
Excel-тестирования и задания
Примеры заданий для проверки уровня владения MS Excel
Здесь Вы можете бесплатно скачать файлы и выполнить задания. Отличная тренировка и возможность проверить свои навыки.
New! 1. Пример Excel-заданий для прохождения собеседования (Sales Analyst)
РЕШЕНИЕ ЗАДАНИЙ. Скачайте файл с решениями и посмотрите видеоразбор ниже.
2. Пример Excel-заданий в зарубежную компанию (аналитик)
2. РЕШЕНИЕ ЗАДАНИЙ. Скачайте файл с решениями и посмотрите видеоразбор ниже.
3. Пример Excel-заданий в FMCG-компанию
3. РЕШЕНИЕ ЗАДАНИЙ. Скачайте файл с решениями и проверьте себя.
На эту страницу будут добавляться новые файлы и задания.
Разборы заданий я буду публиковать в моем блоге @valeriarti и на YouTube — канале Artis Academy.

© 2017-2022 Академия Аналитики Артис Валерии

Полная «режиссерская» версия доклада, сделанного SQA Days 2008
Автор: Сергей Талалаев
Оригинальная публикация
Доклад затрагивает проблему выбора унифицированного хранилища тестовых данных для проведения автоматизированных функциональных и нагрузочных тестов.
Приводимый в докладе подход никоим образом не претендует на истину в последней инстанции и отражает лишь удачный опыт автора в практическом применения данных механизмов в ходе реализации проектов функциональной автоматизации.
1. Предыстория
1.1 Автоматизация: от эйфории до созерцания
Есть несколько типичных ошибок, которые допускаются при первых попытках внедрения автоматизации функционального тестирования. Эти ошибки допускаются естественно из-за отсутствия опыта в такого вида разработках и кроме того в некоторой степени ”поощряются” кажущейся легкостью работы в современных тестовых фреймворках при использовании механизмов макрозаписи (трансляции действий пользователя напрямую в тестовый скрипт). К сожалению подход при котором вся тестовая команда записывает килотонны кода, что вызывает невиданный прилив энтузиазма как у самих членов команды так и у руководства, приводит в конце концов к плачевным результатам.
Рано или поздно наступает тяжелый момент, когда нужно остановиться, отдышаться и трезвым взглядом посмотреть на дело рук своих, чтобы трезво оценить во что же выльется переделка.
В нашем случае ситуация оказалась настолько запущенной, что было принято решении отказаться от существующих скриптов такого вида и написании их с нуля в строгом соответствии с оговоренными правилами которые впоследствии оформились в документ под названием “Test scriprting guideline”.
Я сознательно ушел от подробного разбора причин, которые привели к необходимости столь радикальных действий, чтобы детально рассмотреть их в следующей части доклада.
1.2 Проблема больших чисел
Сформулировать её можно следующим образом: при увеличении масштаба процесса на первый план выходят совершенно неучтенные и казалось бы незначительные факторы.
Правило очень актуальное для экспериментальных областей физики и химии оказывается как нельзя кстати и в процессе разработки автоматизированных тестов. Существует много возможностей для применения этого правила с точки зрения оптимизации процесса, но мы остановимся на следующей зависимости:
Количество скриптов : Время затрачиваемое на их поддержку
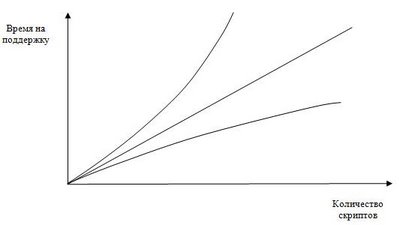
Если отобразить эту зависимость в виде графика где по оси Х будет отображаться количество скриптов а по оси Y – время необходимое для поддрежки этого количства скриптов, то мы получим три варианта развития событий.
Первый вариант – график выше линейного, говорит о том, что при разработке скриптов не использовались методики оптимизации, наверняка есть повторимость кода и структура скриптов не унифицирована.
Второй вариант – линейный, очевидно гораздо лучше первого рассмотренного варианта, но тем не менее он предлагает обычный экстенсивный путь развития при котором чем большее количество скриптов мы хотим реализовать тем большая команда автоматизации нам потребуется.
Третий вариант – очевидно,что именно к нему и нужно стремится, предполагает, что при увеличении скриптов время требуемое на их поддрежку растет незначительно.
Для того чтобы поддержка скриптов не легла непосильным бременем на тестовую команду при разработке тестов нужно обязательно уделять внимание таким моментам как:
- Унификация структуры скриптов (с последующим документированием этой структуры)
- Вынос общих бизнес-функций в библиотеки/классы
- Использование внешних источников данных
Несомненно все три озвученных практики являются важными, но согласно выбранной тематики доклада детальному разбору подвергнем лишь последнюю из этого списка.
1.3 Идентификация проблемы.
Попытаемся сформулировать требования, которым должно удовлетворять внешнее хранилище данных и на основании этих требований оценить возможные варианты реализации.
Существуют 3 независимых пользователя нашего хранилища тестовых данных со своими, совершенно казалось бы не пересекающимися требованиями:

Основным требованием предъявляемым со стороны тестовой команды (а здесь мы имеем ввиду именно функциональных тестировщиков) является простота создания и поддержки тестовых данных и отсутствие необходимости изучения каких-либо узкоспециализированных инструментов и сложных техник.
Со стороны команды автоматизации основное требование – это простота интеграции в существующие скрипты. По крайней мере процесс интеграци долджне быть не сложнее чем при применении стандартных встроенных хранилищ.
Не всегда но тем не менее со стороны заказчика тоже просыпается интерес к тестовым данным, которые используются при проведении автоматических тестов. И основное требование с этой стороны – это доступное визуальное оформление этих тестовых данных.
В следующей части доклада я постараюсь показать вам, что есть стандартные инструменты готовые удовлетворить все три потока требований. Но сначала рассмотрим, что предоставляется для реализации хранилищ самим инструментарием с которым мне приходилось сталкиваться в ходе работы.
2. Стандартные решения – достоинства и недостатки
2.1 Реализация внутренних хранилищ в семействах продуктов IBM Rational
В качестве встроенного хранилища данных в семействе продуктов Rational используются так называемые Датапулы (Datapools). Они представляют собой некий урезанный вариант таблиц базы данных.
Из положительных сторон можно отметить:
- встроенный механизм генерации данных
- родная поддержка на уровне скрипта
- возможность использования как для функционального так и для нагрузочного тестирования
Из минусов:
- неудобство редактирования данных
- отсутствие возможности группировки данных
2.2 Реализация внутренних хранилищ в семействах продуктов HP Mercury
В качестве встроенного хранилища данных в семействе продуктов HP Mercury используются стандартные Excel файлы.
Из положительных сторон можно отметить:
- удобство редактирования
- родная поддержка на уровне скрипта
Из минусов:
- при редактировании через встроенный редактор из файла удалятся всё форматирование
- отсутствие возможности группировки данных
2.3 Другие варианты хранения данных
-
CVS файлы
Неудобство работы напрямую в файле. При использовании того же Excel в качестве редактора получаем 2-х проходную работу. Проблемы с группировкой и отсутствием валидации на входе.
-
XML файлы
Персонал должен как минимум понимать структуру XML, владеть одним из редакторов для манипуляции с файлами такого вида. Сложно задается валидация входных значений.
3. Поиск компромисса
3.1 Почему Excel?
При выборе варианта хранилища данных мы в качестве основного критерия выбрали удобство подготовки и редактирования данных. Акцент при выборе был сознательно смещен в эту сторону так как продукт был действительно большим и сложным и без помощи функциональной тестовой команды автоматизаторам было бы нереально подготовить такой объем данных.
Со стороны команды автоматизации было сделано допущение (впоследствии оно оказалось верным), что на уровне скрипта мы сможем создать механизмы по крайней мере не уступающие стандартным в удобстве использования. С этой позиции Excel был лучшим кандидатом, но в ходе реализации выяснялись некоторые особенности изучив которые мы смогли получить эффективную отдачу от выбранного инструмента. О них поговорим в следующей части доклада.
3.2 Хитрости и трюки
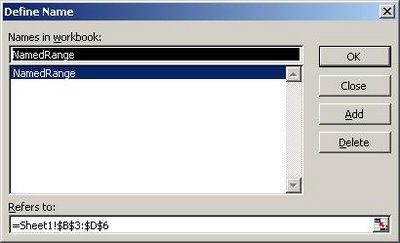
Для того чтобы получить видимые для ODBC таблицы в Excel- файле вы должны определенным образом разметить интересующие вас подмножества ячеек. Для этой цели служит функциональность называемая Names (именованные диапазоны). Создать именованный диапазон можно через “Define name” диалог (Insert > Name > Define) или через Formulas > Define Name в 2007-ом офисе.
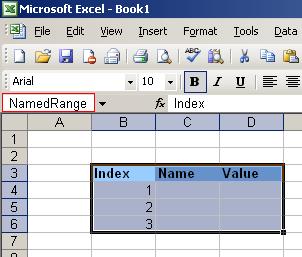
После такого выделения ваши имена становятся доступны как таблицы для ODBC драйвера. Для проверки того что диапазон задан верно необходимо выделить помеченные ячейки и в Navigation bar должно отбразиться заданное имя.
3.3 «Ложка дегтя»: ограничения использования
Конечно все это было бы слишком хорошо если бы не было каких-либо ограничивающих факторов и они к сожалению есть:
- мы не сможем использовать наши тестовые данные для нагрузочных тестов как например в случае использования “родных” хранилищ Rational;
- у нас не будет возможности запускать наши тесты в многоплатформенной среде даже если сама тестовая платформа это позволяет.
Но из своей практики могу отметить, что эти ограничения не являются критичными для большинства тестовых проектов.
4. Из личного опыта: «Датадривен – это просто»
4.1 Задача: разработать автоматические тесты с возможностью кастомизации без изменения кода.
Кастомизация предполагалась следующая:
- скрипты должны были выполнятся как в рамках Smoke тестов так и в рамках основного цикла тестирования
- существовала необходимость использовать скрипты в том числе для загрузки некоторых специфичных начальных тестовых данных с UI (общесистемные данные грузились напрямую в БД на этапе сборки билда)
То есть было необходимо предусмотреть возможность запуска скриптов с разными наборами тестовых данных и также возможность отключения точек проверки для случая заполнения данных.
4.2 Вариант решения
- Использование property файлов для группы скриптов, в которых для каждого скрипта задаются его тестовые данные (в нашем случае имя Excel файла)
- На уровне самого скрипта задался набор данных по умолчанию, который позволял запускать скрипты без параметров
- На уровне property файлов также была возможность отключить отработку точек проверки
Реализация озвученных механизмов естественно потребовала четкой унификации структуры разрабатываемых скриптов, что было зафиксировано в руководстве по разработке скриптов.
4.3 Анализ полученного результата
В результате мы получили достаточно гибкую структуру решающую все поставленные задачи. Кроме того строгая унификация подходов к разработке избавляла нас от серьезных временных затрат при вхождении нового человека в команду автоматизации и при отладке скриптов после изменения UI.
Из минусов можно отметить следующий момент. Так как фреймворк реализовывался на обычном процедуральном языке (расширение VB) то все сервисные механизмы по работе с property файлами должны были присутствовать на уровне скриптов. И хотя реального кода там было не более 10 строк тем не менее это захламляло скрипт.
Дальнейшая реализация такого же подхода в рамках OO-языка (Functional Tester + Java) показала насколько эффективно сервисный код может быть скрыт на верхнем уровне иерархии.
5.1 Возможность использования Excel в качестве источника XML-данных
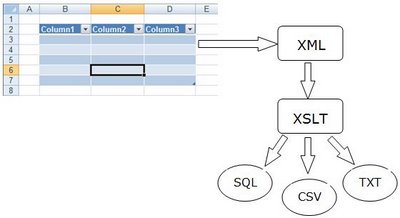
Начиная с 2003-ей версии офиса в Excel появилась возможность интеграции с XML, причем как в сторону загрузки данных в Excel таблицы так и в сторону экспорта табличных данных в XML файл. Эта функциональность (называемая в офисе 2003 Lists а в 2007 – Tables) добавила еще больше гибкости в процедуру подготовки тестовых данных. Теперь появилась возможность оперировать с текстовыми данными практически любого вида. Единственно, что требуется дополнительно реализовать — это XSLT преобразование из полученного в процесе экспорта XML файла к требуемому для приложения виду.
5.2 Варианты применения
Лежащий на поверхности путь преобразования – это подготовка прямых SQL операторов для прямой заливки данных в базу. Кроме того могут понадобиться какие-либо специфичные форматы данных в основе которых лежат табличные данные (например, данные для Web- сервисов).
Очевидное преимущество получаемое от такой схемы работы – это простота поддержки и модификации наряду с гибкостью по отношению к выходным форматам.
6. Из личного опыта: «Пойди туда, не знаю куда – найди то, не знаю что»
6.1 Задача: протестировать процедуру миграции БД
Особенность задачи состояла в том, что заказчик (очень крупная страховая компания) неохотно шел на предоставление информации о структуре данных в старой БД. Не могу сказать что это было вызвано прямым нежеланием сотрудничать с нами. Вероятнее всего желание сотрудничества терялось где-то в хитросплетениях бюрократических процедур и просто не доходило до конкретного исполнителя. Тем не менее сроки для нас были поставлены достаточно жесткие и аппелировать потом к совести заказчика потрясая кипой грозных писем с нашей стороны особого желания не было.
На тот момент функционал по миграции уже более менее был готов к тестированию и для набивки тестовых данных не хватало детализации старой структуры в которую требовалось эти данные загружать.
Таким образом мы понимали, что подготовленные нами данные (а они естественно должны были быть в виде скриптов БД) обязательно потребуют модификации после уточнения оставшихся вопросов.
6.2 Вариант решения
Вот тут как нельзя кстати пригодилась новая функциональность Excel позволяющая выгружать данные в XML.
Мы сначала подготовили данные для понятных нам тестовых случаев и согласно предполагаемой структуре сделали прослойку для генерации скриптов (то есть приготовили набор XSL файлов необходимый для конвертации выгружаемых XML в требуемый нам формат).
Имея на руках уже готовые тестовые данные разговаривать с заказчиком стало гораздо проще. Стало очевидным что с нашей стороны были сделаны все шаги и без их активного участия дальше двигаться невозможно. Поэтому началось активное общение с разбором возникающих проблем и постепенное доведение наших скриптов до рабочего состояния.
6.3 Анализ полученного результата
Из несомненных плюсов примененного подхода хочется отметить, что мы смогли начать работу даже не имея на руках полностью разжеванной спецификации по БД, что при любых других вариантах решения привело к большим затратам по модификации готовых сриптов. Нам этого удалось избежать, сохранив по максиму уже подготовленные данные.
Из минусов или скажем так из особенностей нужно отметить что на стороне тестовой команды должен был присутствовать человек имеющий опыт работы с XML+XSLT. Но это, я считаю, является очень хорошим стимулом к изучению на практике новых областей не совсем типичных для просто функционального тестирования.
7. Из личного опыта: «Хотели бы помочь, но по-своему»
7.1 Задача: получить тестовые данные для проведения UAT от заказчика
В ходе работ по ”оживлению” старого демо-приложения выяснилось, что мы не можем убедиться в корректности работы функциональности отчетов в восстановленном функционале из-за полного отсутствия документации на эту часть приложения. Заказчик воспринял ситуацию адекватно и предложил свою помощь в разрешении проблемы, а именно предложил нам взять на себя подготовкку тестовых данных для этой части функционала. Наша радость к сожалению была очень недолгой, когда мы увидели в каком виде к нам начали приходить эти данные. Ни о какой организованной струтуре речи ни шло. Данные для полей с ограниченным набором списковых значений например могли отличаться от набора к набору ( как пример в одном наборе период назывался “semi-annual”, а в другом – “Semi annual”). Мы пришли к выводу, что на вычистку таких данных уйдет больше времени, если они не будут жестко следовать предопределенному формату.
7.2 Вариант решения
Решено было на основании уже полученных первых данных от заказчика и дальнейших консультаций подготовить шаблон для ввода данных с жесткими ограничениями на вводимые данные. В качестве оболочки для создания такого шаблона был выбран Excel с его функциональностью по валидации вводимых данных. Использовались такие типы валидаии как
- ограничение вводимых значений только значениями из списка
- задание диапазонов допустимых значений
В дальнейшем предполагалось использовать механизм выгрузки подготовленных данных в XML формат и конвертацию полученных XML файлов в последовательность SQL-операторов для загрузки данных напрямую в БД.
7.3 Анализ полученного результата
Шаблоны были успешно подготовлены, опробованы и отосланы заказчику для продолжения работы по набивке данных. Но видимо первый порыв альтруизма уже прошел и дальнейшего продолжения эта история увы не получила. Тем не менее мы со своей стороны получили опыт в реализации шаблонов для входных данных, который несомненно пригодится в будущем.
Обсудить в форуме
Создание
интерактивного теста в Excel
1 этап
1.
Запустите программу MS Excel.
2.
Выполните команду Сервис – Макрос – Безопасность. В
открывшемся диалоговом окне Безопасность во вкладке Уровень
безопасности установите Средняя.
3.
В ячейку D3 введите запись ФИО, а в ячейку D4 – Класс.
2 этап
Программа Excel
позволяет создавать тесты со свободным ответом (когда обучаемому не дается
варианта ответа) и с выборочным ответом (когда обучаемому предлагаются варианты
ответов, из которых он выбирает правильный).
•
При создании теста со свободным ответом создается группа ячеек
для ввода ответа.
•
При создании теста с выборочным ответом или теста на
сопоставление выполняется следующая последовательность действий:
1)
 Выбирается меню Данные.
Выбирается меню Данные.
2)
В ниспадающем меню выбирается команда Проверка.
Рисунок 1
 3) В диалоговом окне выбирается тип данных — Список
3) В диалоговом окне выбирается тип данных — Список
Рисунок 2
 4) В окне Источник
4) В окне Источник
перечисляются варианты ответов
через точку с запятой.
Рисунок 3
Результатом выполнения
операций будет список с выборочными ответами, из которых обучаемый должен будет
выбрать один ответ.

Рисунок 4
4. Закрепим полученные знания из
п.1. Введите в ячейку E4 списки классов, которые будут проходить тестирование.

Рисунок 5
5. Оформим название теста: Тест по
музыке на тему «Музыкальные термины». В строке 6 оформите заголовки столбцов
теста. В ячейки В7:В16 введите вопросы, а в ячейки С7:С16 введите ответы в
виде списка с выборочными четырьмя ответами, среди которых один правильный.
Лист 1 переименуйте Тест.

Рисунок 6
Создадим макрос,
который очищает поля для возможности тестирования многократно и назначим макрос
кнопке с названием Очистка.
4.
Выполните команду Сервис – Макрос – Начать запись. Дайте
имя макросу Очистка. Выделите все поля с ответами и нажмите клавишу delete.
Также удалите фамилию ученика и класс.
5.
Выполните команду Сервис – Макрос – Остановить запись.
Теперь нарисуем кнопку и назначим ей макрос Очистка.
8.
Выполните команду Вид – Панели инструментов – Формы.
9.
Найдите инструмент Кнопка, активизируйте его (щелкните на
нем) и нарисуйте кнопку на листе, правее ответов (см. Рис.6).
10.
Назначьте ей макрос Очистка.
11.
Сохраните тест.
3 этап
Для подведения итогов
тестирования можно предусмотреть специальный лист, переименовав его в
Результат, на котором будут подведены итоги ответов.
Создадим на листе ответов 5 макросов:
•
Ваш ответ – ученик может увидеть свои ответы
•
Результат – ученик может увидеть, на какие вопросы он ответил
неверно.
•
Верный ответ – ученик может увидеть правильные ответы.
•
Оценка – ученик может увидеть свою оценку.
•
Очистка – для возможности многократного тестирования.
12.
В строки А2 и А3 введите записи ФИО и Класс соответственно.
13.
Скопируйте с первого листа номера вопросов и сами вопросы в
столбцы А6:А15 и В6:В15.
14.
Введите остальные заголовки таблицы, согласно рисунку (Ваш ответ,
Результат, Верный ответ).
3

Рисунок 7 Создадим
первый макрос – Ваш ответ.
Перед созданием
макросов на втором листе курсор на листе ответов устанавливайте в какую-нибудь
пустую ячейку, где нет записей, например, для нашего примера F9.
15.
Выполните команду Сервис – Макрос – Начать запись. Дайте
имя макросу Ваш_ответ.
Чтобы на этом листе отображались
фамилия и имя ученика, создадим ссылку на соответствующую ячейку первого листа.
16.
Установите курсор в ячейку В2, нажмите знак «=», перейдите на
лист вопросов и щелкните мышью в ячейку Е4 (Петров Вася) и нажмите клавишу
«Enter». Аналогично введите класс.
17.
Таким же образом в листе ответов введите в ячейку С6 ответ с
листа вопросов.
18.
Скопируйте остальные варианты ответов: установите курсор в ячейку
С6 и подведите его в правый нижний угол этой ячейки. Когда курсор примет вид
«+», протяните вниз до ячейки С16.
19.
Остановите макрос. Нарисуйте кнопку и назначьте ей макрос Ваш
ответ.
Далее оформляем столбец Результат. Для этого
используем логическую функцию «если».
20.
Создайте второй макрос – Результат. На листе ответов
установите курсор в ячейку D6.
21.
Выполните команду Вставка – Функция (или кнопка fx рядом со строкой формул).
Выберите в категории Логические функцию Если.
22.
Заполните поля согласно Рис 7. Текстовые ответы необходимо
заключать в кавычки.
23.
Аналогичным образом заполните ячейки D7:D10.
24.
Остановите макрос. Нарисуйте кнопку и назначьте ей макрос Результат.

Рисунок 8 Далее оформляем столбец Верный ответ.
25.
Создайте третий макрос – назовите его Ответ1. Установите
курсор в ячейку Е6.
Введите в ячейки E6:E15 верные ответы к вопросам.
26.
Остановите макрос. Нарисуйте кнопку и назначьте ей макрос Верный
ответ.
Далее оформляем столбец
Оценка. Для этого используем логическую функцию «если» и статистическую
функцию «счетесли».
27.
В строки В17 и В18 введите соответственно записи Количество
верных ответов, Количество неверных ответов (см. Рис. 7).
28.
Создайте четвертый макрос – назовите его Оценка.
29.
Установите курсор в ячейку С17. Выполните команду Вставка – Функция
( или кнопка fx рядом со строкой формул). Выберите в
категории Статистические функцию Счетесли.
30.
Выделите на листе ответов диапазон D6:D15.
31.
В строке критерий введите запись «верно» и нажмите кнопку ОК.

5
Рисунок 9
32.
Аналогичным образом введите количество неверных ответов. Только в
строке критерий введите запись «неверно».
Для выставления оценки используем
функцию «если». Критерии оценивания:
|
Кол-во верных ответов |
Оценка |
|
9-10 |
5 |
|
7-8 |
4 |
|
5-6 |
3 |
|
>4 |
2 |
Для Excel эта запись будет выглядеть следующим образом:
ЕСЛИ(C17>8;5;ЕСЛИ(C17>6;4;ЕСЛИ(C17>4;3;2)))
33.
Установите курсор в ячейку С21. Выполните команду Вставка –
Функция (или кнопка fx рядом со строкой формул). Выберите в
категории Логические функцию Если.
34.
После открытия окна Аргументы функции щелкните мышью в
ячейку С17. Ее адрес появится в строке Лог_выражение. Далее введите
записи согласно Рис. 10.
35.
Установите курсор в строку Значение_если_ложь и нажмите на
кнопку ЕСЛИ (рядом со строкой формул) для создания следующего вложения функции
Если.

Рисунок 10
При
каждом последующем открытии окна Аргументы функций нужно вводить записи
|
Лог_выражение |
С17>6 |
C17>4 |
|
Значение_если_истина |
4 |
3 |
|
Значение_если_ложь |
(здесь нажимаем кнопку ЕСЛИ) |
2 |
36. Остановите макрос.
Нарисуйте кнопку и назначьте ей макрос Оценка.
17 авг. 2022 г.
читать 3 мин
Одновыборочный z-критерий используется для проверки того, значительно ли среднее значение совокупности отличается от некоторого гипотетического значения.
Двухвыборочный z-критерий используется для проверки того, значительно ли отличаются друг от друга два средних значения совокупности.
В следующих примерах показано, как выполнять каждый тип теста в Excel.
Пример 1: один образец Z-теста в Excel
Предположим, что IQ в популяции нормально распределен со средним значением μ = 100 и стандартным отклонением σ = 15.
Ученый хочет знать, влияет ли новое лекарство на уровень IQ, поэтому она набирает 20 пациентов для его использования в течение одного месяца и записывает их уровни IQ в конце месяца.
Мы можем использовать следующую формулу в Excel, чтобы выполнить z-тест с одним образцом, чтобы определить, вызывает ли новое лекарство значительную разницу в уровнях IQ:
=Z.TEST( A2:A21 , 100, 15)
На следующем снимке экрана показано, как использовать эту формулу на практике:
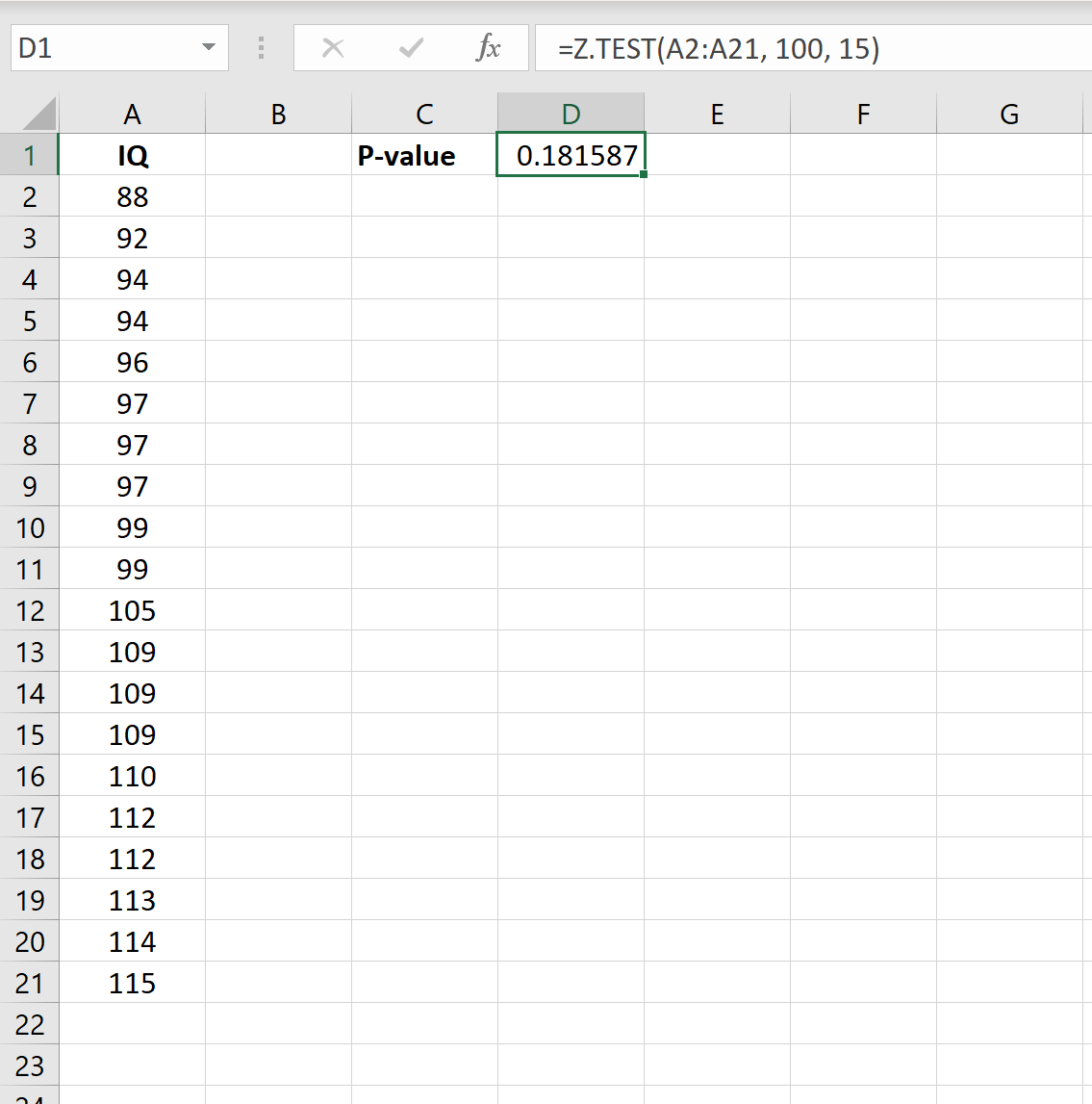
Одностороннее значение p равно 0,181587.Поскольку мы проводим двусторонний тест, мы можем умножить это значение на 2, чтобы получить p = 0,363174 .
Поскольку это p-значение не меньше 0,05, у нас нет достаточных доказательств, чтобы отклонить нулевую гипотезу.
Таким образом, мы делаем вывод, что новый препарат не оказывает существенного влияния на уровень IQ.
Пример 2: два образца Z-теста в Excel
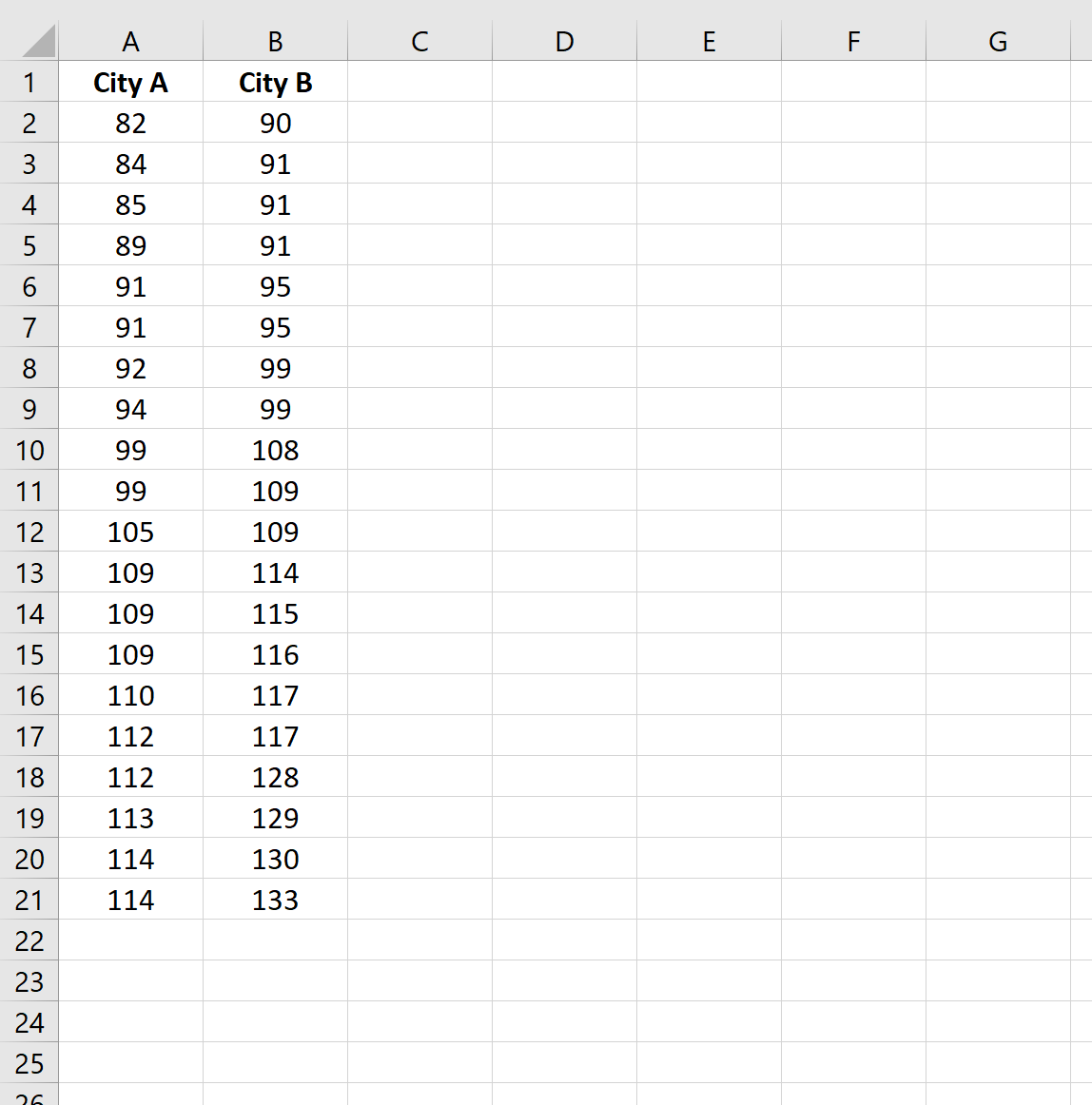
Предположим, что известно, что уровни IQ среди людей в двух разных городах нормально распределены со стандартными отклонениями населения, равными 15.
Ученый хочет знать, различается ли средний уровень IQ между людьми в городе А и городе Б, поэтому он выбирает простую случайную выборку из 20 человек из каждого города и записывает их уровни IQ.
На следующем снимке экрана показаны уровни IQ для людей в каждой выборке:
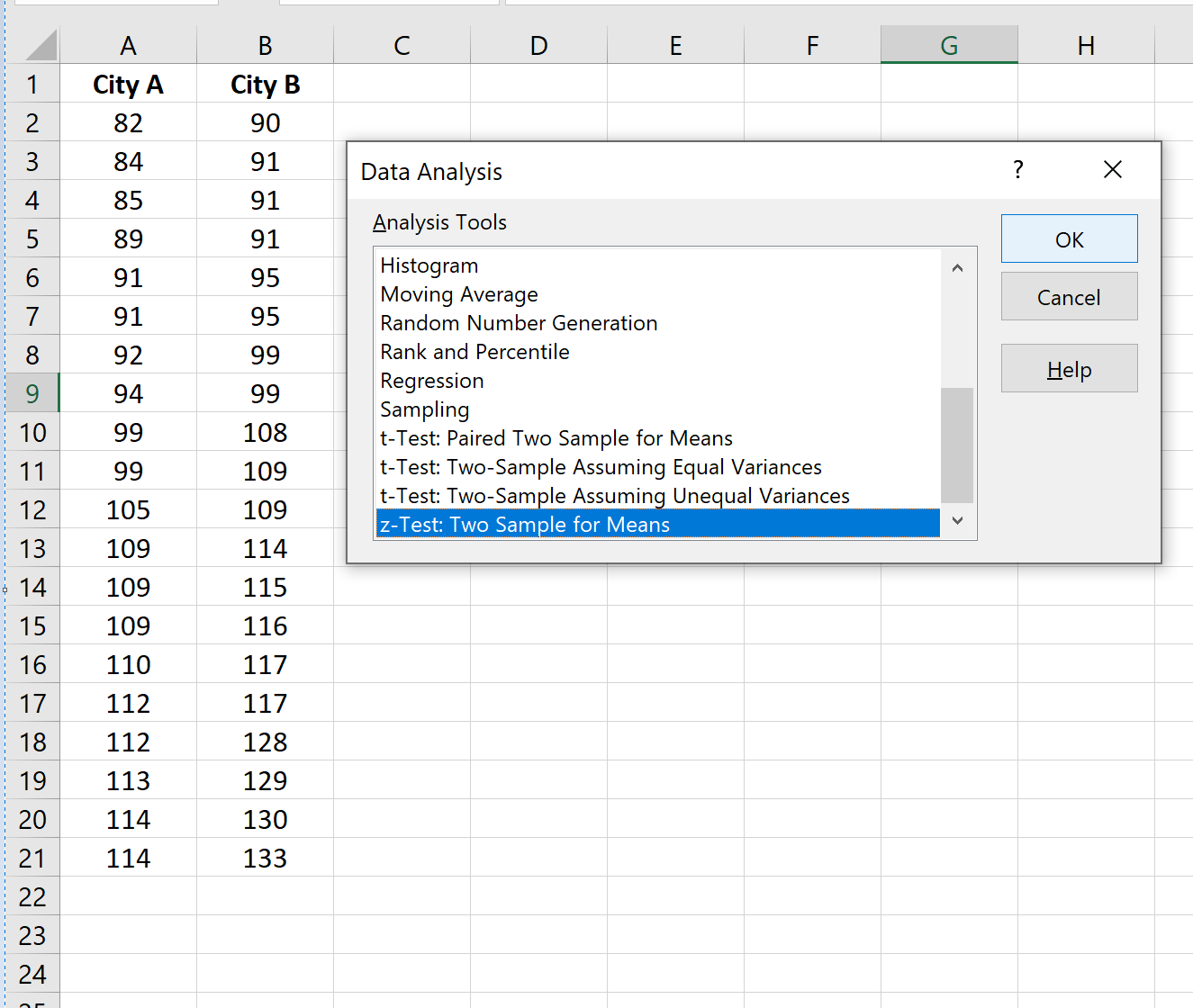
Чтобы выполнить двухвыборочный z-тест, чтобы определить, различается ли средний уровень IQ между двумя городами, щелкните вкладку « Данные » на верхней ленте, затем нажмите кнопку « Анализ данных» в группе « Анализ ».

Если вы не видите параметр « Анализ данных» , вам необходимо сначала загрузить пакет инструментов анализа в Excel.
После того, как вы нажмете эту кнопку, выберите z-Test: Two Sample for Means в новом появившемся окне:
После того, как вы нажмете OK , вы можете заполнить следующую информацию:
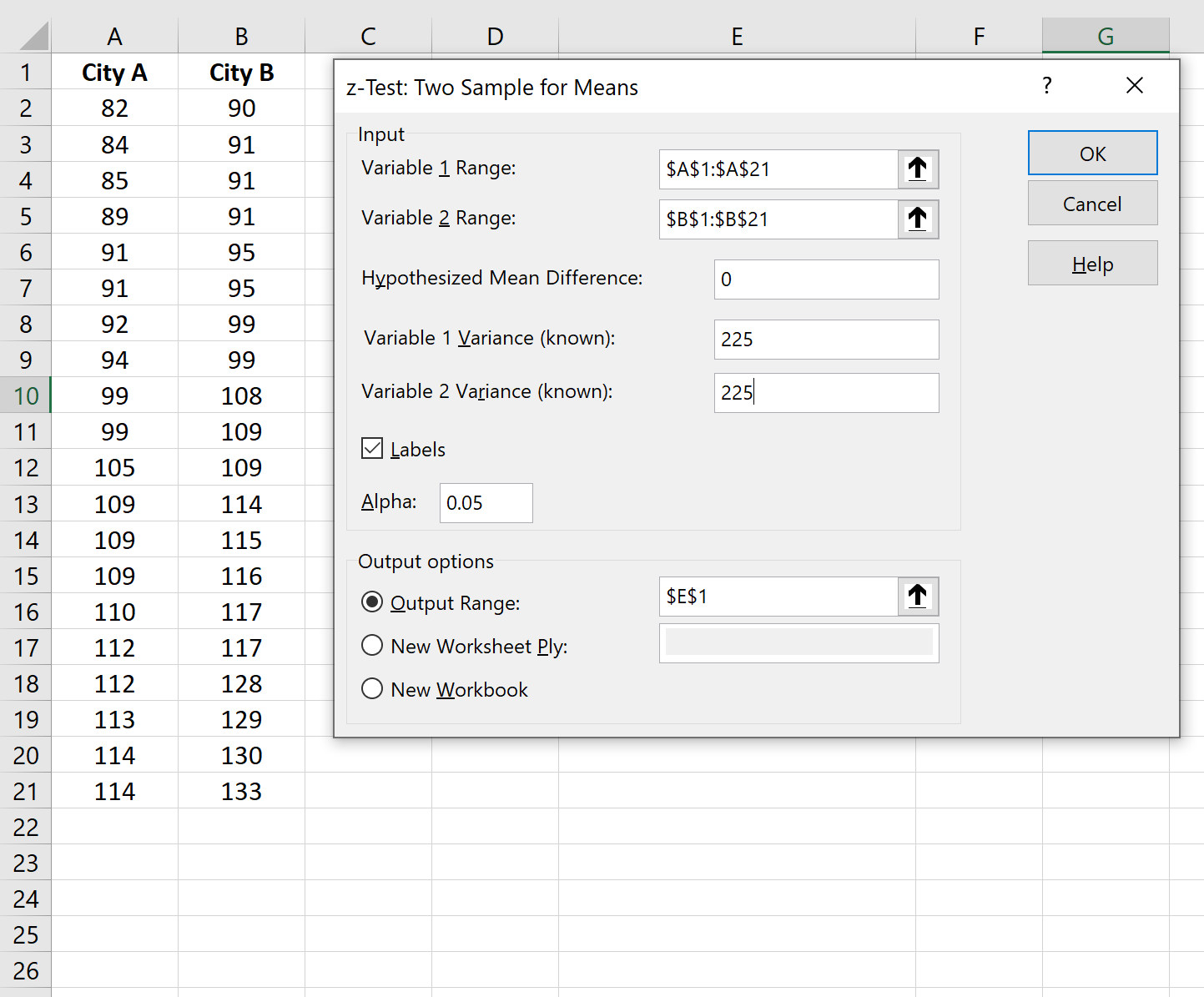
Как только вы нажмете OK , результаты появятся в ячейке E1:
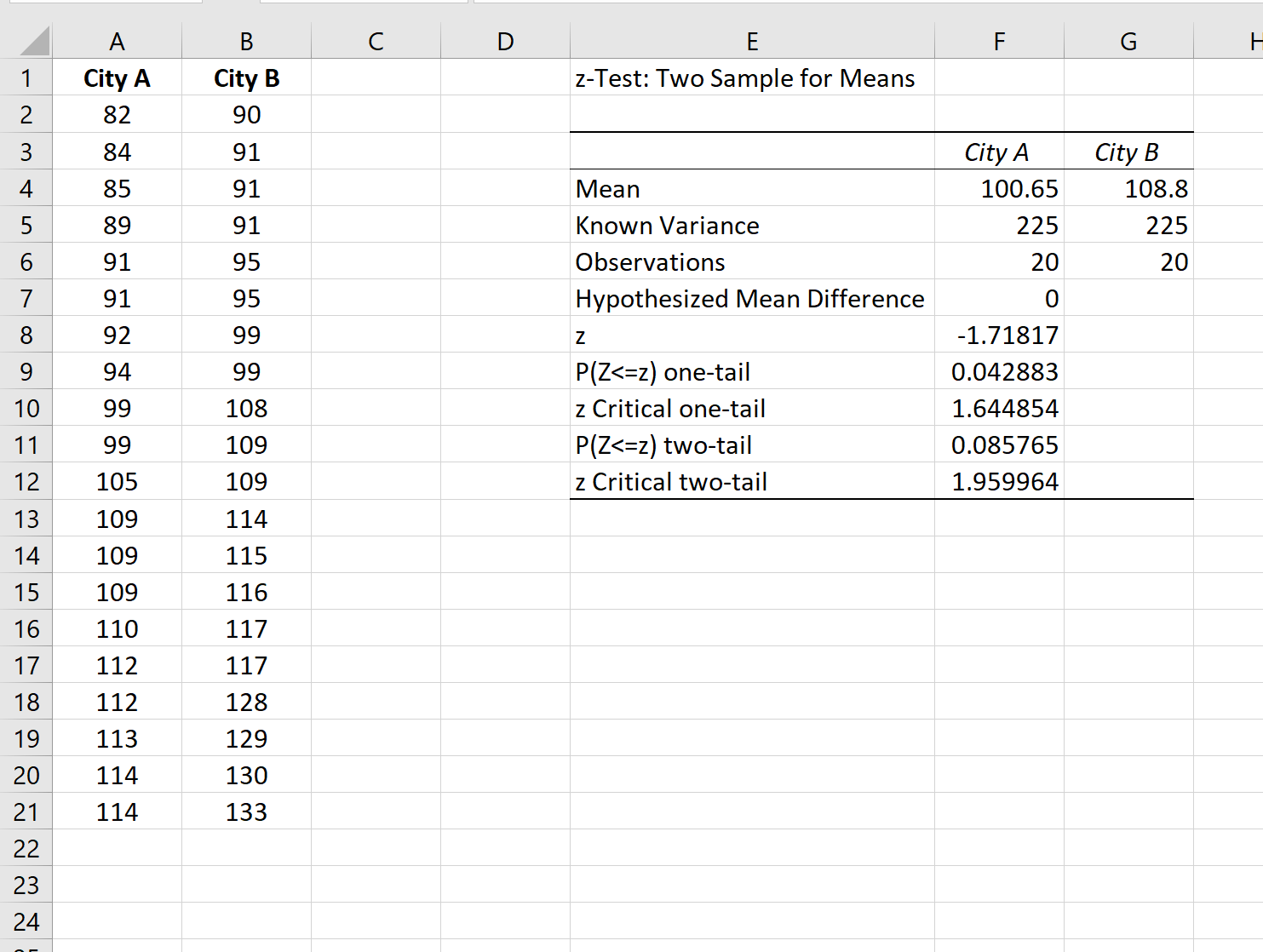
Статистика теста для двух выборочных z-тестов составляет -1,71817 , а соответствующее значение p равно 0,085765.
Поскольку это p-значение не меньше 0,05, у нас нет достаточных доказательств, чтобы отклонить нулевую гипотезу.
Таким образом, мы делаем вывод, что средний уровень IQ между двумя городами существенно не различается.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные статистические тесты в Excel:
Как провести одновыборочный t-тест в Excel
Как провести двухвыборочный t-тест в Excel
Как провести t-тест для парных выборок в Excel
Как выполнить t-критерий Уэлча в Excel
Многие пользователи активно применяют Excel для генерирования отчетов, их последующей редакции. Для удобного просмотра информации и получения полного контроля при управлении данными в процессе работы с программой.
Внешний вид рабочей области программы – таблица. А реляционная база данных структурирует информацию в строки и столбцы. Несмотря на то что стандартный пакет MS Office имеет отдельное приложение для создания и ведения баз данных – Microsoft Access, пользователи активно используют Microsoft Excel для этих же целей. Ведь возможности программы позволяют: сортировать; форматировать; фильтровать; редактировать; систематизировать и структурировать информацию.
То есть все то, что необходимо для работы с базами данных. Единственный нюанс: программа Excel — это универсальный аналитический инструмент, который больше подходит для сложных расчетов, вычислений, сортировки и даже для сохранения структурированных данных, но в небольших объемах (не более миллиона записей в одной таблице, у версии 2010-го года выпуска ).
Структура базы данных – таблица Excel
База данных – набор данных, распределенных по строкам и столбцам для удобного поиска, систематизации и редактирования. Как сделать базу данных в Excel?
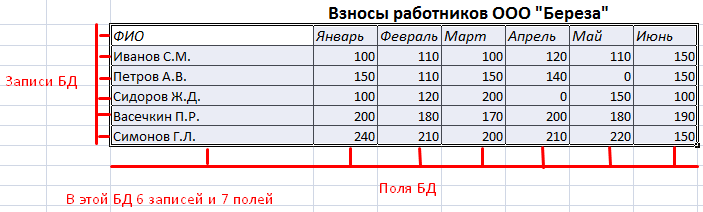
Вся информация в базе данных содержится в записях и полях.
Запись – строка в базе данных (БД), включающая информацию об одном объекте.
Поле – столбец в БД, содержащий однотипные данные обо всех объектах.
Записи и поля БД соответствуют строкам и столбцам стандартной таблицы Microsoft Excel.
Если Вы умеете делать простые таблицы, то создать БД не составит труда.
Создание базы данных в Excel: пошаговая инструкция
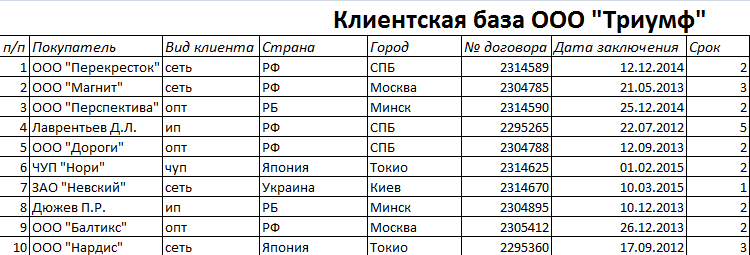
Пошаговое создание базы данных в Excel. Перед нами стоит задача – сформировать клиентскую БД. За несколько лет работы у компании появилось несколько десятков постоянных клиентов. Необходимо отслеживать сроки договоров, направления сотрудничества. Знать контактных лиц, данные для связи и т.п.
Как создать базу данных клиентов в Excel:
- Вводим названия полей БД (заголовки столбцов).
- Вводим данные в поля БД. Следим за форматом ячеек. Если числа – то числа во всем столбце. Данные вводятся так же, как и в обычной таблице. Если данные в какой-то ячейке – итог действий со значениями других ячеек, то заносим формулу.
- Чтобы пользоваться БД, обращаемся к инструментам вкладки «Данные».
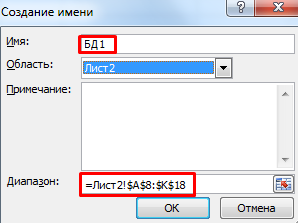
- Присвоим БД имя. Выделяем диапазон с данными – от первой ячейки до последней. Правая кнопка мыши – имя диапазона. Даем любое имя. В примере – БД1. Проверяем, чтобы диапазон был правильным.


Основная работа – внесение информации в БД – выполнена. Чтобы этой информацией было удобно пользоваться, необходимо выделить нужное, отфильтровать, отсортировать данные.
Как вести базу клиентов в Excel
Чтобы упростить поиск данных в базе, упорядочим их. Для этой цели подойдет инструмент «Сортировка».
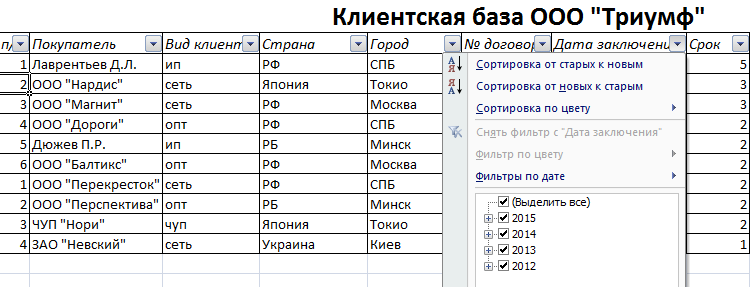
- Выделяем тот диапазон, который нужно отсортировать. Для целей нашей выдуманной компании – столбец «Дата заключения договора». Вызываем инструмент «Сортировка».
- При нажатии система предлагает автоматически расширить выделенный диапазон. Соглашаемся. Если мы отсортируем данные только одного столбца, остальные оставим на месте, то информация станет неправильной. Открывается меню, где мы должны выбрать параметры и значения сортировки.
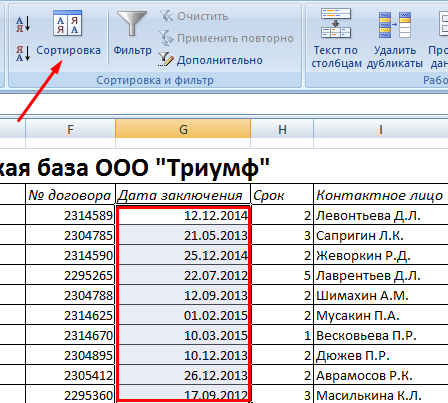
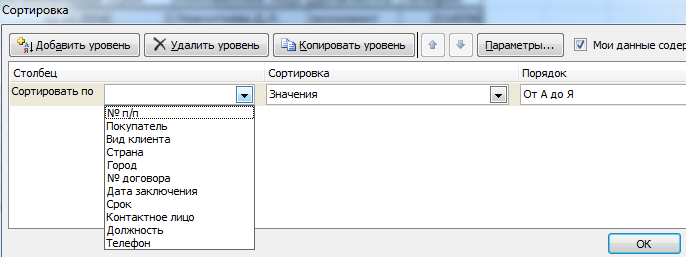
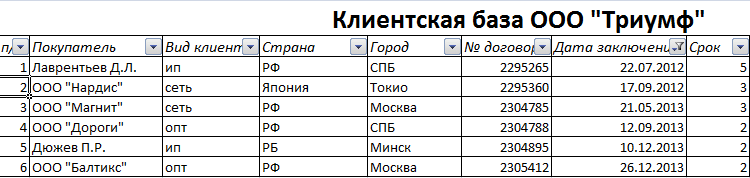
Данные в таблице распределились по сроку заключения договора.
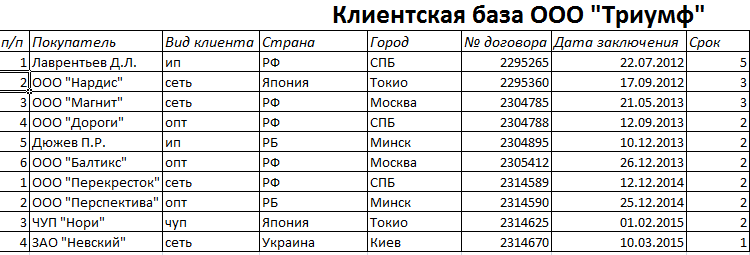
Теперь менеджер видит, с кем пора перезаключить договор. А с какими компаниями продолжаем сотрудничество.
БД в процессе деятельности фирмы разрастается до невероятных размеров. Найти нужную информацию становится все сложнее. Чтобы отыскать конкретный текст или цифры, можно воспользоваться одним из следующих способов:
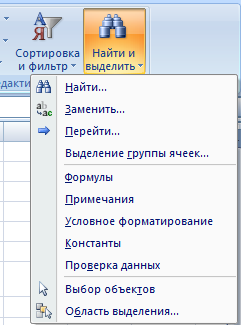
- Одновременным нажатием кнопок Ctrl + F или Shift + F5. Появится окно поиска «Найти и заменить».
- Функцией «Найти и выделить» («биноклем») в главном меню.
Посредством фильтрации данных программа прячет всю не интересующую пользователя информацию. Данные остаются в таблице, но невидимы. В любой момент их можно восстановить.
В программе Excel чаще всего применяются 2 фильтра:
- Автофильтр;
- фильтр по выделенному диапазону.
Автофильтр предлагает пользователю выбрать параметр фильтрации из готового списка.
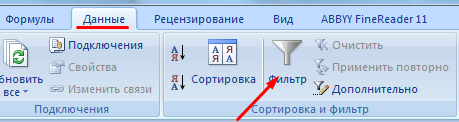
- На вкладке «Данные» нажимаем кнопку «Фильтр».
- После нажатия в шапке таблицы появляются стрелки вниз. Они сигнализируют о включении «Автофильтра».
- Чтобы выбрать значение фильтра, щелкаем по стрелке нужного столбца. В раскрывающемся списке появляется все содержимое поля. Если хотим спрятать какие-то элементы, сбрасываем птички напротив их.
- Жмем «ОК». В примере мы скроем клиентов, с которыми заключали договоры в прошлом и текущем году.
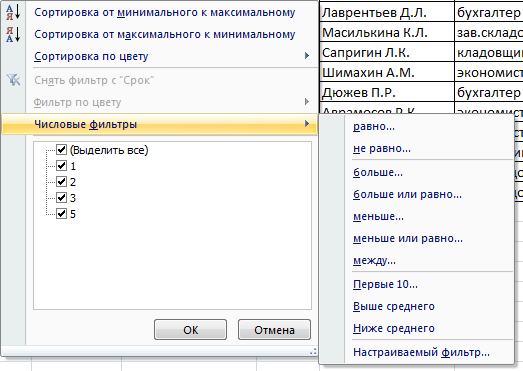
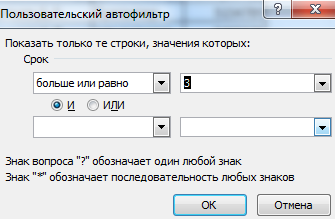
- Чтобы задать условие для фильтрации поля типа «больше», «меньше», «равно» и т.п. числа, в списке фильтра нужно выбрать команду «Числовые фильтры».
- Если мы хотим видеть в таблице клиентов, с которыми заключили договор на 3 и более лет, вводим соответствующие значения в меню пользовательского автофильтра.

Готово!

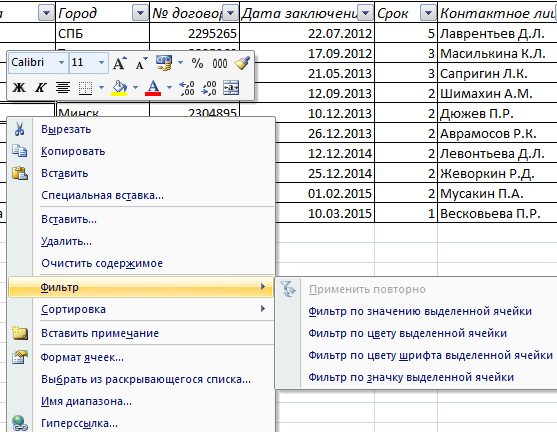
Поэкспериментируем с фильтрацией данных по выделенным ячейкам. Допустим, нам нужно оставить в таблице только те компании, которые работают в Беларуси.
- Выделяем те данные, информация о которых должна остаться в базе видной. В нашем случае находим в столбце страна – «РБ». Щелкаем по ячейке правой кнопкой мыши.
- Выполняем последовательно команду: «фильтр – фильтр по значению выделенной ячейки». Готово.

Если в БД содержится финансовая информация, можно найти сумму по разным параметрам:
- сумма (суммировать данные);
- счет (подсчитать число ячеек с числовыми данными);
- среднее значение (подсчитать среднее арифметическое);
- максимальные и минимальные значения в выделенном диапазоне;
- произведение (результат умножения данных);
- стандартное отклонение и дисперсия по выборке.
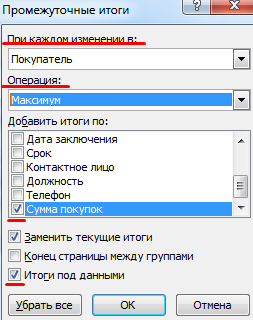
Порядок работы с финансовой информацией в БД:
- Выделить диапазон БД. Переходим на вкладку «Данные» — «Промежуточные итоги».
- В открывшемся диалоге выбираем параметры вычислений.

Инструменты на вкладке «Данные» позволяют сегментировать БД. Сгруппировать информацию с точки зрения актуальности для целей фирмы. Выделение групп покупателей услуг и товаров поможет маркетинговому продвижению продукта.
Готовые образцы шаблонов для ведения клиентской базы по сегментам.
- Шаблон для менеджера, позволяющий контролировать результат обзвона клиентов. Скачать шаблон для клиентской базы Excel. Образец:
- Простейший шаблон.Клиентская база в Excel скачать бесплатно. Образец:
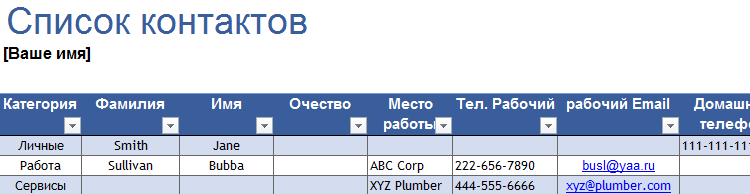
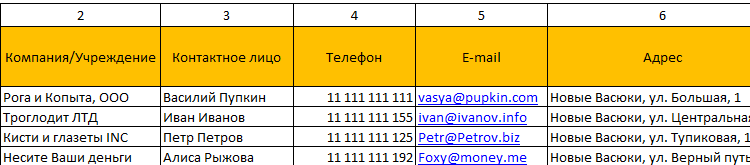
Шаблоны можно подстраивать «под себя», сокращать, расширять и редактировать.
Из песочницы, Тестирование IT-систем, API
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/
Всем привет, я руководитель отдела тестирования, и недавно по работе появилась задача на тестирование API. Для ее решения освоил новый для меня инструмент Postman и JavaScript.
Первоначально на каждый API я писал свои коллекции и готовил тестовые данные в JSON формате. Это достаточно удобно, но при большом количестве тестов и коллекций поддерживать это становится накладно. Да и проводить валидацию данных в JSON не удобно.
Для решения этих проблем я написал макрос для Excel и коллекцию в Postman. Теперь в Postman у меня одна коллекция на все API и стандартный набор функций для обработки входящих данных и валидации возвращаемых результатов. Мне удалось перенести управление тестовыми данными и последовательность выполнения запросов в Excel.
Что было
1. JSON с данными

Раньше тестовый набор хранился в таком виде
2. 2. Последовательность выполнения запросов с обработчиками на JS хранилась в коллекциях Postman.

Что стало
1. Тестовый набор переехал в Excel

Все данные вносятся в Excel (управляющие ключевые символы: R, H, I и т.д. распишу ниже) и дальше при помощи макроса перегоняются в json формат:

2. В Postman

Эксперимент проводил на стандартном наборе CRUD операций, который в дальнейшем можно расширять.
Так как в Postman все операций выполняются только в рамках запроса, пришлось ввести пустой get запрос в конце выполнения которого определяется следующий запрос из последовательности. Выполнить JS код до запроса и определить первый запрос без пустого не получилось.
Во всех запросах Pre-request script и Test секции пустые, весь код унифицирован для запросов и хранится в общих секциях Pre-request script и Test папки API Collection.
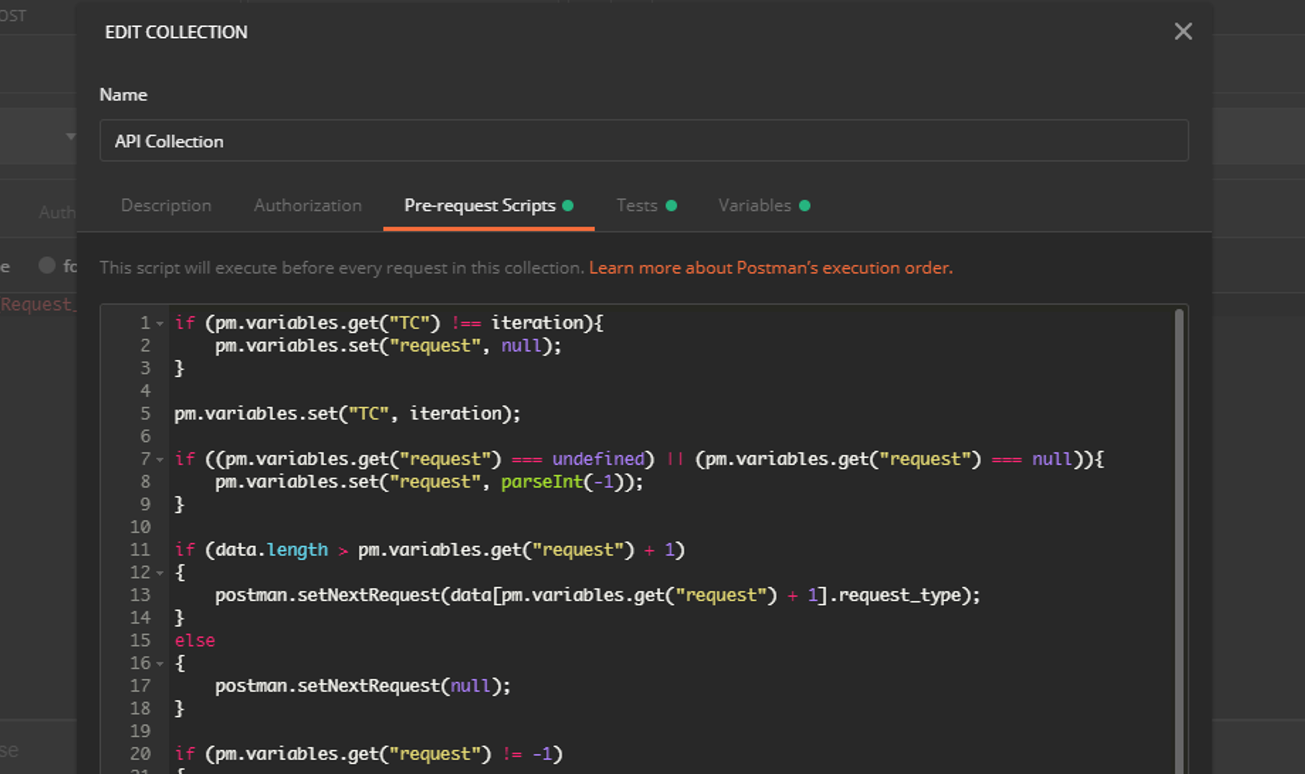
Во всех запросах важно обратить внимание на url и на секцию Body в запросах POST и PUT, их значения определяются переменными, значения в которые вносятся из JSON с данными.
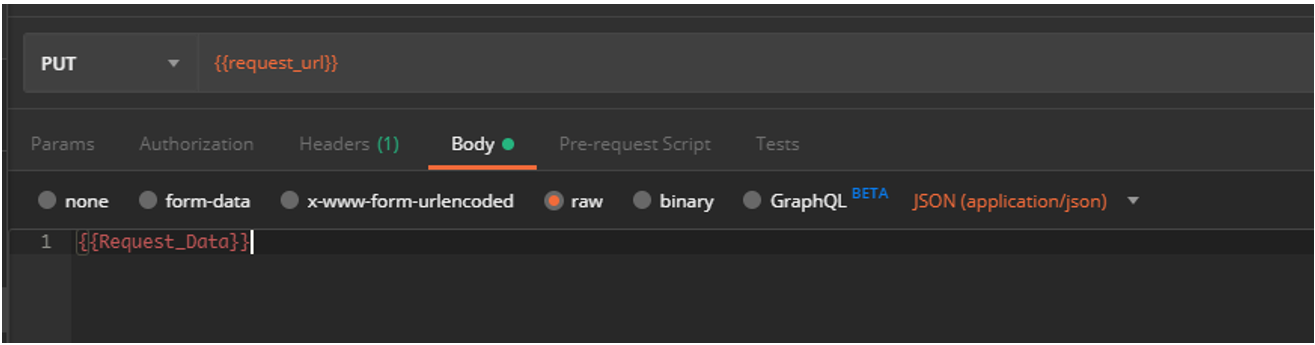
Теперь о самих тестах

Как читать Excel. Первой не пустой строкой идет номер тест кейса, то есть тест кейс хранится вертикально и на этой странице 9 тест кейсов. В текущем наборе в каждом тест кейсе будут выполнены сначала POST запрос, потом Delete.
Как запустить генерацию Json из Excel. В Excel нажать F11 и перейти на «ЭтаКнига», там запустить макрос.
Ключевые слова
R – request, означает начало нового запроса, во второй ячейке строки хранится тип запроса, в третьей адрес, по которому надо обращаться. Обратите внимание, что в url можно указывать переменные Postman

Значение из переменной подтянется
H – Данные для сверки в заголовке, пока ввел только response code, в Postman зашита проверка только на него. Важно чтобы в Excel название было таким же «response code», либо поправить в Postman

I, I2 … – Секция входных данных, поддерживает хранение моделей данных любой вложенности, цифра справа от I отвечает за уровень вложенности. Следующий набор данных вот так завернется в JSON. Если переменная, которая хранит данные пустая, то она не добавится. То есть если в переменной inn не будет значения, то она не добавится, а переменная chief добавится, так как она хранит модель. При этом если вся модель пустая, то она также не добавится.

Данные этой секции будут поданы в теле запроса

O, O2 … — Секция выходных параметров, они будут сравнены с теми, что возвращает response. Как и секция Input поддерживает хранение моделей.
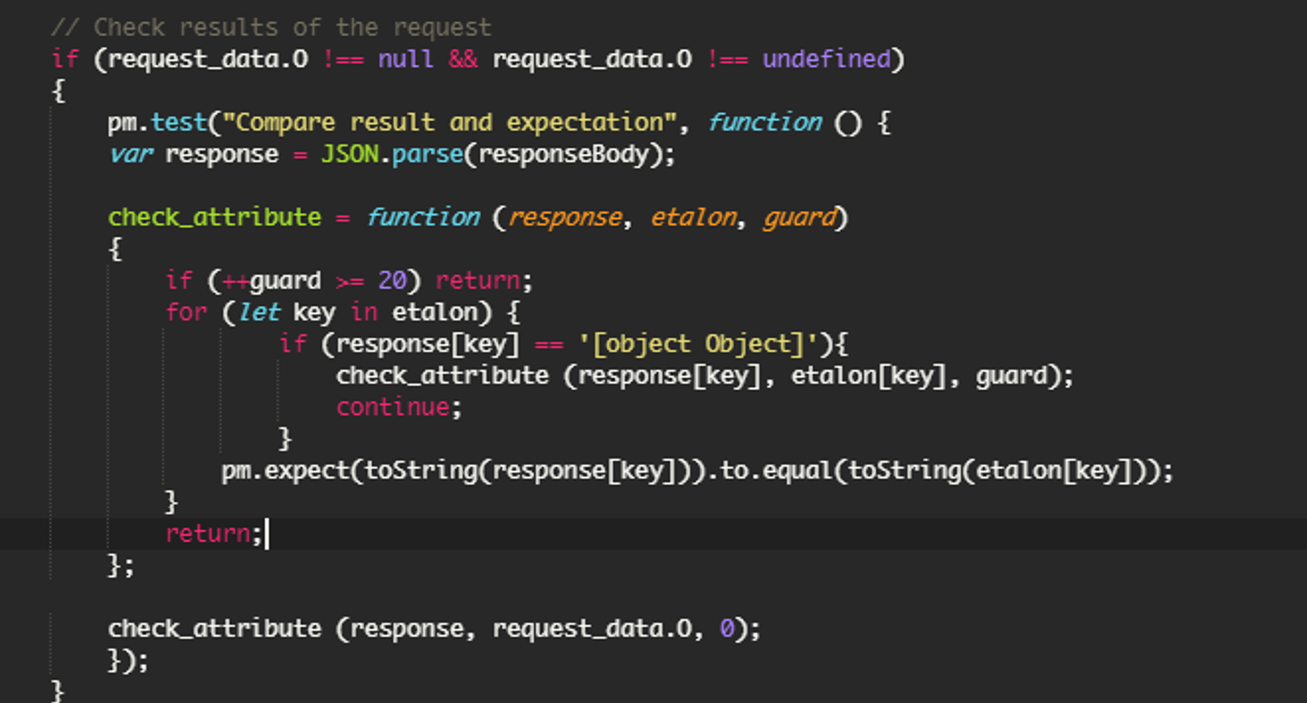
При сравнении данные конвертируются в string, еще я дополнительно ограничил уровень рекурсии, это можно убрать
PO – Postman Output, значения из этой секции будут по имени переменной браться из response body запроса и записываться в переменную Postman.

В Excel достаточно поставить любой символ, в переменную запишется значение из response, а не excel
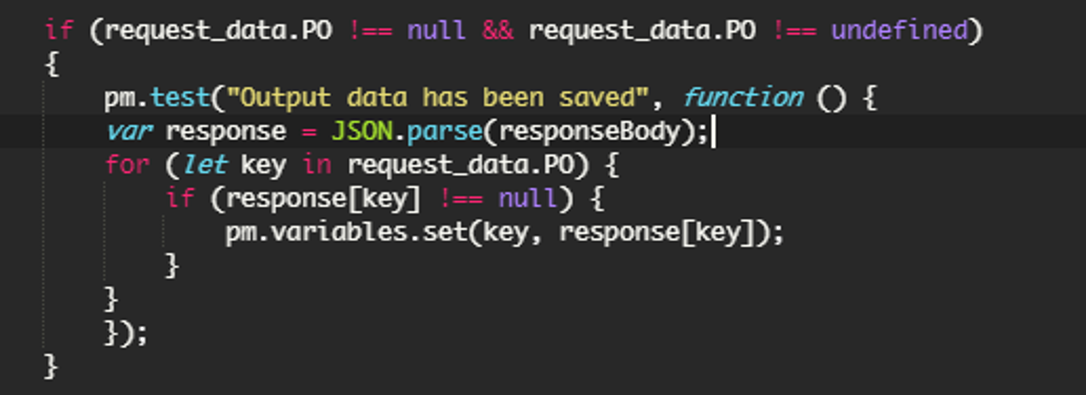
Эта секция нужна, чтобы хранить данные между скриптами, например чтобы удалить объект с id, который был создан в предыдущем реквесте
PC – Postman command, ввел только одну команду “terminate”, она используется для принудительного обрывания после выполнения текущего запроса. Полезно при негативном тесте, чтобы не вызывать шаг с удалением созданного объекта.

Ввод этой команды позволил на одном листе хранить и позитивные и негативные тесты

PI – Postman Input, значения из этой секции будут записаны в переменные Postman перед определением url

Может быть полезным, если надо переопределить переменные, которые указаны в url запроса.
Кстати, в подаваемых данных можно использовать данные из Postman переменных, для этого требуется использовать специальную конструкцию

В кейсе 1 мы внесли полученное значение в переменную, в кейсе 2 его использовали. Можно использовать не только в следующем кейсе, но и в текущем при следующем запросе. Например может потребоваться, если определение объекта для изменения идет не по url, а по значению переменной в запросе.
Подготовка к прогону
А теперь прогон, запускаем Postman runner, в нем выбираем нужную коллекцию и подгружаем файл с тестовыми данными:
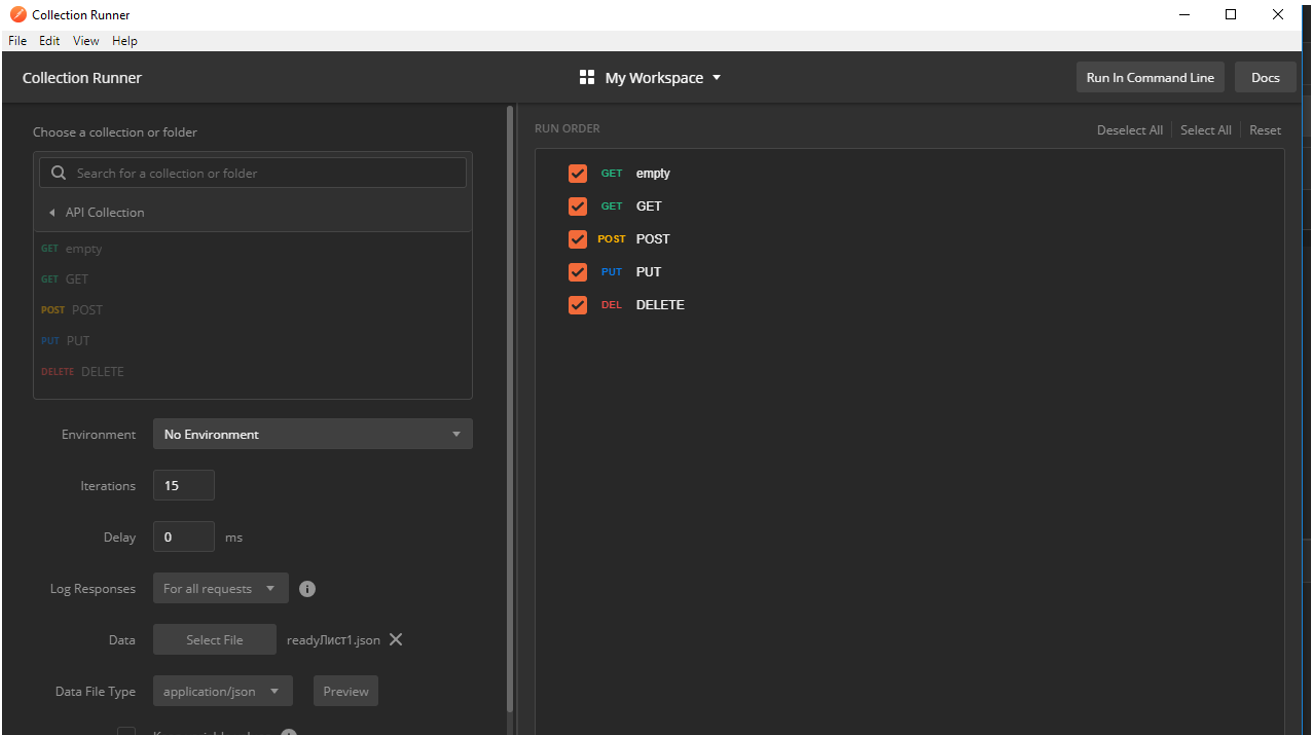
Подавать будем следующий набор:

Здесь описано 15 тестов, при этом шаги 1-11, 13, 15 положительные с результатом 200 при POST запросе и шаги 12, 14 негативные с результатом 400. По ним информация в базу не будет внесена и поэтому секция Output пустая, а также указана команда terminate. Эта команда прервет выполнение последовательности и запрос на удаление «Delete» отправлен не будет.
После кейсов 1-11, 13, 15 мы запоминаем id который присвоился новому объекту, чтобы потом его удалить.
Запускаем

Все 15 тестов прошли успешно, на картинке виден тест 14, в котором не вызывается Delete после POST
В тестах 1-11,13,15 после POST вызывается удаление созданного объекта:

Резюме
- Последовательность выполнения запросов для тестирования API вынесена в Excel и обрабатывается в Postman.
- Все тестовые данные также вынесены в Excel ими удобно управлять и валидировать их. По крайней мере удобней чем в JSON формате.
- Коллекция Postman стандартизирована и при тестировании схожих API не требует доработки.
Ссылки
- Репозиторий на GitHub, там лежит Excel и коллекция Postman
- При разработке использовался VBA-JSON инструмент за авторством Tim Hall
В
процессе обучения постоянно ощущается потребность в хорошо разработанных
методах измерения уровня обученности в самых различных областях знаний. Известно,
что профессиональное тестирование было начато еще в 2200 году до нашей эры,
когда служащие Китайского императора тестировались, чтобы определить их
пригодность для императорской службы. По некоторым оценкам в 1986 году по
крайней мере 800 профессий лицензировались в Соединенных Штатах на основании
тестирования (А.А. Захаров, А.В. Колпаков Современные математические методы
объективных педагогических измерений)
Почти
каждый педагог разрабатывает тестовые задания по своей дисциплине, но не каждый
может грамотно обработать и интерпретировать результаты теста. Напротив,
грамотное конструирование теста на основе знания теории тестирования позволит
педагогу-исследователю создать инструмент, позволяющий провести объективное
измерение знаний, умений и навыков по данному курсу с необходимой точностью.
В
настоящее время существуют два теоретических подхода к созданию тестов:
классическая теория и современная теория IRT (Item Response Theory). Оба
подхода базируются на последующей статистической обработке так называемого
сырого балла (raw score), то есть балла, набранного в результате тестирования.
Только после проведения многократных статистических обработок можно говорить о
создании теста с устойчивыми параметрами качества (надежностью и валидностью).
Для
обработки данных, полученных на этапе тестирования, воспользуемся пакетом MS Office 2000 и электронными таблицами MS Excel.
После сбора эмпирических данных необходимо провести
статистическую обработку, которую будем проводить на ЭВМ. Этап
математико–статистической обработки разобьем на ряд шагов.
Шаг 1. Формирование матрицы тестовых результатов.
Результаты ответов учеников на задания тестов оцениваются в
дихотомической шкале: за каждый правильный ответ учащийся получает один балл, а
за неправильный ответ или за пропуск задания – нуль баллов (см. рис. 1).
Шаг 2. Преобразование
матрицы тестовых результатов.
На втором шаге из матрицы тестовых результатов устраняются строки и
столбцы, состоящие только из нулей или только из единиц. В приведенном выше
примере таких столбцов нет, а строк только две. Одна из них, нулевая строка
соответствует ответам одиннадцатого испытуемого, который не смог выполнить
правильно ни одного задания в тесте.

Рис. 1. Матрица результатов тестирования
В этом случае вывод довольно однозначен: тест непригоден для оценки
знаний такого ученика. Для выявления его уровня знаний тест необходимо
облегчить, добавив несколько более легких заданий, которые, скорее всего,
выполнит правильно большинство остальных испытуемых группы.
Столь же непригоден, но уже по другой причине, тест для оценки знаний
двенадцатого ученика, который выполнил правильно все без исключения задания
теста. Причина непригодности теста заключается в его излишней легкости, не
позволяющий выявить истинный уровень подготовки двенадцатого ученика. Возможно,
двенадцатый ученик знает много чего другого и в состоянии выполнить по
контролируемым разделам содержания гораздо более трудные задания, которые
просто не были включены в тест.
Таким образом, на данном шаге необходимо удалить из матрицы данных 11 и
12 строки.
Шаг 3. Подсчет индивидуальных баллов испытуемых и количество
правильных ответов на каждое задание теста.
Индивидуальный балл испытуемого получается суммированием всех единиц,
полученных им за правильное выполнение задания теста. В Excel для суммирования данных по строке
можно воспользоваться кнопкой Автосумма на панели
инструментов Стандартная. Для удобства полученные индивидуальные баллы
(Хi)
приводятся в последнем столбце матрицы результатов (см. рис. 2).
Число правильных ответов на задания теста (Yi) также получается
суммированием единиц, но уже расположенным по столбцам.(см. рис. 2)
Шаг 4. Упорядочение матрицы результатов.
Значения индивидуальных баллов необходимо
отсортировать по возрастанию, для этого в MS Excel:
1.
выделим блок ячеек, содержащих номера
испытуемых, матрицу результатов и индивидуальные баллы. Начинать выделение
необходимо со столбца X
(индивидуальные баллы).
2.
на панели инструментов Стандартная
нажимаем на кнопку Сортировка по возрастанию . Матрица результатов примет вид, изображенный на рис. 3.

Рис. 2. Матрица
с подсчетом итоговых сумм

Рис. 3 Упорядоченная матрица результатов
Шаг 5. Графическое представление данных.
Эмпирические результаты тестирования можно
представить в виде полигона частот, гистограммы, сглаженной кривой или графика.
Для
построения кривых упорядочим результаты эксперимента и подсчитаем частоту
получения баллов (см. рис. 4-6).

Рис. 4.
Несгруппированный ряд

Рис. 5.
Ранжированный ряд

Рис. 6. Частотное
распределение
Для расчета
рейтинга (ранга) каждого учащегося по индивидуальным балам необходимо применить
функцию РАНГ, которая возвращает ранг числа в списке чисел. Ранг числа –
это его величина относительно других значений в списке.
В MS Excel 2000 для вычисления
ранга используется функция
РАНГ (число;
ссылка; порядок), где
Число – адрес
на ячейку, для которой определяется ранг.
Ссылка — ссылка на массив индивидуальных баллов
(выборка).
Порядок – число, определяющее способ упорядочения. Если порядок
равен 0 (нулю), или опущен, то Excel
определяет ранг числа так, как если бы ссылка была списком, отсортированным в
порядке убывания. Если порядок – любое ненулевое число, то Excel определяет ранг числа так, как
если бы ссылка была списком, отсортированным в порядке возрастания.
Примечание. Функция РАНГ присваивает повторяющимся числам
одинаковый ранг. При этом наличие повторяющихся чисел влияет на ранг
последующих чисел. Например, если в списке целых чисел дважды встречается число
10, имеющее ранг 5, число 11 будет иметь ранг 7 (ни одно из чисел не будет
иметь ранг 6).
По частотному
распределению можно построить гистограмму (см. рис.7).
Гистограмму
можно построить и по индивидуальным баллам (см. рис. 8).

Рис. 7.
Столбиковая гистограмма

Рис. 8. Гистограмма распределения инд. баллов
При разработке тестов необходимо помнить о том, что кривая распределения
индивидуальных баллов, получаемых по репрезентативной выборке, является
следствием кривой распределения трудности заданий теста. Этот факт удачно
иллюстрируется на рис.9.

Рис. 9. Связь распределения
индивидуальных баллов и трудности заданий теста
Для первого распределения слева характерно явное смещение в тесте
в сторону легких заданий, что, несомненно, приведет к появлению большого числа
завышенных баллов у репрезентативной выборки учеников. Большая часть учеников
выполнит почти все задания теста.
Второй случай (слева) отражает существенное смещение в сторону
трудных заданий при разработке теста, что не может не сказаться на снижении
результатов учеников, поэтому распределение индивидуальных баллов имеет явно
выраженный всплеск вблизи начала горизонтальной оси. Основная часть учеников
выполнит незначительное число наиболее легких заданий теста.
B третьем случае
задания теста обладают оптимальной трудностью, поскольку распределение имеет
вид нормальной кривой. Отсюда автоматически возникает нормальность распределения
индивидуальных баллов репрезентативной выборки учеников, что в свою очередь
позволяет считать полученное распределение устойчивым по отношению к
генеральной совокупности.
В профессионально разработанных нормативно-ориентированных тестах
типичным является результат, когда приблизительно 70% учеников выполняют правильно от 30 до 70%
заданий теста. а наиболее часто встречается результат в 50%.
Шаг 6. Определение выборочных
характеристик результатов.
На данном этапе необходимо вычислить среднее
значение, моду, медиану, дисперсию, стандартное отклонение выборки, ассиметрию
и эксцесс (см. рис.10).
Степень отклонения распределения наблюдаемых частот выборки от
симметричного распределения, характерного для нормальной кривой, оценивается с
помощью асимметрии. Наличие асимметрии легко установить визуально, анализируя
полигон частот или гистограмму Более тщательный анализ можно провести с помощью
обобщенных статистических характеристик, предназначенных для оценки величины
асимметрии в распределении.
Функция СКОС MS Excel возвращает
ассиметрию распределения.
СКОС (число 1; число 2), где число1 – ссылка
на массив данных, содержащих индивидуальные баллы учеников.
При интерпретации полученного значения асимметриии 0,277
необходимо обратить внимание на то, что величина ассиметрии получилась
положительной и небольшой (см. рис. 10,
11).

Рис. 10.
Описательные характеристики выборки

Рис. 11. Кривые распределения с
отрицательной, нулевой и положительной ассиметрией (слева направо)
соответственно.
Асимметрия распределения положительна, если основная часть
значений индивидуальных баллов лежит справа от среднего значения, что обычно
характерно для излишне легких тестов.
Асимметрия распределения баллов отрицательна, если большинство
учеников получили оценки ниже среднего балла. Эффект отрицательной асимметрии
встречается в излишне трудных тестах, не сбалансированных правильно по
трудности при отборе заданий
В хорошо сбалансированном по трудности тесте, как уже отмечалось
ранее, распределение баллов имеет вид нормальной кривой. Для нормального
распределения характерна нулевая асимметрия, что вполне естественно, так как
при полной симметрии каждое значение балла, меньшее среднего значения,
уравновешивается другим симметричным, большим чем среднее.
С помощью эксцесса можно получить представление о том,
является ли функция распределения частот островершинной, средневершинной или
плоской.
Для расчета данного параметра применим функцию ЭКСЦЕСС
(число1; число2; …), где число1 – ссылка на массив данных,
содержащих индивидуальные баллы учеников.
В том случае, когда распределение данных бимодально
(имеет две моды), необходимо говорить об эксцессе в окрестности каждой моды.
Бимодальная конфигурация указывает на то, что по результатам выполнения теста
выборка учеников разделилась на две группы. Одна группа справилась с
большинством легких, а другая с большинством трудных заданий теста.