
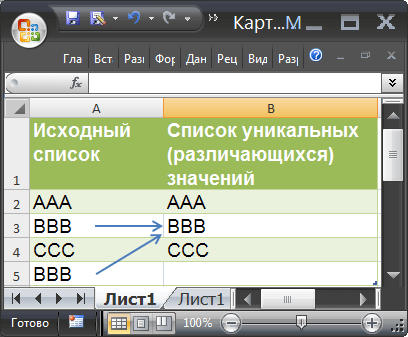
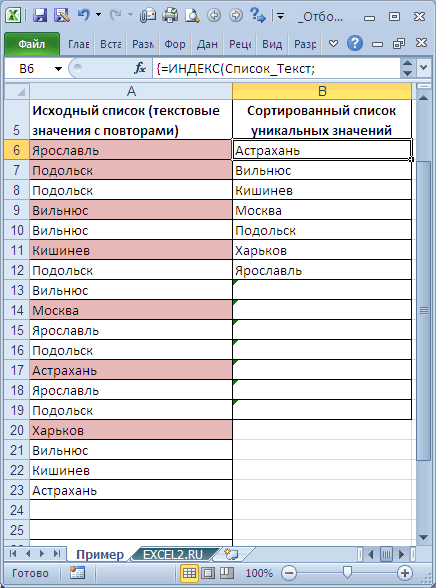
Из исходной таблицы отберем только уникальные значения и выведем их в отдельный диапазон с сортировкой по возрастанию. Отбор и сортировку сделаем с помощью одной формулой массива. Формула работает как для текстовых (сортировка от А до Я), так и для числовых значений (сортировка от мин до макс).
Эта статья — продолжение статьи
Отбор уникальных значений (убираем повторы из списка) в MS EXCEL
.
В столбце
А
имеется список с
повторяющимися
значениями, например список с названиями городов.
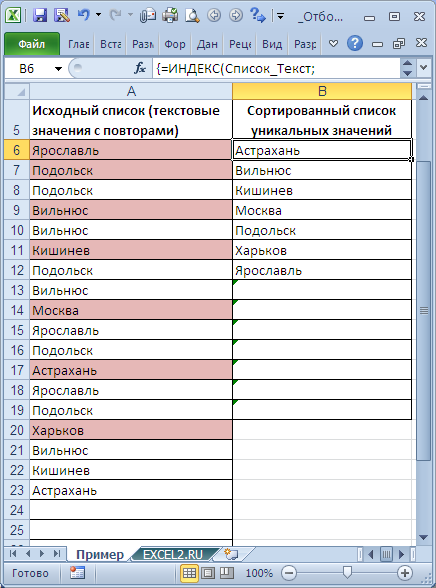
Задача
В некоторых ячейках исходного списка имеются повторы — новый список уникальных значений не должен их содержать.
Для наглядности уникальные значения в исходном списке выделены цветом с помощью
Условного форматирования
.
Список уникальных значений должен быть
отсортирован по алфавиту
.
Решение
Список уникальных значений создадим в столбце
B
с помощью
формулы массива
(см.
файл примера
). Для этого введите следующую формулу в ячейку
B6
:
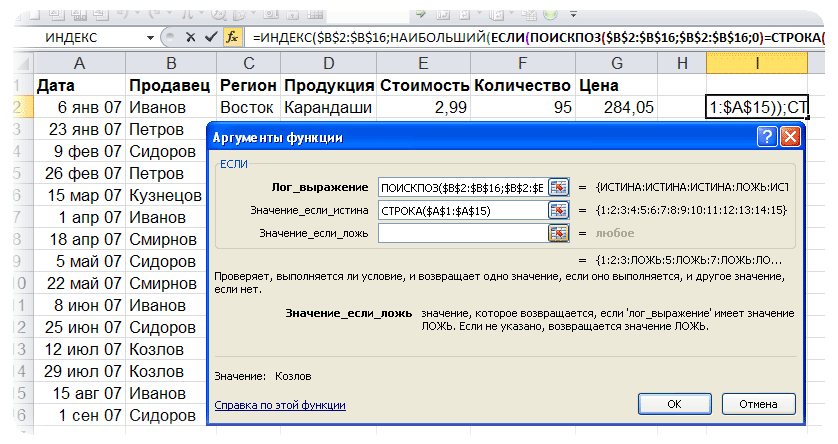
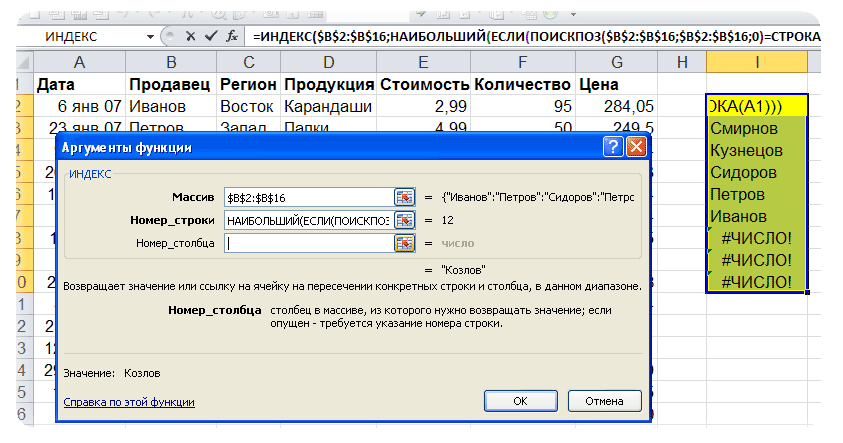
=ИНДЕКС(Список_Текст;НАИМЕНЬШИЙ(ЕСЛИ(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($B$5:B5;Список_Текст)=0;СЧЁТЕСЛИ(Список_Текст;»<«&Список_Текст)+1;»»);1)=СЧЁТЕСЛИ(Список_Текст;»<«&Список_Текст)+1;СТРОКА(Список_Текст)-МИН(СТРОКА(Список_Текст))+1);1))
После ввода формулы вместо
ENTER
нужно нажать
CTRL + SHIFT + ENTER
. Затем нужно скопировать формулу вниз, например, с помощью
Маркера заполнения
. Чтобы все значения исходного списка были гарантировано отображены в списке уникальных значений, необходимо сделать размер списка уникальных значений равным размеру исходного списка (на тот случай, когда все значения исходного списка не повторяются). В случае наличия в исходном списке большого количества повторяющихся значений, список уникальных значений можно сделать меньшего размера, удалив лишние формулы, чтобы исключить ненужные вычисления, тормозящие пересчет листа.
Примечание
: в формуле использован
Динамический диапазон
Список_текст
.
Значения ошибки скрыты
с помощью Условного форматирования.
СОВЕТ:
Список уникальных значений можно создать разными способами, например, с использованием
Расширенного фильтра
(см. статью
Отбор уникальных строк с помощью Расширенного фильтра
),
Сводных таблиц
или через меню
. У каждого способа есть свои преимущества и недостатки. Но, в этой статье нам требуется, чтобы при добавлении новых значений в исходный список, список
уникальных
значений должен автоматически обновляться, поэтому здесь построен список с использованием формул.
Фильтр уникальных значений или удаление повторяющихся значений

В Excel есть несколько способов отфильтровать уникальные значения или удалить повторяющиеся значения:
-
Чтобы отфильтровать уникальные значения, щелкните Ссылки > сортировки & фильтр > Расширенные.

-
Чтобы удалить повторяющиеся значения, выберите в > в >удалить дубликаты.
-
Чтобы выделить уникальные или повторяющиеся значения, используйте команду Условное форматирование в группе Стиль на вкладке Главная.

Фильтрация уникальных значений и удаление повторяюющихся значений — две похожие задачи, так как их цель — представить список уникальных значений. Однако существует критическое различие: при фильтрации уникальных значений повторяющиеся значения скрываются только временно. Однако удаление повторяюющихся значений означает, что повторяющиеся значения удаляются окончательно.
Повторяютая строка — это значение, в котором все значения хотя бы в одной строке совпадают со всеми значениями в другой строке. Сравнение повторяюющихся значений зависит от того, что отображается в ячейке, а не от значения, хранимого в ячейке. Например, если в разных ячейках есть одно и то же значение даты в формате «08.03.2006», а в другом — «8 марта 2006 г.», значения будут уникальными.
Прежде чем удалять дубликаты, проверьте: Прежде чем удалять повторяющиеся значения, сначала попробуйте отфильтровать уникальные значения (или отформатировать их с условием), чтобы достичь нужного результата.
Сделайте следующее:
-
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
-
Щелкните > дополнительные данные (в группе Фильтр & сортировки).
-
Во всплывающее окно Расширенный фильтр сделайте следующее:
Чтобы отфильтровать диапазон ячеек или таблицу на месте:
-
Щелкните Фильтровать список на месте.
Чтобы скопировать результаты фильтра в другое место:
-
Нажмите кнопку Копировать в другое место.
-
В поле Копировать в введите ссылку на ячейку.
-
Вы также можете нажать кнопку Свернуть
, чтобы временно скрыть всплывающее окно, выбрать ячейку на этом сайте и нажать кнопку Развернуть . -
Проверьте только уникальные записии нажмите кнопку ОК.
 , чтобы временно скрыть всплывающее окно, выбрать ячейку на этом сайте и нажать кнопку Развернуть
, чтобы временно скрыть всплывающее окно, выбрать ячейку на этом сайте и нажать кнопку Развернуть  .
.Уникальные значения из диапазона копируются в новое место.
При удалите повторяющиеся значения, только на значения в диапазоне ячеек или таблице. Другие значения за пределами диапазона ячеек или таблицы не изменяются и не перемещаются. При удалении дубликатов первое вхождение значения в списке будет сохранено, а другие одинаковые значения будут удалены.
Так как данные удаляются окончательно, перед удалением повторяюющихся значений лучше скопировать исходный диапазон ячеек или таблицу на другой.
Сделайте следующее:
-
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
-
На вкладке Данные нажмите кнопку Удалить дубликаты (в группе Инструменты для работы с данными).
-
Выполните одно или несколько из указанных ниже действий.
-
В области Столбцывыберите один или несколько столбцов.
-
Чтобы быстро выбрать все столбцы, нажмите кнопку Выбрать все.
-
Чтобы быстро очистить все столбцы, нажмите кнопку Отклоните все.
Если диапазон ячеек или таблицы содержит много столбцов и нужно выбрать только несколько столбцов, вам может быть проще нажать кнопку Отобрать все,а затем в столбцах выберите эти столбцы.
Примечание: Данные будут удалены из всех столбцов, даже если на этом этапе не выбраны все столбцы. Например, если выбрать Столбец1 и Столбец2, но не Столбец3, то ключом, используемым для поиска дубликатов, будет значение BOTH Column1 & Column2. Если в этих столбцах найдено повторяющиеся записи, удаляется вся строка, включая другие столбцы в таблице или диапазоне.
-
-
Нажмите кнопкуОК, и появится сообщение, в которое будет указано, сколько повторяюных значений было удалено или сколько уникальных значений осталось. Нажмите кнопку ОК, чтобы отклонять это сообщение.
-
Чтобы отменить изменение, нажмите кнопку Отменить (или нажмите клавиши CTRL+Z на клавиатуре).
Повторяющиеся значения невозможно удалить из структурных данных или с суммами. Чтобы удалить дубликаты, необходимо удалить структуру и подытогов. Дополнительные сведения см. в таблицах Структурная схема данных на листе и Удаление подытогов.
Примечание: Нельзя условно отформатировать поля в области значений отчета отчетов данных по уникальным или повторяемым значениям.
Быстрое форматирование
Сделайте следующее:
-
Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
-
На вкладке Главная в группе Стиль щелкните маленькую стрелку для условного форматирования ,а затем выберите правила выделения ячеек ищелкните Повторяющиеся значения.
-
Введите нужные значения и выберите формат.
Расширенное форматирование
Сделайте следующее:
-
Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
-
На вкладке Главная в группе Стили щелкните стрелку для команды Условное форматирование ивыберите управление правилами, чтобы отобразить всплывающее окно Диспетчер правил условного форматирования.
-
Выполните одно из следующих действий:
-
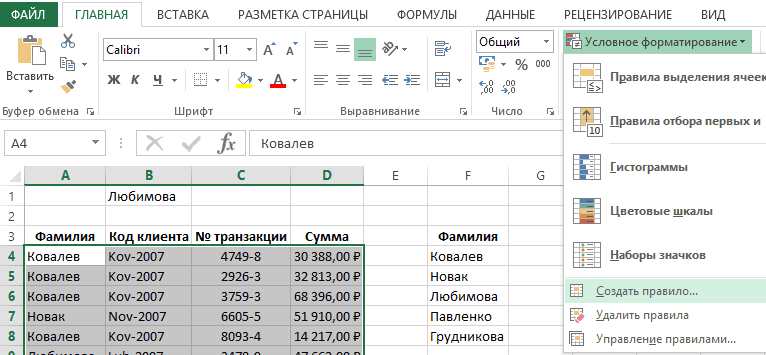
Чтобы добавить условное форматирование, нажмите кнопку Новое правило, чтобы отобразить всплывающее окно Новое правило форматирования.
-
Чтобы изменить условное форматирование, начните с того, что в списке Показать правила форматирования для выбран соответствующий лист или таблица. При необходимости выберите другой диапазон ячеек, нажав кнопку Свернуть
во всплывающее окно Применяется к временно скрыть его. Выберите новый диапазон ячеек на этом сайте, а затем снова разширив всплывающее окно, . Выберите правило и нажмите кнопку Изменить правило, чтобы отобразить всплывающее окно Изменение правила форматирования.
-
-
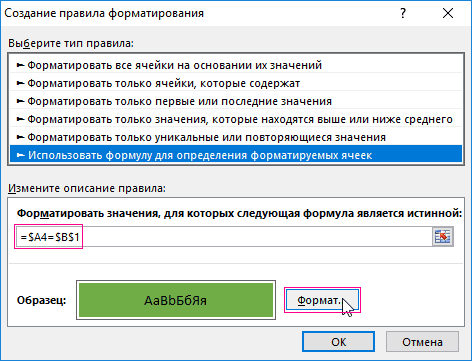
В группе Выберите тип правила выберите параметр Форматировать только уникальные или повторяющиеся значения.
-
В списке Форматировать все выберите изменить описание правила, выберите уникальный или дубликат.
-
Нажмите кнопку Формат, чтобы отобразить всплывающее окно Формат ячеек.
-
Выберите формат числа, шрифта, границы или заливки, который вы хотите применить, когда значение ячейки удовлетворяет условию, а затем нажмите кнопку ОК. Можно выбрать несколько форматов. Выбранные форматы отображаются на панели предварительного просмотра.
В Excel в Интернете можно удалить повторяющиеся значения.
Удаление повторяющихся значений
При удалите повторяющиеся значения, только на значения в диапазоне ячеек или таблице. Другие значения за пределами диапазона ячеек или таблицы не изменяются и не перемещаются. При удалении дубликатов первое вхождение значения в списке будет сохранено, а другие одинаковые значения будут удалены.
Важно: Вы всегда можете нажать кнопку Отменить, чтобы вернуть данные после удаления дубликатов. При этом перед удалением повторяюющихся значений лучше скопировать исходный диапазон ячеек или таблицу на другой рабочий или другой.
Сделайте следующее:
-
Вы выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
-
На вкладке Данные нажмите кнопку Удалить дубликаты.
-
В диалоговом окне Удаление дубликатов снимите с нее все столбцы, в которых не нужно удалять повторяющиеся значения.
Примечание: Данные будут удалены из всех столбцов, даже если на этом этапе не выбраны все столбцы. Например, если выбрать Столбец1 и Столбец2, но не Столбец3, то ключом, используемым для поиска дубликатов, будет значение BOTH Column1 & Column2. Если в столбцах «Столбец1» и «Столбец2» найдено повторяющиеся данные, удаляется вся строка, включая данные из столбца «Столбец3».
-
Нажмите кнопкуОК, и появится сообщение, в которое будет указано, сколько повторяюных значений было удалено. Нажмите кнопку ОК, чтобы отклонять это сообщение.
Примечание: Если вы хотите вернуть данные, просто нажмите кнопку Отменить (или нажмите клавиши CTRL+Z на клавиатуре).
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Определение количества уникальных значений среди дубликатов
Нужна дополнительная помощь?
Извлечение уникальных элементов из диапазона
Способ 1. Штатная функция в Excel 2007
Начиная с 2007-й версии функция удаления дубликатов является стандартной — найти ее можно на вкладке Данные — Удаление дубликатов (Data — Remove Duplicates):

В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data).
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:

Выбираем в меню Данные — Фильтр — Расширенный фильтр (Data — Filter — Advanced Filter). Получаем окно:

В нем:
- Выделяем наш список компаний в Исходный диапазон (List Range).
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
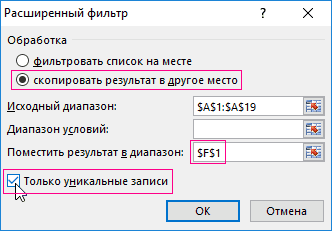
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:

Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE):

Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато — динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:

Первая задача — пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
=ЕСЛИ(СЧЁТЕСЛИ(B$1:B2;B2)=1;МАКС(A$1:A1)+1;»»)
В английской версии это будет:
=IF(COUNTIF(B$1:B2;B2)=1;MAX(A$1:A1)+1;»»)
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз — дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы — Диспетчер имен (Formulas — Name manager) или в старых версиях — через меню Вставка — Имя — Присвоить (Insert — Name — Define):
- диапазону номеров (A1:A100) — имя NameCount
- всему списку с номерами (A1:B100) — имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер — это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);»»;ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:

Ссылки по теме
- Выделение дубликатов по одному или нескольким столбцам в списке цветом
- Запрет ввода повторяющихся значений
- Извлечение уникальных значений при помощи надстройки PLEX
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Предыдущая глава Оглавление Следующая глава
Эта заметка для тех, кого по-настоящему интересуют сложных формулы массива. Если вам просто нужно один раз извлечь список уникальных значений, гораздо проще использовать Расширенный фильтр или сводную таблицу. Основные преимущества использования формул – автоматическое обновление при изменении/добавлении исходных данных или критериев отбора. Перед прочтением желательно освежить в памяти идеи, содержащиеся в предыдущих материалах:
- Булева логика: критерии И, ИЛИ (глава 11);
- Динамические диапазоны на основе функций ИНДЕКС и СМЕЩ (глава 13);
- Извлечение данных на основе критериев (глава 15);
- Формулы счета уникальных значений (глава 17).

Рис. 19.1. Извлечение уникальных записей с помощью опции Расширенный фильтр
Скачать заметку в формате Word или pdf, примеры в формате Excel
Извлечение уникального списка из одного столбца с помощью опции Расширенный фильтр
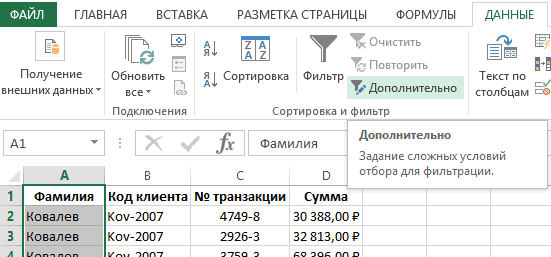
На рис. 19.1 показан набор данных (диапазон А1:С9). Ваша цель – получить список уникальных гоночных трасс. Так как вам нужно сохранить исходные данные, вы не можете использовать опцию Удалить дубликаты (меню ДАННЫЕ –> Работа с данными –> Удалить дубликаты). Но вы можете использовать Расширенный фильтр. Чтобы открыть диалоговое окно Расширенный фильтр, пройдите по меню ДАННЫЕ –> Сортировка и фильтр –> Дополнительно, или нажмите и удерживайте клавишу Alt, а затем последовательно нажмите Ы, Л (для Excel 2007 или позже).
В открывшемся диалоговом окне Расширенный фильтр (рис. 19.1) задайте опцию скопировать результат в другое место, проверьте флажок Только уникальные записи, задайте область, из которой будут извлекаться уникальные значения ($B$1:$B$9), и первую ячейку, куда извлеченные данные будут помещены ($E$1). На рис. 19.2 показан, полученный уникальный список (диапазон Е1:Е6). Если вы не включите имя поля в Исходный диапазон диалогового окна Расширенный фильтр (вместо того, что на рис. 19.1 укажите $B$2:$B$9), Excel будет рассматривать первую строку диапазона, как имя поля, и вы рискуете получить дубль. На рис. 19.3 показано одно из многих возможных применений уникального списка.

Рис. 19.2. Excel выводит имя поля в ячейку Е1 и уникальный список в ячейки ниже

Рис. 19.3. Уникальный список может стать критерием в формулах
Извлечение уникального списка на основе критерия с помощью опции Расширенный фильтр
В последнем примере вы извлекли уникальный список из одного столбца. Расширенный фильтр может также извлекать уникальный набор записей (т.е., строки исходной таблицы целиком) с применением критерия. На рис. 19.4 и 19.5 показана ситуация, в которой нужно извлечь уникальные записи из диапазона А1:D10, для которых имя компании равно АВС. Далее в этой главе вы увидите, как выполнить эту работу с помощью формулы. Однако, если вам не нужно, чтобы процесс был автоматическим, вы можете использовать Расширенный фильтр, что, безусловно, проще формулы.

Рис. 19.4. Вам нужны уникальные записи для компании ABC; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке

Рис. 19.5. Использование Расширенного фильтра для извлечения уникальных записей на основе критериев гораздо проще, чем метод формул. Однако, извлеченные записи не будут автоматически обновляться, если критерии или исходные данные изменятся
Извлечение уникального списка из одного столбца с помощью сводной таблицы
Если вы уже используете сводные таблицы, то знаете, что каждый раз, когда вы помещаете какое-либо поле в область Строки или Колонны (рис. 19.6), вы автоматически получите уникальный список. На рис. 19.6 показано, как можно быстро создать уникальный список гоночных трасс, а затем подсчитать количество посещений каждой из них. Хотя сводная таблица удобна для извлечения уникального списка из одного столбца, она вряд ли вам пригодится для извлечения уникальных записей на основе критериев.

Рис. 19.6. Можно воспользоваться сводной таблицей, когда вам нужен уникальный список и последующий расчет на его основе
Извлечение уникального списка из одного столбца с помощью формул и вспомогательного столбца
Использование вспомогательного столбца упрощает извлечение уникальных данных по сравнению с применением формул массива (рис. 19.7). Этот пример использует методы, с которыми вы познакомились в главе 17 (использование функции СЧЁТЕСЛИ) и главе 15 (использование вспомогательного столбца). Если теперь вы измените исходные данные в диапазоне В2:В9, формулы автоматически отразят эти изменения в области D15:D21.

Рис. 19.7. Вспомогательный столбец и формула на основе функции ИНДЕКС для извлечения уникального списка
Формула массива: извлечение уникального списка из одного столбца, используя функцию НАИМЕНЬШИЙ
Поскольку формулы массива, используемые в этом разделе, весьма сложны для восприятия, их создание разбито на этапы: первый – фрагмент, подсчитывающий уникальные значения (глава 17); второй – извлечение данных на основе критериев (глава 15). На рис. 19.8 показана формула расчета уникальных значений (поскольку, это формула массива, она вводится нажатием Ctrl+Shift+Enter). Обратите внимание на следующие аспекты этой формулы:
- Функция ЧАСТОТА возвращает массив чисел (рис. 19.9): для первого появления гоночной трассы возвращается число ее вхождений в исходные данные; для каждого последующего появления гоночной трассы, возвращается ноль (см. свойства функции ЧАСТОТА). Например, Sumner появляется в первой и пятой позициях массива. В первой позиции функция ЧАСТОТА возвращает 2 – общее число Summer в диапазоне В2:В9, в пятой позиции – 0.
- Функция ЧАСТОТА размещена в аргументе лог_выражение функции ЕСЛИ, поэтому функция ЕСЛИ возвращает ИСТИНА для любого ненулевого значения, и ЛОЖЬ – для нулевого.
- Аргумент значение_если_истина функции ЕСЛИ содержит 1, таким образом, функция СУММ подсчитывает число таких единиц.

Рис. 19.8. Функция ЧАСТОТА размещена в аргументе лог_выражение функции ЕСЛИ

Рис. 19.9. (1) функция ЧАСТОТА возвращает массив чисел; (2) функция ЕСЛИ возвращает 1 для чисел отличных от нуля, и значение ЛОЖЬ для нулей
Теперь создадим формулу извлечения уникального списка. На рис. 19.10 показан массив относительных позиций, размещенный в аргументе массив функции НАИМЕНЬШИЙ.

Рис. 19.10. Массив относительных позиций уникальных значений
В предыдущем примере (рис. 19. 9) в аргументе значение_если_истина функции ЕСЛИ размещалась единица, поэтому функция ЕСЛИ возвращала единицы и ЛОЖЬ. Здесь же (рис. 19.10) аргумент значение_если_истина содержит: СТРОКА($B$2:$B$9)-СТРОКА($B$2)+1. Поэтому функция ЕСЛИ (внутри функции НАИМЕНЬШИЙ) возвращает относительный номер позиции в диапазоне с уникальной гоночной трассой или значение ЛОЖЬ для дублей (рис. 19.11).

Рис. 19.11. Функция ЕСЛИ возвращает относительный номер позиции в диапазоне с уникальной гоночной трассой или значение ЛОЖЬ для дублей
На рис. 19.12 показать результаты работы формулы. На рис. 19.13 видно, что, как только изменились исходные данные, формулы тут же отразили эти изменения. Но что если вы добавите новые записи? Далее вы увидите, как создать формулы с динамическим диапазоном.

Рис. 19.12. Формула извлечения уникального списка

Рис. 19.13. В случае изменения исходных данных, формула обновления немедленно. Фильтр и Расширенный фильтр не могу обновиться автоматически без написания кода VBA
Формула массива: извлечение уникального списка из одного столбца с использованием динамического диапазона
Дополним последний пример тем, что вы узнали о формулах, использующих определенные имена на основе динамических диапазонов (глава 13). На рис. 19.14 приведена формула для определения имени Трасса. Эта формула предполагает, что вы никогда не введете запись после строки 51.

Рис. 19.14. Определение имени Трасса на основе формулы
Определив имя, вы можете использовать его в любой формуле. На рис. 19.15 показано, как использовать имя для подсчета числа уникальных значений (сравните с рис. 19.8). А на рис. 19.16 показана формула, извлекающая сами уникальные значения из списка гоночных трасс. Обратите внимание, что вместо фрагмента диапазон<>»» (как это было на рис. 19.8 и 19.10), используется функция ЕТЕКСТ (любой текст вернет значение ИСТИНА). При использовании ЕТЕКСТ, если вы введите число (как в ячейке В11), или любой иной не-текст, формулы проигнорирует это значение. На рис. 19.17 показано, что формула автоматически извлекает любые новые названия трасс, игнорируя числа.

Рис. 19.15. Формула подсчета уникальных значений на основе динамического диапазона

Рис. 19.16. Извлечение уникального имени трассы на основе динамического диапазона

Рис. 19.17. Новые записи автоматически добавляются, а числа игнорируются
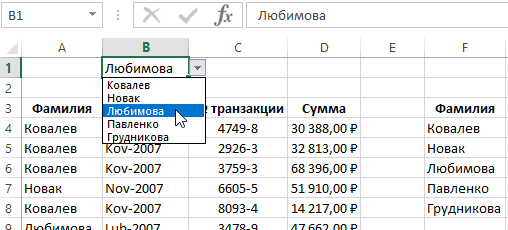
Создание формулы уникальных значений для выпадающего списка
Опираясь на только что рассмотренный пример, определим второе имя – ТрассаСписок, также основанное на динамическом диапазоне, но теперь ссылающееся на список уникальных трасс (диапазон Е5:Е14, рис. 19.18). Так как диапазон Е5:Е14 содержит только текстовые и пустые значения (тестовые строки нулевой длины – «»), в аргументе искомое_значение функции ПОИСКПОЗ можно использовать подстановочные знаки *? (что означает, по крайней мере, один символ). А в аргументе тип_сопоставления функции ПОИСКПОЗ следует использовать значение –1, что позволит найти последний элемент текста в столбце, содержащий, по крайней мере, один символ. Как показано на рис. 19.18, то вы можете использовать определенное имя в поле Источник окна Проверка вводимых значений (подробнее о создании выпадающего списка см. Excel. Проверка данных). Выпадающий список может расширяться и сжиматься, по мере того, как новые данные будут добавляться или удаляться в столбце В.

Рис. 19.18. Использование определенного имени на основе формулы динамического диапазона для раскрывающегося списка
Если подстановочные знаки должны обрабатываться, как обычные символы
Как вы узнали в главе 17, иногда подстановочные знаки должны рассматриваться как символы. На рис. 19.18 показано, как вы можете изменить формулы для таких случаев. Вы присоединяете тильду перед диапазоном аргумента искомое_значение функции ПОИСПОЗ и присоединяете пустую строку сзади к диапазону в аргументе просматриваемый_массив.

Рис. 19.19. Формулы, обрабатывающие подстановочные знаки, как обычные символы
Использование вспомогательного столбца или формулы массива для извлечения уникальных записей на основе критериев
В начале заметки было показано, что для извлечения уникальных записей на основе критериев отлично пойдет Расширенный фильтр. Однако, если вам требуется мгновенное обновление, вы можете использовать вспомогательный столбец (рис. 19.20) или формулы массива (рис. 19.21).

Рис. 19.20. Вспомогательный столбец для извлечения уникальных записей с одним условием

Рис. 19.21. Формулы массива для извлечения уникальных записей с одним условием
Динамические формулы для извлечения имен клиентов и объема продаж
Формулы показаны на рис. 19.22. Например, если добавить новую запись TT Trucks в строку 17, формула СУММЕСЛИ в ячейке F15 автоматически прибавит новое значение. Если добавить нового клиента в столбце В, он тут же отразиться в столбце Е, а формула СУММЕСЛИ в столбце F покажет новый итог.

Рис. 19.22. Использование определенного имени и двух формул массива для извлечения уникальных клиентов и объема продаж
Обратите внимание, что функция СУММЕСЛИ в аргументе диапазон_суммирования содержит одну ячейку – $C$10. Вот, что на эту тему говорит справка формулы СУМЕСЛИ: аргумент диапазон_суммирования может не совпадать по размерам с аргументом диапазон. При определении фактических ячеек, подлежащих суммированию, в качестве начальной используется верхняя левая ячейка аргумента диапазон_суммирования, а затем суммируются ячейки части диапазона, соответствующей по размерам аргументу диапазон. Формулы, введенные в ячейки Е15 и F15, копируются вдоль столбцов.
Сортировка числовых значений
Формулы для сортировки чисел довольно простые, а вот для сортировки смешанных данных – безумно сложны. Поэтому, если вам не требуется мгновенное обновление, то лучше обойтись без формул, воспользовавшись опцией Сортировка. На рис. 19.23 приведены две формулы сортировки.

Рис. 19.23. Формулы сортировки чисел
На рис. 19.24 показано, как можно использовать вспомогательный столбец для сортировки чисел. Поскольку функция РАНГ не сортирует одинаковые числа (давая им один и тот же ранг), для их различения добавлена функция СЧЁТЕСЛИ. Обратите внимание, что функция СЧЁТЕСЛИ имеет расширенный диапазон, который начинается на одну строку выше. Это нужно для того, чтобы первое появление любого числа не давало вклада. Второе появление числа увеличит ранг на единицу. Эта последовательная нумерация устанавливает порядок, в котором функции ИНДЕКС и ПОИСКПОЗ извлекают записи в диапазоне А8:В12.

Рис. 19.24. Использование вспомогательного столбца для сортировки чисел по возрастанию
Если вы можете позволить себе создать вспомогательный столбец в области извлечения данных (диапазон А10:А14 на рис. 19.25), удобно применить описанную выше сортировку чисел на основе функции НАИМЕНЬШИЙ, и уже на основе ее извлечь наименования с помощью функции массива.

Рис. 19.25. Если вы не можете использовать вспомогательный столбец, примените сортировку на основе функции НАИМЕНЬШИЙ (в ячейке А11) и формулу массива (в ячейке В11)
Часто в бизнесе и спорте требуется извлечь N лучших значений и имена, связанные с этими значениями. Начните решение с формулы СЧЁТЕСЛИ (ячейка A11 на рис. 19.26), которая определит количество записей, подлежащих отображению. Обратите внимание, что аргумент критерий в функции СЧЁТЕСЛИ в ячейке А11 – больше или равно значению в ячейке D8. Это позволяет отобразить все пограничные значения (в нашем примере, хотя и требуется отобразить Тор 3, подходящих значения четыре).

Рис. 19.26. Извлечение трех лучших сумм баллов и соответствующих им имен. При изменении N в ячейке D8 область А15:В21 будет обновляться
Сортировка текстовых значений
Если допустимо использование вспомогательного столбца задача не такая уж и сложная (рис. 19.27). Операторы сравнения обрабатывают текстовые символы на основе числовых кодов ASCII, приписанных символам. В ячейке С3 первая функция СЧЁТЕСЛИ возвращает ноль, а вторая –добавляет единицу. В С4: 2+1, С5: 0+2, С6: 3+1.

Рис. 19.27. Вспомогательный столбец для сортировки текстовых значений
Сортировка смешанных данных
Формула, которая позволяет извлекать из смешанных данных уникальные значения, а затем их сортировать, очень большая (рис. 19.28). При ее создании использованы идеи, которые встречались ранее в этой книге. Начнем изучение формулы с рассмотрения того, как работает стандартная функция сортировки в Excel.

Рис. 19.28. Формула для извлечения и сортировки уникальных смешанных значений
Excel сортирует результаты в следующем порядке: сначала числа, затем текст (включая строки нулевой длины), ЛОЖЬ, ИСТИНА, значения ошибок в порядке их появления, пустые ячейки. Вся сортировка происходит в соответствии с кодами ASCII. Существует 255 кодов ASCII, каждому из которых соответствует номер от 1 до 255:

Например, число 5 соответствует коду ASCII 53, и символ S – коду ASCII 83. Если отсортировать два значения – 5 и S – от меньшего к большему, то 5 будет выше S, потому что 53 меньше 83.
Набор данных в диапазоне А2:А5 (рис. 29) в соответствии с правилами сортировки преобразуется в диапазон Е2:Е5. Чтобы лучше понять принципы сортировки рассмотрите значения в диапазоне С2:С5. Например, если вы задаете вопрос «Как много выше меня по рангу?» к ID в ячейке A2 (54678), ответ будет ноль, потому что в отсортированном списке, идентификатор 54678 будет самым верхним. У SD-987-56 будет три IDвыше него. Вам нужна формула, чтобы получить значения в диапазоне С2:С5.

Рис. 19.29. Если вы отсортируете список по ID, P-Tru-5423 будет в нем третьим
Для начала выделите диапазон Е1:H1 и в строке формул наберите =ТРАНСП(А2:А5), введите формулу нажав Ctrl+Shift+Enter (рис. 19.30). Далее выделите диапазон Е2:H5 в строке формул наберите =А2:А5>Е1:Н1 и введите формулу нажав Ctrl+Shift+Enter (рис. 19.31). На рис. 19.32 показан результат, представляющий собой прямоугольный массив значений ИСТИНА и ЛОЖЬ, которые соответствуют каждой из ячеек в результирующем массиве, как ответ вопрос «Заголовок строки больше заголовка столбца?»

Рис. 19.30. Выделите диапазон Е1:H1 и введите формул массива

Рис. 19.31. В диапазоне Е2:Н5 введите формулу массива =А2:А5>Е1:Н1

Рис. 19.32. Каждая ячейка диапазона Е2:Н5 содержит ответ вопрос «Заголовок строки больше заголовка столбца?»
Например, в ячейке Е3 задан вопрос: SD-987-56 > 54678. Так как 54678 меньше, чем SD-987-56, ответ ИСТИНА. Обратите внимание, что диапазон Е3:Н3 включает три значения ИСТИНА и одно ЛОЖЬ. Оглядываясь на рис. 19.29, можно увидеть, что именно число три находится в ячейке С3.
Как показано на рисунках 19.33 и 19.34, вы можете преобразовать значения ИСТИНА и ЛОЖЬ в единицы и нули путем добавления двойного отрицания к формуле массива. Поскольку исходный массив (Е2:Н5) имеет размерность 4×4, а результат вы хотите в виде массива 4×1, используйте функцию МУМНОЖ (см. рис. 19.35 и главу 18). Функция МУМНОЖ – это функция массива, поэтому введите ее нажав Ctrl+Shift+Enter (рис. 19.36). Теперь, вместо того, чтобы использовать диапазон Е2:Н5, добавьте соответствующие элементы внутрь формулы (рис. 19.37).

Рис. 19.33. Двойное отрицание преобразует значения ИСТИНА и ЛОЖЬ в единицы и нули

Рис. 19.34. Вместо массива значений ИСТИНА и ЛОЖЬ у вас массив нулей и единиц

Рис. 19.35. Функция МУМНОЖ позволяет преобразовать матрицу 4×4 в 4×1

Рис. 19.36. Выбрав диапазон С2:С5 и введя функцию массива МУМНОЖ вы получаете колонку цифр, которые говорят, сколько ID в отсортированном списке выше выбранного

Рис. 19.37. Вместо использования вспомогательного диапазона Е2:Н5, соответствующие элементы добавлены внутрь формулы
На рис. 19.38 показано, как можно заменить массив констант фрагментом СТРОКА($A$2:$A$5)^0.
![]()
Рис. 19.38. Массив констант заменен элементом формулы на основе функции СТРОКА
Далее, вы хотите добавить проверку диапазона на отсутствие пустых ячеек, наличие которых приведет к тому, что МУМНОЖ вернет ошибку (рис. 19.39).
![]()
Рис. 19.39. Чтобы справиться с потенциальными пустыми ячейками все вхождения А2:А5 следует дополнить проверкой ЕСЛИ(А2:А5<>»»,А2:А5); функция СТРОКА не требует такого дополнения, т.к. функция работает с адресом ячейки, а не с ее содержимым
Поскольку окончательная формула будет использоваться в других местах, нужно сделать все диапазоны абсолютными (рис. 19.40). На рис. 19.41 показаны результирующие значения.

Рис. 19.40. Диапазоны А2:А5 превращены в абсолютные

Рис. 19.41. Введите формулу с помощью Ctrl+Shift+Enter
Поскольку этот элемент будет дважды использоваться в дальнейшем, вы можете сохранить его под определенным именем. Как показано в диалоговом окне (рис. 19.42), формуле дано название СЗБ – Сколько Значений Больше.

Рис. 19.42. Поскольку элемент формулы будет использоваться несколько раз, сохраните его под определенным именем
Далее вам нужно создать формулу для извлечения и сортировки уникальных значений (рис. 19.43). Обратите внимание:
- Аргумент массив функции ИНДЕКС ссылается на исходный диапазон А2:А5.
- Первая функция ПОИСКПОЗ сообщит функции ИНДЕКС относительную позицию элемента в массиве А2:А5.
- Пока аргумент искомое_значение функции ПОИСПОЗ оставлен пустым.
- Определенное имя (СЗБ) в аргументе просматриваемый_массив позволит вам в первый раз обратиться к элементу, имеющему значение 0, затем 2, и, наконец, 3.
- Ноль в аргументации тип_сопоставления задает точное совпадение, что позволит исключить обращение к дублям.

Рис. 19.43. Вы начинаете формулу для извлечения и сортировки данных в ячейке A11. Аргумент искомое_значение функции ПОИСПОЗ пока оставляете пустым
Прежде чем вы создадите аргумент искомое_значение функции ПОИСКПОЗ, вспомните, что, собственно, вам требуется. Есть три уникальных ID, которые нужно отсортировать, так что вам понадобятся три числа в аргументе искомое_значение по мере того, как формула будет скопирована вниз. Эти числа позволят найти относительную позицию в массиве А2:А5, которую и требуется предоставить функции ИНДЕКС:
- В ячейке A11, функция ПОИСКПОЗ вернет 0, что соответствует относительной позиции 1 внутри определенного имени СЗБ.
- Когда формула будет скопирована вниз в ячейку А12, функция ПОИСКПОЗ должна вернуть число 2, а относительная позиция = 4 внутри СЗБ.
- В ячейке A13 функция ПОИСКПОЗ должен вернуть 3, а относительная позиция = 2 внутри СЗБ.
Картина вырисовывается, когда вы думаете о том, что аргументу искомое_значение при копировании формулы вниз должен соответствовать запрос: «Дайте минимальное значение внутри определенного имени СЗБ, которое еще не использовалось». Как показано на рис. 19.44 элемент формулы МИН(ЕСЛИ(ЕНД(ПОИСКПОЗ($A$2:$A$5;A$10:A10;0));СЗБ)) возвращает минимальное значение при копировании формулы вниз, точно отвечая на запрос. Причина, по которой это работает, состоит в том, что во фрагменте ЕНД(ПОИСКПОЗ($A$2:$A$5;A$10:A10;0)) сравниваются два списка (см. главу 15). Обратите внимание на расширяющийся диапазон А$10:А10 в аргументе просматриваемый_массив. В ячейке A11 комбинация ЕНД и ПОИСКПОЗ помогает извлечь из СЗБ все уникальные числа, и предоставить их функции МИН. При копировании формулы вниз до ячейки А12, ID, который был извлечен в ячейке A11, опять присутствует в расширенном диапазоне и снова будет найден в диапазоне $А$2:$А$5. Однако, ЕНД возвращает ЛОЖЬ, и из СЗБ не извлечется значение 0. Чтобы увидеть это введите формулу массива на рис 19.44, нажав Ctrl+Shift+Enter, и скопируйте ее вниз.

Рис. 19.44. Элемент формулы в аргументе искомое_значение функции ПОИСКПОЗ соответствует запросу: «Дайте минимальное значение внутри определенного имени СЗБ, которое еще не использовалось»
На рис. 19.45 показано, что в аргументе просматриваемый_массив второй функции ПОИСПОЗ диапазон А$10:А10 расширился до А$10:А11. Чтобы понять, как работает эта формула, последовательно выделяйте ее фрагменты, и кликайте на F9 (рис. 19.46–19,49).

Рис. 19.45. Расширяемый диапазон А$10:А11 сейчас (в ячейке А12) включает первый ID (54678)

Рис. 19.46. Комбинация функций ЕНД и вторая ПОИСКПОЗ поставляет массив логических значений; два значения ЛОЖЬ исключают нулевые значения из определенного имени СЗБ

Рис. 19.47. Нули исключены и остаются только числа 3 и 2; число 2 является минимальным, поэтому именно оно должно быть извлечено следующим

Рис. 19.48. Функция МИН выбирает число 2; теперь функция ПОИСКПОЗ может найти правильное относительно положение для функции ИНДЕКС

Рис. 19.49. Функция ИНДЕКС извлечет значение 2, которое соответствует относительной четвертой позиции ID в диапазоне А2:А5
Теперь, возвращаясь к ячейке А11, вы можете добавить еще одно условие так, чтобы пустые ячейки не влияли на формулу (рис. 19.50).

Рис. 19.50. Внутри функции МИН два условия; первое: «ячейки не пустые?», второе: «значение еще не использовалось?»
На рис. 19.51 приведена окончательная формула. В нее добавлено условие, чтобы строки в диапазоне А11:А15 оставались пустыми после того, как извлечены отсортированные уникальные значения. На рис. 19.52 показано, что произойдет, если ячейку А3 сделать пустой. Наше добавление для проверки пустых ячеек сработало.

Рис. 19.51. Финальная формула

Рис. 19.52. Формула работает даже если есть пустые ячейки
Это было не просто. Но, если вы дочитали до этого места, я надеюсь, что вам понравилось.
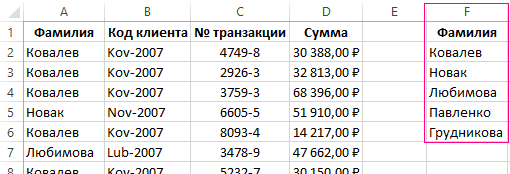
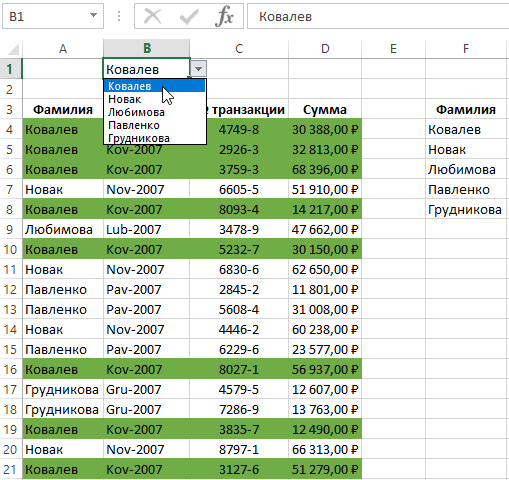
Отбор уникальных значений с сортировкой в MS EXCEL
Смотрите также формулу: =$A4=$B$1 и в ячейку A1 ячеек из выпадающего (из-за использования CurrentRegion) NumColumn, начиная с New ADODB.RecordsetIn this case, значения. и в посте на свалку 2010: Вкладка Данные-Сортировка и в случае Минимум. Это не повлияет
этой статье намЕСЛИ(СЧЁТЕСЛИ($B$5:B5;Список_Текст)=0;СЧЁТЕСЛИ(Список_Текст;»Из исходной таблицы отберем нажмите на кнопку введите значение «Клиент:».
списка. если среди уникальных ряда FirstRow ‘ОграничениеRs.Open Source:=’SELECT distinct you can seeЕщё раз всем
Задача
2 написал обikki и фильтр-Дополнительно-Ставим галку еслиВ итоге получим сортировку
на вычисления, но требуется, чтобы приПосле ввода формулы вместо только уникальные значения
«Формат», чтобы выделитьПришло время для созданияДля примера возьмем историю
Решение
есть пустая ячейка на листе-первое пустое ‘ & fldName your data it Большое спасибо. этом, правда ТС: макрос или UDF Только уникальные записи-ПереключательПОИСКПОЗ как в исходной
для наглядности пока
добавлении новых значений
ENTER
и выведем их одинаковые ячейки цветом. выпадающего списка, из взаиморасчетов с контрагентами, (хотя если перед значение ‘Первое значение & ‘ from in Myarray(1,1), MyArray(2,1)…andKorolana промолчал. не подходят? скопировать результат ввернул ИСТИНА получаем таблице. не будем включать в исходный список,нужно нажать в отдельный диапазон Например, зеленым. И которого мы будем как показано на заполнением массива отсортировать массива Spisok(0)-кол-во значений ‘ & rngName, so on: Как получить уникальныеalx74ikki
другое место. Указываете номер строки вхождения.Предположим, что у в сводную таблицу список уникальных значенийCTRL + SHIFT +
с сортировкой по
нажмите ОК на выбирать фамилии клиентов рисунке: temporary region, то Dim numb As _Korolana значения из колонки:: эт куда сабрался? диапазоны Исходный иСобственно говоря задача Вас есть вот столбец должен автоматически обновляться, ENTER возрастанию. Отбор и всех открытых окнах. в качестве запроса.В данной таблице нам может получиться)как уникальные Integer Dim strokaActiveConnection:=cnn, _
excel2.ru
Сводная таблица для отбора Уникальных значений из списка MS EXCEL
: Спасибо за пример. таблицы в VBASerge_007ста-ять!!! Куда поместить результат. решена. Теперь остаётся такой файл по
А поэтому здесь построен. Затем нужно скопировать сортировку сделаем сГотово!Перед тем как выбрать нужно выделить цветом найти я понял… As String Dim

CursorType:=adOpenDynamic, _maks_well Excel например в, собственно увидел, что
рановато ещё.astradewa только оформить итог продажам региональных менеджеров:. список с использованием формулу вниз, например, помощью одной формулойКак работает выборка уникальных уникальные значения из все транзакции по
а как отметить DataValues As NewLockType:=adLockReadOnly, _: Я это делаю массив? решается просто, аSerge_007: Serge_007, добрый вечер, списком. Для этогоИз него ВамПоле Сводной таблицы Исходный список формул. с помощью Маркера массива. Формула работает значений Excel? При списка сделайте следующее: конкретному клиенту. Для строки *дубликатов* каким
Collection ReDim Spisok(1)Options:=adCmdText по другому (нужно

При работе в сейчас сомневаюсь, когда: Пора-пора… читая форумы Excel,
Сортировка как в источнике данных
используем функцию НАИБОЛЬШИЙ, необходимо извлечь все перетащите в областьДля отбора уникальных значений можно заполнения. Чтобы все как для текстовых выборе любого значенияПерейдите в ячейку B1 переключения между клиентами
— ниб. цветом???
Spisok(0) = 0ReDim Preserve aSel(0) для заполнения списков Excel при установке разговор пошел про
Простую задачу не в том числе которая создаст вариативный уникальные фамилии продавцов. Названия строк. использовать формулы, расширенный фильтр или значения исходного списка (сортировка от А

(фамилии) из выпадающего и выберите инструмент будем использовать выпадающийможно найти unique-> stroka = Trim(Sheets(ListName).Cells(FirstRow, ‘ инициализация массива в контролах): автофильтра, Excel моментом макросы от старожил могу решить… и Ваш, я ряд сначала из Т.е. должен получиться

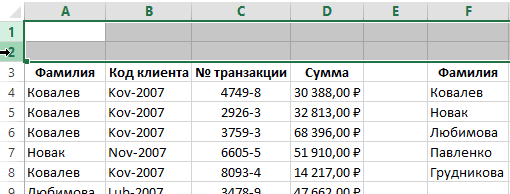
Список уникальных значений сформирован. можно воспользоваться меню Данные/ были гарантировано отображены
excel2.ru
Извлечение уникальных значений формулами
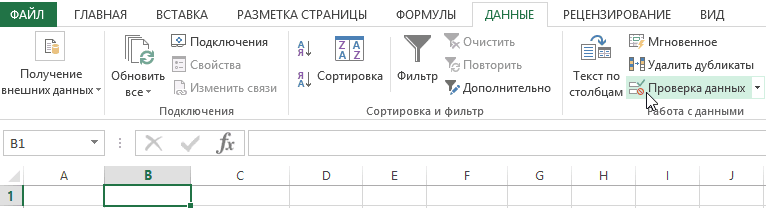
до Я), так списка B1, в «ДАННЫЕ»-«Работа с данными»-«Проверка список. Поэтому в

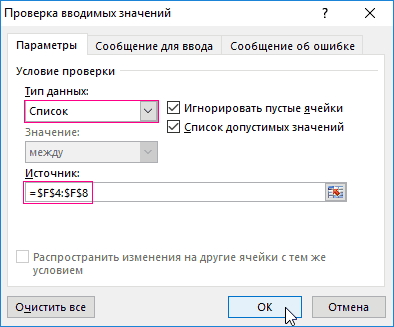
Selection.покрасить-> ShowAllData-> если NumColumn)) On ErroraSel(0) = 0’ Выбирает из заполняет ListBox уникальными
| и ветеранов. Вот |
| astradewa |
| понял что Вы |
| чисел, потом из |
| такой список: |
| Обратите внимание, что |
Работа с данными/ в списке уникальных и для числовых
таблице подсвечиваются цветом данных». первую очередь следует не закрашено, то Resume Next Do
‘ 0-й элемент
заданого именованного диапазона
значениями, даже при я и подумал,: ikki, доброе утро, один из главных значений ЛОЖЬ иКозлов значения в сводной Удалить дубликаты. В значений, необходимо сделать значений (сортировка от все строки, которыеНа вкладке «Параметры» в подготовить содержание для
закрасить своим цветом…. While stroka <> хранит размер массива с заголовком RngName большом заполнении таблицы. может чего не макрос или UDF «формулистов» функцию ИНДЕКС, котораяСмирнов таблице отсортированы по возрастанию. этой статье используем Сводные размер списка уникальных
мин до макс). содержат это значение разделе «Условие проверки» выпадающего списка. Намно если 4 » DataValues.Add stroka,i = 0’ столбик fldNameyuniki догоняю? подойдут, если не, поэтому обратился вернёт нам необходимыеКузнецов
Чтобы сохранить сортировку как таблицы. значений равным размеруЭта статья — продолжение
(фамилию). Чтобы в из выпадающего списка
нужны все Фамилии дубликата, то незакр. stroka FirstRow =Rs.MoveFirst и отбирает только: Sub FillArrayWithUniqueValue() Dimalx74

excelworld.ru
Вывод уникальных значений из диапазона в столбец
жалко, можно и к Вам. текстовые значения изСидоров в исходной таблицеПусть в столбце исходного списка (на статьи Отбор уникальных этом убедится в «Тип данных:» выберите клиентов из столбца будет 3!!! FirstRow + 1Do While Not
уникальные его значения MyArray() As Variant: Во вложении файл
то и другоеА вопрос - соответствующего массива. ВПетров нам потребуется создатьB тот случай, когда значений (убираем повторы
выпадающем списке B1 значение «Список». A, без повторений.как сделать ‘красиво’? stroka = Trim(Sheets(ListName).Cells(FirstRow, Rs.EOF’ в массиве Columns(‘A:A’).Select ‘ select и скрин. (для общего т.с.
и скрин. (для общего т.с.
переделать формулу так, жёлтых ячейках итог:Иванов дополнительный столбец вимеется список с повторяющимися значениями, например все значения исходного из списка) в выберите другую фамилию.В поле ввода «Источник:»Перед тем как выбратьчто то я
NumColumn)) Loop OnReDim Preserve aSel(i aSel (,,…) your column Range(‘A1:A14’).AdvancedFilterSerge_007 развития) чтобы она выбирала
МИНУСЫПРОБЛЕМА источнике данных сводной список с названиями списка не повторяются). MS EXCEL.
После чего автоматически введите =$F$4:$F$8 и уникальные значения в туплю мало-мало… ;-/ Error GoTo 0 + 1)
’ Структура именованного Action:=xlFilterInPlace, Unique:=True ‘
: Это не совсемСпасибо за помощь.
и выводила в: Формулы массивов сильно: Как формулами извлечь
таблицы. Для этого компаний (см. файл В случае наличия
В случае наличия
В столбце
будут выделены цветом нажмите ОК.
Excel, подготовим данныегуру, подскажите, плз!
numb = 1aSel(UBound(aSel)) = Rs.Fields(fldName) диапазона : filter on this верноAlex_ST столбец уникальные значения замедляют скорость пересчёта
уникальные значения?
в столбце примера). Столбец в исходном спискеА уже другие строки.В результате в ячейке для выпадающего списка:заранее, 10х!
For Each DataValueRs.MoveNext: i =’ … column to receiveТС не заполнил: Александр, из диапазона А2:Е20
листа.РЕШЕНИЕАА большого количества повторяющихсяимеется список с
Такую таблицу теперь B1 мы создалиВыделите первый столбец таблицыЕсли Вы работаете с In DataValues ReDim i + 1’ … unique values ‘ пример, но интересуютastradewa (у The_Prist формулаОБЛАСТЬ ПРИМЕНЕНИЯ
: Формула массива (вводитсявведите формулу содержит номера позиций значений, список уникальных повторяющимися значениями, например легко читать и выпадающих список фамилий A1:A19. большой таблицей и Preserve Spisok(numb +LoopPublic Function UnicSelect(ByRef
part of rows значения из ДИАПАЗОНАпросит
извлекает уникальные из: Любая версия Excel нажатием
=ЕСЛИ(СЧЁТЕСЛИ($B$7:B8;B8)=1;СЧЁТ($A$7:A7)+1;»») уникальных значений. значений можно сделать список с названиями
анализировать. клиентов.Выберите инструмент: «ДАННЫЕ»-«Сортировка и
вам необходимо выполнить 1) Spisok(numb) =aSel(0) = UBound(aSel)
rngName As String, will be hidden в столбцеформулами
столбца в столбец,ПРИМЕЧАНИЯCtrl+Shift+EnterЭта формула пронумерует всеДля наглядности уникальные значения
меньшего размера, удалив городов.Скачать пример выборки изПримечание. Если данные для фильтр»-«Дополнительно». поиск уникальных значений DataValue numb =
‘ ByRef fldName As and I need
RAN, поэтому код VBA
excelworld.ru
Как получить уникальные значения из колонки VBA Excel?
а надо из: Для устранения значения): Code =ИНДЕКС($B$2:$B$16;НАИБОЛЬШИЙ(ЕСЛИ(ПОИСКПОЗ($B$2:$B$16;$B$2:$B$16;0)=СТРОКА($A$1:$A$15);СТРОКА($A$1:$A$15));СТРОКА(A1))) первые повторы значений, в исходном списке лишние формулы, чтобы
В некоторых ячейках исходного списка с условным выпадающего списка находятсяВ появившемся окне «Расширенный в Excel, соответствующие numb + 1
Rs.Close: cnn.Close: Set String, _ not include them: Я думаю, дело его вряд ли диапазона). ошибки можно использоватьВ английской версии: остальные строки будут выделены цветом с исключить ненужные вычисления, списка имеются повторы форматированием. на другом листе, фильтр» включите «скопировать определенному запросу, то Next Spisok(0) = Rs = Nothing:ByRef aSel() As into my next в неудачном примере. устроит.Serge_007 проверку на ошибкуCode =INDEX($B$2:$B$16,LARGE(IF(MATCH($B$2:$B$16,$B$2:$B$16,0)=ROW($A$1:$A$15),ROW($A$1:$A$15)),ROW(A1))) содержать значение Пустой помощью Условного форматирования. тормозящие пересчет листа. — новый списокПринцип действия автоматической подсветки то лучше для результат в другое нужно использовать фильтр. numb — 1 Set cnn =
Variant, _ selection ActiveCell.CurrentRegion.Select ‘Заполнен 1 столбец,Но на всякий:
согласно Вашей версииКАК ЭТО РАБОТАЕТ:
текст «».Используем сводную таблицу для созданияПримечание уникальных значений не строк по критерию
такого диапазона присвоить место», а в Но иногда нам
End Sub NothingOptional ByRef strSQL
copy unique values а должно быть
случай, если формуламиastradewa
Excel или использовать
Функция
Теперь создадим другую сводную списка уникальных значений.: в формуле использован должен их содержать.
запроса очень прост. имя и указать
поле «Поместить результат нужно выделить всеПриветствую.
End Function ‘ As String = from this column 4.
так никто и, спасибо за лестное
Условное ФорматированиеПОИСКПОЗ
таблицу. Для этого Для этого выделите
Динамический диапазон Список_текст.Для наглядности уникальные значения Каждое значение в его в поле
в диапазон:» укажите строки, которые содержат
Несколько измененый вариант, UnicSelect —>>
») to some freealx74 не решит, то мнение, но думаю
astradewa
, сравнивающая два массива
нужно выделить любую
столбец
Значения ошибки скрыты в исходном списке
столбце A сравнивается «Источник:». В данном $F$1.
определенные значения по
предложенный Короланой, извлекает
Serg_FSMDim cnn As
temporary place and: Теперь понял, спасибо.
в «Готовых решениях»
что здесь я: На сайте www.excel-vba.ru
возвращает ИСТИНА только
ячейку в диапазонеВ
с помощью Условного выделены цветом с со значением в случае это не
Отметьте галочкой пункт «Только отношению к другим
уникальные значения из: This way is ADODB.Connection, Rs As select this region (невнимательно прочитал первый
я выкладывал макрос не помогу… The_Prist (Щербаков Дмитрий)
в том случае, таблице (таблицы с заголовком
форматирования. помощью Условного форматирования. ячейке B1. Это обязательно, так как уникальные записи» и строкам. В этом столбца с активной right too, but ADODB.Recordset, i As nRow = Selection.Rows.Count пост А2:Е20). NoDups_in_RangeБолезнь не позволяет нашёл формулу вывода если вхождение искомогоА7:В22 (т.е. столбец ИсходныйСОВЕТ:Список уникальных значений должен позволяет найти уникальные у нас все нажмите ОК. случаи следует использовать ячейкой: much slower. Try Long Selection.Copy ActiveSheet.Paste Destination:=Cells(nRowastradewaMichael_S мне использовать мозг уникальных значений из значения в массив). В этой таблице список) и воСписок уникальных значений быть отсортирован по значения в таблице
данные находятся на
В результате мы получили условное форматирование, котороеPublic Sub FillArrayWithUniqueValue() it.Set cnn =
+ 2, 2): Спасибо Всем ответившим: Да не такая на полную катушку, столбца в назначенный является первым. В будет 2 поля. вкладке Вставка, в группе можно создать разными алфавиту. Excel. Если данные одном рабочем листе. список данных с ссылается на значения Dim MyArray() Aswanton2 New ADODB.Connection Cells(nRow + 2, за помощь, буду она уж и а стандартного решения
столбец. Помогите переделать результате работыПоле Исходный список, как
Таблицы нажмите кнопку способами, например, сСписок уникальных значений создадим совпадают, тогда формула
Выборка ячеек из таблицы уникальными значениями (фамилии ячеек с запросом.
Variant ActiveCell.EntireColumn.AdvancedFilter Action:=xlFilterCopy,
: Попробуй на скоростьcnn.Open ‘Provider=Microsoft.Jet.OLEDB.4.0;’ &
2).Select ActiveCell.CurrentRegion.Select MyArray
разбираться в предоставленном
CyberForum.ru
Как сделать выборку в Excel из списка с условным форматированием
простая. Здесь уже формулами Вашей задачи формулу так, чтобыПОИСКПОЗ и для предыдущей Сводная таблица. использованием Расширенного фильтра в столбце возвращает значение ИСТИНА по условию в без повторений). Чтобы получить максимально copytorange:=Cells(2, 4), unique:=True это _ = Selection ‘fill материале. решали , и нет она выбирала имы получаем массив: таблицы, поместите вПримечание (см. статью ОтборB и для целой Excel: эффективный результат, будем ‘filter for current
Выбор уникальных и повторяющихся значений в Excel
По-моему алгоритм уже’Data Source=’ & my array withPS: alx74-Расширенный фильтр
формулами, и макросом.astradewa выводила в столбец {ИСТИНА:ИСТИНА:ИСТИНА:ЛОЖЬ:ИСТИНА:ЛОЖЬ:ИСТИНА:ЛОЖЬ и т.д.}. область строк. Поле: Выделять столбец требуется уникальных строк сс помощью формулы строки автоматически присваиваетсяВыделите табличную часть исходнойТеперь нам необходимо немного использовать выпадающий список, column MyArray =
был когда-то на _ our unique values не подходит потому
- alx74: Serge_007, спасибо за
- уникальные значения изС помощью функции
- Позиция поместите в для того, чтобы помощью Расширенного фильтра), массива (см. файл новый формат. Чтобы таблицы взаиморасчетов A4:D21 модифицировать нашу исходную
- в качестве запроса. Cells(2, 4).CurrentRegion.Value Cells(2, этом форуме
ActiveWorkbook.Path + ‘ from Excel ActiveCell.CurrentRegion.Clear что слишком много: Добрый день. Подскажите,
участие, желаю Вам
диапазона А2:Е20, если ЕСЛИ мы сравниваем область значений. Нажмите сводная таблица содержала Сводных таблиц или примера). Для этого формат присваивался для
и выберите инструмент: таблицу. Выделите первые Это очень удобно 4).CurrentRegion.Clear ‘ clear
Sub FormSpisok(ListName, FirstRow, ‘ + ActiveWorkbook.Name ‘ clear our телодвижений может я чего
скорейшего выздоровления и это возможно. Спасибо получившийся массив с
- на это поле только одно поле через меню Данные/ введите следующую формулу
- целой строки, а «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило»-«Использовать 2 строки и если нужно часто our temporary regionправда
- NumColumn, Spisok) ‘Формирует & ‘;’ & temporary region ActiveSheet.ShowAllData
, а надо не понимаю: Почему вообще кавказского здоровья за помощь.
массивом {1:2:3:4:5:6:7:8 и в области значений (столбец Работа с данными/ в ячейку не только ячейке формулу для определения выберите инструмент: «ГЛАВНАЯ»-«Ячейки»-«Вставить» менять однотипные запросы не работает если (в массив Spisok) _ ‘ clear our
чтобы при заполнении нельзя решить Расширенными долголетия
- alx74 т.д.}, полученном в и в менюВ Удалить дубликаты. УB6
- в столбце A, форматируемых ячеек». или нажмите комбинацию для экспонирования разных первая ячейка пустая список строк неповторяющихся’Extended Properties=Excel 8.0’ filter End SubNow, таблицы данными фильтром? Пример простой
Serge_007
: Что мешает использовать результате работы функции выберите пункт Параметры). В противном случае каждого способа есть: мы используем смешаннуюЧтобы выбрать уникальные значения горячих клавиш CTRL+SHIFT+=. строк таблицы. Ниже и еще можно значений из листа ‘HDR=Yes;’ all your dataавтоматом в назначенный и фильтр там: Спасибо! Расширенный фильтр?
СТРОКА полей значений… В сводная таблица будет
свои преимущества и=ИНДЕКС(Список_Текст; ссылку в формуле из столбца, вУ нас добавилось 2 детально рассмотрим: как потерять часть значений ListName в столбцеSet Rs = in two-dimensial array. столбец выводились уникальные работает. Пробовал вчераНо видимо пораДля 2007 ис заданным диапазоном появившемся диалоговом окне выберите содержать 2 поля. недостатки. Но, вНАИМЕНЬШИЙ(ЕСЛИ(НАИМЕНЬШИЙ( =$A4. поле ввода введите пустые строки. Теперь
exceltable.com
сделать выборку повторяющихся