
Сбор семантики сайта представляет собой сложную и многоступенчатую задачу. Ее успешное решение предусматривает использование различных вспомогательных инструментов, включая специализированные программы и онлайн-сервисы. Но значительную часть выполняемых SEO-оптимизатором операций можно эффективно выполнять в обычных электронных таблицах Excel.
Речь идет не только о сортировке отобранных ключей, но и оформлении списка запросов, его последующем редактировании и чистке, а также подготовке базы данных для работы с другими сервисами или составления технического задания для копирайтера. А потому имеет смысл изучить порядок и особенности сбора семантического ядра в Excel более подробно, включая рассмотрение возможности, где можно скачать пример семантики, составленной в электронных Google Таблицах.
Содержание
- Виды Excel для сбора СЯ
- Этапы сбора семантического ядра с помощью Google Таблиц
- Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
- Шаг №2. Чистка семантического ядра
- Шаг №3. Кластеризация/группировка семантического ядра запросов
- Полезные функции Google Docs и Эксель
- Вспомогательные инструменты
- SeoTools for Excel
- SEO-Excel
- Рекомендации по использованию Google Docs для сбора СЯ
- Вместо вывода
Виды Excel для сбора СЯ
Для решения задач СЕО-оптимизации применяются две версии электронных таблиц. Первая поставляется в рамках стандартного пакета MS Office и представляет собой самостоятельную программу. Вторая – составной элемент Google Docs. Именно последний вариант пользуется сегодня все большим спросом, так как обладает рядом достоинств, в числе которых:
- доступность для любого обладателя аккаунта в Google;
- интеграция с программами из MS Office, включая обычные Эксель и Ворд;
- доступ к облачному хранилищу Google Диск, 15 ГБ которого предоставляется бесплатно и позволяет работать с Google Таблицами с любого устройства – от ПК до смартфона – сразу после авторизации.
На приведенном ниже скриншоте показан пример, как выглядят Google Таблицы. Приводить внешний вид традиционного Excel не имеет смысла, так как он прекрасно известен любому более-менее опытному пользователю ПК.

В остальном работа с обеими версиями программы – Excel и Google Docs – осуществляется по стандартным правилам, хорошо известным большинству пользователей. С учетом нескольких особенностей, характерных для SEO-продвижения сайтов по поисковым запросам.
Этапы сбора семантического ядра с помощью Google Таблиц
Некоторые специализированные сервисы, к примеру, Key Collector или Словоеб, обладают встроенными инструментами для форматирования структуры сайта и перечня ключевых слов и запросов. Поэтому не предполагают применение Excel. Но для значительной части других сервисов, включая один из самых популярных Яндекс Wordstat, использование Google Docs или Excel выступает одним из необходимых этапов работы. Более того, при грамотном применении возможностей электронных Google Таблиц удается упростить и оптимизировать сразу несколько важных операций по чистке семантического ядра. Рассмотрим последовательность предпринимаемых для этого действий с разбивкой на отдельные этапы.
Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
Функционал Excel предоставляет возможность составить список поисковых запросов вручную – посредством анализа продвигаемого сайта и деятельности компании. Но намного проще собрать исходное семантическое ядро с помощью Яндекс Wordstat. Чтобы сделать это, необходимо произвести следующие операции:
- Скачивание и установка расширения Яндекс Wordstat Assistant (подробнее о сервисе и расширениях к нему – на другой страницу нашего сайта). Сделать ссылку. В результате в левой части окна сервиса появится дополнительная панель инструментов.
- Выделение и сохранение интересующих пользователя запросов нажатием кнопки «+».
- Копирование сформированного списка поисковых запросов в Google Таблицы или обычный Эксель. Производится по одному из двух вариантов – с показателем частотности ключа или без него. Выбирается нужный пользователю способ копирования. Пример выполнения операции показан на скриншоте.

Шаг №2. Чистка семантического ядра
Основной задачей оптимизации СЯ запросов выступает повышение эффективности размещенных на сайте ключевых слов и фраз. Первым этапом становится избавление от ключей с низкой или даже нулевой релевантностью. Операция выполняется вручную, так как требует непосредственного участия SEO-специалиста. Ответ на вопрос, как почистить семантическое ядро, предусматривает удаление нескольких видов запросов, включая:
- самые низкочастотные (полное их удаление нецелесообразно, так как важно найти оптимальный баланс запросов с разной частотностью);
- ведущие на сайты конкурентов;
- лишние с предсказуемо низкой релевантностью из-за несоответствия задачам сайта;
- дубли (представляют собой поисковые запросы или фразы, которые различаются порядком слов).
Как было отмечено, удаление ненужных запросов происходит вручную. Для большего удобства и упрощения работы допускается как редактирование текущего листа электронных таблиц Google, так и перенос оптимизированного списка запросов на вновь созданный.
Шаг №3. Кластеризация/группировка семантического ядра запросов
Завершающий этап работы по СЕО-продвижению сайта с помощью Excel предполагает проведение кластеризации или группировки поисковых запросов. Она предусматривает разбивку общего списка ключевых слов или фраз для размещения на отдельные страницы в соответствии с предварительно разработанная структурой интернет-ресурса. Оптимальное количество запросов на каждую равняется 5-6, для очень объемных оно может быть несколько увеличено.
Операция также выполняется вручную с применением традиционного функционала Google Таблиц или Excel. Автоматизировать данные действия специалиста можно только с использованием специализированного инструментария, хотя даже самые современные и многофункциональные сервисы не способны выполнять такую работу на требуемом уровне.
Дальнейшие операции с собранным семантическим ядром производятся в зависимости от задач, стоящих перед СЕО-специалисту. Это может быть или составление технического задания копирайтеру, или дальнейшая оптимизация СЯ с использованием других программ или сервисов. Примеры готовой семантики, составленной в Эксель, можно с легкостью найти в сети, например, по следующей ссылке.
Полезные функции Google Docs и Эксель
Подробно описывать набор функциональных возможностей самой популярной программы электронных таблиц не имеет особого смысла. Опытным пользователям они прекрасно известны, а новичкам намного проще и правильнее разобраться самостоятельно, так как это наверняка пригодится в дальнейшей работе. Главное – знать о существовании таких возможностей, как:
- копирование и удаление ссылок из семантического ядра;
- замена отдельных слов или элементов списка запросов;
- удаление ненужных или лишних пробелов, включенных в СЯ;
- сортировка запросов по значениям любого из столбцов по двум параметрам – алфавиту или числу;
- поиск повторяющихся значений или минус-слов для последующего удаления вручную;
- удаление дубликатов из состава семантического ядра;
- сортировка запросов по цвету ячейки и многое другое.
Вспомогательные инструменты
Google Таблицы и традиционный Эксель обладают обширным функционалом. Но далеко не все опции эффективны применительно к СЕО-продвижению сайтов по поисковым запросам. Именно поэтому активно разрабатываются дополнительные надстройки к традиционным электронным таблицам. Два из них – самые известные и популярные – имеет смысл привести отдельно, хотя количество подобных инструментов постоянно растет.
SeoTools for Excel
Одно из первых расширений для электронных таблиц, которое разработано специально для SEO-продвижения. Обладает обширным функционалом, постоянно обновляется, совместимо с различными онлайн-сервисами и программами. Из недостатков – отсутствие версии для русскоязычных пользователей. Чтобы скачать программу, достаточно перейти на сайт разработчика и зарегистрироваться на нем.

SEO-Excel
Русскоязычный аналог описанной выше надстройки. Содержит более двух десятков инструментов для СЕО-продвижения. Чтобы скачать программу, достаточно зарегистрироваться на сайте, хотя возможно платное использование онлайн-версии продукта. SEO-Excel адаптирован для работы с Яндекс Wordstat и Rush-Analytics, что объясняет популярность среди отечественных специалистов. Дополнительный аргумент скачать и установить надстройку – очень полезная опция генерации различных тегов – H1, Title и Description, заметно упрощающая работу SEO и экономящая его время, в том числе – при составлении технического задания копирайтеру.

Рекомендации по использованию Google Docs для сбора СЯ
Главным достоинством Excel и Google Таблиц справедливо считается доступность. Оборотной стороной становится необходимость выполнять значительную часть операций СЕО-оптимизации вручную. Чтобы упростить собственную работу, имеет смысл воспользоваться несколькими простыми рекомендациями:
- внимательно изучайте руководство пользователя, так как некоторые функции электронных таблиц выступают секретом даже для очень опытных специалистов;
- автоматизируйте самые рутинные и трудоемкие процессы за счет грамотного использования встроенных опций и сервисов;
- скачивайте и устанавливайте дополнительные надстройки, предназначенные для SEO-продвижения (важное дополнение – загрузка должна выполняться только с проверенных сайтов компаний-разработчиков).
Вместо вывода
Важно понимать, что полная автоматизация процесса SEO-продвижения сайта по поисковым запросам попросту невозможна. Никакие сервисы и программы не способны заменить опыт и квалификацию грамотного специалиста, хотя существенно помогают в его работе при грамотном использовании. Именно поэтому имеет смысл сотрудничать с профессионалами, а вложенные средства с лихвой окупаются повышением эффективности интернет-ресурса.
Наша компания оказывает полный комплекс услуг в области SEO-оптимизации на выгодных и привлекательных для клиентов условиях. Для получения персонального коммерческого предложения достаточно связаться с нами любым удобным способом.

Скачать готовые примеры семантических ядер в новом Excel формате
Перейти к содержанию
Скачать бесплатно готовые примеры
семантики для сайтов в Экселе
✓ 20 примеров готовой семантики (описание + бюджет).
✓ Представлены самые популярные (заказываемые) темы.
✓ Быстрый запрос на получение примера для вашей тематики.
✓ Новый формат семантического ядра и отчетов от 07.2022.
✓ Архивы содержат платные ТЗ копирайтеру от TaskБилдер.
✓ Цена от 100$ за семантику «под ключ». Срок от 10 дней.
✓ 8 наших «фишек» и инструментов при сборе СЯ: перейти.
На наших примерах оцените:
✅ Стоимость семантики в вашей/похожей тематике.
✅ Качество сбора/группировки ключей и полноту кластеров.
✅ Удобство оформления и навигацию по ядру в Excel.
✅ Доп. отчеты по анализу конкурентов, сложности продвижения…
✅ Формат платного (Excel+Tskb) и бесплатного (Txt) ТЗ для копирайтера.
Финальная стоимость семантического ядра зависит от:
✅ Региона.
✅ Тематики / номенклатуры продукции.
✅ Нижнего порога частотности: «!WS» / GA.
✅ Вида запросов в ядре (коммерция, инфо, оба варианта).
✅ Сколько ключей вы удалите при утверждении после сбора.
Нет примера вашей тематики? Не можете оценить бюджет?
Подайте бесплатную заявку на пример.
«Бухгалтерские услуги».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 378 шт.
Количество кластеров: 38 шт.
Общая частотность запросов по Wordstat: 12 793.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
«Для строительного сайта».
Бани, готовые элитные дома, новостройки, для модульных зданий, монтаж систем отопления и водоснабжения.
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 8 034 шт.
Количество кластеров: 346 шт.
Общая частотность запросов по Wordstat: 220 127.
Срок выполнения: 13 дней.
![]() Цена: 280 $
Цена: 280 $![]() Скачать пример ядра
Скачать пример ядра
«Сантехника».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 6 200 шт.
Количество кластеров: 590 шт.
Общая частотность запросов по Wordstat: 75 570.
Срок выполнения: 11 дней.
![]() Цена: 340 $
Цена: 340 $![]() Скачать пример ядра
Скачать пример ядра

Хотите пример ядра
по вашему региону и нише?
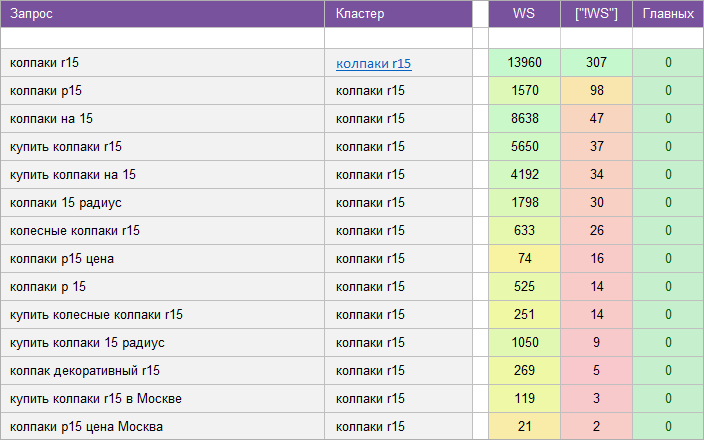
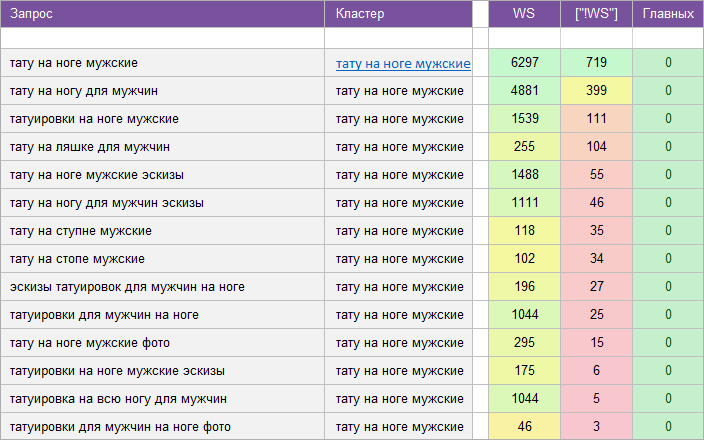
«Салон красоты».
Покраска, маникюр, эромассаж и т.д.
Регион: Москва.
Вид ключевых слов: Коммерческие + Инфо.
Кластеризованных запросов: 11 958 шт.
Количество кластеров: 892 шт.
Общая частотность запросов по Wordstat: 200 897.
Срок выполнения: 12 дней.
![]() Цена: 385 $
Цена: 385 $![]() Скачать пример ядра
Скачать пример ядра
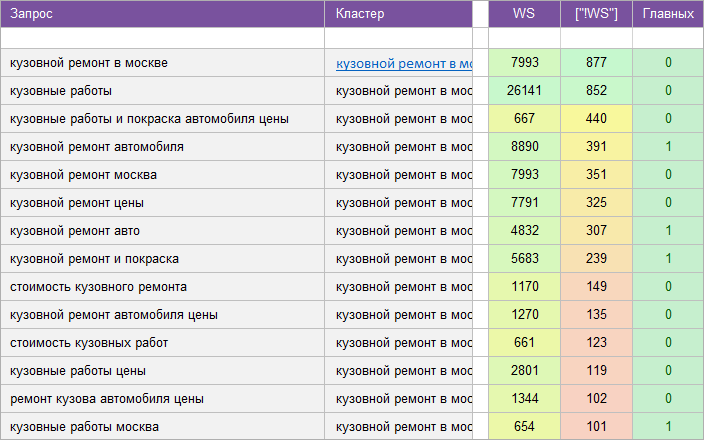
«Автосервис».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 4 073 шт.
Количество кластеров: 396 шт.
Общая частотность запросов по Wordstat: 386 236.
Срок выполнения: 10 дней.
![]() Цена: 175 $
Цена: 175 $![]() Скачать пример ядра
Скачать пример ядра
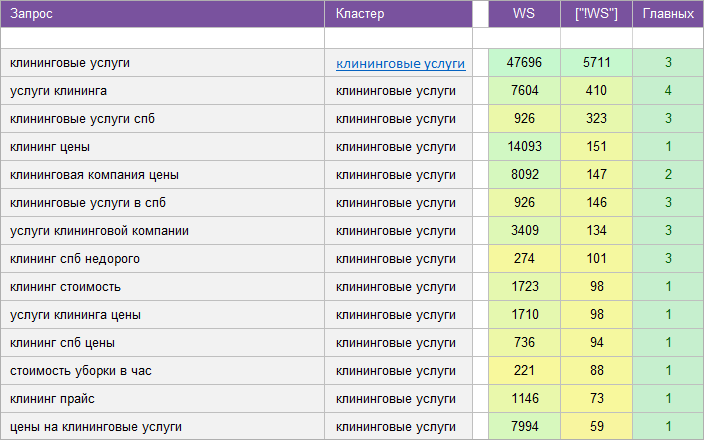
«Услуги клининговой компании».
Регион: Санкт-Петербург.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 100 шт.
Количество кластеров: 167 шт.
Общая частотность запросов по Wordstat: 27 500.
Срок выполнения: 7 дней.
![]() Цена: 115 $
Цена: 115 $![]() Скачать пример ядра
Скачать пример ядра
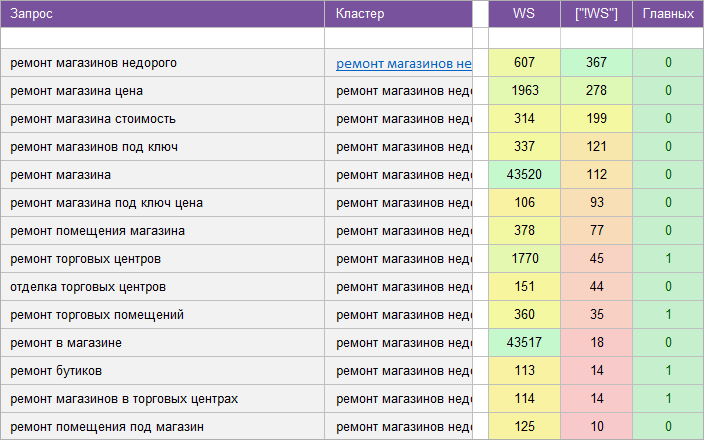
«Ремонт недвижимости».
Ремонт квартир, домов и прочей недвижимости.
Регион: Москва и МО.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 3 288 шт.
Количество кластеров: 306 шт.
Общая частотность запросов по Wordstat: 55 322.
Срок выполнения: 10 дней.
![]() Цена: 165 $
Цена: 165 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
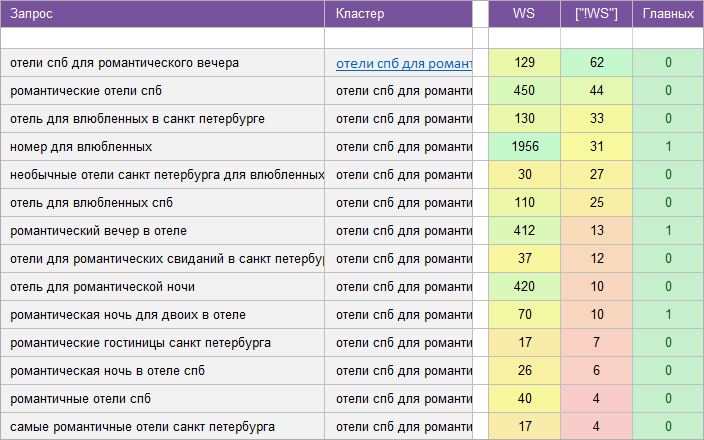
«Для отелей и гостинец».
Регион: Санкт-Петербург и область.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 6 408 шт.
Количество кластеров: 511 шт.
Общая частотность запросов по Wordstat: 123 421.
Срок выполнения: 9 дней.
![]() Цена: 352 $
Цена: 352 $![]() Скачать пример ядра
Скачать пример ядра
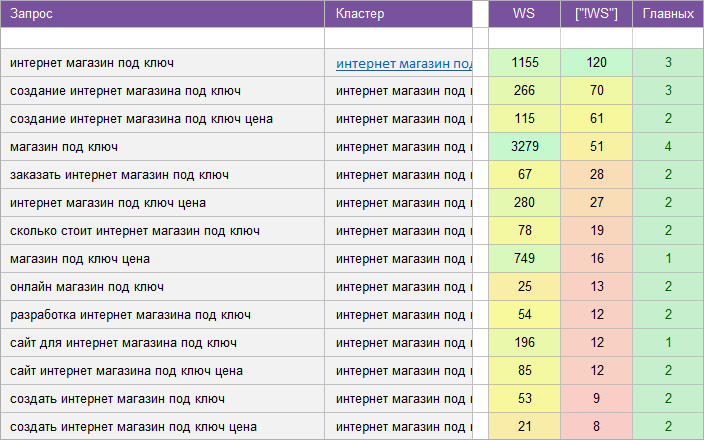
«Для веб-студии».
Регион: Весь Рунет.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 14 500 шт.
Количество кластеров: 926 шт.
Общая частотность запросов по Wordstat: 350 700.
Срок выполнения: 15 дней.
![]() Цена: 725 $
Цена: 725 $![]() Скачать пример ядра
Скачать пример ядра
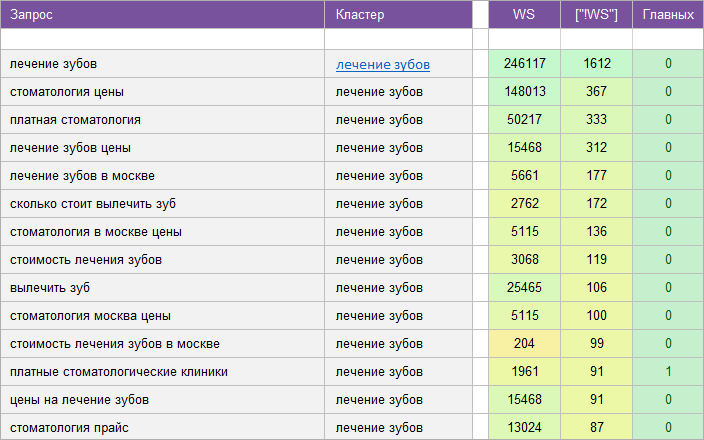
«Стоматология».
Регион: Москва.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 8 253 шт.
Количество кластеров: 650 шт.
Общая частотность запросов по Wordstat: 138 934.
Срок выполнения: 12 дней.
![]() Цена: 300 $
Цена: 300 $![]() Скачать пример ядра
Скачать пример ядра
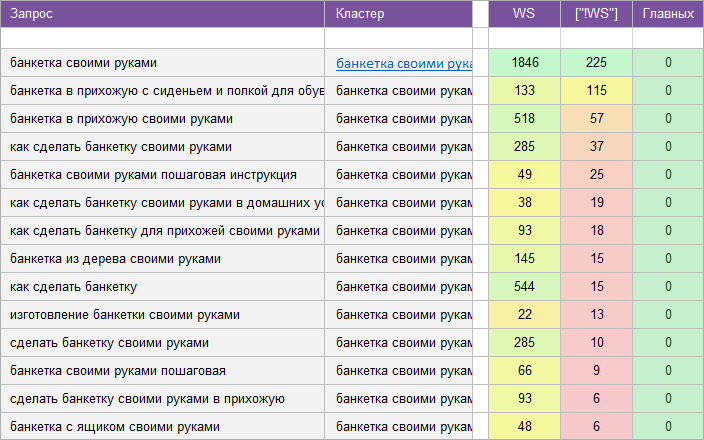
«Мебель и предметы интерьера».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 22 016 шт.
Количество кластеров: 843 шт.
Общая частотность запросов по Wordstat: 899 870.
Срок выполнения: 14 дней.
![]() Цена: 575 $
Цена: 575 $![]() Скачать пример ядра
Скачать пример ядра
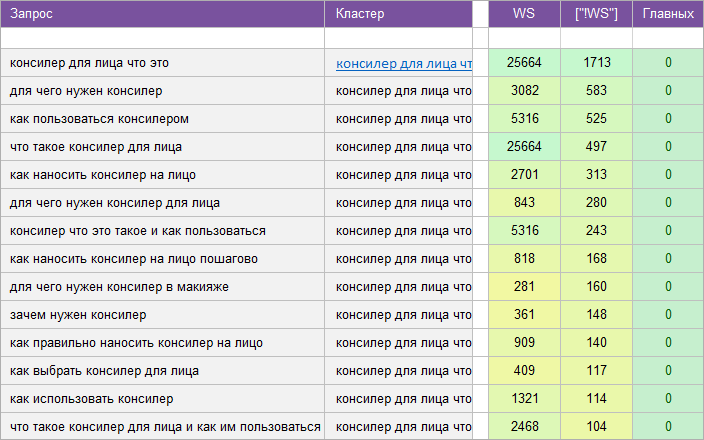
«Для женского сайта».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 16 544 шт.
Количество кластеров: 693 шт.
Общая частотность запросов по Wordstat: 2 358 018.
Срок выполнения: 12 дней.
![]() Цена: 455 $
Цена: 455 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
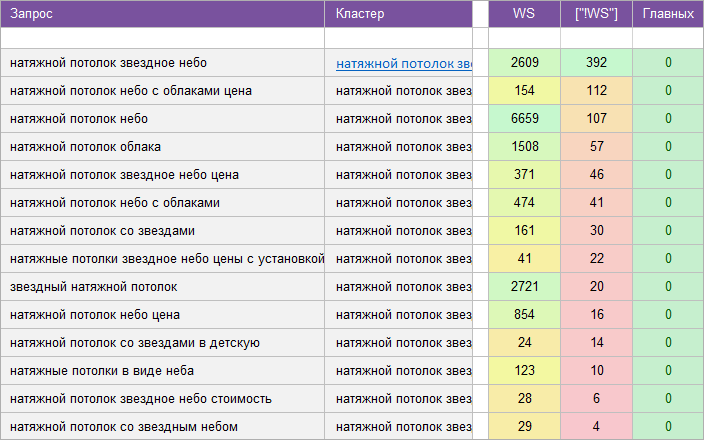
«Натяжные потолки».
Регион: Санкт-Петербург и ЛО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 493 шт.
Количество кластеров: 45 шт.
Общая частотность запросов по Wordstat: 13 558.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
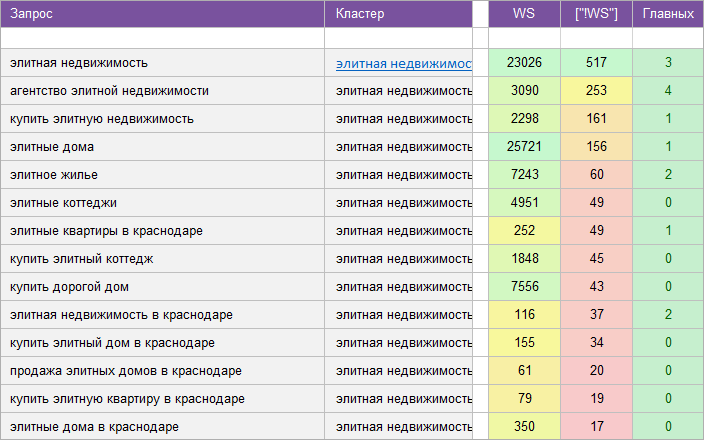
«Агентство недвижимости».
Регион: Краснодар.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 14 469 шт.
Количество кластеров: 1 341 шт.
Общая частотность запросов по Wordstat: 200 056.
Срок выполнения: 15 дней.
![]() Цена: 500 $
Цена: 500 $![]() Скачать пример ядра
Скачать пример ядра
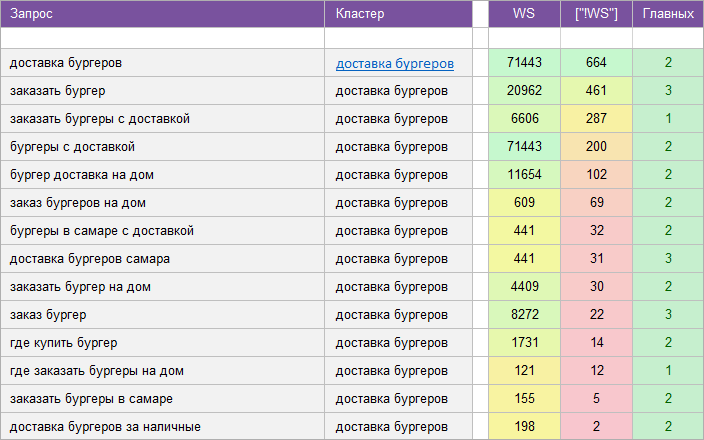
«Доставка еды».
Регион: Самара.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 585 шт.
Количество кластеров: 238 шт.
Общая частотность запросов по Wordstat: 19 501.
Срок выполнения: 9 дней.
![]() Цена: 140 $
Цена: 140 $![]() Скачать пример ядра
Скачать пример ядра
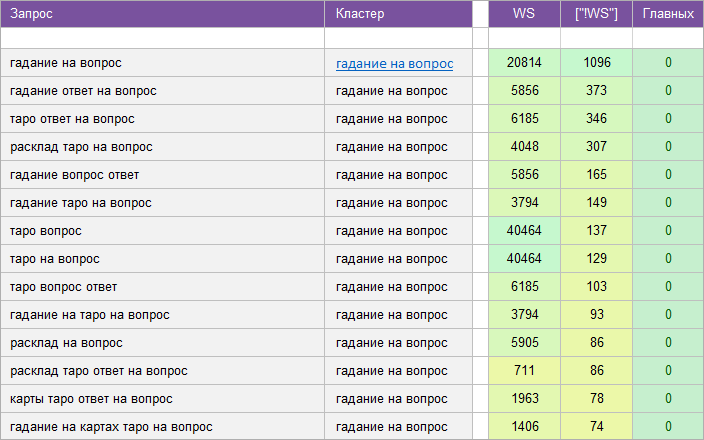
«Карты Таро».
Регион: Россия.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 9 196 шт.
Количество кластеров: 557 шт.
Общая частотность запросов по Wordstat: 992 132.
Срок выполнения: 14 дней.
![]() Цена: 285 $
Цена: 285 $![]() Скачать пример ядра
Скачать пример ядра
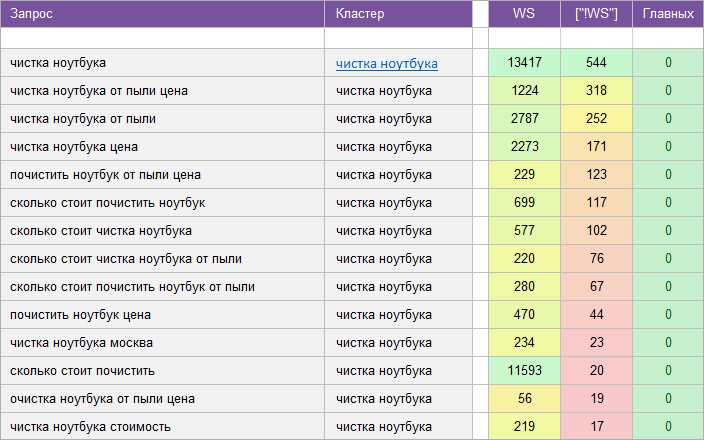
«Ремонт компьютеров и ноутбуков».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 3 437 шт.
Количество кластеров: 321 шт.
Общая частотность запросов по Wordstat: 51 753.
Срок выполнения: 8 дней.
![]() Цена: 190 $
Цена: 190 $![]() Скачать пример ядра
Скачать пример ядра
Самые популярные вопросы — ответы:
На одной странице невозможно собрать примеры во всех тематиках.
Но, вы можете подать заявку на получение бесплатного примера в вашей тематике: заполнить.
На полученном примере вы можете оценить качество нашей семантики.
После изучения наших примеров, вы подаете бриф.
А мы собираем для вас ядро и экономим: средства/нервы/время.
1. Средства. Вам не надо покупать:
✓ Платные сервисы (Serpstat, keys.so) — от 250$.
✓ Программы и скрипты (KeyCollector, a-parser) — от 50$.
✓ Прокси (минимум 10 приватных) — от 20$.
✓ АнтиКаптча — от 30$.
✓ Регистрация и поддержка аккаунтов Яндекса и Google в рабочем состоянии — от 0$.
2. Нервы:
Сотни сообщений за день в Телеграм канале @KeyCollectorCHAT связанных с проблемами сбора, чистки и кластеризации запросов. В последнее время поисковые системы значительно усложнили процесс парсинга.
3. Время:
Мы 9 лет разрабатываем нашу систему по работе с семантикой, отлаживаем все тех. процессы, отбираем лучшие прокси для парсинга и систему разгадывания каптч. Все это позволяет нам максимально автоматизировать и ускорить все процессы.
Без опыта и наработок только сбор запросов и параметров может растянуться у вас на дни.
Наше семантическое ядро состоит из:
✓ Главного файла «yadro.xlsx». Отчеты в файле: «Семантическое ядро», «Структура», «ТОП доменов конкурентов», «Описание полей и колонок».
✓ Дополнительные отчеты (отдельные файлы): «Аналитика по запросам», «Сезонность», «ТОП внешних ссылок», «Популярные слова и фразы»
✓ Тз для копирайтера (платная Excel или бесплатная Txt версия).
Важно: из главного файла «ядро.xlsx» ссылки ведут на дополнительные отчеты и ТЗ для копирайтера.
Это позволяет выполнять быструю навигацию, а не искать доп. отчеты по папкам.
В наших архивах находится больше 6500 готовых ядер, которые мы составили за 9 лет.
Но, мы НЕ продаем готовую семантику.
Почему? Отвечаем:
✓ Семантика — это анализ ТЕКУЩЕГО спроса в тематике. Актуальность семантики — один из главных факторов успешного внедрения на сайт. Со временем семантика «стареет». Появляются новые запросы, у некоторых пропадает спрос (пример: устаревшая модель телефона или кондиционера).
✓ Специфика бизнеса. Нет компаний, которые на 100% предоставляют одинаковые услуги или продают одинаковые товары. Пример: Мы делали 4 ядра в тематике: Клининг (Москва). Все 4 ядра отличаются по размеру, самое маленькое ядро получилось 1300 запросов, а самое большое 3800.
За 9 лет работы мы составляли семантику для сайтов во всех нишах.
На данной странице представлены примеры тематик, с которыми мы чаще всего работали.
Плюс, есть опыт в сложных тематиках: беттинг (ставки на спорт), гемблинг(казино), криптовалюта, гейминг, пластиковые окна и двери, кондиционеры.
Собирали семантику на: русском, английском, польском, немецком языках. Под Бурж и Рунет.
Да. Сейчас ядра у нас выгружаются в 3 версии оформления шаблона. Дата внедрения: 07.2022.
Что нового:
✓ Разработали максимально удобную систему навигации между отчетами и ТЗ для копирайтера.
✓ Подобрали приятную цветовую гамму заливки ячеек. Зеленый – хорошо, красный – плохо/сложно.
✓ Сформировали наглядные графики/таблицы изменения спроса в отчете «Сезонность».
✓ Быстрое скрытие/раскрытие групп колонок в шапке. Позволяет оставить на экране только нужные данные и не терять фокус внимания при анализе.
✓ Максимально простое и подробное описание всех колонок и параметров (вкладка «Описание полей»).
Полная переработка «helpа».
Все это позволяет максимально эффективно работать с собранной аналитикой.
Нет примера в нужной
Вам тематике?
Бесплатная консультация
от руководителя

составлению семантического ядра.
Page load link

Закажите семантическое ядро + внесите предоплату до 31.03.2023 и получите:
1. Скидку на сбор запросов — 15%.
2. Наше новое ТЗ для копирайтера в
Excel + Tskb формате (описание) — 50%.
3. Консультацию от руководителя на 1-1,5 часа
по работе с ядром и ТЗ — бесплатно.

Укажите в брифе ваш
промокод: prom2023
Содержание статьи
- Определение термина
- Зачем нужно семантическое ядро?
- Из чего состоит семантика?
- Как использовать СЯ?
- Примеры семантического ядра
- Составлять самому или делегировать?
- Что ещё нужно знать о семантике
Всем привет. Начинаю цикл статей по семантическому ядру, где мы с вами разберём всё, что можно разобрать по этой теме. С чего начнём? Декарт сказал как-то: «Определив точно значения слов, вы избавите человечество от половины заблуждений». Спасибо, браток! Вот с этого и начнём — определимся, что это вообще такое.
Определение термина
Семантическое ядро — это список поисковых запросов для продвижения сайта. Ну это если не выпендриваться и объяснить простыми словами, как это сделано в моём SEO-словаре. А если мы хотим выпендриться? Как лучше поступить в таком случае? В этом случае можно сослаться на определение из SEO-словаря компании «Пиксель Плюс»: «совокупность целевых поисковых запросов, по которым продвигается или планируется к продвижению проект». Либо на определение SEONews — одного из крупнейших ресурсов по теме SEO: «Семантическое ядро – набор слов и ключевых фраз, по которым будет продвигаться сайт в поисковых системах. Иначе говоря, это слова, по которым пользователи будут находить сайт в результатах поиска». Ну вы поняли.
Зачем нужно семантическое ядро?
Оно нужно для увеличения эффективности от продвижения сайта в поисковых системах. А как именно оно помогает увеличить эту самую эффективность?
Во-первых, наличие правильной семантики позволить вам составить структуру сайта. Вы будете знать, какие рубрики и страницы создать на сайте и в каком порядке, какие должны быть меню и так далее. Соответственно, это поможет систематизировать и упорядочить работу по продвижению сайта, составить план работ, а также не забыть про некоторые важные части этих работ. Без семантики эти работы будут представлять собой совершенный хаос.

Вот как выглядит продвижение сайта без семантического ядра
Во-вторых, семантическое ядро позволит вам сэкономить деньги. Вы сгруппируете часть запросов и не будете создавать под каждый запрос по странице, не будете создавать лишние страницы и будете следовать плану развития, не спуская деньги на ненужные изменения в сайт.
В-третьих, СЯ увеличит эффект от вашего продвижения. Понятная структура сайта, размещение похожих запросов на одной странице, отсутствие страниц, дублирующих друг друга по смыслу — всё это очень высоко оценят поисковые системы.
В-четвёртых, оно позволит вам отслеживать этот эффект. Ведь если у вас нет списка запросов, как вы будете смотреть, какие места по каким запросам занимает сайт в поиске? Без этого также будет тяжело понимать, какие нужно меры предпринимать в случае отсутствия прогресса в продвижении сайта.
В-пятых, на основе семантики вы будете составлять технические задания на тексты, а также SEO-теги к этим текстам. Если же вы будете составлять ТЗ не на основе семантики, а на основе чего-либо другого, то такие тексты с большой вероятностью не принесут вам трафика, поскольку не будут оптимизированы под ключевые слова.
В-шестых, по ходу процесса составления семантического ядра вы можете хорошо изучить ваших конкурентов, и, возможно, вам в голову придут какие-то полезные идеи для совершенствования собственного сайта.
Вот неплохое и очень подробное видео от Semantist.ru, которое шире отвечает, зачем нужна семантика:
В сумме имеем такой вывод, что без семантического ядра вы создадите бесструктурный проект без плана развития, то есть ваши работы по продвижению сайта будут бесполезны. Впрочем, у семантического ядра есть и свои недостатки. Это, прежде всего, трудоёмкость составления, и временные затраты, которые могут занимать один месяц, а то и больше. Кроме того, если вы составили семантику неправильно, то эффект от неё может быть ненамного больше, чем если бы её не было, а финансовые затраты на продвижение в некоторых случаях могут стать выше.
Из чего состоит семантика?
Схема классического семантического ядра проста. Оно состоит из ключевых слов, которые объединены в группы, а эти группы объединены в категории. Также семантика часто содержит данные о запросах — их частотность, показатели конкурентности, геозависимость и так далее.

На изображении выше, например, категории — это «Стулья», «Столы» и «Шкафы», а, например, «Стул ИКЕА МАРТИН» или «Стул ИКЕА КЮРЕ» — это группы запросов.
Зачем нужна такая структура? Деление семантического ядра на категории помогает нам понять, какие рубрики должны быть на сайте, чтобы он успешно продвигался. Деление на группы помогает понять, сколько на сайте должно быть страниц (1 группа запросов = 1 страница на сайте), и в каких категориях они должны быть. Подробнее о типах страниц читайте в этой статье.
Как использовать СЯ?
Семантическое ядро — это то, на основе чего вы планируете работы по продвижению сайта. Сначала вы создаёте на сайте рубрики и меню в соответствии с категориями из семантического ядра. А потом в этих рубриках создаёте страницы, и каждую из этих страниц оптимизируете (прописываете метатеги, создаёте контент) под соответствующую ей группу запросов.
Когда вы создадите по странице на каждую группу запросов, у вас будет готовый сайт, привлекающий трафик (если всё сделано правильно) и который нужно будет в будущем просто дорабатывать. Вот пара видео, где показывается, что делать с семантикой, когда она уже составлена:
Примеры семантического ядра
Вы можете узнать, как выглядит семантическое ядро, скачав вот этот или вот этот примеры семантических ядер в формате Excel. Также готовые примеры в формате xls вы можете скачать на сайте Семён-Ядрёна здесь и здесь.

Так выглядит часть семантического ядра от сервиса «Семён-Ядрён»
Портфолио есть у Rush Analytics, вот оно — там тоже есть пара примеров в формате Excel. Я также отдельно писал статью про единый файл семантики для интернет-проектов, там расписан этот момент подробнее.
Составлять самому или делегировать?
Тут вопрос целиком зависит от того, есть ли у вас свободное время и желание с упорством. Если этого вообще нет — делегируйте. Конечный результат будет не идеальным, а может и вообще оказаться слабоватым, но без свободного времени и желания очень хорошо разобраться в вопросе вы не сможете самостоятельно дать результат лучше. Если же у вас есть время и желание — надо делать самому. Когда я завершу свой цикл статей о семантике, вам достаточно будет лишь следовать моим инструкциям, чтобы на выходе получить очень качественное СЯ.
Раньше, когда я работал на количество сайтов, а не на качество, я заказывал очень недорого, но вполне годно семантику у Семантического жирафа с кворка. Если вы не опытный сеошник, то с вероятностью в 90% он сделает вам ядро лучше, чем вы сделаете это сами. За косарь обычно уложитесь — получите и нормальную эффективность, и экономию времени.
Что ещё нужно знать о семантике
При работе с семантическим ядром, то есть с ключевыми словами, не лишним будет узнать, какие существуют виды этих ключевых слов, что я подробно описывал здесь. Также в отдельной статье я напишу, как правильно составлять СЯ.
Хочется также отдельно сказать о статье на «Текстерре», которая называется «Что такое семантическое ядро и как его составлять». В этой статье они пытаются намекнуть, что, мол, устоявшийся подход к семантике — это подход сеошников старой школы, а мы такие охеренные, что делаем по-другому. Мы, мол, берём в продвижение даже те запросы, которые нихера не имеют частотности, потому что мы современные и крутые, а не тупые старые сеошники. Это попытка манипуляции — противопоставить себя остальному профессиональному сообществу, навесив на неё уничижительный ярлык «старая школа», чтобы заполучить в клиенты тех, кто «купится» на эту «инаковость» (благо «нетакимикаквсе» Россия просто кишмя кишит). На самом деле я не удивлюсь, если они составляют такие ядра только потому, что им лень их чистить от мусорных запросов + чтобы слить побольше бюджетов на тексты, распилив часть из них. Это не означает, что «Текстерра» — лохи; нет, это умные челы, у которых полно высококлассной инфы. Но не все преподносят эту инфу беспристрастно.
Поделились внутренним инструментом, который анализирует собранные фразы и показывает, где и что еще можно добрать.
В маркетинге мы предпочитаем опираться на математику, а не на интуицию. Если есть задача проверить семантику на полноту — значит, должен быть инструмент, который перетрясет собранные фразы и покажет, где и что еще можно добрать. Сервисов аналогичных нет, поэтому мы нашу внутреннюю модель вынесли в Excel-файл — скачивайте и пользуйтесь.
Вам понадобятся: фразы и их частоты — общие и точные.
Принцип такой: вносим в Excel-файл фразы и частоты, жмем на кнопку и через несколько секунд, когда сформируются связи «фраза-хвост» и отсекутся доли нерелевантного объема, по маркерам определяем — где мы не доработали.
А теперь подробнее.
Идеально отработанная семантика
Если семантика отработана идеально, Excel-файл выглядит так:
- значения в столбце H (расчетная частота) близки к значениям в столбце D (точная частота) у всех фраз, кроме низкочастотных и тех, в которых больше всего значимых слов.
- столбец J (коэффициент отработки) зеленого цвета.
- столбец K (коэффициент неотработки) зеленого цвета
Неполная семантика: что упустили и как доработать
По маркерам файла мы можем понять 3 момента.
- Мы не добрали хвосты.
- Не досчитали трафика.
- Собрали некачественные хвосты.
Не добрали хвосты
Если для какой-то фразы (скажем, «Защитная каска») мы упустили хвост со средней или высокой частотой («Защитная каска с наушниками»), мы увидим это по маркерам в файле.
Хвост — дочерняя фраза («Защитная каска с наушниками»), которая состоит из материнской фразы («Защитная каска») и хотя бы одного дополнительного слова («наушник»)
Маркеры:
В столбце J (Коэффициент неотработки) и/ или в столбце K (Коэффициент отработки) ячейки не зеленого цвета, а желтого, оранжевого или красного (чем больше упустили хвостов, тем краснее цвет).
Что делать:
Идем в вордстат — вбиваем каждую такую фразу с минус-словами, находим для нее не включенные релевантные частотные хвосты и добавляем их в семантику.
Если таких хвостов нет, значит, дело не в том, что мы чего-то недобрали, а в том, что мы неправильно определили, какой релевантный объем трафика принесет фраза. Мы включили в него и мусорный объем. Для точного прогноза мусорный объем нужно отсечь — уменьшить коэффициент чистоты в столбце С.
Собрали некачественные хвосты
Если мы включили в семантику хвост с низкой точной частотой, файл нам это тоже покажет.
Маркер:
Значение в столбце J (Коэффициент неотработки) меньше, чем значение в столбце K (Коэффициент отработки).
Что делать:
В столбце P ставим значение 0 — тогда эта фраза не будет учитываться и мы не возьмем ее в продвижение. Так мы сэкономим деньги, потому что у нее была бы высокая цена за пользователя.
Не досчитали трафика
Иногда мы можем для какого-то запроса не точно спрогнозировать трафик — посчитать, что фраза приведет 15 человек, а, на самом деле, она может привести 20. Такие случаи файл нам тоже показывает, чтобы мы не удалили фразу, которую по ошибке посчитали бы мало полезной.
Маркеры:
Текст в столбце F красного цвета.
Что делать:
Увеличиваем коэффициент чистоты в столбце С.
Подготовка файла к работе
Скачайте шаблон и выполните следующие подготовительные шаги.
1. Внесите фразы
Откройте лист sem. Внесите в столбец А собранные фразы, в столбец B — их общие частоты, а в столбец С — точные частоты. Скопируйте эти же фразы (или сформируйте из них любую другую выборку) в столбец F листа work.
2. Задайте правила для создания униформ
Перейдите на лист «Морфо». Здесь собраны предлоги и окончания, которые будут игнорироваться, потому что они не считываются поисковиками как смысловые. Вы можете задавать на этом листе свои правила и исключения.
После того, как на четвертом шаге вы нажмете на кнопку «Расчет частот и отработки», по этим правилам для каждой фразы в столбце B сгенерируются униформы, которые однозначно характеризуют фразы.
3. Установите коэффициент чистоты
Мы делаем это для того, чтобы учитывать только релевантные запросы по каждой фразе. Например, фразу «Средства индивидуальной защиты» могут вбивать в поисковиках 20000 раз за месяц. Но 30% из этих запросов — информационка. И нам нужно это учитывать, чтобы мы не считали, что у нас трафика с этой фразы будет больше.
Перейдите на лист «Properties».
Опираясь на свой опыт, знание проекта и отрасли, задайте базовый коэффициент чистоты.
Например, если вы считаете, что фразы из одного слова («Каски», «Спецодежда») содержат, в среднем, 45% мусора, поставьте в столбце D коэффициент чистоты — 0,55.
Ниже идут уровни вложенности: +1 слово (фразы из двух слов), + 2 слова (фразы из трех слов), + 3 слова (фразы из четырех слов). Для них также проставьте коэффициенты чистоты в столбце D. На скрине это: 0,65, 0,85 и 0,95. Обычно, чем длиннее фраза, тем меньше она замусорена.
Потом для отдельных фраз можно будет увеличить или уменьшить коэффициент чистоты. Это вы увидите по маркерам (мы их описали выше). Коэффициент чистоты для отдельной фразы можно поменять на листе «Work», в столбце С.
4. Нажмите на кнопку «Расчет частот и отработки»
Через несколько секунд уже можно анализировать маркеры и дорабатывать семантику.
Экономия
Кажется, сложно, но на деле это займет 10-20 минут. Проделанная работа позволит корректно сформировать кластеры, привести максимальный трафик и не переплачивать за пользователей.
Так что скачивайте файл, разбирайтесь, пользуйтесь или обращайтесь за продвижением к нам.
Здравствуйте, уважаемые читатели сайта Uspei.com. В этом уроке мы рассмотрим такие вещи как группировка запросов в рамках семантического ядра или кластеризация. Начнем мы с группировки поисковых запросов и чистки ядра. В прошлой статье мы посмотрели, как собирать статистику, какие инструменты для этого можно использовать, и все это почистили, удалив дубликаты. А также мы рассмотрели виды запросов.
У нас есть большой список запросов, из которого мы должны удалить оставшийся мусор и провести группировку. То есть у нас есть здоровенный список запросов. В некоторых тематиках он может доходить до 10 000. Наша задача сейчас разбить его на группы, каждая из которых будет содержать в себе только синонимы. То есть в рамках каждой группы должны быть только синонимы, так как каждая выделенная группа, это будущая отдельная страница и эти запросы в группе мы будем на ней продвигать.

К примеру, если у нас есть запрос “купить ноутбук”, то мы должны сделать группу, в которой будут только синонимы к запросу “купить ноутбук”.
Под синонимом в SEO имеется в виду то, что в запросы, по которым люди ищут, вкладывается один и тот же смысл. К примеру, запросы “купить ноутбук” и “купить ноутбук apple” это НЕ синонимы и они будут входить в разные группы, потому что у них разное понятие. В первом случае человек ищет просто ноутбук и это может быть даже samsung, а совсем не apple. Во втором же случае человек ищет конкретно apple. Ну, еще один пример. Человек ищет “такси” и “междугороднее такси” – тут думаю тоже очевидно и понятно.
Таких групп в рамках большого семантического ядра может быть огромное количество, их может быть более нескольких сотен в редких случаях более тысячи. Вот этот процесс еще называют кластеризацией. Мы рассмотрим, как его сделать вручную, я покажу основы и попытаюсь вывести хотя бы один законченный кластер, потому что в рамках одной статьи мы не сможем классифицировать ядро, но хотя бы вывести какой-то базовый кластер.
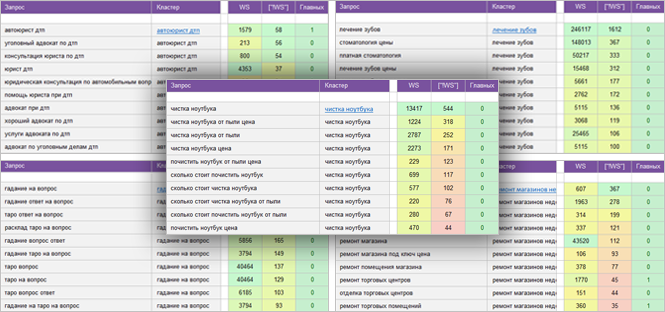
И потом я вам дам ссылки на набор инструментов, который может существенно автоматизировать или ускорить эту группировку или кластеризацию, как это сейчас модно называть.
Кластеризация и чистка семантического ядра в Excel
Возвращаемся к нашему списку запросов и у нас достаточно простой алгоритм. У нас уже отсортированы все запросы по убыванию частотности, то есть от самых популярных до наименее популярных. Дубликаты мы удалили.

Мы берем каждый запрос и смотрим подходит он нам или нет. Например, у нас есть запрос “интернет-магазин”, но если мы занимаемся только ноутбуками, то этот запрос без слова ноутбук нам не подходит. Значит запрос “интернет-магазин” мы удаляем – это не тематический запрос.
Дальше запрос “ноутбук”. Да, в принципе это информационный запрос, но не совсем понятно, что человек вкладывает в этот запрос, когда вбивает его в поисковую строку. Ищет ли он информацию, картинку или он ищет товары или возможно что-то еще.
Если мы сомневаемся в смысле поискового запроса, логично его проверить. Как это делается? Мы копируем запрос и вбиваем его в новой вкладке в ту поисковую систему, с которой мы работаем. Например, Google.
Мы видим, что Google показывает нам набор интернет-магазинов. Мы видим точно, что это запрос коммерческий и если у нас интернет-магазин, мы его оставляем.
И мы добрались до первого подходящего нам запроса. Давайте выделим нашу первую группу запросов, в которую будут входить все слова с упоминанием слова “ноутбук”. Для этого нужно включить фильтр и отфильтровать по текстовому условию “содержит”. Но там могут быть словоформы запроса “ноутбук” поэтому мы просто напишем “ноут” и получаем список строк только с поисковыми запросами, в которых упоминается “ноут”. Я предлагаю вам скопировать и перенести их в новую вкладку.
Каждую вкладку мы будем называть соответственно по тому слову, по которому мы произвели фильтрацию. В первой же вкладке мы вручную (!) выделяем все отфильтрованные ключи и удаляем. После чего очищаем фильтр.
Итак, в первой вкладке у нас остались все ключи, которые НЕ содержат “ноутбук”, а мы переходим во вторую (“ноутбук”) и продолжаем работать теперь уже там.

Итак, следующее слово “ноутбук”. Мы уже разобрались, что это коммерческий запрос и по нему также как и по запросу “купить ноутбук” показываются интернет-магазины, то есть это синонимы и мы оставляем их в одной группе.
“DNS ноутбуки” – как раз это тот самый навигационный запрос и можно предположить, что приставка “DNS” как популярный интернет-магазин будет часто встречаться в списке запросов про ноутбуки. Поэтому давайте сразу удалим все чужие навигационные запросы “DNS”. Фильтр – выделяем вручную и удалить.
“Ноутбуки бу” – аналогично как с “dns” – удаляем, если только мы не продаем б/у ноубуки.
“Купить ноутбук Москва” – тут уже добавляется регион, а мы далеко не в Москве. По сути, запрос повторяет смысловую нагрузку запроса “купить ноутбук” или просто “ноутбук”. Но поскольку добавляется регион, стоит проверить считает ли google эти поисковые запросы синонимами.
Мы берем запрос “купить ноутбук” вбиваем его в google и в другой вкладке вбиваем запрос “купить ноутбук Москва”. И сравниваем результаты поиска на предмет повторения результатов, то есть именно конкретных страничек. Если хотя бы 4-5 страничек одинаковых, то мы можем считать, что это запросы синонимы и Google показывает по ним одинаковый смысл. Если же по этим запросам выдача разная, то “купить ноутбук Москва” навигационный запрос и он нам не нужен.
Идем дальше и таким образом проделываем ту же процедуру – удаляем мусор и создаем новые группы отличные по смыслу.
Очень рекомендую чистить семантику, используя фильтры, если чистить ручками, то есть большой шанс что-то пропустить.
Но когда мы фильтруем, надо быть аккуратным, чтобы не удалить какие-то важные слова случайно отфильтровав их. Например, если в фильтр вбить просто “бу” то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие “бу” – например, сам запрос “ноутБУк” – а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце ” бу” и “бу “, а также через слэш “б/у”. Помните это и будьте внимательны))))).
И вот у нас запрос “ноутбук hp”. Это уже не просто “ноутбук” – это уже более узкая тема, значит мы должны выделить ноутбуки hp в отдельную группу.
Производим фильтрацию “текст содержит” получаем набор запросов и переносим их в новую вкладку “ноутбуки hp”. Из второй вкладки “ноутбук” перенесенные в 3 вкладку результаты удаляем.

Так мы будем повторять эту процедуру, пока в каждой вкладке не останутся только синонимы. То есть дальше мы должны перейти в 3 вкладку “ноутбуки hp” и здесь их разделить еще на более подробные группы. Мы видим, что здесь есть “ноутбук hp pavilion”, ” ноутбук hp compaq” и “ноутбук hp игровой”. Таким образом, эта группа будет разбита еще на 3 группы.
Во вторую вкладку мы вернёмся, когда во всех следующих группах все слова будут синонимами и продолжим этот разбор. Продолжим до тех моментов, пока самая первая наша вкладка не будет разложена на группы, а в ней самой не останутся только нецелевые запросы или запросы, которые тоже будут синонимами.
В итоге наша задача создать файл, в котором у нас будет огромное количество вкладок. В разных темах по-разному – возможно в некоторых темах будет всего 5-6 вкладок, если тема очень маленькая, но основная задача, чтобы в рамках одной вкладки были только запросы синонимы.
Причем не просто слова синонимы в классическом понимании, а синонимы с точки зрения поисковой системы. Вот как из примера “купить ноутбук” и “ноутбук” это синонимы с точки зрения поисковой системы, поэтому они у нас остались в одной группе.
Если во вкладке 20 синонимов и один НЕ СИНОНИМ – выносим его одного в отельную вкладку. Это очень важный момент, так как каждая группа это отдельная страница, на которой эти запросы будут продвигаться, и чем больше будет ошибок и недоработок, тем менее чистой по смыслу станет страница, что скажется результатах поиска. О других ошибках, допускаемых при сборе и группировке семантики ознакомьтесь в этой статье.
Повторю еще раз основную мысль – в каждой вкладке должны быть запросы подходящие по смыслу. Пример, если в текущей вкладке 5 запросов:
- “заработать в интернете”
- “как можно заработать в интернете”
- “где заработать через интернет”
- “как заработать деньги в интернете”
- “как заработать в интернете без обмана”
Первые три запроса останутся в текущей вкладке, так смысл у них один, а последние два уйдут каждый в свою группу-вкладку, так как они не совпадают по смыслу ни с первыми тремя, ни между собой – они более детализированы. В одном случае речь идет о деньгах ( а заработать в наши дни можно все что угодно – биткоины, баллы в играх и т.д.), а во-втором, речь идет о заработке без обмана.
Для понимания я в течение часа сварганил (правда не до конца) семантику по запросам, “заработок в интернете” “заработок в сети” “заработок онлайн”. Первая вкладка – вся семантика, а далее по группам. Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Скачать пример семантического ядра в excele.
Зачем все это нужно и почему все так сложно?
 Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
На самом деле, сейчас это не очевидно, но буквально через два-три этапа вы увидите, что вся поисковая оптимизация, абсолютно все seo, построено на основе правильно собранного семантического ядра. SEO – это не просто любительский способ сделать свой сайт лучше. Это, можно сказать наука, в которой все начинается с “атомов” и именно это приводит к результату.
SEO можно сравнить с большим спортом – боксом или сноубордом или любым другим. Если вы не освоите технику ПРОФЕССИОНАЛЬНЫХ ударов или элементов езды, то это скажется на скорости и выносливости и вы проиграете сопернику, кто этим не пренебрег. Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое – не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места – есть только первая страница и все.
Мы не можем начинать оптимизацию сайта, если мы не сделали семантику, не разбили ее на группы, не обработали и не почистили. И все что мы будем делать дальше, будет основано на семантике.
Приведу конкретный пример. Мы же понимаем, что по каждому запросу поисковик дает свой результат выдачи. Возьмем какую-то небольшую тематику по которой в семантике всего 100 запросов. И вот у одного владельца 100 страниц на сайте, в которых содержимое часто пересекается, структура сайта от этого расплывчатая, поисковик не понимает до конца, какие страницы релевантны запросу больше, а какие меньше. В итоге, кроме путаницы, эти 100 страниц содержат в своем “винегрете” ответы только на 30-40 запросов.
А у второго владельца сайта, благодаря полному собранному кластеризованному семантическому ядру, на каждый запрос есть соответствующая страница, строго релевантная только этому запросу. Поисковик и пользователи четко понимают структуру сайта, а также не страдают “дежавю”, что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
Автоматизация кластеризации семантического ядра
Такая работа по группировке запросов по обработке всей этой статистики вручную занимает достаточно много времени. Особенно если человек делает это первый раз. Но я вам рекомендую, если вы хотите научиться работать запросами, работать с семантикой, хотя бы один раз проведите все это вручную в электронных таблицах. Тогда вы сможете прочувствовать и понять, как это работает.
Если же вы работаете в очень больших объемах, крайне рекомендую использовать профессиональные инструменты. Чаще всего они платные.
Один из самых популярных инструментов по работе с семантикой это инструмент “Key Collector”, которая позволяет автоматизировать большинство процессов по сбору и обработке семантики. Как минимум, она умеет автоматически собирать ключевые слова из yandex wordstat, а также данные о частотности по запросам и другие рекомендации.
Если же у вас есть уже готовое отфильтрованное от мусора семантическое ядро, то вы можете прибегнуть к помощи дополнительных сервисов, которые производят автоматическую кластеризацию. Лидером сейчас на рынке является онлайн-сервис, который называется Rush analytics.
Расценки не очень высокие и в принципе, если у вас один сайт, вы владелец или вебмастер, то вы можете собрать семантику, почистить ее, после чего просто отдать на кластеризацию такому сервису.
- Опубликовано:20.01.2014
- Комментарии:
Нет комментариев - Рубрика:
Продвижение магазинов - Просмотров: 19 910

Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла. Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Скачать файл Excel (.xls)
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
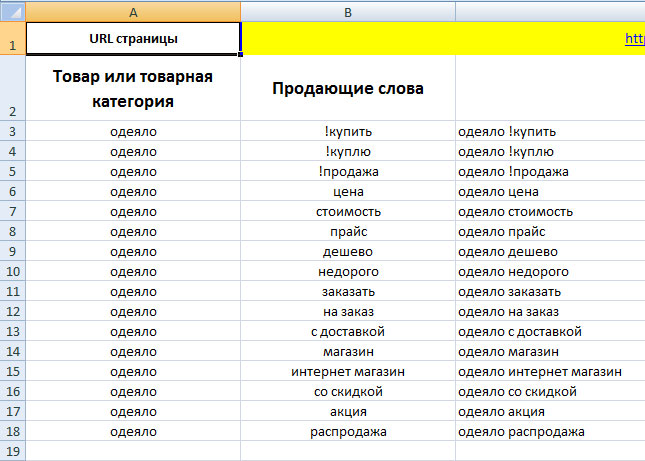
В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:
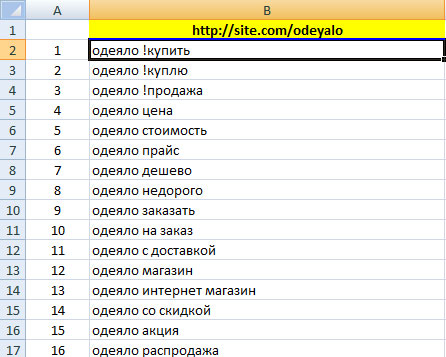
Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Читайте также:
- Рейтинг CRM систем для интернет-магазинов
- Как продвигать магазин в поисковых системах?
SEO-Excel для кластеризации семантического ядра (СЯ)
Содержание
- Кластеризация по составу фразы
- Догруппировка кластеризированной семантики
- Склонение и генерация тегов
SEO-Excel — это надстройка для Microsoft Excel, которая содержит 22 бесплатных инструмента для SEO-специалиста, позволяющая автоматизировать большую часть процессов при работе с семантическим ядром. Презентовал Андрей Ставский из Rush Analytics летом 2017 года, как альтернативу буйжуйской SeoTools for Excel.
Основные возможности:
- Разбор и перегруппировка семантики;
- Генережка SEO тегов и URL;
- Работа с морфологией;
- Парсинг Title и текстов из выдачи Яндекса;
- Построение MindMap по URL.
Системные требования:
- Windows 10 / 8.1 / 8 / 7 / Vista;
- Microsoft Excel 2007 / 2010 / 2013 / 2016 / 365.
Рассмотрим, как SEO-Excel может в помочь в кластеризации семантического ядра на примере запросов для категории Bluetooth наушников крупного интернет магазина. Для этого я собрал запросы из Wordstat по маркерам со стоп-словами, снял частотность, очистил от неявных дублей и брендов.Получили большой список запросов, который в данном виде нам мало чем полезен. Для дальнейшего продвижения по этим запросам, их необходимо сгруппировать по какому-то признаку и закрепить за страницами на сайте. Задачу группировки (кластеризации) запросов как раз и помогает решить надстройка.
Кластеризация по составу фразы
Инструмент “Выжимка”, который позволяет удалять определенные слова из запросов, мы будем использовать для кластеризации семантики по составу фразы.
Копируем запросы в соседний столбец и делаем в нем выжимку, исключая запросы, не влияющие на интент (потребность): купить, цена, интернет, магазин, заказать, стоимость, bluetooth, блютуз, беспроводные, наушник, телефон и т.д. Можно указывать в сокращенном варианте, чтобы исключить также словоформы данных слов.
Далее сортируем столбец с выжимкой по А до Я, выделяем его и применяем инструмент “Красит” ко всем столбцам. Получаем запросы кластеризованные по составу фразы, где в столбце «Выжимка» содержится интент, т.е. запросы с уже сформированной потребностью.Кто хоть немного понимает в наушниках скажет, что капельки, вакуумные, внутриканальные и затычки — это все об одном типе наушников. С точки зрения потребности, эти запросы логично объединить в одну группу. С точки зрения хитрого сеошника, можно разбить и на разные страницы, чтобы за счет точных вхождений попробовать опередить конкурентов в ТОПе.
В Техпорте работают последние:
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/vnutrikanalnye
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/vakkumnye
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/zatychki
- www.mvideo.ru/naushniki/naushniki-3967/f/category=naushniki-vkladyshi-1150
Хотя наушники-капельки проигнорировали. Хитрые, но не до конца…
В МВидео не стали заморачиваться — разместили все на одну страницу
Оба сайта в ТОПе, вот и не понятно, а как же сгруппировать правильно запросы, чтобы и нам там быть, и трафика по-максимуму собрать.
Кластеризировать по данному способу — это очень долго, нудно и не точно, ведь нужно пройтись по всем запросам, определить интент и перегруппировать по ТОПу.
Недостатки кластеризации по составу фразы
- Синонимы и переформулированные фразы попадают в разные кластера и нужно потратить уйму времени, чтобы их руками перебрать и объединить;
- Информационные запросы часто попадают вместе с коммерческими в одну группу;
- Даже после перебора руками, нет уверенности, что группировка правильна. Запросы, которые вы считаете, что нужно продвигать на одну страницу, на самом деле нужно продвигать на разные.
- Для избежания ошибок приходится дополнительно анализировать ТОП выдачи по каждой группе. При больших ядрах — это задача может растянуться на многие месяцы. Ни у кого нет столько времени ждать вашу семантику.
Поэтому группировка по составу фразы не используется в чистом виде. Тем не менее, данный метод позволяет значительно сократить время на обработку семантического ядра после сервисов автоматической кластеризации, которые работают на основании анализа ТОПа поисковой выдачи.
Преимущества кластеризаторов по ТОПу
- Синонимы и переформулированные фразы при «чистой» выдаче попадают в одну группу;
- Проверяется совместимость продвижения запросов на одной странице. Несовместивые запросы разбрасываются по разным группам;
- Существенная экономия времени, особенно на больших ядрах.
Догруппировка кластеризированной семантики
Сервисы автоматической кластеризации по ТОПу позволяют значительно сэкономить время и деньги, группируя запросы на основании подобия сайтов из ТОПа, но и они не лишены недостатков.
Недостатки кластеризации по ТОПу
- Необходимость поиска баланса между полнотой и точностью кластеризации. При высокой полноте группируется больше фраз, но страдает точность, из-за чего в группы попадает много лишнего. При высокой точности очень низкая полнота — группы маленькие и большой список несгруппированных фраз, которые нужно раскидывать самостоятельно. Оптимальная по полноте кластеризация выбирается каждый раз индивидуально;
- Если выдача «плохая», то запросы, которые должны продвигаться на разных страницах, при кластеризации могут попасть в одну группу. Наоборот, запросы с одним интентом, попадают в разные группы.
- Кластеризация запросов без однозначного интента, по которым в выдаче как коммерческие, так и информационные сайты, дает неудовлетворительные результаты. Например, мы бы хотели запрос продвигать например, как коммерческий, но кластеризатор положил его в группу с информационниками.
Догруппировать имеющийся результат согласно нашим требованиям помогут инструменты «Выжимка» и «Разбор».
Определяем состав фразы в файле кластеризации от Rush Analytics. Самыми удачными результаты кластеризации мне показались при силе связи 4.
Запросы «спортивные наушники bluetooth» и «наушники для спорта беспроводные» объединились в одну группу. Вакуумные наушники разбросало 3 по разным кластерам, а вкладыши, мини и капельки — по 2. К тому же попался запрос и без сформированного интента — «наушники для телефона купить». Проходимся таким образом по всем кластерам. Благодаря выжимке это легко читается.
Кластеризатор не дал нам точного ответа, поэтому здесь нужно дополнительно перебрать запросы вручную. При обнаружении ошибок кластеризации, приходится решать, оставлять ли конкретный запрос в данном кластере, переместить в другой или создать новую группу:
Если мы решили объединить «внутриканальные» и «вакуумные» можем сразу задать одинаковые названия кластеров для этих запросов. В данном случае мы используем название «беспроводные наушники внутриканальные».
Если же запросы разбросаны по файлу или мы не знаем, есть ли уже похожий кластер, можно скопировать ключевое слово в соответствующую ячейку «название кластера», например «блютуз наушники капельки купить».
Нет необходимости искать по всему файлу подходящий кластер или запоминать названия уже существующих.
Снимаем заливку и сортируем от А-Я по столбцу с названием кластера. Далее красим все столбцы с помощью инструмента “Красит”.
Произошла группировка запросов по общему названию. В одну группу мы добавили вакуумные и внутриканальные. В тоже время мы не стали «капельки» сводить к общему названию, поэтому они находятся в разных кластерах. Чтобы устранить данный момент, применяем инструмент «Разбор» для быстрого объединения кластеров по названию их вершин.
Для вершин кластеров в столбце «А» необходимо повторно применить выжимку, по которой будет сразу понятно, кластера с каким названием вершин нужно объединить.
Переносим кластера, которые хотим объединить начиная со столбца «В» в одну строку. Удаляем пустые строки и завершаем разбор.
На вкладке “Конечная семантика” получаем объединенные кластера с сортировкой по убыванию суммарной частоты.
Когда кластеризация не показывает однозначного распределения запросов по кластерам, как например в данном примере, приходится принимать решение на основании того, насколько хорошо мы разбираемся в тематике и никакая автоматизация не поможет.
Перед тем, как кластеризировать свои запросы, обязательно изучите специфику продаваемых товаров или услуг.
Получив конечную семантику, мы можем сгенерировать теги для SEO продвижения.
Генерация h2
Заголовок h2 будем задавать по самой частотной фразе в кластере. Для этого сначала отсортируем итоговую семантику по столбцу с частотностью. Применяем инструмент «Сортировка» и запросы в каждом кластере сортируются по убыванию частоты.
С помощью инструмента «h2» указываем столбец с запросами и столбец для заголовка.Берется первая закрашенная ячейка столбца «B» и записывается на весь кластер. С помощью данного инструмента можно быстро протянуть любой идентификатор.
Генерация Title
Для генерации Title есть 2 шаблона:
- с разделителем. Позволяет вставить дополнительные слова в начало и конец Title, который формируется из первых двух запросов, разделенных вертикальной чертой.
- скользящий. Позволяет вставить дополнительные слова в середину и конец Title, который формируется из двух запросов, разделенных дефисом. К преимуществам данного шаблона относятся возможность изменять падеж, использовать название кластера или третий запрос в списке.
Примечание: запросы должны находиться в столбце «B», название кластера — в столбце «A». Title генерируется в первый пустой столбец.
Генерация Description
Для генерации мета-описания воспользуемся инструментом «Description», который позволяет задать префикс, постфикс, изменить падеж запроса и добавить UTF-8 символы.
Примечание: запрос, добавляемый в шаблон, берется из столбца «A». Description генерируется в первый пустой столбец.
Ознакомиться с полным функционалом и скачать SEO-excel бесплатно можно на официальном сайте seo-excel.ru.
На выходе всех сервисов кластеризации получается файл, который нужно дополнительно обрабатывать: объединять и перегруппировать кластера, чистить от мусора. Специалист тратит много времени и ручного труда на выявление ошибок. С настройкой SEO для Excel получается значительно снизить трудо- и времязатраты на доработку кластеризированного семантического ядра.
kytaichuk.ru
Анализ больших семантических ядер, или «Робот-распознаватель» / RealWeb corporate blog / Habr
Говорят, метатеги для целей SEO мертвы и больше нет смысла прописывать заветную строку meta keywords. Действительно, в современных многофакторных алгоритмах этот тег потерял свой вес. Но это вовсе не значит, что нужно отказываться от работы с семантическим ядром сайта — оно по-прежнему бесценно для структурирования сайта, формирования тематики (которой и интересуются поисковики) и даже для контекстной рекламы. Собрать ядро — задача не из лёгких, собрать его с умом и не превратить в «накидайте мне синонимов» — ещё сложнее. Так вот, в статье пойдет речь о макросах и формулах MS Excel, которые упростят обработку больших семантических ядер. Представляем вам небольшого Excel-робота от нашего изобретательного и не жадного специалиста отдела контекстной рекламы RealWeb Дмитрия Тумайкина. Ему и слово.
«Привет, Хабр! C самого начала хочу предупредить читателей, что разработка не является чем-то новым на рынке по логике и принципу работы, но имеет ряд преимуществ перед другими известными инструментами:
- Является полностью бесплатной для всех пользователей(в отличие от KeyCollector и ряда других подобных сервисов).
- Не требует подключения к интернету + использует локальные мощности (есть версия, созданная для Google Docs, но на больших объемах данных работает медленнее вашего компьютера, даже одноядерного, т.к. корпорация добра по привычке ограничивает процессорные мощности на 1-го пользователя.
- Представляет собой оптимизированный (насколько позволяет знание алгоритмов вычислений Excel) алгоритм для обработки больших ядер.
Файл является одним из серии файлов для специалистов по контекстной рекламе (планируются ещё интересные и очень полезные «роботы»). К слову сказать, разработка была создана «с нуля», и уже постфактум стало известно, что на рынке уже есть схожие макросы для табличных редакторов – например, публикация Devaka (макрос для OpenOffice) и разработка команды MFC-team, являющаяся адаптацией этого макроса под MS Excel. Впрочем, ни один из файлов не мог удовлетворить мои потребности как потребности специалиста по контекстной рекламе. У нашей разработки есть свои преимущества, о чём расскажу чуть ниже.
А пока — зачем это нужно?
Допустим, есть большое семантическое ядро. Каким образом оно было получено, нас не интересует. По сути это неструктурированный набор запросов, который мы хотели бы структурировать. Каким образом мы делаем это вручную?
- «Пробежавшись» по запросам глазами, пытаемся понять общую смысловую направленность, выделяем, какие категории запросов присутствуют в ядре.
- Определяем и выделяем слова-маркеры, которые позволят отнести запросы к той или иной категории. Самый примитивный вариант — «целевой-нецелевой», но можно выделять и направленность слов. Например, для компаний, работающих с e-commerce, популярными будут оптовые (опт, база, склад, оптовый…), информационные (как, где, отличие, сравнение, отзывы…), покупающие (магазин, купить, цена, стоимость…), арендные (прокат, напрокат, в прокат, аренда…), гео-маркеры, и т.д…
- Ищем каждый из запросов в исходном списке с помощью фильтров, помечаем эти запросы. Здесь всё зависит от фантазии – если у нас всего два варианта, то достаточно запросы просто отметить разными цветами. Если же вариантов много, чтобы не допустить путаницы, мы могли бы отметить напротив запросов в соседнем столбце в той же колонке название той самой категории, к которой принадлежит слово-маркер, содержащееся в запросе. А чтобы всё было ещё более наглядно, можно указывать в дополнительном столбце и само слово-маркер. К этому в итоге я и пришёл.
- После того, как всё разложено «по полочкам» таким образом – используем полученные списки в своих целях. Специалисты контекстной рекламы выставляют корректировки ставок в зависимости от категории запроса (например, чем «теплее» запрос, тем выше ставка), либо «минусуют» совсем нецелевые запросы.
Будучи искренне верящим в то, что лень — двигатель прогресса, и написавшим по этой причине не один макрос, я начал искать инструменты, которые позволили бы весь процесс максимально автоматизировать. Среди вариантов я не нашёл ни одного, полностью удовлетворяющего моим требованиям. И вот почему.
KeyСollector и СловоЁБ — многофункциональные программы, одна из задач которых – сбор семантического ядра. Первая платная, вторая является урезанной бесплатной версией. В них есть модуль «стоп-слова», позволяющий отметить фразы в таблице, содержащие данные стоп-слова.
Минусы данных программ:
- Невозможно использовать сразу несколько категорий, т.к. фразы будут просто отмечены в таблице. Поэтому анализ ядра на присутствие запросов определенной категории нужно проводить ровно столько раз, сколько у вас категорий.
- Если использовать поиск, не зависящий от словоформы, то могут быть ошибки сопоставления, например, «бельё» и «белый» считаются морфемами одного слова.
http://py7.ru/tools/group/ — инструменты появились в открытом доступе совсем недавно, но завоевали нешуточную популярность. Механика работы данного инструмента немного отличается от KeyCollector-а, но проблемы те же самые – ошибки со словоформами, невозможность анализировать несколько категорий одновременно.
Вышеупомянутые макросы Devaka и MFC. Здесь основной проблемой является то, что оба макроса используют алгоритм поиска по «маске», т.е. если слово-маркер является составляющей частью любого из слов, весь запрос относится к этой категории. В итоге, чем короче слово-маркер – тем больше ошибок, со словами Б и БУ невозможно работать априори, но верхний порог по символам даже в 6 символов не избавит вас от необходимости перепроверять всё сделанное. Например, слово «ванная» встречается в сотнях отглагольных прилагательных (лакированная, гофрированная…). Понятно, что во многих случаях о релевантности и речи не идёт.
И вот именно поэтому…
… я и создал свой файл с
блэкджэком
формулами и макросами. Не мудрствуя лукаво, он просто анализирует, встречается ли слово в точном соответствии в вашем запросе, поэтому никаких ошибок нет априори. Многие формулы (Substring, Multicat) не написаны с нуля, а являются импортированными из надстройки PLEX (за которую отдельная благодарность ее создателю).
Теперь подробнее о разработке, комментарии на скриншоте:
Ссылка на файл: робот-распознаватель
В файле 2 макроса, действующих по простому принципу – они:
- Делят запросы на слова (разделителем считается пробел). По принципу AdWords, только первые 10 слов.
- Сравнивают каждое из слов с «банком минус-слов», который представляет собой именованный динамический диапазон, т.е. в него можно добавлять слова вплоть до конца столбца, и макрос будет подстраиваться под каждый вариант, забирая тем больше процессорного времени, чем больше «банк», и наоборот.
- Если находят слово в банке – возвращают его, если не находят, возвращают «две кавычки» (пустой результат).
- Нехитрой формулой ВПР (вертикальный просмотр) возвращают категорию каждого из слов из соседнего столбца.
- Склеивают все полученные параметры вместе (через пробел) и выводят в соответствующие столбцы напротив.
Пример формулы, которая делает всё это в одной ячейке, сохранён в верхней строке, откуда её можно просто копировать вручную. Есть и макрос, который сделает это за вас, поместив новые данные в диапазон ровно напротив вашего списка ключей (в нём не должно быть пустых ячеек!). Однако такой вариант более ресурсозатратный, и заставит вас достаточно долго ждать, если количество ключевых слов и банк минус слов, допустим, более 5000. Поэтому создан второй макрос, делающий всё то же самое «пошагово» и отбрасывающий по пути ненужные вычисления.
Рекомендации:
- Для ускорения работы макроса рекомендуется «банк минус-слов» иметь в сортированном виде «А-Я» (по слову).
- Использовать нормализованные списки (как ключей, так и минус-слов) – это заметно ускорит расчеты в файле и вашу работу, т.к. сужает семантическое ядро.
- Но быть с ними внимательными (проверять итоговый список). Так, «Дели» (город) и «Делить» — для программ-нормализаторов условно — одно и то же слово. Похожие примеры — «чай» и «чаять» или «покрывала» и «покрыть»
- Не лениться составлять собственные списки минус-слов для разных тематик и делиться ими с коллегами.
- Файл можно использовать для каталогизации любых ядер по любым группам запросов, т.е. не обязательно использовать для минус-слов. Все зависит от задачи и фантазии.
Вот такая история. Берите файл, создавайте семантические ядра, используйте их в контекстной рекламе и SEO, делайте свой сайт лучше, делитесь опытом с другими.
P.S.: Пожелания и багрепорты приветствуются.
На текущий момент в файле используется линейный поиск ВПР. Позже выложу версию файла с бинарным поиском, прирост скорости вычислений на больших объемах будет колоссальный. Список минус-слов, указанный в файле, не является рекомендацией и может навредить вам и/или вашему клиенту, поэтому призываю проверять публичные списки (включая этот) на соответствие тематике вашего клиента, и дополнять его новыми словами. Формулы и макросы работают только в оригинальном файле, и не будут работать в других. Использование макросов в Excel не вредит вашему здоровью».
На этом и заканчивается история Дмитрия о создании полезного макроса. А мы напоминаем, что иногда самые сложные задачи имеют простые решения. MS Excel всегда был и остаётся главным помощником аналитиков, специалистов по контекстной рекламе и SEO-оптимизаторов. Его функции, формулы и макросы способны порождать интересные инструменты, облегчающие труд специалистов. Ну и, конечно, будет очень здорово, если некоторые из разработок будут выкладываться в открытый доступ и приносить реальную практическую пользу.
habr.com
Сбор семантическое ядро: инструкция для начинающих

Старший специалист отдела продвижения компании SEO Интеллект
Основой успешного продвижения сайта в поисковых системах или запуска контекстной рекламы всегда являлось правильно собранное семантическое ядро. В данной статье показан весь процесс сбора и группировки запросов.
Мы разделили работу на три основных этапа:
- Сбор вариаций написания продукта и маркеров.
- Сбор и чистка семантического ядра в Key Collector.
- Кластеризация (группировка) семантического ядра.
Каждый этап мы разберем на примере группы товаров «Шлемы для мотоцикла», для которой и соберем семантическое ядро.
Чтение статьи займет у вас чуть больше 10 минут. Но если вы не очень любите читать, то можете потратить примерно то же время на просмотр ролика.
Этап 1. Сбор вариаций написания продукта и маркеров
Перед сбором запросов необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекса.
Методика
- Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».

- Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.

- Переносим все найденные варианты названия продукта в отдельный файл.

- На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
Для выявления маркеров есть два пути:
1. Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
1.1. Плюс: Сбор всех существующих в спросе маркеров;
1.2. Минус: Долгий и трудозатратный процесс.
2. Поиск и анализ страниц конкурентов в ТОП 10, которые уже имеют страницы с нашим продуктом.
2.1. Плюс: Быстрый процесс;
2.2. Минус: Неполный сбор свойств, если они отсутствуют у конкурентов.
- Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП 10. Это возможно сделать вводом основного запроса прямо в поисковую систему или же воспользоваться инструментом полноценного поиска конкурентов по видимости их сайтов, как было рассказано в 4 пункте первого этапа данной статьи.
- На странице конкурента, нужно обратить внимание на структуру категории, то есть существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.

- Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:

- Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в Microsoft Excel. В результате получим таблицу, аналогичную представленной ниже:

- Для пакетной (разовой) загрузки всех ключевых слов в KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:

Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

После выбора региона можно приступать к сбору семантики.
Методика
- В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

- В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

- После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
- Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

- Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:

- Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:

- Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
- Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.

- Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

- После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
- Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:

Этап 3. Кластеризация (группировка) семантического ядра
Полученный список запросов нам нужно разбить на кластеры для последующей проработки посадочных страниц. Чтобы корректно выполнить эту задачу, нужно использовать сервисы кластеризации запросов, работающие на основе выдачи поисковых систем. Именно такой формат анализа, возможности продвижения тех или иных запросов на одной или разных страницах дает 70% успеха при дальнейшем продвижении сайта.
Популярные программные продукты:
1. KeyAssort – программа для кластеризации и структуризации семантического ядра.
2. Key Collector – функционал «Анализ групп» с типом группировки «По поисковой выдаче»).
Популярные онлайн-сервисы:
1. Engine Seointellect
2. Tools PixelPlus
3. Rush Analytics
Рассмотрим методику группировки запросов с помощью сервиса Engine Seointellect.
Методика
- Полученный список запросов, который мы выгрузили из программы Key Collector, содержит столбец с названием «Группа». Нам необходимо по очереди добавлять все запросы из каждой группы в кластеризатор.

- Заходим в сервис и выбираем в меню слева пункт «Кластеризация запросов». В открывшемся блоке мы видим кнопку «Новая группировка».

- Нажимаем на данную кнопку. На экране появятся следующие поля для заполнения:
1. Добавить запросы – в данный блок мы добавляем все запросы из первой анализируемой группы.
2. Вид группировки включает в себя три вида жесткости кластеризации:
2.1.«Hard» – жесткая группировка.
2.2.«Balance» – группировка средней жесткости.
2.3.«Soft» – группировка низкой жесткости.
Подробнее про различие работы методов группировки можно посмотреть в данном видео:
При группировке коммерческих запросов, как в нашем случае, следует изначально выбирать метод группировки «Hard», если запросы информационные, то рекомендуем пользоваться только методом «Soft».
3. Регион выбираем соответствующий регион продвижения.
4. Мой сайт не нужно указывать, так как эта функция нужна для определения запросов по уже существующим посадочным страницам указанного сайта.

- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа в правой части созданного задания вместо отображения процесса появится иконка «Глаз», на которую необходимо нажать.
- Мы попадаем на страницу результата группировки и можем проанализировать данные:

1. Мы видим, что все наши запросы, кроме одного, попали в одну группу (отмечено зеленым), а значит их можно продвигать вместе на одной посадочной странице.
2. Также присутствует нераспределенный запрос (отмечено синим), это значит, что по данному запросу результаты выдачи сильно отличаются от результатов других запросов. В таком случае следует сделать вывод, что под этот запрос нужно создавать отдельную посадочную страницу бренда Ataki.
3. Справа от группы есть функционал «Показать список URL», нажав на который откроется блок со ссылками на страницы из ТОП 10, по которым была проведена кластеризация.
- Если бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можно продвигать в готовых группах. Можно просто увидеть эти запросы и перенести в нужную группу, но если фраз много, то их следует отправить на группировку по методу «Soft». Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
- Проведя данные действия с каждой группой из нашего файла, мы получим готовый список разделенных запросов, для последующей проработки страниц.
Финальная версия файла семантического ядра
Итоговый файл с семантическим ядром должен представлять собой таблицу, включающую следующие столбцы с данными:
1. Запрос
2. Группа
3. Базовая частотность
4. Уточненная частотность
5. Посадочная страница
Все группы мы рекомендуем отделять чертой друг от друга, чтобы впоследствии с таким файлом было легче работать:

Выводы
Теперь вы знаете, насколько трудозатратным является процесс сбора и группировки семантического ядра для продвижения сайта или настройки контекстной рекламы.
Это лишь базовая инструкция, которая не охватывает многих нюансов, возникающих в процессе, но именно эта работа является основой успешного достижения целей продвижения, а значит выполнять ее некачественно равносильно бездействию, так как вы не добьетесь никаких результатов без «построенного фундамента».
www.seonews.ru
Как собрать семантическое ядро для сайта правильно

Два основных подхода
Чтобы составить семантическое ядро, нужно собрать множество ключевых фраз и дополнительных релевантных слов, участвующих в продвижении. Существует 2 метода сбора информации. Первый — сначала найти ключи, ориентируясь на запросы пользователей, а затем сформировать на их основе структуру страниц сайта. Второй подход — сперва создать каркас будущего ресурса сайта, а затем заниматься сео-анализом запросов, исходя из целей и задач пользователя.
Традиционное СЕО. В традиционной картине мира сеошника сайт должен продвигаться в топ выдачи поисковиков за счёт размещения на страницах оптимизированных текстов. Краеугольный камень этой модели — анализ запросов пользователей. Грубо говоря, специалист собирает фразы, по которым люди хотят найти тот или иной товар/услугу или получить нужную информацию. Затем он включает эти словосочетания в текст в нужном количестве. Особенность традиционного подхода к созданию семантического ядра: он не нацелен на повышение удобства пользователей. Этот метод призван лишь «добывать» трафик на сайт из поисковой выдачи.
Бизнес-подход. Этой моделью оперируют маркетологи, которым важно решить «боли» клиентов и улучшить поведенческие факторы сайта. Бизнес-подход предполагает, что сначала будет составлена структура сайта, и уже с учётом имеющихся страниц составляется семантическое ядро. Преимущество маркетинговой тактики: специалист более грамотно продумывает структуру сайта с учётом целей и задач посетителей. Он помогает будущим клиентам с легкостью находить ответы на свои вопросы и принимать решение.
Виды семантических ядер
Семантическое ядро может создаваться для нескольких целей:
-
для формирования контентного плана сайта и его последующего продвижения в поиске;
-
для объявлений Яндекс.Директа;
-
для снятия позиций сайта.
Каждый из этих видов семантического ядра отличается. Стоит рассмотреть особенности СЯ для создания контентного плана и дальнейшего наполнения ресурса текстами.
Создание структуры
Структура сайта — это схема разделов, подразделов и категорий со страницами. Благодаря правильно выстроенной иерархии посетитель быстро находит нужную информацию: описание товара, прайс, отзывы, порядок оказания услуг. Создавая структуру сайта, маркетолог ориентируется в первую очередь на задачи пользователя и во вторую — на результаты анализа поисковых запросов. Порядок работ:
-
Определить основные разделы. Для digital-агентства это могут быть такие категории, как услуги, проекты, цены, блог.
-
Создать категории. К примеру, в раздел «Услуги» входит поисковое продвижение, крауд-маркетинг (использование ссылок), дизайн, аудит сайта, оптимизация кода и юзабилити и др.
-
Создать страницы и распределить по ним ключевые запросы.
Важным инструментом сео-продвижения является внутренняя перелинковка — создание сети ссылок, ведущих с одних страниц сайта на другие. Так пользователю будет проще ориентироваться.
Виды и особенности ключей

Скорость сео-продвижения зависит от конкуренции в выбранной нише и грамотного выбора ключевых фраз по частотности. Этот параметр означает, сколько раз люди занесли в строку поиска определённое словосочетание. К примеру, через Яндекс пользователи делают запрос «как составить семантическое ядро» 1000 раз в месяц. Виды ключей по частотности:
-
высокочастотные — к ним относятся фразы и слова с частотой более 5 тысяч;
-
среднечастотные — от 1 до 5;
-
низкочастотные — до тысячи.
Существует множество стратегий продвижения по низко-, средне- и высокочастотным запросам. Однако учитывать только одну группу нет смысла. Важно грамотно подходить к выбору ключевых фраз из каждой категории.
Продвижение по каким запросам лучше выбрать
За попадание в топ по средне- и высокочастотным запросам ведётся серьезная борьба между сео-специалистами. Поэтому конкуренция среди веб-мастеров и маркетологов, продвигающихся в интернете по данным запросам, довольно высока. Гораздо легче попасть в топ выдачи по низкочастотным фразам. Однако и при таком подходе важно учитывать конкуренцию.
Строение ключевой фразы
Она содержит несколько слов. Основное называется телом. К примеру, в словосочетании «создать сайт» слово сайт является телом. «Создать» — уточняющее. Его называют спецификатором. Если после тела находится уточнение — это «хвост». Таким образом, ключевая фраза состоит из тела, спецификатора и хвоста. При сборе семантического ядра важно учитывать их характер. К примеру, если вы будете продвигать страницу по запросам «купить дом» и «продать дом», поисковые системы будут ранжировать ее хуже, чем если бы вы создали 2 разные страницы под каждый запрос отдельно. Спецификаторы не должны противоречить друг другу.
Инструменты для сбора семантического ядра
Подбор ключевых фраз ведётся с помощью специализированных сервисов и программ, анализирующих поведение интернет-пользователей. Один из основных инструментов сбора данных для семантического ядра — сервис «Подбор слов Яндекса» или WordStat. Он позволяет отсортировать ключи по частотности, проверить их популярность на определённом временном промежутке (за год). Этот сервис помогает понять, как собирать семантическое ядро и расширять его дополнительными фразами. Выяснить, сколько раз пользователи набирали определённую фразу, можно путем записи слов в поисковую строку сервиса. Так, «собрать семантическое ядро» ищут 1400 раз в месяц. Если добавить уточняющее слово «как», результат будет почти вдвое меньше.

Учитывая число показов, маркетолог выбирает и группирует похожие ключи, добавляя их в семантическое ядро сайта.
Базовые ключи
К ним относят те фразы и слова, которые напрямую связаны с деятельностью компании или тематикой ресурса. К примеру, для интернет-магазина по продаже электроники к основным можно причислить «электроника», «телефоны», «компьютерная техника», «интернет-магазин электроники», «интернет-магазин техники и электроники». Основные группы ключей формируют верхний уровень структуры сайта. На их основе создаётся каталог, разделы и категории.
Расширение ядра
Поскольку структура сайта может быть очень глубокой, семантическое ядро должно состоять из запросов разной частотности, объединённых единой иерархией. Ключи собирают из левого столбца WordStat. Они сформированы уникальными спецификаторами и хвостами. Частотность таких запросов показана по убывающей. Чтобы расширить ядро, нужно забивать в поиск сервиса по очереди все базовые ключи и выбирать те запросы, которые с ними встречаются. Для удобства можно пользоваться различными расширениями, позволяющими быстро и удобно копировать только нужные фразы. Одним из таких является Yandex Wordstat Helper.

Если вы хотите посмотреть, сколько раз определенную фразу запрашивали пользователи определенного региона, выберите нужный из списка.
Дополнительные или LSI-слова
Поисковые алгоритмы совершенствуются с каждым годом, распознавая ухищрения сео-специалистов и веб-мастеров. Роботы анализируют сайты с позиции полезности текстов. Это не значит, что можно вообще не вписывать ключевые слова. Однако, если бездумно вписывать фразы в текст, сайт в топ поиска вывести не получится. Чтобы поисковые системы воспринимали его как релевантный (соответствующий) запросам пользователей, на нём должен быть контент, всесторонне описывающий товар, услугу, ситуацию, проблему. Исходя из анализа наиболее часто встречаемых запросов, можно утверждать, что люди ищут определённые товары и услуги вместе с другими. К примеру, выбирая планшет в интернет-магазине, будущий покупатель хочет знать не только его цену и характеристики, но и информацию о производителе, акциях на разные модели.
Что такое LSI
LSI — это один из поисковых алгоритмов, оценивающих совокупность ключей и их синонимов. Зачастую потенциальные покупатели перед совершением сделки хотят всесторонне рассмотреть имеющиеся предложения. Они вводят множество запросов, с разных сторон описывающих товар. Это и учитывают поисковые машины. Дополнительные слова можно брать из правого столбика WordStat, а также из подсказок Яндекса и Google.

Подсказки расположены и внизу страницы с результатами выдачи.

Минус-слова
Чтобы отсеять ненужный «мусор» из ключевых фраз, по которым на сайт могут попасть нецелевые посетители, в сервисе WordStat придуманы специальные операторы — знаки, указывающие системе, какие слова показывать, а какие — нет. После ключа нужно поставить знак «-» и следом за ним (без пробела) указать минус-слово, а затем обновить результаты поиска. Ненужная часть запроса исчезнет из списка. Помимо оператора «-» существует множество других, позволяющих сео-специалисту сэкономить время на подборе нужных ключей для семантического ядра. К примеру, если заключить фразу в кавычки, сервис покажет количество запросов в месяц именно этой фразы, без дополнительных слов. Если добавить к кавычкам оператор «!», WordStat сделает статистику по словам в том виде, в котором они записаны в поисковой строке, без учета изменённых падежей, времени и числа.
Анализ конкурентов
Сайты конкурентов, успешно пробившиеся на верхние позиции поисковой выдачи, служат отличным источником ключевых запросов для семантического ядра. Чтобы получить нужные фразы, нужно проанализировать тексты страниц, хорошо ранжируемых в поисковиках. Для аудита текстов конкурентов используют такие сервисы, как https://advego.com/text/seo/
и https://istio.com/rus/text/analyz/. С их помощью можно определить, какие слова использованы в тексте чаще всего, какие словосочетания из 2–3 или 4 слов встречаются несколько раз.
Оформление результатов работы
Получившиеся ключевые запросы стоит рассортировать по определённым характеристикам: телам и однокоренным спецификаторам. К примеру, ключи «купить телефон» и «купить телефон онлайн» нужно отделить от «заказать телефон». Также стоит вынести в отдельные группы всё, что связано с планшетами, ноутбуками и другими гаджетами. Стандартное распределение ключевых фраз — таблица в Excel. Группы должны располагаться таким образом, чтобы было понятно, как страницы с этими запросами будут расположены относительно друг друга в структуре сайта. Для удобства можно выделить группы ключевиков, которые относятся к определённому уровню иерархии, одним цветом.
Распределение фраз по кластерам
Инструменты для кластеризации. Для автоматической кластеризации (разбивки ключей на группы) семантического ядра используют платные онлайн-инструменты:
-
Topvisor.ru. Сервис группирует запросы на основе результатов топ-10 поисковой выдачи.
-
SerpStat.com. Этим инструментом можно выделить ключевики, служащие вопросами, а также отфильтровать фразы с привязкой к городу/региону. Главная особенность этого сервиса заключается в возможности собирать семантические ядра конкурентов.
-
Ahrefs.com. Сервис позволяет оценить сложность попадания в топ по определённому ключевому запросу. Этот параметр используют вместе с частотностью фразы. Благодаря этому можно одновременно выбирать как сложно продвигаемые фразы, так и низко конкурентные — из группы низко- и среднечастотных.
Как кластеризовать. Кластеризовать полученные в WordStat запросы стоит на информационные и транзакционные. Первые относятся к получению информации, каких-то сведений, данных. Транзакционные запросы — это фразы с глаголами «купить», «скачать», «заказать». Часть из них — коммерческие, т. е. предполагающие покупку или продажу чего-либо. Их также стоит выделить в отдельную группу.
Что делать с семантическим ядром
После того как семантическое ядро собрано, определённые ключевики используют для создания контент-плана. Эти фразы помогут копирайтеру определить, о чём конкретно пользователь узнает, посетив сео-оптимизированную страницу. Он должен найти на ней ответ. Ключи, выбранные из семантического ядра, идут в метатеги Title и Description, а также в заголовки h2 и h3. Одна из главных задач ключей и дополнительных слов — располагаться непосредственно в тексте и помогать пользователю быстро находить нужную информацию.
Как подобрать корректные запросы
В Google и Яндексе используется интентный поиск. Интент — это смысл запроса. К примеру, «замки Германия» может относиться как к архитектурным строениям, так и к запорным устройствам для дверей немецких производителей. Поисковые системы анализируют предыдущую активность пользователя и определяют интент (смысл), который несет под собой тот или иной запрос. Для продвижения сайта в семантическое ядро стоит включать лишь те запросы, которые по смыслу подходят под тематику ресурса. Чтобы определить интенты и понять, как собрать ядро для сайта, набирайте запросы в поисковике и смотрите, что выдаёт система.
Ошибки и как их избежать
Одна из главных ошибок начинающих сео-оптимизаторов — чрезмерные попытки оптимизировать тексты ключами с ущербом для полезности материала и в некоторых случаях — даже для его читаемости. Поисковики плохо относятся к таким манипуляциям и могут понизить сайт в выдаче. Чтобы не допустить ошибок, собирая семантическое ядро, стоит воспользоваться помощью профессиональных сео-специалистов. Мы составляем семантические ядра с учётом специфики сайтов, особенностей продвижения в выбранной нише и конкурентности запросов. Опытные сео-аналитики помогут вам попасть на первые позиции поисковой выдачи.
www.rookee.ru
Без применения специализированных программ
Рассмотрим этапы формирования семантического ядра на основе сервиса Яндекс Вордстат (как им пользоваться). Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Возьмем направление «рольставни» для компании, которая занимается установкой защитных конструкций и их обслуживанием по Москве и области. В первую очередь актуальны запросы, которые формулируют люди, заинтересованные в покупке таких изделий или у которых возникли проблемы с эксплуатацией. Вводим маску в строку подбора, выбираем регион, например, Москва и область:

В колонке слева Wordstat показывает запросы пользователей, которые набирали со словом «рольставни». В правой колонке дополнительные запросы. Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.

Вордстат даёт 2000 запросов по одному направлению. На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:

Скачать файл Эксель-исходник
Группировка (кластеризация) запросов в семантическом ядре
После сбора запросов, группируем (кластеризируем). Для этого используют 3 вида кластеризации:
- по смыслу;
- по SERP;
- смешанный.
Разбивка «По смыслу» предполагает, что из запросов выделяется основной посыл, что хочет получить человек. В собранном перечне запросы делятся так:
- рольставни +в туалет
- рольставни +на окна
- сантехнические рольставни
- рольставни +в туалет купить
- рольставни +в санузел
- рольставни наружные
- рольставни +в туалет москва
- сантехнические рольставни +в туалет
- рольставни +на окна наружные
- рольставни +в туалет купить москва
- прозрачные рольставни
- рольставни сантехнические купить
- рольставни +в туалет цена
- рольставни +на окна цена
- рольставни +в санузел москва
- прозрачные рольставни +для веранды
Туалет: 1, 3, 4, 5, 7, 8, 10, 12, 13, 15. Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Окна: 2, 6, 9, 14. Установка на окна предполагает, что рольставни буду наружными (запрос №6).
Прозрачные: 11, 16.
Кластеризация по «SERP» предполагает использование специализированной программы или сервиса (например, keyassort.ru). Получается, что это автоматизированный процесс. SERP – это результат поисковой выдачи, проще говоря ТОП-10. Алгоритм действий здесь такой:
- Выбранные фразы добавляются в программу.
- По каждому запросу программа проверяет ТОП-10 или ТОП-20 в Яндекс (Гугл) и сохраняет результат в таблице.
- Далее программа анализирует сохраненные данные и соотносит страницы в выдаче и фразы. И запросы, по которым встречаются одни и те же страницы сайтов в выдаче, объединяет в одну группу.
Такой способ кластеризации подходит для многотысячной семантики и экономит время. По опыту студии, в результате разбивки качество получаемых ядер низкое и требует корректировок.
Смешанный метод – «SERP» и здравый смысл. Применение двух способов одновременно. Случается, что разбив ядро по смыслу, остаются фразы, назначение которых спорно и их сложно объединить в группы. В этом случае снимается СЕРП и на основе анализа разбиваются фразы.
Популярный вопрос «сколько фраз должно быть в одном кластере?». Ограничений нет, от одного запроса до нескольких сотен. Студия DIUS ведет проекты, где одна страница ранжируется по 200-300 запросам. Бывает наоборот, что первоначально добавили в кластер 100 запросов, но при оптимизации зашли только 50. Тогда детально и подробно изучаем оставшиеся фразы, делим по дополнительным признакам и создаем под них новые разделы или оптимизируем другие страницы.
Но такой подход требует опыта, т.к. поисковики негативно относятся, когда под похожие запросы создаются две страницы. В этом случае понижаются позиции по обеим страницам. В этом случае, внимательно изучайте конкурентов в выдаче, возможно на одну страницу следует добавить вхождений.
Для группировки ядра по направлению «Рольставни» воспользуемся методом «По смыслу», т.к. фраз всего 350 и группировка не займет много времени.
Делим фразы по: типу продукции, назначению, параметрам (цвет, материал) и т.д. И также нужно будет отбросить ненужные фразы, назовем эту группу «мусор». В неё попадают нецелевые фразы, которые содержат слова:
- леруа мерлен;
- своими руками;
- фото и видео;
- города не из Московской области;
- бу, схемы, инструкции.
Просмотрев и задав кластер для каждого запроса, получаются следующие группы:

Из 350 подобранных фраз получилось 85 мусорных, остальные распределились на 36 групп по типам и назначению изделия. В первой колонке группа, во второй сколько содержит слов из 350 подобранных:
| Группа | Количество фраз |
| основная | 63 |
| туалет | 61 |
| область | 35 |
| на окна | 28 |
| гараж | 7 |
| прозрачные | 6 |
| монтаж | 5 |
| электропривод | 5 |
| ремонт | 4 |
| шкаф | 4 |
| фотопечать | 4 |
| ванная | 3 |
| дача | 3 |
| комната | 3 |
| дверь | 3 |
| терраса | 2 |
| алютех | 2 |
| балкон | 2 |
| дорхан | 2 |
| перфорированные | 2 |
| торговые | 2 |
| встроенные | 2 |
| веранда | 2 |
| беседка | 2 |
| двери | 1 |
| проем | 1 |
| внутренние | 1 |
| управление | 1 |
| поликарбонат | 1 |
| защитные | 1 |
| мебельные | 1 |
| антивандальные | 1 |
| паркинг | 1 |
| противопожарные | 1 |
| стеклянные | 1 |
| квартира | 1 |
| утепленные | 1 |
| мусор | 85 |
Полученные кластеры в свою очередь группируем по смыслу и получаем структуру сайта для оптимизации:
- Рольставни:
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т.д.
- Назначение: окна, двери, квартира, проем, торговые, мебельные, туалет, гараж, паркинг и т.д.
- Профиль: алютех, дорхан.
- Опции: с электроприводом, с фотопечатью.
- Сервис
- Ремонт
- Монтаж
Из 2000 фраз, которые выдает Вордстат по заданному слову, получится составить структуру сайт гораздо шире, чем приведенная в примере. Естественно ориентируйтесь на ключевики, которые характеризуют продукцию или услуги компании. Если какой-то тип продукции или услуг компания не производит отправляйте их в раздел «мусор».
Расширение семантического ядра в Wordstat
Как подсказывает вордстат на скрине выше, некоторые называют рольставни другим словом – «роллеты». Поэтому для расширения ядра получения дополнительных фраз по ним также собираются фразы:

И:

Эти фразы добавляются в созданные группы или по ним создаются новые. Поисковики понимают, что «рольставни» и «роллеты» — это одно и тоже, поэтому совмещайте их в одних целевых кластерах.
Расширение ядра при помощи поисковых подсказок Yandex.ru
Дополнительным способом расширения семантики используют такой метод как «поисковые подсказки». Когда пользователь Яндекса вводит запрос в строку, поисковик предлагает варианты, исходя из статистики популярных запросов, дополняющие слова:

Видно, что на запрос «рольставни» поисковик предлагает запросы, которые уже были отобраны из сервиса Вордстат. Ориентируйтесь на фразы из 3-4 слов:

Тогда получится дополнить ядро. Вручную собирать подсказки трудозатратно, для этого целесообразно использовать профессиональные программы по сбору семантики или сервисы. РашАналитикс помогает собирать подсказки. На сервисе предусмотрена бесплатная регистрация, и сразу даётся 200 баллов.
Для сбора добавьте фразы из 3-4 слов из семантического ядра. Задайте популярные мусорные слова, чтобы сервис автоматически из убрал из результатов: своими руками, бу, леруа мерлен. В результате получаем такие дополнительные слова из подсказок:

Полученные фразы чистим от мусорных и проверяем частоту через Вордстат:

Сколько запросов собирать в ядро
По сути ограничений нет, чем больше фраз подобрано в семантическое ядро, тем лучше будет проработан сайт с точки зрения структуры и содержания. Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:

Ясно, что посетителей интересует:
- Цена такой конструкции.
- Варианты исполнения: с электроприводом или механические.
- Материалы изготовления: тканевые, металлические.
- Как устанавливают изделие.
- Для каких окон: квартиры, дачи, частный дом.
- Дополнительные функциональные свойства: защитные, антивандальные и т.д.
Каждый запрос в группе – это единица смысла, которую нужно отразить на созданной странице. Во-первых, это позволит употребить ключевые слова, что сделает сайт релевантным этому кластеру. Во-вторых, на странице будет опубликована полезная для посетителя информация.
Очистка семантики от мусора
При сборе многотысячного семантического ядра в список попадёт много нецелевых фраз:
- Тип продукции или схожий вид услуг, которыми компания не занимается. В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
- В запросах часто появляются названия фирм конкурентов, когда пользователь пишет товар или услугу, и указывает название компании.
- У людей, проживающих в Москве и имеющих коттедж в другом регионе, например, Твери, отразится это в запросах, когда они будут заказывать рольставни, ворота и т.д. Указывая город в сервисе, вы задаете географию пользователей, интересы которых могут лежать за пределами этого региона.
- Также убирайте из ядра ошибочные написания и опечатки. Если раньше под такие запросы создавались страницы, то сейчас поисковые алгоритмы обнаружив опечатку исправляют её и выдача формируется по корректной словоформе. И если появятся новые ошибки в названиях, это значит, что в ближайшее время алгоритм это учтет.
От нецелевых запросов следует избавляться по следующим причинам:
- Если пользователь зайдет на сайт и обнаружит, что компания из другого региона – он закроет страницу. Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
- Также это расценивается алгоритмами как поисковый спам, когда компания привлекает посетителей по запросам, задачи по которым она не решает.
- По некоторым запросам, типа «рейтинг компаний по рольставням», поисковики показывают сайты справочники, бизнес-каталоги, агрегаторы. По таким фразам не добраться до ТОП-10, если только не делать каталог организаций. Убрав их из ядра оптимизатор экономит время и ресурсы.
Как разбить семантическое ядро по типу запросов
Также стоит учесть разделение запросов по интенту пользователя:
- информационные;
- коммерческие.
Подробнее об этом в материале блога.
Для коммерческих запросов создаются разделы услуг, на которых предлагаются к продаже услуги и товары. Они называются коммерческими, т.к. предполагают, что у пользователя, при запросе прямое намерение купить или заказать продукцию, представленную на сайте. В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
Информационные запросы подразумевают, что пользователь хочет получить сведения о пользовании продукцией, инструкций и т.п. В таких запросах часто фигурируют вопросы: как, какой, зачем, что лучше, почему и т.д. Для таких групп создается раздел статей на сайте, который отвечают на популярные вопросы людей перед покупкой, например, по рольставняим: как выбрать, какой профиль лучше и т.д. Формируется дополнительное ядро запросов для написания полезных материалов. Его собирают из Вордстат, добавив к фразе конструкцию «+как»:

Также с «+где», «+когда» и т.д.
При этом информационные запросы геонезависимые, поэтому регион ставьте Россия. Грамотное использование инфозапросов даёт целевые переходы из поисковиков, которые также конвертятся в обращения и покупки. Для этого используйте «Лестницу Бена Ханта» — подробней в статье.
Предлагаем создание
семантического ядра для сайта
Что делать с семантическим ядром после составления
Итак, семантика собрана, разбита на группы. Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Сначала еще раз посмотрите каждую группу, проверьте на соответствие ассортименту компании. На сколько формулировки соответствуют предлагаемым видам продукции или услуг.
Структура сайта на основе семантики
На основе семантического ядра разрабатываем структуру сайта:
- Главная страница под высокочастотные и прямые фразы. В случае с «Рольставни» — это: рольставни, рольставни купить / цена / заказать и т.д.
- Планируем разделы, в которые включаются виды продукции (услуг) и вспомогательные страницы (гарантии, отзывы, доставка, контактная информация, о компании) цель которых убедить посетителя в надежности представленной компании.
- Подразделы – группы запросов распределенные по видам, типам и т.д. В представленном примере «Рольставни» в разделе Профиль, будут 2 подраздела: Алютех и Дорхан, из которых производят изделия.
Содержание страниц
Как говорилось выше, семантика для маркетолога – это источник креатива и полезного контента. В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
Превратитесь на время в маркетолога, изучите каждую фразу под микроскопом. Что подразумевает человек в запросе. Какие у него опасения и как их развеять. В какой формате человек хочет получить решение проблемы и как показать, что компания выполнит желаемое. Какие факторы принятия решения влияют на него и как их усилить на странице? Таким образом составится уникальный контент, полезный для посетителя с коммерческим эффектом.
Вывод
Ручное составление семантического ядра при помощи Яндекс Вордстат трудозатратное мероприятие. Оно подходит для разовой работы и для небольших сайтов. При профессиональном продвижении сайтов целесообразно приобрести программу Кей Коллектор, которая упрощает работы и сокращает время по формирование семантики в разы. При этом она позволяет детально работать с группой и каждым словом. Пример сбора ядра в Key Collector можете посмотреть здесь.