
Skip to content
В руководстве объясняется, как разделить ячейки в Excel с помощью формул и стандартных инструментов. Вы узнаете, как разделить текст запятой, пробелом или любым другим разделителем, а также как разбить строки на текст и числа.
Разделение текста из одной ячейки на несколько — это задача, с которой время от времени сталкиваются все пользователи Excel. В одной из наших предыдущих статей мы обсуждали, как разделить ячейки в Excel с помощью функции «Текст по столбцам» и «Мгновенное заполнение». Сегодня мы подробно рассмотрим, как можно разделить текст по ячейкам с помощью формул.
Чтобы разбить текст в Excel, вы обычно используете функции ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT) или ПСТР (MID) в сочетании с НАЙТИ (FIND) или ПОИСК (SEARCH). На первый взгляд, некоторые рассмотренные ниже приёмы могут показаться сложными. Но на самом деле логика довольно проста, и следующие примеры помогут вам разобраться.
Для преобразования текста в ячейках в Excel ключевым моментом является определение положения разделителя в нем. Что может быть таким разделителем? Это запятая, точка с запятой, наклонная черта, двоеточие, тире, восклицательный знак и т.п. И, как мы далее увидим, даже целое слово.
- Как распределить ФИО по столбцам
- Как использовать разделители в тексте
- Разделяем текст по переносам строки
- Как разделить длинный текст на множество столбцов
- Как разбить «текст + число» по разным ячейкам
- Как разбить ячейку вида «число + текст»
- Разделение ячейки по маске (шаблону)
- Использование инструмента Split Text
В зависимости от вашей задачи эту проблему можно решить с помощью функции ПОИСК (без учета регистра букв) или НАЙТИ (с учетом регистра).
Как только вы определите позицию разделителя, используйте функцию ЛЕВСИМВ, ПРАВСИМВ и ПСТР, чтобы извлечь соответствующую часть содержимого.
Для лучшего понимания пошагово рассмотрим несколько примеров.
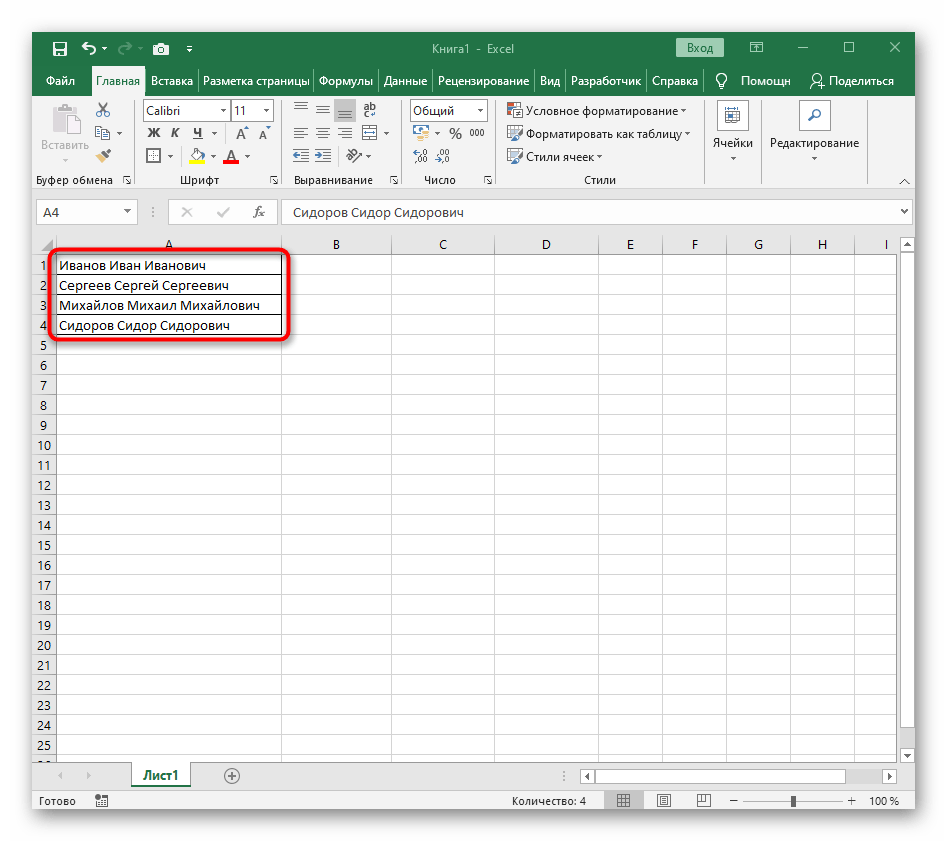
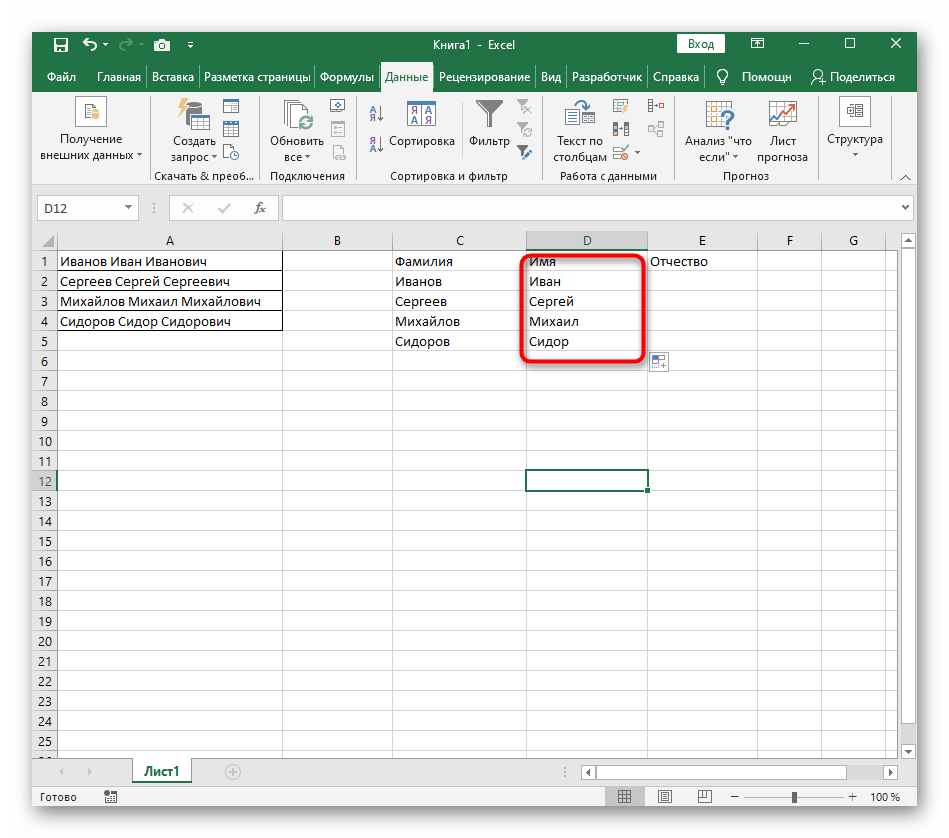
Делим текст вида ФИО по столбцам.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек, который демонстрируется ниже.
В столбце A нашей таблицы записаны Фамилии, имена и отчества сотрудников. Необходимо разделить их на 3 столбца.
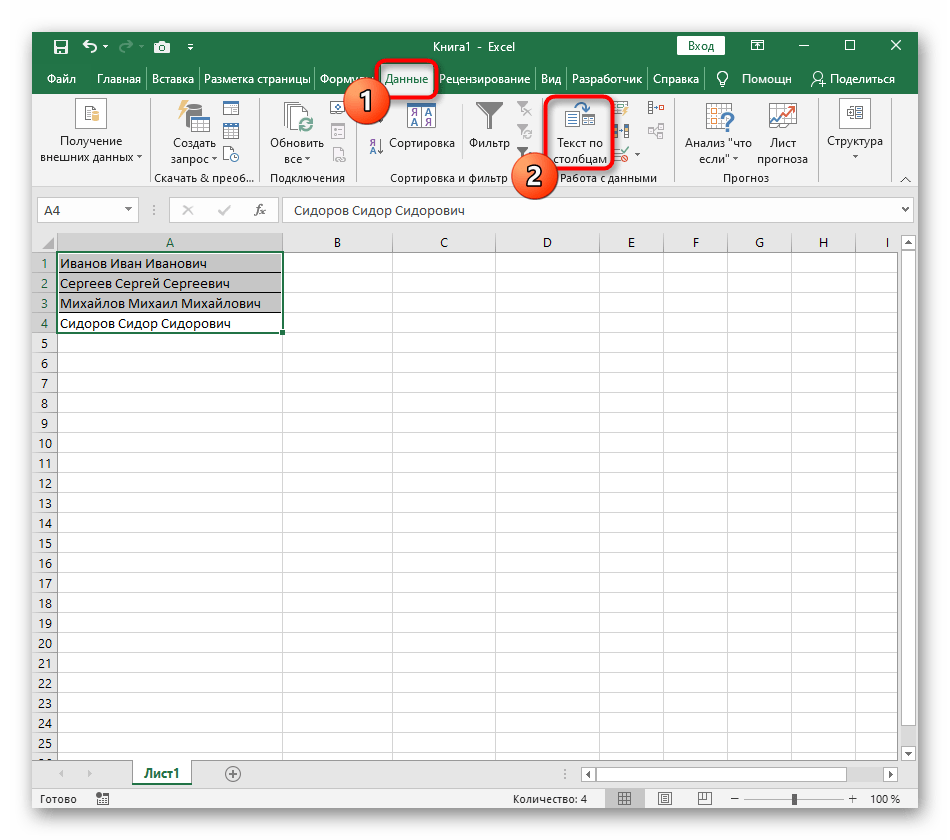
Можно сделать это при помощи инструмента «Текст по столбцам». Об этом методе мы достаточно подробно рассказывали, когда рассматривали, как можно разделить ячейку по столбцам.
Кратко напомним:
На ленте «Данные» выбираем «Текст по столбцам» — с разделителями.

Далее в качестве разделителя выбираем пробел.
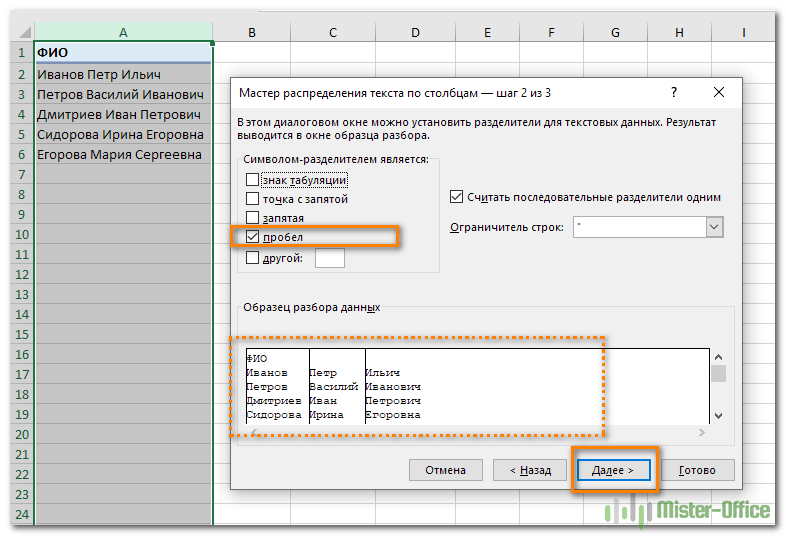
Обращаем внимание на то, как разделены наши данные в окне образца.
В следующем окне определяем формат данных. По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру.
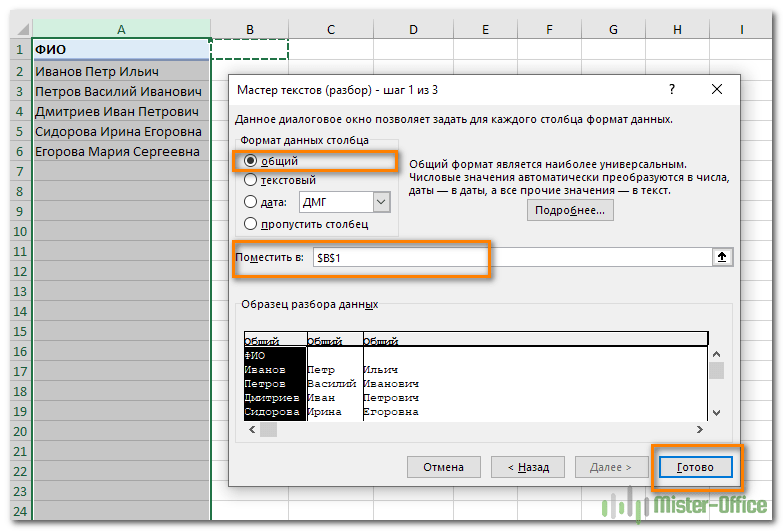
В итоге имеем следующую картину:

При желании можно дать заголовки новым столбцам B,C,D.
А теперь давайте тот же результат получим при помощи формул.
Для многих это удобнее. В том числе и по той причине, что если в таблице появятся новые данные, которые нужно разделить, то нет необходимости повторять всю процедуру с начала, а просто нужно скопировать уже имеющиеся формулы.
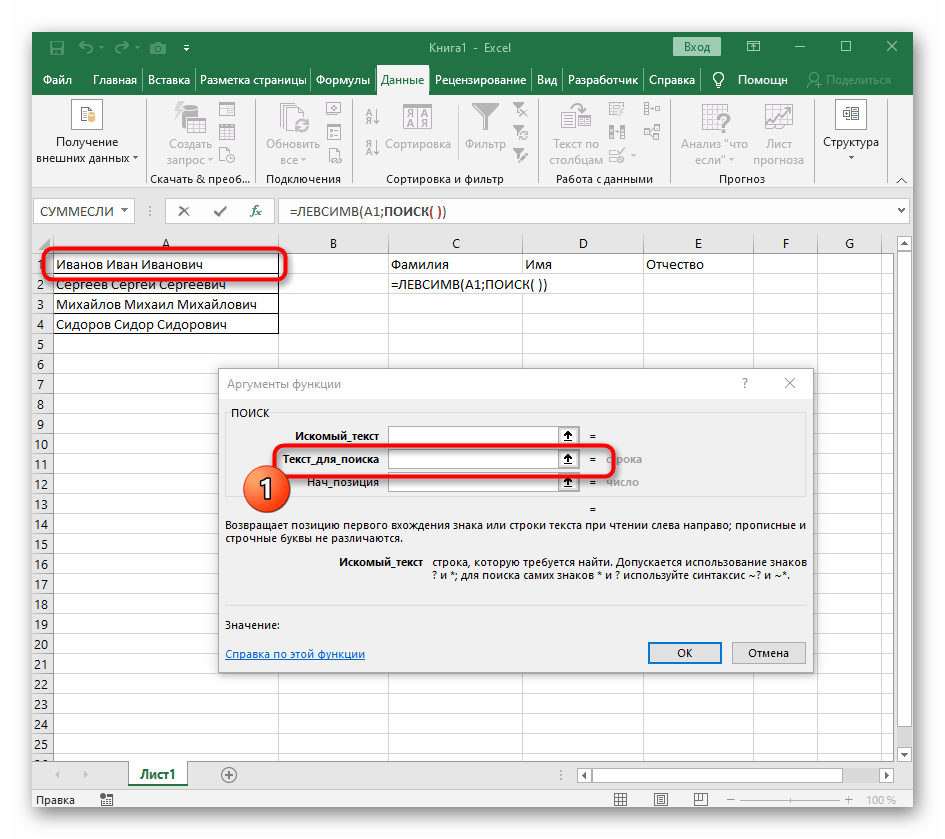
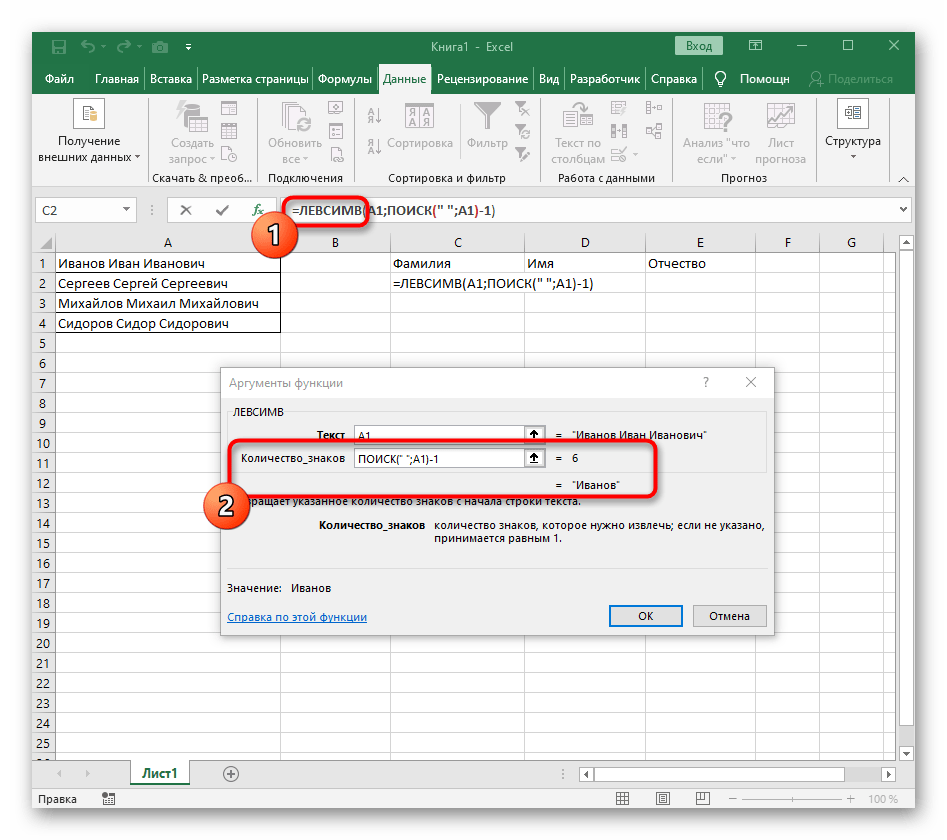
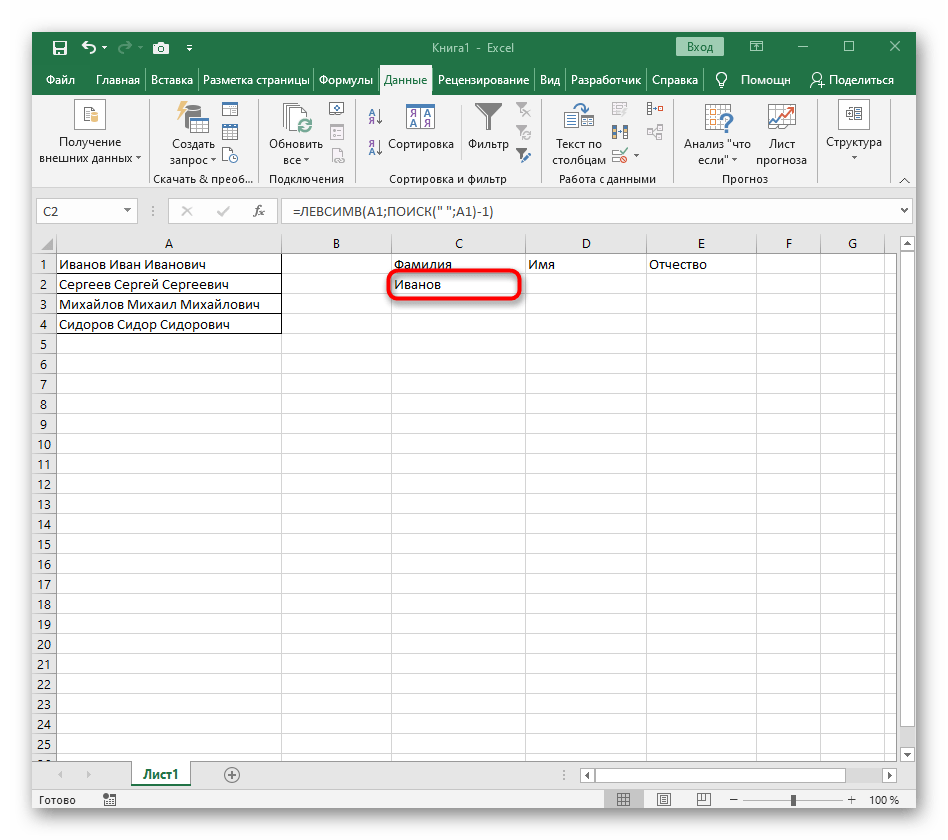
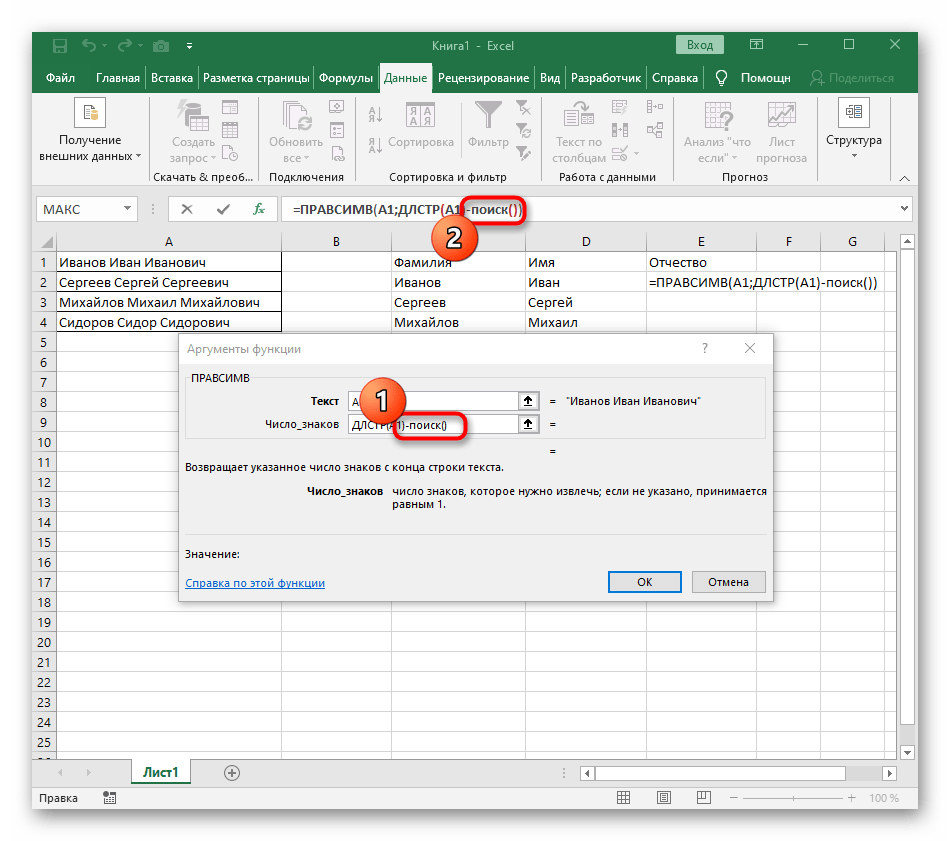
Итак, чтобы выделить из нашего ФИО фамилию, будем использовать выражение
=ЛЕВСИМВ(A2; ПОИСК(» «;A2;1)-1)
В качестве разделителя мы используем пробел. Функция ПОИСК указывает нам, в какой позиции находится первый пробел. А затем именно это количество букв (за минусом 1, чтобы не извлекать сам пробел) мы «отрезаем» слева от нашего ФИО при помощи ЛЕВСИМВ.
Далее будет чуть сложнее.
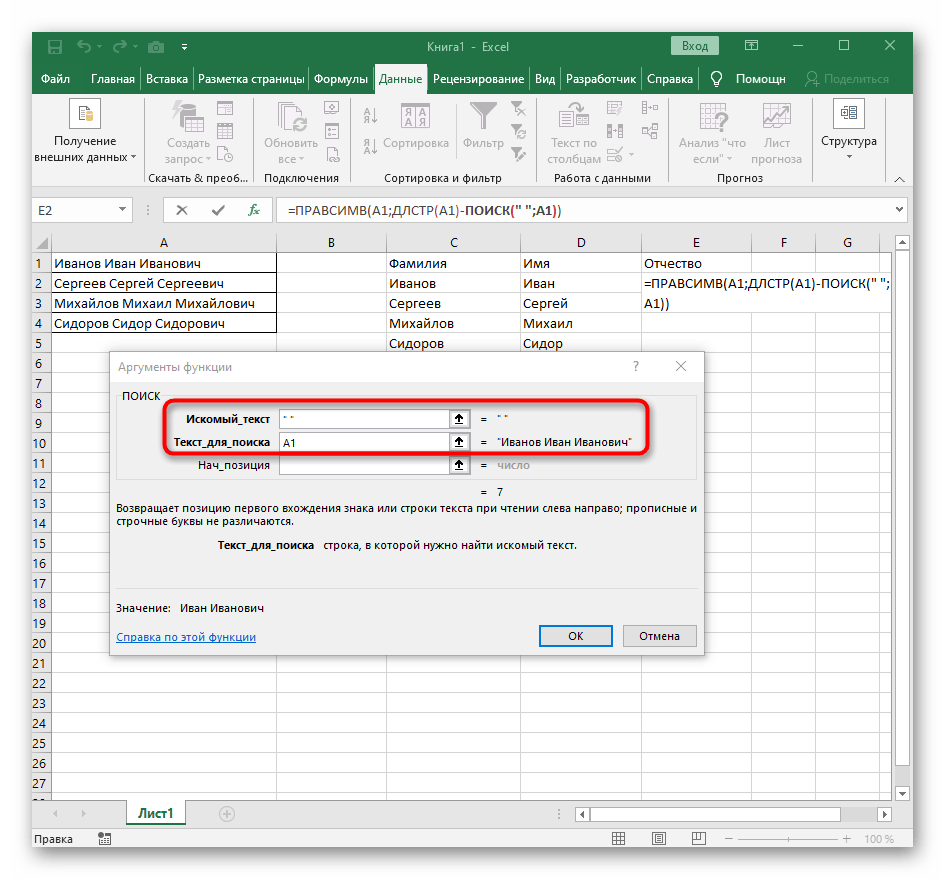
Нужно извлечь второе слово, то есть имя. Чтобы вырезать кусочек из середины, используем функцию ПСТР.
=ПСТР(A2; ПОИСК(» «;A2) + 1; ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) — 1)
Как вы, наверное, знаете, функция Excel ПСТР имеет следующий синтаксис:
ПСТР (текст; начальная_позиция; количество_знаков)
Текст извлекается из ячейки A2, а два других аргумента вычисляются с использованием 4 различных функций ПОИСК:
- Начальная позиция — это позиция первого пробела плюс 1:
ПОИСК(» «;A2) + 1
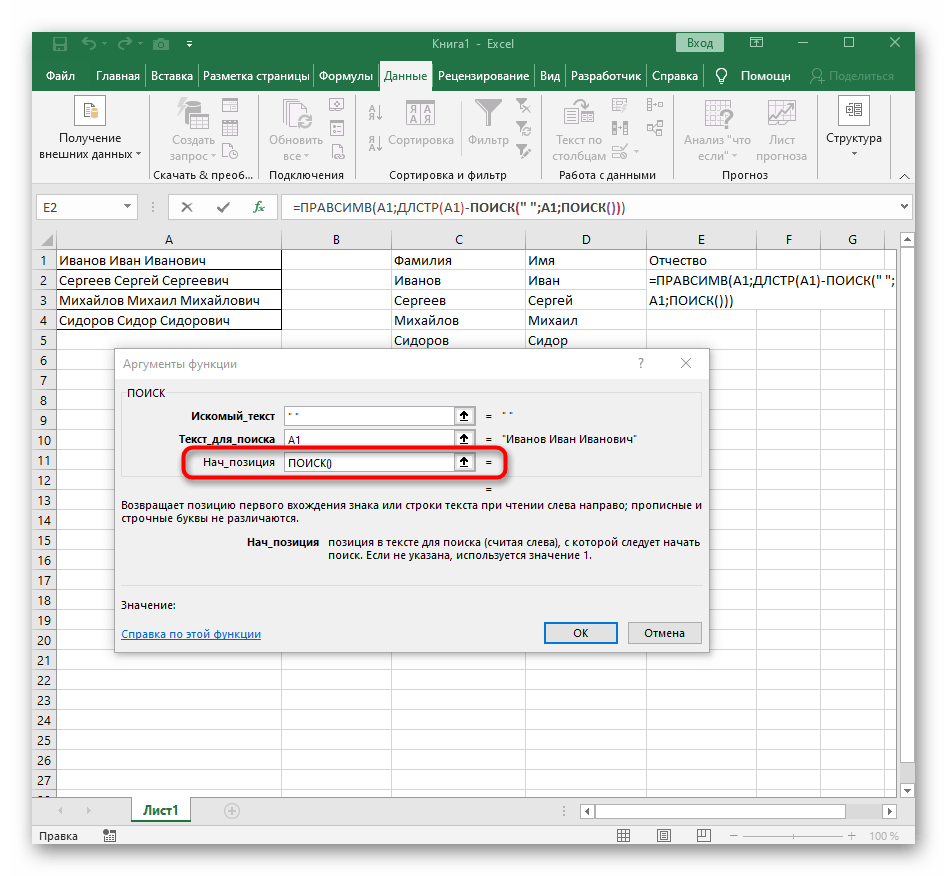
- Количество знаков для извлечения: разница между положением 2- го и 1- го пробелов, минус 1:
ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) – 1
В итоге имя у нас теперь находится в C.
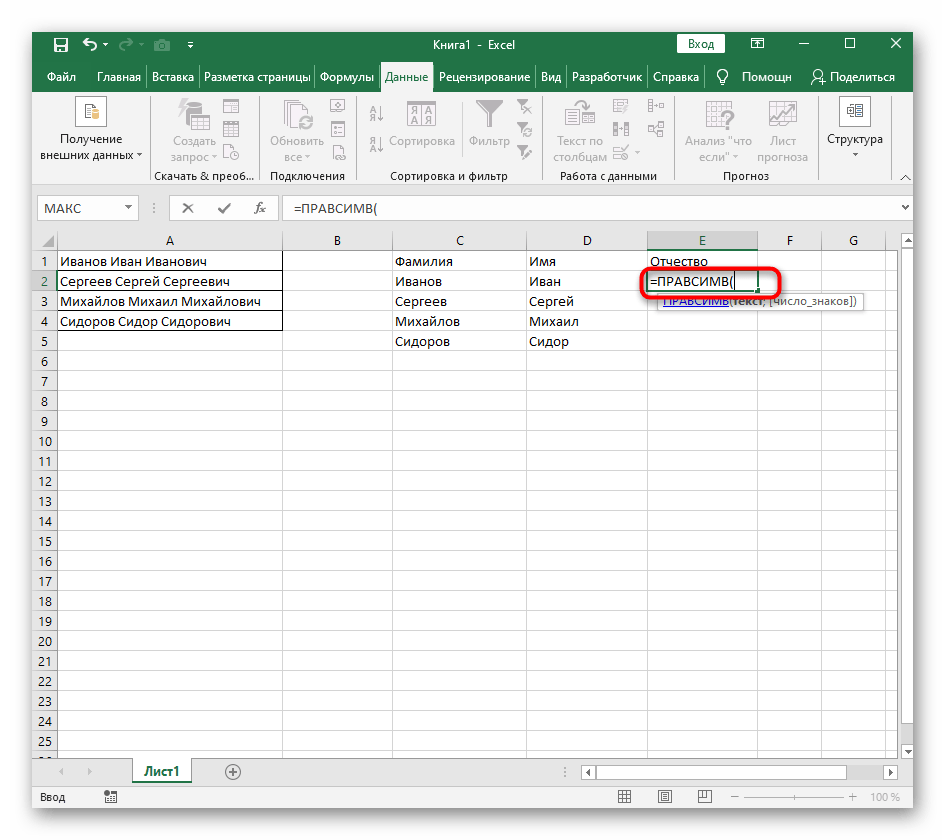
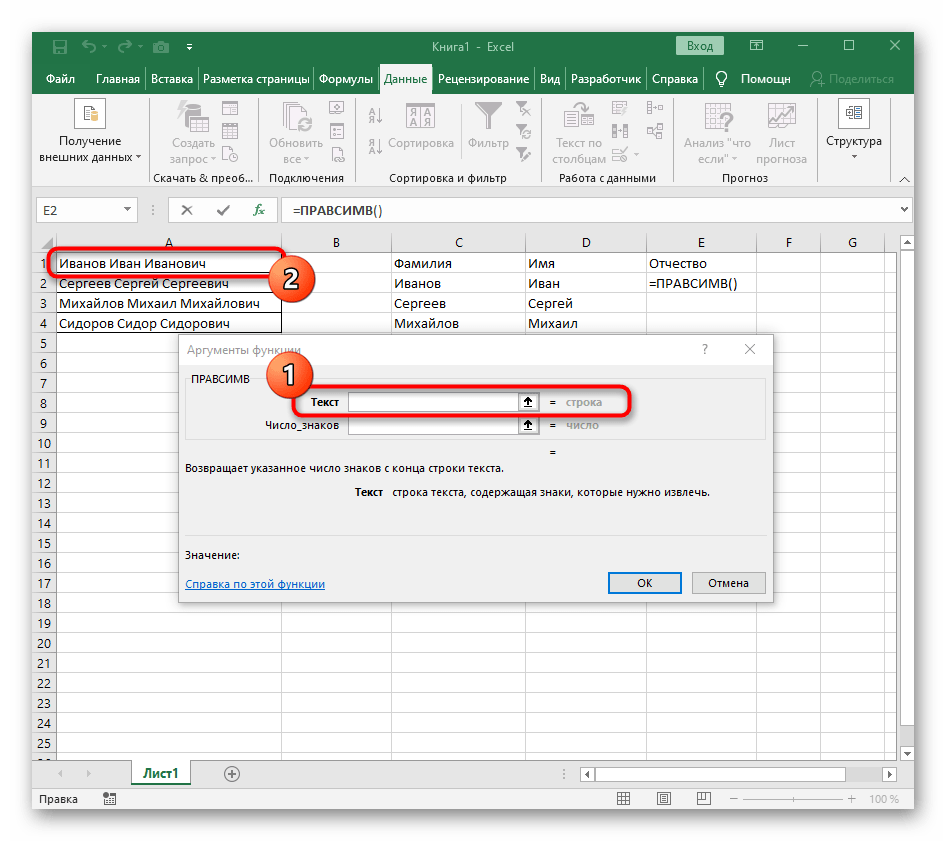
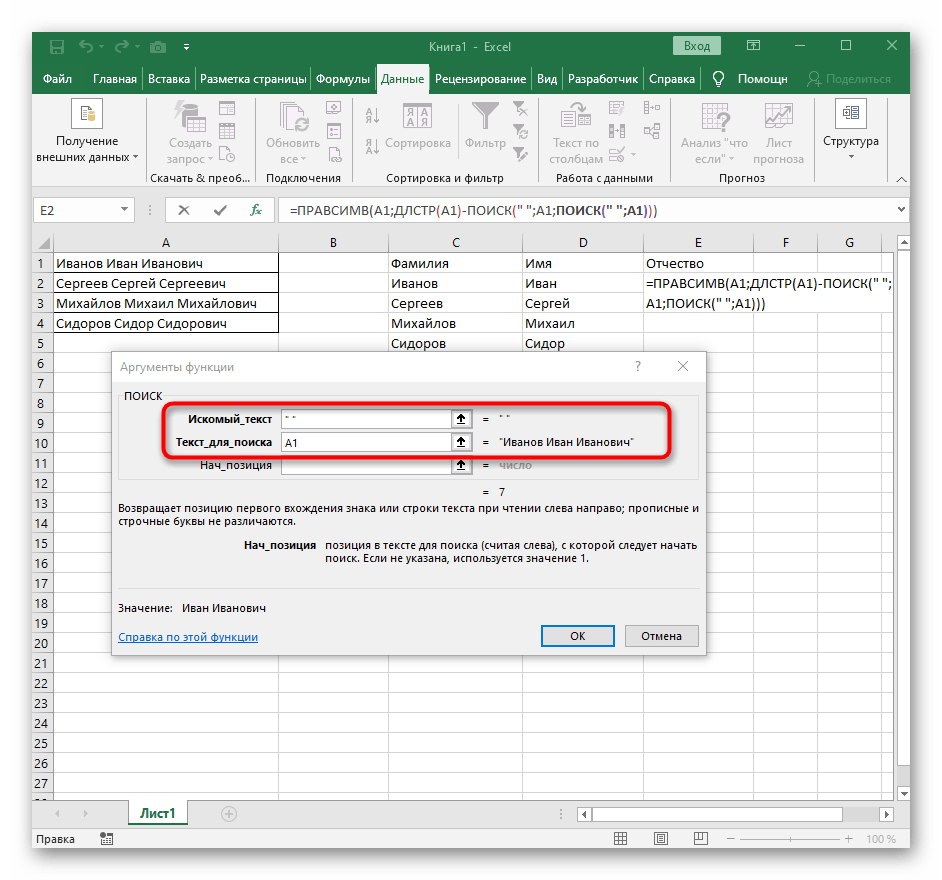
Осталось отчество. Для него используем выражение:
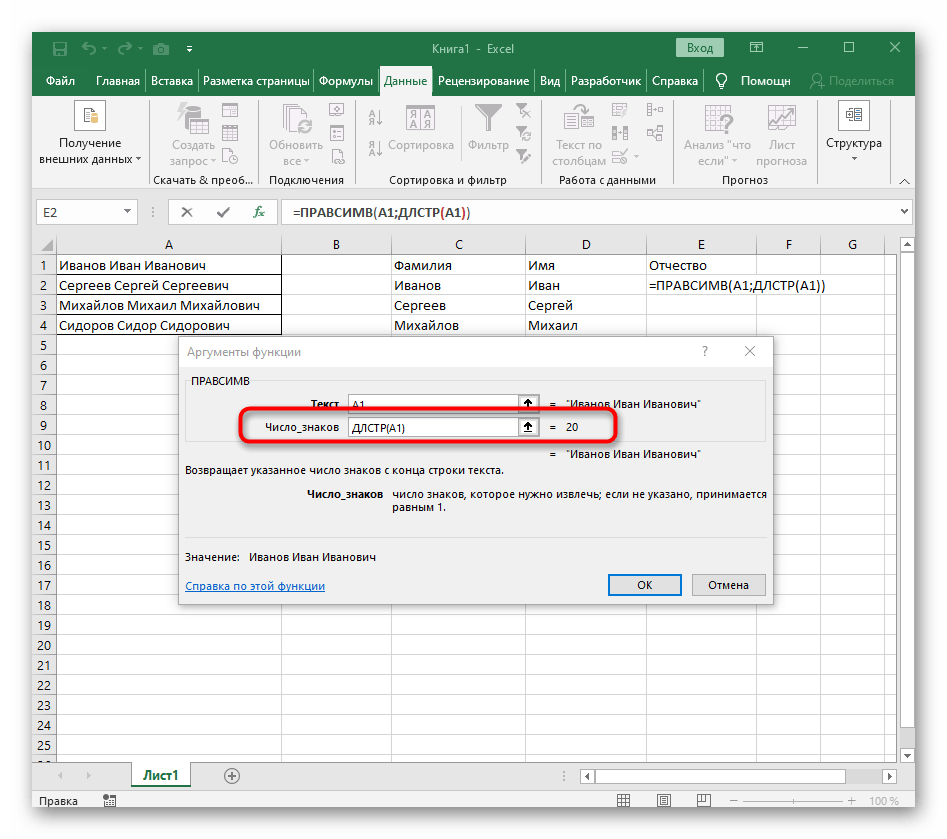
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(» «; A2; ПОИСК(» «; A2) + 1))
В этой формуле функция ДЛСТР (LEN) возвращает общую длину строки, из которой вы вычитаете позицию 2- го пробела. Получаем количество символов после 2- го пробела, и функция ПРАВСИМВ их и извлекает.
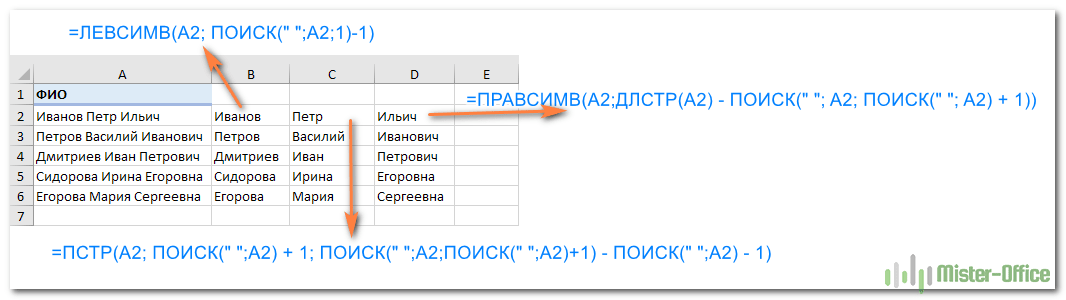
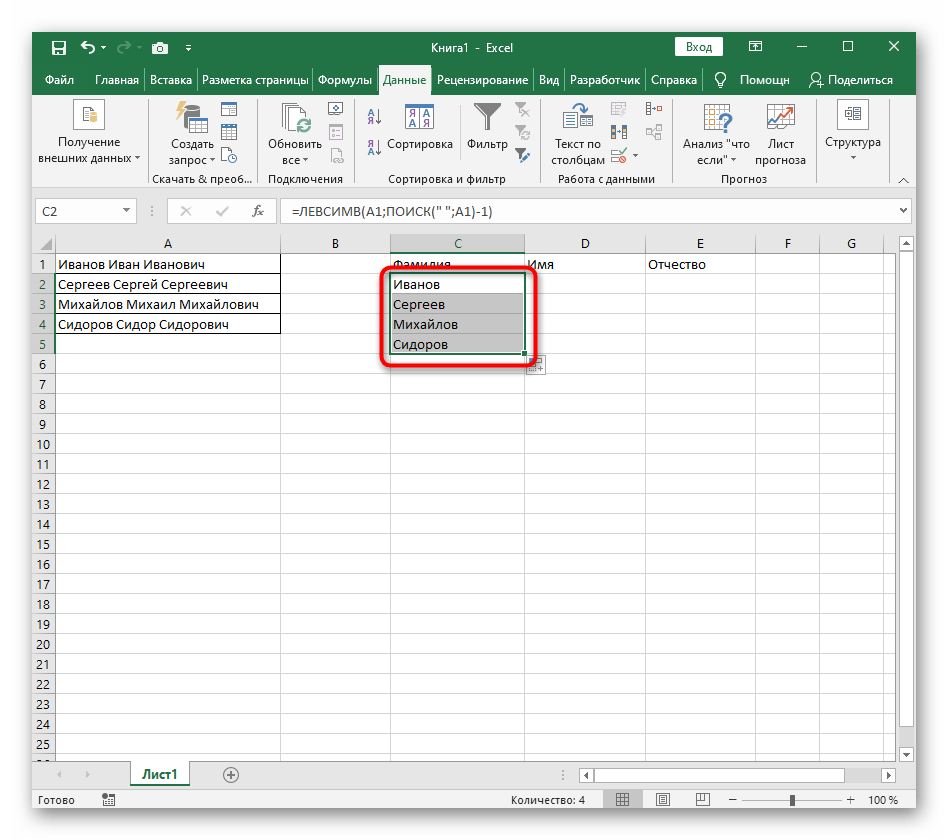
Вот результат нашей работы по разделению фамилии, имени и отчества из одной по отдельным ячейкам.
Распределение текста с разделителями на 3 столбца.
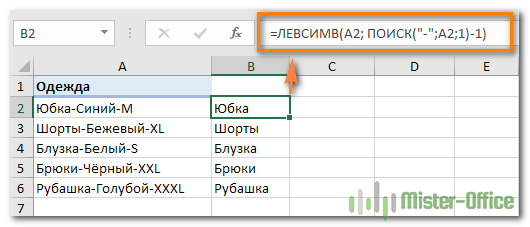
Предположим, у вас есть список одежды вида Наименование-Цвет-Размер, и вы хотите разделить его на 3 отдельных части. Здесь разделитель слов – дефис. С ним и будем работать.
- Чтобы извлечь Наименование товара (все символы до 1-го дефиса), вставьте следующее выражение в B2, а затем скопируйте его вниз по столбцу:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Здесь функция мы сначала определяем позицию первого дефиса («-«) в строке, а ЛЕВСИМВ извлекает все нужные символы начиная с этой позиции. Вы вычитаете 1 из позиции дефиса, потому что вы не хотите извлекать сам дефис.
- Чтобы извлечь цвет (это все буквы между 1-м и 2-м дефисами), запишите в C2, а затем скопируйте ниже:
=ПСТР(A2; ПОИСК(«-«;A2) + 1; ПОИСК(«-«;A2;ПОИСК(«-«;A2)+1) — ПОИСК(«-«;A2) — 1)
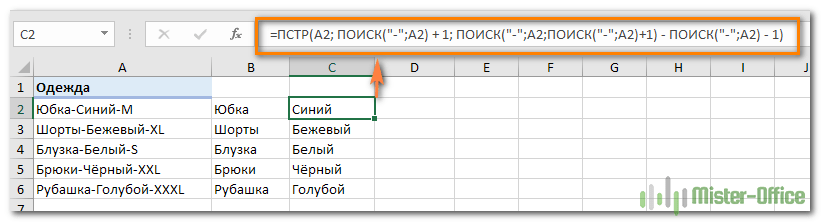
Логику работы ПСТР мы рассмотрели чуть выше.
- Чтобы извлечь размер (все символы после 3-го дефиса), введите следующее выражение в D2:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(«-«; A2; ПОИСК(«-«; A2) + 1))

Аналогичным образом вы можете в Excel разделить содержимое ячейки в разные ячейки любым другим разделителем. Все, что вам нужно сделать, это заменить «-» на требуемый символ, например пробел (« »), косую черту («/»), двоеточие («:»), точку с запятой («;») и т. д.
Примечание. В приведенных выше формулах +1 и -1 соответствуют количеству знаков в разделителе. В нашем примере это дефис (то есть, 1 знак). Если ваш разделитель состоит из двух знаков, например, запятой и пробела, тогда укажите только запятую («,») в ваших выражениях и используйте +2 и -2 вместо +1 и -1.
Как разбить текст по переносам строки.
Чтобы разделить слова в ячейке по переносам строки, используйте подходы, аналогичные тем, которые были продемонстрированы в предыдущем примере. Единственное отличие состоит в том, что вам понадобится функция СИМВОЛ (CHAR) для передачи символа разрыва строки, поскольку вы не можете ввести его непосредственно в формулу с клавиатуры.
Предположим, ячейки, которые вы хотите разделить, выглядят примерно так:

Напомню, что перенести таким вот образом текст внутри ячейки можно при помощи комбинации клавиш ALT + ENTER.
Возьмите инструкции из предыдущего примера и замените дефис («-») на СИМВОЛ(10), где 10 — это код ASCII для перевода строки.
Чтобы извлечь наименование товара:
=ЛЕВСИМВ(A2; ПОИСК(СИМВОЛ(10);A2;1)-1)
Цвет:
=ПСТР(A2; ПОИСК(СИМВОЛ(10);A2) + 1; ПОИСК(СИМВОЛ(10);A2; ПОИСК(СИМВОЛ(10);A2)+1) — ПОИСК(СИМВОЛ(10);A2) — 1)
Размер:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(СИМВОЛ(10); A2; ПОИСК(СИМВОЛ(10); A2) + 1))
Результат вы видите на скриншоте выше.
Таким же образом можно работать и с любым другим символом-разделителем. Достаточно знать его код.
Как распределить текст с разделителями на множество столбцов.
Изучив представленные выше примеры, у многих из вас, думаю, возник вопрос: «А что, если у меня не 3 слова, а больше? Если нужно разбить текст в ячейке на 5 столбцов?»
Если действовать методами, описанными выше, то формулы будут просто мега-сложными. Вероятность ошибки при их использовании очень велика. Поэтому мы применим другой метод.
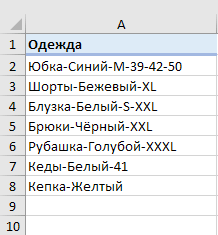
Имеем список наименований одежды с различными признаками, перечисленными через дефис. Как видите, таких признаков у нас может быть от 2 до 6. Делим текст в наших ячейках на 6 столбцов так, чтобы лишние столбцы в отдельных строках просто остались пустыми.
Для первого слова (наименования одежды) используем:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Как видите, это ничем не отличается от того, что мы рассматривали ранее. Ищем позицию первого дефиса и отделяем нужное количество символов.
Для второго столбца и далее понадобится более сложное выражение:
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1);1)-1);»»)
Замысел здесь состоит в том, что при помощи функции ПОДСТАВИТЬ мы удаляем из исходного содержимого наименование, которое уже ранее извлекли (то есть, «Юбка»). Вместо него подставляем пустое значение «» и в результате имеем «Синий-M-39-42-50». В нём мы снова ищем позицию первого дефиса, как это делали ранее. И при помощи ЛЕВСИМВ вновь выделяем первое слово (то есть, «Синий»).
А далее можно просто «протянуть» формулу из C2 по строке, то есть скопировать ее в остальные ячейки. В результате в D2 получим
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1);1)-1);»»)
Обратите внимание, жирным шрифтом выделены произошедшие при копировании изменения. То есть, теперь из исходного текста мы удаляем все, что было уже ранее найдено и извлечено – содержимое B2 и C2. И вновь в получившейся фразе берём первое слово — до дефиса.
Если же брать больше нечего, то функция ЕСЛИОШИБКА обработает это событие и вставит в виде результата пустое значение «».
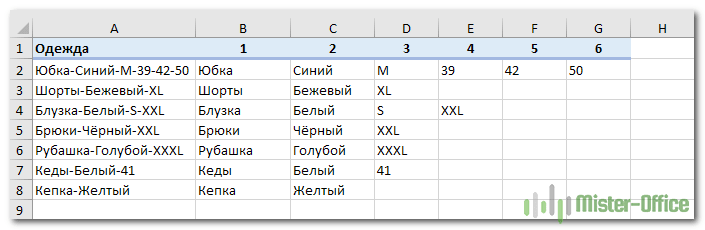
Скопируйте формулы по строкам и столбцам, на сколько это необходимо. Результат вы видите на скриншоте.
Таким способом можно разделить текст в ячейке на сколько угодно столбцов. Главное, чтобы использовались одинаковые разделители.
Как разделить ячейку вида ‘текст + число’.
Начнем с того, что не существует универсального решения, которое работало бы для всех буквенно-цифровых выражений. Выбор зависит от конкретного шаблона, по которому вы хотите разбить ячейку. Ниже вы найдете формулы для двух наиболее распространенных сценариев.
Предположим, у вас есть столбец смешанного содержания, где число всегда следует за текстом. Естественно, такая конструкция рассматривается Excel как символьная. Вы хотите поделить их так, чтобы текст и числа отображались в отдельных ячейках.
Результат может быть достигнут двумя разными способами.
Метод 1. Подсчитайте цифры и извлеките это количество символов
Самый простой способ разбить выражение, в котором число идет после текста:
Чтобы извлечь числа, вы ищите в строке все возможные числа от 0 до 9, получаете общее их количество и отсекаете такое же количество символов от конца строки.
Если мы работаем с ячейкой A2:
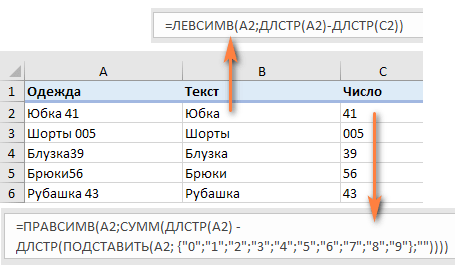
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Чтобы извлечь буквы, вы вычисляете, сколько их у нас имеется. Для этого вычитаем количество извлеченных цифр (C2) из общей длины исходной ячейки A2. После этого при помощи ЛЕВСИМВ отрезаем это количество символов от начала ячейки.
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))
здесь A2 – исходная ячейка, а C2 — извлеченное число, как показано на скриншоте:
Метод 2: узнать позицию 1- й цифры в строке
Альтернативное решение — использовать эту формулу массива для определения позиции первой цифры:
{=МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))}
Как видите, мы последовательно ищем каждое число из массива {0,1,2,3,4,5,6,7,8,9}. Чтобы избежать появления ошибки если цифра не найдена, мы после содержимого ячейки A2 добавляем эти 10 цифр. Excel последовательно перебирает все символы в поисках этих десяти цифр. В итоге получаем опять же массив из 10 цифр — номеров позиций, в которых они нашлись. И из них функция МИН выбирает наименьшее число. Это и будет та позиция, с которой начинается группа чисел, которую нужно отделить от основного содержимого.
Также обратите внимание, что это формула массива и ввод её нужно заканчивать не как обычно, а комбинацией клавиш CTRL + SHIFT + ENTER.
Как только позиция первой цифры найдена, вы можете разделить буквы и числа, используя очень простые формулы ЛЕВСИМВ и ПРАВСИМВ.
Чтобы получить текст:
=ЛЕВСИМВ(A2; B2-1)
Чтобы получить числа:
=ПРАВСИМВ(A2; ДЛСТР(A2)-B2+1)
Где A2 — исходная строка, а B2 — позиция первого числа.

Чтобы избавиться от вспомогательного столбца, в котором мы вычисляли позицию первой цифры, вы можете встроить МИН в функции ЛЕВСИМВ и ПРАВСИМВ:
Для вытаскивания текста:
=ЛЕВСИМВ(A2; МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))-1)
Для чисел:
=ПРАВСИМВ(A2; ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))+1)
Этого же результата можно достичь и чуть иначе.
Сначала мы извлекаем из ячейки числа при помощи вот такого выражения:
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) -ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
То есть, сравниваем длину нашего текста без чисел с его исходной длиной, и получаем количество цифр, которое нужно взять справа. К примеру, если текст без цифр стал короче на 2 символа, значит справа надо «отрезать» 2 символа, которые и будут нашим искомым числом.
А затем уже берём оставшееся:
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))

Как видите, результат тот же. Можете воспользоваться любым способом.
Как разделить ячейку вида ‘число + текст’.
Если вы разделяете ячейки, в которых буквы стоят после цифр, вы можете отделять числа по следующей формуле:
=ЛЕВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Она аналогична рассмотренной в предыдущем примере, за исключением того, что вы используете функцию ЛЕВСИМВ вместо ПРАВСИМВ, чтобы получить число теперь уже из левой части выражения.
Теперь, когда у вас есть числа, отделите буквы, вычитая количество цифр из общей длины исходной строки:
=ПРАВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(B2))
Где A2 — исходная строка, а B2 — искомое число, как показано на снимке экрана ниже:

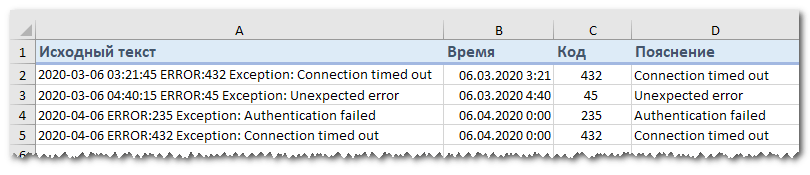
Как разбить текст по ячейкам по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список схожих строк на некоторые элементы или подстроки. Сложность состоит в том, что исходный текст должен быть разделен не при каждом появлении определенного разделителя (например, пробела), а только при некоторых определенных вхождениях. Следующий пример упрощает понимание.
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала:

Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и поясняющие сведения были размещены в 3 отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем также есть пробелы. Также есть пробелы в тексте пояснения, который также должен весь находиться слитно в одном столбце.
Решением является разбиение строки по следующей маске: * ERROR: * Exception: *
Здесь звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
То есть в данном случае в качестве разделителя по столбцам выступают не отдельные символы, а целые слова.
Итак, в начале ищем позицию первого разделителя.
=ПОИСК(«ERROR:»;A2;1)
Затем аналогичным образом находим позицию, в которой начинается второй разделитель:
=ПОИСК(«Exception:»;A2;1)
Итак, для ячейки A2 шаблон выглядит следующим образом:
С 1 по 20 символ – дата и время. С 21 по 26 символ – разделитель “ERROR:”. Далее – код ошибки. С 31 по 40 символ – второй разделитель “Exception:”. Затем следует описание ошибки.
Таким образом, в первый столбец мы поместим первые 20 знаков:
=—ЛЕВСИМВ(A2;ПОИСК(«ERROR:»;A2;1)-1)
Обратите внимание, что мы взяли на 1 позицию меньше, чем начало первого разделителя. Кроме того, чтобы сразу конвертировать всё это в дату, ставим перед формулой два знака минус. Это автоматически преобразует цифры в число, а дата как раз и хранится в виде числа. Остается только установить нужный формат даты и времени стандартными средствами Excel.
Далее нужно получить код:
=ПСТР(A2;ПОИСК(«ERROR:»;A2;1)+6;ПОИСК(«Exception:»;A2;1)-(ПОИСК(«ERROR:»;A2;1)+6))
Думаю, вы понимаете, что 6 – это количество знаков в нашем слове-разделителе «ERROR:».
Ну и, наконец, выделяем из этой фразы пояснение:
=ПРАВСИМВ(A2;ДЛСТР(A2)-(ПОИСК(«Exception:»;A2;1)+10))
Аналогично добавляем 10 к найденной позиции второго разделителя «Exception:», чтобы выйти на координаты первого символа сразу после разделителя. Ведь функция говорит нам только то, где разделитель начинается, а не заканчивается.
Таким образом, ячейку мы распределили по 3 столбцам, исключив при этом слова-разделители.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек в Excel, который демонстрируется в следующей части этого руководства.
Как разделить ячейки в Excel с помощью функции разделения текста Split Text.
Альтернативный способ разбить столбец в Excel — использовать функцию разделения текста, включенную в надстройку Ultimate Suite for Excel. Она предоставляет следующие возможности:
- Разделить ячейку по символу-разделителю.
- Разделить ячейку по нескольким разделителям.
- Разделить ячейку по маске (шаблону).
Чтобы было понятнее, давайте более подробно рассмотрим каждый вариант по очереди.
Разделить ячейку по символу-разделителю.
Выбирайте этот вариант, если хотите разделить содержимое ячейки при каждом появлении определённого символа .
Для этого примера возьмем строки шаблона Товар-Цвет-Размер , который мы использовали в первой части этого руководства. Как вы помните, мы разделили их на 3 разных столбца, используя 3 разные формулы . А вот как добиться того же результата за 2 быстрых шага:
- Предполагая, что у вас установлен Ultimate Suite , выберите ячейки, которые нужно разделить, и щелкните значок «Разделить текст (Split Text)» на вкладке «Ablebits Data».
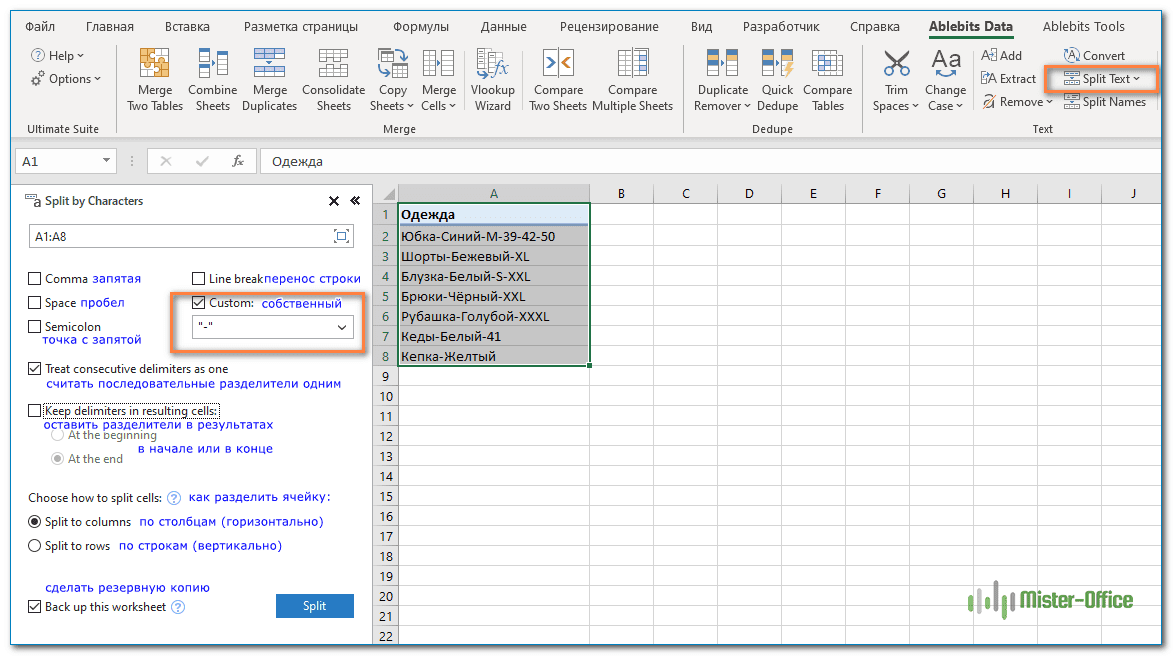
- Панель Разделить текст откроется в правой части окна Excel, и вы выполните следующие действия:
- Разверните группу «Разбить по символам (Split by Characters)» и выберите один из предопределенных разделителей или введите любой другой символ в поле «Пользовательский (Custom)» .
- Выберите, как именно разбивать ячейки: по столбцам или строкам.
- Нажмите кнопку «Разделить (Split)» .
Примечание. Если в ячейке может быть несколько последовательных разделителей (например, более одного символа пробела подряд), установите флажок « Считать последовательные разделители одним».
Готово! Задача, которая требовала 3 формул и 5 различных функций, теперь занимает всего пару секунд и одно нажатие кнопки.

Разделить ячейку по нескольким разделителям.
Этот параметр позволяет разделять текстовые ячейки, используя любую комбинацию символов в качестве разделителя. Технически вы разделяете строку на части, используя одну или несколько разных подстрок в качестве границ.
Например, чтобы разделить предложение на части, используя запятые и союзы, активируйте инструмент «Разбить по строкам (Split by Strings)» и введите разделители, по одному в каждой строке:

В данном случае в качестве разделителей мы используем запятую и союз “или”.
В результате исходная фраза разделяется при появлении любого разделителя:

Примечание. Союзы «или», а также «и» часто могут быть частью слова в вашей исследуемой фразе, так что не забудьте ввести пробел до и после них, чтобы предотвратить разрывы слов на части.
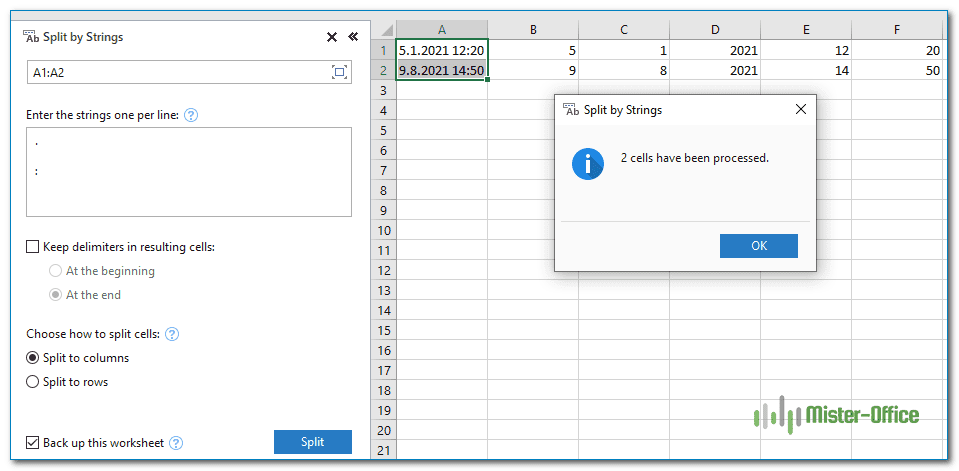
А вот еще один пример. Предположим, вы импортировали столбец дат из внешнего источника, и выглядит он следующим образом:
5.1.2021 12:20
9.8.2021 14:50
Этот формат не является обычным для Excel, и поэтому ни одна из функций даты не распознает здесь какие-либо элементы даты или времени. Чтобы разделить день, месяц, год, часы и минуты на отдельные ячейки, введите следующие символы в поле Spilt by strings:
- Точка (.) Для разделения дня, месяца и года
- Двоеточие (:) для разделения часов и минут
- Пробел для разграничения даты и времени

Нажмите кнопку Split, и вы сразу получите результат:
Разделить ячейки по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список однородных строк на некоторые элементы или подстроки.
Сложность заключается в том, что исходный текст не может быть разделен при каждом появлении заданного разделителя, а только при некоторых определенных вхождениях. Следующий пример упростит понимание.
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала. Чуть выше в этой статье мы разбивали этот текст по ячейкам при помощи формул. А сейчас используем специальный инструмент. И вы сами решите, какой из способов удобнее и проще.
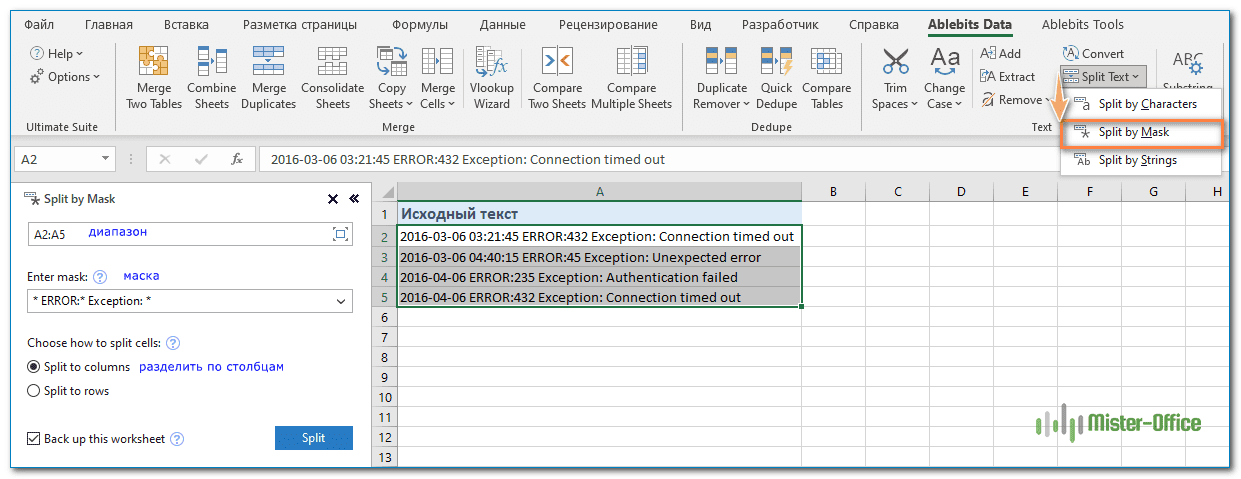
Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и пояснительная информация, были в трех отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем имеются пробелы, которые должны отображаться в одном столбце, и есть пробелы в тексте пояснения, который также должен быть расположен в отдельном столбце.
Решением является разбиение строки по следующей маске:
* ERROR:* Exception: *
Где звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
А теперь нажмите кнопку «Разбить по маске (Split by Mask)» на панели «Split Text» , введите маску в соответствующее поле и нажмите «Split».
Результат будет примерно таким:

Примечание. При разделении строки по маске учитывается регистр. Поэтому не забудьте ввести символы в шаблоне точно так, как они отображаются в исходных данных.
Большое преимущество этого метода — гибкость. Например, если все исходные строки имеют значения даты и времени, и вы хотите, чтобы они отображались в разных столбцах, используйте эту маску:
* * ERROR:* Exception: *
Проще говоря, маска указывает надстройке разделить исходные строки на 4 части:
- Все символы перед 1-м пробелом в строке (дата)
- Символы между 1-м пробелом и словом ERROR: (время)
- Текст между ERROR: и Exception: (код ошибки)
- Все, что идет после Exception: (текст описания)

Думаю, вы согласитесь, что использование надстройки Split Text гораздо быстрее и проще, нежели использование формул.
Надеюсь, вам понравился этот быстрый и простой способ разделения строк в Excel. Если вам интересно попробовать, ознакомительная версия доступна для загрузки здесь.
Вот как вы можете разделить текст по ячейкам таблицы Excel, используя различные комбинации функций, а также специальные инструменты. Благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Читайте также:
 Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…
Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…  Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…
Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…  Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…
Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…  Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…
Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…  Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…
Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…  Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Еще…Меньше
Windows: 2208 (сборка 15601)
Mac: 16.65 (сборка 220911)
Веб: представлено 15 сентября 2022
г.
iOS: 2.65 (сборка 220905)
Android: 16.0.15629
Разделяет текстовые строки с помощью разделителей столбцов и строк.
Функция TEXTSPLIT работает так же, как мастер преобразования текста в столбцы, но в виде формулы. Она позволяет разбивать на столбцы или строки. Эта функция обратна функции ОБЪЕДИНИТЬ.
Синтаксис
=ТЕКСТРАЗД(text,col_delimiter,[row_delimiter],[ignore_empty], [match_mode], [pad_with])
Синтаксис функции ТЕКСТРАЗД поддерживает следующие аргументы.
-
текст Текст, который нужно разделить. Обязательный.
-
разделитель_столбцов Текст, помечающий точку, в которой текст разлит по столбцам.
-
разделитель_строк Текст, помечающий точку, в которую следует слить текст вниз по строкам. Необязательный.
-
игнорировать_пустые Укажите значение TRUE, чтобы игнорировать последовательные разделители. По умолчанию имеет значение FALSE, которое создает пустую ячейку. Необязательный.
-
match_mode Укажите значение 1, чтобы выполнить совпадение без учета регистра. По умолчанию используется значение 0, которое выполняет сопоставление с учетом регистра. Необязательный.
-
заполняющее_значение Значение, которым нужно дополнить результат. Значение по умолчанию: #Н/Д.
Замечания
Если имеется несколько разделителей, необходимо использовать константу массива. Например, для разделения одновременно с помощью запятой и точки используйте формулу =ТЕКСТРАЗД(A1;{«,»,».»}).
Примеры
Скопируйте пример данных и вставьте их в ячейку A1 нового листа Excel. При необходимости измените ширину столбцов, чтобы видеть все данные.
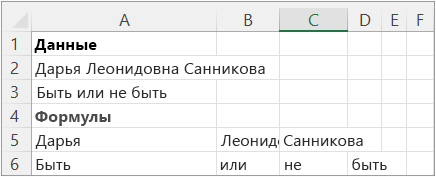
Разделите имя и фразу с помощью общего разделителя.
|
Данные |
|
Дарья Леонидовна Санникова |
|
Быть или не быть |
|
Формулы |
|
=TEXTSPLIT(A2, » «) |
|
=TEXTSPLIT(A3, » «) |
На следующем рисунке показаны результаты.
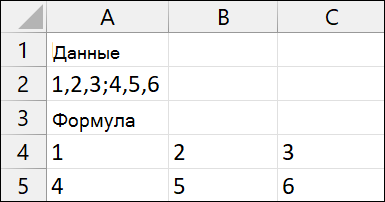
Разделите константы массива в A2 на массив 2X3.
|
Данные |
||||
|
1,2,3;4,5,6 |
||||
|
Формулы |
||||
|
=ТЕКСТРАЗД(A2;»,»,»;») |
На следующем рисунке показаны результаты.
|
Данные |
||||||
|
Делай. Или не делай. Не пробуй. – Аноним |
||||||
|
Формулы |
||||||
|
=ТЕКСТРАЗД(A2;».») |
||||||
|
=ТЕКСТРАЗД(A2;{«.»,»-«}) |
||||||
|
=ТЕКСТРАЗД(A2;{«.»,»-«};;ЛОЖЬ) |
На следующем рисунке показаны результаты.
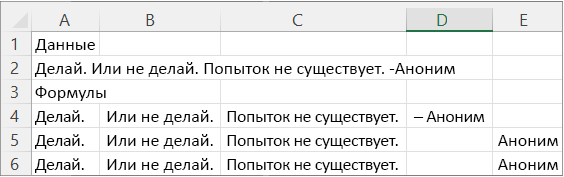
|
Данные |
|||
|
Делай. Или не делай. Не пробуй. – Аноним |
|||
|
Формулы |
|||
|
=ТЕКСТРАЗД(A2;;».») |
На следующем рисунке показаны результаты.
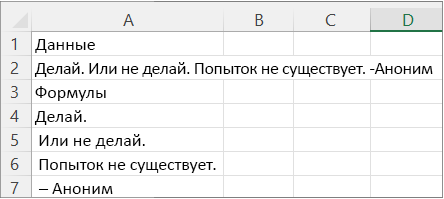
|
Данные |
|||
|
Делай. Или не делай. Не пробуй. – Аноним |
|||
|
Формулы |
|||
|
=ТЕКСТРАЗД(A2;;{«.»,»-«}) |
На следующем рисунке показаны результаты.

|
Данные |
|||
|
Делай. Или не делай. Не пробуй. – Аноним |
|||
|
Формулы |
|||
|
=ТЕКСТРАЗД(A2;;{«.»,»-«};ИСТИНА) |
На следующем рисунке показаны результаты.

Совет Чтобы удалить ошибку #Н/Д, используйте функцию ЕСНД. Можно также добавить аргумент «заполняющее_значение».
|
Данные |
|||||
|
Делай. Или не делай. Не пробуй. – Аноним |
|||||
|
Формулы |
|||||
|
=ТЕКСТРАЗД(A2;» «,».»;ИСТИНА) |
На следующем рисунке показаны результаты.
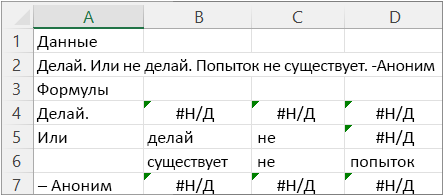
См. также
Текстовые функции (справочник)
Функция ТЕКСТДО
Функция ТЕКСТПОСЛЕ
Функция ОБЪЕДИНИТЬ
Функция CONCAT
Нужна дополнительная помощь?
Делим слипшийся текст на части
Итак, имеем столбец с данными, которые надо разделить на несколько отдельных столбцов. Самые распространенные жизненные примеры:
- ФИО в одном столбце (а надо — в трех отдельных, чтобы удобнее было сортировать и фильтровать)
- полное описание товара в одном столбце (а надо — отдельный столбец под фирму-изготовителя, отдельный — под модель для построения, например, сводной таблицы)
- весь адрес в одном столбце (а надо — отдельно индекс, отдельно — город, отдельно — улица и дом)
- и т.д.
Поехали..
Способ 1. Текст по столбцам
Выделите ячейки, которые будем делить и выберите в меню Данные — Текст по столбцам (Data — Text to columns). Появится окно Мастера разбора текстов:

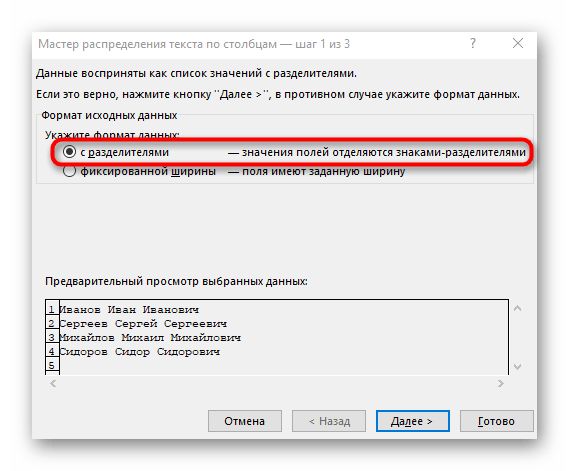
На первом шаге Мастера выбираем формат нашего текста. Или это текст, в котором какой-либо символ отделяет друг от друга содержимое наших будущих отдельных столбцов (с разделителями) или в тексте с помощью пробелов имитируются столбцы одинаковой ширины (фиксированная ширина).
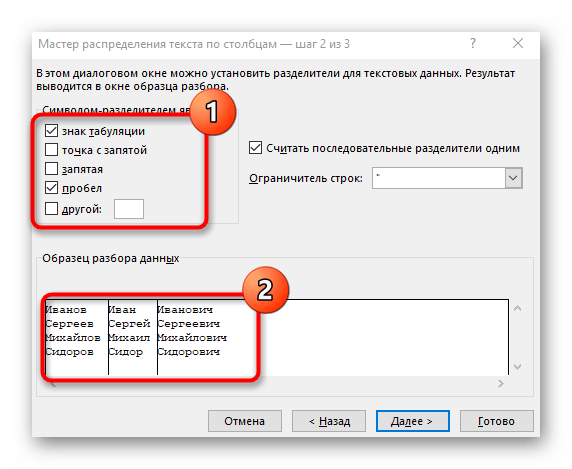
На втором шаге Мастера, если мы выбрали формат с разделителями (как в нашем примере) — необходимо указать какой именно символ является разделителем:

Если в тексте есть строки, где зачем-то подряд идут несколько разделителей (несколько пробелов, например), то флажок Считать последовательные разделители одним (Treat consecutive delimiters as one) заставит Excel воспринимать их как один.
Выпадающий список Ограничитель строк (Text Qualifier) нужен, чтобы текст заключенный в кавычки (например, название компании «Иванов, Манн и Фарбер») не делился по запятой
внутри названия.
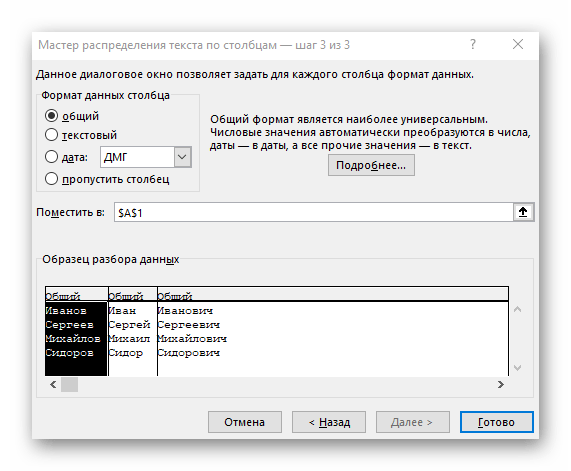
И, наконец, на третьем шаге для каждого из получившихся столбцов, выделяя их предварительно в окне Мастера, необходимо выбрать формат:
- общий — оставит данные как есть — подходит в большинстве случаев
- дата — необходимо выбирать для столбцов с датами, причем формат даты (день-месяц-год, месяц-день-год и т.д.) уточняется в выпадающем списке
- текстовый — этот формат нужен, по большому счету, не для столбцов с ФИО, названием города или компании, а для столбцов с числовыми данными, которые Excel обязательно должен воспринять как текст. Например, для столбца с номерами банковских счетов клиентов, где в противном случае произойдет округление до 15 знаков, т.к. Excel будет обрабатывать номер счета как число:

Кнопка Подробнее (Advanced) позволяет помочь Excel правильно распознать символы-разделители в тексте, если они отличаются от стандартных, заданных в региональных настройках.
Способ 2. Как выдернуть отдельные слова из текста
Если хочется, чтобы такое деление производилось автоматически без участия пользователя, то придется использовать небольшую функцию на VBA, вставленную в книгу. Для этого открываем редактор Visual Basic:
- в Excel 2003 и старше — меню Сервис — Макрос — Редактор Visual Basic (Tools — Macro — Visual Basic Editor)
- в Excel 2007 и новее — вкладка Разработчик — Редактор Visual Basic (Developer — Visual Basic Editor) или сочетание клавиш Alt+F11
Вставляем новый модуль (меню Insert — Module) и копируем туда текст вот этой пользовательской функции:
Function Substring(Txt, Delimiter, n) As String
Dim x As Variant
x = Split(Txt, Delimiter)
If n > 0 And n - 1 <= UBound(x) Then
Substring = x(n - 1)
Else
Substring = ""
End If
End Function
Теперь можно найти ее в списке функций в категории Определенные пользователем (User Defined) и использовать со следующим синтаксисом:
=SUBSTRING(Txt; Delimeter; n)
где
- Txt — адрес ячейки с текстом, который делим
- Delimeter — символ-разделитель (пробел, запятая и т.д.)
- n — порядковый номер извлекаемого фрагмента
Например:

Способ 3. Разделение слипшегося текста без пробелов
Тяжелый случай, но тоже бывает. Имеем текст совсем без пробелов, слипшийся в одну длинную фразу (например ФИО «ИвановИванИванович»), который надо разделить пробелами на отдельные слова. Здесь может помочь небольшая макрофункция, которая будет автоматически добавлять пробел перед заглавными буквами. Откройте редактор Visual Basic как в предыдущем способе, вставьте туда новый модуль и скопируйте в него код этой функции:
Function CutWords(Txt As Range) As String
Dim Out$
If Len(Txt) = 0 Then Exit Function
Out = Mid(Txt, 1, 1)
For i = 2 To Len(Txt)
If Mid(Txt, i, 1) Like "[a-zа-я]" And Mid(Txt, i + 1, 1) Like "[A-ZА-Я]" Then
Out = Out & Mid(Txt, i, 1) & " "
Else
Out = Out & Mid(Txt, i, 1)
End If
Next i
CutWords = Out
End Function
Теперь можно использовать эту функцию на листе и привести слипшийся текст в нормальный вид:

Ссылки по теме
- Деление текста при помощи готовой функции надстройки PLEX
- Что такое макросы, куда вставлять код макроса, как их использовать
Как извлечь часть текста в Эксель
Извлечение части текста – самая распространенная задача при работе с текстом в Excel. Часто к этой задаче и сводится вся работа над текстом. Чтобы получить часть символов из строки, нужно владеть функциями поиска, удаления лишних символов, определения длины строки и др.
Для получения части текста, в Эксель есть 3 функции:
- ЛЕВСИМВ(Строка; Количество_символов) – выводит заданное количество символов с левого края. Например, =ЛЕВСИМВ(А1;10) выведет 10 первых символов строки в ячейке А1 . Функция имеет 2 обязательных аргумента – Строка-источник и количество выводимых символов;
 Функция ЛЕВСИМВ в Эксель
Функция ЛЕВСИМВ в Эксель
- ПРАВСИМВ(Строка; Количество_символов) – функция схожа с предыдущей, она выводит заданное количество символов справа. То есть, =ПРАВСИМВ(А1;10) в результате выдаст 10 последних символов из строки А1 .
 Функция ПРАВСИМВ в Excel
Функция ПРАВСИМВ в Excel
- ПСТР(Строка; Начальный_символ; Количество символов) – выбирает из текста нужное количество знаков, начиная с заданного. Например, =ПСТР(А1;5;3) выведет 3 символа начиная с 5-го (5-7 символы строки).
 Функция ПСТР в Эксель
Функция ПСТР в Эксель
Все эти функции в подсчёте количества символов учитывают лишние пробелы, непечатаемые символы, поэтому рекомендую сначала очистить текст от лишних знаков.
Функции ЛЕВИСМВ, ПРАВСИМВ, ПСТР – это простой и мощный инструмент, если используется в комбинации с другими текстовыми функциями. Вы увидите это в уроке-практикуме по строчным функциям.
А следующий пост мы посвятим поиску нужного текста в строке. Заходите и читайте. Только хорошее владение функциями позволит вам эффективно выполнять задачи в Microsoft Excel!
Если вы еще не прочли посты о написании формул и применении функций – обязательно это сделайте, без них изучение функций Excel будет сложнее и дольше!
Microsoft Excel
трюки • приёмы • решения
Как извлечь слова из строки таблицы Excel
Формулы в этой статье полезны для извлечения слов из текста, содержащегося в ячейке. Например, вы можете создать формулу для извлечения первого слова в предложении.
Извлечение первого слова из строки
Чтобы извлечь первое слово из строки, формула должна найти позицию первого символа пробела, а затем использовать эту информацию в качестве аргумента для функции ЛЕВСИМВ. Следующая формула делает это: =ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1) .
Эта формула возвращает весь текст до первого пробела в ячейке A1. Однако у нее есть небольшой недостаток: она возвращает ошибку, если текст в ячейке А1 не содержит пробелов, потому что состоит из одного слова. Несколько более сложная формула решает проблему с помощью новой функции ЕСЛИОШИБКА, отображая все содержимое ячейки, если произошла ошибка:
=ЕСЛИОШИБКА(ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1);A1) .
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;»»;»»)))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»)))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;»»;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))))
Извлечение всего, кроме первого слова строки
Следующая формула возвращает содержимое ячейки А1, за исключением первого слова:
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «:A1;1)) .
Если ячейка А1 содержит текст 2008 Operating Budget, то формула вернет Operating Budget.
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1));»»)
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));»»;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1)))
Как вытащить число или часть текста из текстовой строки в Excel
Сегодня мы с вами рассмотрим весьма распространённую ситуацию, возникающую в работе экономиста связанную с анализом данных.
Как правило, экономисту поручают проведение всевозможных видов анализа на основании бухгалтерских данных, группировку их специальным образом, получение дополнительных срезов, отличающихся от имеющихся бухгалтерских аналитик и т.д.
Речь здесь уже идет о преобразовании данных бухгалтерского учета в данные управленческого учета. Мы не будем говорить о необходимости сближения бухгалтерского и управленческого учета, или, по крайней мере, получения нужных срезов и аналитик в имеющихся учетных программах в автоматическом режиме. К сожалению, зачастую экономисту приходиться «перелопачивать» огромные объемы информации вручную.
И здесь, очень многое зависит, насколько эффективно организована работа, насколько экономист владеет своим основным прикладным инструментом – программой Excel, знает ее возможности и эффективные приемы обработки информации. Ведь одну и туже задачу можно решать разными способами, затрачивая разное количество времени и усилий.
Рассмотрим конкретную ситуацию. Вам нужно подготовить отчёт в разрезе, который нельзя получить в бухгалтерской программе. Вы выгрузили в Excel отчет по проводкам (оборотно-сальдовую ведомость, карточку счета и т.д. – не суть важно) и видите, что для нормальной фильтрации данных или создания сводной таблицы для анализа данных у вас не хватает одного признака (аналитики, разреза, субконто и т.д.).
Критически взглянув на таблицу, вы видите, что необходимый вам признак операции находиться тут же в таблице, но не в отдельной ячейке, а внутри текста. Например, код филиала в наименовании документа. А вам как раз надо подготовить отчет по поставщикам в разрезе филиалов, т.е. по двум признакам, один из которых отсутствует в приемлемом для дальнейшей обработки информации виде.
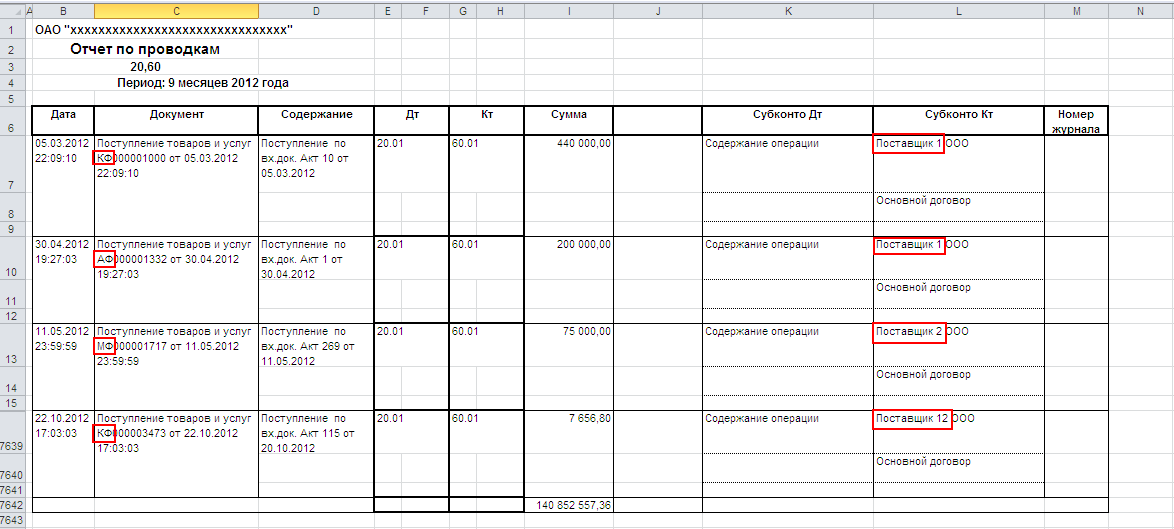
Если в таблице находиться десять операций, то проще проставить признак вручную в соседнем столбце, однако если записей несколько тысяч, то это уже проблематично.
Вся трудность, в том чтобы извлечь код из текстовой строки.
Возможна ситуация, когда этот код находиться всегда в начале текстовой строки или всегда в конце.
В этом случае, мы можем извлекать код или часть текста при помощи функций ЛЕВСИМВ и ПРАВСИМВ, которые возвращают заданное количество знаков соответственно с начала строки или с конца строки.
Текст – обязательный аргумент. Текстовая строка, содержащая символы, которые требуется извлечь.
Количество_знаков — необязательный аргумент. Количество символов, извлекаемых функцией ЛЕВСИМВ (ПРАВСИМВ).
«Количество_знаков» должно быть больше нуля или равно ему. Если «количество_знаков» превышает длину текста, функция ЛЕВСИМВ (ПРАВСИМВ) возвращает весь текст. Если значение «количество_знаков» опущено, оно считается равным 1.
Зная количество знаков, которые содержит код, мы легко извлечем необходимые символы.
Сложнее если нужные нам символы находятся в середине текста.
Извлечь число, текст, код и т.д. из середины текстовой строки может функция ПСТР, возвращает заданное число знаков из строки текста, начиная с указанной позиции.
=ПСТР(текст; начальная_позиция; количество_знаков)
Текст – обязательный аргумент. Текстовая строка, содержащая символы, которые требуется извлечь.
Начальная_позиция – обязательный аргумент. Позиция первого знака, извлекаемого из текста. Первый знак в тексте имеет начальную позицию 1 и так далее.
Количество_знаков – обязательный аргумент. Указывает, сколько знаков должна вернуть функция ПСТР.
Самый простой случай – если код находиться на одном и том же месте от начала строки. Например, у нас наименование документа начинается всегда одинаково «Поступление товаров и услуг ХХ ….»
Наш признак «ХХ» — код филиала начинается с 29 знака и имеет 2 знака в своем составе.
В нашем случае формула будет иметь вид:
Однако не всегда все так безоблачно. Предположим, мы не можем со 100% уверенностью сказать, что наименование документа у нас во всех строках будет начинаться одинаково, но мы точно знаем, что признак филиала закодирован в номере документа следующим образом:
Первый символ – первая буква в наименовании филиала, второй символ – это буква Ф (филиал) и далее следует пять нулей «00000». Причем меняется только первый символ — первая буква наименования филиала.
Обладая такими существенными знаниями, мы можем смело использовать функцию ПОИСК, которая находит нужный нам текст в текстовой строке и возвращают начальную позицию нужного нам текста внутри всей текстовой строки.
=ПОИСК(искомый_текст; текст_для_поиска; [нач_позиция])
Искомый_текст – обязательный аргумент. Текст, который требуется найти.
Просматриваемый_текст – обязательный аргумент. Текст, в котором нужно найти значение аргумента искомый_текст.
Нач_позиция – необязательный аргумент. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Функция ПОИСК не учитывает регистр. Если требуется учитывать регистр, используйте функцию НАЙТИ.
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (
Обозначив меняющийся первый символ знаком вопроса (?), мы можем записать итоговую формулу для выделения кода филиала в таком виде:
Эта формула определяет начальную позицию кода филиала в наименовании документа, а затем возвращает два знака кода, начиная с найденной позиции.
В результате, мы получим в отдельном столбце код филиала, который сможем использовать как признак для фильтрации, сортировки или создания сводной таблицы.
Как отрезать (удалить) лишний текст слева или справа в ячейке «Эксель».
Бывают ситуации, когда необходимо отрезать/ удалить строго определенное количество символов в тексте справа или слева. Например, когда вы имеете список адресов, и вначале каждого адреса стоит шестизначный индекс. Нужно убрать почтовые индексы из списка, но через замену их не уберешь, так как они имеют совершенно разные значения и не находятся опцией замены.
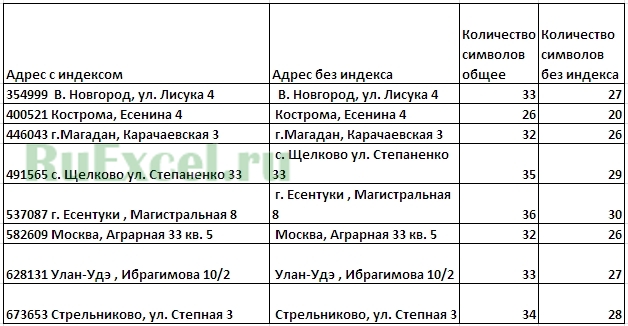 Функции, которая отрезает лишнее количество символов в ячейке, найти не удается, но существует система из двух функций, которые можно применить. Это система из функции ЛЕВСИМВ (или ПРАВСИМВ) и функции ДЛСТР (длина строки).
Функции, которая отрезает лишнее количество символов в ячейке, найти не удается, но существует система из двух функций, которые можно применить. Это система из функции ЛЕВСИМВ (или ПРАВСИМВ) и функции ДЛСТР (длина строки).
Рассмотрим их применение.
Вначале находим количество символов в тексте при помощи функции ДЛСТР. Для этого запускаем менеджер функций, выбираем ДЛСТР, указываем ячейку с текстом. Функция ДЛСТР посчитает количество символов.
Зная длину лишнего текста — 6 знаков в индексе, вычитаем их из общего числа символов посчитанных функцией ДЛСТР и получаем то количество символов, которое должно остаться в тексте, когда удалим индекс.
Полученное значение – количество оставляемых в тексте знаков, вписываем в функцию ЛЕВСИМВ или ПРАВСИМВ. Если нужно удалить знаки справа, то используем ЛЕВСИМВ, если слева, то ПРАВСИМВ. Нажимаем «Enter». Функция ЛЕВСИМВ или ПРАВСИМВ присваивает ячейке нужное нам количество символов из текста в новую ячейку, исключая ненужный нам индекс.
Для уменьшения количества ячеек с расчетами эти функции можно записать в систему следующего вида:
ПРАВСИМВ(…*¹;(ДЛСТР(…*¹)-6)).
Где …*¹- адрес ячейки, из которой берем текст.
Как в Эксель (Excel) вытащить часть текста из ячейки в другую ячейку?
Как в Excel извлечь часть текста из ячейки?
Например, в ячейке написана категория товара и информация о товаре.
Как выташить в отдельную ячейку только название категории («Перчатки хозяйственные», «Молоток слесарный» и т.п.)?


Если у Вас данные (которые нужно обработать, все эти «молотки» и «перчатки») всегда отделены от остальной части текста запятой и первая ячейка с данными это B2, то формула такая
напишите ее в любую свободную ячейку (например правее) в той же строке, а потом растяните вниз и все ваши тысячи строк будут обработаны.

Очевидно, что вытащить часть текста в другую ячейку можно с помощью специальных функций для работы со строками.
В Excel их довольно много, и в первую очередь можно выделить такие функции, как:
ЛЕВСИМВ и ПРАВСИМВ — излекают определённое число символов слева и справа соответственно.
ДЛСТР — длина строки.
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
ПОДСТРОКА — извлекает подстроку из текста, которая отделена определённым символом-разделителе м.
ПСТР — извлекает указанное число знаков из строки (начиная с указанной позиции).
КОНЕЦСТРОКИ и НАЧАЛОСТРОКИ — возвращает строку после / до указанной подстроки.
Но здесь всё зависит от того, как именно эти данные расположены в исходной строке — одно дело в самом конце / начале, а другое — в середине.
В любом случае нужно постараться найти какой-то признак — слово или символ, до или после которого в ячейке находятся нужные данные, после чего использовать его в качестве аргумента в функциях, про которые я написал выше.
Пример 1
Исходные данные такие:

Предположим, нужно извлечь в отдельную ячейку цену товара (3500 рублей, 4200 рублей).
Можно увидеть, что в этих ячейках цене предшествует текст «размеры, » — то есть можно воспользоваться функцией КОНЕЦСТРОКИ и вытащить всё, что находится после этого текста.

Итак, ставим курсор в ячейку, куда нужно извлечь цену, и на вкладке «Формулы» выбираем «Текстовые» -> «КОНЕЦСТРОКИ».

Указываем аргументы функции (обязательные):
ТЕКСТ — указываем ячейку, из которой нужно извлечь подстроку (B2 или B3).
НАЙТИ — указываем подстроку, после которой должно начаться извлечение текста («размеры, «).
Нажимаем на кнопку «OK» и получаем то, что было нужно:

Формула получилась такая:
А если требуется, чтобы было только число (без рублей), то можно, например, использовать функцию НАЧАЛОСТРОКИ.
В этом случае в качестве 1 аргумента (исходной строки) вводим формулу, созданную выше, а в качестве 2 аргумента — » «.

Пример 2

Нужно извлечь в отдельную ячейку название цвета (красный, коричневый и т.п.).
Здесь всё проще, так как название цвета находится в самом конце строки — и можно, например, использовать функцию ПРАВСИМВ.

У этой функции 2 аргумента:

Текст — указываем ячейку, из которой нужно извлечь подстроку.
Число_знаков — это разность между длиной исходной строки (функция ДЛСТР) и позицией запятой в этой строке (функция НАЙТИ), также дополнительно нужно отнять единицу, так как после запятой стоит пробел.
Формула и результат:

Но мне всё же больше нравится вариант с упомянутой выше функцией КОНЕЦСТРОКИ.

Она менее громоздкая и не содержит вложенных функций.

Эксель многие любят за то, что можно быстро обрабатывать и менять таблицы, так как надо.
Вот и в этом случаи, для того, чтобы вытащить из ячейки текст, нужно в пустой рядом столбик ввести формулу. Но тут не так всё просто. В зависимости от того, с какой стороны нужен текст, вводим формулу Левсимв и Правсимв. Одна из этих функций выведет нужный текст справа, другая слева. При этом формула будет выглядеть примерно так:=ЛЕВСИМВ(В1;10). В данном случаи 10 число символов. Но если число символов не одинаковое, то метод не совсем подойдёт.
Тогда можно будет попробовать функцию текстовые, конец строки. Если перед нужной вам фразой стоит одно и тоже слово в каждой строке. Появится окошко, и в строке найти добавить это слова. Нужный текст после этого слова переместится.

Если в таблице одна или 2 строки, тогда можно воспользоваться функцией нажатия клавиш Ctrl+C скопировать и Ctrl+V вставить, а если в таблице нужно поменять цену для большого количества параметров, переходите в шапку инструментов, и действуйте по алгоритму, который находится под кнопой формулы — текстовые и в выпадающем меню находите среди абракадабры из сокращений «конецстроки»

далее следуя указаниям меняете в открытых окнах параметры. Подставляете какие заданы, а машина сама все посчитает. За это эксель и любят бухгалтеры, по мне так самая кривая программа после ворда. имхо для бв.
Что касается абракадабры в выпадающем меню, на это есть подсказки, например
ЛЕВСИМВ — левые символы
ПРАВСИМВ — правые символы
ДЛСТР — длина строки
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
КОНЕЦСТРОКИ возврат строки до конца
НАЧАЛОСТРОКИ — возврат строки в начало

Открывайте ячейку из которой надо вытащить часть текста, клацаете по тексту что бы курсор в тексте начал моргать, выделяете эту часть текста которую хотите утащить в другое место, щелкаете по выделенке ПКМ (правой кнопкой мышки) выбираете «копировать»
Переходите в окно куда нужно вставить, щелкаете в нем ЛКМ (левой кнопкой мышки) что бы активировать работу ввода данных в этой ячейки, следом щелкаете ПКМ, выбираете «вставить» и все.

Довольно сложный вопрос, но в Ексель можно сделать и такое, в этом редакторе есть подобные функции работы со строками.
Эти функции мы ищем в верхнем меню во вкладке «Формулы» — «Текстовые»:

Желательно, чтобы записи в ячейках были бы хоть как-то структурированы, например, если в ячейках сначала записано наименование товара, потом через запятую, в конце записи, цена товара, с такими ячейками будет работать несложно. Поработаем вот с этими ячейками, попробуем цену товара перенести в отдельные ячейки:

Текст у нас написан для этого отлично, цена товара стоит в конце строки, после слова «размеры» и запятой, поэтому мы воспользуемся функцией КОНЕЦСТРОКИ из вкладки «Текстовые» (см. выше). Открывается вот такое окошечко, в поле ТЕКСТ указываем столбец, в котором находятся наши ячейки, в поле НАЙТИ — слова, после которых текст надо переносить в отдельную ячейку.

Нажимаем ОК, получаем то, что хотели:

Теперь можно, используя тот же алгоритм, поработать с новыми ячейками с помощью функции НАЧАЛОСТРОКИ и получить число без рублей:
30.11.2012 Полезные советы, Управленческий учет
Сегодня мы с вами рассмотрим весьма распространённую ситуацию, возникающую в работе экономиста связанную с анализом данных.
Как правило, экономисту поручают проведение всевозможных видов анализа на основании бухгалтерских данных, группировку их специальным образом, получение дополнительных срезов, отличающихся от имеющихся бухгалтерских аналитик и т.д.
Речь здесь уже идет о преобразовании данных бухгалтерского учета в данные управленческого учета. Мы не будем говорить о необходимости сближения бухгалтерского и управленческого учета, или, по крайней мере, получения нужных срезов и аналитик в имеющихся учетных программах в автоматическом режиме. К сожалению, зачастую экономисту приходиться «перелопачивать» огромные объемы информации вручную.
И здесь, очень многое зависит, насколько эффективно организована работа, насколько экономист владеет своим основным прикладным инструментом – программой Excel, знает ее возможности и эффективные приемы обработки информации. Ведь одну и туже задачу можно решать разными способами, затрачивая разное количество времени и усилий.
Рассмотрим конкретную ситуацию. Вам нужно подготовить отчёт в разрезе, который нельзя получить в бухгалтерской программе. Вы выгрузили в Excel отчет по проводкам (оборотно-сальдовую ведомость, карточку счета и т.д. – не суть важно) и видите, что для нормальной фильтрации данных или создания сводной таблицы для анализа данных у вас не хватает одного признака (аналитики, разреза, субконто и т.д.).
Критически взглянув на таблицу, вы видите, что необходимый вам признак операции находиться тут же в таблице, но не в отдельной ячейке, а внутри текста. Например, код филиала в наименовании документа. А вам как раз надо подготовить отчет по поставщикам в разрезе филиалов, т.е. по двум признакам, один из которых отсутствует в приемлемом для дальнейшей обработки информации виде.

Если в таблице находиться десять операций, то проще проставить признак вручную в соседнем столбце, однако если записей несколько тысяч, то это уже проблематично.
Вся трудность, в том чтобы извлечь код из текстовой строки.
Возможна ситуация, когда этот код находиться всегда в начале текстовой строки или всегда в конце.
В этом случае, мы можем извлекать код или часть текста при помощи функций ЛЕВСИМВ и ПРАВСИМВ, которые возвращают заданное количество знаков соответственно с начала строки или с конца строки.
=ЛЕВСИМВ(текст; [количество_знаков])
=ПРАВСИМВ(текст; [количество_знаков])
Где:
Текст – обязательный аргумент. Текстовая строка, содержащая символы, которые требуется извлечь.
Количество_знаков — необязательный аргумент. Количество символов, извлекаемых функцией ЛЕВСИМВ (ПРАВСИМВ).
«Количество_знаков» должно быть больше нуля или равно ему. Если «количество_знаков» превышает длину текста, функция ЛЕВСИМВ (ПРАВСИМВ) возвращает весь текст. Если значение «количество_знаков» опущено, оно считается равным 1.
Зная количество знаков, которые содержит код, мы легко извлечем необходимые символы.
Сложнее если нужные нам символы находятся в середине текста.
Извлечь число, текст, код и т.д. из середины текстовой строки может функция ПСТР, возвращает заданное число знаков из строки текста, начиная с указанной позиции.
=ПСТР(текст; начальная_позиция; количество_знаков)
Где:
Текст – обязательный аргумент. Текстовая строка, содержащая символы, которые требуется извлечь.
Начальная_позиция – обязательный аргумент. Позиция первого знака, извлекаемого из текста. Первый знак в тексте имеет начальную позицию 1 и так далее.
Количество_знаков – обязательный аргумент. Указывает, сколько знаков должна вернуть функция ПСТР.
Самый простой случай – если код находиться на одном и том же месте от начала строки. Например, у нас наименование документа начинается всегда одинаково «Поступление товаров и услуг ХХ….»
Наш признак «ХХ» — код филиала начинается с 29 знака и имеет 2 знака в своем составе.
В нашем случае формула будет иметь вид:
=ПСТР(С7;29;2)
Однако не всегда все так безоблачно. Предположим, мы не можем со 100% уверенностью сказать, что наименование документа у нас во всех строках будет начинаться одинаково, но мы точно знаем, что признак филиала закодирован в номере документа следующим образом:
Первый символ – первая буква в наименовании филиала, второй символ – это буква Ф (филиал) и далее следует пять нулей «00000». Причем меняется только первый символ — первая буква наименования филиала.
Обладая такими существенными знаниями, мы можем смело использовать функцию ПОИСК, которая находит нужный нам текст в текстовой строке и возвращают начальную позицию нужного нам текста внутри всей текстовой строки.
=ПОИСК(искомый_текст; текст_для_поиска; [нач_позиция])
Где:
Искомый_текст – обязательный аргумент. Текст, который требуется найти.
Просматриваемый_текст – обязательный аргумент. Текст, в котором нужно найти значение аргумента искомый_текст.
Нач_позиция – необязательный аргумент. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Функция ПОИСК не учитывает регистр. Если требуется учитывать регистр, используйте функцию НАЙТИ.
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (~).
Обозначив меняющийся первый символ знаком вопроса (?), мы можем записать итоговую формулу для выделения кода филиала в таком виде:
=ПСТР(C7;ПОИСК(«?Ф00000»;C7);2)
Эта формула определяет начальную позицию кода филиала в наименовании документа, а затем возвращает два знака кода, начиная с найденной позиции.
В результате, мы получим в отдельном столбце код филиала, который сможем использовать как признак для фильтрации, сортировки или создания сводной таблицы.
In this guide, we’re going to show you how to split text in Excel by a delimiter.
Download Workbook
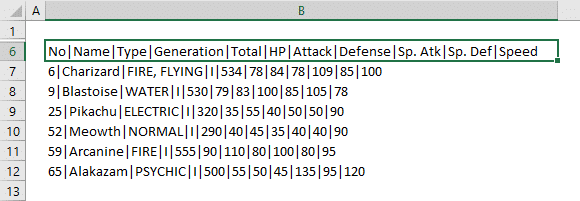
We have a sample data which contains concatenated values separated by “|” characters. It is important that the data includes a specific delimiter character between each chunk of data to make splitting text easier.
Text to Columns feature for splitting text
When splitting text in Excel, the Text to Columns is one of the most common methods. You can use the Text to Columns feature with all versions of Excel. This feature can split text by a specific character count or delimiter.
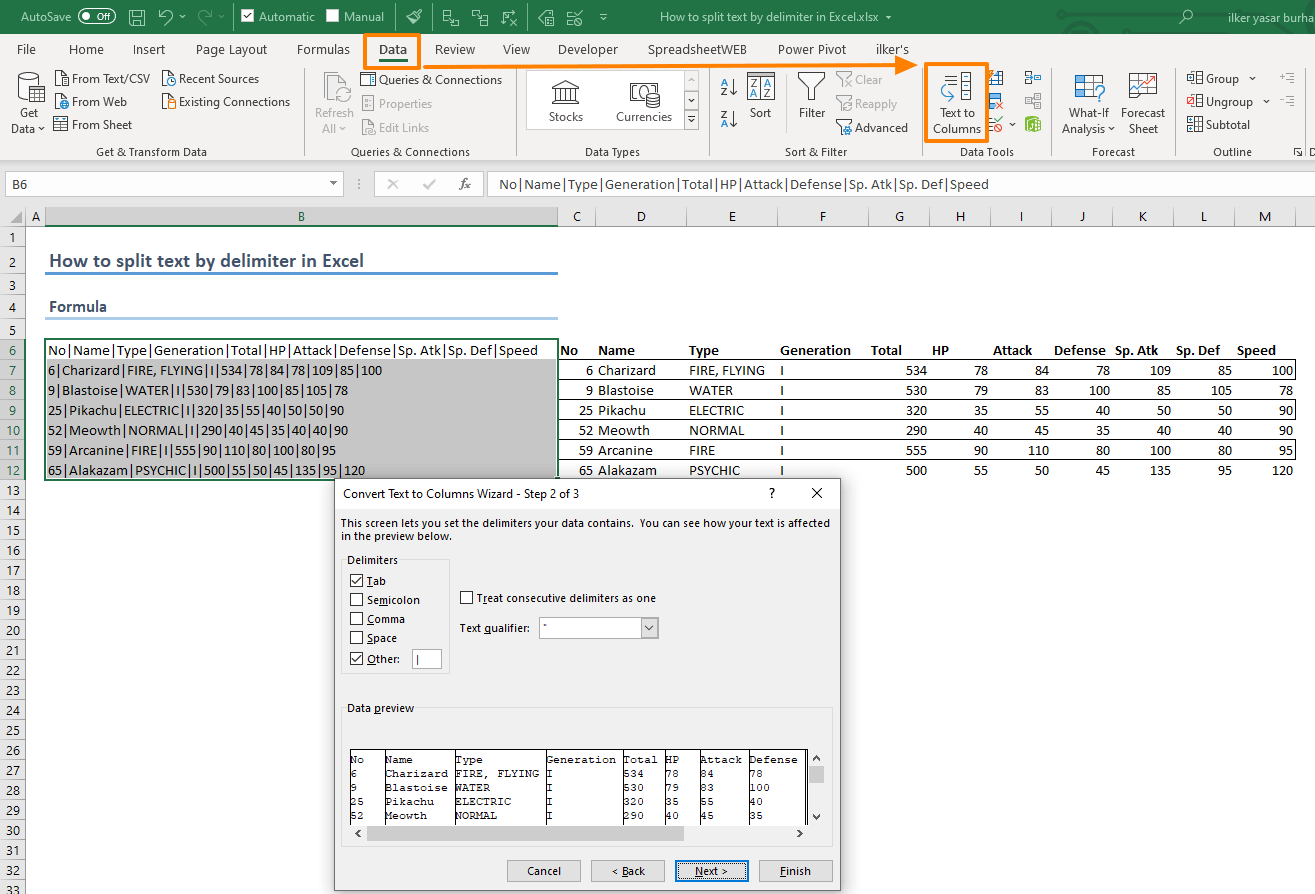
- Start with selecting your data. You can use more than one cell in a column.
- Click Data > Text to Columns in the Ribbon.
- On the first step of the wizard, you have 2 options to choose from — these are slicing methods. Since our data in this example is split by delimiters, our choice is going to be Delimited.
- Click Next to continue
- Select the delimiters suitable to your data or choose a character length and click Next.
- Choose corresponding data types for the columns and the destination cell. Please note that if the destination cell is the same cell as where your data is, the original data will be overwritten.
- Click Finish to see the outcome.
Using formulas to split text
Excel has a variety of text formulas that you can use to locate delimiters and parse data. When using formulas to do so, Excel automatically updates the parsed values when the source is updated.
The formula used in this example uses Microsoft 365’s dynamic array feature, which allows you to populate multiple cells without using array formulas. If you can see the SEQUENCE formula, you can use this method.
Syntax
=TRIM(MID(SUBSTITUTE( text, separator, REPT( “ “, LEN( text ))),(SEQUENCE( 1, column count ) — 1 ) * LEN( text ) + 1,LEN( text )))
How it works
The formula replaces each separator character with space characters first. (see SUBSTITUTE) The number of space characters will be equal to the original string’s character count, which is enough number of spaces to separate each string block (see REPT and LEN).
The SEQUENCE function generates an array of numbers starting with 1, up to the number of maximum columns. Multiplying these sequential numbers with the length of the original string returns character numbers indicating the start of each block.
This approach uses the MID function to parse each string block with given start character number and the number of characters to return. Since the separators are replaced with space characters, each parsed block includes these spaces around the actual string. The TRIM function then removes these spaces.

Flash Fill
The Flash Fill is an Excel tool which can detect the pattern when entering data. A common example is to separate or merge first name and last names. Let’s say column A contains the first name — last name combinations. If you type in the corresponding first name in the same row for column B, Excel shows you a preview for the rest of the column.
Please note that the Flash Fill is available for Excel 2013 and newer versions only.
You can see the same behavior with strings using delimiters to separate data. Just select a cell in the adjacent column and start typing. Occasionally Excel will display a preview. If not, press Ctrl + E like below to split your text.

Power Query
Power Query is a powerful feature, not only for splitting text, but for data management in general. Power Query comes with its own text splitting tool which allows you to split text in multiple ways, like by delimiters, number of characters, or case of letters.
If you are using Excel 2016 or newer — including Microsoft 365 — you can find Power Query options under the Data tab’s Get & Transform section. Excel 2010 and 2013 users should download and install the Power Query as an add-in.
- Select the cells containing the text.
- Click Data > From Sheet. If the data is not in an Excel Table, Excel converts it into an Excel Table first.
- Once the Power Query window is open, find the Split Column under the Transform tab and click to see the options.
- Select the approach that fits your data layout. The data in our example is using By Delimiter since the data is separated by “|”.
- Power Query will show the delimiter character. If you are not seeing the expected delimiter, choose from the list or enter it yourself.
- Click OK to split text.
- If your data includes headers in its first row, like our example does, click Transform > Use First Row as Headers to keep them as headers.
- One you satisfied with the result, click the Home > Close & Load button to move the split data into your workbook.

VBA
VBA is the last text splitting option we want to show in this article. You can use VBA in two ways to split text:
- By calling the Text to Columns feature using VBA,
- Using VBA’s Split function to create array of sub-strings and using a loop to distribute the sub-strings into adjacent cells in the same row.
Text to Columns by VBA
The following code can split data from selected cells into the adjacent columns. Note that each supported delimiter is listed as an argument which you can enable or disable by giving them either True or False. Briefly, True means that you want to set that argument as a delimiter and False means ignore that character.

An easy way to generate a VBA code to split text is to record a macro. Start a recording section using the Record Macro button in the Developer tab, and use the Text to Columns feature. Once the recording is stopped, Excel will save the code for what you did during recording.
The code:
Sub VBATextToColumns_Multiple()
Dim MyRange As Range
Set MyRange = Selection ‘To work on a static range replace Selection via Range object, e.g., Range(“B6:B12”)
MyRange.TextToColumns _
Destination:=MyRange(1, 1).Offset(, 1), _
DataType:=xlDelimited, _
TextQualifier:=xlDoubleQuote, _
ConsecutiveDelimiter:=False, _
Tab:=True, _
SemiColon:=False, _
Comma:=False, _
Space:=False, _
Other:=True, _
OtherChar:=»|»
End Sub
Split Function
Split function can be useful if you want to keep the split blocks in an array. You can only use this method for splitting because of the single delimiter constraint. The following code loops through each cell in a selected column, splits and stores text by the delimiter “|”, and uses another loop to populate the values in the array on cells. The final EntireColumn.AutoFit command adjusts the column widths.

The code:
Sub SplitText()
Dim StringArray() As String, Cell As Range, i As Integer
For Each Cell In Selection ‘To work on a static range replace Selection via Range object, e.g., Range(“B6:B12”)
StringArray = Split(Cell, «|») ‘Change the delimiter with a character suits your data
For i = 0 To UBound(StringArray)
Cell.Offset(, i + 1) = StringArray(i)
Cell.Offset(, i + 1).EntireColumn.AutoFit ‘This is for column width and optional.
Next i
Next
End Sub
Содержание
- Способ 1: Использование автоматического инструмента
- Способ 2: Создание формулы разделения текста
- Шаг 1: Разделение первого слова
- Шаг 2: Разделение второго слова
- Шаг 3: Разделение третьего слова
- Вопросы и ответы

Способ 1: Использование автоматического инструмента
В Excel есть автоматический инструмент, предназначенный для разделения текста по столбцам. Он не работает в автоматическом режиме, поэтому все действия придется выполнять вручную, предварительно выбирая диапазон обрабатываемых данных. Однако настройка является максимально простой и быстрой в реализации.
- С зажатой левой кнопкой мыши выделите все ячейки, текст которых хотите разделить на столбцы.
- После этого перейдите на вкладку «Данные» и нажмите кнопку «Текст по столбцам».
- Появится окно «Мастера разделения текста по столбцам», в котором нужно выбрать формат данных «с разделителями». Разделителем чаще всего выступает пробел, но если это другой знак препинания, понадобится указать его в следующем шаге.
- Отметьте галочкой символ разделения или вручную впишите его, а затем ознакомьтесь с предварительным результатом разделения в окне ниже.
- В завершающем шаге можно указать новый формат столбцов и место, куда их необходимо поместить. Как только настройка будет завершена, нажмите «Готово» для применения всех изменения.
- Вернитесь к таблице и убедитесь в том, что разделение прошло успешно.
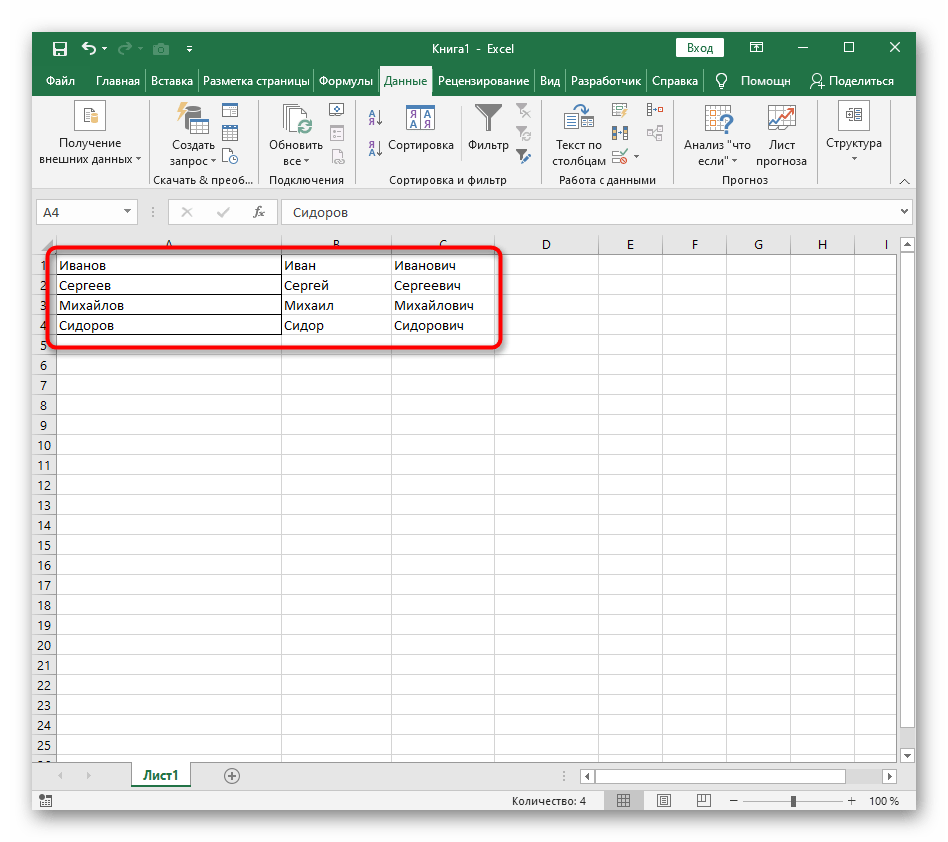
Из этой инструкции можно сделать вывод, что использование такого инструмента оптимально в тех ситуациях, когда разделение необходимо выполнить всего один раз, обозначив для каждого слова новый столбец. Однако если в таблицу постоянно вносятся новые данные, все время разделять их таким образом будет не совсем удобно, поэтому в таких случаях предлагаем ознакомиться со следующим способом.
Способ 2: Создание формулы разделения текста
В Excel можно самостоятельно создать относительно сложную формулу, которая позволит рассчитать позиции слов в ячейке, найти пробелы и разделить каждое на отдельные столбцы. В качестве примера мы возьмем ячейку, состоящую из трех слов, разделенных пробелами. Для каждого из них понадобится своя формула, поэтому разделим способ на три этапа.
Шаг 1: Разделение первого слова
Формула для первого слова самая простая, поскольку придется отталкиваться только от одного пробела для определения правильной позиции. Рассмотрим каждый шаг ее создания, чтобы сформировалась полная картина того, зачем нужны определенные вычисления.
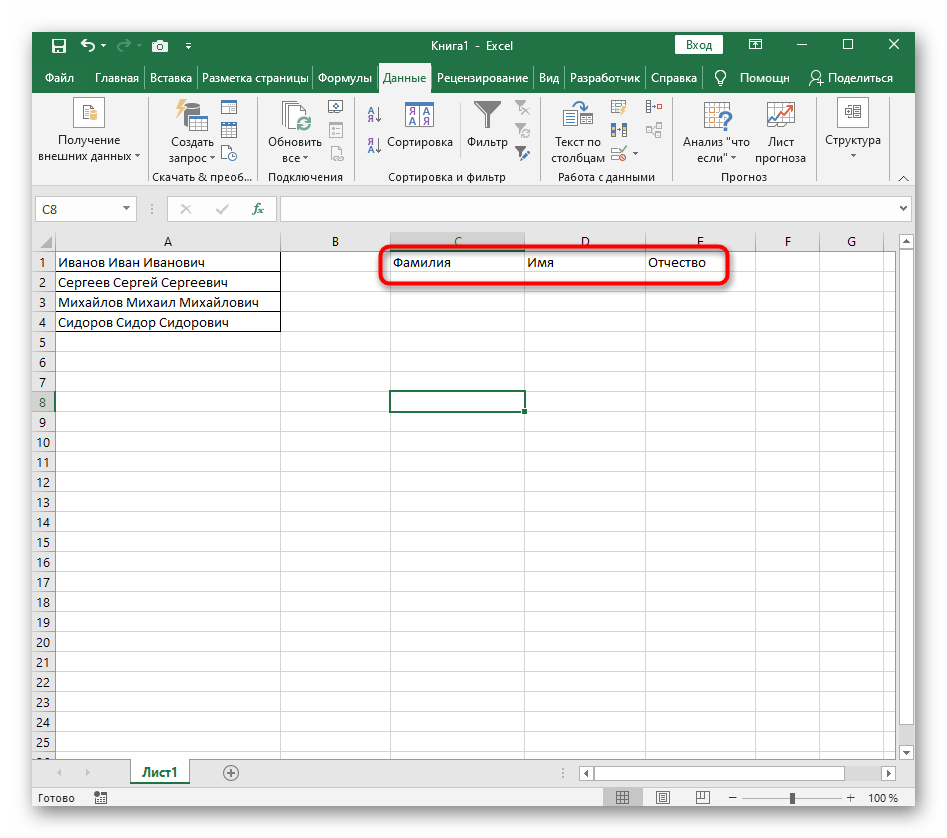
- Для удобства создадим три новые столбца с подписями, куда будем добавлять разделенный текст. Вы можете сделать так же или пропустить этот момент.
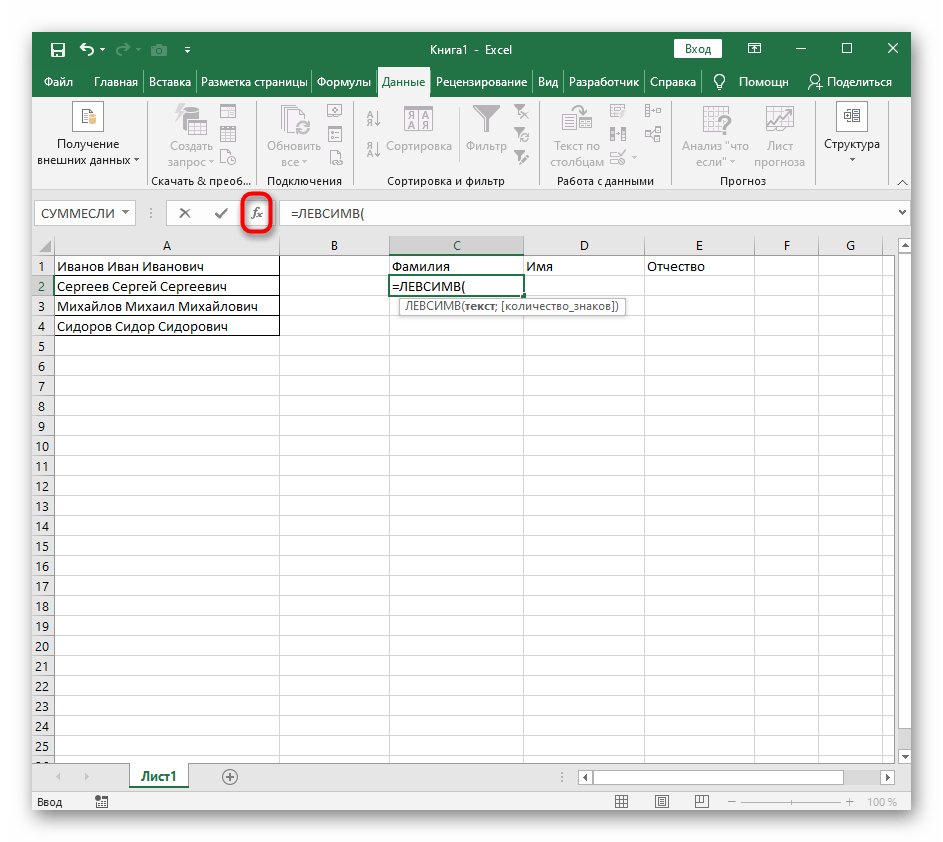
- Выберите ячейку, где хотите расположить первое слово, и запишите формулу
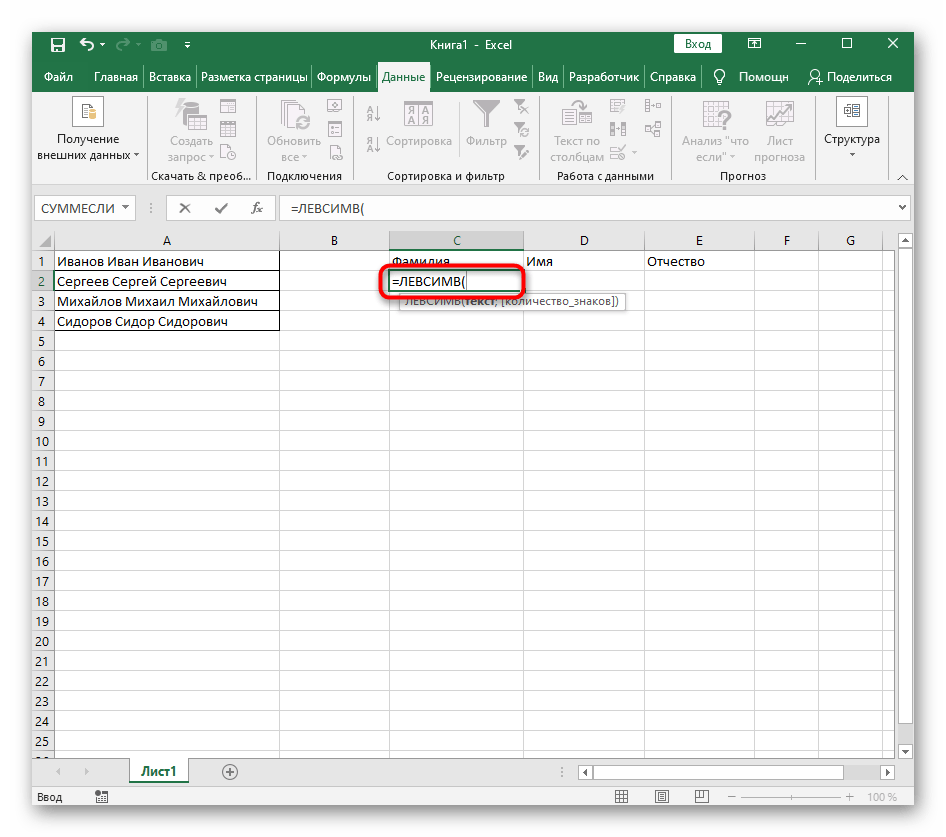
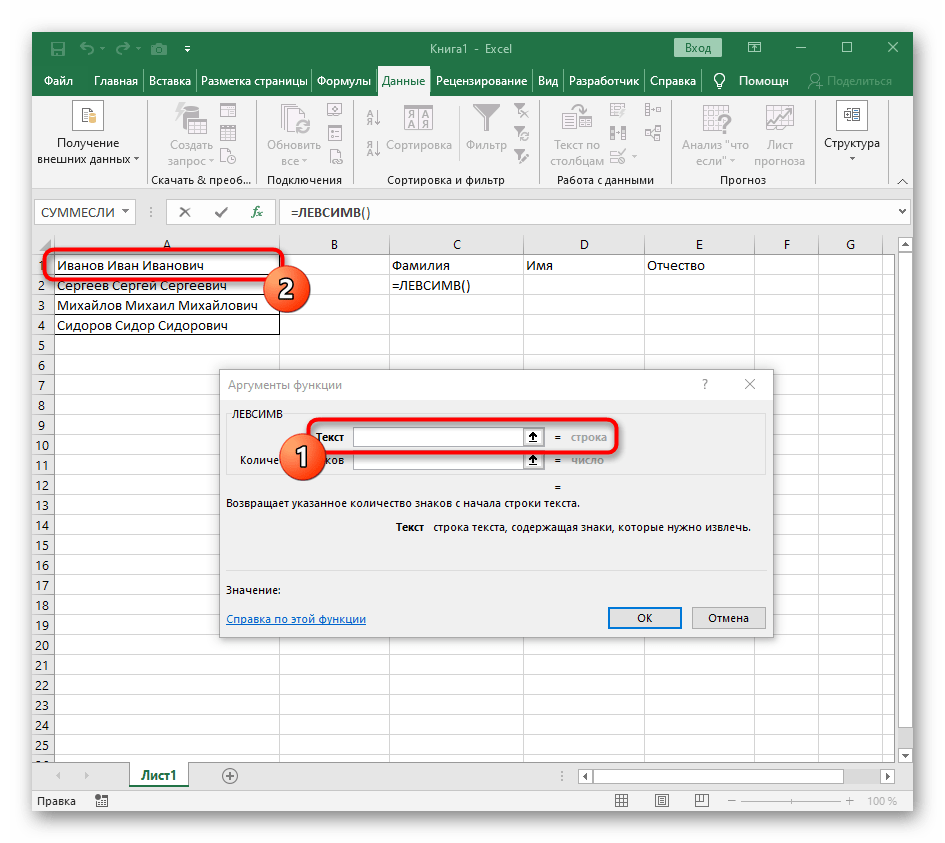
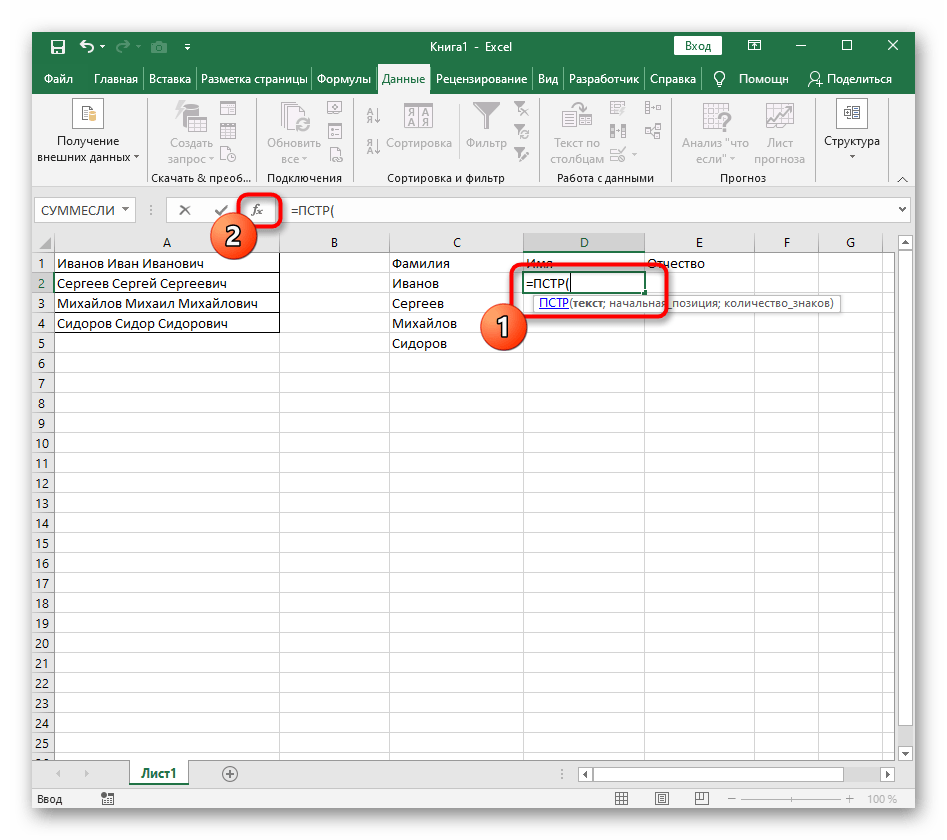
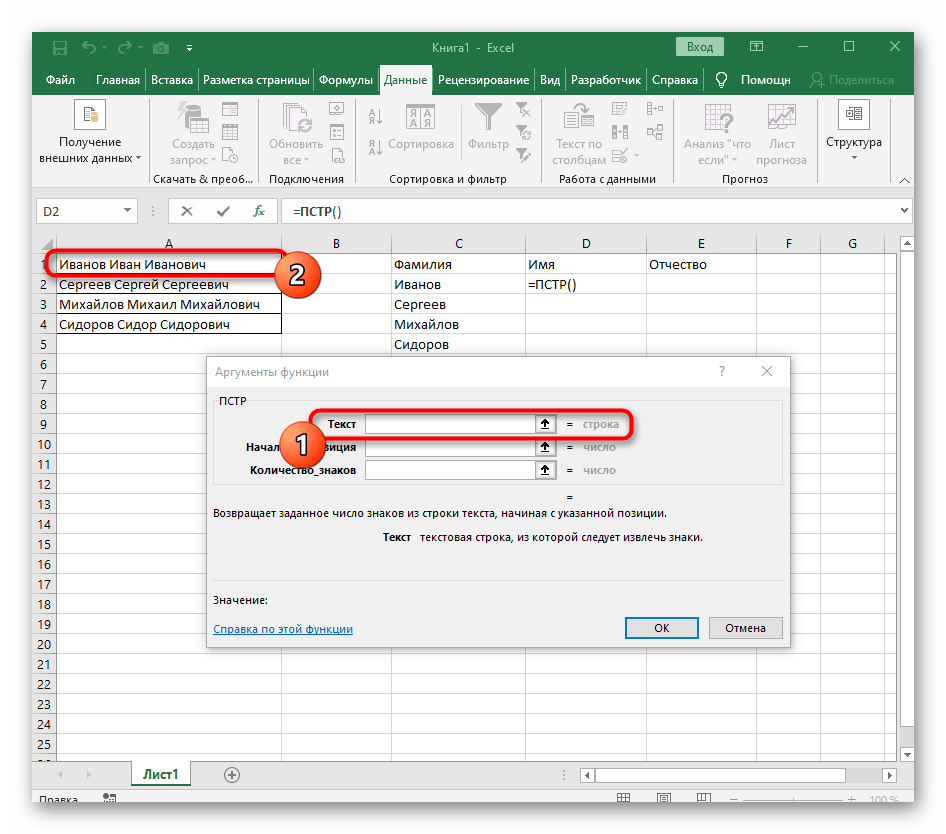
=ЛЕВСИМВ(. - После этого нажмите кнопку «Аргументы функции», перейдя тем самым в графическое окно редактирования формулы.
- В качестве текста аргумента указывайте ячейку с надписью, кликнув по ней левой кнопкой мыши на таблице.
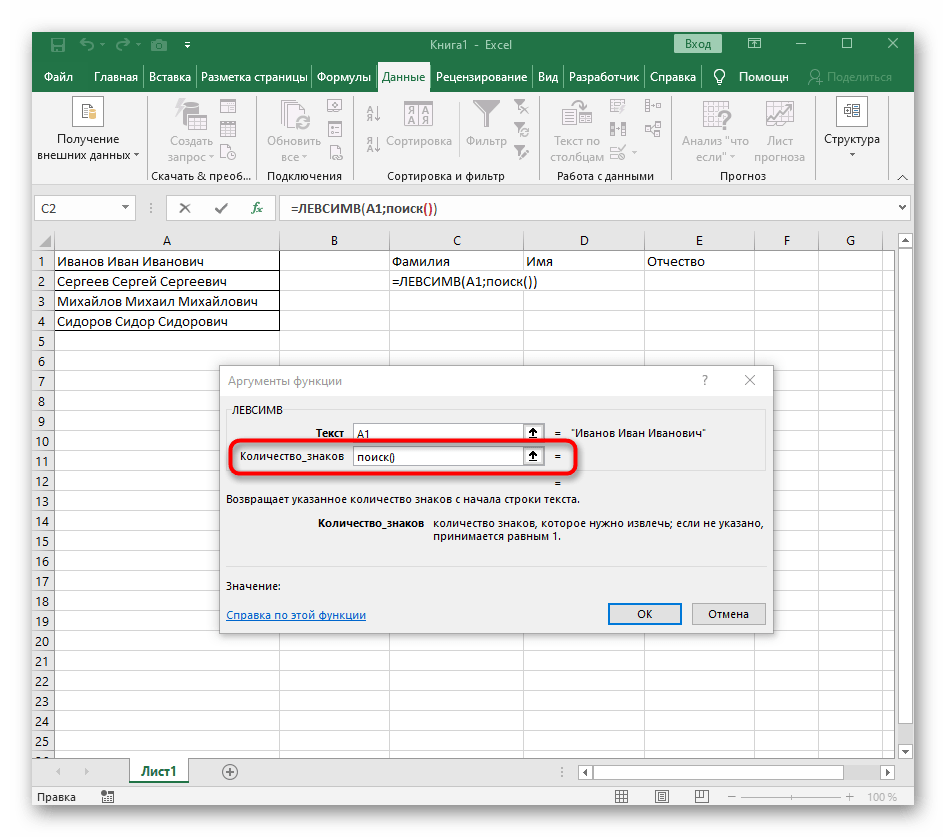
- Количество знаков до пробела или другого разделителя придется посчитать, но вручную мы это делать не будем, а воспользуемся еще одной формулой —
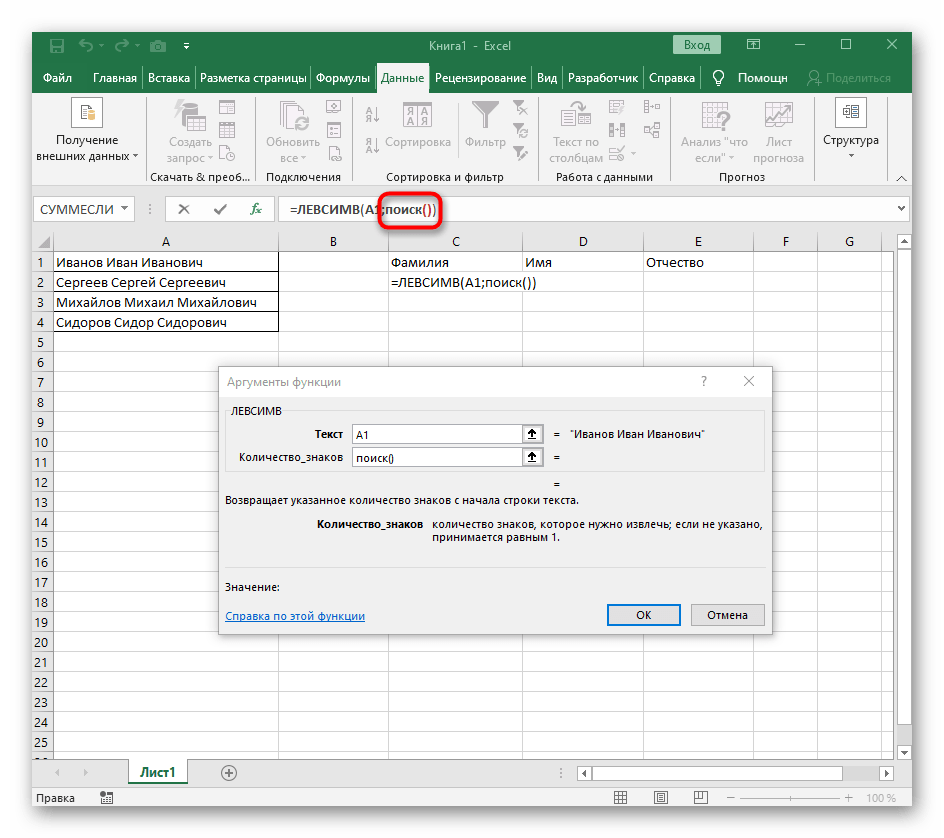
ПОИСК(). - Как только вы запишете ее в таком формате, она отобразится в тексте ячейки сверху и будет выделена жирным. Нажмите по ней для быстрого перехода к аргументам этой функции.
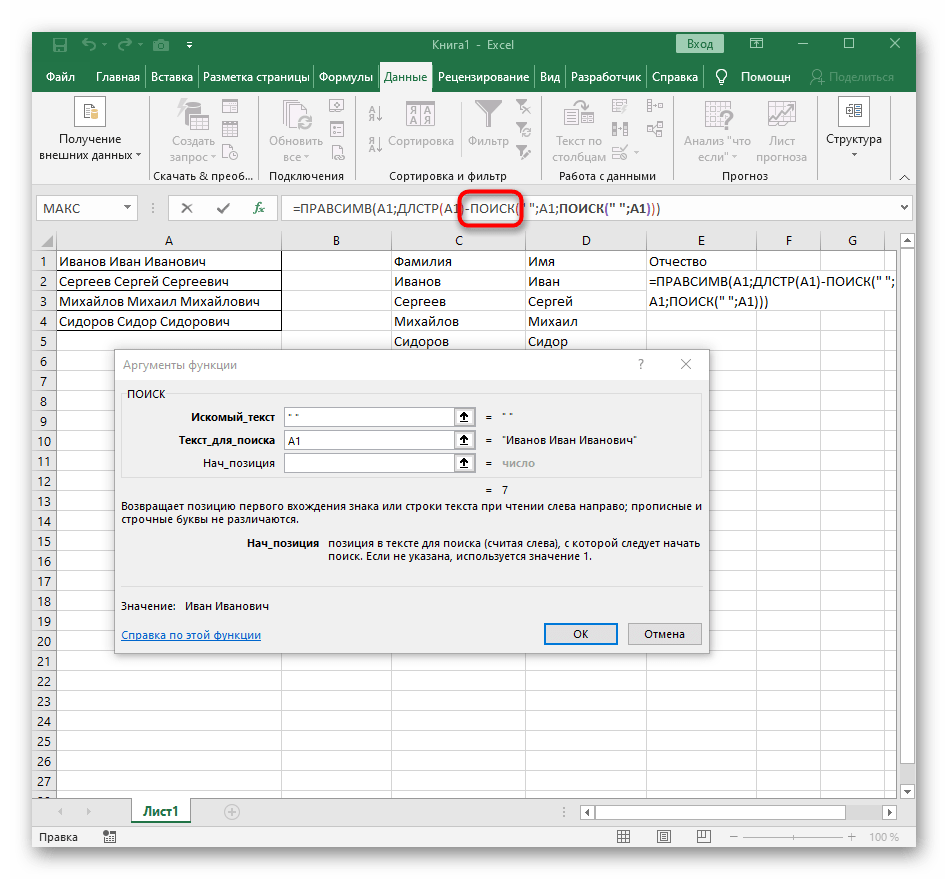
- В поле «Искомый_текст» просто поставьте пробел или используемый разделитель, поскольку он поможет понять, где заканчивается слово. В «Текст_для_поиска» укажите ту же обрабатываемую ячейку.
- Нажмите по первой функции, чтобы вернуться к ней, и добавьте в конце второго аргумента
-1. Это необходимо для того, чтобы формуле «ПОИСК» учитывать не искомый пробел, а символ до него. Как видно на следующем скриншоте, в результате выводится фамилия без каких-либо пробелов, а это значит, что составление формул выполнено правильно. - Закройте редактор функции и убедитесь в том, что слово корректно отображается в новой ячейке.
- Зажмите ячейку в правом нижнем углу и перетащите вниз на необходимое количество рядов, чтобы растянуть ее. Так подставляются значения других выражений, которые необходимо разделить, а выполнение формулы происходит автоматически.

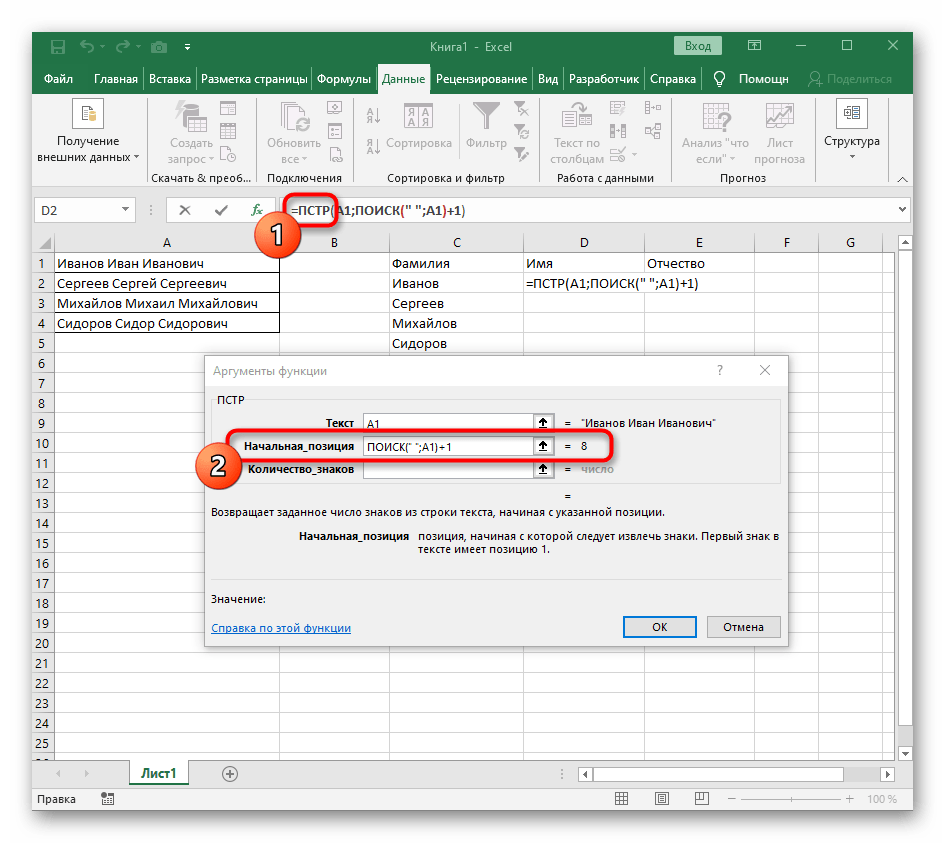
Полностью созданная формула имеет вид =ЛЕВСИМВ(A1;ПОИСК(" ";A1)-1), вы же можете создать ее по приведенной выше инструкции или вставить эту, если условия и разделитель подходят. Не забывайте заменить обрабатываемую ячейку.
Шаг 2: Разделение второго слова
Самое трудное — разделить второе слово, которым в нашем случае является имя. Связано это с тем, что оно с двух сторон окружено пробелами, поэтому придется учитывать их оба, создавая массивную формулу для правильного расчета позиции.
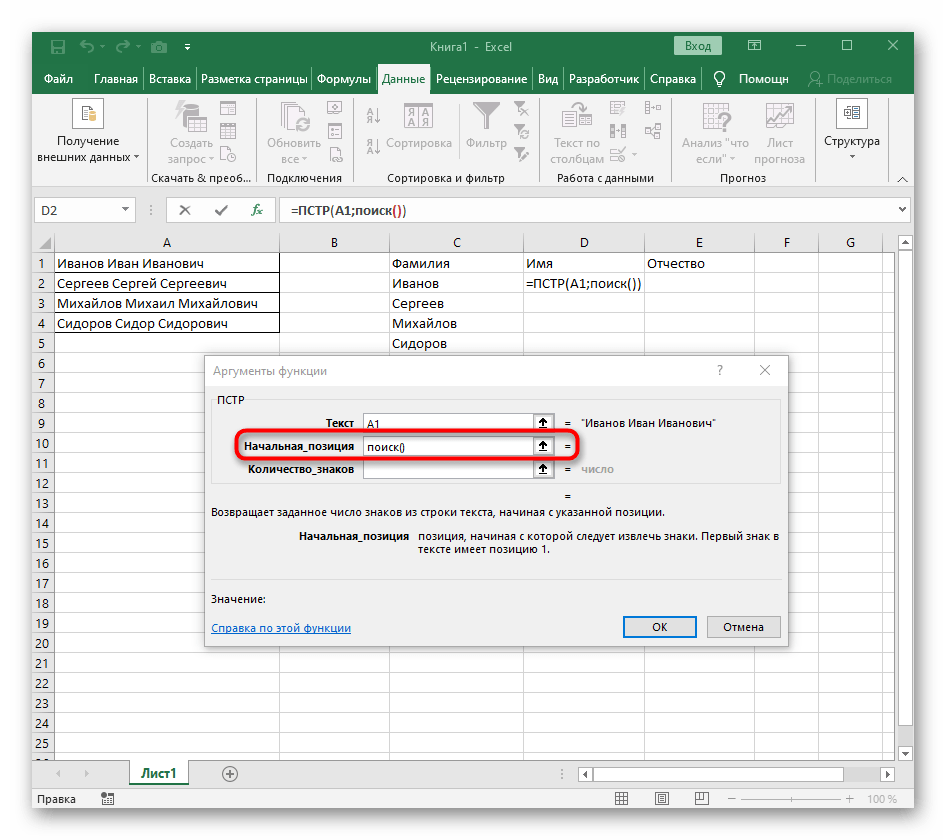
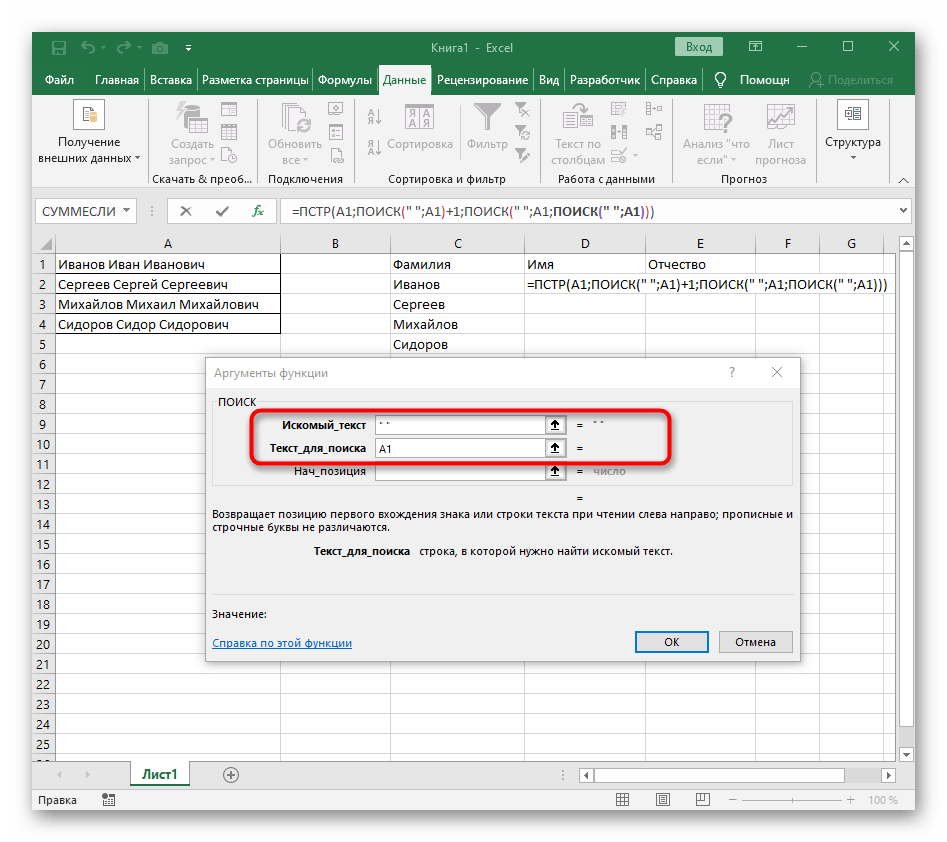
- В этом случае основной формулой станет
=ПСТР(— запишите ее в таком виде, а затем переходите к окну настройки аргументов. - Данная формула будет искать нужную строку в тексте, в качестве которого и выбираем ячейку с надписью для разделения.
- Начальную позицию строки придется определять при помощи уже знакомой вспомогательной формулы
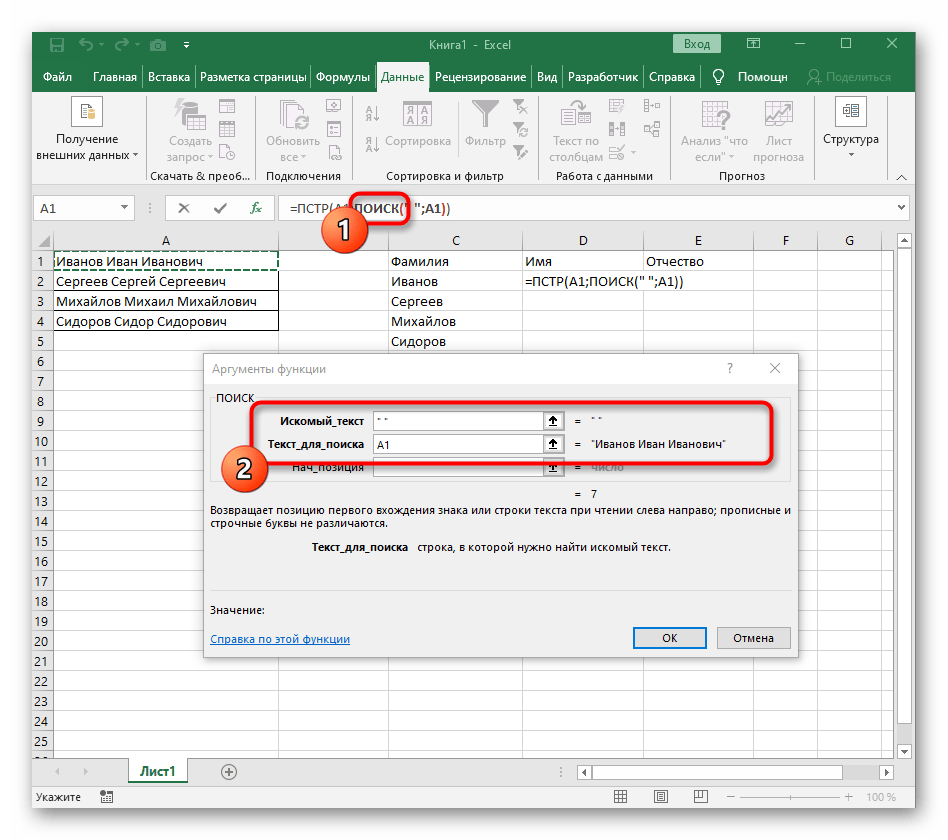
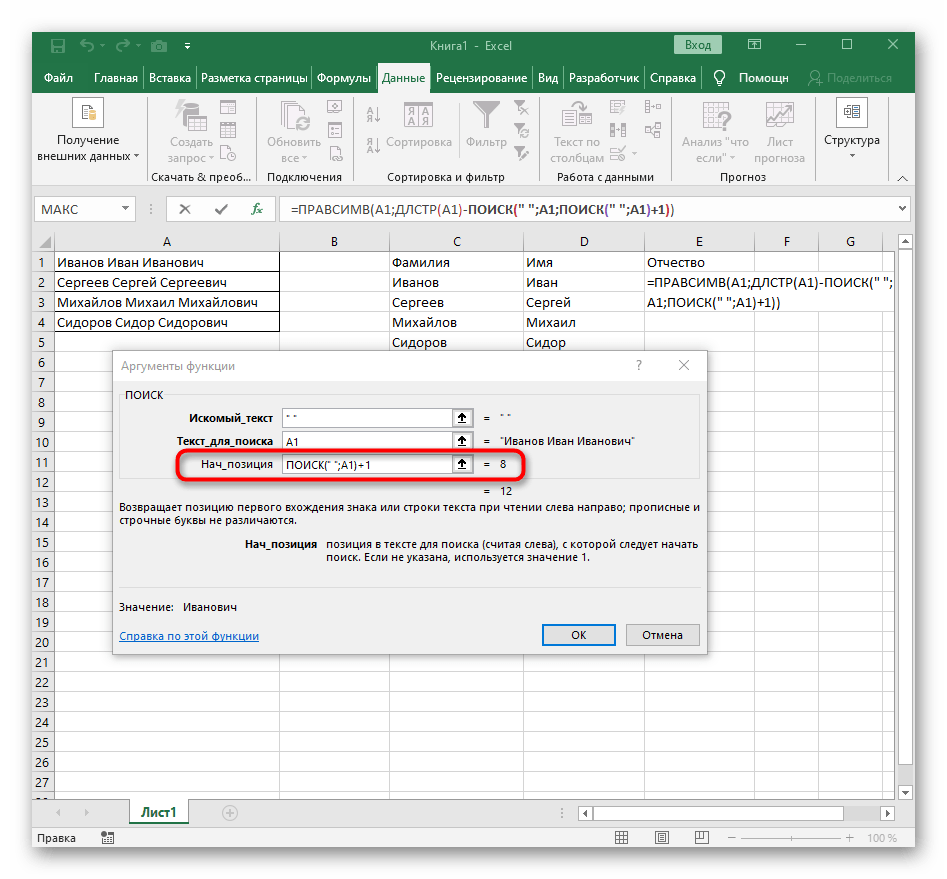
ПОИСК(). - Создав и перейдя к ней, заполните точно так же, как это было показано в предыдущем шаге. В качестве искомого текста используйте разделитель, а ячейку указывайте как текст для поиска.
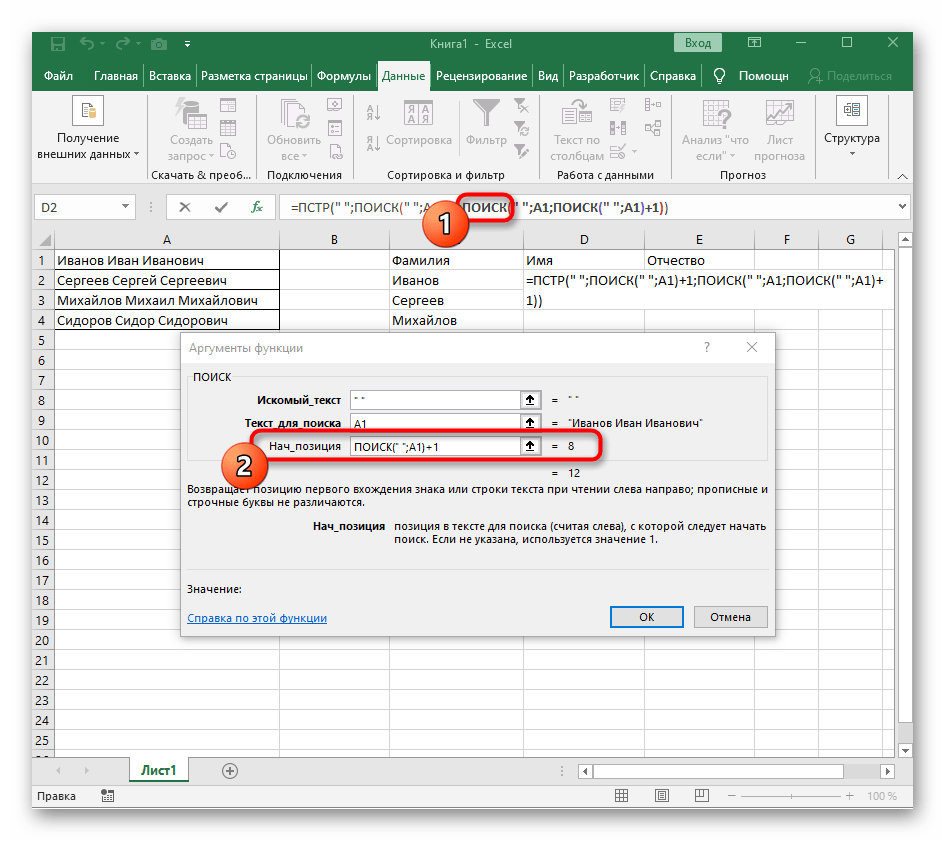
- Вернитесь к предыдущей формуле, где добавьте к функции «ПОИСК»
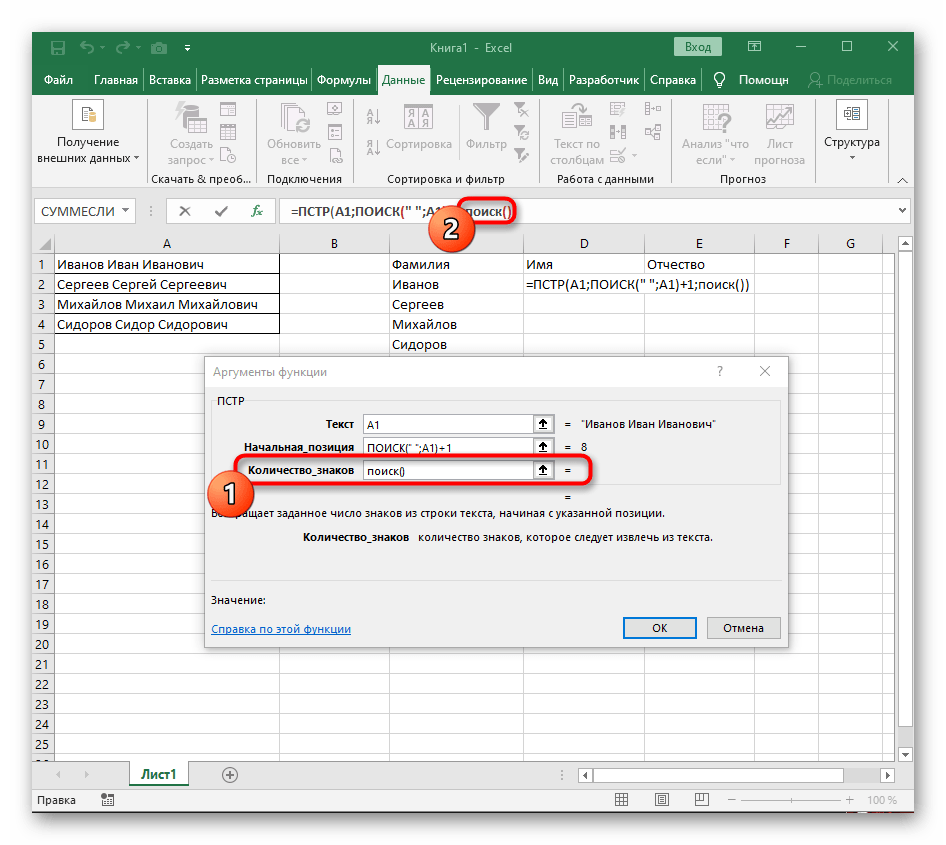
+1в конце, чтобы начинать счет со следующего символа после найденного пробела. - Сейчас формула уже может начать поиск строки с первого символа имени, но она пока еще не знает, где его закончить, поэтому в поле «Количество_знаков» снова впишите формулу
ПОИСК(). - Перейдите к ее аргументам и заполните их в уже привычном виде.
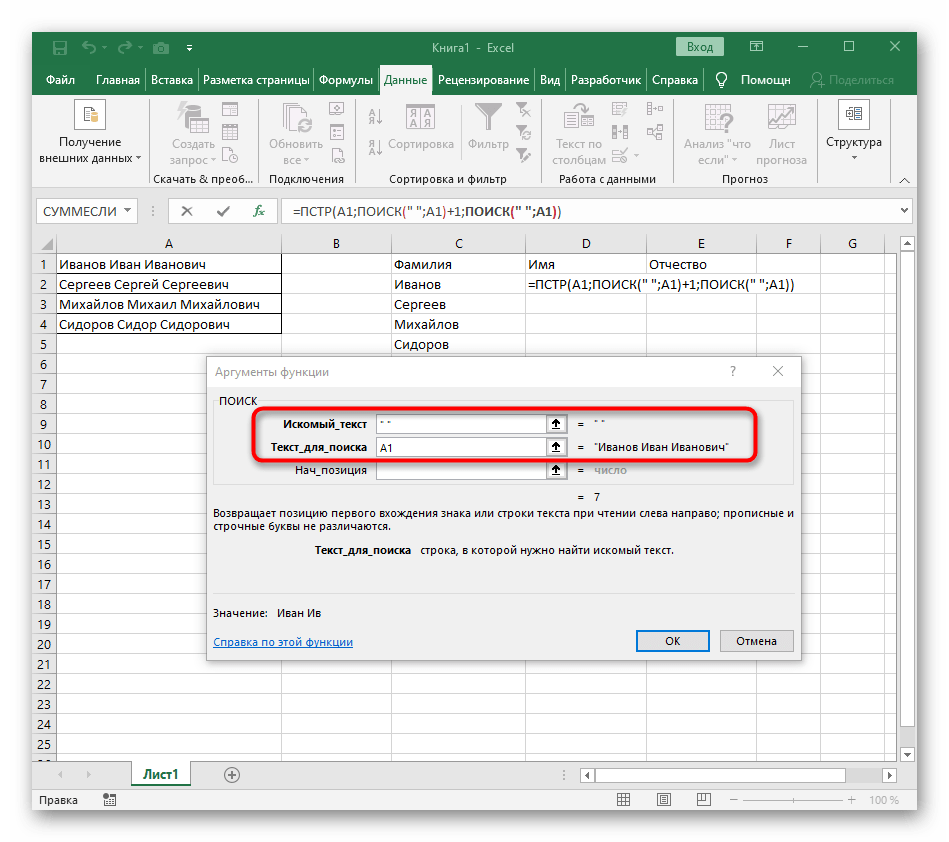
- Ранее мы не рассматривали начальную позицию этой функции, но теперь там нужно вписать тоже
ПОИСК(), поскольку эта формула должна находить не первый пробел, а второй. - Перейдите к созданной функции и заполните ее таким же образом.
- Возвращайтесь к первому
"ПОИСКУ"и допишите в «Нач_позиция»+1в конце, ведь для поиска строки нужен не пробел, а следующий символ. - Кликните по корню
=ПСТРи поставьте курсор в конце строки «Количество_знаков». - Допишите там выражение
-ПОИСК(" ";A1)-1)для завершения расчетов пробелов. - Вернитесь к таблице, растяните формулу и удостоверьтесь в том, что слова отображаются правильно.
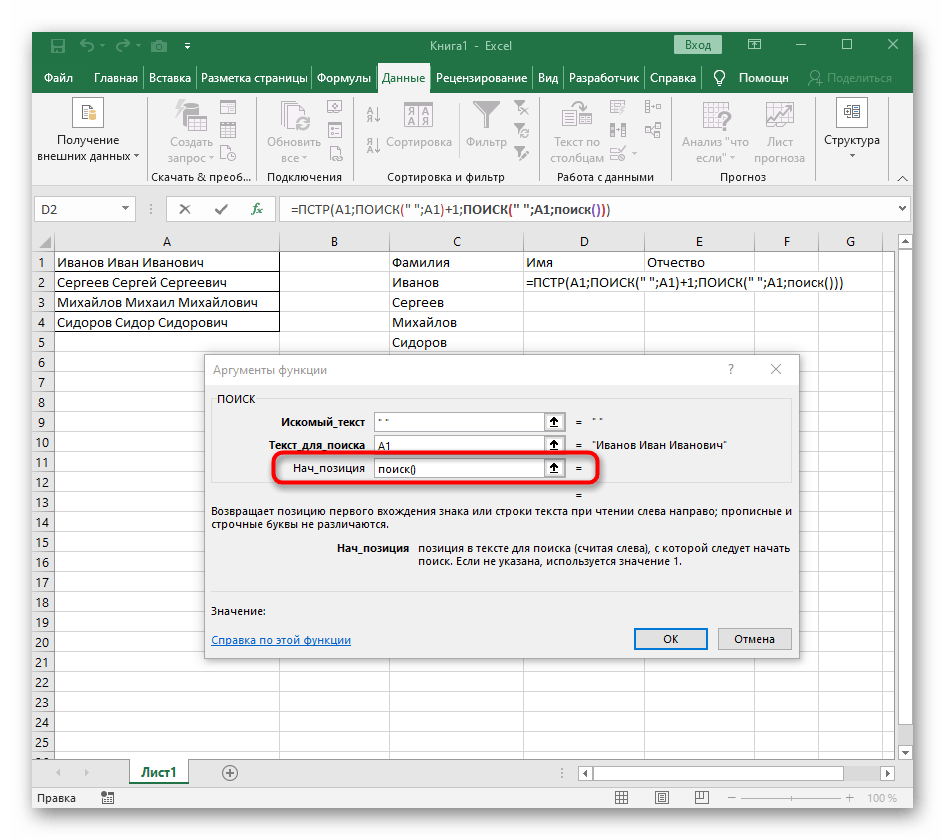
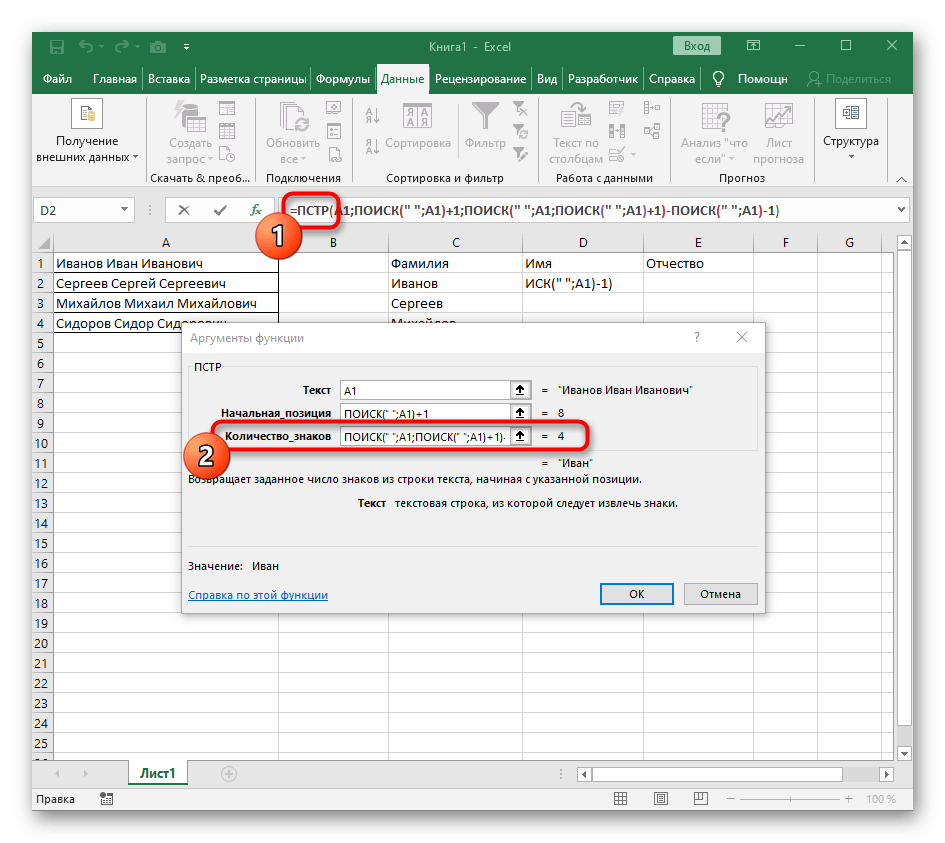
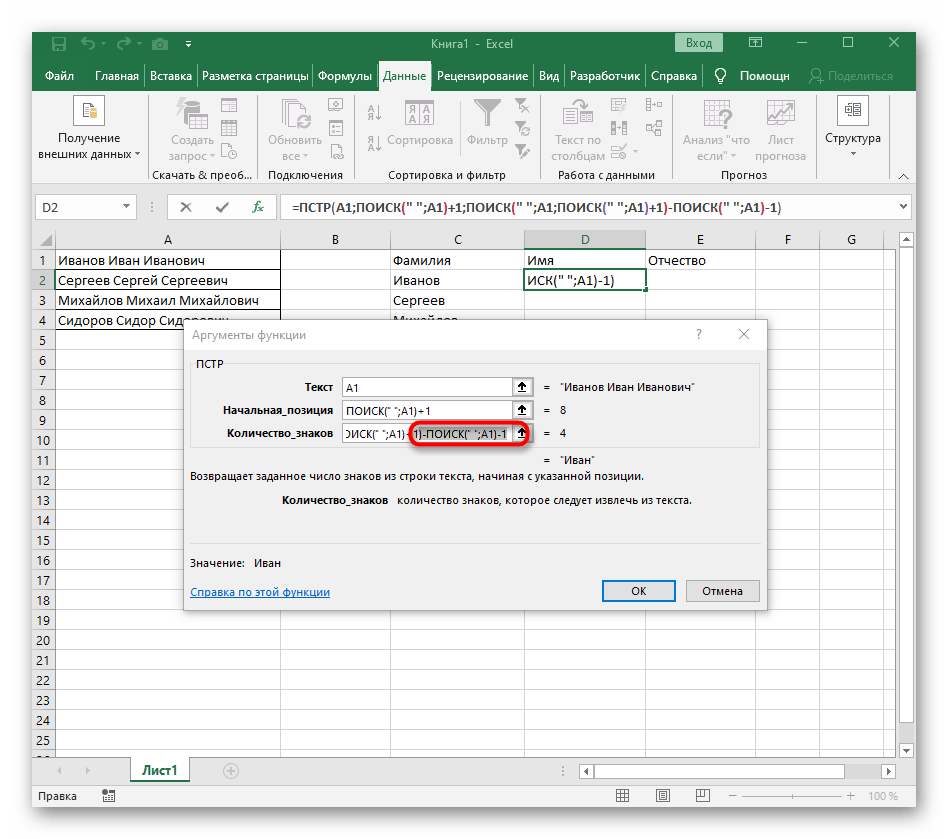
Формула получилась большая, и не все пользователи понимают, как именно она работает. Дело в том, что для поиска строки пришлось использовать сразу несколько функций, определяющих начальные и конечные позиции пробелов, а затем от них отнимался один символ, чтобы в результате эти самые пробелы не отображались. В итоге формула такая: =ПСТР(A1;ПОИСК(" ";A1)+1;ПОИСК(" ";A1;ПОИСК(" ";A1)+1)-ПОИСК(" ";A1)-1). Используйте ее в качестве примера, заменяя номер ячейки с текстом.
Шаг 3: Разделение третьего слова
Последний шаг нашей инструкции подразумевает разделение третьего слова, что выглядит примерно так же, как это происходило с первым, но общая формула немного меняется.
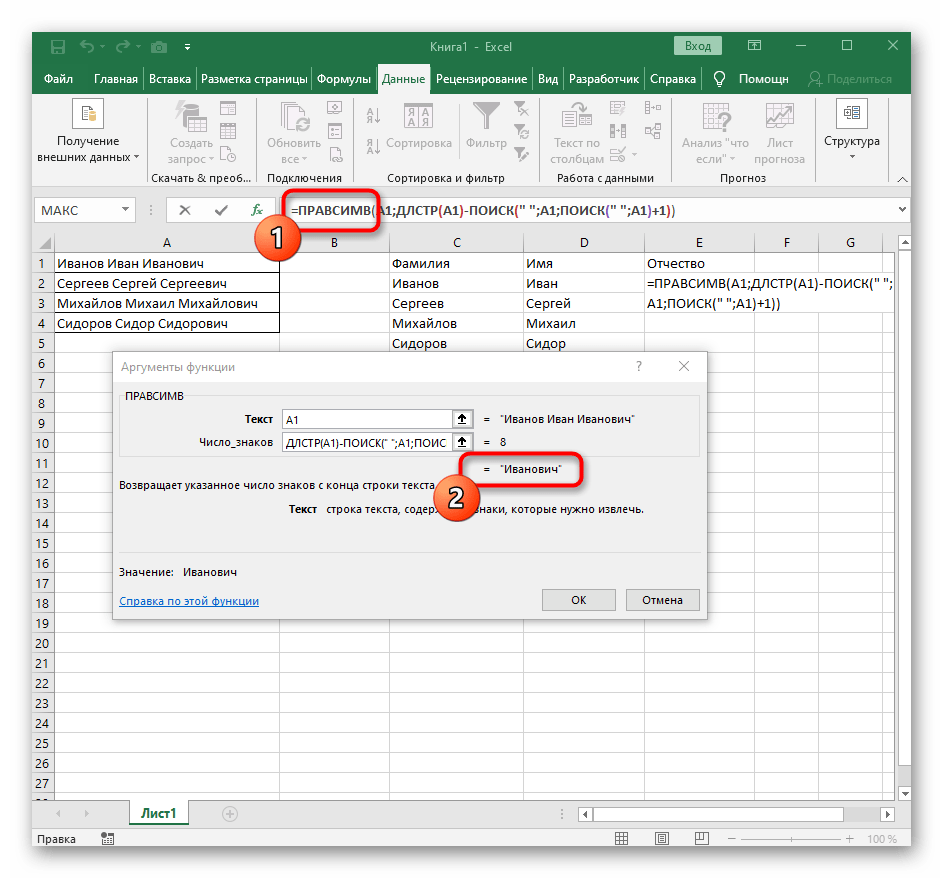
- В пустой ячейке для расположения будущего текста напишите
=ПРАВСИМВ(и перейдите к аргументам этой функции. - В качестве текста указывайте ячейку с надписью для разделения.
- В этот раз вспомогательная функция для поиска слова называется
ДЛСТР(A1), где A1 — та же самая ячейка с текстом. Эта функция определяет количество знаков в тексте, а нам останется выделить только подходящие. - Для этого добавьте
-ПОИСК()и перейдите к редактированию этой формулы. - Введите уже привычную структуру для поиска первого разделителя в строке.
- Добавьте для начальной позиции еще один
ПОИСК(). - Ему укажите ту же самую структуру.
- Вернитесь к предыдущей формуле «ПОИСК».
- Прибавьте для его начальной позиции
+1. - Перейдите к корню формулы
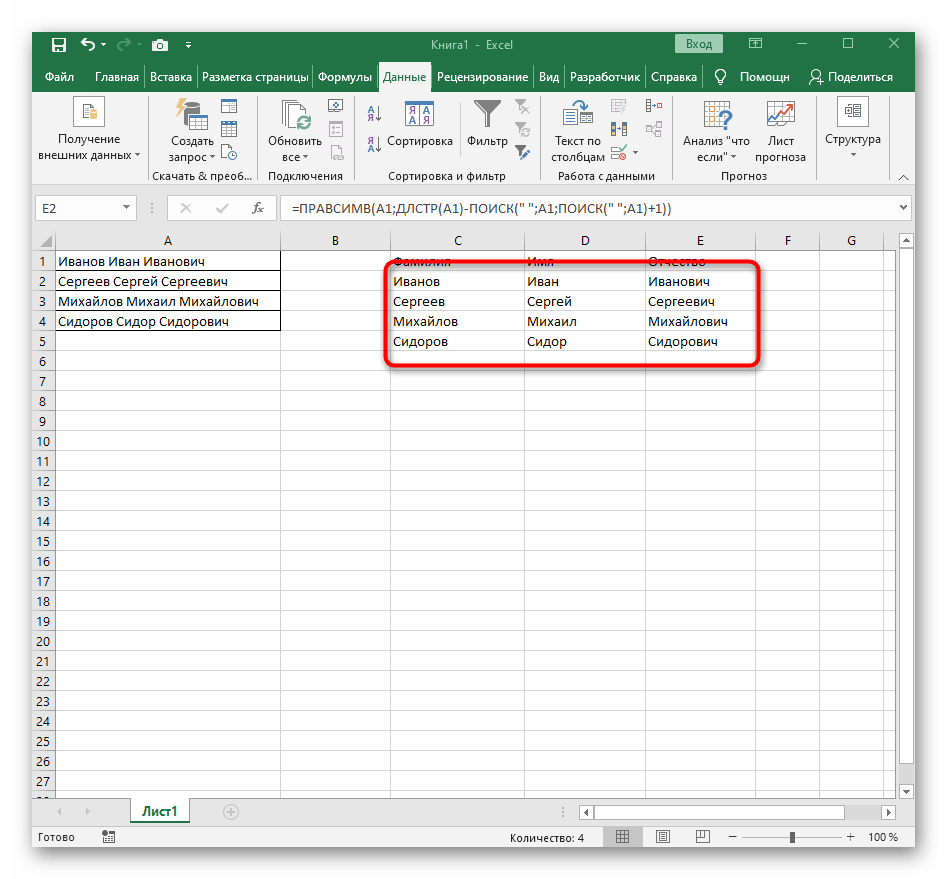
ПРАВСИМВи убедитесь в том, что результат отображается правильно, а уже потом подтверждайте внесение изменений. Полная формула в этом случае выглядит как=ПРАВСИМВ(A1;ДЛСТР(A1)-ПОИСК(" ";A1;ПОИСК(" ";A1)+1)). - В итоге на следующем скриншоте вы видите, что все три слова разделены правильно и находятся в своих столбцах. Для этого пришлось использовать самые разные формулы и вспомогательные функции, но это позволяет динамически расширять таблицу и не беспокоиться о том, что каждый раз придется разделять текст заново. По необходимости просто расширяйте формулу путем ее перемещения вниз, чтобы следующие ячейки затрагивались автоматически.
Еще статьи по данной теме:
Помогла ли Вам статья?
ПСТР – довольно популярная функция, которая используется как профессиональными пользователями Excel, так и начинающими. Но также вторая категория людей может не понимать, в каких случаях уместно ее применять. А назначение у этой функции очень простое – она помогает вытащить маленькую подстроку из одной большой. Но при этом возможностей, которые она предоставляет, значительно больше. В частности, она применяется для разделения строк. Давайте рассмотрим эту волшебную функцию Excel более подробно.
Содержание
- Функция ПСТР (MID) — подробное описание
- Функция ПСТРБ (новая функция)
- В чем разница между ПСТР и ПСТРБ?
- Функция ПСТР на английском
- Функция ПСТР и VBA в Excel
- Распространенные ошибки в использовании функции ПСТР
- Как вырезать часть текста ячейки в Эксель
- Как рассчитать возраст по дате рождения в Эксель
- Несколько особенностей использования ПСТР в Excel
- Примеры использования функции ПСТР
Функция ПСТР (MID) — подробное описание
Итак, мы поняли, что ПСТР – это функция. которая используется для того, чтобы достать из одного фрагмента текста какой-то определенный. Но она несколько отличается от функции «Найти и заменить», которая может реализовываться как через меню Excel, так и посредством формул. Она возвращает строку, начинающуюся с определенного символа.
Синтаксис предельно прост:
=ПСТР(текст; начальная_позиция; число_знаков)
Давайте более подробно поймем, какие аргументы используются в этой функции:
- Текст. Содержимым ячейки могут выступать значения в разных форматах как ссылки, так и текстовая строка. Впрочем, может использоваться и ячейка любого другого формата. Например, можно таким способом достать месяц из даты. Для этого нужно в поле «Текст» указать ссылку на ячейку с датой. Важно убедиться, что она была предварительно конвертирована в текстовый формат.
- Первоначальная позиция. Это числовое значение того символа, с какого начинается извлечение подстроки.
- Число знаков. Это количество знаков, которые необходимо достать из строки. Если же нужно извлечь дату, то она всегда имеет размер в 10 символов.
Каждый аргумент указывать обязательно. Предположим, мы ввели необходимые данные. И результат у нас получился следующий.
=ПСТР(A1;17;10)
Функция ПСТРБ (новая функция)
Эта новая функция выполняет почти те же самые операции, только результат возвращает в байтах, а не в количестве знаков.
В чем разница между ПСТР и ПСТРБ?
Появляется вопрос: а в чем принципиальная разница? Дело в том, что некоторые символы считаются двухбайтовыми, а ряд из них – однобайтные. В случае с функцией ПСТРБ те знаки, которые занимают два байта в памяти, считаются всегда как 2. Прежде всего, двухбайтовыми являются японские, китайские и корейские символы.
Функция ПСТР на английском
Если человек пользуется англоязычной версией Excel, ему необходимо знать, как записывается эта функция на английском языке. За то, чтобы вытащить определенное количество знаков из строки, отвечает функция MID. Соответственно, если необходимо ориентироваться на количество байтов, то используется формула с MIDB.
Функция ПСТР и VBA в Excel
С помощью языка программирования VBA можно писать подпрограммы, которые выполняют ряд действий автоматически. В этой среде также есть альтернатива функции ПСТР. Давайте приведем пример.
Range(«A2»).Value = Mid(Range(«A1»), 17, 10)
Распространенные ошибки в использовании функции ПСТР
При использовании функции ПСТР возможны ошибки, если неправильно соблюдать синтаксис или нарушить некоторые основополагающие правила:
- Нельзя писать в качестве аргумента этой функции отрицательное значение. В таком случае будет выдана ошибка #ЗНАЧ.
- Важно следить, чтобы начальная позиция не была большим числом, чем длина искомой строки. В ином случае будет выдано пустое значение.
Как вырезать часть текста ячейки в Эксель
А теперь давайте начнем обзор практических примеров, как возможно применение функции ПСТР.
Допустим, у нас есть электронная таблица, где содержится информация о том, какие товары продаются, а конкретно: марка и название определенной продукции. И перед нами стоит задача разделить наименование и марку и разместить эту информацию в подходящих колонках.
Сама таблица выглядит следующим образом.
Чтобы заполнить колонку с названиями товара, необходимо в верхнюю строку под заголовком вставить такую формулу.
=ПСТР(A2;1;НАЙТИ(» «;A2))
В нашем примере функция НАЙТИ используется для того, чтобы определить порядковый номер позиции, где есть только один символ пробела. В качестве аргумента функции найти, соответственно, пишем пробел, заключенный в кавычки.
После этого получаем такой результат.
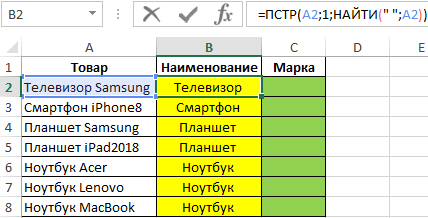
Если же перед нами стоит задача заполнить колонку с информацией о марке продаваемых товаров, необходимо воспользоваться формулой массива такого плана.
=ПСТР(A2:A8;НАЙТИ(» «;A2:A8)+1;100)
Здесь мы снова видим, что использовали функцию НАЙТИ, с помощью какой в этом примере ищем первоначальную позицию, содержащую пробел. Также мы добавили единицу к содержимому аргумента, чтобы перенести взор программы на первый символ марки товара. Чтобы упростить задачу поиска последнего символа мы просто решили написать число 100, которое гарантированно превышает длину строки.
Так можете делать и вы.
После того, как программа выполнит все необходимые расчеты, получаем следующую таблицу.
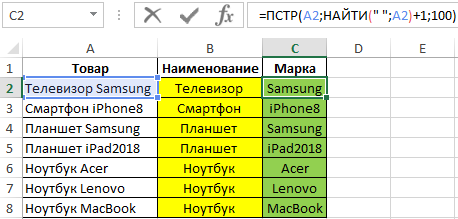
Как рассчитать возраст по дате рождения в Эксель
Теперь приведем еще один пример, с каким сотрудники, часто использующие Эксель, сталкиваются довольно часто. Перед нами есть база данных, содержащая три колонки: Фамилия, имя, отчество, а также дата рождения. И перед нами стоит задача определить, сколько лет человеку в данный момент, с использованием ПСТР.
Вот так выглядит таблица, с которой мы будем работать.
Чтобы в этом случае вернуть строку с фамилией и возрастом, необходимо осуществить запись в строку формул следующего текста (в соответствующих местах аргументы функций нужно заменить на свои).
=ПСТР(A2;1;НАЙТИ(» «;A2))&» — «&РАЗНДАТ(B2;СЕГОДНЯ();»Y»)
Эта функция сначала определяет ту часть строчки, которая содержится до символа пробела. Это делается с помощью функции НАЙТИ аналогично приведенным выше примерам. Далее с использованием функции РАЗНДАТ мы определяем количество полных лет. В нашем случае мы автоматически отсекаем тот участок дней, который остался до следующего дня рождения в этом году. Именно поэтому данная функция сможет указать всегда правильный возраст.
После этого весь результат вычислений переводится в текстовый формат. Далее необходимо соединить строки между собой. Это можно сделать с помощью символа &. После того, как будут выполнены все необходимые действия, появится такая результирующая таблица.
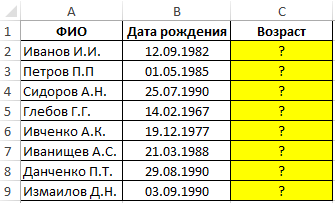
Несколько особенностей использования ПСТР в Excel
А теперь давайте немного пройдемся по теории после того, как была наглядно продемонстрирована работа функции. Итак, мы знаем, что функция ПСТР имеет следующий синтаксис:
=ПСТР(текст;начальная_позиция;число_знаков)
И еще раз, давайте рассмотрим каждый аргумент уже более глубоко и опишем некоторые особенности сквозь призму этой функции.
- Текст. Это обязательный аргумент, который нужно передавать функции. Представляет собой или ссылку на ячейку, или непосредственно строку, из которой нужно извлекать требуемую информацию. Важно обратить внимание, что в последнем случае ее нужно облачать в кавычки. Независимо от формата строки, из нее будет доставаться определенная информация. Какая именно – задается следующими аргументами.
- Начальная позиция. Этот аргумент также обязательный. Его задача – задать стартовую точку отсчета. Являет собой обязательно целое число, которое относится к положительным числам. То бишь, минимальное значение – 1. Если оказывается, что в аргумент была передана дробная часть, она отсекается.
- Число знаков. И этот аргумент является обязательным. Таким образом, все аргументы, используемые в этой функции, необходимо использовать. Здесь есть такой нюанс. Если оказывается, что было в него передано число, которое больше длины строки, то возвращается вся строка.
Также важно понимать, что для функции ПТСРБ используется очень похожий синтаксис за тем лишь исключением, что вместо количества знаков после стартовой позиции задается количество байтов, начиная с этой точки.
Напоминаем, что синтаксис следующий:
=ПСТРБ(текст;начальная_позиция;число_байтов)
Как говорится, повторение – мать учения. Поэтому давайте подведем небольшие промежуточные итоги:
- Если на месте стартовой позиции задавать значение, которое по размеру больше исходной строки, то после всех операций, выполняемых функцией ПСТР вернется пустое значение.
- Если применять единицу в качестве исходной позиции, а количество знаков указать такое, которое будет больше строки или равняться ей, то в качестве итога будет выведено все содержимое этой строки. Таким образом, можно использовать эту функцию в роли альтернативы, пусть и не такой удобной, ссылки на ячейку. В Excel ситуации бывают разные, поэтому иногда приходится выкручиваться из любой ситуации, в том числе, и такими причудливыми способами.
- Будет возвращена ошибка #ЗНАЧ!, если использовать отрицательное значение в качестве начальной позиции. То же касается ситуации, если аргумент с числом знаков задается отрицательным значением. Важно запомнить навсегда, использовать нулевое или отрицательное значение в этом аргументе нельзя.
Примеры использования функции ПСТР
А теперь давайте приведем один пример, как можно использовать функцию ПСТР на практике. Для начала нужно понять, что количество байтов, которые занимает один символ, зависит от языков. Если кодировка в языке однобайтовая, то и один символ занимает ровно один байт. В таком случае нет разницы, какую формулу использовать: ПСТР или ПСТРБ.
Но может быть и двухбайтовый язык из перечня выше. В таком случае есть разница, какую функцию использовать.
Один из возможных вариантов, как можно использовать функцию ПСТР, является разделение текста на несколько ячеек по колонкам. Предположим, у нас есть такая таблица, в которой содержатся даты, разделенные по колонкам дата, день, месяц, год. Перед нами стоит задача автоматически, средствами Excel, элементы занести в соответствующие столбцы.
Сама таблица выглядит следующим образом:
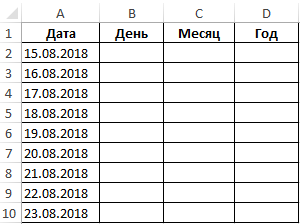
В этом случае нужно применить формулу массива, а именно такую.
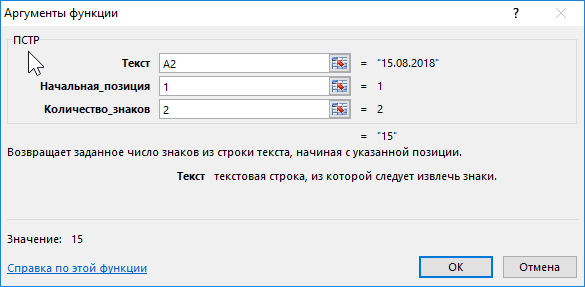
Какие аргументы использовались в этом случае?
- А2:А10. Здесь перечисляется набор ячеек, представление дат в которых выполнено в текстовой форме. Из них и будет доставаться день.
- 1 — это число, обозначающее первоначальную позицию, с которой будет осуществляться извлечение.
- 2 – это последняя позиция.
Как видим, разница между первым и вторым числом не очень большая. Все потому, что нам достаточно извлекать символы, находящиеся по соседству. Поэтому с первого начинаем и вторым заканчиваем.
Точно таким же образом осуществляется выделение номеров месяца и лет, чтобы записать их в соответствующих колонках. Нужно при этом учитывать, что месяц в датах, представленных в таком формате, необходимо записывать, начиная четвертым символом, а год – с 7-го.
Не забывайте, что перед извлечением необходимо превратить строку с датой в текстовый формат.
Соответственно, для нахождения месяца и года и добавления их в соответствующие колонки, необходимо записать такие формулы в первые их ячейки:
=ПСТР(A2:A10;4;2)
=ПСТР(A2:A10;7;4)
В результате, у нас получается следующая таблица.
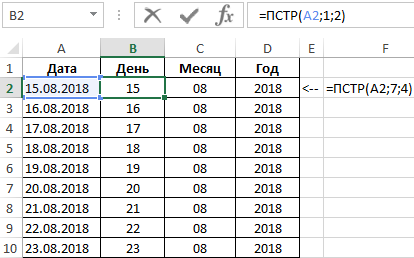
Как видим, у нас так получилось разбить текстовую строку на несколько частей и записать соответствующие значения в ячейках. Но это возможно лишь при установлении текстового формата. Аналогичные операции можно провернуть со временем и любым другим форматом при условии предварительного конвертирования в формат строки.
Таким образом, возможностей у функции ПСТР огромное количество. Ее можно использовать для обработки огромных массивов информации. А поскольку каждый год количество данных, которые нужно эффективно анализировать, постоянно увеличивается, необходимо искать качественные способы автоматизации. И хотя некоторые считают, что Эксель несколько устарел, в своей нише альтернатив этой программе нет. Хотя бы потому, что зная несколько формул, можно добиваться почти любого функционала электронных таблиц. Больших успехов вам и легкости в освоении этого ремесла.
Оцените качество статьи. Нам важно ваше мнение: