

Скачать готовые примеры семантических ядер в новом Excel формате
Перейти к содержанию
Скачать бесплатно готовые примеры
семантики для сайтов в Экселе
✓ 20 примеров готовой семантики (описание + бюджет).
✓ Представлены самые популярные (заказываемые) темы.
✓ Быстрый запрос на получение примера для вашей тематики.
✓ Новый формат семантического ядра и отчетов от 07.2022.
✓ Архивы содержат платные ТЗ копирайтеру от TaskБилдер.
✓ Цена от 100$ за семантику «под ключ». Срок от 10 дней.
✓ 8 наших «фишек» и инструментов при сборе СЯ: перейти.
На наших примерах оцените:
✅ Стоимость семантики в вашей/похожей тематике.
✅ Качество сбора/группировки ключей и полноту кластеров.
✅ Удобство оформления и навигацию по ядру в Excel.
✅ Доп. отчеты по анализу конкурентов, сложности продвижения…
✅ Формат платного (Excel+Tskb) и бесплатного (Txt) ТЗ для копирайтера.
Финальная стоимость семантического ядра зависит от:
✅ Региона.
✅ Тематики / номенклатуры продукции.
✅ Нижнего порога частотности: «!WS» / GA.
✅ Вида запросов в ядре (коммерция, инфо, оба варианта).
✅ Сколько ключей вы удалите при утверждении после сбора.
Нет примера вашей тематики? Не можете оценить бюджет?
Подайте бесплатную заявку на пример.
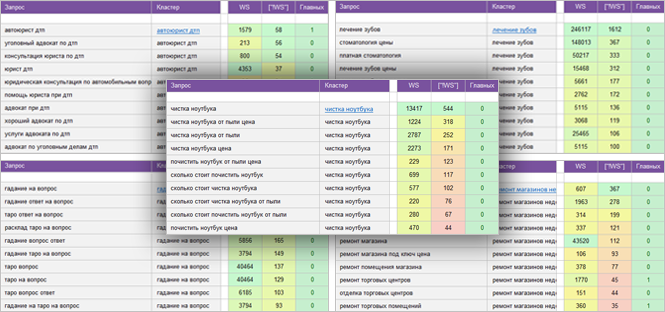
«Бухгалтерские услуги».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 378 шт.
Количество кластеров: 38 шт.
Общая частотность запросов по Wordstat: 12 793.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
«Для строительного сайта».
Бани, готовые элитные дома, новостройки, для модульных зданий, монтаж систем отопления и водоснабжения.
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 8 034 шт.
Количество кластеров: 346 шт.
Общая частотность запросов по Wordstat: 220 127.
Срок выполнения: 13 дней.
![]() Цена: 280 $
Цена: 280 $![]() Скачать пример ядра
Скачать пример ядра
«Сантехника».
Регион: Москва и МО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 6 200 шт.
Количество кластеров: 590 шт.
Общая частотность запросов по Wordstat: 75 570.
Срок выполнения: 11 дней.
![]() Цена: 340 $
Цена: 340 $![]() Скачать пример ядра
Скачать пример ядра

Хотите пример ядра
по вашему региону и нише?
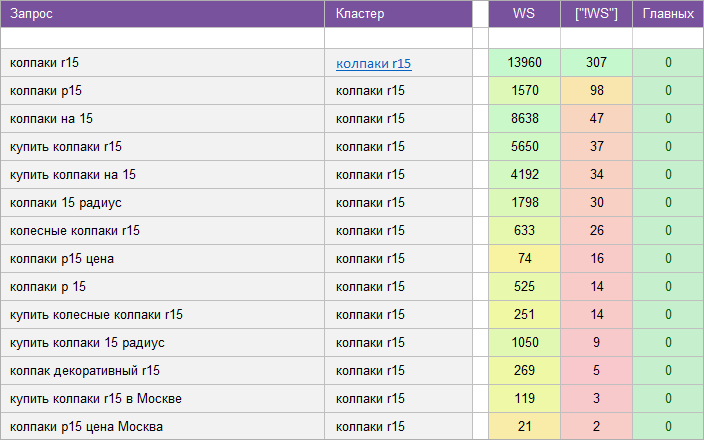
«Салон красоты».
Покраска, маникюр, эромассаж и т.д.
Регион: Москва.
Вид ключевых слов: Коммерческие + Инфо.
Кластеризованных запросов: 11 958 шт.
Количество кластеров: 892 шт.
Общая частотность запросов по Wordstat: 200 897.
Срок выполнения: 12 дней.
![]() Цена: 385 $
Цена: 385 $![]() Скачать пример ядра
Скачать пример ядра
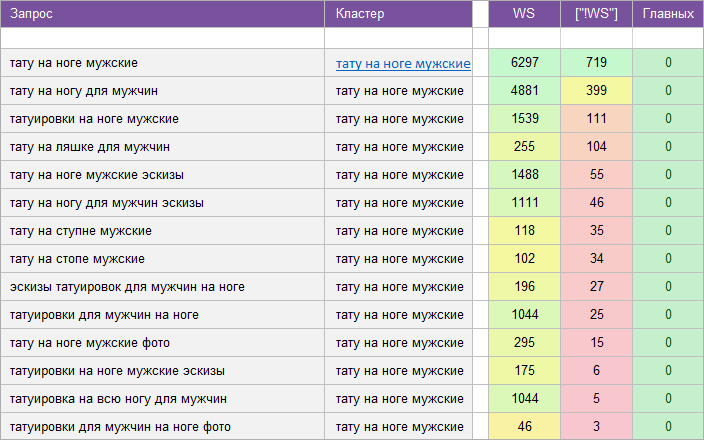
«Автосервис».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 4 073 шт.
Количество кластеров: 396 шт.
Общая частотность запросов по Wordstat: 386 236.
Срок выполнения: 10 дней.
![]() Цена: 175 $
Цена: 175 $![]() Скачать пример ядра
Скачать пример ядра
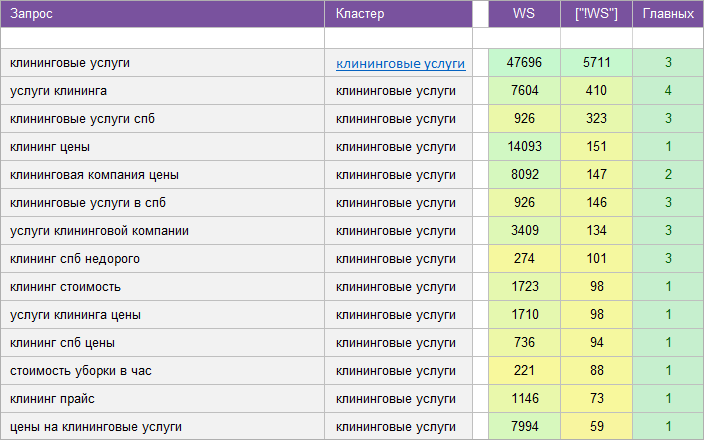
«Услуги клининговой компании».
Регион: Санкт-Петербург.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 100 шт.
Количество кластеров: 167 шт.
Общая частотность запросов по Wordstat: 27 500.
Срок выполнения: 7 дней.
![]() Цена: 115 $
Цена: 115 $![]() Скачать пример ядра
Скачать пример ядра
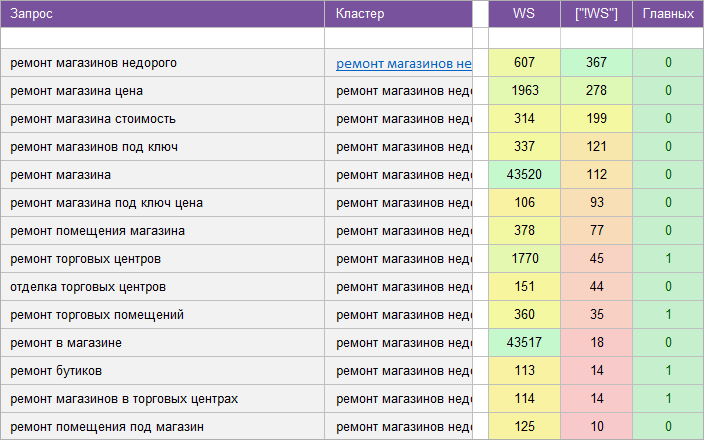
«Ремонт недвижимости».
Ремонт квартир, домов и прочей недвижимости.
Регион: Москва и МО.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 3 288 шт.
Количество кластеров: 306 шт.
Общая частотность запросов по Wordstat: 55 322.
Срок выполнения: 10 дней.
![]() Цена: 165 $
Цена: 165 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
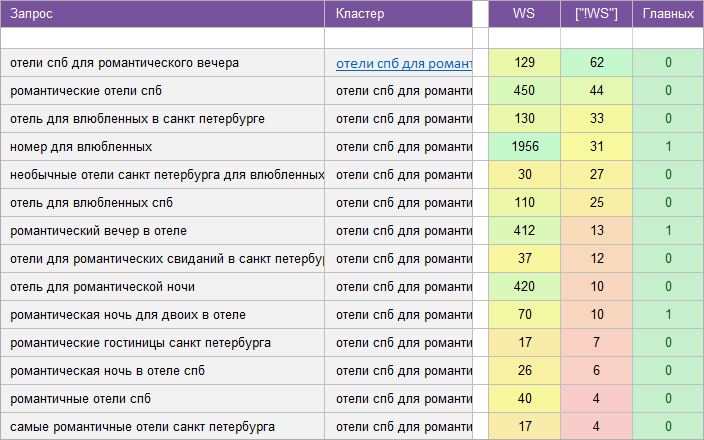
«Для отелей и гостинец».
Регион: Санкт-Петербург и область.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 6 408 шт.
Количество кластеров: 511 шт.
Общая частотность запросов по Wordstat: 123 421.
Срок выполнения: 9 дней.
![]() Цена: 352 $
Цена: 352 $![]() Скачать пример ядра
Скачать пример ядра
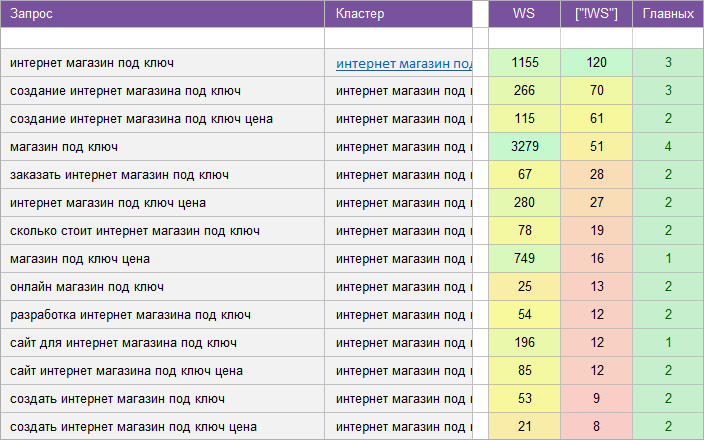
«Для веб-студии».
Регион: Весь Рунет.
Вид ключевых слов: Коммерция .
Кластеризованных запросов: 14 500 шт.
Количество кластеров: 926 шт.
Общая частотность запросов по Wordstat: 350 700.
Срок выполнения: 15 дней.
![]() Цена: 725 $
Цена: 725 $![]() Скачать пример ядра
Скачать пример ядра
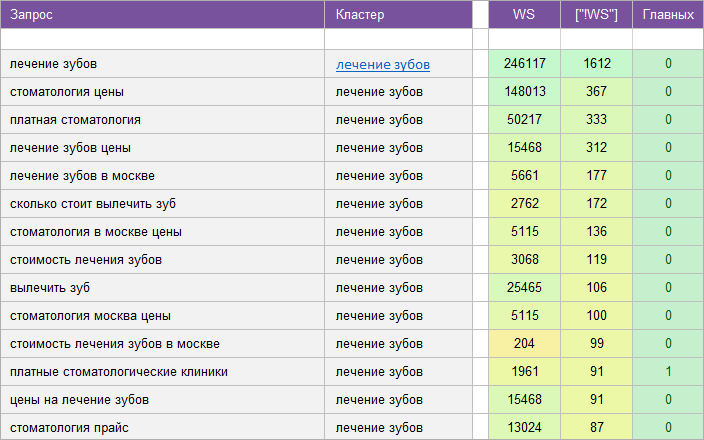
«Стоматология».
Регион: Москва.
Вид ключевых слов: Коммерция + Инфо.
Кластеризованных запросов: 8 253 шт.
Количество кластеров: 650 шт.
Общая частотность запросов по Wordstat: 138 934.
Срок выполнения: 12 дней.
![]() Цена: 300 $
Цена: 300 $![]() Скачать пример ядра
Скачать пример ядра
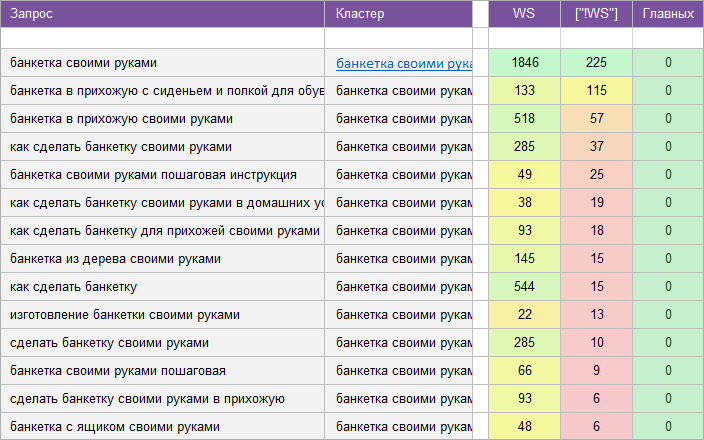
«Мебель и предметы интерьера».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 22 016 шт.
Количество кластеров: 843 шт.
Общая частотность запросов по Wordstat: 899 870.
Срок выполнения: 14 дней.
![]() Цена: 575 $
Цена: 575 $![]() Скачать пример ядра
Скачать пример ядра
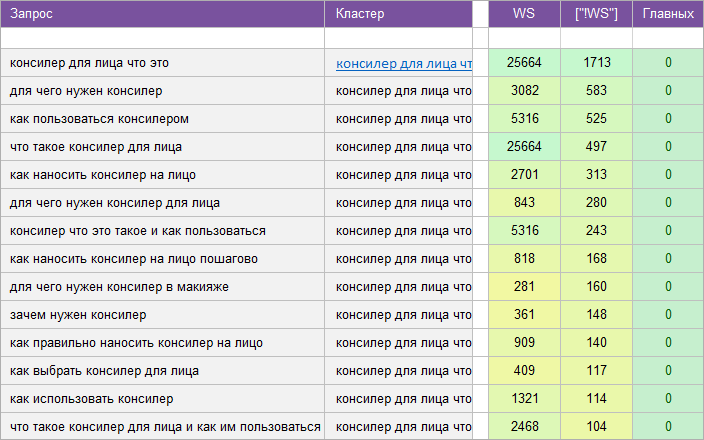
«Для женского сайта».
Регион: Без региона.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 16 544 шт.
Количество кластеров: 693 шт.
Общая частотность запросов по Wordstat: 2 358 018.
Срок выполнения: 12 дней.
![]() Цена: 455 $
Цена: 455 $![]() Скачать пример ядра
Скачать пример ядра
Хотите пример ядра
по вашему региону и нише?
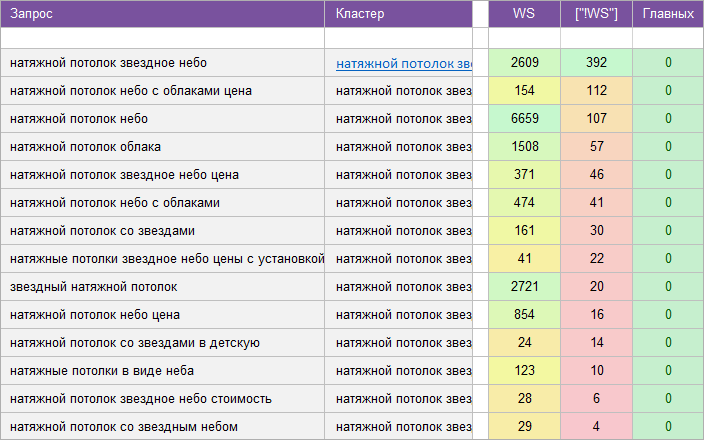
«Натяжные потолки».
Регион: Санкт-Петербург и ЛО.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 493 шт.
Количество кластеров: 45 шт.
Общая частотность запросов по Wordstat: 13 558.
Срок выполнения: 6 дней.
![]() Цена: 70 $
Цена: 70 $![]() Скачать пример ядра
Скачать пример ядра
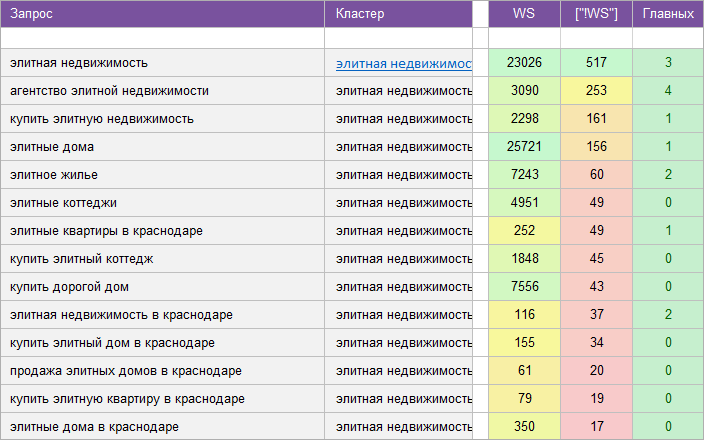
«Агентство недвижимости».
Регион: Краснодар.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 14 469 шт.
Количество кластеров: 1 341 шт.
Общая частотность запросов по Wordstat: 200 056.
Срок выполнения: 15 дней.
![]() Цена: 500 $
Цена: 500 $![]() Скачать пример ядра
Скачать пример ядра
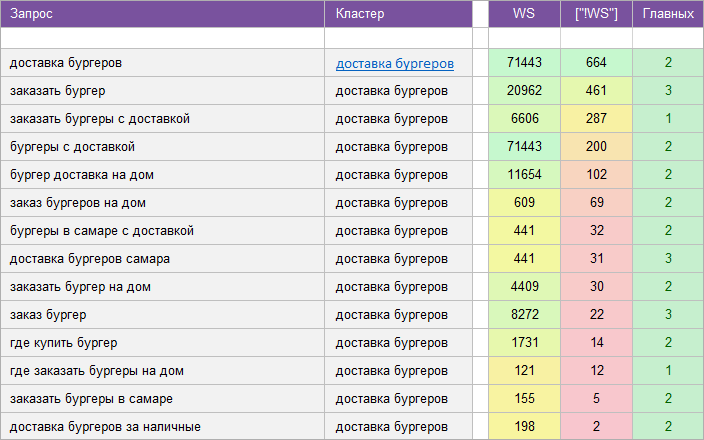
«Доставка еды».
Регион: Самара.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 2 585 шт.
Количество кластеров: 238 шт.
Общая частотность запросов по Wordstat: 19 501.
Срок выполнения: 9 дней.
![]() Цена: 140 $
Цена: 140 $![]() Скачать пример ядра
Скачать пример ядра
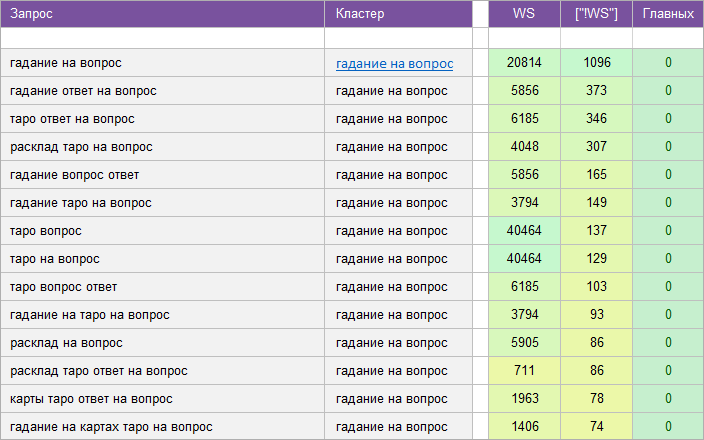
«Карты Таро».
Регион: Россия.
Вид ключевых слов: Информационные.
Кластеризованных запросов: 9 196 шт.
Количество кластеров: 557 шт.
Общая частотность запросов по Wordstat: 992 132.
Срок выполнения: 14 дней.
![]() Цена: 285 $
Цена: 285 $![]() Скачать пример ядра
Скачать пример ядра
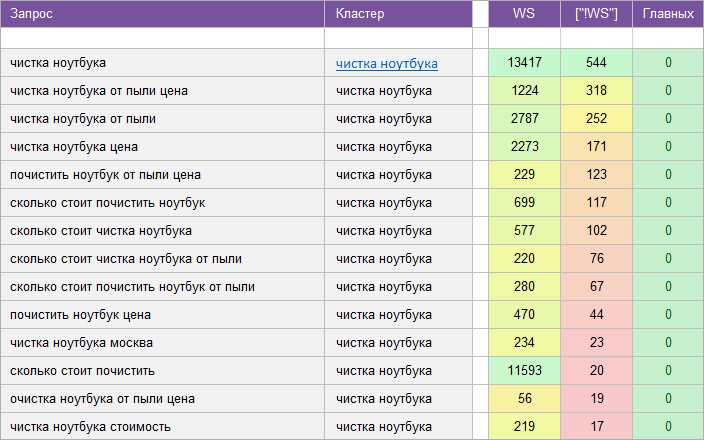
«Ремонт компьютеров и ноутбуков».
Регион: Москва.
Вид ключевых слов: Коммерческие.
Кластеризованных запросов: 3 437 шт.
Количество кластеров: 321 шт.
Общая частотность запросов по Wordstat: 51 753.
Срок выполнения: 8 дней.
![]() Цена: 190 $
Цена: 190 $![]() Скачать пример ядра
Скачать пример ядра
Самые популярные вопросы — ответы:
На одной странице невозможно собрать примеры во всех тематиках.
Но, вы можете подать заявку на получение бесплатного примера в вашей тематике: заполнить.
На полученном примере вы можете оценить качество нашей семантики.
После изучения наших примеров, вы подаете бриф.
А мы собираем для вас ядро и экономим: средства/нервы/время.
1. Средства. Вам не надо покупать:
✓ Платные сервисы (Serpstat, keys.so) — от 250$.
✓ Программы и скрипты (KeyCollector, a-parser) — от 50$.
✓ Прокси (минимум 10 приватных) — от 20$.
✓ АнтиКаптча — от 30$.
✓ Регистрация и поддержка аккаунтов Яндекса и Google в рабочем состоянии — от 0$.
2. Нервы:
Сотни сообщений за день в Телеграм канале @KeyCollectorCHAT связанных с проблемами сбора, чистки и кластеризации запросов. В последнее время поисковые системы значительно усложнили процесс парсинга.
3. Время:
Мы 9 лет разрабатываем нашу систему по работе с семантикой, отлаживаем все тех. процессы, отбираем лучшие прокси для парсинга и систему разгадывания каптч. Все это позволяет нам максимально автоматизировать и ускорить все процессы.
Без опыта и наработок только сбор запросов и параметров может растянуться у вас на дни.
Наше семантическое ядро состоит из:
✓ Главного файла «yadro.xlsx». Отчеты в файле: «Семантическое ядро», «Структура», «ТОП доменов конкурентов», «Описание полей и колонок».
✓ Дополнительные отчеты (отдельные файлы): «Аналитика по запросам», «Сезонность», «ТОП внешних ссылок», «Популярные слова и фразы»
✓ Тз для копирайтера (платная Excel или бесплатная Txt версия).
Важно: из главного файла «ядро.xlsx» ссылки ведут на дополнительные отчеты и ТЗ для копирайтера.
Это позволяет выполнять быструю навигацию, а не искать доп. отчеты по папкам.
В наших архивах находится больше 6500 готовых ядер, которые мы составили за 9 лет.
Но, мы НЕ продаем готовую семантику.
Почему? Отвечаем:
✓ Семантика — это анализ ТЕКУЩЕГО спроса в тематике. Актуальность семантики — один из главных факторов успешного внедрения на сайт. Со временем семантика «стареет». Появляются новые запросы, у некоторых пропадает спрос (пример: устаревшая модель телефона или кондиционера).
✓ Специфика бизнеса. Нет компаний, которые на 100% предоставляют одинаковые услуги или продают одинаковые товары. Пример: Мы делали 4 ядра в тематике: Клининг (Москва). Все 4 ядра отличаются по размеру, самое маленькое ядро получилось 1300 запросов, а самое большое 3800.
За 9 лет работы мы составляли семантику для сайтов во всех нишах.
На данной странице представлены примеры тематик, с которыми мы чаще всего работали.
Плюс, есть опыт в сложных тематиках: беттинг (ставки на спорт), гемблинг(казино), криптовалюта, гейминг, пластиковые окна и двери, кондиционеры.
Собирали семантику на: русском, английском, польском, немецком языках. Под Бурж и Рунет.
Да. Сейчас ядра у нас выгружаются в 3 версии оформления шаблона. Дата внедрения: 07.2022.
Что нового:
✓ Разработали максимально удобную систему навигации между отчетами и ТЗ для копирайтера.
✓ Подобрали приятную цветовую гамму заливки ячеек. Зеленый – хорошо, красный – плохо/сложно.
✓ Сформировали наглядные графики/таблицы изменения спроса в отчете «Сезонность».
✓ Быстрое скрытие/раскрытие групп колонок в шапке. Позволяет оставить на экране только нужные данные и не терять фокус внимания при анализе.
✓ Максимально простое и подробное описание всех колонок и параметров (вкладка «Описание полей»).
Полная переработка «helpа».
Все это позволяет максимально эффективно работать с собранной аналитикой.
Нет примера в нужной
Вам тематике?
Бесплатная консультация
от руководителя

составлению семантического ядра.
Page load link

Закажите семантическое ядро + внесите предоплату до 31.03.2023 и получите:
1. Скидку на сбор запросов — 15%.
2. Наше новое ТЗ для копирайтера в
Excel + Tskb формате (описание) — 50%.
3. Консультацию от руководителя на 1-1,5 часа
по работе с ядром и ТЗ — бесплатно.

Укажите в брифе ваш
промокод: prom2023
Сбор семантики сайта представляет собой сложную и многоступенчатую задачу. Ее успешное решение предусматривает использование различных вспомогательных инструментов, включая специализированные программы и онлайн-сервисы. Но значительную часть выполняемых SEO-оптимизатором операций можно эффективно выполнять в обычных электронных таблицах Excel.
Речь идет не только о сортировке отобранных ключей, но и оформлении списка запросов, его последующем редактировании и чистке, а также подготовке базы данных для работы с другими сервисами или составления технического задания для копирайтера. А потому имеет смысл изучить порядок и особенности сбора семантического ядра в Excel более подробно, включая рассмотрение возможности, где можно скачать пример семантики, составленной в электронных Google Таблицах.
Содержание
- Виды Excel для сбора СЯ
- Этапы сбора семантического ядра с помощью Google Таблиц
- Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
- Шаг №2. Чистка семантического ядра
- Шаг №3. Кластеризация/группировка семантического ядра запросов
- Полезные функции Google Docs и Эксель
- Вспомогательные инструменты
- SeoTools for Excel
- SEO-Excel
- Рекомендации по использованию Google Docs для сбора СЯ
- Вместо вывода
Виды Excel для сбора СЯ
Для решения задач СЕО-оптимизации применяются две версии электронных таблиц. Первая поставляется в рамках стандартного пакета MS Office и представляет собой самостоятельную программу. Вторая – составной элемент Google Docs. Именно последний вариант пользуется сегодня все большим спросом, так как обладает рядом достоинств, в числе которых:
- доступность для любого обладателя аккаунта в Google;
- интеграция с программами из MS Office, включая обычные Эксель и Ворд;
- доступ к облачному хранилищу Google Диск, 15 ГБ которого предоставляется бесплатно и позволяет работать с Google Таблицами с любого устройства – от ПК до смартфона – сразу после авторизации.
На приведенном ниже скриншоте показан пример, как выглядят Google Таблицы. Приводить внешний вид традиционного Excel не имеет смысла, так как он прекрасно известен любому более-менее опытному пользователю ПК.

В остальном работа с обеими версиями программы – Excel и Google Docs – осуществляется по стандартным правилам, хорошо известным большинству пользователей. С учетом нескольких особенностей, характерных для SEO-продвижения сайтов по поисковым запросам.
Этапы сбора семантического ядра с помощью Google Таблиц
Некоторые специализированные сервисы, к примеру, Key Collector или Словоеб, обладают встроенными инструментами для форматирования структуры сайта и перечня ключевых слов и запросов. Поэтому не предполагают применение Excel. Но для значительной части других сервисов, включая один из самых популярных Яндекс Wordstat, использование Google Docs или Excel выступает одним из необходимых этапов работы. Более того, при грамотном применении возможностей электронных Google Таблиц удается упростить и оптимизировать сразу несколько важных операций по чистке семантического ядра. Рассмотрим последовательность предпринимаемых для этого действий с разбивкой на отдельные этапы.
Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
Функционал Excel предоставляет возможность составить список поисковых запросов вручную – посредством анализа продвигаемого сайта и деятельности компании. Но намного проще собрать исходное семантическое ядро с помощью Яндекс Wordstat. Чтобы сделать это, необходимо произвести следующие операции:
- Скачивание и установка расширения Яндекс Wordstat Assistant (подробнее о сервисе и расширениях к нему – на другой страницу нашего сайта). Сделать ссылку. В результате в левой части окна сервиса появится дополнительная панель инструментов.
- Выделение и сохранение интересующих пользователя запросов нажатием кнопки «+».
- Копирование сформированного списка поисковых запросов в Google Таблицы или обычный Эксель. Производится по одному из двух вариантов – с показателем частотности ключа или без него. Выбирается нужный пользователю способ копирования. Пример выполнения операции показан на скриншоте.

Шаг №2. Чистка семантического ядра
Основной задачей оптимизации СЯ запросов выступает повышение эффективности размещенных на сайте ключевых слов и фраз. Первым этапом становится избавление от ключей с низкой или даже нулевой релевантностью. Операция выполняется вручную, так как требует непосредственного участия SEO-специалиста. Ответ на вопрос, как почистить семантическое ядро, предусматривает удаление нескольких видов запросов, включая:
- самые низкочастотные (полное их удаление нецелесообразно, так как важно найти оптимальный баланс запросов с разной частотностью);
- ведущие на сайты конкурентов;
- лишние с предсказуемо низкой релевантностью из-за несоответствия задачам сайта;
- дубли (представляют собой поисковые запросы или фразы, которые различаются порядком слов).
Как было отмечено, удаление ненужных запросов происходит вручную. Для большего удобства и упрощения работы допускается как редактирование текущего листа электронных таблиц Google, так и перенос оптимизированного списка запросов на вновь созданный.
Шаг №3. Кластеризация/группировка семантического ядра запросов
Завершающий этап работы по СЕО-продвижению сайта с помощью Excel предполагает проведение кластеризации или группировки поисковых запросов. Она предусматривает разбивку общего списка ключевых слов или фраз для размещения на отдельные страницы в соответствии с предварительно разработанная структурой интернет-ресурса. Оптимальное количество запросов на каждую равняется 5-6, для очень объемных оно может быть несколько увеличено.
Операция также выполняется вручную с применением традиционного функционала Google Таблиц или Excel. Автоматизировать данные действия специалиста можно только с использованием специализированного инструментария, хотя даже самые современные и многофункциональные сервисы не способны выполнять такую работу на требуемом уровне.
Дальнейшие операции с собранным семантическим ядром производятся в зависимости от задач, стоящих перед СЕО-специалисту. Это может быть или составление технического задания копирайтеру, или дальнейшая оптимизация СЯ с использованием других программ или сервисов. Примеры готовой семантики, составленной в Эксель, можно с легкостью найти в сети, например, по следующей ссылке.
Полезные функции Google Docs и Эксель
Подробно описывать набор функциональных возможностей самой популярной программы электронных таблиц не имеет особого смысла. Опытным пользователям они прекрасно известны, а новичкам намного проще и правильнее разобраться самостоятельно, так как это наверняка пригодится в дальнейшей работе. Главное – знать о существовании таких возможностей, как:
- копирование и удаление ссылок из семантического ядра;
- замена отдельных слов или элементов списка запросов;
- удаление ненужных или лишних пробелов, включенных в СЯ;
- сортировка запросов по значениям любого из столбцов по двум параметрам – алфавиту или числу;
- поиск повторяющихся значений или минус-слов для последующего удаления вручную;
- удаление дубликатов из состава семантического ядра;
- сортировка запросов по цвету ячейки и многое другое.
Вспомогательные инструменты
Google Таблицы и традиционный Эксель обладают обширным функционалом. Но далеко не все опции эффективны применительно к СЕО-продвижению сайтов по поисковым запросам. Именно поэтому активно разрабатываются дополнительные надстройки к традиционным электронным таблицам. Два из них – самые известные и популярные – имеет смысл привести отдельно, хотя количество подобных инструментов постоянно растет.
SeoTools for Excel
Одно из первых расширений для электронных таблиц, которое разработано специально для SEO-продвижения. Обладает обширным функционалом, постоянно обновляется, совместимо с различными онлайн-сервисами и программами. Из недостатков – отсутствие версии для русскоязычных пользователей. Чтобы скачать программу, достаточно перейти на сайт разработчика и зарегистрироваться на нем.

SEO-Excel
Русскоязычный аналог описанной выше надстройки. Содержит более двух десятков инструментов для СЕО-продвижения. Чтобы скачать программу, достаточно зарегистрироваться на сайте, хотя возможно платное использование онлайн-версии продукта. SEO-Excel адаптирован для работы с Яндекс Wordstat и Rush-Analytics, что объясняет популярность среди отечественных специалистов. Дополнительный аргумент скачать и установить надстройку – очень полезная опция генерации различных тегов – H1, Title и Description, заметно упрощающая работу SEO и экономящая его время, в том числе – при составлении технического задания копирайтеру.

Рекомендации по использованию Google Docs для сбора СЯ
Главным достоинством Excel и Google Таблиц справедливо считается доступность. Оборотной стороной становится необходимость выполнять значительную часть операций СЕО-оптимизации вручную. Чтобы упростить собственную работу, имеет смысл воспользоваться несколькими простыми рекомендациями:
- внимательно изучайте руководство пользователя, так как некоторые функции электронных таблиц выступают секретом даже для очень опытных специалистов;
- автоматизируйте самые рутинные и трудоемкие процессы за счет грамотного использования встроенных опций и сервисов;
- скачивайте и устанавливайте дополнительные надстройки, предназначенные для SEO-продвижения (важное дополнение – загрузка должна выполняться только с проверенных сайтов компаний-разработчиков).
Вместо вывода
Важно понимать, что полная автоматизация процесса SEO-продвижения сайта по поисковым запросам попросту невозможна. Никакие сервисы и программы не способны заменить опыт и квалификацию грамотного специалиста, хотя существенно помогают в его работе при грамотном использовании. Именно поэтому имеет смысл сотрудничать с профессионалами, а вложенные средства с лихвой окупаются повышением эффективности интернет-ресурса.
Наша компания оказывает полный комплекс услуг в области SEO-оптимизации на выгодных и привлекательных для клиентов условиях. Для получения персонального коммерческого предложения достаточно связаться с нами любым удобным способом.
Поделились внутренним инструментом, который анализирует собранные фразы и показывает, где и что еще можно добрать.
В маркетинге мы предпочитаем опираться на математику, а не на интуицию. Если есть задача проверить семантику на полноту — значит, должен быть инструмент, который перетрясет собранные фразы и покажет, где и что еще можно добрать. Сервисов аналогичных нет, поэтому мы нашу внутреннюю модель вынесли в Excel-файл — скачивайте и пользуйтесь.
Вам понадобятся: фразы и их частоты — общие и точные.
Принцип такой: вносим в Excel-файл фразы и частоты, жмем на кнопку и через несколько секунд, когда сформируются связи «фраза-хвост» и отсекутся доли нерелевантного объема, по маркерам определяем — где мы не доработали.
А теперь подробнее.
Идеально отработанная семантика
Если семантика отработана идеально, Excel-файл выглядит так:
- значения в столбце H (расчетная частота) близки к значениям в столбце D (точная частота) у всех фраз, кроме низкочастотных и тех, в которых больше всего значимых слов.
- столбец J (коэффициент отработки) зеленого цвета.
- столбец K (коэффициент неотработки) зеленого цвета
Неполная семантика: что упустили и как доработать
По маркерам файла мы можем понять 3 момента.
- Мы не добрали хвосты.
- Не досчитали трафика.
- Собрали некачественные хвосты.
Не добрали хвосты
Если для какой-то фразы (скажем, «Защитная каска») мы упустили хвост со средней или высокой частотой («Защитная каска с наушниками»), мы увидим это по маркерам в файле.
Хвост — дочерняя фраза («Защитная каска с наушниками»), которая состоит из материнской фразы («Защитная каска») и хотя бы одного дополнительного слова («наушник»)
Маркеры:
В столбце J (Коэффициент неотработки) и/ или в столбце K (Коэффициент отработки) ячейки не зеленого цвета, а желтого, оранжевого или красного (чем больше упустили хвостов, тем краснее цвет).
Что делать:
Идем в вордстат — вбиваем каждую такую фразу с минус-словами, находим для нее не включенные релевантные частотные хвосты и добавляем их в семантику.
Если таких хвостов нет, значит, дело не в том, что мы чего-то недобрали, а в том, что мы неправильно определили, какой релевантный объем трафика принесет фраза. Мы включили в него и мусорный объем. Для точного прогноза мусорный объем нужно отсечь — уменьшить коэффициент чистоты в столбце С.
Собрали некачественные хвосты
Если мы включили в семантику хвост с низкой точной частотой, файл нам это тоже покажет.
Маркер:
Значение в столбце J (Коэффициент неотработки) меньше, чем значение в столбце K (Коэффициент отработки).
Что делать:
В столбце P ставим значение 0 — тогда эта фраза не будет учитываться и мы не возьмем ее в продвижение. Так мы сэкономим деньги, потому что у нее была бы высокая цена за пользователя.
Не досчитали трафика
Иногда мы можем для какого-то запроса не точно спрогнозировать трафик — посчитать, что фраза приведет 15 человек, а, на самом деле, она может привести 20. Такие случаи файл нам тоже показывает, чтобы мы не удалили фразу, которую по ошибке посчитали бы мало полезной.
Маркеры:
Текст в столбце F красного цвета.
Что делать:
Увеличиваем коэффициент чистоты в столбце С.
Подготовка файла к работе
Скачайте шаблон и выполните следующие подготовительные шаги.
1. Внесите фразы
Откройте лист sem. Внесите в столбец А собранные фразы, в столбец B — их общие частоты, а в столбец С — точные частоты. Скопируйте эти же фразы (или сформируйте из них любую другую выборку) в столбец F листа work.
2. Задайте правила для создания униформ
Перейдите на лист «Морфо». Здесь собраны предлоги и окончания, которые будут игнорироваться, потому что они не считываются поисковиками как смысловые. Вы можете задавать на этом листе свои правила и исключения.
После того, как на четвертом шаге вы нажмете на кнопку «Расчет частот и отработки», по этим правилам для каждой фразы в столбце B сгенерируются униформы, которые однозначно характеризуют фразы.
3. Установите коэффициент чистоты
Мы делаем это для того, чтобы учитывать только релевантные запросы по каждой фразе. Например, фразу «Средства индивидуальной защиты» могут вбивать в поисковиках 20000 раз за месяц. Но 30% из этих запросов — информационка. И нам нужно это учитывать, чтобы мы не считали, что у нас трафика с этой фразы будет больше.
Перейдите на лист «Properties».
Опираясь на свой опыт, знание проекта и отрасли, задайте базовый коэффициент чистоты.
Например, если вы считаете, что фразы из одного слова («Каски», «Спецодежда») содержат, в среднем, 45% мусора, поставьте в столбце D коэффициент чистоты — 0,55.
Ниже идут уровни вложенности: +1 слово (фразы из двух слов), + 2 слова (фразы из трех слов), + 3 слова (фразы из четырех слов). Для них также проставьте коэффициенты чистоты в столбце D. На скрине это: 0,65, 0,85 и 0,95. Обычно, чем длиннее фраза, тем меньше она замусорена.
Потом для отдельных фраз можно будет увеличить или уменьшить коэффициент чистоты. Это вы увидите по маркерам (мы их описали выше). Коэффициент чистоты для отдельной фразы можно поменять на листе «Work», в столбце С.
4. Нажмите на кнопку «Расчет частот и отработки»
Через несколько секунд уже можно анализировать маркеры и дорабатывать семантику.
Экономия
Кажется, сложно, но на деле это займет 10-20 минут. Проделанная работа позволит корректно сформировать кластеры, привести максимальный трафик и не переплачивать за пользователей.
Так что скачивайте файл, разбирайтесь, пользуйтесь или обращайтесь за продвижением к нам.
- Опубликовано:20.01.2014
- Комментарии:
Нет комментариев - Рубрика:
Продвижение магазинов - Просмотров: 19 910

Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла. Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Скачать файл Excel (.xls)
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
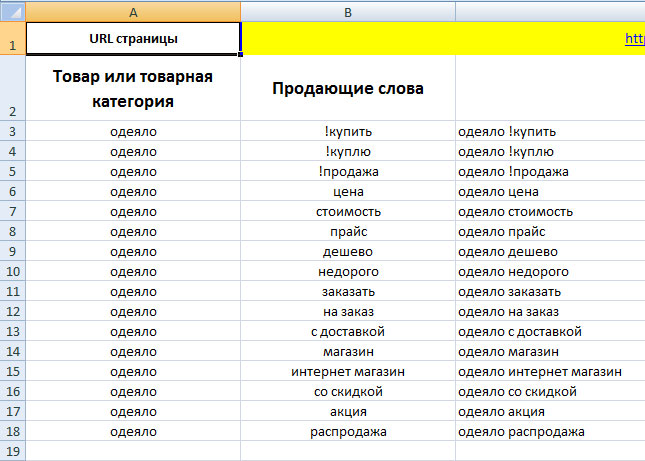
В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:
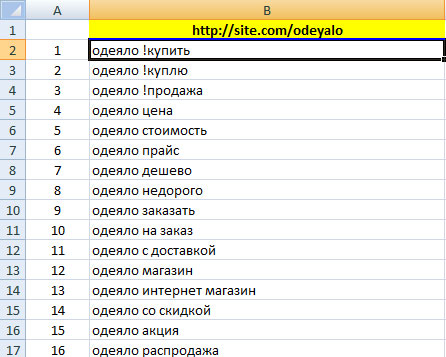
Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Читайте также:
- Рейтинг CRM систем для интернет-магазинов
- Как продвигать магазин в поисковых системах?
SEO-Excel для кластеризации семантического ядра (СЯ)
Содержание
- Кластеризация по составу фразы
- Догруппировка кластеризированной семантики
- Склонение и генерация тегов
SEO-Excel — это надстройка для Microsoft Excel, которая содержит 22 бесплатных инструмента для SEO-специалиста, позволяющая автоматизировать большую часть процессов при работе с семантическим ядром. Презентовал Андрей Ставский из Rush Analytics летом 2017 года, как альтернативу буйжуйской SeoTools for Excel.
Основные возможности:
- Разбор и перегруппировка семантики;
- Генережка SEO тегов и URL;
- Работа с морфологией;
- Парсинг Title и текстов из выдачи Яндекса;
- Построение MindMap по URL.
Системные требования:
- Windows 10 / 8.1 / 8 / 7 / Vista;
- Microsoft Excel 2007 / 2010 / 2013 / 2016 / 365.
Рассмотрим, как SEO-Excel может в помочь в кластеризации семантического ядра на примере запросов для категории Bluetooth наушников крупного интернет магазина. Для этого я собрал запросы из Wordstat по маркерам со стоп-словами, снял частотность, очистил от неявных дублей и брендов.Получили большой список запросов, который в данном виде нам мало чем полезен. Для дальнейшего продвижения по этим запросам, их необходимо сгруппировать по какому-то признаку и закрепить за страницами на сайте. Задачу группировки (кластеризации) запросов как раз и помогает решить надстройка.
Кластеризация по составу фразы
Инструмент “Выжимка”, который позволяет удалять определенные слова из запросов, мы будем использовать для кластеризации семантики по составу фразы.
Копируем запросы в соседний столбец и делаем в нем выжимку, исключая запросы, не влияющие на интент (потребность): купить, цена, интернет, магазин, заказать, стоимость, bluetooth, блютуз, беспроводные, наушник, телефон и т.д. Можно указывать в сокращенном варианте, чтобы исключить также словоформы данных слов.
Далее сортируем столбец с выжимкой по А до Я, выделяем его и применяем инструмент “Красит” ко всем столбцам. Получаем запросы кластеризованные по составу фразы, где в столбце «Выжимка» содержится интент, т.е. запросы с уже сформированной потребностью.Кто хоть немного понимает в наушниках скажет, что капельки, вакуумные, внутриканальные и затычки — это все об одном типе наушников. С точки зрения потребности, эти запросы логично объединить в одну группу. С точки зрения хитрого сеошника, можно разбить и на разные страницы, чтобы за счет точных вхождений попробовать опередить конкурентов в ТОПе.
В Техпорте работают последние:
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/vnutrikanalnye
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/vakkumnye
- www.techport.ru/katalog/products/hi-fi-i-audio/naushniki/tag/zatychki
- www.mvideo.ru/naushniki/naushniki-3967/f/category=naushniki-vkladyshi-1150
Хотя наушники-капельки проигнорировали. Хитрые, но не до конца…
В МВидео не стали заморачиваться — разместили все на одну страницу
Оба сайта в ТОПе, вот и не понятно, а как же сгруппировать правильно запросы, чтобы и нам там быть, и трафика по-максимуму собрать.
Кластеризировать по данному способу — это очень долго, нудно и не точно, ведь нужно пройтись по всем запросам, определить интент и перегруппировать по ТОПу.
Недостатки кластеризации по составу фразы
- Синонимы и переформулированные фразы попадают в разные кластера и нужно потратить уйму времени, чтобы их руками перебрать и объединить;
- Информационные запросы часто попадают вместе с коммерческими в одну группу;
- Даже после перебора руками, нет уверенности, что группировка правильна. Запросы, которые вы считаете, что нужно продвигать на одну страницу, на самом деле нужно продвигать на разные.
- Для избежания ошибок приходится дополнительно анализировать ТОП выдачи по каждой группе. При больших ядрах — это задача может растянуться на многие месяцы. Ни у кого нет столько времени ждать вашу семантику.
Поэтому группировка по составу фразы не используется в чистом виде. Тем не менее, данный метод позволяет значительно сократить время на обработку семантического ядра после сервисов автоматической кластеризации, которые работают на основании анализа ТОПа поисковой выдачи.
Преимущества кластеризаторов по ТОПу
- Синонимы и переформулированные фразы при «чистой» выдаче попадают в одну группу;
- Проверяется совместимость продвижения запросов на одной странице. Несовместивые запросы разбрасываются по разным группам;
- Существенная экономия времени, особенно на больших ядрах.
Догруппировка кластеризированной семантики
Сервисы автоматической кластеризации по ТОПу позволяют значительно сэкономить время и деньги, группируя запросы на основании подобия сайтов из ТОПа, но и они не лишены недостатков.
Недостатки кластеризации по ТОПу
- Необходимость поиска баланса между полнотой и точностью кластеризации. При высокой полноте группируется больше фраз, но страдает точность, из-за чего в группы попадает много лишнего. При высокой точности очень низкая полнота — группы маленькие и большой список несгруппированных фраз, которые нужно раскидывать самостоятельно. Оптимальная по полноте кластеризация выбирается каждый раз индивидуально;
- Если выдача «плохая», то запросы, которые должны продвигаться на разных страницах, при кластеризации могут попасть в одну группу. Наоборот, запросы с одним интентом, попадают в разные группы.
- Кластеризация запросов без однозначного интента, по которым в выдаче как коммерческие, так и информационные сайты, дает неудовлетворительные результаты. Например, мы бы хотели запрос продвигать например, как коммерческий, но кластеризатор положил его в группу с информационниками.
Догруппировать имеющийся результат согласно нашим требованиям помогут инструменты «Выжимка» и «Разбор».
Определяем состав фразы в файле кластеризации от Rush Analytics. Самыми удачными результаты кластеризации мне показались при силе связи 4.
Запросы «спортивные наушники bluetooth» и «наушники для спорта беспроводные» объединились в одну группу. Вакуумные наушники разбросало 3 по разным кластерам, а вкладыши, мини и капельки — по 2. К тому же попался запрос и без сформированного интента — «наушники для телефона купить». Проходимся таким образом по всем кластерам. Благодаря выжимке это легко читается.
Кластеризатор не дал нам точного ответа, поэтому здесь нужно дополнительно перебрать запросы вручную. При обнаружении ошибок кластеризации, приходится решать, оставлять ли конкретный запрос в данном кластере, переместить в другой или создать новую группу:
Если мы решили объединить «внутриканальные» и «вакуумные» можем сразу задать одинаковые названия кластеров для этих запросов. В данном случае мы используем название «беспроводные наушники внутриканальные».
Если же запросы разбросаны по файлу или мы не знаем, есть ли уже похожий кластер, можно скопировать ключевое слово в соответствующую ячейку «название кластера», например «блютуз наушники капельки купить».
Нет необходимости искать по всему файлу подходящий кластер или запоминать названия уже существующих.
Снимаем заливку и сортируем от А-Я по столбцу с названием кластера. Далее красим все столбцы с помощью инструмента “Красит”.
Произошла группировка запросов по общему названию. В одну группу мы добавили вакуумные и внутриканальные. В тоже время мы не стали «капельки» сводить к общему названию, поэтому они находятся в разных кластерах. Чтобы устранить данный момент, применяем инструмент «Разбор» для быстрого объединения кластеров по названию их вершин.
Для вершин кластеров в столбце «А» необходимо повторно применить выжимку, по которой будет сразу понятно, кластера с каким названием вершин нужно объединить.
Переносим кластера, которые хотим объединить начиная со столбца «В» в одну строку. Удаляем пустые строки и завершаем разбор.
На вкладке “Конечная семантика” получаем объединенные кластера с сортировкой по убыванию суммарной частоты.
Когда кластеризация не показывает однозначного распределения запросов по кластерам, как например в данном примере, приходится принимать решение на основании того, насколько хорошо мы разбираемся в тематике и никакая автоматизация не поможет.
Перед тем, как кластеризировать свои запросы, обязательно изучите специфику продаваемых товаров или услуг.
Получив конечную семантику, мы можем сгенерировать теги для SEO продвижения.
Генерация h2
Заголовок h2 будем задавать по самой частотной фразе в кластере. Для этого сначала отсортируем итоговую семантику по столбцу с частотностью. Применяем инструмент «Сортировка» и запросы в каждом кластере сортируются по убыванию частоты.
С помощью инструмента «h2» указываем столбец с запросами и столбец для заголовка.Берется первая закрашенная ячейка столбца «B» и записывается на весь кластер. С помощью данного инструмента можно быстро протянуть любой идентификатор.
Генерация Title
Для генерации Title есть 2 шаблона:
- с разделителем. Позволяет вставить дополнительные слова в начало и конец Title, который формируется из первых двух запросов, разделенных вертикальной чертой.
- скользящий. Позволяет вставить дополнительные слова в середину и конец Title, который формируется из двух запросов, разделенных дефисом. К преимуществам данного шаблона относятся возможность изменять падеж, использовать название кластера или третий запрос в списке.
Примечание: запросы должны находиться в столбце «B», название кластера — в столбце «A». Title генерируется в первый пустой столбец.
Генерация Description
Для генерации мета-описания воспользуемся инструментом «Description», который позволяет задать префикс, постфикс, изменить падеж запроса и добавить UTF-8 символы.
Примечание: запрос, добавляемый в шаблон, берется из столбца «A». Description генерируется в первый пустой столбец.
Ознакомиться с полным функционалом и скачать SEO-excel бесплатно можно на официальном сайте seo-excel.ru.
На выходе всех сервисов кластеризации получается файл, который нужно дополнительно обрабатывать: объединять и перегруппировать кластера, чистить от мусора. Специалист тратит много времени и ручного труда на выявление ошибок. С настройкой SEO для Excel получается значительно снизить трудо- и времязатраты на доработку кластеризированного семантического ядра.
Как составить семантическое ядро за 5 шагов
Сбор семантического ядра — один из самых важных этапов создания контекстной рекламной кампании.
Борьба за клиента начинается именно на уровне семантики: от того, как много запросов, по которым не размещаются ваши конкуренты, вы сможете найти; от того, насколько хорошо вы проработаете список минус-слов, и будет зависеть успех вашей рекламы.
Сегодня я расскажу вам о том, как мы составляем семантическое ядро в «ЛидМашине».
Шаг 1. Подготовка к сбору семантического ядра
В рамках подготовки к сбору семантики нужно составить таблицу, в которую вы будете заносить ключевые запросы, по которым клиенты могут искать ваш продукт. Пример таблицы приведен ниже.
Первый столбец определяет товар или услугу (ответ на вопрос «Что вы предлагаете?»). Для примера возьмем срочные кредиты. Как люди могут искать в поисковиках кредиты? Они могут вбивать запрос «кредиты», могут искать «займы», могут искать «кредитные карты», и т.п.
Второй столбец определяет действие, которое с вашим товаром или услугой можно совершить. Что можно сделать с кредитом? Его можно взять, получить, оформить. Все возможные синонимы заносите в таблицу.
Третий столбец характеризует географическое положение, которые пользователи могут указывать совершенно по-разному. Например, пользователь может указать свою принадлежность к Санкт-Петербургу при помощи слов «Питер», «СПб».
В четвертом столбце будут содержаться характеристики вашего продукта — какой он? Каким может быть кредит? Без поручителей, по паспорту, без справок… Все варианты, по которым люди могут искать ваш продукт, заносите в таблицу.
Поскольку наш продукт имеет определенный параметр — срочность, мы вводим дополнительный столбец, характеризующий это свойство. Как люди могут выражать потребность в срочных деньгах? Они могут искать «срочные» кредиты, «быстрые» кредиты, «экспресс-кредиты», «кредиты за час». Продумайте все возможные варианты и занесите их в таблицу.
Откуда брать все эти варианты запросов? Во-первых, из головы. Устройте мозговой штурм, придумывайте различный варианты, по которым пользователи могут вас искать. Когда идеи закончатся, на помощь вам придут Яндекс Метрика со своим отчетом «Поисковые фразы», Google Analytics с отчетами по ключевым фразам в органическом трафике и запросами в «Поисковой оптимизации». Порой там можно обнаружить совершенно невероятные запросы, по которым люди находят ваш сайт.
Не обходите стороной Планировщик ключевых слов от GoogleAdWords: укажите продукт, адрес сайта и просмотрите предложенные варианты: среди них часто встречаются необычные ключи, которые могут вам подойти. Найти варианты ключевых слов также можно при помощи сервисов SpyWords (умный подбор запросов и ключевики конкурентов) и Serpstat.
В последнем можно собрать поисковые подсказки. С подсказками ваша семантика будет максимально широкой.
Шаг 2. Составляем список ключевых запросов
Из получившейся таблицы мы будем составлять семантическое ядро. Нам нужно по очереди скомпоновать между собой ключевики из разных столбцов, «перемножить» их друг с другом, чтобы получить все возможные комбинации. Через MS Excel выполнять эту работу слишком долго, поэтому мы пользуемся сервисами — компоновщиками ключевых фраз. Существует их большое количество, вы обязательно найдете удобный для вас. Мы чаще всего используем генератор от Promotools.ru.
Пользоваться генераторами просто: вы поочередно заносите ключевики в соответствующие ячейки, и система автоматически выдает вам все возможные комбинации.
Скопируйте их в отдельный файл MS Excel. После того как вы прогоните через программу все столбцы из таблички, у вас должен получиться большой список, состоящий из нескольких тысяч ключевых запросов. Безусловно, некоторая часть этих запросов будет «мусорной» — от них мы и будем избавляться на следующем этапе.
Шаг 3. Удаляем мусорные запросы
Чтобы избавиться от нерелевантных запросов и собрать частоты по целевым, воспользуйтесь программой Key Collector. Загрузите в нее весь список и запустите сбор статистики из WordStat. Полученный список будет содержать все запросы пользователей, в том числе и те, показ рекламы по которым нежелателен. Поэтому список нужно очистить от минус-слов.
Перейдите на вкладку «Данные», нажмите кнопку «Анализ групп». Программа создаст группы слов, из которых состоят ваши ключевые запросы.
Пометьте флажками слова, по которым не должен происходить показ рекламы, и скопируйте их в отдельный файлик MS Excel— это будет список минус-слов. Автоматически пометки перенесутся в основной список минус-слов. Вам нужно будет удалить все помеченные запросы. Получившийся после удаления минус-слов список экспортируйте — это готовые ключи, по которым вы будете настраивать контекстную рекламу.
Шаг 4. Группировка ключевых запросов
Полученный список ключей для удобства настройки рекламных кампаний нужно будет сегментировать. Просмотрите готовый список и выделите для себя слова, на основе которых будут сформированы группы ключевиков. Далее используйте фильтры по этим словам — с их помощью вы найдете все фразы, содержащие заданное слово.
Перенесите их на отдельные листы — каждому листу впоследствии будет соответствовать одна группа объявлений.
Когда все ключевые запросы будут разбиты по листам, составление семантического ядра для Яндекс.Директ завершится. Не забудьте перенести в готовый файл список минус-слов. Если же вы планируете размещаться в GoogleAdWords, вам следует учесть пару нюансов при составлении семантического ядра.
Читайте также (откроется в новой вкладке): Настройка контекстной рекламы: 5 очевидных ошибок.
Шаг 5. Побеждаем коварный Google AdWords
Первое правило при работе в Google AdWords — минус-слова должны быть во всех возможных словоформах. Для склонения минус-слов мы используем сервис от HTraffic. Зачем нужно склонять слова? Дело в том, что Google останавливает показ объявлений только по конкретным словоформам ключевиков. Например, если вы добавили минус-слово «бесплатный», показ рекламного объявления по словам «бесплатная», «бесплатные» и т.п. по-прежнему будет идти.
Второе правило — очищайте ключевые запросы от предлогов. Если вы указали в точном соответствии фразу с предлогом, например, [кредиты в Санкт-Петербурге], то ваше объявление по запросу «кредиты Санкт-Петербург» показано не будет. Поэтому лучше использовать ключевую фразу [кредиты Санкт-Петербург].
Наш способ составления семантического ядра позволяет найти большое количество низкочастотных и среднечастотных запросов, но может отнять немало времени. Чтобы ускорить этот процесс, я сделала шаблон для составления семантического ядра.
Делитесь в комментариях своими фишками и способами сбора семантики!
Page not found — WaterMillSky®, Москва, Россия
Unfortunately the page you’re looking doesn’t exist (anymore) or there was an error in the link you followed or typed. This way to the home page.
Blog
- 11/07/2021 — Финансовый прогноз с 08 по 14 ноября 2021 года
- 10/31/2021 — Как создать отличную страницу «О нас»
- 10/31/2021 — Финансовый прогноз с 01 по 07 ноября 2021 года
- 10/29/2021 — Как написать текст для страницы FAQ
- 10/26/2021 — 20+ онлайн-инструментов для удалённых сотрудников
- 10/24/2021 — Финансовый прогноз с 25 по 31 октября 2021 года
- 10/13/2021 — Как уменьшить возвраты товара в интернет-магазине
- 10/12/2021 — Простые идеи для доставки товаров из интернет-магазинов
- 10/07/2021 — Увеличиваем продажи интернет-магазина: семь проверенных дисконтных стратегий
- 10/01/2021 — Как подготовить интернет-магазин к «Чёрной пятнице» 2021 года
- 09/27/2021 — SEO-2021: новости Google за август
- 09/16/2021 — Звёздные моменты 2021 года
- 08/12/2021 — SEO-2021: новости Google за июль
- 07/23/2021 — Узнайте больше нового и получите ещё больше из поиска Google
- 07/20/2021 — Новый инструмент и советы для безопасного поиска в Google
- 07/18/2021 — Как обновления Google Search улучшают результаты поиска в 2021 году
- 07/17/2021 — Как искусственный интеллект MUM помогает лучше понимать информацию
- 07/17/2021 — SEO-2021: новости Google за июнь
- 07/13/2021 — Как Google делает поиск более безопасным: пять надёжных способов
- 06/16/2021 — SEO-2021: новости Google за май
- 05/10/2021 — SEO-2021: новости Google за апрель
- 05/03/2021 — Как Google поддерживает актуальность и полезность поиска
- 04/14/2021 — Когда и почему Google удаляет контент из результатов органического поиска
- 04/13/2021 — FAQ Google по Core Web Vitals и Page Experience. Версия март 2021 года
- 04/04/2021 — SEO-2021: новости Google за март
- 03/03/2021 — SEO-2021: новости Google за февраль
- 02/26/2021 — Как создать продающие описания для товарных страниц
- 02/01/2021 — SEO-2021: новости Google за январь
- 01/09/2021 — SEO-2020: новости Google за декабрь
- 12/21/2020 — Обзор главных событий в Google за 2020 год
- 12/17/2020 — Декабрьские обновления в Google API Search Console
- 12/16/2020 — Обновление инструмента для тестирования структурированных данных
- 12/03/2020 — SEO-2020: новости Google за ноябрь
- 11/28/2020 — Советы для бизнеса: как сделать отличный мобильный сайт
- 11/27/2020 — Ещё раз про Сеть Знаний и Панели Знаний
- 11/16/2020 — Как в поиске Google создаются подсказки для автозаполнения
- 11/14/2020 — Как Google предоставляет надёжную информацию в поиске
- 11/12/2020 — Прощай, Google Webmasters. Здравствуй, Google Search Central
- 11/11/2020 — Когда Page Experience появится в поиске Google
- 11/08/2020 — Как использовать Instagram Analytics для развития бизнеса
- 11/05/2020 — SEO-2020: новости Google за октябрь
- 10/31/2020 — Самые интересные вопросы о переносе веб-сайтов
- 10/29/2020 — Главные проблемы с мобильной индексацией новых и ранее запущенных сайтов
- 10/26/2020 — Рекомендации Google для оформления страниц Чёрной пятницы и Киберпонедельника
- 10/12/2020 — SEO-2020: новости Google за сентябрь
- 09/17/2020 — Googlebot переходит на протокол HTTP/2
- 09/17/2020 — SEO-2020: новости Google в августе
- 09/07/2020 — Информация о лицензии для изображений в Google Images
- 09/06/2020 — Новые отчёты в Search Console: технология Signed HTTP Exchange (SXG) помогает устранять ошибки AMP
- 08/26/2020 — Рекомендации для ритейла: как контролировать изображения просканированных товаров в поиске Google
- 08/18/2020 — SEO-2020: новости Google в июле
- 08/16/2020 — Видеоконференция для веб-мастеров Lightning Talk: расширенные результаты и поисковая консоль
- 08/13/2020 — Изменения в Google Search Console API
- 07/26/2020 — Подготовка сайта к мобильной индексации 2021 года
- 07/14/2020 — SEO-2020: новости Google в июне
- 07/07/2020 — Инструмент Google Rich Results Test вышел из бета-тестирования
- 07/06/2020 — Советы для бизнеса: как подготовить сайт после решения CJEU о файлах cookie
- 07/04/2020 — Как в 2020 году Google использует отчёты о спаме
- 07/01/2020 — Советы для бизнеса: домашний офис и собственные дети
- 06/27/2020 — Советы для бизнеса: как помочь местному бизнесу в 2020 году
- 06/24/2020 — Как Google боролся с поисковым спамом в 2019 году
- 06/21/2020 — Развитие оценки удобства страницы для лучшего пользовательского опыта
- 06/09/2020 — SEO-2020: новости Google в мае
- 05/26/2020 — Часто задаваемые вопросы о JavaScript и ссылках
- 05/25/2020 — Советы для бизнеса: как крупным компаниям поддержать малый бизнес
- 05/24/2020 — Советы для бизнеса: 10 моментов, которые нужно знать о контракте для внештатных сотрудников
- 05/23/2020 — Советы для бизнеса: как использовать бизнес-опыт для здравого смысла
- 05/22/2020 — Советы для бизнеса: 8 способов завершить запуск нового сайта
- 05/21/2020 — Новые отчёты в Search Console: контент с разметкой Guided Recipes появится в Google Assistant
- 05/20/2020 — Переводчик Google Translate для некоммерческого использования
- 05/19/2020 — Советы для бизнеса: лучшие онлайн инструменты для совместной удаленной работы
- 05/09/2020 — Основы SEO-оптимизации по стандартам 2020 года
- 05/07/2020 — Советы для бизнеса: восемь шагов, чтобы защитить своё дело
- 05/07/2020 — SEO-2020: новости Google в апреле
- 05/06/2020 — Search Console 2020: новые отчёты для специальных объявлений Special Announcement
- 05/02/2020 — Советы для бизнеса: организуйте самовывоз для продолжения работы
- 04/29/2020 — Советы для бизнеса: 5 простых шагов для быстрого запуска онлайн-продаж
- 04/07/2020 — SEO-2020: новости Google в марте
- 03/27/2020 — Онлайн-бизнес на паузе. Что делать владельцам сайтов
- 03/18/2020 — Новые типы семантической разметки для виртуальных, отложенных и отменённых событий
- 03/07/2020 — SEO-2020: новости Google в феврале
- 03/06/2020 — Переход всех веб-сайтов на мобильную индексацию
- 03/02/2020 — Лучшие практики для быстрого показа новостей в поиске Google
- 03/01/2020 — Экспорт данных отчётов в Search Console: ещё больше и лучше
- 02/28/2020 — Как показать новые мероприятия или события в локальном поиске Google
- 02/13/2020 — SEO-2020: новости Google в январе
- 02/10/2020 — Search Console 2020: новые отчёты для сниппетов с отзывами
- 02/09/2020 — Как самозанятым заработать больше денег на вольных хлебах
- 01/31/2020 — Новости поиска Google Search за январь 2020 года
- 01/28/2020 — Новый отчёт в Search Console 2020: обновление инструмента Removals
- 01/22/2020 — Google завершает поддержку схемы Data-Vocabulary
- 01/21/2020 — Удачный сайт-резюме или как понравиться работодателю
- 01/20/2020 — Безопасные настройки файлов Cookie для браузеров с защищенными соединениями
- 01/18/2020 — Google Search Console: первые обучающие видеоролики 2020 года
- 01/02/2020 — Обзор SEO-2019: поиск по нулевому клику, алгоритм BERT, локальный спам и многое другое
- 12/30/2019 — Почему Jimdo — лучший конструктор сайтов для творческих личностей и малого бизнеса
- 12/29/2019 — Важные события в Google за 2019 год
- 12/26/2019 — Полный список всех обновлений поисковых алгоритмов Google в 2019 году
- 12/11/2019 — Запуск нового Publisher Center
- 12/07/2019 — Программа «Early Adopters Program» для отслеживания посылок через поиск Google
- 12/04/2019 — Google Search Console 2019: новая панель сообщений
- 11/29/2019 — Эксклюзив от Jimdo: юридический текст для сайта, гарантированно совместимый с GDPR
- 11/28/2019 — Новости поиска Google за ноябрь 2019 года
- 11/21/2019 — Google Search Console 2019: отчётность по результатам поиска продуктов
- 11/02/2019 — Как получить расширенные сниппеты для сайта в виде блоков с ответами
- 09/30/2019 — Дополнительные параметры для просмотра контента веб-сайтов в поиске Google
- 09/23/2019 — Решение CJEU о файлах cookie в 2019 году: как Jimdo подготовит ваш сайт
- 07/31/2019 — «Swipe To Visit»: новая функция в мобильном поиске для Google Images
- 07/23/2019 — Браузер «Спутник» сертифицирован для ОС РОСА
- 07/07/2019 — Советы Jimdo: чек-лист для проверки юзабилити текста
- 06/10/2019 — Мобильная индексация новых доменов действует по умолчанию
- 05/30/2019 — Поисковая система «Спутник» – пять лет в полёте!
- 05/28/2019 — Браузер «Спутник». Корпоративная версия 2019 года
- 05/15/2019 — Google Карты 2019: ресторан, меню, блюда
- 05/06/2019 — SEO-2019: новости Google в апреле
- 04/09/2019 — SEO-2019: новости Google в марте
- 03/11/2019 — Google Job Search найдёт вакансии для российских пользователей
- 03/04/2019 — SEO-2019: новости Google в феврале
- 02/09/2019 — SEO-2019: новости Google в январе
- 01/10/2019 — SEO-2018: новости Google в декабре
- 01/10/2019 — Ключевое обновление: браузер «Спутник» перешел на ядро Chromium 64
- 12/30/2018 — Корпоративные решения: браузер «Спутник» поможет создавать мобильные рабочие места
- 12/21/2018 — Мобильный индекс: почему важны структурированные данные и альтернативный текст для изображений
- 12/03/2018 — SEO-2018: новости Google в ноябре
- 11/03/2018 — SEO-2018: новости Google в октябре
- 10/05/2018 — SEO-2018: новости Google в сентябре
- 09/12/2018 — SEO-2018: новости Google в августе
- 08/23/2018 — SEO-2018: новости Google в июле
- 07/15/2018 — SEO-2018: новости Google в июне
- 07/11/2018 — Платон Щукин: вечная сага об идеальных текстах
- 06/22/2018 — Кулинарные рецепты в Google Home через Google Assistant
- 06/20/2018 — Благородные цели: как Google помогает веб-мастерам и разработчикам оригинального контента
- 06/14/2018 — SEO-2018: новости Google в мае
- 06/13/2018 — Советы Jimdo: 11 золотых правил для написания профессионального контента
- 05/13/2018 — SEO-2018: новости Google в апреле
- 04/29/2018 — SEO-2018: новости Google в марте
- 04/14/2018 — Апрельское обновление: браузер «Спутник» для актуальных версий OS Windows
- 04/13/2018 — SEO-2018: новости Google в феврале
- 03/26/2018 — Запуск Google Mobile-First Indexing
- 03/18/2018 — SEO-2018: первые новости Google в январе
- 03/15/2018 — Реклама и деньги: как Google регулирует рекламную экосистему
- 03/11/2018 — Как привлечь пользователей с помощью AMP-страниц высокого качества
- 03/09/2018 — Анализ тональности текстов с помощью машинного обучения
- 03/07/2018 — Как Google Chrome защищает Интернет с помощью протокола HTTPS
- 02/24/2018 — Бесплатные виджеты: 20 лучших предложений для свадебного сайта
- 02/16/2018 — AMP-истории: новый визуальный формат для мобильных устройств
- 02/15/2018 — Яндекс Лайт.Браузер для смартфонов на Android
- 02/15/2018 — Google Featured Snippets: ещё раз о расширенных сниппетах и блоках с готовыми ответами
- 02/13/2018 — SEO-2017: новости Google в декабре
- 02/07/2018 — Как Google улучшал поисковую консоль Search Console
- 02/06/2018 — Автоматический SEO-аудит сайта с помощью расширения Lighthouse для браузера Chrome
- 01/31/2018 — Новые подробности о возможном апдейте поискового алгоритма Google Search
- 01/24/2018 — SEO-советы Джона Мюллера: как объединить четыре домена
- 01/21/2018 — Факторы мобильного ранжирования: скорость загрузки страницы
- 01/10/2018 — Реальные данные в отчёте PageSpeed Insights
- 01/09/2018 — Новая поисковая консоль: первые впечатления от знакомства
- 01/08/2018 — Опции Jimdo: уведомления и вопросы
- 01/07/2018 — SEO-2017: новости Google в ноябре
- 01/05/2018 — #NoHacked 3.0: как восстановить сайт после взлома
- 12/31/2017 — Как подготовить сайт к мобильному индексу
- 12/31/2017 — Декабрьское обновление поискового алгоритма Google
- 12/24/2017 — Инструмент Google для тестирования результатов расширенных сниппетов
- 12/23/2017 — Google представил новую серию видео по SEO для веб-мастеров
- 12/21/2017 — Правила расширенных мета-тегов: рекомендации Google для создания сниппетов
- 12/18/2017 — Мобильный браузер «Спутник» для OS Android: декабрьское обновление
- 12/18/2017 — NoHacked 3.0: как предупредить и обезвредить
- 12/16/2017 — Google NoHacked 3.0: как узнать, что сайт в безопасности
- 12/14/2017 — Поисковая оптимизация 2018: Google обновил «Руководство для начинающих»
- 12/09/2017 — Рендеринг проиндексированных AJAX-страниц
- 12/06/2017 — Рекомендации Google: язык разметки «Events»
- 11/30/2017 — SEO-2017: новости Google в октябре
- 11/11/2017 — Великие идеи для блога копирайтера
- 10/27/2017 — SEO-2017: бархатный сентябрь
- 10/26/2017 — Разработки Jimdo: новые категории и функции блога
- 10/12/2017 — Советы Google: как создать ценный контент
- 10/12/2017 — Советы для начинающих: как разработать бизнес-план
- 09/30/2017 — Доверенный браузер «Спутник» с криптографией на Astra Linux
- 09/13/2017 — Как создать сайт и получить доверие клиентов
- 09/11/2017 — SEO-2017: летние новости
- 09/07/2017 — Алгоритм Королёв: нейронный поиск по уникальным запросам
- 09/06/2017 — Обновленный браузер «Спутник» для мобильных устройств с Android
- 09/05/2017 — SEO-2017: урожайный август
- 08/29/2017 — Fast Fetch: ускоренный рендеринг рекламных AMP-объявлений
- 08/22/2017 — Новый дашборд: все ваши сайты в одном месте
- 08/21/2017 — SEO-2017: знойный июль
- 08/21/2017 — Вопросы и ответы: найдите на Google Maps и узнайте в мобильном поиске
- 08/14/2017 — Значки для рецептов: поиск изображений по вкусным миниатюрам
- 08/04/2017 — Новости поисковой консоли Google: отчеты Index Coverage и AMP Fixing Flow
- 07/10/2017 — Советы по SEO: 5 минут для оптимизации веб-страницы
- 07/07/2017 — Браузер «Спутник» работает на Windows 10 Creators Update
- 07/04/2017 — SEO-2017: мокрый июнь
- 06/28/2017 — SEO-2017: весенние новости
- 06/27/2017 — SEO-2017: оптимизируем сайт для мобильных устройств
- 06/24/2017 — Июньское обновление: мобильный браузер «Спутник» для Android
- 06/20/2017 — Google Search для работодателей: открытые вакансии для лучших соискателей
- 06/19/2017 — Баден-Баден: добрые вести в июне
- 06/17/2017 — Юбилей Jimdo: интересные факты из 10-летней истории
- 06/15/2017 — Мобильный индекс: обещанного два года ждут
- 06/13/2017 — SEO-2017: холодный май
- 06/10/2017 — Эволюция Капчи: Google внедрил API-интерфейс reCAPTCHA для Android
- 06/09/2017 — SEO-2017: бурный апрель
- 06/03/2017 — Лучшие сниппетты для пользователей
- 05/26/2017 — Избитая тема: ещё раз о спамовых ссылках в статейном продвижении
- 05/25/2017 — Google I/O 2017: 100+ анонсов передовых разработок
- 05/22/2017 — Обновленный дизайн и новые функции блога на Jimdo
- 05/19/2017 — Google Analytics 2017: расширенная поддержка AMP-страниц
- 05/12/2017 — Материалы по теме: «Спутник» с персональной лентой публикаций
- 05/12/2017 — Похожие товары: поиск картинок Google в расширенных карточках
- 05/11/2017 — Стильные советы: ищем модную одежду на Google Картинках
- 05/10/2017 — Парковка по картам: Google Maps помогут вспомнить, где находится автомобиль
- 05/09/2017 — Как Google боролся с веб-спамом: отчет за 2016 год
- 05/07/2017 — Спорный контент: как Google улучшает качество поиска
- 05/05/2017 — Полезные подсказки: теперь на русском и других языках
- 04/28/2017 — SEO-2017: солнечный март
- 04/22/2017 — Упорный алгоритм: Баден-Баден шлёт «чёрную метку»
- 04/12/2017 — Марсианский глобус: виртуальная хроника изучения
Красной планеты - 04/10/2017 — Советы Google: платить не надо, отклонить
- 04/07/2017 — Алгоритм Баден-Баден: вторая волна
- 04/04/2017 — Тесты закончились: сервис Google Optimize стал
доступным для всех - 03/31/2017 — Google Safe Browsing: обновление инструмента «Статус сайта»
- 03/29/2017 — Гэри Илш: новости о Mobile-First Индексе
- 03/26/2017 — Алгоритм Фред («Fred»): официальное подтверждение
Google - 03/23/2017 — Алгоритмы Яндекса: Баден-Баден против SEO
- 03/22/2017 — Google NoHacked: обзор 2016 года
- 03/21/2017 — Платон Щукин: 12 вопросов о переезде на протокол HTTPS
- 03/21/2017 — CTR и показатель отказов: как улучшить кликабельность
сайта в Google - 03/14/2017 — Что в интересного в URL AMP-страниц?
- 03/13/2017 — Google Карты для Android: маршрут в один клик и данные
в онлайн-режиме - 03/13/2017 — Умный перевод: нейросети на службе лингвистов
- 03/12/2017 — Мобильный помощник: универсальное приложение на каждый
день - 03/11/2017 — Золотое молчание Google
- 03/11/2017 — SEO-2017: краткий февраль
- 03/05/2017 — Яндекс-2017: зимние SEO-новости
- 03/02/2017 — Самые популярные статьи 2016 года
- 03/01/2017 — Оставайтесь в безопасности: HTTPS для каждого веб-сайта
- 03/01/2017 — Закрыто в течение дня
- 02/28/2017 — Спутник-Карты 2017: уникальный интерфейс с новым дизайном
- 02/16/2017 — Google Safe Browsing: новая защита от вредоносной
активности - 02/16/2017 — Отзывы критиков и разметка schema.org для продвижения локального бизнеса
- 02/15/2017 — Протокол HTTPS: безопасная интернет-экосистема для
всех и каждого - 02/15/2017 — SEO-2017: многообещающий январь
- 02/11/2017 — Опасный браузер: как защититься от вредоносных
расширений - 02/09/2017 — Безопасные технологии: как Google заботится о
пользователях - 02/08/2017 — Как Google сражался с «ветряными мельницами»
- 02/05/2017 — Шифрование по ГОСТу: доверенный браузер «Спутник» с российской криптографической защитой
- 02/04/2017 — Новый API для Mobile-Friendly Test
- 01/30/2017 — Google Assistant: персональный помощник в мире высоких
технологий - 01/29/2017 — Ещё раз о ссылках в виджетах
- 01/28/2017 — Советы Google: как
защитить сайт от пользовательского спама - 01/26/2017 — Осенние SEO-новости Яндекса
- 01/24/2017 — Google Firebase для Mobile: как повысить качество мобильных приложений в
2017 году - 01/24/2017 — Технология Google AMP
Lite: облегченный формат для AMP-страниц - 01/23/2017 — Краулинговый бюджет: FAQ от Гэри Илш
- 01/19/2017 — «Спутник» для Windows: рекламоотвод, режим для
чтения и часовой - 01/12/2017 — Google против межстраничной рекламы
- 01/01/2017 — Декабрьские SEO-новости Google
- 12/31/2016 — Как выявить проблемы для страниц AMP-формата
- 12/31/2016 — Как сервис Google Search Console помогает
сайтам с AMP-страницами - 12/30/2016 — Восемь рекомендаций для AMP-страниц по оптимизации
мобильного сайта - 12/30/2016 — Что такое AMP?
- 12/29/2016 — Как настроить аналитику на AMP-страницах
- 12/29/2016 — Советы Платона Щукина: как сделать сайт безопасным
- 12/23/2016 — Мобильные приложения: прогноз погоды на Google Android
- 12/23/2016 — Как настроить объявления на AMP-страницах
- 12/22/2016 — Мобильный поиск Google: ещё быстрее и удобнее в 2017
году - 12/18/2016 — Летние SEO-новости Яндекса
- 12/12/2016 — Яндекс, Палех и нейронные сети
- 12/12/2016 — Все ресурсы в одном наборе: новые сводные отчеты в поисковой
консоли Google Search Console - 12/09/2016 — Google-2017: «зелёная» энергия для питания дата центров
- 12/03/2016 — Google Santa Tracker 2016
- 12/02/2016 — Расширенные Rich Cards: местные рестораны и
онлайн-курсы - 12/02/2016 — Рекомендации Google: как не стать мишенью хакеров
- 12/01/2016 — Ноябрьские SEO-новости Google
- 12/01/2016 — Контент для Feature-Phone: новые правила сканирования и индексирования
- 12/01/2016 — Гудбай, Content Keywords
- 11/17/2016 — Google-Фотосканер: мобильное приложение для цифровых копий
- 11/17/2016 — Google Analytics 2016 года: дополнительные оповещения по безопасности
сайта - 11/14/2016 — «Спутник Лайт»: мобильный веб-браузер для смартфонов с iOS
- 11/14/2016 — Как начать работу с AMP-страницами для мобильных устройств
- 11/14/2016 — Контент AMP-страниц: предварительный просмотр в мобильной
выдаче Google - 11/07/2016 — Тесты Google: индексация Mobile-First
- 11/01/2016 — Октябрьские SEO-новости Google
- 10/26/2016 — Доверие и реклама: на чём зарабатывает компания Google
- 10/26/2016 — Весенние SEO-новости Яндекса
- 10/21/2016 — Используете ускоренные мобильные страницы? Пройдите тест «Проверка страниц AMP»
- 10/03/2016 — AMP-страницы: новые вопросы веб-мастеров к Google
- 10/01/2016 — Сентябрьские SEO-новости Google
- 09/30/2016 — Мобильный поиск Google: ускоренные AMP-страницы в
основной выдаче - 09/23/2016 — Знакомьтесь, алгоритм Penguin 4.0
- 09/19/2016 — Рекомендации Google: как новостному сайту перейти на
протокол HTTPS - 09/17/2016 — Google против пиратов: обновление отчёта за 2016 год
- 09/01/2016 — Августовские SEO-новости Google
- 08/20/2016 — Июльские SEO-новости Google
- 08/11/2016 — Советы Платона Щукина: как проиндексировать мобильный сайт на поддомене
- 07/24/2016 — Инновации Google: восемь интересных вещей с конференции I/O 2016
- 07/21/2016 — Июньские SEO-новости Google
- 06/23/2016 — Расширенный поиск: введение в карты Rich Cards
- 06/20/2016 — В одном наборе: сводная статистика по всем сайтам в Search Console
- 06/16/2016 — Зимние SEO-новости Яндекса
- 06/09/2016 — Советы Платона Щукина: как подружить сайт с мобильными
устройствами - 06/05/2016 — Криптография по ГОСТу: «Спутник» тестирует браузер с
шифрованием - 06/02/2016 — Майские SEO-новости Google
- 05/31/2016 — Мобильный браузер Спутник: обновление для устройств с Android
- 05/29/2016 — Эволюция Google: юбилейная конференция I/O 2016 года
- 05/27/2016 — Переводи легко: Google Переводчик
2016 для устройств с Android и iOS - 05/26/2016 — Санкции Google: скрытое перенаправление
мобильных пользователей - 05/23/2016 — Мобильные приложения: Google Android Auto
- 05/19/2016 — Виртуальная клавиатура Google Gboard с поиском для iOS
- 05/14/2016 — Яндекс.Карты 2016 для пешеходов
- 05/05/2016 — Как в 2015 году Google боролся с
веб-спамом - 05/01/2016 — Бесконтактные платежные технологии: Яндекс.Деньги, NFC и Android
- 04/30/2016 — Апрельские SEO-новости Google
- 04/29/2016 — Отчёты Google за 2015 год – безопасный Android
- 04/29/2016 — Google Переводчик: 10 фактов к юбилею онлайн-сервиса
- 04/26/2016 — Персональный подход: личные поисковые подсказки в «Спутнике»
- 04/24/2016 — Мартовские SEO-новости Google
- 04/22/2016 — Советы Платона Щукина: Яндекс.Вебмастер
- 04/18/2016 — Февральские SEO-новости Google
- 04/15/2016 — «Спутник.Аналитика» собирает
статистику и анализирует данные - 04/11/2016 — Январские SEO-новости Google
- 03/26/2016 — Советы Платона Щукина – как сделать правильный фавикон
- 03/22/2016 — Новые фишки для браузера «Спутник» – пользовательские
экраны и детский режим по таймеру - 03/17/2016 — Карты Google Maps 2016 для Android и iPhone
- 03/10/2016 — «Спутник» поддержал конкурс «Позитивный контент-2016»
- 02/24/2016 — Как в 2015 году Google боролся с
некачественными рекламными материалами - 02/19/2016 — Пять вопросов для Google
- 02/17/2016 — Обновление Google My Maps для
Android - 02/12/2016 — 9 секретов Минусинска
- 02/03/2016 — Как переехать на протокол HTTPS: рекомендации Google
- 02/02/2016 — Яндекс приготовил Владивосток
- 01/12/2016 — Panda вошел в состав основного ядра алгоритма ранжирования Google
- 12/31/2015 — Советы Платона Щукина: настройка индексирования сайта
- 12/14/2015 — Новое кино от «Спутника»
- 12/09/2015 — Мобильный поиск от Google и развлекательный контент
- 12/03/2015 — Платон Щукин и правильные сниппеты
- 11/17/2015 — Google Карты 2015 в режиме офлайн
- 11/08/2015 — Шесть рекомендаций от Яндекса – как переехать на HTTPS
- 11/05/2015 — Яндекс рассказал о сроках и способах выхода из-под
санкций - 10/26/2015 — В браузере «Спутник» появились новые модули
- 10/06/2015 — Браузер «Спутник» для российских семей
- 09/22/2015 — Естественная ссылка от Яндекса
- 09/22/2015 — Google покарает за повторные нарушения «Руководства для Веб-Мастеров»
- 09/11/2015 — Яндекс против продавцов SEO-ссылок
- 09/08/2015 — Рождение нового образа Google
- 09/02/2015 — Google против межстраничной рекламы для установки
мобильных приложений - 08/24/2015 — Глобальное обновление панорам на Яндекс.Картах
- 08/18/2015 — Google Карты расскажут о дорожных пробках
- 08/06/2015 — Ответы на вопросы по Google Panda 4.2
- 07/23/2015 — Алгоритм Panda 4.2 в действии
- 07/16/2015 — Яндекс снова обновил Минусинск
- 07/14/2015 — Читалка от Firefox
- 06/16/2015 — Планшетный браузер от Спутника
- 06/11/2015 — Как Google заботится о безопасности и
конфиденциальности пользовательских данных - 06/07/2015 — Google, смартфоны и микро-моменты
- 06/04/2015 — Сохрани мгновения на Google Фото
- 06/02/2015 — Зачем нужно обновлять веб-браузеры
- 05/28/2015 — Спутник — первая годовщина
- 05/21/2015 — Минусинск принёс первые результаты
- 05/17/2015 — Алгоритм Минусинск начал действовать
- 05/09/2015 — Спутник – День Победы
- 04/29/2015 — Новый сервис «Спутник.Дети»
- 04/25/2015 — Текст на картинке
- 04/17/2015 — Безопасный просмотр сайтов вместе с Google
- 04/15/2015 — Яндекс против SEO-ссылок
- 04/10/2015 — Как подружить статические интернет-страницы с мобильными
устройствами - 04/03/2015 — Google против дорвеев
- 03/30/2015 — Новая версия мобильного веб-браузера от Спутника
- 03/28/2015 — «Спутник» подключил аптеки «А5»
- 03/18/2015 — Knowledge-Based Trust – очередная инновация от Google
- 03/11/2015 — Поисковый алгоритм Google будет учитывать
дружественность сайтов к мобильным устройствам - 02/23/2015 — Мобильный веб-браузер от «Спутника»
- 02/12/2015 — Юбилей у Google Карт
- 02/02/2015 — Google Карты для мобильных устройств получили стильный
интерфейс - 01/23/2015 — Google Penguin 3.X – обновления продолжаются
- 01/06/2015 — Сервис Google Карты Россия пополнился
онлайн-инструментом Map Maker - 12/22/2014 — Мэтт Каттс рассказал об ошибках Google, допущенных при борьбе с веб-спамом
- 11/20/2014 — Google выделит сайты, адаптированные для мобильных
устройств - 11/17/2014 — Каким образом Googlebot анализирует навигационные
строчки на веб-странице - 10/28/2014 — Поисковик «Спутник» запустил версию для мобильных
устройств - 10/27/2014 — Google предупредил о
нежелательности блокировки файлов JavaScript и CSS - 10/22/2014 — Google Penguin 3.0 – официальная информация
- 10/21/2014 — Penguin 3.0 в действии
- 10/17/2014 — «Спутник» поможет оформить жалобу
- 10/14/2014 — Как избежать неприятностей при покупке домена с
историей - 09/30/2014 — Как Google распознает версии веб-сайтов для мобильных
устройств - 09/16/2014 — Google поможет найти ошибки в коде JavaScript
- 09/09/2014 — Поисковый портал «Спутник» усиливает безопасность онлайн-сервисов
- 09/02/2014 — Как Google ранжирует веб-ресурсы: сайты-лилипуты
против интернет-гигантов - 08/19/2014 — Google будет лучше ранжировать авторитетные веб-сайты
- 08/12/2014 — Мэтт Каттс рекомендует создавать веб-сайт с HTML-версией
- 07/29/2014 — Гостевые посты и ссылочное продвижение
- 07/09/2014 — Как Google производит изменения в поисковых алгоритмах
- 06/25/2014 — Как узнать, за что понизились позиции сайта в Google
- 05/30/2014 — Мэтт Каттс развеял мифы в сфере SEO-продвижения веб-сайтов
- 05/22/2014 — Запуск бета-версии информационно-поискового портала «Спутник»
- 05/20/2014 — Яндекс напоминает: соблюдайте правила оптимизации сайтов
- 05/16/2014 — Ещё раз о покупных ссылках в Google
- 05/11/2014 — Как удерживать топовые позиции в Google
- 05/10/2014 — Инструмент «Синонимы» улучшает работу Яндекс.Поиска на веб-сайте
- 04/26/2014 — Мэтт Каттс снова пояснил, каким должен быть контент для сайта с точки зрения пользователей
- 04/25/2014 — Google Scraper Report поможет веб-мастерам добиться справедливости
- 04/19/2014 — Google + Spider.io – новый уровень защиты рекламных объявлений
- 04/17/2014 — Google-Карты 2014 — обновление популярного картографического сервиса
- 04/02/2014 — Мэтт Каттс и ссылочное ранжирование. Вечная песня о главном
- 03/23/2014 — Поисковик Google произвёл обновления в работе алгоритма Baby Panda
- 03/16/2014 — Google работает над обновлением алгоритма «Панда»
- 03/13/2014 — Яндекс приступил к поэтапной отмене ссылочного ранжирования
- 03/11/2014 — Мэтт Каттс о роли социальных сигналов в поисковом ранжировании веб-сайтов
- 03/03/2014 — Принципы Google по отношению к контенту для видеосайтов
- 02/27/2014 — Итоги олимпийского проекта от Яндекса
- 02/20/2014 — На Google-Maps добавились панорамные изображения населенных пунктов и природных объектов России
- 02/18/2014 — Очередные изменения в Google Webmaster Tools
- 02/13/2014 — Google запретил практику гостевого блоггинга для целей SEO-продвижения
- 02/09/2014 — Google представил новый раздел FAQ, раскрывающий политику AdSense в сфере контекстной рекламы
- 02/03/2014 — Позиция Google по отношению к ссылкам в виджетах
- 01/31/2014 — Яндекс запустил уникальный веб-проект – «Зимние Олимпийские Игры 2014»
- 01/23/2014 — Как Google относится к дублированному текстовому контенту
- 01/16/2014 — Как Google решает проблемы с гостевым блоггингом на низкокачественных ресурсах
- 01/10/2014 — Коммерческая реклама в Google Display Network: плати только за реальные просмотры
- 12/31/2013 — Google делится секретами: как выйти из под фильтров поисковой системы
- 12/24/2013 — Приложение Google Analytics поможет ускорить загрузку веб-сайта
- 12/03/2013 — Google разработал устройство для безопасной идентификации интернет-пользователей
- 11/19/2013 — Поисковик Google получил патент на уникальный алгоритм по определению качества контента
- 11/05/2013 — Яндекс чистит выдачу – АГС-40 в действии
- 10/15/2013 — Что знает Google о заблуждениях веб-мастеров и SEO-специалистов
- 10/01/2013 — Интернет-гигант Google обновил функционал Google-Maps и приготовил новые карты для российских пользователей
- 09/10/2013 — Дополнительные возможности от Google улучшают структуризацию данных
- 08/20/2013 — Google открывает эпоху платного интернет-телевидения
- 08/06/2013 — Новый браузер от Firefox — дополнительные возможностей для пользователей
Как собрать семантическое ядро с помощью Key Collector
Раз вы читаете эту статью, значит, вы уже знаете какую роль играет для сайта правильно подобранная семантика. А если нет, то скажу коротко — семантика это фундамент любого продвижения.
Итак, мы переходим к созданию нашего ядра запросов, с чего начать?
А начинаем мы со сбора основных ключевых фраз, хотя бы 10-15 начальных придётся составить самим, ну или взять их с конкурентов в ТОПе.
Дальше мы переходим к программе Key Collector. И да — она платная, но я буду рассказывать на её примере. Почему именно эта платная программа? Потому что эта одна из немногих программ, которая окупила каждый потраченный на себя рубль. Если хотите собрать ядро бесплатно, то переходите по ссылке выше, но качество ядра будет соответствующее.
Переходим к обязательным настройкам Key Collector, что нужно сделать в первую очередь, чтобы сбор ядра и статистики по нему вообще был возможен?
Мои настройки Key Collector
Настройки Яндекс Директа. Сюда лучше добавить хотя бы 5-6 левых аккаунтов, а лучше 10, чтобы процесс сбора статистики по Директу не занимал много времени.
Настройки Google.Adwords. Сюда мы вписываем любой тестовый аккаунт, который создадим в гугл.
Так же предлагаю купить антикапчу — это не дорогой и эффективный способ сэкономить ваше время на распознавание изображений, я использую сервис anti-captcha.com
Ну и для полноты счастья, чтобы максимально ускорить свой процесс сбора, я использую ещё прокси, их покупаю на proxy6.net. Мест где приобрести прокси в интернете достаточно, так что вы можете найти и дешевле, но не покупайте прокси, которыми пользуется кто-то ещё — толку от них не будет.
- Формулы KEI можете взять в сети или придумать свою. У меня есть и те и другие, из сети я взял от Семёна Ядрёна.
KEI = ( KEI_YandexMainPagesCount * 6 ) + ( KEI_YandexTitlesCount + KEI_GoogleTitlesCount ) + ( KEI_YandexDocCount / 73000 )
- Как происходит сбор, с чего начать?
Основные этапы сбора запросов в Key Collector
- Начинаем с пакетного сбора слов из левой колонки Яндекс.Wordstat по заданному списку, о подготовки которого я писал выше.
- Когда Левая колонка собрана, то по тому же списку собираем правую колонку
- Далее переходим к пакетному сбору поисковых подсказок
- Сбор с Google.Adwords
- Пакетный сбор похожих поисковых запросов
- Данные с Яндекс.Метрики. Логинимся в Яндекс, можно левого аккаунта, но на него нужно передать доступ к Метрики и Вебмастеру.
- И на последок выгружаем данные с Яндекс.Вебмастера.
Лучше использовать именно эту последовательность, чтобы потом было проще отсеять мусорные фразы, а они обычно обильнее идут начиная с 4 пункта.
После того, как мы собрали кучу ключевых слов, их нужно очистить от мусора. Для этого используем фильтры и стоп слова.
Через фильтры мы можем найти как по исключающим словам, так и по включающим лишние(для отсева) или нужные(для перемещения в новую группу) нам ключи.
Но чтобы найти стоп-слова нам нужно отметить галочками именно лишние слова, которые нам не подходят.
Для определения стоп-слов используем вкладку Данные => Анализ групп. Выбираем Тип: по отдельным словам. Жмём правой клавишей мыши на любом выделенном слове и выбираем к пункт Отправить все слова из определений целиком отмеченных групп в окно стоп-слов.
После того как мы очистили от мусора все ключи мы можем опять пойти по второму кругу и закинуть уже все наши очищенные ключевые фразы в сбор по левой колонке, правой и т.д., пока не придём к нужному нам количеству ключевых фраз для работы.
Обычно хорошее ядро идёт от 100 тысяч фраз перед отсевом.
После чего лучше распределить все запросы по группам, используя фильтрацию, в идеале, чтобы группы были равны разделам сайта.
Все разделы можно обозначить разными цветами, нажав на них правой клавишей мыши и выбрав нужный цвет, и отсортировать их таким же путём.
Перед сбором статистических данных лучше совместить все разделы в одну большую мульти-группу, для этого выделяем все разделы используя клавишу shift или ctrl и нажимаем на иконку включения мульти-группы.
Сбор статистических данных
Остался последний этап сбора данных по СЯ.
- Сбор статистики Яндекс.Директ
- Сбор статистики Google.Adwords
- Сбор позиций Яндекса
- Сбор позиций Гугла
- Сбор релевантных страниц по Яндексу или Гуглу
- Сбор данных SERP, и нашего значения KEI
И рассчитываем KEI по имеющимся данным.
Анализ данных СЯ в Key Collector и выгрузка результатов
И вот мы подошли к самому интересному! Для анализа данных мы будем использовать раздел Данные.
В нём переходим в Градиент по значениям и выставляем ту калонку, по которой нам нужен будет этот градиент, например KEI 1(если вы задали формулу), выбираем Окрасить всю строку и нажимаем ОК.
Аллилуйя! Теперь мы видим зелёным цветом самые легко продвигаемые запросы, а красным за которые может и браться не стоит!
Но этого ещё не достаточно, давайте отсортируем колонки по тем значениям, которые нам нужны, например по частотности «!» и отсутствие релевантных страниц на нашем сайте или позиций.
Теперь, когда самые частотные запросы будут сверху и мы исключили все страницы, по которым у нас есть позиции или релевантность, мы можем смело брать их для дальнейшего анализа.
Но это ещё не всё! Нам нужно понять какие ещё запросы мы можем продвигать вместе с выбранными нами на одной странице?
Для этого переходим в раздел Анализ групп и выбираем тип: По поисковой выдачи и выставляем там силу SERP и ТОП в зависимости от типа запроса.
Например для информационных страниц выставляем SERP = 2 или 3 и ТОП10 или даже ТОП20, а для коммерческих SERP = 4 или 5 и ТОП10.
Далее нажимаем вычислить группировку и экспортируем всё это дело в XLS.
Теперь у нас есть кластеры с которыми мы можем работать, используя ключевые слова из каждой группы для продвижения на одной странице.
А чтобы найти самые вкусные кластеры нам нужно будет анализировать наше ядро, для этого снимаем режим мультигруппы и выделяем с зажатой клавишей ctrl те группы, которые мы будем выгружать и выгружаем их опять же с зажатой клавишей ctrl.
Или для выгрузки всех групп просто зажимаем клавишу Shift и жмём на ту же кнопку выгрузки в XLS.
P.S.: Не забываем, что колонки выгрузки у нас будут совпадать с теми, которые отображаются в программе, поэтому можно создать в настройках Вид => Шаблон вида тот шаблон, который мы будем использовать и в дальнейшем в своих проектах.
Источник: artur2k.ru
Добрый день, дорогие читатели! Сегодня Вас ждет практический пост на тему семантического ядра. В этом пошаговом руководстве я покажу 3 способа распределения найденных ключевых слов с помощью MS Excel. Дело это очень важное, особенно, если количество поисковых запросов для семантического ядра получилось очень большим. Все способы просты до безобразия, но позволяют сэкономить много времени любому блоггеру и веб-мастеру. А время — это самое ценное, что у нас есть, ведь потраченные впустую часы нельзя вернуть назад.
Зачем нужно распределять ключевые слова СЯ
Действительно, зачем блоггеру или веб-мастеру распределять найденные поисковые запросы? Все очень просто — это необходимо делать тогда, когда нужно найти ключевые слова для самого веб-ресурса или его категории, а не для отдельного поста. В этом случае число найденных запросов семантического ядра сайта или рубрики будет в разы больше, чем количество фраз для одной статьи.
К сожалению, многие владельцы сайтов (особенно блоггеры, которые проходили курсы типа «Твой старт») почти всегда ищут запросы только для будущего поста. Вот задумал веб-мастер написать статейку — пошел он в Вордстат, насобирал там несколько запросов и ключевые слова для статьи готовы. 🙂
Такой метод конечно хорош, когда необходимо срочно написать пост, который ранее не был запланирован (например, кто-то предложил сделать рекламную статью, или читатели попросили пояснить одну методику в следующей статье и т.д.). Но такая ситуация у грамотного блоггера и веб-мастера обычно редко бывает — у него все ходы записаны заранее, чтобы видеть дальнейший путь продвижения своего ресурса.
Поэтому для полноценного сайта всегда создается основное семантическое ядро, которое позволяет владельцу охватить почти всю тематику своих будущих статей. Благодаря такому подходу все запросы раскладываются по полочкам — каждые ключевые слова кладутся в свои рубрики. Тем самым веб-мастеру намного проще (!!!) увидеть структуру своего ресурса, он знает уже заранее, по какому пути развития пойдет его ресурс и на что необходимо обратить свое внимание в плане seo (об этом я подробнее рассказал в этом посте).
Разумеется, запросов для основного ядра будет огромное число. Поэтому все найденные ключевики нужно распределять по темам будущих статей. А чтобы это сделать, нужно заняться рутинной работой в MS Excel. Поэтому я и предлагаю Вам посмотреть 3 разных способа распределения поисковых фраз и тогда Вы сможете выбрать для себя самый лучший вариант.
1 способ распределения
Для пояснения всех способов распределения, возьму небольшую подборку поисковых запросов на тему «контент». Для этого у меня есть таблица в Excel, которая получена из программы Key Collector. Точно такую же таблицу Вы можете экспортировать с помощью бесплатного софта Словоеб. Важно, чтобы слова таблицы прошли уже 2-й этап поиска ключевиков — анализ поисковых запросов сайта.
Итак, готовая таблица для распределения запросов у нас есть, пора совершать следующие действия:
Создание новых листов в таблице. Для того, чтобы сохранить отобранные ключевики по темам, нужно создать специальные листы. Для этого переходим на нижнюю вкладку Excel и нажимаем кнопку «Вставить лист»:
Теперь новому листу нужно дать название, которое будет отражать тематику выбранных запросов. В моем примере я сделаю рубрику «Уникальность» — нажимаю правой кнопкой мыши на вкладку «Лист 2» и выполняю следующие действия:
В итоге в процессе работы создается столько нужных вкладок, чтобы отразить все группы ключевых слов.
Распределение запросов по группам. Теперь осталось только из общего списка поисковых фраз выбирать запросы для каждой группы:
Таким образом последовательно каждую строчку из общего списка мы переносим в свой лист запросов. Далее уже в каждом листе можно по той же схеме распределять запросы уже для конкретных статей:
Этот способ самый простой и отлично подходит для того, чтобы распределить не более 50-ти ключевых слов. Но если запросов намного больше, на выполнение нашей задачи будет уходить очень много времени. Существенно сократить его позволяет следующий вариант распределения.
2-й способ распределения
Этот способ основан на окраске поисковых запросов общего списка, которые в дальнейшем в зависимости от цвета распределяются по группам. Вот последовательность действий.
Фоновая окраска запросов по тематикам. Начиная с первого ключевого слова, даем каждому запросу свой цветовой фон. Для этого выделяем ячейку выбранного запроса (не всю строку целиком, а только ячейку!), нажимаем инструмент «Цвет заливки» и красим стандартным цветом фон ячейки:
Таким образом мы окрашиваем все ключевые слова своим цветом, где выбранный фон означает свою тематику:
По количеству цветов далее создаем новые листы, как было показано в первом способе. Теперь нам нужно перекинуть запросы своего цвета в соответствующую группу (лист).
Фильтрация запросов по цвету. Для того, чтобы выбрать сразу все нужные нам запросы одной тематики (одного цвета), необходимо воспользоваться инструментом «Сортировка и фильтр»:
После нажатия кнопки «Сортировка» нам необходимо выбрать условия фильтрации (картинка кликабельна!!!):
Распределение запросов. После выполнения всех действий в начале таблицы появятся запросы выбранного нами цвета. Теперь мы их легко можем перенести в соответствующий созданный новый лист — вырезаем как показано в первом способе эти запросы и вставляем в новую вкладку. Аналогично проводим действия с остальными цветами, пока не перенесем все цветные ключевики по своим темам.
Этот способ хорошо работает, когда в основном списке не так много тем поисковых запросов. Ключевых слов, конечно же может быть любое количество. Чтобы пробежаться по всему списку и покрасить фразы в соответствующий фон много времени не займет. Но если же тематик будет очень много, тогда придется все их держать в голове, что сильно затрудняет процесс выборки. В таком случае поможет 3-й способ.
3-й способ распределения
Он использует все тот же инструмент фильтрации в Excel. С его помощью можно выполнять распределения любого числа найденных запросов по многочисленным темам. Но здесь рабочий процесс немного сложнее и поэтому я решил его показать в следующем видеоролике (для примера я взял список запросов, в котором более 800 слов):
На этом наш практический урок закончился. До новых встреч, друзья!
[wfbox type=»withtitle» title=»Где можно заказать отличное семантическое ядро?»]
Если Вы хотите собрать настоящее семантическое ядро для коммерческого сайта или информационного ресурса, рекомендую обратиться ко мне.
[/wfbox]
С уважением, Ваш Максим Довженко
«Семантическое ядро» в три шага – статьи про интернет-маркетинг
Просматривая оптимизаторские сайты, мы почти на каждом найдем упоминание о некоем «семантическом ядре», которое надо составить перед тем, как приступать к оптимизации сайта. Яндекс-Поиск выдает уже
481 страницу, на которой упоминается это словосочетание. Термин чисто российский, на Западе ничего похожего на «semantic kernel» нет, там в ходу фраза «keyword list» — список ключевых слов.
История термина довольно забавна. Недавно я нашел свою старую статью 2000-2001 года, которую сегодня трудно прочесть без широкой улыбки — Ядро запросов — базовый метод… Тем не менее, идея, что пользователи вводят запросы, а на страницах сайтов находятся ответы, и формулировка запроса отличается от формулировки ответа — вполне здравая. Содержание любой страницы веба соответствует смыслу некоей совокупности реальных поисковых запросов, и Игорь Ашманов в статье «Вывод сайта на экраны радаров» (Журнал «Интернет-маркетинг», 2002) предложил обозначить эту смысловую связь между запросом и ответом более кратко. Ядро запросов стало семантическим ядром.
Термин прижился и слегка изменился по сути. Сегодня под «семантическим ядром» рассматривают не совокупность запросов, смыслу которых отвечает отдельная страница сайта, а совокупность запросов, ответом на котрые может служить информация, находящаяся на сайте в целом. Технически, это список запросов (профильных запросов), по которым отслеживается продвижение сайта.
В отличие от «начала века», когда не открытых баз данных для анализа поисковых запросов и составления такого списка, сегодня информации достаточно. В Рунете статистика запросов открыта на Яндексе, Рамблере, Апорте (через Бегун), Google и Mail.ru. Но инструментов для удобной работы с этой информацией — нет. Попытаемся исправить это положение и предлагаем читателям опробовать методику работы и новый макрос для быстрого составления списка профильных запросов, или «семантического ядра».
Методика
Составление списка запросов для продвижение проходит в три этапа.
- Составление списка масок.
- Расширение списка масок.
- Получение списка запросов.
«Маска» — это ключевое слово или словосочетание, обозначающее тему — наиболее частотный запрос. По маске Вы запрашиваете сервис статистики поисковых запросов выдать список запросов. Например, если маска — «автомобиль», то список запросов по этой маске — это список запросов, в каждом из которых есть слово «автомобиль» — «автомобиль ВАЗ», «автомобиль ГАЗ цена» и т.п. Маска «продажа автомобилей» — запросы «продажа автомобилей», «продажа автомобилей в Москве», «продажа автомобилей в кредит», «продажа б/у автомобилей» и т.п.
Первичный список масок составляет сам веб-мастер. Допустим, речь идет об автосалоне, который продает и ремонтирует автомобили «Фольксваген». Очевидно, что главная маска — это слово «фольксваген».
Но слово «фольксваген» пользователи пишут, минимум, 20 различными способами и сходу все варианты не придумать. Для решения этого вопроса служит сервис Рамблер-Ассоциации. Вот ссылка на pdf-вариант статьи одного из разработчиков Рамблера Владислава Шабанова «Алгоритм формирования ассоциативных связей и его применение в поисковых системах». Попросту, пользователь в течение одного захода в поисковик обычно формулирует несколько «ассоциативных» запросов, сервис Рамблер-Ассоциации отслеживает их, и если будет введен хотя бы один из запросов ассоциативной цепочки, может показать все остальные. В нашем случае, допустим, пользователь ввел запрос «фольцваген», но удовлетворительного ответа не нашел, узнал, как правильно пишется название этого автомобиля и со второй попытки ввел уже «фольксваген». Формулировки «фольксваген — фольцваген» стали ассоциируемыми. И теперь, когда мы интересуемся ассоциациями на «фольксваген», можем увидеть и ошибочный запрос, который, тем не менее, реально вводят пользователи поисковых систем.
Таким образом мы расширяем наш список масок. С помощью Рамблер-Ассоциаций это сделать гораздо быстрее и легче, чем пытаться «логически» вычислить синонимы, сопутствующие запросы, варианты на латинице и др.
Технически это делается так. Зайдем на «Арнольда» (легкая версия Рамблер-поиска) — www.r0.ru и введем запрос «фольксваген». В ответе Рамблера увидим наверху строчку «У нас также ищут…» Это и есть ассоциативные формулировки. Клик по последнему «еще >>» раскроет их полный список.
Мы увидим формулировки «фольцваген», «vw», «фольсваген», «wv», «wolksvagen», «volksvagen», «вольксваген», «folkswagen», «фолксваген», которые легко смогли получить, выбрав на первом шаге лишь одну-единственную базовую маску.
И последний этап — на основании выбранных масок нам необходимо получить список реальных формулировок поисковых запросов и их частот, чтобы оценить, по каким запросам стоит начинать а анализировать продвижение сайта. Сделать это легко с помощью другого сервиса Рамблера — Статистика по поисковым запросам.
Прежде чем работать со статистикой ОЧЕНЬ РЕКОМЕНДУЮ изучить раздел «Помощь». Особенно, если вы привыкли к работе со статистикой Яндекс-Директа. Статистика Рамблера намного точнее и удобнее, чем Яндекса, но в ней нет любимого инструмента для «лентяев» — морфоразбора. Если вы вводите маску «машина», то и получите запросы со словом «машина». Запросы со словами «машин», «машины», «машиной», «машинами» и т.д. останутся «за бортом». Рамблер-статистика дает подсказки о различных словоформах, но право выбора оставляет за пользователем. Поэтому, как минимум, сразу же стоит научиться пользоваться простейшим квантором — звездочкой (см. Помощь Рамблера).
Макрос для автоматизации работы
Рамблер выдает результаты в виде html-страниц, а работать удобно с таблицами. Поэтому мы написали небольшой макрос, который автоматизирует некоторые из описанных выше операций. Вот ссылка на конечный вид таблицы-примера — example.xls
Алгоритм работы. Общее: а) во время работы с макросами не держать открытыми другие окна браузера, все, что необходимо, программа откроет сама; б) на кнопки нажимать с небольшой паузой: нажать, подержать нажатой 2-3 секунды, отпустить.
- В колонку «Маски» ввести сверху вниз список масок, не допуская пустых ячеек между верхней и нижней масками.
- Нажать на клавишу «Ассоциации». Программа последовательно (от верхнего до нижнего, остановится на первой пустой ячейке) передаст запросы-маски в Рамблер, получит ответ, выделит список ассоциаций и заполнит таблицу «Ассоциации». Колонка «Количество» покажет, сколько раз встретилась та или иная формулировка в списке ассоциаций при проверке, т.е. выведет наиболее типичные ассоциативные запросы.
- Список ассоциаций необходимо «зачистить» — удалить ненужные формулировки. Зачистка делается вручную, эта операция требует размышления, поэтому не автоматизируется. После зачистки сформировать список оставшихся ассоциаций в колонке «Ассоциации» сверху вниз без пустых ячеек. Это удобно сделать при помощи стандартной опции меню MS Excel: Данные — Сортировка.
- При необходимости для формулировок расширенного списка масок (колонка «Ассоциации») можно использовать кванторы, например, вместо маски «фольксваген» поставить «фольксваген». Звездочка обозначает возможность добавить любое количество букв на этом месте, поэтому при такой маске мы получим список запросов, где будут формулировки не только со словом «фольксваген», но и «фольксвагена», «фольксвагенов» и т.д.
- Задать в ячейке G3 пороговое ограничение популярности запроса (по умолчанию стоит 300). Рамблер выдает информацию о популярности запроса на основании данных своей баннерной системы — в двух колонках: «Первая» и «Все». «Первая» обозначает, сколько раз были показаны баннеры на первой странице с результатами поиска Рамблера по данному запросу, т.е. фактическую частоту запроса. «Все» — это общее количество показов баннера по данному запросу на всех страницах, не только на первой. При съеме запросов макрос снимет формулировки, для которых общее количество показов баннера не менее, чем значение, указанное в качестве порога в ячейке G3.
- Нажать на клавишу «Запросы».
- Зачистить полученный список от лишних формулировок и отсортировать по убыванию либо общего количества показов, либо частоты запросов.
Профессиональная оптимизация — это постоянная работа с большими объемами статистических данных. Для значительной экономии времени в будущем стоит потратить немного сил, чтобы научиться беглой работе с электронными таблицами MS Excel, для которых мы пишем макросы.
Предлагаемая методика и макрос позволяют при небольшом навыке составить «семантическое ядро» сайта за полчаса-час. Для сравнения, стоимость подобной работы в разных компаниях оценивается от 30 до 300 долларов.
Товар для маргиналов
De omnibus dubitandum — сомневайся во всем! Слова приписывают и Декарту, и Марксу, а в наиболее известном переводе — «Подвергай все сомненью» — нашему Козьме Пруткову.
В прошлом выпуске в ответ на вопрос подписчика мы опубликовали рассказ о партнерской программе Masterbell. Но рассказ о преимуществах партнерских программ был бы неполон без небольшого анализа самого товара.
Прежде чем принять решение о вступлении в ту или иную партнерскую программу, необходимо попытаться выяснить, кто и почему будет покупать товар, распространяемый по партнерке. В нашем случае товаром является предоплаченная телефонная карточка. PIN-код, который активизирует на счете некую сумму. Аудитория для которой делается предложение купить карту через Интернет, находится на Западе. Т.е. подразумевается, что у потенциального покупателя есть компьютер, доступ в Сеть и кредитная карта, чтобы оплатить заказываемую телефонную карту. Но возникает вполне разумный вопрос — а зачем ему тогда нужна телефонная карта?
Дело в том, что на Западе типичный вид продажи — это продажа в кредит. В том числе и оплата телефонных переговоров. Вы говорите целый месяц, и в конце учетного периода получаете счет. При этом стоимость разговора что по предоплаченной карточке, что в кредит практически не отличается.
Естественно, телефон в кредит — это услуга для солидных клиентов, которым можно верить, что они оплатят счет. Если у вас есть дом, работа, безупречная кредитная история — нет проблем. Если проблемы есть — за телефон возьмут залоговую сумму. Но компьютер, Интернет и кредитная карточка и есть одни из атрибутов «приличного гражданина», к которым так же автоматически прилагается и телефон с кредитным счетом.
Вывод простой — телефонные карты покупают маргиналы. Нищие слои населения, новые эмигранты, неблагонадежные, гастарбайтеры. В Америке телефонные карточки не рекламируются по американским каналам, только по национальным — русскоязычным, испаноязычным (на немецких каналах такой рекламы тоже нет).
Велика ли вероятность, что обладатели компьютера и телефона с кредитным счетом будут покупать в Сети предоплаченную карточку. Велика ли вероятность, что это станут делать те, у кого нет компьютера? И кто же тогда «потенциальные покупатели», у которых есть компьютер и Интернет, но нет приличного телефона?
Семантическое ядро: что это и как его правильно составить
Дата публикации: 31.03.2021
Семантическое ядро – перечень слов и словосочетаний, наиболее полно отражающих тематику сайта и разделенных на сходные по смыслу группы. Проще говоря, это те самые поисковые запросы (ключевые слова/фразы, ключи) по которым будет вестись продвижение в поисковых системах. Составляя семантическое ядро сайта, мы отвечаем на вопрос: какую информацию пользователи могут найти на нашем сайте.
Создание семантического ядра можно разделить на несколько этапов:
- Подбор запросов-масок – общих поисковых фраз, соответствующих тематике вашего сайта.
- Расширение семантического ядра при помощи сервисов, поисковых подсказок, анализа ключей конкурентов.
- Чистка неподходящих поисковых фраз.
- Кластеризация – группировка ключевых слов по смыслу и их распределение по страницам сайта.
- Оптимизация полученных фраз.
Когда мы работаем с семантическим ядром, мы определяем, какая страница точнее всего отвечает на конкретный поисковый запрос или группу запросов. Еще какое-то время назад SEO-специалисты искали наиболее частотные ключевые слова по теме сайта и вписывали их в текст ради хорошей видимости по ним в поиске. Однако последние несколько лет наблюдается тенденция, при которой релевантным документом считается не тот, где больше соответствующих ключевых запросов, а тот, где наиболее полно раскрывается намерение пользователя.
Однако, как бы сильно мы ни стремились создать качественный интересный контент, без семантического ядра он не сможет полно раскрыть тему и, как следствие, привлечь хороший целевой трафик. В конкуренции с сайтами, которые продвигаются по высокочастотным и среднечастотным запросам, наш сайт будет существенно уступать. Именно поэтому без составления правильной семантики, раскрывающей потребности пользователей, не обходится ни одно продвижение сайта.
Классификация поисковых запросов
При составлении семантического ядра необходимо четко понимать, какого типа запросы нужны для продвижения нашего сайта. Рассмотрим подробно их классификацию.
По частотности запросы бывают:
- Высокочастотные (ВЧ) – определяют тему сайта; именно они чаще всего используются при поиске сайтов определенной тематики. Такие запросы состоят из 1-2 слов, и в среднем количество показов по ним составляет от 1000-3000 до нескольких сотен тысяч в месяц.
- Среднечастотные (СЧ) – чуть менее популярные, но все же востребованные ключи. Как правило, это отдельные направления в теме. Состоят из 2-3 слов. Количество показов 500-1000 в месяц.
- Низкочастотные (НЧ)– ключевые запросы с точной частотностью от 50 до 500 показов. Чаще всего содержат 3-4 слова. Такие запросы позволяют привлечь на сайт целевую аудиторию, которая точно знает, что ей необходимо.
- Микронизкочастотные (МЧ) – запросы с частотностью ниже 50 показов в месяц, которые крайне редко (а иногда и лишь единожды) вводят в поиске.
По конкурентности выделяют высококонкурентные (ВК), среднеконкурентные (СК) и низкоконкурентные (НК) запросы. Чем большее количество сайтов и площадок используют запрос, тем он высококонкурентнее. В большинстве случаев высоконкурентный запрос будет также и высокочастотным.
По потребности запросы делятся на:
- Информационные – выражают желание пользователя найти интересующую его информацию.
- Навигационные – характеризуются потребностью пользователя найти конкретный сайт или информацию о нем.
- Транзакционные – отражают желание пользователя совершить какое-либо действие, например, «скачать книгу голодные игры», «смотреть игру престолов онлайн», «слушать новый альбом земфиры» и т.д. Среди транзакционных запросов отдельно выделяют коммерческие – это те запросы, которые отражают потребность пользователя в покупке товара или заказе услуги («купить кондиционер» или «заказать химчистку дивана на дому»). Транзакционный запрос не всегда будет коммерческим, но коммерческий всегда будет транзакционным.
Помимо перечисленных выше типов запросов есть еще общие или нечеткие запросы. Как правило, они очень короткие, неявные, определить по ним намерение пользователя сложно (например, «телефон»). Добавлять такие запросы в семантическое ядро стоит с осторожностью и только после оценки затрат на их продвижение, т. к. велика вероятность того, что они приведут на сайт нецелевой трафик.
Если планируется продвигать коммерческий сайт или интернет-магазин, то при составлении семантического ядра стоит делать упор на ВЧ, СЧ и НЧ коммерческие запросы. В семантическом ядре информационного сайта или портала должны быть СЧ и НЧ низкоконкурентные информационные запросы, которые будут органично вписаны в статьи.
Как правильно составить семантическое ядро – пошаговое руководство
Разберем создание семантического ядра на примере сайта рынка фермерских продуктов в Тюмени.
1. Поиск основных фраз
Для начала надо выписать как можно больше запросов-масок (их еще называют маркерами), связанных с продуктами или услугами на вашем сайте. Такие запросы высокочастотны, как правило, состоят из 1-2 слов. Это могут быть отдельные услуги, категории товаров, популярные в вашей области темы. Чтобы максимально охватить тематику, в качестве масок можно использовать названия разделов, всевозможные синонимы, термины и даже специфичный для вашей сферы сленг.
Помимо этого, особое внимание стоит уделить изучению семантического ядра конкурентов. Найдите сайты прямых конкурентов, просмотрите разделы, перейдите на несколько страниц каталога. Возможно, вы почерпнете идеи в названиях разделов или товарных позиций. Далее необходимо изучить ключевые запросы конкурентов, сделать это можно через сервис keys.so или любой другой бесплатный аналог. Проанализируйте ключи на предмет подходящих запросов из 1-2 слов, которые вы не внесли в свой список ранее.
2. Поиск синонимов
При обращении к поисковым системам пользователи могут использовать слова близкие по смыслу, но разные по написанию, например, «шлифовальная шкурка» и «наждачная бумага». Если вы не найдете как можно больше таких синонимов, то при парсинге (сборе и систематизации информации) упустите большое количество ключей, хорошо раскрывающих потребности пользователя.
Хорошим источником базовых запросов могут быть поисковые подсказки – варианты наиболее популярных запросов, которые появляются выпадающим списком в строке поиска в тот момент, когда мы вводим какой-либо запрос в браузере. Часто среди поисковых подсказок можно найти фразы с хорошей частотностью и относительно низкой конкурентностью, поэтому не стоит пренебрегать этим способом сбора запросов.
Также помочь с неочевидными ключевыми словами может Яндекс Вордстат. На каждый введенный запрос сервис показывает две колонки с запросами и количеством показов по всем возможным вариантам использования ключевого слова. В левой колонке – словосочетания и фразы, которые содержат в себе указанный нами запрос, а в правой – запросы, которые на него похожи. Именно второй вариант подходит для раскрытия темы. При помощи расширения для браузера Yandex Wordstat Helper вы сможете добавить фразы из обеих колонок в отдельный список, который позднее можно скопировать вместе с базовой частотностью одним нажатием кнопки.
3. Расширение основных запросов
После того как мы собрали максимальное количество масок, можно приступать к расширению основных запросов. Сделать это можно при помощи различных программ и сервисов, например, мы для этой задачи воспользуемся Key Collector, сервисами Клик.Ру и Букварикс.
Начнем с того, что список записанных нами ранее общих запросов мы отправляем на парсинг в KeyCollector. Создаем новый проект и переходим на вкладку «Парсинг». Кликаем по иконке «Сбор фраз из Yandex.Wordstat», указываем регион, выбираем режим сбора «Левая колонка» и добавляем список запросов, нажимаем «Начать». По окончании процесса появится окно с отчетом о результатах.
Пока идет парсинг, продолжим собирать запросы. Для этого составим список конкурентных сайтов. Выбирать нужно конкурентов с наиболее подходящей нашему сайту достаточно узкой тематикой, с хорошими показателями трафика и количеством запросов в ТОПе, чтобы на выходе не получить слишком большой объем семантики.
На данном этапе нам необходимо найти как можно больше подходящих ключей среди запросов конкурентов. Один из способов это сделать – через медиапланирование в сервисе Клик.ру, для использования которого у вас должен быть свой аккаунт. После авторизации перейдите на вкладку «Инструменты» и пункт «Семантика», выберите «Подбор слов и медиапланирование».
Укажите свой сайт, выберите в списке рекламную систему (рекомендуем оставить Яндекс Директ, но по желанию можно оставить обе), выберите регион и кликните по «Начать новый подбор». Полученный список отобразится в разделе «Автоматический подбор слов» – «Автоматически подобранные слова». Добавьте ключевые слова в медиаплан – блок страницы, в котором вы сможете просмотреть выбранные вами запросы, их частотность и позиции, а также информацию для настройки контекстной рекламы. Для этого нажмите на «Показать все» – выделите запросы – «Добавить в медиаплан». При наличии дублей слов, сервис покажет их список и предложит выбрать, какие из них следует удалить.
После этого необходимо добавить в наш список конкурентов. На вкладке «Слова конкурентов» вы сможете увидеть список автоматически подобранных конкурентов вашего сайта и количество используемых ими ключевых слов. Если запросов немного, то можно просмотреть их все и самим выбрать подходящие для добавления в медиаплан. Дополнительно можно внести конкурентов вручную и проверить наличие их запросов в сервисе. Имейте в виду, что есть лимит на количество анализируемых конкурентов, и это еще одна из причин, почему нам нужны наиболее близкие к нашей тематике сайты.
Добавив все ключевые слова в медиаплан, выгрузите список файлом с расширением .xls.
Еще один способ расширить базовые запросы – воспользоваться сервисом Букварикс. По очереди вводим в поиске доменные имена сайтов наших конкурентов и, в зависимости от количества ключевых слов, либо отбираем вручную те запросы, которые могут быть нам полезны, либо выгружаем полный список кликом по кнопке внизу страницы с результатами.
На момент, когда мы соберем достаточно ключей конкурентов, Key Collector уже должен закончить парсинг базовых запросов. Объединяем в один общий список все полученные нами запросы из медиаплана Клик.ру и Букварикса.
Среди огромного количества запросов достаточно много так называемых «неявных дублей» – дубликатов, которые по сути являются одним и тем же поисковым запросом, но отличаются расположением слов в фразе. Помимо этого, встречаются запросы с различными спецсимволами, которые использовались для расчета частотности. Чтобы впоследствии нам не приходилось просматривать отдельно каждый запрос на наличие символов или перестановки слов, воспользуемся бесплатной чисткой семантического ядра от мусора – «Нормализатором» от Клик.ру. Все, что от нас требуется, это добавить запросы (списком или файлом .xlsx, как вам удобнее), отметить галочками все пункты действий с ядром и кликнуть на «Выполнить». Очищенный список ключевых фраз отобразится в списке задач ниже, нужно лишь дождаться статуса «Выполнен в чч.мм.сс». Кликаем по иконке рядом и скачиваем файл с очищенными ключевыми запросами.
В некоторых тематиках количество ключевых слов на этот момент может составлять несколько тысяч, но не стоит пугаться – сейчас мы приступим к нескольким этапам чистки получившегося списка.
4. Минус-слова
В процессе сбора ключевых запросов всегда находятся те, в состав которых входят слова и словосочетания, которые делают запросы нерелевантными для нашего сайта. Например, если компания занимается исключительно продажей нового оборудования для строительства, то в нашем случае такими словами будут «аренда» и «б/у». Чтобы сразу отсечь ключи, которые могут привести на сайт нецелевой трафик, стоит подготовить список минус-слов. Для этого необходимо подумать, какие слова ассоциируются с вашей темой, но не подходят для продвижения именно вашего сайта.
Если сходу составить список минус-слов сложно, или вы хотите сделать его максимально полным, то собрать его можно при помощи Key Collector. Для этого мы добавляем в проект наш список пропущенных через «Нормализатор» ключевых запросов («Добавить фразы» в верхнем левом углу), переходим на вкладку «Данные» и выбираем «Анализ групп». В появившемся окне выберите тип группировки «По отдельным словам». Просмотрите получившийся список и отметьте кликом по синей иконке те слова и его словоформы, которые вам не подходят.
После этого кликните на «Минус-слова», откроется окно с выбранными вами ранее словами. Внимательно проверьте, чтобы среди них не было ключевых слов. Отметьте галочками необходимые минус-слова – «Показать найденные фразы» – выберите все и нажмите «Удалить фразы».
Если же у вас уже есть готовый список минус-слов, добавьте его в проект вручную, выбрав на панели «Минус-слова» – «добавить несколько минус-слов». Далее повторите все те же действия, что мы описали выше.
5. Определение базовой и точной частотности
После того как мы отсеяли запросы с минус-словами, приступаем к определению базовой и точной частотности по региону, в котором будет продвигаться наш сайт. Базовая частотность показывает, сколько раз за месяц искали определенный запрос во всех словоформах и с добавлением к нему любых слов. Точная частотность отображает количество показов в поиске только по указанной форме запроса.
В KeyCollector переходим на вкладку «Парсинг» и выбираем «Сбор прогнозов бюджета из Я.Директ». В появившемся окне выбираем регион и выбираем формат запросов частот без кавычек и с кавычками, кликаем «Начать». Когда процесс сбора будет завершен, с помощью фильтра выделяем и удаляем запросы с нулевой частотностью. Если запросов осталось достаточно много, имеет смысл просмотреть те, у которых точная частотность равна 1, и вручную удалить неподходящие.
6. Чистка ключевых слов от мусора
Следующим по списку идет отсев запросов «пустышек» – фраз, которые редко используются в точной словоформе, но имеют высокую базовую частоту. Для обнаружения таких воспользуемся функцией Key Collector «KEI» на главной и перейдем в редактор формул. В пункте «Формула 1» укажем
( Module_YandexWordstat.BaseFrequency ) / ( Module_YandexWordstat.QuoteFrequency ), сохраним и вычислим KEI по первой формуле.
В результате у нас появился третий столбец с данными. Отсортируем их от большего к меньшему и тщательно просмотрим запросы с KEI выше 50. Чем выше показатель KEI, тем больше шансов, что перед нами «пустышка». Однако списывать со счета сразу все запросы с высоким KEI не нужно, т. к. среди них могут быть нужные нам целевые запросы.
Если на данном этапе вы обнаружили, что запросов по-прежнему слишком много (в 2-3 раза больше необходимого), то следует вернуться на шаг назад и почистить запросы с точной частотностью меньше 2, 3, 5 и т. д. показов в месяц. Оставшиеся ключевые слова необходимо проверить вручную и удалить неподходящие.
После того, как у вас на руках осталось необходимое количество ключевых запросов, самое время приступить к их группировке и распределению по страницам сайта.
7. Кластеризация
Полученные в ходе предыдущих этапов ключевые слова необходимо объединить в семантические кластеры – близкие по смыслу группы запросов. Кластеры имеют многоуровневую структуру: выделяются кластеры первого, второго, третьего и т.д. порядков, число которых зависит от того, насколько широкая у сайта тематика. Как правило, в большинстве тематик двухуровневая структура.
При небольшом количестве запросов (100-300) многие SEO-специалисты предпочитают делать кластеризацию вручную, т.к. она займет приблизительно столько же времени, как если ее проводить при помощи специализированных программ. Если ключей больше 300, то целесообразнее будет сделать полуавтоматическую группировку в программе.
Мы рассмотрим проведение кластеризации при помощи платной программы KeyAssort. Для более комфортной работы с ней рекомендуем использовать Антикапчу и приобрести XML лимиты.
Запускаем программу, создаем новый проект. Переходим во вкладку «Файл» – «Импорт» – выбираем удобный способ добавления запросов. Нажимаем «Собрать данные» и дожидаемся окончания сбора. Затем указываем наш сайт (без протокола и префикса www), выбираем уровень кластеризации и кликаем по «Кластеризовать». Оптимальной степенью кластеризации в режиме Middle будет 3, однако при необходимости ее можно менять в большую или меньшую степень. Чем выше степень кластеризации, тем больше в результате получится более точных групп.
8. Выбор тем и группировка
Получившиеся после кластеризации группы необходимо внимательно просмотреть: выбрать группы для запросов из категории «Не сгруппировано», объединить близкие по смыслу запросы в подходящей группе или создать для них новую. На основании полученных после сбора данных KeyAssort привяжет кластерам ссылку на страницу, которая подходит под группу запросов, однако это происходит далеко не всегда. Для вашего удобства после группировки вы можете переименовать кластер и в название добавить ссылку релевантной страницы.
9. Удаление запросов другого типа контента
Ранее мы уже обсуждали, какие типы запросов подходят для информационных сайтов и интернет-магазинов, и поэтому крайне важно на завершающих этапах составления семантического ядра убедиться, что все запросы по своим интентам соответствуют типу нашего сайта. Для этого необходимо еще раз пройтись по всем группам и при необходимости удалить неподходящие ключевые слова. Если возникают сомнения относительно вида запроса, то можно сравнить по нему выдачу ПС или прибегнуть к помощи программ и сервисов.
Готовые группы выделяем и переносим в правую часть экрана KeyAssort, выбираем «Экспорт» и кликаем по удобному нам варианту.
10. Оптимизация фраз
Наше семантическое ядро почти готово, для удобной работы осталось лишь его оптимизировать. Для этого отсортируйте в Excel или Key Collector ключевые фразы от А до Я. Просмотрите их, и для каждой группы оставьте только те ключи, которые раскрывают тему с разных сторон и содержат синонимы.
Получившееся семантическое ядро послужит наглядным планом работ, который необходимо выполнить на сайте: доработать или создать новую структуру, подготовить полезный и интересный контент, оптимизировать тексты и метаданные. Грамотная работа с семантическим ядром поможет улучшить позиции и обеспечит прирост целевого трафика из органической выдачи.
3 частые ошибки при создании семантического ядра
1. Сбор фраз по верхам
Если запросы вводят очень редко или неопределенными периодами, то такие запросы могут не попасть в статистику Вордстата. Если вы полагаетесь только на него, то упускаете огромный пласт ключевых фраз, многие из которых могут быть с хорошей конверсией и низкой конкуренцией. Потратьте время, но изучите поисковые подсказки, поисковую выдачу, сайты и контекстную рекламу конкурентов ради максимально полного семантического ядра.
2. Смешивание информационных и коммерческих запросов на одной странице
Разбавлять семантическое ядро сайта интернет-магазина информационными запросами может быть полезно только в том случае, если они вписаны в тексты раздела со статьями. Если же их добавить на страницы каталога вместе с коммерческими запросами, то может случиться так, что эти страницы попадут в выдачу только по информационным, или только по коммерческим запросам. То же самое касается коммерческих ключевых запросов, которые добавляют в статью информационного сайта. Пользователи, которые перейдут на страницу в поисках товара или услуги и вместо этого обнаружат статью, вероятнее всего сразу ее покинут, тем самым повысив уровень отказов и ухудшив поведенческие факторы.
Чтобы этого не произошло, тщательно проверяйте «коммерческость» у собранных вами запросов. Сделать это можно с помощью сравнения страниц, которые находятся в ТОПе по интересующим запросам или воспользовавшись инструментами Пиксель Тулс и Just-Magiс.
3. Выбор для продвижения очень конкурентных запросов
Высокая конкуренция по выбранным запросам существенно усложняет продвижение как молодому, так и более авторитетному сайту, ведь претендентов на высокие позиции в выдаче слишком много, а требования к таким сайтам гораздо выше. К тому же, по высококонкурентным запросам в ТОПе выдачи уже давно уверенно расположились сайты крупных брендов и интернет-магазины, потеснить которые будет практически нереально. Куда проще продвинуть сайт по СК и НК запросам, ведь, как правило, релевантных страниц по ним меньше и не все они хорошего качества, что позволит сэкономить время и бюджет.
О семантике электронных таблиц с функциями, определяемыми листом
Александр Асп Бок начал свою академическую карьеру в качестве доктора философии. студент Питера Сестофта в рамках проекта «Популярное параллельное программирование» (P3) в ИТ-университете Копенгагена. Его основное внимание было сосредоточено на разработке стратегий параллельной оценки для ускорения вычислений в электронных таблицах для конечных пользователей. Работа реализована в программе электронных таблиц Funcalc. Позже он был постдоком, работая над дальнейшей оптимизацией Funcalc.
Томас Бегхольм — доцент кафедры информатики Ольборгского университета. Его исследовательские интересы включают языки программирования и анализ программ в области параллельного программирования, встроенных систем реального времени и критически важных систем безопасности, а также работает с объектно-ориентированным анализом программ и вычислительным мышлением. Томас имеет степень магистра наук с отличием в области программной инженерии и докторскую степень. по информатике из Ольборгского университета, Дания.
Питер Сестофт — профессор и глава факультета компьютерных наук Копенгагенского ИТ-университета.Он работает в основном с технологиями языков программирования, включая функциональные, объектно-ориентированные и параллельные языки программирования, их использование, реализацию и оптимизацию. Он является соавтором вместе с Джонсом и Гомардом стандартного справочника по частичной оценке (1993 г.) и автором пяти других книг, последней из которых является 2-е издание «Концепции языка программирования», Springer 2017.
Бент Томсен — профессор (MSO) на факультете информатики Ольборгского университета, Дания.Его исследования связаны с языками программирования и технологиями программирования с приложениями в параллельных, параллельных, распределенных, мобильных, встроенных системах и системами обработки данных. Он был главным научным сотрудником ICL, Великобритания, и руководителем группы по легкому языку программирования в ECRC в Мюнхене, Германия. Бент — дипломированный инженер и европейский инженер (Eur Ing). Он член Британского компьютерного общества. Бент имеет степень магистра наук. по информатике из Ольборгского университета, Дания, доктор философии. и DIC из Имперского колледжа Лондонского университета, Великобритания.
Лоне Лет Томсен — доцент и председатель учебного совета факультета информатики Ольборгского университета, Дания. Ее исследовательские интересы включают функциональное параллельное программирование, Интернет и Интернет вещей, распараллеливание электронных таблиц и технологии программирования будущего. Она была главным научным сотрудником в ICL, Великобритания, и членом группы в группе упрощенного языка программирования в ECRC, Германия. Лоун — дипломированный инженер и европейский инженер (Eur Ing). Она член Британского компьютерного общества.Одинокий имеет степень магистра наук. Имеет степень доктора философии в области программной инженерии и вычислительных систем Ольборгского университета, Дания. и DIC из Имперского колледжа Лондонского университета, Великобритания.
© 2020 Авторы. Опубликовано Elsevier Ltd.
Бесплатный шаблон и руководство для исследования ключевых слов
Обновлено: сентябрь 2021 г.
Здесь, в Jellyfish Training, мы верим в силу эффективного исследования ключевых слов. Независимо от того, являетесь ли вы новичком или специалистом в области SEO, наш бесплатный шаблон для исследования ключевых слов в Google Таблицах поможет вам сфокусировать свое исследование независимо от вашего уровня.
В этом руководстве мы проведем вас через каждый этап исследовательского процесса. Мы расскажем, как проводить исследования ключевых слов до анализа их ранжирования и сопоставления содержания. Для начала откройте шаблон исследования ключевых слов. Эта версия предназначена только для просмотра, поэтому вам нужно будет сделать копию. Вы можете сделать это, перейдя в Файл , затем Сделайте копию
Это руководство является частью нашего стандартного курса SEO. Если вы хотите улучшить свою стратегию SEO и овладеть основами поисковой оптимизации, ознакомьтесь с ассортиментом учебных курсов по SEO , проводимых нашими штатными экспертами.
Как проводить исследование ключевых слов с помощью нашего бесплатного шаблона исследования ключевых слов в Google Таблицах
После того, как вы сделали копию шаблона, вы готовы приступить к исследованию ключевых слов. Чтобы вы могли извлечь из этого руководства максимальную пользу, мы разделили его на семь этапов:
- Выбор темы
- Создание списка семян
- Составление списка ключевых слов с помощью Google Рекламы
- Анализ и уточнение вашего списка
- Анализ намерений
- Окончательный выбор ключевого слова
- Ранжирование ключевых слов и отображение содержимого
Давайте рассмотрим каждый шаг более подробно, чтобы вы могли использовать шаблон наилучшим образом.
Шаг 1. Выберите темы
Прежде чем углубляться в ключевые слова, сначала необходимо рассмотреть темы. Это важный шаг, который поможет направить исследование ключевых слов в правильном направлении. Итак, чтобы понять ваши темы, вам нужно подумать о своих продуктах или услугах и своих клиентах. Затем определите основные темы или сообщения вашего веб-сайта и торговой площадки.
Вот пример. Бренд средств по уходу за кожей, ориентированный на рынок премиум-класса с экологическими целями, мог бы выбрать роскошный крем для лица, экологичный лосьон для тела и органический уход за кожей в качестве своих тем.
В зависимости от вашего бизнеса, ваш веб-сайт может быть ориентирован только на одну тему или на несколько тем. После того, как вы определились с темами, вы можете перечислить их на вкладке Seed List вашего шаблона.
Шаг 2. Создайте свой список семян
Определив список тем, пора подумать о поисковых запросах, которые ваши идеальные клиенты могут использовать для поиска предлагаемых вами продуктов, услуг или информации.
Откройте свой шаблон и добавьте ключевые слова, которые, по вашему мнению, ваша целевая аудитория может использовать для поиска вашего веб-сайта, начиная с вашей темы и затем разветвляясь. Также важно учитывать все три типа запросов:
- Навигационные запросы : поисковый запрос с явным намерением, когда пользователь ищет определенный веб-сайт или поставщика. По этим запросам сложнее ранжировать, если вы не являетесь владельцем бренда.
- Информационные запросы : поисковый запрос, по которому пользователь ищет информацию, например «советы по созданию лучшей стратегии SEO».
- Транзакционные запросы : поисковый запрос, который может включать названия брендов или выглядеть универсальным, и пользователь намеревается совершить покупку.
Имея в виду эти запросы, создайте в своем шаблоне список из 6–12 ключевых фраз. Это отличная возможность также использовать поисковые запросы, определенные в Google Search Console или Google Ads.
Шаг 3. Составьте списки ключевых слов с помощью Планировщика ключевых слов Google Рекламы
Следующий шаг направлен на поиск эффективных ключевых слов с использованием исходного списка.
Доступ к Планировщик ключевых слов Инструмент
Вам потребуется доступ к своей учетной записи Google Рекламы или создать новую учетную запись, используя любую учетную запись Google. После входа в систему перейдите к Инструменты вверху страницы и выберите Планировщик ключевых слов в раскрывающемся меню.
Расширьте свой исходный список
Планировщик ключевых слов Google возьмет ваш исходный список (-ы) и расширит их, предоставив соответствующие условия поиска, которые пользователи могут использовать для поиска веб-сайта или веб-страницы, подобной вашей.Вот что вам нужно сделать:
- Выберите опцию «Обнаружить новые ключевые слова».
- Скопируйте ключевые слова из своего первого исходного списка и вставьте их в поле «Ваш продукт или услуга». Убедитесь, что параметры таргетинга соответствуют предполагаемым географическим и языковым целям.
- После того, как вы нажмете Получите результаты , Google будет возвращать среднемесячные данные поиска по ключевым словам в вашем исходном списке, а также все термины, которые Google считает связанными.
- Щелкните синюю стрелку в верхнем правом углу Планировщика ключевых слов Google, чтобы загрузить список ключевых слов в электронную таблицу.
Шаг 4. Проанализируйте и уточните полный список ключевых слов
После загрузки электронной таблицы (файла .csv) вы увидите несколько столбцов данных. Вам нужно сосредоточиться только на трех столбцах: «Ключевое слово», «Сред. Ежемесячные поисковые запросы »и« Конкуренция ». Разберите лист, удалив все остальные столбцы.
Теперь изучите ключевые слова, появляющиеся в списке. Вы обнаружите, что некоторые из них кажутся нерелевантными, не относящимися к теме или обеспечивают слишком мало поисковых запросов, чтобы их можно было включить в ваш окончательный выбор ключевых слов.
Как правило, чем больше запросов получает ключевое слово, тем лучше, потому что мы знаем, что люди ищут именно этот запрос. Но чем выше объем поиска, тем выше конкуренция, поэтому мы не хотим выбирать только большие объемы поиска.
С другой стороны, ключевые слова, идентифицированные как «низкий объем поиска», получают очень мало поискового трафика в Google. Их можно определить как ключевые слова, генерирующие 250 запросов в месяц. Такой низкий объем поиска указывает на то, что эти ключевые слова могут не иметь отношения к нашей целевой аудитории и не будут привлекать посетителей на ваш веб-сайт.
Мы рекомендуем нацеливаться на ключевые слова с высокими средними объемами поиска в вашем первоначальном исследовании. Иногда ключевые слова с низкой сложностью могут улучшить ваш рейтинг на страницах результатов поисковых систем (SERP), поскольку они обычно гораздо менее конкурентоспособны; при необходимости вы можете вернуться к ним позже.
Наконец, уточните свой список ключевых слов, удалив те, которые мы определили выше как нерелевантные или с низким объемом поиска. Теперь у вас есть последний выбор ключевых слов, также известный как «чистый список».
Шаг 5: Анализ намерений
В SEO важно убедиться, что страницы, на которые вы ориентируетесь по какому-либо конкретному ключевому слову, соответствуют цели запроса. Чтобы помочь вам определить, следует ли использовать ключевые слова для таргетинга на целевые, вспомогательные или информационные страницы, полезно систематизировать ключевые слова по коммерческим целям.
Во-первых, создайте новый столбец в своей электронной таблице и отметьте ключевые фразы, которые напрямую соответствуют вашим основным продуктам или услугам с «высоким» намерением конверсии.Если пользователь может быть заинтересован в вашем продукте или услуге, но вряд ли совершит конверсию, пометьте их как «средние». Если запрос относится к вашей аудитории, но на данном этапе они, вероятно, не заинтересованы в вашем предложении, отметьте их как «низкие».
Шаг 6: окончательный выбор ключевого слова
Ваш «чистый список» будет включать все ключевые слова, на которые вы должны рассчитывать таргетинг в рамках своей кампании. Естественно, некоторые из этих фраз будут иметь большую ценность, чем другие — некоторые будут «тщеславными» ключевыми словами, а другие — «ключевыми словами с длинным хвостом».Вот как мы их определяем:
Тщеславные ключевые слова: Широкие фразы, представляющие целую отрасль или тему, по которым трудно ранжироваться, но которые имеют более высокий объем поиска.
Длиннохвостые ключевые слова: Более длинные и конкретные ключевые фразы, по которым легче ранжироваться, но с меньшим объемом поиска.
Итак, чтобы уточнить выбор ключевых слов, рекомендуется разделить «чистый список» на следующие группы:
- Основные возможности — Ключевые слова, перечисленные в вашем окончательном выборе, которые обеспечивают наиболее желательные возможности для конверсии и объема поиска.Ваш веб-сайт обычно ориентирован на эти основные возможности.
- Вторичные возможности — Альтернативные (часто с длинным хвостом) ключевые слова, которые изменяют основные возможности. Эти ключевые слова, как правило, вызывают меньший объем поиска, но все же предлагают релевантность, хотя, возможно, более низкую конверсию, и их можно включить в вашу SEO-кампанию.
- Третичные возможности — Дополнительные альтернативные ключевые слова, которые обеспечивают наименее прибыльные возможности с точки зрения объема поиска и средне-низкого намерения конверсии.В большинстве случаев они будут наименее нацелены в рамках кампании SEO. Это те фразы, на которые вы, вероятно, нацеливаетесь с помощью вспомогательного контента или сообщений в блогах.
Шаг 7. Ранжирование ключевых слов и отображение содержимого
После того, как вы завершили выбор ключевых слов, следующим шагом будет проверка, ранжируете ли вы уже по определенным ключевым словам. Этот процесс позволит вам обнаружить пробелы в содержании или ключевые страницы, которые работают не так, как вы ожидали. Вам нужно будет задать такие вопросы, как:
- Есть ли приоритетные ключевые слова, которые вы определили, по которым вы не ранжируетесь? Это поможет вам определить возможности для нового контента.
- Эффективность некоторых комбинаций страниц и ключевых слов ниже средней эффективности по сайту? Если да, то эти страницы потребуют дальнейшего анализа и усиления.
- Являются ли страницы, которые ранжируются по выбранным вами ключевым словам, тем, чего вы ожидаете? В противном случае вы можете каннибализировать поиск — это когда две или более страниц на вашем веб-сайте конкурируют за один и тот же поисковый запрос и потребуют исправления или дальнейшего анализа.
Инструмент, который мы используем для определения нашего рейтинга ключевых слов, — это Accuranker, но вы можете использовать гораздо больше инструментов SEO, в том числе:
Выполнив действия, описанные в этом руководстве по исследованию ключевых слов для каждой из выбранных вами тем, вы будете готовы к продвижению своей кампании.Если вы хотите узнать больше о стратегиях SEO, посетите нашу страницу о расширенном исследовании ключевых слов.
CPSV-AP Specification v2.2.1 — Шаблон электронной таблицы
В области содержимого отображаются элементы, которые были созданы или переданы в коллекцию. Это вид по умолчанию при входе в коллекцию.
1 из 8
В области содержимого отображаются элементы, созданные или совместно используемые в решении. Это вид по умолчанию при вводе решения.
2 из 8
Меню навигации обеспечивает доступ к основным разделам коллекции, таким как список участников, ее описание и т. Д.
3 из 8
Меню навигации обеспечивает доступ к основным разделам решения, таким как список участников, его описание и т. Д.
4 из 8
Щелкая эти значки, вы можете просматривать определенные типы содержимого в области содержимого.
5 из 8
Присоединяясь к коллекции, вы становитесь ее участником с возможностью создавать для нее контент.
6 из 8
Загрузите содержимое выпуска решения, например стандарт, спецификацию или программное обеспечение.
7 из 8
Поиск по всей платформе Joinup и поддерживаемым ею элементам контента.
8 из 8
Пример теоретического графа для электронной таблицы с рис. 1
Контекст 1
… видите, что три компонента интерпретации полностью определяют соответствие между функциональными блоками в электронной таблице и объектами, вызванными моделью намерения.Чтобы убедиться в силе этой конструкции, вернемся к нашему примеру и посмотрим на импорт зарплат из Salaries.xsl. Здесь у нас есть другая интерпретация значений для функционального блока [F 6: F 6]: эта электронная таблица не рассчитывается миллионами, поэтому мы выбрали k: = {x → x US $} и получили функции импорта k ◦ j — 1 = {x US $ → 10 — 6 x US $} в намерении и j — 1 ◦ k = {x → 10 — 6 x} в электронной таблице. В заключение мы отмечаем, что установка онтологии, происхождения и интерпретации ячейки дает нам полное и явное описание ее намерения, и мы можем отнести все дальнейшие семантические услуги к модели намерения.Например, мы можем проверить (используя вывод в модели намерений) эту часть электронной таблицы, установив равенство j — 1 ◦ F ◦ j и ρ (c). Система SACHS — это незавершенная надстройка для MS Excel (написанная на Visual Basic для приложений), целью которой является предоставление средств семантической справки для электронных таблиц. Хотя он был разработан для системы управления DFKI, он работает для любой электронной таблицы, намерение которой было закодировано как документ OMDoc, например наш рабочий пример. Мы разработали SACHS как инвазивную технологию, которая расширяет хорошо используемые (и, следовательно, хорошо известные) программные системы изнутри для преодоления препятствий при использовании — см. [Koh05b] для обсуждения.Следуя [BWK00], мы проектируем интерфейс SACHS как многовидовой интерфейс, где семантические службы в SACHS позволяют пользователю исследовать назначение электронной таблицы. В оставшейся части раздела мы представим актуальные и предполагаемые услуги и обсудим их реализацию в SACHS. Очень простой сервис, который отсутствует в MS Excel, — это общая визуализация формул в электронной таблице вместе с вычисленными значениями. SACHS предоставляет это в виде многовидового интерфейса — см. Рисунок 2. Для сервисов, которые визуализируют намерение, ячейки в электронной таблице должны интерпретироваться, т.е.е., связанные с элементами сопроводительного документа OMDoc, например, показано на рисунке 3. Как правило, все ячейки в функциональном блоке связаны с определением OMDoc — определением его предполагаемой функции, в то время как утверждения OMDoc подтверждают свои формулы. Это задание внутренне представлено дополнительным листом внутри электронной таблицы, который мы называем «интерпретацией SACHS». Это вручную поддерживается автором электронной таблицы. В случае системы управления DFKI электронные таблицы не создаются вручную, а создаются из управляющей базы данных, поэтому интерпретация в системе SACHS опосредуется уровнем символических ключевых слов, которые защищают настройку от изменений в конкретной схеме генерации электронной таблицы.Как только интерпретация установлена, мы можем напрямую использовать различные элементы информации OMDoc для соответствующих объектов (см. Пунктирные стрелки на рисунке 3). Например, элемент метаданных Dublin Core dc: subject определения может использоваться как метка SACHS для ячейки, которую он интерпретирует. Более того, функция комментариев в MS Excel лишена возможности создавать комментарии SACHS, основанные на соответствующем элементе dc: description, который содержит краткое описание рассматриваемого объекта.Напротив, элемент CMP в определении OMDoc содержит подробное объяснение с использованием семантически размеченных представлений объектов из модели намерений. Это могут быть математические формулы, закодированные как объекты OpenMath, такие как функция дохода ρ, или технические термины, такие как «разница», которые мы заключили в угловые скобки на рисунке 3. Дополнительное преимущество семантической аннотации заключается в том, что значение обоих можно изучить дополнительно: Элемент внешнего интерфейса «Объяснения SACHS» позволяет это, предоставляя «точки перехода» из текста в те ячейки, которые присвоены определениям этих символов через лист интерпретации SACHS.После перехода пользователь может искать доступную семантическую информацию об этой конкретной ячейке и так далее. Формула, лежащая в основе ячейки, отражается в элементе формулы FMP соответствующего определения в семантическом документе (см. Рисунок 3) в формате OpenMath, это позволяет нам представить ее пользователю в 5 математических обозначениях: i = 1 i (1984 ) более читабельно, чем «= СУММ (B9: B13)». С семантической точки зрения наиболее интересной и, вероятно, полезной является возможность предлагать контекстные представления, показанные синим всплывающим окном на рис. 4.Такие представления позволяют пользователю понять связи между ячейками электронной таблицы и фоновой информацией. Это представление объединяет информацию о намерении ячейки с точки зрения предполагаемой функции ее функционального блока и предполагаемых аргументов. • как значение ячейки вычисляется из значений ее аргументов. • и намерения аргументов. Все информационные точки во всплывающем окне имеют гиперссылки на соответствующие источники в документе OMDoc или в электронной таблице. В будущей версии SACHS эти гиперссылки могут предварительно создать экземпляр модели намерения со значениями аргументов и позволить исследование с точки зрения текущей ячейки — в нашем примере на рисунке 4 намерение было привязано к 1984 году.Обратите внимание, что наш пример здесь показывает только ситуацию для ячеек, вычисленных по формуле. Для других источников происхождения всплывающее окно будет отображать объект происхождения, заданный интерпретацией формулы. Например, для ячейки [B 9] объект происхождения «импортирован из Salaries.xls [B 5]», поэтому мы можем визуализировать данные из этой ячейки, используя существующее всплывающее окно SACHS. Поскольку OMDoc организован на основе теорий, предоставление многоуровневых теоретических графов, как в системе C Point [Koh05a], — это полезные услуги, о которых можно подумать.Мы проанализировали причины трудностей пользователей с пониманием и присвоением сложных электронных таблиц, например, в системах финансового контроллинга. Мы утверждаем, что основная причина заключается в том, что электронные таблицы слабы как активные документы, потому что лежащие в их основе семантические документы смещены в сторону вычислительных аспектов и не могут моделировать происхождение, интерпретацию и онтологические отношения объектов и концепций, операционализируемых системой. Чтобы исправить ситуацию, мы предлагаем явно смоделировать намерение электронной таблицы как модель намерения в коллекции словарей содержимого OMDoc, которые служат явной базой знаний для электронной таблицы.Наконец, мы представляем незавершенную систему SACHS, которая основана на такой модели намерений, чтобы предлагать различные семантические услуги, которые помогают пользователю понимать и взаимодействовать с электронными таблицами. По сути, наш подход использует двойную двойственность, указанную Фенселем в [Fen08] • Онтологии определяют формальную семантику …
Контекст 2
… видим, что три компонента интерпретации полностью определяют соответствие между функциональными блоками в электронной таблице и объектами, вызванными моделью намерения.Чтобы убедиться в силе этой конструкции, вернемся к нашему примеру и посмотрим на импорт зарплат из Salaries.xsl. Здесь у нас есть другая интерпретация значений для функционального блока [F 6: F 6]: эта электронная таблица не рассчитывается миллионами, поэтому мы выбрали k: = {x → x US $} и получили функции импорта k ◦ j — 1 = {x US $ → 10 — 6 x US $} в намерении и j — 1 ◦ k = {x → 10 — 6 x} в электронной таблице. В заключение мы отмечаем, что установка онтологии, происхождения и интерпретации ячейки дает нам полное и явное описание ее намерения, и мы можем отнести все дальнейшие семантические услуги к модели намерения.Например, мы можем проверить (используя вывод в модели намерений) эту часть электронной таблицы, установив равенство j — 1 ◦ F ◦ j и ρ (c). Система SACHS — это незавершенная надстройка для MS Excel (написанная на Visual Basic для приложений), целью которой является предоставление средств семантической справки для электронных таблиц. Хотя он был разработан для системы управления DFKI, он работает для любой электронной таблицы, намерение которой было закодировано как документ OMDoc, например наш рабочий пример. Мы разработали SACHS как инвазивную технологию, которая расширяет хорошо используемые (и, следовательно, хорошо известные) программные системы изнутри для преодоления препятствий при использовании — см. [Koh05b] для обсуждения.Следуя [BWK00], мы проектируем интерфейс SACHS как многовидовой интерфейс, где семантические службы в SACHS позволяют пользователю исследовать назначение электронной таблицы. В оставшейся части раздела мы представим актуальные и предполагаемые услуги и обсудим их реализацию в SACHS. Очень простой сервис, который отсутствует в MS Excel, — это общая визуализация формул в электронной таблице вместе с вычисленными значениями. SACHS предоставляет это в виде многовидового интерфейса — см. Рисунок 2. Для сервисов, которые визуализируют намерение, ячейки в электронной таблице должны интерпретироваться, т.е.е., связанные с элементами сопроводительного документа OMDoc, например, показано на рисунке 3. Как правило, все ячейки в функциональном блоке связаны с определением OMDoc — определением его предполагаемой функции, в то время как утверждения OMDoc подтверждают свои формулы. Это задание внутренне представлено дополнительным листом внутри электронной таблицы, который мы называем «интерпретацией SACHS». Это вручную поддерживается автором электронной таблицы. В случае системы управления DFKI электронные таблицы не создаются вручную, а создаются из управляющей базы данных, поэтому интерпретация в системе SACHS опосредуется уровнем символических ключевых слов, которые защищают настройку от изменений в конкретной схеме генерации электронной таблицы.Как только интерпретация установлена, мы можем напрямую использовать различные элементы информации OMDoc для соответствующих объектов (см. Пунктирные стрелки на рисунке 3). Например, элемент метаданных Dublin Core dc: subject определения может использоваться как метка SACHS для ячейки, которую он интерпретирует. Более того, функция комментариев в MS Excel лишена возможности создавать комментарии SACHS, основанные на соответствующем элементе dc: description, который содержит краткое описание рассматриваемого объекта.Напротив, элемент CMP в определении OMDoc содержит подробное объяснение с использованием семантически размеченных представлений объектов из модели намерений. Это могут быть математические формулы, закодированные как объекты OpenMath, такие как функция дохода ρ, или технические термины, такие как «разница», которые мы заключили в угловые скобки на рисунке 3. Дополнительное преимущество семантической аннотации заключается в том, что значение обоих можно изучить дополнительно: Элемент внешнего интерфейса «Объяснения SACHS» позволяет это, предоставляя «точки перехода» из текста в те ячейки, которые присвоены определениям этих символов через лист интерпретации SACHS.После перехода пользователь может искать доступную семантическую информацию об этой конкретной ячейке и так далее. Формула, лежащая в основе ячейки, отражается в элементе формулы FMP соответствующего определения в семантическом документе (см. Рисунок 3) в формате OpenMath, это позволяет нам представить ее пользователю в 5 математических обозначениях: i = 1 i (1984 ) более читабельно, чем «= СУММ (B9: B13)». С семантической точки зрения наиболее интересной и, вероятно, полезной является возможность предлагать контекстные представления, показанные синим всплывающим окном на рис. 4.Такие представления позволяют пользователю понять связи между ячейками электронной таблицы и фоновой информацией. Это представление объединяет информацию о намерении ячейки с точки зрения предполагаемой функции ее функционального блока и предполагаемых аргументов. • как значение ячейки вычисляется из значений ее аргументов. • и намерения аргументов. Все информационные точки во всплывающем окне имеют гиперссылки на соответствующие источники в документе OMDoc или в электронной таблице. В будущей версии SACHS эти гиперссылки могут предварительно создать экземпляр модели намерения со значениями аргументов и позволить исследование с точки зрения текущей ячейки — в нашем примере на рисунке 4 намерение было привязано к 1984 году.Обратите внимание, что наш пример здесь показывает только ситуацию для ячеек, вычисленных по формуле. Для других источников происхождения всплывающее окно будет отображать объект происхождения, заданный интерпретацией формулы. Например, для ячейки [B 9] объект происхождения «импортирован из Salaries.xls [B 5]», поэтому мы можем визуализировать данные из этой ячейки, используя существующее всплывающее окно SACHS. Поскольку OMDoc организован на основе теорий, предоставление многоуровневых теоретических графов, как в системе C Point [Koh05a], — это полезные услуги, о которых можно подумать.Мы проанализировали причины трудностей пользователей с пониманием и присвоением сложных электронных таблиц, например, в системах финансового контроллинга. Мы утверждаем, что основная причина заключается в том, что электронные таблицы слабы как активные документы, потому что лежащие в их основе семантические документы смещены в сторону вычислительных аспектов и не могут моделировать происхождение, интерпретацию и онтологические отношения объектов и концепций, операционализируемых системой. Чтобы исправить ситуацию, мы предлагаем явно смоделировать намерение электронной таблицы как модель намерения в коллекции словарей содержимого OMDoc, которые служат явной базой знаний для электронной таблицы.Наконец, мы представляем незавершенную систему SACHS, которая основана на такой модели намерений, чтобы предлагать различные семантические услуги, которые помогают пользователю понимать и взаимодействовать с электронными таблицами. По сути, наш подход использует двойную двойственность, указанную Фенселем в [Fen08] • Онтологии определяют формальную семантику …
Контекст 3
… на основе согласованной терминологии. В ходе анализа мы смотрим на формальную семантику электронных таблиц и обнаруживаем семантическую предвзятость, которая затрудняет понимание, поскольку не может моделировать согласованную терминологию и, следовательно, приводит к проблемам удобства использования в реальном мире.В предлагаемом нами решении мы расширяем формальную семантику электронных таблиц, чтобы использовать явно представленные согласованные термины. В то время как семантическая справочная система для системы управления на основе электронных таблиц была исходной мотивацией для нашего анализа, мы считаем, что явное представление модели намерений электронной таблицы имеет гораздо больше приложений: его можно использовать для проверки формул, для внесения изменений. управление в соответствии с [MW07] и автоматическое создание адаптированных для пользователя таблиц.Наш подход, кажется, связан с «Таблицами классов» [EE05], введенными Энгельсом и Эрвигом. Их описания классов также можно рассматривать как внешнюю структурированную модель намерений, на которую ссылается отображение интерпретации. Нам придется более внимательно изучить связь с нашей работой, но кажется, что их работа страдает той же семантической предвзятостью в отношении вычислительных проблем, что и сами электронные таблицы. Но классы с обширной документацией или UML-диаграммами могут помочь в создании справочной системы, такой как SACHS.В будущем мы планируем расширить репертуар семантических сервисов системы SACHS. Например, мы представляем двойную службу по сравнению с услугой на рисунке 4, которая может визуализировать, где используется значение ячейки, чтобы получить интуитивное представление о релевантности значения ячейки. На данный момент наш подход предполагает, что автор электронной таблицы документирует намерение электронной таблицы как документ OMDoc, а также аннотирует электронную таблицу с информацией об интерпретации. Обе задачи ложатся тяжелым бременем на автора и в настоящее время ограничивают наш подход критически важными или чрезвычайно сложными электронными таблицами.Но мы ожидаем, что бремя определения онтологии будет уменьшаться по мере появления все большего количества словарей контента для общих моделей (например, стандартных методов бухгалтерского учета). Для интерпретаций мы планируем адаптировать методы вывода заголовка, модуля и шаблона [AE04; AE06], чтобы частично автоматизировать процесс аннотации с помощью предложений. Но будущие расширения не ограничиваются электронными таблицами. Обратите внимание, что семантический анализ в разделе 2 в значительной степени не зависит от вычислительной информации, которая лежит в основе электронных таблиц.Семантическая информация, которая нам нужна, относится только к использованию сеток данных в качестве пользовательского интерфейса для сложных функций. В будущем мы планируем обобщить архитектуру модели намерений, представленную в разделе 3, на случай сеток данных — например, таблицы результатов экспериментов или растровые данные со спутниковых снимков. Более того, мы хотим разработать собственную инфраструктуру для представления «сеток данных» в качестве функции взаимодействия с пользователем в OMDoc: в соответствии с форматом, функция происхождения и интерпретации позволила бы связать презентации сеток с их намерениями, не покидая языка.Системы на основе OMDoc могут уловить семантику и предложить на ее основе сложные взаимодействия. Это привело бы к гораздо более общим активным документам. Мы могли бы даже изменить подход, представленный в этой статье, и сгенерировать электронные таблицы SACHS из документов OMDoc в качестве активных документов. В качестве теоретического расширения мы предполагаем, что сопоставления интерпретаций на самом деле можно рассматривать как логические морфизмы [RK08], что позволило бы нам повторно использовать большую часть функциональных возможностей OMDoc более высокого уровня, основанных на них.Наконец, мы признаем, что мы все еще находимся в самом начале понимания последствий просмотра электронных таблиц как активных и семантических документов. Мы были весьма удивлены глубиной смысла даже в нашем очень простом примере и с нетерпением ждем дальнейшего …
Ваша собственная поисковая система для документов, изображений, таблиц, файлов, интранета и новостей
Расширение возможностей пользователей и независимых организаций
Безопасность и конфиденциальность конфиденциальных документов: запущенная на вашем компьютере, ноутбуке или сервере поисковая система не будет отправлять ни проиндексированные документы или данные, ни поисковые запросы шпионским облачным службам.
Работа с открытыми стандартами для семантической сети и связанных данных, таких как HTTP, HTML, CSS, RSS, RDF, SKOS, Dublin Core и REST-API , делает открытую поисковую платформу гибкой, расширяемой и совместимой со стандартным программным обеспечением и открытой для собственные разработки.
Таким образом, вы можете легко подключаться, обогащать и интегрировать данные из другого программного обеспечения, приложений или веб-служб, используя совместимые и открытые веб-стандарты, а также использовать открытые данные и связанные открытые данные, такие как открытая энциклопедия Википедия, открытая база данных Викиданные или открытый словарь-викисловарь. для улучшения поиска и аналитики.
Архитектура программного обеспечения не зависит от платформы (Java и Python), имеет модульную структуру (пусть она проста) и совместима.
Таким образом, в основном модули представляют собой просто интеграцию с мощными стандартными инструментами и бесплатными программными компонентами или приложениями на основе поисковой системы с открытым исходным кодом Apache Solr или Elasticsearch, мощных инструментов Linux и стандартных веб-фреймворков (Drupal, Semantic Mediawiki, Django), Apache Tika для контента. извлечение, инструменты совместной веб-аннотации гипотез, пространственная обработка естественного языка и машинно-ориентированная структура для распознавания именованных сущностей, графовая база данных Neo4j для визуального анализа графов и структура веб-сканирования с открытым исходным кодом.
Подобно тому, как мы используем стандартные программные компоненты с открытым исходным кодом, вы можете использовать и интегрировать компоненты нашей поисковой системы и исследовательские инструменты с существующей стандартной программной средой и настраивать множество вариантов мощных стандартных инструментов и фреймворков.
При необходимости вы можете масштабировать до больших данных и очень больших наборов документов с большим количеством документов:
Основные компоненты с открытым исходным кодом, такие как Apache Lucene, Apache Solr и Elastic Search, масштабируются до поискового кластера для очень больших объемов данных, большой нагрузки и высокой доступности.
Но даже дешевого старого стандартного оборудования хватит для поискового сервера по гигабайтам, терабайтам или миллионам документов.
Поисковая система работает даже в автономном режиме или без хоста на одном портативном компьютере без необходимости во внутренней сети, подключении к Интернету или серверу.
Оптимизация листинга Amazon или как помочь вашим продуктам выделиться
До сих пор, вероятно, Google был вашим главным приоритетом в электронной коммерции. Однако в настоящее время сосредоточение внимания на оптимизации листинга Amazon имеет решающее значение для большинства брендов, которые хотят добиться успеха на постоянно растущем и все более конкурентном онлайн-рынке.
Любой бренд, новый или популярный, при запуске продаж на Amazon сталкивается со следующими проблемами:
-
Многочисленные товары для продажи, но не хватает времени, чтобы их правильно перечислить;
-
Жесткая конкуренция в области SEO на Amazon и отсутствие специальных навыков;
-
Отсутствие навыков письма и знания HTML для создания качественных описаний перечисленных товаров.
Ситуация осложняется тем, что Google и Amazon — два крупнейших канала онлайн-торговли — сильно различаются.
Как и Google, Amazon — это поисковая система со своими правилами и предпочтениями. Основное различие между Amazon и Google заключается в том, что первый — это алгоритм, основанный на покупателе, цель которого — предоставить клиентам соответствующие списки, которые с большей вероятностью будут конвертироваться в покупки. Другими словами, Amazon включает рейтинг кликов и коэффициент конверсии в свой алгоритм ранжирования.
ПРОДАЖИ — № 1 ДЛЯ БРЕНДОВ И ПРИОРИТЕТ № 1 ДЛЯ AMAZON.
Второе основное отличие состоит в том, что вам не нужно думать об оптимизации вне страницы, поскольку для Amazon не работает построение ссылок.
Чтобы увеличить продажи, вам необходимо изучить ключи алгоритма поисковой системы Amazon A9. Оптимизация для Amazon — сложная задача, если вы не являетесь профессионалом в поисковой оптимизации, но есть несколько способов облегчить себе жизнь, сделав оптимизацию листинга Amazon за вас.
AMAZON LISTING ОПТИМИЗАЦИЯ УСЛУГ
Сегодня существует большое количество услуг с комплексными решениями как для продавцов, так и для вендоров. Weby Corp предоставляет полный спектр решений Amazon как новым, так и известным брендам.
Оптимизация листинга на Amazon — это то, в чем мы преуспеваем. Чтобы помочь вашему бренду выделиться на Amazon, мы предоставляем целый комплекс услуг по оптимизации. Рассмотрим каждую из них подробнее.
Тщательное исследование ключевых слов для определения релевантных поисковых запросов
Исследование ключевых слов — это первый шаг в копирайтинге Amazon SEO. Это критически важно для успешного запуска продукта. Чтобы убедиться, что мы сделали все, чтобы привлечь потенциального клиента, мы проводим полный анализ ключевых слов конкурентов и анализируем все запросы потенциальных клиентов как на Amazon, так и на Google.
В наших исследованиях ключевых слов мы используем только лучшие приложения для исследования продуктов и революционные маркетинговые инструменты Amazon.
Меры по предотвращению нерелевантных поисков
Мы стараемся исключить все возможные нерелевантные поисковые фразы, чтобы избежать отказов — ситуаций, когда человек нажимает на объявление, а затем покидает его — потому что показанный товар на самом деле не то, что ищет покупатель для. Итак, если вы поместите слово «дешевый» в свое описание, убедитесь, что ваш продукт действительно дешев, иначе вы рискуете увеличить показатель отказов.
Если у листинга слишком много отскока трафика, он будет понижен алгоритмом Amazon A9, поскольку Amazon интересуется только теми листингами, которые конвертируются в продажи. Это не невероятные изображения или мастерски созданные пункты списка в ваших объявлениях, хотя они имеют значение для Amazon, продажи являются единственным показателем успеха (или неудачи) вашего объявления. Все остальные шаги по оптимизации предпринимаются для достижения лучшей конверсии.
Создание семантического ядра
Мы составляем семантическое ядро (полный список ключевых слов) для каждого продукта, стараясь не пропустить единственное возможное релевантное словосочетание, которое могут использовать те клиенты, которые заинтересованы в продукте.
Мы принимаем во внимание, что Amazon довольно скуп на количество символов и позволяет нам использовать только 250 символов для заголовков и 2000 для описаний. Вот почему мы правильно расставляем приоритеты по ключевым словам и правильно размещаем их в листинге.
Использование ключевых слов для оптимизации листинга Amazon.
Поскольку продукты на Amazon в основном находят через поиск, мы заполняем списки продуктов Amazon всеми возможными условиями поиска из списка релевантных ключевых слов.
На этом этапе мы подготавливаем:
-
Заголовок, богатый ключевыми словами, чтобы повысить рейтинг вашего продукта;
-
Пять пунктов маркированного списка с ценными ключевыми словами, написанных четко, чтобы покупатель знал все, что ему нужно для совершения покупки.
-
Оптимизированное описание продукта, написанное убедительно, чтобы увеличить конверсию продаж и помочь вам выиграть продажу.
-
Внутренние (скрытые) ключевые слова для ранжирования по более релевантным поисковым запросам, даже по тем, о которых ваши конкуренты не задумывались.
Выбор оптимальных изображений продуктов для оптимизации листинга Amazon
Изображения продуктов невероятно важны для высоких показателей конверсии. Они должны быть не только профессиональными и высокого разрешения, но и соответствовать требованиям к изображениям продуктов Amazon.
К счастью для наших партнеров, мы уделяем особое внимание тому, как представлена их продукция. Это связано с тем, что мы понимаем, что высококачественное первичное изображение повысит CTR, в то время как дополнительные информативные изображения, которые подчеркивают сильные стороны и уникальные торговые предложения продукта, улучшают конверсию.
Кроме того, мы заполняем все теги изображений и заголовки изображений соответствующими ключевыми словами, чтобы помочь товарному списку занять более высокое место в обычном поиске.
Использование видео для оптимизации листинга Amazon.
Видео о продуктах — еще одна прекрасная возможность выделить свой бренд на все более конкурентном рынке Amazon.
Почему видео важны для оптимизации листинга Amazon? Ответ довольно прост. Видео улучшают конверсию, и это фактор номер один для алгоритма ранжирования Amazon A9.
Эти огромные статистические данные говорят сами за себя:
-
90% покупателей считают видео полезными в процессе принятия решения;
-
88% покупателей говорят, что видео лучше объясняют особенности и преимущества продукта, чем простой текст;
-
72% людей предпочли бы использовать видео, чтобы узнать о продукте или услуге;
-
Качественное видео о продукте на странице может увеличить конверсию до 80%;
-
Если потенциальному покупателю нравится видео о продукте, он на 97% с большей вероятностью купит продукт и на 139% с большей вероятностью запомнит название бренда.
(Источник — статистика видеомаркетинга HubSpot)
Выбор лучшей категории продуктов
Amazon использует довольно сложную структуру для группировки продуктов по общим и конкретным категориям, которые могут сбить с толку новых пользователей. Действительно, может быть сложно найти подходящую категорию для рыболовных снастей, если вы не заядлый рыболов. Или почти невозможно выбрать лучшую категорию для обуви из более чем полусотни, предлагаемых Amazon, особенно если вы не специалист в области моды.
Мы гарантируем, что обе подкатегории высокого уровня и все следующие подкатегории, используемые для ваших продуктов, являются правильными. Это очень важно, потому что размещение продукта в правильной категории может повысить рейтинг Amazon на 80 процентов.
Создание содержимого A + и содержимого A ++ для оптимизации листинга Amazon.
Мы оптимизируем списки с помощью контента A +, чтобы создать более убедительную историю продукта. Контент A + — это дополнительный контент, который во многом помогает повысить коэффициент конверсии, делая списки продуктов очень информативными и интересными.
Используя различные статические и динамические модули Amazon A +, мы можем помочь вам максимально эффективно использовать ваш продукт.
Некоторые краткие факты о контенте A +, которые могут вас заинтересовать:
-
Контент A + не индексируется — поэтому он в основном используется для повышения конверсии;
-
Качественный контент A + может увеличить конверсию на 3-5%;
-
A + совместим с мобильными устройствами;
-
Включение сравнительных таблиц в контент A + может повысить общую конверсию бренда.
Примеры содержимого A +
Существует два типа страниц сведений A +: базовый, позволяющий использовать пять модулей, и A ++ / Premium, допускающий семь. Узнайте больше о Amazon Premium A + Content.
Если вы хотите доверить продвижение своего бренда и оптимизацию листинга Amazon профессионалам, Weby Corp готова стать вашим надежным партнером в розничной торговле и продвижении.
Компонент сетки данных React и экспорт в Excel
Сетка данных KendoReact предоставляет параметры для экспорта данных в Excel.
Чтобы включить экспорт в Excel:
-
Установите пакет
kendo-react-excel-export.Копировать код
npm install @ progress / kendo-react-excel-export @ progress / kendo-licensing -
Импортируйте компонент ExcelExport в свое приложение React.
Копировать код
импорт {ExcelExport} из '@ progress / kendo-response-excel-export'; -
Оберните сетку в компонент ExcelExport и используйте функцию ExcelExport
save, чтобы экспортировать сетку и сохранить ее в файл Excel.
В следующем примере демонстрируется базовая реализация функции экспорта в Excel таблицы.
Вы можете полностью управлять конфигурацией экспорта в Excel с помощью аргументов, которые передаются функции save компонента KendoReact Excel Export.
ExcelExport позволяет:
Перенос сетки
Если сетка передается в ExcelExport как дочерняя, а ее столбцы определяются декларативно с использованием компонентов GridColumn , они будут обнаружены автоматически.Вам по-прежнему необходимо передать данные Grid в функцию save или как свойство data в компонент ExcelExport.
Передача столбцов сетки
Сетка предоставляет свои столбцы через поле столбцов . Чтобы передать столбцы сетки, передайте их данные и столбцы функции save компонента ExcelExport.
Экспорт определенных данных
Чтобы экспортировать определенные данные, передайте данные в функцию save компонента ExcelExport.Например, если для сетки включена разбивка по страницам, но вам нужно экспортировать все страницы, передайте необработанные данные в функцию save .
Настройка экспортируемых столбцов
Можно использовать те же данные, что и в таблице, и настроить экспортируемые столбцы. Чтобы экспортировать столбцы, которые отличаются от текущих столбцов сетки, включите компоненты ExcelExportColumn и ExcelExportColumnGroup в качестве дочерних для ExcelExport.
- Во время экспорта в Excel сетка не использует форматы столбцов.Форматы столбцов несовместимы с Excel. Дополнительные сведения см. На странице о форматах, поддерживаемых Excel.
- Максимальный размер экспортируемого файла в Excel имеет системный предел. Для больших наборов данных настоятельно рекомендуется использовать серверное решение.
- При использовании ExcelExport в старых браузерах, таких как Internet Explorer 9 и Safari, необходимо реализовать прокси-сервер.
Здравствуйте, уважаемые читатели сайта Uspei.com. В этом уроке мы рассмотрим такие вещи как группировка запросов в рамках семантического ядра или кластеризация. Начнем мы с группировки поисковых запросов и чистки ядра. В прошлой статье мы посмотрели, как собирать статистику, какие инструменты для этого можно использовать, и все это почистили, удалив дубликаты. А также мы рассмотрели виды запросов.
У нас есть большой список запросов, из которого мы должны удалить оставшийся мусор и провести группировку. То есть у нас есть здоровенный список запросов. В некоторых тематиках он может доходить до 10 000. Наша задача сейчас разбить его на группы, каждая из которых будет содержать в себе только синонимы. То есть в рамках каждой группы должны быть только синонимы, так как каждая выделенная группа, это будущая отдельная страница и эти запросы в группе мы будем на ней продвигать.

К примеру, если у нас есть запрос “купить ноутбук”, то мы должны сделать группу, в которой будут только синонимы к запросу “купить ноутбук”.
Под синонимом в SEO имеется в виду то, что в запросы, по которым люди ищут, вкладывается один и тот же смысл. К примеру, запросы “купить ноутбук” и “купить ноутбук apple” это НЕ синонимы и они будут входить в разные группы, потому что у них разное понятие. В первом случае человек ищет просто ноутбук и это может быть даже samsung, а совсем не apple. Во втором же случае человек ищет конкретно apple. Ну, еще один пример. Человек ищет “такси” и “междугороднее такси” – тут думаю тоже очевидно и понятно.
Таких групп в рамках большого семантического ядра может быть огромное количество, их может быть более нескольких сотен в редких случаях более тысячи. Вот этот процесс еще называют кластеризацией. Мы рассмотрим, как его сделать вручную, я покажу основы и попытаюсь вывести хотя бы один законченный кластер, потому что в рамках одной статьи мы не сможем классифицировать ядро, но хотя бы вывести какой-то базовый кластер.
И потом я вам дам ссылки на набор инструментов, который может существенно автоматизировать или ускорить эту группировку или кластеризацию, как это сейчас модно называть.
Кластеризация и чистка семантического ядра в Excel
Возвращаемся к нашему списку запросов и у нас достаточно простой алгоритм. У нас уже отсортированы все запросы по убыванию частотности, то есть от самых популярных до наименее популярных. Дубликаты мы удалили.

Мы берем каждый запрос и смотрим подходит он нам или нет. Например, у нас есть запрос “интернет-магазин”, но если мы занимаемся только ноутбуками, то этот запрос без слова ноутбук нам не подходит. Значит запрос “интернет-магазин” мы удаляем – это не тематический запрос.
Дальше запрос “ноутбук”. Да, в принципе это информационный запрос, но не совсем понятно, что человек вкладывает в этот запрос, когда вбивает его в поисковую строку. Ищет ли он информацию, картинку или он ищет товары или возможно что-то еще.
Если мы сомневаемся в смысле поискового запроса, логично его проверить. Как это делается? Мы копируем запрос и вбиваем его в новой вкладке в ту поисковую систему, с которой мы работаем. Например, Google.
Мы видим, что Google показывает нам набор интернет-магазинов. Мы видим точно, что это запрос коммерческий и если у нас интернет-магазин, мы его оставляем.
И мы добрались до первого подходящего нам запроса. Давайте выделим нашу первую группу запросов, в которую будут входить все слова с упоминанием слова “ноутбук”. Для этого нужно включить фильтр и отфильтровать по текстовому условию “содержит”. Но там могут быть словоформы запроса “ноутбук” поэтому мы просто напишем “ноут” и получаем список строк только с поисковыми запросами, в которых упоминается “ноут”. Я предлагаю вам скопировать и перенести их в новую вкладку.
Каждую вкладку мы будем называть соответственно по тому слову, по которому мы произвели фильтрацию. В первой же вкладке мы вручную (!) выделяем все отфильтрованные ключи и удаляем. После чего очищаем фильтр.
Итак, в первой вкладке у нас остались все ключи, которые НЕ содержат “ноутбук”, а мы переходим во вторую (“ноутбук”) и продолжаем работать теперь уже там.

Итак, следующее слово “ноутбук”. Мы уже разобрались, что это коммерческий запрос и по нему также как и по запросу “купить ноутбук” показываются интернет-магазины, то есть это синонимы и мы оставляем их в одной группе.
“DNS ноутбуки” – как раз это тот самый навигационный запрос и можно предположить, что приставка “DNS” как популярный интернет-магазин будет часто встречаться в списке запросов про ноутбуки. Поэтому давайте сразу удалим все чужие навигационные запросы “DNS”. Фильтр – выделяем вручную и удалить.
“Ноутбуки бу” – аналогично как с “dns” – удаляем, если только мы не продаем б/у ноубуки.
“Купить ноутбук Москва” – тут уже добавляется регион, а мы далеко не в Москве. По сути, запрос повторяет смысловую нагрузку запроса “купить ноутбук” или просто “ноутбук”. Но поскольку добавляется регион, стоит проверить считает ли google эти поисковые запросы синонимами.
Мы берем запрос “купить ноутбук” вбиваем его в google и в другой вкладке вбиваем запрос “купить ноутбук Москва”. И сравниваем результаты поиска на предмет повторения результатов, то есть именно конкретных страничек. Если хотя бы 4-5 страничек одинаковых, то мы можем считать, что это запросы синонимы и Google показывает по ним одинаковый смысл. Если же по этим запросам выдача разная, то “купить ноутбук Москва” навигационный запрос и он нам не нужен.
Идем дальше и таким образом проделываем ту же процедуру – удаляем мусор и создаем новые группы отличные по смыслу.
Очень рекомендую чистить семантику, используя фильтры, если чистить ручками, то есть большой шанс что-то пропустить.
Но когда мы фильтруем, надо быть аккуратным, чтобы не удалить какие-то важные слова случайно отфильтровав их. Например, если в фильтр вбить просто “бу” то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие “бу” – например, сам запрос “ноутБУк” – а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце ” бу” и “бу “, а также через слэш “б/у”. Помните это и будьте внимательны))))).
И вот у нас запрос “ноутбук hp”. Это уже не просто “ноутбук” – это уже более узкая тема, значит мы должны выделить ноутбуки hp в отдельную группу.
Производим фильтрацию “текст содержит” получаем набор запросов и переносим их в новую вкладку “ноутбуки hp”. Из второй вкладки “ноутбук” перенесенные в 3 вкладку результаты удаляем.

Так мы будем повторять эту процедуру, пока в каждой вкладке не останутся только синонимы. То есть дальше мы должны перейти в 3 вкладку “ноутбуки hp” и здесь их разделить еще на более подробные группы. Мы видим, что здесь есть “ноутбук hp pavilion”, ” ноутбук hp compaq” и “ноутбук hp игровой”. Таким образом, эта группа будет разбита еще на 3 группы.
Во вторую вкладку мы вернёмся, когда во всех следующих группах все слова будут синонимами и продолжим этот разбор. Продолжим до тех моментов, пока самая первая наша вкладка не будет разложена на группы, а в ней самой не останутся только нецелевые запросы или запросы, которые тоже будут синонимами.
В итоге наша задача создать файл, в котором у нас будет огромное количество вкладок. В разных темах по-разному – возможно в некоторых темах будет всего 5-6 вкладок, если тема очень маленькая, но основная задача, чтобы в рамках одной вкладки были только запросы синонимы.
Причем не просто слова синонимы в классическом понимании, а синонимы с точки зрения поисковой системы. Вот как из примера “купить ноутбук” и “ноутбук” это синонимы с точки зрения поисковой системы, поэтому они у нас остались в одной группе.
Если во вкладке 20 синонимов и один НЕ СИНОНИМ – выносим его одного в отельную вкладку. Это очень важный момент, так как каждая группа это отдельная страница, на которой эти запросы будут продвигаться, и чем больше будет ошибок и недоработок, тем менее чистой по смыслу станет страница, что скажется результатах поиска. О других ошибках, допускаемых при сборе и группировке семантики ознакомьтесь в этой статье.
Повторю еще раз основную мысль – в каждой вкладке должны быть запросы подходящие по смыслу. Пример, если в текущей вкладке 5 запросов:
- “заработать в интернете”
- “как можно заработать в интернете”
- “где заработать через интернет”
- “как заработать деньги в интернете”
- “как заработать в интернете без обмана”
Первые три запроса останутся в текущей вкладке, так смысл у них один, а последние два уйдут каждый в свою группу-вкладку, так как они не совпадают по смыслу ни с первыми тремя, ни между собой – они более детализированы. В одном случае речь идет о деньгах ( а заработать в наши дни можно все что угодно – биткоины, баллы в играх и т.д.), а во-втором, речь идет о заработке без обмана.
Для понимания я в течение часа сварганил (правда не до конца) семантику по запросам, “заработок в интернете” “заработок в сети” “заработок онлайн”. Первая вкладка – вся семантика, а далее по группам. Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Скачать пример семантического ядра в excele.
Зачем все это нужно и почему все так сложно?
 Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
На самом деле, сейчас это не очевидно, но буквально через два-три этапа вы увидите, что вся поисковая оптимизация, абсолютно все seo, построено на основе правильно собранного семантического ядра. SEO – это не просто любительский способ сделать свой сайт лучше. Это, можно сказать наука, в которой все начинается с “атомов” и именно это приводит к результату.
SEO можно сравнить с большим спортом – боксом или сноубордом или любым другим. Если вы не освоите технику ПРОФЕССИОНАЛЬНЫХ ударов или элементов езды, то это скажется на скорости и выносливости и вы проиграете сопернику, кто этим не пренебрег. Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое – не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места – есть только первая страница и все.
Мы не можем начинать оптимизацию сайта, если мы не сделали семантику, не разбили ее на группы, не обработали и не почистили. И все что мы будем делать дальше, будет основано на семантике.
Приведу конкретный пример. Мы же понимаем, что по каждому запросу поисковик дает свой результат выдачи. Возьмем какую-то небольшую тематику по которой в семантике всего 100 запросов. И вот у одного владельца 100 страниц на сайте, в которых содержимое часто пересекается, структура сайта от этого расплывчатая, поисковик не понимает до конца, какие страницы релевантны запросу больше, а какие меньше. В итоге, кроме путаницы, эти 100 страниц содержат в своем “винегрете” ответы только на 30-40 запросов.
А у второго владельца сайта, благодаря полному собранному кластеризованному семантическому ядру, на каждый запрос есть соответствующая страница, строго релевантная только этому запросу. Поисковик и пользователи четко понимают структуру сайта, а также не страдают “дежавю”, что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
Автоматизация кластеризации семантического ядра
Такая работа по группировке запросов по обработке всей этой статистики вручную занимает достаточно много времени. Особенно если человек делает это первый раз. Но я вам рекомендую, если вы хотите научиться работать запросами, работать с семантикой, хотя бы один раз проведите все это вручную в электронных таблицах. Тогда вы сможете прочувствовать и понять, как это работает.
Если же вы работаете в очень больших объемах, крайне рекомендую использовать профессиональные инструменты. Чаще всего они платные.
Один из самых популярных инструментов по работе с семантикой это инструмент “Key Collector”, которая позволяет автоматизировать большинство процессов по сбору и обработке семантики. Как минимум, она умеет автоматически собирать ключевые слова из yandex wordstat, а также данные о частотности по запросам и другие рекомендации.
Если же у вас есть уже готовое отфильтрованное от мусора семантическое ядро, то вы можете прибегнуть к помощи дополнительных сервисов, которые производят автоматическую кластеризацию. Лидером сейчас на рынке является онлайн-сервис, который называется Rush analytics.
Расценки не очень высокие и в принципе, если у вас один сайт, вы владелец или вебмастер, то вы можете собрать семантику, почистить ее, после чего просто отдать на кластеризацию такому сервису.
Содержание статьи
- Определение термина
- Зачем нужно семантическое ядро?
- Из чего состоит семантика?
- Как использовать СЯ?
- Примеры семантического ядра
- Составлять самому или делегировать?
- Что ещё нужно знать о семантике
Всем привет. Начинаю цикл статей по семантическому ядру, где мы с вами разберём всё, что можно разобрать по этой теме. С чего начнём? Декарт сказал как-то: «Определив точно значения слов, вы избавите человечество от половины заблуждений». Спасибо, браток! Вот с этого и начнём — определимся, что это вообще такое.
Определение термина
Семантическое ядро — это список поисковых запросов для продвижения сайта. Ну это если не выпендриваться и объяснить простыми словами, как это сделано в моём SEO-словаре. А если мы хотим выпендриться? Как лучше поступить в таком случае? В этом случае можно сослаться на определение из SEO-словаря компании «Пиксель Плюс»: «совокупность целевых поисковых запросов, по которым продвигается или планируется к продвижению проект». Либо на определение SEONews — одного из крупнейших ресурсов по теме SEO: «Семантическое ядро – набор слов и ключевых фраз, по которым будет продвигаться сайт в поисковых системах. Иначе говоря, это слова, по которым пользователи будут находить сайт в результатах поиска». Ну вы поняли.
Зачем нужно семантическое ядро?
Оно нужно для увеличения эффективности от продвижения сайта в поисковых системах. А как именно оно помогает увеличить эту самую эффективность?
Во-первых, наличие правильной семантики позволить вам составить структуру сайта. Вы будете знать, какие рубрики и страницы создать на сайте и в каком порядке, какие должны быть меню и так далее. Соответственно, это поможет систематизировать и упорядочить работу по продвижению сайта, составить план работ, а также не забыть про некоторые важные части этих работ. Без семантики эти работы будут представлять собой совершенный хаос.

Вот как выглядит продвижение сайта без семантического ядра
Во-вторых, семантическое ядро позволит вам сэкономить деньги. Вы сгруппируете часть запросов и не будете создавать под каждый запрос по странице, не будете создавать лишние страницы и будете следовать плану развития, не спуская деньги на ненужные изменения в сайт.
В-третьих, СЯ увеличит эффект от вашего продвижения. Понятная структура сайта, размещение похожих запросов на одной странице, отсутствие страниц, дублирующих друг друга по смыслу — всё это очень высоко оценят поисковые системы.
В-четвёртых, оно позволит вам отслеживать этот эффект. Ведь если у вас нет списка запросов, как вы будете смотреть, какие места по каким запросам занимает сайт в поиске? Без этого также будет тяжело понимать, какие нужно меры предпринимать в случае отсутствия прогресса в продвижении сайта.
В-пятых, на основе семантики вы будете составлять технические задания на тексты, а также SEO-теги к этим текстам. Если же вы будете составлять ТЗ не на основе семантики, а на основе чего-либо другого, то такие тексты с большой вероятностью не принесут вам трафика, поскольку не будут оптимизированы под ключевые слова.
В-шестых, по ходу процесса составления семантического ядра вы можете хорошо изучить ваших конкурентов, и, возможно, вам в голову придут какие-то полезные идеи для совершенствования собственного сайта.
Вот неплохое и очень подробное видео от Semantist.ru, которое шире отвечает, зачем нужна семантика:
В сумме имеем такой вывод, что без семантического ядра вы создадите бесструктурный проект без плана развития, то есть ваши работы по продвижению сайта будут бесполезны. Впрочем, у семантического ядра есть и свои недостатки. Это, прежде всего, трудоёмкость составления, и временные затраты, которые могут занимать один месяц, а то и больше. Кроме того, если вы составили семантику неправильно, то эффект от неё может быть ненамного больше, чем если бы её не было, а финансовые затраты на продвижение в некоторых случаях могут стать выше.
Из чего состоит семантика?
Схема классического семантического ядра проста. Оно состоит из ключевых слов, которые объединены в группы, а эти группы объединены в категории. Также семантика часто содержит данные о запросах — их частотность, показатели конкурентности, геозависимость и так далее.

На изображении выше, например, категории — это «Стулья», «Столы» и «Шкафы», а, например, «Стул ИКЕА МАРТИН» или «Стул ИКЕА КЮРЕ» — это группы запросов.
Зачем нужна такая структура? Деление семантического ядра на категории помогает нам понять, какие рубрики должны быть на сайте, чтобы он успешно продвигался. Деление на группы помогает понять, сколько на сайте должно быть страниц (1 группа запросов = 1 страница на сайте), и в каких категориях они должны быть. Подробнее о типах страниц читайте в этой статье.
Как использовать СЯ?
Семантическое ядро — это то, на основе чего вы планируете работы по продвижению сайта. Сначала вы создаёте на сайте рубрики и меню в соответствии с категориями из семантического ядра. А потом в этих рубриках создаёте страницы, и каждую из этих страниц оптимизируете (прописываете метатеги, создаёте контент) под соответствующую ей группу запросов.
Когда вы создадите по странице на каждую группу запросов, у вас будет готовый сайт, привлекающий трафик (если всё сделано правильно) и который нужно будет в будущем просто дорабатывать. Вот пара видео, где показывается, что делать с семантикой, когда она уже составлена:
Примеры семантического ядра
Вы можете узнать, как выглядит семантическое ядро, скачав вот этот или вот этот примеры семантических ядер в формате Excel. Также готовые примеры в формате xls вы можете скачать на сайте Семён-Ядрёна здесь и здесь.

Так выглядит часть семантического ядра от сервиса «Семён-Ядрён»
Портфолио есть у Rush Analytics, вот оно — там тоже есть пара примеров в формате Excel. Я также отдельно писал статью про единый файл семантики для интернет-проектов, там расписан этот момент подробнее.
Составлять самому или делегировать?
Тут вопрос целиком зависит от того, есть ли у вас свободное время и желание с упорством. Если этого вообще нет — делегируйте. Конечный результат будет не идеальным, а может и вообще оказаться слабоватым, но без свободного времени и желания очень хорошо разобраться в вопросе вы не сможете самостоятельно дать результат лучше. Если же у вас есть время и желание — надо делать самому. Когда я завершу свой цикл статей о семантике, вам достаточно будет лишь следовать моим инструкциям, чтобы на выходе получить очень качественное СЯ.
Раньше, когда я работал на количество сайтов, а не на качество, я заказывал очень недорого, но вполне годно семантику у Семантического жирафа с кворка. Если вы не опытный сеошник, то с вероятностью в 90% он сделает вам ядро лучше, чем вы сделаете это сами. За косарь обычно уложитесь — получите и нормальную эффективность, и экономию времени.
Что ещё нужно знать о семантике
При работе с семантическим ядром, то есть с ключевыми словами, не лишним будет узнать, какие существуют виды этих ключевых слов, что я подробно описывал здесь. Также в отдельной статье я напишу, как правильно составлять СЯ.
Хочется также отдельно сказать о статье на «Текстерре», которая называется «Что такое семантическое ядро и как его составлять». В этой статье они пытаются намекнуть, что, мол, устоявшийся подход к семантике — это подход сеошников старой школы, а мы такие охеренные, что делаем по-другому. Мы, мол, берём в продвижение даже те запросы, которые нихера не имеют частотности, потому что мы современные и крутые, а не тупые старые сеошники. Это попытка манипуляции — противопоставить себя остальному профессиональному сообществу, навесив на неё уничижительный ярлык «старая школа», чтобы заполучить в клиенты тех, кто «купится» на эту «инаковость» (благо «нетакимикаквсе» Россия просто кишмя кишит). На самом деле я не удивлюсь, если они составляют такие ядра только потому, что им лень их чистить от мусорных запросов + чтобы слить побольше бюджетов на тексты, распилив часть из них. Это не означает, что «Текстерра» — лохи; нет, это умные челы, у которых полно высококлассной инфы. Но не все преподносят эту инфу беспристрастно.
Примеры семантических ядер различных тематик

| Проект #1 | |
| Тематика | Планшеты |
| Было кластеризовано запросов: | 14000 |
| Общая частотность всех запросов в кластерах: | 5089344 |
| Средняя частотность кластера: | 363 |
| Количество кластеров: | 4260 |
| Количество кластеров с частотностью больше 100: | 1701 |
| Скачать готовое семантическое ядро проекта | ядро |
Краткое описание проекта
Тематика сайта: электроника «Планшеты», регион — Москва
Что было сделано:
- Собрали ключевые слова по Yandex Wordstat по тематике
- Собрали поисковые подсказки по данной тематике
- Собрали частотность Yandex Wordstat
- Провели кластеризацию (группировку) полученных данных
- Было кластеризовано запросов 14000
- Общая частотность всех запросов в кластерах: 5089344
- Средняя частотность кластера: 363
- Количество кластеров: 4260
- Количество кластеров с частотностью больше 100: 1701
- Были найдены подсветки с поисковой выдачи Yandex
- Определен лучший URL в выдаче по данному кластеру

| Проект #2 | |
| Тематика | Пластиковые окна |
| Было кластеризовано запросов: | 2690 |
| Общая частотность всех запросов в кластерах: | 612237 |
| Средняя частотность кластера: | 227 |
| Количество кластеров: | 615 |
| Количество кластеров с частотностью больше 100: | 91 |
Краткое описание проекта
Тематика сайта: Пластиковые окна, регион — Москва
Что было сделано:
- Собрали ключевые слова по Yandex Wordstat по тематике
- Собрали поисковые подсказки по данной тематике
- Собрали частотность Yandex Wordstat
- Провели кластеризацию (группировку) полученных данных
- Было кластеризовано запросов 2690
- Общая частотность всех запросов в кластерах: 612237
- Средняя частотность кластера: 227
- Количество кластеров: 615
- Количество кластеров с частотностью больше 100: 91
- Были найдены подсветки с поисковой выдачи Yandex
- Определен лучший URL в выдаче по данному кластеру
Так же были определены лидеры тематики.

| Проект #3 | |
| Тематика | Автостекла |
| Было кластеризовано запросов: | 398 |
| Общая частотность всех запросов в кластерах: | 46323 |
| Средняя частотность кластера: | 196 |
| Количество кластеров: | 101 |
| Количество кластеров с частотностью больше 100: | 20 |
| Скачать готовое семантическое ядро проекта | ядро |
Краткое описание проекта
Тематика сайта: Автостекла, регион — Москва
Что было сделано:
- Собрали ключевые слова по Yandex Wordstat по тематике
- Собрали поисковые подсказки по данной тематике
- Собрали частотность Yandex Wordstat
- Провели кластеризацию (группировку) полученных данных
- Было кластеризовано запросов 398
- Общая частотность всех запросов в кластерах: 46323
- Средняя частотность кластера: 196
- Количество кластеров: 101
- Количество кластеров с частотностью больше 100: 20
- Были найдены подсветки с поисковой выдачи Yandex
- Определен лучший URL в выдаче по данному кластеру
Так же были определены лидеры тематики.
Найдены релевантные URL

| Проект #4 | |
| Тематика | Украшения из золота |
| Было кластеризовано запросов: | 4465 |
| Общая частотность всех запросов в кластерах: | 2164925 |
| Средняя частотность кластера: | 882 |
| Количество кластеров: | 889 |
| Количество кластеров с частотностью больше 100: | 292 |
| Скачать готовое семантическое ядро проекта | ядро |
Краткое описание проекта
Тематика сайта: Украшения из золота, регион — Киев
Что было сделано:
- Собрали ключевые слова по Yandex Wordstat по тематике
- Собрали поисковые подсказки по данной тематике
- Собрали частотность Yandex Wordstat
- Провели кластеризацию (группировку) полученных данных
- Было кластеризовано запросов 4465
- Общая частотность всех запросов в кластерах: 2164925
- Средняя частотность кластера: 882
- Количество кластеров: 889
- Количество кластеров с частотностью больше 100:292
- Были найдены подсветки с поисковой выдачи Yandex
- Определен лучший URL в выдаче по данному кластеру
Так же были определены лидеры тематики.
Кейсы по росту трафика после внедрения семантического ядра

| Интернет магазин женской одежды | |
| Тематика: | Одежда |
| Трафик до внедрения СЯ: | 02 |
| Трафик после внедрения СЯ: | 3800 |
| Рост трафика за 3 месяца | 190000% |
Захват ТОПа по платьям
Тематика сайта: интернет магазин по продаже женской одежды.
Что было сделано:
- Для данного сайта было собрано и сгруппировано семантическое ядро по следующим темам: «Верхняя женская одежда», «Платья»
- На сайте была разработана и внедрена система создания теговых страниц
- Проведена переоптимизация существующих страниц сайта под собранное семантическое ядро
- Было создано 147 дополнительных страниц с оптимизированными заголовками и мета-тегами
- Были размещены тексты, созданные с учетом кластеров ключевых слов
- Приняты меры по ускорению индексации новых страниц
- Не куплено ни одной ссылки
Достигнутые результаты:
- Рост трафика 190000% за 3 месяца
- Трафик — 3800 визитов в день
- 141500 визитов в месяц по целевым запросам
- Лидерство в тематике «Платья» в Яндексе и Google

| Интернет магазин мебели | |
| Тематика: | Мебель |
| Трафик до внедрения СЯ: | 200 |
| Трафик после внедрения СЯ: | 550 |
| Рост трафика за 3 месяца | 271% |
Вывод регионального магазина на московский рынок
Тематика сайта: интернет магазин по продаже мебели
Что было сделано:
- Для данного сайта было собрано и сгруппировано семантическое ядро по теме: «Мебель».
- На сайте была разработана и внедрена система создания фильтров и теговых страниц
- Проведена переоптимизация существующих страниц сайта под собранное семантическое ядро
- Было создано 194 дополнительных страниц с оптимизированными заголовками и мета-тегами
- Были размещены тексты, созданные с учетом кластеров ключевых слов
- Была реализована гео-стратегия выхода на московский рынок
- Не куплено ни одной ссылки
Достигнутые результаты:
- Рост трафика 271% за 3 месяца
- Трафик — 550 визитов в день
- 24150 визитов в месяц по целевым запросам
- Успешный выход регионального игрока на конкурентный московский рынок

| Онлайн гипермаркет | |
| Тематика: | Онлайн гипермаркет товаров из Китая |
| Трафик до внедрения СЯ: | 540 |
| Трафик после внедрения СЯ: | 1780 |
| Рост трафика за 5 месяцев | 329% |
Трехкратный рост трафика на гипермаркете
Тематика сайта: онлайн гипермаркет товаров из Китая
Что было сделано:
- Для данного сайта было собрано и сгруппировано семантическое ядро по следующим темам: Мебель, Головные устройства для авто, магнитолы, Чай, Верхняя одежда. Была максимально обработана семантика по темам «Платья», «Квадрокоптеры».
- На сайте была разработана и внедрена система создания теговых страниц и расширенной фильтрации
- Проведена переоптимизация существующих страниц сайта под собранное семантическое ядро
- Было создано 312 дополнительных страниц с оптимизированными заголовками и мета-тегами.
- К каждой такой странице были привязаны (в интерфейсе сайта) ключевые слова, по которым оптимизируется данная страница. Это позволило эффективно отслеживать оптимизацию конкретной страницы.
- Были размещены тексты, созданные с учетом кластеров ключевых слов
Достигнутые результаты:
- Рост трафика 329% за 5 месяца
- Трафик — 1780 визитов в день
- 58000 визитов в месяц по целевым запросам
- Успешное занятие ТОПов по целевым товарным категориям
Как составить семантическое ядро сайта
Часть 2 (практика)
В первой части нашей статьи мы рассказали, что такое семантическое ядро и дали общие рекомендации о том, как его составить.
Пришло время разобрать этот процесс в деталях, шаг за шагом создавая семантическое ядро для вашего сайта. Запаситесь карандашами и бумагой, а главное временем. И присоединяйтесь …
Составляем семантическое ядро для сайта

Сфера деятельности компании: складские услуги в Москве.
Сайт был разработан специалистами нашего сервиса 1PS.RU, и семантическое ядро сайта разрабатывалось поэтапно в 6 шагов:
Шаг 1. Составляем первичный список ключевых слов.
Проведя опрос нескольких потенциальных клиентов, изучив три сайта, близких нам по тематике и пораскинув собственными мозгами, мы составили несложный список ключевых слов, которые на наш взгляд отображают содержание нашего сайта: складской комплекс, аренда склада, услуги по хранению, логистика, аренда складских помещений, тёплые и холодные склады.
Задание 1: Просмотрите сайты конкурентов, посоветуйтесь с коллегами, проведите «мозговой штурм» и запишите все слова, которые, по вашему мнению, описывают ВАШ сайт.
Шаг 2. Расширение списка.
Воспользуемся сервисом http://wordstat.yandex.ru/. В строку поиска вписываем поочерёдно каждое из слов первичного списка:

Копируем уточнённые запросы из левого столбца в таблицу Excel, просматриваем ассоциативные запросы из правого столбца, выбираем среди них релевантные нашему сайту, так же заносим в таблицу.
Проведя анализ фразы «Аренда склада», мы получили список из 474 уточнённых и 2 ассоциативных запросов.


Проведя аналогичный анализ остальных слов из первичного списка, мы получили в общей сложности 4 698 уточнённых и ассоциативных запросов, которые вводили реальные пользователи в прошедшем месяце.
Задание 2: Соберите полный список запросов своего сайта, прогнав каждое из слов своего первичного списка через статистику запросов Яндекс.Вордстат.
Шаг 3. Зачистка
Во-первых, убираем все фразы с частотой показов ниже 50: «сколько стоит аренда склада» — 45 показов, «Аренда склада 200 м» — 35 показов и т.д.
Во-вторых, удаляем фразы, не имеющие отношения к нашему сайту, например, «Аренда склада в Санкт-Петербурге» или «Аренда склада в Екатеринбурге», так как наш склад находится в Москве.
Так же лишней будет фраза «договор аренды склада скачать» – данный образец может присутствовать на нашем сайте, но активно продвигаться по данному запросу нет смысла, так как, человек, который ищет образец договора, вряд ли станет клиентом. Скорее всего, он уже нашёл склад или сам является владельцем склада.
После того, как вы уберетё все лишние запросы, список значительно сократится. В нашем случае с «арендой склада» из 474 уточнённых запросов осталось 46 релевантных сайту.

А когда мы почистили полный список уточнённых запросов (4 698 фраз), то получили Семантическое Ядро сайта, состоящее из 174 ключевых запросов.
Задание 3: Почистите созданный ранее список уточнённых запросов, исключив из него низкочастоники с количеством показов меньше 50 и фразы, не относящиеся к вашему сайту.
Шаг 4. Доработка
Поскольку на каждой странице можно использовать 3-5 различных ключевиков, то все 174 запроса нам не понадобятся.
Учитывая, что сам сайт небольшой (максимум 4 страницы), то из полного списка выбираем 20, которые на наш взгляд наиболее точно описывают услуги компании.
Вот они: аренда склада в Москве, аренда складских помещений, склад и логистика, таможенные услуги, склад ответственного хранения, логистика складская, логистические услуги, офис и склад аренда, ответственное хранение грузов и так далее….
Среди этих ключевых фраз есть низкочастотные, среднечастотные и высокочастотные запросы.
Заметьте, данный список существенно отличается от первичного, взятого из головы. И он однозначно более точен и эффективен.
Задание 4: Сократите список оставшихся слов до 50, оставив только те, которые по вашему опыту и мнению, наиболее оптимальны для вашего сайта. Не забудьте, что финальный список должен содержать запросы различной частоты.
Заключение
Ваше семантическое ядро готово, теперь самое время применить его на практике:
- пересмотрите тексты вашего сайта, быть может, их стоит переписать.
- напишите несколько статей по вашей тематике, используя выбранные ключевые фразы, разместите статьи на сайте, а после того, как поисковики проиндексируют их, проведите регистрацию в каталогах статей. Читайте «Один необычный подход к статейному продвижению».
- обратите внимание на поисковую рекламу. Теперь, когда у вас есть семантическое ядро, эффект от рекламы будет значительно выше.

Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла. Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:

В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:

Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Без применения специализированных программ
Рассмотрим этапы формирования семантического ядра на основе сервиса Яндекс Вордстат (как им пользоваться). Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Возьмем направление «рольставни» для компании, которая занимается установкой защитных конструкций и их обслуживанием по Москве и области. В первую очередь актуальны запросы, которые формулируют люди, заинтересованные в покупке таких изделий или у которых возникли проблемы с эксплуатацией. Вводим маску в строку подбора, выбираем регион, например, Москва и область:

В колонке слева Wordstat показывает запросы пользователей, которые набирали со словом «рольставни». В правой колонке дополнительные запросы. Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.

Вордстат даёт 2000 запросов по одному направлению. На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:

Скачать файл Эксель-исходник
Группировка (кластеризация) запросов в семантическом ядре
После сбора запросов, группируем (кластеризируем). Для этого используют 3 вида кластеризации:
- по смыслу;
- по SERP;
- смешанный.
Разбивка «По смыслу» предполагает, что из запросов выделяется основной посыл, что хочет получить человек. В собранном перечне запросы делятся так:
- рольставни +в туалет
- рольставни +на окна
- сантехнические рольставни
- рольставни +в туалет купить
- рольставни +в санузел
- рольставни наружные
- рольставни +в туалет москва
- сантехнические рольставни +в туалет
- рольставни +на окна наружные
- рольставни +в туалет купить москва
- прозрачные рольставни
- рольставни сантехнические купить
- рольставни +в туалет цена
- рольставни +на окна цена
- рольставни +в санузел москва
- прозрачные рольставни +для веранды
Туалет: 1, 3, 4, 5, 7, 8, 10, 12, 13, 15. Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Окна: 2, 6, 9, 14. Установка на окна предполагает, что рольставни буду наружными (запрос №6).
Прозрачные: 11, 16.
Кластеризация по «SERP» предполагает использование специализированной программы или сервиса (например, keyassort.ru). Получается, что это автоматизированный процесс. SERP – это результат поисковой выдачи, проще говоря ТОП-10. Алгоритм действий здесь такой:
- Выбранные фразы добавляются в программу.
- По каждому запросу программа проверяет ТОП-10 или ТОП-20 в Яндекс (Гугл) и сохраняет результат в таблице.
- Далее программа анализирует сохраненные данные и соотносит страницы в выдаче и фразы. И запросы, по которым встречаются одни и те же страницы сайтов в выдаче, объединяет в одну группу.
Такой способ кластеризации подходит для многотысячной семантики и экономит время. По опыту студии, в результате разбивки качество получаемых ядер низкое и требует корректировок.
Смешанный метод – «SERP» и здравый смысл. Применение двух способов одновременно. Случается, что разбив ядро по смыслу, остаются фразы, назначение которых спорно и их сложно объединить в группы. В этом случае снимается СЕРП и на основе анализа разбиваются фразы.
Популярный вопрос «сколько фраз должно быть в одном кластере?». Ограничений нет, от одного запроса до нескольких сотен. Студия DIUS ведет проекты, где одна страница ранжируется по 200-300 запросам. Бывает наоборот, что первоначально добавили в кластер 100 запросов, но при оптимизации зашли только 50. Тогда детально и подробно изучаем оставшиеся фразы, делим по дополнительным признакам и создаем под них новые разделы или оптимизируем другие страницы.
Но такой подход требует опыта, т.к. поисковики негативно относятся, когда под похожие запросы создаются две страницы. В этом случае понижаются позиции по обеим страницам. В этом случае, внимательно изучайте конкурентов в выдаче, возможно на одну страницу следует добавить вхождений.
Для группировки ядра по направлению «Рольставни» воспользуемся методом «По смыслу», т.к. фраз всего 350 и группировка не займет много времени.
Делим фразы по: типу продукции, назначению, параметрам (цвет, материал) и т.д. И также нужно будет отбросить ненужные фразы, назовем эту группу «мусор». В неё попадают нецелевые фразы, которые содержат слова:
- леруа мерлен;
- своими руками;
- фото и видео;
- города не из Московской области;
- бу, схемы, инструкции.
Просмотрев и задав кластер для каждого запроса, получаются следующие группы:

Из 350 подобранных фраз получилось 85 мусорных, остальные распределились на 36 групп по типам и назначению изделия. В первой колонке группа, во второй сколько содержит слов из 350 подобранных:
| Группа | Количество фраз |
| основная | 63 |
| туалет | 61 |
| область | 35 |
| на окна | 28 |
| гараж | 7 |
| прозрачные | 6 |
| монтаж | 5 |
| электропривод | 5 |
| ремонт | 4 |
| шкаф | 4 |
| фотопечать | 4 |
| ванная | 3 |
| дача | 3 |
| комната | 3 |
| дверь | 3 |
| терраса | 2 |
| алютех | 2 |
| балкон | 2 |
| дорхан | 2 |
| перфорированные | 2 |
| торговые | 2 |
| встроенные | 2 |
| веранда | 2 |
| беседка | 2 |
| двери | 1 |
| проем | 1 |
| внутренние | 1 |
| управление | 1 |
| поликарбонат | 1 |
| защитные | 1 |
| мебельные | 1 |
| антивандальные | 1 |
| паркинг | 1 |
| противопожарные | 1 |
| стеклянные | 1 |
| квартира | 1 |
| утепленные | 1 |
| мусор | 85 |
Полученные кластеры в свою очередь группируем по смыслу и получаем структуру сайта для оптимизации:
- Рольставни:
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т.д.
- Назначение: окна, двери, квартира, проем, торговые, мебельные, туалет, гараж, паркинг и т.д.
- Профиль: алютех, дорхан.
- Опции: с электроприводом, с фотопечатью.
- Сервис
- Ремонт
- Монтаж
Из 2000 фраз, которые выдает Вордстат по заданному слову, получится составить структуру сайт гораздо шире, чем приведенная в примере. Естественно ориентируйтесь на ключевики, которые характеризуют продукцию или услуги компании. Если какой-то тип продукции или услуг компания не производит отправляйте их в раздел «мусор».
Расширение семантического ядра в Wordstat
Как подсказывает вордстат на скрине выше, некоторые называют рольставни другим словом – «роллеты». Поэтому для расширения ядра получения дополнительных фраз по ним также собираются фразы:

И:

Эти фразы добавляются в созданные группы или по ним создаются новые. Поисковики понимают, что «рольставни» и «роллеты» — это одно и тоже, поэтому совмещайте их в одних целевых кластерах.
Расширение ядра при помощи поисковых подсказок Yandex.ru
Дополнительным способом расширения семантики используют такой метод как «поисковые подсказки». Когда пользователь Яндекса вводит запрос в строку, поисковик предлагает варианты, исходя из статистики популярных запросов, дополняющие слова:

Видно, что на запрос «рольставни» поисковик предлагает запросы, которые уже были отобраны из сервиса Вордстат. Ориентируйтесь на фразы из 3-4 слов:

Тогда получится дополнить ядро. Вручную собирать подсказки трудозатратно, для этого целесообразно использовать профессиональные программы по сбору семантики или сервисы. РашАналитикс помогает собирать подсказки. На сервисе предусмотрена бесплатная регистрация, и сразу даётся 200 баллов.
Для сбора добавьте фразы из 3-4 слов из семантического ядра. Задайте популярные мусорные слова, чтобы сервис автоматически из убрал из результатов: своими руками, бу, леруа мерлен. В результате получаем такие дополнительные слова из подсказок:

Полученные фразы чистим от мусорных и проверяем частоту через Вордстат:

Сколько запросов собирать в ядро
По сути ограничений нет, чем больше фраз подобрано в семантическое ядро, тем лучше будет проработан сайт с точки зрения структуры и содержания. Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:

Ясно, что посетителей интересует:
- Цена такой конструкции.
- Варианты исполнения: с электроприводом или механические.
- Материалы изготовления: тканевые, металлические.
- Как устанавливают изделие.
- Для каких окон: квартиры, дачи, частный дом.
- Дополнительные функциональные свойства: защитные, антивандальные и т.д.
Каждый запрос в группе – это единица смысла, которую нужно отразить на созданной странице. Во-первых, это позволит употребить ключевые слова, что сделает сайт релевантным этому кластеру. Во-вторых, на странице будет опубликована полезная для посетителя информация.
Очистка семантики от мусора
При сборе многотысячного семантического ядра в список попадёт много нецелевых фраз:
- Тип продукции или схожий вид услуг, которыми компания не занимается. В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
- В запросах часто появляются названия фирм конкурентов, когда пользователь пишет товар или услугу, и указывает название компании.
- У людей, проживающих в Москве и имеющих коттедж в другом регионе, например, Твери, отразится это в запросах, когда они будут заказывать рольставни, ворота и т.д. Указывая город в сервисе, вы задаете географию пользователей, интересы которых могут лежать за пределами этого региона.
- Также убирайте из ядра ошибочные написания и опечатки. Если раньше под такие запросы создавались страницы, то сейчас поисковые алгоритмы обнаружив опечатку исправляют её и выдача формируется по корректной словоформе. И если появятся новые ошибки в названиях, это значит, что в ближайшее время алгоритм это учтет.
От нецелевых запросов следует избавляться по следующим причинам:
- Если пользователь зайдет на сайт и обнаружит, что компания из другого региона – он закроет страницу. Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
- Также это расценивается алгоритмами как поисковый спам, когда компания привлекает посетителей по запросам, задачи по которым она не решает.
- По некоторым запросам, типа «рейтинг компаний по рольставням», поисковики показывают сайты справочники, бизнес-каталоги, агрегаторы. По таким фразам не добраться до ТОП-10, если только не делать каталог организаций. Убрав их из ядра оптимизатор экономит время и ресурсы.
Как разбить семантическое ядро по типу запросов
Также стоит учесть разделение запросов по интенту пользователя:
- информационные;
- коммерческие.
Подробнее об этом в материале блога.
Для коммерческих запросов создаются разделы услуг, на которых предлагаются к продаже услуги и товары. Они называются коммерческими, т.к. предполагают, что у пользователя, при запросе прямое намерение купить или заказать продукцию, представленную на сайте. В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
Информационные запросы подразумевают, что пользователь хочет получить сведения о пользовании продукцией, инструкций и т.п. В таких запросах часто фигурируют вопросы: как, какой, зачем, что лучше, почему и т.д. Для таких групп создается раздел статей на сайте, который отвечают на популярные вопросы людей перед покупкой, например, по рольставняим: как выбрать, какой профиль лучше и т.д. Формируется дополнительное ядро запросов для написания полезных материалов. Его собирают из Вордстат, добавив к фразе конструкцию «+как»:

Также с «+где», «+когда» и т.д.
При этом информационные запросы геонезависимые, поэтому регион ставьте Россия. Грамотное использование инфозапросов даёт целевые переходы из поисковиков, которые также конвертятся в обращения и покупки. Для этого используйте «Лестницу Бена Ханта» — подробней в статье.
Предлагаем создание
семантического ядра для сайта
Что делать с семантическим ядром после составления
Итак, семантика собрана, разбита на группы. Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Сначала еще раз посмотрите каждую группу, проверьте на соответствие ассортименту компании. На сколько формулировки соответствуют предлагаемым видам продукции или услуг.
Структура сайта на основе семантики
На основе семантического ядра разрабатываем структуру сайта:
- Главная страница под высокочастотные и прямые фразы. В случае с «Рольставни» — это: рольставни, рольставни купить / цена / заказать и т.д.
- Планируем разделы, в которые включаются виды продукции (услуг) и вспомогательные страницы (гарантии, отзывы, доставка, контактная информация, о компании) цель которых убедить посетителя в надежности представленной компании.
- Подразделы – группы запросов распределенные по видам, типам и т.д. В представленном примере «Рольставни» в разделе Профиль, будут 2 подраздела: Алютех и Дорхан, из которых производят изделия.
Содержание страниц
Как говорилось выше, семантика для маркетолога – это источник креатива и полезного контента. В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
Превратитесь на время в маркетолога, изучите каждую фразу под микроскопом. Что подразумевает человек в запросе. Какие у него опасения и как их развеять. В какой формате человек хочет получить решение проблемы и как показать, что компания выполнит желаемое. Какие факторы принятия решения влияют на него и как их усилить на странице? Таким образом составится уникальный контент, полезный для посетителя с коммерческим эффектом.
Вывод
Ручное составление семантического ядра при помощи Яндекс Вордстат трудозатратное мероприятие. Оно подходит для разовой работы и для небольших сайтов. При профессиональном продвижении сайтов целесообразно приобрести программу Кей Коллектор, которая упрощает работы и сокращает время по формирование семантики в разы. При этом она позволяет детально работать с группой и каждым словом. Пример сбора ядра в Key Collector можете посмотреть здесь.