
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
- Китайский OCR
- Немецкий OCR
- Нидерландский OCR
- Английский OCR
- Французский OCR
- Итальянский OCR
Как распознать текст с изображения?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Язык и формат
Выберите все языки, используемые в документе. Кроме того, выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл
Эти сайты и программы помогут извлечь текстовое содержимое изображений и бумаг, чтобы вам было удобнее с ним работать.
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.
2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB*2.
FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
Перейти на сайт FineReader →
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
Перейти на сайт Online OCR →
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
Перейти на сайт img2txt →
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
Скачать Microsoft OneNote →
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Скачать Readiris 17 →
Читайте также 💻📎🖌
- 7 лучших текстовых редакторов, работающих в браузере
- Easy Screen OCR для Windows и macOS распознает текст с картинок или прямо с экрана
- Лучшие инструменты для массового переименования файлов в Windows, macOS и Linux
- 7 лучших текстовых редакторов, поддерживающих Markdown
- 10 отличных текстовых редакторов для разных платформ
*Деятельность Meta Platforms Inc. и принадлежащих ей социальных сетей Facebook и Instagram запрещена на территории РФ.
Для работы проектов iXBT.com нужны файлы cookie и сервисы аналитики.
Продолжая посещать сайты проектов вы соглашаетесь с нашей
Политикой в отношении файлов cookie
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.

Оптическое распознавание символов (OCR — Optical Character Recognition) — механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
- PDF — Adobe Acrobat Pro — эталон всех распознавателей.
- PDF24 tools — богатый инструментарий для работы с PDF-документами, включает OCR.
- NewOCR — заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
- Img2txt — сервис отличается красивым интерфейсом, но спасёт ли его это?
- Free Online OCR — простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
- Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков”. Текст был написан в ворде, затем переведён в PDF. Сложность может представлять надпись нестандартным шрифтом, мелкие буквы, а также текст на эмблеме, но в целом документ простой и имеет текстовый слой.
- Тот же фрагмент, но без текстового слоя — скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
- Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном — Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи — для работы с pdf-файлами.
Простой файл с текстовым слоем:

Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:

Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:

Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория — это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
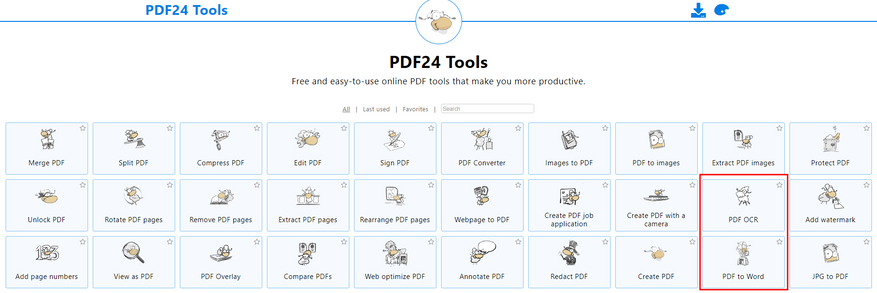
PDF24 tools — многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:

Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же — пустой лист. Но сервис предлагает три режима конвертации:
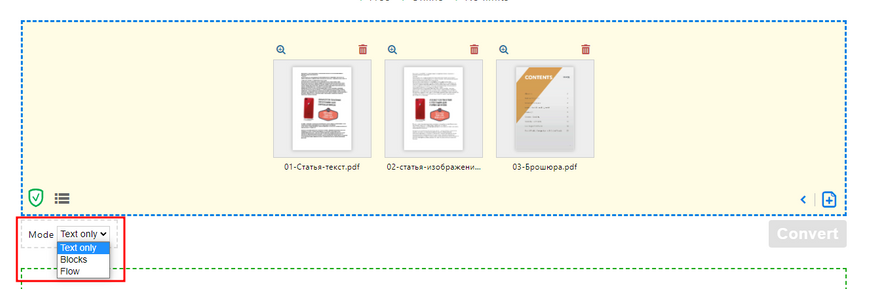
Я попробовал все три, лучший результат выдал третий режим «только текст»:

Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:

Вердикт:
Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR — нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
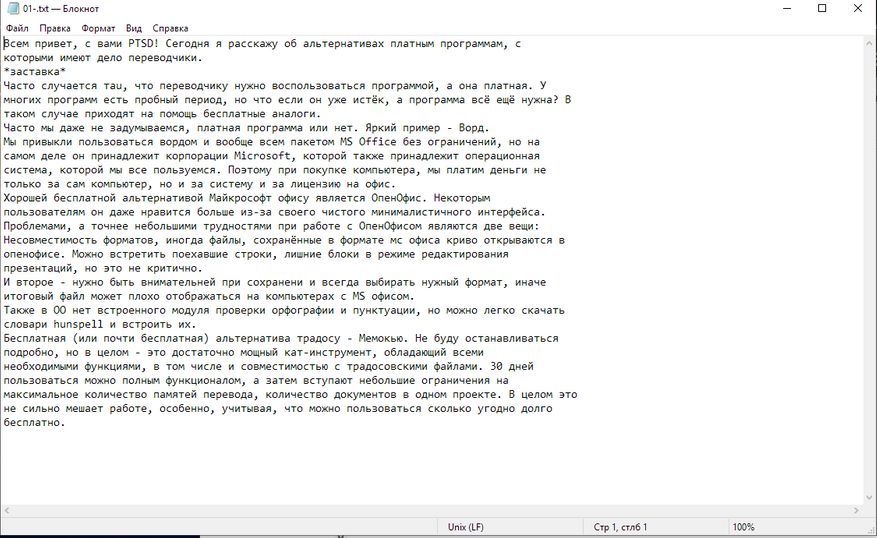
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:

Неплохо распознал основной язык — русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word. От чего это зависит — не знаю.
Сложный файл с непостоянным текстовым слоем:
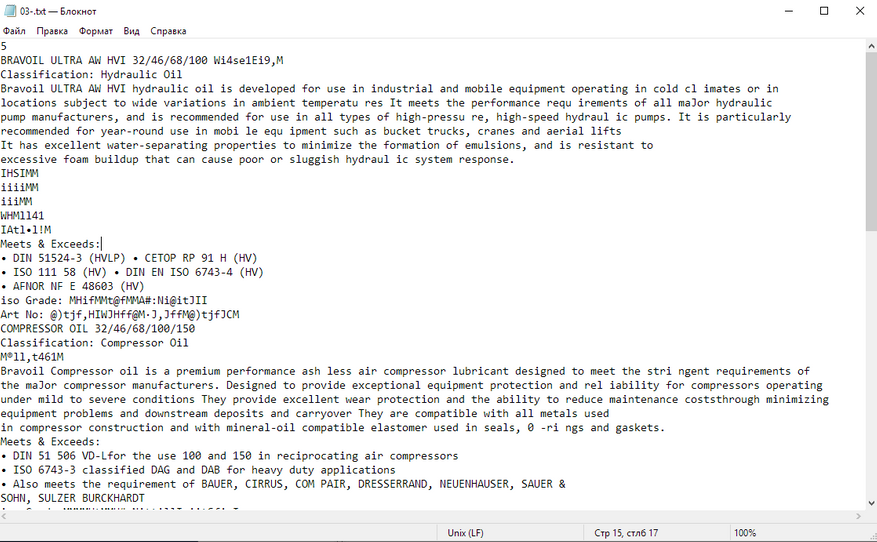
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Вердикт:
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет. А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше. Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
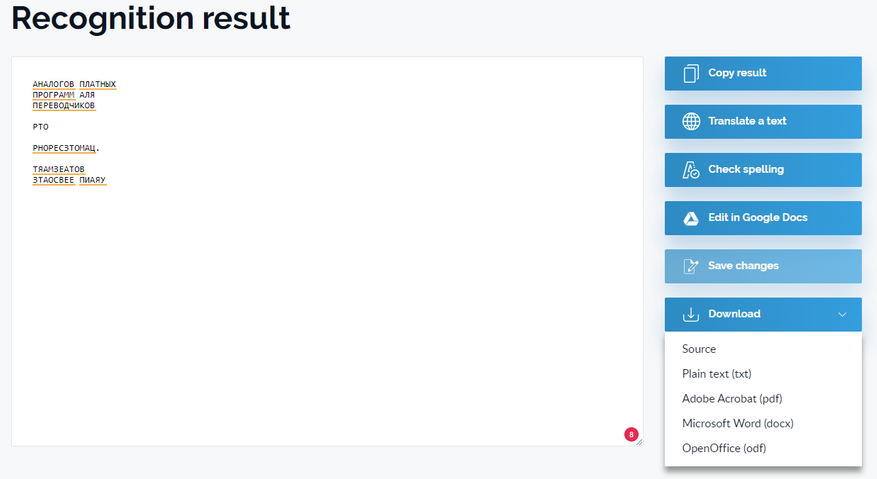
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
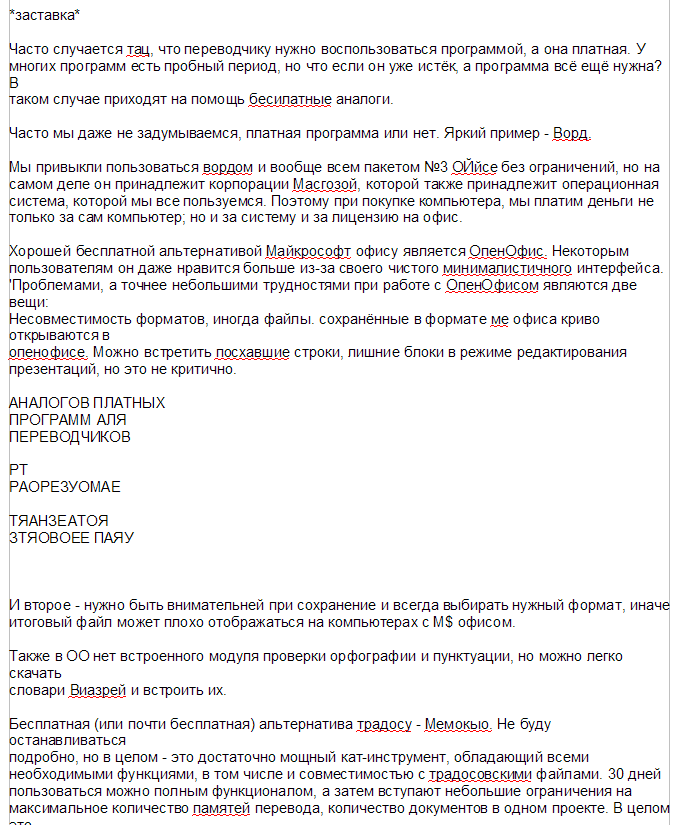
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
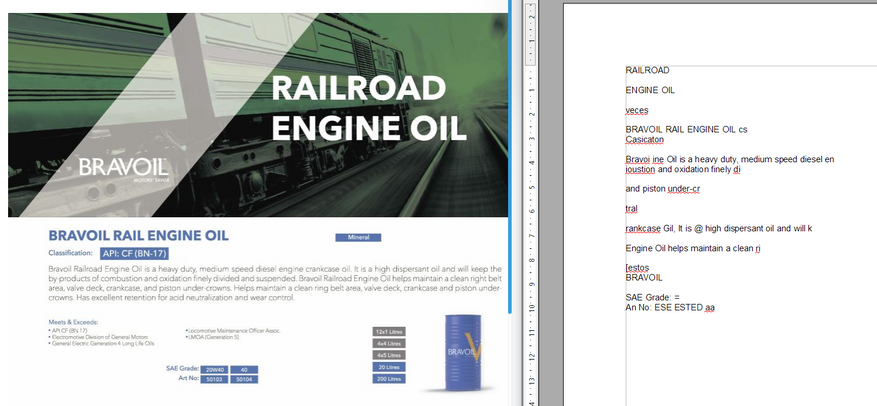
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Вердикт:
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда — это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум — 8 мб.
Online OCR — сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:

Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки — это ерунда. Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:

Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:

Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей. Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:

Вердикт:
Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
Я слышу слово «абьюз» или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными. Забавно получается.
Читайте другие статьи переводческого цикла:
Конвертор картинки в текст позволяет извлекать текст из изображения или конвертировать PDF в Doc, Excel или текстовый формат онлайн с помощью оптического распознавания символов
Реклама
1 ШАГ — Загрузить
Файл…
| 2 ШАГ — Выбрать язык и выходной формат |
3 — Конвертировать
Максимальный размер 15 mb.
Реклама
Используйте OCR онлайн |
для извлечения текста и символов из отсканированных PDF-документов (включая многостраничные файлы), фотографий и изображений, снятых цифровой камерой
Картинка в текст |
Любые изображения JPG, BMP или PNG могут быть преобразованы в текстовые форматы вывода с тем же макетом, что и исходный файл
Конвертировать PDF в DOC |
Конвертируйте PDF в WORD или EXCEL онлайн. Извлечение текста из отсканированных PDF-документов, фотографий и сканированных изображений бесплатно
Совместимость с iOS и Android |
Вы можете конвертировать файлы с мобильных устройств (iPhone или Android) или ПК (WindowsLinuxMacOS)
Безопасное преобразование |
Все документы, загруженные под гостевой учетной записью, будут автоматически удалены после конвертации. Выходные файлы для зарегистрированных пользователей хранятся один месяц
Бесплатный сервис |
Услуга OCR бесплатна для пользователей «Гость» (без регистрации) и позволяет конвертировать 15 файлов в час
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Выбрать языки источника
Перетащите документ в эту область
(Поддерживаемые форматы: PDF, BMP, GIF, JPG, JPEG, TIFF, PNG)
Как работает наш OCR сервис
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ?
Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
С помощью нашего сервиса вы можете преобразовать документы в формате Microsoft Word в формат PDF. Также, в любое время вы можете выполнить преобразование PDF в Word. Если необъодимо сконвертировать книгу в формате DJVU, воспользуйтесь этой ссылкой Djvu в PDF. Наш сервис также позволяет конвертировать изображения в pdf. Чтобы получить PDF из электронной книги ePub или документа Fb2, воспользуйтесь ссылкой ePub в PDF. Дополнительно разделение или объединение PDF можно выполнить на соответствующих страницах: Разделить PDF и Склеить PDF.
Что такое OCR
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
-
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
-
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения».
Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
-
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Преимущества нашего OCR сервиса
Широкий набор исходных форматов
Отсканированные PDF документы и различные форматы изображений
Нет ограничений
Как большие многостраничные книги, так и небольшие изображения
Ресурсы клиента
Всё распознавание выполняется на наших серверах