сброс цвета
Сбросить цвет текста или ссылки с помощью .text-reset, чтобы он унаследовал цвет от своего родителя.
<p class="text-muted">
Скрытый текст со <a href="#" class="text-reset">ссылкой для сброса.</a>.
</p>Оформление текста
Украшайте текст в компонентах классами оформления текста.
<p class="text-decoration-underline">Под этим текстом есть линия.</p>
<p class="text-decoration-line-through">В этом тексте проходит линия.</p>
<a href="#" class="text-decoration-none">Текстовое оформление этой ссылки удалено.</a>Sass
Переменные
// stylelint-disable value-keyword-case
$font-family-sans-serif: system-ui, -apple-system, "Segoe UI", Roboto, "Helvetica Neue", Arial, "Noto Sans", "Liberation Sans", sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
$font-family-monospace: SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
// stylelint-enable value-keyword-case
$font-family-base: var(--#{$variable-prefix}font-sans-serif);
$font-family-code: var(--#{$variable-prefix}font-monospace);
// $font-size-root affects the value of `rem`, which is used for as well font sizes, paddings, and margins
// $font-size-base affects the font size of the body text
$font-size-root: null;
$font-size-base: 1rem; // Assumes the browser default, typically `16px`
$font-size-sm: $font-size-base * .875;
$font-size-lg: $font-size-base * 1.25;
$font-weight-lighter: lighter;
$font-weight-light: 300;
$font-weight-normal: 400;
$font-weight-bold: 700;
$font-weight-bolder: bolder;
$font-weight-base: $font-weight-normal;
$line-height-base: 1.5;
$line-height-sm: 1.25;
$line-height-lg: 2;
$h1-font-size: $font-size-base * 2.5;
$h2-font-size: $font-size-base * 2;
$h3-font-size: $font-size-base * 1.75;
$h4-font-size: $font-size-base * 1.5;
$h5-font-size: $font-size-base * 1.25;
$h6-font-size: $font-size-base;
Карты
Утилиты с размером шрифта генерируются из этой карты в сочетании с нашим API утилит.
$font-sizes: (
1: $h1-font-size,
2: $h2-font-size,
3: $h3-font-size,
4: $h4-font-size,
5: $h5-font-size,
6: $h6-font-size
);
API утилит
Утилиты шрифта и текста указаны в нашем API утилит в scss/_utilities.scss. Узнайте, как использовать API утилит.
"font-family": (
property: font-family,
class: font,
values: (monospace: var(--#{$variable-prefix}font-monospace))
),
"font-size": (
rfs: true,
property: font-size,
class: fs,
values: $font-sizes
),
"font-style": (
property: font-style,
class: fst,
values: italic normal
),
"font-weight": (
property: font-weight,
class: fw,
values: (
light: $font-weight-light,
lighter: $font-weight-lighter,
normal: $font-weight-normal,
bold: $font-weight-bold,
bolder: $font-weight-bolder
)
),
"line-height": (
property: line-height,
class: lh,
values: (
1: 1,
sm: $line-height-sm,
base: $line-height-base,
lg: $line-height-lg,
)
),
"text-align": (
responsive: true,
property: text-align,
class: text,
values: (
start: left,
end: right,
center: center,
)
),
"text-decoration": (
property: text-decoration,
values: none underline line-through
),
"text-transform": (
property: text-transform,
class: text,
values: lowercase uppercase capitalize
),
"white-space": (
property: white-space,
class: text,
values: (
wrap: normal,
nowrap: nowrap,
)
),
"word-wrap": (
property: word-wrap word-break,
class: text,
values: (break: break-word),
rtl: false
),
Преимуществом веб-типографики является то, что она базируется на знаниях, накопленных за столетия развития традиционной печатной типографики. По той же причине веб-типографика должна следовать стандартам лучших практик и передового опыта.
Однако, веб это пространство коммуникации со своими особенностями. Настолько, что плавный переход от печати к веб-типографике становится вызовом. Джейсон Санта Мария в своей книге о веб-типографике пишет:
Печатные книги это статический формат. От первого дизайнерского макета книга без изменений проходит свой путь к вам через типографию, склад и книжную полку. В точно таком же виде, как было задумано.
В вебе один и тот же сайт может выглядеть различно в зависимости от многих факторов — различий устройств, разрешения их экранов, личных настроек браузеров и прочего. Как далее пишет Джейсон, некоторые из этих факторов…
Могут дать впечатление, что шрифт слишком мелкий, другие выносят часть содержимого за пределы экрана, а третьи могут полностью испортить просмотр страницы.
Но также известно, что “веб это лучшее место для текста”. Текст в Интернете можно “искать, копировать, переводить, передавать в виде ссылки, распечатывать; текст в вебе удобен и доступен”.
Гибкость веба не означает отказ от контроля. Наоборот, как веб-дизайнеры мы ожидаем возможности делать осознанный выбор во всем, что составляет нашу работу и текст не исключение. Это и то, как располагается текст, его размер, шрифт и все, что позволяет донести основную идею сайта.
Главный инструмент для манипуляции видом текста в вебе это CSS.
Свойства CSS, рассматриваемые в этой статье, вы можете найти в модуле спецификации CSS текста.
Этот модуль описывает верстку CSS, то есть свойства CSS, управляющие переводом источника текста в форматированный и разделенный на строки текст.
Другими словами, модуль CSS текста это все, что касается вывода символов и слов в браузере, отступов, выравнивания, переносов и прочего.
Что считать базовой единицей текста или слова, где можно разбивать слова и прочие правила, зависит от языка сайта. Поэтому очень важно задавать данные об используемом языке в HTML-документе (обычно это атрибут lang в элементе html).
В этой статье я не буду обсуждать следующие вещи:
- шрифты, т.е. визуальное представление символов и их свойства;
- свойства CSS по декорированию текста, такие как подчеркивание, тени текста или акцентирование.
Если вы любопытны, вы найдете последнюю документацию о шрифтах и декорировании текста в модуле CSS шрифты третьего уровня и в модуле декорирования текста CSS третьего уровня.
Управление регистром букв: text-transform
Иногда возникает необходимость вывести слова или первые символы слов с заглавной буквы. В CSS для управления регистром буквы есть свойство text-transform.
Дефолтное значение text-transform равно none, то есть по умолчанию регистр букв не изменяется.
Значение capitalize
Если вы хотите сделать заглавной первую букву каждого слова, оставив все остальные в первоначальном виде, то этого можно достичь задав значение capitalize.
Разметка:
<h2>alice's adventures in wonderland</h2>
Стили:
h2 {
text-transform: capitalize;
}
Отметьте, что capitalize не следует традиционным правилам — оно делает заглавными первые буквы всех слов, включая предлоги. И если вы хотите следовать нормам английского языка, вам придется делать это вручную.
Значение uppercase
Если ваша цель — сделать все буквы заглавными, то подходящим значением будет uppercase:
Разметка:
<h2>alice's adventures in wonderland</h2>
Стили:
h2 {
text-transform: uppercase;
}

Значение lowercase
Это значение наоборот делает все символы строчными. Естественно, оно не оказывает никакого воздействия на уже имеющиеся строчные буквы.
Разметка:
<h2>alice's adventures in wonderland</h2>
Стили:
h2 {
text-transform: lowercase;
}
Значение full-width
Это значение появилось в спецификации недавно. Это значение ограничивает символ внутри квадрата, аналогично иероглифам. И применение этого свойство облегчает выравнивание латинских символов с идеографическими.
Не у всех символов есть соответствующая форма, и, значит, не на все символы будет влиять это значение:
Разметка:
<h2>alice's adventures in wonderland</h2>
Стили:
h2 {
text-transform: full-width;
}
Это свойство на данный момент поддерживается только в Firefox.
Дополнительная информация
Браузеры отлично поддерживают свойство text-transform, у всех основных браузеров с ним нет проблем.
Единственное исключение это значение full-width, которое работает пока только в Firefox. И такая непопулярность вполне может повлечь исключение этого значения из спецификаций.
Также есть небольшое отличие в обработке capitalize у Firefox и остальных браузеров.
Вот, например, Firefox:

Заметьте, что первая буква после дефиса не капитализируется. А вот тот же самый пример в Chrome:

В Chrome не делается исключений для первых букв после дефисов — они переводятся в заглавный регистр также как остальные. И это является дефолтным поведением для всех браузеров, кроме упомянутого выше Firefox.
И, наконец, не забывайте о каскадировании. Задание свойства text-transform для элемента-контейнера будет унаследовано всеми его потомками. Чтобы избежать неожиданных результатов, задавайте дочерним элементам text-transform в значение none.
Демонстрация значений свойства text-transform
Обработка пробелов: white-space
Когда вы нажимаете клавишу Tab, пробел или форсированно обрываете строку (с клавишей ENTER или тегом <br>), вы создаете пробелы в своем документе.
По умолчанию браузеры объединяют все последовательности пробелов в один, удаляют обрывы строки и заставляют строки занимать ширину контейнера. Это удобно потому что позволяет делать отступы и разделять фрагменты текста, сохраняя исходник документа читаемым и поддерживаемым, не заботясь о его отображении в браузере.
Однако, что делать, если у нас другая цель? Предположим, вы хотите сохранить все пробелы, которые вы создали в HTML-документе. Или вы хотите, чтобы фрагмент текста выводился как сниппет кода, со всеми отступами. Или же вы хотите вывести текст в одну линию, без переносов.
В тех случаях, когда вам нужно изменить дефолтное поведение браузера, свойство white-space предлагает несколько интересных вариантов.
Ключевое слово normal идентично дефолтному поведению — все лишние пробелы схлопываются в один, строка переводится после достижения края контейнера.
Значение pre
Ключевое слово pre позволяет вам вывести текст с сохранением всех пробелов и всех форсированных переводов строки в исходнике. И при превышении пределов контейнера строка не будет обрываться.
element {
white-space: pre;
}
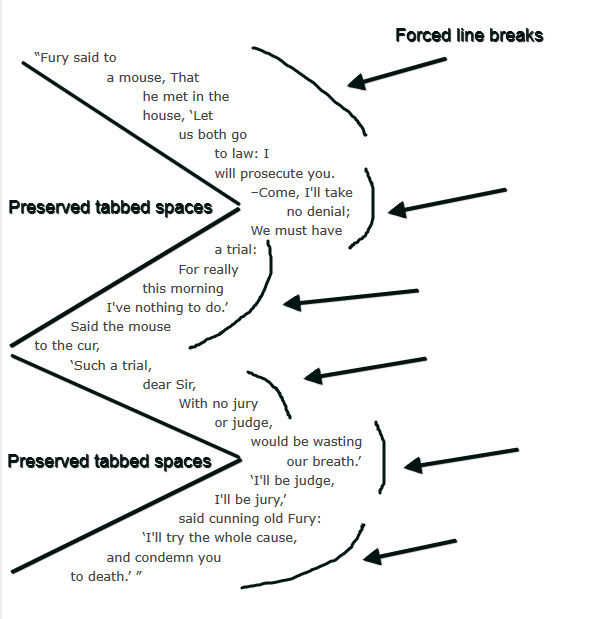

Если вы используете табы, то вы можете управлять их размером в пробелах с помощью свойства tab-size. Оно принимает значение в виде целого числа.
element {
white-space: pre;
-moz-tab-size: 4;
-o-tab-size: 4;
tab-size: 4;
}
Свойство tab-size поддерживают все современные браузеры, кроме браузеров от Microsoft (и даже Edge, увы), но если вы уверены, что вам это надо, используйте полифилл.
Значение pre-wrap
Это значение позволяет сохранить все множественные пробелы на месте, но если строка не вмещается в контейнер, она автоматически переносится.
Ключевое слово pre-wrap позволяет вам достигнуть желаемого результата.
element {
white-space: pre-wrap;
}
Отметьте, как каждая строка, выведенная в браузере, повторяет все переводы строки из исходника при наличии места в контейнере.


Однако, если вы уменьшите ширину браузера, вы заметите, что все строки ограничены шириной контейнера.
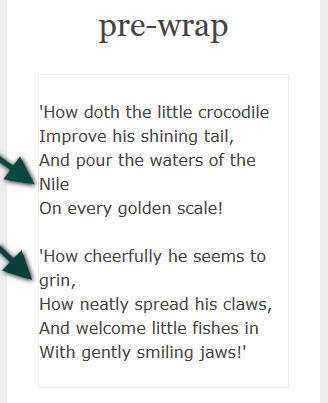
Значение pre-line
И, наконец, еще одно интересное значение свойства white-space — pre-line. Оно действует как дефолтное в части схлопывания пробелов в один и ограничения строки размером контейнера. Однако оно отрабатывает все форсированные переводы строки.
element {
white-space: pre-line;
}
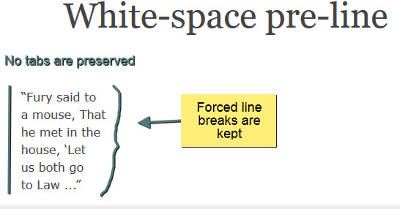

Демо на Codepen со значениями pre, pre-wrap и pre-line.
Значение nowrap
nowrap это, возможно, самое известное значение для white-space. Сталкивались вы с необходимостью задать какому-либо элементу дизайна неразрывность вне зависимости от ширины контейнера? Это делается с помощью white-space: nowrap;.
Луис Лазарис указывает на следующий случай использования этого значения.

На примере выше ссылка обозначена символом » и переносить его на следующую линию не желательно.

В этом и подобных случаях поможет значение nowrap.
Другой интересный случай использования nowrap описан Сарой Суайдан в справочнике по CSS от Codrops. Сара указывает, что это значение можно применять к любому строчному контенту, включая изображения.
Значение
nowrapможно использовать для создания горизонтального списка изображений в скроллящемся элементе (карусели), обеспечивая их совместный вывод внутри контейнера.
Я проиллюстрирую это предложение, создав базовую карусель на jQuery с использованием white-space: nowrap. Вот демо:
Управляем переносом строки с разбитием слов
Иногда дизайн портиться из-за отдельных очень длинных слов, не переносящихся на следующую строку и переполняющих контейнер. Это может быть длинный URL или комментарий с зажатой клавишей.
Для таких случаев у нас есть специальные свойства CSS.
Свойство word-wrap/overflow-wrap
Свойство overflow-wrap (раннее известное как word-wrap и до сих пор поддерживаемое во всех основных браузерах) работает, если свойство white-space допускает перенос в соответствии с размером строки. Возможные значения — normal и break-word.
Со значением normal слова разбиваются на всех традиционных маркерах — пробелы, дефисы и т.д.
Значение break-word позволяет разбить длинные слова, если иначе строка будет превышать доступный размер.
На картинке ниже изображен пример длинного слова, выходящего за пределы контейнера:

Теперь зададим этому элементу свойство overflow-wrap (и свойство word-wrap для совместимости) в значение break-word:
element {
word-wrap: break-word;
overflow-wrap: break-word;
}
Теперь сверхдлинное слово разбито на несколько строк, заполняющих всю ширину контейнера.

Свойство hyphens
Разбитие длинных слов это, конечно, хорошо. Однако, полученный текст может смутить читателей. Лучше будет, если разбитие слова будет сопровождаться установкой дефиса. Таким образом, читателям сразу становится ясно, что это одно слово, разделенное между строками. Этого можно достичь используя свойство hyphens, его можно сочетать с word-wrap: break-word.
Конкретно это значит, что значение auto свойства hyphens позволяет вывести дефис на месте разбития слова, если язык документа позволяет это делать в имеющемся источнике HTML. Чтобы это сработало, не забудьте задать правильный атрибут lang своему документу:
.break-word.hyphens-auto {
-moz-hyphens: auto;
-webkit-hyphens: auto;
-ms-hyphens: auto;
hyphens: auto;
}

Вы также можете отключить вывод дефисов, задав hyphens значение none:
.break-word.hyphens-none {
-moz-hyphens: none;
-webkit-hyphens: none;
-ms-hyphens: none;
hyphens: none;
}

Также у вас есть возможность вывести дефисы на разрывах строки там, где вы поставили их в разметке. Это делается с помощью значения manual:
.break-word.hyphens-manual {
-moz-hyphens: manual;
-webkit-hyphens: manual;
-ms-hyphens: manual;
hyphens: manual;
}


Основные браузеры поддерживают свойство hyphens с помощью вендорных префиксов, но в реализации есть некоторые различия. Последние на момент написания статьи версии Chrome (44) и Opera (30) не поддерживали значение auto.
Примеры с разбитием слов и переносами на Codepen
Управляем пространством между словами и буквами
Читаемость фрагмент текста зачастую зависит от нескольких факторов. В некоторых случаях, уменьшение или увеличение пространства между словами или буквами, то есть трекинг существенно улучшает читаемость.
В CSS есть свойства word-spacing и letter-spacing для управления расстоянием между словами и буквами соответственно.
Свойство word-spacing
Это свойство может принимать следующие значения:
normal<length>(задание непосредственно числового значения в абсолютных единицах)percentage(задание значения в процентах)
normal выводит заданное по умолчанию расстояние между буквами. Это расстояние зависит от используемого шрифта и браузера.
.normal {
word-spacing: normal;
}
Числовое значение добавляет указанный промежуток к дефолтному ( вычитает, если задано отрицательное значение):
.length {
word-spacing: 0.5em;
}
Значение в процентах работает также как и числовое. На данный момент оно не поддерживается браузерами и, скорее всего, будет удалено из будущих черновиков спецификации.
.percentage {
word-spacing: 1%;
}

Свойство letter-spacing
Свойство letter-spacing принимает два вида значений: normal или числовое значение с единицами измерения.
Свойство normal сбрасывает любое раннее установленное значение letter-spacing на дефолтное. Например, если вы задали родительскому элементу letter-spacing в 1em, вы можете отменить это для дочерних с помощью normal.
element {
letter-spacing: normal;
}

Числовое значение задается в единицах исчисления, например в em или в пикселях, вы можете увеличить расстояние дефолтное расстояние или уменьшить задав отрицательное значение.
element {
letter-spacing: 1em;
}

Дополнение
word-spacing применимо не только к словам — его можно использовать с любым строчным или строчно-блочным содержимым.
Также вы можете анимировать word-spacing и letter-spacing. Однако в CSS-переходах значение normal в letter-spacing не работает в Firefox (39), просто замените значение на 0em.
Вот небольшое демо с анимацией текста, использующей word-spacing и letter-spacing:
Опции CSS для выравнивания текста: text-align
Свойство text-align используется в вебе уже давно. Оно контролирует выравнивание строчного контента (текста или изображений) внутри блочного контейнера. Ключевые слова left и right выравнивают содержимое по соответствующим краям контейнера. center — выравнивает по центру, а justify делает все строки одинаковой длины (кроме последней в абзаце).
В спецификации появилась пара новых значений, полезных для сайтов,использующих написание справа налево (RTL): start и end.
Для обычных языков (LTR) они соответствуют left и right соответственно. А для языков (RTL) start соответствует right, а end — left.
element {
text-align: start;
}

element {
text-align: end;
}

Применение text-align: match-parent к дочернему элементу вынудит его унаследовать тоже выравнивание, что и у родительского элемента. И значения start и end в таком случае будут расчитаны исходя из направления языка родительского элемента.
Свойство text-align-last
Это свойство отвечает за выравнивание последней строки абзаца текста. Оно принимает те же ключевые значения, что и text-align, за исключением того, что дефолтным является значение auto. auto выравнивает последнюю строку в соответствии со значением text-align, если text-align не задано используется значение start.
На момент написания, это свойство плохо поддерживается браузерами. Поэтому пока стоит избегать его использования или делать это с осторожностью.
Демо с современными свойствами для выравнивания текста на Codepen
Отступы в тексте: text-indent
Отступы в тексте обычно делаются в первой строке параграфа, хотя и не являются распространенной практикой на веб-сайтах. Вместо этого обычно помещается пустая строка, разделяющая параграфы.
Тем не менее, иногда отступ в первой строке иногда используется, например, для имитации классических книжных дизайнов.

Если вы хотите использовать эту технику в своем дизайне, в CSS есть свойство text-indent. Рассмотрим его возможные значения.
Числовое значение можно задать в пикселях, em’aх и других поддерживаемых единицах:
element {
text-indent: 2em;
}
В том числе и в процентах от ширины контейнера:
element {
text-indent: 6%;
}
Значение each-line добавляет отступ не только первой строке, но и любой строке после разрыва строки (ENTER или <br>). На строки, переносимые по причине заполнения контейнера эти отступы не распространяются.
Значение hanging добавляет отступ ко всем строкам, кроме первой.
Два последних значения: each-line и hanging являются экспериментальными и не реализованы на данный момент ни в одном из браузеров.
Демонстрация отступов текста на Codepen