
|
Группа: Пользователи Ранг: Прохожий Сообщений: 7
Замечаний: |

Добрый день! Задача такая: Нужно найти одинаковые индексы, найти их среднее значение и в отсортированном массиве удалить все лишнии, оставив только один. Число индексов имеет свой придел, но он очень большой, будем считать, что они рандомные, но иногда имеют схожость.
П.С. Сортировка происходит руками, вопрос в том, нужно её делать как первый этап или уже как второй?!
Прикрипил пример. Спасибо!
К сообщению приложен файл:
11111.xlsx
(10.4 Kb)
KKKKKKKKK
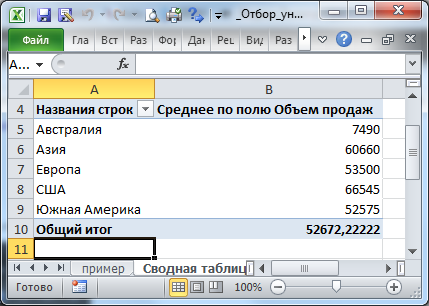
Имеется таблица, состоящая их двух столбцов: из столбца с повторяющимися текстовыми значениями и столбца с числами. Создадим таблицу состоящую только из строк с уникальными текстовыми значениями. По числовому столбцу произведем вычисление среднего.
Разовьем идеи, изложенные в статье
Отбор уникальных значений (убираем повторы)
.
Пусть исходная таблица содержит 2 столбца: текстовый –
Список регионов
и числовой —
Объем продаж
. Столбец
Список регионов
содержит повторяющиеся значения (см.
файл примера
).
Уникальные
значения выделены цветом с помощью
Условного форматирования
.
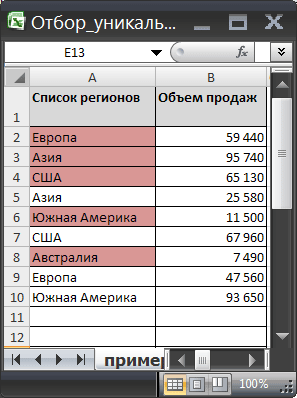
Задача
Создадим на основе исходной, таблицу, в которой в столбце с перечнем регионов будут содержаться только
уникальные
названия регионов (т.е. без повторов), а в соседнем столбце будут вычислены средние продажи для каждого региона.
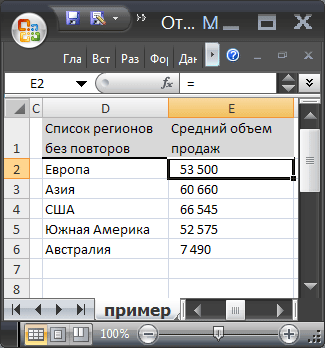
Решение
Создадим
Динамические диапазоны
:
Регионы
(названия регионов из столбца
А
) и
Продажи
(объемы продаж из столбца
B
).
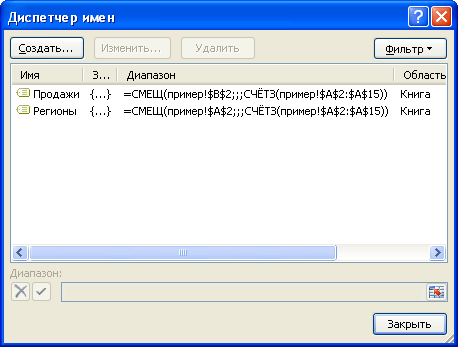
Если в исходный список будет добавлено новое значение, то оно будет автоматически включено в
Динамический диапазон
и нижеследующие формулы не придется модифицировать.
Для создания списка уникальных значений введем в ячейку
D2
формулу массива
:
=ЕСЛИОШИБКА(ИНДЕКС(Регионы; ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$1:D1;Регионы);0));»»)
Для подсчета средних продаж в столбце
E
запишем формулу:
=ЕСЛИОШИБКА(СУММЕСЛИ(Регионы;D2;Продажи)/ СЧЁТЕСЛИ(Регионы;D2);»»)
Отображение нулей в строках, в которых нет регионов, уберем
пользовательским форматом
# ##0;-# ##0; (см. статью
Скрытие значений равных 0
).
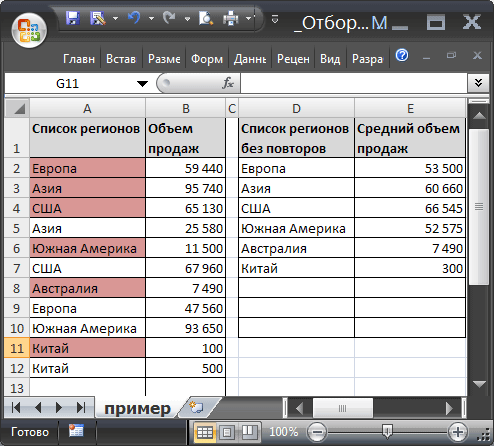
Тестируем
1. Введите в ячейку
А11
новый регион —
Китай
2. Введите объем продаж —
100
3. Введите в
А12
—
Китай
4. Введите объем продаж —
500
5. В соседней таблице справа в ячейке
D7
будет выведено название региона
Китай
со средним объемом продаж
300
СОВЕТ:
Другим подходом к решению этой задачи является использование
Сводных таблиц
.
Skip to content
Зачем считать дубликаты? Мы можем получить ответ на множество интересных вопросов. К примеру, сколько клиентов сделало покупки, сколько менеджеров занималось продажей, сколько раз работали с определённым поставщиком и т.д. Если вы хотите посчитать точное количество повторяющихся записей на листе Excel, используйте один из следующих способов для подсчета дубликатов.
- Подсчет количества каждого из дубликатов.
- Считаем общее количество дубликатов в столбце.
- Количество совпадений по части ячейки.
- Как посчитать количество дубликатов внутри ячейки.
- Подсчет дубликатов строк.
Подсчет количества каждого из дубликатов.
Если у вас, к примеру, есть столбец с наименованиями товаров, вам часто может понадобиться узнать, сколько дубликатов имеется для каждого из них.
Чтобы узнать, сколько раз та или иная запись встречается в вашей рабочей таблице Excel, используйте простую формулу COUNTIF, где A2 — первый, а A8 — последний элемент списка:
=СЧЁТЕСЛИ($A$2:$A$17;A2)
Как показано на следующем снимке экрана, программа подсчитывает вхождения каждого элемента: «Fanta» встречается 2 раза, «Sprite» — 3 раза, и так далее.

Если вы хотите указать на 1- е , 2- е , 3- е и т. д. появление каждого элемента, используйте:
=СЧЁТЕСЛИ($A$2:$A2;A2)
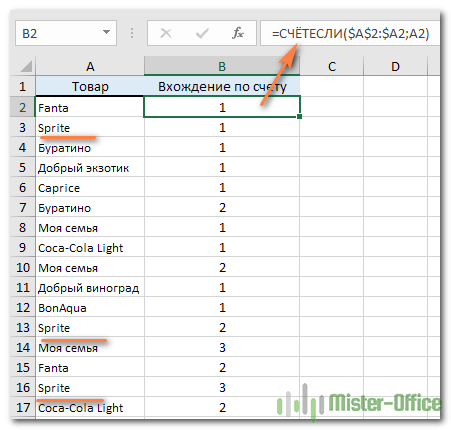
Мы отметили на рисунке первое, второе и третье появление Sprite.
Аналогичным образом вы можете посчитать количество повторяющихся строк. Единственное отличие состоит в том, что вам нужно будет использовать функцию СЧЁТЕСЛИМН() вместо СЧЁТЕСЛИ(). Например:
=СЧЁТЕСЛИМН($A$2:$A$17;A2;$B$2:$B$17;B2;$C$2:$C$17;C2)

На скриншоте мы отметили одинаковые строки.
После подсчета повторяющихся значений вы можете скрыть уникальные и просматривать только одинаковые, или наоборот. Для этого примените автофильтр Excel.
Считаем общее количество дубликатов в столбце.
Самый простой способ подсчета повторений в столбце — это использовать любую из формул, которые мы использовали для идентификации дубликатов в Excel (ссылки смотрите в конце этой статьи). И затем вы можете подсчитать повторы:
=СЧЁТЕСЛИ(диапазон, «Дубликат»)
Пересчитываем метки, которые вы использовали для поиска дубликатов.
В этом примере наше выражение принимает следующую форму:
=СЧЁТЕСЛИ(B2:B17;»Дубликат»)

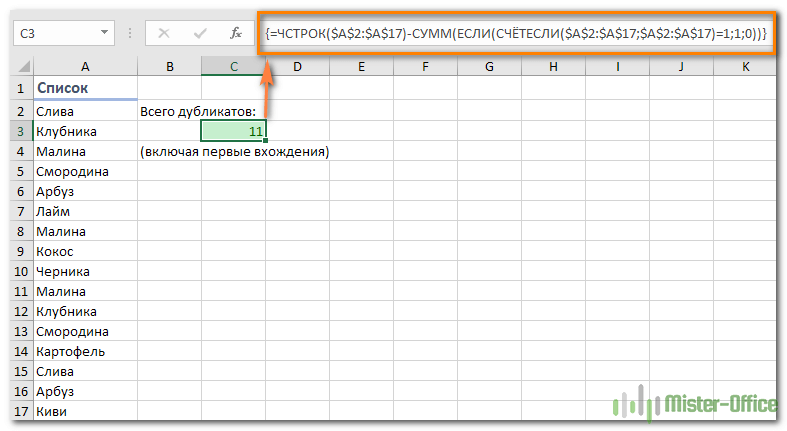
Еще один способ подсчета числа повторений в Excel — с использованием более сложной формулы массива. Преимущество этого подхода в том, что он не требует вспомогательного столбца:
{=ЧСТРОК($A$2:$A$17)-СУММ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17;$A$2:$A$17)=1;1;0))}
Поскольку это формула массива, не забудьте нажать Ctrl + Shift + Enter, чтобы завершить ввод.
Кроме того, имейте в виду, что она подсчитывает все повторяющиеся записи, включая первые вхождения:
Можно обойтись и без формулы маиисва:
=СУММПРОИЗВ(—(СЧЁТЕСЛИ(A2:A17;A2:A17)>1))
Это работает и с текстом, и с числами, а пустые ячейки игнорируются, что также очень полезно.
Теперь давайте посчитаем количество дубликатов без учета их первого появления в таблице.
Здесь также есть два способа. Первый – с использованием вспомогательного столбца В.

В столбце B проставляем соответствующие отметки, как мы это уже не раз делали.
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;»Дубликат»;»»)
Далее определяем количество ячеек, содержимое которых встречается не в первый раз:
=СЧЁТЕСЛИ(B2:B17;»Дубликат»)
или формула массива
{=СЧЁТЗ(A2:A17)-СУММ(1/СЧЁТЕСЛИ(A2:A17;A2:A17))}
Ну а можно пойти от обратного. Считаем количество уникальных записей вот таким простым и элегантным способом:
{=СУММ(1/СЧЁТЕСЛИ(A2:A17;A2:A17))}
Возможно,вам эта формула массива будет полезна при подсчете уникальных значений.
Ну а теперь школьная задачка: если у нас всего 16 слов (можно использовать функцию СЧЁТЗ), и из них 10 – уникальных, то сколько будет неуникальных? Правильно – 6!
Количество совпадений по части ячейки.
Предположим, у нас в ячейке записано не только название товара, но и другая дополнительная информация: товарная группа, номер счёта, единицы измерения и т.п. Как в этом случае подсчитать число упоминаний определённого товара?
Будем проверять часть содержимого, используя функцию СЧЕТЕСЛИ и знаки подстановки.
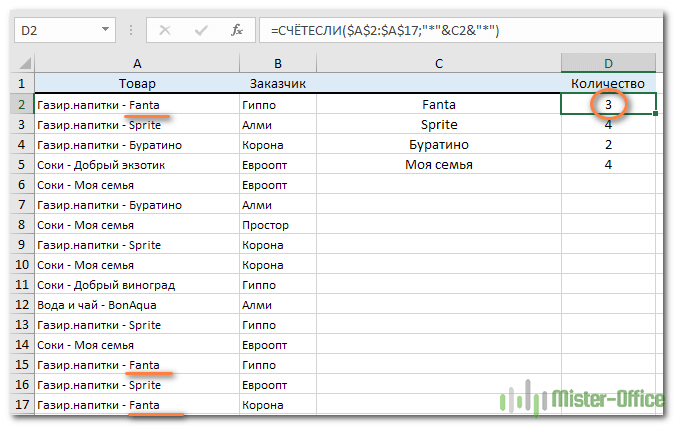
Делаем это так:
=СЧЁТЕСЛИ($A$2:$A$17;»*»&C2&»*»)
Ищем любое вхождение искомого слова при помощи знаков подстановки “*”.
Как посчитать количество дубликатов внутри ячейки.
Случается, что список находится вовсе не в таблице, а в одной ячейке ($A$2):
Рассмотренные нами выше приемы здесь точно не сработают. Но в Excel хватает других возможностей, и все можно сделать так же достаточно просто:

=(ДЛСТР($D$1)-ДЛСТР(ПОДСТАВИТЬ($D$1;D3;»»)))/ДЛСТР(D3)
При помощи ДЛСТР считаем количество символов в ячейке со списком товаров ($A$2)
Затем при помощи ПОДСТАВИТЬ заменяем в указанном тексте заданное слово на пустое «». По умолчанию заменяем все повторы. А фактически – удаляем их.
Теперь наша задача – узнать, сколько слов мы удалили. При помощи ДЛСТР узнаем количество символов, оставшихся в списке после этой замены. Вычитаем из первоначального количества символов количество оставшихся, то есть узнаем, сколько символов было удалено. Делим результат на число букв в искомом слове.
Результат вы видите на скриншоте выше.
Подсчет дубликатов строк.
Чтобы найти общее количество повторяющихся строк, вставьте функцию СЧЁТЕСЛИМН() вместо СЧЕТЕСЛИ() и укажите все столбцы, которые вы хотите проверить на наличие совпадений. Например, чтобы подсчитать повторяющиеся строки на основе столбцов A и B, введите следующую формулу массива в свой лист Excel:
{=ЧСТРОК($A$2:$A$17)-СУММ(ЕСЛИ(СЧЁТЕСЛИМН($A$2:$A$17;$A$2:$A$17;$B$2:$B$17;$B$2:$B$17)=1;1;0))}
Как видите, выполнить подсчет повторяющихся значений в таблицах Excel можно множеством различных способов.
Рекомендуем также:
Average a number expressing the central or typical value in a set of data, in particular the mode, median, or (most commonly) the mean, which is calculated by dividing the sum of the values in the set by their number. The basic formula for the average of n numbers x1,x2,……xn is
A = (x1 + x2 ........xn)/ n
In Excel, there is an average function for this purpose, but it can be calculated manually also using SUM and COUNT functions like this
= SUM(D1:D5)/COUNT(D1:D5)
Here
- SUM: This function is used to find the sum of values in the required range of cells.
- COUNT: This function is used to get the count of the required range of cells containing numeric values.
AVERAGE Function
Excel provides a direct function named AVERAGE to calculate the average (or mean) of the numbers in the range specified in the function’s argument. In this function, maximum of 255 arguments can be given (numbers / cell references/ ranges/ arrays or constants).
Syntax:
= AVERAGE(Num1, [Num2], ...)
Here
- Num1 [Required]: Provide range, cell references, or the first number for calculating the average.
- Num2, … [Optional]: Provide additional numbers or range of cell references for calculating the average.
Example:
AVERAGE(C1:C5)
This will give the average of numeric values in the range C1 to C5.
Note: In the above-mentioned methods, any criteria for calculating the average cannot be mentioned. For this excel provide another function called AVERAGEIF.
Average Cells Based On One Criterion
Excel provides a direct function named AVERAGEIF to calculate the average (or mean) of the numbers in the range specified that meets particular criteria specified in the function’s argument.
Syntax:
= AVERAGEIF(Range_Cells_For_Criteria, Criteria, [Range_Cells_For_Average])
Here
- Range_Cells_For_Criteria [Required]: Give the range of cells on which criteria are to be tested.
- Criteria [Required]: This is the condition on which to decide the cells to average. The criteria can be given in the form of an expression(logical), text-value or number, or reference to a cell, e.g. 100 or “>100” or “Apple” or A7.
- Range_Cells_For_Average [Optional]: Specify the cells on which the average needs to be calculated. Range_Cells_For_Criteria is used to find the average if it is not included.
Note:
- An empty cell in average_range is ignored here.
- Cells in the range that contain TRUE or FALSE are ignored here.
- If the range is blank, return the #DIV0! Error value.
- Empty cell in the criteria is treated as 0.
Using Double Quotes (“”) In Criteria
In Excel, the text values are surrounded by double quotations (“”), but integers are not, in general. But when numbers are used in criteria(s) with a logical operator, the number and operator must also be wrapped in quotes.
Examples:
1. To calculate the average of only positive numbers excluding 0 in the range A2 to A6
= AVERAGEIF(A2:A6,”>0″) is correct.
= AVERAGEIF(A2:A6,>0) is incorrect as the logical operator should be included in double-quotes.
2. To get the average age (AGE is in column C) of the employees living in the city having id = 1 (CityId is in column D)
= AVERAGEIF(D2:D10, “=1”, C2:C10) is correct
= AVERAGEIF(D2:D10, 1, C2:C10) is also correct as here also D2 to D10 cells will be checked for value 1.
3. To get the average age (AGE is in column C) of the employees living in a city named Mumbai (City is in column B)
= AVERAGEIF(B2:B10, “Mumbai”, C2:C10) is correct
= AVERAGEIF(B2:B10, Mumbai, C2:C10) is incorrect as text should be included in double-quotes.
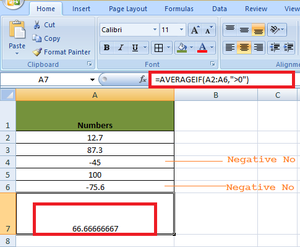
Example 1: To calculate the average of only positive numbers excluding 0 in the range A2 to A6.
Solution: In this example, a single criterion is given- “>0″. So all the numbers in the range that are greater than 0 come in the criteria. The average will be calculated as
(12.7 + 87.2 + 100) / 3 = 66.66666667
So, the average formula for the above example is
AVERAGEIF(A2:A6,">0")
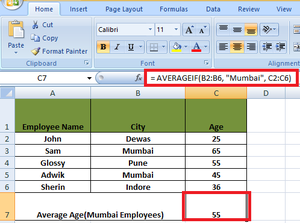
Example 2: To get the average age (AGE is in column C) of the employees living in a city named Mumbai (City is in column B).
Solution: Let’s break the example into different parts so that the individual parts can then be substituted in the AVERAGEIF function
- Criteria: “Mumbai”.
- Cells for criteria: B2 to B6.
- Cells for average: C2 to C6 that meet the criteria.
The average age of the employees living in Mumbai
= (65 + 45) /2 = 55
So, the average formula for this example is
AVERAGEIF(B2:B6,"Mumbai",C2:C6)
Average Cells Based On Multiple Criterion
Excel provides a direct function named AVERAGEIFS to calculate the average (or mean) of the numbers in the range specified that meets multiple criteria specified in the function’s argument.
Syntax:
AVERAGEIFS(RangeForAverage,RangeForCriteria1,Criteria1,
[RangeForCriteria2, Criteria2],..)
Here
- RangeForAverage [Required]: Provide the cell range on which average needs to be computed.
- RangeForCriteria1: Range on which criteria1 is applied.
- Criteria1: The first criteria to apply on the RangeForCriteria1.
Note:
- All ranges are required along with their criteria.
- Criteria1 is required, the rest are optional.
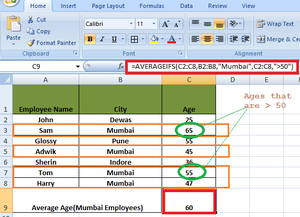
Example 1: To calculate the average age of the employees living in Mumbai whose ages are > 50.
Solution: The following criteria are used to solve the problem
- RangeForAverage: C2 to C8.
- Criteria 1: “Mumbai”.
- RangeForCriteria1: B2 to B8.
- Criteria 2: “>50”.
- RangeForCriteria1: C2 to C8.
Here, the average is calculated on basis of two criteria- Employees living in Mumbai and employees whose Age > 50
AVERAGEIFS(C2:C8,B2:B8,"Mumbai",C2:C8,">50")
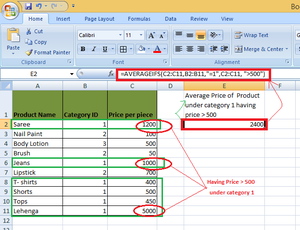
Example 2: To get the average price of the product with Category ID 1 and having a Price greater than Rs 500/-.
Solution: The following criteria will be used for the AVERAGEIF function
- RangeForAverage: C2 to C11.
- Criteria 1: “=1”.
- RangeForCriteria1: B2 to B11.
- Criteria 2: “>500”.
- RangeForCriteria2: C2 to C11.
Here, the average is calculated on the basis of two criteria- Product having Category ID 1 and Price greater than 500
AVERAGEIFSC2:C11,B2:B11,"=1",C2:C11,">500")
Using Values From Another Cell
The concatenation of text can be used to use the value from another cell. Concatenation is the process of connecting two or more values to form a text string. There are two ways for concatenation of the strings in Excel
- Logical & operator can be used.
- Concatenate function in Excel for concatenation of two texts.
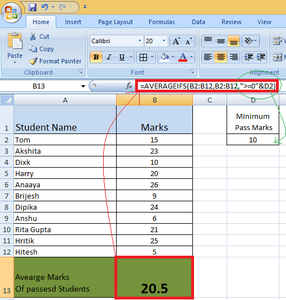
Example: To get average marks (marks are in column B) of passed students having minimum passing marks value contained in cell D2.
Solution: In this example, the logical & operator will be used to concatenate the two conditions for finding the result
- Marks greater than 0.
- Minimum passing marks i.e. 10.
Here, D2 has a value of 10, so the minimum pass marks are 10, the following criteria will be used- “>=”&D2. This will concat “>=” & value contained in cell D2, i.e. 10. After concatenation, the criteria will become “>=10”.
So, in this example
- RangeForAverage- B2 to B12.
- Criteria1- Marks greater than 0.
- RangeForCriteria1- B2 to B12.
The following formula will be used to calculate the average
=AVERAGEIFS(B2:B12,B2:B12,">=0"&D2)
Wildcards
Excel provides wildcard characters that can be used in the criteria. Some wild cards are
- * (asterisk): This symbol can be used to represent any number of characters.
- ? (question mark): This symbol can be used to represent a single character.
- ~ (tilde): This symbol is used before the above two wild cards and also tilde itself so that when there is a need to match a text containing * or? Or ~, Excel does not treat them as a wildcard. To treat them as normal characters in Excel criteria, the tilde is used before them.
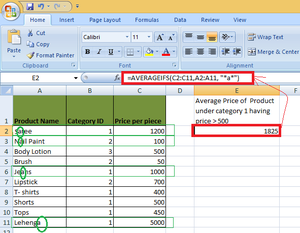
Examples: There are the product names in column A (From A1 to A10) and their respective price in column C.
- AVERAGEIFS(C2:C11, A:A11, “*a*”): To find the average price of all the products who have character ‘a’ anywhere in their name.
- AVERAGEIFS(C2:C11, A:A11, “?a*”): To find the average price of all the products that have the second character ‘a’ in their name.
- AVERAGEIFS(C2:C11, A:A11, “?aree”): To find the average price of all the products that have a single character before ‘aree’ in their name.
- AVERAGEIFS(C2:C11, A:A11, ” ~*Saree “): To find the average price of all the products that have a name is *Saree.
Example: To find the average price of all the products that have character ‘a’ anywhere in their name.
Solution: In this example
- Product Saree, Nail Paint, Jeans, and Lehenga contains the character ‘a’ in them.
- The average prices for these products will be
= (1200+ 100+ 1000+ 5000)/4 = 7300/4 = 1825
So, the complete formula for calculating the average is as follows
AVERAGEIFS(C2:C11,A2:A11,"*a")
Conclusion
Using AVERAGE, it is possible to find average without any criteria. Using AVERAGEIF, the average can be calculated with particular criteria and using AVERAGEIFS, the average can be computed with multiple criteria(s).
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
|
Функция |
Описание |
|
СРОТКЛ |
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего. |
|
СРЗНАЧ |
Возвращает среднее арифметическое аргументов. |
|
СРЗНАЧА |
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения. |
|
СРЗНАЧЕСЛИ |
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию. |
|
СРЗНАЧЕСЛИМН |
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям. |
|
БЕТА.РАСП |
Возвращает интегральную функцию бета-распределения. |
|
БЕТА.ОБР |
Возвращает обратную интегральную функцию указанного бета-распределения. |
|
БИНОМ.РАСП |
Возвращает отдельное значение вероятности биномиального распределения. |
|
БИНОМ.РАСП.ДИАП |
Возвращает вероятность пробного результата с помощью биномиального распределения. |
|
БИНОМ.ОБР |
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему. |
|
ХИ2.РАСП |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.РАСП.ПХ |
Возвращает одностороннюю вероятность распределения хи-квадрат. |
|
ХИ2.ОБР |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.ОБР.ПХ |
Возвращает обратное значение односторонней вероятности распределения хи-квадрат. |
|
ХИ2.ТЕСТ |
Возвращает тест на независимость. |
|
ДОВЕРИТ.НОРМ |
Возвращает доверительный интервал для среднего значения по генеральной совокупности. |
|
ДОВЕРИТ.СТЬЮДЕНТ |
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента. |
|
КОРРЕЛ |
Возвращает коэффициент корреляции между двумя множествами данных. |
|
СЧЁТ |
Подсчитывает количество чисел в списке аргументов. |
|
СЧЁТЗ |
Подсчитывает количество значений в списке аргументов. |
|
СЧИТАТЬПУСТОТЫ |
Подсчитывает количество пустых ячеек в диапазоне. |
|
СЧЁТЕСЛИ |
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
|
СЧЁТЕСЛИМН |
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
|
КОВАРИАЦИЯ.Г |
Возвращает ковариацию, среднее произведений парных отклонений. |
|
КОВАРИАЦИЯ.В |
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных. |
|
КВАДРОТКЛ |
Возвращает сумму квадратов отклонений. |
|
ЭКСП.РАСП |
Возвращает экспоненциальное распределение. |
|
F.РАСП |
Возвращает F-распределение вероятности. |
|
F.РАСП.ПХ |
Возвращает F-распределение вероятности. |
|
F.ОБР |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ОБР.ПХ |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ТЕСТ |
Возвращает результат F-теста. |
|
ФИШЕР |
Возвращает преобразование Фишера. |
|
ФИШЕРОБР |
Возвращает обратное преобразование Фишера. |
|
ПРЕДСКАЗ |
Возвращает значение линейного тренда. Примечание: В Excel 2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями. |
|
ПРЕДСКАЗ.ETS |
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS). |
|
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ |
Возвращает доверительный интервал для прогнозной величины на указанную дату. |
|
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ |
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду. |
|
ПРЕДСКАЗ.ETS.СТАТ |
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда. |
|
ПРЕДСКАЗ.ЛИНЕЙН |
Возвращает будущее значение на основе существующих значений. |
|
ЧАСТОТА |
Возвращает распределение частот в виде вертикального массива. |
|
ГАММА |
Возвращает значение функции гамма |
|
ГАММА.РАСП |
Возвращает гамма-распределение. |
|
ГАММА.ОБР |
Возвращает обратное значение интегрального гамма-распределения. |
|
ГАММАНЛОГ |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАММАНЛОГ.ТОЧН |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАУСС |
Возвращает значение на 0,5 меньше стандартного нормального распределения. |
|
СРГЕОМ |
Возвращает среднее геометрическое. |
|
РОСТ |
Возвращает значения в соответствии с экспоненциальным трендом. |
|
СРГАРМ |
Возвращает среднее гармоническое. |
|
ГИПЕРГЕОМ.РАСП |
Возвращает гипергеометрическое распределение. |
|
ОТРЕЗОК |
Возвращает отрезок, отсекаемый на оси линией линейной регрессии. |
|
ЭКСЦЕСС |
Возвращает эксцесс множества данных. |
|
НАИБОЛЬШИЙ |
Возвращает k-ое наибольшее значение в множестве данных. |
|
ЛИНЕЙН |
Возвращает параметры линейного тренда. |
|
ЛГРФПРИБЛ |
Возвращает параметры экспоненциального тренда. |
|
ЛОГНОРМ.РАСП |
Возвращает интегральное логарифмическое нормальное распределение. |
|
ЛОГНОРМ.ОБР |
Возвращает обратное значение интегрального логарифмического нормального распределения. |
|
МАКС |
Возвращает наибольшее значение в списке аргументов. |
|
МАКСА |
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МАКСЕСЛИ |
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек. |
|
МЕДИАНА |
Возвращает медиану заданных чисел. |
|
МИН |
Возвращает наименьшее значение в списке аргументов. |
|
МИНЕСЛИ |
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек. |
|
МИНА |
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МОДА.НСК |
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных. |
|
МОДА.ОДН |
Возвращает значение моды набора данных. |
|
ОТРБИНОМ.РАСП |
Возвращает отрицательное биномиальное распределение. |
|
НОРМ.РАСП |
Возвращает нормальное интегральное распределение. |
|
НОРМ.ОБР |
Возвращает обратное значение нормального интегрального распределения. |
|
НОРМ.СТ.РАСП |
Возвращает стандартное нормальное интегральное распределение. |
|
НОРМ.СТ.ОБР |
Возвращает обратное значение стандартного нормального интегрального распределения. |
|
ПИРСОН |
Возвращает коэффициент корреляции Пирсона. |
|
ПРОЦЕНТИЛЬ.ИСКЛ |
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа). |
|
ПРОЦЕНТИЛЬ.ВКЛ |
Возвращает k-ю процентиль для значений диапазона. |
|
ПРОЦЕНТРАНГ.ИСКЛ |
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы). |
|
ПРОЦЕНТРАНГ.ВКЛ |
Возвращает процентную норму значения в наборе данных. |
|
ПЕРЕСТ |
Возвращает количество перестановок для заданного числа объектов. |
|
ПЕРЕСТА |
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов. |
|
ФИ |
Возвращает значение функции плотности для стандартного нормального распределения. |
|
ПУАССОН.РАСП |
Возвращает распределение Пуассона. |
|
ВЕРОЯТНОСТЬ |
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов. |
|
КВАРТИЛЬ.ИСКЛ |
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы. |
|
КВАРТИЛЬ.ВКЛ |
Возвращает квартиль набора данных. |
|
РАНГ.СР |
Возвращает ранг числа в списке чисел. |
|
РАНГ.РВ |
Возвращает ранг числа в списке чисел. |
|
КВПИРСОН |
Возвращает квадрат коэффициента корреляции Пирсона. |
|
СКОС |
Возвращает асимметрию распределения. |
|
СКОС.Г |
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего. |
|
НАКЛОН |
Возвращает наклон линии линейной регрессии. |
|
НАИМЕНЬШИЙ |
Возвращает k-ое наименьшее значение в множестве данных. |
|
НОРМАЛИЗАЦИЯ |
Возвращает нормализованное значение. |
|
СТАНДОТКЛОН.Г |
Вычисляет стандартное отклонение по генеральной совокупности. |
|
СТАНДОТКЛОН.В |
Оценивает стандартное отклонение по выборке. |
|
СТАНДОТКЛОНА |
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения. |
|
СТАНДОТКЛОНПА |
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения. |
|
СТОШYX |
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. |
|
СТЬЮДРАСП |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.2Х |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.ПХ |
Возвращает t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ОБР |
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы. |
|
СТЬЮДЕНТ.ОБР.2Х |
Возвращает обратное t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ТЕСТ |
Возвращает вероятность, соответствующую проверке по критерию Стьюдента. |
|
ТЕНДЕНЦИЯ |
Возвращает значения в соответствии с линейным трендом. |
|
УРЕЗСРЕДНЕЕ |
Возвращает среднее внутренности множества данных. |
|
ДИСП.Г |
Вычисляет дисперсию по генеральной совокупности. |
|
ДИСП.В |
Оценивает дисперсию по выборке. |
|
ДИСПА |
Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
|
ДИСПРА |
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
|
ВЕЙБУЛЛ.РАСП |
Возвращает распределение Вейбулла. |
|
Z.ТЕСТ |
Возвращает одностороннее значение вероятности z-теста. |


Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.
Статьи по теме
Excel (по категориям)
Excel (по алфавиту)