
В прошлой статье мы уже разобрали, что такое временной ряд и функцию тренда. Теперь подробнее разберемся с терминологией и остановимся на одной из моделей временного ряда.
Из чего состоит временной ряд
Уровни временного ряда (Yt) представляют из себя сумму двух компонент:
- Регулярную составляющую
- Случайную составляющую
В свою очередь регулярная составляющая состоит из:
- Тренда
- Сезонности
- Циклической составляющей
Однако, в модели необязательно наличие всех этих компонент сразу.
Случайная компонента отражает влияние случайных возмущений на модель, которые по отдельности имеют незначительное воздействие, но суммарно их влияние ощущается.
То есть, в общем случае временной ряд представляет из себя наличие четырех составляющих:
- Тренд (Tt)
- Сезонность (St)
- Цикличность (Ct)
- Случайные возмущения (Et)
Циклическая компонента, по сравнению с сезонностью, имеет более длительный эффект и меняется от цикла к циклу. Поэтому, ее обычно объединяют с трендом.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
- Аддитивная модель

-
Мультипликативная модель

-
Смешанная модель

При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:

Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).
Алгоритм построения модели
- Выравниваем ряд с помощью скользящей средней, то есть сглаживаем ряд и отфильтровываем высокочастотные колебания.
- Рассчитываем значение сезонной компоненты St.
- Рассчитываем значения Tt с использованием полученного уравнения тренда.
- Используя полученные значения St и Tt, находим прогнозные значения уровней временного ряда.
- Оцениваем качество модели.
Реализация на практике
Итак, мы имеем на руках данные о продажах за 2016 и 2017 год и хотим спрогнозировать продажи на 2018 год.


Шаг 1
Следуя нашему алгоритму, мы должны сгладить временной ряд. Воспользуемся методом скользящей средней. Видим, что в каждом году есть большие пики (май-июнь 2016 и апрель 2017), поэтому возьмем период сглаживания пошире, например, месячную динамику, т.е. 12 месяцев.
Удобнее брать период сглаживания в виде нечетного числа, тогда формула для расчета уровней сглаженного ряда:

yi — фактическое значение i-го уровня ряда,
yt — значение скользящей средней в момент времени t,
2p+1 — длина интервала сглаживания.
Но так как мы решили использовать месячную динамику в виде четного числа 12, то данная формула нам не подойдет и мы воспользуемся этой:
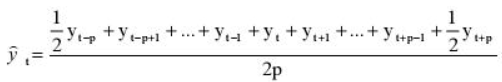
Иными словами, мы учитываем половины от крайних уровней ряда в диапазоне, в остальном формула не претерпела больше никаких изменений. Вот ее точный вид для нашей задачи:
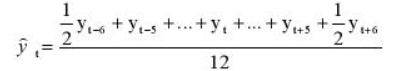
Сглаживаем наши уровни ряда и растягиваем формулу вниз:

Сразу можем построить график из известных значений уровня продаж и их сглаженной. Выведем ее уравнение и значение коэффициента детерминации R^2:

В качестве сглаженной я выбрала полином третьей степени, так как он лучше всего описывал уровни временного ряда и имел наибольший R^2.

Шаг 2
Так как мы рассматриваем аддитивную модель вида: 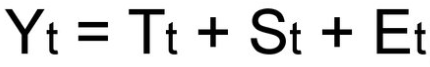
Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и значениями скользящей средней St+Et = Yt-Tt, так как Yt и Tt мы уже знаем.

Используем оценки сезонной компоненты (St+Et) для расчета значений сезонной компоненты St. Для этого найдем средние за каждый интервал (по всем годам) оценки сезонной компоненты St.

Средняя оценка сезонной компоненты находится как сумма по столбцу, деленная на количество заполненных строк в этом столбце. В нашем случае оценки сезонной составляющей расположились в строках без пересечений, поэтому сумма по столбцам состоит из одиночных значений, следовательно и среднее будет таким же. Если бы мы располагали периодом побольше, например с 2015, у нас бы добавилась еще одна строка и мы смогли бы полноценно найти среднее, поделив сумму на 2.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем интервалам должна быть равна нулю. Поэтому найдя значение случайной составляющей, поделив сумму средних оценок сезонной составляющей на 12, мы вычитаем ее значение из каждой средней оценки и получаем скорректированную сезонную компоненту, St.
Далее, заполняем нашу таблицу значениями сезонной составляющей дублируя ряд каждые 12 месяцев, то есть три раза:

Шаг 3
Теперь рассчитываем значения уровня тренда T(t) по тому уравнению, которое мы получили при построении сглаженного тренда на первом шаге.
T(t) = -23294+34114*t-1593*t^2+26,3*t^3
Вместо t используем значения из столбца Период из соответствующей строки.

Шаг 4
Имея рассчитанные значения S(t) и T(t) мы можем рассчитать прогнозные значения уровней ряда Y(t). Для этого накладываем уровни сезонности на тренд.

Теперь построим график известных значений Y(t) и спрогнозированных за 2018 год.

Вот мы и нашли спрогнозированные значения уровней продаж на 2018 год. Значения отражают возрастающую тенденцию и сезонные пики. Конечно, эти данные не дают 100% точности, ведь существует множество внешних воздействий, которые могут изменить направление тренда, поэтому к прогнозным значениям обычно строят доверительный интервал, это такой коридор, внутри которого могут колебаться прогнозные значения с заданной вероятностью (чаще всего выбирают 95%). Но об этом я расскажу в следующей статье.
Шаг 5
Осталось оценить точность модели. Для этого будем использовать среднюю ошибку аппроксимации, которая поможет рассчитать ошибку в относительном выражении. Иными словами, это среднее отклонение расчетных значений от фактических, которое вычисляется по формуле:

yi — спрогнозированные уровни ряда,
yi* — фактические уровни ряда,
n — количество складываемых элементов.
Модель может считаться адекватной, если:

Итак, рассчитываем ошибку аппроксимации для нашего случая. Так как в основе нашего тренда лежит полином третьей степени, прогнозные значения начинают хорошо повторять фактические значения к концу 2016 года, думаю, я думаю, поэтому корректнее было бы рассчитать ошибку аппроксимации для значений 2017 года.

Сложив весь столбец с ошибками аппроксимации и поделив на 12, получаем среднюю ошибку аппроксимации 4,13%. Это значение меньше 15% и можем сделать вывод об адекватности модели.
Не забывайте, что прогнозы не бывают точными на 100%. Любые неожиданные внешние воздействия могут развернуть значения уровней ряда в неизвестном направлении 🙂
Полезные ссылки:
- Ссылка на пример Google Sheets
- Построение функции тренда в Excel. Быстрый прогноз без учета сезонности
- Бывшев В.А. Эконометрика
- Об авторе
- Свежие записи

Сезонность спроса – это явление, при котором спрос на определенные товары и услуги изменяется под влиянием внешних факторов. В контексте вашего сайта – это колебания трафика, зависящие от внешних факторов. Этот параметр аналитики, помогает точнее оценить периоды роста и падения трафика и причины этих скачков.
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.
Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ. Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
=ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.
«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.
- Выделяем незаполненную ячейку на листе, куда планируется выводить результат обработки. Жмем на кнопку «Вставить функцию».
- Открывается Мастер функций. В категории «Статистические» выделяем наименование «ПРЕДСКАЗ», а затем щелкаем по кнопке «OK».
- Запускается окно аргументов. В поле «X» указываем величину аргумента, к которому нужно отыскать значение функции. В нашем случаем это 2018 год. Поэтому вносим запись «2018». Но лучше указать этот показатель в ячейке на листе, а в поле «X» просто дать ссылку на него. Это позволит в будущем автоматизировать вычисления и при надобности легко изменять год.
В поле «Известные значения y» указываем координаты столбца «Прибыль предприятия». Это можно сделать, установив курсор в поле, а затем, зажав левую кнопку мыши и выделив соответствующий столбец на листе.
Аналогичным образом в поле «Известные значения x» вносим адрес столбца «Год» с данными за прошедший период.
После того, как вся информация внесена, жмем на кнопку «OK».
- Оператор производит расчет на основании введенных данных и выводит результат на экран. На 2018 год планируется прибыль в районе 4564,7 тыс. рублей. На основе полученной таблицы мы можем построить график при помощи инструментов создания диаграммы, о которых шла речь выше.
- Если поменять год в ячейке, которая использовалась для ввода аргумента, то соответственно изменится результат, а также автоматически обновится график. Например, по прогнозам в 2019 году сумма прибыли составит 4637,8 тыс. рублей.





Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ. Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
=ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ, а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа», но он не является обязательным и используется только при наличии постоянных факторов.
Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.
- Производим обозначение ячейки для вывода результата и запускаем Мастер функций обычным способом. В категории «Статистические» находим и выделяем наименование «ТЕНДЕНЦИЯ». Жмем на кнопку «OK».
- Открывается окно аргументов оператора ТЕНДЕНЦИЯ. В поле «Известные значения y» уже описанным выше способом заносим координаты колонки «Прибыль предприятия». В поле «Известные значения x» вводим адрес столбца «Год». В поле «Новые значения x» заносим ссылку на ячейку, где находится номер года, на который нужно указать прогноз. В нашем случае это 2019 год. Поле «Константа» оставляем пустым. Щелкаем по кнопке «OK».
- Оператор обрабатывает данные и выводит результат на экран. Как видим, сумма прогнозируемой прибыли на 2019 год, рассчитанная методом линейной зависимости, составит, как и при предыдущем методе расчета, 4637,8 тыс. рублей.



Виды сезонности
Обычно выделяют три вида сезонности, они отличаются по спаду в разнице продаж:
Умеренная: разница в пределах 10-20%, практически не влияет на финансовое самочувствие компании. Характерно для товаров повседневного спроса. Продавцы и поставщики чувствуют себя комфортно на протяжении всего года;
Яркая: разница спада продаж достигает 30-40%, приходится стимулировать спрос, чтобы не случился кассовый разрыв;
Жёсткая: падение продаж на 50-100%, нет шансов вернуть объёмы на прежние показатели. Есть ли смысл стимулировать спрос на новогодние ёлочные игрушки и валентинки в августе?
Причины сезонности
В первую очередь, сезонная торговля зависит от смены времен года — это главная причина возникновения сезонностей, и это связано с изменением средней температуры и климата. Очевидно, что спрос на товары уличного спорта и велосипеда проседает зимой, а популярность тёплых вещей возрастает.
Еще одна главная причина сезонности — это календарные события. Перед Новым годом люди массово закупаются подарками и продуктами для праздничного стола, а перед 23 февраля — носками для мужчин.
Устоявшиеся традиции и привычки тоже вносят большой вклад в сезонность. Если до Нового года наблюдается всплеск потребительской активности, то после 1 января наступает «мертвый сезон». Это связано с новогодними каникулами, которые утверждены на законодательном уровне. Большинство людей сидят и отдыхают дома после покупок и праздника, а значит меньше ходят в магазины. Поэтому компании часто сокращают маркетинговый бюджет на январь, потому что сезонный спрос падает.
Как использовать сезонность в маркетинговой кампании
Планирование эффективной сезонной кампании требует не только отличной организации, но и времени. Ниже приведены некоторые советы, которые помогут выстроить эффективную кампанию.
Выберите правильное предложение под сезон
В каждом сезоне актуальны свои предложения. Главное здесь — быть избирательным, проводить исследования и собирать данные о том, когда ваши клиенты наиболее активны.
Если есть достаточно понятная взаимосвязь между событием или сезоном и вашим предложением, тем легче адаптировать их и связать вместе. Но даже для услуг, не привязанных к времени года, можно придумать повод для вовлечения аудитории.
Не забывайте и о спонтанных событиях — открытие новых туристических направлений, законодательные запреты и разрешения могут послужить триггером для успешного продаж.
Например, если выйдет закон о полном запрете авиапассажирам провоза внешних аккумуляторов ёмкостью выше 5 000 mAh в ручной клади, продажи ваших скромных пауэрбанков на 2 000 mAh могут подскочить при запуске грамотной маркетинговой кампании.
О таких банальностях, как цветы и торты на 8 марта и 1 сентября не стоит и говорить. В эти праздники не готовит специальные предложения только тот, у кого бизнес абсолютно не может быть ассоциирован с ними — например, продажи бурильного оборудования.
Постройте коммуникации
- Составьте карту пути клиента и точки контакта с ним. Карта даёт общее представление об опыте клиента: первоначальный контакт, процесс взаимодействия и перспективы долгосрочных отношений.
- Обратитесь к эмоциям — это позволит создать более тесную связь с вашей аудиторией и сделает их восприимчивыми к вашему сообщению.
- Призыв к действию: разработайте CTA для всех этапов коммуникации. Для каждого шага должно быть продумано ясное побуждение к действию. Не заставляйте людей продираться сквозь многослойные намёки.
Выделите бюджет
Ключом к успешной сезонной маркетинговой кампании является точная настройка бюджет во избежание сюрпризов.
Помимо увеличенных расходов на интернет-маркетинг, продумайте, какие дополнительные затраты могут иметь место:
- Бонусы и подарки для клиентов;
- Расходы на мероприятия;
- Расходы на зарплату сезонных работников;
- Транспортные расходы, если вы рассылаете подарки.
Чтобы оптимизировать расходы на рекламу, используйте сквозную аналитику — она отражает полную картину эффективности каждого канала коммуникации.
Ниже на рисунке представлены исходные данные. Допустим по этим данным необходимо составить прогноз продаж на 2020-й год, не смотря на то что собранные статистические данные заканчиваются в декабре 2019-го года. Первым шагом является использование функции ПРЕДСКАЗ и расширение десезонализированных данных на очередные 12 месяцев. Формулы в таблицах:
- Расчет коэффициента сезонности для каждого месяца в году:
- Расчет десезонализации на основе коэффициентов:
- Формула для прогнозирования показателей реализации в январе 2020-го года находится в том же столбце в ячейке C26 и выглядит следующим образом:
- Формула прогноза сезонности на 2020-й год:




Для прогнозирования будущих значений функция ПРЕДСКАЗ использует метод линейной регрессии. Функция содержит 3 аргумента:

- X – в данном аргументе будет указан месяц, для которого следует получить текущее прогнозируемое значение.
- Известные значения y – аргумент содержит десезонализированные данные столбца C.
- Известные значения x – здесь указаны месяца соответствующие данным по продажам в столбце A.
После создания с помощью функции ПРЕДСКАЗ прогнозируемых значений для всех месяцев следует восстановить сезонность данных, применяя коэффициенты в таблице, показанной на последнем рисунке выше.
Для расчета значений тренда:
- Определим коэффициенты уравнения линейного тренда y=bx+a с помощью функции Excel =Линейн(). Для этого в ячейки Excel вводим функцию =линейн(объёмы продаж за 5 лет; номера периодов; 1;0).
 Выделяем 2 ячейки, в левой – формула =линейн(), нажимаем комбинацию клавиш в следующей последовательности (F2 + Ctrl+Shift+Enter). Excel рассчитает для нас значение коэффициентов a и b.
Выделяем 2 ячейки, в левой – формула =линейн(), нажимаем комбинацию клавиш в следующей последовательности (F2 + Ctrl+Shift+Enter). Excel рассчитает для нас значение коэффициентов a и b. - Рассчитываем значения тренда. Для этого в уравнение y=bx+a подставляем рассчитанные коэффициенты тренда b и а, x – номер периода во временном ряде. Получаем y-значения линейного тренда для каждого периода.
Для расчета коэффициентов сезонности:
- Рассчитываем отклонение фактических значений от значений тренда. Для этого фактические значения делим на значения тренда;
- Для каждого месяца определяем среднее отклонение за последние 5 лет.
- Определяем общий индекс сезонности — среднее значение коэффициентов, рассчитанных в 4 пункте;
- Рассчитываем коэффициенты сезонности
Из чего состоит временной ряд
Уровни временного ряда (Yt) представляют из себя сумму двух компонент:
- Регулярную составляющую
- Случайную составляющую
В свою очередь регулярная составляющая состоит из:
- Тренда
- Сезонности
- Циклической составляющей
Однако, в модели необязательно наличие всех этих компонент сразу.
Случайная компонента отражает влияние случайных возмущений на модель, которые по отдельности имеют незначительное воздействие, но суммарно их влияние ощущается.
То есть, в общем случае временной ряд представляет из себя наличие четырех составляющих:
- Тренд (Tt)
- Сезонность (St)
- Цикличность (Ct)
- Случайные возмущения (Et)
Циклическая компонента, по сравнению с сезонностью, имеет более длительный эффект и меняется от цикла к циклу. Поэтому, ее обычно объединяют с трендом.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
Аддитивная модель 


При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:

- Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
- Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).

Источники
- https://racurs.agency/blog/seo/sezonnost-sprosa/
- https://lumpics.ru/forecasting-in-excel/
- https://blog.calltouch.ru/chto-takoe-sezonnost-sprosa-i-kak-stimulirovat-prodazhi-v-nesezon/
- https://exceltable.com/formuly/formula-predskaz-dlya-prognoza-prodazh
- https://4analytics.ru/prognozirovanie/kak-rasschitat-prognoz-prodaj-s-uchetom-rosta-i-sezonnosti-v-excel.html
- https://iiorao.ru/word/kak-sdelat-prognoz-prodazh-v-excel.html
history 4 июля 2021 г.
- Группы статей
В
первом разделе статьи
модели для прогнозирования временных рядов сравниваются с моделями, построение которых основано на причинно-следственных закономерностях.
Во
втором разделе
приведен краткий обзор трендов временных рядов (линейный и сезонный тренд, стационарный процесс). Для каждого тренда предложена модель для прогнозирования.
Затем даны ссылки на сайты по теории прогнозирования временных рядов и содержащие базы статистических данных.
Disclaimer:
Напоминаем, что задача сайта excel2.ru (раздел
Временные ряды
) продемонстрировать использование MS EXCEL для решения задач, связанных с прогнозированием временных рядов. Поэтому, статистические термины и определения приводятся лишь для логики изложения и демонстрации идей. Сайт не претендует на математическую строгость изложения статистики. Однако в наших статьях:
• ПОЛНОСТЬЮ описан встроенный в EXCEL инструментарий по анализу временных рядов (в составе
надстройки Пакет анализа
, различных
типов Диаграмм
(
гистограмма
,
линия тренда
) и формул);
• созданы файлы примера для построения соответствующих графиков, прогнозов и их интервалов предсказания, вычисления ошибок, генерации рядов (с
трендами
и
сезонностью
) и пр.
Модели временных рядов и модели предметной области
Напомним, что временным рядом (англ. Time Series) называют совокупность наблюдений изучаемой величины, упорядоченную по времени. Наблюдения производятся через одинаковые периоды времени. Другой информацией, кроме наблюдений, исследователь не обладает.
Основной целью исследования временного ряда является его прогнозирование – предсказание будущих значений изучаемой величины. Прогнозирование основывается только на анализе значений ряда в предыдущие периоды, точнее — на идентификации трендов ряда. Затем, после определения трендов, производится моделирование этих трендов и, наконец, с помощью этих моделей — экстраполяция на будущие периоды.
Таким образом, прогнозирование основывается на фактических данных (значениях временного ряда) и модели (
скользящее среднее
,
экспоненциальное сглаживание
,
двойное и тройное экспоненциальное сглаживание
и др.).
Примечание
: Прогнозирование методом Скользящее среднее в MS EXCEL подробно рассмотрено в
одноименной статье
.
В отличие от методов временных рядов,
где зависимости ищутся внутри самого процесса
, в «моделях предметной области» (англ. «Causal Models») кроме самих данных используют еще и законы предметной области.
Примером построения «моделей предметной области» (
моделей строящихся на основе причинно-следственных закономерностей, априорно известных независимо от имеющихся данных
) может быть промышленный процесс изготовления защитной ткани. Пусть в таком процессе известно, что прочность материала ткани зависит от температуры в реакторе, в котором производится процесс полимеризации (температура — контролируемый фактор). Однако, прочность материала является все же случайной величиной, т.к. зависит помимо температуры также и от множества других факторов (качества исходного сырья, температуры окружающей среды, номера смены, умений аппаратчика реактора и пр.). Эти другие факторы в процессе производства стараются держать постоянными (сырье проходит входной контроль и его поставщик не меняется; в помещении, где стоит реактор, поддерживается постоянная температура в течение всего года; аппаратчики проходят обучение и регулярно проводится переаттестация). Задачей статистических методов в этом случае – предсказать значение случайной величины (прочности) при заданном значении изменяемого фактора (температуры).
Обычно для описания таких процессов (зависимость случайной величины от управляемого фактора) являются предметом изучения в разделе статистики «
Регрессионный анализ
», т.к. есть основания сделать гипотезу о существовании причинно-следственной связи между управляемым фактором и прогнозируемой величиной.
Модели, строящиеся на основе причинно-следственных закономерностей, упомянуты в этой статье для того чтобы акцентировать, что их изучение предшествует теме «временные ряды». Так, часть методов, например «Регрессионный анализ» (используется
метод наименьших квадратов — МНК
), используется при анализе временных рядов, но изучаются в моделях предметной области, поэтому неподготовленным «пытливым умам» не стоит игнорировать раздел статистики «
Статистический вывод
», в котором проверяются гипотезы о
равенстве среднего значения
и строятся
доверительные интервалы для оценки среднего
, и упомянутый выше «Регрессионный анализ».
Кратко о типах процессов и моделях для их прогнозирования
Выбор подходящей модели прогнозирования делается с учетом типа моделируемого процесса (наличие трендов). Рассмотрим основные типы процессов.
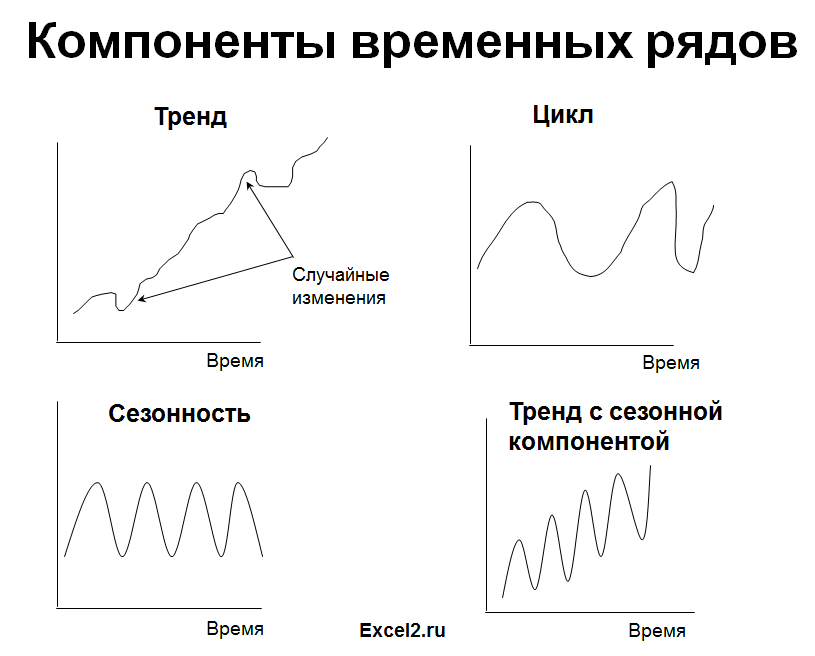
1. Стационарный процесс
Стационарный процесс – это случайный процесс чьи характеристики не зависят от времени их наблюдения. Этими характеристиками являются
среднее значение
,
дисперсия
и автоковариация. В стационарном процессе не могут быть выделены предсказуемые паттерны. Соответственно ряды демонстрирующие тренд и сезонность — не стационарны. А вот ряд с цикличностью (апериодической) является стационарным, т.к. на долгосрочном временном интервале появление циклов предсказать невозможно.
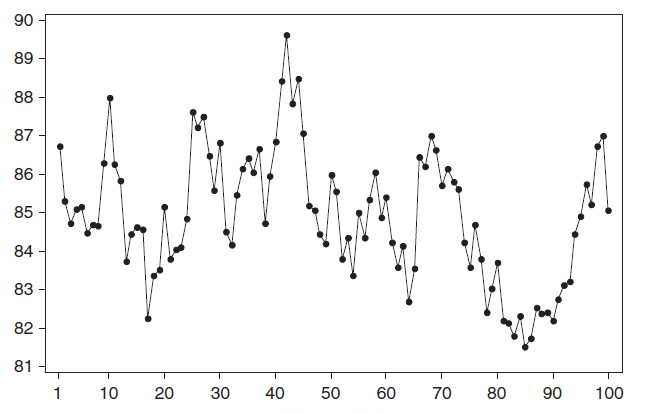
Почему стационарный процесс важен? Так как стационарность подразумевает нахождение процесса в состоянии статистической стабильности, то такие временные ряды имеют постоянное среднее значение и дисперсию, которые определяются стандартным образом.
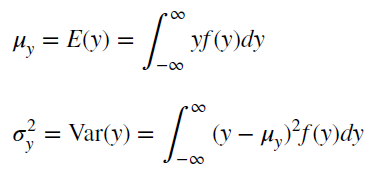
Также для стационарного процесса определяется
функция автокорреляции
– совокупность коэффициентов корреляции значений временного ряда с собственными значениями, сдвинутыми по времени на один или несколько периодов. Сдвиг на несколько временных периодов часто называется лагом (обозначается k).
Функция автокорреляции является важным источником информации о временном ряде.
Примером стационарного процесса является колебания биржевого индекса, состоящего из стоимости акций нескольких компаний, около определённого значения (в период стабильности рынка).
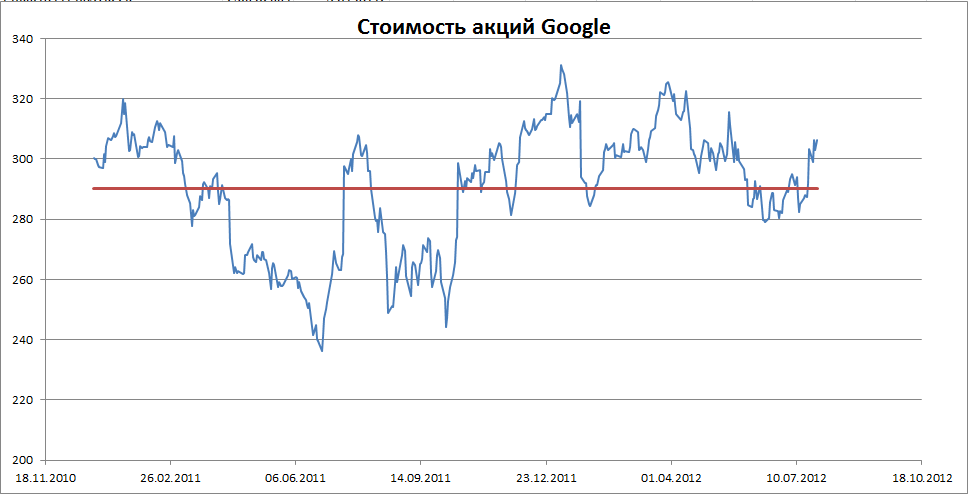
Примечание
: график стоимости акций построен на реальных данных, см.
файл примера Google
.
Специальным видом стационарного процесса является белый шум. У этого процесса: среднее значений ряда равно 0, имеется конечная дисперсия и отсутствует корреляция между значениями исходного ряда и рядом сдвинутым на произвольное количество периодов (лагов). В MS EXCEL белый шум можно сгенерировать функцией СЛЧИС().
2. Линейный тренд
Некоторые процессы генерируют тренд (монотонное изменение значений ряда). Например, линейный тренд y=a*x+b, точнее y=a*t+b, где t – это время. Примером такого (не стационарного) процесса может быть монотонный рост стоимости недвижимости в некотором районе.
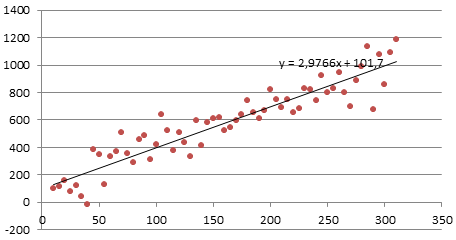
Для вычисления прогнозного значения можно воспользоваться методами
Регрессионного анализа
и подобрать параметры тренда: наклон и смещение по вертикали.
Примечание
: Про генерацию случайных значений, демонстрирующих линейный тренд, можно посмотреть в статье
Генерация данных для простой линейной регрессии в EXCEL
.
3. Процессы, демонстрирующие сезонность
В сезонном процессе присутствует точно или примерно фиксированный интервал изменений, например, продажи некоторых товаров имеют четко выраженный пик в ноябре-декабре каждого года в связи с праздником.
Для прогнозирования вычисляется индекс сезонности, затем ряд очищается от сезонной компоненты. Если ряд также демонстрирует тренд, то после очистки от сезонности используются методы регрессионного анализа для вычисления тренда.
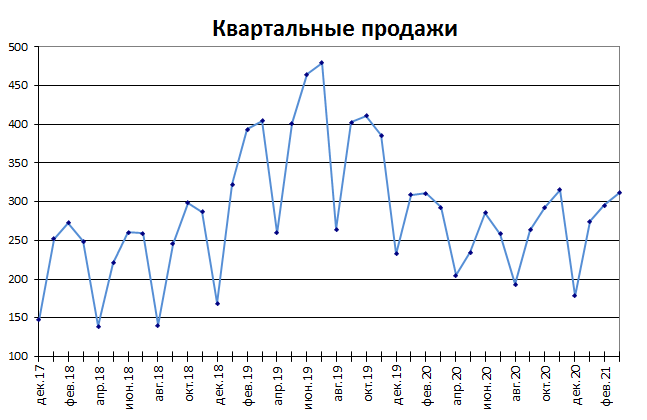
Примечание
: Про генерацию случайных значений, демонстрирующих сезонность, можно посмотреть в статье Генерация сезонных трендов в EXCEL.
Часто на практике встречаются ряды, являющиеся комбинацией вышеуказанных типов тенденций.
О моделях прогнозирования
В качестве простейшей модели для прогноза можно взять последнее значение индекса. Этой модели соответствует следующий ход мысли исследователя: «Если значение индекса вчера было 306, то и завтра будет 306».
Этой модели соответствует формула Y
прогноз(t)
= Y
t-1
(прогноз в момент времени t равен значению временного ряда в момент t-1).
Другой моделью является среднее за последние несколько периодов (
скользящее среднее
). Этой модели соответствует другой ход мысли исследователя: «Если среднее значение индекса за последние n периодов было 540, то и завтра будет 540». Этой модели соответствует формула Y
прогноз(t)
=(Y
t-1
+ Y
t-2
+…+Y
t-n
)/n
Обратите внимание, что значения временного ряда берутся с одинаковым весом 1/n, то есть более ранние значения (в момент t-n) влияют на прогноз также как и недавние (в момент t-1). Конечно, в случае, если речь идет о стационарном процессе (без тренда), такая модель может быть приемлема. Чем больше количество периодов усреднения (n), тем меньше влияние каждого индивидуального наблюдения.
Третьей моделью для стационарного процесса может быть
экспоненциальное сглаживание
. В этом случае веса более ранних периодов будут меньше чем веса поздних. При этом учитываются все предыдущие наблюдения. Вес каждого последующего наблюдения больше на 1-α (Фактор затухания), где α (альфа) – это константа сглаживания (от 0 до 1).
Этой модели соответствует формула Y
прогноз(t)
=α*Y
t-1
+ α*(1-α)*Y
t-2
+ α*(1-α)2*Y
t-3
+…)
Формулу можно переписать через предыдущий прогноз Y
прогноз(t)
=α*Y
t-1
+(1- α)* Y
прогноз(t-1)
= α*(Y
t-1
— Y
прогноз(t-1)
)+Y
прогноз(t-1)
= α*(ошибка прошлого прогноза)+ прошлый прогноз
При экспоненциальном сглаживании прогнозное значение равно сумме последнего наблюдения с весом альфа и предыдущего прогноза с весом (1-альфа). Этой модели соответствует следующий ход мысли исследователя: «Вчера рано утром я предсказывал, что индекс будет равен 500, но вчера в конце дня значение индекса составило 480 (ошибка составила 20). Поэтому за основу сегодняшнего прогноза я беру вчерашний прогноз и корректирую его на величину ошибки, умноженную на альфа. Параметр альфа (константа) я найду методом экспоненциального сглаживания».
Подробнее о методе прогнозирования на основе экспоненциального сглаживания можно
найти в этой статье
.
Полезный сигнал и шум
Из-за случайного разброса, присущему временному ряду, временной ряд представляют как комбинацию двух различных компонентов: полезного сигнала и шума (ошибки). Полезный сигнал следует одному из 3-х вышеуказанных типов процессов. Сигнал может быть смоделирован и соответственно спрогнозирован. Шум представляет собой случайные ошибки (со средним значением =0, отсутствием корреляции и с фиксированной
дисперсией
).
Основной задачей моделирования идентификация полезного сигнала, имеющего определенный тренд, от непредсказуемого шума. Для этого как раз и используются Модели сглаживания.
Ссылки на источники статистических данных и обучающие материалы
Все источники англоязычные.
Сайт о применении EXCEL в статистике
Национальный Институт Стандартов и технологии
https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc4.htm
Using R for Time Series Analysis
https://a-little-book-of-r-for-time-series.readthedocs.io/en/latest/src/timeseries.html#time-series-analysis
Учебник по прогнозированию временных рядов
https://otexts.com/fpp2/
Данные по болезням в Великобритании
https://ms.mcmaster.ca/~bolker/measdata.html
Курсы в Eberly College of Science (есть ссылки на базы данных)
https://online.stat.psu.edu/stat501/lesson/welcome-stat-501
https://online.stat.psu.edu/stat510/
Рассмотрим
построение модели аддитивного ряда
средствами Exel
2007 на примере изучения объемов потребления
электроэнергии (млн кВТ*ч) жителями
региона за 16 кварталов и на основании
полученной модели спрогнозируем объем
потребляемой электроэнергии на следующие
полгода. Построенный пример описан в
![]() .
.
Пусть
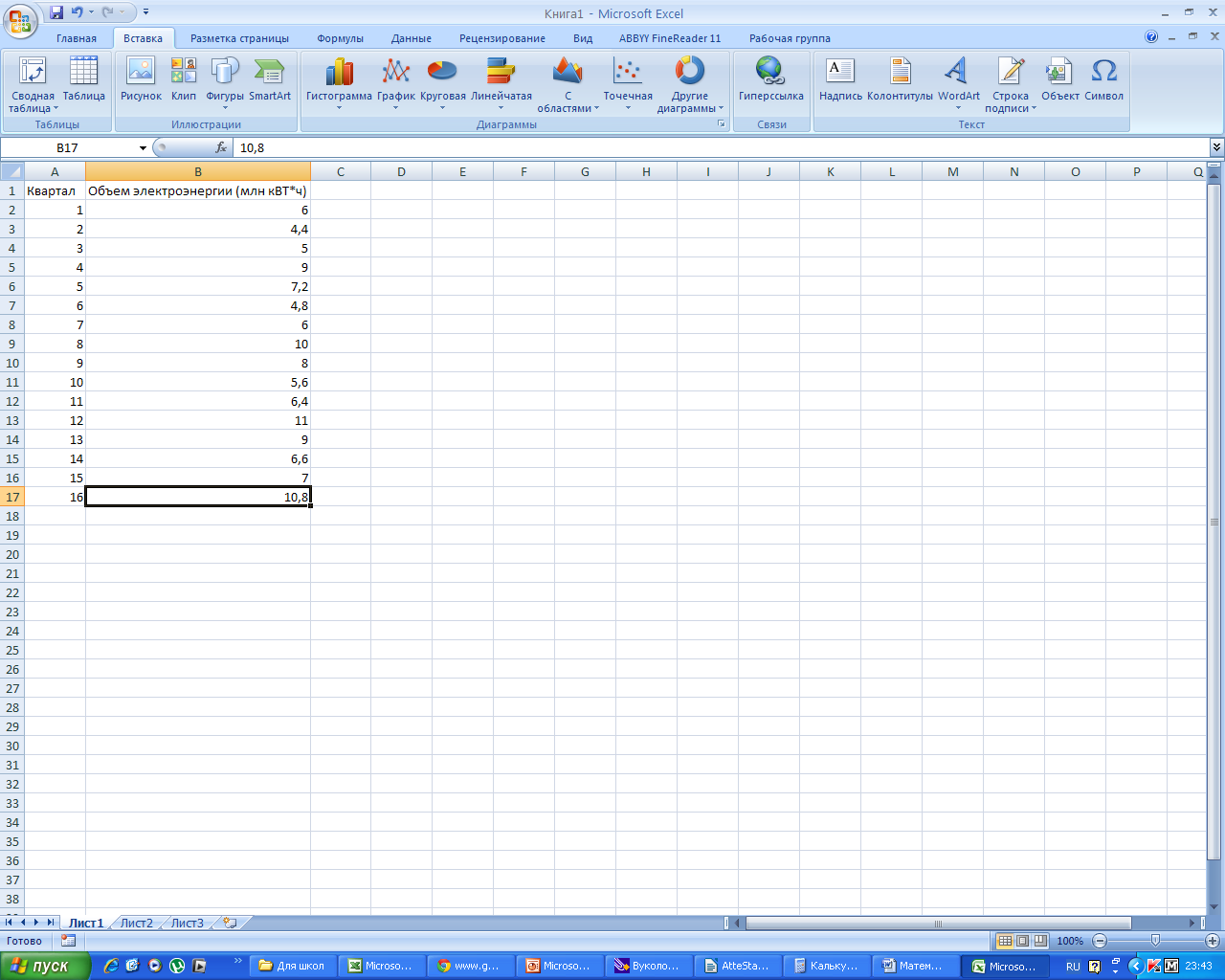
известный объем потребляемой электроэнергии
задан таблицей 1.
Таблица
1. Потребление электроэнергии жителями
региона, млн кВТ*ч
|
№ кварт. |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
|
Объем (млн |
6,0 |
4,4 |
5,0 |
9,0 |
7,2 |
4,8 |
6,0 |
10 |
8,0 |
5,6 |
6,4 |
11 |
9,0 |
6,6 |
7,0 |
10.8 |
-
Внесем
эти данные в таблицу

-
В
главном меню выбираем «ВСТАВКА»
-
В
главном меню выбираем «ТОЧЕЧНАЯ»
-
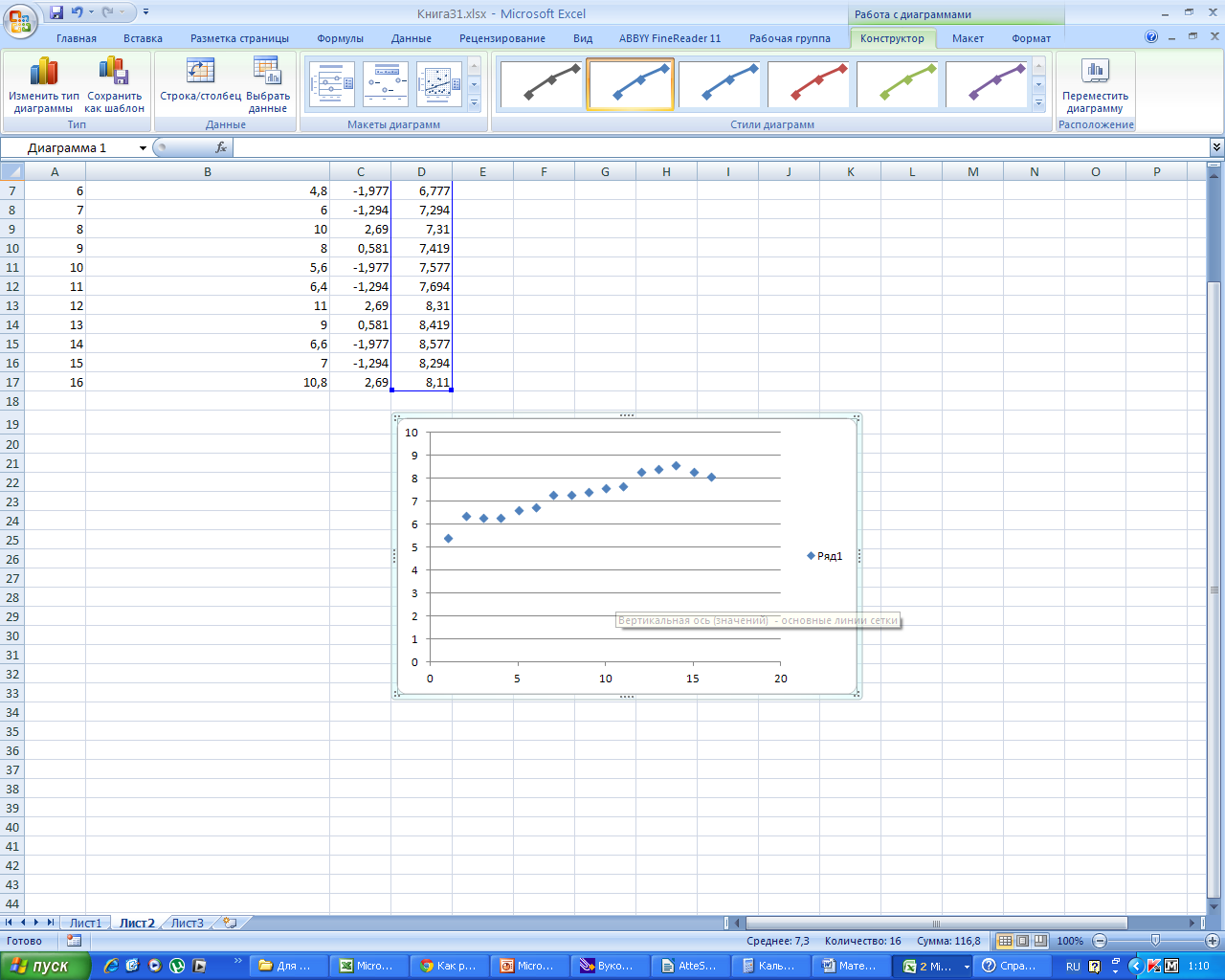
Получаем
график

-
Теперь
считаем сезонную компоненту и среднюю
ошибку аппроксимации. Для этого открываем
лист 2 и копируем в него первые два
столбца. По методике, описанной в
1рассчитаем значения сезонной компоненты.
Таблица
1- Расчет оценок сезонной компоненты в
аддитивной модели
|
Номер |
Потребление |
Итого |
Скользящая |
Центрированная |
Оценка |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
6,0 |
– |
– |
– |
– |
|
2 |
4,4 |
24,4 |
6,10 |
– |
– |
|
3 |
5,0 |
25,6 |
6,40 |
6,250 |
–1,250 |
|
4 |
9,0 |
26,0 |
6,50 |
6,450 |
2,550 |
|
5 |
7,2 |
27,0 |
6,75 |
6,625 |
0,575 |
|
6 |
4,8 |
28,0 |
7,00 |
6,875 |
–2,075 |
|
7 |
6,0 |
28,8 |
7,20 |
7,100 |
–1,100 |
|
8 |
10,0 |
29,6 |
7,40 |
7,300 |
2,700 |
|
9 |
8,0 |
30,0 |
7,50 |
7,450 |
0,550 |
|
10 |
5,6 |
31,0 |
7,75 |
7,625 |
–2,025 |
|
11 |
6,4 |
32,0 |
8,00 |
7,875 |
–1,475 |
|
12 |
11,0 |
33,0 |
8,25 |
8,125 |
2,875 |
|
13 |
9,0 |
33,6 |
8,40 |
8,325 |
0,675 |
|
14 |
6,6 |
33,4 |
8,35 |
8,375 |
–1,775 |
|
15 |
7,0 |
– |
– |
– |
– |
|
16 |
10,8 |
– |
– |
– |
– |
Таблица
расчета оценок сезонной компоненты в
аддитивной модели заполняется по
следующему правилу:
1
столбец
– известный номер квартала;
2
столбец
– известный объем потребляемой
электроэнергии(млн кВТ*ч);
3
столбец
– складываем последовательно значения
четырех ячеек 2 столбца и записываем их
на одну клетку ниже;
4
столбец
– каждое значение 3 столбца делим на 4
(период сезонных колебаний);
5
столбец
– складываем последовательно значения
двух ячеек 4 столбца, делим эту сумму на
2 и записываем на одну клетку ниже;
6
столбец
– из элементов 2 столбца вычитаем
элементы 5 столбца.
Рассчитаем
значения сезонной компоненты S
Для
этой цели составим следующую расчетную
таблицу 3, в которую последовательно
разместим данные из 6 столбца табл. 2.
Таблица
3- Расчет значений сезонной компоненты
в аддитивной модели
|
Показатель |
Год |
Номер |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
–1,250 |
2,550 |
|
|
2 |
0,575 |
–2,075 |
–1,100 |
2,700 |
|
|
3 |
0,550 |
–2,025 |
–1,475 |
2,875 |
|
|
4 |
0,675 |
–1,775 |
– |
– |
|
|
Итого |
1,800 |
–5,875 |
–3,825 |
8,125 |
|
|
Средняя |
0,600 |
–1,958 |
–1,275 |
2,708 |
|
|
Скорректированная |
0,581 |
–1,977 |
–1,294 |
2,690 |
Средняя
оценка сезонной компоненты (![]() )
)
рассчитывается как итого за квартал
/3.
В
аддитивных моделях с сезонной компонентой
предполагается , что сезонные воздействия
за период взаимопогашаются. Это означает,
что сумма значений сезонной компоненты
по всем кварталам должна быть равна 0.
Для
данной модели имеем 0,600+ (–1,958) + (–1,275) +
2,708 = 0,075![]()
0.
Определим
корректирующий коэффициент k
=
0,075/4 = 0,01875.
Рассчитаем
скорректированные значения сезонной
компоненты, как разность между ее средней
оценкой и корректирующим коэффициентом
k:
![]()
k.
Проверим
условие равенства нулю суммы значений
сезонной компоненты: 0,581
– 1,977 – 1,294 + 2,690 = 0.
-
Подставим
значения скорректированной сезонной
компоненты в столбец С.
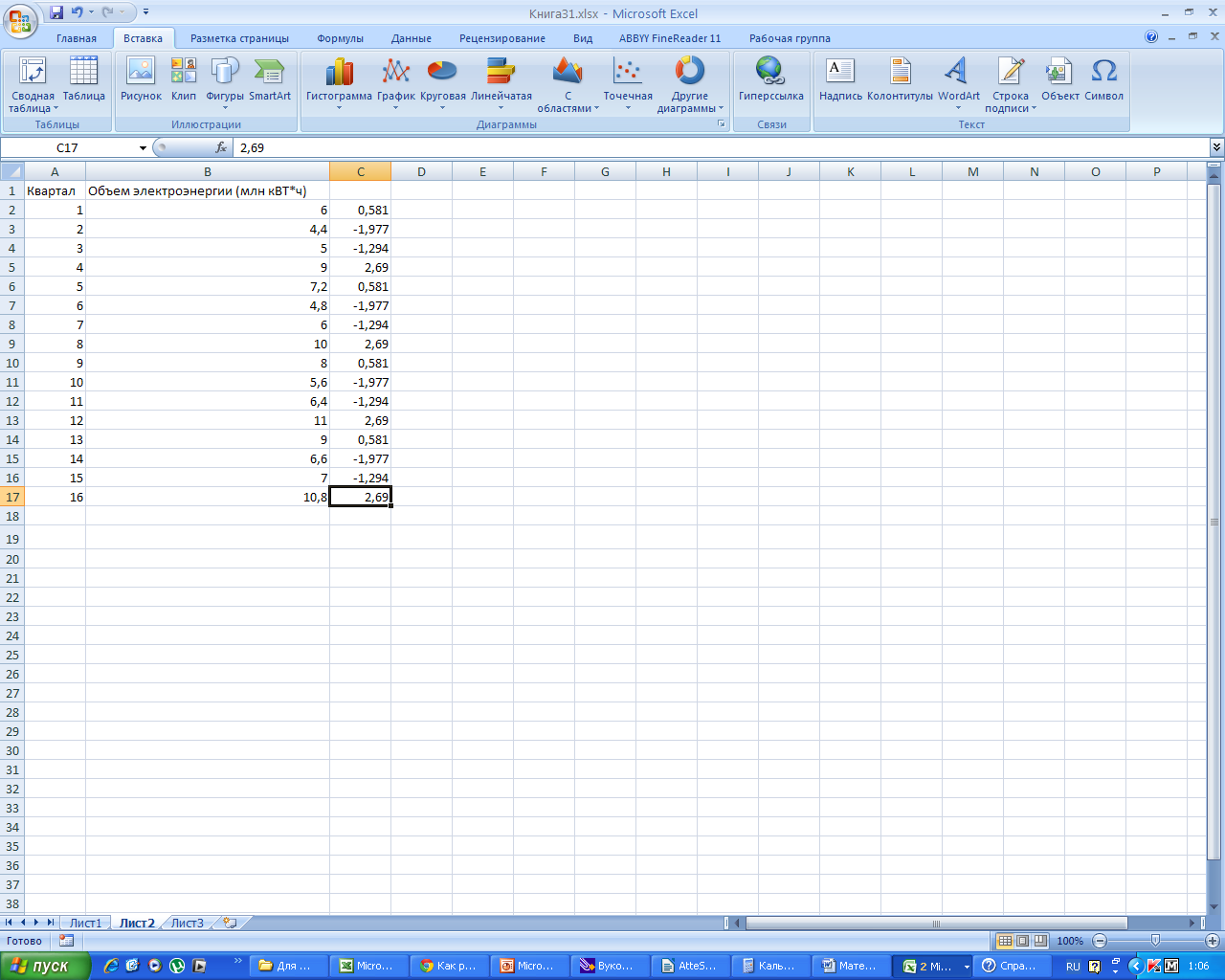
-
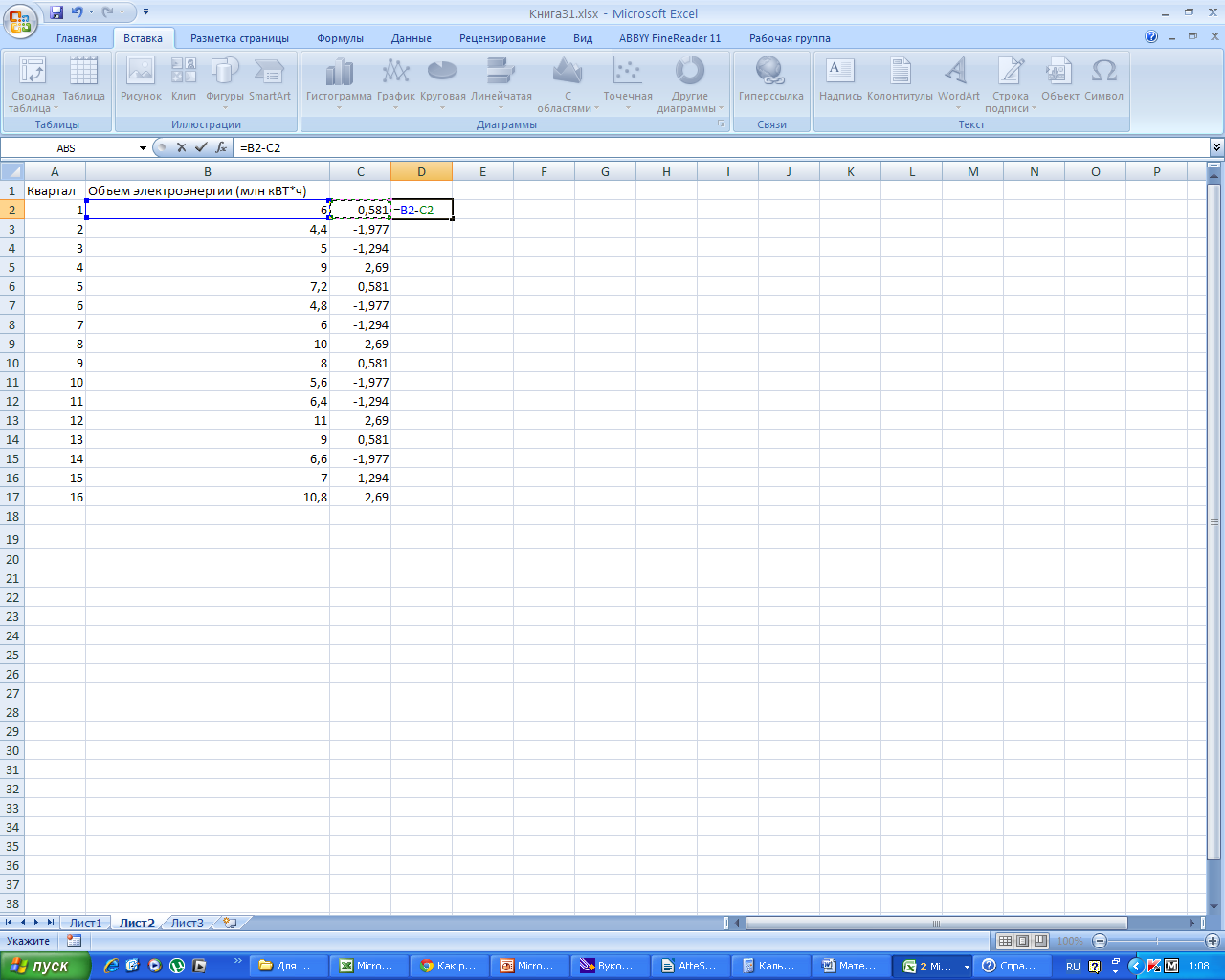
Заполняем
столбец D,
как разность В и С.
Получаем
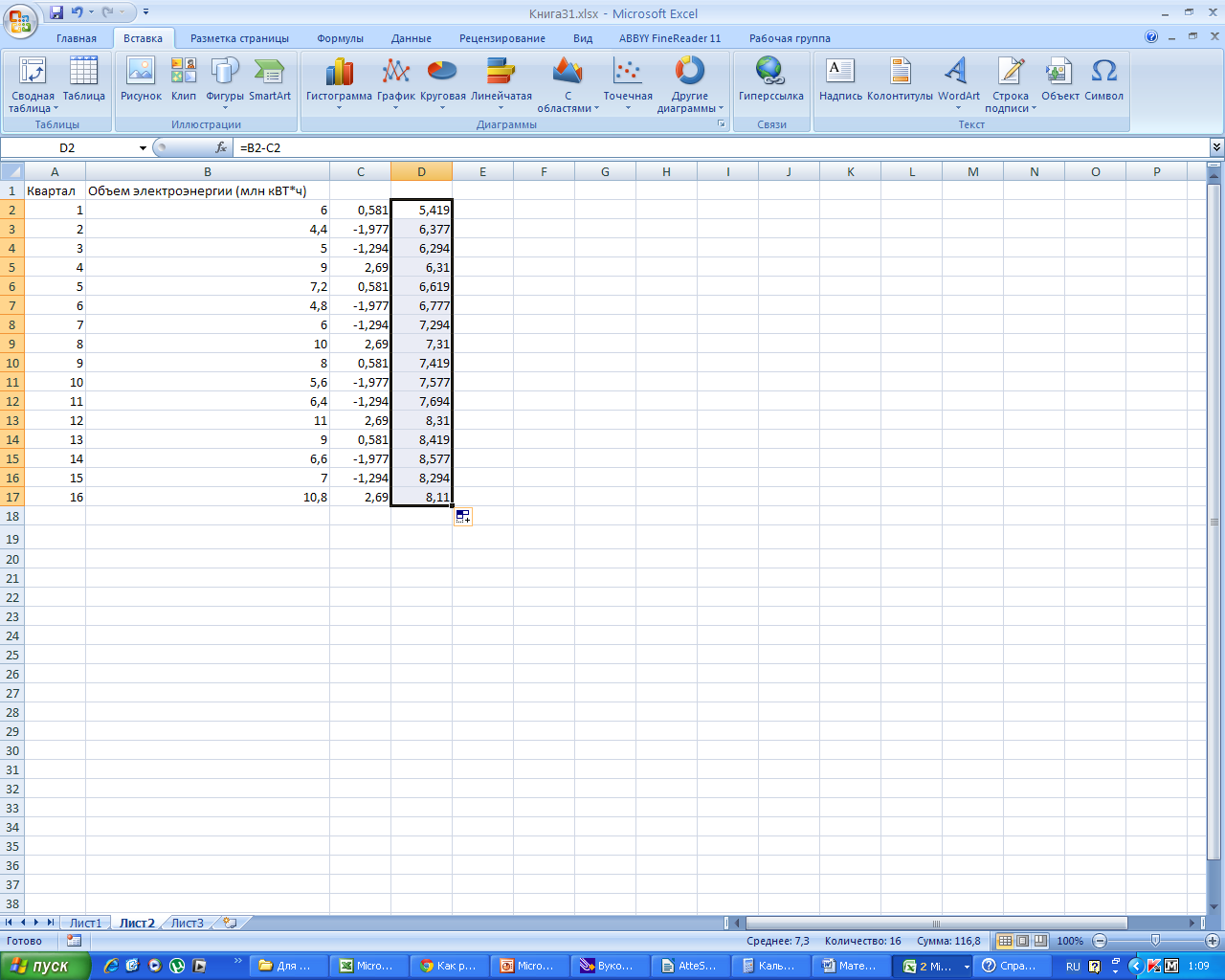
-
Пошагово
выбираем ту линию тренда, где наибольшее
значение имеет R2.
Для
этого ставим курсор на точки поля
корреляции и выбираем тренд, расставляя
галочки в окна, «показать уравнение на
диаграмме» и «поместить на диаграмму
величину достоверности аппроксимации».


-
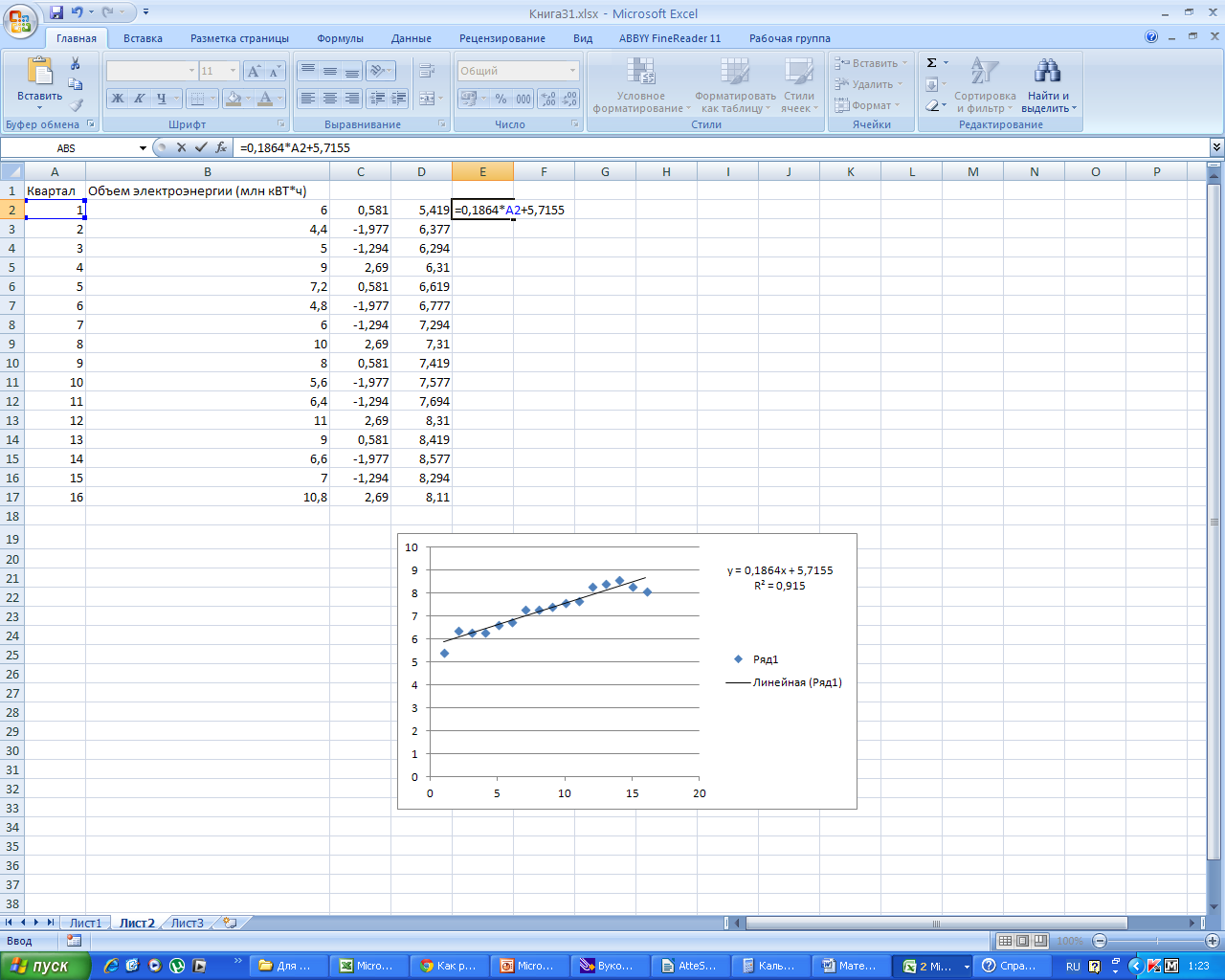
В
столбец Е вбиваем формулу для уравнения
тренда y=
0, 1864x
+ 5, 7155 и получаем расчетные значения
для тренда.

-
Заполним
столбец F,
как сумму C
и Е, и найдем ошибку аппроксимации.

Для
нахождения ошибки аппроксимации заполним
столбец G.
Для этого в столбец G
вставляем формулу

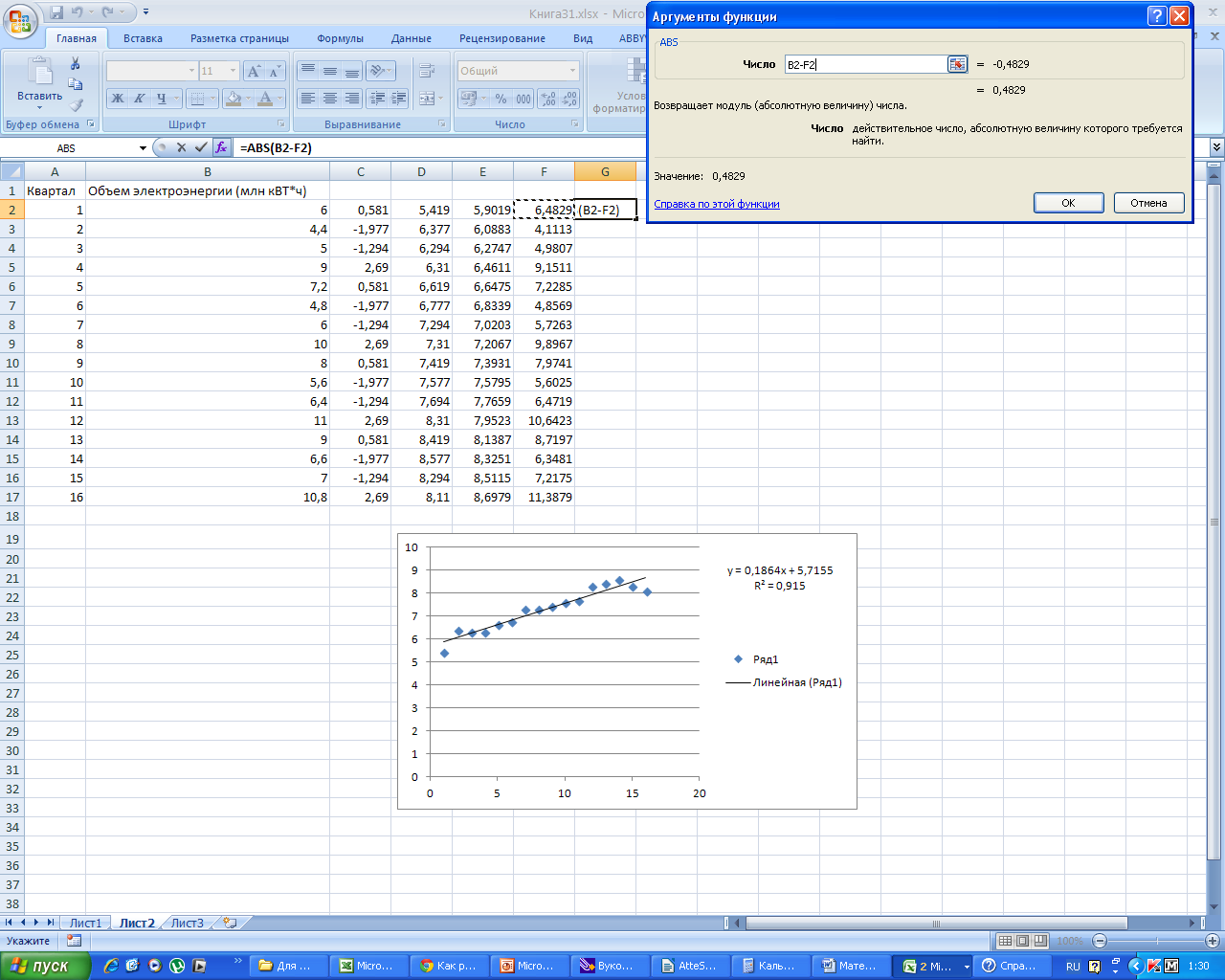
Получаем

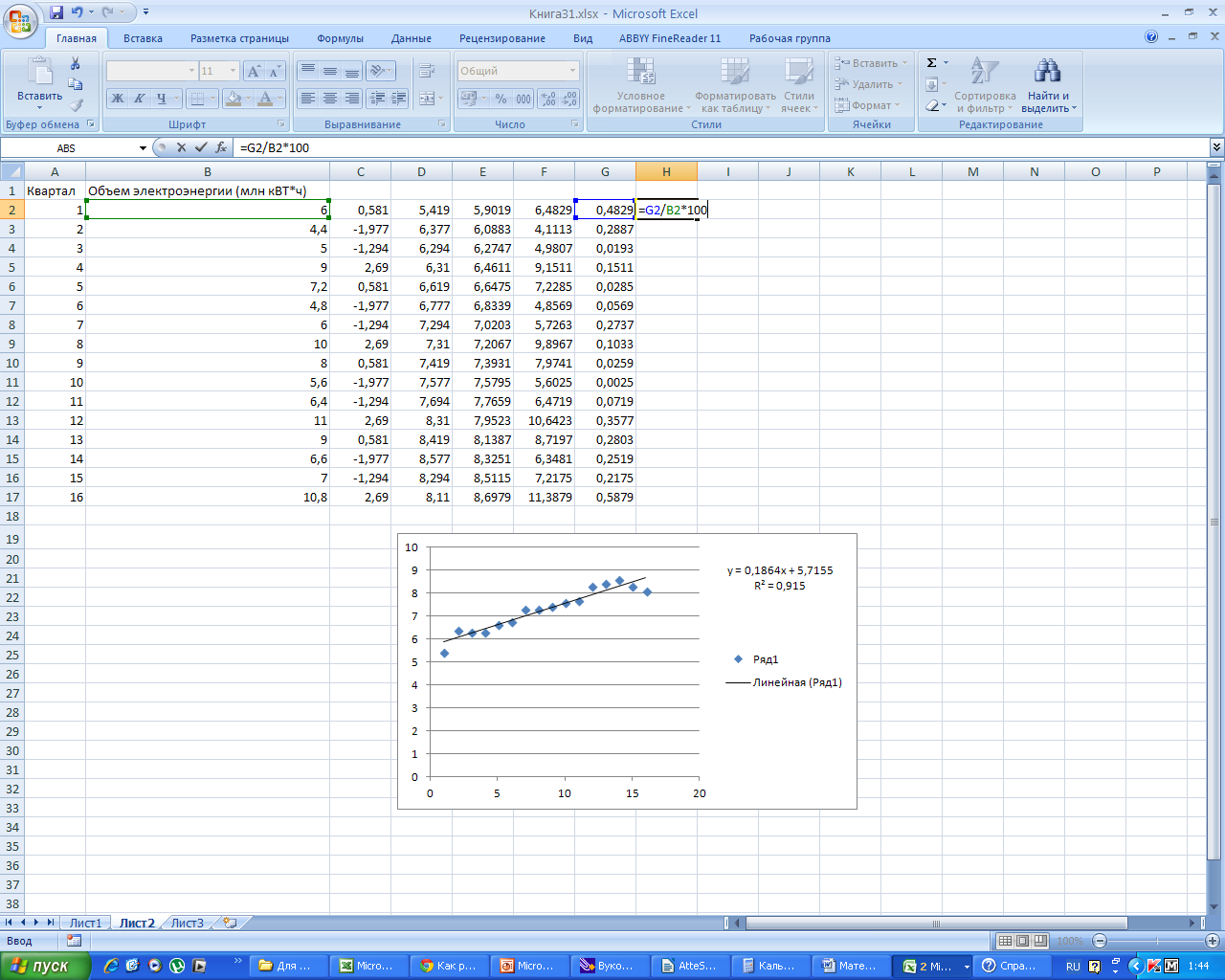
Найдем
среднюю ошибку аппроксимации, заполнив
столбец Н. Для этого разделим G
на В и умножим на 100%.
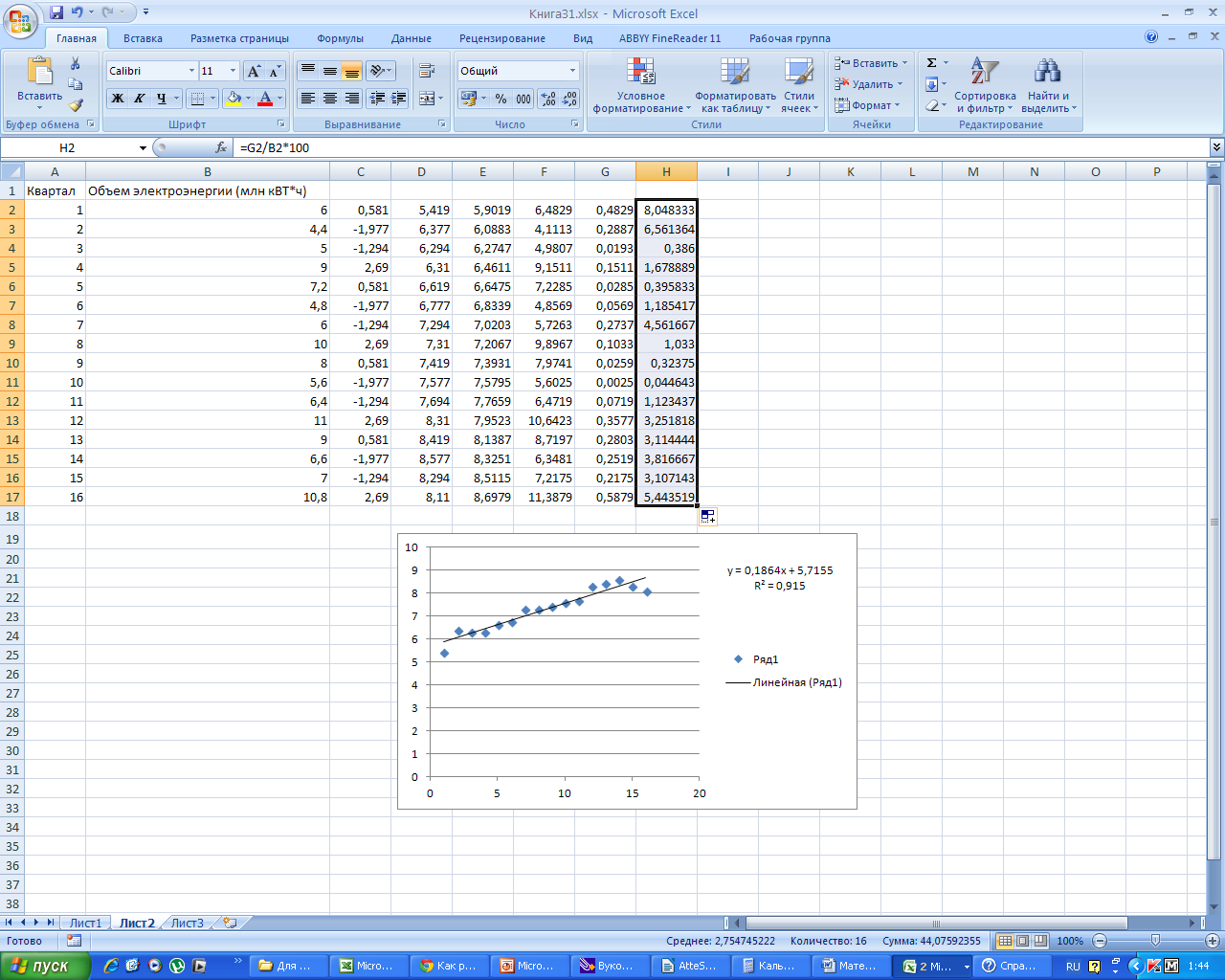


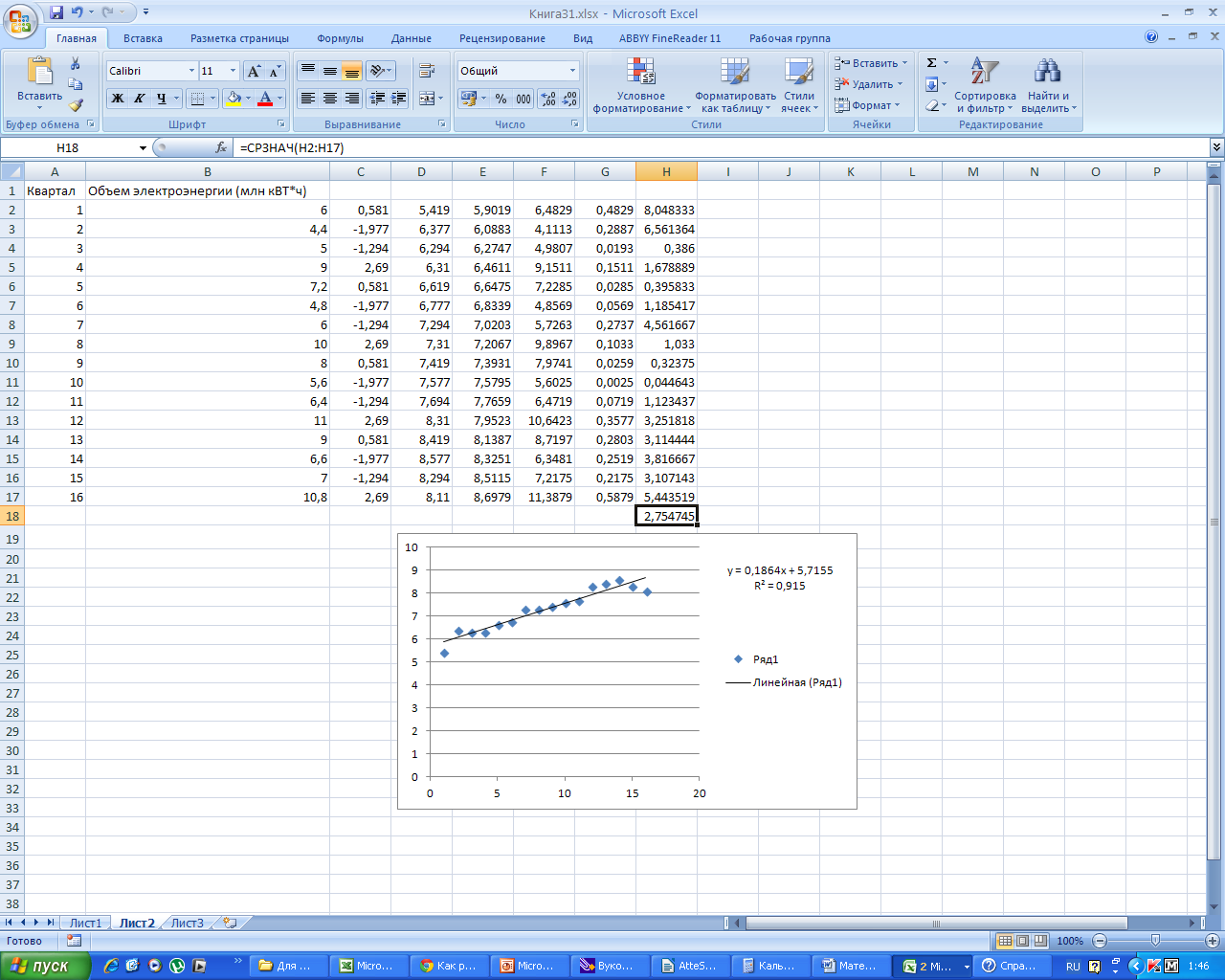
Таким
образом, заметим, что R2
= 0,915
0,75, средняя ошибка аппроксимации равна
2,75%< 3%. Значит, данная модель является
надежной.
Спрогнозируем
значения потребляемой электроэнергии
на следующий квартал. Для этого
воспользуемся вновь электронной
таблицей.

Заметим,
что полученное число 8,8843
млн. кВт/ч.
практически не отличается от полученного
ранее значения ![]() млн.
млн.
кВт/ч.
Приложение
2.
Соседние файлы в папке pravila
- #
- #
- #
- #
 Из данной статьи вы узнаете
Из данной статьи вы узнаете
- Что такое аддитивная сезонность,
- Как рассчитать аддитивную сезонность в Excel,
- Как учесть аддитивную сезонность в прогнозе.
Что такое аддитивная сезонность?
Сезонность можно разделить на 2 типа:
- Аддитивная;
- Мультипликативная.
В математике:
- Аддитивность — это операция сложения, формула прогноза F = T + S;
- Мультиплекативность – это операция умножения, формула прогноза F=T*S.
Где,
- T – это средняя или тренд;
- S – сезонность;
- F – прогноз.
Аддитивная сезонность измеряется в тех же единицах, что и ряд, т.е. если мы рассматриваем ряд с продажами в рублях по месяцам, то аддитивная сезонность будет выражена в отклонениях одного месяца относительно средней или тренда в рублях.
Мультипликативная сезонность измеряется в относительных единицах – коэффициентах и в среднем равна 1. Т.е. коэффициент января у нас может получится — 0,9, февраля — 1,1…
Аддитивную сезонность имеет смысл использовать, если амплитуда колебаний сезонности из года в год не меняется. Если амплитуда колебаний сезонности из года в год меняется (т.е. размах уменьшается или увеличивается), то используем мультипликативную сезонность.
Как рассчитать аддитивную сезонность в Excel?
Скачайте Excel-файл с примером расчета аддитивной сезонности
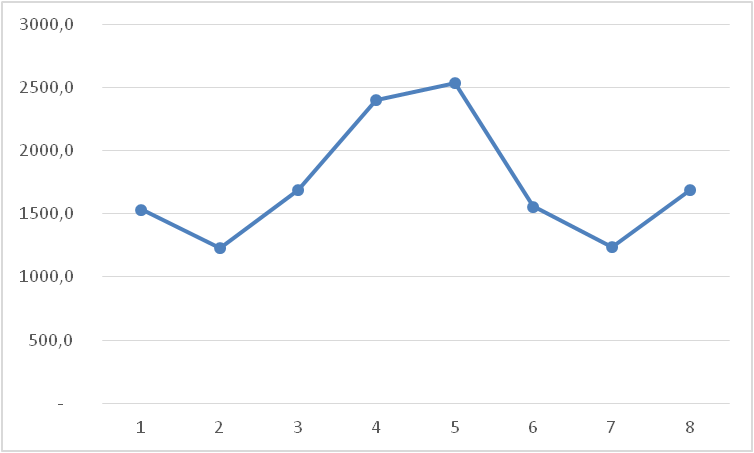
Возьмем продажи, например, муки по месяцам. Сезонность есть, но продажи из года в год стабильны, возрастающей амплитуды колебаний сезонности не наблюдается.
Для расчета аддитивной сезонности:
- Выделим линейный тренд из данных;
- Рассчитаем разницу «фактические продажи минус тренд»;
- Определим аддитивную сезонность по месяцам — среднее отклонение продаж от тренда для каждого месяца.
1. Выделим линейный тренд из данных.
Для расчета значений тренда для каждого периода времени пронумеруем значения временного ряда – продажи по месяцам:
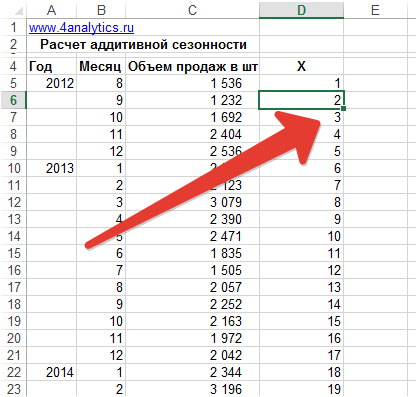
С помощью функции Excel =предсказ() рассчитаем значения тренда по месяцам:
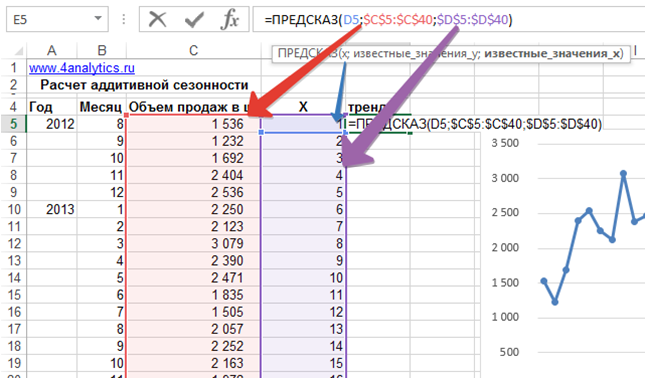
=ПРЕДСКАЗ где
- D5 – X – номер периода, для которого рассчитываем значение тренда;
- $C$5:$C$40 – известные значения y — фиксированная ссылка на диапазон с объемами продаж;
- $D$5:$D$40 – известные значения X – фиксированная ссылка на диапазон с номерами периодов.
Как зафиксировать ссылку, читайте в статье «Как зафиксировать ссылку в Excel».
Рассчитали значения тренда:
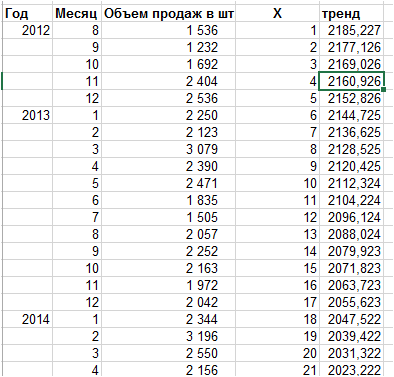
2. Рассчитываем разницу значений ряда и тренда — объем продаж минус тренд:
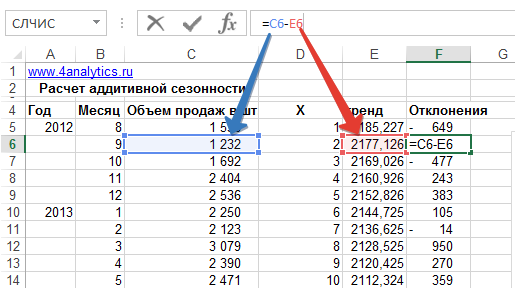
3. Определим аддитивную сезонность по месяцам — среднее отклонение продаж от тренда для каждого месяца.
Определяем среднее отклонение для каждого месяца:
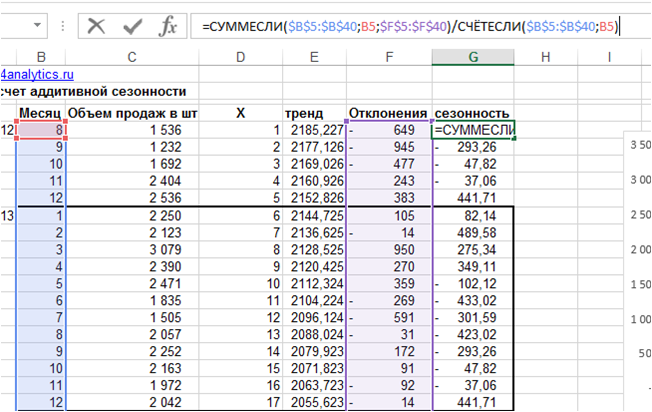
Т.к. первый и последний годы не полные, чтобы не запутаться с месяцами и формулами, воспользуемся формулой:
=СУММЕСЛИ($B$5:$B$40;B5;$F$5:$F$40)/СЧЁТЕСЛИ($B$5:$B$40;B5), где
- =СУММЕСЛИ — формула суммирует отклонения по заданным месяцам
- $B$5:$B$40; — ссылка на диапазон с номерами месяцев
- B5; — номер конкретного месяца для суммирования
- $F$5:$F$40 — ссылка на диапазон для суммирования
- / — делим сумму за определенный месяц на количество, получаем среднее по месяцам
- СЧЁТЕСЛИ — формула считает количество месяцев в диапазоне
- $B$5:$B$40; — диапазон с номерами месяцев
- B5 – номер конкретного месяца для счета
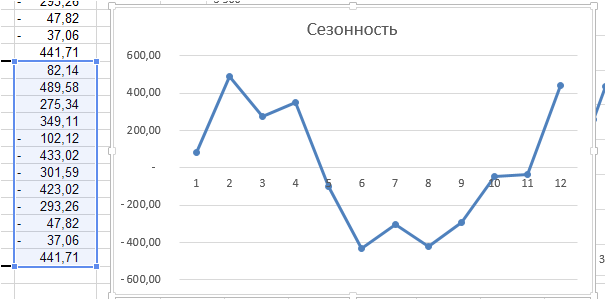
Получаем среднее отклонение по месяцам – аддитивную сезонность:
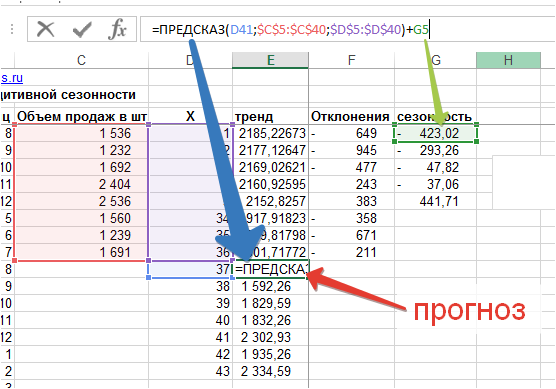
Для расчета прогноза:
- Продлеваем тренд в будущее;
- К тренду прибавляем аддитивную сезонность соответствующего месяца.
Получаем прогноз:
Скачайте Excel-файл с примером расчета аддитивной сезонности
Программа Forecast4AC PRO умеет автоматически подбирать аддитивную или мультипликативную сезонность, модель прогноза и подходит для прогноза большого массива данных.
Если есть вопросы, пожалуйста, обращайтесь!
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.