
Сбор семантики сайта представляет собой сложную и многоступенчатую задачу. Ее успешное решение предусматривает использование различных вспомогательных инструментов, включая специализированные программы и онлайн-сервисы. Но значительную часть выполняемых SEO-оптимизатором операций можно эффективно выполнять в обычных электронных таблицах Excel.
Речь идет не только о сортировке отобранных ключей, но и оформлении списка запросов, его последующем редактировании и чистке, а также подготовке базы данных для работы с другими сервисами или составления технического задания для копирайтера. А потому имеет смысл изучить порядок и особенности сбора семантического ядра в Excel более подробно, включая рассмотрение возможности, где можно скачать пример семантики, составленной в электронных Google Таблицах.
Содержание
- Виды Excel для сбора СЯ
- Этапы сбора семантического ядра с помощью Google Таблиц
- Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
- Шаг №2. Чистка семантического ядра
- Шаг №3. Кластеризация/группировка семантического ядра запросов
- Полезные функции Google Docs и Эксель
- Вспомогательные инструменты
- SeoTools for Excel
- SEO-Excel
- Рекомендации по использованию Google Docs для сбора СЯ
- Вместо вывода
Виды Excel для сбора СЯ
Для решения задач СЕО-оптимизации применяются две версии электронных таблиц. Первая поставляется в рамках стандартного пакета MS Office и представляет собой самостоятельную программу. Вторая – составной элемент Google Docs. Именно последний вариант пользуется сегодня все большим спросом, так как обладает рядом достоинств, в числе которых:
- доступность для любого обладателя аккаунта в Google;
- интеграция с программами из MS Office, включая обычные Эксель и Ворд;
- доступ к облачному хранилищу Google Диск, 15 ГБ которого предоставляется бесплатно и позволяет работать с Google Таблицами с любого устройства – от ПК до смартфона – сразу после авторизации.
На приведенном ниже скриншоте показан пример, как выглядят Google Таблицы. Приводить внешний вид традиционного Excel не имеет смысла, так как он прекрасно известен любому более-менее опытному пользователю ПК.

В остальном работа с обеими версиями программы – Excel и Google Docs – осуществляется по стандартным правилам, хорошо известным большинству пользователей. С учетом нескольких особенностей, характерных для SEO-продвижения сайтов по поисковым запросам.
Этапы сбора семантического ядра с помощью Google Таблиц
Некоторые специализированные сервисы, к примеру, Key Collector или Словоеб, обладают встроенными инструментами для форматирования структуры сайта и перечня ключевых слов и запросов. Поэтому не предполагают применение Excel. Но для значительной части других сервисов, включая один из самых популярных Яндекс Wordstat, использование Google Docs или Excel выступает одним из необходимых этапов работы. Более того, при грамотном применении возможностей электронных Google Таблиц удается упростить и оптимизировать сразу несколько важных операций по чистке семантического ядра. Рассмотрим последовательность предпринимаемых для этого действий с разбивкой на отдельные этапы.
Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
Функционал Excel предоставляет возможность составить список поисковых запросов вручную – посредством анализа продвигаемого сайта и деятельности компании. Но намного проще собрать исходное семантическое ядро с помощью Яндекс Wordstat. Чтобы сделать это, необходимо произвести следующие операции:
- Скачивание и установка расширения Яндекс Wordstat Assistant (подробнее о сервисе и расширениях к нему – на другой страницу нашего сайта). Сделать ссылку. В результате в левой части окна сервиса появится дополнительная панель инструментов.
- Выделение и сохранение интересующих пользователя запросов нажатием кнопки «+».
- Копирование сформированного списка поисковых запросов в Google Таблицы или обычный Эксель. Производится по одному из двух вариантов – с показателем частотности ключа или без него. Выбирается нужный пользователю способ копирования. Пример выполнения операции показан на скриншоте.

Шаг №2. Чистка семантического ядра
Основной задачей оптимизации СЯ запросов выступает повышение эффективности размещенных на сайте ключевых слов и фраз. Первым этапом становится избавление от ключей с низкой или даже нулевой релевантностью. Операция выполняется вручную, так как требует непосредственного участия SEO-специалиста. Ответ на вопрос, как почистить семантическое ядро, предусматривает удаление нескольких видов запросов, включая:
- самые низкочастотные (полное их удаление нецелесообразно, так как важно найти оптимальный баланс запросов с разной частотностью);
- ведущие на сайты конкурентов;
- лишние с предсказуемо низкой релевантностью из-за несоответствия задачам сайта;
- дубли (представляют собой поисковые запросы или фразы, которые различаются порядком слов).
Как было отмечено, удаление ненужных запросов происходит вручную. Для большего удобства и упрощения работы допускается как редактирование текущего листа электронных таблиц Google, так и перенос оптимизированного списка запросов на вновь созданный.
Шаг №3. Кластеризация/группировка семантического ядра запросов
Завершающий этап работы по СЕО-продвижению сайта с помощью Excel предполагает проведение кластеризации или группировки поисковых запросов. Она предусматривает разбивку общего списка ключевых слов или фраз для размещения на отдельные страницы в соответствии с предварительно разработанная структурой интернет-ресурса. Оптимальное количество запросов на каждую равняется 5-6, для очень объемных оно может быть несколько увеличено.
Операция также выполняется вручную с применением традиционного функционала Google Таблиц или Excel. Автоматизировать данные действия специалиста можно только с использованием специализированного инструментария, хотя даже самые современные и многофункциональные сервисы не способны выполнять такую работу на требуемом уровне.
Дальнейшие операции с собранным семантическим ядром производятся в зависимости от задач, стоящих перед СЕО-специалисту. Это может быть или составление технического задания копирайтеру, или дальнейшая оптимизация СЯ с использованием других программ или сервисов. Примеры готовой семантики, составленной в Эксель, можно с легкостью найти в сети, например, по следующей ссылке.
Полезные функции Google Docs и Эксель
Подробно описывать набор функциональных возможностей самой популярной программы электронных таблиц не имеет особого смысла. Опытным пользователям они прекрасно известны, а новичкам намного проще и правильнее разобраться самостоятельно, так как это наверняка пригодится в дальнейшей работе. Главное – знать о существовании таких возможностей, как:
- копирование и удаление ссылок из семантического ядра;
- замена отдельных слов или элементов списка запросов;
- удаление ненужных или лишних пробелов, включенных в СЯ;
- сортировка запросов по значениям любого из столбцов по двум параметрам – алфавиту или числу;
- поиск повторяющихся значений или минус-слов для последующего удаления вручную;
- удаление дубликатов из состава семантического ядра;
- сортировка запросов по цвету ячейки и многое другое.
Вспомогательные инструменты
Google Таблицы и традиционный Эксель обладают обширным функционалом. Но далеко не все опции эффективны применительно к СЕО-продвижению сайтов по поисковым запросам. Именно поэтому активно разрабатываются дополнительные надстройки к традиционным электронным таблицам. Два из них – самые известные и популярные – имеет смысл привести отдельно, хотя количество подобных инструментов постоянно растет.
SeoTools for Excel
Одно из первых расширений для электронных таблиц, которое разработано специально для SEO-продвижения. Обладает обширным функционалом, постоянно обновляется, совместимо с различными онлайн-сервисами и программами. Из недостатков – отсутствие версии для русскоязычных пользователей. Чтобы скачать программу, достаточно перейти на сайт разработчика и зарегистрироваться на нем.

SEO-Excel
Русскоязычный аналог описанной выше надстройки. Содержит более двух десятков инструментов для СЕО-продвижения. Чтобы скачать программу, достаточно зарегистрироваться на сайте, хотя возможно платное использование онлайн-версии продукта. SEO-Excel адаптирован для работы с Яндекс Wordstat и Rush-Analytics, что объясняет популярность среди отечественных специалистов. Дополнительный аргумент скачать и установить надстройку – очень полезная опция генерации различных тегов – H1, Title и Description, заметно упрощающая работу SEO и экономящая его время, в том числе – при составлении технического задания копирайтеру.

Рекомендации по использованию Google Docs для сбора СЯ
Главным достоинством Excel и Google Таблиц справедливо считается доступность. Оборотной стороной становится необходимость выполнять значительную часть операций СЕО-оптимизации вручную. Чтобы упростить собственную работу, имеет смысл воспользоваться несколькими простыми рекомендациями:
- внимательно изучайте руководство пользователя, так как некоторые функции электронных таблиц выступают секретом даже для очень опытных специалистов;
- автоматизируйте самые рутинные и трудоемкие процессы за счет грамотного использования встроенных опций и сервисов;
- скачивайте и устанавливайте дополнительные надстройки, предназначенные для SEO-продвижения (важное дополнение – загрузка должна выполняться только с проверенных сайтов компаний-разработчиков).
Вместо вывода
Важно понимать, что полная автоматизация процесса SEO-продвижения сайта по поисковым запросам попросту невозможна. Никакие сервисы и программы не способны заменить опыт и квалификацию грамотного специалиста, хотя существенно помогают в его работе при грамотном использовании. Именно поэтому имеет смысл сотрудничать с профессионалами, а вложенные средства с лихвой окупаются повышением эффективности интернет-ресурса.
Наша компания оказывает полный комплекс услуг в области SEO-оптимизации на выгодных и привлекательных для клиентов условиях. Для получения персонального коммерческого предложения достаточно связаться с нами любым удобным способом.
Здравствуйте, уважаемые читатели сайта Uspei.com. В этом уроке мы рассмотрим такие вещи как группировка запросов в рамках семантического ядра или кластеризация. Начнем мы с группировки поисковых запросов и чистки ядра. В прошлой статье мы посмотрели, как собирать статистику, какие инструменты для этого можно использовать, и все это почистили, удалив дубликаты. А также мы рассмотрели виды запросов.
У нас есть большой список запросов, из которого мы должны удалить оставшийся мусор и провести группировку. То есть у нас есть здоровенный список запросов. В некоторых тематиках он может доходить до 10 000. Наша задача сейчас разбить его на группы, каждая из которых будет содержать в себе только синонимы. То есть в рамках каждой группы должны быть только синонимы, так как каждая выделенная группа, это будущая отдельная страница и эти запросы в группе мы будем на ней продвигать.

К примеру, если у нас есть запрос “купить ноутбук”, то мы должны сделать группу, в которой будут только синонимы к запросу “купить ноутбук”.
Под синонимом в SEO имеется в виду то, что в запросы, по которым люди ищут, вкладывается один и тот же смысл. К примеру, запросы “купить ноутбук” и “купить ноутбук apple” это НЕ синонимы и они будут входить в разные группы, потому что у них разное понятие. В первом случае человек ищет просто ноутбук и это может быть даже samsung, а совсем не apple. Во втором же случае человек ищет конкретно apple. Ну, еще один пример. Человек ищет “такси” и “междугороднее такси” – тут думаю тоже очевидно и понятно.
Таких групп в рамках большого семантического ядра может быть огромное количество, их может быть более нескольких сотен в редких случаях более тысячи. Вот этот процесс еще называют кластеризацией. Мы рассмотрим, как его сделать вручную, я покажу основы и попытаюсь вывести хотя бы один законченный кластер, потому что в рамках одной статьи мы не сможем классифицировать ядро, но хотя бы вывести какой-то базовый кластер.
И потом я вам дам ссылки на набор инструментов, который может существенно автоматизировать или ускорить эту группировку или кластеризацию, как это сейчас модно называть.
Кластеризация и чистка семантического ядра в Excel
Возвращаемся к нашему списку запросов и у нас достаточно простой алгоритм. У нас уже отсортированы все запросы по убыванию частотности, то есть от самых популярных до наименее популярных. Дубликаты мы удалили.

Мы берем каждый запрос и смотрим подходит он нам или нет. Например, у нас есть запрос “интернет-магазин”, но если мы занимаемся только ноутбуками, то этот запрос без слова ноутбук нам не подходит. Значит запрос “интернет-магазин” мы удаляем – это не тематический запрос.
Дальше запрос “ноутбук”. Да, в принципе это информационный запрос, но не совсем понятно, что человек вкладывает в этот запрос, когда вбивает его в поисковую строку. Ищет ли он информацию, картинку или он ищет товары или возможно что-то еще.
Если мы сомневаемся в смысле поискового запроса, логично его проверить. Как это делается? Мы копируем запрос и вбиваем его в новой вкладке в ту поисковую систему, с которой мы работаем. Например, Google.
Мы видим, что Google показывает нам набор интернет-магазинов. Мы видим точно, что это запрос коммерческий и если у нас интернет-магазин, мы его оставляем.
И мы добрались до первого подходящего нам запроса. Давайте выделим нашу первую группу запросов, в которую будут входить все слова с упоминанием слова “ноутбук”. Для этого нужно включить фильтр и отфильтровать по текстовому условию “содержит”. Но там могут быть словоформы запроса “ноутбук” поэтому мы просто напишем “ноут” и получаем список строк только с поисковыми запросами, в которых упоминается “ноут”. Я предлагаю вам скопировать и перенести их в новую вкладку.
Каждую вкладку мы будем называть соответственно по тому слову, по которому мы произвели фильтрацию. В первой же вкладке мы вручную (!) выделяем все отфильтрованные ключи и удаляем. После чего очищаем фильтр.
Итак, в первой вкладке у нас остались все ключи, которые НЕ содержат “ноутбук”, а мы переходим во вторую (“ноутбук”) и продолжаем работать теперь уже там.

Итак, следующее слово “ноутбук”. Мы уже разобрались, что это коммерческий запрос и по нему также как и по запросу “купить ноутбук” показываются интернет-магазины, то есть это синонимы и мы оставляем их в одной группе.
“DNS ноутбуки” – как раз это тот самый навигационный запрос и можно предположить, что приставка “DNS” как популярный интернет-магазин будет часто встречаться в списке запросов про ноутбуки. Поэтому давайте сразу удалим все чужие навигационные запросы “DNS”. Фильтр – выделяем вручную и удалить.
“Ноутбуки бу” – аналогично как с “dns” – удаляем, если только мы не продаем б/у ноубуки.
“Купить ноутбук Москва” – тут уже добавляется регион, а мы далеко не в Москве. По сути, запрос повторяет смысловую нагрузку запроса “купить ноутбук” или просто “ноутбук”. Но поскольку добавляется регион, стоит проверить считает ли google эти поисковые запросы синонимами.
Мы берем запрос “купить ноутбук” вбиваем его в google и в другой вкладке вбиваем запрос “купить ноутбук Москва”. И сравниваем результаты поиска на предмет повторения результатов, то есть именно конкретных страничек. Если хотя бы 4-5 страничек одинаковых, то мы можем считать, что это запросы синонимы и Google показывает по ним одинаковый смысл. Если же по этим запросам выдача разная, то “купить ноутбук Москва” навигационный запрос и он нам не нужен.
Идем дальше и таким образом проделываем ту же процедуру – удаляем мусор и создаем новые группы отличные по смыслу.
Очень рекомендую чистить семантику, используя фильтры, если чистить ручками, то есть большой шанс что-то пропустить.
Но когда мы фильтруем, надо быть аккуратным, чтобы не удалить какие-то важные слова случайно отфильтровав их. Например, если в фильтр вбить просто “бу” то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие “бу” – например, сам запрос “ноутБУк” – а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце ” бу” и “бу “, а также через слэш “б/у”. Помните это и будьте внимательны))))).
И вот у нас запрос “ноутбук hp”. Это уже не просто “ноутбук” – это уже более узкая тема, значит мы должны выделить ноутбуки hp в отдельную группу.
Производим фильтрацию “текст содержит” получаем набор запросов и переносим их в новую вкладку “ноутбуки hp”. Из второй вкладки “ноутбук” перенесенные в 3 вкладку результаты удаляем.

Так мы будем повторять эту процедуру, пока в каждой вкладке не останутся только синонимы. То есть дальше мы должны перейти в 3 вкладку “ноутбуки hp” и здесь их разделить еще на более подробные группы. Мы видим, что здесь есть “ноутбук hp pavilion”, ” ноутбук hp compaq” и “ноутбук hp игровой”. Таким образом, эта группа будет разбита еще на 3 группы.
Во вторую вкладку мы вернёмся, когда во всех следующих группах все слова будут синонимами и продолжим этот разбор. Продолжим до тех моментов, пока самая первая наша вкладка не будет разложена на группы, а в ней самой не останутся только нецелевые запросы или запросы, которые тоже будут синонимами.
В итоге наша задача создать файл, в котором у нас будет огромное количество вкладок. В разных темах по-разному – возможно в некоторых темах будет всего 5-6 вкладок, если тема очень маленькая, но основная задача, чтобы в рамках одной вкладки были только запросы синонимы.
Причем не просто слова синонимы в классическом понимании, а синонимы с точки зрения поисковой системы. Вот как из примера “купить ноутбук” и “ноутбук” это синонимы с точки зрения поисковой системы, поэтому они у нас остались в одной группе.
Если во вкладке 20 синонимов и один НЕ СИНОНИМ – выносим его одного в отельную вкладку. Это очень важный момент, так как каждая группа это отдельная страница, на которой эти запросы будут продвигаться, и чем больше будет ошибок и недоработок, тем менее чистой по смыслу станет страница, что скажется результатах поиска. О других ошибках, допускаемых при сборе и группировке семантики ознакомьтесь в этой статье.
Повторю еще раз основную мысль – в каждой вкладке должны быть запросы подходящие по смыслу. Пример, если в текущей вкладке 5 запросов:
- “заработать в интернете”
- “как можно заработать в интернете”
- “где заработать через интернет”
- “как заработать деньги в интернете”
- “как заработать в интернете без обмана”
Первые три запроса останутся в текущей вкладке, так смысл у них один, а последние два уйдут каждый в свою группу-вкладку, так как они не совпадают по смыслу ни с первыми тремя, ни между собой – они более детализированы. В одном случае речь идет о деньгах ( а заработать в наши дни можно все что угодно – биткоины, баллы в играх и т.д.), а во-втором, речь идет о заработке без обмана.
Для понимания я в течение часа сварганил (правда не до конца) семантику по запросам, “заработок в интернете” “заработок в сети” “заработок онлайн”. Первая вкладка – вся семантика, а далее по группам. Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Скачать пример семантического ядра в excele.
Зачем все это нужно и почему все так сложно?
 Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
На самом деле, сейчас это не очевидно, но буквально через два-три этапа вы увидите, что вся поисковая оптимизация, абсолютно все seo, построено на основе правильно собранного семантического ядра. SEO – это не просто любительский способ сделать свой сайт лучше. Это, можно сказать наука, в которой все начинается с “атомов” и именно это приводит к результату.
SEO можно сравнить с большим спортом – боксом или сноубордом или любым другим. Если вы не освоите технику ПРОФЕССИОНАЛЬНЫХ ударов или элементов езды, то это скажется на скорости и выносливости и вы проиграете сопернику, кто этим не пренебрег. Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое – не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места – есть только первая страница и все.
Мы не можем начинать оптимизацию сайта, если мы не сделали семантику, не разбили ее на группы, не обработали и не почистили. И все что мы будем делать дальше, будет основано на семантике.
Приведу конкретный пример. Мы же понимаем, что по каждому запросу поисковик дает свой результат выдачи. Возьмем какую-то небольшую тематику по которой в семантике всего 100 запросов. И вот у одного владельца 100 страниц на сайте, в которых содержимое часто пересекается, структура сайта от этого расплывчатая, поисковик не понимает до конца, какие страницы релевантны запросу больше, а какие меньше. В итоге, кроме путаницы, эти 100 страниц содержат в своем “винегрете” ответы только на 30-40 запросов.
А у второго владельца сайта, благодаря полному собранному кластеризованному семантическому ядру, на каждый запрос есть соответствующая страница, строго релевантная только этому запросу. Поисковик и пользователи четко понимают структуру сайта, а также не страдают “дежавю”, что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
Автоматизация кластеризации семантического ядра
Такая работа по группировке запросов по обработке всей этой статистики вручную занимает достаточно много времени. Особенно если человек делает это первый раз. Но я вам рекомендую, если вы хотите научиться работать запросами, работать с семантикой, хотя бы один раз проведите все это вручную в электронных таблицах. Тогда вы сможете прочувствовать и понять, как это работает.
Если же вы работаете в очень больших объемах, крайне рекомендую использовать профессиональные инструменты. Чаще всего они платные.
Один из самых популярных инструментов по работе с семантикой это инструмент “Key Collector”, которая позволяет автоматизировать большинство процессов по сбору и обработке семантики. Как минимум, она умеет автоматически собирать ключевые слова из yandex wordstat, а также данные о частотности по запросам и другие рекомендации.
Если же у вас есть уже готовое отфильтрованное от мусора семантическое ядро, то вы можете прибегнуть к помощи дополнительных сервисов, которые производят автоматическую кластеризацию. Лидером сейчас на рынке является онлайн-сервис, который называется Rush analytics.
Расценки не очень высокие и в принципе, если у вас один сайт, вы владелец или вебмастер, то вы можете собрать семантику, почистить ее, после чего просто отдать на кластеризацию такому сервису.
- Опубликовано:20.01.2014
- Комментарии:
Нет комментариев - Рубрика:
Продвижение магазинов - Просмотров: 19 910

Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла. Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Скачать файл Excel (.xls)
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
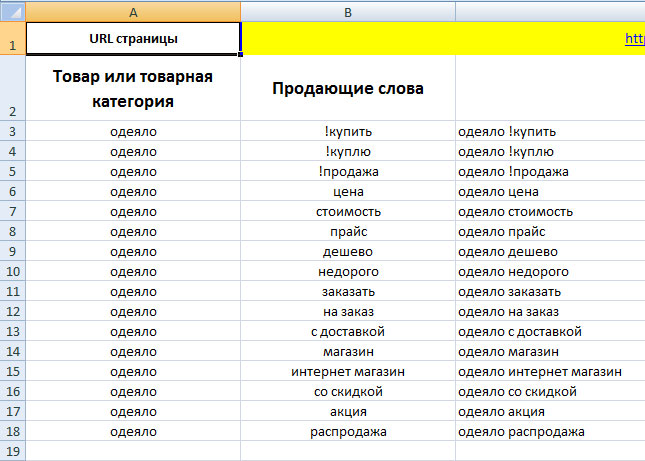
В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:
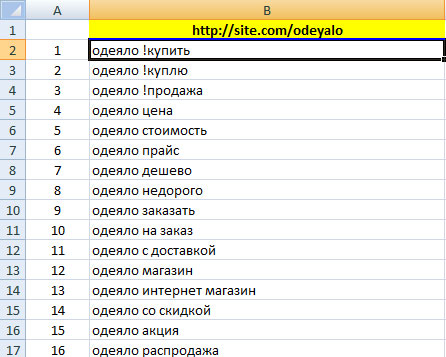
Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Читайте также:
- Рейтинг CRM систем для интернет-магазинов
- Как продвигать магазин в поисковых системах?

Скачать готовые примеры семантических ядер в новом Excel формате
Перейти к содержанию
Скачать бесплатно готовые примеры
семантики для сайтов в Экселе
✓ 20 примеров готовой семантики (описание + бюджет).
✓ Представлены самые популярные (заказываемые) темы.
✓ Быстрый запрос на получение примера для вашей тематики.
✓ Новый формат семантического ядра и отчетов от 07.2022.
✓ Архивы содержат платные ТЗ копирайтеру от TaskБилдер.
✓ Цена от 100$ за семантику «под ключ». Срок от 10 дней.
✓ 8 наших «фишек» и инструментов при сборе СЯ: перейти.
На наших примерах оцените:
✅ Стоимость семантики в вашей/похожей тематике.
✅ Качество сбора/группировки ключей и полноту кластеров.
✅ Удобство оформления и навигацию по ядру в Excel.
✅ Доп. отчеты по анализу конкурентов, сложности продвижения…
✅ Формат платного (Excel+Tskb) и бесплатного (Txt) ТЗ для копирайтера.
Финальная стоимость семантического ядра зависит от:
✅ Региона.
✅ Тематики / номенклатуры продукции.
✅ Нижнего порога частотности: «!WS» / GA.
✅ Вида запросов в ядре (коммерция, инфо, оба варианта).
✅ Сколько ключей вы удалите при утверждении после сбора.
Нет примера вашей тематики? Не можете оценить бюджет?
Подайте бесплатную заявку на пример.
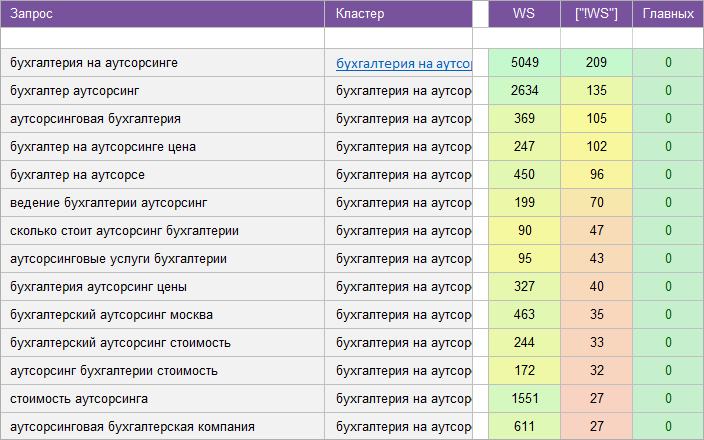
«Бухгалтерские услуги».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 378 шт.
Количество кластеров: 38 шт.
Общая частотность запросов по Wordstat: 12 793.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
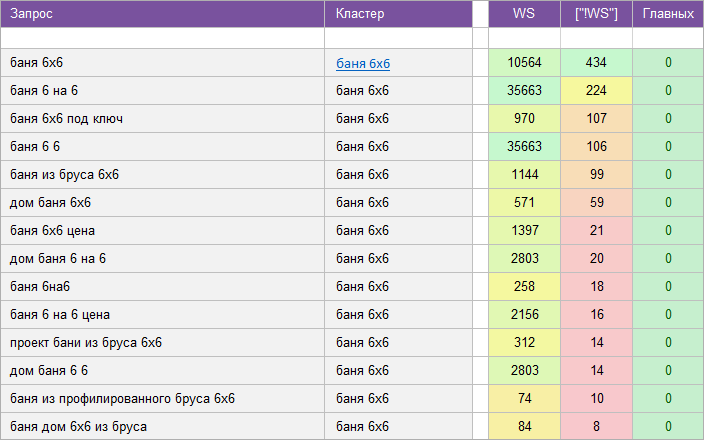
«Для строительного сайта».
Бани, готовые элитные дома, новостройки, для модульных зданий, монтаж систем отопления и водоснабжения.
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 8 034 шт.
Количество кластеров: 346 шт.
Общая частотность запросов по Wordstat: 220 127.
Срок выполнения: 13 дней.
![]() Цена: 280 $
Цена: 280 $![]() Скачать пример ядра
Скачать пример ядра
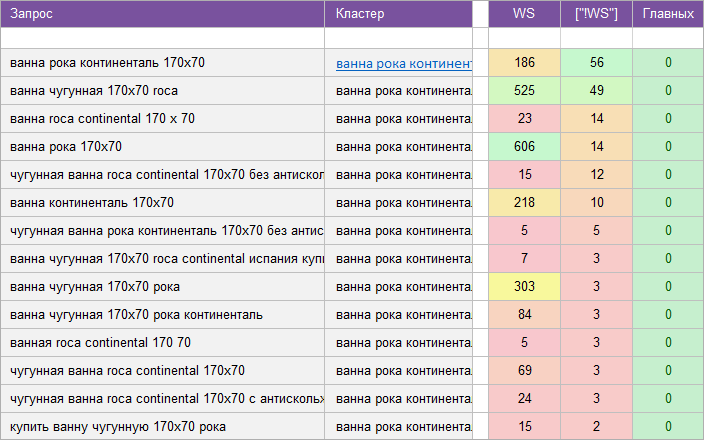
«Сантехника».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 6 200 шт.
Количество кластеров: 590 шт.
Общая частотность запросов по Wordstat: 75 570.
Срок выполнения: 11 дней.
![]() Цена: 340 $
Цена: 340 $![]() Скачать пример ядра
Скачать пример ядра

Хотите пример ядра
по вашему региону и нише?
«Салон красоты».
Покраска, маникюр, эромассаж и т.д.
Регион: Москва.
Вид ключевых слов: Коммерческие + Инфо.
Кластеризованных запросов: 11 958 шт.
Количество кластеров: 892 шт.
Общая частотность запросов по Wordstat: 200 897.
Срок выполнения: 12 дней.
![]() Цена: 385 $
Цена: 385 $![]() Скачать пример ядра
Скачать пример ядра
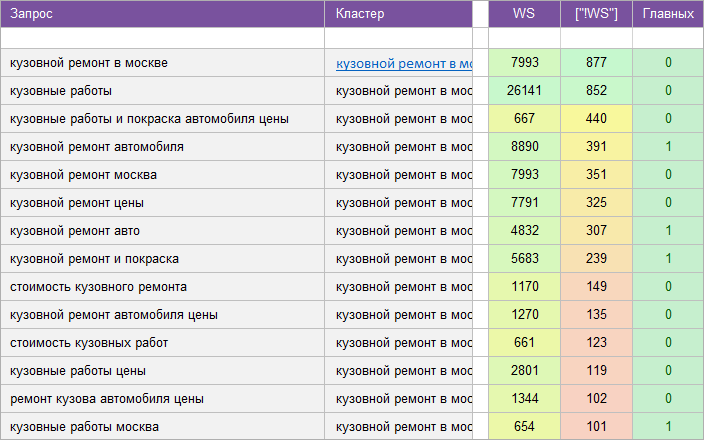
«Автосервис».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 4 073 шт.
Количество кластеров: 396 шт.
Общая частотность запросов по Wordstat: 386 236.
Срок выполнения: 10 дней.
![]() Цена: 175 $
Цена: 175 $![]() Скачать пример ядра
Скачать пример ядра
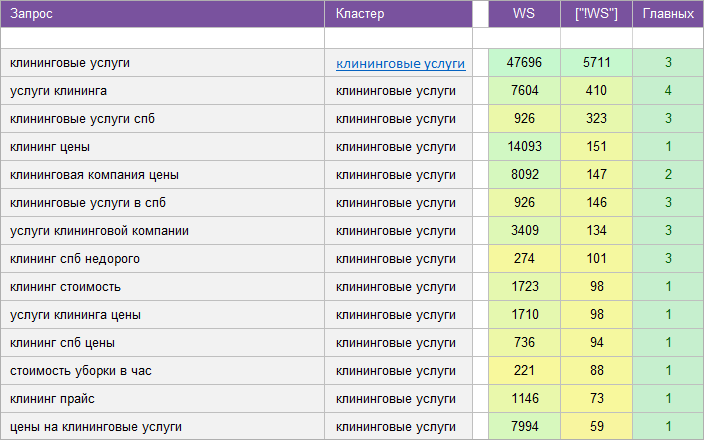
«Услуги клининговой компании».
Регион: Санкт-Петербург.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 100 шт.
Количество кластеров: 167 шт.
Общая частотность запросов по Wordstat: 27 500.
Срок выполнения: 7 дней.
![]() Цена: 115 $
Цена: 115 $![]() Скачать пример ядра
Скачать пример ядра
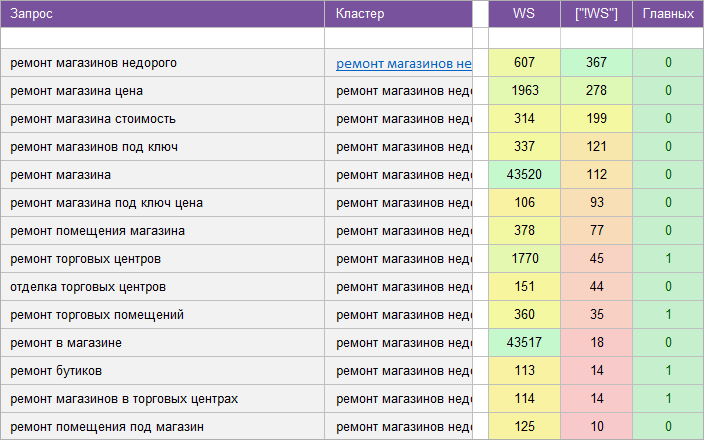
«Ремонт недвижимости».
Ремонт квартир, домов и прочей недвижимости.
Регион: Москва и МО.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 3 288 шт.
Количество кластеров: 306 шт.
Общая частотность запросов по Wordstat: 55 322.
Срок выполнения: 10 дней.
![]() Цена: 165 $
Цена: 165 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
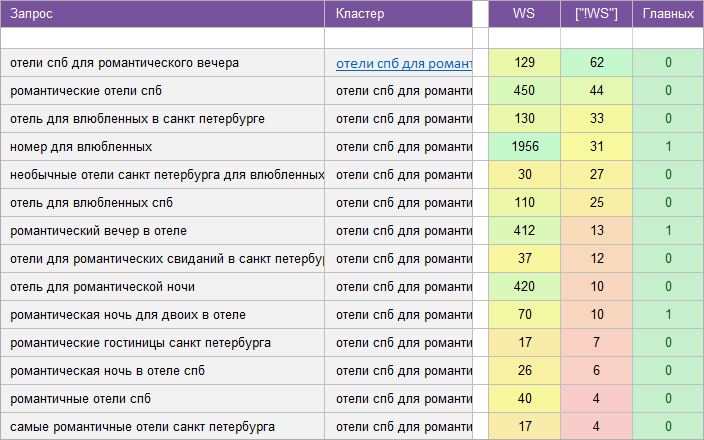
«Для отелей и гостинец».
Регион: Санкт-Петербург и область.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 6 408 шт.
Количество кластеров: 511 шт.
Общая частотность запросов по Wordstat: 123 421.
Срок выполнения: 9 дней.
![]() Цена: 352 $
Цена: 352 $![]() Скачать пример ядра
Скачать пример ядра
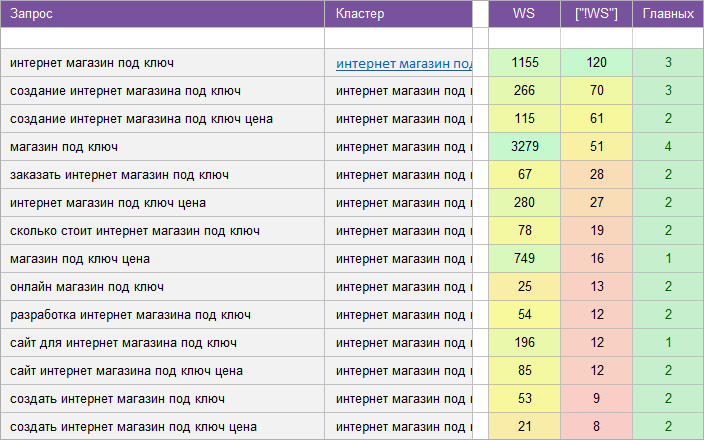
«Для веб-студии».
Регион: Весь Рунет.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 14 500 шт.
Количество кластеров: 926 шт.
Общая частотность запросов по Wordstat: 350 700.
Срок выполнения: 15 дней.
![]() Цена: 725 $
Цена: 725 $![]() Скачать пример ядра
Скачать пример ядра
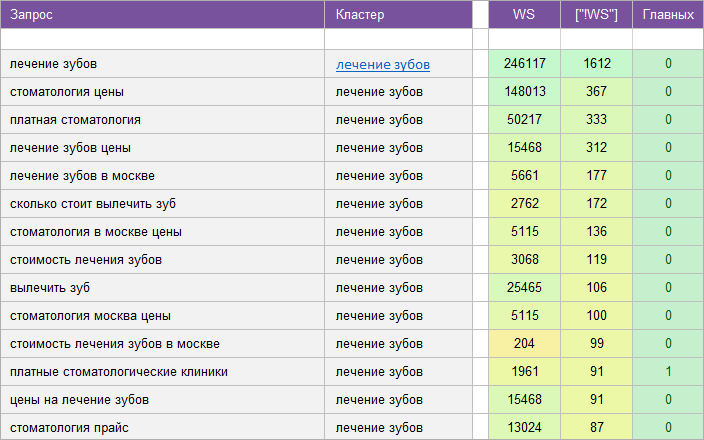
«Стоматология».
Регион: Москва.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 8 253 шт.
Количество кластеров: 650 шт.
Общая частотность запросов по Wordstat: 138 934.
Срок выполнения: 12 дней.
![]() Цена: 300 $
Цена: 300 $![]() Скачать пример ядра
Скачать пример ядра
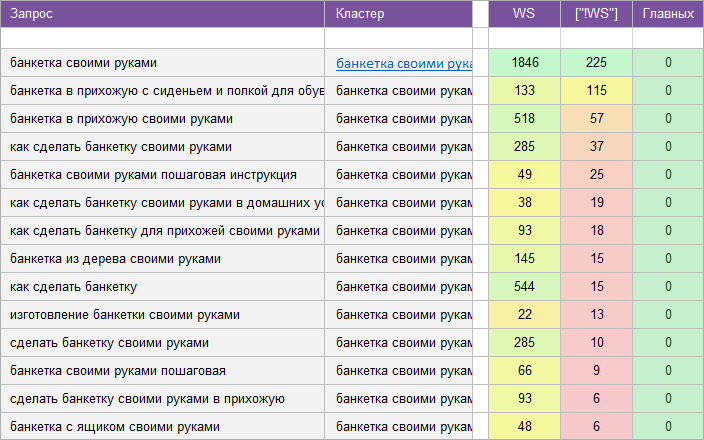
«Мебель и предметы интерьера».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 22 016 шт.
Количество кластеров: 843 шт.
Общая частотность запросов по Wordstat: 899 870.
Срок выполнения: 14 дней.
![]() Цена: 575 $
Цена: 575 $![]() Скачать пример ядра
Скачать пример ядра
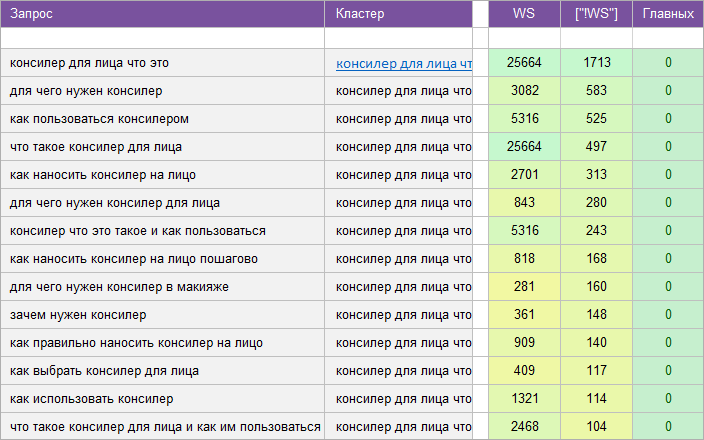
«Для женского сайта».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 16 544 шт.
Количество кластеров: 693 шт.
Общая частотность запросов по Wordstat: 2 358 018.
Срок выполнения: 12 дней.
![]() Цена: 455 $
Цена: 455 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
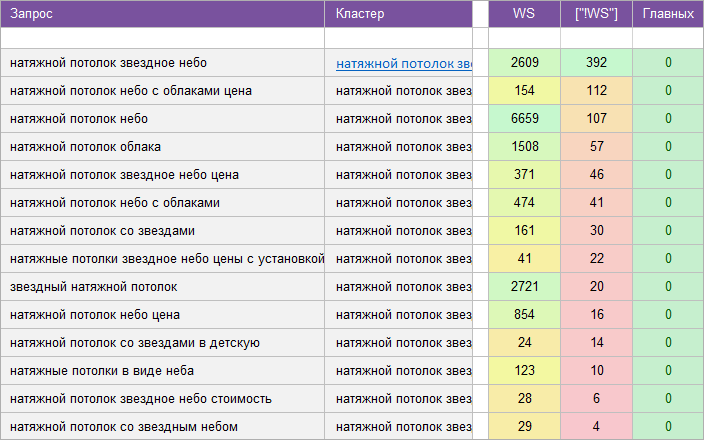
«Натяжные потолки».
Регион: Санкт-Петербург и ЛО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 493 шт.
Количество кластеров: 45 шт.
Общая частотность запросов по Wordstat: 13 558.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
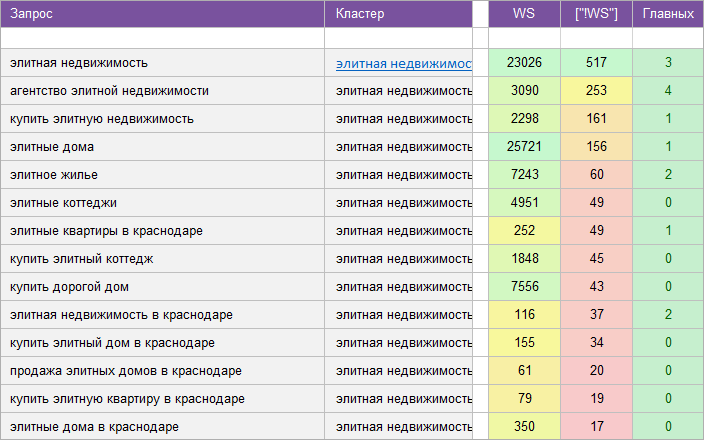
«Агентство недвижимости».
Регион: Краснодар.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 14 469 шт.
Количество кластеров: 1 341 шт.
Общая частотность запросов по Wordstat: 200 056.
Срок выполнения: 15 дней.
![]() Цена: 500 $
Цена: 500 $![]() Скачать пример ядра
Скачать пример ядра
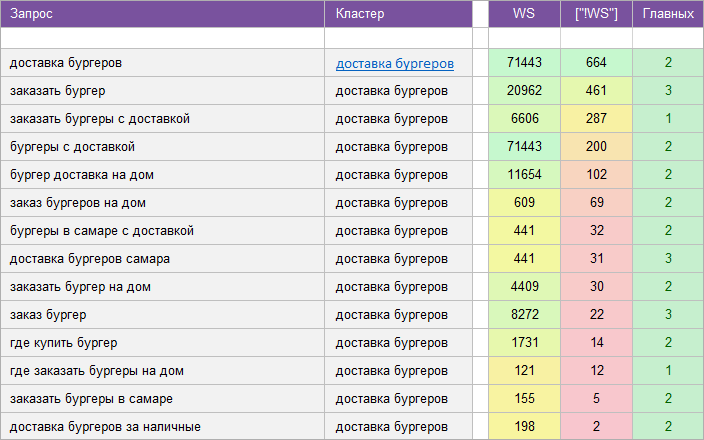
«Доставка еды».
Регион: Самара.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 585 шт.
Количество кластеров: 238 шт.
Общая частотность запросов по Wordstat: 19 501.
Срок выполнения: 9 дней.
![]() Цена: 140 $
Цена: 140 $![]() Скачать пример ядра
Скачать пример ядра
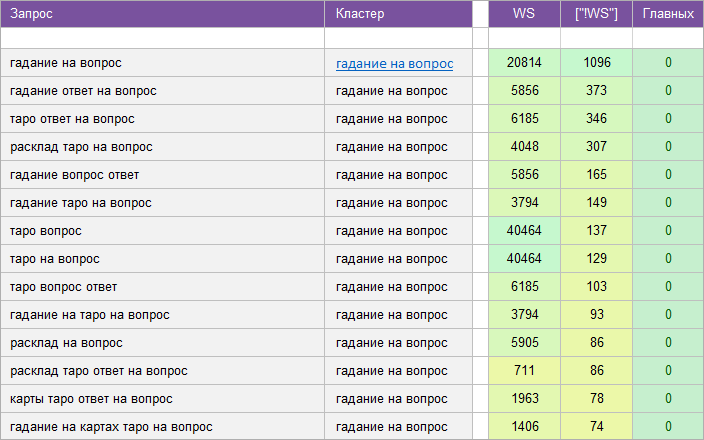
«Карты Таро».
Регион: Россия.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 9 196 шт.
Количество кластеров: 557 шт.
Общая частотность запросов по Wordstat: 992 132.
Срок выполнения: 14 дней.
![]() Цена: 285 $
Цена: 285 $![]() Скачать пример ядра
Скачать пример ядра
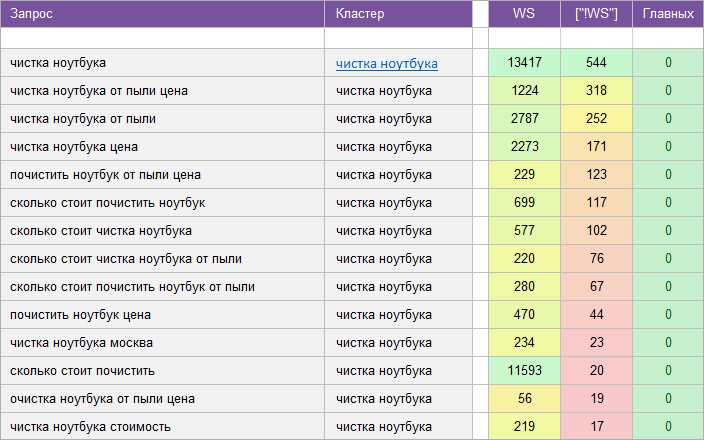
«Ремонт компьютеров и ноутбуков».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 3 437 шт.
Количество кластеров: 321 шт.
Общая частотность запросов по Wordstat: 51 753.
Срок выполнения: 8 дней.
![]() Цена: 190 $
Цена: 190 $![]() Скачать пример ядра
Скачать пример ядра
Самые популярные вопросы — ответы:
На одной странице невозможно собрать примеры во всех тематиках.
Но, вы можете подать заявку на получение бесплатного примера в вашей тематике: заполнить.
На полученном примере вы можете оценить качество нашей семантики.
После изучения наших примеров, вы подаете бриф.
А мы собираем для вас ядро и экономим: средства/нервы/время.
1. Средства. Вам не надо покупать:
✓ Платные сервисы (Serpstat, keys.so) — от 250$.
✓ Программы и скрипты (KeyCollector, a-parser) — от 50$.
✓ Прокси (минимум 10 приватных) — от 20$.
✓ АнтиКаптча — от 30$.
✓ Регистрация и поддержка аккаунтов Яндекса и Google в рабочем состоянии — от 0$.
2. Нервы:
Сотни сообщений за день в Телеграм канале @KeyCollectorCHAT связанных с проблемами сбора, чистки и кластеризации запросов. В последнее время поисковые системы значительно усложнили процесс парсинга.
3. Время:
Мы 9 лет разрабатываем нашу систему по работе с семантикой, отлаживаем все тех. процессы, отбираем лучшие прокси для парсинга и систему разгадывания каптч. Все это позволяет нам максимально автоматизировать и ускорить все процессы.
Без опыта и наработок только сбор запросов и параметров может растянуться у вас на дни.
Наше семантическое ядро состоит из:
✓ Главного файла «yadro.xlsx». Отчеты в файле: «Семантическое ядро», «Структура», «ТОП доменов конкурентов», «Описание полей и колонок».
✓ Дополнительные отчеты (отдельные файлы): «Аналитика по запросам», «Сезонность», «ТОП внешних ссылок», «Популярные слова и фразы»
✓ Тз для копирайтера (платная Excel или бесплатная Txt версия).
Важно: из главного файла «ядро.xlsx» ссылки ведут на дополнительные отчеты и ТЗ для копирайтера.
Это позволяет выполнять быструю навигацию, а не искать доп. отчеты по папкам.
В наших архивах находится больше 6500 готовых ядер, которые мы составили за 9 лет.
Но, мы НЕ продаем готовую семантику.
Почему? Отвечаем:
✓ Семантика — это анализ ТЕКУЩЕГО спроса в тематике. Актуальность семантики — один из главных факторов успешного внедрения на сайт. Со временем семантика «стареет». Появляются новые запросы, у некоторых пропадает спрос (пример: устаревшая модель телефона или кондиционера).
✓ Специфика бизнеса. Нет компаний, которые на 100% предоставляют одинаковые услуги или продают одинаковые товары. Пример: Мы делали 4 ядра в тематике: Клининг (Москва). Все 4 ядра отличаются по размеру, самое маленькое ядро получилось 1300 запросов, а самое большое 3800.
За 9 лет работы мы составляли семантику для сайтов во всех нишах.
На данной странице представлены примеры тематик, с которыми мы чаще всего работали.
Плюс, есть опыт в сложных тематиках: беттинг (ставки на спорт), гемблинг(казино), криптовалюта, гейминг, пластиковые окна и двери, кондиционеры.
Собирали семантику на: русском, английском, польском, немецком языках. Под Бурж и Рунет.
Да. Сейчас ядра у нас выгружаются в 3 версии оформления шаблона. Дата внедрения: 07.2022.
Что нового:
✓ Разработали максимально удобную систему навигации между отчетами и ТЗ для копирайтера.
✓ Подобрали приятную цветовую гамму заливки ячеек. Зеленый – хорошо, красный – плохо/сложно.
✓ Сформировали наглядные графики/таблицы изменения спроса в отчете «Сезонность».
✓ Быстрое скрытие/раскрытие групп колонок в шапке. Позволяет оставить на экране только нужные данные и не терять фокус внимания при анализе.
✓ Максимально простое и подробное описание всех колонок и параметров (вкладка «Описание полей»).
Полная переработка «helpа».
Все это позволяет максимально эффективно работать с собранной аналитикой.
Нет примера в нужной
Вам тематике?
Бесплатная консультация
от руководителя

составлению семантического ядра.
Page load link

Закажите семантическое ядро + внесите предоплату до 31.03.2023 и получите:
1. Скидку на сбор запросов — 15%.
2. Наше новое ТЗ для копирайтера в
Excel + Tskb формате (описание) — 50%.
3. Консультацию от руководителя на 1-1,5 часа
по работе с ядром и ТЗ — бесплатно.

Укажите в брифе ваш
промокод: prom2023
Поделились внутренним инструментом, который анализирует собранные фразы и показывает, где и что еще можно добрать.
В маркетинге мы предпочитаем опираться на математику, а не на интуицию. Если есть задача проверить семантику на полноту — значит, должен быть инструмент, который перетрясет собранные фразы и покажет, где и что еще можно добрать. Сервисов аналогичных нет, поэтому мы нашу внутреннюю модель вынесли в Excel-файл — скачивайте и пользуйтесь.
Вам понадобятся: фразы и их частоты — общие и точные.
Принцип такой: вносим в Excel-файл фразы и частоты, жмем на кнопку и через несколько секунд, когда сформируются связи «фраза-хвост» и отсекутся доли нерелевантного объема, по маркерам определяем — где мы не доработали.
А теперь подробнее.
Идеально отработанная семантика
Если семантика отработана идеально, Excel-файл выглядит так:
- значения в столбце H (расчетная частота) близки к значениям в столбце D (точная частота) у всех фраз, кроме низкочастотных и тех, в которых больше всего значимых слов.
- столбец J (коэффициент отработки) зеленого цвета.
- столбец K (коэффициент неотработки) зеленого цвета
Неполная семантика: что упустили и как доработать
По маркерам файла мы можем понять 3 момента.
- Мы не добрали хвосты.
- Не досчитали трафика.
- Собрали некачественные хвосты.
Не добрали хвосты
Если для какой-то фразы (скажем, «Защитная каска») мы упустили хвост со средней или высокой частотой («Защитная каска с наушниками»), мы увидим это по маркерам в файле.
Хвост — дочерняя фраза («Защитная каска с наушниками»), которая состоит из материнской фразы («Защитная каска») и хотя бы одного дополнительного слова («наушник»)
Маркеры:
В столбце J (Коэффициент неотработки) и/ или в столбце K (Коэффициент отработки) ячейки не зеленого цвета, а желтого, оранжевого или красного (чем больше упустили хвостов, тем краснее цвет).
Что делать:
Идем в вордстат — вбиваем каждую такую фразу с минус-словами, находим для нее не включенные релевантные частотные хвосты и добавляем их в семантику.
Если таких хвостов нет, значит, дело не в том, что мы чего-то недобрали, а в том, что мы неправильно определили, какой релевантный объем трафика принесет фраза. Мы включили в него и мусорный объем. Для точного прогноза мусорный объем нужно отсечь — уменьшить коэффициент чистоты в столбце С.
Собрали некачественные хвосты
Если мы включили в семантику хвост с низкой точной частотой, файл нам это тоже покажет.
Маркер:
Значение в столбце J (Коэффициент неотработки) меньше, чем значение в столбце K (Коэффициент отработки).
Что делать:
В столбце P ставим значение 0 — тогда эта фраза не будет учитываться и мы не возьмем ее в продвижение. Так мы сэкономим деньги, потому что у нее была бы высокая цена за пользователя.
Не досчитали трафика
Иногда мы можем для какого-то запроса не точно спрогнозировать трафик — посчитать, что фраза приведет 15 человек, а, на самом деле, она может привести 20. Такие случаи файл нам тоже показывает, чтобы мы не удалили фразу, которую по ошибке посчитали бы мало полезной.
Маркеры:
Текст в столбце F красного цвета.
Что делать:
Увеличиваем коэффициент чистоты в столбце С.
Подготовка файла к работе
Скачайте шаблон и выполните следующие подготовительные шаги.
1. Внесите фразы
Откройте лист sem. Внесите в столбец А собранные фразы, в столбец B — их общие частоты, а в столбец С — точные частоты. Скопируйте эти же фразы (или сформируйте из них любую другую выборку) в столбец F листа work.
2. Задайте правила для создания униформ
Перейдите на лист «Морфо». Здесь собраны предлоги и окончания, которые будут игнорироваться, потому что они не считываются поисковиками как смысловые. Вы можете задавать на этом листе свои правила и исключения.
После того, как на четвертом шаге вы нажмете на кнопку «Расчет частот и отработки», по этим правилам для каждой фразы в столбце B сгенерируются униформы, которые однозначно характеризуют фразы.
3. Установите коэффициент чистоты
Мы делаем это для того, чтобы учитывать только релевантные запросы по каждой фразе. Например, фразу «Средства индивидуальной защиты» могут вбивать в поисковиках 20000 раз за месяц. Но 30% из этих запросов — информационка. И нам нужно это учитывать, чтобы мы не считали, что у нас трафика с этой фразы будет больше.
Перейдите на лист «Properties».
Опираясь на свой опыт, знание проекта и отрасли, задайте базовый коэффициент чистоты.
Например, если вы считаете, что фразы из одного слова («Каски», «Спецодежда») содержат, в среднем, 45% мусора, поставьте в столбце D коэффициент чистоты — 0,55.
Ниже идут уровни вложенности: +1 слово (фразы из двух слов), + 2 слова (фразы из трех слов), + 3 слова (фразы из четырех слов). Для них также проставьте коэффициенты чистоты в столбце D. На скрине это: 0,65, 0,85 и 0,95. Обычно, чем длиннее фраза, тем меньше она замусорена.
Потом для отдельных фраз можно будет увеличить или уменьшить коэффициент чистоты. Это вы увидите по маркерам (мы их описали выше). Коэффициент чистоты для отдельной фразы можно поменять на листе «Work», в столбце С.
4. Нажмите на кнопку «Расчет частот и отработки»
Через несколько секунд уже можно анализировать маркеры и дорабатывать семантику.
Экономия
Кажется, сложно, но на деле это займет 10-20 минут. Проделанная работа позволит корректно сформировать кластеры, привести максимальный трафик и не переплачивать за пользователей.
Так что скачивайте файл, разбирайтесь, пользуйтесь или обращайтесь за продвижением к нам.