
Рассмотрим понятие процентиля, функцию
ПРОЦЕНТИЛЬ.ВКЛ()
, процентиль-ранг и построим кривую процентилей.
Сначала разберемся на примерах, что такое
процентиль
, затем рассмотрим соответствующие функции MS EXCEL.
Задача.
Проектируют койку на круизном лайнере. Необходимо, чтобы 95% пассажиров помещались на койке в полный рост. Как вычислить длину койки?
Для решения задачи потребуется найти рост, ниже которого 95% населения. Для этого нужно сделать
репрезентативную выборку
, скажем, из 2000 человек,
отсортировать значения выборки по возрастанию
, потом определить значение с позицией равной 1901 (2000*95%+1). Пусть найденный рост оказался равен 190 см.
Ответ
: Длина койки должна быть 190 см (+ запас для комфортного размещения на койке).
Значение 190 см называется 95%-й
процентилью
данной
выборки
, т.е. 95% опрошенных людей имеет рост <190 см.
Примечание
: Найденное значение (190см) является
оценкой
95%-й
процентили
всей
генеральной совокупности
, из которой взята
выборка
.
СОВЕТ
: Понятие
процентиля
связано с понятием
квантиля функции распределения
. Поэтому имеет смысл освежить в памяти понятия
функции распределения и обратной функции
.
На основании вышесказанного сформулируем определение для
процентили
:
K-й Процентиль представляет такое собой значение
Х
в наборе данных, которое разделяет набор на две части: одна часть содержит K процентов данных,
меньших Х
, а другая часть содержит все остальные значения набора (т.е. 1-
K
процентов данных б
о
льших Х).
Приведем алгоритм для нахождения
k
-й процентили выборки:
-
отсортировать значения
выборки
по возрастанию (пусть в
выборке
всего N значений); -
найти такую позицию в списке
, для которой k% значений оказалось бы меньше этого значения. Это можно сделать с помощью формулы N*k%+1 (затем,
округлить его до целого
);
-
значение, находящееся в этой позиции, и будет
k
-й процентилью
(примерно), т.к. k% значений массива данных будет меньше этого значения.
Примечание
: Более точный алгоритм расчета
процентилей
дан ниже в разделе про функцию
ПРОЦЕНТИЛЬ.ВКЛ()
.
Еще одна
задача
.
Зачет «автоматом» поставят только тем студентам, которые в течение семестра набрали в течение семестра больше баллов, чем 90%-я Процентиль (другими словами 10% лучшим студентам поставят зачет «автоматом»).
Так как порог установлен в
процентилях
, то заданному % студентов придется сдавать экзамен вне зависимости от набранных баллов (т.е. 90% студентов в любом случае будут сдавать экзамен). А вот если бы порог был установлен в абсолютных значениях, например, 380 баллов из 400, то вполне вероятна ситуация, когда половине студентов поставили бы «автоматом» (если бы они, конечно, набрали бы больше 380 баллов). Или наоборот, при общих слабых результатах ни один студент не получил бы зачет «автоматом». Установка порога в
процентилях
создает предпосылки здоровой конкуренции (или, наоборот, сговора: даже если никто особо не учился, то в любом случае 10% получат зачет «автоматом»).
Решим эту задачу, используя заданные значения
выборки
. Пусть всего 120 студентов, значения баллов за семестр разместим в диапазоне
A8:A127
(см.
Файл примера
, лист
Пример-Студенты
). Максимальный суммарный балл = 400. Порог получения зачета «автоматом» — больше баллов, чем 90%-я
Процентиль
.
Понятно, чтобы определить тех студентов, которые получат зачет «автоматом» нужно отсортировать их по набранным баллам и отобрать 10% (т.е. 12 студентов) с максимальными баллами. Но, чтобы студенты сами определились, начинать ли им готовиться к экзамену или нет, достаточно сообщить им проходной балл (90%-ю
процентиль
). Рассчитаем этот проходной балл.
Для наглядности построим
Гистограмму распределения с накоплением
.
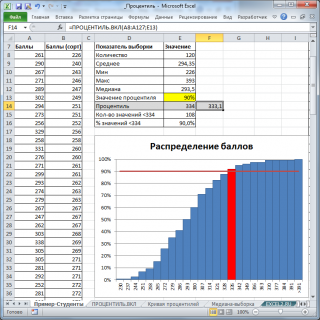
90%-ю
процентиль
можно найти с помощью формулы
=НАИМЕНЬШИЙ(A8:A127;ЦЕЛОЕ(120*0,9)+1)
Эта формула создана на основе алгоритма, приведенного выше. Результат формулы — 334 балла.
Как видно из рисунка выше, количество значений массива (студентов), у которых баллы хуже, действительно равно 108 (90% от 120). Следовательно, как и предполагалось, 12 студентов получат зачет «автоматом».
Примечание
:
Найденное значение
процентили
334 является приблизительным. Точное значение дает формула
=ПРОЦЕНТИЛЬ.ВКЛ(A8:A127;0,9)
, которое равно 331,4. О том как работает функция
ПРОЦЕНТИЛЬ.ВКЛ()
читайте ниже.
Как показывает опыт, для данных выборки
K
-я
процентиль
не всегда отделяет точно
К
процентов значений, которые меньше ее. Например, в нашем примере найдем 80%-ю
процентиль.
Оказывается, что только 79% значений меньше 80%-й
процентили
(318). Это происходит из-за округления. Для
выборок
с большим количеством значений (>100) обычно наблюдается хорошее соответствие. Повторы значений также могут привести к несоответствию значения
процентиля
и соответствующего % значений (см. ниже).
Примечание
:
Процентили
часто называют
перцентилями
(с этим соглашается и MS WORD) или
центилями
. В версии MS EXCEL 2007 и более ранних использовалась функция
ПЕРСЕНТИЛЬ()
, которая оставлена для совместимости. Но, начиная с версии EXCEL 2010, появились функции
ПРОЦЕНТИЛЬ.ВКЛ()
и
ПРОЦЕНТИЛЬ.ИСКЛ()
– английское название PERCENTILE.EXC(), а
Условное форматирование
предлагает настроить правило с использованием именно
процентилей
. В свою очередь,
надстройка Пакет Анализа
имеет инструмент
Ранг и Персентиль
.
Google также отдает предпочтение
процентилям
, выдавая гораздо больше результатов на запрос «процентиль», чем на запрос «перцентиль» (на начало 2016 года).
Таким образом, для
процентилей
используется 3 названия:
процентиль
(MS EXCEL, Google)
, персентиль
(MS EXCEL)
, перцентиль
(MS WORD)
.
Ниже детально рассмотрим как работает функция
ПРОЦЕНТИЛЬ.ВКЛ()
и создадим ее аналог с помощью альтернативной формулы. Также рассмотрим функцию
ПРОЦЕНТРАНГ.ВКЛ()
и
кривую процентилей
.
СОВЕТ
:
Нижеследующие разделы следует читать пользователям, владеющими базовыми понятиями
математической статистики (случайная величина, функция распределения)
.
Функция
ПРОЦЕНТИЛЬ.ВКЛ()
Начиная с версии MS EXCEL 2010 для расчета
процентилей
используется функция
ПРОЦЕНТИЛЬ.ВКЛ()
– английское название PERCENTILE.INC(). В более ранних версиях MS EXCEL использовался ее аналог — функция
ПЕРСЕНТИЛЬ()
.
Напомним определение
процентиля
, данное выше:
K-й Процентиль представляет такое собой значение
Х
в наборе данных, которое разделяет набор на две части: одна часть содержит K% данных,
меньших Х
, а другая часть содержит все остальные значения набора (т.е. 1-
K
% данных б
о
льших Х).
Разберем детально как работает функция
ПРОЦЕНТИЛЬ.ВКЛ()
.
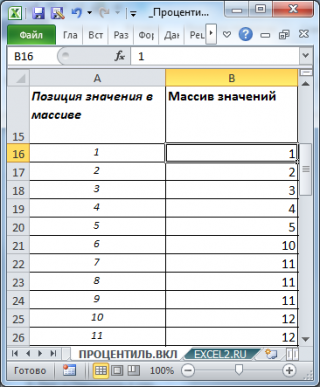
Пусть имеется массив значений (
выборка
). В массиве 49 значений, массив расположен в диапазоне
B15:B63
, имеются
повторы значений
, массив для удобства
отсортирован по возрастанию
(см.
файл примера
, лист
ПРОЦЕНТИЛЬ.ВКЛ
).
Рассчитаем 0,08-ю
процентиль
(
8%-процентиль
) с помощью формулы
=ПРОЦЕНТИЛЬ.ВКЛ(B15:B63; 0,08)
. Получим, что 0,08-я
процентиль
равна 4,84.
Проанализируем, что мы получили.
-
Во-первых, значения 4,84 нет в массиве (есть 4 и 5), т.е. функция
ПРОЦЕНТИЛЬ.ВКЛ()
интерполирует значения. -
Во-вторых, процент значений меньших 4,84 равен не точно 8%, а 8,16%=4/49*100% (т.к. всего 4 значения в массиве меньше 4,84). Это произошло, т.к. в
выборке
относительно мало значений. -
Другой причиной расхождения могут стать повторы. Например, заменив, первые 4 значения в массиве (т.е. 1; 2; 3; 4) числом 5, мы получим вместо 8,16% — 0%. Это произошло потому, что теперь 0,08-я
процентиль
равна 5, а в
выборке
нет ни одного значения меньше 5.
Как видно из рисунка ниже первое значение (
минимальное
, равное 1) является 0-й
процентилью
.
Соответственно, 1-й
процентилью
(100%
процентилью
), является
максимальное значение
равное 120 (см.
файл примера
лист ПРОЦЕНТИЛЬ.ВКЛ).
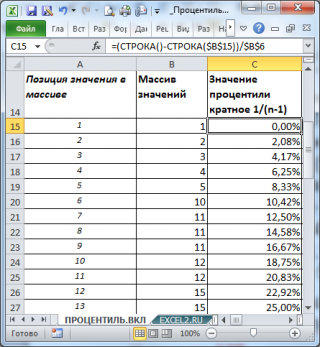
Как видно из рисунка, следующее за минимальным значением (т.е. число 2) является 0,0208-й
процентилью
. Значение 0,0208 или 2,08% — это (k-1)*1/(n-1), где n – это количество значений в массиве (в нашем массиве n=49), а k – это позиция числа в массиве (в данном случае k=2, где 2 – это позиция, а не само число).
Поясним эту формулу. Для вычисления
процентили
принимается, что весь диапазон значений массива (от мин до макс) разбит n значениями на равные интервалы (их всего n-1). Соответственно, 1/(n-1), это «ширина» интервала (весь диапазон равен 1 или 100%). Обратите внимание, что «ширина» интервала не зависит от данных, а только от их количества. В нашем случае «ширина» интервала равна 0,0208 или 2,08%.
Приведем алгоритм расчета
12,50%-процентили
функцией
ПРОЦЕНТИЛЬ.ВКЛ()
(см. ячейку
С21
):
ПРОЦЕНТИЛЬ.ВКЛ()
определяет «ширину» интервала (в долях или процентах): =1/(49-1)=0,0208;-
подсчитывает
Количество интервалов
, которые были укладываются в 12,50%, т.е. =12,50%/2,08%=6 (значение
процентиля
кратно ширине интервала, т.е. делится нацело); - 6-й интервал располагается между числами массива 10 и 11. Верхняя граница последнего 6-го интервала равна 11;
-
Следовательно,
12,50%-я процентиль
равна 11 (см. ячейку
B
21
).
По аналогии с
непрерывной функцией распределения
(см.
статью про квантили
), получается, что 12,50% значений должно быть меньше полученного числа 11 (в соответствии с определением
процентиля
). Фактически получается, что таких значений 6 (1; 2; 3; 4; 5; 10) и процент значений меньших 11 равен 12,24%=6/49 (причины расхождения: повторы и небольшое количество значений).
Если значение
процентиля
не кратно ширине интервала (ширина интервала равна 1/(n-1)), то имеет место интерполирование. Например, вспомним результат вычисления
0,08-й процентили
равный 4,84. Значение
процентили
(т.е. не результат, а %) равно 0,08 (8%), что соответствует 3-м целым интервалам (8%/2,08%=
3
,84) и некой доли (0,84) от ширины следующего интервала. Границами этого «неполного» интервала являются значения 4 (
0,0625-я процентиль
) и 5 (
0,0833-я процентиль
). Т.к. разница между 5 и 4 равна 1, то умножая «пройденную» долю интервала (0,84) на длину интервала в абсолютных значениях (=5-4=1), получаем 0,84. В итоге получаем 4,84: 4 – левая граница интервала + часть следующего (5-4)*0,84.
Если бы в массиве вместо 5 было значение 6, то значение
0,08-й процентили
было бы равно 5,68 (4 – левая граница интервала + (6-4)*0,84=1,68).
Альтернативный расчет
процентили
с помощью формул приведен в
файле примера
.
Примечание
: Некоторые значения
процентилей
имеют специальные названия:
-
25-я
процентиль
называется 1-й квартилью; -
50-я
процентиль
называетсяМедианой
(2-я квартиль);
-
75-я
процентиль
называется 3-й квартилью.
Функция
ПРОЦЕНТРАНГ.ВКЛ()
и Кривая процентилей
Функция
ПРОЦЕНТРАНГ.ВКЛ()
используется для оценки относительного положения значения в массиве. Для заданного значения функция вычисляет сколько значений в массиве меньше или равно ему. Точнее — какой процент значений массива меньше или равен ему. Результат функции называется
процентиль-ранг (percentile rank)
. Понятно, что для максимального значения
процентиль-ранг
равен 0,00%, а для наименьшего — 100% (все значения массива меньше или равны ему).
Функция
ПРОЦЕНТРАНГ.ВКЛ()
, английская версия – PERCENTRANK(), является, в каком-то смысле, обратной функции
ПРОЦЕНТИЛЬ.ВКЛ()
: т.е. задавая в качестве аргумента значение из массива, функция
ПРОЦЕНТРАНГ.ВКЛ()
вернет
значение процентили
кратной 1/(n-1).
Как видно из рисунка выше, для повторяющихся значений функция
ПРОЦЕНТРАНГ.ВКЛ()
вернет, естественно, одинаковые значения. Также поступает функция
РАНГ.РВ()
или
РАНГ()
(см. статью
Функция РАНГ() в MS EXCEL
).
Действительно, функции
РАНГ.РВ()
и
ПРОЦЕНТРАНГ.ВКЛ()
очень похожи. Первая
возвращает позицию числа в массиве
в зависимости от его значения. Вторая, в принципе, делает тоже самое, но результат выводится в % от общего количества значений в массиве.
Как видно из картинки выше, чтобы получить
процентиль-ранг
необходимо значение ранга уменьшить на 1 и разделить на n-1. Значение
ранга
, естественно, должно быть
отсортировано по возрастанию
.
По
выборке
можно оценить
функцию распределения
Генеральной совокупности
, из которой взята данная
выборка.
Для этой цели построим
Кривую процентилей
(percentile curve или percentile rank plot).
Кривая
процентилей
представляет собой график зависимости
процентиль-ранга
от значений
выборки
.
Возьмем
выборку
состоящую из 100 значений (см.
файл примера
лист
Кривая процентилей
). Значения содержатся в диапазоне
А5:А104
.
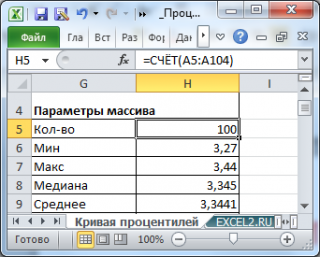
Сначала построим
таблицу частот
для каждого из значений
выборки
.
Примечание
: В отличие от
Гистограммы
, где
кумулятивная
таблица частот
строится для интервалов значений,
таблицу частот
для
Кривой
процентилей
строят для
каждого
из значений
выборки
.
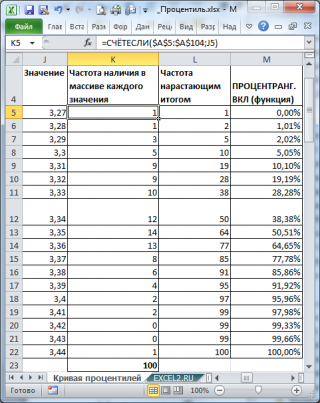
Из таблицы видно (столбец
Частота нарастающим итогом
), что
примерно
1 процент значений меньше или равен значения 3,27,
примерно
2 процента на уровне или ниже 3,28, 5 процентов на уровне или ниже 3,29, и так далее. График
Кривой
процентилей
для этих данных приведен на картинке ниже.
СОВЕТ
: Про построение графиков см. статью
Основные типы диаграмм
.
Следует отметить, что использование данных из таблицы приведет к точечному виду кривой (так как
процентиль-ранг
будет изменяться скачком для каждого значения
выборки
). Поэтому, сглаженная кривая, построенная на основе этих данных будет лучше представлять оцениваемую
функцию распределения
(пунктирная кривая).
Построив пунктирную кривую, становится ясно, зачем нам пришлось вводить понятие
процентиль-ранга: процентиль-ранг
– является приблизительной вероятностью выбрать случайную величину меньше или равную соответствующему значению (сравните с определением функции распределения). Это, в частности следует из расчета
процентиль-ранга
по формуле
=СЧЁТЕСЛИ($A$5:$A$104;»<«&A5)/ (СЧЁТ($A$5:$A$104)-1)
Обратите внимание, что при построении
Кривой процентилей
никакие значения из
выборки
не были удалены или сгруппированы. В этом смысле, построение
Кривой процентилей
это более точная процедура для оценки вида
функции распределения
, чем построение
Гистограммы данных
(так как информация не теряется в процессе построения). Правда, для этого требуется достаточно большая выборка (лучше >100 значений).
Примечание
: Формула
=(РАНГ.РВ(A5;$A$5:$A$104;1)-1)/ (СЧЁТ($A$5:$A$104)-1)
эквивалентна формуле
=ПРОЦЕНТРАНГ.ВКЛ($A$5:$A$104;A5;5)
17 авг. 2022 г.
читать 2 мин
Вы можете использовать функцию ПРОЦЕНТРАНГ в Excel, чтобы вычислить ранг значения в наборе данных в процентах от общего набора данных.
Эта функция использует следующий базовый синтаксис:
=PERCENTRANK( A2:A16 , A2 )
В этом конкретном примере вычисляется процентильный ранг значения A2 в диапазоне A2:A16 .
В Excel также есть две другие функции процентиля:
- PERCENTRANK.INC : вычисляет процентильный ранг значения, включая наименьшее и наибольшее значения.
- PERCENTRANK.EXC : вычисляет процентильный ранг значения, исключая наименьшее и наибольшее значения.
В следующих примерах показано, как использовать эти функции на практике.
Пример: вычисление процентиля в Excel
Предположим, у нас есть следующий набор данных, который показывает результаты экзаменов, полученные 15 учениками в определенном классе:
Теперь предположим, что мы хотели бы вычислить процентильный ранг оценки каждого учащегося.
Мы можем ввести следующую формулу в ячейку B2:
=PERCENTRANK( $A$2:$A$16 , A2 )
Затем мы можем скопировать и вставить эту формулу в каждую оставшуюся ячейку в столбце B:
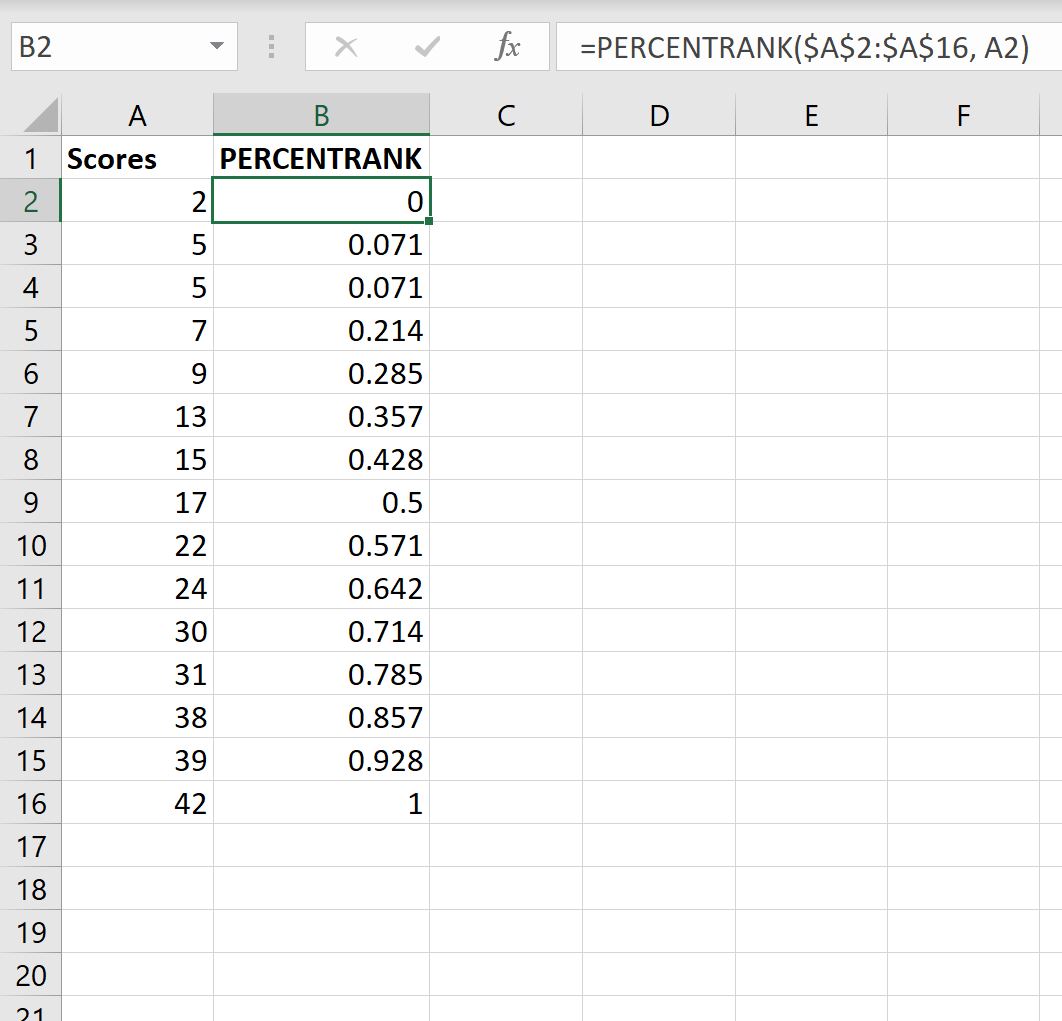
Вот как интерпретировать каждое значение процентного ранга:
- Учащийся, набравший 2 балла, занял 0 процентиль (или 0%) в классе.
- Учащиеся, набравшие 5 баллов, заняли процентиль 0,071 (или 7,1%) в классе.
- Учащийся, набравший 7 баллов, занял процентиль 0,214 (или 21,4%) в классе.
И так далее.
Обратите внимание, что когда мы используем функцию PERCENTRANK , наименьшее значение в наборе данных всегда будет иметь процентильный ранг 0, а самое большое значение в наборе данных всегда будет иметь процентильный ранг 1.
На следующем снимке экрана также показано, как использовать функции PERCENTRANK.INC и PERCENTRANK.EXC :
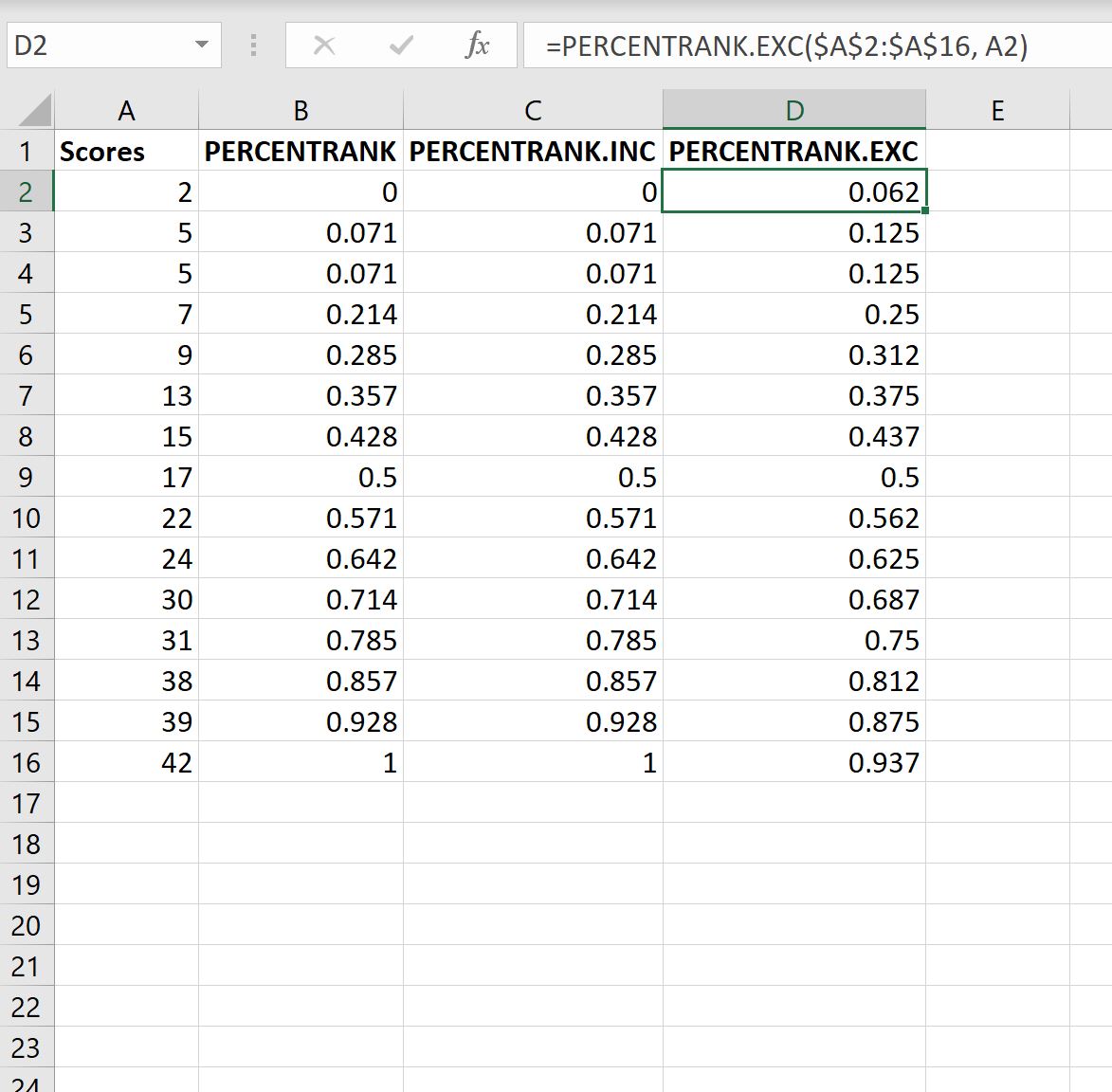
Здесь следует отметить две вещи:
1. Функция ПРОЦЕНТИЛЬ.ВКЛ возвращает точно такие же значения, что и функция ПРОЦЕНТИЛЬ .
2. Функция ПРОЦЕНТИЛЬ.ИСКЛ не возвращает значение 0 и 1 для наименьшего и наибольшего значений в наборе данных соответственно.
Полную документацию по функции ПРОЦЕНТРАНГ в Excel вы можете найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как преобразовать Z-баллы в процентили в Excel
Как рассчитать среднее и стандартное отклонение в Excel
Как рассчитать межквартильный диапазон в Excel
Процентиль — это статистическая метрика, которая часто используется при работе с данными.
Она дает нам представление о положении конкретной точки данных, в отношении ко всему массиву этих данных (т.е. о позиции/ранге в наборе данных).
В практической жизни я видел, как процентиль используется на конкурсных экзаменах, где по заданному баллу вы получаете процентиль. Он позволяет вам понять, на каком месте вы находитесь по сравнению со всеми остальными людьми, которые сдавали этот экзамен.
В этой статье я расскажу все, что вам нужно знать о функциях для вычисления процентиля в Excel, и покажу примеры расчета 90-го процента или 50-го процента в Excel.
Итак, давайте приступим!
Содержание
- Что такое процентиль? Простое объяснение!
- Функции для вычисления ПРОЦЕНТИЛЯ в Excel
- PERCENTILE.INC vs PERCENTILE.EXC —вчемразница?
Что такое процентиль? Простое объяснение!
Процентиль говорит вам об относительном положении точки данных в отношении ко всему набору этих данных.

Например, у нас есть оценки 100 студентов и мы знаем, что 90-й процентиль равен 84, это означает, что если кто-то набрал 84 балла, то его оценка будет выше 90% студентов.
Также и здесь, если 50-й процентиль равен 60, это означает, что любой, кто получил оценку 60, получил оценку выше 50% людей с более низкими баллами и ниже 50% людей с более высокими.
Такой метод лучше, чем просто оценка, потому что он дает более широкое понимание относительно всех имеющихся данных.
Например, если я скажу вам, что ваш балл — 90, вы не поймете, где вы находитесь относительно других. Но если я скажу вам, что процентиль вашего балла — 90-й, вы сразу поймете, что справились лучше, чем 90% людей, сдававших экзамен.
Рассчитать процентиль в Excel очень просто, так как в нем есть встроенные функции для этого.
Функции для вычисления ПРОЦЕНТИЛЯ в Excel
В Excel существует три варианта как можно рассчитать процентиль. Если вы используете Excel 2010 или последующие версии, вы сможете использовать все три функции.
- PERCENTILE — это старая функция, которая на данный момент не используется. Вы, конечно, можете использовать ее, но лучше использовать новые (если они есть в вашей версии Excel). Аргумент k для этой функции является значением между 0 и 1.
- PERCENTILE.INC — это новая функция (которая работает точно так же, как функция PERCENTILE). В большинстве случаев лучше использовать именно эту функцию. Аргумент k для этой функции является значением между 0 и 1.
- PERCENTILE.EXC — работает также как функция PERCENTILE.INC с одним отличием — аргументом k для этой функции будет значение от 0 до 1, но исключает значения K от 0 до 1/(N+1), а также от N/(N+1) до 1 (где N — размер выборки).
Проще говоря, используйте функцию PERCENTILE.INC (а если вы используете Excel 2007 или предыдущие версии, используйте функцию PERCENTILE).
Ниже приведен синтаксис функции PERCENTILE.INC в Excel:
=PERCENTILE.INC(массив;k) где:
- array- это диапазон ячеек, в которых находятся значения, для которых нужно узнать K-й процентиль.
- k — это значение между 0 и 1(или вы можете указать %), которое задает k-й процентиль. Например, если вы хотите рассчитать 90-ый процентиль, это будет 0,9 или 90%, а для 50-го процентиля это будет 0,5 или 50%.
Синтаксис остается таким же для функций PERCENTILE и PERCENTILE.EXC.
Вычисление 90-го процентиля в Excel (или 50-го процентиля)
Допустим, у вас есть набор данных, как показано на картинке ниже, и вы хотите вычислить 90-ый процентиль для этого набора данных.
Ниже приведена формула для вычисления 90-го процентиля:
=PERCENTILE.INC(A2:A21;90%) 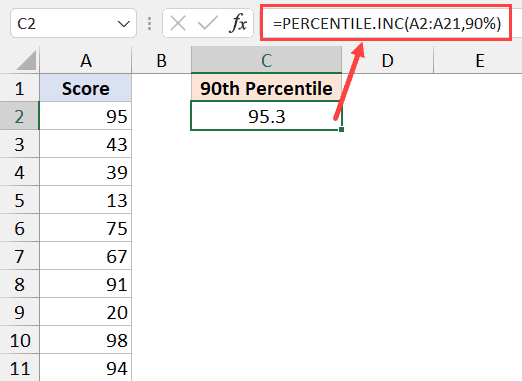
В приведенной выше формуле я использовал 90% в качестве значения k. Также можно использовать 0,9, чтобы вычислить 90-й процентиль.
Результат этой формулы указывает, что 90% значений в этом наборе данных лежит ниже 95,3.
Обратите внимание, что для работы этой формулы вам не нужно сортировать данные. Сортировка и выдача конечного результата — это то, что функция PERCENTILE делает автоматически.
Точно также, если нужно вычислить 50-й процентиль, можно использовать приведенную ниже формулу:
=PERCENTILE.INC(A2:A21;50%) PERCENTILE.INC vs PERCENTILE.EXC — в чем разница?
Если вам интересно, почему в Excel существуют две отдельные функции процентиля, сейчас я это объясню.
Когда вы используете функцию PERCENTILE.INC, она вычисляет процентиль, используя первое и последнее значение в наборе данных. Если же вам нужно исключить первое и последнее значение из расчета, вам нужно использовать функцию PERCENTILE.EXC.
В большинстве случаев можно использовать функцию PERCENTILE.INC.
Но раз уж мы заговорили о разнице между этими функциями, я наглядно продемонстрирую её.
Допустим, у нас есть набор данных, как показано на картинке ниже, где я рассчитал разные процентили (в столбце C), используя как функцию PERCENTILE.INC, так и функцию PERCENTILE.EXC.
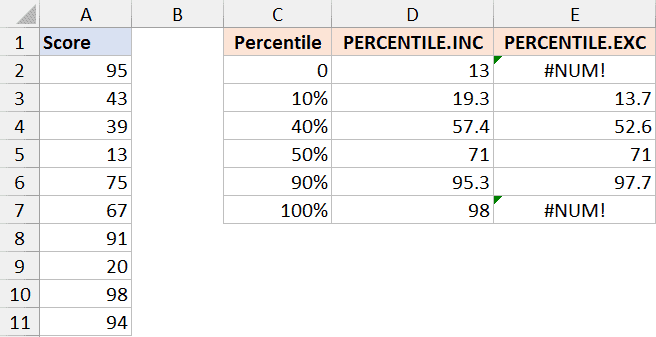
Как вы можете заметить, помимо того что результаты каждой функции разные, еще и функция PERCENTILE.EXC возвращает ошибку #NUM!, когда мы пытаемся вычислить 0-ой и 100-ый процентиль.
На самом деле, функция PERCENTILE.EXC выдаст ошибку для любого значения между:
- 0 и 1/(N+1)
- N/(N+1) и 1
где N — количество строк данных в наборе(таблице) (10 в данном примере).
Таким образом, функция выдаст ошибку #NUM! для любых K значений, лежащих между 0 и 1/11 или 10/11 и 1.
Поэтому хорошо что функция PERCENTILE.EXC существует, но в большинстве случаев мы будем использовать функцию PERCENTILE или PERCENTILE.INC.
Надеюсь, вам помогло данное руководство!
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
|
Функция |
Описание |
|
СРОТКЛ |
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего. |
|
СРЗНАЧ |
Возвращает среднее арифметическое аргументов. |
|
СРЗНАЧА |
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения. |
|
СРЗНАЧЕСЛИ |
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию. |
|
СРЗНАЧЕСЛИМН |
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям. |
|
БЕТА.РАСП |
Возвращает интегральную функцию бета-распределения. |
|
БЕТА.ОБР |
Возвращает обратную интегральную функцию указанного бета-распределения. |
|
БИНОМ.РАСП |
Возвращает отдельное значение вероятности биномиального распределения. |
|
БИНОМ.РАСП.ДИАП |
Возвращает вероятность пробного результата с помощью биномиального распределения. |
|
БИНОМ.ОБР |
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему. |
|
ХИ2.РАСП |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.РАСП.ПХ |
Возвращает одностороннюю вероятность распределения хи-квадрат. |
|
ХИ2.ОБР |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.ОБР.ПХ |
Возвращает обратное значение односторонней вероятности распределения хи-квадрат. |
|
ХИ2.ТЕСТ |
Возвращает тест на независимость. |
|
ДОВЕРИТ.НОРМ |
Возвращает доверительный интервал для среднего значения по генеральной совокупности. |
|
ДОВЕРИТ.СТЬЮДЕНТ |
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента. |
|
КОРРЕЛ |
Возвращает коэффициент корреляции между двумя множествами данных. |
|
СЧЁТ |
Подсчитывает количество чисел в списке аргументов. |
|
СЧЁТЗ |
Подсчитывает количество значений в списке аргументов. |
|
СЧИТАТЬПУСТОТЫ |
Подсчитывает количество пустых ячеек в диапазоне. |
|
СЧЁТЕСЛИ |
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
|
СЧЁТЕСЛИМН |
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
|
КОВАРИАЦИЯ.Г |
Возвращает ковариацию, среднее произведений парных отклонений. |
|
КОВАРИАЦИЯ.В |
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных. |
|
КВАДРОТКЛ |
Возвращает сумму квадратов отклонений. |
|
ЭКСП.РАСП |
Возвращает экспоненциальное распределение. |
|
F.РАСП |
Возвращает F-распределение вероятности. |
|
F.РАСП.ПХ |
Возвращает F-распределение вероятности. |
|
F.ОБР |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ОБР.ПХ |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ТЕСТ |
Возвращает результат F-теста. |
|
ФИШЕР |
Возвращает преобразование Фишера. |
|
ФИШЕРОБР |
Возвращает обратное преобразование Фишера. |
|
ПРЕДСКАЗ |
Возвращает значение линейного тренда. Примечание: В Excel 2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями. |
|
ПРЕДСКАЗ.ETS |
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS). |
|
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ |
Возвращает доверительный интервал для прогнозной величины на указанную дату. |
|
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ |
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду. |
|
ПРЕДСКАЗ.ETS.СТАТ |
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда. |
|
ПРЕДСКАЗ.ЛИНЕЙН |
Возвращает будущее значение на основе существующих значений. |
|
ЧАСТОТА |
Возвращает распределение частот в виде вертикального массива. |
|
ГАММА |
Возвращает значение функции гамма |
|
ГАММА.РАСП |
Возвращает гамма-распределение. |
|
ГАММА.ОБР |
Возвращает обратное значение интегрального гамма-распределения. |
|
ГАММАНЛОГ |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАММАНЛОГ.ТОЧН |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАУСС |
Возвращает значение на 0,5 меньше стандартного нормального распределения. |
|
СРГЕОМ |
Возвращает среднее геометрическое. |
|
РОСТ |
Возвращает значения в соответствии с экспоненциальным трендом. |
|
СРГАРМ |
Возвращает среднее гармоническое. |
|
ГИПЕРГЕОМ.РАСП |
Возвращает гипергеометрическое распределение. |
|
ОТРЕЗОК |
Возвращает отрезок, отсекаемый на оси линией линейной регрессии. |
|
ЭКСЦЕСС |
Возвращает эксцесс множества данных. |
|
НАИБОЛЬШИЙ |
Возвращает k-ое наибольшее значение в множестве данных. |
|
ЛИНЕЙН |
Возвращает параметры линейного тренда. |
|
ЛГРФПРИБЛ |
Возвращает параметры экспоненциального тренда. |
|
ЛОГНОРМ.РАСП |
Возвращает интегральное логарифмическое нормальное распределение. |
|
ЛОГНОРМ.ОБР |
Возвращает обратное значение интегрального логарифмического нормального распределения. |
|
МАКС |
Возвращает наибольшее значение в списке аргументов. |
|
МАКСА |
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МАКСЕСЛИ |
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек. |
|
МЕДИАНА |
Возвращает медиану заданных чисел. |
|
МИН |
Возвращает наименьшее значение в списке аргументов. |
|
МИНЕСЛИ |
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек. |
|
МИНА |
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МОДА.НСК |
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных. |
|
МОДА.ОДН |
Возвращает значение моды набора данных. |
|
ОТРБИНОМ.РАСП |
Возвращает отрицательное биномиальное распределение. |
|
НОРМ.РАСП |
Возвращает нормальное интегральное распределение. |
|
НОРМ.ОБР |
Возвращает обратное значение нормального интегрального распределения. |
|
НОРМ.СТ.РАСП |
Возвращает стандартное нормальное интегральное распределение. |
|
НОРМ.СТ.ОБР |
Возвращает обратное значение стандартного нормального интегрального распределения. |
|
ПИРСОН |
Возвращает коэффициент корреляции Пирсона. |
|
ПРОЦЕНТИЛЬ.ИСКЛ |
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа). |
|
ПРОЦЕНТИЛЬ.ВКЛ |
Возвращает k-ю процентиль для значений диапазона. |
|
ПРОЦЕНТРАНГ.ИСКЛ |
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы). |
|
ПРОЦЕНТРАНГ.ВКЛ |
Возвращает процентную норму значения в наборе данных. |
|
ПЕРЕСТ |
Возвращает количество перестановок для заданного числа объектов. |
|
ПЕРЕСТА |
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов. |
|
ФИ |
Возвращает значение функции плотности для стандартного нормального распределения. |
|
ПУАССОН.РАСП |
Возвращает распределение Пуассона. |
|
ВЕРОЯТНОСТЬ |
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов. |
|
КВАРТИЛЬ.ИСКЛ |
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы. |
|
КВАРТИЛЬ.ВКЛ |
Возвращает квартиль набора данных. |
|
РАНГ.СР |
Возвращает ранг числа в списке чисел. |
|
РАНГ.РВ |
Возвращает ранг числа в списке чисел. |
|
КВПИРСОН |
Возвращает квадрат коэффициента корреляции Пирсона. |
|
СКОС |
Возвращает асимметрию распределения. |
|
СКОС.Г |
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего. |
|
НАКЛОН |
Возвращает наклон линии линейной регрессии. |
|
НАИМЕНЬШИЙ |
Возвращает k-ое наименьшее значение в множестве данных. |
|
НОРМАЛИЗАЦИЯ |
Возвращает нормализованное значение. |
|
СТАНДОТКЛОН.Г |
Вычисляет стандартное отклонение по генеральной совокупности. |
|
СТАНДОТКЛОН.В |
Оценивает стандартное отклонение по выборке. |
|
СТАНДОТКЛОНА |
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения. |
|
СТАНДОТКЛОНПА |
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения. |
|
СТОШYX |
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. |
|
СТЬЮДРАСП |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.2Х |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.ПХ |
Возвращает t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ОБР |
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы. |
|
СТЬЮДЕНТ.ОБР.2Х |
Возвращает обратное t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ТЕСТ |
Возвращает вероятность, соответствующую проверке по критерию Стьюдента. |
|
ТЕНДЕНЦИЯ |
Возвращает значения в соответствии с линейным трендом. |
|
УРЕЗСРЕДНЕЕ |
Возвращает среднее внутренности множества данных. |
|
ДИСП.Г |
Вычисляет дисперсию по генеральной совокупности. |
|
ДИСП.В |
Оценивает дисперсию по выборке. |
|
ДИСПА |
Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
|
ДИСПРА |
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
|
ВЕЙБУЛЛ.РАСП |
Возвращает распределение Вейбулла. |
|
Z.ТЕСТ |
Возвращает одностороннее значение вероятности z-теста. |


Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.
Статьи по теме
Excel (по категориям)
Excel (по алфавиту)
Процентили
— это характеристики набора данных, которые выражают ранги элементов массива в виде чисел от 1 до 100, и являются показателем того, какой процент значений находится ниже определенного уровня.
Например, значение 30-й процентили указывает, что 30% значений располагается ниже этого уровня.
На конкретном примере поясним понятие процентиля:
Пример 1 . Группа студентов из 20 человек получила на экзамене по статистике следующие балы: три студента — 5 баллов, 8 студентов — 4 балла, 6 студентов — 3 бала и 3 студента — 2 балла. Вычислить процентиль успеваемости каждого студента.
Решение.
Формула процентиля
Процентиль = n(x≤X)/N*100
n(x≤X) — число студентов, получивших бал не менее X ,
X — количество балов конкретного студента, процентиль которого находим ,
N — число всех студентов .
Для удобства вычислений ранжируем выборку балов от максимального значения до минимального ( в порядке убывания): 5,5,5,4,4,4,4,4,4,4,4,3,3,3,3,3,3,2,2,2
Допустим нам необходимо определить процентиль студента Иванова получившего на экзамене 5 баллов:
Находим n(x≤X)=n(x≤5)=20 — т.е. 20 студентов получили бал не выше 5, тода
Процентиль (Иванова) = 20/20*100=100
Допустим необходимо определить процентиль студента Петрова получившего на экзамене 4 балла:
Находим n(x≤X)=n(x≤4)=17 — т.е. 17 студентов получили бал не выше 4, тода
Процентиль (Петрова) = 17/20*100=85
Допустим необходимо определить процентиль студента Сидорова получившего на экзамене 3 балла:
Находим n(x≤X)=n(x≤3)=9 — т.е. 9 студентов получили бал не выше 3, тода
Процентиль (Иванова) = 9/20*100=45
После расчета процентиля можно составить таблицу стандартизации. Для наших баллов она будет выглядеть следующим образом:
Алгоритм расчета процентилей
1. Для каждого человека посчитать, какое количество человек набрало столько же или меньше баллов.
2. Посчитать сколько процентов составляет это количество от всей выборки.
Процентиль – это процент людей из выборки, набравших столько же или меньше баллов, чем конкретный человек.
Процентиль является достаточно распространенной шкалой стандартизации, среди психологов, социологов, биологов, медиков и т.д., т.к. очень удобен и понятен. Его диапазон от 1 до 100.
Процентили указывают на относительное положение индивида в выборке стандартизации. Их также можно рассматривать, как ранговые градации, общее число которых равно 100, с той лишь разницей, что при ранжировании принято начинать отсчет сверху, т.е. с лучшего члена группы, получающего ранг 1. В случае же процентилей отсчет ведется снизу, поэтому, чем ниже процентиль, тем хуже позиция индивида.
Процентиль может использоваться для стандартизации как нормально распределенных случайных величин СВ, так и данных с ненормальным распределением.
Расчет процентилей в Excel
Для расчета процентилей нам понадобится функция СЧЕТЕСЛИ.
Для расчета, для каждого значения нужно ввести формулу:
=(СЧЁТЕСЛИ(диапазон;условие)*100)/N , где N – количество человек.
Процентили в EXCEL
Рассмотрим понятие процентиля, функцию ПРОЦЕНТИЛЬ.ВКЛ() , процентиль-ранг и построим кривую процентилей.
Сначала разберемся на примерах, что такое процентиль , затем рассмотрим соответствующие функции MS EXCEL.
Задача. Проектируют койку на круизном лайнере. Необходимо, чтобы 95% пассажиров помещались на койке в полный рост. Как вычислить длину койки?
Для решения задачи потребуется найти рост, ниже которого 95% населения. Для этого нужно сделать репрезентативную выборку , скажем, из 2000 человек, отсортировать значения выборки по возрастанию , потом определить значение с позицией равной 1901 (2000*95%+1). Пусть найденный рост оказался равен 190 см. Ответ : Длина койки должна быть 190 см (+ запас для комфортного размещения на койке).
Значение 190 см называется 95%-й процентилью данной выборки , т.е. 95% опрошенных людей имеет рост 100) обычно наблюдается хорошее соответствие. Повторы значений также могут привести к несоответствию значения процентиля и соответствующего % значений (см. ниже).
Примечание : Процентили часто называют перцентилями (с этим соглашается и MS WORD) или центилями . В версии MS EXCEL 2007 и более ранних использовалась функция ПЕРСЕНТИЛЬ() , которая оставлена для совместимости. Но, начиная с версии EXCEL 2010, появились функции ПРОЦЕНТИЛЬ.ВКЛ() и ПРОЦЕНТИЛЬ.ИСКЛ() – английское название PERCENTILE.EXC(), а Условное форматирование предлагает настроить правило с использованием именно процентилей . В свою очередь, надстройка Пакет Анализа имеет инструмент Ранг и Персентиль .  Google также отдает предпочтение процентилям , выдавая гораздо больше результатов на запрос «процентиль», чем на запрос «перцентиль» (на начало 2016 года).
Google также отдает предпочтение процентилям , выдавая гораздо больше результатов на запрос «процентиль», чем на запрос «перцентиль» (на начало 2016 года).
Таким образом, для процентилей используется 3 названия: процентиль (MS EXCEL, Google) , персентиль (MS EXCEL) , перцентиль (MS WORD) .
Ниже детально рассмотрим как работает функция ПРОЦЕНТИЛЬ.ВКЛ() и создадим ее аналог с помощью альтернативной формулы. Также рассмотрим функцию ПРОЦЕНТРАНГ.ВКЛ() и кривую процентилей .
СОВЕТ : Нижеследующие разделы следует читать пользователям, владеющими базовыми понятиями математической статистики (случайная величина, функция распределения) .
Функция ПРОЦЕНТИЛЬ.ВКЛ()
Начиная с версии MS EXCEL 2010 для расчета процентилей используется функция ПРОЦЕНТИЛЬ.ВКЛ() – английское название PERCENTILE.INC(). В более ранних версиях MS EXCEL использовался ее аналог — функция ПЕРСЕНТИЛЬ() .
Напомним определение процентиля , данное выше: K-й Процентиль представляет такое собой значение Х в наборе данных, которое разделяет набор на две части: одна часть содержит K% данных, меньших Х , а другая часть содержит все остальные значения набора (т.е. 1- K % данных б о льших Х).
Разберем детально как работает функция ПРОЦЕНТИЛЬ.ВКЛ() .
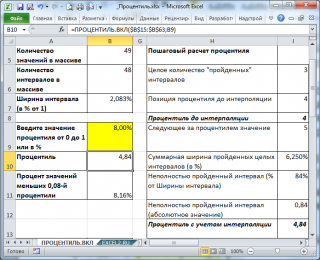
Пусть имеется массив значений ( выборка ). В массиве 49 значений, массив расположен в диапазоне B15:B63 , имеются повторы значений , массив для удобства отсортирован по возрастанию (см. файл примера , лист ПРОЦЕНТИЛЬ.ВКЛ ). 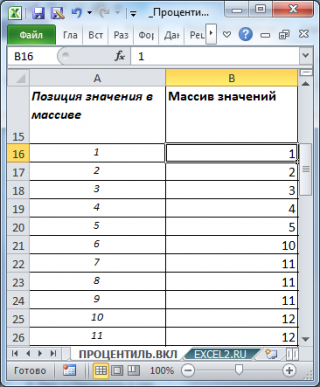
Рассчитаем 0,08-ю процентиль ( 8%-процентиль ) с помощью формулы =ПРОЦЕНТИЛЬ.ВКЛ(B15:B63; 0,08) . Получим, что 0,08-я процентиль равна 4,84.
Проанализируем, что мы получили.
- Во-первых, значения 4,84 нет в массиве (есть 4 и 5), т.е. функция ПРОЦЕНТИЛЬ.ВКЛ() интерполирует значения.
- Во-вторых, процент значений меньших 4,84 равен не точно 8%, а 8,16%=4/49*100% (т.к. всего 4 значения в массиве меньше 4,84). Это произошло, т.к. в выборке относительно мало значений.
- Другой причиной расхождения могут стать повторы. Например, заменив, первые 4 значения в массиве (т.е. 1; 2; 3; 4) числом 5, мы получим вместо 8,16% — 0%. Это произошло потому, что теперь 0,08-я процентиль равна 5, а в выборке нет ни одного значения меньше 5.
Как видно из рисунка ниже первое значение ( минимальное , равное 1) является 0-й процентилью . 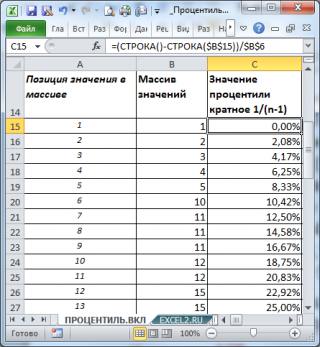
Соответственно, 1-й процентилью (100% процентилью ), является максимальное значение равное 120 (см. файл примера лист ПРОЦЕНТИЛЬ.ВКЛ).
Как видно из рисунка, следующее за минимальным значением (т.е. число 2) является 0,0208-й процентилью . Значение 0,0208 или 2,08% — это (k-1)*1/(n-1), где n – это количество значений в массиве (в нашем массиве n=49), а k – это позиция числа в массиве (в данном случае k=2, где 2 – это позиция, а не само число).
Поясним эту формулу. Для вычисления процентили принимается, что весь диапазон значений массива (от мин до макс) разбит n значениями на равные интервалы (их всего n-1). Соответственно, 1/(n-1), это «ширина» интервала (весь диапазон равен 1 или 100%). Обратите внимание, что «ширина» интервала не зависит от данных, а только от их количества. В нашем случае «ширина» интервала равна 0,0208 или 2,08%.
Приведем алгоритм расчета 12,50%-процентили функцией ПРОЦЕНТИЛЬ.ВКЛ() (см. ячейку С21 ):
- ПРОЦЕНТИЛЬ.ВКЛ() определяет «ширину» интервала (в долях или процентах): =1/(49-1)=0,0208;
- подсчитывает Количество интервалов , которые были укладываются в 12,50%, т.е. =12,50%/2,08%=6 (значение процентиля кратно ширине интервала, т.е. делится нацело);
- 6-й интервал располагается между числами массива 10 и 11. Верхняя граница последнего 6-го интервала равна 11;
- Следовательно, 12,50%-я процентиль равна 11 (см. ячейку B21 ).
По аналогии с непрерывной функцией распределения (см. статью про квантили ), получается, что 12,50% значений должно быть меньше полученного числа 11 (в соответствии с определением процентиля ). Фактически получается, что таких значений 6 (1; 2; 3; 4; 5; 10) и процент значений меньших 11 равен 12,24%=6/49 (причины расхождения: повторы и небольшое количество значений).
Если значение процентиля не кратно ширине интервала (ширина интервала равна 1/(n-1)), то имеет место интерполирование. Например, вспомним результат вычисления 0,08-й процентили равный 4,84. Значение процентили (т.е. не результат, а %) равно 0,08 (8%), что соответствует 3-м целым интервалам (8%/2,08%= 3 ,84) и некой доли (0,84) от ширины следующего интервала. Границами этого «неполного» интервала являются значения 4 ( 0,0625-я процентиль ) и 5 ( 0,0833-я процентиль ). Т.к. разница между 5 и 4 равна 1, то умножая «пройденную» долю интервала (0,84) на длину интервала в абсолютных значениях (=5-4=1), получаем 0,84. В итоге получаем 4,84: 4 – левая граница интервала + часть следующего (5-4)*0,84.
Если бы в массиве вместо 5 было значение 6, то значение 0,08-й процентили было бы равно 5,68 (4 – левая граница интервала + (6-4)*0,84=1,68).
Альтернативный расчет процентили с помощью формул приведен в файле примера . 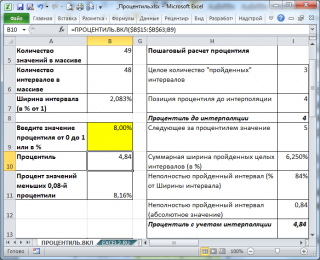
Примечание : Некоторые значения процентилей имеют специальные названия:
- 25-я процентиль называется 1-й квартилью;
- 50-я процентиль называется Медианой (2-я квартиль);
- 75-я процентиль называется 3-й квартилью.
Функция ПРОЦЕНТРАНГ.ВКЛ() и Кривая процентилей
Функция ПРОЦЕНТРАНГ.ВКЛ() используется для оценки относительного положения значения в массиве. Для заданного значения функция вычисляет сколько значений в массиве меньше или равно ему. Точнее — какой процент значений массива меньше или равен ему. Результат функции называется процентиль-ранг (percentile rank) . Понятно, что для максимального значения процентиль-ранг равен 0,00%, а для наименьшего — 100% (все значения массива меньше или равны ему).
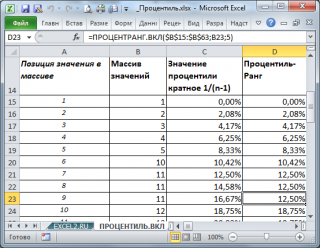
Функция ПРОЦЕНТРАНГ.ВКЛ() , английская версия – PERCENTRANK(), является, в каком-то смысле, обратной функции ПРОЦЕНТИЛЬ.ВКЛ() : т.е. задавая в качестве аргумента значение из массива, функция ПРОЦЕНТРАНГ.ВКЛ() вернет значение процентили кратной 1/(n-1). 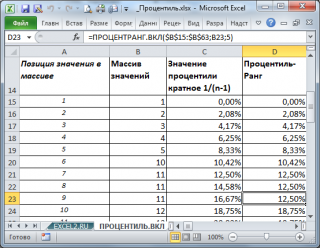
Как видно из рисунка выше, для повторяющихся значений функция ПРОЦЕНТРАНГ.ВКЛ() вернет, естественно, одинаковые значения. Также поступает функция РАНГ.РВ() или РАНГ() (см. статью Функция РАНГ() в MS EXCEL ).
Действительно, функции РАНГ.РВ() и ПРОЦЕНТРАНГ.ВКЛ() очень похожи. Первая возвращает позицию числа в массиве в зависимости от его значения. Вторая, в принципе, делает тоже самое, но результат выводится в % от общего количества значений в массиве. 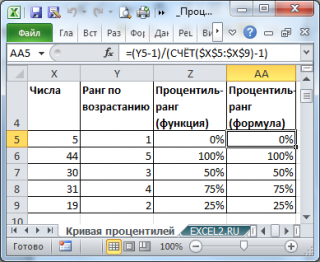
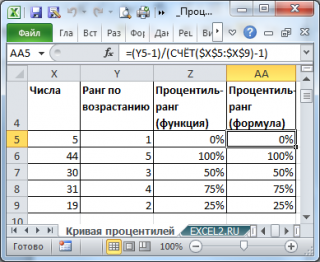
Как видно из картинки выше, чтобы получить процентиль-ранг необходимо значение ранга уменьшить на 1 и разделить на n-1. Значение ранга , естественно, должно быть отсортировано по возрастанию .
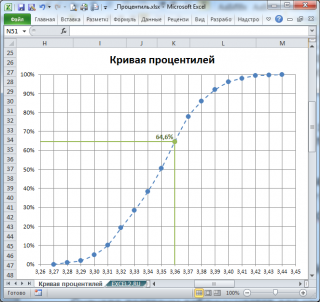
По выборке можно оценить функцию распределения Генеральной совокупности , из которой взята данная выборка. Для этой цели построим Кривую процентилей (percentile curve или percentile rank plot). 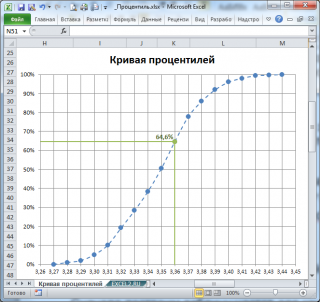 Кривая процентилей представляет собой график зависимости процентиль-ранга от значений выборки .
Кривая процентилей представляет собой график зависимости процентиль-ранга от значений выборки .
Возьмем выборку состоящую из 100 значений (см. файл примера лист Кривая процентилей ). Значения содержатся в диапазоне А5:А104 . 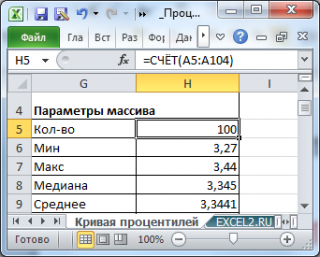
Сначала построим таблицу частот для каждого из значений выборки .
Примечание : В отличие от Гистограммы , где кумулятивная таблица частот строится для интервалов значений, таблицу частот для Кривой процентилей строят для каждого из значений выборки . 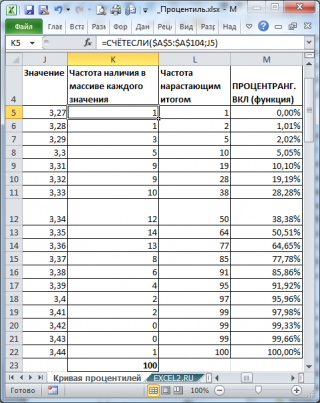
Из таблицы видно (столбец Частота нарастающим итогом ), что примерно 1 процент значений меньше или равен значения 3,27, примерно 2 процента на уровне или ниже 3,28, 5 процентов на уровне или ниже 3,29, и так далее. График Кривой процентилей для этих данных приведен на картинке ниже.
СОВЕТ : Про построение графиков см. статью Основные типы диаграмм .
Следует отметить, что использование данных из таблицы приведет к точечному виду кривой (так как процентиль-ранг будет изменяться скачком для каждого значения выборки ). Поэтому, сглаженная кривая, построенная на основе этих данных будет лучше представлять оцениваемую функцию распределения (пунктирная кривая).
Построив пунктирную кривую, становится ясно, зачем нам пришлось вводить понятие процентиль-ранга: процентиль-ранг – является приблизительной вероятностью выбрать случайную величину меньше или равную соответствующему значению (сравните с определением функции распределения). Это, в частности следует из расчета процентиль-ранга по формуле =СЧЁТЕСЛИ($A$5:$A$104;» 100 значений).
Примечание : Формула =(РАНГ.РВ(A5;$A$5:$A$104;1)-1)/ (СЧЁТ($A$5:$A$104)-1) эквивалентна формуле =ПРОЦЕНТРАНГ.ВКЛ($A$5:$A$104;A5;5)
КВАРТИЛЬ: какие формулы расчета использует Excel
Квартиль — одна из статистик, используемая при описании выборок (подробнее о различных статистиках см. Определение среднего значения, вариации и формы распределения. Описательные статистики). В то время как медиана разделяет упорядоченный массив пополам, квартили разбивают набор данных на четыре части. Первый квартиль – это число, разделяющее выборку на две части: 25% элементов меньше, а 75% — больше значения первого квартиля. Третий квартиль — это число, разделяющее выборку также на две части: 75% элементов меньше, а 25% — больше третьего квартиля.

Рис. 1. 5-числовые сводки: М – медиана, Н1 и Н2 – сгибы (они же квартили)
Скачать заметку в формате Word или pdf, примеры в формате Excel (файл содержит код VBA).
Для расчета квартилей в Excel2007 и более ранних версиях использовалась функция КВАРТИЛЬ. Начиная с версии Excel2010 применяются две функции: КВАРТИЛЬ.ВКЛ и КВАРТИЛЬ.ИСКЛ (функция КВАРТИЛЬ оставлена для совмещения с более ранними версиями Excel; эта функция возвращает те же значения, что и КВАРТИЛЬ.ВКЛ). Эти две функции возвращают различные значения, но я нигде не нашел, какой алгоритм они используют при расчетах. Замечу, что для корректной работы функций данные можно не упорядочивать.
Изучение литературы показало, что в отличие от большинства других статистик, единодушия в методике расчета квартилей нет)) Я нашел упоминание о девяти различных подходах…
Начнем с метода Джона Тьюки, описанного им в, уже ставшем классическом, труде Анализ результатов наблюдений. Разведочный анализ, изданном в 1977 г. Он начинает с введения трех сводок, характеризующих выборку: минимальное, максимальное значения и медиана. Далее он продолжает: «Если мы хотим добавить еще два числа, чтобы образовать 5-числовую сводку, то естественно определять их подсчетом до половины расстояния от каждого из концов к медиане. Процесс нахождения медианы, а затем и этих новых значений можно представить себе, как складывание листа бумаги. Поэтому эти новые значения естественно назвать сгибами» (англ. – hinge; рис. 1). Мы их называем квартилями.
Такие рисунки выглядят очень аккуратно, если число элементов выборки N = 4k + 1, например, 9, 13, 17… Но как быть, если в выборке 12 или 19 элементов? Наглядную картину представил Jon Peltier в серии заметок в своем блоге. Упорядочим элементы случайной выборки и разместим их над линейкой (рис. 2; случайная выборка, элементы которой упорядочены называется вариационным рядом). Серые числа под линейкой – индекс ряда (Джон зачем-то в качестве выборки – над линейкой – взял ряд целых чисел; наверное, чтобы запутать нас). Красное число над рядом – значение сводки; если оно дробное, значит полученное значение является интерполяцией между соседними значениями. Мы определяем медиану, как среднее значение набора данных, а первую квартиль – как медиану нижней половины данных.

Рис. 2. Инклюзивные квартили
Когда Джон Тьюки впервые предложил такой подход, он решил, что медиана (если число элементов в выборке нечетное) должна быть включена как в нижнюю (левую на рисунке), так и в верхнюю половинку данных при определении медиан этих половинок, то есть сгибов. Поэтому такой подход и называется инклюзивным (с включением).
Эксклюзивный подход. Некоторым статистикам не нравится, что медиана учитывается дважды. Они решили, что сгибы должны быть определены как медианы верхней и нижней половин набора данных, из которых срединное значение исключено (рис. 3). Такой взгляд отстаивали Moore и McCabe, или кратко M&M. Если набор данных содержит четное количество значений, инклюзивные и эксклюзивные квартили равны, так как нет элемента выборки (соответствующего центральной медиане), который можно было бы включить или исключить из рассмотрения. Для нечетного числа элементов, инклюзивные сгибы всегда ближе к медиане.

Рис. 3. Эксклюзивные квартили
Третий подход – компромисс между Тьюки и М&M – называется Эмпирическая функции распределения или Интегральная функция распределения (английская аббревиатура CDF). В случае нечетного числа значений в наборе данных, следует включить или исключить медиану, ориентируясь на то, чтобы оставшиеся половинки содержали нечетное число элементов. Например, если в выборке 9 элементов, медиану следует включить, а при 11 элементах – исключить. В обоих случаях половинки будут содержать по 5 элементов. Преимущество этого компромисса заключается в том, что в качестве значения квартиля всегда получается один из элементов набора данных (а не среднее значение двух соседних элементов). CDF является методом по умолчанию в статистическом пакете SAS.
Все возможные случаи N. Мы не всегда можем изобразить данные в W-образной форме, как на рис. 1, поэтому удобнее пользоваться линейкой. В общем случае возможны четыре варианта по числу элементов в выборке: N = 4k, N = 4k + 1, N = 4k + 2, N = 4k + 3… и три подхода к расчету квартилей: Тьюки, M&M, CDF (рис. 4–7).

Рис. 4. Число элементов в выборке N = 4k; все три метода дают одинаковые значения квартилей

Рис. 5. Число элементов в выборке N = 4k + 1; M&M дает значения, отстоящие дальше от медианы

Рис. 6. Число элементов в выборке N = 4k + 2; все три метода дают одинаковые значения квартилей

Рис. 7. Число элементов в выборке N = 4k + 3
Методы интерполяции. Помимо трех описанных выше методов, применяют и целый ряд индексных алгоритмов. Мы рассмотрим три из них. Первый индекс во всех методах равен 0, а последний – N–1, N, N + 1. Например, для N=8 индексированные ряды представлены на рис. 8.

Рис. 8. Индексные ряды на основе N–1, N и N + 1 для N = 8
Положение перцентиля р – доля длины индексной линии, или р(N–1), рN, р(N+1), соответственно. р = 0,25 соответствует первому квартилю, а р = 0,75 – третьему. Ниже наглядно представлен расчет квартилей при различном числе элементов в выборке и трех методах интерполяции на основе N–1, N и N + 1 (рис. 9, 11–13). Обратите внимание, что рассчитанные числа (по формулам справа от линеек) являются не значениями квартилей, а значениями индексов квартилей. Над линейками показано значение квартилей для ряда значений <1, 2, 3, 4, 5, 6, 7, 8>.

Рис. 9. Число элементов в выборке N = 4k
Если, например, наша выборка <2, 3, 5, 8, 11, 12, 14, 17>, то расчет квартилей на основе N–1-метода даст индексы 1,75, 3,5 и 5,25, и значения квартилей 4,5, 9,5 и 12,5 (рис. 10).

Рис. 10. От индексов к значениям квартилей для N–1-метода и N = 4k

Рис. 11. Число элементов в выборке N = 4k + 1

Рис. 12. Число элементов в выборке N = 4k + 2

Рис. 13. Число элементов в выборке N = 4k + 3
Какой алгоритм считать стандартным для вычисления квартилей?
В 1996 году Роб Дж. Хиндман и Янан Фан опубликовали статью в American Statistician под названием Квантили выборок в статистических пакетах. В ней они рассматривали различные алгоритмы расчета квантилей (квартили – это частный случай квантилей). Их целью было указать методологию, которая могла бы стать стандартом для поставщиков статистического программного обеспечения, чтобы расчет квартилей не зависел от типа пакета. В статье они описали девять методов для расчета квантилей. Таблица показывает некоторые статистические пакеты и используемые в них алгоритмы (рис. 14; таблица, этот раздел заметки и код VBA ниже базируются на тексте с сайта Bacon Bits). Обратите внимание, что R и Maple применяют весь спектр алгоритмов.

Рис. 14. Алгоритмы, используемые в статистических пакетах
Кстати, Хиндман и Фан в завершении своей статьи рекомендовали метод 8 в качестве стандарта для статистических пакетов. По их мнению, этот метод оценки квантиля не зависит от распределения, что делает его наиболее приемлемым для расчета.
Расчет квартилей в Excel
Функция Excel КВАРТИЛЬ.ИСКЛ использует следующую формулу для расчета квартилей:

где Qp – p-й квантиль: p = 0 – для минимального значения, 0,25 – для первого квартиля, 0,5 – для медианы, 0,75 – для третьего квартиля, 1 – для максимального значения;
x – индекс квантиля (может быть дробным); x = (n+1)p, где n – число элементов в выборке; обратите внимание на (n+1), поэтому метод и называется N+1-интерполяция;
i – индекс элемента в упорядоченной выборке; самое большое целое всё еще меньшее, чем x;
Формула для КВАРТИЛЬ.ВКЛ отличается только методом расчета х: x = (n-1)p+1; обратите внимание на (n–1), поэтому метод называется N–1-интерполяция. Подробнее с работой формул можно ознакомиться в приложенном Excel-файле на листе Формулы.
Расчет квартилей в R и SAS
Функция quantile в R использует все девять алгоритмов расчета квантилей, в соответствии с нумерацией, предложенной Hyndman and Fan в работе 1996 г. (рис. 15; если вы не знакомы с R, рекомендую начать с Алексей Шипунов. Наглядная статистика. Используем R!). Квантиль при i-м методе расчета:

где i – номер метода, 1 ≤ i ≤ 9, (j–m)/n ≤ p = 0 And i
Инструменты Excel для построения интервальных оценок параметров распределений
Все, рассмотренные в этом разделе инструменты вычисляют значения квантилей как значения функций, обратных соответствующим функциям распределения. Все эти функции – библиотечные функции Excel из группы функций «Статистические»,.

Функция вычисления критических точек распределения Лапласа

Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) стандартного нормального распределения.
Функция вычисления критических точек распределения Стьюдента
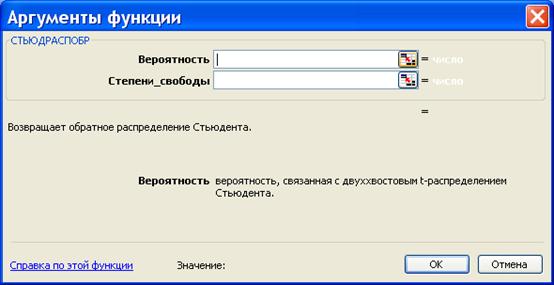
Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) распределения Стьюдента с числом степеней свободы, равным значению, введенному в поле «Степени свободы» (понятно, что это натуральное число).
Важно знать, что функция Excel СТЬЮДРАСПОБР( p , k ) возвращает значение t , при котором P (| x | > t ) = p , x — значение случайной величины, имеющей распределение Стьюдента с k степенями свободы.
Поэтому решение уравнения  в Excel возвращает функция СТЬЮДРАСПОБР( a , n – 1).
в Excel возвращает функция СТЬЮДРАСПОБР( a , n – 1).
Функция вычисления критических точек распределения 
Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) распределения  с числом степеней свободы, равным значению, введенному в поле «Степени свободы» (понятно, что это натуральное число).
с числом степеней свободы, равным значению, введенному в поле «Степени свободы» (понятно, что это натуральное число).
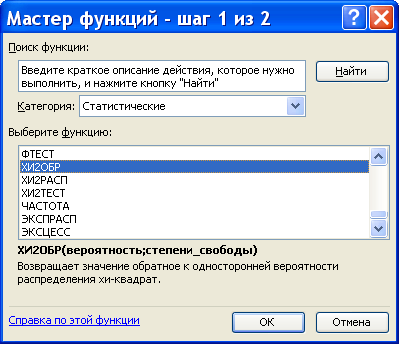
В Excel функция распределения случайной величины определена нестандартно: F x ( x ) = P ( x > x ). Поэтому для вычисления квантиля 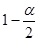 вводим в качестве аргумента функции ХИ2ОБР значение вероятности, равное
вводим в качестве аргумента функции ХИ2ОБР значение вероятности, равное 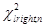 , а для вычисления
, а для вычисления 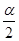 – .
– .
Вычислить процентиль в Excel 2010
Это мой список ниже. Я пытаюсь вычислить 95% звонков, которые вернулись за сколько миллисекунд.
Что означают приведенные выше данные-это-
Теперь я должен выяснить 95% percentile из приведенных выше данных. Что означает 95% времени, звонки возвращались в эти миллисекунды.
Может ли кто-нибудь сказать мне, как это сделать в Excel листе? Спасибо за помощь
Я использую Excel 2010. Я скопировал оба столбца в моем листе Excel, как это делается, чтобы вычислить процент.
Обновление:-
С списке ниже, я получаю 95 percentil Е 66. Так что это означает 95% времени, звонки вернулись в 66 milliseconds , что, наверное, неправильно. Это выглядит для меня 95% времени, звонки вернулись в
Я использую эту формулу-
3 Ответа
Дополнительный столбец упростит вычисления, но вы можете вычислить без него, если хотите.
Предполагая, что миллисекунды в A2:A21 и количество вызовов в B2:B21 можно использовать эту формулу массива
подтверждено с помощью CTRL + SHIFT + ENTER
или эта версия без массива
Я получаю результат 63 с обоими — изменение на 0.75 (75-й процентиль) , и вы получаете 59
Установите новый столбец «количество вызовов в момент времени или ниже» и попросите его вычислить сумму количества вызовов текущей строки плюс все номера вызовов в более высоких строках (более низкие времена). Затем установите столбец рядом с тем, который называется «Percentile», и вычислите его, разделив «Number of Calls at or Below Time» на общее количество принятых вызовов. Независимо от того, какая первая строка показывает процентиль выше, чем 95%, это та, которая содержит 95-й процентиль.
Получите стандартное отклонение времени в миллисекундах и используйте его для (95%
2 x std) подсчитайте количество вызовов ниже
2 стандартных отклонений?
Похожие вопросы:
Я пытаюсь вычислить 95th Percentile из наборов данных, которые я заполнил в моем ниже ConcurrentHashMap . Мне интересно узнать, сколько звонков вернулось в 95-й процентиль времени Моя карта будет.
Я пытаюсь вычислить процентиль для каждого значения в столбце a от DataFrame x . Есть ли лучший способ написать следующий фрагмент кода? x[pcta] = [stats.percentileofscore(x[a].values, i) for i in.
Нам нужно вычислить процентиль (95-й и 99-й) в отчете SSRS на основе общего набора данных, который возвращает агрегированные данные с интервалом в 15 минут. Процентиль должен быть за день в целом.
Этот вопрос здесь, похоже, не помогает: вычисление процентилей (Ruby ) Я хотел бы вычислить 95-й процентиль (или, действительно, любой другой желаемый процентиль) из массива чисел. В конечном счете.
//I have a list of students List Students < lond StudentId; double Marks; int Rank; double Percentile; >Я снабжен идентификатором и метками, и мне нужно вычислить ранг и процентиль.
Я пытаюсь подсчитать, сколько звонков вернулось за 95 процентиль времени. Ниже приведен мой результирующий набор. Я работаю с Excel 2010 Milliseconds Number 0 1702 1 15036 2 14262 3 13190 4 9137 5.
я пытаюсь вычислить 95-й процентиль для нескольких значений качества воды, сгруппированных по водоразделу. например. Watershed WQ 50500101 62.370661 50500101 65.505046 50500101 58.741477 50500105.
Я пытаюсь вычислить процентиль столбца в A DataFrame? Я не могу найти ни одной функции percentile_approx в функциях агрегации Spark. Например, в Hive у нас есть percentile_approx, и мы можем.
Я хочу вычислить 95-й процентиль распределения. Я думаю, что я не могу использовать proc means , потому что мне нужно значение, в то время как выход proc means -это таблица. Я должен использовать.
У меня есть dataframe со столбцом, который имеет числовые значения. Этот столбец плохо аппроксимируется нормальным распределением. Учитывая другое числовое значение, а не в этом столбце, как я могу.