
17 авг. 2022 г.
читать 3 мин
Мультиколлинеарность в регрессионном анализе возникает, когда две или более независимых переменных сильно коррелируют друг с другом, так что они не предоставляют уникальную или независимую информацию в регрессионной модели. Если степень корреляции между переменными достаточно высока, это может вызвать проблемы при подгонке и интерпретации регрессионной модели.
К счастью, мультиколлинеарность можно обнаружить с помощью метрики, известной как коэффициент инфляции дисперсии (VIF) , который измеряет корреляцию и силу корреляции между независимыми переменными в регрессионной модели.
В этом руководстве объясняется, как рассчитать VIF в Excel.
Пример: расчет VIF в Excel
В этом примере мы выполним множественную линейную регрессию, используя следующий набор данных, описывающий атрибуты 10 баскетболистов. Мы подгоним регрессионную модель, используя рейтинг в качестве переменной отклика и очки, передачи и подборы в качестве объясняющих переменных. Затем мы определим значения VIF для каждой независимой переменной.
Шаг 1: Выполните множественную линейную регрессию.
В верхней ленте перейдите на вкладку «Данные» и нажмите «Анализ данных». Если вы не видите эту опцию, вам необходимо сначала установить бесплатный пакет инструментов анализа .

Как только вы нажмете «Анализ данных», появится новое окно. Выберите «Регрессия» и нажмите «ОК».
Заполните необходимые массивы для переменных ответа и независимых переменных, затем нажмите OK.
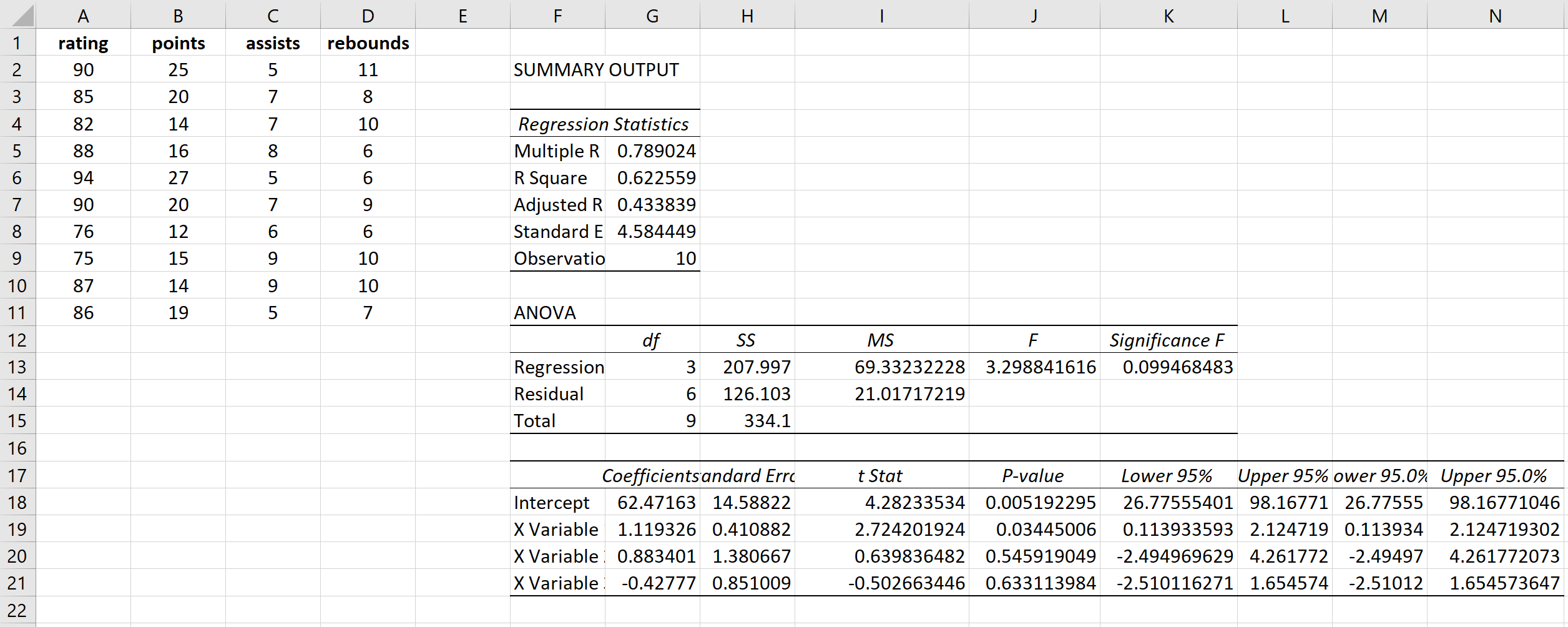
Это дает следующий результат:
Шаг 2: Рассчитайте VIF для каждой независимой переменной.
Затем мы можем рассчитать VIF для каждой из трех независимых переменных, выполнив отдельные регрессии, используя одну независимую переменную в качестве переменной отклика, а две другие — в качестве независимых переменных.
Например, мы можем рассчитать VIF для переменных очков , выполнив множественную линейную регрессию, используя очки в качестве переменной отклика, а передачи и подборы в качестве независимых переменных.
Это дает следующий результат:
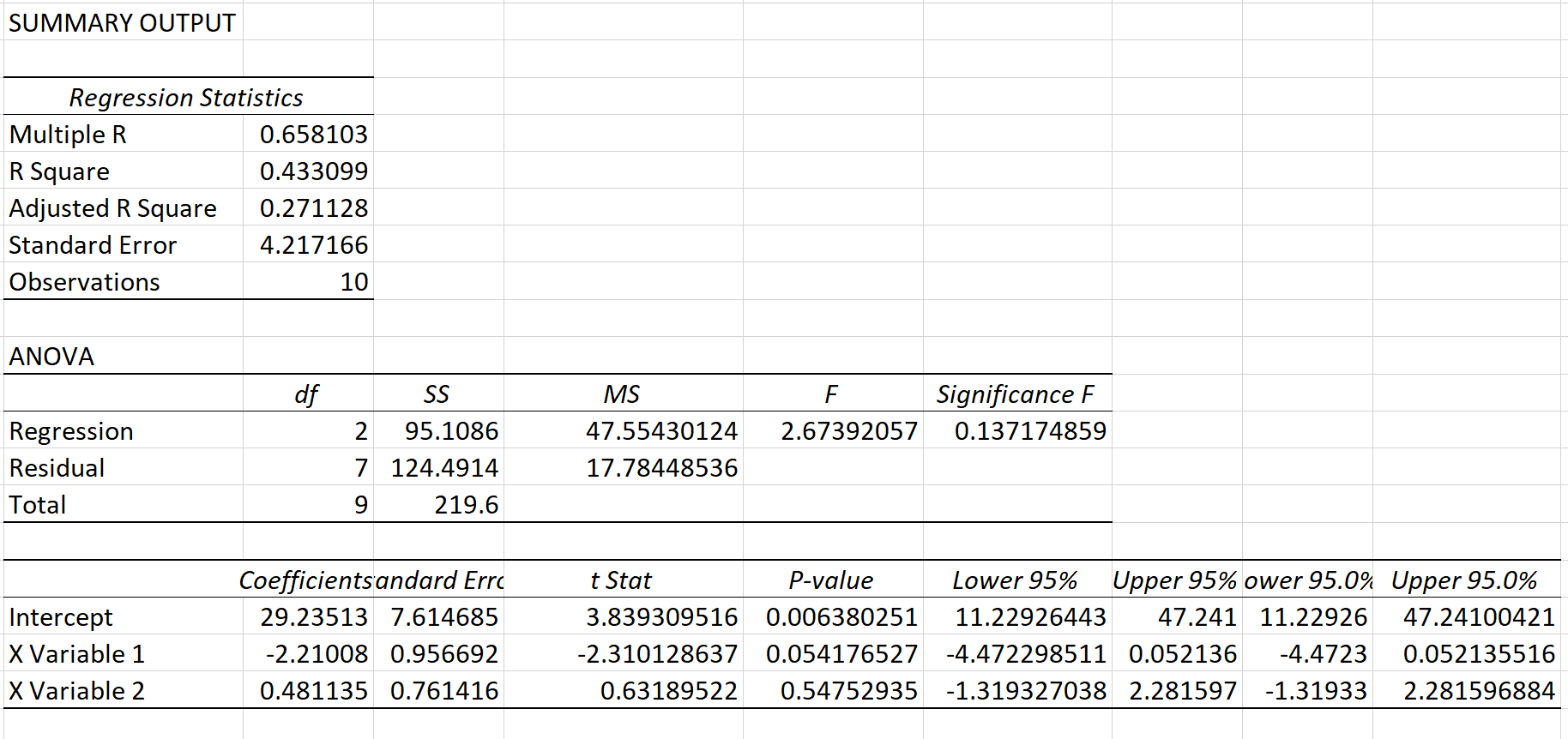
VIF для очков рассчитывается как 1/(1 – R Square) = 1/(1 – 0,433099) = 1,76 .
Затем мы можем повторить этот процесс для двух других переменных: передач и подборов .
Получается, что VIF для трех объясняющих переменных таковы:
баллы: 1,76
передач: 1,96
подборов: 1,18
Как интерпретировать значения VIF
Значение VIF начинается с 1 и не имеет верхнего предела. Общее эмпирическое правило для интерпретации VIF выглядит следующим образом:
- Значение 1 указывает на отсутствие корреляции между данной независимой переменной и любыми другими независимыми переменными в модели.
- Значение от 1 до 5 указывает на умеренную корреляцию между данной объясняющей переменной и другими независимыми переменными в модели, но часто она недостаточно серьезна, чтобы требовать внимания.
- Значение больше 5 указывает на потенциально сильную корреляцию между данной независимой переменной и другими независимыми переменными в модели. В этом случае оценки коэффициентов и p-значения в выходных данных регрессии, вероятно, ненадежны.
Учитывая, что каждое из значений VIF для независимых переменных в нашей регрессионной модели близко к 1, мультиколлинеарность в нашем примере не является проблемой.
|
адрес ячейки |
формула |
реализация в MS Excel |
|
|
|
|
|
|
=СРЗНАЧ(K57:K80) |
В результате получим значение средней
относительной ошибки аппроксимации
четырехфакторной модели
![]()
.
Так как выполняется условие
![]()
,
то качество модели хорошее. По значению
коэффициента детерминации
делаем вывод, что полученное уравнение
регрессии объясняет колебания
результативного признака
на
![]()
,
остальные 0,92% приходятся на факторы, не
учтенные в модели. Следовательно,
построенную модель можно использовать
для дальнейшего экономического анализа
и прогноза.
На основании полученного уравнения
регрессии
сделаем следующие выводы. При
увеличении фондоемкости на 1 тыс. грн.
(при условии, неизменности остальных
факторов) производительность труда
увеличивается в среднем на 0,3 млн.
грн./год. При увеличении стажа работы
на 1 год (при условии, неизменности
остальных факторов) производительность
труда увеличивается в среднем на 0,17
млн. грн./год. При увеличении средней
заработной платы на 1 тыс. грн. (при
условии, неизменности остальных факторов)
производительность труда увеличивается
в среднем на 2,93 млн. грн./год. При увеличении
потерь рабочего времени на 1 % (при
условии, неизменности остальных факторов)
производительность труда уменьшается
в среднем на 1,57 млн. грн./год.
Для того, чтобы сделать окончательный
вывод о возможности использования
модели в экономическом анализе необходимо
проверить для построенной модели
выполнение условий Гаусса-Маркова
(наличие мультиколлинеарности между
факторами-аргументами, гетероскедастичности
и автокорреляции возмущений).
4.2. Проверка предпосылки отсутствия
мультиколлинеарности между
факторами-аргументами. Методы устранения
мультиколлинеарности (задание
3.2).
4.2.1. Теоретические замечания. Одним
из условий МНК при оценке параметров
регрессионной модели является
предположение о линейной независимости
объясняющих переменных. Для экономических
показателей это условие выполняется
не всегда. Тогда говорят о наличии
мультиколлинеарности между
факторами-аргументами модели. Под
мультиколлинеарностью понимается
высокая взаимная коррелированность
объясняющих переменных.
Основными последствиями мультиколлинеарности
являются:
-
снижение точности оцениваемых параметров;
-
оценки параметров модели не являются
состоятельными (небольшое увеличение
количества наблюдений приводит к
значительным изменениям в оценках
параметров); -
экономическая
интерпретация параметров уравнения
регрессии затруднена, так как некоторые
из его коэффициентов могут иметь
неправильные, с точки зрения экономической
теории, знаки и неоправданно большие
значения.
Признаки мультиколлинеарности:
-
наличие высоких значений парных
коэффициентов корреляции

; -
определитель матрицы

близок к нулю;
-
существенное
приближение коэффициента множественной
корреляции к единице; -
наличие малых
значений оценок параметров модели при
высоком уровне коэффициента детерминациии
-критерия
Фишера; -
существенное изменение оценок параметров
модели при дополнительном введении в
нее новой объясняющей переменной; -
резкое изменение значений параметров
при дополнительном увеличении числа
наблюдений.
Алгоритм Фаррара-Глобера позволяет
статистически подтверждать или
опровергать гипотезу о наличии тесной
корреляционной связи между аргументами
![]()
модели. Основу алгоритма составляют
три статистических критерия (данные
критерии детально описаны в лабораторной
работе №1), с помощью которых проверяется
мультиколлинеарность.
На первом шаге с помощью критерия
![]()
Пирсона определяют наличие
мультиколлинеарности во всем массиве
данных
![]()
.
На втором шаге с помощью
—
критерия Фишера определяют для каждого
аргумента
![]()
существует, или нет мультиколлинеарность
между ним и другими факторами.
На третьем шаге с помощью
-критерия
Стьюдента определяют наибольшую связь
между выделенным
![]()
на втором шаге и всеми остальными
факторами поочередно.
При выявлении мультиколлинеарности
нужно предпринять меры для ее устранения.
Для этого можно использовать следующие
методы.
Исключить из модели одну из переменных
мультиколлинеарной пары. Но такой метод
часто противоречит действительности
экономических связей между факторами
и к нему надо относиться осторожно.
Можно преобразовать объясняющие
переменные и вместо их абсолютных
значений взять их отклонения от среднего
значения
![]()
.
Можно также взять их относительные
значения:

или стандартизировать объясняющие
переменные.
Если вышеуказанные приёмы не помогают
исключить мультиколлинеарность, то
надо поменять спецификацию модели
(взять не линейную, а другой вид модели).
Если и эти действия не привели к
необходимой цели, то есть мы не избавились
от мультиколлинеарности, то оценки
параметров следует рассчитывать с
помощью другого метода, например, метода
главных компонент.
4.2.2. Организация данных и расчетов на
листе MS Excel.
Рассмотрим пример выполнения
лабораторной работы № 3 (задание
3.2).
Проверим наличие мультиколлинеарности
между четырьмя факторами-аргументами,
влияние, которых на результативный
фактор изучалось в работе первой части
лабораторной работы №3.
Для проверки мультиколлинеарности в
массиве данных выполним расчеты на
листе MS Excel
(рис. 4.6) по формулам (2.1), (2.3), (2.4), (2.6), (2.7)
лаб. раб. № 1, а также найдем табличные
значения соответствующих критериев (в
табл. 2.1 описаны функции MS
Excel для выполнения
расчетов).
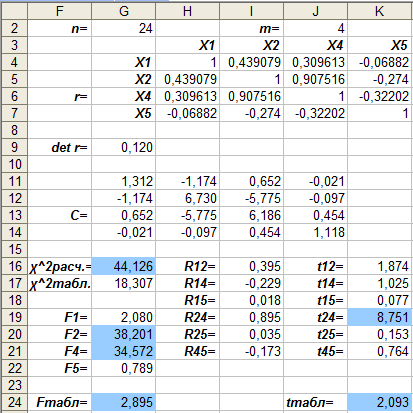
Рис. 4.6.
Организация данных и расчетов по
алгоритму Фаррара-Глобера
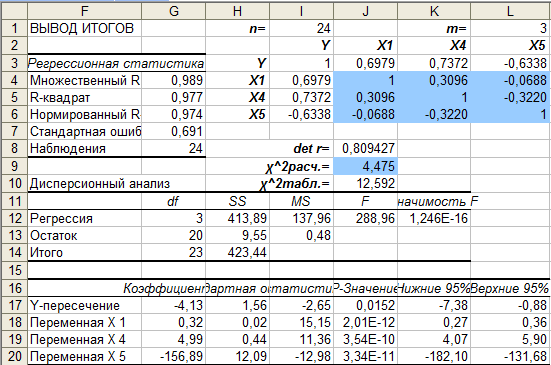
Рис. 4.7. Отчет
функции «Регрессия» по трехфакторной
модели и проверка мультиколлинеарности
объясняющих факторов
4.2.3. Выводы по результатам проверки
наличия мультиколлинеарности между
факторами-аргументами. На основании
проведенных расчетов сделаем следующие
выводы.
-
Так как

то в массиве переменных

существует мультиколлинеарность.
-
Так как
условие(

)
выполняется для статистик

и

то делаем вывод (с достоверностью 95%) о
статистической значимости коэффициентов
множественной корреляции показателей

и тесной линейной зависимости каждого
из факторов с остальными. -
Так как
условие(

)
выполняется только для статистики

,
то коэффициент частной корреляции

статистически значим. Следовательно,
между показателем стажа
работы(года) и средней заработной платой
(тыс. грн.) существует тесная линейная
зависимость (исключая влияние остальных
факторов).
Для того, чтобы уменьшить влияние
мультиколлинеарности на оценки параметров
модели исключим переменную стаж
работы
из модели (так как
![]()
).
Используя функцию «Регрессия»
оценим параметры трехфакторной модели
и проверим, удалось ли, избавится от
мультиколлинеарности (рис. 4.7).
На основании значений параметров модели
в ячейках
![]()
(рис. 4.7.) запишем уравнение трехфакторной
модели:
![]()
.
Сравнивая с моделью, которая включала
второй фактор
![]()
(![]()
)
видим, что параметры
![]()
и
![]()
изменились незначительно, параметр
![]()
— более существенно. Коэффициент
детерминации на третьем шаге уменьшился
незначительно:
![]()
.
Так как
![]()
![]()
,
то в массиве переменных трехфакторной
модели
![]()
мультиколлинеарность отсутствует. Так
как для построения модели использовались
«пространственные» данные для
окончательного вывода о качестве модели
необходимо проверить гипотезу об
отсутствии гетероскедастичности
возмущений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Множественная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
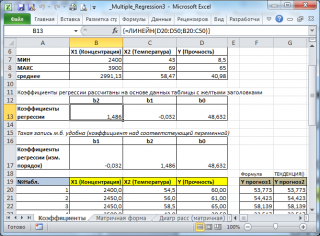
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений 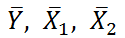 , т.е.:
, т.е.: 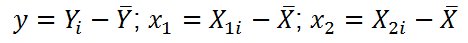
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
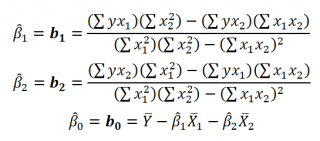
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
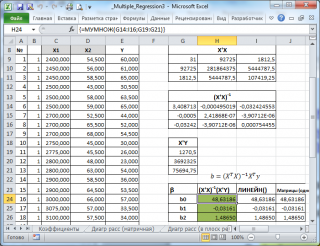
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
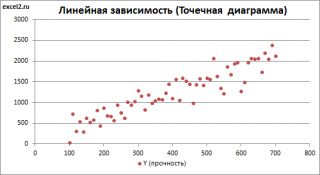
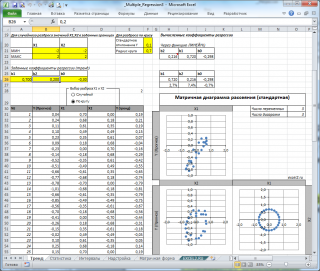
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
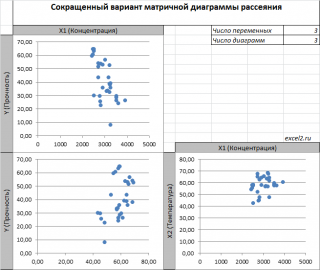
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
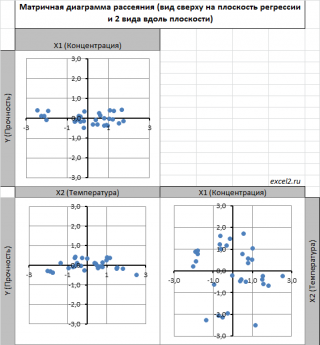
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
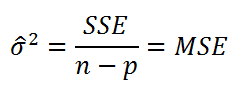
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
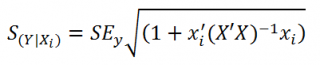
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
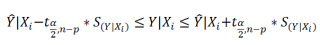
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
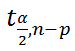 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
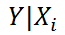 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
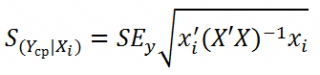
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
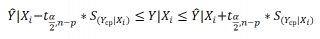
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
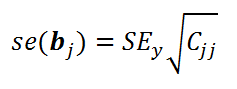
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
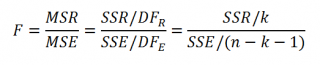
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
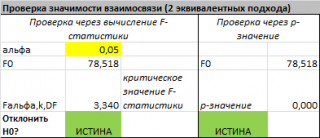
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
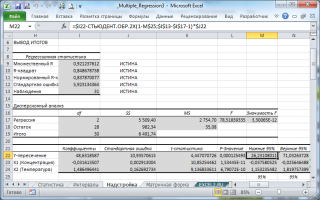
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
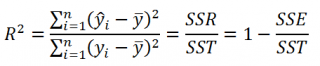
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
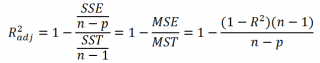
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).
Пример решения эконометрической задачи в Excel
Ниже приведено условие задачи и текстовая часть решения. Закачка полного решения, файлы word+Excel в архиве rar, начнется автоматически через 10 секунд. Если закачка не началась, кликните по этой ссылке.
Видеоурок по решению этой задачи в Excel вы можете посмотреть здесь.
По предложенным вам экспериментальным данным, представляющим собою макроэкономические показатели или показатели финансовой (денежно-кредитной) системы некоторой страны, т.е. случайной выборке объема n – построить математическую модель зависимости случайной величины Y от случайных величин X1 и X2. Построение и оценку качества экономико-математической (эконометрической) модели вести в следующей последовательности:
•Построить корреляционную матрицу для случайных величин и оценить статистическую значимость корреляции между ними.
•Исходя из наличия между эндогенной переменной и экзогенными переменными, линейной зависимости, оценить параметры регрессионной модели по методу наименьших квадратов. Вычислите вектора регрессионных значений эндогенной переменной и случайных отклонений.
•Найдите средние квадратические ошибки коэффициентов регрессии. Используя критерий Стьюдента проверьте статистическую значимость параметров модели. Здесь и далее принять уровень значимости 0,05(т. е. надежность 95%).
•Вычислите эмпирический коэффициент детерминации и скорректированный коэффициент детерминации. Проверьте, используя критерий Фишера, адекватность линейной модели.
•Установите наличие (отсутствие) автокорреляции случайных отклонений модели. Используйте для этого метод графического анализа, статистику Дарбина-Уотсона и критерий Бреуша-Годфри.
•Установите наличие (отсутствие) гетероскедастичности случайных отклонений модели. Используйте для этого графический анализ, тест Вайта и тест Парка для вариантов с добавочным индексом А (графический метод, тест Глейзера и тест Бреуша-Пагана для вариантов с добавочным индексом В).
•Обобщите результаты оценивания параметров модели и результаты проверки модели на адекватность.
В таблице 1.1. приведены е же квартальные данные о валовом внутреннем продукте (млн. евро) ; экспорта товаров и услуг (млн. евро ) ; эффективный обменный курс евро к национальной волюте для Испании на период с 2000 по 2007 годы.
Еж еквартальные данные о валовом внутреннем продукте, экспорте товаров и услуг , эффективном обменном курсе евро к национальной валюте для И сландии на период с 2000 по 2007 годы
Задачи с решениями в Excel по эконометрике
В этом разделе вы найдете решенные задач по разным разделам эконометрики, выполненные с применением пакета электронных таблиц MS Excel. Большая часть работ снабжена подробным текстовым отчетом.
Если вам нужна помощь в выполнении контрольных работ по эконометрике в Excel, обращайтесь: эконометрика на заказ
Решение эконометрики в Экселе
Задача 1. Парная регрессия.
Для исходных данных, приведенных ниже, рассчитайте
- коэффициенты линейного регрессионного уравнения
- рассчитайте остаточную дисперсию
- вычислите значения коэффициентов корреляции и детерминации
- рассчитайте коэффициент эластичности
- рассчитайте доверительные границы уравнения регрессии (по уровню 0,95, t=2,44)
- в одной системе координат постройте: уравнение регрессии, экспериментальные точки, доверительные границы уравнения регрессии
Задача 2. Построить требуемое уравнение регрессии. Вычислить коэффициент детерминации, коэффициент эластичности, бета коэффициент и дать их смысловую нагрузку в терминах задачи. Проверить адекватность уравнения с помощью F теста. Найти дисперсии оценок и 95% доверительные интервалы для параметров регрессии. Данные взять из таблицы. Найти прогнозируемое значение объясняемой переменной для некоторого значения объясняющей переменной, не заданной в таблице.
Построить уравнение линейной регрессии объема валового выпуска (в млн. руб.) от стоимости основных производственных фондов (млн. руб.).
Задача 3. Множественная регрессия.
Построить требуемое уравнение регрессии. Вычислить коэффициент детерминации, частные коэффициенты эластичности, частные бета коэффициенты и дать их смысловую нагрузку в терминах задачи. Проверить адекватность уравнения с помощью F теста. Найти оценку матрицы ковариаций оценок параметров регрессии и 95% доверительные интервалы для параметров регрессии. Проверить наличие мультиколлинеарности в модели. Данные взять из таблицы.
Построить уравнение линейной регрессии себестоимости единицы товара (в сотнях руб.) от величины энерговооруженности (кВт) и производительности труда (тов/час).
Задача 4. Трендовые модели
Проверить ряд на наличие тренда. Сгладить ряд методом простой скользящей средней $(m = 3)$, экспоненциальным сглаживанием $(alpha = 0,3; alpha = 0,8)$. Построить исходный и сглаженные ряды. На основании построенных рядов определить вид трендовой модели. Построить трендовую модель.
Сделать прогноз изучаемого признака на два шага вперед.
87; 77; 75; 74; 69; 66; 62; 61; 59; 57; 57; 52; 50; 48; 46; 43; 43; 41; 38; 35
Задача 5. По заданным статистическим данным постройте линейную модель множественной регрессии и исследуйте её.
- Постройте линейную модель множественной регрессии.
- Запишите стандартизованное уравнение множественной регрессии. На основе стандартизованных коэффициентов регрессии и средних коэффициентов эластичности ранжировать факторы по степени их влияния на результат.
- Найдите коэффициенты парной, частной и множественной корреляции. Проанализируйте их.
- Найдите скорректированный коэффициент множественной детерминации. Сравните его с нескорректированным (общим) коэффициентом детерминации.
- С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии и коэффициента детерминации $R^2_$.
- С помощью частных F-критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора $x_1$ после $x_2$ и фактора $x_2$ после $x_1$.
- Составьте уравнение линейной парной регрессии, оставив лишь один значащий фактор.
Задача 6. По данным опроса 15 женщин, находящихся в роддоме, исследовать зависимость веса новорожденного (у) от среднего числа сигарет (х), выкуриваемых матерью в день, с учетом числа уже имеющихся у матери детей (z).
источники:
http://easyhelp.su/subjects/ekonometrika_reshenie_zadach/primer_resheniya_ekonometricheskoj_zadachi_v_excel/
http://www.matburo.ru/ex_ec.php?p1=ecexcel
Задание 2
1. Построить матрицу парных коэффициентов корреляции. Проверить наличие мультиколлинеарности. Обосновать отбор факторов в модель.
2. Построить уравнение множественной регрессии в линейной форме с выбранными факторами.
3. Оценить статистическую значимость уравнения регрессии и его параметров с помощью критериев Фишера и Стьюдента.
4. Построить уравнение регрессии со статистически значимыми факторами. Оценить качество уравнения регрессии с помощью коэффициента детерминации R 2 . Оценить точность построенной модели.
5. Оценить прогноз объема выпуска продукции, если прогнозные значения факторов составляют 75% от их максимальных значений.
Условия задачи (Вариант 21)
По данным, представленным в таблице 1 (n =17), изучается зависимость объема выпуска продукции Y (млн. руб.) от следующих факторов (переменных):
X 1 – численность промышленно-производственного персонала, чел.
X 2 – среднегодовая стоимость основных фондов, млн. руб.
X 3 – износ основных фондов, %
X 4 – электровооруженность, кВт×ч.
X 5 – техническая вооруженность одного рабочего, млн. руб.
X 6 – выработка товарной продукции на одного работающего, руб.
Таблица 1. Данные выпуска продукции
| № | Y | X 1 | X 2 | X 3 | X 4 | X 5 | X 6 |
| 39,5 | 4,9 | 3,2 | |||||
| 46,4 | 60,5 | 20,4 | |||||
| 43,7 | 24,9 | 9,5 | |||||
| 35,7 | 50,4 | 34,7 | |||||
| 41,8 | 5,1 | 17,9 | |||||
| 49,8 | 35,9 | 12,1 | |||||
| 44,1 | 48,1 | 18,9 | |||||
| 48,1 | 69,5 | 12,2 | |||||
| 47,6 | 31,9 | 8,1 | |||||
| 58,6 | 139,4 | 29,7 | |||||
| 70,4 | 16,9 | 5,3 | |||||
| 37,5 | 17,8 | 5,6 | |||||
| 62,0 | 27,6 | 12,3 | |||||
| 34,4 | 13,9 | 3,2 | |||||
| 35,4 | 37,3 | 19,0 | |||||
| 40,8 | 55,3 | 19,3 | |||||
| 48,1 | 35,1 | 12,4 |
Построить матрицу парных коэффициентов корреляции. Проверить наличие мультиколлинеарности. Обосновать отбор факторов в модель
В таблице 2 представлена матрица коэффициентов парной корреляции
для всех переменных, участвующих в рассмотрении. Матрица получена с помощью инструмента Корреляция
из пакета Анализ данных
в Excel.
Таблица 2. Матрица коэффициентов парной корреляции
| Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
|
| Y | |||||||
| X1 | 0,995634 | ||||||
| X2 | 0,996949 | 0,994947 | |||||
| X3 | -0,25446 | -0,27074 | -0,26264 | ||||
| X4 | 0,12291 | 0,07251 | 0,107572 | 0,248622 | |||
| X5 | 0,222946 | 0,166919 | 0,219914 | -0,07573 | 0,671386 | ||
| X6 | 0,067685 | -0,00273 | 0,041955 | -0,28755 | 0,366382 | 0,600899 |
Визуальный анализ матрицы позволяет установить:
1) У
имеет довольно высокие парные корреляции с переменными Х1, Х2 (>0,5)
и низкие с переменными Х3,Х4,Х5,Х6 (<0,5);
2) Переменные анализа Х1, Х2 демонстрируют довольно высокие парные корреляции, что обуславливает необходимость проверки факторов на наличие между ними мультиколлинеарности. Тем более, что одним из условий классической регрессионной модели является предположение о независимости объясняющих переменных.
Для выявления мультиколлинеарности факторов выполним тест Фаррара-Глоубера
по факторам Х1,Х2,Х3,Х4,Х5,Х6
.
Проверка теста Фаррара-Глоубера на мультиколлинеарность факторов включает несколько этапов.
1) Проверка наличия мультиколлинеарности всего массива переменных
.
Одним из условий классической регрессионной модели является предположение о независимости объясняющих переменных. Для выявления мультиколлинеарности между факторами вычисляется матрица межфакторных корреляций R с помощью Пакета анализа данных (таблица 3).
Таблица 3.Матрица межфакторных корреляций R
| X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
|
| X1 | 0,994947 | -0,27074 | 0,07251 | 0,166919 | -0,00273 | |
| X2 | 0,994947 | -0,26264 | 0,107572 | 0,219914 | 0,041955 | |
| X3 | -0,27074 | -0,26264 | 0,248622 | -0,07573 | -0,28755 | |
| X4 | 0,07251 | 0,107572 | 0,248622 | 0,671386 | 0,366382 | |
| X5 | 0,166919 | 0,219914 | -0,07573 | 0,671386 | 0,600899 | |
| X6 | -0,00273 | 0,041955 | -0,28755 | 0,366382 | 0,600899 |
Между факторами Х1 и Х2, Х5 и Х4, Х6 и Х5 наблюдается сильная зависимость (>0,5).
Определитель det (R) = 0,001488 вычисляется с помощью функции МОПРЕД. Определитель матрицы R стремится к нулю, что позволяет сделать предположение об общей мультиколлинеарности факторов.
2) Проверка наличия мультиколлинеарности каждой переменной с другими переменными:
· Вычислим обратную матрицу R -1 с помощью функции Excel МОБР (таблица 4):
Таблица 4. Обратная матрица R -1
| X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
|
| X1 | 150,1209 | -149,95 | 3,415228 | -1,70527 | 6,775768 | 4,236465 |
| X2 | -149,95 | 150,9583 | -3,00988 | 1,591549 | -7,10952 | -3,91954 |
| X3 | 3,415228 | -3,00988 | 1,541199 | -0,76909 | 0,325241 | 0,665121 |
| X4 | -1,70527 | 1,591549 | -0,76909 | 2,218969 | -1,4854 | -0,213 |
| X5 | 6,775768 | -7,10952 | 0,325241 | -1,4854 | 2,943718 | -0,81434 |
| X6 | 4,236465 | -3,91954 | 0,665121 | -0,213 | -0,81434 | 1,934647 |
· Вычисление F-критериев , где – диагональные элементы матрицы , n=17, k = 6 (таблица 5).
Таблица 5. Значения F-критериев
| F1 (Х1) | F2 (Х2) | F3 (Х3) | F4 (Х4) | F5 (Х5) | F6 (Х6) |
| 89,29396 | 89,79536 | 0,324071 | 0,729921 | 1,163903 | 0,559669 |
· Фактические значения F-критериев сравниваются с табличным значением F табл = 3,21
(FРАСПОБР(0,05;6;10)) при n1= 6 и n2 = n — k – 1=17-6-1=10 степенях свободы и уровне значимости α=0,05, где k – количество факторов.
· Значения F-критериев для факторов Х1 и Х2 больше табличного, что свидетельствует о наличии мультиколлинеарности между данными факторами. Меньше всего влияет на общую мультиколлинеарность факторов фактор Х3.
3) Проверка наличия мультиколлинеарности каждой пары переменных
· Вычислим частные коэффициенты корреляции по формуле , где – элементы матрицы (таблица 6)
Таблица 6. Матрица коэффициентов частных корреляций
| X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
|
| X1 | ||||||
| X2 | 0,996086 | |||||
| X3 | -0,22453 | 0,197329 | ||||
| X4 | 0,093432 | -0,08696 | 0,415882 | |||
| X5 | -0,32232 | 0,337259 | -0,1527 | 0,581191 | ||
| X6 | -0,24859 | 0,229354 | -0,38519 | 0,102801 | 0,341239 |
· Вычисление t
-критериев по формуле  (таблица 7)
(таблица 7)
n — число данных = 17
K — число факторов = 6
Таблица 7.t-критерии для коэффициентов частной корреляции
| X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
|
| X1 | ||||||
| X2 | 35,6355 | |||||
| X3 | -0,72862 | 0,636526 | ||||
| X4 | 0,296756 | -0,27604 | 1,446126 | |||
| X5 | -1,07674 | 1,13288 | -0,4886 | 2,258495 | ||
| X6 | -0,81158 | 0,745143 | -1,31991 | 0,326817 | 1,147999 |
t табл = СТЬЮДРАСПОБР(0,05;10) = 2,23
Фактические значения t-критериев сравниваются с табличным значением при степенях свободы n-k-1 = 17-6-1=10 и уровне значимости α=0,05;
t21 > tтабл
t54 > tтабл
Из таблиц 6 и 7 видно, что две пары факторов X1 и Х2, Х4 и Х5 имеют высокую статистически значимую частную корреляцию, то есть являются мультиколлинеарными. Для того чтобы избавиться от мультиколлинеарности, можно исключить одну из переменных коллинеарной пары. В паре Х1 и Х2 оставляем Х2, в паре Х4 и Х5 оставляем Х5.
Таким образом, в результате проверки теста Фаррара-Глоубера остаются факторы: Х2, Х3, Х5, Х6.
Завершая процедуры корреляционного анализа, целесообразно посмотреть частные корреляции выбранных факторов с результатом Y.
Построим матрицу парных коэффициентов корреляции, исходя из данных таблицы 8.
Таблица 8. Данные выпуска продукции с отобранными факторами Х2, Х3, Х5, Х6.
| № наблю-дения | Y | X 2 | X 3 | X 5 | X 6 |
| 39,5 | 3,2 | ||||
| 46,4 | 20,4 | ||||
| 43,7 | 9,5 | ||||
| 35,7 | 34,7 | ||||
| 41,8 | 17,9 | ||||
| 49,8 | 12,1 | ||||
| 44,1 | 18,9 | ||||
| 48,1 | 12,2 | ||||
| 47,6 | 8,1 | ||||
| 58,6 | 29,7 | ||||
| 70,4 | 5,3 | ||||
| 37,5 | 5,6 | ||||
| 12,3 | |||||
| 34,4 | 3,2 | ||||
| 35,4 | |||||
| 40,8 | 19,3 | ||||
| 48,1 | 12,4 |
В последнем столбце таблицы 9 представлены значения t-критерия для столбца У.
Таблица 9.Матрица коэффициентов частной корреляции с результатом Y
| Y | X2 | X3 | X5 | X6 | t критерий (t табл (0,05;11)= 2,200985 |
|
| Y | 0,996949 | -0,25446 | 0,222946 | 0,067685 | ||
| X2 | 0,996949 | -0,26264 | 0,219914 | 0,041955 | 44,31676 | |
| X3 | -0,25446 | -0,26264 | -0,07573 | -0,28755 | 0,916144 | |
| X5 | 0,222946 | 0,219914 | -0,07573 | 0,600899 | -0,88721 | |
| X6 | 0,067685 | 0,041955 | -0,28755 | 0,600899 | 1,645749 |
Из таблицы 9 видно, что переменная Y
имеет высокую и одновременно статистически значимую частную корреляцию с фактором Х2.
По территориям Южного федерального округа РФ приводятся данные за 2011 год
|
Территории федерального округа |
Валовой региональный продукт, млрд. руб., Y |
Инвестиции в основной капитал, млрд. руб., X1 |
|
1. Респ. Адыгея |
||
|
2. Респ. Дагестан |
||
|
3. Респ. Ингушетия |
||
|
4. Кабардино-БалкарскаяРесп. |
||
|
5. Респ. Калмыкия |
||
|
6. Карачаево-ЧеркесскаяРесп. |
||
|
7. Респ. Северная Осетия — Алания |
||
|
8. Краснодарский кра) |
||
|
9. Ставропольский край |
||
|
10. Астраханская обл. |
||
|
11. Волгоградская обл. |
||
|
12. Ростовская обл. |
- 1. Рассчитайте матрицу парных коэффициентов корреляции; оцените статистическую значимость коэффициентов корреляции.
- 2. Постройте поле корреляции результативного признака и наиболее тесно связанного с ним фактора.
- 3. Рассчитайте параметры линейной парной регрессии для каждого фактора Х..
- 4. Оцените качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Выберите лучшую модель.
составит 80% от его максимального значения. Представьте графически: фактические и модельные значения, точки прогноза.
- 6. Используя пошаговую множественную регрессию (метод исключения или метод включения), постройте модель формирования цены квартиры за счёт значимых факторов. Дайте экономическую интерпретацию коэффициентов модели регрессии.
- 7. Оцените качество построенной модели. Улучшилось ли качество модели по сравнению с однофакторной моделью? Дайте оценку влияния значимых факторов на результат с помощью коэффициентов эластичности,в — и -? коэффициентов.
При решении данной задачи расчеты и построение графиков и диаграмм будем вести с использованием настройки Excel Анализ данных.
1. Рассчитаем матрицу парных коэффициентов корреляции и оценим статистическую значимость коэффициентов корреляции
В диалоговом окне Корреляция в поле Входной интервал вводим диапазон ячеек, содержащих исходные данные. Так как мы выделили и заголовки столбцов, то устанавливаем флажок Метки в первой строке.
Получили следующие результаты:
Таблица 1.1 Матрица парных коэффициентов корреляции
Анализ матрицы коэффициентов парной корреляции показывает, что зависимая переменная Y, т.е валового регионального продукта имеет более тесную связь с Х1 (инвестиции в основной капитал). Коэффициент корреляции равен 0,936. Это означает, что на 93,6% зависимая переменная Y (валовой региональный продукт) зависит от показателя Х1 (инвестиции в основной капитал).
Статистическая значимость коэффициентов корреляции определим с помощью t-критерия Стьюдента. Табличное значение сравниваем с расчетными значениями.
Вычислим табличное значение с помощью функции СТЬЮДРАСПОБР.
t табл.=0,129 при доверительной вероятности равной 0,9 и степенью свободы (n-2).
Статистическим значимым является фактор Х1.
2. Построим поле корреляции результативного признака (валового регионального продукта) и наиболее тесно связанного с ним фактора (инвестиции в основной капитал)
Для этого воспользуемся инструментом построения точечной диаграммы программы Excel.
В результате получаем поле корреляции цены валового регионального продукта, млрд. руб. и инвестиции в основной капитал, млрд. руб. (рисунок 1.1.).
Рисунок 1.1
3. Рассчитаем параметры линейной парной регрессии для каждого фактора Х
Для расчета параметров линейной парной регрессии воспользуемся инструментом Регрессия, входящим в настойку Анализ данных.
В диалоговом окне Регрессия в поле Входной интервал Y вводим адрес диапазона ячеек, которые представляет зависимую переменную. В поле
Входной интервал Х вводим адрес диапазона, который содержит значения независимых переменных. Выполним вычисления параметры парной регрессии для фактора Х.
Для Х1 получили следующие данные, представленные в таблице 1.2:
Таблица 1.2
Уравнение регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал имеет вид:
4. Оценим качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Установим, какая модель является лучшей.
Коэффициент детерминации, среднюю ошибку аппроксимации мы получили в результате расчетов, проведенных в пункте 3. Полученные данные представлены в следующих таблицах:
Данные по Х1:
Таблица 1.3а
Таблица 1.4б
А) Коэффициент детерминации определяет, какая доля вариации признака У учтена в модели и обусловлена влиянием на него фактора Х. Чем больше значение коэффициента детерминации, тем теснее связь между признаками в построенной математической модели.
В программе Excel обозначается R-квадрат.
Исходя из данного критерия наиболее адекватной является модель уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
Б) Среднюю ошибку аппроксимации рассчитаем по формуле:
![]()
где числитель — сумма квадратов отклонения расчетных значений от фактических. В таблицах она находится в столбце SS, строке Остатки.
Среднее значение цены квартиры рассчитаем в Excel с помощью функции СРЗНАЧ. = 24,18182 млрд. руб.
При проведении экономических расчетов модель считается достаточно точной, если средняя ошибка аппроксимации меньше 5%, модель считается приемлемой, если средняя ошибка аппроксимации меньше 15%.
![]()
По данному критерию, наиболее адекватной является математическая модель для уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
В) Для проверки значимости модели регрессии используется F-тест. Для этого выполняется сравнение и критического (табличного)значений F-критерия Фишера.
Расчетные значения приведены в таблицах 1.4б (обозначены буквой F).
Табличное значение F-критерий Фишера рассчитаем в Excel с помощью функции FРАСПОБР. Вероятность возьмем равной 0,05. Получили: = 4,75
Расчетные значения F-критерий Фишера для каждого фактора сравним с табличным значением:
71,02 > = 4,75 модель по данному критерию адекватна.
Проанализировав данные по всем трем критериям, можно сделать вывод, что наиболее лучшей является математическая модель, построена для фактора валового регионального продукта, которая описана линейным уравнением
5. Для выбранной модели зависимости цены валового регионального продукта
осуществим прогнозирование среднего значения показателя при уровне значимости, если прогнозное значения фактора составит 80% от его максимального значения. Представим графически: фактические и модельные значения, точки прогноза.
Рассчитаем прогнозное значение Х, по условию оно составит 80% от максимального значения.
Рассчитаем Х max в Excel с помощью функции МАКС.
0,8 *52,8 = 42,24
Для получения прогнозных оценок зависимой переменной подставим полученное значение независимой переменной в линейное уравнение:
5,07+2,14*42,24 = 304,55 млрд. руб.
Определим доверительный интервал прогноза, который будет иметь следующие границы:
Для вычисления доверительного интервала для прогнозного значения рассчитываем величину отклонения от линии регрессии.
Для модели парной регрессии величина отклонения рассчитывается:


т.е. значение стандартной ошибки из таблицы 1.5а.
(Так как число степеней свободы равно единицы, то знаменатель будет равен n-2). корреляция парная регрессия прогноз
Для расчета коэффициента воспользуемся функцией Excel СТЬЮДРАСПОБР, вероятность возьмем равную 0,1, число степеней свободы 38.
![]()
Значение рассчитаем с помощью Excel, получим 12294.

Определим верхнюю и нижнюю границы интервала.
- 304,55+27,472= 332,022
- 304,55-27,472= 277,078
Таким образом, прогнозное значение = 304,55 тыс.долл., будет находиться между нижней границей, равной 277,078 тыс.долл. и верхней границей, равной 332,022 млдр. Руб.
Фактические и модельные значения, точки прогноза представлены графически на рисунке 1.2.

Рисунок 1.2
6. Используя пошаговую множественную регрессию (метод исключения), построим модель формирования цены валового регионального продукта за счёт значимых факторов
Для построения множественной регрессии воспользуемся функцией Регрессия программы Excel, включив в нее все факторы. В результате получаем результативные таблицы, из которых нам необходим t-критерий Стьюдента.
Таблица 1.8а
Таблица 1.8б
Таблица 1.8в.
Получаем модель вида:
Поскольку < (4,75 < 71,024), уравнение регрессии следует признать адекватным.
Выберем наименьшее по модулю значение t-критерия Стьюдента, оно равно 8,427, сравниваем его с табличным значением, которые рассчитываем в Excel, уровень значимости берем равным 0,10, число степеней свободы n-m-1=12-4=8: =1,8595
Поскольку 8,427>1,8595 модель следует признать адекватной.
7. Для оценки значимого фактора полученной математической модели, рассчитаем коэффициенты эластичности, и — коэффициенты
Коэффициент эластичности показывает, насколько процентов изменится результативный признак при изменении факторного признака на 1%:
Э X4 = 2,137 *(10,69/24,182) = 0,94%
То есть с ростом инвестиции в основной капитал 1% стоимость в среднем возрастает на 0,94%.
Коэффициент показывает на какую часть величины среднего квадратического отклонения меняется среднее значение зависимой переменной с изменением независимой переменной на одно среднеквадратическое отклонение.
2,137* (14.736/33,632) = 0,936.
Данные средних квадратических отклонений взяты из таблиц, полученных с помощью инструменты Описательная статистика.
Таблица 1.11 Описательная статистика (Y)
Таблица 1.12 Описательная статистика (Х4)
Коэффициент определяет долю влияния фактора в суммарном влиянии всех факторов:
Для расчета коэффициентов парной корреляции вычисляем матрицу парных коэффициентов корреляции в программе Excel с помощью инструмента Корреляция настройки Анализа данных.
Таблица 1.14
(0,93633*0,93626) / 0,87 = 1,00.
Вывод: Из полученных расчетов можно сделать вывод, что результативный признак Y (валовой региональный продукт) имеет большую зависимость от фактора X1 (инвестиции в основной капитал) (на 100%).
Список литературы
- 1. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. — М.: Дело, 1998. — с. 69 — 74.
- 2. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др. 2002. — с. 49 — 105.
- 3. Доугерти К. Введение в эконометрику: Пер. с англ. — М.: ИНФРА-М, 1999. — XIV, с. 262 — 285.
- 4. Айвызян С.А., Михтирян В.С. Прикладная математика и основы эконометрики. -1998., с 115-147
. - 5. Кремер Н.Ш., Путко Б.А. Эконометрика. -2007. с 175-251.
Коэффициент корреляции отражает степень взаимосвязи между двумя показателями. Всегда принимает значение от -1 до 1. Если коэффициент расположился около 0, то говорят об отсутствии связи между переменными.
Если значение близко к единице (от 0,9, например), то между наблюдаемыми объектами существует сильная прямая взаимосвязь. Если коэффициент близок к другой крайней точке диапазона (-1), то между переменными имеется сильная обратная взаимосвязь. Когда значение находится где-то посередине от 0 до 1 или от 0 до -1, то речь идет о слабой связи (прямой или обратной). Такую взаимосвязь обычно не учитывают: считается, что ее нет.
Расчет коэффициента корреляции в Excel
Рассмотрим на примере способы расчета коэффициента корреляции, особенности прямой и обратной взаимосвязи между переменными.
Значения показателей x и y:
Y – независимая переменная, x – зависимая. Необходимо найти силу (сильная / слабая) и направление (прямая / обратная) связи между ними. Формула коэффициента корреляции выглядит так:

Чтобы упростить ее понимание, разобьем на несколько несложных элементов.


Между переменными определяется сильная прямая связь.
Встроенная функция КОРРЕЛ позволяет избежать сложных расчетов. Рассчитаем коэффициент парной корреляции в Excel с ее помощью. Вызываем мастер функций. Находим нужную. Аргументы функции – массив значений y и массив значений х:

Покажем значения переменных на графике:

Видна сильная связь между y и х, т.к. линии идут практически параллельно друг другу. Взаимосвязь прямая: растет y – растет х, уменьшается y – уменьшается х.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.

Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».


Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Экономические данные представляют собой количественные характеристики каких-либо экономических объектов или процессов. Они формируются под действием множества факторов, не все из которых доступны внешнему контролю. Неконтролируемые факторы могут принимать случайные значения из некоторого множества значений и тем самым обусловливать случайность данных, которые они определяют. Одной из основных задач в экономических исследованиях является анализ зависимостей между переменными.
Рассматривая зависимости между признаками, необходимо выделить прежде всего два типа связей:
- функциональные —
характеризуются полным соответствием между изменением факторного признака и изменением результативной величины: каждому значению признака-фактора соответствуют вполне определенные значения результативного признака.
Этот тип связи выражается в виде формульной зависимости. Функциональная зависимость может связывать результативный признак с одним или несколькими факторными признаками. Так, величина заработной платы при повременной оплате труда зависит от количества отработанных часов; - корреляционные
— между изменением двух признаков нет полного соответствия, воздействие отдельных факторов проявляется лишь в среднем, при массовом наблюдении фактических данных. Одновременное воздействие на изучаемый признак большого количества разнообразных факторов приводит к тому, что одному и тому же значению признака-фактора соответствует целое распределение значений результативного признака,
поскольку в каждом конкретном случае прочие факторные признаки могут изменять силу и направленность своего воздействия.
Следует иметь в виду, что при наличии функциональной зависимости между признаками можно, зная величину факторного признака, точно определить величину результативного признака.
При наличии же корреляционной зависимости устанавливается лишь тенденция изменения результативного признака
при изменении величины факторного признака.
Изучая взаимосвязи между признаками, их классифицируют по направлению, форме, числу факторов:
- по направлению
связи делятся на прямые
и обратные.
При прямой связи направление изменения результативного признака совпадает с направлением изменения признака-фактора. При обратной связи направление изменения результативного признака противоположно направлению изменения признака- фактора. Например, чем выше квалификация рабочего, тем выше уровень производительности его труда (прямая связь). Чем выше производительность труда, тем ниже себестоимость единицы продукции (обратная связь); - по форме
(виду функции) связи делят на линейные
(прямолинейные) и нелинейные
(криволинейные). Линейная связь отображается прямой линией, нелинейная — кривой (парабол ой, гиперболой и т.п.). При линейной связи с возрастанием значения факторного признака происходит равномерное возрастание (убывание) значения результативного признака; - по количеству факторов, действующих на результативный признак,
связи подразделяют на однофакторные
(парные) и многофакторные.
Изучение зависимости вариации признака от окружающих условий и составляет содержание теории корреляции .
При проведении корреляционного анализа вся совокупность данных рассматривается как множество переменных (факторов), каждая из которых содержит п
наблюдений.
При изучении взаимосвязи между двумя факторами их, как правило, обозначают Х=
(х р х 2 ,
…,х п)
и Y= (у { , у 2 ,
…,у и).
Ковариация —
это статистическая мера взаимодействия
двух переменных. Например, положительное значение ковариации доходности двух ценных бумаг показывает, что доходности этих ценных бумаг имеют тенденцию изменяться в одну сторону.
Ковариация между двумя переменными X
и Y
рассчитывается следующим образом:
где- фактические значения переменных
X
и г;

Если случайные величины Хи Y
независимы, теоретическая ковариация равна нулю.
Ковариация зависит от единиц, в которых измеряются переменные Хи
У, она является ненормированной величиной. Поэтому для измерения силы связи
между двумя переменными используется другая статистическая характеристика, называемая коэффициентом корреляции.
Для двух переменных X
и Y коэффициент парной корреляции
определяется следующим образом:

где SSy —
оценки дисперсий величин Хи Y.
Эти оценки характеризуют степень разброса
значений х { ,х 2 , …,х п (у 1 ,у 2 ,у п)
вокруг своего среднего х (у
соответственно), или вариабельность
(изменчивость) этих переменных на множестве наблюдений.
Дисперсия
(оценка дисперсии) определяется по формуле

В общем случае для получения несмещенной оценки дисперсии сумму квадратов следует делить на число степеней свободы оценки (п-р),
где п —
объем выборки, р —
число наложенных на выборку связей. Так как выборка уже использовалась один раз для определения среднего X,
то число наложенных связей в данном случае равно единице (р =
1), а число степеней свободы оценки (т.е. число независимых элементов выборки) равно (п —
1).
Более естественно измерять степень разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый среднеквадратическим отклонением
(стандартным отклонением
) или стандартной ошибкой
переменной X
(переменной Y)
и определяемый соотношением

Слагаемые в числителе формулы (3.2.1) выражают взаимодействие двух переменных и определяют знак корреляции (положительная или отрицательная). Если, например, между переменными существует сильная положительная взаимосвязь (увеличение одной переменной при увеличении второй), каждое слагаемое будет положительным числом. Аналогично, если между переменными существует сильная отрицательная взаимосвязь, все слагаемые в числителе будут отрицательными числами, что в результате дает отрицательное значение корреляции.
Знаменатель выражения для коэффициента парной корреляции [см. формулу (3.2.2)] просто нормирует числитель таким образом, что коэффициент корреляции оказывается легко интерпретируемым числом, не имеющим размерности, и принимает значения от -1 до +1.
Числитель выражения для коэффициента корреляции, который трудно интерпретировать из-за необычных единиц измерения, есть ковариация ХиУ.
Несмотря на то что иногда она используется как самостоятельная характеристика (например, в теории финансов для описания совместного изменения курсов акций на двух биржах), удобнее пользоваться коэффициентом корреляции. Корреляция и ковариация представляют, по сути, одну и ту же информацию, однако корреляция представляет эту информацию в более удобной форме.
Для качественной оценки коэффициента корреляции применяются различные шкалы, наиболее часто — шкала Чеддока. В зависимости от значения коэффициента корреляции связь может иметь одну из оценок:
- 0,1-0,3 — слабая;
- 0,3-0,5 — заметная;
- 0,5-0,7 — умеренная;
- 0,7-0,9 — высокая;
- 0,9-1,0 — весьма высокая.
Оценка степени тесноты связи с помощью коэффициента корреляции проводится, как правило, на основе более или менее ограниченной информации об изучаемом явлении. В связи с этим возникает необходимость оценки существенности линейного коэффициента корреляции, дающая возможность распространить выводы по результатам выборки на генеральную совокупность.
Оценка значимости коэффициента корреляции при малых объемах выборки выполняется с использованием 7-критерия Стьюдента. При этом фактическое (наблюдаемое) значение этого критерия определяется по формуле

Вычисленное по этой формуле значение / набл сравнивается с критическим значением 7-критерия, которое берется из таблицы значений /-критерия Стьюдента (см. Приложение 2) с учетом заданного уровня значимости ос и числа степеней свободы (п
— 2).
Если 7 набл > 7 табл, то полученное значение коэффициента корреляции признается значимым (т.е. нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается). И таким образом делается вывод, что между исследуемыми переменными есть тесная статистическая взаимосвязь.
Если значение г у х
близко к нулю, связь между переменными слабая. Если корреляция между случайными величинами:
- положительная, то при возрастании одной случайной величины другая имеет тенденцию в среднем возрастать;
- отрицательная, то при возрастании одной случайной величины другая имеет тенденцию в среднем убывать. Удобным графическим средством анализа парных данных является диаграмма рассеяния
, которая представляет каждое наблюдение в пространстве двух измерений, соответствующих двум факторам. Диаграмму рассеяния, на которой изображается совокупность значений двух признаков, называют еще корреляционным полем.
Каждая точка этой диаграммы имеет координаты х (. и у г
По мере того как возрастает сила линейной связи, точки на графике будут лежать более близко к прямой линии, а величина г
будет ближе к единице.
Коэффициенты парной корреляции используются для измерения силы линейных связей различных пар признаков из их множества. Для множества признаков получают матрицу коэффициентов парной корреляции.
Пусть вся совокупность данных состоит из переменной Y = =
(у р у 2 ,
…, у п)
и т
переменных (факторов) X,
каждая из которых содержит п
наблюдений. Значения переменных Y
и X,
содержащиеся в наблюдаемой совокупности, записываются в таблицу (табл. 3.2.1).
Таблица 3.2.1
|
Переменная Номер наблюдения |
|||||
|
Х тЗ |
|||||
|
Х тп |
На основании данных, содержащихся в этой таблице, вычисляют матрицу коэффициентов парной корреляции R,
она симметрична относительно главной диагонали:

Анализ матрицы коэффициентов парной корреляции используют при построении моделей множественной регрессии.
Одной корреляционной матрицей нельзя полностью описать зависимости между величинами. В связи с этим в многомерном корреляционном анализе рассматривается две задачи:
- 1. Определение тесноты связи одной случайной величины с совокупностью остальных величин, включенных в анализ.
- 2. Определение тесноты связи между двумя величинами при фиксировании или исключении влияния остальных величин.
Эти задачи решаются соответственно с помощью коэффициентов множественной и частной корреляции.
Решение первой задачи (определение тесноты связи одной случайной величины с совокупностью остальных величин, включенных в анализ) осуществляется с помощью выборочного коэффициента множественной корреляции
по формуле

где R —
R
[см. формулу (3.2.6)]; Rjj —
алгебраическое дополнение элемента той же матрицы R.
Квадрат коэффициента множественной корреляции Щ
j 2 j
_j J+l m
принято называть выборочным множественным коэффициентом детерминации
; он показывает, какую долю вариации (случайного разброса) исследуемой величины Xj
объясняет вариация остальных случайных величин Х { , Х
2 ,…, Х т.
Коэффициенты множественной корреляции и детерминации являются величинами положительными, принимающими значения в интервале от 0 до 1. При приближении коэффициента R
2 к единице можно сделать вывод о тесноте взаимосвязи случайных величин, но не о ее направлении. Коэффициент множественной корреляции может только увеличиваться, если в модель включать дополнительные переменные, и не увеличится, если исключать какие-либо из имеющихся признаков.
Проверка значимости коэффициента детерминации осуществляется путем сравнения расчетного значения /’-критерия Фишера

с табличным F
raбл. Табличное значение критерия (см. Приложение 1) определяется заданным уровнем значимости а и степенями свободы v l = mnv 2 = n-m-l.
Коэффициент R 2
значимо отличается от нуля, если выполняется неравенство

Если рассматриваемые случайные величины коррелируют друг с другом,
то на величине коэффициента парной корреляции частично сказывается влияние других величин. В связи с этим возникает необходимость исследования частной корреляции между величинами при исключении влияния других случайных величин (одной или нескольких).
Выборочный частный коэффициент корреляции
определяется по формуле

где R Jk , Rjj, R kk —
алгебраические дополнения к соответствующим элементам матрицы R
[см. формулу (3.2.6)].
Частный коэффициент корреляции, также как и парный коэффициент корреляции, изменяется от -1 до +1.
Выражение (3.2.9) при условии т =
3 будет иметь вид

Коэффициент г 12(3) называется коэффициентом корреляции между х {
и х 2 при фиксированном х у
Он симметричен относительно первичных индексов 1, 2. Его вторичный индекс 3 относится к фиксированной переменной.
Пример 3.2.1. Вычисление коэффициентов парной,
множественной и частной корреляции.
В табл. 3.2.2 представлена информация об объемах продаж и затратах на рекламу одной фирмы, а также индекс потребительских расходов за ряд текущих лет.
- 1. Построить диаграмму рассеяния (корреляционное поле) для переменных «объем продаж» и «индекс потребительских расходов».
- 2. Определить степень влияния индекса потребительских расходов на объем продаж (вычислить коэффициент парной корреляции).
- 3. Оценить значимость вычисленного коэффициента парной корреляции.
- 4. Построить матрицу коэффициентов парной корреляции по трем переменным.
- 5. Найти оценку множественного коэффициента корреляции.
- 6. Найти оценки коэффициентов частной корреляции.
1. В нашем примере диаграмма рассеяния имеет вид, приведенный на рис. 3.2.1. Вытянутость облака точек на диаграмме рассеяния вдоль наклонной прямой позволяет сделать предположение, что существует некоторая объективная тенденция прямой линейной связи между значениями переменных Х 2
Y
(объем продаж).

Рис. 3.2.1.
2. Промежуточные расчеты при вычислении коэффициента корреляции между переменными Х 2
(индекс потребительских расходов) и Y
(объем продаж) приведены в табл. 3.2.3.
Средние значения
случайных величин Х 2
и Y,
которые являются наиболее простыми показателями, характеризующими последовательности jCj, х 2 ,
…, х 16 и y v y 2 ,
…, у 16 , рассчитаем по следующим формулам:

|
Объем продаж Y, тыс. руб. |
Индекс потреби тельских расходов |
Объем продаж Y, тыс. руб. |
Индекс потреби тельских расходов |
||
Таблица 3.2.3
|
л:, — х |
(И — У)(х, — х) |
(х, — х) 2 |
(у,- — у) 2 |
||||
Дисперсия
характеризует степень разброса значений x v x 2 ,х :

Рассмотрим теперь решение примера 3.2.1 в Excel.
Чтобы вычислить корреляцию средствами Excel, можно воспользоваться функцией =коррел (), указав адреса двух столбцов чисел, как показано на рис. 3.2.2. Ответ помещен в D8 и равен 0,816.

Рис. 3.2.2.
(Примечание. Аргументы функции коррел должны быть числами или именами, массивами или ссылками, содержащими числа. Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
Если массив! и массив2 имеют различное количество точек данных, то функция коррел возвращает значение ошибки #н/д.
Если массив1 либо массив2 пуст или если о (стандартное отклонение) их значений равно нулю, то функция коррел возвращает значение ошибки #дел/0 !.)
Критическое значение /-статистики Стьюдента может быть также получено с помощью функции стьюдраспробр 1 пакета Excel. В качестве аргументов функции необходимо задать число степеней свободы, равное п
— 2 (в нашем примере 16 — 2= 14) и уровень значимости а (в нашем примере а = 0,1) (рис. 3.2.3). Если фактическое значение
/-статистики, взятое по модулю, больше критического,
то с вероятностью (1 — а) коэффициент корреляции значимо отличается от нуля.

Рис. 3.2.3. Критическое значение /-статистики равно 1,7613
В Excel входит набор средств анализа данных (так называемый пакет анализа), предназначенный для решения различных статистических задач. Для вычисления матрицы коэффициентов парной корреляции R
следует воспользоваться инструментом Корреляция (рис. 3.2.4) и установить параметры анализа в соответствующем диалоговом окне. Ответ будет помещен на новый рабочий лист (рис. 3.2.5).
1 В Excel 2010 название функции стьюдраспробр изменено на стью-
ДЕНТ.ОБР.2Х.

Рис. 3.2.4.

Рис. 3.2.5.
- Основоположниками теории корреляции считаются английские статистики Ф. Гальтон (1822-1911) и К. Пирсон (1857-1936). Термин «корреляция» был заимствован из естествознания и обозначает «соотношение, соответствие». Представление о корреляции как взаимозависимости между случайными переменными величинами лежит воснове математико-статистической теории корреляции.
Матрица парных коэффициентов корреляции
| Y |
X1 |
X2 |
X3 |
X4 |
X5 |
|
| Y | ||||||
| X1 | 0,732705 | |||||
| X2 | 0,785156 | 0,706287 | ||||
| X3 | 0,179211 | -0,29849 | 0,208514 | |||
| X4 | 0,667343 | 0,924333 | 0,70069 | 0,299583 | ||
| X5 | 0,709204 | 0,940488 | 0,691809 | 0,326602 | 0,992945 |
В узлах матрицы находятся парные коэффициенты корреляции, характеризующие тесноту взаимосвязи между факторными признаками. Анализируя эти коэффициенты, отметим, что чем больше их абсолютная величина, тем большее влияние оказывает соответствующий факторный признак на результативный. Анализ полученной матрицы осуществляется в два этапа:
1. Если в первом столбце матрицы есть коэффициенты корреляции, для которых /r / < 0,5, то соответствующие признаки из модели исключаются. В данном случае в первом столбце матрицы коэффициентов корреляции исключается фактор или коэффициент роста уровня инфляции. Данный фактор оказывает меньшее влияние на результативный признак, нежели оставшиеся четыре признака.
2. Анализируя парные коэффициенты корреляции факторных признаков друг с другом, (r XiXj), характеризующие тесноту их взаимосвязи, необходимо оценить их независимость друг от друга, поскольку это необходимое условие для дальнейшего проведения регрессионного анализа. В виду того, что в экономике абсолютно независимых признаков нет, необходимо выделить, по возможности, максимально независимые. Факторные признаки, находящиеся в тесной корреляционной зависимости друг с другом, называются мультиколлинеарными. Включение в модель мультиколлинеарных признаков делает невозможным экономическую интерпретацию регрессионной модели, так как изменение одного фактора влечет за собой изменение факторов с ним связанных, что может привести к «поломке» модели в целом.
Критерий мультиколлениарности факторов выглядит следующим образом:
/r XiXj / > 0,8
В полученной матрице парных коэффициентов корреляции этому критерию отвечают два показателя, находящиеся на пересечении строк ![]() и . Из каждой пары этих признаков в модели необходимо оставить один, он должен оказывать большее влияние на результативный признак. В итоге из модели исключаются факторы и , т.е. коэффициент роста себестоимости реализованной продукции и коэффициент роста объёма её реализации.
и . Из каждой пары этих признаков в модели необходимо оставить один, он должен оказывать большее влияние на результативный признак. В итоге из модели исключаются факторы и , т.е. коэффициент роста себестоимости реализованной продукции и коэффициент роста объёма её реализации.
Итак, в регрессионную модель вводим факторы Х1 и Х2.
Далее осуществляется регрессионный анализ (сервис, анализ данных, регрессия). Вновь составляет таблица исходных данных с факторами Х1 и Х2. Регрессия в целом используется для анализа воздействия на отдельную зависимую переменную значений независимых переменных (факторов) и позволяет корреляционную связь между признаками представить в виде некоторой функциональной зависимости называемой уравнением регрессии или корреляционно-регрессионной моделью.
В результате регрессионного анализа получаем результаты расчета многомерной регрессии. Проанализируем полученные результаты.
Все коэффициенты регрессии значимы по критерию Стьюдента. Коэффициент множественной корреляции R составил 0,925, квадрат этой величины (коэффициент детерминации) означает, что вариация результативного признака в среднем на 85,5% объясняется за счет вариации факторных признаков, включенных в модель. Коэффициент детерминированности характеризует тесноту взаимосвязи между совокупностью факторных признаков и результативным показателем. Чем ближе значение R-квадрат к 1, тем теснее взаимосвязь. В нашем случае показатель, равный 0,855, указывает на правильный подбор факторов и на наличие взаимосвязи факторов с результативным показателем.
Рассматриваемая модель адекватна, поскольку расчетное значение F-критерия Фишера существенно превышает его табличное значение (F набл =52,401; F табл =1,53).
В качестве общего результата проведенного корреляционно-регрессионного анализа выступает множественное уравнение регрессии, которое имеет вид:
Полученное уравнение регрессии отвечает цели корреляционно-регрессионного анализа и является линейной моделью зависимости балансовой прибыли предприятия от двух факторов: коэффициента роста производительности труда и коэффициента имущества производственного назначения.
На основании полученной модели можно сделать вывод о том, что при увеличении уровня производительности труда на 1% к уровню предыдущего периода величина балансовой прибыли возрастет на 0,95 п.п.; увеличение же коэффициента имущества производственного назначения на 1% приведет к росту результативного показателя на 27,9 п.п. Слелдовательно, доминирующее влияние на рост балансовой прибыли оказывает увеличение стоимости имущества производственного назначения (обновление и рост основных средств предприятия).
По множественной регрессионной модели выполняется многофакторный прогноз результативного признака. Пусть известно, что Х1 = 3,0, а Х3 = 0,7. Подставим значения факторных признаков в модель, получим Упр = 0,95*3,0 + 27,9*0,7 – 19,4 = 2,98. Таким образом, при увеличении производительности труда и модернизации основных средств на предприятии балансовая прибыль в 1 квартале 2005 г. по отношению к предыдущему периоду (IV квартал 2004 г.) возрастет на 2,98%.
![Контрольная работа по ЭММ и ПМ вариант №12 (решена в Excel) [13.02.13]](https://studrb.ru/files/works_screen/1/35/13.png)
Тема: Контрольная работа по ЭММ и ПМ вариант №12 (решена в Excel)
Раздел: Бесплатные рефераты по ЭММ и ПМ
Тип: Контрольная работа | Размер: 23.99K | Скачано: 210 | Добавлен 13.02.13 в 10:48 | Рейтинг: +1 | Еще Контрольные работы
Задача
Исследуется взаимосвязь курса доллара США с курсами евро, японской иены и английского фунта стерлингов. Имеются данные об официальных курсах валют, установленных Центральным банком Российской Федерации, за двенадцать дней.
| День | Доллар США, руб./долл. | Евро, руб./евро | Японская иена, руб./100 иен | Английский фунт, руб./фунт |
| 1 | 28,12 | 36,13 | 26,97 | 52,63 |
| 2 | 28,18 | 35,97 | 26,8 | 52,32 |
| 3 | 28,13 | 35,97 | 26,77 | 52,26 |
| 4 | 28,08 | 36 | 26,63 | 52,28 |
| 5 | 28,06 | 36,13 | 26,53 | 52,43 |
| 6 | 28,03 | 36,28 | 26,7 | 52,58 |
| 7 | 28,02 | 36,34 | 26,67 | 52,9 |
| 8 | 28 | 36,47 | 26,63 | 52,99 |
| 9 | 27,99 | 36,54 | 26,6 | 52,81 |
| 10 | 27,93 | 36,5 | 26,5 | 52,89 |
| 11 | 27,95 | 36,52 | 26,55 | 52,62 |
| 12 | 27,97 | 36,54 | 26,52 | 52,67 |
1. Постройте матрицу парных коэффициентов линейной корреляции. Выполните тест Фаррара -Глоубера на мультиколлинеарность. 2. Постройте линейную регрессионную модель курса доллара США, обосновав отбор факторов. Оцените параметры модели.
3. Оцените качество построенной модели.
4. Изменение курсов каких валют существенно влияет на изменение курса доллара США? Изменение какого фактора сильнее всего влияет на изменение курса доллара США? Оцените вклад каждого из факторов в вариацию курса доллара США с помощью D -коэффициентов. 5. Присутствует ли в остатках регрессии автокорреляция первого порядка? 6. Можно ли считать остатки случайными?
7. Спрогнозируйте курс доллара на следующие два дня.
Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные корректировки и доработки. Узнайте стоимость своей работы
Бесплатная оценка
+1
13.02.13 в 10:48
Автор:![]() Jonya
Jonya
Понравилось? Нажмите на кнопочку ниже. Вам не сложно, а нам приятно).
Чтобы скачать бесплатно Контрольные работы на максимальной скорости, зарегистрируйтесь или авторизуйтесь на сайте.
Важно! Все представленные Контрольные работы для бесплатного скачивания предназначены для составления плана или основы собственных научных трудов.
Друзья! У вас есть уникальная возможность помочь таким же студентам как и вы! Если наш сайт помог вам найти нужную работу, то вы, безусловно, понимаете как добавленная вами работа может облегчить труд другим.
Добавить работу
Если Контрольная работа, по Вашему мнению, плохого качества, или эту работу Вы уже встречали, сообщите об этом нам.
Добавление отзыва к работе
Добавить отзыв могут только зарегистрированные пользователи.
Похожие работы
- Контрольная по эконометрике вариант 12