
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает двустороннее обратное t-распределения Стьюдента.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция СТЬЮДЕНТ.ОБР.2Х и Функция СТЬЮДЕНТ.ОБР.
Синтаксис
СТЬЮДРАСПОБР(вероятность;степени_свободы)
Аргументы функции СТЬЮДРАСПОБР описаны ниже.
-
Вероятность Обязательный. Вероятность, соответствующая двустороннему распределению Стьюдента.
-
Степени_свободы Обязательный. Число степеней свободы, характеризующее распределение.
Замечания
-
Если любой из аргументов не является числом, то СТИФР.#VALUE! значение ошибки #ЗНАЧ!.
-
Если вероятность <= 0 или вероятность > 1, то #NUM! значение ошибки #ЗНАЧ!.
-
Если значение «степени_свободы» не является целым, оно усекается.
-
Если deg_freedom < 1, то #NUM! значение ошибки #ЗНАЧ!.
-
Функция СТЬЮДРАСПОБР возвращает значение t, для которого P(|X| > t) = вероятность, где X — случайная величина, соответствующая t-распределению, и P(|X| > t) = P(X < -t или X > t).
-
Одностороннее t-значение может быть получено при замене аргумента «вероятность» на 2*вероятность. Для вероятности 0,05 и 10 степеней свободы двустороннее значение вычисляется по формуле СТЬЮДРАСПОБР(0,05;10) и равно 2,28139. Одностороннее значение для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10), возвращающей значение 1,812462.
Примечание: В некоторых таблицах вероятность описана как (1-p).
Если задано значение вероятности, то функция СТЬЮДРАСПОБР ищет значение x, для которого функция СТЬЮДРАСП(x, степени_свободы, 2) = вероятность. Однако точность функции СТЬЮДРАСПОБР зависит от точности СТЬЮДРАСП. В функции СТЬЮДРАСПОБР для поиска применяется метод итераций. Если поиск не закончился после 100 итераций, функция возвращает значение ошибки #Н/Д.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
Описание |
|
|
0,05464 |
Вероятность, соответствующая двустороннему распределению Стьюдента. |
|
|
60 |
Степени свободы |
|
|
Формула |
Описание |
Результат |
|
=СТЬЮДРАСПОБР(A2;A3) |
T-значение t-распределения Стьюдента на основе аргументов в ячейках A2 и A3. |
1,96 |
Нужна дополнительная помощь?
Функция СТЮДРАСПОБР предназначена для расчета значения квантиля уровня, соответствующего известной вероятности (указывается в качестве первого аргумента), распределения Стьюдента для известных степеней свободы и возвращает обратное t-распределение.
Распределение Стьюдента и нормальное распределение в Excel
Рассматриваемая функция возвращает значение t, соответствующее условию P(|x|>t)=p. Здесь x является значением некоторой случайной величины с распределением Стьюдента, у которого число степеней свобод соответствует k (второй аргумент функции СТЮДРАСПОБР).
Примечания:
- Распределение Стьюдента является одним из видов распределения случайной величины, близкое к нормальному распределению с характерным отличием – сниженная концентрацией отклонений в средней части распределения. Иное название – t-распределение.
- Квантилем считается некоторое значение, которое с определенной вероятностью (фиксированной) не будет превышено случайной величиной.
- Функция СТЮДРАСПОБР считается устаревшей начиная с версии MS Office 2010. Она оставлена для обеспечения совместимости с другими табличными редакторами и документами, созданными в более старых версиях табличного редактора. В новых версиях следует использовать усовершенствованные аналоги: СТЬЮДЕНТ.ОБР.2Х или СТЬЮДЕНТ.ОБР.
Подробнее о нормальном распределении читайте: НОРМСТРАСП функция стандартного нормального распределения в Excel.
Ниже рассмотрим примеры использования функции СТЮДРАСПОБР в Excel.
Определение одностороннего и двустороннего t распределение Стьюдента
Пример 1. Определить односторонне и двустороннее t-значения для распределения Стьюдента, характеризующееся вероятностью 0,17 и числом степени свобод 16.
Вид таблицы данных:
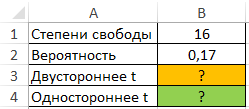
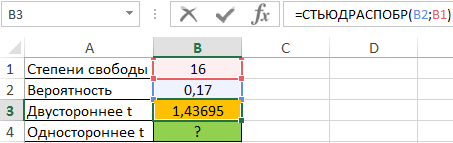
Для расчета двустороннего t-значения используем функцию:
=СТЬЮДРАСПОБР(B2;B1)
Результат вычислений:
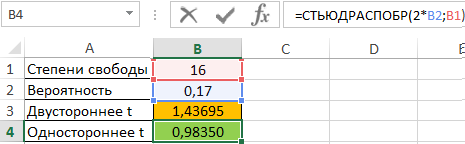
Для двустороннего t используем удвоенное значение вероятности:
=СТЬЮДРАСПОБР(2*B2;B1)
В результате получим:
Число степеней свободы в распределении Стьюдента
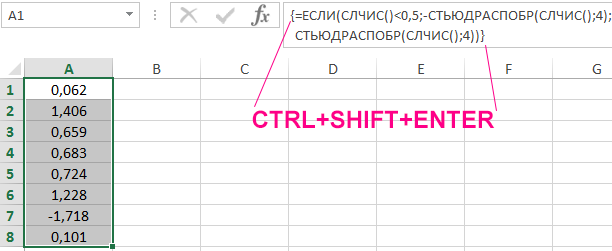
Пример 2. Сгенерировать 8 случайных чисел с использованием функции СЛЧИС, для которых распределение Стьюдента имеет 4 степени свободы.
Поскольку вероятность того, что случайна величина примет как отрицательное, так и положительное значение является одинаковой и равна 0,5 (распределение Стьюдента симметрично относительно вертикальной оси графика), используем функцию ЕСЛИ для проверки значений.
Выделим 8 ячеек и запишем следующую функцию (вводить как формулу массива CTRL+SHIFT+Enter):
То есть, если случайное значение вероятности, сгенерированное функцией СЛЧИС меньше 0,5, будет сгенерировано отрицательное t-значение, иначе – положительное.
Результат вычислений:
Как пользоваться функцией распределения Стьюдента СТЮДРАСПОБР В EXCEL
Функция имеет следующий синтаксис:
=СТЬЮДРАСПОБР(вероятность;степени_свободы)
Описание аргументов:
- вероятность – обязательный для заполнения, принимает числовое значение вероятности для двустороннего распределения Стьюдента из диапазона от 0 (не включительно) до 1.
- степени_свободы – обязательный для заполнения, принимает числовое значение степеней свободы, которые определяют исследуемое распределение.
Примечания:
- Если один из аргументов функции указан в виде значения нечислового типа данных, результатом выполнения рассматриваемой функции будет код ошибки #ЗНАЧ!. Логические значения, имена и текстовые строки, преобразуемые в числа, не приводят к возникновению ошибки. Например, функция =СТЮДРАСПОБР(“0,4”;ИСТИНА) вернет значение 1,32638.
- Если аргумент вероятность задан числом, не находящимся в промежутке от 0 (не включительно) до 1, функция СТЮДРАСПОБР вернет код ошибки #ЧИСЛО!. Аналогичная ошибка возникает, если аргумент степени_свободы задан числом, которое меньше 1.
- Для расчета односторонней t-величины следует в качестве аргумента вероятность указать значение удвоенной вероятности.
Описание:Возвращает t-значение распределения
Стьюдента как функцию вероятности и
числа степеней свободы.
Синтаксис:
СТЬЮДРАСПОБР(вероятность;степени_свободы)
Вероятность— вероятность, соответствующая
двустороннему распределению Стьюдента.
Степени_свободы— число степеней свободы, характеризующее
распределение.
Замечания:
—
Если любой из аргументов не является
числом, то функция СТЬЮДРАСПОБР возвращает
значение ошибки #ЗНАЧ!.
—
Если вероятность < 0 или
вероятность > 1, то функция
СТЬЮДРАСПОБР возвращает значение ошибки
#ЧИСЛО!.
—
Если значение аргумента «степени_свободы»
не является целым числом, оно усекается.
—
Если степени_свободы < 1, то функция
СТЬЮДРАСПОБР возвращает значение ошибки
#ЧИСЛО!.
—
Функция СТЬЮДРАСПОБР возвращает значение
t, для которого P(|X| > t) = вероятность,
где X — случайная величина, соответствующая
t-распределению, и P(|X| > t) = P(X < -t или X
> t).
—
Одностороннее t-значение может быть
получено при замене аргумента «вероятность»
на 2*вероятность. Для вероятности 0,05 и
10 степеней свободы двустороннее значение
вычисляется по формуле СТЬЮДРАСПОБР(0,05;10)
и равно 2,28139. Одностороннее значение
для той же вероятности и числа степеней
свободы может быть вычислено по формуле
СТЬЮДРАСПОБР(2*0,05;10), возвращающей
значение 1,812462.
ПРИМЕЧАНИЕ. В некоторых таблицах вероятность описана
как (1-p).
Если
задано значение вероятности, то функция
СТЬЮДРАСПОБР ищет значение x, для которого
функция СТЬЮДРАСП(x, степени_свободы,
2) = вероятность. Однако точность функции
СТЬЮДРАСПОБР зависит от точности
СТЬЮДРАСП. В функции СТЬЮДРАСПОБР для
поиска применяется метод итераций. Если
поиск не закончился после 100 итераций,
функция возвращает значение ошибки
#Н/Д.
75. Функция тенденция
Описание:Возвращает значения в соответствии с
линейным трендом. Аппроксимирует прямой
линией (по методу наименьших квадратов)
массивы «известные_значения_y» и
«известные_значения_x». Возвращает
значения y, соответствующие этой прямой
для заданного массива «новые_значения_x».
Синтаксис:
ТЕНДЕНЦИЯ(известные_значения_y;известные_значения_x;новые_значения_x;конст)
Известные_значения_y— множество значений y, которые уже
известны для соотношения y = mx + b.
—
Если массив «известные_значения_y» имеет
один столбец, то каждый столбец массива
«известные_значения_x» интерпретируется
как отдельная переменная.
—
Если массив «известные_значения_y» имеет
одну строку, то каждая строка массива
«известные_значения_x» интерпретируется
как отдельная переменная.
Известные_значения_x— необязательное множество значений
x, которые уже известны для соотношения
y = mx + b.
—
Массив «известные_значения_x» может
содержать одно или несколько множеств
переменных. Если используется только
одна переменная, то аргументы
«известные_значения_y» и «известные_значения_x»
могут быть диапазонами любой формы при
условии, что они имеют одинаковую
размерность. Если используется более
одной переменной, то аргумент
«известные_значения_y» должен быть
вектором (то есть диапазоном высотой в
одну строку или шириной в один столбец).
—
Если аргумент «известные_значения_x»
опущен, то предполагается, что это массив
{1;2;3;…} того же размера, что и массив
«известные_значения_y».
Новые_значения_x— новые значения x, для которых функция
ТЕНДЕНЦИЯ возвращает соответствующие
значения y.
—
Аргумент «новые_значения_x», так же как
и аргумент «известные_значения_x», должен
содержать по одному столбцу (или строке)
для каждой независимой переменной.
Таким образом, если «известные_значения_y»
— это один столбец, то «известные_значения_x»
и «новые_значения_x» должны иметь
одинаковое количество столбцов. Если
«известные_значения_y» — это одна строка,
то аргументы «известные_значения_x» и
«новые_значения_x» должны иметь одинаковое
количество строк.
—
Если аргумент «новые_значения_x» опущен,
то предполагается, что он совпадает с
аргументом «известные_значения_x».
—
Если опущены оба аргумента —
«известные_значения_x» и «новые_значения_x»,
— то предполагается, что это массивы
{1;2;3;…} того же размера, что и
«известные_значения_y».
Конст— логическое значение, которое указывает,
требуется ли, чтобы константа b была
равна 0.
—
Если аргумент «конст» имеет значение
ИСТИНА или опущен, то b вычисляется
обычным образом.
—
Если аргумент «конст» имеет значение
ЛОЖЬ, то b полагается равным 0 и значения
m подбираются таким образом, чтобы
выполнялось условие y = mx.
Соседние файлы в папке Лабораторная работа_1
- #
- #
- #
Рассмотрим Распределение Стьюдента (t-распределение). С помощью функции MS EXCEL
СТЬЮДЕНТ.РАСП()
построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение Стьюдента
(также называется
t
-распределением
) применяется в различных методах математической статистики:
-
при построении
доверительных интервалов для среднего
(используется функция
ДОВЕРИТ.СТЬЮДЕНТ()
); -
для
оценки различия двух выборочных средних
(используется функция
СТЬЮДЕНТ.ТЕСТ()
); -
при
проверке гипотез (выборка небольшого размера, стандартное отклонение не известно)
,
- в линейном регрессионном анализе (при проверке гипотез на значимость отдельных регрессионных коэффициентов).
Определение
: Если случайная величина Z распределена по
стандартному нормальному закону
N(0;1) и случайная величина U имеет
распределение ХИ-квадрат
с ν степенями свободы, то случайная величина T=Z/√(U/v) имеет
t-распределение
.
Плотность распределения
Стьюдента
выражается формулой:
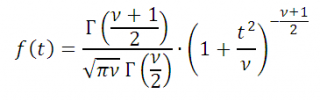
при −∞ < t < ∞
СОВЕТ
: Подробнее о
Функции распределения
и
Плотности вероятности
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Распределение
Стьюдента
(англ.
Student
’
s
t
—
distribution
)
зависит от одного параметра, который называется
степенью свободы
(
df
,
degrees
of
freedom
). Например, при
построении доверительного интервала для среднего
число степеней свободы
равно df=n-1, где n – размер
выборки
. При увеличении
числа степеней свободы
это распределение стремится к
стандартному нормальному распределению
.
В центральной части распределения (около 0) при df=25, относительная разница со
стандартным нормальным распределением
составляет порядка 1%, а при df=100 разница составляет 0,25%.
По аналогии со
стандартным нормальным распределением
,
t
-распределение
часто называется «стандартизированным», т.к. у него нет параметра отвечающего за положение (
среднее
всегда равно 0).
Дисперсию
t
-распределения
можно вычислить по формуле =df/(df-2)
Графики функций
В
файле примера на листе График
приведены
графики плотности распределения
вероятности и
интегральной функции распределения
.
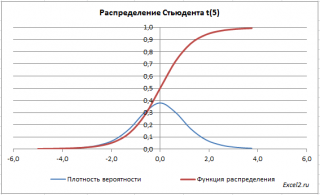
График
плотности распределения Стьюдента
, как и
стандартного
нормального распределения
, является симметричным и колоколообразным, но с более тяжелыми хвостами.
Ниже для сравнения приведены графики
плотности стандартного нормального распределения
и
распределения Стьюдента.
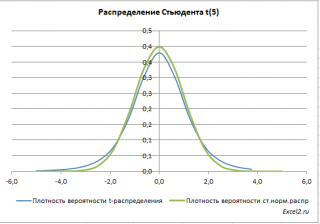
Примечание
: Для построения
функции распределения
и
плотности вероятности
можно использовать диаграмму типа
График
или
Точечная
(со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью
Основные типы диаграмм
.
t-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для
t-распределения
имеется функция
СТЬЮДЕНТ.РАСП()
, английское название — T.DIST(), которая позволяет вычислить
плотность вероятности
(см. формулу выше) и
интегральную функцию распределения
(вероятность, что случайная величина Х, имеющая
распределение Стьюдента
, примет значение меньше или равное х, P(X <= x)).
Примечание
: В
файле примера на листе Функции
приведены основные функции MS EXCEL, связанные с этим распределением.
Кроме этой функции в MS EXCEL имеется еще довольно много других функций, относящихся к данному распределению, но по большому счету их функционал покрывается функцией
СТЬЮДЕНТ.РАСП()
.
Кроме того,
СТЬЮДЕНТ.РАСП()
является единственной функцией, которая возвращает
плотность вероятности
(третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают
интегральную функцию распределения
, т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P(X <= x), P(X > x) или даже P(|X| > x).
Очевидно, что справедливо равенство
=СТЬЮДЕНТ.РАСП.ПХ(x;n)+СТЬЮДЕНТ.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P(X > x), а второе P(X <= x).
До MS EXCEL 2010 в EXCEL была только функция
СТЬЮДРАСП()
, которая позволяет вычислить
функцию распределения
(точнее — правостороннюю вероятность, т.е. P(X>x)) и объединяет возможности нескольких новых функций MS EXCEL 2010:
СТЬЮДЕНТ.РАСП(x; n; ЛОЖЬ)
,
СТЬЮДЕНТ.РАСП.ПХ()
,
СТЬЮДЕНТ.РАСП.2Х()
. Функция
СТЬЮДРАСП()
оставлена в MS EXCEL 2010 для совместимости.
-
Если значение аргумента «хвосты» = 1, функция
СТЬЮДРАСП()
вычисляет правостороннюю вероятность P(X > x), где X — случайная переменная, соответствующая t-распределению. Под термином «хвост» подразумевается «хвост» распределения, в данном случае правый. На графике
плотности вероятности
этому «хвосту» будет соответствовать площадь фигуры под графиком (выделена синим), которая ограничена слева вертикальной линией X = x.
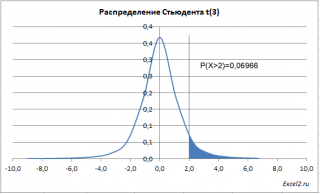
-
Если значение аргумента «хвосты» = 2, функция
СТЬЮДРАСП()
вычисляет вероятность P(|X| > x) или другими словами P(X > x или X < -x). Т.е. формула
=СТЬЮДРАСП(x;n;2)
эквивалентна
=СТЬЮДРАСП(x;n;1)*2
-
Функцией
СТЬЮДРАСП()
значения x < 0 не поддерживаются и нельзя записать
СТЬЮДРАСП(-x;n;1)
. Чтобы вычислить вероятность P(X <= x), в том числе и для отрицательных х, используйте формулу
=ЕСЛИ(x>0;СТЬЮДРАСП(x;n;1);1-СТЬЮДРАСП(-x;n;1))
.
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного
x
: P(X <=
x
). Это можно сделать несколькими функциями:
=СТЬЮДЕНТ.РАСП(x; n; ИСТИНА)
или
=1-СТЬЮДЕНТ.РАСП(-x; n; ИСТИНА)
, используется свойство симметричности плотности распределения относительно оси Х.
=1-СТЬЮДЕНТ.РАСП.ПХ(x;n)
или
=СТЬЮДЕНТ.РАСП.ПХ(-x;n)
, функция
СТЬЮДЕНТ.РАСП.ПХ()
возвращает вероятность P(X > x), так называемую правостороннюю вероятность, поэтому, чтобы найти P(X <= x), необходимо вычесть ее результат от 1 или воспользоваться свойством t-распределения t(-х)=1-t(x).
=1-СТЬЮДЕНТ.РАСП.2Х(x;n)/2
или
=1-СТЬЮДРАСП(x;n;2)/2
, в этой формуле
х
может принимать только положительные значения (подробнее об этой функции см. ниже);
=1-СТЬЮДРАСП(x; n; 1)
, в этой формуле
х
может принимать только положительные значения, функция
СТЬЮДРАСП()
, как и
СТЬЮДЕНТ.РАСП.ПХ()
, возвращает «правостороннюю вероятность», т.е. P(X > x).
Аналогичные вычисления для P(X > x) и P(|X| > x) приведены в
файле примера на листе Функции
, в том числе и для x<0.
Обратная функция t-распределения
Обратная функция используется для вычисления
альфа
—
квантилей
, т.е. для вычисления значений
x
при заданной вероятности
альфа
, причем
х
должен удовлетворять выражению P{X<=x}=
альфа
.
Функция
СТЬЮДЕНТ.ОБР()
используется для вычисления как двухсторонних, так и
односторонних доверительных интервалов
. А функции
СТЬЮДЕНТ.ОБР.2Х()
и
СТЬЮДРАСПОБР()
созданы специально для вычисления
квантилей
, необходимых для расчета двусторонних
доверительных интервалов:
в качестве аргумента нужно указывать
уровень значимости
альфа
, а не
альфа/2
, как для
СТЬЮДЕНТ.ОБР()
.
Вышеуказанные функции можно взаимозаменять, т.к. нижеуказанные формулы возвращают одинаковый результат:
=СТЬЮДЕНТ.ОБР(альфа;n) =-СТЬЮДРАСПОБР(альфа*2;n) =-СТЬЮДЕНТ.ОБР.2Х(альфа*2;n)
Некоторые примеры расчетов приведены в
файле примера на листе Функции
.
Примечание
: Ниже приведено соответствие русских и английских названий функций:
СТЬЮДЕНТ.РАСП.ПХ()
— англ. название T.DIST.RT, т.е. T-DISTribution Right Tail, the right-tailed Student’s t-distribution
СТЬЮДЕНТ.РАСП.2Х()
— англ. название T.DIST.2T, т.е. T-DISTribution 2 Tails
СТЬЮДЕНТ.ОБР()
— англ. название T.INV, т.е. T-distribution INVerse
СТЬЮДРАСП()
— англ. название TDIST, т.е. T-DISTribution
СТЬЮДРАСПОБР()
— англ. название TINV, т.е. T-distribution INVerse (the right-tailed inverse of the Student’s t-distribution)
СТЬЮДЕНТ.ОБР.2Х()
— англ. название T.INV.2T
Функции MS EXCEL, использующие t-распределение
Как было сказано выше, при
построении доверительных интервалов
используется функция
ДОВЕРИТ.СТЬЮДЕНТ()
— англ. название CONFIDENCE.T.
Например, формула
=ДОВЕРИТ.СТЬЮДЕНТ(альфа;СТАНДОТКЛОН.В(B20:B79); СЧЁТ(B20:B79))
эквивалентна классической формуле для вычисления доверительного интервала
=СТЬЮДЕНТ.ОБР(1-альфа/2; СЧЁТ(B20:B79)-1)* СТАНДОТКЛОН.В(B20:B79)/КОРЕНЬ(СЧЁТ(B20:B79))
где предполагается, что
выборка
находится в диапазоне
B20:B79
.
Как видим, особых преимуществ в использовании
ДОВЕРИТ.СТЬЮДЕНТ()
нет.
Другая функция —
СТЬЮДЕНТ.ТЕСТ()
— англ. название T.TEST, используется для
оценки различия двух выборочных средних
.
Оценка параметров распределения
Т.к. обычно
t-распределение
используется для целей математической статистики (вычисление
доверительных интервалов,
проверки гипотез и др.),
и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Рассматриваемая функция возвращает значение t, соответствующее условию P(|x|>t)=p. Здесь x является значением некоторой случайной величины с распределением Стьюдента, у которого число степеней свобод соответствует k (второй аргумент функции СТЮДРАСПОБР).
Пример 1. Определить односторонне и двустороннее t-значения для распределения Стьюдента, характеризующееся вероятностью 0,17 и числом степени свобод 16.
Теперь перейдем непосредственно к вопросу, как рассчитать данный показатель в Экселе. Его можно произвести через функцию СТЬЮДЕНТ.ТЕСТ. В версиях Excel 2007 года и ранее она называлась ТТЕСТ. Впрочем, она была оставлена и в позднейших версиях в целях совместимости, но в них все-таки рекомендуется использовать более современную — СТЬЮДЕНТ.ТЕСТ. Данную функцию можно использовать тремя способами, о которых подробно пойдет речь ниже.
Проще всего производить вычисления данного показателя через Мастер функций.
Выполняется расчет, а результат выводится на экран в заранее выделенную ячейку.
Функцию СТЬЮДЕНТ.ТЕСТ можно вызвать также путем перехода во вкладку «Формулы» с помощью специальной кнопки на ленте.
Этапы статистического вывода (statistic inference)
- Первый из них – это вопрос, который мы хотим изучить с помощью статистических методов. То есть первый этап: что изучаем? И какие у нас есть предположения относительно результата? Этот этап называется этап статистических гипотез.
- Второй этап – нужно определиться с тем, какие у нас есть в реальности данные для того, чтобы ответить на первый вопрос. Этот этап – тип данных.
- Третий этап состоит в том, чтобы выбрать корректный для применения в данной ситуации статистический критерий.
- Четвертый этап это логичный этап применения интерпретации любой формулы, какие результаты мы получили.
- Пятый этап это создание, синтез выводов относительно первого, второго, третьего, четвертого, пятого этапа, то есть что же получили и что же это в реальности значит.
Пример использования т-критерия Стьюдента
А пример будет достаточно простой: мне интересно, стали ли люди выше за последние 100 лет. Для этого нужно подобрать некоторые данные. Я обнаружил интересную информацию в достаточно известной статье The Guardian (Tall story’s men and women have grown taller over last century, Study Shows (The Guardian, July 2016), которая сравнивает средний возраст человека в разных странах в 1914 году и в аналогичных странах в 2014 году.
Там приведены данные практически по всем государствам. Однако, я взял лишь 5 стран для простоты вычислений: это Россия, Германия, Китай, США и ЮАР, соответственно 1914 год и 2014 год.
Общее количество наблюдений – 5 в 1914 году в группе 1914 года и общее значение также 5 в 2014 году. Будем думать опять же для простоты, что эти данные сопоставимы, и с ними можно работать.
Дальше нужно выбрать критерии – критерии, по которым мы будем давать ответ. Равны ли средние по росту в 1914 году x̅1914 и в 2014 году x̅2014. Я считаю, что нет. Поэтому моя гипотеза это то, что они не равны (x̅1914≠x̅2014). Соответственно альтернативная гипотеза моему предположению, так называемая нулевая гипотеза (нулевая гипотеза консервативна, обратная вашей, часто говорит об отсутствии статистически значимых связей/зависимостей) будет говорить о том, что они между собой на самом деле равны (x̅1914=x̅2014), то есть о том, что все эти находки случайны, и я, по сути, не прав.
Для чего используется t-критерий Стьюдента?
t-критерий Стьюдента используется для определения статистической значимости различий средних величин. Может применяться как в случаях сравнения независимых выборок (например, группы больных сахарным диабетом и группы здоровых), так и при сравнении связанных совокупностей (например, средняя частота пульса у одних и тех же пациентов до и после приема антиаритмического препарата). В последнем случае рассчитывается парный t-критерий Стьюдента
В каких случаях можно использовать t-критерий Стьюдента?
Для применения t-критерия Стьюдента необходимо, чтобы исходные данные имели нормальное распределение. Также имеет значение равенство дисперсий (распределения) сравниваемых групп (гомоскедастичность). При неравных дисперсиях применяется t-критерий в модификации Уэлча (Welch’s t).
При отсутствии нормального распределения сравниваемых выборок вместо t-критерия Стьюдента используются аналогичные методы непараметрической статистики, среди которых наиболее известными является U-критерий Манна — Уитни.
Как интерпретировать значение t-критерия Стьюдента?
Полученное значение t-критерия Стьюдента необходимо правильно интерпретировать. Для этого нам необходимо знать количество исследуемых в каждой группе (n1 и n2). Находим число степеней свободы f по следующей формуле:
f = (n1 + n2) – 2
После этого определяем критическое значение t-критерия Стьюдента для требуемого уровня значимости (например, p=0,05) и при данном числе степеней свободы f по таблице (см. ниже).
Сравниваем критическое и рассчитанное значения критерия:
- Если рассчитанное значение t-критерия Стьюдента равно или больше критического, найденного по таблице, делаем вывод о статистической значимости различий между сравниваемыми величинами.
- Если значение рассчитанного t-критерия Стьюдента меньше табличного, значит различия сравниваемых величин статистически не значимы.
Внесите исходные данные группы
Вы можете внести данные для расчета критерия Т-Стьюдента поочередно вручную или скопировать их из вашего Excel файла.

Внесите исходные данные группы
Вы можете внести данные поочередно вручную или скопировать их из вашего Excel файла.

Критические точки распределения Стьюдента
| Число степеней свободы k |
Уровень значимости α (двусторонняя критическая область) | |||||
| 0.10 | 0.05 | 0.02 | 0.01 | 0.002 | 0.001 | |
| 1 | 6.31 | 12.7 | 31.82 | 63.7 | 318.3 | 637.0 |
| 2 | 2.92 | 4.30 | 6.97 | 9.92 | 22.33 | 31.6 |
| 3 | 2.35 | 3.18 | 4.54 | 5.84 | 10.22 | 12.9 |
| 4 | 2.13 | 2.78 | 3.75 | 4.60 | 7.17 | 8.61 |
| 5 | 2.01 | 2.57 | 3.37 | 4.03 | 5.89 | 6.86 |
| 6 | 1.94 | 2.45 | 3.14 | 3.71 | 5.21 | 5.96 |
| 7 | 1.89 | 2.36 | 3.00 | 3.50 | 4.79 | 5.40 |
| 8 | 1.86 | 2.31 | 2.90 | 3.36 | 4.50 | 5.04 |
| 9 | 1.83 | 2.26 | 2.82 | 3.25 | 4.30 | 4.78 |
| 10 | 1.81 | 2.23 | 2.76 | 3.17 | 4.14 | 4.59 |
| 11 | 1.80 | 2.20 | 2.72 | 3.11 | 4.03 | 4.44 |
| 12 | 1.78 | 2.18 | 2.68 | 3.05 | 3.93 | 4.32 |
| 13 | 1.77 | 2.16 | 2.65 | 3.01 | 3.85 | 4.22 |
| 14 | 1.76 | 2.14 | 2.62 | 2.98 | 3.79 | 4.14 |
| 15 | 1.75 | 2.13 | 2.60 | 2.95 | 3.73 | 4.07 |
| 16 | 1.75 | 2.12 | 2.58 | 2.92 | 3.69 | 4.01 |
| 17 | 1.74 | 2.11 | 2.57 | 2.90 | 3.65 | 3.95 |
| 18 | 1.73 | 2.10 | 2.55 | 2.88 | 3.61 | 3.92 |
| 19 | 1.73 | 2.09 | 2.54 | 2.86 | 3.58 | 3.88 |
| 20 | 1.73 | 2.09 | 2.53 | 2.85 | 3.55 | 3.85 |
| 21 | 1.72 | 2.08 | 2.52 | 2.83 | 3.53 | 3.82 |
| 22 | 1.72 | 2.07 | 2.51 | 2.82 | 3.51 | 3.79 |
| 23 | 1.71 | 2.07 | 2.50 | 2.81 | 3.59 | 3.77 |
| 24 | 1.71 | 2.06 | 2.49 | 2.80 | 3.47 | 3.74 |
| 25 | 1.71 | 2.06 | 2.49 | 2.79 | 3.45 | 3.72 |
| 26 | 1.71 | 2.06 | 2.48 | 2.78 | 3.44 | 3.71 |
| 27 | 1.71 | 2.05 | 2.47 | 2.77 | 3.42 | 3.69 |
| 28 | 1.70 | 2.05 | 2.46 | 2.76 | 3.40 | 3.66 |
| 29 | 1.70 | 2.05 | 2.46 | 2.76 | 3.40 | 3.66 |
| 30 | 1.70 | 2.04 | 2.46 | 2.75 | 3.39 | 3.65 |
| 40 | 1.68 | 2.02 | 2.42 | 2.70 | 3.31 | 3.55 |
| 60 | 1.67 | 2.00 | 2.39 | 2.66 | 3.23 | 3.46 |
| 120 | 1.66 | 1.98 | 2.36 | 2.62 | 3.17 | 3.37 |
| ∞ | 1.64 | 1.96 | 2.33 | 2.58 | 3.09 | 3.29 |
| 0.05 | 0.025 | 0.01 | 0.005 | 0.001 | 0.0005 | |
| Уровень значимости α (односторонняя критическая область) |
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.

Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП – «классическое» левостороннее t-распределение Стьюдента. На вход подается значение t-критерия, количество степеней свободы и опция (0 или 1), определяющая, что нужно рассчитать: плотность или значение функции. На выходе получаем, соответственно, плотность или вероятность того, что случайная величина окажется меньше указанного в аргументе t-критерия, т.е. левосторонний p-value.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α, а для правого 1 — α.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
H0: μ = 50 кг
Ha: μ ≠ 50 кг
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
![]()
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двусторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975. Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.

Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
![]()
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Источники
- https://exceltable.com/funkcii-excel/raspredeleniya-styudenta-styudraspobr
- https://lumpics.ru/calculation-student-test-in-excel/
- https://lit-review.ru/biostatistika/t-kriterijj-styudenta-za-12-minut/
- https://medstatistic.ru/methods/methods.html
- https://statpsy.ru/t-student/onlajn-raschet-kriteriya-t-styudenta-dlya-nezavisimyh-vyborok/
- https://math.semestr.ru/corel/table-student.php
- https://statanaliz.info/statistica/proverka-gipotez/raspredelenie-t-kriteriya-styudenta-dlya-proverki-gipotezy-i-rascheta-doveritelnogo-intervala-v-ms-excel/
Статьи
Карта сайта
Главная страница
Ввод текста помогает оформлять заголовки таблиц, записывать
определенные пояснения. Допустим, нам надо рассчитать объем раствора по его
массе 10 г и плотности 1,25 г/мл, используя простейшую формулу V=m/d. Введем
в ячейки В5, С5, D5 заголовки столбцов будущей таблицы,
обозначения величин m, d и V, и приступим к вводу чисел. В
ячейку В6 введем численное значение массы 10. Заканчиваем ввод, нажимая Enter, и убеждаемся, что тест в ячейке, как правило, смещен к правой границе, а число к левой. Это удобно, так как позволяет замечать ошибки
ввода. В ячейку С6 введем дробное число 1,25. Здесь надо учесть, что в
зависимости от настройки конкретного компьютера для разделения целой и дробной
части числа может использоваться или запятая, или точка. При неправильном вводе
наши символы будут восприниматься как текст, или даже как дата (янв.25).
Наконец, в ячейке D6 введем формулу, по
которой Excel будет проводить вычисления. Ввод формулы начинается со знака
равенства (=). Затем надо показать программе, где находится первое число в
нашей формуле, масса раствора, дать адрес этой ячейки — В6. Конечно, можно
набрать этот адрес с клавиатуры, надо только учитывать, что В – это символ
английского алфавита. Поэтому, гораздо проще просто щелкнуть по нужной ячейке и
ее адрес будет введен автоматически (=В6). Далее надо ввести знак
арифметического действия. Эти знаки удобно вводить с правой части клавиатуры,
напоминающей клавиатуру калькулятора. Здесь есть клавиши со знаком сложения
(+), вычитания (-), умножения (*) и деления (/). И, наконец, надо показать
компьютеру, где находится делитель – щелкаем мышкой по ячейке С6 и получаем
окончательный вид формулы (=В6/С6). Нажимаем Enter, и,
если все было набрано правильно, получаем в ячейке D6 результат
(8). Таким образом, формулы возвращают в ячейку результат вычислений, число. Но
если щелкнуть по ячейке и посмотреть на строку формул, мы увидим, что на самом
деле находится в ней.
Иногда формула может возвращать и сообщение об ошибке. Щелкнем
по ячейке В6 и введем вместо числа 10 символы «10 г». В ячейке D6
тут же окажется сообщение #ЗНАЧ!, которое говорит о
неверном значении в одной из ячеек. Действительно, запись «10 г» воспринимается
уже как текст. Чтобы исправить ошибку надо снова вместо «10 г» ввести число
10. (Для исправления неверных действий можно использовать и кнопку «Отменить»
на панели инструментов). Щелкнем теперь по ячейке С6 и нажмем клавишу “Del”. Этим мы удалим содержимое ячейки, и в соседней ячейке
тут же получим сообщение #ДЕЛ/0! (ошибка деления на 0). Действительно,
на ноль делить нельзя и ошибку надо исправить.
Итак, мы научились вводить числа и формулы, а значит и проводить
простейшие вычисления в Excel. Но как упростить эту процедуру, если таких
вычислений много? Здесь помогают приемы копирования, и автоматического
заполнения ячеек методом «протягивания». Пусть у нас 10 порций раствора массой 10 г, и в ячейки В6, В7 …, В16 надо ввести 10, 10, … и т.д. Щелкнем по ячейке В6, где число 10 уже
введено. В черной рамке выделенной ячейки, внизу справа, есть маленький черный
квадратик. При наведении на него указателя мышки, последний меняет форму. Если
в этот момент «взяться» (нажать левую кнопку мыши) и потянуть вниз, до ячейки
В16, то все десять ячеек окажутся автоматически заполнены нужным числом. Не
труднее заполнить и 100 ячеек!
А если массы растворов отличаются на некоторую постоянную
величину, например 10, 12,5, 15 г и т.д.? В этом случае достаточно ввести два
значения: число 10 в ячейку В6 и число 12,5 в ячейку В7. Теперь надо выделить
эти две ячейки. Для этого щелкаем по первой ячейке и, не отпуская кнопки, ведем
до второй. Теперь обе ячейки обведены жирной рамкой. Снова беремся за черный
квадратик и тянем вниз. Получаем ряд значений от 10 до 35.
Поскольку предполагается, что раствор у нас один и тот же,
оставим колонку С в покое и попробуем методом протягивания скопировать формулу,
которая у нас набрана в ячейке D6. Проделываем уже
описанную операцию: выделяем ячейку, беремся, протягиваем… и получаем во всех
ячейках, кроме первой, ошибку! Разберемся, почему это произошло, для чего
щелкнем по ячейке D7 и посмотрим на строку формул. В
ячейке D6 было написано «=В6/С6», а в ячейке D7 уже «=В7/С7»! То есть, при копировании формул Excel
автоматически меняет адреса ячеек, откуда он берет данные для расчетов. И это
совершенно правильно, когда речь идет о массе раствора. Но плотность раствора у
нас постоянная, как показать программе, что адрес этой ячейки менять не надо?
Для этого мы должны познакомиться с такими понятиями, как
относительный и абсолютный адрес. Те адреса, которые мы использовали,
называются относительными и меняются при копировании. Адрес в абсолютной форме
сопровождается знаками доллара и выглядит так: $C$6. Вот
эту поправку нам и надо внести в формулу в ячейке D6.
Исправлять записи в ячейках удобнее в строке формул. Щелкнем
сначала по ячейке D6, (формула появится в строке
формул), затем в нужном месте строки формул – там появится курсор. Конечно
знаки доллара можно ввести с клавиатуры, но проще, установив курсор на адресе
С6, нажать на клавиатуре клавишу F4. Понажимайте ее
несколько раз и посмотрите, как будет меняться адрес. Он может быть полностью
абсолютным, абсолютным по строчке, по колонке, и полностью относительным.
Добейтесь нужного вида и нажмите Enter. Формула
исправлена, теперь ее снова можно протянуть до ячейки D16.
Если все сделано правильно, вы получите ряд значений от 8 до 28 мл.
Итак, если Вы не только прочитали, но и проделали все, о чем шла
речь выше, Вы научились многому. Вы умеете вводить текст, числа и формулы,
вносить исправления, устранять ошибки, копировать и заполнять ячейки рядами
данных. Не мешает сохранить результаты своей работы. Процедуры сохранения файла
и его открытия полностью совпадают с работой в Worde и не должны вызвать у Вас затруднений.
Формулы с
функциями.
Но в наших расчетах использовались только простейшие
арифметические действия. Для более сложных расчетов нужно научиться
использовать функции. Этим мы займемся на втором листе нашей книги.
Для перехода на нужный лист достаточно щелкнуть по его ярлычку.
Начнем работу с краткого повторения пройденного: дадим листу 2 имя «Ошибки», в
ячейку А3 введем текст «Данные эксперимента», в ячейки А5 и В5 — заголовки
новой таблицы «№» и «Х». Предполагается что мы проделали серию из 10 опытов,
измеряя некоторую величину Х (здесь не важно, что это, длина побега или объем
раствора). Номера опытов от 1 до 10 легко ввести протягиванием, а вот численные
значения Х надо последовательно ввести (табл.1).
Таблица 1. Примерный вид листа
«Ошибки»

Записи в колонках D и
Е – это подсказки, которые помогут разобраться с тем, какие характеристики мы
будем рассчитывать. Колонка F у
Вас должна быть пока пустой, в нее будем помещать наши формулы.
Обработку результатов начнем с расчета числа опытов n. Казалось бы это очевидное число, но в ходе работы, какой-то
результат мы можем отбросить, или провести еще пару опытов. Желательно, чтобы
нам не пришлось при этом переделывать все формулы. Для определения числа
значений используется специальная функция, которая называется СЧЕТ. Для ввода
формулы с функциями используется Мастер функций, который запускается командой
«Вставка функции» через меню «Вставка» – «Функция» или кнопкой на панели
инструментов с обозначением fx. Щелкнем мышкой по ячейке F6,
где должен находиться результат и запустим Мастер функций.

Первый шаг работы (рисунок 1) служит
для выбора нужной функции. Все функции разделены, в зависимости от своего
назначения на несколько категорий (математические, логические и др.). Для
обработки данных эксперимента используются в основном статистические функции.
Поэтому, прежде всего в списке категорий выбираем категорию «Статистические».
Во втором окне появляется список статистических функций. Если щелкнуть по любой
из них, внизу появляется краткое описание функции. Специальной ссылкой можно
вызвать систему помощи Excel, в которой данная функция будет разобрана
подробно, с примерами. Список функций упорядочен по алфавиту, что позволяет без
труда нужную нам функцию СЧЕТ («Подсчитывает количество чисел в списке
аргументов»). Выделив щелчком эту функцию, нажимаем кнопку Ok и переходим к шагу 2.

Второй шаг (рисунок 2) служит для задания аргументов функции.
Функции СЧЕТ надо указать, какие числа ей надо пересчитывать, или в каких
ячейках находятся эти числа. Диапазон ячеек указывается адресами первой и
последней ячейки, записанными через двоеточие, в нашем случае данные находятся
в ячейках В6:В15. Как и в других случаях эти адреса лучше не вводить, а показать
мышкой. Для этого устанавливаем указатель мышки на первую ячейку, нажимаем
левую кнопку и ведем до последней. Обратите внимание, что окно аргументов можно
перемещать, если оно заслоняет нужную часть экрана. Кроме того, рядом с полем
для ввода есть маленькая кнопка с красной стрелочкой. При щелчке по ней окно
аргументов сворачивается до узкой полоски. Когда мы показываем в основном окне
диапазон ячеек, в окне аргументов появляется запись диапазона адресов, а рядом
с ним – значения чисел из первых ячеек. Предварительное значение функции тоже
показывается после ввода ее аргументов. Это помогает избегать ошибок. Помогает
работе с мастером функций и подсказка под полем для ввода аргументов, в которой
разъясняется их смысл и возможные значения. Заканчивается работа с мастером
функций нажатием кнопки “Ok” или клавиши “Enter”. Если все сделано правильно, в ячейке F6 появится нужное значение “10”.
Следующие два этапа обработки серии опытов проводятся
аналогично. В ячейке F7 c
помощью функции СРЗНАЧ рассчитывается
среднее значение выборки, в ячейке F8 – стандартное
отклонение выборки, с помощью функции СТАНДОТКЛОН.
. Будьте аккуратны при выборе функций
– среди них есть очень похожие по названию. Аргументами этих функций служит все
тот же диапазон ячеек.
Следующая формула сложная, частично она набирается как обычная
формула, начиная с символа ”=”. Указав, где находится делимое S и набрав знак операции (=F8/), вызываем
мастер функций. Функция КОРЕНЬ – математическая, поэтому на первом шаге
выбираем категорию математических функций. Аргументом этой функции служит число
опытов, которое мы рассчитали в ячейке F6. Окончательный
вид формулы “=F8/ КОРЕНЬ(F6)”.
Для расчета доверительного интервала необходимо определить
коэффициент Стьюдента. Он зависит от вероятности ошибки (при обычно задаваемой
надежности 95% вероятность ошибки составляет 5%), и от числа степеней свободы n-1). Для нахождения коэффициента Стьюдента используется
статистическая функция Excel СТЬЮДРАСПОБР (“Стьюдента распределение обратное“).
Особенностью этой функции является то, что первый аргумент, число 5% (или 0,05)
вводится в соответствующее окно с клавиатуры. Для второго указываем адрес
ячейки, где находится значение n,
затем дописываем в окне “-1”. Получаем запись “F6-1”.
Для нахождения
доверительного интервала используется обычная формула умножения. Конечно,
вместо букв там должны стоять адреса ячеек, где находятся коэффициент Стьюдента
и стандартное отклонение среднего. Как правило, значение доверительного
интервала округляется до одной значащей цифры, такой же порядок окружения
должен быть и у среднего. Поэтому окончательный результат можно записать так: с
95%-ной надежностью Х = 14,80±0,05. В заключение посчитаем относительную ошибку определения Х: d = ДИ / Хср (формула: “=F11/F7”).
Значение относительной ошибки обычно выражают в процентах, у нас 0,3%.
Если Вы впервые
работаете в Excel, описанная процедура обработки данных эксперимента может
показаться очень сложной. Но на практике, вводить формулы, с помощью мастера
функций, ничуть не сложнее, чем обычные арифметические. К тому же, один раз
подготовив лист Excel для обработки данных, можно скопировать его, и ввести
результаты новой серии опытов в колонку В. Результаты будут тут же рассчитаны
автоматически.
Изучение
зависимостей.
Часто в исследованиях изучается зависимость некоторой величины
от другой. Характер этих зависимостей стремятся выразить математическими
формулами, коэффициенты которой могут иметь определенный физический смысл.
Наиболее употребительна и проста в обработке линейная зависимость, которую
можно выразить уравнением прямой у = kx + b. При этом коэффициент k показывает
степень влияния х на у, а b – некоторое
начальное значение у. Поскольку значения, полученные в ходе эксперимента,
всегда включают некоторую ошибку, экспериментальные точки не лежат строго на
прямой. Как же провести по этим разбросанным точкам наилучшую линию. Для этого
используется статистический метод «наименьших квадратов» предлагающий
достаточно сложные функции для нахождения коэффициентов k и b, а также для оценки их
достоверности.
В Excel эта
задача решается при помощи статистических функций НАКЛОН (наклон прямой
относительно оси Х, коэффициент k) и ОТРЕЗОК (отрезок
отсекаемый прямой на оси Y, коэффициент b). Кроме того, Excel позволяет
построить график зависимости, саму прямую, которая называется линией тренда, а
также вывести уравнение прямой на график.
Для знакомства с этим возможностями перейдем на Лист 3 нашей
книги, назовем его «Зависимость» и введем необходимые исходные данные (таблица
2).
Таблица 2. Примерный вид листа
«Зависимость»

В колонках В и С вводятся данные эксперимента по измерению
величин Х и У, записи в колонке Е играют роль подсказок, колонка F заполняется по мере обработки.
Начнем с ячейки F3.
Ввод формул проводится с помощью мастера функций так, как это
описывалось ранее. Маленькое отличие заключается в том, что у функций НАКЛОН и ОТРЕЗОК два
аргумента: диапазон ячеек со значениями Y и диапазон ячеек со значениями Х.
Щелкаем мышкой сначала по полю для ввода первого аргумента, показываем нужный
диапазон (С3:С13). Затем щелкаем по второму поля и повторяем ввод (В3:В13).
Также рассчитывается и значение функции ОТРЕЗОК в ячейке F4.
Для оценки достоверности можно использовать квадрат коэффициента
корреляции Пирсона (R2). Если он равен 1, то
имеет место полная корреляция с моделью, т.е. точки лежат строго на прямой. В
противоположном случае, если коэффициент равен 0, то уравнение линейной
зависимости полностью неудачно. Для его нахождения используется статистическая
функция КВПИРСОН. Таким образом, данные
нашего эксперимента с достоверностью 0,98 описываются уравнением у = 1,42х+0,905.
Рассмотрим теперь второй метод обработки и представления
результатов эксперимента в виде графика. Для построения графиков и диаграмм в Excel’e используется
Мастер диаграмм, который можно запустить, используя меню Вставка – Диаграмма,
или кнопки на панели инструментов с условным изображением диаграммы.
Предварительно щелкнем мышкой по любой свободной ячейке нашего листа.
Рисунок 3. 
На первом шаге (рисунок 3) выбирается тип и вид диаграммы. Для
построения графика зависимости одной величины от другой используются точечные
диаграммы, причем лучше (из-за разброса точек) выбирать вид «Точки не
соединенные линиями». Заканчиваем выбор, щелкая по кнопке «Далее».
На втором шаге необходимо указать, где у нас находится
независимая величина Х и зависящая от нее Y (рисунок 4).
Для этого щелкаем по ярлычку вкладки «Ряд» и затем по кнопке «Добавить».
Рисунок 4. 
Открываются поля для указания Х и Y. Ввод
значений адресов в эти поля не отличаются от работы с Мастером функций (только
при вводе Y предварительно
сотрите условное значение “={1}”. Если Вы правильно выполните эту часть работы,
на поле вверху уже появится примерный вид графика.
Следующие два шага имеют отношение к оформлению и размещению
графика. На первый раз можно, ничего не меняя, просто нажимать кнопки «Далее» и
«Готово». Полученный черновой вариант графика всегда можно редактировать,
изменять или удалять его отдельные элементы. Обычно для этого щелкают по
нужному элементу графика правой (!) кнопкой мышки. При этом открывается
контекстное меню, в котором выбирают подходящую команду.
Если правой кнопкой мышки щелкнуть по одной из точек графика, то
в контекстном меню можно увидеть команду «Добавить линию тренда». Это и есть
необходимая нам линия. Добавляется она тоже в два шага. На первом выбирается
тип (линейный), на втором – параметры. На вкладке Параметры нам важно поставить
галочки против слов: «показывать уравнение» и «поместить величину
достоверности». Если из теоретических предпосылок понятно, что прямая должна
проходить через начало координат (при нулевой концентрации скорость реакции,
очевидно, равна нулю) поставим галочку и в данном пункте. Примерный вид графика
после добавления линии тренда представлен на рисунке 5. Выведенное уравнение
прямой и величины достоверности совпадает с рассчитанными ранее.
Рисунок 5.
Итак, мы рассмотрели важнейшие приемы работы в Microsoft Excel, необходимые для качественной
обработки данных эксперимента. Разумеется эти приемы не исчерпывают всех
возможностей Excel, и могут развиваться в ходе работы.
Автор статьи с удовольствием ответит на все вопросы, связанные с работой в
данной программе. Желаю успеха!
Задать вопрос.
Обновлено: 16.04.2023
Для нахождения критических значений распределения Стьюдента в MS Excel есть встроенная функцияСТЬЮДРАСПОБР. Эта функция возвращает двустороннее tкрит критическое значение распределения Стьюдента как функцию вероятности и числа степеней свободы.
Синтаксис: СТЬЮДРАСПОБР(p; df)
p — вероятность, соответствующая двусторонней критической области распределения Стьюдента;
df— число степеней свободы, характеризующее распределение.
Критическая точка (t-значение) для односторонней критической области может быть получена при замене аргумента «вероятность» на 2*«вероятность». Для вероятности 0,05 и числа степеней свободы равного 10, критическое значение для двухсторонней критической области критическое значение вычисляют с помощью функции СТЬЮДРАСПОБР(0,05;10) и оно равно 2,28139. Критическое значение для односторонней критической области для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10) и равняется 1,812462.
Рис.2.18. Таблица значений функции плотности распределения Стьюдента при различном числе степеней свободы df (режим отображения данных)
Рис.2.19. Графики функции плотности распределения Стьюдента при различном числе степеней свободы df
Рис.2.20. Нахождение двусторонних критических значений распределения Стьюдента для различных p-значений
Рис.2.21 Геометрический смысл двустороннего критического значения для распределения Стьдента для p-значения равного 0,05.
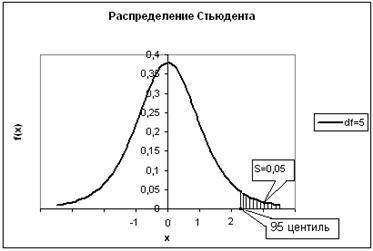
Рис.2.22 Геометрический смысл одностороннего критического значения для распределения Стьюдента для p-значения, равного 0,05
Рис.2.23. Построение таблицы значений функции плотности распределения Стьюдента при различном числе степеней свободы df (режим отображения формул).
С помощью рис. 2.19 сделайте вывод об изменении графика распределения Стьюдента в зависимости от числа степеней свободы и его близости к кривой нормального распределения. По данным рис.2.20 сделайте выводы об изменении критических t значений в зависимости от p-значений. По рис.2.21 и 2.22 оцените односторонние и двусторонние критические значения при фиксированном числе степеней свободы и одном и том же уровне значимости p.
Распределение Фишера
Для нахождения критических значений распределения Фишера в MS Excel имеется встроенная функция FРАСПОБР().
Синтаксис: FРАСПОБР(p;df1;df2)
p — это p-значение;
df1 — это число степеней свободы числителя;
df2 — это число степеней свободы знаменателя.
Решение приведено на рис.2.24-2.29.
Рис.2.24. Таблица значений функции плотности распределения Фишера при различном числе степеней свободы df2 и фиксированном значениичисла степеней свободы df1, равном 5(режим отображения данных).
Рис.2.25. Нахождение критических значений распределения Фишера для различных p-значений

Рис.2.26. Геометрический смысл критических значений для различных p-значений распределения Фишера
Рис.2.27. Графики функции плотности распределения Фишера при различном числе степеней свободы df2 и фиксированном значениичисла степеней свободы df1, равном 5
Рис.2.28. Построение таблицы значений функции плотности распределения Фишера при различном числе степеней свободы df2 и фиксированном значениичисла степеней свободы df1 равном 5(режим отображения формул)
Рис.2.29. Нахождение критических значений распределения Фишера для различных p-значений (режим отображения формул)
1. Гмурман В.Е. Теория вероятностей и математическая статистика, изд.9, М., Высшая школа, 2003, с.480.
2. Господариков В.П. и др. Математический практикум, ч.5, Теория вероятности и математическая статистика. Теория функций комплексного переменного. Операционное исчисление. Теория поля. Санкт-Петербургский горный ин-т , СПб, 2003, с.187
3. Бер К., Кэйри П., Анализ данных с помощью Microsoft Excel, М., Вильямс, 2004, с. 560.
Функции, определенные пользователем (user define function), написаны на встроенном языке VBA (Visual Basic for Application) для вычисления плотностей некоторых распределений (рис.П1.1). Для того, чтобы они были доступны на рабочем листе MS Excel, необходимо проделать следующее:
1). Открыть окно редактора VBA, выполнив следующие действия:

Сервис Макрос Редактор Visual Bаsic
2). Открыть папку Modules в Project Explorer
3). Скопировать и вставить (или набрать) текст функций в окно редактора
4). Сохранить набранный текст.
5). После этого эти функции будут доступны в «Мастере функций» в категории «Определенные пользователем» на рабочем листе.
Распределение c 2 (хи – квадрат)
Синтаксис CPDF(p;df)
где x — значение, для которого строится функция плотности распределения;
df —число степеней свободы.
Function CPDF(x, df)
x1 = x ^ (0.5 * (df — 2))
x2 = Exp(-0.5 * x)
x3 = 2 ^ (df / 2)
x4 = Exp(Application.GammaLn(df / 2))
CPDF = x1 * x2 / (x3 * x4)
End Function

Распределение Стьюдента (t-распределение) Синтаксис
Сборник интересных функций с практическими примерами, картинками, подробным описанием синтаксиса и параметров.
Синтаксис и параметры функций

Пример функции ГАММА и расчет параметров гамма-функции в Excel.
Результаты после расчетов формул для нахождения гамма-функции и ФАКТР. Как рассчитать соотношение корня числа Пи и результата вычисления функции ГАММА при значении x=1/2?

Примеры функции ПРОИЗВЕД для произведения расчетов в Excel.
Как рассчитать квадратный корень произведения чисел матрицы? Расчет вероятности комбинаций четырех разных игральных карт из одной колоды.

Примеры функции ПЕРСЕНТИЛЬ для расчета перцентиля в Excel.
Примеры формул для расчетов методом перцентилей с использованием функции ПЕРСЕНТИЛЬ. Что такое перцентиль и как его использовать в формуле?

Функция ЕОШ для проверки ячеек на ошибки в Excel.
Примеры использования функции ЕОШ в формулах для проверки ячеек на ошибки в их значениях. Как заменять ошибки в ячейках своими значениями?

СТЬЮДРАСПОБР функция распределения Стьюдента в Excel.
Пример расчетов одностороннего и двухстороннего t-распределения Стьюдента с помощью функции СТЬЮДРАСПОБР. Ка пользоваться функцией СТЬЮДРАСПОБР?

Функция ОСПЛТ для расчета регулярного платежа по кредиту в Excel.
Примеры как рассчитать регулярные расходы на погашение платежей по кредитам с помощью финансовой функции ОСПЛТ. Формула аннуитетной схемы регулярных платежей.

Функции распределения ПУАССОН и ПУАССОН.РАСП в Excel.
Примеры расчета распределения вероятностей разной плотности случайной величины по закону Пуассона. Как рассчитать биномиальное распределение Пуассона?

Как сделать комментарий в формуле Excel пример функции Ч.
Примеры использования функции Ч для преобразования всех типов значений в число. Способ добавления комментариев к формулам. Суммирование логических значений.

Примеры формул с функцией ЕЧИСЛО в Excel для проверки на число.
Как работать с функцией ЕЧИСЛО для формул проверки является ли строка числом. Проверка типов данных значений таблицы в строках и столбцах.
В этой статье описаны синтаксис формулы и использование функции СТЬЮДРАСП в Microsoft Excel.
Описание
Возвращает процентные точки (вероятность) для t-распределения Стьюдента, где числовое значение (x) — вычисляемое значение t, для которого должны быть вычислены вероятности. T-распределение используется для проверки гипотез при малом объеме выборки. Данную функцию можно использовать вместо таблицы критических значений t-распределения.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция СТЬЮДЕНТ.РАСП.2Х и Функция СТЬЮДЕНТ.РАСП.ПХ.
Синтаксис
Аргументы функции СТЬЮДРАСП описаны ниже.
X Обязательный. Числовое значение, для которого требуется вычислить распределение.
Степени_свободы Обязательный. Целое, указывающее число степеней свободы.
Хвосты Обязательный. Определяет количество возвращаемых хвостов распределения. Если значение «хвосты» = 1, функция СТЬЮДРАСП возвращает одностороннее распределение. Если значение «хвосты» = 2, функция СТЬЮДРАСП возвращает двустороннее распределение.
Замечания
Аргументы «степени_свободы» и «хвосты» усекаются до целых значений.
Если значение аргумента «хвосты» = 1, функция СТЬЮДРАСП вычисляется как СТЬЮДРАСП = P(X > x), где X — случайная переменная, соответствующая t-распределению. Если значение аргумента «хвосты» = 2, функция СТЬЮДРАСП вычисляется как СТЬЮДРАСП = P(|X| > x) = P(X > x или X < -x).
Поскольку значения x < 0 не поддерживаются, то, используя функцию СТЬЮДРАСП при x < 0, следует помнить, что СТЬЮДРАСП(-x,df,1) = 1 – СТЬЮДРАСП(x,df,1) = P(X > -x), а СТЬЮДРАСП(-x,df,2) = СТЬЮДРАСП(x df,2) = P(|X| > x).
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Рассмотрим Распределение Стьюдента (t-распределение). С помощью функции MS EXCEL СТЬЮДЕНТ.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение Стьюдента (также называется t -распределением ) применяется в различных методах математической статистики:
- при построении доверительных интервалов для среднего (используется функция ДОВЕРИТ.СТЬЮДЕНТ() );
- для оценки различия двух выборочных средних (используется функция СТЬЮДЕНТ.ТЕСТ() );
- при проверке гипотез (выборка небольшого размера, стандартное отклонение не известно) ,
- в линейном регрессионном анализе (при проверке гипотез на значимость отдельных регрессионных коэффициентов).
Определение : Если случайная величина Z распределена по стандартному нормальному закону N(0;1) и случайная величина U имеет распределение ХИ-квадрат с ν степенями свободы, то случайная величина T=Z/√(U/v) имеет t-распределение .

Плотность распределения Стьюдента выражается формулой:

при −∞ файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .
График плотности распределения Стьюдента , как и стандартного нормального распределения , является симметричным и колоколообразным, но с более тяжелыми хвостами.
Ниже для сравнения приведены графики плотности стандартного нормального распределения и распределения Стьюдента.

Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
t-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для t-распределения имеется функция СТЬЮДЕНТ.РАСП() , английское название — T.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и интегральную функцию распределения (вероятность, что случайная величина Х, имеющая распределение Стьюдента , примет значение меньше или равное х, P(X файле примера на листе Функции приведены основные функции MS EXCEL, связанные с этим распределением.
Кроме этой функции в MS EXCEL имеется еще довольно много других функций, относящихся к данному распределению, но по большому счету их функционал покрывается функцией СТЬЮДЕНТ.РАСП() .
Кроме того, СТЬЮДЕНТ.РАСП() является единственной функцией, которая возвращает плотность вероятности (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P(X x) или даже P(|X| > x).
Очевидно, что справедливо равенство
=СТЬЮДЕНТ.РАСП.ПХ(x;n)+СТЬЮДЕНТ.РАСП(x;n;ИСТИНА)=1 т.к. первое слагаемое вычисляет вероятность P(X > x), а второе P(X СТЬЮДРАСП() , которая позволяет вычислить функцию распределения (точнее — правостороннюю вероятность, т.е. P(X>x)) и объединяет возможности нескольких новых функций MS EXCEL 2010: СТЬЮДЕНТ.РАСП(x; n; ЛОЖЬ) , СТЬЮДЕНТ.РАСП.ПХ() , СТЬЮДЕНТ.РАСП.2Х() . Функция СТЬЮДРАСП() оставлена в MS EXCEL 2010 для совместимости.
- Если значение аргумента «хвосты» = 1, функция СТЬЮДРАСП() вычисляет правостороннюю вероятность P(X > x), где X — случайная переменная, соответствующая t-распределению. Под термином «хвост» подразумевается «хвост» распределения, в данном случае правый. На графике плотности вероятности этому «хвосту» будет соответствовать площадь фигуры под графиком (выделена синим), которая ограничена слева вертикальной линией X = x.

- Если значение аргумента «хвосты» = 2, функция СТЬЮДРАСП() вычисляет вероятность P(|X| > x) или другими словами P(X > x или X =СТЬЮДРАСП(x;n;2) эквивалентна =СТЬЮДРАСП(x;n;1)*2
- Функцией СТЬЮДРАСП() значения x СТЬЮДРАСП(-x;n;1) . Чтобы вычислить вероятность P(X =ЕСЛИ(x>0;СТЬЮДРАСП(x;n;1);1-СТЬЮДРАСП(-x;n;1)) .
Примеры
Аналогичные вычисления для P(X > x) и P(|X| > x) приведены в файле примера на листе Функции , в том числе и для x СТЬЮДЕНТ.ОБР() используется для вычисления как двухсторонних, так и односторонних доверительных интервалов . А функции СТЬЮДЕНТ.ОБР.2Х() и СТЬЮДРАСПОБР() созданы специально для вычисления квантилей , необходимых для расчета двусторонних доверительных интервалов: в качестве аргумента нужно указывать уровень значимости альфа , а не альфа/2 , как для СТЬЮДЕНТ.ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. нижеуказанные формулы возвращают одинаковый результат: =СТЬЮДЕНТ.ОБР(альфа;n) =-СТЬЮДРАСПОБР(альфа*2;n) =-СТЬЮДЕНТ.ОБР.2Х(альфа*2;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Примечание : Ниже приведено соответствие русских и английских названий функций: СТЬЮДЕНТ.РАСП.ПХ() — англ. название T.DIST.RT, т.е. T-DISTribution Right Tail, the right-tailed Student’s t-distribution СТЬЮДЕНТ.РАСП.2Х() — англ. название T.DIST.2T, т.е. T-DISTribution 2 Tails СТЬЮДЕНТ.ОБР() — англ. название T.INV, т.е. T-distribution INVerse СТЬЮДРАСП() — англ. название TDIST, т.е. T-DISTribution СТЬЮДРАСПОБР() — англ. название TINV, т.е. T-distribution INVerse (the right-tailed inverse of the Student’s t-distribution) СТЬЮДЕНТ.ОБР.2Х() — англ. название T.INV.2T
Функции MS EXCEL, использующие t-распределение
Как было сказано выше, при построении доверительных интервалов используется функция ДОВЕРИТ.СТЬЮДЕНТ() — англ. название CONFIDENCE.T.
Например, формула =ДОВЕРИТ.СТЬЮДЕНТ(альфа;СТАНДОТКЛОН.В(B20:B79); СЧЁТ(B20:B79)) эквивалентна классической формуле для вычисления доверительного интервала =СТЬЮДЕНТ.ОБР(1-альфа/2; СЧЁТ(B20:B79)-1)* СТАНДОТКЛОН.В(B20:B79)/КОРЕНЬ(СЧЁТ(B20:B79))
где предполагается, что выборка находится в диапазоне B20:B79 .
Как видим, особых преимуществ в использовании ДОВЕРИТ.СТЬЮДЕНТ() нет.
Другая функция — СТЬЮДЕНТ.ТЕСТ() — англ. название T.TEST, используется для оценки различия двух выборочных средних .
Оценка параметров распределения
Т.к. обычно t-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Читайте также:
- Ошибка драйвера isis 80fd0000
- 1с фреш что это такое
- Как нарисовать розу в paint
- Как перевести рубли в доллары в excel
- Как раскрасить лицо в фотошопе