
Поделились внутренним инструментом, который анализирует собранные фразы и показывает, где и что еще можно добрать.
В маркетинге мы предпочитаем опираться на математику, а не на интуицию. Если есть задача проверить семантику на полноту — значит, должен быть инструмент, который перетрясет собранные фразы и покажет, где и что еще можно добрать. Сервисов аналогичных нет, поэтому мы нашу внутреннюю модель вынесли в Excel-файл — скачивайте и пользуйтесь.
Вам понадобятся: фразы и их частоты — общие и точные.
Принцип такой: вносим в Excel-файл фразы и частоты, жмем на кнопку и через несколько секунд, когда сформируются связи «фраза-хвост» и отсекутся доли нерелевантного объема, по маркерам определяем — где мы не доработали.
А теперь подробнее.
Идеально отработанная семантика
Если семантика отработана идеально, Excel-файл выглядит так:
- значения в столбце H (расчетная частота) близки к значениям в столбце D (точная частота) у всех фраз, кроме низкочастотных и тех, в которых больше всего значимых слов.
- столбец J (коэффициент отработки) зеленого цвета.
- столбец K (коэффициент неотработки) зеленого цвета
Неполная семантика: что упустили и как доработать
По маркерам файла мы можем понять 3 момента.
- Мы не добрали хвосты.
- Не досчитали трафика.
- Собрали некачественные хвосты.
Не добрали хвосты
Если для какой-то фразы (скажем, «Защитная каска») мы упустили хвост со средней или высокой частотой («Защитная каска с наушниками»), мы увидим это по маркерам в файле.
Хвост — дочерняя фраза («Защитная каска с наушниками»), которая состоит из материнской фразы («Защитная каска») и хотя бы одного дополнительного слова («наушник»)
Маркеры:
В столбце J (Коэффициент неотработки) и/ или в столбце K (Коэффициент отработки) ячейки не зеленого цвета, а желтого, оранжевого или красного (чем больше упустили хвостов, тем краснее цвет).
Что делать:
Идем в вордстат — вбиваем каждую такую фразу с минус-словами, находим для нее не включенные релевантные частотные хвосты и добавляем их в семантику.
Если таких хвостов нет, значит, дело не в том, что мы чего-то недобрали, а в том, что мы неправильно определили, какой релевантный объем трафика принесет фраза. Мы включили в него и мусорный объем. Для точного прогноза мусорный объем нужно отсечь — уменьшить коэффициент чистоты в столбце С.
Собрали некачественные хвосты
Если мы включили в семантику хвост с низкой точной частотой, файл нам это тоже покажет.
Маркер:
Значение в столбце J (Коэффициент неотработки) меньше, чем значение в столбце K (Коэффициент отработки).
Что делать:
В столбце P ставим значение 0 — тогда эта фраза не будет учитываться и мы не возьмем ее в продвижение. Так мы сэкономим деньги, потому что у нее была бы высокая цена за пользователя.
Не досчитали трафика
Иногда мы можем для какого-то запроса не точно спрогнозировать трафик — посчитать, что фраза приведет 15 человек, а, на самом деле, она может привести 20. Такие случаи файл нам тоже показывает, чтобы мы не удалили фразу, которую по ошибке посчитали бы мало полезной.
Маркеры:
Текст в столбце F красного цвета.
Что делать:
Увеличиваем коэффициент чистоты в столбце С.
Подготовка файла к работе
Скачайте шаблон и выполните следующие подготовительные шаги.
1. Внесите фразы
Откройте лист sem. Внесите в столбец А собранные фразы, в столбец B — их общие частоты, а в столбец С — точные частоты. Скопируйте эти же фразы (или сформируйте из них любую другую выборку) в столбец F листа work.
2. Задайте правила для создания униформ
Перейдите на лист «Морфо». Здесь собраны предлоги и окончания, которые будут игнорироваться, потому что они не считываются поисковиками как смысловые. Вы можете задавать на этом листе свои правила и исключения.
После того, как на четвертом шаге вы нажмете на кнопку «Расчет частот и отработки», по этим правилам для каждой фразы в столбце B сгенерируются униформы, которые однозначно характеризуют фразы.
3. Установите коэффициент чистоты
Мы делаем это для того, чтобы учитывать только релевантные запросы по каждой фразе. Например, фразу «Средства индивидуальной защиты» могут вбивать в поисковиках 20000 раз за месяц. Но 30% из этих запросов — информационка. И нам нужно это учитывать, чтобы мы не считали, что у нас трафика с этой фразы будет больше.
Перейдите на лист «Properties».
Опираясь на свой опыт, знание проекта и отрасли, задайте базовый коэффициент чистоты.
Например, если вы считаете, что фразы из одного слова («Каски», «Спецодежда») содержат, в среднем, 45% мусора, поставьте в столбце D коэффициент чистоты — 0,55.
Ниже идут уровни вложенности: +1 слово (фразы из двух слов), + 2 слова (фразы из трех слов), + 3 слова (фразы из четырех слов). Для них также проставьте коэффициенты чистоты в столбце D. На скрине это: 0,65, 0,85 и 0,95. Обычно, чем длиннее фраза, тем меньше она замусорена.
Потом для отдельных фраз можно будет увеличить или уменьшить коэффициент чистоты. Это вы увидите по маркерам (мы их описали выше). Коэффициент чистоты для отдельной фразы можно поменять на листе «Work», в столбце С.
4. Нажмите на кнопку «Расчет частот и отработки»
Через несколько секунд уже можно анализировать маркеры и дорабатывать семантику.
Экономия
Кажется, сложно, но на деле это займет 10-20 минут. Проделанная работа позволит корректно сформировать кластеры, привести максимальный трафик и не переплачивать за пользователей.
Так что скачивайте файл, разбирайтесь, пользуйтесь или обращайтесь за продвижением к нам.
Сбор семантики сайта представляет собой сложную и многоступенчатую задачу. Ее успешное решение предусматривает использование различных вспомогательных инструментов, включая специализированные программы и онлайн-сервисы. Но значительную часть выполняемых SEO-оптимизатором операций можно эффективно выполнять в обычных электронных таблицах Excel.
Речь идет не только о сортировке отобранных ключей, но и оформлении списка запросов, его последующем редактировании и чистке, а также подготовке базы данных для работы с другими сервисами или составления технического задания для копирайтера. А потому имеет смысл изучить порядок и особенности сбора семантического ядра в Excel более подробно, включая рассмотрение возможности, где можно скачать пример семантики, составленной в электронных Google Таблицах.
Содержание
- Виды Excel для сбора СЯ
- Этапы сбора семантического ядра с помощью Google Таблиц
- Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
- Шаг №2. Чистка семантического ядра
- Шаг №3. Кластеризация/группировка семантического ядра запросов
- Полезные функции Google Docs и Эксель
- Вспомогательные инструменты
- SeoTools for Excel
- SEO-Excel
- Рекомендации по использованию Google Docs для сбора СЯ
- Вместо вывода
Виды Excel для сбора СЯ
Для решения задач СЕО-оптимизации применяются две версии электронных таблиц. Первая поставляется в рамках стандартного пакета MS Office и представляет собой самостоятельную программу. Вторая – составной элемент Google Docs. Именно последний вариант пользуется сегодня все большим спросом, так как обладает рядом достоинств, в числе которых:
- доступность для любого обладателя аккаунта в Google;
- интеграция с программами из MS Office, включая обычные Эксель и Ворд;
- доступ к облачному хранилищу Google Диск, 15 ГБ которого предоставляется бесплатно и позволяет работать с Google Таблицами с любого устройства – от ПК до смартфона – сразу после авторизации.
На приведенном ниже скриншоте показан пример, как выглядят Google Таблицы. Приводить внешний вид традиционного Excel не имеет смысла, так как он прекрасно известен любому более-менее опытному пользователю ПК.

В остальном работа с обеими версиями программы – Excel и Google Docs – осуществляется по стандартным правилам, хорошо известным большинству пользователей. С учетом нескольких особенностей, характерных для SEO-продвижения сайтов по поисковым запросам.
Этапы сбора семантического ядра с помощью Google Таблиц
Некоторые специализированные сервисы, к примеру, Key Collector или Словоеб, обладают встроенными инструментами для форматирования структуры сайта и перечня ключевых слов и запросов. Поэтому не предполагают применение Excel. Но для значительной части других сервисов, включая один из самых популярных Яндекс Wordstat, использование Google Docs или Excel выступает одним из необходимых этапов работы. Более того, при грамотном применении возможностей электронных Google Таблиц удается упростить и оптимизировать сразу несколько важных операций по чистке семантического ядра. Рассмотрим последовательность предпринимаемых для этого действий с разбивкой на отдельные этапы.
Шаг №1. Перенос данных из Яндекс Wordstat в Google Excel
Функционал Excel предоставляет возможность составить список поисковых запросов вручную – посредством анализа продвигаемого сайта и деятельности компании. Но намного проще собрать исходное семантическое ядро с помощью Яндекс Wordstat. Чтобы сделать это, необходимо произвести следующие операции:
- Скачивание и установка расширения Яндекс Wordstat Assistant (подробнее о сервисе и расширениях к нему – на другой страницу нашего сайта). Сделать ссылку. В результате в левой части окна сервиса появится дополнительная панель инструментов.
- Выделение и сохранение интересующих пользователя запросов нажатием кнопки «+».
- Копирование сформированного списка поисковых запросов в Google Таблицы или обычный Эксель. Производится по одному из двух вариантов – с показателем частотности ключа или без него. Выбирается нужный пользователю способ копирования. Пример выполнения операции показан на скриншоте.

Шаг №2. Чистка семантического ядра
Основной задачей оптимизации СЯ запросов выступает повышение эффективности размещенных на сайте ключевых слов и фраз. Первым этапом становится избавление от ключей с низкой или даже нулевой релевантностью. Операция выполняется вручную, так как требует непосредственного участия SEO-специалиста. Ответ на вопрос, как почистить семантическое ядро, предусматривает удаление нескольких видов запросов, включая:
- самые низкочастотные (полное их удаление нецелесообразно, так как важно найти оптимальный баланс запросов с разной частотностью);
- ведущие на сайты конкурентов;
- лишние с предсказуемо низкой релевантностью из-за несоответствия задачам сайта;
- дубли (представляют собой поисковые запросы или фразы, которые различаются порядком слов).
Как было отмечено, удаление ненужных запросов происходит вручную. Для большего удобства и упрощения работы допускается как редактирование текущего листа электронных таблиц Google, так и перенос оптимизированного списка запросов на вновь созданный.
Шаг №3. Кластеризация/группировка семантического ядра запросов
Завершающий этап работы по СЕО-продвижению сайта с помощью Excel предполагает проведение кластеризации или группировки поисковых запросов. Она предусматривает разбивку общего списка ключевых слов или фраз для размещения на отдельные страницы в соответствии с предварительно разработанная структурой интернет-ресурса. Оптимальное количество запросов на каждую равняется 5-6, для очень объемных оно может быть несколько увеличено.
Операция также выполняется вручную с применением традиционного функционала Google Таблиц или Excel. Автоматизировать данные действия специалиста можно только с использованием специализированного инструментария, хотя даже самые современные и многофункциональные сервисы не способны выполнять такую работу на требуемом уровне.
Дальнейшие операции с собранным семантическим ядром производятся в зависимости от задач, стоящих перед СЕО-специалисту. Это может быть или составление технического задания копирайтеру, или дальнейшая оптимизация СЯ с использованием других программ или сервисов. Примеры готовой семантики, составленной в Эксель, можно с легкостью найти в сети, например, по следующей ссылке.
Полезные функции Google Docs и Эксель
Подробно описывать набор функциональных возможностей самой популярной программы электронных таблиц не имеет особого смысла. Опытным пользователям они прекрасно известны, а новичкам намного проще и правильнее разобраться самостоятельно, так как это наверняка пригодится в дальнейшей работе. Главное – знать о существовании таких возможностей, как:
- копирование и удаление ссылок из семантического ядра;
- замена отдельных слов или элементов списка запросов;
- удаление ненужных или лишних пробелов, включенных в СЯ;
- сортировка запросов по значениям любого из столбцов по двум параметрам – алфавиту или числу;
- поиск повторяющихся значений или минус-слов для последующего удаления вручную;
- удаление дубликатов из состава семантического ядра;
- сортировка запросов по цвету ячейки и многое другое.
Вспомогательные инструменты
Google Таблицы и традиционный Эксель обладают обширным функционалом. Но далеко не все опции эффективны применительно к СЕО-продвижению сайтов по поисковым запросам. Именно поэтому активно разрабатываются дополнительные надстройки к традиционным электронным таблицам. Два из них – самые известные и популярные – имеет смысл привести отдельно, хотя количество подобных инструментов постоянно растет.
SeoTools for Excel
Одно из первых расширений для электронных таблиц, которое разработано специально для SEO-продвижения. Обладает обширным функционалом, постоянно обновляется, совместимо с различными онлайн-сервисами и программами. Из недостатков – отсутствие версии для русскоязычных пользователей. Чтобы скачать программу, достаточно перейти на сайт разработчика и зарегистрироваться на нем.

SEO-Excel
Русскоязычный аналог описанной выше надстройки. Содержит более двух десятков инструментов для СЕО-продвижения. Чтобы скачать программу, достаточно зарегистрироваться на сайте, хотя возможно платное использование онлайн-версии продукта. SEO-Excel адаптирован для работы с Яндекс Wordstat и Rush-Analytics, что объясняет популярность среди отечественных специалистов. Дополнительный аргумент скачать и установить надстройку – очень полезная опция генерации различных тегов – H1, Title и Description, заметно упрощающая работу SEO и экономящая его время, в том числе – при составлении технического задания копирайтеру.

Рекомендации по использованию Google Docs для сбора СЯ
Главным достоинством Excel и Google Таблиц справедливо считается доступность. Оборотной стороной становится необходимость выполнять значительную часть операций СЕО-оптимизации вручную. Чтобы упростить собственную работу, имеет смысл воспользоваться несколькими простыми рекомендациями:
- внимательно изучайте руководство пользователя, так как некоторые функции электронных таблиц выступают секретом даже для очень опытных специалистов;
- автоматизируйте самые рутинные и трудоемкие процессы за счет грамотного использования встроенных опций и сервисов;
- скачивайте и устанавливайте дополнительные надстройки, предназначенные для SEO-продвижения (важное дополнение – загрузка должна выполняться только с проверенных сайтов компаний-разработчиков).
Вместо вывода
Важно понимать, что полная автоматизация процесса SEO-продвижения сайта по поисковым запросам попросту невозможна. Никакие сервисы и программы не способны заменить опыт и квалификацию грамотного специалиста, хотя существенно помогают в его работе при грамотном использовании. Именно поэтому имеет смысл сотрудничать с профессионалами, а вложенные средства с лихвой окупаются повышением эффективности интернет-ресурса.
Наша компания оказывает полный комплекс услуг в области SEO-оптимизации на выгодных и привлекательных для клиентов условиях. Для получения персонального коммерческого предложения достаточно связаться с нами любым удобным способом.
Содержание:
- Для чего seo специалисту нужно уметь работать с Excel
- Полезные функции Excel при составлении семантического ядра
- Удаление ссылок в Excel
- Замена символов и элементов в таблице
- Удаление лишних пробелов
- Сортировка по частоте или алфавиту
- Поиск и выделение дубликатов ячеек
- Удаление дублей запросов
- Поиск и удаление минус слов
- Сортировка данных по цвету заливки ячеек
- Еще несколько функций Excel при выполнении других задач seo специалиста
- Закрепление строки для удобства работы
- Расширение ячейки до нужной ширины
- Работа с регистром символов
- Подсчет количества символов в мета-тегах
- Подсчет количества запросов в ТОПе
- Проверка сколько дней прошло с какой-то даты
- Подводим итоги
При продвижении сайта каждый seo специалист регулярно сталкивается с обработкой большого количества данных, которые необходимо группировать, фильтровать и структурировать. Удобнее всего выполнять эти задачи с помощью программы Excel или Google Таблиц.
Таблицы позволяют уменьшить затрачиваемое время на выполнение тех или иных задач, организовать работу и сделать ее более продуктивной. Особенно это удобно при ручной кластеризации запросов в семантическом ядре.
Но в то же время большое количество возможностей программы Excel может поставить начинающего seo специалиста в тупик. В этой статье мы подготовили основные функции и формулы таблиц, которые могут вам понадобиться.
Полезные функции Excel при составлении семантического ядра
1. Удаление ссылок в Excel
Очень простая функция, которая работает одинаково как в Экселе, так и в Гугл таблицах. Она понадобится вам, если вы экспортировали или вставили данные в таблицу, которые содержат ссылки.
Например, при работе с Яндекс.Вордстатом вы не использовали браузерное расширение yandex wordstat assistant (с которым однозначно работать удобнее), а просто скопировали запросы и вставили в таблицу. Тогда каждое ключевое слово будет содержать ссылку на сервис и затруднять работу, поэтому нужно преобразовать их в обычный текст.
Выделяем необходимый диапазон, кликаем правой кнопкой мышки и нажимаем “Удалить гиперссылки”.
![]()
2. Замена символов и элементов в таблице
Это быстрый способ чистки данных и может пригодится при составлении семантического ядра. Например, вставив запросы в таблицу Excel, вы увидите, что многие из них содержат спецсимвол “+”. Для того чтобы массово удалить его, нужно воспользоваться функцией “Найти и заменить”.
В Google таблицах она находится во вкладке “Изменить”, в таблицах Microsoft Excel в главном разделе “Найти и выделить > Заменить”. Или можно просто нажать комбинацию клавиш Ctrl+H. В открывшемся диалоговом окне в поле “Найти” пишем знак +, поле “Заменить” оставляем пустым. Нажимаем “Заменить все” и получаем список ключевых слов без дополнительных операторов.
![]()
3. Удаление лишних пробелов
При обработке ключевых слов в таблице Excel могут попадаться такие ячейки, которые начинаются с пробелов или содержат несколько пробелов подряд между словами. Для того чтобы избавиться от них воспользуйтесь функцией “=СЖПРОБЕЛЫ()”.
![]()
4. Сортировка по частоте или алфавиту
У вас имеется две колонки с данными. В одной — это список ключевых слов, во второй — их частотность. Если необходимо совершить сортировку запросов в зависимости от их частотности, выделяем эти две колонки, изначально поставив курсор на колонку с частотностью и растянув выделение ниже. Далее нажимаем “Данные > Сортировать диапазон по столбцу B, А-Я”.
![]()
Если же необходимо отсортировать по алфавиту, тогда выполняем все те же действия, но при выделении изначально поставить курсор на колонку с запросами.
![]()
5. Поиск и выделение дубликатов ячеек
Seo специалисту эта функция будет очень полезна при группировке запросов в семантическом ядре, она позволит быстро найти повторяющиеся ключевые слова в таблице.
В Excel выделяем столбец, в котором хотим найти дубликаты, далее на Главной вкладке нажимаем “Условное форматирование > Правила выделения ячеек > Повторяющиеся значения”. Выбираем цвет заливки ячеек и готово.
![]()
В Google Таблицах это выполняется немного сложнее и есть несколько способов решения данной задачи.
Например, можно выполнить следующие действия: “Формат > Условное форматирование > Добавить правило > В разделе “Правила форматирования” выбираем “Ваша формула” и вставляем вот такую формулу без кавычек “=И(НЕ(ЕПУСТО(A1)); СЧЁТЕСЛИ($A$1:$Z; «=» & A1) > 1)”. При вводе этой комбинации не будут учитываться пустые ячейки, а запросы, которые указаны в выбранном диапазоне более одного раза будут подсвечены.
![]()
Второй способ может сразу решить несколько задач, которые необходимо выполнять SEO специалисту при группировке запросов в семантическом ядре — установить браузерное расширение Remove Duplicates (оно доступно только на английском языке).
![]()
С его помощью можно выделить или сразу удалить повторяющиеся ячейки. После установки, чтобы воспользоваться им выделяем нужный нам диапазон ячеек, нажимаем “Дополнения > Remove Duplicate > Find duplicates or uniques”.
![]()
Можем создать резервную копию этого листа, поставив галочку напротив “Create a backup copy of the sheet”. Далее выберете тип данных, по которым необходимо будет отбирать ячейки, например, дубликаты, исключая первое вхождение.
![]()
Если в выбранном диапазоне присутствуют пустые ячейки, поставьте галочку напротив поля “Skip empty cells”, чтобы пропустить их. Если в колонке с ключевыми словами для семантического ядра присутствует заголовок с названием страницы, где они в последующем будут размещены, то выберете пункт “My column has header”, чтобы название не учитывалось. Также в поле “Case sensitive” можно указать вести поиск с учетом регистра или нет.
![]()
Последний шаг — выбрать, что необходимо сделать с дубликатами:
- залить ячейку цветом;
- добавить еще один столбец с указанием статуса Duplicate;
- копировать или переместить их;
- очистить ячейки;
- полностью удалить строки, которые содержат повторения.
![]()
Если необходимо просто выделить цветом дубли запросов, то выбираем первый вариант и нажимаем кнопку подтверждения действия.
6. Удаление дублей запросов
Если при ручной кластеризации запросов семантического ядра в Excel нужно сразу удалить повторяющиеся ячейки, тогда в разделе “Данные” выбираем пункт “Удалить дубликаты”, предварительно выделив нужный диапазон.
В Google Таблицах можно воспользоваться специальной формулой для отображения только уникальных значений. В свободной колонке вводим комбинацию без кавычек “=(UNIQUE (A1:A100))”, где A1:A100 — это столбец с ключевыми словами. К сожалению, данный способ не подойдет, если в колонке содержатся слова, написанные разным регистром.
![]()
Второй способ для гугл таблиц — воспользоваться дополнением Remove Duplicates, о котором писали в предыдущем пункте.
Получить бесплатную консультацию от SEO-эксперта по вашему сайту
7. Поиск и удаление минус слов
Условное форматирование можно еще использовать для подсвечивания ячеек, которые содержат или не содержат определенные значения. SEO специалисту эта функция может понадобиться, чтобы выделить запросы в семантическом ядре, которые имеют так называемые минус слова.
![]()
В Excel “Условное форматирование” находится в главном разделе, в Google таблицах во вкладке “Данные”. Устанавливаем правила форматирования “Текст содержит” и указываем начало нашего минус слова (начало, потому что окончание слова может быть разным), выбираем цвет заливки и нажимаем “Готово”. Далее для последующей обработки выделенных ячеек, их можно отсортировать по цвету (об этом подробнее в 8-м пункте).
![]()
Еще один способ быстро найти и удалить минус слова — это использование фильтров. С их помощью можно сделать так, что в таблице будут отображаться только те ячейки, которые соответствуют заданным параметрам. Для этого выделяем диапазон ячеек с ключевыми словами, в Excel переходим в раздел “Данные”, нажимаем “Фильтр”, если работаем в Google Таблицах, тогда “Данные > Создать фильтр”.
![]()
Нажимаем на появившийся значок фильтра в верхней части столбца, выбираем “Фильтровать по условию > Текст содержит”. Получаем список запросов, которые содержат минус слово, и удаляем их.
![]()
8. Сортировка данных по цвету заливки ячеек
В программе Excel предусмотрена фильтрация данных в зависимости от цвета заливки ячеек, для этого в разделе “Данные > Фильтр” выберите условия фильтрации по цвету.
![]()
В Гугл таблицах встроенной такой функции нет и для ее использования необходимо скачать еще одно браузерное расширение “Сортировка диапазона +”. Это дополнение позволит сортировать данные по цвету заливки ячейки и по цвету текста.
![]()
Еще несколько функций Excel при выполнении других задач seo специалиста
1. Закрепление строки для удобства работы
Если вы занимаетесь seo, то вы знаете, что часто приходится работать с большим количеством данных. Каждый столбец в таблице соответствует определенному показателю и имеет название (заголовок). Чтобы эти названия были всегда на виду, нужно воспользоваться функцией закрепления. Нажимаем “Вид > Закрепить > 1 строку”.
![]()
2. Расширение ячейки до нужной ширины
Этот пункт мы добавили в наше руководство для более удобной работы с Excel, а не для выполнения конкретных SEO задач.
Чтобы расширить ячейку, которая содержит текст, до оптимального размера, наведите курсор мыши на разделительную полосу столбцов и кликнете дважды.
![]()
3. Работа с регистром символов
Если необходимо сделать первое слово в ячейке с большой буквы, можно воспользоваться следующей формулой: “=ПРОПИСН(ЛЕВСИМВ(СТРОЧН(A1);1))&ПСТР(СТРОЧН(A1);2;ДЛСТР(A1)-1)”.
![]()
Если наоборот вам нужно сделать все буквы в нижнем регистре, тогда воспользуйтесь формулой “=СТРОЧН(A1)”.
![]()
4. Подсчет количества символов в мета-тегах
Вы как seo-специалист уже сгруппировали запросы в семантическом ядре и приступили к прописыванию мета-тегов (title, description), и вам необходимо подсчитать, какое количество символов в итоге получилось. Для выполнения этой задачи воспользуйтесь формулой “=ДЛСТР(A1)”.
![]()
После чего с помощью условного форматирования можно подсветить ячейки, которые больше или меньше рекомендуемого размера.
5. Подсчет количества запросов в ТОПе
В имеющейся выгрузке с позициями сайта необходимо подсчитать, какое количество из этих запросов находится, например, в ТОП 10. Для этого воспользуемся формулой “=СЧЁТЕСЛИ(A1:A50;»<=10″)”, где “A1:A50” — это выделенный диапазон с позициями.
![]()
6. Проверка сколько дней прошло с какой-то даты
Рассмотрим как эта функция может быть полезна в SEO. Допустим вы дали задание исполнителю разместить бесплатные ссылки на свой сайт. В ТЗ указали, что оплата будет производится в том случае, если ссылка “прожила” более 7 дней, проверка осуществляется по истечению этого времени. Чтобы можно было точно отследить количество прошедших дней воспользуйтесь формулой “=ЕСЛИ(ЕПУСТО(B2);; РАЗНДАТ(B2; СЕГОДНЯ(); «D»))”, где вместо B2 указывайте адрес ячейки, в которой прописана дата размещения ссылки.
![]()
Подводим итоги
В этой статье мы рассмотрели основные функции и возможности программы Excel и Google таблиц, которые могут пригодится как начинающему seo-специалисту, так и опытному. Для выполнения ежедневных задач вам не нужно заучивать эти сложные формулы, достаточно будет просто знать, что они есть и в случае необходимости вы можете ими воспользоваться.
Осваивайте Excel, применяйте полученную информацию на практике и делитесь своим собственным опытом в комментариях.
Чувствуете что бизнесу нужен апгрейд?
Получить бесплатную консультацию от специалиста по вашему проекту
Подробнее
Здравствуйте, уважаемые читатели сайта Uspei.com. В этом уроке мы рассмотрим такие вещи как группировка запросов в рамках семантического ядра или кластеризация. Начнем мы с группировки поисковых запросов и чистки ядра. В прошлой статье мы посмотрели, как собирать статистику, какие инструменты для этого можно использовать, и все это почистили, удалив дубликаты. А также мы рассмотрели виды запросов.
У нас есть большой список запросов, из которого мы должны удалить оставшийся мусор и провести группировку. То есть у нас есть здоровенный список запросов. В некоторых тематиках он может доходить до 10 000. Наша задача сейчас разбить его на группы, каждая из которых будет содержать в себе только синонимы. То есть в рамках каждой группы должны быть только синонимы, так как каждая выделенная группа, это будущая отдельная страница и эти запросы в группе мы будем на ней продвигать.

К примеру, если у нас есть запрос “купить ноутбук”, то мы должны сделать группу, в которой будут только синонимы к запросу “купить ноутбук”.
Под синонимом в SEO имеется в виду то, что в запросы, по которым люди ищут, вкладывается один и тот же смысл. К примеру, запросы “купить ноутбук” и “купить ноутбук apple” это НЕ синонимы и они будут входить в разные группы, потому что у них разное понятие. В первом случае человек ищет просто ноутбук и это может быть даже samsung, а совсем не apple. Во втором же случае человек ищет конкретно apple. Ну, еще один пример. Человек ищет “такси” и “междугороднее такси” – тут думаю тоже очевидно и понятно.
Таких групп в рамках большого семантического ядра может быть огромное количество, их может быть более нескольких сотен в редких случаях более тысячи. Вот этот процесс еще называют кластеризацией. Мы рассмотрим, как его сделать вручную, я покажу основы и попытаюсь вывести хотя бы один законченный кластер, потому что в рамках одной статьи мы не сможем классифицировать ядро, но хотя бы вывести какой-то базовый кластер.
И потом я вам дам ссылки на набор инструментов, который может существенно автоматизировать или ускорить эту группировку или кластеризацию, как это сейчас модно называть.
Кластеризация и чистка семантического ядра в Excel
Возвращаемся к нашему списку запросов и у нас достаточно простой алгоритм. У нас уже отсортированы все запросы по убыванию частотности, то есть от самых популярных до наименее популярных. Дубликаты мы удалили.

Мы берем каждый запрос и смотрим подходит он нам или нет. Например, у нас есть запрос “интернет-магазин”, но если мы занимаемся только ноутбуками, то этот запрос без слова ноутбук нам не подходит. Значит запрос “интернет-магазин” мы удаляем – это не тематический запрос.
Дальше запрос “ноутбук”. Да, в принципе это информационный запрос, но не совсем понятно, что человек вкладывает в этот запрос, когда вбивает его в поисковую строку. Ищет ли он информацию, картинку или он ищет товары или возможно что-то еще.
Если мы сомневаемся в смысле поискового запроса, логично его проверить. Как это делается? Мы копируем запрос и вбиваем его в новой вкладке в ту поисковую систему, с которой мы работаем. Например, Google.
Мы видим, что Google показывает нам набор интернет-магазинов. Мы видим точно, что это запрос коммерческий и если у нас интернет-магазин, мы его оставляем.
И мы добрались до первого подходящего нам запроса. Давайте выделим нашу первую группу запросов, в которую будут входить все слова с упоминанием слова “ноутбук”. Для этого нужно включить фильтр и отфильтровать по текстовому условию “содержит”. Но там могут быть словоформы запроса “ноутбук” поэтому мы просто напишем “ноут” и получаем список строк только с поисковыми запросами, в которых упоминается “ноут”. Я предлагаю вам скопировать и перенести их в новую вкладку.
Каждую вкладку мы будем называть соответственно по тому слову, по которому мы произвели фильтрацию. В первой же вкладке мы вручную (!) выделяем все отфильтрованные ключи и удаляем. После чего очищаем фильтр.
Итак, в первой вкладке у нас остались все ключи, которые НЕ содержат “ноутбук”, а мы переходим во вторую (“ноутбук”) и продолжаем работать теперь уже там.

Итак, следующее слово “ноутбук”. Мы уже разобрались, что это коммерческий запрос и по нему также как и по запросу “купить ноутбук” показываются интернет-магазины, то есть это синонимы и мы оставляем их в одной группе.
“DNS ноутбуки” – как раз это тот самый навигационный запрос и можно предположить, что приставка “DNS” как популярный интернет-магазин будет часто встречаться в списке запросов про ноутбуки. Поэтому давайте сразу удалим все чужие навигационные запросы “DNS”. Фильтр – выделяем вручную и удалить.
“Ноутбуки бу” – аналогично как с “dns” – удаляем, если только мы не продаем б/у ноубуки.
“Купить ноутбук Москва” – тут уже добавляется регион, а мы далеко не в Москве. По сути, запрос повторяет смысловую нагрузку запроса “купить ноутбук” или просто “ноутбук”. Но поскольку добавляется регион, стоит проверить считает ли google эти поисковые запросы синонимами.
Мы берем запрос “купить ноутбук” вбиваем его в google и в другой вкладке вбиваем запрос “купить ноутбук Москва”. И сравниваем результаты поиска на предмет повторения результатов, то есть именно конкретных страничек. Если хотя бы 4-5 страничек одинаковых, то мы можем считать, что это запросы синонимы и Google показывает по ним одинаковый смысл. Если же по этим запросам выдача разная, то “купить ноутбук Москва” навигационный запрос и он нам не нужен.
Идем дальше и таким образом проделываем ту же процедуру – удаляем мусор и создаем новые группы отличные по смыслу.
Очень рекомендую чистить семантику, используя фильтры, если чистить ручками, то есть большой шанс что-то пропустить.
Но когда мы фильтруем, надо быть аккуратным, чтобы не удалить какие-то важные слова случайно отфильтровав их. Например, если в фильтр вбить просто “бу” то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие “бу” – например, сам запрос “ноутБУк” – а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце ” бу” и “бу “, а также через слэш “б/у”. Помните это и будьте внимательны))))).
И вот у нас запрос “ноутбук hp”. Это уже не просто “ноутбук” – это уже более узкая тема, значит мы должны выделить ноутбуки hp в отдельную группу.
Производим фильтрацию “текст содержит” получаем набор запросов и переносим их в новую вкладку “ноутбуки hp”. Из второй вкладки “ноутбук” перенесенные в 3 вкладку результаты удаляем.

Так мы будем повторять эту процедуру, пока в каждой вкладке не останутся только синонимы. То есть дальше мы должны перейти в 3 вкладку “ноутбуки hp” и здесь их разделить еще на более подробные группы. Мы видим, что здесь есть “ноутбук hp pavilion”, ” ноутбук hp compaq” и “ноутбук hp игровой”. Таким образом, эта группа будет разбита еще на 3 группы.
Во вторую вкладку мы вернёмся, когда во всех следующих группах все слова будут синонимами и продолжим этот разбор. Продолжим до тех моментов, пока самая первая наша вкладка не будет разложена на группы, а в ней самой не останутся только нецелевые запросы или запросы, которые тоже будут синонимами.
В итоге наша задача создать файл, в котором у нас будет огромное количество вкладок. В разных темах по-разному – возможно в некоторых темах будет всего 5-6 вкладок, если тема очень маленькая, но основная задача, чтобы в рамках одной вкладки были только запросы синонимы.
Причем не просто слова синонимы в классическом понимании, а синонимы с точки зрения поисковой системы. Вот как из примера “купить ноутбук” и “ноутбук” это синонимы с точки зрения поисковой системы, поэтому они у нас остались в одной группе.
Если во вкладке 20 синонимов и один НЕ СИНОНИМ – выносим его одного в отельную вкладку. Это очень важный момент, так как каждая группа это отдельная страница, на которой эти запросы будут продвигаться, и чем больше будет ошибок и недоработок, тем менее чистой по смыслу станет страница, что скажется результатах поиска. О других ошибках, допускаемых при сборе и группировке семантики ознакомьтесь в этой статье.
Повторю еще раз основную мысль – в каждой вкладке должны быть запросы подходящие по смыслу. Пример, если в текущей вкладке 5 запросов:
- “заработать в интернете”
- “как можно заработать в интернете”
- “где заработать через интернет”
- “как заработать деньги в интернете”
- “как заработать в интернете без обмана”
Первые три запроса останутся в текущей вкладке, так смысл у них один, а последние два уйдут каждый в свою группу-вкладку, так как они не совпадают по смыслу ни с первыми тремя, ни между собой – они более детализированы. В одном случае речь идет о деньгах ( а заработать в наши дни можно все что угодно – биткоины, баллы в играх и т.д.), а во-втором, речь идет о заработке без обмана.
Для понимания я в течение часа сварганил (правда не до конца) семантику по запросам, “заработок в интернете” “заработок в сети” “заработок онлайн”. Первая вкладка – вся семантика, а далее по группам. Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Скачать пример семантического ядра в excele.
Зачем все это нужно и почему все так сложно?
 Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают – зачем это все нужно? Какую практическую пользу это несет?
На самом деле, сейчас это не очевидно, но буквально через два-три этапа вы увидите, что вся поисковая оптимизация, абсолютно все seo, построено на основе правильно собранного семантического ядра. SEO – это не просто любительский способ сделать свой сайт лучше. Это, можно сказать наука, в которой все начинается с “атомов” и именно это приводит к результату.
SEO можно сравнить с большим спортом – боксом или сноубордом или любым другим. Если вы не освоите технику ПРОФЕССИОНАЛЬНЫХ ударов или элементов езды, то это скажется на скорости и выносливости и вы проиграете сопернику, кто этим не пренебрег. Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое – не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места – есть только первая страница и все.
Мы не можем начинать оптимизацию сайта, если мы не сделали семантику, не разбили ее на группы, не обработали и не почистили. И все что мы будем делать дальше, будет основано на семантике.
Приведу конкретный пример. Мы же понимаем, что по каждому запросу поисковик дает свой результат выдачи. Возьмем какую-то небольшую тематику по которой в семантике всего 100 запросов. И вот у одного владельца 100 страниц на сайте, в которых содержимое часто пересекается, структура сайта от этого расплывчатая, поисковик не понимает до конца, какие страницы релевантны запросу больше, а какие меньше. В итоге, кроме путаницы, эти 100 страниц содержат в своем “винегрете” ответы только на 30-40 запросов.
А у второго владельца сайта, благодаря полному собранному кластеризованному семантическому ядру, на каждый запрос есть соответствующая страница, строго релевантная только этому запросу. Поисковик и пользователи четко понимают структуру сайта, а также не страдают “дежавю”, что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
Автоматизация кластеризации семантического ядра
Такая работа по группировке запросов по обработке всей этой статистики вручную занимает достаточно много времени. Особенно если человек делает это первый раз. Но я вам рекомендую, если вы хотите научиться работать запросами, работать с семантикой, хотя бы один раз проведите все это вручную в электронных таблицах. Тогда вы сможете прочувствовать и понять, как это работает.
Если же вы работаете в очень больших объемах, крайне рекомендую использовать профессиональные инструменты. Чаще всего они платные.
Один из самых популярных инструментов по работе с семантикой это инструмент “Key Collector”, которая позволяет автоматизировать большинство процессов по сбору и обработке семантики. Как минимум, она умеет автоматически собирать ключевые слова из yandex wordstat, а также данные о частотности по запросам и другие рекомендации.
Если же у вас есть уже готовое отфильтрованное от мусора семантическое ядро, то вы можете прибегнуть к помощи дополнительных сервисов, которые производят автоматическую кластеризацию. Лидером сейчас на рынке является онлайн-сервис, который называется Rush analytics.
Расценки не очень высокие и в принципе, если у вас один сайт, вы владелец или вебмастер, то вы можете собрать семантику, почистить ее, после чего просто отдать на кластеризацию такому сервису.

Раздел SEM & SEO содержит в себе функции, необходимые для поискового маркетинга.
Чтобы не смешивать эти профессиональные функции с общими, он был выделен в отдельный блок. Раздел частично копирует структуру всей надстройки — содержит меню «Извлечь», «Удалить», и «Изменить». Этот раздел будет пополняться новыми функциями так как рынок поисковой рекламы динамично развивается и ему нужны новые инструменты.
Изменить
Данный раздел содержит в себе возможности по изменению:
- Типов соответствия ключевых фраз;
- Словоформ – лемматизация;
- Файла загрузки рекламных кампаний – Яндекс.Директа в формат Google Ads.
Удалить
Меню удалить с функциями исключительно для поискового маркетинга содержит в себе:
- Удаление стоп-слов;
- Удаление utm-меток и get-параметров;
- Удаление модификаторов у стоп слов.
Извлечь
Меню извлечь содержит возможности по извлечению текстовой информации из URL. Сюда входит парсинг Title, H1, коды ответа сервера.
Извлечение гиперссылок из анкорных ссылок может пригодиться, когда вы копипастите ссылки с какого-нибудь сайта (например, конкурента) и хотите быстро извлечь из них непосредственно адреса ссылок.
Поисковые подсказки
Раздел содержит различные способы сбора поисковых подсказок из таких поисковых систем как Yandex, Google, YouTube, Amazon, Bing.
Семантический анализ
В этой группе инструментов:
- Частотный анализ n-грамм (последовательностей из n слов);
- Инструмент по автоматическому отключению синонимов Яндекс.Директа;
- Анализ поисковых запросов.
Поиск не релевантных слов в массиве фраз.
Кластеризация
Данный макрос производит статистическую обработку семантического ядра на основе анализа частотности встречаемости слов в нём.
Владельцы сайтов и новички часто сталкиваются с вопросом, как собрать семантическое ядро. Речь идёт о запросах, которые пользователь вбивает в строку поисковой системы с целью просмотра нужной ему информации. Чем лучше собрано СЯ, тем проще копирайтеру написать хороший текст. Это не только влияет на позиции в выдаче, но и повышает вероятность просмотра пользователем именно вашего контента. Итак, как собрать СЯ?
Ключевики для SEO сайта

Семантическое ядро — набор слов и словосочетаний, отражающих тематику сайта. Составление СЯ является важным этапом поискового продвижения. Оно необходимо для определения целевых страниц и дальнейшего планирования работ на сайте. Ключи собирают как для всего ресурса, так и для отдельных его частей. Всё определяется целями и приоритетами сайта.
Нужен ли сбор СЯ
Ещё не так давно семантическое ядро собирали для того, чтобы найти высокочастотные ключи и вставить их в текст. В итоге получались неплохие позиции в выдаче. Но в последние годы алгоритмы поисковых систем усовершенствовали. Теперь важно не просто присутствие ключей, а их смысловое размещение в качественном тексте. У Google появились такие требования в 2013 году, а у «Яндекса» — в 2016 г.
Статьи без хорошего СЯ не смогут полностью раскрыть тему и конкурировать в выдаче. Они будут попросту бессмысленные и неэффективные для продвижения. Поэтому важно грамотно собрать семантику, способную раскрыть потребности пользователя.
Стоимость продвижения сайта формируется индивидуально. Все зависит от набора услуг, которые будут применяться в процессе продвижения сайта. Список мероприятий формируется в зависимости от типа сайта, его текущего технического состояния, а также от позиции ключевых запросов в результатах поиска.
Классификация запросов
Ключевые фразы классифицируют по нескольким признакам. Если рассматривать популярность, их разбивают на такие группы:
- Низкочастотные (НЧ). Имеют около 50–500 показов в месяц. Состоят обычно из 3–4 слов.
- Среднечастотные (СЧ). Такие ключевики пользователи вводят около 1 000 раз. Словосочетания включают 2–3 слова.
- Высокочастотные (ВЧ). «Горячие» ключи из 1–2 слов. Число показов начинается от 1 000 и достигает нескольких сотен тысяч. Обычно такие фразы используют для главных страниц сайтов, чтобы попасть на хорошие позиции в поисковой выдаче.
В целом учитывайте, что популярность ключевиков зависит и от тематики. Если она распространённая, показов будет больше. Для менее популярных тематик ключи с 1 000 запросами уже считаются высокочастотными.
При сборе СЯ смотрят и на конкурентность ключей. Они бывают:
- высококонкурентными (ВК);
- среднеконкурентными СК);
- низкоконкурентными (НК).
Ключевые фразы распределяют ещё и по потребностям юзеров. Так, различают:
- информационные. Пользователи вводят их для поиска полезной или интересной статьи. Например, как починить стиральную машину, где хранить шубу и т. д.;
- транзакционные. Эти ключи используют тогда, когда планируется совершить коммерческое действие. Примеры: «Заказать роллы на дом», «Купить ноутбук». Сюда также относят другие фразы с транзакционными словами (цена, продажа, интернет-магазин и пр.);
- прочие запросы. В эту категорию относят неоднозначные фразы. Например, человек вводит в строку слово «печенье». Не всегда понятно, хочет он купить кондитерское изделие, испечь его или просто узнать интересную информацию о нём.
Некоторые специалисты выделяют ещё группу навигационных ключей. Сюда относят запросы, вводимые пользователем для поиска конкретного интернет-ресурса. Если они не касаются вашего сайта, пропускайте их.
Поэтапная инструкция
Формирование хорошего СЯ — задача довольно сложная и длительная. Необходимо пройти все главные шаги, которые включают следующее.
Поиск ключевых словосочетаний

Для начала проработайте первичный список ВЧ слов и фраз, как можно точнее характеризующих тему. Их именуют маркерами. Обычно это названия направлений, типы товаров, часто употребляемые запросы. Они включают 1–2 слова, насчитывают более десятка тысяч показов. Слишком длинные ключевики не берите, поскольку в дальнейшем возникнут сложности с минус-словами.
Формировать основные фразы лучше с помощью сервиса «Яндекс.Вордстат». В строку ввода вбивается запрос, после чего информация по нему отображается в двух колонках. В левой размещены словосочетания, в которых он содержится, в правой — фразы, подходящие для расширения СЯ.
По умолчанию «Яндекс.Вордстат» выводит базовую частотность фразы. Однако это значение неточное, так как отражает популярность не только запроса, но и словоформ, дополнительных слов.
Чтобы увидеть результат, приближённый к правде, используют операторы:
- кавычки («доставка пиццы») — учитываются словоформы, но игнорируются хвосты (к примеру, уточнение «на дом»);
- восклицательный знак (!доставка !пиццы) — фиксируется словоформа и учитывается хвост;
- кавычки и восклицательный знак («!доставка !пиццы») — показывается точная цифра запроса указанной фразы в месяц;
- плюс (доставка пиццы +как) — используется для учёта предлогов и местоимений;
- минус (доставка пиццы -как) — отсеиваются ненужные слова.
Ускорить сбор семантики поможет установка бесплатного расширения для браузеров Wordstat Assistant. В «Яндекс.Вордстат» появляются плюсики, нажав на которые в окно плагина копируются запросы вместе с частотностью.
Подбор синонимов
При введении запроса в строку поиска можно указать синонимы. Например, «авто — машина». Чтобы СЯ охватывало достаточно запросов, необходимо собрать максимум близких по значению слов. Для этого берите результаты из правой колонки «Яндекс.Вордстат», сниппетов конкурентов, ищите специальные термины и сленговые выражения по теме. В итоге получится довольно обширный список.
Расширение главных фраз
Далее потребуется спарсить частотность ключевиков, чтобы определить потребности пользователей. Удобнее всего работать в Key Collector, так как программа подбирает ключи через «Вордстат», отсекает лишние фразы с помощью минус-слов, фильтрует запросы по частоте, определяет сезонность и т. д. Инструмент платный, но с ним собрать семантическое ядро сайта намного проще и быстрее.
Есть и бесплатный аналог — SlovoEB. Инструмент собирает ключи через «Вордстат», парсит поисковые подсказки и пр. Для работы с программой нужно создать отдельный аккаунт, чтобы в случае блокировки не было проблем.
Тем, кто не хочет вникать в специфику работы программ, подойдут сервисы Just-Magic и Rush Analytics. Хотя в идеале лучше потратить время и освоить функциональные инструменты.
Проработка минус-слов
Очень часто игнорируют эту процедуру, прибегая к удалению неподходящих фраз, но на самом деле проработка минус-фраз значительно экономит время. Составляйте списки с помощью инструмента Key Collector. Зайдите во вкладку «Анализ» через «Данные», укажите тип группировки по отдельным словам и пройдитесь по перечню. Если есть неподходящий ключевик, кликайте на синюю кнопку и добавляйте его в минус-фразы.
Парсинг подсказок

В момент ввода запроса поисковики предлагают варианты продолжения фразы. Именно эти ключи называются подсказками. Большинство из них не учитывается сервисом «Яндекс.Вордстат», поэтому при формировании СЯ их придётся собирать отдельно.
По умолчанию «Кей Коллектор» парсит фразы с перебором их окончаний и с пробелом после каждого словосочетания. Если для вас в приоритете скорость сбора, а не количество ключевиков, укажите галочку в пункте «Собирать только ТОП подсказок без перебора и пробела после фразы».
Выявление частотности для ключевиков

В обязательном порядке нужно определить точную и базовую частоту, убрать лишнее. Целевые словосочетания, даже если у них небольшое количество показов, нужно оставить. В дальнейшем такие фразы помогут разработать полноценную структуру текста.
- повторы;
- ключевики с прочими знаками;
- дубли словосочетаний.
С оставшимися можно работать. Используйте «Кей Коллектор» и действуйте таким образом:
Для запросов до 7 слов:
- выберите соответствующий фильтр в графе «фраза»;
- зайдите в «сбор Yandex.Direct»;
- уточните регион;
- укажите режим «Гарантированные показы»;
- уточните период сбора — 1 мес.;
- проставьте галочки в нужных местах;
- кликните на кнопку «Получить данные».
Для запросов от 8 слов:
- выберите фильтр «Состоит как минимум из 8 слов»;
- задайте регион;
- кликните на значок лупы и выберите «Собрать все виды частот».
Таким простым способом вы сможете определить точную и базовую частоту, чтобы использовать эти сведения в работе с СЯ.
Удаление мусора
Когда число показов определено, необходимо отсеять неподходящие ключевики. Следуйте такой инструкции при работе с Key Collector:
- Выберите «Анализ групп» и отсортируйте ключевики по числу употребления слов. Наша цель — обнаружить нецелевые и частые, чтобы отнести их к минус-фразам.
- Добавьте к этому списку обнаруженные минус-слова, пересмотрите его, чтобы случайно не оставить целевые, а затем отсейте «Отмеченные фразы».
- Избавьтесь от фраз-пустышек — редко используемых в точном вхождении, но имеющих ВЧ.
- Выполните расчёт KEY 1 и отсейте фразы с показателем от 100 и выше.
Те ключевики, что у нас остались, можно группировать по целевым страницам.
Кластеризация
Следующий шаг — работа с инструментом «Majento Кластеризатор». С его помощью его вы кластеризуете запросы по топу. Смысл процесса состоит в том, что нужно объединить в группы ключевики.
Их комбинируют так:
- общие урлы друг с другом;
- с наиболее частотным ключом в группе.
В зависимости от числа совпадений, для разных сайтов существуют пороги кластеризации: 2, 3 … 10.
Важный плюс этого способа в том, что группировка фраз происходит по потребностям аудитории. Так вы определите, какие ключи можно применить на одной целевой странице.
Анализ конкуренции
Продвижение по ВК запросам зачастую бессмысленно. На высокие позиции попасть будет очень трудно, а без них невозможно гнать трафик на страницу.

Аудит сайта — это анализ и изучение сайта с целью выявления всех ошибок и факторов, оказывающих влияние на техническую и коммерческую успешность интернет-проекта.
Эксперты советуют опираться на точную частотность группы словосочетаний, по которым пишется текст, и на конкуренцию по «Мутагену». Проверить её можно вручную — для этого введите соответствующий запрос в сервисе или через массовые задания.
Или используйте Key Collector.
Подбор тем и группировка
После кластеризации у вас получились готовые группы. Теперь осталось выбрать темы для сайта. Лучше пользоваться двумя инструментами: Majento и Key Collector. Инструкция будет следующей:
- Выгрузите из группы Majento в формате CSV.
- Комбинируйте запросы в Excel по маске «группа:ключ».
- Загрузите готовый перечень в «Кей Коллектор».
- Уберите для новых ключей частотность.
- Найдите кластеры с уникальным интентом. Они должны включать от 3 фраз и иметь суммарное количество показов по всем запросам от 300. После этого наиболее частотные проверяем по «Мутагену» и отбираем для работы ключевики с конкуренцией до 12.
- Анализируйте оставшиеся группы. При наличии близких по смыслу фраз объедините их.
После группировки ключевиков получите перечень подходящих тем для текстов и СЯ под них.
Отсеивание фраз другого типа контента
При формировании СЯ важно учитывать, что коммерческие ключевики не нужны в информационных статьях. Это же правило действует и в обратную сторону — интернет-магазину ни к чему запросы для блогов, поэтому просмотрите текущие группы и удалите всё ненужное.
Оптимизация запросов
Это последний этап сбора семантического ядра. Теперь приступайте к его оптимизации, чтобы облегчить работу копирайтера. Для этого нужно:
- выполнить сортировку ключей от А до Я;
- отобрать фразы, раскрывающие тему с разных сторон;
- отсеять ключи с показами меньше 7 в месяц.
Если игнорировать ручную группировку ключей, посадочная страница окажется оптимизированной под несовместимые фразы, посещаемость такого сайта может быть невысокой.
Источник: http://wezom.com.ua/blog/kak-sobrat-sja
Что такое семантическое ядро сайта
Семантическое ядро – это список запросов, по которым пользователи могут найти сайт, и по которым он продвигается. Раскрутка любого проекта начинается с подбора семантики. Это фундамент, на котором строится продвижение.

Для чего нужно семантическое ядро сайта
Построение структуры сайта
Гораздо проще выстраивать структуру на основе собранной семантики, чем делать наобум, а потом вносить бесконечные правки – это выйдет дороже и дольше. Имея у себя список ключевых слов, можно понять, какие нужно создать категории, подкатегории и пункты меню.
Если речь идет о наполнении блога, семантическое ядро поможет при составлении контент-плана на длительный период.
Внутренняя оптимизация
Работы по продвижению включают SEO-оптимизацию мета-тегов title и description, заголовков h1-h6, текстов и изображений. Семантическое ядро необходимо для того, чтобы понимать, под какие слова «затачивать» страницу и составить ТЗ для копирайтера.
Перелинковка
Продвигаемые ключевики используются в качестве анкоров для внутренней перелинковки страниц.
Формирование анкоров для размещения внешних ссылок
Ссылки разделяют на безанкорные (перейти по ссылке, тут, вот, УРЛ страницы и т. п.) и анкорные. Чтобы продвижение было максимально эффективным, анкоры должны содержать вхождения ключевых слов. В качестве текста ссылки для отдельно взятой страницы берутся ключевики, под которые она продвигается.
Также при наличии семантического ядра вы можете рассчитать бюджет на ссылочное продвижение через сервисы Rookee, Promopult и др.
Анализ конкурентов
Собрав семантическое ядро, можно посмотреть конкурентов из ТОП-10 и проанализировать их преимущества. Учитывая чужой опыт, вы избежите ошибок при продвижении.
Какие бывают ключевые слова их классификация
По частотности:
Высокочастотные (ВЧ) – к ним относятся наиболее популярные ключевики с частотностью от 10000 и выше показов в месяц. Под такие ключи целесообразно продвигать страницы, имеющие наибольший вес – главную и категории.
Среднечастотные (СЧ) – с частотой 1 000-10000. Под них «затачивают» страницы категорий и подкатегорий.
Низкочастотные (НЧ) – до 1 000 показов в месяц. Идут на подкатегории и карточки товаров.
Однако нужно учесть и тематику. К примеру, в узкоспециализированных тематиках (медицинское оборудование, b2b, промышленность и т. п.) фраза с частотностью 500 показов в месяц может быть самой крупной и считаться высокочастотной.
При продвижении молодого ресурса лучше отдать предпочтение СЧ- и НЧ-ключевикам – так вы быстрее продвинетесь в ТОП-10 и получите первый трафик, а позже можно прорабатывать ВЧ-фразы. Если сразу начать с высокочастотных, то это будет более затратно, а результат вы увидите нескоро.
По конкурентности:
Высококонкурентные – по ним в выдаче находится более 1 млн результатов:

часто состоят из 1-3 слов;
относятся к коммерческим тематикам (не всегда);
высокие ставки в Яндекс.Директе;
в выдаче преобладают Главные страницы;
региональность – Москва или без региона;
много качественных документов – даже документы со 2-3 страниц вполне адекватно отвечают на вопрос пользователя.
Среднеконкурентные – от 100000 до 1 млн результатов.
Здесь уже более адекватная стоимость продвижения и ставок в Директе, а качество выдачи заметно ниже.
Низкоконкурентные – менее 100000 результатов.
Они примечательны тем, что:
качество выдачи, как правило, ниже среднего, то есть даже у нового сайта есть все шансы обойти конкурентов;
среди них можно найти не только НЧ-, но и СЧ-, и даже ВЧ-ключевики;
поисковые алгоритмы чаще всего не оказывают сильного влияния на них.
Ваша задача – подготовить качественный контент, проработать коммерческие факторы и разместить внешние ссылки, и на всё это не нужно будет тратить космические бюджеты. Некоторые низкоконкурентные ключевики достаточно всего лишь раз употребить в тексте, чтобы они вышли в топ.
По цели поиска:
Общие – обычно состоят из одного слова, и невозможно точно определить, какое намерение было у пользователя при поиске данного запроса. В выдаче по ним могут присутствовать как коммерческие сайты, так и блоги. Например, «SEO», «авто», «цветы».
Информационные – поиск сведений о чем-либо.
Навигационные – поиск определенного места в городе/стране/регионе.
Витальные – содержат название конкретного сайта или компании.
Транзакционные – подразумевают совершение действия, включают такие слова, как «купить», «заказать», «скачать» и т. п.
Брендовые – содержат название марки, фирмы-производителя.
Мультимедийные – поиск изображений, видео- и аудиоконтента.
По отношению к бизнесу:
Коммерческие – выражают желание купить товар или услугу.
Некоммерческие – вводят пользователи, которые просто ищут информацию. На коммерческих ресурсах их можно использовать при наполнении блога для привлечения дополнительного трафика.
По геозависимости:
Геозависимые – привязаны к региону. Например, если вы будете искать «такси» в Москве, то поисковик покажет сайты московских компаний, а если из Санкт-Петербурга – сайты будут другие, местные.
Геонезависимые – выдача по ним не меняется в зависимости от региона. Это инфозапросы или словосочетания, содержащие название города. Например, при поиске «такси в Москве» выдача будет одинаковой в любом городе.
По сезонности:
Сезонные – те, на которые спрос повышается в зависимости от времени года (туристическая тематика, спорттовары, строительство, одежда и обувь и пр.).
Всесезонные – востребованы одинаково в любое время года.
Анатомия ключевых слов
Важно также разбираться в строении запросов. Каждая ключевая фраза имеет тело – это его основа, спецификатор – показывает принадлежность к той или иной группе и хвост.
Например, запрос «авто» состоит только из тела. Мы можем добавить к нему спецификатор: «купить авто» – коммерческий запрос, «фото авто» – информационный и мультимедийный. Добавив хвосты, получим «купить авто недорого», «купить авто в кредит», «купить авто новое» и т. п.
Добавление хвостов позволяет снизить частотность основного ключевика и расширить семантику.
Если вы хотите научиться оптимизировать сайты и стать суперменом-сеошником, то можем предложить курс «SEO-оптимизация: продвижение сайтов в поисковых системах». После курсов проведете аудит сайта и создадите стратегию продвижения. Научитесь анализировать конкурентов, сформируете семантическое ядро. Прогнозируя результаты продвижения, сможете оптимизировать бюджет. Привлекательно? Записывайтесь!
Как правильно составить СЯ
Алгоритм составления работы следующий:
Подбор ключевиков, включая синонимы и различные формулировки запросов.
Составление списка минус-слов.
Непосредственно сбор данных при помощи специальных программ и онлайн-сервисов.
Кластеризация семантики и распределение по страницам.
Составление карты релевантности.
Далее мы подробно рассмотрим каждый из этапов.
Как правильно подобрать ключевые слова для сбора семантики
В первую очередь определитесь с тем, какие типы ключевиков должны быть в списке СЯ. Для интернет-магазина или сайта услуг понадобятся коммерческие запросы, информационные – для блога или портала, мультимедийные – для фотобанков и онлайн-медиатек.
При подборе СЯ нужно учесть:
Синонимы. Используйте словари, погрузитесь в нишу, посмотрите поисковые подсказки.
Смежные запросы. Их можно додумать логически или воспользоваться сервисом Яндекс.Вордстат:

Разные формулировки одного и того же слова и сленговые выражения. Например, «аккумуляторы» могут искать как «АКБ». Без знания тематики вы рискуете потерять как минимум треть полезных запросов! Некоторые товары и услуги могут искать на разных языках (например, «ауди» и «audi») – учтите и это.
Поисковики умеют вычислять логическую взаимосвязь между разными формулировками, поэтому наиболее релевантной окажется та страница, где употребляются различные варианты фраз.
При подборе фраз для карточек товаров добавьте к каждому из названий продуктов «купить», «заказать», «цена», «стоимость» и т. п. и спарсите получившиеся комбинации через Key Collector. Яндекс.Вордстат показывает не все длинные словосочетания.
После сбора данных потребуется очистка СЯ от ненужных или мусорных ключевиков. Чтобы сразу не собирать то, что не пригодится в дальнейшем, заранее подготовьте список минус-слов. Можно найти готовые базы, например, по городам, но их всё равно придется просмотреть и откорректировать вручную, чтобы случайно не удалить нужное.
Сервисы для составления семантического ядра
Наиболее популярные и часто используемые – это Яндекс WordStat и Google Keyword Planner Tool. Есть возможность выставить регион, собрать похожие запросы и задать минус-слова.
Более продвинутые сервисы и программы:
Key Collector – самая известная программа, без которой не обходится ни один SEO-специалист. Позволяет собрать семантику, задать минус-слова, выполнить группировку и кластеризацию, подобрать поисковые подсказки. Стоит она недорого (от 1800 руб. за первую лицензию) и существенно экономит время.
SlovoEb – бесплатная версия Key Collector. В ней реализованы не все возможности платной программы и многое придется делать вручную, но если вы нечасто работаете с семантикой, то это – оптимальный вариант.
Promopult – сервис для закупки ссылок, в котором есть много полезных инструментов, в том числе и возможность подбора СЯ исходя из тематики проекта и бюджета. Спарсить данные можно бесплатно.
Just-Magic– позволяет собрать семантику для отдельных страниц, кластеризовать ее, а также проверить текстовый контент. Сервис платный – от 1 000 руб.
Rush Analytics – быстрый и многофункциональный сервис, с его помощью можно собрать семантическое ядро для Яндекса или Гугла с подсказками, выполнить кластеризацию, проанализировать текстовый контент, регулярно мониторить позиции и проверять индексацию. Тестовый период – 2 недели, при этом на балансе 200 лимитов. Цена – от 799 руб. при оплате за год.
Мутаген – не только парсит семантику, но и позволяет оценить конкурентность. Ежедневно доступно 20 проверок. Платная версия – от 30 руб. за 100 проверок.
Как получить семантическое ядро другого сайта?
В этом вам помогут сервисы:
Megaindex – в нем есть масса полезных инструментов для сеошника (аудит конкурентов, сбор сниппетов, анализ видимости и многое другое), в том числе и возможность посмотреть семантику конкурентов:

Как видите, в бесплатной версии доступно всего 5 строк. Минимальный тариф – от 1490 руб./мес.
Serpstat– обладает широким функционалом. Выгружает видимость любого проекта, дает подсказки для расширения семантики и позволяет мониторить конкурентов. Сервис платный, цена – от $19 в месяц. Доступна демоверсия.
Spy Words– платный сервис (от 1950 руб./мес.). Позволяет снять и сравнить данные конкурентов, отследить динамику позиций и кластеризовать данные.
Semrush– сервис, ориентированный на работу с Гугл. Позволяет провести аудит и получить данные по позициям. Показывает стоимость клика или действия и конкурентность. Самый дешевый тариф – от $99 в месяц, доступна демоверсия.
Как сгруппировать ключевые слова и построить карту релевантности
После того, как вы собрали семантику и почистили ее от минус-слов, необходимо выполнить группировку. Можно сделать это вручную. В таком случае лучше заранее нарисовать структуру проекта (mindmap) с разделами и подразделами и в процессе вычитки добавлять в нее данные. Этот способ очень долгий, поэтому не рекомендуем использовать его для больших объемов работ.
Гораздо проще и быстрее воспользоваться специальными программами и сервисами, например,
Источник: http://webpromoexperts.net/blog/chto-takoe-semanticheskoe-yadro-sayta/
Что такое семантическое ядро блога
Статьи по теме
Анализ ключевых слов — ключ к эффективному контенту сайта
Онлайн-версия программы Базы Пастухова
Кластеризация простыми словами для блоггеров
Здравствуйте, уважаемые читатели! Часто при личных беседах с веб-мастерами вижу непонимание важности ключевых слов для поискового продвижения. Поэтому я решил написать отдельный пост на эту важную тему. Что такое семантическое ядро сайта, его плюсы и минусы, пример готового ядра, советы по его правильному составлению — тема этой статьи. Вы узнаете, почему в плане seo-продвижения так важны для веб-ресурса правильно подобранные ключевики. Почувствуете их важность и исключительность, увидите силу от их использования.
Почему я написал этот пост? Во-первых, моя статья предназначена для начинающих веб-мастеров, которые только начали разбираться в сео продвижении. И во-вторых, в топ-20 в Яндексе нет ни одной статьи, которая подробно бы раскрыла пользователю из поиска суть семантического ядра. Исправим этот недочет. Надеюсь, русский поисковик это зачтет. 🙂
Понятие семантического ядра
Что это такое
Каждый из нас умеет пользоваться телефонным справочником. Будь то карманный алфавитный вариант в виде записной книжки или большой печатный талмуд всех телефонов города — принцип его использования очень прост. Мы ищем по определенной фамилии все контактные данные искомого человека. Для этого нам надо знать полностью ФИО человека. Обычно, уже зная фамилию человека, мы можем легко посмотреть в справочнике все записи и выбрать нужную. То есть, зная определенное слово (фамилия), мы можем получить все данные по человеку, которые записаны в книжке.

По такому принципу и работает семантика сайта — мы в поисковой системе набираем поисковый запрос (аналог той фамилии, контакты для которой ищем в справочнике) и получаем список самых точно отвечающих на него документов из различных веб-ресурсов. Эти документы являются отдельными страницами сайтов или блогов, контент на которых оптимизирован под запрашиваемый нами поисковый запрос, который называется ключевым словом. Таким образом, обычное семантическое ядро является набором поисковых запросов (ключевых слов), которые точно характеризуют тематику веб-ресурса, вид его деятельности (обычно для коммерческих сайтов, которые предлагают услуги или товары в сети Интернет).

Поэтому семантическое ядро выполняет очень важную функцию — оно позволяет веб-ресурсу получить на свои страницы пользователей из поисковых систем, которые необходимы для выполнения различных задач. Например, для коммерческого сайта такими задачами могут быть продажа товаров или услуг, для новостного портала — рекламирование сторонних источников с помощью контекстной или баннерной рекламы, для блога — рекламирование партнерских программ и т.д. То есть ядро является именно тем фундаментом, которое необходимо для получения поискового трафика с помощью seo продвижения. Без правильного и качественного набора ключевых слов получить такой трафик не реально.
Поэтому, если мы хотим использовать ресурсы и возможности поисковых систем для раскрутки своего веб-ресурса, ему нужно иметь грамотное семантическое ядро. Если же мы не хотим получать поисковый трафик, если нам не нужна целевая аудитория из поиска, то наличие семантики для нашего сайта не обосновано. Ключевые слова нам не нужны.
Типы семантического ядра
В поисковом продвижении существует основное и второстепенное семантическое ядро. Основное подразумевает под собой набор главных ключевых слов, с помощью которых данный сайт реализует поставленные перед ним цели и задачи. Например, это могут быть те поисковые запросы, по которым переходят из поиска потенциальные покупатели товаров или услуг на коммерческом сайте. То есть благодаря запросам основного ядра сайт или блог выполняют свое предназначение. Именно по таким ключевикам идет превращение обычного пользователя из поиска в клиента.
Второстепенное семантическое ядро позволяет веб-ресурсу решить менее значимые задачи или получить дополнительный трафик для привлечения большего числа потенциальных клиентов. В таком случае спектр ключевых слов может быть не только основной тематики сайта, но и смежных тем. Обычно используется в ряде коммерческих сайтов, которые хотят конвертировать посетителей с помощью дополнительных статей для продажи услуг или товаров на продающих страницах. Например, так поступают многие сайты, предоставляющие seo-услуги. На их веб-ресурсах кроме основных продающих и поясняющих страниц существует дополнительный большой набор документов, которые вместе образуют вариант блога.

У блоггеров основным ядром является список ключевых слов, которые приносят ему поисковый трафик, так как он и является основной задачей при монетизации блога с помощью целевой аудитории из поиска. А второстепенной семантики обычно у блога не бывает. Потому что какая бы ни была задача у блога, весь трафик по всем продвигаемым в поисковых системах страницам идет на решение его коммерческой задачи. Но, обычно ключевые слова по основной тематике дают намного больше коммерческих переходов, чем ключи непрофильной темы.
Что нужно знать при создании семантического ядра
Ключевые слова для семантического ядра выбираются по различным параметрам (частотность, конкурентность и т.д.). Об этом я подробно написал в статье о классификации поисковых запросов. В зависимости от этих параметров подбираются семантические ядра для коммерческих сайтов, для блогов, для новостных порталов и т.д. Выбор тех или иных значений этих характеристик зависит от трех составляющих — от стратегии продвижения, от количества выделенного на него бюджета и тематики сферы деятельности продвигаемого сайта.
Стратегия продвижения диктует план подбора ключевых слов, акцентрируя свое внимание на взаимосвязь продвигаемых страниц с сайтом и их качество. Во-первых, здесь важна схема перелинковки страниц — от ее правильного выбора зависит число и важность документов, которые будут продвигаться в поисковых системах, Для каждого веб-ресурса схема должна быть своя, с помощью которой будет лучшее распределение веса на раскручиваемые документы. Во-вторых, необходимо знать объем контента продвигаемой страницы (для которого подбираются ключевики) — в зависимости от количества символов используется то или другое число ключевиков для нее.
От количества бюджета зависит возможность использования в семантическом ядре конкурентных запросов. Чем больше материальных средств может веб-мастер выделить на свой проект, тем лучшие слова он может включить в его семантику. Ведь не секрет, что самые качественные раскрученные ключевики всегда стоят приличных денег за попадание в топ-10 по ним. А значит для продвижения страниц по этим ключевым запросам недостаточно внутренней оптимизации — необходима закупка внешних ссылок, нужны материальные ресурсы для их закупки.
От тематики зависит в первую очередь минимальный порог частотности ключевого слова, который можно использовать для получения поискового трафика. Чем конкурентней тематика и чем она уже (в плане ее популярности), тем больше свой взор веб-мастер кидает в сторону низко- и микрочастотных слов (частотность их менее 50-100 в зависимости от тематики). Например, тема моего блога (seo и веб аналитика) очень узкая и большее число ключевых слов я не смогу использовать для создания семантического ядра. Поэтому большая часть ключевиков моего блога — это поисковые запросы НЧ и МК с частотностью не более 100. Если сравнить с популярными темами (например, кулинария — НЧ запросы в ней доходят до 1000!), то можно легко понять, что получить серьезный трафик по мелкой теме очень трудно — нужно иметь огромное число ключевых слов маленькой частотности (зато не конкурентной). А значит нужно иметь огромное число продвигаемых страниц.

План создания семантического ядра
Чтобы создать семантическое ядро, необходимо выполнить ряд последовательных действий:
- Выбрать те тематики сайта, для которых будут подбираться ключевые слова. Здесь необходимо выписать все направления деятельности, которой посвящен веб-ресурс. Если это интернет-магазин, значит выписываем основные категории товаров (отдельно для товаров обычно ключевые слова не ищут, если только товар не имеет номерной модели, а только общую). Если это блог, то все подтемы общей тематики, а также отдельные названия важных статей. Если сайт по предоставлению услуг, то будущими ключевыми словами будут названия этих услуг и т.д.
- На основе выбранных тематик составить список масок — первоначальных запросов, по которым будет парситься наше семантическое ядро. Более подробно по понятию списка Вы можете узнать из этого поста. еще один пост на эту тему, где описывается пример составления масок будущего СЯ сайта.
- Узнать регион продвижения Вашего сайта. В зависимости от местоположения ресурса некоторые ключевые слова могут иметь разную степень конкурентности. Чем уже и точнее регион, тем больше его важность в плане продвижения. Например, многие ключевые слова не так конкуренты по региону Россия, как по Москве.
- Спарсить всевозможные поисковые запросы с поисковой системы Яндекс и Google (если необходимо) с помощью различных способов (ручной, в программе Key Collector, анализ конкурентов и т.д.). Описанные варианты парсинга, для которых я написал подробные пошаговые руководства, можно найти по ссылкам в блоке дополнительных статей после этого поста.
- Полученные поисковые запросы необходимо проанализировать и оставить самые качественные из них. Анализ поисковых запросов осуществляется по ряду параметров, который позволит отсеять слова-пустышки, сможет отделить конкурентные слова от неконкурентых и показать самые эффективные ключевики.
- Распределить полученные ключевые слова по документам веб-ресурса. Финишный этап в создании семантического ядра, в котором необходимо для каждой продвигаемой страницы в зависимости от условий продвижения закрепить свои ключевики. Благодаря такому распределению веб-мастер может сразу видеть главный запрос и дополнительные, но и предположить структуру будущего контента. Здесь же идет деление ядра на основное и второстепенное (если в этом есть необходимость).
После того, как полное семантическое ядро сайта создано, в плане продвижения пора браться за внутреннюю оптимизацию страниц и затем делать эффективную перелинковку.
Пример готового семантического ядра (таблица ключевиков)
Для того, чтобы Вы могли увидеть готовый результат, я решил выложить кусочек заказанного у меня семантического ядра. На этом скриншоте Вы увидите таблицу подобранных ключевиков (картинка кликабельна) :

Как видите, все ключевые слова распределены по статьям (распределение осуществляет заказчик самостоятельно или я за отдельную плату). Сразу видно, какие поисковые запросы из таблицы могут идти как главный запрос, а какие в виде дополнительных ключевиков. Все это позволяет заказчику не мешкая внедрять полученные ключевые слова сразу в готовые посты или делать примерный план будущих постов — все четко и понятно видно.
[wfbox type=»withtitle» title=»Где можно заказать отличное семантическое ядро?»]
Если Вы желаете собрать полноценное семантическое ядро для коммерческого сайта или информационного проекта, рекомендую обратиться ко мне.
Плюсы и минусы семантического ядра
Как и в любом деле, создание семантического ядра имеет свои положительные и отрицательные стороны. Сначала поговорим о минусах:
- Для получения качественного семантического ядра сайта нужны различные варианты затрат. Если Вы заказали свой список ключевых слов у специалиста, то такими затратами будут приличная сумма. Чем больше слов заказываете, тем больше рублей отдаете. Если же Вы подбираете ключевики самостоятельно, то можете потратить достаточно много времени, пока научитесь подбирать самые эффективные запросы. Но полученный опыт и качество ключей вернут потраченные часы за сбором ядра в виде отличной конверсии и целевого поискового трафика.
- Для отбора и анализа лучших ключевых слов из уже спарсенных необходимы знания. Не каждый веб-мастер будет копаться в этом деле — ведь кроме знаний оптимизации нужно владеть азами работы в Excel и уметь считать (для форматирования данных, в первую очередь). Но, опять же, если все это будет, качество Вашего семантического ядра будет в разы выше, чем простой набор спарсенных ключей из Вордстата.
Как видите, минусов немного, но они существенные. И если материальные средства не так важны, то изучение нужного материала требует времени, которое цениться больше всего. Ведь его нельзя вернуть… Перейдем к плюсам:
- Самый большой и важный плюс — Вы получаете крепкий фундамент для продвижения своего веб-ресурса. Без ключевых слов видимость сайта или блога будет очень низкой, что не даст привлечь на него большой поисковый трафик. А значит не будут реализованы поставленные задачи и цели. Не достаточно для привлечения пользователей поисковых систем писать просто качественный контент. Поисковикам необходимо еще наличие ключевых слов в статье (в тексте) и на странице (в ее мета-данных). Поэтому создание семантического ядра — первый этап, без которого поисковое продвижение просто нереально!
- Благодаря хорошему семантическому ядру (конечно, с учетом его грамотной внутренней оптимизации), продвигаемые страницы веб-ресурса будут не только получать именно целевых пользователей из поиска, но и позволять сайту иметь отличные поведенческие факторы. При использовании плохих ключевиков (или их отсутствия) показатель отказов заметно вырастает, число целевых конверсий уменьшается.
- Имея под рукой готовое семантическое ядро, любой веб-мастер будет иметь представление будущего своего веб-ресурса с точки зрения создания контента. Глядя на ключевые слова, он увидит будущие темы своих статей на сайте. То есть он может планировать свою деятельность намного эффективней — заранее дать копирайтеру задание, лучше подготовиться к сезонным скачкам или придумать очередной цикл постов.
Советы блоггеру по созданию семантического ядра
Как Вы знаете, мой блог в первую очередь ориентирован на блоггеров. И не потому, что я сам уже заядлый блоггер и без очередной новой статьи на workformation.ru жить не могу. 🙂 Для мастеров пера, мозгов и мыши информации о получении поискового трафика в Рунете очень мало — в основном все пишут о сео продвижении коммерческих сайтов. Тема подбора ключевых слов не является исключением. Поэтому, я решил поделиться с Вами некоторыми секретами по созданию своего СЯ:
- Как правило, на блоге создается (находится) большое число постов. Поэтому ключевых слов для них надо искать много. Но не стоит брать первые попавшиеся — поищите лучшие варианты, оцените их, проанализируйте параметры поисковых запросов. Возможно Вы затратите больше времени, но зато получите на выходе качественные ключи, которые смогут привлечь лучший трафик, чем сборище первых увиденных поисковых запросов. Сделайте себе установку — каждый день поиск ключевиков для одной статьи. Набив руку, Вы намного быстрее будете собирать их для своего ядра, тем самым за один раз обслужив 3-5 постов.
- Не надо читать кучу seo материалов, не кидайтесь на супер-пупер новинки в оптимизации и не ищите идеального способа создания семантики для своего блога — его не существует! Возьмите тот, который Вам понятен. И подбирайте с помощью него ключевые слова. Но доверяйте только проверенным материалам о СЯ.
- Часто бывает, когда нам сложно придумать тему для нашего будущего поста. Особенно, с точки зрения поискового продвижения, когда во главу угла становиться получение максимального поискового трафика. Готовое семантическое ядро помогает избавиться от этой проблемы раз и навсегда — перед Вашими глазами в любой момент времени (!) сможете наблюдать готовые темы следующих статей. И не только — таким образом можно прикинуть будущий цикл постов, который может потом превратиться и в свой инфопродукт. 🙂

И напоследок самый важный совет. Не гонитесь за большими и толстыми ключевиками. Не будет от этого толку, только проблем себе насобираете, потратив море времени впустую. Берите в оборот мой следующий трехфазный принцип подбора ключевиков, который я успешно использую на своем блоге (более 80% ключевых слов находятся в топ-30, около 49% в топ-10 в Яндексе и более 20-ти% в Google — и это в моей сложной конкурентной тематике!):
- Полученные спарсенные слова, которые Вы собрали своим способом (например, с помощью Вордстата, программы Словоеб, анализа конкурентов и т.д.) проверьте на конкурентность — оцените их стоимость продвижения (как это сделать, можно узнать из моей бесплатной книги или можете прочитать в отдельной дополнительной статье — ссылка после этого поста). Уберите все конкурентные запросы, оставьте только с минимальной стоимостью (например, в SeoPult это ключевики стоимостью в 100 рублей, в SeoPult Pro — 25).
- Для оставшихся поисковых запросов оцените их качество. Для этого необходимо посчитать соотношение точной и базовой частотностей (есть как в книге, так и в посте про анализ поисковых запросов). Исключите в зависимости от тематики некачественные слова, исключите слова-пустышки.
- Теперь уже среди полученных качественных слов сделайте их распределение по статьям. Если пост имеет более одного ключа, выберите самый жирный из них (но этот ключевик должен иметь большую точную частотность, чем другие). Он будет являться главным запросом, приносящим большую часть поискового трафика по продвигаемой статье. Если из предложенных для статьи ключевых слов на главенство подходят два ключа (больше двух — редкость), берите оба. Один пропишите в title, другой в h1.
На этом совете я закончу свою статью о семантическом ядре. Хочу верить, что она Вам понравилась и теперь тема семантики веб-ресурса для Вас не является такой уж страшной тайной. Как обычно, жду Ваши небольшие вопросы в комментариях, а постоянные читатели блога имеют право на бесплатную консультацию. Спасибо за внимание и до встречи!
Источник: http://maksimdovzhenko.ru/semanticheskoe-yadro-sajta.html
- Опубликовано:20.01.2014
- Комментарии:
Нет комментариев - Рубрика:
Продвижение магазинов - Просмотров: 19 909

Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла. Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Скачать файл Excel (.xls)
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
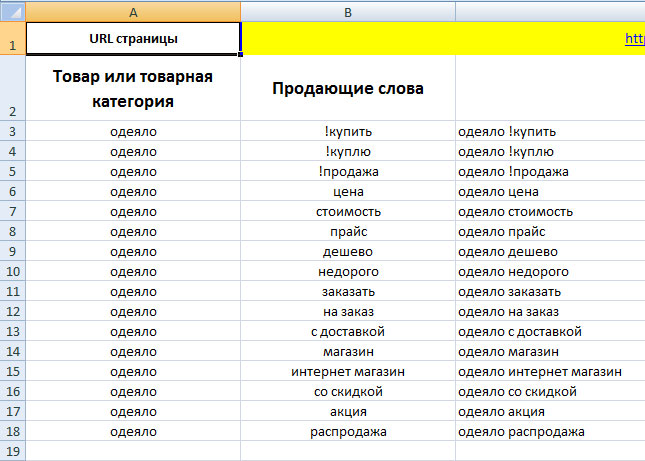
В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:
Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Читайте также:
- Рейтинг CRM систем для интернет-магазинов
- Как продвигать магазин в поисковых системах?