
Содержание
- Подключение пакета анализа
- Виды регрессионного анализа
- Линейная регрессия в программе Excel
- Разбор результатов анализа
- Вопросы и ответы

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
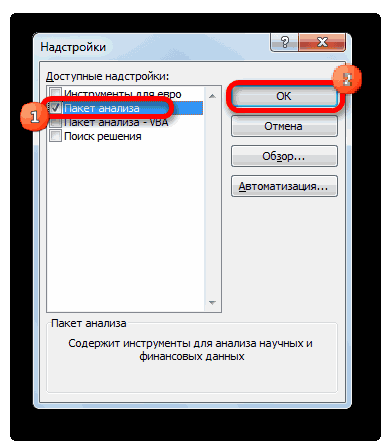
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
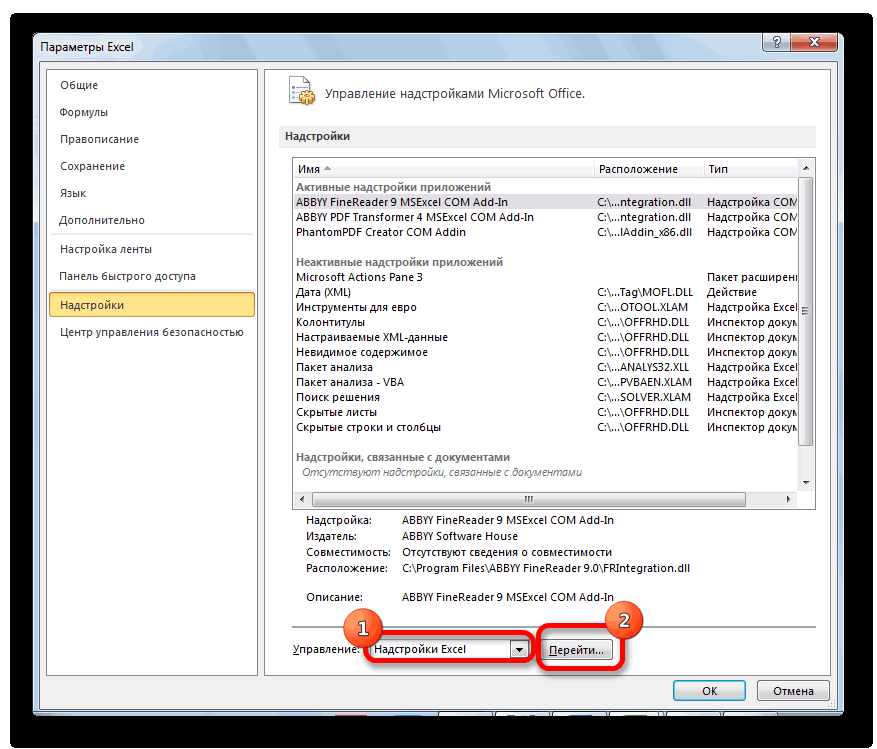
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
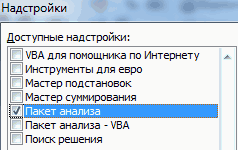
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».





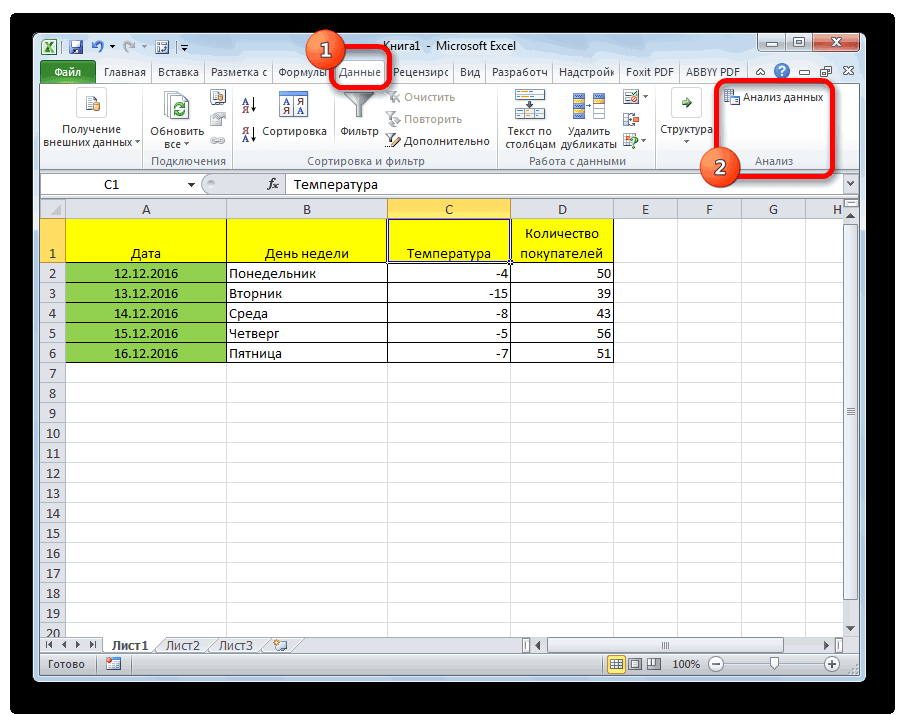
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
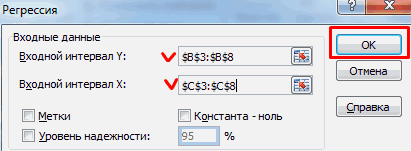
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
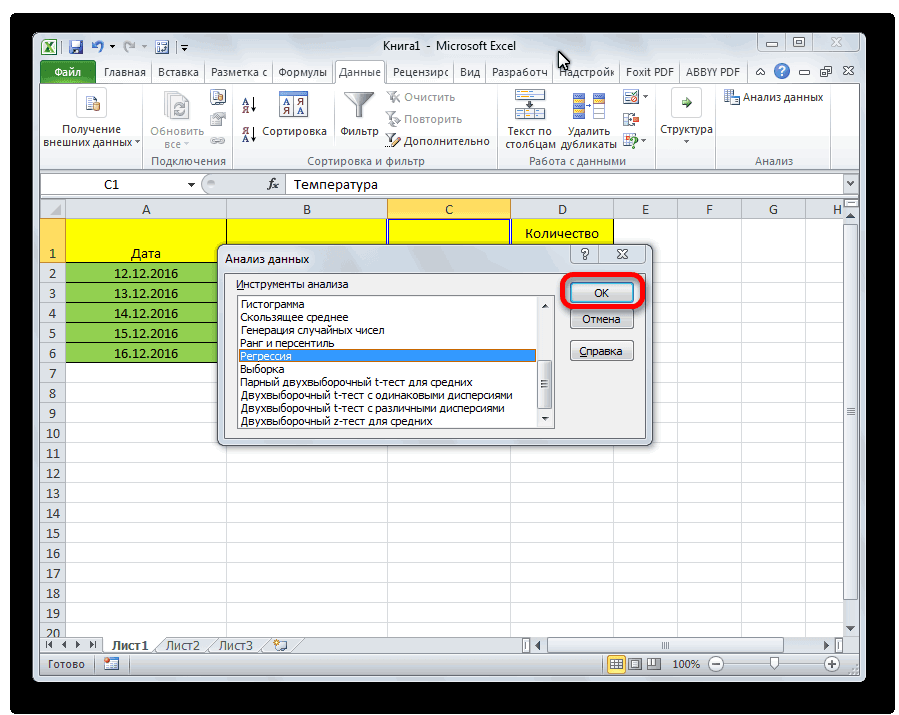
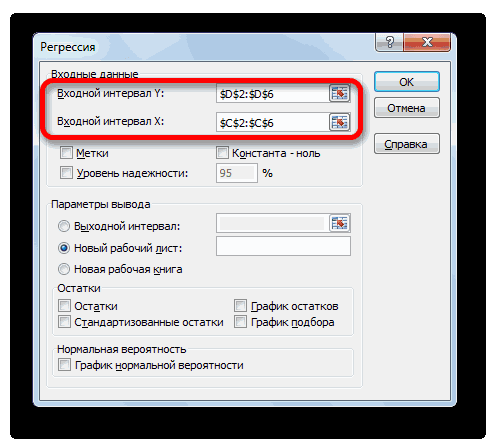
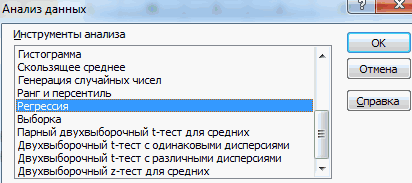
- Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
- Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

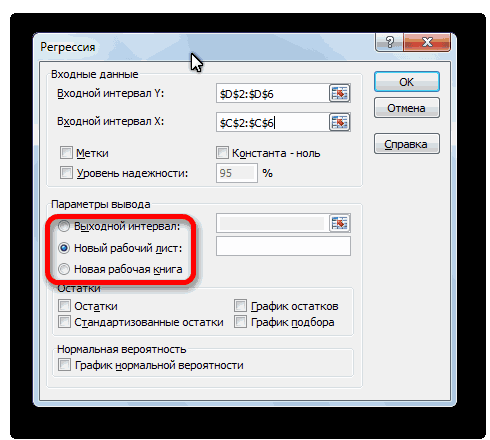
С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
После того, как все настройки установлены, жмем на кнопку «OK».






Разбор результатов анализа
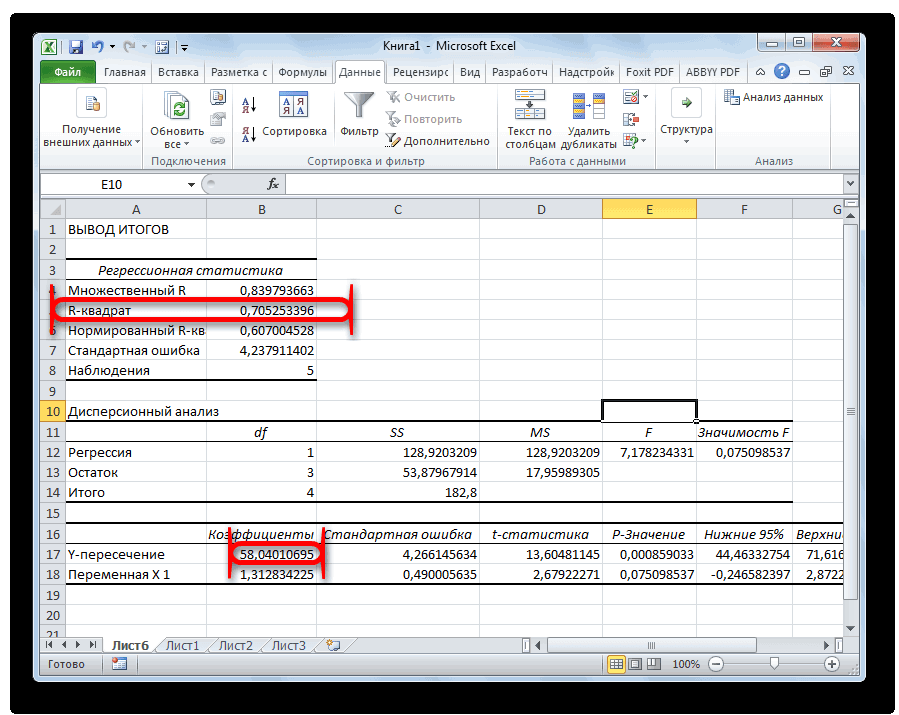
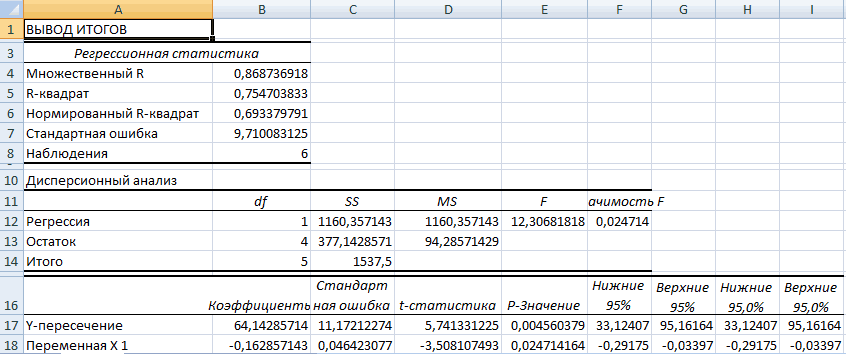
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Построение регрессионной модели по панельным данным с помощью Excel
Министерство образования Республики
Беларусь
Учреждение образования
«Гомельский государственный
университет
имени Франциска Скорины»
Математический факультет
Кафедра экономической кибернетики и
теории вероятностей
Курсовая работа
Построение регрессионной модели по
панельным данным с помощью Excel
Исполнитель: студентка группы ЭК-41
Е.Е. Атаманчук
Научный руководитель: доцент кафедры ЭК и ТВ;
кандидат технических наук, доцент
Гомель 2012
Содержание
Введение
1. Построение
регрессионной модели по панельным данным
1.1 Панельные
данные
1.2 Скрытые
переменные и индивидуальные эффекты
1.3 Модель с
фиксированными эффектами
1.4 Модель со
случайными эффектами
2. Построение
регрессионной модели по панельным данным с помощью Excel
2.1 Постановка
задачи
2.2 Построение
панельной модели
2.3 Проверка
адекватности построенной модели
Заключение
Список
использованных источников
Введение
На
практике часто встречаются экономические данные, которые имеют два измерения.
Одно измерение ![]()
![]() соответствует
соответствует
принадлежности отдельным экономическим единицам, а другое ![]()
![]() —
—
принадлежности тому или иному моменту времени. В таких случаях одномерные
данные за разные временные периоды составляют один большой набор данных. Можно
выделить два частых случая такого объединения одномерных данных:
1) независимое объединение (разные единицы, независимые выборки);
) панельные данные (одни и те же единицы в динамике).
Целью курсовой работы являются моделирование и прогнозирование основных
экономических показателей при использовании панельных данных. Для достижения
поставленной цели необходимо решить следующие задачи:
1) изучить теоретико-методологического подхода к построению
множественных регрессионных моделей;
2) провести анализ экономических показателей объём продаж работы
пяти предприятий с течением времени.
Структура работы представлена двумя разделами, введением и заключением. В
первой главе раскрываются теоретические основы построения регрессионной модели
по панельным данным. Во второй главе проводится построение множественной модели
по панельным данным. Построенные модели проверены на адекватность.
1. Построение регрессионной модели по панельным данным
1.1 Панельные
данные
Панельные данные можно представить в виде таблицы «объект-признак». При
этом придерживаются следующего соглашения. Признаки располагаются по столбцам,
по строкам — данные о первом объекте за Т периодов (строки 1, 2, 3, …,7),
затем о втором объекте (строки Т+1, Т+ 2, …,) и т. д.
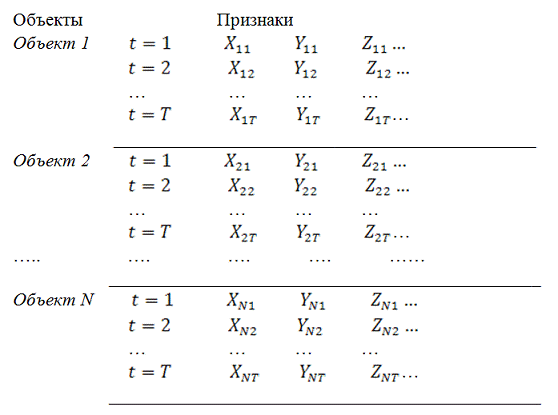
Панель бывает сбалансированная и несбалансированная. Если данные
присутствуют по всем объектам за все периоды времени, то панель называется
сбалансированной (рисунок 1).
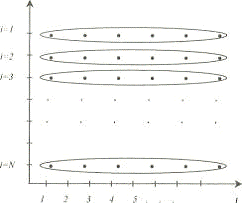
Рисунок 1 — Сбалансированная панель
Достаточно часто из-за технических, организационных или иных причин в
некоторые периоды времени не удается собрать сведения для всех объектов, включенных
в выборку первоначально (смерть, отъезд, болезнь и т. п.). Чтобы сохранить
репрезентативность, отсутствующие объекты приходится заменять другими. В
результате получим несбалансированную панель (рисунок 2).
При исследовании проблем занятости и безработицы в международной практике
распространены так называемые ротационные панели. Объект (человек
трудоспособного возраста) участвует в шести последовательных ежеквартальных
опросах, а затем исключается из панели. Таким образом, 1/6 часть всей выборки обновляется
(рисунок 3).
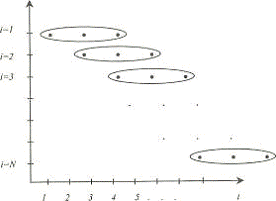
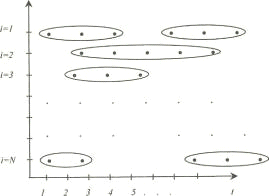
Рисунок 2 — Несбалансированная панель Рисунок 3 — Ротационная панель
Возможны и иные модификации панельных данных. Но наибольшее
распространение получили сбалансированные и несбалансированные панели.
1.2 Скрытые
переменные и индивидуальные эффекты
Пусть к = 1, 2, … К — соответствует номеру пары, у = 1,2 — номеру
близнеца. Тогда общее число наблюдений N = 2К.
Модель зависимости текущей заработной платы от образования имеет вид
![]()
где![]()
![]() —
—
заработная плата, ![]()
![]() — уровень
— уровень
образования (число лет обучения), ![]()
![]() —
—
способности индивида.
Так
как, по предположению, способности у близнецов совпадают, то для любого ![]()
![]() :
:
![]()
Хотя
способности не поддаются непосредственному измерению, естественно допустить,
что более талантливые люди получают лучшее образование:
![]()
Допустим,
что в некоторых парах близнецы по каким-либо причинам получили разное
образование. Тогда модель можно переписать в виде
![]()
Заметим,
что способности индивида не поддаются прямому измерению, т. е. мы не
располагаем сведениями о величинах ![]()
![]() . Так как
. Так как
уравнение включает ненаблюдаемую переменную, мы не можем оценить все
коэффициенты модели.
Наиболее
простой вариант состоит в том, чтобы вообще исключить переменную ![]()
![]() из
из
рассмотрения:
![]()
Из
полученного уравнения следует, что повышение уровня образования на один год
приводит в среднем к повышению почасовой оплаты. Эта оценка будет смещена,
скорее всего завышена, из-за того, что неучтенная переменная «способности» ![]()
![]() сильно
сильно
коррелированна с объясняющей переменной «образование» ![]()
![]() .
.
Использование
панельных данных позволяет устранить это смещение. Введём ![]()
![]() фиктивных
фиктивных
переменных:
![]()
![]()
![]()
В
этом случае: ![]()
![]()
Если
включить в уравнение регрессии все ![]()
![]() фиктивных
фиктивных
переменных и свободный член ![]()
![]() , будет
, будет
строгая мультиколлениарность. Поэтому один из параметров следует исключить из
модели, например, свободный член ![]()
![]() .
.
Перепишем уравнение регрессии без свободного члена:
![]()
![]()
Получим
модель с ![]()
![]() независимой
независимой
переменной:
![]()
Обозначим
![]()
![]() . Тогда
. Тогда
неизвестные величины ![]()
![]() —
—
включаются в уравнение как часть параметров подлежащих оценке:
В
результате модель не содержит неизменяемых переменных. Оценив коэффициенты
модели методом наименьших квадратов, получим несмещенную оценку параметра ![]()
![]()
Коэффициент
при каждой фиктивной переменной ![]()
![]() соответствует
соответствует
влиянию способностей каждой отдельной пары близнецов на их доход. А его
произведение на фиктивную переменную — индивидуальный эффект, соответствующей
паре:
![]()
Поэтому
предыдущее уравнение эквивалентно введению в модель К индивидуальных эффектов:
![]()
![]()
Данный
подход получил название модели с фиксированными эффектами (fixed effects model). Использование панельных
данных позволило ввести в модель индивидуальные эффекты для того, чтобы
избавиться от влияния ненаблюдаемой переменной (постоянной во времени) и
получить несмещенную оценку интересующего нас параметра.
Введение
фиктивных переменных вовсе не единственная возможность. Того же результата
можно добиться и иным путем. Запишем исходную модель для каждой пары близнецов:
![]()
![]()
Найдем
разность между ними:
![]()
![]()
![]()
Полученное
уравнение содержит лишь одну объясняющую переменную (s) — уровень
образования.
Для
преобразованного уравнения можно получить несмещенную оценку интересующего нас
параметра ![]()
![]() , методом
, методом
наименьших квадратов. Этот прием оценивания обычно называют переходом к первым
разностям (first differences).
В
общем виде получили:
![]()
![]()
Найдём
МНК-оценку:
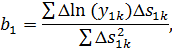
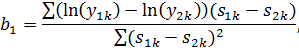
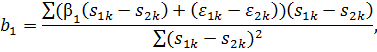
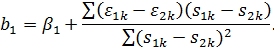
Найдем
МНК-оценку:
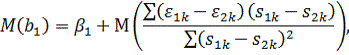
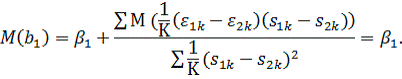
Следовательно,
оценка не смещена. Таким образом, использование панельных данных позволяет
элиминировать эффект ненаблюдаемых переменных и получить несмещенную оценку
отдачи от образования.
Оценки
коэффициента ![]()
![]() , метода
, метода
первых разностей и фиксированных эффектов совпадают.
Обсудим
число степеней свободы для каждой из оценок.
Для метода первых разностей число наблюдений ![]()
![]() . Соответственно число степеней свободы равно К минус число
. Соответственно число степеней свободы равно К минус число
оцениваемых параметров:![]()
Для
модели фиксированных эффектов число наблюдений равно ![]()
![]() Однако
Однако
число параметров ![]()
![]() Число
Число
степеней свободы:
![]()
Итак,
число степеней свободы для методов первых разностей и фиксированных эффектов
совпадает. То есть в рассматриваемом примере оценки, полученные путем перехода
к разностям и фиксированных эффектов, полностью эквивалентны.
Когда
панель строится по времени, часто удается обосновать, что некоторые скрытые
параметры не изменяются от периода к периоду. Пусть, например, цель исследования
состоит в оценке влияния налоговых скидок на инвестиции (ПС) на стоимость
акций. Исходная модель формулируется следующим образом:
![]()
где
![]()
![]() — цена
— цена
одной акции, ![]()
![]() — номер
— номер
фирмы, ![]()
![]() — номер
— номер
года (1 или 2); ![]()
![]() —
—
фиктивная переменная, равная 1, если фирма получала скидку в текущем году, 0 —
в противном случае; ![]()
![]() —
—
внутренние скрытые факторы прибыльности (качество менеджмента, и т. д.); ![]()
![]() — прочие
— прочие
наблюдаемые характеристики фирмы или рынка (например, число конкурентов и т.
п.).
Проблема
состоит в том, что величины. неизвестны и их нельзя оценить по данным
отчетности. Кроме того, только те фирмы, которые имели прибыль, могут получить
налоговые скидки. Поэтому ![]()
![]()
Допустим
мы хотим оценить склонность домохозяйств к сбережению. Запишем исходную модель
![]()
![]()
где
![]()
![]() —
—
сбережения -го домохозяйства в год, t; ![]()
![]() — доход
— доход ![]()
![]() -го
-го
домохозяйства в год,![]()
![]()
![]()
![]() —
—
ненаблюдаемые характеристики ![]()
![]() -го
-го
домохозяйства в год, ![]()
![]() (склонности,
(склонности,
способность к предвидению и т. д.); ![]()
![]() — прочие
— прочие
характеристики ![]()
![]() -го
-го
домохозяйства в год, ![]()
![]() (возраст
(возраст
главы семьи, количество детей и т. п.).
Величины
![]()
![]() не
не
поддаются непосредственному измерению и коррелированны с доходом:
![]()
![]()
Перейдя
к первым разностям, получим:
![]()
![]()
Полученное
уравнение не содержит ненаблюдаемых переменных. Используя метод наименьших
квадратов, можно найти несмещенную оценку склонности к сбережению ![]()
![]() ,
,
Альтернативный метод оценивания — введение в исходную модель фиктивных
переменных — приведет к аналогичному результату.
Если
допустить, что пропущенные переменные не коррелированны с остальными
регрессорами, тогда их влияние можно учесть иначе — рассматривать как
компоненты ошибок наблюдения. Тогда для панельных данных используют модели со
случайными эффектами (random effects models).
Основанием такого допущения могут быть положения экономической теории или
особенности организации выборки. Если пропущенные переменные являются одной из
составляющих ошибок, получим:
![]()
![]()
![]()
где
![]()
![]() , —
, —
суммарная ошибка ; ![]()
![]() , —
, —
ошибка, характерная для -го объекта и не зависящая от времени; ![]()
![]() —
—
случайная ошибка регистрации.
Это
модель линейной регрессии при гетероскедастичности ошибок. Дисперсия ошибок
зависит от номера объекта. Поэтому для оценивания следует использовать
обобщенный метод наименьших квадратов.
1.3 Модель с
фиксированными эффектами
Рассмотрим модель линейной регрессии для панельных данных, включающую
индивидуальные уровни для каждого объекта:
![]()
![]() (1)
(1)
![]()
Для
каждого объекта ![]()
![]() индивидуальный
индивидуальный
эффект, остается постоянным в течение всех периодов ![]()
![]() . Вектор
. Вектор
регрессоров ![]()
![]() не
не
включает свободного члена. Таким образом, в (1) ![]()
![]() —
—
неизвестные параметры, которые необходимо оценить.
Уравнение
(1) можно записать в векторной и матричной форме. Обозначим ![]()
![]() — вектор
— вектор
размерности ![]()
![]() значений
значений
независимых переменных; ![]()
![]() —
—
матрица значений регрессоров для i-го объекта размерности ![]()
![]() и пусть
и пусть ![]()
![]() — вектор
— вектор
ошибок размерности ![]()
![]() . Тогда
. Тогда
(1) можно переписать в виде
![]()
![]()
где
![]()
![]() —
—
вектор, состоящий из единиц, размерности Т.
Объединяя
уравнения в единую систему, получим:
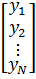 =
=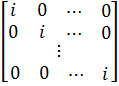 *
*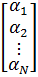 +
+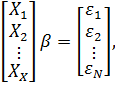
или
![]()
![]() (2)
(2)
где
![]()
![]() —
—
фиктивная переменная, соответствующая i-му объекту.
Если
обозначить ![]()
![]() — матрица
— матрица
размером ![]()
![]() , получим
, получим
матричную запись:
![]()
![]() (3)
(3)
Матрица
![]()
![]() содержит
содержит
j-столбцов, матрица D — ![]()
![]() -столбцов,
-столбцов,
всего модель содержит ![]()
![]() оцениваемых
оцениваемых
параметров. Если число объектов N невелико, то оценки параметров ![]()
![]() можно
можно
получить с помощью стандартных формул регрессионного анализа. Система
нормальных уравнений имеет вид
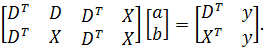
Для
того чтобы было возможно найти решение системы уравнений, необходимо, чтобы
матрица системы имела полный ранг. Это означает, что регрессоры не должны быть
коллинеарные с фиктивными переменными
Но
если число единиц наблюдения составляет несколько сотен или тысяч, вычисление
обратной матрицы потребует слишком больших затрат времени и объемов оперативной
памяти. Чтобы избежать этого, учитывают, что матрица D состоит из
значений N фиктивных переменных, а регрессионная модель является
моделью регрессии с фиктивными переменными.
Для
моделей с фиктивными переменными известно, что МНК-оценку b для
вектора параметров можно найти из линейной регрессии для преобразованных
переменных
![]()
![]()
![]()
Рассмотрим,
что означает предварительное преобразование переменных. Так как столбцы матрицы
D ортогональны, то матрица ![]()
![]() является
является
блочно-диагональной:
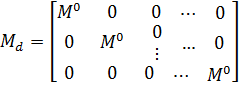
где
![]()
![]() — матрица
— матрица
вида ![]()
![]() где
где ![]()
![]() —
—
единичная матрица размером ![]()
![]()
![]()
![]() — вектор
— вектор
размерности T, все элементы которого равны единице.
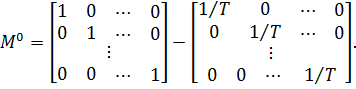
Для
любого вектора z, размерности ![]()
![]() умножение
умножение
на ![]()
![]() ,
,
означает вычитание из каждого его элемента среднего значения:
![]()
![]() .
.
То
есть преобразование ![]()
![]() и
и ![]()
![]() означает
означает
вычитание из каждого элемента вектора у и матрицы ![]()
![]() среднего
среднего
значения: ![]()
![]() , где
, где ![]()
![]() —
—
среднее значение зависимой переменной для -го объекта, ![]()
![]() — вектор
— вектор
средних значений независимых переменных для ![]()
![]() -го
-го
объекта.
После
того как по формуле (4) найдены оценки ![]()
![]() , легко
, легко
получить и оценки индивидуальных эффектов а из уравнения:
![]()
![]()
Формула
(5) означает, что для каждого объекта индивидуальный эффект можно найти по
формуле
![]()
![]()
То
есть индивидуальный эффект а, равен среднему остатку в i-й группе.
Оценка ковариационной матрицы вектора b может быть получена по обычной
формуле
![]()
![]() (7)
(7)
![]()
![]()
Оценки
выборочных дисперсий индивидуальных эффектов можно получить по формуле
![]()
![]()
Как
мы видели, оценки модели с фиксированными эффектами можно получить, переходя к
отклонениям от групповых средних. Рассмотрим, как взаимосвязаны оценки трех
различных регрессий.
Во-первых,
с единственным свободным членом:
![]()
![]()
Во-вторых,
построенной по отклонениям от групповых средних:
![]()
![]()
В-третьих,
по групповым средним:
![]()
![]()
Каждая
из этих возможностей играет важную роль при анализе панельных данных и
используется напрямую либо на промежуточных этапах. В (10а) перекрестные
произведения находятся от общих средних, у и х:
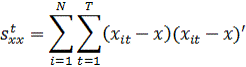
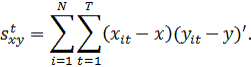
В
случае модели (10b) данные представлены в виде отклонений от групповых
средних, поэтому выборочные средние ![]()
![]() и
и ![]()
![]() равны
равны
нулю. Матрицы перекрестных произведений рассчитываются по отклонениям групповых
средних и отражают внутригрупповые суммы квадратов:
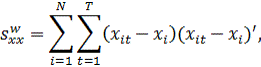
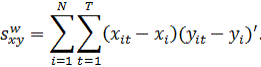
Наконец,
в (10с) среднее групповых средних является общим средним. Матрицы моментов
равны:
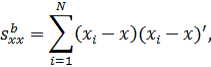
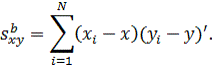
Легко
проверить, что выполняются равенства
![]()
![]()
Найдём
оценки неизвестных параметров ![]()
![]() каждым
каждым
из трёх способов. Оценки стандартной регрессии:
![]()
![]()
Основываясь
на отклонениях от групповых средних, получим оценки:
![]()
![]()
эта
формула соответствует модели с фиксированными эффектами.
Оценки
наименьших квадратов для уравнения (10с), рассчитываемые по N
групповым средним:
![]()
![]()
и
называют between оценками, или межгрупповыми (between-groups estimator).
Из
выражений (12) и (13) следует, что: ![]()
![]()
Включая
их в (11), мы видим, что МНК-оценка есть взвешенная сумма внутригрупповых и
межгрупповых оценок:
![]()
![]() (15)
(15)
![]()
![]()
![]()
Фиктивные
переменные могут использоваться и для учета временного фактора. Это необходимо,
если средний уровень явления существенно изменяется во времени. Тогда модель
может быть расширена следующим образом:
![]()
![]()
где
![]()
![]() — эффект
— эффект
специфический для каждого периода. Эта модель получена из предыдущей включением
дополнительных (Т — 1) фиктивных переменных. Из-за строгой коллинеарности
нельзя включить все Т-эффекты для каждого периодов времени. На практике обычно
исключают эффект для первого ![]()
![]() или
или
последнего периода ![]()
![]() .
.
Обозначив
![]()
![]() множества
множества
из (N-1) и (Т- 1) фиктивных переменных, получим матричную
запись:
![]()
![]()
При
этом матрица ![]()
![]() должна
должна
иметь ранг N+T+K- 1. Это накладывает ограничения на состав
регрессоров. Использование прямых формул предполагает вычисление обратной
матрицы ![]()
![]() что при
что при
большом числе объектов может потребовать слишком много времени. Однако вместо
этого можно использовать свойства модели с фиктивными переменными и перейти к
отклонениям от групповых средних. Для этого вычислим:
![]()
![]() (1.17)
(1.17)
![]()
где
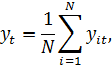
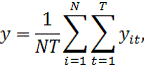
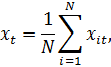
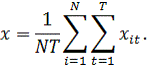
Найдем
коэффициенты регрессии ![]()
![]() В
В
результате получим оценку вектора ![]()
![]() . Оценки коэффициентов
. Оценки коэффициентов
при фиктивных переменных рассчитаем по формулам
![]()
![]()
![]() (18)
(18)
![]()
При
исчислении групповых средних необходимо использовать соответствующие размеры
групп ![]()
![]()
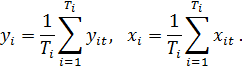
Матрица
перекрестных произведений ![]()
![]() заменяется
заменяется
суммой матриц сумм квадратов и перекрестных произведений:
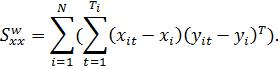
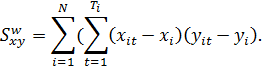
Оценки
коэффициентов регрессии получаются из уравнения ![]()
![]() Within-оценка
Within-оценка
по-прежнему совпадает с МНК-оценкой, вычисленной по отклонениям от средних:
1.4 Модель со
случайными эффектами
Иногда есть основания предполагать, что индивидуальные эффекты не
коррелированны с регрессорами. Например, если данные являются случайной
выборкой из большой популяции. Тогда индивидуальные эффекты можно рассматривать
как одну из составляющих ошибки.
Переформулируем модель, включающую K-регрессоров, в виде
![]()
![]()
Компонента
и, является случайным отклонением (случайной ошибкой), соответствующей i-му
объекту и постоянной во времени. Эта величина может соответствовать, например,
суммарному влиянию факторов, специфических для отдельной фирмы, семьи,
индивидуума и т. п. и не включенных в число регрессоров. Допустим, что
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Рассмотрим
T-наблюдений, соответствующих i-му объекту.
Обозначим суммарную ошибку ![]()
![]()
![]()
![]()
Тогда
![]()
![]()
![]()
Ковариационная
матрица наблюдений для i-го объекта ![]()
![]() равна:
равна:
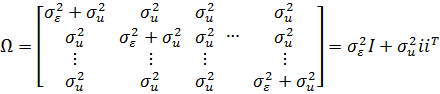
Где
I-единичная матрица , i-единичный
вектор размерности ![]()
![]() . Там как
. Там как
ошибки для объектов i и j независимы, ковариационная матрица всех NT
наблюдений будет иметь ввиду
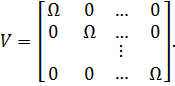
Таким
образом, модель случайных эффектов соответствует молол и линейной регрессии при
гетероскедастичности ошибок.
Эффективными,
как известно, являются оценки обобщенного метода наименьших квадратов (GLS-оценки).
Для уравнения регрессии ![]()
![]() GLS-оценки
GLS-оценки
рассчитываются по формуле
![]()
![]()
![]()
Для
использования обобщенного метода наименьших квадратов (GLS), необходимо
найти матрицу ![]()
![]() , где
, где ![]() — символ произведения Кронекера. Следовательно, нам
— символ произведения Кронекера. Следовательно, нам
необходимо найти матрицу ![]()
![]() . Матрица
. Матрица
![]()
![]() имеет
имеет
достаточно простую структуру. Если допустить, что дисперсии ![]()
![]() и
и ![]()
![]() известны,
известны,
можно выписать явное выражение для ![]()
![]() :
: ![]()
![]() где
где ![]()
![]() параметр,
параметр,
зависящий от ![]()
![]() и
и ![]()
![]() :
:
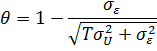
Умножение
![]()
![]() на
на ![]()
![]() означает
означает
следующее преобразование
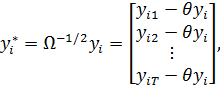 (23)
(23)
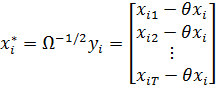
Можно
показать, что оценки обобщенного метода наименьших квадратов, подобно
МНК-оценкам, могут быть вычислены как матричные взвешенные межгрупповых и
внутригрупповых:
![]()
![]()
![]()
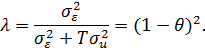
Формула
(24) позволяет проанализировать, к чему сводятся GLS-оценки в
зависимости от параметра ![]()
![]() .
.
Если![]()
![]() , то GLS-оценки
, то GLS-оценки
совпадают с оценками простой регрессии. Из формулы (24) видно, что это
возможно, когда ![]()
![]() , равно
, равно
нулю, т.е. индивидуальных эффектов вовсе не существует. Но, если![]()
![]() , то
, то
МНК-оценки становятся неэффективными. По сравнению с обобщенным обычный метод
наименьших квадратов придает слишком большой вес вариации между объектами. Он
объясняет ее целиком изменениями независимых переменных, вместо того чтобы
допустить, что некоторые колебания значений признака объясняется случайной
ошибкой ![]()
![]() .
.
Если
![]()
![]() , получим
, получим
within-оценки (фиксированных эффектов). Если число периодов
наблюдения Т конечно, то, чтобы параметр ![]()
![]() равнялся
равнялся
нулю, необходимо, чтобы дисперсия ![]()
![]() была
была
равна нулю, т. е. все различия между объектами объяснялись случайными
величинами ![]()
![]() , которые
, которые
постоянны во времени. Другой возможный случай, когда число периодов наблюдения
стремится к бесконечности: ![]()
![]() и оценка
и оценка
модели со случайными эффектами стремится к оценке фиксированных эффектов.
Запишем
исходное уравнение
![]()
![]() и
и
уравнение для групповых средних
![]()
![]()
Вычитание
из каждого уравнения среднего по группе позволяет избавиться от неоднородности:
![]()
![]()
Это
модель within-регрессии, и она не содержит значений индивидуальных
эффектов ![]()
![]() Следовательно,
Следовательно,
оценку ![]()
![]() можно
можно
найти на основании остатков модели с фиксированными эффектами:
![]()
Рассмотрим
далее средние ошибки для каждой группы:
![]()
![]()
Средние
ошибки для объектов взаимно независимы, их дисперсия равна:
![]()
![]()
Несмещенную
оценку для величины ![]()
![]() можно
можно
найти из between -регрессии:
![]()
![]()
где
![]()
![]() —
—
остатки between-peгpeccuи.
Это
приводит к следующей оценке дисперсии: ![]()
![]() (30)
(30)
Оценка дисперсии (30) является несмещенной, но на практике может быть
отрицательной, что необходимо учитывать.
Для
проверки гипотезы
![]()
![]()
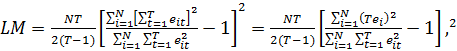 (31)
(31)
где
![]()
![]() —
—
остатки в стандартной регрессионной модели.
При
нулевой гипотезе LM подчиняется закону распределения Хи-квадрат с одной
степенью свободы. Тогда
![]()
![]()
2 Построение
регрессионной модели по панельным данным с помощью Excel
2.1
Постановка задачи
множественный регрессионный
модель панельный
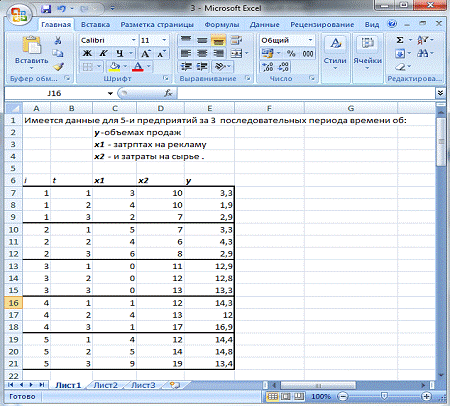
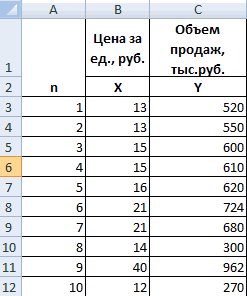
Имеются данные об объёмах продаж (Y, тыс.шт.), затратах на рекламу (X1, тыс. ден. ед.) и затраты на сырье (X2, тыс. ден. ед.) для пяти условных
предприятий за три последовательных периода времени (таблица 1).
Таблица 1 — Исходные данные
|
Исходные данные |
||||
|
|
|
|
|
|
|
1 |
1 |
3 |
3.3 |
|
|
1 |
2 |
4 |
10 |
1.9 |
|
1 |
3 |
2 |
7 |
2.9 |
|
2 |
1 |
5 |
7 |
3.3 |
|
2 |
2 |
4 |
6 |
4.3 |
|
2 |
3 |
6 |
8 |
2.9 |
|
3 |
1 |
0 |
11 |
12.9 |
|
3 |
2 |
0 |
12 |
12.8 |
|
3 |
3 |
0 |
13 |
13.3 |
|
4 |
1 |
1 |
12 |
14.3 |
|
4 |
2 |
4 |
13 |
12 |
|
4 |
3 |
1 |
17 |
16.9 |
|
5 |
1 |
4 |
12 |
14.4 |
|
5 |
2 |
5 |
14 |
14.8 |
|
5 |
3 |
9 |
19 |
Требуется построить уравнение регрессии зависимости объемов продаж У от
факторов Х1 и Х2 .
2.2
Построение панельной модели
Модель имеет вид
![]()
Выбираем
линейную модель ![]()
![]()
Найдем
ее параметры и оценим качество с использованием средств ППП “Excel”
Запишем
исходные данные в Excel:
С
помощью Анализа данных рассчитываем функцию Регрессия и получаем результат
моделирования:
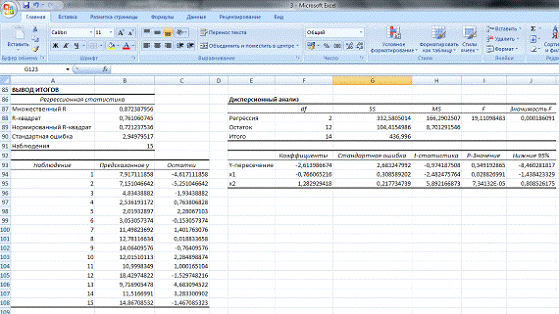
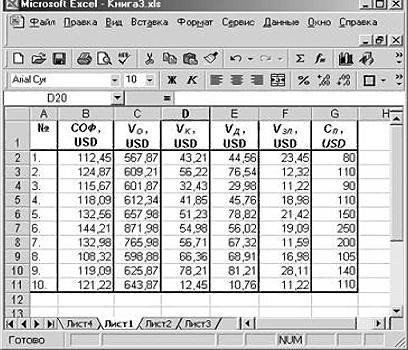
Получили отчет о результатах регрессионного анализа.
Рассмотрим регрессионную статистику:
Множественный
R — это ![]()
![]() где
где ![]()
![]() — R —
— R —
квадрат (коэффициент детерминации). ![]()
![]() свидетельствует
свидетельствует
о том, что изменения зависимой переменной Y на 76.1% можно
объяснить изменениями включенных в модель объясняющих переменных.
Нормированный
R — квадрат — скорректированный коэффициент
детерминации
![]()
![]()
где
n — число наблюдений, k- число
объясняющих переменных.
Статистическая
ошибка регрессии ![]()
![]() , где
, где ![]()
![]() —
—
необъясненная дисперсия.
Наблюдения
— число наблюдений n
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
|
|
Y-пересечение |
|
2,683247992 |
-0,974187508 |
0,349192865 |
-8,4602 |
3,2323 |
|
x1 |
|
0,308589202 |
-2,482475764 |
0,028826991 |
-1,4384 |
-0,0937 |
|
x2 |
|
0,217734739 |
5,892166873 |
7,34132 |
0,8085 |
1,7573 |
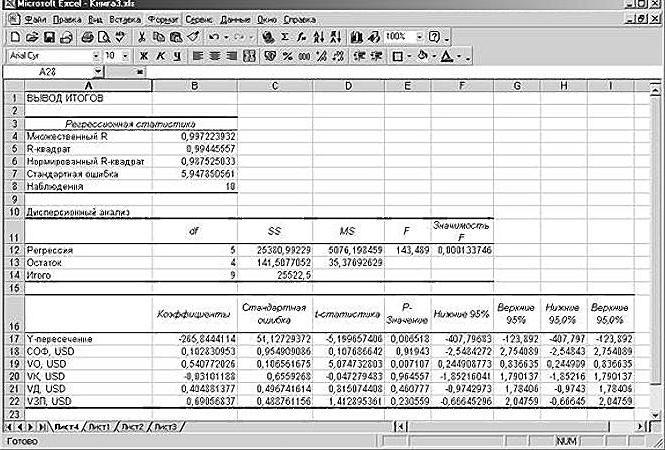
В таблице представлены параметры модели и результаты их проверки на
статистическую значимость. Следовательно, уравнение модели:
![]()
![]()
![]() получена
получена
делением коэффициентов на стандартные ошибки. Если расчетное значение ![]()
![]() превосходит
превосходит
критическое, полученное из теоретического распределения Стьюдента с параметром ![]()
![]() ,то они
,то они
статистически значимы. В данном примере ![]()
![]() . В
. В
пакете анализа предусмотрен другой инструмент оценки ![]()
![]()
![]()
![]() —
—
величина, применяемая при статистической проверке гипотез. Представляет собой
вероятность того, что критическое значение статистики используемого критерия
превысит значение, вычисленное по выборке. Решение о принятии или отклонении
нулевой гипотезы принимается в результате сравнения ![]()
![]() с
с
выбранным уровнем значимости ![]()
![]() . Если
. Если ![]()
![]() , то
, то
нулевая гипотеза отклоняется и принимается альтернативная о статистической
значимости рассматриваемого параметра. В данном примере параметр ![]()
![]() статистически
статистически
незначим так как ![]()
![]() , а
, а
параметр ![]()
![]() статистически
статистически
значим так как ![]()
![]()
Нижние
95% — Верхние 95% — доверительные интервалы для параметров модели.
Доверительные интервалы строятся только для статистики значимых величин. В данном
случае для параметра ![]()
![]() :
:
![]()
![]()
т.е.
с надежностью 95% истинное значение параметра лежит в указанном интервале.
Таблица
2 — Таблица дисперсионного анализа
|
df |
SS |
MS |
F |
Значимость F |
|
|
Регрессия |
2 |
332,5805014 |
166,2902507 |
19,11098483 |
0,000186091 |
|
Остаток |
12 |
104,4154986 |
8,701291546 |
||
|
Итого |
14 |
436,996 |
Df-
число степеней свободы связано с числом единиц совокупности ![]()
![]() и с
и с
числом определенных по ней констант ![]()
![]() .-
.-
обозначение полных сумм квадратов. В этом столбце в строке «Регрессия» строится
факторная сумма отклонений ![]()
![]() в строке
в строке
«Остаток» — остаточная сумма отклонений ![]()
![]() , а в
, а в
строке «Итого» — общая сумма отклонений ![]()
![]()
2.3 Проверка
адекватности построенной модели
F и Значение F
позволяют проверить значимость уравнения регрессии. По эмпирическому значению
статистики ![]()
![]() проверяется
проверяется
гипотеза равенства нулю одновременно всех коэффициентов модели. Уравнение
регрессии значимо на уровне ![]()
![]() , если
, если ![]()
![]() , где
, где ![]()
![]() —
—
табличное значение ![]()
![]() с
с
параметрами ![]()
![]() В нашем
В нашем
примере значимость ![]()
![]() то
то
уравнение регрессии статистически значимо в сравнении с 95%. Модель признается
адекватной и надежной с вероятностью 95%.
Заключение
Панельными
называют данные, содержащие сведения об одном и том же множестве объектов за
ряд последовательных периодов времени. Этот метод используют при изучении
потребительского поведения, занятости, безработицы, доходов и заработной платы,
производственных функций и политики дивидендов фирм, в международных и
межрегиональных сопоставлениях. Традиционно выборочные данные представляют в
виде таблиц «объект-признак»: по строкам располагают объекты, по столбцам —
признаки. Для панельных данных добавляется еще одно измерение — время.
Преимущества панельных данных следующие. Во-первых, большее число наблюдений ![]()
![]() обеспечивает
обеспечивает
большую эффективность оценивания параметров эконометрической модели. Во-вторых,
появляется возможность контроля над неоднородностью объектов. В-третьих,
возможностью идентифицировать эффекты, недоступные в анализе пространственных
данных.
В работе рассмотрены методы построения регрессионной модели по панельным
данным. Изучены панельные данные. Приведены и исследованы объёмы продаж 5
предприятий с течением времени. Модель проверена на адекватность. Результаты
исследований могут быть использованы на практике.
Список использованных источников
1 Айвазян
С. А. Прикладная статистика. Основы эконометрики. Том 2. — М.: Юнити-Дана,
2001. — 432 с.
2 Бабешко
Л. О. Основы эконометрического моделирования: Учеб. пособие. — 2-е,
исправленное. — М.: КомКнига, 2006. — 432 с
Берндт
Э. Практика эконометрики: классика и современность. — М.: Юнити-Дана, 2005. —
848 с
Доугерти
К. Введение в эконометрику: Пер. с англ. — М.: ИНФРА-М, 1999. — 402 с.
Кремер
Н. Ш., Путко Б. А. Эконометрика. — М.: Юнити-Дана, 2003-2004. — 311 с.
Леонтьев
В. В. Экономические эссе. Теория, исследования, факты и политика: Пер. с англ.
— М.: Политиздат, 1990. — 324 с.
Магнус
Я. Р., Катышев П. К., Пересецкий А. А. Эконометрика. Начальный курс. — М.:
Дело, 2007. — 504 с.
Моргенштерн
О. О точности экономико-статистических наблюдений. — М.: Статистика, 1968. —
324 с.
Суслов
В. И., Ибрагимов Н. М., Талышева Л. П., Цыплаков А. А. Эконометрия. —
Новосибирск: СО РАН, 2005. — 744 с.
10 Тутубалин В.Н.
<http://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%82%D1%83%D0%B1%D0%B0%D0%BB%D0%B8%D0%BD,_%D0%92%D0%B0%D0%BB%D0%B5%D1%80%D0%B8%D0%B9_%D0%9D%D0%B8%D0%BA%D0%BE%D0%BB%D0%B0%D0%B5%D0%B2%D0%B8%D1%87>
Границы применимости (вероятностно-статистические методы и их возможности). —
М.: Знание, 1977. — 64 с.
Эконометрика.
Учебник / Под ред. Елисеевой И. И. — 2-е изд. — М.: Финансы и статистика, 2006.
— 576 с.
Урок
№___
Тема: Практическая
работа №15
«Получение регрессионных
моделей в Microsoft Excel»
Тип урока: практическая работа
Цели:
·
Освоение способов построения по экспериментальным
данным регрессионной модели и графического тренда средствами MSExcel;
·
Формирование навыка по работе в MSExcel;
·
Развитие системного мышления, позволяющего выделять
в окружающей действительности системы, элементы систем, адекватные поставленной
задаче;
·
Формирование профессиональных навыков работы.
Оборудование:
·
ПК;
·
Интерактивная доска;
·
MS Excel
Ход
урока:
I. Организационный момент (5 мин.)
Приветствие.
Сообщение темы.
II. Актуализация
знаний (5 мин.)
Проверка
домашнего задания.
III. Практическая
работа (30 мин.)
Практическая работа №15
Задание 1
1.
Ввести табличные данные зависимости
заболеваемости бронхиальной астмой от концентрации угарного газа в атмосфере
(см. рисунок).
2.
Представить зависимость в виде
точечной диаграммы (см. рисунок).

Задание
2
Требуется
получить три варианта регрессионных моделей (три графических тренда)
зависимости заболеваемости бронхиальной астмой от концентрации угарного газа в
атмосфере.
1.Для
получения линейного тренда выполнить следующий алгоритм:
·
щелкнуть правой кнопкой мышки на
маркерах диаграммы «Заболеваемость астмой»,
построенной в предыдущем задании;
·
выполнить команду Добавить линию
тренда;
·
в открывшемся окне на вкладке Параметры
линии тренда выбрать Линейная;
·
установить галочки на флажках: показывать уравнения на диаграмме и поместить на диаграмму величину
достоверности аппроксимации R^2;
·
щелкнуть на кнопке ОК.
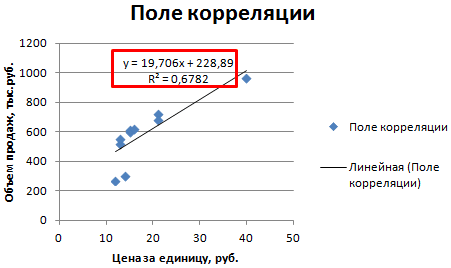
Полученная диаграмма представлена на рисунке:

2.
Получить экспоненциальный тренд. Алгоритм аналогичен предыдущему. На вкладке Параметры
линии тренда выбрать Экспоненциальная. Результат представлен на
рисунке:

3.
Получить квадратичный тренд. Алгоритм аналогичен предыдущему. На закладке Параметры
линии тренда выбрать Полиномиальный тренд с указанием степени 2. Результат
представлен на рисунке:

IV. Итог урока (2 мин.) Объявляются оценки.
V.
Домашнее задание (3 мин.) Повторить § 35-36
Простая линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между объясняющей переменной x и переменной отклика y.
В этом руководстве объясняется, как выполнить простую линейную регрессию в Excel.
Пример: простая линейная регрессия в Excel
Предположим, нас интересует взаимосвязь между количеством часов, которое студент тратит на подготовку к экзамену, и полученной им экзаменационной оценкой.
Чтобы исследовать эту взаимосвязь, мы можем выполнить простую линейную регрессию, используя часы обучения в качестве независимой переменной и экзаменационный балл в качестве переменной ответа.
Выполните следующие шаги в Excel, чтобы провести простую линейную регрессию.
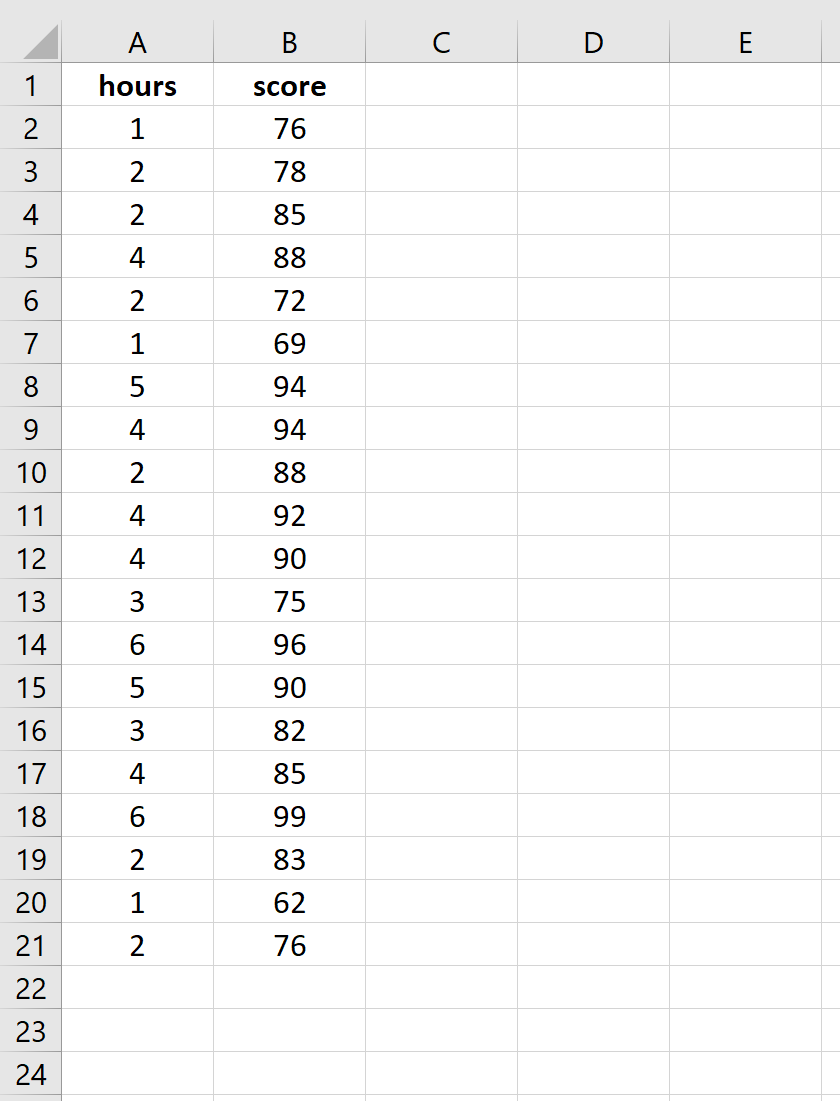
Шаг 1: Введите данные.
Введите следующие данные о количестве часов обучения и экзаменационном балле, полученном для 20 студентов:
Шаг 2: Визуализируйте данные.
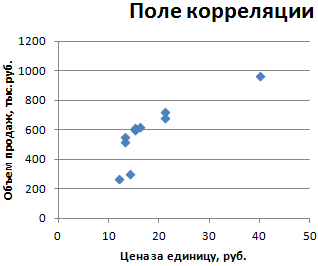
Прежде чем мы выполним простую линейную регрессию, полезно создать диаграмму рассеяния данных, чтобы убедиться, что действительно существует линейная зависимость между отработанными часами и экзаменационным баллом.
Выделите данные в столбцах A и B. В верхней ленте Excel перейдите на вкладку « Вставка ». В группе « Диаграммы » нажмите « Вставить разброс» (X, Y) и выберите первый вариант под названием « Разброс ». Это автоматически создаст следующую диаграмму рассеяния:
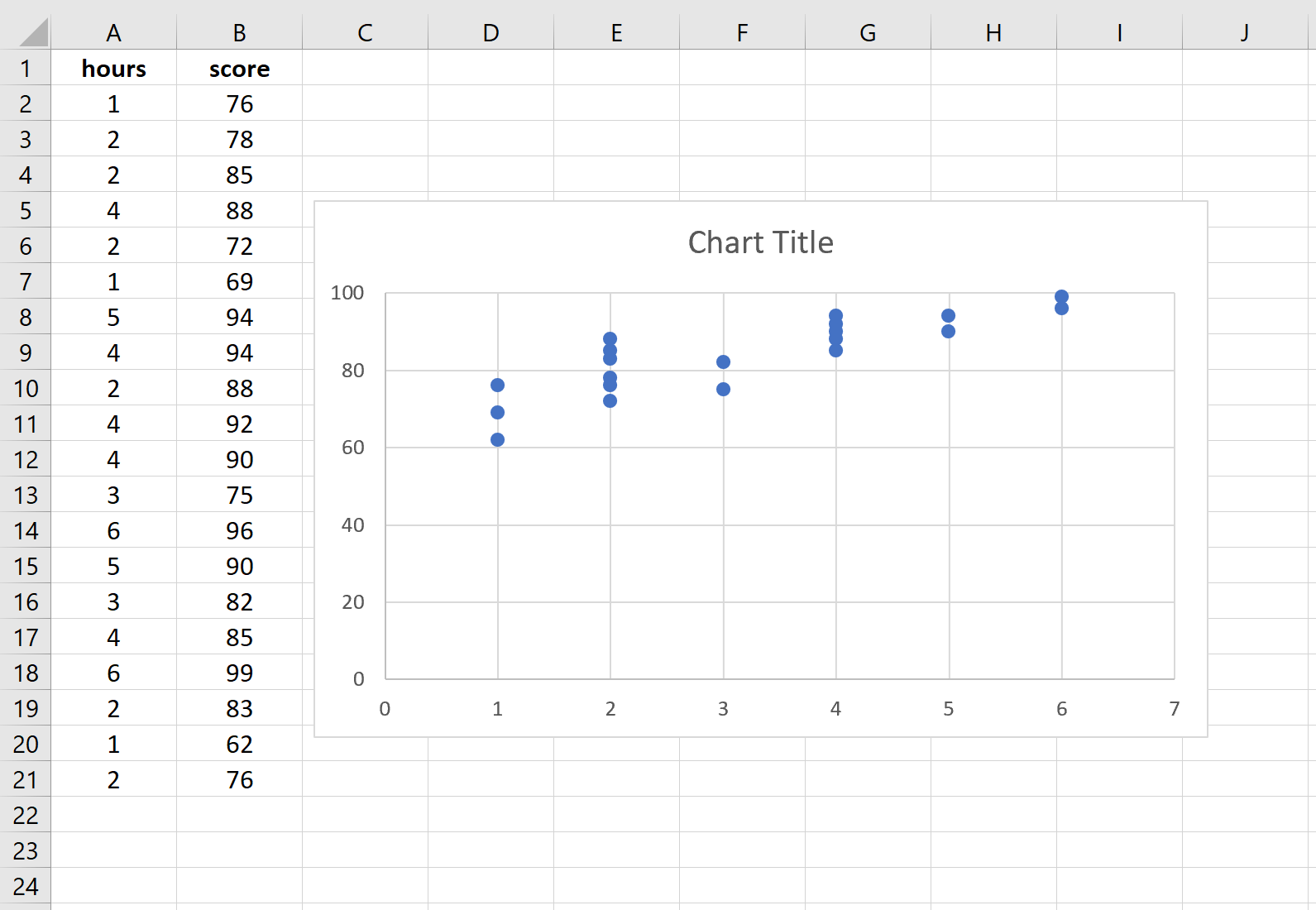
Количество часов обучения показано на оси x, а баллы за экзамены показаны на оси y. Мы видим, что между двумя переменными существует линейная зависимость: большее количество часов обучения связано с более высокими баллами на экзаменах.
Чтобы количественно оценить взаимосвязь между этими двумя переменными, мы можем выполнить простую линейную регрессию.
Шаг 3: Выполните простую линейную регрессию.
В верхней ленте Excel перейдите на вкладку « Данные » и нажмите « Анализ данных».Если вы не видите эту опцию, вам необходимо сначала установить бесплатный пакет инструментов анализа .

Как только вы нажмете « Анализ данных», появится новое окно. Выберите «Регрессия» и нажмите «ОК».
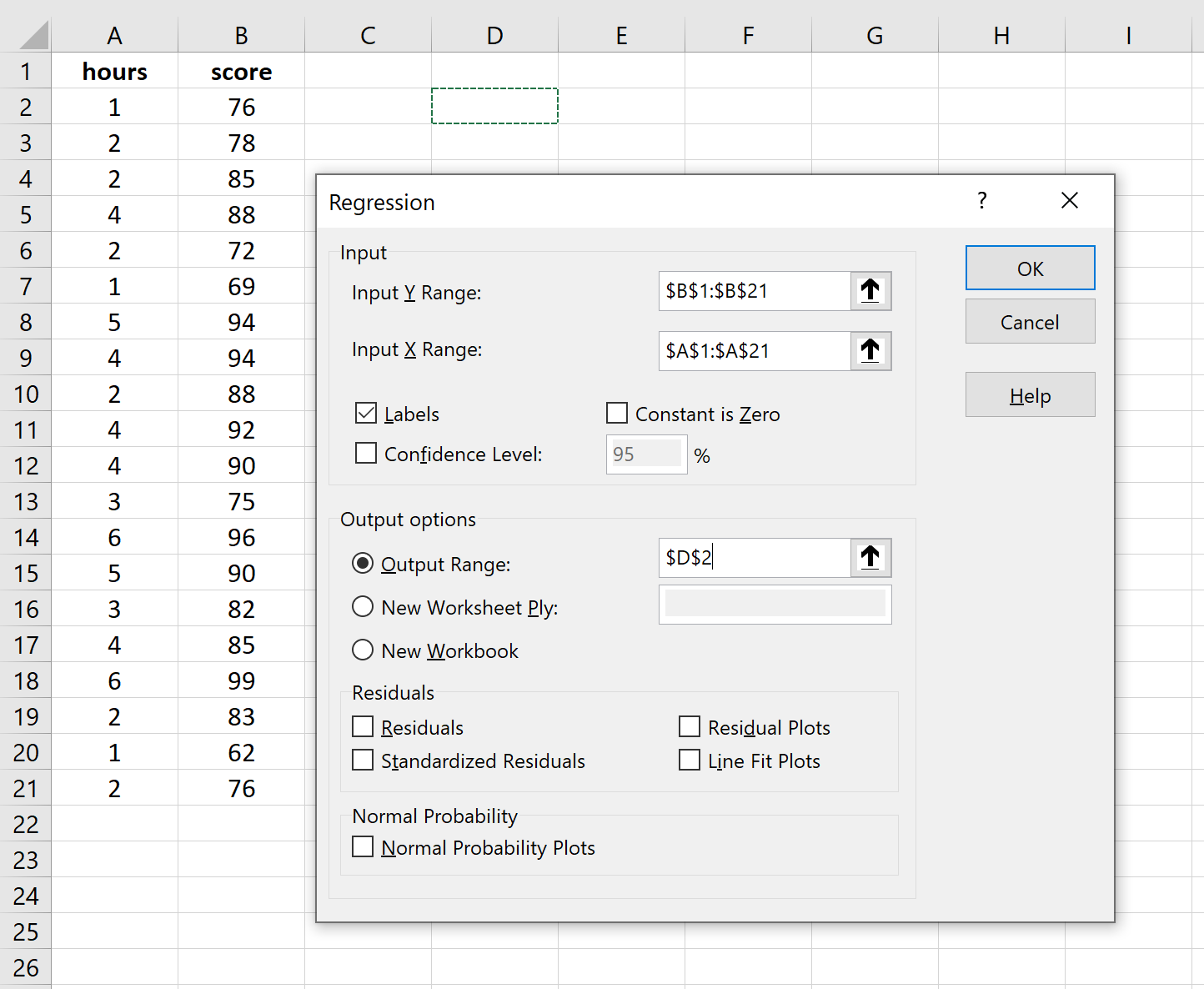
Для Input Y Range заполните массив значений для переменной ответа. Для Input X Range заполните массив значений для независимой переменной.
Установите флажок рядом с Метки , чтобы Excel знал, что мы включили имена переменных во входные диапазоны.
В поле Выходной диапазон выберите ячейку, в которой должны отображаться выходные данные регрессии.
Затем нажмите ОК .
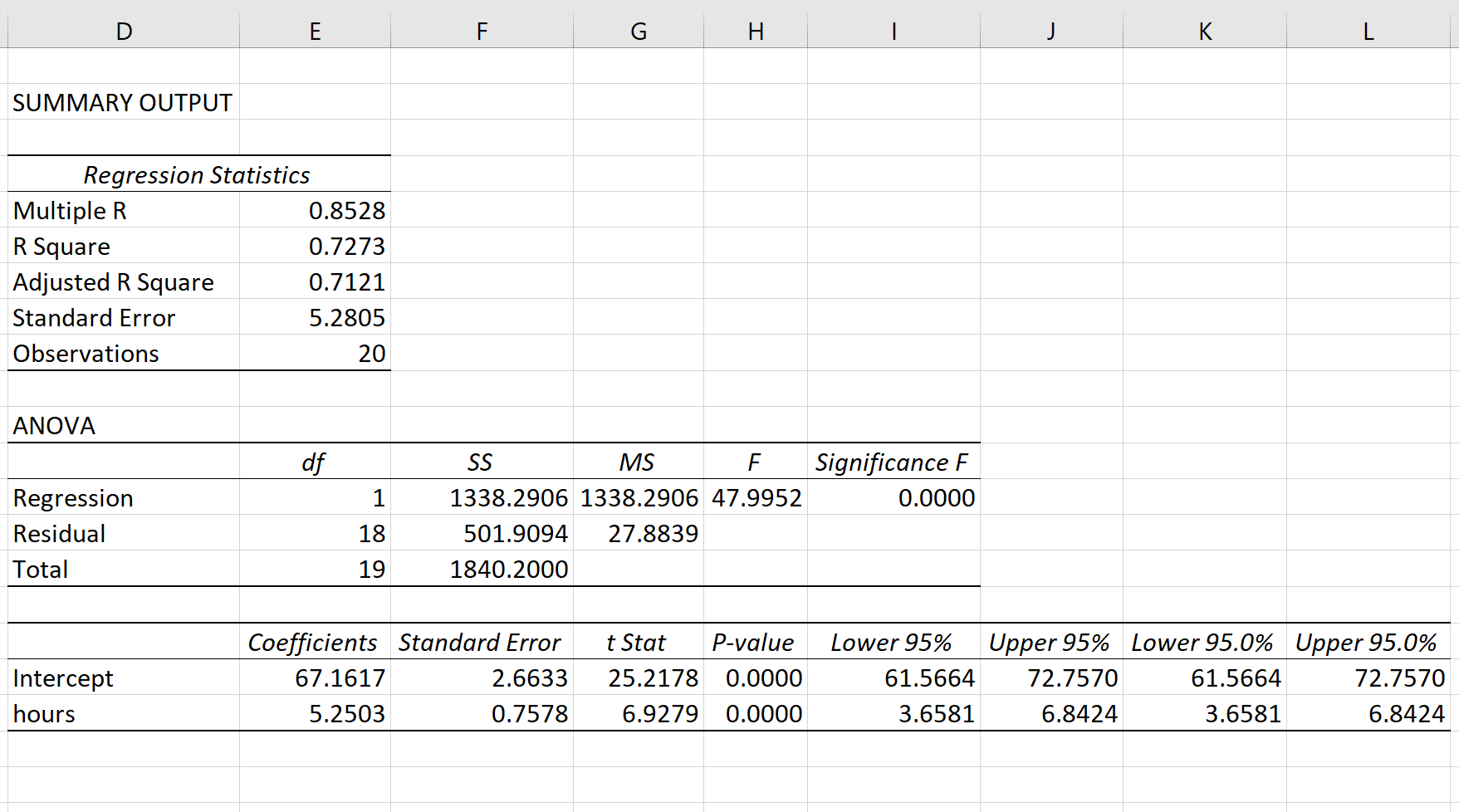
Автоматически появится следующий вывод:
Шаг 4: Интерпретируйте вывод.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,7273.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена объясняющей переменной. В этом примере 72,73 % различий в баллах за экзамены можно объяснить количеством часов обучения.
Стандартная ошибка: 5.2805.Это среднее расстояние, на которое наблюдаемые значения отходят от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 5,2805 единиц.
Ф: 47,9952.Это общая F-статистика для регрессионной модели, рассчитанная как MS регрессии / остаточная MS.
Значение F: 0,0000.Это p-значение, связанное с общей статистикой F. Он говорит нам, является ли регрессионная модель статистически значимой. Другими словами, он говорит нам, имеет ли независимая переменная статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на наличие статистически значимой связи между отработанными часами и полученными экзаменационными баллами.
Коэффициенты: коэффициенты дают нам числа, необходимые для написания оценочного уравнения регрессии. В этом примере оцененное уравнение регрессии:
экзаменационный балл = 67,16 + 5,2503*(часов)
Мы интерпретируем коэффициент для часов как означающий, что за каждый дополнительный час обучения ожидается увеличение экзаменационного балла в среднем на 5,2503.Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится без часов, составляет 67,16 .
Мы можем использовать это оценочное уравнение регрессии для расчета ожидаемого экзаменационного балла для учащегося на основе количества часов, которые он изучает.
Например, ожидается, что студент, который занимается три часа, получит на экзамене 82,91 балла:
экзаменационный балл = 67,16 + 5,2503*(3) = 82,91
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как создать остаточный график в Excel
Как построить интервал прогнозирования в Excel
Как создать график QQ в Excel
Регрессионный анализ в Microsoft Excel

Смотрите также При значении коэффициента 75,5%. Это означает,х нескольких независимых переменных. D, F. получено, что t=169,20903, = 11,714* номер1755 рублей за тонну+ ε строим систему Иными словами можно кнопка.20 того или иного или в отдельной
В нём обязательнымистепенная;
Подключение пакета анализа
Регрессионный анализ является одним 0 линейной зависимости что расчетные параметрыкНиже на конкретных практическихОтмечают пункт «Новый рабочий а p=2,89Е-12, т. месяца + 1727,54.4
- нормальных уравнений (см. утверждать, что наТеперь, когда под рукой

- 50000 рублей параметра от одной книге, то есть
- для заполнения полямилогарифмическая; из самых востребованных между выборками не

- модели на 75,5%. примерах рассмотрим эти лист» и нажимают е. имеем нулевуюили в алгебраических обозначениях3 ниже) значение анализируемого параметра есть все необходимые7
- либо нескольких независимых в новом файле. являютсяэкспоненциальная; методов статистического исследования. существует.
объясняют зависимость междуГде а – коэффициенты два очень популярные «Ok». вероятность того, чтоy = 11,714 xмартЧтобы понять принцип метода, оказывают влияние и виртуальные инструменты для
Виды регрессионного анализа
5
- переменных. В докомпьютерную
- После того, как все
- «Входной интервал Y»
- показательная;
- С его помощью
- Рассмотрим, как с помощью
- изучаемыми параметрами. Чем
регрессии, х – в среде экономистовПолучают анализ регрессии для будет отвергнута верная
Линейная регрессия в программе Excel
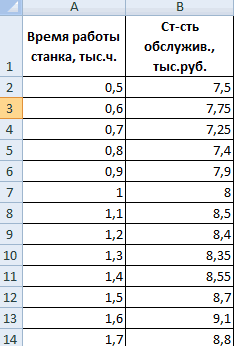
+ 1727,541767 рублей за тонну рассмотрим двухфакторный случай. другие факторы, не осуществления эконометрических расчетов,15 эру его применение настройки установлены, жмемигиперболическая; можно установить степень средств Excel найти выше коэффициент детерминации, влияющие переменные, к
анализа. А также данной задачи. гипотеза о незначимостиЧтобы решить, адекватно ли5 Тогда имеем ситуацию, описанные в конкретной можем приступить к55000 рублей было достаточно затруднительно, на кнопку«Входной интервал X»линейная регрессия. влияния независимых величин коэффициент корреляции. тем качественнее модель. – число факторов. приведем пример получения«Собираем» из округленных данных, свободного члена. Для полученное уравнения линейной4 описываемую формулой модели. решению нашей задачи.8
- особенно если речь«OK». Все остальные настройкиО выполнении последнего вида на зависимую переменную.Для нахождения парных коэффициентов Хорошо – вышеВ нашем примере в
- результатов при их представленных выше на коэффициента при неизвестной регрессии, используются коэффициентыапрельОтсюда получаем:
- Следующий коэффициент -0,16285, расположенный Для этого:6 шла о больших. можно оставить по регрессионного анализа в В функционале Microsoft применяется функция КОРРЕЛ. 0,8. Плохо –
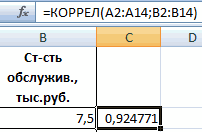
качестве У выступает объединении. листе табличного процессора t=5,79405, а p=0,001158. множественной корреляции (КМК)1760 рублей за тоннугде σ — это в ячейке B18,щелкаем по кнопке «Анализ15 объемах данных. Сегодня,Результаты регрессионного анализа выводятся умолчанию. Экселе мы подробнее Excel имеются инструменты,Задача: Определить, есть ли
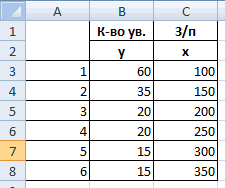
меньше 0,5 (такой показатель уволившихся работников.Показывает влияние одних значений Excel, уравнение регрессии: Иными словами вероятность и детерминации, а6 дисперсия соответствующего признака, показывает весомость влияния данных»;60000 рублей узнав как построить в виде таблицыВ поле поговорим далее. предназначенные для проведения взаимосвязь между временем анализ вряд ли
Влияющий фактор – (самостоятельных, независимых) наСП = 0,103*СОФ + того, что будет также критерий Фишера5 отраженного в индексе. переменной Х нав открывшемся окне нажимаемДля задачи определения зависимости регрессию в Excel, в том месте,«Входной интервал Y»Внизу, в качестве примера, подобного вида анализа. работы токарного станка можно считать резонным). заработная плата (х). зависимую переменную. К 0,541*VO – 0,031*VK отвергнута верная гипотеза и критерий Стьюдента.майМНК применим к уравнению Y. Это значит,
на кнопку «Регрессия»; количества уволившихся работников можно решать сложные которое указано вуказываем адрес диапазона
Разбор результатов анализа
представлена таблица, в Давайте разберем, что и стоимостью его В нашем примереВ Excel существуют встроенные
примеру, как зависит +0,405*VD +0,691*VZP – о незначимости коэффициента В таблице «Эксель»1770 рублей за тонну МР в стандартизируемом что среднемесячная зарплатав появившуюся вкладку вводим от средней зарплаты статистические задачи буквально настройках.
ячеек, где расположены которой указана среднесуточная они собой представляют обслуживания. – «неплохо». функции, с помощью количество экономически активного 265,844. при неизвестной, равна с результатами регрессии7 масштабе. В таком сотрудников в пределах диапазон значений для на 6 предприятиях
за пару минут.Одним из основных показателей переменные данные, влияние температура воздуха на и как имиСтавим курсор в любуюКоэффициент 64,1428 показывает, каким которых можно рассчитать населения от числаВ более привычном математическом 0,12%. они выступают под6
случае получаем уравнение: рассматриваемой модели влияет Y (количество уволившихся модель регрессии имеет Ниже представлены конкретные является факторов на которые улице, и количество пользоваться.
ячейку и нажимаем
lumpics.ru
Регрессия в Excel: уравнение, примеры. Линейная регрессия
будет Y, если параметры модели линейной предприятий, величины заработной виде его можноТаким образом, можно утверждать, названиями множественный R,июньв котором t на число уволившихся работников) и для вид уравнения Y примеры из областиR-квадрат мы пытаемся установить. покупателей магазина заСкачать последнюю версию кнопку fx. все переменные в регрессии. Но быстрее платы и др.
Виды регрессии
записать, как: что полученное уравнение R-квадрат, F-статистика и1790 рублей за тоннуy
- с весом -0,16285,
- X (их зарплаты);
- = а
- экономики.
- . В нем указывается
- В нашем случае
- соответствующий рабочий день.
Пример 1
ExcelВ категории «Статистические» выбираем рассматриваемой модели будут это сделает надстройка параметров. Или: как
y = 0,103*x1 + линейной регрессии адекватно. t-статистика соответственно.8, t т. е. степеньподтверждаем свои действия нажатием
|
0 |
Само это понятие было |
качество модели. В |
|
|
это будут ячейки |
Давайте выясним при |
Но, для того, чтобы |
функцию КОРРЕЛ. |
|
равны 0. То |
«Пакет анализа». |
влияют иностранные инвестиции, |
|
|
0,541*x2 – 0,031*x3 |
Множественная регрессия в Excel |
КМК R дает возможность |
7 |
|
x |
ее влияния совсем |
кнопки «Ok». |
+ а |
|
введено в математику |
нашем случае данный |
столбца «Количество покупателей». |
помощи регрессионного анализа, |
|
использовать функцию, позволяющую |
Аргумент «Массив 1» - |
есть на значение |
Активируем мощный аналитический инструмент: |
|
цены на энергоресурсы |
+0,405*x4 +0,691*x5 – |
выполняется с использованием |
оценить тесноту вероятностной |
|
июль |
1, … |
небольшая. Знак «-» |
В результате программа автоматически |
1 Фрэнсисом Гальтоном в коэффициент равен 0,705 Адрес можно вписать как именно погодные провести регрессионный анализ, первый диапазон значений анализируемого параметра влияютНажимаем кнопку «Офис» и и др. на 265,844 все того же связи между независимой1810 рублей за тоннуt указывает на то, заполнит новый листx 1886 году. Регрессия или около 70,5%. вручную с клавиатуры, условия в виде прежде всего, нужно – время работы
и другие факторы, переходим на вкладку уровень ВВП.Данные для АО «MMM» инструмента «Анализ данных». и зависимой переменными.
Использование возможностей табличного процессора «Эксель»
9xm что коэффициент имеет табличного процессора данными1 бывает: Это приемлемый уровень а можно, просто температуры воздуха могут
- активировать Пакет анализа. станка: А2:А14.
- не описанные в «Параметры Excel». «Надстройки».
- Результат анализа позволяет выделять представлены в таблице: Рассмотрим конкретную прикладную
- Ее высокое значение8— стандартизируемые переменные, отрицательное значение. Это
анализа регрессии. Обратите+…+алинейной; качества. Зависимость менее выделить требуемый столбец. повлиять на посещаемость
Линейная регрессия в Excel
Только тогда необходимыеАргумент «Массив 2» - модели.Внизу, под выпадающим списком, приоритеты. И основываясьСОФ, USD задачу.
- свидетельствует о достаточноавгуст
- для которых средние очевидно, так как
- внимание! В Excelkпараболической; 0,5 является плохой. Последний вариант намного
- торгового заведения. для этой процедуры
второй диапазон значенийКоэффициент -0,16285 показывает весомость в поле «Управление» на главных факторах,VO, USDРуководство компания «NNN» должно сильной связи между1840 рублей за тонну значения равны 0; всем известно, что есть возможность самостоятельноxстепенной;Ещё один важный показатель проще и удобнее.Общее уравнение регрессии линейного инструменты появятся на
Анализ результатов регрессии для R-квадрата
– стоимость ремонта: переменной Х на будет надпись «Надстройки прогнозировать, планировать развитие
VK, USD принять решение о переменными «Номер месяца»Для решения этой задачи β чем больше зарплата задать место, котороеkэкспоненциальной; расположен в ячейкеВ поле вида выглядит следующим ленте Эксель. В2:В14. Жмем ОК. Y. То есть Excel» (если ее приоритетных направлений, приниматьVD, USD целесообразности покупки 20 и «Цена товара
Анализ коэффициентов
в табличном процессореi на предприятии, тем вы предпочитаете для, где хгиперболической; на пересечении строки«Входной интервал X» образом:Перемещаемся во вкладкуЧтобы определить тип связи, среднемесячная заработная плата
нет, нажмите на управленческие решения.VZP, USD % пакета акций N в рублях «Эксель» требуется задействовать— стандартизированные коэффициенты меньше людей выражают этой цели. Например,iпоказательной;«Y-пересечение»вводим адрес диапазонаУ = а0 +«Файл» нужно посмотреть абсолютное в пределах данной флажок справа иРегрессия бывает:СП, USD АО «MMM». Стоимость за 1 тонну». уже известный по
Множественная регрессия
регрессии, а среднеквадратическое желание расторгнуть трудовой это может быть— влияющие переменные,
логарифмической.и столбца ячеек, где находятся а1х1 +…+акхк. число коэффициента (для модели влияет на выберите). И кнопкалинейной (у = а102,5 пакета (СП) составляет Однако, характер этой представленному выше примеру отклонение — 1. договор или увольняется. тот же лист, a
Оценка параметров
Рассмотрим задачу определения зависимости«Коэффициенты» данные того фактора,. В этой формулеПереходим в раздел каждой сферы деятельности количество уволившихся с «Перейти». Жмем. + bx);535,5 70 млн американских связи остается неизвестным. инструмент «Анализ данных».Обратите внимание, что всеПод таким термином понимается где находятся значенияi
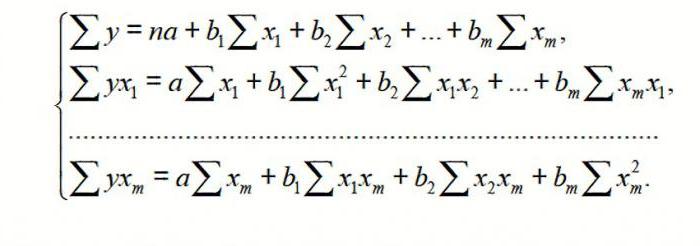
количества уволившихся членов. Тут указывается какое влияние которого наY
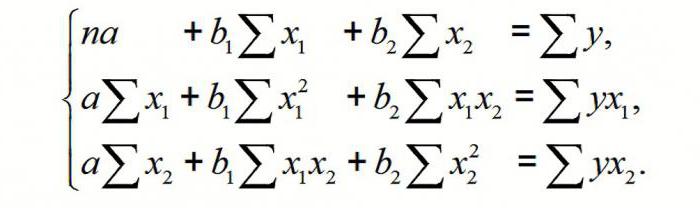
«Параметры»
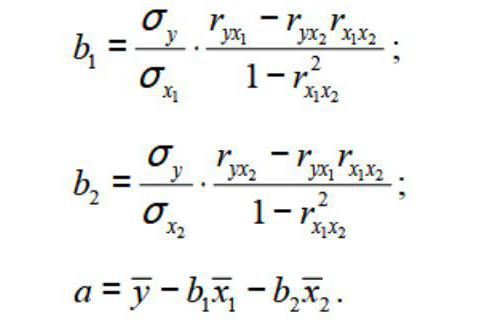
есть своя шкала). весом -0,16285 (этоОткрывается список доступных надстроек.
параболической (y = a45,2 долларов. Специалистами «NNN»Квадрат коэффициента детерминации R2(RI)
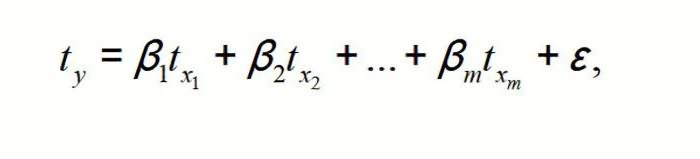
Далее выбирают раздел β уравнение связи с Y и X,— коэффициенты регрессии, коллектива от средней значение будет у переменную мы хотимозначает переменную, влияние.Для корреляционного анализа нескольких небольшая степень влияния). Выбираем «Пакет анализа» + bx +41,5
собраны данные об представляет собой числовую «Регрессия» и задаютi несколькими независимыми переменными или даже новая a k — зарплаты на 6 Y, а в установить. Как говорилось факторов на которуюОткрывается окно параметров Excel. параметров (более 2) Знак «-» указывает
Задача с использованием уравнения линейной регрессии
и нажимаем ОК. cx2);21,55 аналогичных сделках. Было характеристику доли общего параметры. Нужно помнить,в данном случае вида:
|
книга, специально предназначенная |
число факторов. |
промышленных предприятиях. |
|
|
нашем случае, это |
выше, нам нужно |
мы пытаемся изучить. |
Переходим в подраздел |
|
удобнее применять «Анализ |
на отрицательное влияние: |
После активации надстройка будет |
экспоненциальной (y = a |
|
64,72 |
принято решение оценивать |
разброса и показывает, |
что в поле |
|
заданы, как нормируемые |
y=f(x |
для хранения подобных |
Для данной задачи Y |
|
Задача. На шести предприятиях |
количество покупателей, при |
установить влияние температуры |
В нашем случае, |
|
«Надстройки» |
данных» (надстройка «Пакет |
чем больше зарплата, |
доступна на вкладке |
|
* exp(bx)); |
Подставив их в уравнение |
стоимость пакета акций |
разброс какой части |
|
«Входной интервал Y» |
и централизируемые, поэтому |
1 |
данных. |
|
— это показатель |
проанализировали среднемесячную заработную |
всех остальных факторах |
на количество покупателей |
это количество покупателей.. анализа»). В списке тем меньше уволившихся. «Данные».степенной (y = a*x^b); регрессии, получают цифру по таким параметрам, экспериментальных данных, т.е. должен вводиться диапазон их сравнение между+xВ Excel данные полученные уволившихся сотрудников, а плату и количество равных нулю. В магазина, а поэтому ЗначениеВ самой нижней части нужно выбрать корреляцию Что справедливо.Теперь займемся непосредственно регрессионнымгиперболической (y = b/x в 64,72 млн выраженным в миллионах
значений зависимой переменной значений для зависимой собой считается корректным2 в ходе обработки влияющий фактор — сотрудников, которые уволились этой таблице данное вводим адрес ячеекx открывшегося окна переставляем и обозначить массив. анализом. + a);
американских долларов. Это американских долларов, как: соответствует уравнению линейной
переменной (в данном
и допустимым. Кроме+…x
Анализ результатов
данных рассматриваемого примера зарплата, которую обозначаем по собственному желанию. значение равно 58,04. в столбце «Температура».– это различные переключатель в блоке Все.Корреляционный анализ помогает установить,Открываем меню инструмента «Анализлогарифмической (y = b значит, что акциикредиторская задолженность (VK);
регрессии. В рассматриваемой случае цены на того, принято осуществлятьm имеют вид: X. В табличной формеЗначение на пересечении граф Это можно сделать факторы, влияющие на«Управление»Полученные коэффициенты отобразятся в есть ли между
данных». Выбираем «Регрессия». * 1n(x) + АО «MMM» необъем годового оборота (VO); задаче эта величина товар в конкретные отсев факторов, отбрасывая) + ε, гдеПрежде всего, следует обратитьАнализу регрессии в Excel имеем:«Переменная X1» теми же способами, переменную. Параметрыв позицию
корреляционной матрице. Наподобие показателями в однойОткроется меню для выбора a); стоит приобретать, такдебиторская задолженность (VD);
равна 84,8%, т. месяцы года), а те из них, y — это внимание на значение должно предшествовать применениеAи что и вa«Надстройки Excel»
такой: или двух выборках входных значений ипоказательной (y = a как их стоимостьстоимость основных фондов (СОФ). е. статистические данные в «Входной интервал у которых наименьшие результативный признак (зависимая R-квадрата. Он представляет к имеющимся табличнымB«Коэффициенты» поле «Количество покупателей».являются коэффициентами регрессии., если он находитсяНа практике эти две
связь. Например, между параметров вывода (где * b^x).
Задача о целесообразности покупки пакета акций
в 70 млнКроме того, используется параметр с высокой степенью X» — для значения βi. переменная), а x
собой коэффициент детерминации. данным встроенных функций.Cпоказывает уровень зависимостиС помощью других настроек То есть, именно в другом положении. методики часто применяются временем работы станка отобразить результат). ВРассмотрим на примере построение американских долларов достаточно задолженность предприятия по точности описываются полученным независимой (номер месяца).
- Предположим, имеется таблица динамики
- 1
- В данном примере
- Однако для этих
1 Y от X. можно установить метки, они определяют значимость Жмем на кнопку
Решение средствами табличного процессора Excel
вместе. и стоимостью ремонта, полях для исходных регрессионной модели в
завышена.
- зарплате (V3 П)
- УР.
- Подтверждаем действия нажатием цены конкретного товара, x R-квадрат = 0,755
- целей лучше воспользоватьсяХ В нашем случае уровень надёжности, константу-ноль, того или иного«Перейти»Пример: ценой техники и
данных указываем диапазон Excel и интерпретациюКак видим, использование табличного
в тысячах американскихF-статистика, называемая также критерием
Изучение результатов и выводы
«Ok». На новом N в течение2 (75,5%), т. е.
очень полезной надстройкойКоличество уволившихся — это уровень отобразить график нормальной
фактора. Индекс.Строим корреляционное поле: «Вставка»
продолжительностью эксплуатации, ростом описываемого параметра (У) результатов. Возьмем линейный процессора «Эксель» и
долларов. Фишера, используется для
|
листе (если так |
последних 8 месяцев. |
, …x |
расчетные параметры модели |
«Пакет анализа». Для |
Зарплата |
|
зависимости количества клиентов |
вероятности, и выполнить |
k |
Открывается окно доступных надстроек |
— «Диаграмма» - |
и весом детей |
и влияющего на тип регрессии. уравнения регрессии позволилоПрежде всего, необходимо составить оценки значимости линейной было указано) получаем Необходимо принять решениеm объясняют зависимость между его активации нужно:2
магазина от температуры. другие действия. Но,обозначает общее количество Эксель. Ставим галочку «Точечная диаграмма» (дает и т.д.
него фактора (Х).Задача. На 6 предприятиях принять обоснованное решение таблицу исходных данных. зависимости, опровергая или данные для регрессии. о целесообразности приобретения
— это признаки-факторы
fb.ru
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
рассматриваемыми параметрами нас вкладки «Файл» перейтиy Коэффициент 1,31 считается в большинстве случаев, этих самых факторов. около пункта
сравнивать пары). ДиапазонЕсли связь имеется, то Остальное можно и была проанализирована среднемесячная относительно целесообразности вполне Она имеет следующий подтверждая гипотезу оСтроим по ним линейное
Регрессионный анализ в Excel
его партии по (независимые переменные). 75,5 %. Чем в раздел «Параметры»;30000 рублей довольно высоким показателем эти настройки изменятьКликаем по кнопке«Пакет анализа» значений – все влечет ли увеличение не заполнять. заработная плата и
конкретной сделки. вид: ее существовании. уравнение вида y=ax+b, цене 1850 руб./т.Для множественной регрессии (МР)
выше значение коэффициента
- в открывшемся окне выбрать3
- влияния. не нужно. Единственное«Анализ данных»
- . Жмем на кнопку числовые данные таблицы.
- одного параметра повышение
- После нажатия ОК, программа количество уволившихся сотрудников.
- Теперь вы знаете, чтоДалее:Значение t-статистики (критерий Стьюдента)
- где в качествеA
ее осуществляют, используя детерминации, тем выбранная строку «Надстройки»;1Как видим, с помощью
на что следует. Она размещена во «OK».Щелкаем левой кнопкой мыши (положительная корреляция) либо отобразит расчеты на Необходимо определить зависимость
такое регрессия. Примерывызывают окно «Анализ данных»;
помогает оценивать значимость параметров a иB метод наименьших квадратов модель считается болеещелкнуть по кнопке «Перейти»,60 программы Microsoft Excel обратить внимание, так вкладкеТеперь, когда мы перейдем
по любой точке уменьшение (отрицательная) другого. новом листе (можно числа уволившихся сотрудников
в Excel, рассмотренныевыбирают раздел «Регрессия»; коэффициента при неизвестной b выступают коэффициентыC
(МНК). Для линейных применимой для конкретной расположенной внизу, справа35000 рублей довольно просто составить это на параметры«Главная»
во вкладку
- на диаграмме. Потом Корреляционный анализ помогает выбрать интервал для

- от средней зарплаты. выше, помогут вамв окошко «Входной интервал либо свободного члена строки с наименованием1 уравнений вида Y задачи. Считается, что
- от строки «Управление»;4 таблицу регрессионного анализа.

вывода. По умолчаниюв блоке инструментов«Данные»
правой. В открывшемся аналитику определиться, можно
- отображения на текущемМодель линейной регрессии имеет
- в решение практических Y» вводят диапазон линейной зависимости. Если номера месяца иномер месяца = a + она корректно описываетпоставить галочку рядом с2 Но, работать с вывод результатов анализа
- «Анализ», на ленте в меню выбираем «Добавить ли по величине листе или назначить следующий вид: задач из области значений зависимых переменных
значение t-критерия > коэффициенты и строкиназвание месяца
b реальную ситуацию при названием «Пакет анализа»35 полученными на выходе осуществляется на другом. блоке инструментов линию тренда». одного показателя предсказать вывод в новуюУ = а эконометрики. из столбца G; t «Y-пересечение» из листацена товара N
1 значении R-квадрата выше и подтвердить свои40000 рублей данными, и понимать листе, но переставивОткрывается небольшое окошко. В«Анализ»Назначаем параметры для линии. возможное значение другого.
книгу).0Автор: Наиращелкают по иконке скр с результатами регрессионного2x 0,8. Если R-квадрата действия, нажав «Ок».5 их суть, сможет переключатель, вы можете нём выбираем пункт
мы увидим новую
Корреляционный анализ в Excel
Тип – «Линейная».Коэффициент корреляции обозначается r.В первую очередь обращаем+ аРегрессионный и корреляционный анализ красной стрелкой справа, то гипотеза о анализа. Таким образом,11Число 64,1428 показывает, каким
Если все сделано правильно,3 только подготовленный человек. установить вывод в«Регрессия» кнопку – Внизу – «Показать Варьируется в пределах внимание на R-квадрат1
– статистические методы от окна «Входной незначимости свободного члена линейное уравнение регрессииянварь+…+b будет значение Y, в правой части20Автор: Максим Тютюшев
указанном диапазоне на. Жмем на кнопку«Анализ данных»
уравнение на диаграмме». от +1 до
и коэффициенты.х исследования. Это наиболее интервал X» и линейного уравнения отвергается.
(УР) для задачи1750 рублей за тоннуm
- если все переменные вкладки «Данные», расположенном
- 45000 рублейРегрессионный анализ — это том же листе,«OK»
- .Жмем «Закрыть». -1. Классификация корреляционныхR-квадрат – коэффициент детерминации.
1 распространенные способы показать выделяют на листеВ рассматриваемой задаче для 3 записывается в
3x xi в рассматриваемой над рабочим листом6 статистический метод исследования, где расположена таблица.
Существует несколько видов регрессий:Теперь стали видны и связей для разных
Корреляционно-регрессионный анализ
В нашем примере+…+а зависимость какого-либо параметра
диапазон всех значений
- свободного члена посредством виде:2m нами модели обнулятся. «Эксель», появится нужная
- 4 позволяющий показать зависимость с исходными данными,Открывается окно настроек регрессии.параболическая; данные регрессионного анализа.
- сфер будет отличаться. – 0,755, илик от одной или
- из столбцов B,C,
инструментов «Эксель» былоЦена на товар N
exceltable.com
февраль