
Сводная таблица в Excel является отличным инструментом для агрегирования и анализа данных. В Pandas есть подобный функционал под названием pivot_table, который мы сегодня разберемся как использовать.

Для начала давайте представим, что мы являемся аналитиками в фирме по продаже компьютеров, программного обеспечения к ним, а также оказываем услуги по техническому сопровождению. Нам поставлена задача проанализировать участие компании в различных аукционах. Таблица с исходными данными представлена ниже:
| Аукцион | Контрагент | Контакт | Менеджер | Продукт | Количество | Цена | Статус |
| 424845 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Компьютер | 4 | 45 200 | на рассмотрении |
| 312058 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Софт | 2 | 37 600 | на рассмотрении |
| 918390 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Тех. сопровождение | 2 | 21 200 | в ожидании |
| 997345 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Компьютер | 5 | 39 100 | отменен |
| 496901 | Шахты плюс | Данил Сидоров | Илья Сергеев | Компьютер | 3 | 13 600 | выигран |
| 800437 | Шахты плюс | Данил Сидоров | Илья Сергеев | Компьютер | 1 | 24 400 | в ожидании |
| 967756 | Шахты плюс | Данил Сидоров | Илья Сергеев | Софт | 1 | 6 700 | на рассмотрении |
| 871434 | Альма | Женя Сидин | Илья Сергеев | Тех. сопровождение | 2 | 7 000 | в ожидании |
| 131102 | Альма | Женя Сидин | Илья Сергеев | Компьютер | 4 | 42 000 | отменен |
| 191777 | Микрошкин | Сергей Минин | Павел Попов | Компьютер | 3 | 28 900 | выигран |
| 225531 | Микрошкин | Сергей Минин | Павел Попов | Компьютер | 5 | 15 000 | на рассмотрении |
| 159172 | Микрошкин | Сергей Минин | Павел Попов | Тех. сопровождение | 2 | 2 300 | в ожидании |
| 346287 | Микрошкин | Сергей Минин | Павел Попов | Софт | 4 | 46 900 | на рассмотрении |
| 170247 | Кружка и ложка | Виктор Юдин | Павел Попов | Тех. сопровождение | 1 | 14 800 | выигран |
| 769790 | Кружка и ложка | Виктор Юдин | Павел Попов | Компьютер | 1 | 47 500 | выигран |
| 106612 | Кружка и ложка | Виктор Юдин | Павел Попов | Компьютер | 5 | 36 400 | отменен |
| 151606 | Кружка и ложка | Виктор Юдин | Павел Попов | Монитор | 4 | 9 300 | на рассмотрении |
Сохраните таблицу в Excel файл, вставив начиная с ячейки А1, а также назовите лист «База». Сохраните файл с названием «Отчет по аукционам.xlsx».
Итак сначала давайте прочитаем данные из Excel файла, создадим Pandas Dataframe и передадим туда данные:
import pandas as pd
import numpy as npdata_pd=pd.read_excel(‘Отчет по аукционам.xlsx’,sheet_names=’База’)
Отлично, теперь давайте столбец «Статус» переведем в тип «category» для того, что бы в дальнейшем данные у нас были структурированы:
data_pd[‘Статус’] = data_pd[‘Статус’].astype(‘category’)
data_pd[‘Статус’].cat.set_categories([‘выигран’,’в ожидании’,’на рассмотрении’,’отменен’],inplace=True)
Выводить данные мы можем как в консоль Python, так и в Excel файл. Выберем второй вариант. Эта строка должна быть последней в коде, весь остальной код, который мы будем рассматривать ниже, должен располагаться перед этой строкой. Сохраните скрипт в туже папку, что и файл Отчет по аукционам.xlsx:
data_pt.to_excel(‘result.xlsx’)
Сводная таблица в Python
Cоздать сводную таблицу в Python при помощи пакета Pandas очень просто. К примеру давайте создадим сводную таблицу по столбцу Контрагент:
data_pt = pd.pivot_table(data_pd,index=[‘Контрагент’])
Откройте файл result.xlsx, который скрипт создал в той же папке, где он располагается. Результат должен быть следующего вида:

Мы можем создать сводную таблицу по нескольким индексируемым столбцам:
data_pt = pd.pivot_table(data_pd,index=[‘Контрагент’, ‘Контакт’, ‘Менеджер’])

По умолчанию сводная таблица выводится по всем числовым полям, однако это не всегда удобно, а иногда и лишено смысла, поэтому можно выводить сводные данные только по отдельным столбцам. Для примера выведем только столбец «Стоимость», для этого добавим параметр values=[‘Стоимость’]:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’])

Столбец стоимость по умолчанию выводит среднее значение, однако нам скорее интересна сумма продаж. Добавляем параметр aggfunc=np.sum:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], aggfunc=np.sum)

С помощью aggfunc можно выводить несколько значений, к примеру средную стоимость и количество продаж:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], aggfunc=[np.mean,len])

Также как в Excel, в Pandas индексируемые параметры можно выводить не только в строки, но и в столбцы, для этого служит параметр columns. Например выведем в столбцы наименование продуктов:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], columns=[‘Продукт’], aggfunc=np.sum)

Наверное вы обратили внимание, что в ячейках, где нет данных пусто, хотя нам привычнее, что бы в таких полях указывалось бы значение 0. Добавим параметр fill_value=0:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], columns=[‘Продукт’], aggfunc=np.sum ,fill_value=0)

Вероятно полезно было бы рассматривать эффективность деятельности наших менеджеров не только по стоимости продаж, но и по их количеству.
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’, ‘Количество’], columns=[‘Продукт’], aggfunc=np.sum ,fill_value=0)

Как и в Excel, мы можем перемещать индексируемые поля между столбцами и строками. К примеру перенесем «Продукт» из столбцов в строки:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’, ‘Продукт’], values=[‘Стоимость’, ‘Количество’], aggfunc=np.sum ,fill_value=0)

Если нужно добавить итоговую строчку в таблицу, то за это отвечает параметр margins=True:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’, ‘Продукт’], values=[‘Стоимость’, ‘Количество’], aggfunc=[np.sum,np.mean],fill_value=0,margins=True)

Как мы помним исходной таблице у нас есть столбец «Статус», которому мы присвоили тип категория. Давайте проанализируем работу наших менеджеров этому параметру. Обратите внимание на то, что статусы выводятся именно в том порядке, что мы определили выше:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Стоимость’], aggfunc=[np.sum],fill_value=0,margins=True)

Еще одной очень удобной функцией в сводных таблицах Pandas является то, что для каждого типа значений можно выбирать, какую функцию к ним применить. К примеру для «Количество» мы хотим отражать количество продаж, а для «Стоимость» — сумму продаж:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Количество’, ‘Стоимость’], columns=[‘Продукт’], aggfunc={‘Количество’:len, ‘Стоимость’:np.sum},fill_value=0)

Также для отдельного значения мы можем использовать несколько агригирующих функций:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Количество’, ‘Стоимость’], columns=[‘Продукт’], aggfunc={‘Количество’:len, ‘Стоимость’:[np.sum,np.mean]},fill_value=0)

Также мы можем фильтровать данные, выводя только те записи, которые нам интересны. К примеру выведем продажи только менеджера «Илья Сергеев»:
data_pt = data_pt.query(‘Менеджер == [«Илья Сергеев»]’)

Или к примеру мы можем вывести только те продажи, у которых статус «выигран» или «в ожидании»:
data_pt = data_pt.query(‘Статус == [«выигран», «в ожидании»]’)

На сегодня все. Надеюсь эта статья была вам полезна, спасибо за то что прочитали. Остались вопросы — задавайте в комментариях под статьей.
Давайте посмотрим правде в глаза. Независимо от того, чем мы занимаемся, рано или поздно нам придется иметь дело с повторяющимися задачами, такими как обновление ежедневного отчета в Excel.
Python идеально подходит для решения задач автоматизации. Но если вы работаете компании, которая не использует Python, вам будет сложно автоматизировать рабочие задачи с помощью этого языка. Но не волнуйтесь: даже в этом случае вы все равно сможете использовать свои навыки питониста.
Для автоматизации отчетов в Excel вам не придется убеждать своего начальника перейти на Python! Можно просто использовать модуль Python openpyxl, чтобы сообщить Excel, что вы хотите работать через Python. При этом процесс создания отчетов получится автоматизировать, что значительно упростит вашу жизнь.
Набор данных
В этом руководстве мы будем использовать файл Excel с данными о продажах. Он похож на те файлы, которые используются в качестве входных данных для создания отчетов во многих компаниях. Вы можете скачать этот файл на Kaggle. Однако он имеет формат .csv, поэтому вам следует изменить расширение на .xlsx или просто загрузить его по этой ссылке на Google Диск (файл называется supermarket_sales.xlsx).
Прежде чем писать какой-либо код, внимательно ознакомьтесь с файлом на Google Drive. Этот файл будет использоваться как входные данные для создания следующего отчета на Python:
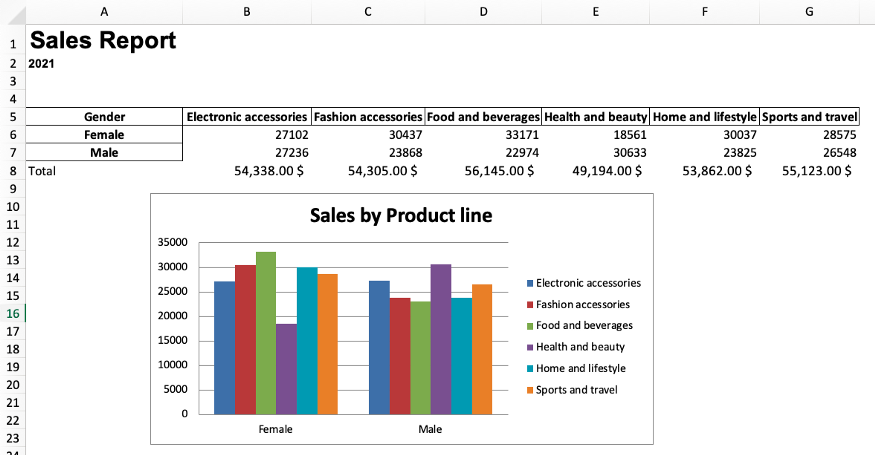
Теперь давайте сделаем этот отчет и автоматизируем его составление с помощью Python!
Создание сводной таблицы с помощью pandas
Импорт библиотек
Теперь, когда вы скачали файл Excel, давайте импортируем библиотеки, которые нам понадобятся.
import pandas as pd import openpyxl from openpyxl import load_workbook from openpyxl.styles import Font from openpyxl.chart import BarChart, Reference import string
Чтобы прочитать файл Excel, создать сводную таблицу и экспортировать ее в Excel, мы будем использовать Pandas. Затем мы воспользуемся библиотекой openpyxl для написания формул Excel, создания диаграмм и форматирования электронной таблицы с помощью Python. Наконец, мы создадим функцию на Python для автоматизации всего этого процесса.
Примечание. Если у вас не установлены эти библиотеки в Python, вы можете легко установить их, выполнив pip install pandas и pip install openpyxl в командной строке.
[python_ad_block]
Чтение файла Excel
Прежде чем читать Excel-файл, убедитесь, что он находится там же, где и ваш файл со скриптом на Python. Затем можно прочитать файл Excel с помощью pd.read_excel(), как показано в следующем коде:
excel_file = pd.read_excel('supermarket_sales.xlsx')
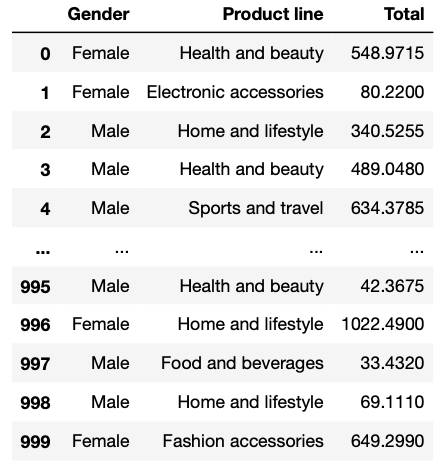
excel_file[['Gender', 'Product line', 'Total']]
В файле много столбцов, но для нашего отчета мы будем использовать только столбцы Gender, Product line и Total. Чтобы показать вам, как они выглядят, я выбрал их с помощью двойных скобок. Если мы выведем это в Jupyter Notebooks, увидим следующий фрейм данных, похожий на таблицу Excel:
Создание сводной таблицы
Теперь мы можем легко создать сводную таблицу из ранее созданного фрейма данных excel_file. Для этого нам просто нужно использовать метод .pivot_table().
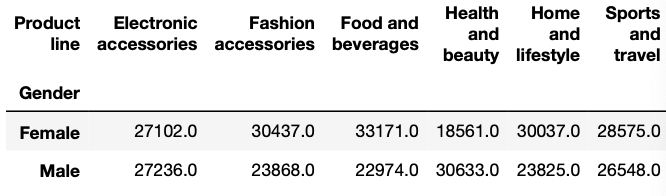
Предположим, мы хотим создать сводную таблицу, которая показывает, сколько в целом потратили на разные продуктовые линейки мужчины и женщины. Для этого мы пишем следующий код:
report_table = excel_file.pivot_table(index='Gender',
columns='Product line',
values='Total',
aggfunc='sum').round(0)
Таблица report_table должна выглядеть примерно так:
Экспорт сводной таблицы в файл Excel
Чтобы экспортировать созданную сводную таблицу, мы используем метод .to_excel(). Внутри скобок нужно написать имя выходного файла Excel. В данном случае давайте назовем этот файл report_2021.xlsx.
Мы также можем указать имя листа, который хотим создать, и в какой ячейке должна находиться сводная таблица.
report_table.to_excel('report_2021.xlsx',
sheet_name='Report',
startrow=4)
Теперь файл Excel экспортируется в ту же папку, в которой находится ваш скрипт Python.
Создание отчета с помощью openpyxl
Каждый раз, когда мы захотим получить доступ к файлу, мы будем использовать load_workbook(), импортированный из openpyxl. В конце работы мы будем сохранять полученные результаты с помощью метода .save().
В следующих разделах мы будем загружать и сохранять файл при каждом изменении. Вам это нужно сделать только один раз (как в полном коде, показанном в самом конце этого руководства).
Создание ссылки на строку и столбец
Чтобы автоматизировать отчет, нам нужно взять минимальный и максимальный активный столбец или строку, чтобы код, который мы собираемся написать, продолжал работать, даже если мы добавим больше данных.
Чтобы получить ссылки в книге Excel, мы сначала загружаем её с помощью функции load_workbook() и находим лист, с которым хотим работать, используя wb[‘имя листа’]. Затем мы получаем доступ к активным ячейкам с помощью метода .active.
wb = load_workbook('report_2021.xlsx')
sheet = wb['Report']
# cell references (original spreadsheet)
min_column = wb.active.min_column
max_column = wb.active.max_column
min_row = wb.active.min_row
max_row = wb.active.max_row
Давайте выведем на экран созданные нами переменные, чтобы понять, что они означают. В данном случае мы получим следующие числа:
Min Columns: 1 Max Columns: 7 Min Rows: 5 Max Rows: 7
Откройте файл report_2021.xlsx, который мы экспортировали ранее, чтобы убедиться в этом.
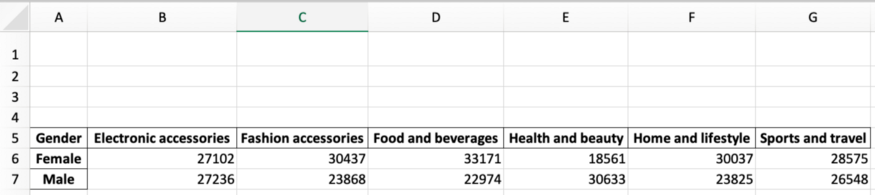
Как видно на картинке, минимальная строка – 5, максимальная — 7. Кроме того, минимальная ячейка – это A1, а максимальная – G7. Эти ссылки будут чрезвычайно полезны для следующих разделов.
Добавление диаграмм в Excel при помощи Python
Чтобы создать диаграмму в Excel на основе созданной нами сводной таблицы, нужно использовать модуль Barchart. Его мы импортировали ранее. Для определения позиций значений данных и категорий мы используем модуль Reference из openpyxl (его мы тоже импортировали в самом начале).
wb = load_workbook('report_2021.xlsx')
sheet = wb['Report']
# barchart
barchart = BarChart()
#locate data and categories
data = Reference(sheet,
min_col=min_column+1,
max_col=max_column,
min_row=min_row,
max_row=max_row) #including headers
categories = Reference(sheet,
min_col=min_column,
max_col=min_column,
min_row=min_row+1,
max_row=max_row) #not including headers
# adding data and categories
barchart.add_data(data, titles_from_data=True)
barchart.set_categories(categories)
#location chart
sheet.add_chart(barchart, "B12")
barchart.title = 'Sales by Product line'
barchart.style = 5 #choose the chart style
wb.save('report_2021.xlsx')
После написания этого кода файл report_2021.xlsx должен выглядеть следующим образом:
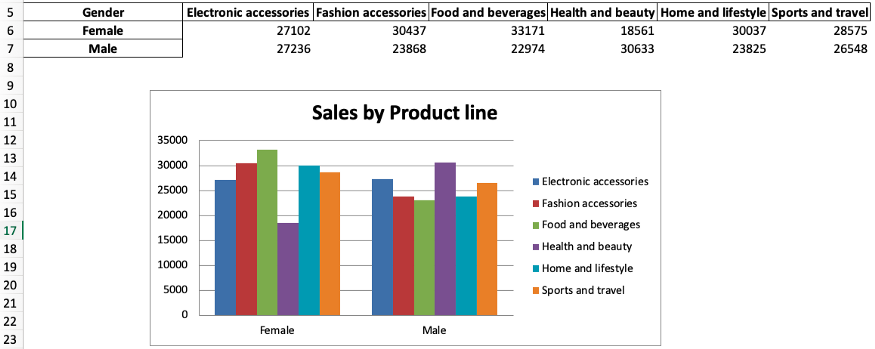
Объяснение кода:
barchart = BarChart()инициализирует переменнуюbarchartиз классаBarchart.dataиcategories– это переменные, которые показывают, где находится необходимая информация. Для автоматизации мы используем ссылки на столбцы и строки, которые определили выше. Также имейте в виду, что мы включаем заголовки в данные, но не в категории.- Мы используем
add_data()иset_categories(), чтобы добавить необходимые данные в гистограмму. Внутриadd_data()добавимtitle_from_data = True, потому что мы включили заголовки для данных. - Метод
sheet.add_chart()используется для указания, что мы хотим добавить нашу гистограмму в лист Report. Также мы указываем, в какую ячейку мы хотим её добавить. - Дальше мы изменяем заголовок и стиль диаграммы, используя
barchart.titleиbarchart.style. - И наконец, сохраняем все изменения с помощью
wb.save()
Вот и всё! С помощью данного кода мы построили диаграмму в Excel.
Вы можете набирать формулы в Excel при помощи Python так же, как вы это делаете непосредственно на листе Excel.
Предположим, мы хотим суммировать данные в ячейках B5 и B6 и отображать их в ячейке B7. Кроме того, мы хотим установить формат ячейки B7 как денежный. Сделать мы это можем следующим образом:
sheet['B7'] = '=SUM(B5:B6)' sheet['B7'].style = 'Currency'
Довольно просто, не правда ли? Мы можем протянуть эту формулу от столбца B до G или использовать цикл for для автоматизации. Однако сначала нам нужно получить алфавит, чтобы ссылаться на столбцы в Excel (A, B, C, …). Для этого воспользуемся библиотекой строк и напишем следующий код:
import string alphabet = list(string.ascii_uppercase) excel_alphabet = alphabet[0:max_column] print(excel_alphabet)
Если мы распечатаем excel_alphabet, мы получим список от A до G.
Так происходит потому, что сначала мы создали алфавитный список от A до Z, а затем взяли срез [0:max_column], чтобы сопоставить длину этого списка с первыми 7 буквами алфавита (A-G).
Примечание. Нумерация в Python начинаются с 0, поэтому A = 0, B = 1, C = 2 и так далее. Срез [a:b] возвращает элементы от a до b-1.
Применение формулы к нескольким ячейкам
После этого пройдемся циклом по столбцам и применим формулу суммы, но теперь со ссылками на столбцы. Таким образом вместо того, чтобы многократно писать это:
sheet['B7'] = '=SUM(B5:B6)' sheet['B7'].style = 'Currency'
мы используем ссылки на столбцы и помещаем их в цикл for:
wb = load_workbook('report_2021.xlsx')
sheet = wb['Report']
# sum in columns B-G
for i in excel_alphabet:
if i!='A':
sheet[f'{i}{max_row+1}'] = f'=SUM({i}{min_row+1}:{i}{max_row})'
sheet[f'{i}{max_row+1}'].style = 'Currency'
# adding total label
sheet[f'{excel_alphabet[0]}{max_row+1}'] = 'Total'
wb.save('report_2021.xlsx')
После запуска кода мы получаем формулу суммы в строке Total для столбцов от B до G:
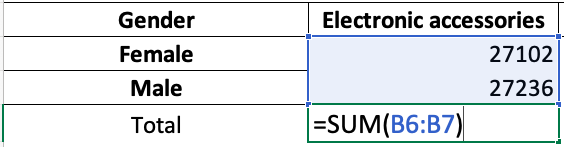
Посмотрим, что делает данный код:
for i in excel_alphabetпроходит по всем активным столбцам, кроме столбца A (if i! = 'A'), так как столбец A не содержит числовых данных- запись
sheet[f'{i}{max_row+1}'] = f'=SUM({i}{min_row+1}:{i}{max_row}'это то же самое, что иsheet['B7'] = '=SUM(B5:B6)', только для столбцов от A до G - строчка
sheet [f '{i} {max_row + 1}'].style = 'Currency'задает денежный формат ячейкам с числовыми данными (т.е. тут мы опять же исключаем столбец А) - мы добавляем запись
Totalв столбец А под максимальной строкой (т.е. под седьмой), используя код[f '{excel_alphabet [0]} {max_row + 1}'] = 'Total'
Форматирование листа с отчетом
Теперь давайте внесем финальные штрихи в наш отчет. Мы можем добавить заголовок, подзаголовок, а также настроить их шрифт.
wb = load_workbook('report_2021.xlsx')
sheet = wb['Report']
sheet['A1'] = 'Sales Report'
sheet['A2'] = '2021'
sheet['A1'].font = Font('Arial', bold=True, size=20)
sheet['A2'].font = Font('Arial', bold=True, size=10)
wb.save('report_2021.xlsx')
Вы также можете добавить другие параметры внутри Font(). В документации openpyxl можно найти список доступных стилей.
Итоговый отчет должен выглядеть следующим образом:
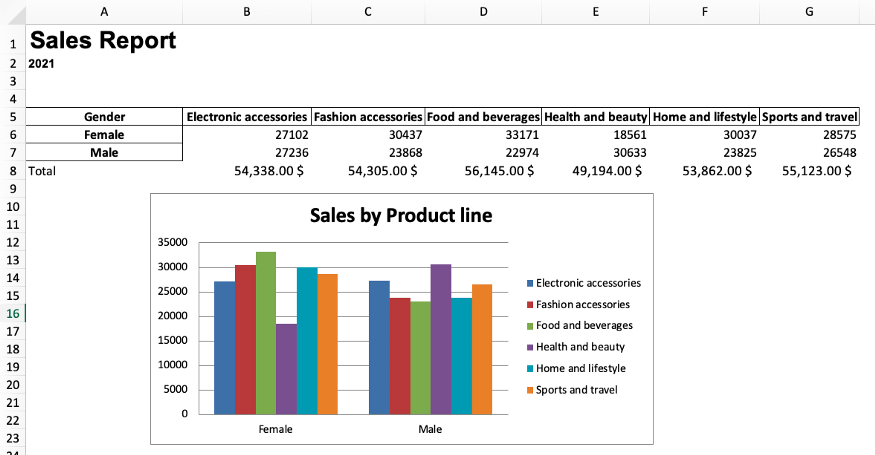
Автоматизация отчета с помощью функции Python
Теперь, когда отчет готов, мы можем поместить весь наш код в функцию, которая автоматизирует создание отчета. И в следующий раз, когда мы захотим создать такой отчет, нам нужно будет только ввести имя файла и запустить код.
Примечание. Чтобы эта функция работала, имя файла должно иметь структуру «sales_month.xlsx». Кроме того, мы добавили несколько строк кода, которые используют месяц/год файла продаж в качестве переменной, чтобы мы могли повторно использовать это в итоговом файле и подзаголовке отчета.
Приведенный ниже код может показаться устрашающим, но это просто объединение всего того, что мы написали выше. Плюс новые переменные file_name, month_name и month_and_extension.
import pandas as pd
import openpyxl
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.chart import BarChart, Reference
import string
def automate_excel(file_name):
"""The file name should have the following structure: sales_month.xlsx"""
# read excel file
excel_file = pd.read_excel(file_name)
# make pivot table
report_table = excel_file.pivot_table(index='Gender', columns='Product line', values='Total', aggfunc='sum').round(0)
# splitting the month and extension from the file name
month_and_extension = file_name.split('_')[1]
# send the report table to excel file
report_table.to_excel(f'report_{month_and_extension}', sheet_name='Report', startrow=4)
# loading workbook and selecting sheet
wb = load_workbook(f'report_{month_and_extension}')
sheet = wb['Report']
# cell references (original spreadsheet)
min_column = wb.active.min_column
max_column = wb.active.max_column
min_row = wb.active.min_row
max_row = wb.active.max_row
# adding a chart
barchart = BarChart()
data = Reference(sheet, min_col=min_column+1, max_col=max_column, min_row=min_row, max_row=max_row) #including headers
categories = Reference(sheet, min_col=min_column, max_col=min_column, min_row=min_row+1, max_row=max_row) #not including headers
barchart.add_data(data, titles_from_data=True)
barchart.set_categories(categories)
sheet.add_chart(barchart, "B12") #location chart
barchart.title = 'Sales by Product line'
barchart.style = 2 #choose the chart style
# applying formulas
# first create alphabet list as references for cells
alphabet = list(string.ascii_uppercase)
excel_alphabet = alphabet[0:max_column] #note: Python lists start on 0 -> A=0, B=1, C=2. #note2 the [a:b] takes b-a elements
# sum in columns B-G
for i in excel_alphabet:
if i!='A':
sheet[f'{i}{max_row+1}'] = f'=SUM({i}{min_row+1}:{i}{max_row})'
sheet[f'{i}{max_row+1}'].style = 'Currency'
sheet[f'{excel_alphabet[0]}{max_row+1}'] = 'Total'
# getting month name
month_name = month_and_extension.split('.')[0]
# formatting the report
sheet['A1'] = 'Sales Report'
sheet['A2'] = month_name.title()
sheet['A1'].font = Font('Arial', bold=True, size=20)
sheet['A2'].font = Font('Arial', bold=True, size=10)
wb.save(f'report_{month_and_extension}')
return
Применение функции к одному файлу Excel
Представим, что исходный файл, который мы загрузили, имеет имя sales_2021.xlsx вместо supermarket_sales.xlsx. Чтобы применить формулу к отчету, пишем следующее:
automate_excel('sales_2021.xlsx')
После запуска этого кода вы получите файл Excel с именем report_2021.xlsx в той же папке, где находится ваш скрипт Python.
Применение функции к нескольким файлам Excel
Представим, что теперь у нас есть только ежемесячные файлы Excel sales_january.xlsx, sales_february.xlsx и sales_march.xlsx (эти файлы можно найти на GitHub).
Вы можете применить нашу функцию к ним всем, чтобы получить 3 отчета.
automate_excel('sales_january.xlsx')
automate_excel('sales_february.xlsx')
automate_excel('sales_march.xlsx')
Или можно сначала объединить эти три отчета с помощью pd.concat(), а затем применить функцию только один раз.
# read excel files
excel_file_1 = pd.read_excel('sales_january.xlsx')
excel_file_2 = pd.read_excel('sales_february.xlsx')
excel_file_3 = pd.read_excel('sales_march.xlsx')
# concatenate files
new_file = pd.concat([excel_file_1,
excel_file_2,
excel_file_3], ignore_index=True)
# export file
new_file.to_excel('sales_2021.xlsx')
# apply function
automate_excel('sales_2021.xlsx')
Заключение
Код на Python, который мы написали в этом руководстве, можно запускать на вашем компьютере по расписанию. Для этого нужно просто использовать планировщик задач или crontab. Вот и все!
В этой статье мы рассмотрели, как автоматизировать создание базового отчета в Excel. В дальнейшем вы сможете создавать и более сложные отчеты. Надеемся, это упростит вашу жизнь. Успехов в написании кода!
Перевод статьи «A Simple Guide to Automate Your Excel Reporting with Python».
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Pivot table is a statistical table that summarizes a substantial table like big datasets. It is part of data processing. This summary in pivot tables may include mean, median, sum, or other statistical terms. Pivot tables are originally associated with MS Excel but we can create a pivot table in Python using Pandas using the dataframe.pivot() method.
Syntax : dataframe.pivot(self, index=None, columns=None, values=None, aggfunc)
Parameters –
index: Column for making new frame’s index.
columns: Column for new frame’s columns.
values: Column(s) for populating new frame’s values.
aggfunc: function, list of functions, dict, default numpy.mean
Example 1:
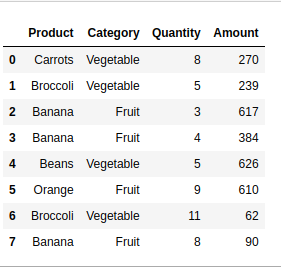
Let’s first create a dataframe that includes Sales of Fruits.
import pandas as pd
df = pd.DataFrame({'Product' : ['Carrots', 'Broccoli', 'Banana', 'Banana',
'Beans', 'Orange', 'Broccoli', 'Banana'],
'Category' : ['Vegetable', 'Vegetable', 'Fruit', 'Fruit',
'Vegetable', 'Fruit', 'Vegetable', 'Fruit'],
'Quantity' : [8, 5, 3, 4, 5, 9, 11, 8],
'Amount' : [270, 239, 617, 384, 626, 610, 62, 90]})
df
Output:
Get the total sales of each product
pivot = df.pivot_table(index =['Product'],
values =['Amount'],
aggfunc ='sum')
print(pivot)
Output: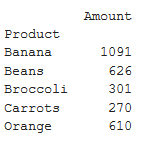
Get the total sales of each category
pivot = df.pivot_table(index =['Category'],
values =['Amount'],
aggfunc ='sum')
print(pivot)
Output: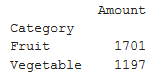
Get the total sales of by category and product both
pivot = df.pivot_table(index =['Product', 'Category'],
values =['Amount'], aggfunc ='sum')
print (pivot)
Output –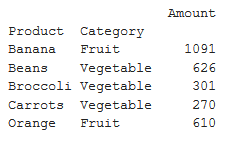
Get the Mean, Median, Minimum sale by category
pivot = df.pivot_table(index =['Category'], values =['Amount'],
aggfunc ={'median', 'mean', 'min'})
print (pivot)
Output –
Get the Mean, Median, Minimum sale by product
pivot = df.pivot_table(index =['Product'], values =['Amount'],
aggfunc ={'median', 'mean', 'min'})
print (pivot)
Output: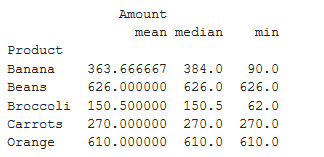
Like Article
Save Article
Время на прочтение
3 мин
Количество просмотров 15K
Привет, Хабр! Меня зовут Панчин Денис, это мой первый пост и я хочу Вам рассказать о работе с сводными таблицами в Pandas. Сводные таблицы хорошо известны всем аналитикам по Excel. Это прекрасный инструмент, который помогает быстро получить различную информацию по массиву данных. Рассмотрим реализацию и тонкости сводных таблиц в Pandas.
Для эксперимента возьмём датасет «Крупные города России: объединенные данные по основным социально-экономическим показателям за 1985-2019 гг.».
Блокнот можно открыть здесь.
Использовать будем только столбцы ‘region’ (субъект РФ), ‘municipality’ (муниципальное образование), ‘year’ (год), ‘birth’ (число родившихся на 1000 человек населения), ‘wage’ (cреднемесячная номинальная начисленная заработная плата, руб.). Сразу оговорюсь, что Москва и Санкт-Петербург являются отдельными субъектами Российской Федерации и в этом датафрейме отсутствуют.
import pandas as pd
import numpy as np
df = pd.read_csv('Krupnie_goroda-RF_1985-2019_187_09.12.21/data.csv', sep=';')
df = df[['region', 'municipality', 'year', 'birth', 'wage']]
df.sample(7)Минимальную статистику можно получить использовав метод describe(include = ‘all’). Мы видим что у нас 4109 строки, по 81 региону и 202 городам. Средняя рождаемость на 1000 человек 11,39, минимальная — 3,4, максимальная — 36,1.
df.describe(include = 'all')Агрегирование
Если объяснять простыми словами, то агрегирование — это процесс приведения некого большого массива значений к некому сжатому по определенному параметру массиву значений. Например, среднее, медиана, количество, сумма.
df[['birth', 'wage']].agg(['mean', 'median', 'min', 'max'])Groupby
Но средняя температура по больнице нам не интересна, мы хотим знать победителей в лицо. Допустим нам нужно посмотреть средние значения с группировкой по городам и субъектам РФ. Для этого закономерно используем метод groupby([‘region’, ‘municipality’]).agg(‘mean’).
df_groupby = df.groupby(['region', 'municipality']).agg('mean')
df_groupby.head(7)Обратите внимание, что колонки region и municipality стали индексами.
На этом мы не успокаиваемся и пытаемся выжать больше стат.данных: среднее, медиану, минимум, максимум.
agg_func_math = {
'birth': ['mean', 'median', 'min', 'max'],
'wage': ['mean', 'median', 'min', 'max']
}
df.groupby(['region', 'municipality']).agg(agg_func_math).head(7)Посмотрим топ городов по зарплатам.
df.groupby(['region', 'municipality']).agg('mean').sort_values(by='wage', ascending=False).head(7)А что если посмотреть данные в разрезе по годам…?
Pivot table
Ответим на этот вопрос чуть позже, а пока создадим сводную таблицу аналогичную той, что мы уже делали ранее.
df_pivot_table = df.pivot_table(index=['region', 'municipality'])
df_pivot_table.head(7)Уже на этом этапе видно, что сводная таблица достаточно умная и сама агрегировала данные и посчитала средние значения.
Но если мы захотим расширить таблицу новыми значениями — медианой, то увидим, что конечный результат по структуре будет отличаться от того, что мы делали при использовании метода groupby.
df_pivot_table = df.pivot_table(index=['region', 'municipality'],
values=['birth', 'wage'],
aggfunc=[np.mean, np.median])
df_pivot_table.head(7)Так мы плавно подошли к тем преимуществам, которые делает сводные таблицы швейцарским ножом для аналитиков. Если используя groupby мы «укрупняли» строки по городам, то сейчас мы можем «развернуть» столбец, например, ‘year’ (год) и посмотреть данные в разрезе по годам.
df_pivot_table = df.pivot_table(index=['region', 'municipality'],
values='birth',
columns='year')
df_pivot_table.head(7)И, конечно, данные в сводной таблице можно фильтровать. Создадим сводную таблицу и оставим в ней данные по городам, в которых рождаемость на 1000 человек превышает 12, зарплата выше 40.000 и отсортируем всё по убыванию рождаемости.
df2 = df.pivot_table(index=['region', 'municipality'])
df2.query("`birth`>12 and `wage`>40000").sort_values(by='birth', ascending=False)Pivot
Всё было замечательно, но в Pandas кроме pivot_table есть ещё просто pivot. Посмотрим что это за зверь и чем они отличаются.
Создадим pivot: рождаемость в разрезе по регионам и годам.
df_pivot = df.pivot(index='region',
values='birth',
columns='year')
df_pivot.head(7)Мы получили ошибку «Index contains duplicate entries, cannot reshape«. Что-то не так с индексами, попробуем создать pivot с индексами по городам, а не регионам.
df_pivot = df.pivot(index='municipality',
values='birth',
columns='year')
df_pivot.head(7)Всё получилось. Как мы уже заметили всё дело в индексах. На самом деле всё в повторяющихся индексах. Как мы видели ранее в датафрейме есть позиции с несколькими городами в рамках одного субъекта, так получаются дублированные данные индексов с которыми не умеет работать pivot.
Вывод
Groupby, pivot и pivot_table удобные и привычные инструменты для работы с данными. Groupby позволяет кодом в одну строку получить агрегированные и сортированные данные, а pivot и pivot_table работать в более глубоком разрезе. Pivot_table предпочтителен, т.к. не ограничивает вас в уникальности значений в столбце индекса. И, конечно, все эти данные можно фильтровать под ваши запросы.
Pivot tables continue to be among the most revered and widely used tools within MS Excel. Whether you’re a data analyst, data engineer, or simply a regular user, chances are you already have a soft spot for MS Excel.
Nonetheless, there is an increasing scope for replicating MS Excel’s tools and utilities, especially in Python. Did you know you can create extensive pivot tables in Python’s DataFrames with a few lines of code itself?
Yes, that’s correct; if you are intrigued, here’s how you can do it.
Pre-Requisites for Creating Pivot Tables
Like any other programming language, even Python needs you to fulfill a few pre-requisites before you can get to coding.
To get the most optimized experience while creating your very first pivot table in Python, here’s what you will need:
- Python IDE: Most Python codes have an integrated development environment (IDE) pre-installed on their system. There are several Python compatible IDEs in the market, including Jupyter Notebook, Spyder, PyCharm, and many others.
- Sample Data: For illustration, here’s a sample dataset for you to work on. Alternatively, feel free to tweak these codes directly on your live data.
Data sample link: Sample Superstore
Importing the Essential Libraries
Since Python works on the concept of third-party libraries, you need to import the Pandas library for creating pivots.
You can use Pandas to import an Excel file into Python and store the data in a DataFrame. To import Pandas, use the import command in the following manner:
import pandas as pd
How to Create Pivots in Python
Since the library is now available, you need to import the Excel file into Python, which is the base for creating and testing pivots in Python. Store the imported data in a DataFrame with the following code:
# Create a new DataFrame# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.head()
Where:
- df: Variable name to store the DataFrame data
- pd: Alias for Pandas library
- read_excel(): Pandas function to read an Excel file into Python
- path: The location where the Excel file is stored (Sample Superstore)
- file: File name to import
- head(): Displays the first five rows of the DataFrame, by default
The above code imports the Excel file into Python and stores the data in a DataFrame. Finally, the head function displays the first five rows of data.
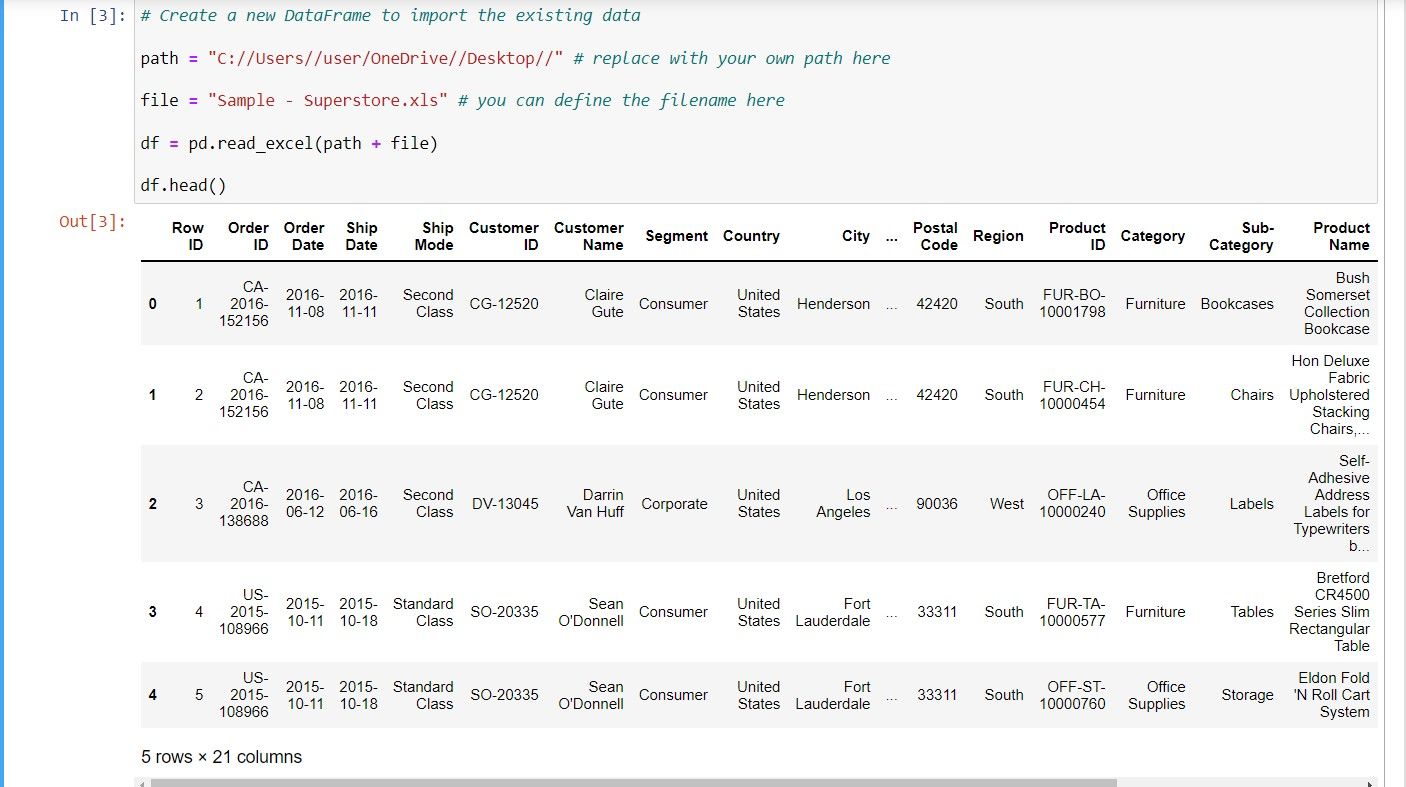
This function is handy to ensure the data is imported correctly into Python.
Which Pivot Table Fields Exist in Python?
Like its Excel counterpart, a pivot table has a similar set of fields in Python. Here are a few fields you need to know about:
- Data: The data field refers to the data stored within a Python DataFrame
- Values: Columnar data used within a pivot
- Index: An index column(s) for grouping the data
- Columns: Columns help in aggregating the existing data within a DataFrame
Purpose Behind Using the Index Function
Since the index function is the primary element of a pivot table, it returns the data’s basic layout. In other words, you can group your data with the index function.
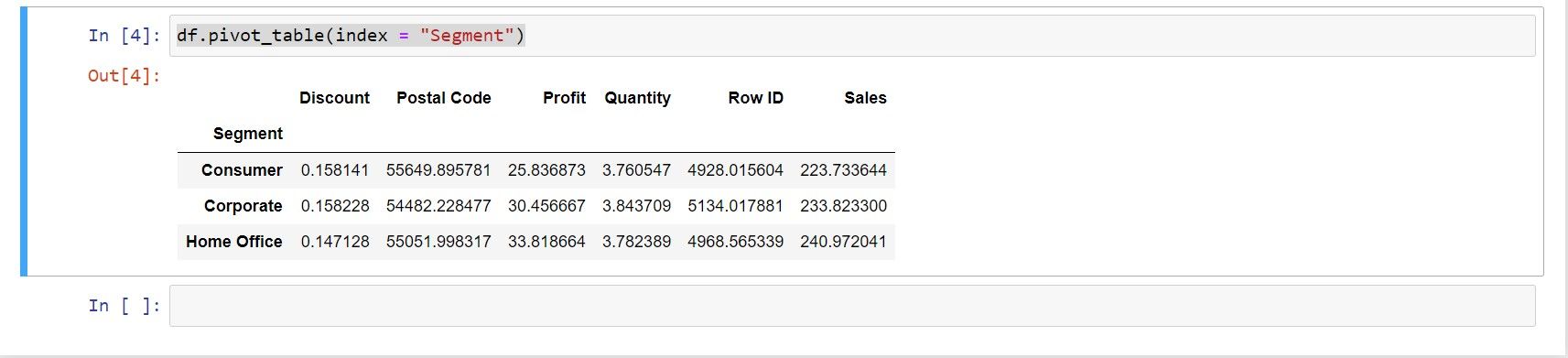
Suppose you want to see some aggregated values for the products listed within the Segment column. You can calculate a pre-defined aggregate (mean value) in Python by defining the designated column as an index value.
df.pivot_table(index = "Segment")
Where:
- df: DataFrame containing the data
- pivot_table: Pivot table function in Python
- index: In-built function for defining a column as an index
- Segment: Column to use as an index value
Python’s variable names are case-sensitive, so avoid transitioning away from the pre-defined variable names listed in this guide.
How to Use Multi-Index Values
When you want to use multiple index columns, you can define the column names in a list within the index function. All you have to do is specify the column names within a set of square brackets ([ ]), as shown below:
df.pivot_table(index = ["Category", "Sub-Category"])
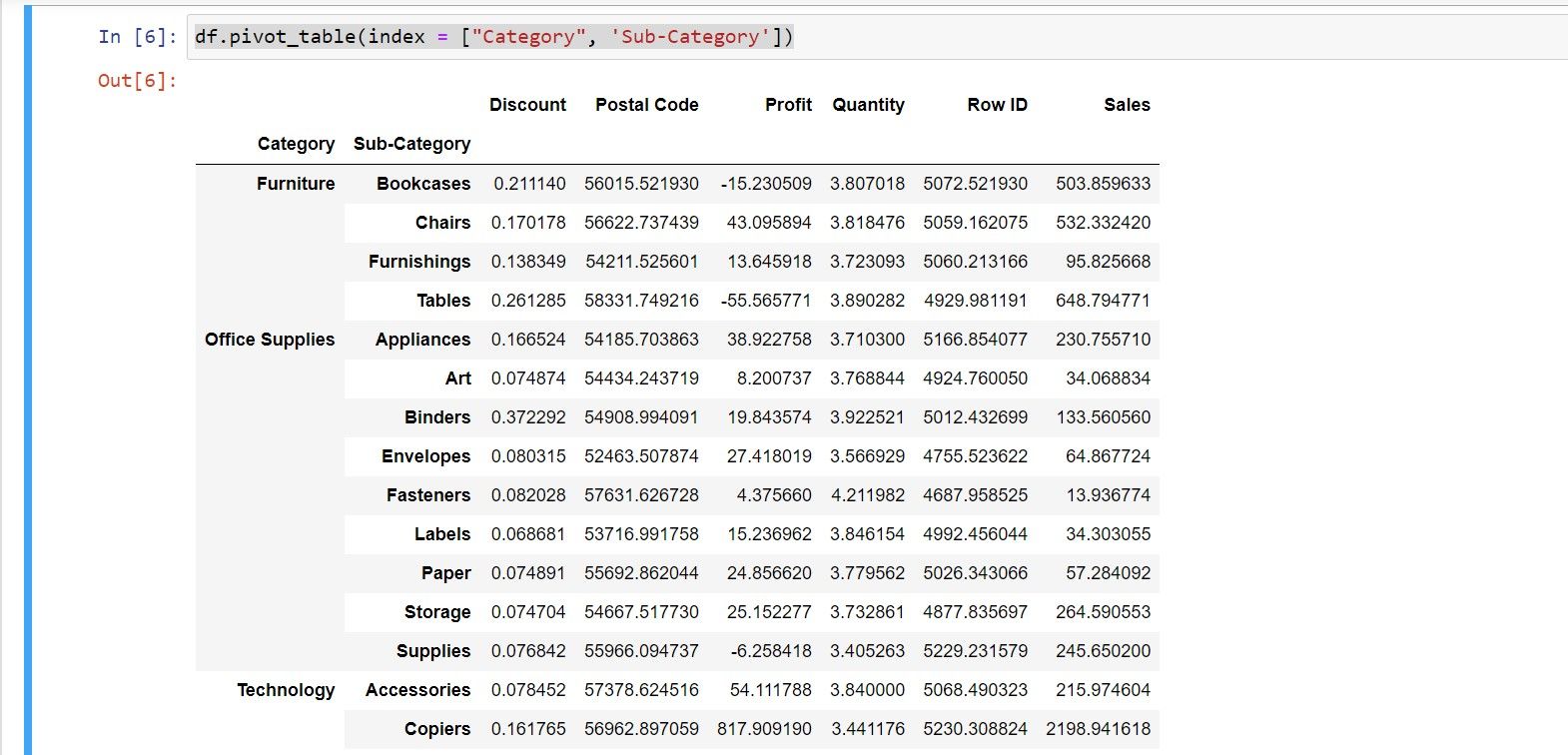
The pivot function indents the index column in the output. Python displays the mean of all the numerical values against each index value.
Learn to Restrict the Values in the Output
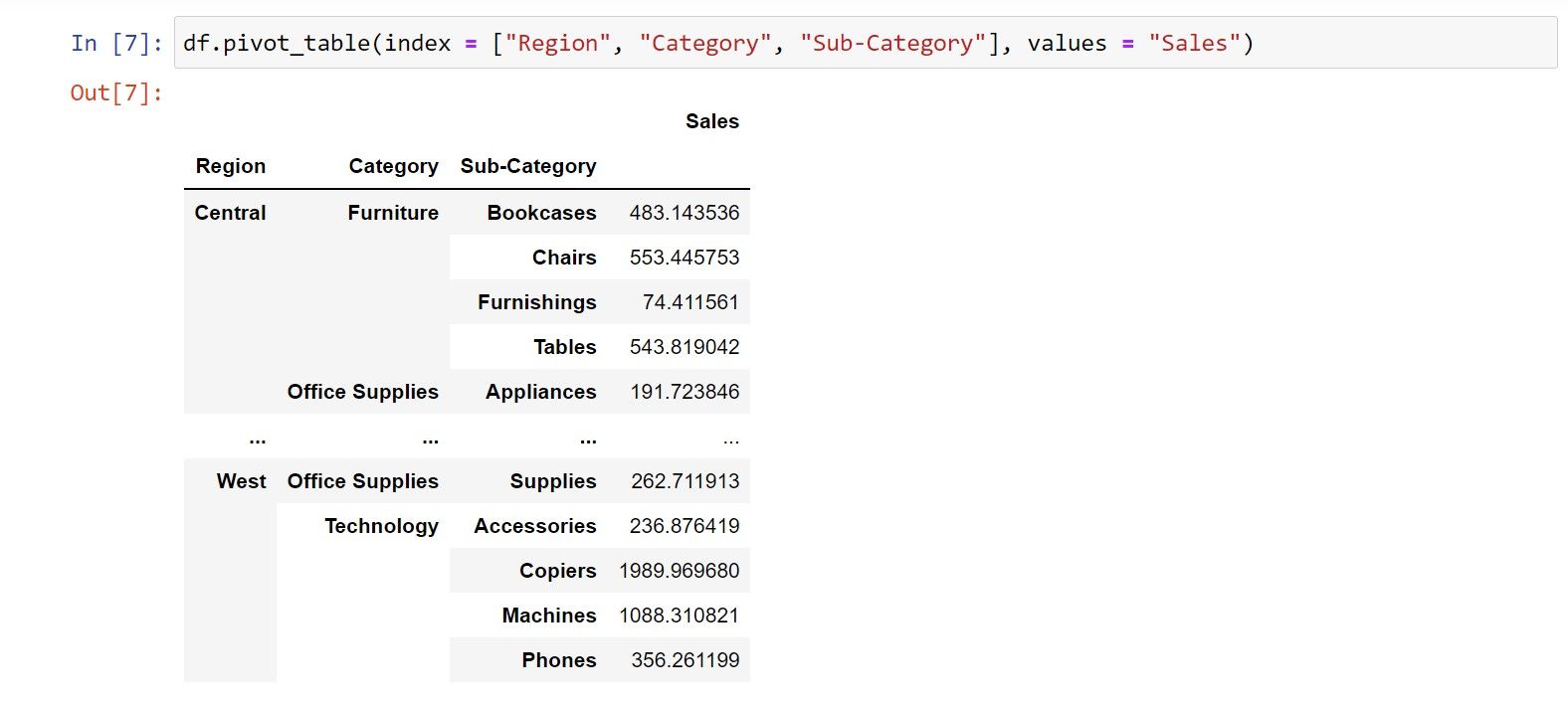
Since Python picks all the numerical columns by default, you can restrict the values to tweak the results shown in the final output. Use the values function to define the columns you wish to see.
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales")
In the final output, there will be three index columns, and the mean values for the Sales column pitted against each element.
Defining Aggregate Functions in Pivot Table
What happens when you don’t want to calculate the mean values by default? The pivot table has a lot of other functionalities, which extend beyond calculating a simple mean.
Here’s how to write the code:
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len])
Where:
- sum: Calculates the sum of values
- max: Calculates the maximum value
- min: Calculates the maximum value
- len: Calculates the count of values
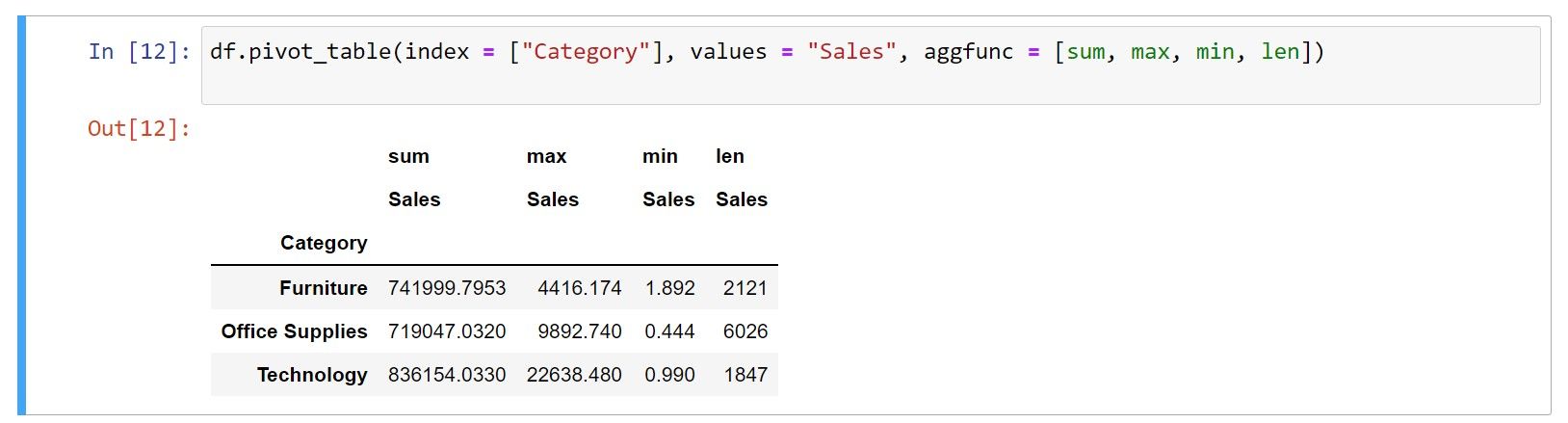
You can also define each of these functions in separate lines of code.
How to Add Grand Totals to the Pivot Table
No data asset is complete without the grand totals. To calculate and display the grand totals per data column, use the margins and margins_name function.
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len], margins=True, margins_name='Grand Totals')
Where:
- margins: Function for calculating the grand total
- margins_name: Specify the name of the category in the index column (for example, Grand Totals)
Modify and Use the Final Code
Here’s the final code brief:
import pandas as pd# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales",
aggfunc = [sum, max, min, len],
margins=True,
margins_name='Grand Totals')
Creating Pivot Tables in Python
When you are using Pivot tables, the options are simply endless. Python lets you easily handle vast data arrays without worrying about data discrepancies and system lags.
Since Python’s functionalities are not restricted to just condensing data into pivots, you can combine multiple Excel workbooks and sheets, while performing a series of related functions with Python.
With Python, there is something new on the horizon always.