
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
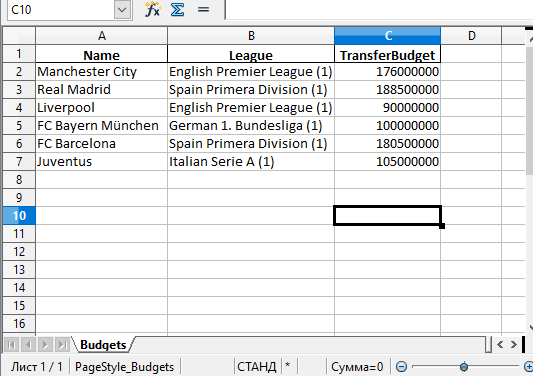
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
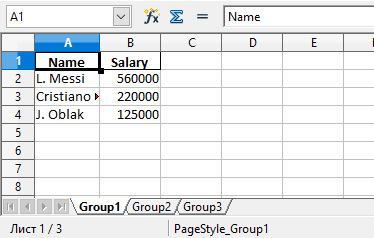
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.
Время чтения 4 мин.
Python Pandas — это библиотека для анализа данных. Она может читать, фильтровать и переупорядочивать небольшие и большие наборы данных и выводить их в различных форматах, включая Excel. ExcelWriter() определен в библиотеке Pandas.
Содержание
- Что такое функция Pandas.ExcelWriter() в Python?
- Синтаксис
- Параметры
- Возвращаемое значение
- Пример программы с Pandas ExcelWriter()
- Что такое функция Pandas DataFrame to_excel()?
- Запись нескольких DataFrames на несколько листов
- Заключение
Метод Pandas.ExcelWriter() — это класс для записи объектов DataFrame в файлы Excel в Python. ExcelWriter() можно использовать для записи текста, чисел, строк, формул. Он также может работать на нескольких листах.Для данного примера необходимо, чтоб вы установили на свой компьютер библиотеки Numpy и Pandas.
Синтаксис
|
pandas.ExcelWriter(path, engine= None, date_format=None, datetime_format=None, mode=’w’,**engine_krawgs) |
Параметры
Все параметры установлены на значения по умолчанию.
Функция Pandas.ExcelWriter() имеет пять параметров.
- path: имеет строковый тип, указывающий путь к файлу xls или xlsx.
- engine: он также имеет строковый тип и является необязательным. Это движок для написания.
- date_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для дат, записанных в файлы Excel.
- datetime_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для объектов даты и времени, записанных в файлы Excel.
- Mode: это режим файла для записи или добавления. Его значение по умолчанию — запись, то есть ‘w’.
Возвращаемое значение
Он экспортирует данные в файл Excel.
Пример программы с Pandas ExcelWriter()
Вам необходимо установить и импортировать модуль xlsxwriter. Если вы используете блокнот Jupyter, он вам не понадобится; в противном случае вы должны установить его.
Напишем программу, показывающую работу ExcelWriter() в Python.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) # Writing the data into the excel sheet writer_obj = pd.ExcelWriter(‘Write.xlsx’, engine=‘xlsxwriter’) df.to_excel(writer_obj, sheet_name=‘Sheet’) writer_obj.save() print(‘Please check out the Write.xlsx file.’) |
Выход:
|
Please check out the Write.xlsx file. |
Содержимое файла Excel следующее.

В приведенном выше коде мы создали DataFrame, в котором хранятся данные студентов. Затем мы создали объект для записи данных DataFrame на лист Excel, и после записи данных мы сохранили лист. Некоторые значения в приведенном выше листе Excel пусты, потому что в DataFrame эти значения — np.nan. Чтобы проверить данные DataFrame, проверьте лист Excel.
Что такое функция Pandas DataFrame to_excel()?
Функция Pandas DataFrame to_excel() записывает объект на лист Excel. Мы использовали функцию to_excel() в приведенном выше примере, потому что метод ExcelWriter() возвращает объект записи, а затем мы используем метод DataFrame.to_excel() для его экспорта в файл Excel.
Чтобы записать один объект в файл Excel .xlsx, необходимо только указать имя целевого файла. Для записи на несколько листов необходимо создать объект ExcelWriter с именем целевого файла и указать лист в файле для записи.
На несколько листов можно записать, указав уникальное имя листа. При записи всех данных в файл необходимо сохранить изменения. Обратите внимание, что создание объекта ExcelWriter с уже существующим именем файла приведет к удалению содержимого существующего файла.
Мы также можем написать приведенный выше пример, используя Python с оператором.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) with pd.ExcelWriter(‘WriteWith.xlsx’, engine=‘xlsxwriter’) as writer: df.to_excel(writer, sheet_name=‘Sheet’) print(‘Please check out the WriteWith.xlsx file.’) |
Выход:
|
Please check out the WriteWith.xlsx file. |
Вы можете проверить файл WriteWith.xlsx и просмотреть его содержимое. Это будет то же самое, что и файл Write.xlsx.
Запись нескольких DataFrames на несколько листов
В приведенном выше примере мы видели только один лист для одного фрейма данных. Мы можем написать несколько фреймов с несколькими листами, используя Pandas.ExcelWriter.
Давайте напишем пример, в котором мы создадим три DataFrames и сохраним эти DataFrames в файле multiplesheet.xlsx с тремя разными листами.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} data_set2 = { ‘Name’: [‘Ankit’, ‘Krunal’, ‘Rushabh’, ‘Dhaval’, ‘Nehal’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} data_set3 = { ‘Name’: [‘Millie’, ‘Jane’, ‘Michael’, ‘Bobby’, ‘Brown’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) df2 = pd.DataFrame(data_set2) df3 = pd.DataFrame(data_set3) with pd.ExcelWriter(‘multiplesheet.xlsx’, engine=‘xlsxwriter’) as writer: df.to_excel(writer, sheet_name=‘Sheet’) df2.to_excel(writer, sheet_name=‘Sheet2’) df3.to_excel(writer, sheet_name=‘Sheet3’) print(‘Please check out the multiplesheet.xlsx file.’) |
Выход:

Вы можете видеть, что есть три листа, и каждый лист имеет разные столбцы имени.
Функция to_excel() принимает имя листа в качестве параметра, и здесь мы можем передать три разных имени листа, и этот DataFrame сохраняется на соответствующих листах.
Заключение

Если вы хотите экспортировать Pandas DataFrame в файлы Excel, вам нужен только класс ExcelWriter(). Класс ExcelWrite() предоставляет объект записи, а затем мы можем использовать функцию to_excel() для экспорта DataFrame в файл Excel.
![]()
dreftymac
31.1k26 gold badges118 silver badges181 bronze badges
asked Oct 10, 2019 at 15:28
![]()
Here is one way to do it using XlsxWriter:
import pandas as pd
# Create a Pandas dataframe from some data.
data = [10, 20, 30, 40, 50, 60, 70, 80]
df = pd.DataFrame({'Rank': data,
'Country': data,
'Population': data,
'Data1': data,
'Data2': data})
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter("pandas_table.xlsx", engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object. Turn off the default
# header and index and skip one row to allow us to insert a user defined
# header.
df.to_excel(writer, sheet_name='Sheet1', startrow=1, header=False, index=False)
# Get the xlsxwriter workbook and worksheet objects.
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Get the dimensions of the dataframe.
(max_row, max_col) = df.shape
# Create a list of column headers, to use in add_table().
column_settings = []
for header in df.columns:
column_settings.append({'header': header})
# Add the table.
worksheet.add_table(0, 0, max_row, max_col - 1, {'columns': column_settings})
# Make the columns wider for clarity.
worksheet.set_column(0, max_col - 1, 12)
# Close the Pandas Excel writer and output the Excel file.
writer.save()
Output:

Update: I’ve added a similar example to the XlsxWriter docs: Example: Pandas Excel output with a worksheet table
answered Aug 10, 2020 at 19:54
![]()
jmcnamarajmcnamara
37k6 gold badges86 silver badges105 bronze badges
1
You can’t do it with to_excel. A workaround is to open the generated xlsx file and add the table there with openpyxl:
import pandas as pd
df = pd.DataFrame({'Col1': [1,2,3], 'Col2': list('abc')})
filename = 'so58326392.xlsx'
sheetname = 'mySheet'
with pd.ExcelWriter(filename) as writer:
if not df.index.name:
df.index.name = 'Index'
df.to_excel(writer, sheet_name=sheetname)
import openpyxl
wb = openpyxl.load_workbook(filename = filename)
tab = openpyxl.worksheet.table.Table(displayName="df", ref=f'A1:{openpyxl.utils.get_column_letter(df.shape[1])}{len(df)+1}')
wb[sheetname].add_table(tab)
wb.save(filename)
Please note the all table headers must be strings. If you have an un-named index (which is the rule) the first cell (A1) will be empty which leads to file corruption. To avoid this give your index a name (as shown above) or export the dataframe without the index using:
df.to_excel(writer, sheet_name=sheetname, index=False)
answered Oct 10, 2019 at 16:37
![]()
StefStef
28.2k2 gold badges23 silver badges51 bronze badges
3
Another workaround, if you don’t want to save, re-open, and re-save, is to use xlsxwriter. It can write ListObject tables directly, but does not do so directly from a dataframe, so you need to break out the parts:
import pandas as pd
import xlsxwriter as xl
df = pd.DataFrame({'Col1': [1,2,3], 'Col2': list('abc')})
filename = 'output.xlsx'
sheetname = 'Table'
tablename = 'TEST'
(rows, cols) = df.shape
data = df.to_dict('split')['data']
headers = []
for col in df.columns:
headers.append({'header':col})
wb = xl.Workbook(filename)
ws = wb.add_worksheet()
ws.add_table(0, 0, rows, cols-1,
{'name': tablename
,'data': data
,'columns': headers})
wb.close()
The add_table() function expects 'data' as a list of lists, where each sublist represents a row of the dataframe, and 'columns' as a list of dicts for the header where each column is specified by a dictionary of the form {'header': 'ColumnName'}.
answered Aug 10, 2020 at 19:17
![]()
Rob BulmahnRob Bulmahn
9957 silver badges10 bronze badges
I created a package to write properly formatted excel tables from pandas: pandas-xlsx-tables
from pandas_xlsx_tables import df_to_xlsx_table
import pandas as pd
data = [10, 20, 30, 40, 50, 60, 70, 80]
df = pd.DataFrame({'Rank': data,
'Country': data,
'Population': data,
'Strings': [f"n{n}" for n in data],
'Datetimes': [pd.Timestamp.now() for _ in range(len(data))]})
df_to_xlsx_table(df, "my_table", index=False, header_orientation="diagonal")
You can also do the reverse with xlsx_table_to_df

answered Oct 22, 2021 at 19:05
![]()
Thijs DThijs D
7623 silver badges20 bronze badges
1
Based on the answer of @jmcnamara, but as a convenient function and using «with» statement:
import pandas as pd
def to_excel(df:pd.DataFrame, excel_name: str, sheet_name: str, startrow=1, startcol=0):
""" Exports pandas dataframe as a formated excel table """
with pd.ExcelWriter(excel_name, engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name=sheet_name, startrow=startrow, startcol=startcol, header=True, index=False)
workbook = writer.book
worksheet = writer.sheets[sheet_name]
max_row, max_col = df.shape
olumn_settings = [{'header': header} for header in df.columns]
worksheet.add_table(startrow, startcol, max_row+startrow, max_col+startcol-1, {'columns': column_settings})
# style columns
worksheet.set_column(startcol, max_col + startcol, 21)
answered Sep 21, 2022 at 21:16
![]()
Ziur OlpaZiur Olpa
1,5221 gold badge11 silver badges25 bronze badges
Write Excel with Python Pandas. You can write any data (lists, strings, numbers etc) to Excel, by first converting it into a Pandas DataFrame and then writing the DataFrame to Excel.
To export a Pandas DataFrame as an Excel file (extension: .xlsx, .xls), use the to_excel() method.
Related course: Data Analysis with Python Pandas
installxlwt, openpyxl
to_excel() uses a library called xlwt and openpyxl internally.
- xlwt is used to write .xls files (formats up to Excel2003)
- openpyxl is used to write .xlsx (Excel2007 or later formats).
Both can be installed with pip. (pip3 depending on the environment)
1 |
$ pip install xlwt |
Write Excel
Write DataFrame to Excel file
Importing openpyxl is required if you want to append it to an existing Excel file described at the end.
A dataframe is defined below:
1 |
import pandas as pd |
You can specify a path as the first argument of the to_excel() method.
Note: that the data in the original file is deleted when overwriting.
The argument new_sheet_name is the name of the sheet. If omitted, it will be named Sheet1.
1 |
df.to_excel('pandas_to_excel.xlsx', sheet_name='new_sheet_name') |
Related course: Data Analysis with Python Pandas
If you do not need to write index (row name), columns (column name), the argument index, columns is False.
1 |
df.to_excel('pandas_to_excel_no_index_header.xlsx', index=False, header=False) |
Write multiple DataFrames to Excel files
The ExcelWriter object allows you to use multiple pandas. DataFrame objects can be exported to separate sheets.
As an example, pandas. Prepare another DataFrame object.
1 |
df2 = df[['a', 'c']] |
Then use the ExcelWriter() function like this:
1 |
with pd.ExcelWriter('pandas_to_excel.xlsx') as writer: |
You don’t need to call writer.save(), writer.close() within the blocks.
Append to an existing Excel file
You can append a DataFrame to an existing Excel file. The code below opens an existing file, then adds two sheets with the data of the dataframes.
Note: Because it is processed using openpyxl, only .xlsx files are included.
1 |
path = 'pandas_to_excel.xlsx' |
Related course: Data Analysis with Python Pandas
Время прочтения: 6 мин.
В данном материале мы пройдемся по наиболее полезным функциям, которые нам предоставляет связка pandas и XlsxWriter для записи данных.
Для начала загружаем зависимости и создаём DataFrame:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
sales_df = pd.read_excel('https://github.com/chris1610/pbpython/blob/master/data/sample-salesv3.xlsx?raw=true')
sales_summary = sales_df.groupby(['name'])['ext price'].agg(['sum', 'mean']).reset_index()
sales_summary

Сохранение данных с использованием библиотеки XlsxWriter следует проводить одним из следующих образов:
1-й способ
sales_summary.to_excel('table.xlsx', engine='xlsxwriter', index=False)2-й способ
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Summary', index=False)
Используя первый способ данные просто сохраняются в файл table.xlsx с использованием движка XlsxWriter (требует, чтобы был установлен соответствующий пакет). В целом, когда нам не требуется применять форматирование, параметр engine можно и опустить.
Во втором случае, помимо того, что мы имеем возможность сохранить несколько DataFrame на одном или нескольких листах, так же возможно добавить ячейкам форматирование, вставить графики и специализированные таблицы.
Автофильтрация
Наиболее простой в реализации функцией форматирования будет добавления автофильтров. Для этого на соответствующем листе следует вызвать метод autofilter и указать диапазон применения фильтрования:
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False)
sheet = wb.sheets['Sheet1']
sheet.autofilter('A1:C'+str(sales_summary.shape[0]))
Возможно применение и индексной нотации:
sheet.autofilter(0, 0, sales_summary.shape[0], 2)(Более подробно о autofilter по ссылке )
По документации требуется указывать полностью диапазон ячеек, использующихся в автофильтре, но в реальности excel корректно применяет фильтр даже когда указан только диапазон колонок, что несколько упрощает работу. Например, как в следующем случае:
sheet.autofilter(0, 0, 0, 2)Настройка размеров ячеек
Изначально XlsxWriter предоставляет нам инструменты для установки высоты и ширины как для целых строк и столбцов, так и для их диапазонов, с некоторой оговоркой.
Чтобы установить высоту одной строки следует использовать метод:
sheet.set_row(0, 20)где 0 – индекс строки, 20 – высота строки.
Для установки высоты нескольких строк потребуется провести итерацию по всем нужным строкам, или же можно установить значение высоты строки по умолчанию для всего документа:
sheet.set_default_row(20)Для установки ширины столбца есть такой метод:
sheet.set_column(0, 0, 30) # Установить ширину одного столбца A в 30
sheet.set_column(0, 2, 30) # Установить ширину столбцов A, B, C в 30
sheet.set_column('A:C', 30) # Установить ширину столбцов A, B, C в 30
Важно заметить, что хоть официальная документация и утверждает, что при настройке ширины столбцов не должно быть пересекающихся диапазонов, однако следующий код прекрасно работает:
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False)
sheet = wb.sheets['Sheet1']
sheet.autofilter(0, 0, 0, 2)
sheet.set_column('A:C', 30)
sheet.set_column('B:B', 8)

Установка значения по умолчанию для ширины столбцов не предусмотрена автором библиотеки. Так же библиотека не предусматривает инструмента для определения автоматической ширины или высоты ячеек, приходится мириться с этим неудобством и искать похожие по функциям обходные решения на форумах (например, тут).
Форматирование текста
Форматирование текста, такое как изменение размера, шрифта, цвета и т.д. так же делается с использованием уже известных нам функций: set_column и set_row.
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False)
sheet = wb.sheets['Sheet1']
cell_format = wb.book.add_format()
cell_format.set_bold()
cell_format.set_font_color('red')
sheet.set_row(1, 40, cell_format) # Установка стиля для строки 2 и высоты 40
cell_format = wb.book.add_format()
cell_format.set_bold()
cell_format.set_font_color('green')
sheet.set_column(2, 2, 20, cell_format) # Установка стиля для столбца C и ширины 20
cell_format = wb.book.add_format()
cell_format.set_bold()
cell_format.set_font_color('blue')
sheet.set_column('A:B', 20, cell_format) # Установка стиля для столбцов A и B и ширины 20
В результате получаем следующий файл:

Из таблицы виден важный факт:
стиль ячеек не может быть перезаписан. На строку с заголовками pandas уже применил форматирование, таким образов мы на него уже воздействовать никак не можем. Аналогично со строкой 2, ячейки которой по идее должны были окраситься в синий и зеленый цвета, однако этого не произошло.
Если есть сильное желание придать свой собственный формат строке с заголовками таблицы, то можно сделать так:
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False, header=False, startrow=1)
sheet = wb.sheets['Sheet1']
cell_format = wb.book.add_format()
cell_format.set_font_color('purple')
cell_format.set_bg_color('#AAAAAA')
cell_format.set_font_size(18)
sheet.write_row(0, 0, sales_summary.columns, cell_format) # сразу пишем целую строку данных
# аналогично
#for col, name in enumerate(sales_summary.columns):
# sheet.write(0, col, name, cell_format)

Добавление графиков
Помимо чистых цифр, бывает полезно добавить в таблицу некоторую сопровождающую информацию, например графики. Они могут быть сгенерированы средствами Excel или же как обыкновенное сгенерированное изображение.
Добавление сгенерированного изображения максимально просто и понятно.
- Создаём изображение
- Сохраняем его как файл
- Указываем полный или относительный путь к файлу изображения, ячейку, в которую хотим поместить изображение и дополнительные опции, если нужно (например отступ от края ячейки, масштабирование ширины, высоты изображения и т.д.. Подробнее о списке опций по ссылке
Пример добавления изображения в документ:
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False)
sheet = wb.sheets['Sheet1']
sheet.set_column('A:C', 12)
plt.pie(sales_summary['sum'], labels=sales_summary['name'], radius=1.4)
plt.savefig('pie.jpeg', dpi=200, bbox_inches='tight')
sheet.insert_image('E2', 'pie.jpeg')

С другой стороны, для добавления графиков используется непосредственно средствами библиотеки XlsxWriter метод add_chart объекта типа worksheet, в параметрах которого можно указать тип графика (pie в данном случае). После этого нужно заполнить списки категорий и значений через метод add_series. Данный метод принимает ссылки в буквенной и в численной нотации.
Перед добавлением графика на лист, можно дополнительно отформатировать внешний вид легенды, добавить ещё данных на ту же область, добавить названия осей и т.д. Под конец необходимо добавить график на лист вызовом метода insert_chart. Более подробно о работе с графиками в XlsxWriter можно почитать по ссылке
with pd.ExcelWriter('table.xlsx', engine='xlsxwriter') as wb:
sales_summary.to_excel(wb, sheet_name='Sheet1', index=False)
sheet = wb.sheets['Sheet1']
sheet.set_column('A:C', 12)
chart = wb.book.add_chart({'type': 'pie'})
chart.add_series({
'categories': '=Sheet1!$A$2:$A$'+str(sales_summary.shape[0]+1),
'values': '=Sheet1!$B$2:$B$'+str(sales_summary.shape[0]+1),
})
# Аналогично
#chart.add_series({
# 'categories': ['Sheet1', 1, 0, sales_summary.shape[0], 0],
# 'values': ['Sheet1', 1, 1, sales_summary.shape[0], 1],
#})
chart.set_legend({'position': 'bottom'})
sheet.insert_chart('E2', chart, {
'x_scale': 2, 'y_scale': 2
})
#Аналогично
#sheet.insert_chart(1, 4, chart, {
# 'x_scale': 1.5, 'y_scale': 2
#})

Мы рассмотрели некоторые возможности, которые предоставляет нам связка библиотек Pandas и XlsxWriter. Их очень легко и удобно встраивать в собственные проекты. Использование средств, описанных в данной статье, не исчерпывают все возможности этих библиотек, но даже с этим скромным инструментарием в кармане, вы можете сделать ваши выгрузки намного более информативными и приятными глазу.