
Даны определения Функции распределения случайной величины и Плотности вероятности непрерывной случайной величины. Эти понятия активно используются в статьях о статистике сайта
www.excel2.ru
. Рассмотрены примеры вычисления Функции распределения и Плотности вероятности с помощью функций MS EXCEL
.
Введем базовые понятия статистики, без которых невозможно объяснить более сложные понятия.
Генеральная совокупность и случайная величина
Пусть у нас имеется
генеральная совокупность
(population) из N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики Х.
Примером генеральной совокупности (ГС) может служить совокупность весов однотипных деталей, которые производятся станком.
Поскольку в математической статистике, любой вывод делается только на основании характеристики Х (абстрагируясь от самих объектов), то с этой точки зрения
генеральная совокупность
представляет собой N чисел, среди которых, в общем случае, могут быть и одинаковые.
В нашем примере, ГС — это просто числовой массив значений весов деталей. Х – вес одной из деталей.
Если из заданной ГС мы выбираем случайным образом один объект, имеющей характеристику Х, то величина Х является
случайной величиной
. По определению, любая
случайная величина
имеет
функцию распределения
, которая обычно обозначается F(x).
Функция распределения
Функцией распределения
вероятностей
случайной величины
Х называют функцию F(x), значение которой в точке х равно вероятности события X
F(x) = P(X
Поясним на примере нашего станка. Хотя предполагается, что наш станок производит только один тип деталей, но, очевидно, что вес изготовленных деталей будет слегка отличаться друг от друга. Это возможно из-за того, что при изготовлении мог быть использован разный материал, а условия обработки также могли слегка различаться и пр. Пусть самая тяжелая деталь, произведенная станком, весит 200 г, а самая легкая — 190 г. Вероятность того, что случайно выбранная деталь Х будет весить меньше 200 г равна 1. Вероятность того, что будет весить меньше 190 г равна 0. Промежуточные значения определяются формой Функции распределения. Например, если процесс настроен на изготовление деталей весом 195 г, то разумно предположить, что вероятность выбрать деталь легче 195 г равна 0,5.
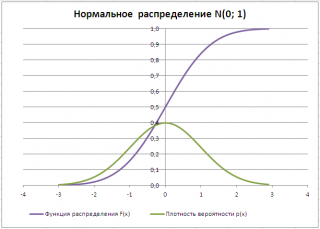
Типичный график
Функции распределения
для непрерывной случайной величины приведен на картинке ниже (фиолетовая кривая, см.
файл примера
):
В справке MS EXCEL
Функцию распределения
называют
Интегральной
функцией распределения
(
Cumulative
Distribution
Function
,
CDF
).
Приведем некоторые свойства
Функции распределения:
Функция распределения
F(x) изменяется в интервале [0;1], т.к. ее значения равны вероятностям соответствующих событий (по определению вероятность может быть в пределах от 0 до 1);
Функция распределения
– неубывающая функция;-
Вероятность того, что случайная величина приняла значение из некоторого диапазона [x1;x2): P(x
1
<=X
2)=F(x
2
)-F(x
1
).
Существует 2 типа распределений:
непрерывные распределения
и
дискретные распределения
.
Дискретные распределения
Если случайная величина может принимать только определенные значения и количество таких значений конечно, то соответствующее распределение называется
дискретным
. Например, при бросании монеты, имеется только 2 элементарных исхода, и, соответственно, случайная величина может принимать только 2 значения. Например, 0 (выпала решка) и 1 (не выпала решка) (см.
схему Бернулли
). Если монета симметричная, то вероятность каждого исхода равна 1/2. При бросании кубика случайная величина принимает значения от 1 до 6. Вероятность каждого исхода равна 1/6. Сумма вероятностей всех возможных значений случайной величины равна 1.
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности дискретных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
Непрерывные распределения и плотность вероятности
В случае
непрерывного распределения
случайная величина может принимать любые значения из интервала, в котором она определена. Т.к. количество таких значений бесконечно велико, то мы не можем, как в случае дискретной величины, сопоставить каждому значению случайной величины ненулевую вероятность (т.е. вероятность попадания в любую точку (заданную до опыта) для
непрерывной случайной величины
равна нулю). Т.к. в противном случае сумма вероятностей всех возможных значений случайной величины будет равна бесконечности, а не 1. Выходом из этой ситуации является введение так называемой
функции плотности распределения p(x)
. Чтобы найти вероятность того, что непрерывная случайная величина Х примет значение, заключенное в интервале (а; b), необходимо найти приращение
функции распределения
на этом интервале:
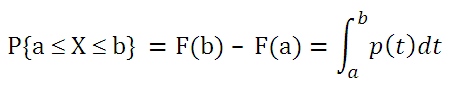
Как видно из формулы выше
плотность распределения
р(х) представляет собой производную
функции распределения
F(x), т.е. р(х) = F’(x).
Типичный график
функции плотности распределения
для непрерывной случайно величины приведен на картинке ниже (зеленая кривая):
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности непрерывных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
В литературе
Функция плотности распределения
непрерывной случайной величины может называться:
Плотность вероятности, Плотность распределения, англ. Probability Density Function (PDF)
.
Чтобы все усложнить, термин
Распределение
(в литературе на английском языке —
Probability
Distribution
Function
или просто
Distribution
)
в зависимости от контекста может относиться как
Интегральной
функции распределения,
так и кее
Плотности распределения.
Из определения
функции плотности распределения
следует, что p(х)>=0. Следовательно, плотность вероятности для непрерывной величины может быть, в отличие от
Функции распределения,
больше 1. Например, для
непрерывной равномерной величины
, распределенной на интервале [0; 0,5]
плотность вероятности
равна 1/(0,5-0)=2. А для
экспоненциального распределения
с параметром
лямбда
=5, значение
плотности вероятности
в точке х=0,05 равно 3,894. Но, при этом можно убедиться, что вероятность на любом интервале будет, как обычно, от 0 до 1.
Напомним, что
плотность распределения
является производной от
функции распределения
, т.е. «скоростью» ее изменения: p(x)=(F(x2)-F(x1))/Dx при Dx стремящемся к 0, где Dx=x2-x1. Т.е. тот факт, что
плотность распределения
>1 означает лишь, что функция распределения растет достаточно быстро (это очевидно на примере
экспоненциального распределения
).
Примечание
: Площадь, целиком заключенная под всей кривой, изображающей
плотность распределения
, равна 1.
Примечание
: Напомним, что функцию распределения F(x) называют в функциях MS EXCEL
интегральной функцией распределения
. Этот термин присутствует в параметрах функций, например в
НОРМ.РАСП
(x; среднее; стандартное_откл;
интегральная
). Если функция MS EXCEL должна вернуть
Функцию распределения,
то параметр
интегральная
, д.б. установлен ИСТИНА. Если требуется вычислить
плотность вероятности
, то параметр
интегральная
, д.б. ЛОЖЬ.
Примечание
: Для
дискретного распределения
вероятность случайной величине принять некое значение также часто называется плотностью вероятности (англ. probability mass function (pmf)). В справке MS EXCEL
плотность вероятности
может называть даже «функция вероятностной меры» (см. функцию
БИНОМ.РАСП()
).
Вычисление плотности вероятности с использованием функций MS EXCEL
Понятно, что чтобы вычислить
плотность вероятности
для определенного значения случайной величины, нужно знать ее распределение.
Найдем
плотность вероятности
для
стандартного нормального распределения
N(0;1) при x=2. Для этого необходимо записать формулу
=НОРМ.СТ.РАСП(2;ЛОЖЬ)
=0,054 или
=НОРМ.РАСП(2;0;1;ЛОЖЬ)
.
Напомним, что
вероятность
того, что
непрерывная случайная величина
примет конкретное значение x равна 0. Для
непрерывной случайной величины
Х можно вычислить только вероятность события, что Х примет значение, заключенное в интервале (а; b).
Вычисление вероятностей с использованием функций MS EXCEL
1) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
(см. картинку выше), приняла положительное значение. Согласно свойству
Функции распределения
вероятность равна F(+∞)-F(0)=1-0,5=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(9,999E+307;ИСТИНА) -НОРМ.СТ.РАСП(0;ИСТИНА)
=1-0,5. Вместо +∞ в формулу введено значение 9,999E+307= 9,999*10^307, которое является максимальным числом, которое можно ввести в ячейку MS EXCEL (так сказать, наиболее близкое к +∞).
2) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
, приняла отрицательное значение. Согласно определения
Функции распределения,
вероятность равна F(0)=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(0;ИСТИНА)
=0,5.
3) Найдем вероятность того, что случайная величина, распределенная по
стандартному нормальному распределению
, примет значение, заключенное в интервале (0; 1). Вероятность равна F(1)-F(0), т.е. из вероятности выбрать Х из интервала (-∞;1) нужно вычесть вероятность выбрать Х из интервала (-∞;0). В MS EXCEL используйте формулу
=НОРМ.СТ.РАСП(1;ИСТИНА) — НОРМ.СТ.РАСП(0;ИСТИНА)
.
Все расчеты, приведенные выше, относятся к случайной величине, распределенной по
стандартному нормальному закону
N(0;1). Понятно, что значения вероятностей зависят от конкретного распределения. В статье
Распределения случайной величины в MS EXCEL
приведены распределения, для которых в MS EXCEL имеются соответствующие функции, позволяющие вычислить вероятности.
Обратная функция распределения (Inverse Distribution Function)
Вспомним задачу из предыдущего раздела:
Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению, приняла отрицательное значение.
Вероятность этого события равна 0,5.
Теперь решим обратную задачу: определим х, для которого вероятность, того что случайная величина Х примет значение
медиану
или 50-ю
процентиль
).
Для этого необходимо на графике
функции распределения
найти точку, для которой F(х)=0,5, а затем найти абсциссу этой точки. Абсцисса точки =0, т.е. вероятность, того что случайная величина Х примет значение <0, равна 0,5.
В MS EXCEL используйте формулу
=НОРМ.СТ.ОБР(0,5)
=0.
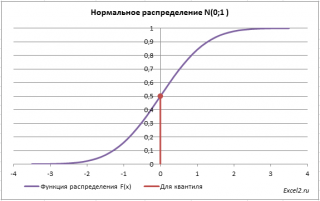
Однозначно вычислить значение
случайной величины
позволяет свойство монотонности
функции распределения.
Обратите внимание, что для вычисления обратной функции мы использовали именно
функцию распределения
, а не
плотность распределения
. Поэтому, в аргументах функции
НОРМ.СТ.ОБР()
отсутствует параметр
интегральная
, который подразумевается. Подробнее про функцию
НОРМ.СТ.ОБР()
см. статью про
нормальное распределение
.
Обратная функция распределения
вычисляет
квантили распределения
, которые используются, например, при
построении доверительных интервалов
. Т.е. в нашем случае число 0 является 0,5-квантилем
нормального распределения
. В
файле примера
можно вычислить и другой
квантиль
этого распределения. Например, 0,8-квантиль равен 0,84.
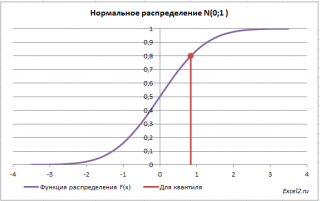
В англоязычной литературе
обратная функция распределения
часто называется как Percent Point Function (PPF).
Примечание
: При вычислении
квантилей
в MS EXCEL используются функции:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
2.1.2. Эмпирическая функция распределения
Это статистический аналог функции распределения из теорвера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх (по определению).
На промежутке – и далее процесс продолжается по принципу накопления частот:
– если , то ;
– если , то ;
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого значения «икс» (см. чертёж выше).
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 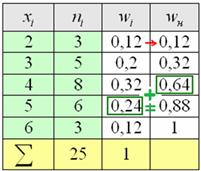
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Построенную функцию принято записывать в кусочном виде:
а её график представляет собой ступенчатую фигуру: 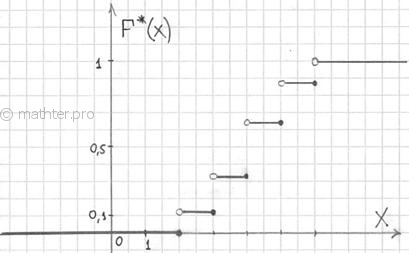
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Теперь смотрим видео, о том, как построить эту функцию в Экселе (Ютуб).
И, конечно, вспомним основной метод математической статистики. Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя появляется в результате исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА функция эмпирическая, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрное задание для закрепления материала:
Пример 5
Дано статистическое распределение совокупности: 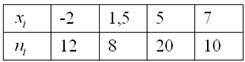
Составить эмпирическую функцию распределения, выполнить чертёж
Решаем самостоятельно – все числа уже в Экселе! Свериться с образцом можно в конце книги. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 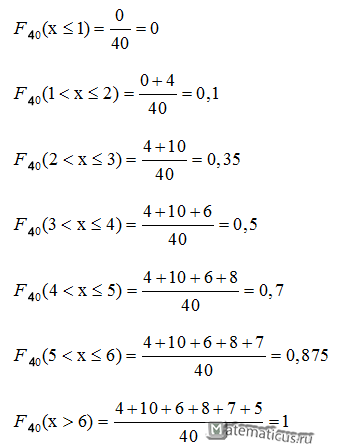
Эмпирическая функция распределения имеет вид

Построим график кусочно-постоянной эмпирической функции распределения
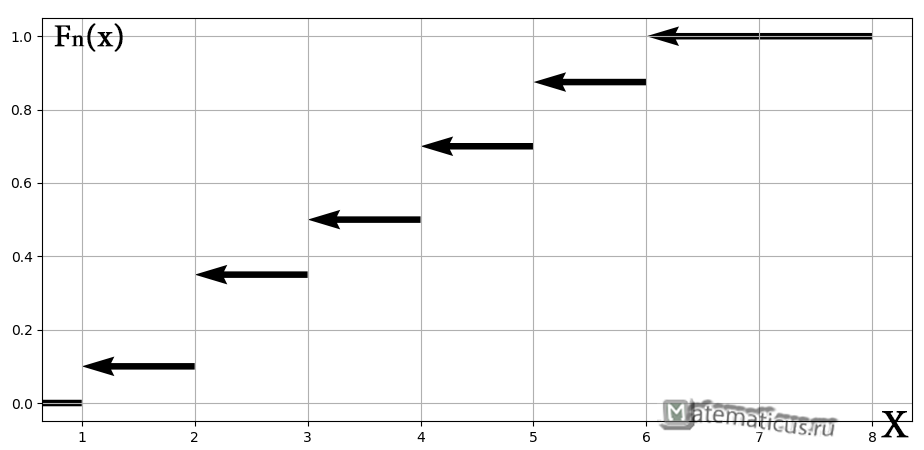
таким образом, по данным выборки можно приближенно построить функцию для неизвестной функции выборки.
2 комментария
У вас опечатка, где вы написали n=30, n=4+10+6+8+7+5=30 и F_30, так как n=40.
Построить эмпирическое распределение результатов тестирования в баллах для следующей выборки: 69, 85, 78, 85, 83, 81, 95, 88, 97, 92, 74, 83, 89, 77, 93.
В ячейку А1 введите слова Результаты, в диапазон А2:А16 – результаты тестирования.
Выберите ширину интервала 5 баллов. Тогда при крайних результатах 69 и 97 баллов, получится 7 интервалов. В ячейку С1 введите название интервалов Границы. В диапазон С2:С8 введите граничные значения интервалов: 70, 75, 80, 85, 90, 95, 100.
Введите заголовки создаваемой таблицы: в ячейку D1 – Абсолютные частоты, в ячейку Е1 – Относительные частоты, в F1 – Накопленные частоты.
Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек D2:D8, вызовите Мастер функций, категория – Статистические, функция – Частота, в поле Массив данных введите диапазон данных тестирования А2:А16, в поле Массив интервалов введите диапазон интервалов С2:С8, нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце D2:D8 появится массив абсолютных частот.
В ячейке D9 найдите общее количество результатов тестирования, с помощью Автосумма.
Заполните столбец относительных частот. В ячейку Е2 введите формулу =$D2/$D$9 .
Протягиванием скопируйте полученное значение в диапазон Е3:Е8. Получим массив относительных частот.
Заполните столбец накопленных частот. В ячейку F2 скопируйте значение относительной частоты из ячейки Е2. В ячейку F3 введите формулу =F2+E3. Протягиванием скопируйте полученное значение в диапазон F4:F8. Получим массив накопленных частот.
В результате получим таблицу, представленную на рисунке 1.
Пусть Nх — число наблюдений, при которых значение признака Х меньше Х. При объеме выборки, равном П, относительная частота события Х XK.
Сама же функция F*(X) служит для оценки теоретической функции распределения F(X) генеральной совокупности.
Пример 3. Построить эмпирическую функцию по заданному распределению выборки:

Решение. Находим объем выборки: П = 10 + 15 + 25 = 50. Наименьшая варианта равна 2, поэтому F*(X) = 0 при Х ≤ 2. Значение Х 6. Напишем формулу искомой эмпирической функции:
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).
Интервальный вариационный ряд и его характеристики
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Здесь k — число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $ F=x_-x_ $
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $ k=1+lfloorlog_2 Nrfloor $ или, через десятичный логарифм: $ k=1+lfloor 3,322cdotlg Nrfloor $
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Частота интервалов – число, показывающее сколько раз значения, относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания случайной величины X в заданные интервалы.
Эмпирические распределения — Мегаобучалка
Существует также теоретическая функция распределения (функция распределения генеральной совокупности). Ее отличие от выборочной функции распределения состоит в определении объективной возможности или вероятности события X
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.

Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.

Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Все несколько проще Данные- Анализ данных- Генерация случайных чисел Распределение Нормальное Данные- Анализ данных- Гистограмма- Галка на вывод графика Карманы можно даже не задавать. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
8. Постройте диаграмму относительных и накопленных частот. Щелчком указателя мыши по кнопке Анализ данных вкладки Данные вызовите Пакет анализа, выберите в нем опцию Гистограмма и постройте график абсолютных и накопленных частот. После редактирования диаграмма будет иметь такой вид, как на рис. 2.
Как сменить строки и столбцы в гистограмме
Для того чтобы сменить порядок строк и столбцов в гистограмме проделайте следующие шаги:


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Построить эмпирическое распределение веса студентов в килограммах для следующей выборки 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
8. Постройте диаграмму относительных и накопленных частот. Щелчком указателя мыши по кнопке Анализ данных вкладки Данные вызовите Пакет анализа, выберите в нем опцию Гистограмма и постройте график абсолютных и накопленных частот. После редактирования диаграмма будет иметь такой вид, как на рис. 2.

Эмпирическая функция распределения
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так: =(МАКС( Исходные_данные )-МИН( Исходные_данные ))/7 где Исходные_данные – именованный диапазон , содержащий наши данные.
Как построить график
Построение графика эмпирической функции распределения возможно после вычисления ее значений на всей числовой оси. Для рассмотренного примера схематическое изображение будет выглядеть так:

Эмпирическая функция распределения
Гистограмма распределения – это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции ЧАСТОТА() и диаграммы.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Характеристики нормального распределения
- Значения рассматриваемой функции F * (x) располагаются на отрезке [0; 1].
- Функция имеет неубывающий характер.
- При минимальной варианте x1 верно равенство F * (x)=0 при условии, что х1. При максимальной варианте хkверно равенство F * (x)=1 при условии х>xk.
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка ).
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция НОРМ.РАСП.
Синтаксис
НОРМРАСП(x;среднее;стандартное_откл;интегральная)
Аргументы функции НОРМРАСП описаны ниже.
-
X Обязательный. Значение, для которого строится распределение.
-
Среднее Обязательный. Среднее арифметическое распределения.
-
Стандартное_откл Обязательный. Стандартное отклонение распределения.
-
Интегральная — обязательный аргумент. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Замечания
-
Если «standard_dev» не является числом, то возвращается #VALUE! значение ошибки #ЗНАЧ!.
-
Если standard_dev ≤ 0, то нормДАТ возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если среднее = 0, стандартное_откл = 1 и интегральная = ИСТИНА, то функция НОРМРАСП возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП.
-
Уравнение для плотности нормального распределения (аргумент «интегральная» содержит значение ЛОЖЬ) имеет следующий вид:

-
Если аргумент «интегральная» имеет значение ИСТИНА, формула описывает интеграл с пределами от минус бесконечности до x.
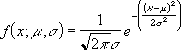
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
Описание |
|
|
42 |
Значение, для которого нужно вычислить распределение |
|
|
40 |
Среднее арифметическое распределения |
|
|
1,5 |
Стандартное отклонение распределения |
|
|
Формула |
Описание |
Результат |
|
=НОРМРАСП(A2;A3;A4;ИСТИНА) |
Интегральная функция распределения для приведенных выше условий |
0,9087888 |
|
=НОРМРАСП(A2;A3;A4;ЛОЖЬ) |
Функция плотности распределения для приведенных выше условий |
0,10934 |
Нужна дополнительная помощь?
17 авг. 2022 г.
читать 2 мин
Распределение частоты описывает, как часто разные значения встречаются в наборе данных. Это полезный способ понять, как значения данных распределяются в наборе данных.
К счастью, легко создать и визуализировать частотное распределение в Excel, используя следующую функцию:
=ЧАСТОТА(массив_данных,массив_бинов)
куда:
- data_array : массив необработанных значений данных
- bins_array: массив верхних пределов для бинов
В следующем примере показано, как использовать эту функцию на практике.
Пример: частотное распределение в Excel
Предположим, у нас есть следующий набор данных из 20 значений в Excel:
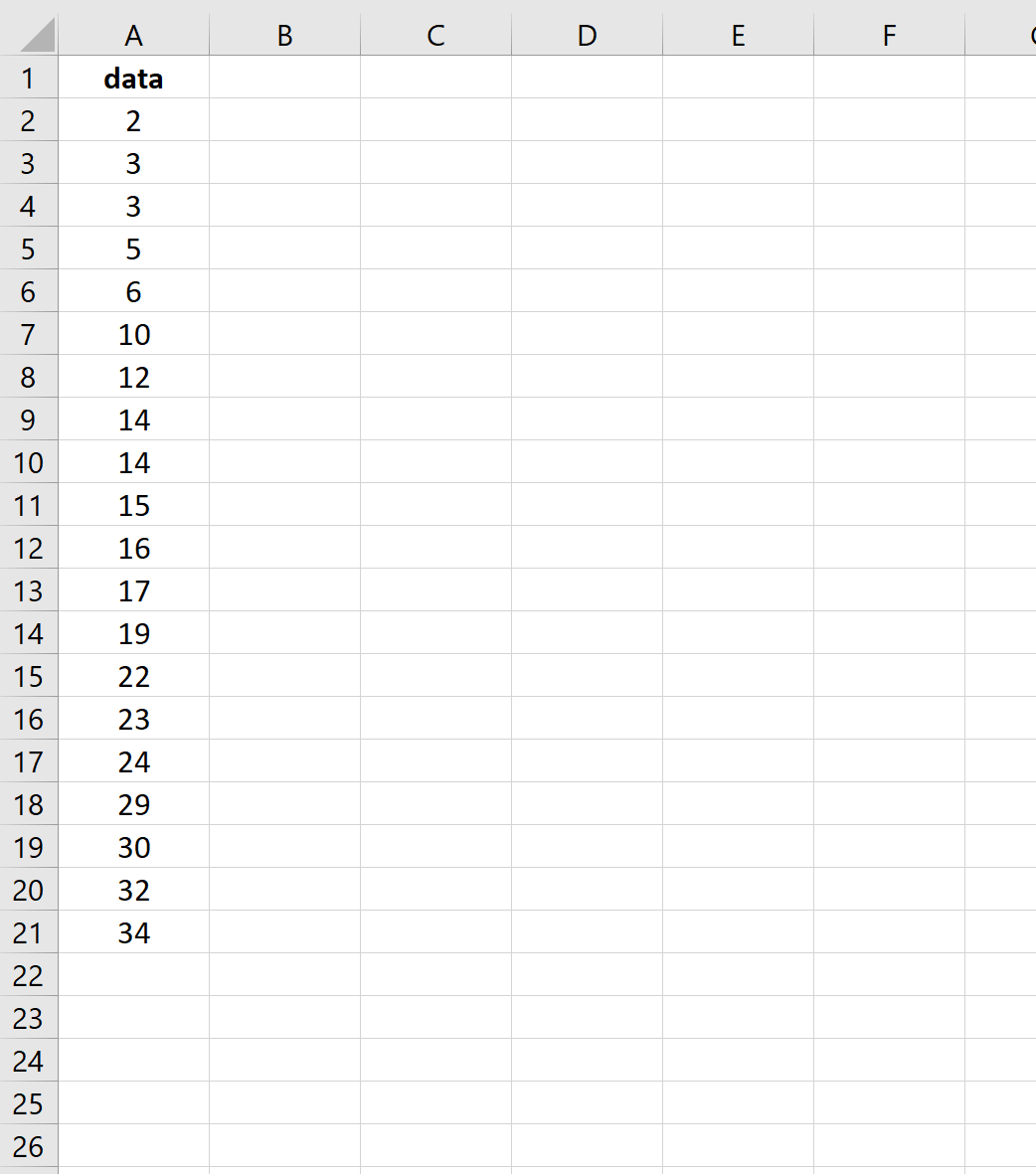
Во-первых, мы укажем Excel, какие верхние пределы мы хотели бы использовать для интервалов нашего частотного распределения. Для этого примера мы выберем 10, 20 и 30. То есть мы найдем частоты для следующих интервалов:
- от 0 до 10
- с 11 до 20
- от 21 до 30
- 30+
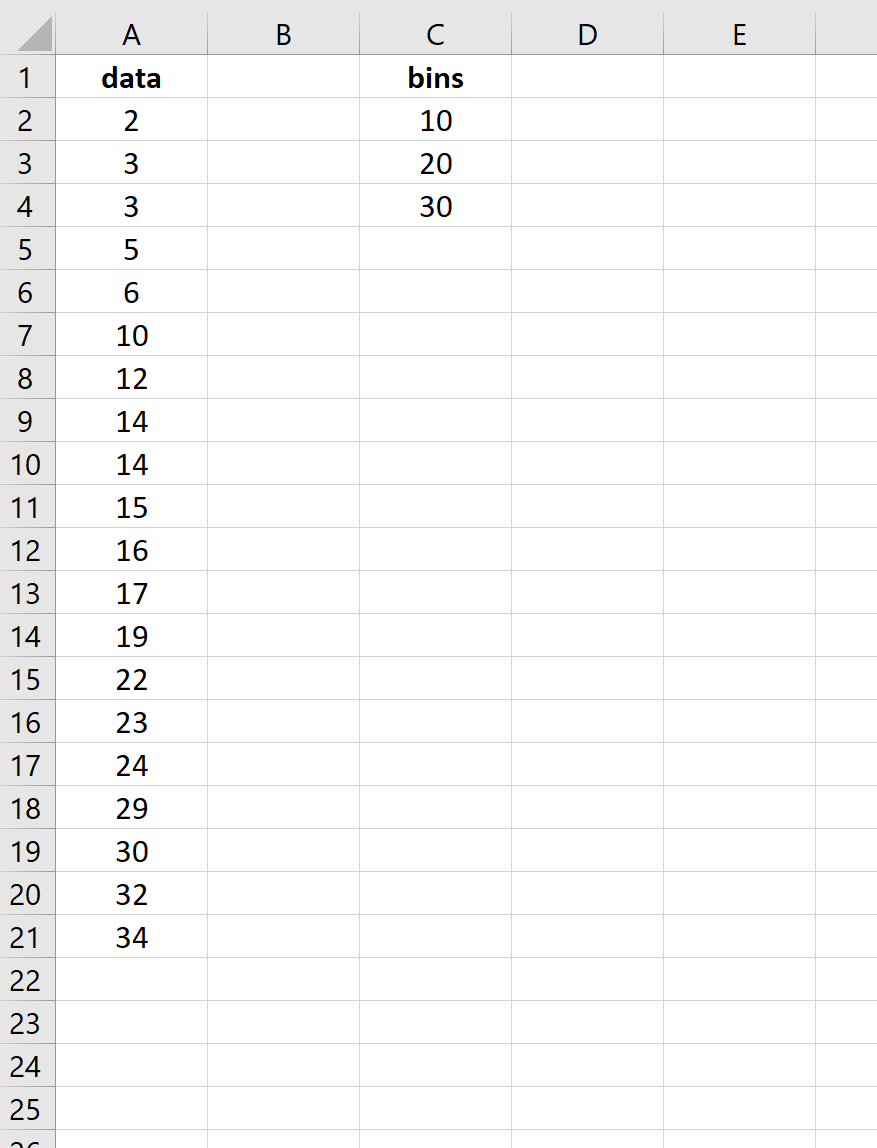
Далее мы будем использовать следующую функцию =FREQUENCY() для вычисления частот для каждого бина:
=ЧАСТОТА( A2:A21 , C2:C4 )
Вот результаты:
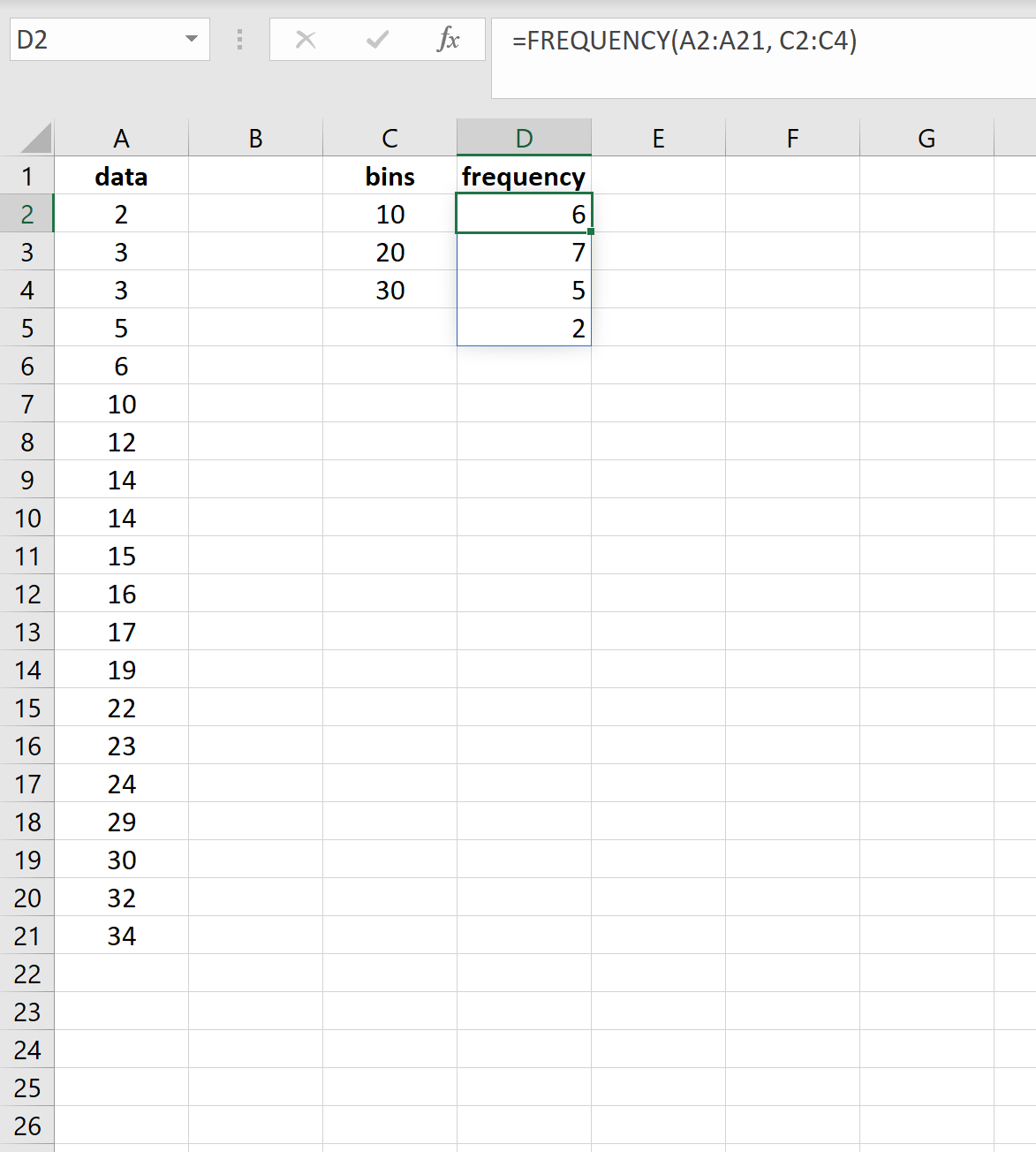
Результаты показывают, что:
- 6 значений в наборе данных находятся в диапазоне от 0 до 10.
- 7 значений в наборе данных находятся в диапазоне 11-20.
- 5 значений в наборе данных находятся в диапазоне 21-30.
- 2 значения в наборе данных больше 30.
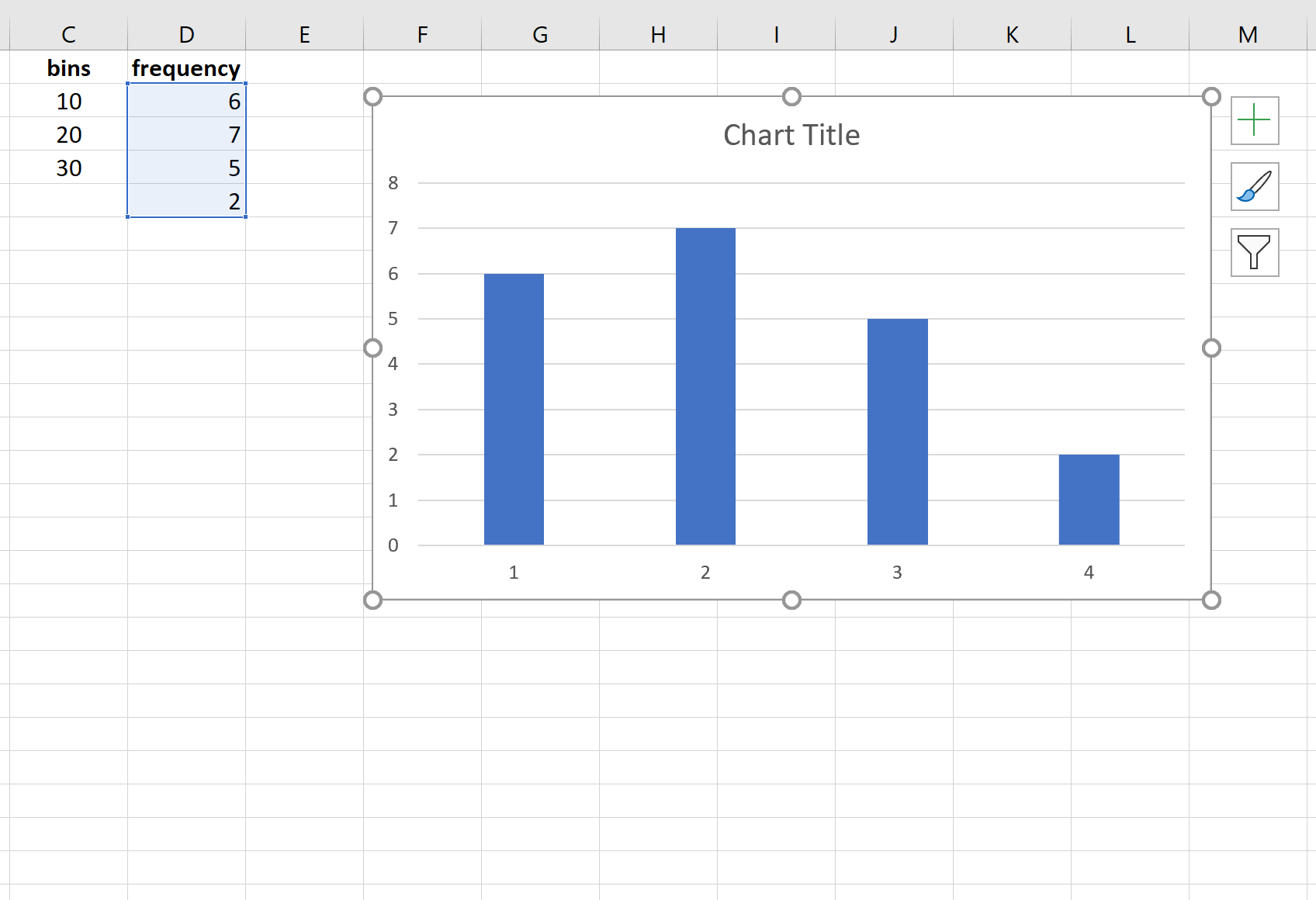
Затем мы можем использовать следующие шаги для визуализации этого частотного распределения:
- Выделите частоты в диапазоне D2:D5 .
- Нажмите на вкладку « Вставка », затем нажмите на диаграмму под названием « Двухмерный столбец » в группе « Диаграммы ».
Появится следующая диаграмма, отображающая частоты для каждого бина:
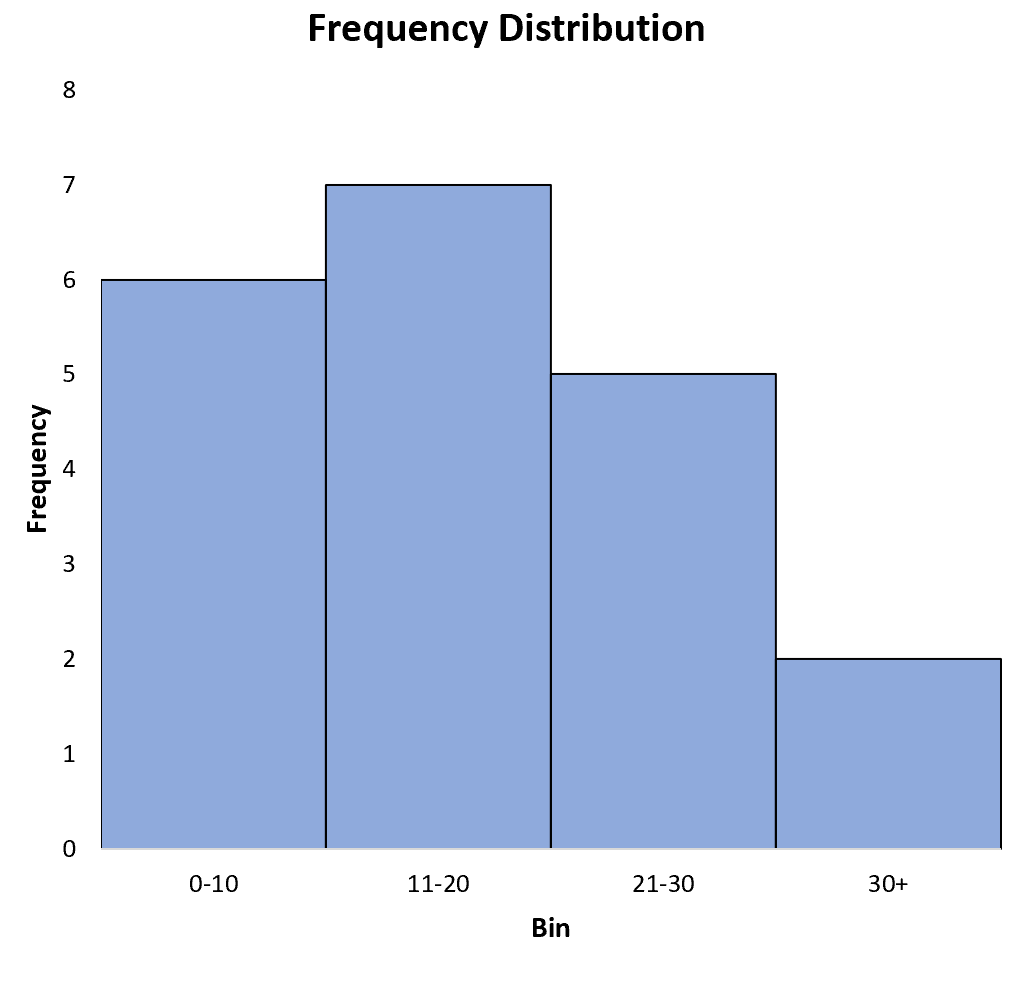
Не стесняйтесь изменять метки осей и ширину полос, чтобы сделать диаграмму более эстетичной:
Вы можете найти больше учебников по Excel здесь .
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.