
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
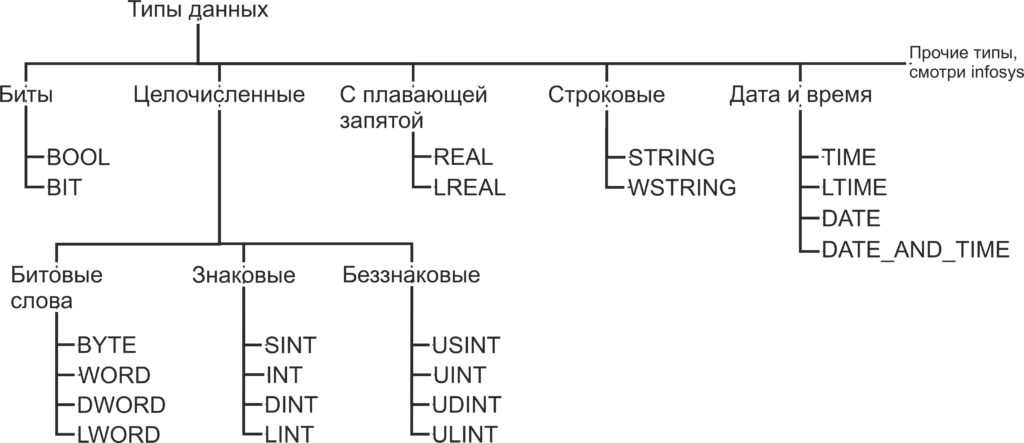
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
Боюсь, что вопрос, поставленный таким образом не имеет ответа.
Далее моя «компиляция» (выдержки) из книги «Ядро Linux. Описание процесса разработки» (просто недавно прочел, и думаю, цитаты будут к месту).
==
Машинное слово (word) — это количество данных, которые процессор может обработать за одну операцию. Когда говорят о n-разрядной машине, то чаще всего имеют в виду размер машинного слова. Например, когда говорят, что Intel Core i7 является 64-разрядным, то имеется в виду размер машинного слова, равный 64 разрядам, или 8 байтам.
Размер регистров вобщего назначения процессора соответствует размеру машинного слова этого процессора.
В ОС Linux размер виртуального адресного пространства соответствует размеру машинного слова, следовательно размер указателя равен ему.
Размер типа long языка C также равен машинному слову, тогда как размер типа int может быть меньше.
==
Т.е. по мнению писателей ядра Linux надо написать
typedef long WORD;
или
typedef unsigned long WORD;
Далее просто цитата из книги:
Слова, двойные слова и путаница в терминологии
В некоторых операционных системах и процессорах стандартную порцию данных
не называют машинным словам. Вместо этого словом называется фиксированная
порция данных, название которой выбрано случайным образом случайным образом
или имеет исторические корни. Например, в некоторых системах данные могут
разбиваться на байты (byte - 8 бит), слова (word - 16 бит), двойные слова
(double word - 32 бит) и учетверенные слова (quad word - 64 бит), несмотря
на то, что на самом деле система является 32-разрядной. Подобная система
наименований была принята в системах на основе Windows NT, а также в современной
Windows 7.
Таким образом, @Чистяков Владислав, без уточнения для решения каких задач Вам нужен тип WORD, корректно ответить не получится.
Правильный выбор типа переменной может быть критическим при разработке встраниваемых приложений на микроконтроллерах, потому что для него количество доступных ресурсов всегда ограничено. Правильный выбор типа переменной может сохранить как процессорное время, так и уменьшить размер программы.
[Типы char]
Для 8-битного процессора (AVR как раз относится к 8-битным) самым предпочтительной переменной будет тип char или unsigned char. Очевидно почему — потому что разрядность такой переменной точно соответствует разрядности регистров и большинства инструкций. Имя типа char произошло от слова «character», т. е. «символ», потому что тип char с самых истоков вычислительных систем всегда использовался для хранения кодов символов (ASCII). Тип char знаковый (самый старший бит 8-битного значения хранит знак числа), и он может кодировать ряд значений от -128 до +127 в дополнительном коде. Беззнаковый тип unsigned char может хранить числа без знака (положительные числа) в диапазоне от 0 до 255. Некоторые компиляторы могут исопользовать встроенный тип byte, который является эквивалентом типа unsigned char.
Заголовочный файл inttypes.h определяет другие популярные имена для 8-битных типов: int8_t и uint8_t (см. далее раздел «inttypes.h»).
[Пользовательские типы]
Язык C разрешает пользователю определять свои собственные типы, для чего используется слово typedef:
typedef unsigned char byte; // создание типа byte
typedef unsigned int word; // создание типа word (для AVR тип int имеет разрядность 16 бит)
byte myVal1; // определение 8-битной переменной word myVal2; // определение 16-битной переменной
Другими словани, определение пользовательского типа имеет следующую общую форму:
typedef стандартный_тип пользовательский_тип
Некоторые программисты почему-то любят определять типы с помощью ключевого слова #define. Это не самый лучший способ, однако работает:
#define byte unsigned char
#define word unsigned int
byte myVal1; // определение 8-битной переменной word myVal2; // определение 16-битной переменной
[inttypes.h]
В составе библиотечных файлов компилятора WinAVR (т. е. avr-gcc) есть заголовочный файл, где для удобства определены некоторые часто используемые пользовательские типы:
typedef signed char int8_t; // 8-битная переменная со знаком
typedef unsigned char uint8_t; // 8-битная переменная без знака
typedef int int16_t; // 16-битная переменная со знаком
typedef unsigned int uint16_t; // 16-битная переменная без знака
typedef long int32_t; // 32-битная переменная со знаком
typedef unsigned long uint32_t; // 32-битная переменная без знака
typedef long long int64_t; // 64-битная переменная со знаком
typedef unsigned long long uint64_t;// 64-битная переменная без знака
Обратите внимание, что здесь в имени типа сразу закодирована его разрядность. Это очень удобно, потому что не надо помнить, какая разрядность у какого типа. Мне больше нравится другое, более короткое определение типов с указанием разрядности:
typedef signed char s8; // 8-битная переменная со знаком
typedef unsigned char u8; // 8-битная переменная без знака
typedef int s16; // 16-битная переменная со знаком
typedef unsigned int u16; // 16-битная переменная без знака
typedef long s32; // 32-битная переменная со знаком
typedef unsigned long u32; // 32-битная переменная без знака
typedef long long s64; // 64-битная переменная со знаком
typedef unsigned long long u64; // 64-битная переменная без знака
Здесь символ s обозначает «signed», т. е. число со знаком, а символ u обозначает «unsigned», т. е. число без знака. Цифры 8, 16, 32 и 64 обозначают разрядность типа.
[Ссылки]
1. More about C types in AVR-GCC site:winavr.scienceprog.com.
Этот раздел является переводом туториала C++ Language
Псевдонимы типов (typedef/using)
Псевдоним типа — это другое имя, по которому можно идентифицировать тип. В C++ любой допустимый тип может иметь псевдоним, чтобы на него можно было ссылаться, используя другое имя.
В C++ есть два синтаксиса для создания таких псевдонимов типов. Первий из них унаследован от языка Си и использует ключевое слово typedef:
typedef существующий_тип псевдоним ;где существующий_тип является любым типом, фундаментальным или сложным, а псевдоним — это идентификатор с новым именем, назначаемым типу.
Например:
typedef char C;
typedef unsigned int WORD;
typedef char * pChar;
typedef char field [50];Здесь определяются четыре псевдонима типов: C, WORD, pChar и field как char, unsigned int, char* и char[50], соответственно. Объявленные однажды, эти псевдонимы могут быть использованы в любом объявлении так же, как и любой другой допустимый тип:
C mychar, anotherchar, *ptc1;
WORD myword;
pChar ptc2;
field name;Недавно был введен второй синтаксис для определения псевдонимов типов в языке C++:
using псевдоним = существующий_тип ;Например, псевдонимы того же типа, что и выше, могут быть определены как:
using C = char;
using WORD = unsigned int;
using pChar = char *;
using field = char [50];Псевдонимы, определенные с использованием typedef и с использованием using являются семантически эквивалентными. Единственным различием являются некоторые ограничения typedef в области шаблонов, отсутствующие для using. Следовательно, using является более общим, хотя typedef имеет более длинную историю и, вероятно, чаще встречается в существующем коде.
Обратите внимание, что ни typedef, ни using не создают новый тип данных. Они только создают синонимы существующих типов. Это означает, что тип переменной myword, объявленной выше с типом WORD, может рассматриваться как unsigned int; на самом деле это не имеет значения, так как оба в действительности ссылаются на один и тот же тип.
Псевдонимы типов могут использоваться для сокращения длины длинных или вводящих в заблуждение имен типов, но они наиболее полезны в качестве инструментов для абстрагирования программ от используемых ими базовых типов. Например, используя псевдоним int для ссылки на определенный тип параметра вместо непосредственного использования int, можно легко заменить его на long (или другой тип) в следующих версиях, изменив тип только в объявлении псевдонима.
Объединения
Объединения предоставляют доступ к одной области памяти, представляя ее в виде различных типов данных. Объявление и использование объединения такие же, что и у структуры, но функциональность полностью различается:
union type_name {
member_type1 member_name1;
member_type2 member_name2;
member_type3 member_name3;
.
.
} object_names;Это создаст новый тип объединения, идентифицируемый как type_name, все поля которого занимают одно и то же физическое пространство в памяти. Размер этого типа равен размеру наибольшего из его членов. Например:
union mytypes_t {
char c;
int i;
float f;
} mytypes;это объявляет объект (mytypes) с тремя членами:
mytypes.c
mytypes.i
mytypes.fВсе члены этого объединения имеют различные типы данных. Однако, по той причине, что все они ссылаются на одну и ту же область памяти, модификация одного из этих членов влияет на значение каждого из них. Невозможно хранить различные значения в этих членах, не зависящее от других.
Одним из применений объединений является возможность доступа к значению как полностью, так и в виде массива или структуры более мелких элементов. Например:
union mix_t {
int l;
struct {
short hi;
short lo;
} s;
char c[4];
} mix;Если мы предполагаем, что система, на которой исполняется программа, имеет тип int с размером 4 байта, а тип short 2 байта, объединение, определенное выше, предоставляет доступ к одной и той же группе из четырех байт: mix.l, mix.s и mix.c, которые мы можем использовать в зависимости от того как мы хотим получить доступ к этим байтам: как к целому значению типа int, как к двум значениям типа short или как к массиву элементов типа char, соответственно. В примере смешаны типы, массивы и структуры в объединении, чтобы продемонстрировать различные способы доступа к данным. Для little-endian систем это объединение может быть представлено как:
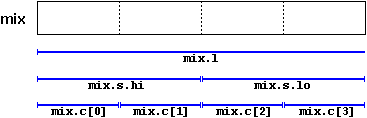
Точное выравнивание и порядок членов объединения в памяти зависят от системы, что может создавать проблемы переносимости.
Анонимные объединения
Когда объединения являются членами класса (или структуры), они могут быть объявлены без имени. В этом случае, они становятся анонимными объединениями, а их члены доступны из объектов непосредственно по именам членов. Например, рассмотрим различия между этими двумя объявлениями структур:
| Структура с обычным объединением | Структура с анонимным объединением |
| struct book1_t { char title[50]; char author[50]; union { float dollars; int yen; } price; } book1; |
struct book2_t { char title[50]; char author[50]; union { float dollars; int yen; }; } book2; |
Единственное различие между двумя этими типами заключается в том, что в первом случае объединение имеет имя (price), тогда как во втором случае имени нет. Это влияет на способ доступа к членам dollars и yen объекта этого типа. Для объекта первого типа (с обычным объединением), это будет:
book1.price.dollars
book1.price.yenтогда как для объекта второго типа (с анонимным объединением), это будет:
book2.dollars
book2.yenОпять же, помните, что ввиду того, что это объединение, члены dollars и yen в действительности разделяют один и тот же участок памяти, так что они не могут быть использованы для хранения различных значений в одно и то же время. Для price может быть задан либо dollars, либо yen, но не оба одновременно.
Перечислимые типы (enum)
Перечислимые типы — это типы, которые определяются набором пользовательских идентификаторов, известных как перечислители, в качестве возможных значений. Объекты перечислимых типов могут принимать любой из этих перечислителей в качестве значения.
Их синтаксис:
enum type_name {
value1,
value2,
value3,
.
.
} object_names;Это создает тип type_name, который может принимать в качеcтве значения любое из value1, value2, value3, … Объекты (переменные) этого типа могут быть непосредственно созданы как object_names.
Например, новый тип переменной с именем colors_t может быть определен для хранения цветов с помощью следующего объявления:
enum colors_t {black, blue, green, cyan, red, purple, yellow, white};Обратите внимание, что в этом объявлении нет другого типа, ни фундаментального, ни составного. Проще говоря, это создает совершенно новый тип данных, не основывая его на каком-либо другом существующем типе. Возможными значениями переменных этого нового типа color_t могут быть перечислители, указанные в фигурных скобках. Например, после объявления перечислимого типа colors_t допустимы следующие выражения:
colors_t mycolor;
mycolor = blue;
if (mycolor == green) mycolor = red;Значения перечислимых типов, объявленные при помощи enum, могут быть неявно приведены к целочисленному типу и наоборот. Фактически, элементам таких enum всегда соответствует внутренний целочисленный эквивалент, в который и из которого они могут быть преобразованы неявно. Если не указано иное, целочисленный эквивалент первого элемента перечисления равен 0, эквивалент второго равен 1, эквивалент третьего равен 2 и так далее. Следовательно, в типе данных colors_t, определенном выше, black является эквивалентом 0, blue эквивалент 1, green эквивалент 2 и так далее.
Конкретное целочисленное значение может быть указано для любого из возможных значений в перечислимом типе. Если для какого-либо элемента в перечислении не указано конкретное числовое значение, оно предполагается равным значению предыдущего элемента плюс 1. Например:
enum months_t { january=1, february, march, april,
may, june, july, august,
september, october, november, december} y2k;В этом случае переменная y2k перечислимого типа months_t может содержать любое из 12 возможных значений, которые идут с january по december и которые эквивалентны значениям от 1 до 12 (не от 0 до 11, так как january равен 1).
Неявное приведение работает в обоих направлениях: значению типа months_t может быть присвоено значение 1 (которое будет эквивалентно january) или целочисленной переменной может быть присвоено значение january (эквивалент 1).
Перечислимые типы enum class
В C++ можно создавать реальные типы перечислений, которые не могут быть неявно преобразованы в int и не имеют значений перечислителя типа int, таким образом сохраняя безопасность типов. Они объявляются с помощью enum class (или enum struct) вместо enum:
enum class Colors {black, blue, green, cyan, red, purple, yellow, white};К каждому из значений перечисления типа enum class необходимо обращаться через его тип (это также возможно для enum, однако, не является обязательным). Например:
Colors mycolor;
mycolor = Colors::blue;
if (mycolor == Colors::green) mycolor = Colors::red;Перечислимые типы, объявленные enum class, имеют больший контроль над их базовым типом; это может быть любой целочисленный тип данных, такой как char, short или unsigned int, который служит для указания размера типа. Это указывается с помощью двоеточия и базового типа, следующими за перечислимым типом. Например:
enum class EyeColor : char {blue, green, brown};Здесь EyeColor является новым типом, имеющим такой же размер, что и тип char (1 байт).
В VC ++ 6.0 BYTE, WORD, DWORD — это целое число без знака, которое определено в WINDEF.h
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned long DWORD;Другими словами, BYTE — это тип без знака, WORD — беззнаковый короткий тип, а DWORD — беззнаковый длинный тип.
В VC ++ 6.0 1 байт символа, short — 2 байта, int и long — 4 байта, поэтому можно считать, что переменные, определяемые BYTE, WORD, DWORD, — это 1 раздел, 2 байта, 4 слова. Раздел.
То есть: BYTE = unsigned char, WORD = unsigned short, DWORD = unsigned long
DWORD обычно используется для сохранения адреса или сохранения указателя
Разница между словом и словом
Определение WORD и DWORD в основном для: 1. Легко трансплантировать; 2. Более строгая проверка типов
WORD фиксируется на 2 байта, DWORD фиксируется на 4 байта
Int, с разными операционными системами, имеет разное количество байтов, в 32-битной операционной системе — 4 байта, в 16-битной операционной системе — 2 байта
В операции сериализации, поскольку сериализация хранится в соответствии с потоком байтов, чтобы гарантировать, что она не будет выровнена, необходимо использовать тип данных с четким числом байтов.