
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = mx + b
или
y = m1x1 + m2x2 +… + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив {mn;mn-1;…;m1;b}. Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
-
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
-
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
-
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
-
-
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
-
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
-
Если массив известные_значения_x опущен, то предполагается, что это массив {1;2;3;…}, имеющий такой же размер, что и массив известные_значения_y.
-
-
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
-
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
-
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
-
-
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
-
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив {mn;mn-1,…,m1;b;sen,sen-1,…,se1;seb;r2;sey; F,df;ssreg,ssresid}.
-
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
-
|
Величина |
Описание |
|---|---|
|
se1,se2,…,sen |
Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
|
seb |
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ). |
|
r2 |
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, каквычисляется 2, см. в разделе «Замечания» далее в этой теме. |
|
sey |
Стандартная ошибка для оценки y. |
|
F |
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
|
df |
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df. |
|
ssreg |
Регрессионная сумма квадратов. |
|
ssresid |
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.

Замечания
-
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1).Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y.Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
-
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1)Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2) -
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:

где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
-
Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y(known_x) для прямой линии или РОСТ(known_y, known_x в) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
-
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r2— индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r2 равно ssreg/sstotal.
-
В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
-
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
-
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
-
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
-
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
-
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
-
Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
-
-
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
=ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
-
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Известные значения y |
Известные значения x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Результат (наклон) |
Результат (y-пересечение) |
|
2 |
1 |
|
Формула (формула массива в ячейках A7:B7) |
|
|
=ЛИНЕЙН(A2:A5;B2:B5;;ЛОЖЬ) |
Пример 2. Простая линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Месяц |
Продажи |
|---|---|
|
1 |
3 100 ₽ |
|
2 |
4 500 ₽ |
|
3 |
4 400 ₽ |
|
4 |
5 400 ₽ |
|
5 |
7 500 ₽ |
|
6 |
8 100 ₽ |
|
Формула |
Результат |
|
=СУММ(ЛИНЕЙН(B1:B6; A2:A7)*{9;1}) |
11 000 ₽ |
|
Вычисляет предполагаемый объем продаж в девятом месяце на основе данных о продажах за период с первого по шестой месяцы. |
Пример 3. Множественная линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Общая площадь (x1) |
Количество офисов (x2) |
Количество входов (x3) |
Время эксплуатации (x4) |
Оценочная цена (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 ₽ |
|
2333 |
2 |
2 |
12 |
144 000 ₽ |
|
2356 |
3 |
1,5 |
33 |
151 000 ₽ |
|
2379 |
3 |
2 |
43 |
150 000 ₽ |
|
2402 |
2 |
3 |
53 |
139 000 ₽ |
|
2425 |
4 |
2 |
23 |
169 000 ₽ |
|
2448 |
2 |
1,5 |
99 |
126 000 ₽ |
|
2471 |
2 |
2 |
34 |
142 900 ₽ |
|
2494 |
3 |
3 |
23 |
163 000 ₽ |
|
2517 |
4 |
4 |
55 |
169 000 ₽ |
|
2540 |
2 |
3 |
22 |
149 000 ₽ |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Формула (формула динамического массива, введенная в A19) |
||||
|
=ЛИНЕЙН(E2:E12; A2:D12; ИСТИНА; ИСТИНА) |
Пример 4. Использование статистики F и r2
В предыдущем примере коэффициент определения (r2)составляет 0,99675 (см. ячейку A17 в результатах для ЛИТН), что указывает на крепкая связь между независимыми переменными и ценой продажи. F-статистику можно использовать для определения случайности этих результатов с таким высоким значением r2.
Предположим, что на самом деле взаимосвязи между переменными не существует, просто статистический анализ вывел сильную взаимозависимость по взятой равномерной выборке 11 зданий. Величина «Альфа» используется для обозначения вероятности ошибочного вывода о существовании сильная взаимозависимости.
Значения F и df в результатах функции LINEST можно использовать для оценки вероятности возникновения более высокого F-значения. F можно сравнивать с критическими значениями в опубликованных F-таблицах или с помощью функции FРАСП в Excel для вычисления вероятности случайного возникновения большего F-значения. Соответствующее F-распределение имеет v1 и v2 степени свободы. Если n — количество точек данных и конст = ИСТИНА или опущен, то v1 = n – df – 1 и v2 = df. (Если конст = ЛОЖЬ, то v1 = n – df и v2 = df.) Функция FIST с синтаксисом FDIST(F;v1;v2) возвращает вероятность возникновения более высокого F-значения, случайного. В этом примере df = 6 (ячейка B18) и F = 459,753674 (ячейка A18).
Предположим, что альфа имеет значение 0,05, v1 = 11 – 6 – 1 = 4, а v2 = 6, критический уровень F составляет 4,53. Поскольку F = 459,753674 значительно больше 4,53, вероятность того, что F-значение этого высокой случайности превышает 4,53, крайне маловероятно. (Если значение «Альфа» = 0,05, гипотеза о том, что между known_y и known_x нет связи, отклоняется при превышении F критического уровня (4,53).) Функцию FDIST в Excel можно использовать для получения вероятности случайного возникновения F-значения. Например, FIST(459,753674, 4, 6) = 1,37E-7, очень небольшая вероятность. Можно сделать вывод о том, что формула регрессии полезна для предсказания оценочного значения офисных зданий в этой области, найдя критический уровень F в таблице или с помощью функции FDIST. Помните, что крайне важно использовать правильные значения 1 и 2, вычисленные в предыдущем абзаце.
Пример 5. Вычисление t-статистики
Другой тест позволяет определить, подходит ли каждый коэффициент наклона для оценки стоимости здания под офис в примере 3. Например, чтобы проверить, имеет ли срок эксплуатации здания статистическую значимость, разделим -234,24 (коэффициент наклона для срока эксплуатации здания) на 13,268 (оценка стандартной ошибки для коэффициента времени эксплуатации из ячейки A15). Ниже приводится наблюдаемое t-значение:
t = m4 ÷ se4 = –234,24 ÷ 13,268 = –17,7
Если абсолютное значение t достаточно велико, можно сделать вывод, что коэффициент наклона можно использовать для оценки стоимости здания под офис в примере 3. В таблице ниже приведены абсолютные значения четырех наблюдаемых t-значений.
Если обратиться к справочнику по математической статистике, то окажется, что t-критическое двустороннее с 6 степенями свободы равно 2,447 при Альфа = 0,05. Критическое значение также можно также найти с помощью функции Microsoft Excel СТЬЮДРАСПОБР. СТЬЮДРАСПОБР(0,05; 6) = 2,447. Поскольку абсолютная величина t, равная 17,7, больше, чем 2,447, срок эксплуатации — это важная переменная для оценки стоимости здания под офис. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных.
|
Переменная |
t-наблюдаемое значение |
|---|---|
|
Общая площадь |
5,1 |
|
Количество офисов |
31,3 |
|
Количество входов |
4,8 |
|
Возраст |
17,7 |
Абсолютная величина всех этих значений больше, чем 2,447. Следовательно, все переменные, использованные в уравнении регрессии, полезны для предсказания оценочной стоимости здания под офис в данном районе.
Задача отыскания функциональной зависимости очень важна, поэтому для ее решения в MS Excel введен набор функций, основанных на методе наименьших квадратов. В качестве результата выдаются не только коэффициенты функции, приближающей данные, но и статистические характеристики полученных результатов.
Смысл выходной статистической информации функции ЛИНЕЙН
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, вычисляя прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую.
Общий синтаксис вызова функции ЛИНЕЙН имеет следующий вид:
ЛИНЕЙН(известные_значения_y;известные_значения_x;конст;статистика)
Для работы с функцией необходимо заполнить как минимум 1 обязательный и при необходимости 3 необязательных аргумента:
- Известные_значения_y − это множество значений y, которые уже известны для соотношения y=mx+b.
- Известные_значения_x − это множество известных значений x. Если этот аргумент опущен, то предполагается, что это массив {1; 2; 3; …} такого же размера, как и известные_значения_y.
- Конст − это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если в функции ЛИНЕЙН аргумент константа имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx.
- Статистика − это логическое значение, которое указывает, требуется ли выдать дополнительную статистику по регрессии.
Примеры использования функции ЛИНЕЙН в Excel
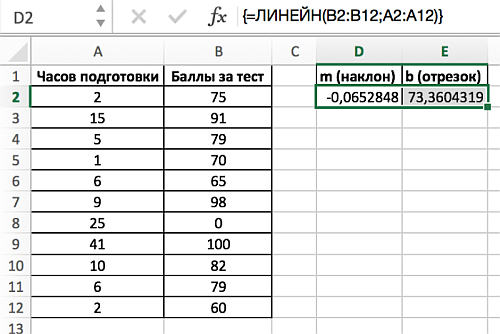
Для решения первой задачи – о соотношении часов подготовки студентов к тесту и результатов теста, как х и у соответственно, – необходимо применить следующий порядок действий (в связи с тем, что ЛИНЕЙН является функцией, которая возвращает массив):
- Выделите диапазон D2:Е2, так как функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y – баллы, которые студенты заработали на последнем тестировании (диапазон ячеек В2:В12).
- Затем введите известные значения х – количество часов, которые студенты потратили на подготовку к тестам (диапазон А2:А12).
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.
Результатом применения функции становится:
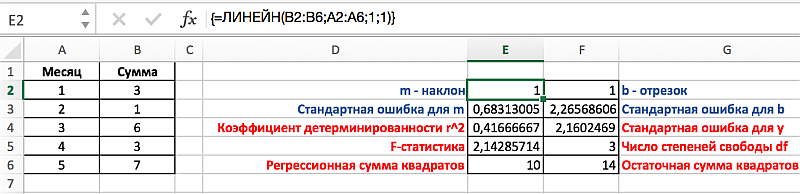
Теперь, на примере решения второй задачи, разберем необходимость в отображении не только наклона и отрезка, но и дополнительной статистики. Для примера, на диапазоне А1:В6 выстроим таблицу с соотношением у и х соответствующих сумме заработка студентом денежных средств за период в 5 месяцев. Так как мы имеем лишь одну переменную х, то необходимо выделить диапазон состоящий из двух столбцов и пяти строк. Важно отметить, что в том случае, если переменных х будет больше, то количество столбцов может изменяться соответственно их количеству, однако строк будет всегда 5.
Применительно к решаемой нами задаче, выделим диапазон Е2:F6, затем введем формулу аналогично предыдущей задаче, но в данном случае третьему и четвертому аргументу присвоим значение 1 соответствующее ИСТИНЕ. Для вывода параметров статистики функции ЛИНЕЙН необходимо нажат Ctrl+Shift+Enter, результат должен соответствовать следующему рисунку, на котором представлено обозначение дополнительных статистик:
Вернемся к примеру № 1, касающемуся зависимости между часами подготовки студентов к тесту и баллов за тест. Добавим к условию задачи данные о баллах за домашнее задание — представляющие дополнительную переменную х, что свидетельствует о необходимости применения множественной регрессии.
В случае множественной регрессии, когда значения «y» зависят от двух переменных «х», функция ЛИНЕЙН возвращает 12 статистик. На рисунке с модифицированной таблицей от 1 примера, представленном ниже используются следующие обозначения:
- y = зависимая переменная;
- x1 = независимая переменная 1 = баллы за домашнее задание;
- x2 = независимая переменная 2 = часы подготовки к тесту.
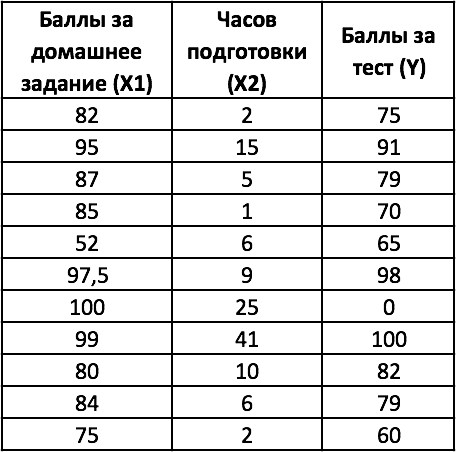
Чтобы выполнить множественную регрессию:
- Выделите диапазон В3:D7 (число столбцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу =ЛИНЕЙН(D14:D24;B14:C24;1;1). Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В14:С24.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В14:С24 до значений х2, наклон сначала указан для х2.
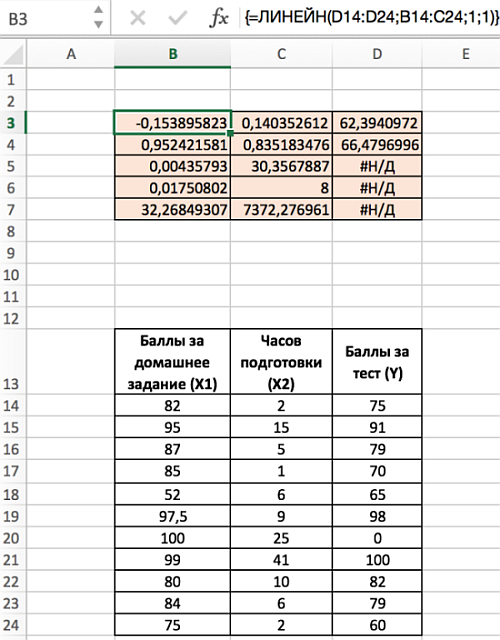
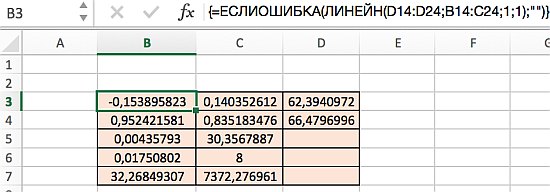
Диапазон D5:D7 содержит ошибку #Н/Д – значащую, что формула не может обнаружить значения для данных ячеек. Визуально наличие ошибки отвлекает от сути решения, поэтому далее предложим вариант избавления от нее. Так, если дополнить формулу содержащую функцию ЛИНЕЙН функцией ЕСЛИОШИБКА, то можно значительно улучшить вид таблицы, результат которой представлен ниже:
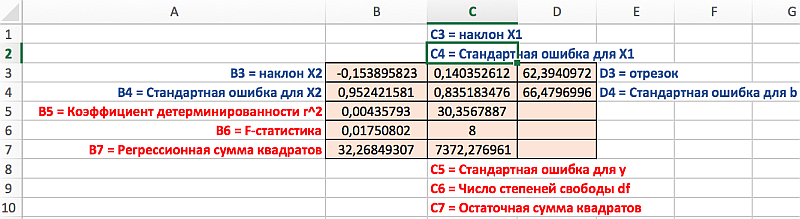
Распределение статистик в таблице их значение представлено на следующем рисунке:
Скачать примеры функции ЛИНЕЙН в Excel
В результате мы получили всю необходимую выходную статистическую информацию, которая нас интересует.
С Помощью Каких Статистических Функций в ms Excel Можно Получить Линейную Зависимость y kx b
Таким образом, все значения оси ординат, находящиеся в зоне менее 1 ПДК, не представляют опасности (функция принадлежности равна нулю), а в зоне более 10 ПДК — несут максимальную опасность (функция принадлежности равна единице). Интервал значений от 1 до 10 ПДК выражается линейной зависимостью. [c.6]
Поскольку для большого числа объединений не была установлена линейная зависимость между фактическим удельным расходом и приведенными выше факторами, то наряду с линейной моделью для всех объединений была опробована многофакторная степенная модель, которая описывается так называемой функцией Кобба— Дугласа ( 2 ) [c.52]
Наиболее часто рекомендуется пользоваться следующими функциями прямая зависимость, полином с целочисленными степенями, степенная функция, показательная функция. В настоящей работе рассматриваются гипотезы о наличии связи между себестоимостью добычи нефти и попутного газа и факторами в форме множественной линейной, полиномов трех первых степеней, мультипликативная функция Кобба — Дугласа и кинетическая производственная функция. [c.79]
Нахождение оптимального варианта возможно для линейной зависимости или выпуклой функции 5,- 3-= =f(ti-j), которая методом кусочно-линейной аппроксимации сводится к решению линейной задачи. [c.117]
Корреляционная зависимость в отличие от функциональной является неполной, проявляется лишь в среднем и только в массе наблюдений. При корреляционной связи изменению аргумента соответствует несколько значений функций. В зависимости от количества отобранных факторов различают парные и многофакторные модели различного вида линейные, степенные, логарифмические. В практике прогнозирования наибольшее распространение получили линейные модели вида [c.129]
Рассматривает линейную зависимость между зависимой и независимой переменными. Описывается в форме Y = а + ЬХ, в то время как нелинейная регрессия предполагает нелинейную зависимость, например, экспоненциальную и квадратическую функции. См. Регрессионный анализ. [c.462]
Хотя первоначальная продажная цена нового товара является сравнительно высокой (в среднем на 8,5—10,0% выше, чем при пробной продаже), на этой стадии она не подлежит снижению. По своим характеристикам цена максимальна и эластична, то есть она имеет предельный рассчитываемый уровень, при котором обеспечивается сбыт, а количественные соотношения спроса и продажной цены отвечают линейным зависимостям функции эластичности. [c.127]
Если функцию регрессии можно удовлетворительным образом аппроксимировать линейной зависимостью, то такая регрессия [c.92]
На практике может оказаться, что функцию регрессии невозможно описать удовлетворительным образом ни линейной зависимостью, ни любой из перечисленных в предыдущем параграфе нелинейных функций. Тогда стоит попытаться аппроксимировать ее комбинацией этих функций. Делается это следующим образом [c.130]
Для степенной функции ух = а х6 /и = 1и формула F-крите-рия примет тот же вид, что и при линейной зависимости [c.85]
Рассмотрим применение фиктивных переменных для функции спроса. Предположим, что по группе лиц мужского и женского пола изучается линейная зависимость потребления кофе от цены. В общем виде для совокупности обследуемых уравнение регрессии имеет вид [c.141]
Такая обратная зависимость также является убывающей максимальная цена при покупке большего количества того же самого товара всегда снижается. Связь прямой и обратной функций спроса может быть наглядно продемонстрирована на примере линейной зависимости [c.39]
Такая обратная зависимость также является возрастающей минимальная цена при производстве и продаже большего количества того же самого товара всегда повышается, прежде всего из-за возрастания альтернативных издержек, о котором говорилось в предыдущей главе. Связь прямой и обратной функций предложения также может быть наглядно продемонстрирована на примере линейной зависимости [c.43]
Слово «программирование» объясняется здесь тем, что неизвестные переменные, которые отыскиваются в процессе решения задачи, обычно в совокупности определяют программу план) работы некоторого экономического объекта. Слово «линейное» отражает факт линейной зависимости между переменными. При этом, как указано, задача обязательно имеет экстремальный характер, т.е. состоит в отыскании экстремума (максимума или минимума) целевой функции. [c.170]
ЛИНЕЙНЫЕ ЗАВИСИМОСТИ, СООТНОШЕНИЯ — экономико-математические модели в виде уравнений, в которых экономические величины (аргумент и функция) связаны между собой линейным образом. Простейший пример линейной зависимости у = kx. Графически линейная зависимость изображается прямой линией. [c.163]
В 1.4 мы ограничились линейной функцией, характеризующей зависимость темпа выхода загрязнений в окружающую среду г от темпа подачи загрязнений на очистные сооружения [c.72]
Нетрудно показать, что для линейной зависимости (7.54) потока закупок от разности цен этот поток при р = р (PQ) также является гауссовым случайным процессом с корреляционной функцией [c.258]
В общем случае m условий равенства (9.68) и (9.70) означают, что в точке ж градиенты целевой функции и функций /а- линейно зависимы, т.е. найдется такой вектор Л с составляющими Аа-, что [c.332]
Условие стационарности любой из функций Д на множестве, определяемом остальными условиями задачи, может быть записано (аналогично условиям оптимальности) как условие линейной зависимости [c.333]
Отсюда видно, что при данных уи и yv величина у представляет собой линейную функцию относительно числа детей. Это же подтверждается и графическим расположением точек (xi,yi). Второй этап. Определим неизвестные параметры а и 6 линейной зависимости [c.326]
В дальнейшем нам понадобятся понятия линейной зависимости и независимости функций. [c.374]
Например, функции у = ж, уч = Зж линейно зависимы, а функции т/1 = ж, т/2 = х + 1 линейно независимы. [c.374]
От того, линейно зависимы или линейно независимы функции yi и у2, зависит ответ на вопрос является ли функция у = = С у + Сч уч общим решением уравнения (18.8) [c.374]
При отыскании общего и частного решений уравнений (18.21) и (18.22) важную роль играет понятие линейной зависимости и независимости функций yi(x), У2(х),. . уп(х]. [c.398]
Определение линейной зависимости и независимости для двух функций у и у2 было дано на с. 374. Приведем более общее определение, пригодное для любого конечного числа функций. [c.398]
Функции т/1 (ж), уз(х),. . уп(х] называют линейно зависимыми в интервале (а, 6), если существуют постоянные числа //i, не все равные нулю, такие, что [c.398]
Как отмечалось, функции полезности, связанные друг с другом возрастающей линейной зависимостью v(w) = а + bu(w), b > 0, описывают одну и ту же систему предпочтений субъекта. Так как и (w) = bit (w) и v»(w) = bu»(w), абсолютные меры Эрроу—Пратта для функций u(w) и v(w) совпадают это позволяет утверждать, что мера Эрроу-Пратта выражает свойства предпочтений индивида, а не представляющей их функции полезности. То же относится и к относительной мере Эрроу— Пратта [c.660]
Структура оптимизационной модели состоит из целевой функции, области допустимых решений и системы ограничений, определяющих эту область. Целевая функция в самом общем виде, в свою очередь, также состоит из трех элементов управляемых переменных, неуправляемых переменных и формы функции (вида зависимости между ними). Если все функции, описывающие некоторую экономическую ситуацию линейны, то имеем задачу линейного программирования, к которой и будет сведена задача игры с природой о нахождении оптимального ассортимента продукции, выпускаемой швейным производством. [c.23]
| Рисунок 12. Выявление нелинейной составляющей функции у = 1 Ох + зш(л») + 0.5// после вычитания линейной зависимости у = 1 O.Y . ( Здесь г) — гауссовый случайный шум) | <img class=»aligncenter» src=»/images-s1/12/pomoshyu-kakix-statisticheskix-C9DA7C7.png» alt=»Рисунок 12. Выявление нелинейной составляющей функции у = 1 Ох + зш(л») + 0.5// после вычитания линейной зависимости у = 1 O.Y . ( Здесь г) — гауссовый случайный шум) » height=»300″ /> |
Для определения параметров линейного тренда по методу наименьших квадратов используется статистическая функция ЛИНЕЙН, для определения экспоненциального тренда -ЛГРФПРИБЛ. Порядок вычисления был рассмотрен в 1-м разделе практикума. В качестве зависимой переменной в данном примере выступает время (г = 1, 2,. . л). Приведем результаты вычисления функций ЛИНЕЙН и ЛГРФПРИБЛ (рис. 4.2 и 4.3). [c.151]
В теореме 5 рассмотрен случай, когда каждая строка матрица R является линейной комбинацией строк матрицы X, при этом r(X R ) = г(Х ) и класс оцениваемых функций остается прежним. В этом параграфе рассматривается обратная ситуация, когда строки матрицы R не являются линейно зависимыми от строк матрицы X, т. е. o (Rf) Псо1(Х ) = 0 . Как будет видно, наилучшая аффинная несмещенная оценка имеет в этом случае довольно простой вид. [c.341]

Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. Если же вы хотите что-то уточнить, я с радостью помогу!
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
Графически решить задачу аппроксимации означает, провести такую кривую , точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
| Рисунок 12. Выявление нелинейной составляющей функции у = 1 Ох + зш(л») + 0.5// после вычитания линейной зависимости у = 1 O.Y . ( Здесь г) — гауссовый случайный шум) | <img class=»aligncenter» src=»/images-s1/12/pomoshyu-kakix-statisticheskix-C9DA7C7.png» alt=»Рисунок 12. Выявление нелинейной составляющей функции у = 1 Ох + зш(л») + 0.5// после вычитания линейной зависимости у = 1 O.Y . ( Здесь г) — гауссовый случайный шум) » height=»300″ /> |
Для определения параметров линейного тренда по методу наименьших квадратов используется статистическая функция ЛИНЕЙН, для определения экспоненциального тренда -ЛГРФПРИБЛ. Порядок вычисления был рассмотрен в 1-м разделе практикума. В качестве зависимой переменной в данном примере выступает время (г = 1, 2,. . л). Приведем результаты вычисления функций ЛИНЕЙН и ЛГРФПРИБЛ (рис. 4.2 и 4.3). [c.151]
Линейная функция « y = kx + b » и её график
Прежде чем перейти к изучению функции « y = kx » внимательно изучите урок
«Что такое функция в математике» и «Как решать задачи на функцию».
Функцию вида « y = kx + b » называют линейной функцией.
Буквенные множители « k » и « b » называют числовыми коэффициентами .
Вместо « k » и « b » могут стоять любые числа (положительные, отрицательные или дроби).
Другими словами, можно сказать, что « y = kx + b » — это семейство всевозможных функций, где вместо « k » и « b » стоят числа.
Давайте определим для каждой функций выше, чему равны числовые коэффициенты « k » и « b » .
Обратите особое внимание на функцию « y = 0,5x » в таблице. Часто совершают ошибку при поиске в ней числового коэффициента « b ».
Рассматривая функцию « y = 0,5x », неверно утверждать, что числового коэффициента « b » в функции нет.
Числовый коэффициент « b » присутствет в функции типа « y = kx + b » всегда. В функции « y = 0,5x » числовый коэффициент « b » равен нулю .
Как построить график линейной функции
« y = kx + b »
Запомните!
Графиком линейной функции « y = kx + b » является прямая .
Так как графиком функции « y = kx + b » является прямая линия , функцию называют линейной функцией.
Из геометрии вспомним аксиому (утверждение, которое не требует доказательств), что через любые две точки можно провести прямую и притом только одну.
Исходя из аксиомы выше следует, что чтобы построить график функции вида
« у = kx + b » нам достаточно будет найти всего две точки.
Найдем значение функции « y » для двух произвольных значений « x ». Подставим, например, вместо « x » числа « 0 » и « 1 ».
Выбирая произвольные числовые значения вместо « x », лучше брать числа « 0 » и « 1 ». С этими числами легко выполнять расчеты.
Полученные значения « x » и « y » — это координаты точек графика функции.
Запишем полученные координаты точек « y = −2x + 1 » в таблицу.
| Точка | Координата по оси « Оx » (абсцисса) | Координата по оси « Оy » (ордината) |
|---|---|---|
| (·)A | 0 | 1 |
| (·)B | 1 | −1 |

Теперь проведем прямую через отмеченные точки. Эта прямая будет являться графиком функции « y = −2x + 1 ».

Как решать задачи на
линейную функцию « y = kx + b »
Построить график функции « y = 2x + 3 ». Найти по графику:
Используем правила, по которым мы строили график функции выше. Для построения графика функции « y = 2x + 3 » достаточно найти всего две точки.
Выберем два произвольных числовых значения для « x ». Для удобства расчетов выберем числа « 0 » и « 1 ».
Выполним расчеты и запишем их результаты в таблицу.
| Точка | Координата по оси « Оx » |
Координата по оси « Оy » |
|---|---|---|
| (·)A | 0 | y(0) = 2 · 0 + 3 = 3 |
| (·)B | 1 | y(1) = 2 ·1 + 3 = 5 |
Отметим полученные точки на прямоугольной системе координат.

Соединим полученные точки прямой. Проведенная прямая будет являться графиком функции « y = 2x + 3 ».

Теперь работаем с построенным графиком функции « y = 2x + 3 ».
Требуется найти значение « y », соответствующее значению « x »,
которое равно −1; 2; 3; 5 .
Тему «Как получить координаты точки функции» с графика функции мы уже подробно рассматривали в уроке «Как решать задачи на функцию».
В этому уроке для решения задачи выше вспомним только основные моменты.
Запомните!
Чтобы найти значение « y » по известному значению « x » на графике функции необходимо:
- провести перпендикуляр от оси « Ox » (ось абсцисс) из заданного числового значения « x » до пересечения с графиком функции;
- из полученной точки пересечения перпендикуляра и графика функции провести еще один перпендикуляр к оси « Oy » (ось ординат);
- полученное числовое значение на оси « Oy » и будет искомым значением.
По правилам выше найдем на построенном ранее графике функции « y = 2x + 3 » необходимые значения функции « y » для « x » равным −1; 2; 3; 5 .
| Заданное значение « x » | Полученное с графика значение « y » |
|---|---|
| −1 | 1 |
| 2 | 7 |
| 3 | 9 |
| 5 | 13 |
Переходим ко второму заданию задачи. Требуется найти значение « x », если значение « y » равно 1; 4; 0; −1 .
Выполним те же действия, что и при решении предыдущего задания. Разница будет лишь в том, что изначально мы будем проводить перпендикуляры от оси « Oy » .
| Заданное значение « y » | Полученное с графика значение « x » |
|---|---|
| −1 | −2 |
| 0 | −1,5 |
| 1 | −1 |
| 4 | 0,5 |
Как проверить, проходит ли график через точку
Не выполняя построения графика функции « y = 2x −
», выяснить, проходит ли график через точки с координатами (0; −
) и (1; −2) .
Запомните!
Чтобы проверить принадлежность точки графику функции нет необходимости строить график функции.
Достаточно подставить координаты точки в формулу функции (координату по оси « Ox » вместо « x », а координату по оси « Oy » вместо « y ») и выполнить арифметические расчеты.
Как найти точки пересечения графика с осями
Найти координаты точек пересечения графика функции « y = −1,5x + 3 » с осями координат.
Для начала построим график функции « y = −1,5x + 3 » и на графике отметим точки пересечения с осями.
Выберем два произвольных числовых значения для « x » и рассчитаем значение « y » по формуле функции. Например, для x = 0 и x = 1 .
| Точка | Координата по оси « Оx » |
Координата по оси « Оy » |
|---|---|---|
| (·)A | 0 | y(0) = −1,5 · 0 + 3 = 3 |
| (·)B | 1 | y(1) = −1,5 · 1 + 3 = 1,5 |
Отметим полученные точки на системе координат и проведем через них прямую. Тем самым мы построим график функции « y = −1,5x + 3 ».

Теперь найдем координаты точек пересечения графика функции с осями по формуле функции.
Запомните!
Чтобы найти координаты точки пересечения графика функции
с осью « Oy » (осью ординат) нужно:
- приравнять координату точки по оси « Ox » к нулю (x = 0) ;
- подставить вместо « x » в формулу функции ноль и найти значение « y »;
- записать полученные координаты точки пересечения с осью « Oy » .
Подставим вместо « x » в формулу функции « y = −1,5x + 3 » число ноль.
Запомните!
Чтобы найти координаты точки пересечения графика функции
с осью « Ox » (осью абсцисс) нужно:
- приравнять координату точки по оси « Oy » к нулю (y = 0) ;
- подставить вместо « y » в формулу функции ноль и найти значение « x »;
- записать полученные координаты точки пересечения с осью « Oy » .
Подставим вместо « y » в формулу функции « y = −1,5x + 3 » число ноль.
Чтобы было проще запомнить, какую координату точки нужно приравнивать к нулю, запомните «правило противоположности».
Если нужно найти координаты точки пересечения графика с осью « Ox » , то приравниваем « y » к нулю.
И наооборот. Если нужно найти координаты точки пересечениа графика с осью « Oy » , то приравниваем « x » к нулю.
Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Чем больше displaystyle k по модулю то есть несмотря на знак , тем круче под большим углом к оси абсцисс displaystyle Ox расположена прямая. Если же вы хотите что-то уточнить, я с радостью помогу!
Мы хотим постоянно улучшать этот учебник и вы можете нам в этом помочь.
Оформите доступ и пользуйтесь учебником ЮКлэва без ограничений (100+ статей по всем темам ОГЭ и ЕГЭ, 2000+ разобранных задач, 20+ вебинаров-практикумов)

Линейная функция (ЕГЭ 2023) | ЮКлэва
- приравнять координату точки по оси « Ox » к нулю (x = 0) ;
- подставить вместо « x » в формулу функции ноль и найти значение « y »;
- записать полученные координаты точки пересечения с осью « Oy » .
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Не выполняя построения графика функции « y = 2x −
», выяснить, проходит ли график через точки с координатами (0; −
) и (1; −2) .
Как сделать апроксимацию в excel?
Выполнение аппроксимации
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.
где ln – это величина натурального логарифма. Отсюда и наименование метода.
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:



Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Опубликовано 05 Янв 2014
Рубрика: Справочник Excel | 18 комментариев
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда. ». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R2.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
Итоги.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R2>0,87. Отличный результат – при R2>0,94.
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»).
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
(04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R2
Подробности Автор: Administrator Родительская категория: Заметки Категория: Компьютерная повседневность Создано: 28 января 2013 Обновлено: 15 мая 2014 Просмотров: 28651
Чтобы приступить к аппроксимации кривой ваших экспериментальных данных в Excel 2003:
2. Выделите линию функции на графике и нажмите правую кнопку мыши, выберите «Добавить линию тренда»
3. Выберите тип аппроксимации во вкладке «Тип» в откурывшемся диалоговом окне «Линия тренда»
4. На вкладке «Параметры» — прогностические параметры, показывать уравнение на графике или нет
В MS Excel аппроксимация экспериментальных данных осуществляется путем построения их графика (x – отвлеченные величины) или точечного графика (x – имеет конкретные значения) с последующим подбором подходящей аппроксимирующей функции (линии тренда).
1. Создайте диаграмму (график).
2. Выделите линию функции на графике и нажмите правую кнопку мыши, выберите «Добавить линию тренда».
3. Выберите тип аппроксимации во вкладке «Тип» в откурывшемся диалоговом окне «Линия тренда».
4. На вкладке «Параметры» — прогностические параметры, показывать уравнение на графике или нет.
— известны показатели прибыли (их можно обозначить Y) в зависимости от размера капиталовложений (X);
— известны объемы реализации фирмы (Y) за шесть недель ее работы. В этом случае, X – это последовательность недель.
Иногда говорят, что требуется построить эмпирическую модель. Эмпирической называется модель, построенная на основе реальных наблюдений. Если модель удается найти, можно сделать прогноз о поведении исследуемого явления и процесса в будущем и, возможно, выбрать оптимальное направление ее развития.
В общем случае задача аппроксимации экспериментальных данных имеет следующую постановку:
Пусть известны данные, полученные практическим путем (в ходе n экспериментов или наблюдений), которые можно представить парами чисел (хi; уi). Зависимость между ними отражает таблица:
Выяснить вид функции можно либо из теоретических соображений, либо анализируя расположение точек (хi; уi) на координатной плоскости.
Графически решить задачу аппроксимации означает, провести такую кривую , точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
Для решения задачи аппроксимации используют метод наименьших квадратов.
При этом функция считается наилучшим приближением к , если для нее сумма квадратов отклонений «теоретических» значений , найденных по эмпирической формуле, от соответствующих опытных значений , имеет наименьшее значение по сравнению с другими функциями, из числа которых выбирается искомое приближение.
Математическая запись метода наименьших квадратов имеет вид:
Таким образом, задача аппроксимации распадается на две части.
Сначала устанавливают вид зависимости и, соответственно, вид эмпирической формулы, то есть решают, является ли она линейной, квадратичной, логарифмической или какой-либо другой. Если нет каких-либо теоретических соображений для подбора вида формулы, обычно выбирают функциональную зависимость из числа наиболее простых, сравнивая их графики с графиком заданной функции.
После этого определяются численные значения неизвестных параметров выбранной эмпирической формулы, для которых приближение к заданной функции оказывается наилучшим.
Простейшим видом эмпирической модели с двумя параметрами, используемой для аппроксимации результатов экспериментов, является линейная регрессия, описываемая линейной функцией:
Для модели линейной регрессии метод наименьших квадратов (1) запишется :
Для решения (2) относительно а и b приравнивают к нулю частные производные:
В итоге для нахождения a и b надо решить систему линейных алгебраических уравнений вида:
Реализовать метод наименьших квадратов в случае линейной регрессии в Excel можно различными способами.
1 способ. Построить систему линейных алгебраических уравнений, подставив в (3) все известные значения, и решить ее, например, матричным методом (см. зад. 4).
В формульном виде элемент расчетной таблицы приведен на рис. 26.
2 способ. Решить в Excel задачу оптимизации (2), применив для этого Поиск решения (см. зад. 5).
Замечание 2. В диалоговом окне команды Поиск решения следует задать целевую ячейку, направление цели – на минимум и изменяемые ячейки (рис. 28). Данная задача ограничений не содержит.
Замечание3. В качестве эмпирических моделей с двумя параметрами могут использоваться и нелинейные модели вида:
Описанный способ решения метода наименьших квадратов применим и для нелинейных зависимостей.
3 способ. Для нахождения значений параметров a и b в случае линейной регрессии можно использовать следующие встроенные в Excel статистические функции:
Причем, функция НАКЛОН ( ) возвращает значение параметра а, функция ОТРЕЗОК( ) возвращает значение параметра b. Функция ЛИНЕЙН( ) возвращает одновременно оба параметра линейной зависимости, так как является функцией массива. Поэтому для ввода функции ЛИНЕЙН( ) в таблицу надо соблюдать следующие правила:
· по окончании нажать одновременно комбинацию клавиш Ctrl+ Shift+Enter.
В результате в левой ячейке получится значение параметра а, а в правой – значение параметра b.
При создании линии тренда в Excel на основе данных диаграммы применяется та или иная аппроксимация. Excel позволяет выбрать один из пяти аппроксимирующих линий или вычислить линию, показывающую скользящее среднее.
Кроме того, Excel предоставляет возможность выбирать значения пересечения линии тренда с осью Y, а также добавлять к диаграмме уравнение аппроксимации и величину достоверности аппроксимации (R2). Также, можно определять будущие и прошлые значения данных, исходя из линии тренда и связанного с ней уравнения аппроксимации.
2. Выполнить команду Диаграмма, Добавить линию тренда или переместить указатель на ряд данных, щелкнуть правой кнопкой мыши, а затем в контекстном меню выбрать команду Добавить линию тренда. В появившемся окне Линия тренда раскрыть вкладку Тип (рис. 29)
3. В списке Построен на ряде – выделить ряд данных, к которому нужно добавить линию тренда (Рис.29).
4. В группе Построение линии тренда (аппроксимация и сглаживание) выбрать один из шести типов аппроксимации (сглаживания). – линейная, логарифмическая, полиномиальная, степенная, экспоненциальная, скользящее среднее (Рис.29)
5. Чтобы установить параметры линии тренда надо раскрыть вкладку Параметры диалогового окна Линия тренда(рис. 30)
Показывать уравнение на диаграмме – осуществляет вывод уравнения аппроксимации на диаграмму в виде текстового поля.
Поместить на диаграмму величину достоверности аппроксимации R2– осуществляет вывод на диаграмму достоверности аппроксимации в виде текста.
Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. Если же вы хотите что-то уточнить, я с радостью помогу!
Графически решить задачу аппроксимации означает, провести такую кривую , точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
Линейная функция y kx b и её график
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
Корреляционная зависимость в отличие от функциональной является неполной, проявляется лишь в среднем и только в массе наблюдений. При корреляционной связи изменению аргумента соответствует несколько значений функций. В зависимости от количества отобранных факторов различают парные и многофакторные модели различного вида линейные, степенные, логарифмические. В практике прогнозирования наибольшее распространение получили линейные модели вида [c.129]
Функция
ЛИНЕЙН()
специально создана для оценки параметров линейной регрессии, а также для вывода регрессионной статистики (коэффициента детерминации, стандартных ошибок,
F
-статистики
и др.).
Функция
ЛИНЕЙН()
может использоваться для
простой регрессии
(в этом случае прогнозируемая переменная Y зависит от одной контролируемой переменной Х) и для
множественной регрессии
(Y зависит от нескольких Х).
Рассмотрим функцию на примере
простой регрессии
(оценивается
наклон
и
сдвиг
линии регрессии). Использование функции в случае
множественной регрессии
рассмотрено в соответствующей статье про
множественную регрессию
.
Функция
ЛИНЕЙН()
возвращает несколько значений, поэтому для вывода результатов потребуется несколько ячеек. Часто функцию вводят как
формулу массива
: нажатием клавиш
CTRL
+
SHIFT
+
ENTER
,
но, как будет показано ниже, для вывода результатов вычислений это не обязательно.
Функция работает в 2-х режимах. В простейшем случае, когда 4-й аргумент функции опущен или установлен ЛОЖЬ, функция возвращает только 2 значения — это оценки параметров модели: наклона a и сдвига b.
Для того, чтобы вычислить оценки:
- выделите 2 ячейки в одной строке,
-
в
Строке формул
введите, например, =
ЛИНЕЙН(C23:C83;B23:B83)
-
нажмите
CTRL
+
SHIFT
+
ENTER
.
В левой ячейке будет рассчитано значение
наклона
, в правой –
сдвига
.
Примечание
: В справке MS EXCEL результат функции
ЛИНЕЙН()
соответствующий
наклону
обозначается буквой m, а
сдвиг
– буквой b.
Примечание
: Без
формул массива
можно обойтись. Для этого нужно использовать функцию
ИНДЕКС()
, которая выведет нужное значение. Например, чтобы вывести величину
сдвига
линии регрессии введите формулу =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;2)
. Если 4-й аргумент функции опущен или установлен ЛОЖЬ, то функция
ЛИНЕЙН()
в возвращает массив значений вида 1х2 (т.е. 2 ячейки, расположенные в одной строке). Поэтому, для вывода величины
сдвига
прямой линии регрессии, первый аргумент функции
ИНДЕКС()
, который является номером строки, должен быть равен 1, а второй аргумент, номер столбца, должен быть равен 2. Чтобы вывести значение
наклона
линии регрессии формулу
=ЛИНЕЙН(C23:C83;B23:B83)
достаточно ввести просто как обычную формулу и нажать
ENTER
. Конечно, можно использовать и формулу
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;1)
.
Теперь о втором, более сложном режиме функции. Этот режим нужно использовать, если требуется вывести дополнительную статистику (4-й аргумент функции должен быть установлен ИСТИНА). В этом случае функция
ЛИНЕЙН()
возвращает 10 значений в диапазоне 5х2 ячеек (5 строк и 2 столбца). Как и в более простом режиме, в первой строке возвращаются оценки параметров модели:
наклона
и
сдвига
.
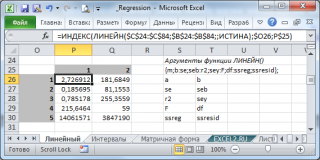
Чтобы ввести функцию как
формулу массива
выполните следующие действия:
- выделите диапазон 5х2 ячеек (2 столбца и 5 строк),
-
в
Строке формул
введите формулу
ЛИНЕЙН($C$23:$C$83;$B$23:$B$83;;ИСТИНА)
-
чтобы ввести формулу нажмите одновременно комбинацию клавиш
CTRL
+
SHIFT
+
ENTER
Примечание
: Чтобы обойтись без
формул массива
нужно использовать функцию
ИНДЕКС()
, которая выведет нужное значение. Например, чтобы вывести
коэффициент детерминации
R
2
введите формулу =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;1)
. 3 – это номер строки диапазона 5х2, а 1 – это номер столбца. В
файле примера на листе Линейный
в диапазоне
Q
26:
R
30
показано как вывести все значения, возвращаемые функцией
ЛИНЕЙН()
без
формул массива
.
Итак, установив 4-й аргумент равным ИСТИНА и введя функцию тем или иным способом, функция выведет:
-
в строке 1:
оценки параметров модели
(наклон и сдвиг).
-
в строке 2:
Стандартные ошибки для наклона и сдвига
. Ошибки обозначаются se и seb;
-
в строке 3:
коэффициент детерминации
и
стандартную ошибку регрессии
. Обозначаются R
2
и SEy; -
в строке 4:
значение F-статистики и число степеней свободы
. Обозначаются F и df;
-
в строке 5: Суммы квадратов SSR, SSE определяющие
изменчивость объясненную и необъясненную моделью
(см. в статьеПростая линейная регрессия
разделы про коэффициент детерминации и
статью про F-тест
). В справке MS EXCEL SSR, SSE обозначаются как
ssreg
(Regression Sum of Squares) и
ssresid
(Residuals Sum of Squares) соответственно.
Примечание
: Разобраться в значениях, возвращаемых функцией
ЛИНЕЙН()
, можно лишь разобравшись в теории линейной регрессии.
В
файле примера
также приведены формулы, позволяющие сделать расчеты без функции
ЛИНЕЙН()
– см. диапазон
Q
34:
R
38
. Альтернативные формулы помогают разобраться в алгоритме расчета вышеуказанных статистических показателей.
Регрессионный анализ в Microsoft Excel

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Помимо этой статьи, на сайте еще 12704 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Функция ЛИНЕЙН
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = m1x1 + m2x2 +. + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив . Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив известные_значения_x опущен, то предполагается, что это массив <1;2;3;. >, имеющий такой же размер, что и массив известные_значения_y.
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив .
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
Стандартные значения ошибок для коэффициентов m1,m2. mn.
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ).
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, как вычисляется 2, см. в разделе «Замечания» далее в этой теме.
Стандартная ошибка для оценки y.
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными.
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df.
Регрессионная сумма квадратов.
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Замечания
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1).
Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y.
Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1)
Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:
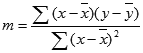
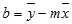
где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ( известные_значения_y ).
Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y( known_x) для прямой линии или РОСТ( known_y, known_x в ) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r 2 — индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r 2 равно ssreg/sstotal.
В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Простая линейная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Примечание : Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место множественная регрессия .
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части — оценке неизвестных параметров линейной модели .
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем прочность этого волокна (Y) зависит только от рабочей температуры процесса в реакторе (Х), которая задается оператором.
Построим диаграмму рассеяния (см. файл примера лист Линейный ), созданию которой посвящена отдельная статья . Вообще, построение диаграммы рассеяния для целей регрессионного анализа де-факто является стандартом.
СОВЕТ : Подробнее о построении различных типов диаграмм см. статьи Основы построения диаграмм и Основные типы диаграмм .
Приведенная выше диаграмма рассеяния свидетельствует о возможной линейной взаимосвязи между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание : Наличие даже такой очевидной линейной взаимосвязи не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие причинной взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание : Как известно, уравнение прямой линии имеет вид Y = m * X + k , где коэффициент m отвечает за наклон линии ( slope ), k – за сдвиг линии по вертикали ( intercept ), k равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х ( рабочую температуру процесса ) при некотором значении Х i и произвести несколько наблюдений переменной Y ( прочность нити ). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого значения . При увеличении количества измерений, среднее этих измерений, будет стремиться к математическому ожиданию случайной величины Y (при Х i ) равному μy(i)=Е(Y i ).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела Проверка статистических гипотез . В статье о проверке гипотезы о среднем значении генеральной совокупности в качестве нулевой гипотезы предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае простой линейной регрессии в качестве нулевой гипотезы предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ y(i) =α* Х i +β. Уравнение μ y(i) =α* Х i +β можно переписать в обобщенном виде (для всех Х и μ y ) как μ y =α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
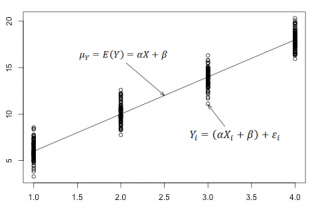
Данная линия называется регрессионной линией генеральной совокупности (population regression line), параметры которой ( наклон a и сдвиг β ) нам не известны (по аналогии с гипотезой о среднем значении генеральной совокупности , где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х + β , к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют линейной регрессионной моделью . Часто Х еще называют независимой переменной (еще предиктором и регрессором , английский термин predictor , regressor ), а Y – зависимой (или объясняемой , response variable ). Так как регрессор у нас один, то такая модель называется простой линейной регрессионной моделью ( simple linear regression model ). α часто называют коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε i была адекватной — требуется:
- Ошибки ε i должны быть независимыми переменными;
- При каждом значении Xi ошибки ε i должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε i ]=0);
- При каждом значении Xi ошибки ε i должны иметь равные дисперсии (обозначим ее σ 2 ).
Примечание : Последнее условие называется гомоскедастичность — стабильность, гомогенность дисперсии случайной ошибки e. Т.е. дисперсия ошибки σ 2 не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε i ]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε i ]= Е[a*Xi+β]+ Е[ε i ]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия случайной переменной Y равна дисперсии ошибки ε, т.е. VAR(Y)= VAR(ε)=σ 2 . Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε i ).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует регрессионная линия генеральной совокупности , т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений .
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно a и b . Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Первая задача регрессионного анализа – оценка неизвестных параметров ( estimation of the unknown parameters ). Подробнее см. раздел Оценки неизвестных параметров модели .
Вторая задача регрессионного анализа – Проверка адекватности модели ( model adequacy checking ).
Примечание : Оценки параметров модели обычно вычисляются методом наименьших квадратов (МНК), которому посвящена отдельная статья .
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры простой линейной регрессионной модели Y=a*X+β+ε оценим с помощью метода наименьших квадратов (в статье про МНК подробно описано этот метод ).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
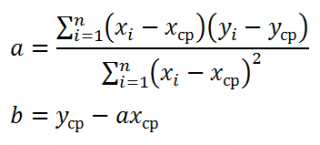
Таким образом, мы получим уравнение прямой линии Y= a *X+ b , которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание : В статье про метод наименьших квадратов рассмотрены случаи аппроксимации линейной и квадратичной функцией , а также степенной , логарифмической и экспоненциальной функцией .
Оценку параметров в MS EXCEL можно выполнить различными способами:
Сначала рассмотрим функции НАКЛОН() , ОТРЕЗОК() и ЛИНЕЙН() .
Пусть значения Х и Y находятся соответственно в диапазонах C 23: C 83 и B 23: B 83 (см. файл примера внизу статьи).
Примечание : Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью Генерация данных для линейной регрессии в MS EXCEL ).
В MS EXCEL наклон прямой линии а ( оценку коэффициента регрессии ), можно найти по методу МНК с помощью функции НАКЛОН() , а сдвиг b ( оценку постоянного члена или константы регрессии ), с помощью функции ОТРЕЗОК() . В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции ЛИНЕЙН() , английская версия LINEST (см. статью об этой функции ).
Формула =ЛИНЕЙН(C23:C83;B23:B83) вернет наклон а . А формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) — сдвиг b . Здесь требуются пояснения.
Функция ЛИНЕЙН() имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН() возвращает только оценки параметров модели: a и b .
Примечание : Остальные значения, возвращаемые функцией ЛИНЕЙН() , нам потребуются при вычислении стандартных ошибок и для проверки значимости регрессии . В этом случае аргумент статистика должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в Строке формул
- нажать CTRL+SHIFT+ENTER (см. статью про формулы массива ).
Если в Строке формул выделить формулу = ЛИНЕЙН(C23:C83;B23:B83) и нажать клавишу F9 , то мы увидим что-то типа <3,01279389265416;154,240057900613>. Это как раз значения a и b . Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу = ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83)) . При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция ТРАНСП() транспонировала строку в столбец ).
Чтобы разобраться в этом подробнее необходимо ознакомиться с формулами массива .
Чтобы не связываться с вводом формул массива , можно использовать функцию ИНДЕКС() . Формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1) или просто ЛИНЕЙН(C23:C83;B23:B83) вернет параметр, отвечающий за наклон линии, т.е. а . Формула =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) вернет параметр b .
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент а , можно также вычислить через коэффициент корреляции и стандартные отклонения выборок :
= КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению ковариации выборок Х и Y и дисперсии выборки Х:
И, наконец, запишем еще одну формулу для нахождения сдвига b . Воспользуемся тем фактом, что линия регрессии проходит через точку средних значений переменных Х и Y.
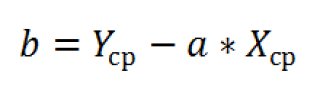
Вычислив средние значения и подставив в формулу ранее найденный наклон а , получим сдвиг b .
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры линии регрессии можно найти в матричной форме (см. файл примера лист Матричная форма ).
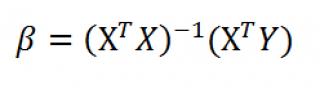
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг b ), β1 (наклон a ).
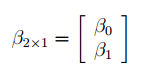
Матрица Х равна:
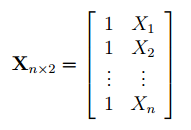
Матрица Х называется регрессионной матрицей или матрицей плана . Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица Х T – это транспонированная матрица Х . Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом Y обозначен столбец значений переменной Y.
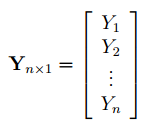
Чтобы перемножить матрицы используйте функцию МУМНОЖ() . Чтобы найти обратную матрицу используйте функцию МОБР() .
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
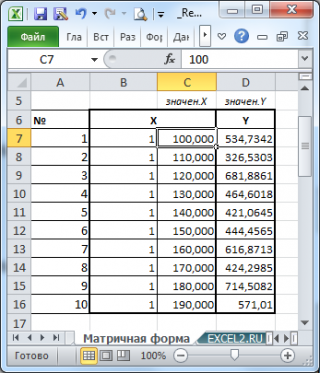
Слева от него достроим столбец с 1 для матрицы Х.
и введя ее как формулу массива в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае множественной регрессии .
Построение линии регрессии
Для отображения линии регрессии построим сначала диаграмму рассеяния , на которой отобразим все точки (см. начало статьи ).
Для построения прямой линии используйте вычисленные выше оценки параметров модели a и b (т.е. вычислите у по формуле y = a * x + b ) или функцию ТЕНДЕНЦИЯ() .
Формула = ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23) возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца В2 .
Примечание : Линию регрессии можно также построить с помощью функции ПРЕДСКАЗ() . Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции ТЕНДЕНЦИЯ() работает только в случае одного регрессора. Функция ТЕНДЕНЦИЯ() может быть использована и в случае множественной регрессии (в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
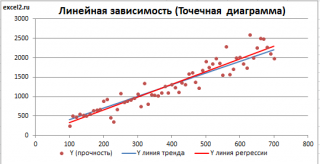
Как видно из диаграммы выше линия тренда и линия регрессии не обязательно совпадают: отклонения точек от линии тренда случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента Линия тренда. Для этого выделите диаграмму, в меню выберите вкладку Макет , в группе Анализ нажмите Линия тренда , затем Линейное приближение. В диалоговом окне установите галочку Показывать уравнение на диаграмме (подробнее см. в статье про МНК ).
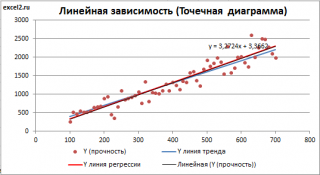
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами линией регрессии, а параметры уравнения a и b должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание: Для того, чтобы вычисленные параметры уравнения a и b совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был Точечная, а не График , т.к. тип диаграммы График не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; . Именно эти значения и берутся при расчете параметров линии тренда . Убедиться в этом можно если построить диаграмму График (см. файл примера ), а значения Хнач и Хшаг установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с a и b .
Коэффициент детерминации R 2
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения регрессионной модели ). Очевидно, что лучшей оценкой для yi будет среднее значение ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание : Далее будет использована терминология и обозначения дисперсионного анализа .
После построения регрессионной модели для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
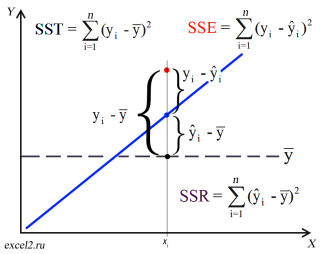
Очевидно, что используя регрессионную модель мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
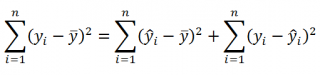
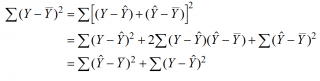
или в других, общепринятых в зарубежной литературе, обозначениях:
Total Sum of Squares = Regression Sum of Squares + Error Sum of Squares
Примечание : SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность дисперсии (вариации) и соответственно описывают разброс (изменчивость): Общую изменчивость (Total variation), Изменчивость объясненную моделью (Explained variation) и Необъясненную изменчивость (Unexplained variation).
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью / Общая изменчивость.
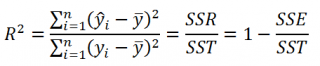
Этот показатель равен квадрату коэффициента корреляции и в MS EXCEL его можно вычислить с помощью функции КВПИРСОН() или ЛИНЕЙН() :
R 2 принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии ( Standard Error of a regression ) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение линейной регрессионной модели Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со средним значением μ и дисперсией σ 2 .
Оценив значение дисперсии σ 2 и вычислив из нее квадратный корень – получим Стандартную ошибку регрессии. Чем точки наблюдений на диаграмме рассеяния ближе находятся к прямой линии, тем меньше Стандартная ошибка.
Примечание : Вспомним , что при построении модели предполагается, что среднее значение ошибки ε равно 0, т.е. E[ε]=0.
Оценим дисперсию σ 2 . Помимо вычисления Стандартной ошибки регрессии эта оценка нам потребуется в дальнейшем еще и при построении доверительных интервалов для оценки параметров регрессии a и b .
Для оценки дисперсии ошибки ε используем остатки регрессии — разности между имеющимися значениями yi и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки дисперсии σ 2 используют следующую формулу:
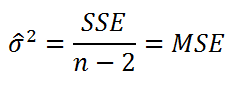
где SSE – сумма квадратов значений ошибок модели ε i =yi — ŷi ( Sum of Squared Errors ).
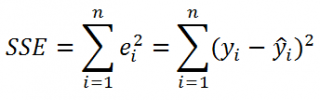
SSE часто обозначают и как SSres – сумма квадратов остатков ( Sum of Squared residuals ).
Оценка дисперсии s 2 также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов ошибок или MSRES (Mean Square of Residuals), т.е. среднее квадратов остатков . Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание : Напомним, что когда мы использовали МНК для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на линии регрессии.
Математическое ожидание случайной величины MSE равно дисперсии ошибки ε, т.е. σ 2 .
Чтобы понять почему SSE выбрана в качестве основы для оценки дисперсии ошибки ε, вспомним, что σ 2 является также дисперсией случайной величины Y (относительно среднего значения μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi = a * Хi + b (значение уравнения регрессии при Х= Хi), то логично использовать именно SSE в качестве основы для оценки дисперсии σ 2 . Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае простой линейной регрессии число степеней свободы равно n-2, т.к. при построении линии регрессии было оценено 2 параметра модели (на это было «потрачено» 2 степени свободы ).
Итак, как сказано было выше, квадратный корень из s 2 имеет специальное название Стандартная ошибка регрессии ( Standard Error of a regression ) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см. этот раздел ). Если ошибки предсказания ε имеют нормальное распределение , то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от линии регрессии . SEy имеет размерность переменной Y и откладывается по вертикали. Часто на диаграмме рассеяния строят границы предсказания соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
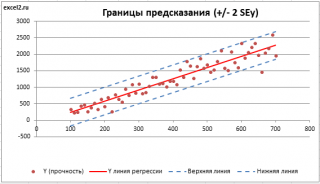
В MS EXCEL стандартную ошибку SEy можно вычислить непосредственно по формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе Оценка неизвестных параметров линейной модели мы получили точечные оценки наклона а и сдвига b . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ).
Стандартная ошибка коэффициента регрессии a вычисляется на основании стандартной ошибки регрессии по следующей формуле:
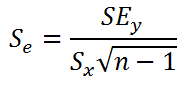
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
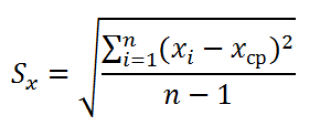
где Sey – стандартная ошибка регрессии, т.е. ошибка предсказания значения переменой Y ( см. выше ).
В MS EXCEL стандартную ошибку коэффициента регрессии Se можно вычислить впрямую по вышеуказанной формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции ЛИНЕЙН() :
Формулы приведены в файле примера на листе Линейный в разделе Регрессионная статистика .
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
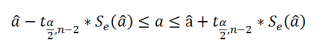
где — квантиль распределения Стьюдента с n-2 степенями свободы. Величина а с «крышкой» является другим обозначением наклона а .
Например для уровня значимости альфа=0,05, можно вычислить с помощью формулы =СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
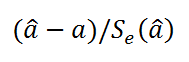
является t-распределением Стьюдента с n-2 степенью свободы (то же справедливо и для наклона b ).
Примечание : Подробнее о построении доверительных интервалов в MS EXCEL можно прочитать в этой статье Доверительные интервалы в MS EXCEL .
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии. Здесь мы считаем, что коэффициент регрессии a имеет распределение Стьюдента с n-2 степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
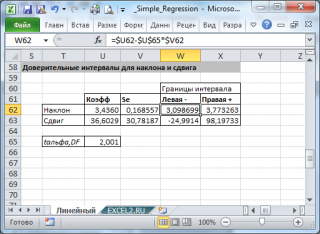
Примечание : Подробнее о построении доверительных интервалов с использованием t-распределения см. статью про построение доверительных интервалов для среднего .
Стандартная ошибка сдвига b вычисляется по следующей формуле:
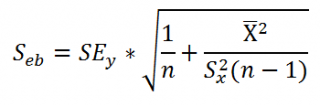
В MS EXCEL стандартную ошибку сдвига Seb можно вычислить с помощью функции ЛИНЕЙН() :
При построении двухстороннего доверительного интервала для сдвига его границы определяются аналогичным образом как для наклона : b +/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда коэффициент регрессии a равен 0.
Чтобы убедиться, что вычисленная нами оценка наклона прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда нулевую гипотезу Н 0 не удается отвергнуть.
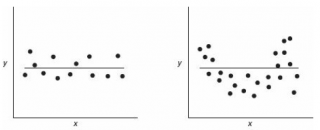
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом коэффициент линейной корреляции равен 0.
Ниже — 2 ситуации, когда нулевая гипотеза Н 0 отвергается.
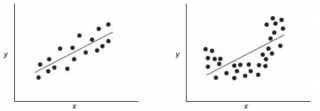
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить уровень значимости , пусть альфа=0,05;
- Рассчитать с помощью функции ЛИНЕЙН() стандартное отклонение Se для коэффициента регрессии (см. предыдущий раздел );
- Рассчитать число степеней свободы: DF=n-2 или по формуле = ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t 0 =a/S e , которая имеет распределение Стьюдента с числом степеней свободы DF=n-2;
- Сравнить значение тестовой статистики |t0| с пороговым значением t альфа ,n-2. Если значение тестовой статистики больше порогового значения, то нулевая гипотеза отвергается ( наклон не может быть объяснен лишь случайностью при заданном уровне альфа) либо
- вычислить p-значение и сравнить его с уровнем значимости .
В файле примера приведен пример проверки гипотезы:
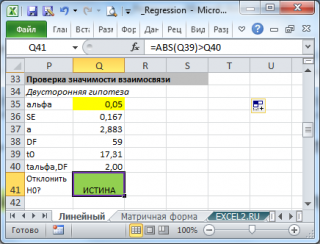
Изменяя наклон тренда k (ячейка В8 ) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание : Проверка значимости взаимосвязи эквивалентна проверке статистической значимости коэффициента корреляции . В файле примера показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью процедуры F-тест .
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры простой линейной регрессионной модели Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ= a * Хi + b
Ŷ также является точечной оценкой для среднего значения Yi при заданном Хi. Но, при построении доверительных интервалов используются различные стандартные ошибки .
Стандартная ошибка нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели a и b ;
- случайность ошибки модели ε.
Учет этих неопределенностей приводит к стандартной ошибке S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
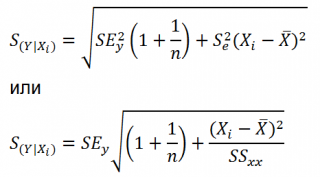
где SS xx – сумма квадратов отклонений от среднего значений переменной Х:
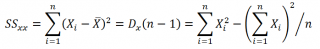
В MS EXCEL 2010 нет функции, которая бы рассчитывала эту стандартную ошибку , поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал или Интервал предсказания для нового наблюдения (Prediction Interval for a New Observation) построим по схеме показанной в разделе Проверка значимости взаимосвязи переменных (см. файл примера лист Интервалы ). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х ср ), то интервал будет постепенно расширяться при удалении от Х ср .
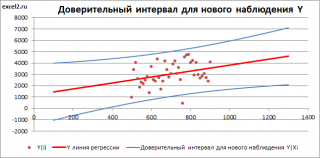
Границы доверительного интервала для нового наблюдения рассчитываются по формуле:
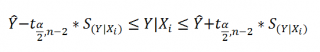
Аналогичным образом построим доверительный интервал для среднего значения Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае доверительный интервал будет уже, т.к. средние значения имеют меньшую изменчивость по сравнению с отдельными наблюдениями ( средние значения, в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
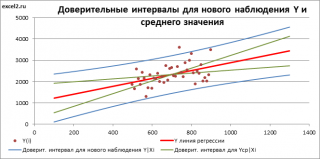
Стандартная ошибка S(Yср|Xi) вычисляется по практически аналогичным формулам как и стандартная ошибка для нового наблюдения:
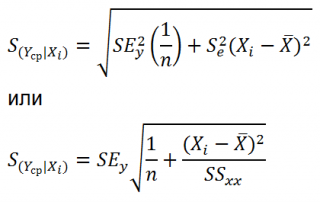
Как видно из формул, стандартная ошибка S(Yср|Xi) меньше стандартной ошибки S(Y|Xi) для индивидуального значения .
Границы доверительного интервала для среднего значения рассчитываются по формуле:
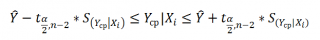
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел Предположения линейной регрессионной модели ).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках простой линейной модели n остатков имеют только n-2 связанных с ними степеней свободы . Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о нормальности распределения ошибок строят график проверки на нормальность (Normal probability Plot).
В файле примера на листе Адекватность построен график проверки на нормальность . В случае нормального распределения значения остатков должны быть близки к прямой линии.
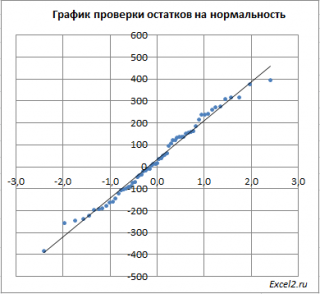
Так как значения переменной Y мы генерировали с помощью тренда , вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор о нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
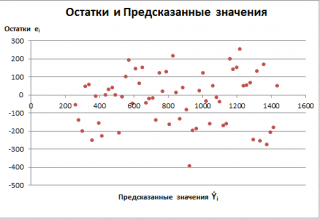
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе Стандартная ошибка регрессии оценкой стандартного отклонения ошибок является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
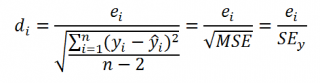
SEy можно вычислить с помощью функции ЛИНЕЙН() :
Иногда нормирование остатков производится на величину стандартного отклонения остатков (это мы увидим в статье об инструменте Регрессия , доступного в надстройке MS EXCEL Пакет анализа ), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
источники:
http://support.microsoft.com/ru-ru/office/%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F-%D0%BB%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD-84d7d0d9-6e50-4101-977a-fa7abf772b6d
http://excel2.ru/articles/prostaya-lineynaya-regressiya-v-ms-excel
Рассмотрим построение линии
регрессии с помощью MS Excel на примере
следующей задачи. Известна табличная
зависимость G(L). Построить линию регрессии
и вычислить ожидаемое значение в точках
0, 0.75, 1.75, 2.8,4.5.

Введем таблицу значений в лист MS Excel и
построим точечный график. Рабочий лист
примет вид (см. рис. 2).

Рисунок 2
Чтобы в ячейках K2,
L2
получить коэффициенты линейной
зависимости a и b
необходимо выделить эти две ячейки
мышью, выбрать функцию ЛИНЕЙН
в списке статистических
функций

Ввести в поле Известные_значения_y
значения из ячеек B2:J2,
а в поле Известные_значения_x
значения из ячеек B1:J1.
Нажать Ok.
Не забыть, что функция ЛИНЕЙН
работает со значениями x
и y в виде массивов.
Т. е. необходимо нажать F2,
а затем Ctrl+Shift+Enter.
В результате получим следующие
коэффициенты (см. рис 3)
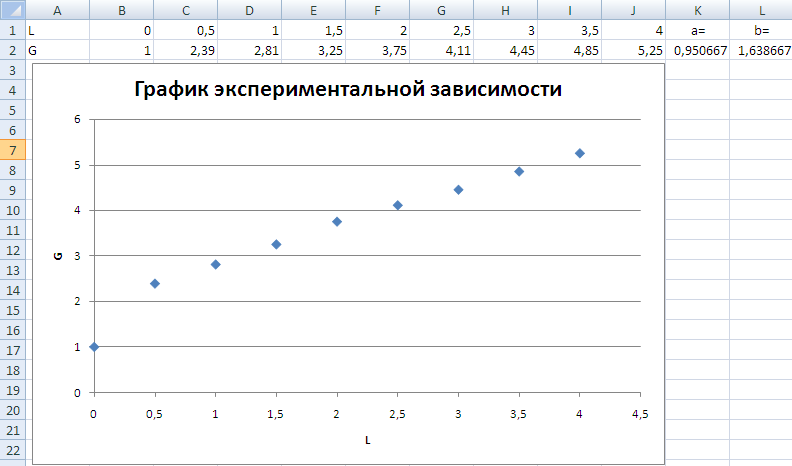
Рисунок 3
В ячейке M2
будет рассчитываться
значение коэффициента корреляции, для
чего туда следует ввести формулу
=КОРРЕЛ(B1:J1;B2:J2).
В результате рабочий лист примет вид
(см. рис. 4).

Рисунок 4
Теперь с помощью функции
ТЕНДЕНЦИЯ вычислим
ожидаемое значение в точках 0,
0.75, 1.75, 2.8, 4.5. Для этого
в ячейки L9:L13
занесем эти значения, а в ячейки M9:M13
введем формулу =ТЕНДЕНЦИЯ(B2:J2;B1:J1;L9:L13)
для расчета ожидаемых
значений. Для этого выделим ячейки
M9:M13 выберем
в списке статистических функций функцию
ТЕНДЕНЦИЯ и
заполним ее как указано ниже

Нажимаем OK. Так
как функция ТЕНДЕНЦИЯ работает с данными
как с массивами то необходимо дополнительно
нажать F2,
а затем Ctrl+Shift+Enter.
В результате получим следующие
значения.
|
x |
y |
|
0 |
1,638667 |
|
0,75 |
2,351667 |
|
1,75 |
3,302333 |
|
2,8 |
4,300533 |
|
4,5 |
5,916667 |
Изобразим линию регрессии
на диаграмме. Для этого выделим
экспериментальные точки на графике,
щелкнем правой кнопкой мыши и выберем
команду Исходные данные.
В появившемся диалоговом окне (см. рис.
5), для добавления линии регрессии щелкнем
по кнопке Добавить.

Рисунок 5
В качестве имени введем Линия
регрессии, в качестве
Значения Х L9:L13,
в качестве Значения Y
M9:M13.
Далее выделяем линию регрессии, для
изменения ее типа щелкаем правой кнопкой
мыши и выбираем команду Тип
диаграммы (рис. 6).
Для форматирования линии регрессии
дважды щелкаем по ней (рис. 7), можно
изменить толщину линии, цвет, тип маркера
и т.д.
 Рисунок 6
Рисунок 6
Рисунок 7
После форматирования графика рабочий
лист примет вид, изображенный на рис.
8.

Рисунок 8
Квадратичная функция
Необходимо определить
параметры функции y=a0+a1*x+a2*x2.
Составим функцию
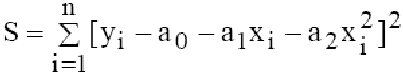
Для этой функции запишем
систему уравнений:

Получим

Для нахождения параметров
a0,
a1,
a2
необходимо решить эту
систему линейных алгебраических
уравнений (например, методом Крамера
или методом обратной матрицы).
Кубическая функция
Необходимо определить
параметры многочлена третьей степени:
y=a0+a1*x+a2*x2+a3*x3.
СоставимфункциюS:
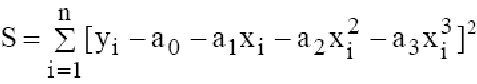
Система уравнений для
нахождения параметров a0,
a1,
a2,
a3
имеет вид:

Для нахождения параметров
a0, a1,
a2, a3
необходимо решить
систему четырёх линейных алгебраических
уравнений.
Если в качестве аналитической
зависимости выберем многочлен k-й степени
y=a0+a1x+…+ak
xk,
то система уравнений для определения
параметров ai
принимает вид:

Подбор параметров функции
y=a*xb.
Для нахождения параметров
функции y=a*xb
проведем логарифмирование
функции y.
Lg y = Lg a + b Lg x
Сделаем замену Y
= lg y; X
= lg x; A = lg
a. Получим линейную
зависимость Y = A+bX.
Найдем коэффициенты линии регрессии A
и b.
Затем определяем a=10A.
Мы получили значение параметров функции
y=a*xb.
Подбор параметров функции
y=a*ebx.
Прологарифмируем выражение
y = a*ebx;
Lg y = Lg a + b*x*Lg e;
Проведём замену Y=Lg
y. Вновь получаем линейную
зависимость Y=Bx+A,
где A= Lg a;
B=b*Lg e.
Найдем A и
B. Затем
определим значение параметров a
и b,
a=10A
и b=B/Lg(e).
Ниже проведены замены переменных,
которые преобразовывают функции вида
y=f(x, a, b) к
линейной зависимости Y=
Ax+B.


Подбор параметров функции
y=a*xb*ecx
Прологарифмируем выражение
y=a*xb*ecx,
после логарифмирования оно принимает
вид:
Lg y=Lg a+b*Lg x+c*Lg ex
Сделаем замену Y=Lgy,
A=Lga,
C=c*Lge.
После замены выражение принимает вид:
Y=A+b*Lg X+CX
Для функции этой составим
функцию S:
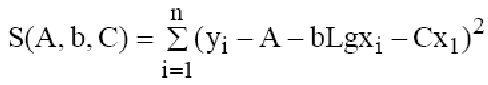
Параметры A,
b и С
следует выбрать таким
образом, чтобы функция S
была минимальной. После
элементарных преобразований получим
систему трёх линейных алгебраических
уравнений для определения коэффициентов
A, b
и C.

Решив систему, получим значения
A, b,
C. После
чего вычисляем
a=10A;
c=C/Lg(e).
Соседние файлы в папке Методички
- #
- #
- #
- #
- #
- #
- #
Получим числовые характеристики коэффициентов этого уравнения.

Рис 2. График линейной аппроксимации.

Рис 3. График квадратичной аппроксимации.

Рис 4. График экспоненциальной аппроксимации.
Полученное при построении линии тренда значение коэффициента детерминированности для экспоненциальной зависимости не совпадает с истинным значением (это значение было сосчитано вручную выше) поскольку при вычислении коэффициента детерминированности с помощью функции ЛИНЕЙН используются не истинные значения , а преобразованные значения с дальнейшей линеаризацией.
Использование функции ЛИНЕЙН
Назначение функции ЛИНЕЙН
Рассмотрим назначение функции ЛИНЕЙН.
Эта функция использует метод наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные.
Функция возвращает массив, который описывает полученную прямую. Уравнение для прямой линии имеет следующий вид:
y=m1*x1 + m2*x2 + …b или y=m*x + b
где зависимое значение y является функцией независимого значения x. Значения m — это коэффициенты, соответствующие каждой независимой переменной x, а b — это постоянная. Заметим, что y,x и m могут быть векторами.
Функция ЛИНЕЙН возвращает массив . ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Получение числовых характеристик зависимости
Для построения числовых характеристик создаем табличную формулу, которая будет занимать 5 строк и 2 столбца (см. таблицу 10).В этот интервал вводим функцию ЛИНЕЙН. Для этого была выполнена следующая последовательность действий:
1. Выделяем область A58:B62.
2. Вызываем Мастера функций.
3. Выбираем функцию ЛИНЕЙН.
4. Определяем аргументы функции:
· В качестве изв_знач_x указываем B2:B16.
· В качестве изв_знач_y указываем C2:C16.
· Третье поле константа оставляем пустым.
· В четвертом поле стат набираем истина.
5. Нажимаем кнопку Закончить.
6. Устанавливаем курсор в строку формул.
7. Нажимаем комбинацию клавиш Ctrl + Shift + Enter, чтобы обеспечить ввод табличной формулы.
Результатом выполнения данных действий является таблица 10.

Поясним назначение некоторых величин, расположенных в таблице 10.
Величины расположенные в ячейках A58 и B58 характеризуют соответственно наклон и сдвиг.
А58 — коэффициент детерминированности.
А59 — F — наблюдаемое значение.
B60 — число степеней свободы.
A61 — регрессионная сумма квадратов.
B62 — остаточная сумма квадратов.
Блок-схема
Далее проверим свои вычисления с помощью программы написанной на языке Turbo Pascal, а для этого составим блок-схему:
—>Информационные технологии —>
Функция ЛИНЕЙН вычисляет коэффициенты m и b прямой линии y = mx + b , которая наилучшим образом аппроксимирует имеющиеся данные, а также дополнительную регрессионную статистику. Функция возвращает массив данных, который описывает полученную прямую. Синтаксис функции:
ЛИНЕЙН(известные_y, [известные_x], [константа], [статистика])
Пример 1
Даны x и y: (0, 3), (1, 1), (2, 6), (3, 3), (4, 7). Найти коэффициенты m и b прямой линии y = mx + b , наилучшим образом аппроксимирующей эти данные по критерию наименьших квадратов.
Подготовим таблицу как показано ниже. Ячейки E2:F6 не заполняйте, они будут заполнены автоматически.
- В A2:A6 введены значения x, блоку присвоено имя х.
- В В2:В6 введены значения y, блоку присвоено имя y.
- В E2:F6 введена табличная формула . Для того чтобы ввести табличную формулу, надо выделить блок ячеек E2:F6, ввести формулу и нажать комбинацию клавиш Ctrl Shift Enter . Фигурные скобки вводить вручную не надо.
Пояснение к блоку статистических результатов функции Линейн.
- В E2 записан коэффициент m, в F2 — коэффициент b.
- В E3:F3 стандартные отклонения для этих коэффициентов.
- В E4 записан так называемый коэффициент детерминации R2. Этот коэффициент лежит на отрезке [0; 1]. Считается, что чем ближе этот коэффициент к 1, тем лучше регрессионное уравнение описывает зависимость. Иногда к такой интерпретации надо относиться с осторожностью.
- В F4 находится стандартная ошибка для оценки у.
- В E5 записано значение F-статистики, а в F5 — количество степеней свободы.
- В E6:F6 записана регрессионная сумма квадратов (10) и остаточная сумма квадратов (14).
Функция НАКЛОН
Функция НАКЛОН вычисляет коэффициент m — тангенс угла наклона прямой регрессии. Например: =НАКЛОН(y;x)
Функция ОТРЕЗОК
Функция ОТРЕЗОК вычисляет коэффициент b — отрезок, отсекаемый прямой на оси ординат. Например: =ОТРЕЗОК(y;x)
Функция ПРЕДСКАЗ
Вычисляет или предсказывает будущее значение по существующим значениям. Предсказываемое значение — это y-значение, соответствующее заданному x-значению. x- и y-значения — известны; новое значение предсказывается с использованием линейной регрессии. Этой функцией можно воспользоваться для прогнозирования.
ПРЕДСКАЗ ( x ; известные_y ; известные_x )
x — точка данных, для которой предсказывается значение.
Функция ТЕНДЕНЦИЯ
Возвращает значения в соответствии с линейным трендом. Аппроксимирует прямой линией (по методу наименьших квадратов) массивы «известные_y» и «известные_x». Возвращает значения y, соответствующие этой прямой для заданного массива «новые_x».
ТЕНДЕНЦИЯ ( известные_y ;[известные_x];[новые_x];[константа])
Новые_x — новые значения x, для которых функция ТЕНДЕНЦИЯ возвращает соответствующие значения y.
Пример 2.
Постройте таблицу по образцу. В примечаниях показаны имена ячеек или формулы. В A5:A9 известныеX, в B5:B9 известныеY. Блоку A5:A12 присвоено имя Х. Рассчитайте Предсказ, Тенденцию и прямую mx+b.
Постройте диаграмму по образцу. На диаграмме видно, что прямая пересекает ось ординат в точке 2 (b=2), а наклон прямой равен 45° (m=1). Прямые Предсказ, Тенденция и mx+b слились в одну линию.
Функция линейн в excel пример
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику (подробнее см. справку MS Excel).

Рис. 22.1. Четыре аргумента функции ЛИНЕЙН
Скачать заметку в формате Word или pdf, примеры в формате Excel
Линейная регрессия
На рис. 22.2 показан набор данных (он уже анализировался в главе 9, когда мы обсуждали функции НАКЛОН, ОТРЕЗОК, ПРЕДСКАЗ и ТЕНДЕНЦИЯ). Поскольку ЛИНЕЙН является функцией массива и вы хотите, чтобы она вернула два значения, выполните следующие действия:
- Выделите диапазон D2:Е2. Функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y. Это – баллы, которые студенты заработали на последнем тестировании.
- Введите известные значения х. Это количество часов, которые студенты потратили на подготовку к тестам.
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.

Рис. 22.2. Функция ЛИНЕЙН возвращает наклон и отрезок, если массив расположен в горизонтальном диапазоне

Рис. 22.3. Функция массива ЛИНЕЙН заменяет две отдельные функции – НАКЛОН и ОТРЕЗОК
Если вам всё же нужно вывести результаты функции ЛИНЕЙН в вертикальный массив, воспользуйтесь ухищрением (рис. 22.4).

Рис. 22.4. Формулы для вывода результатов в вертикальный массив
Если вы хотите отобразить не только наклон и отрезок, но и дополнительные статистики, выделите диапазон на один столбец больше, чем столбцов с переменными х, и высотой 5 строк. Как показано на рис. 22.5, поскольку у вас лишь одна переменная х, выделите диапазон Е2:F6 (2 столбца по 5 строк). Третьему и четвертому аргументам присвойте значения ИСТИНА: вы хотите, чтобы b считалось обычным образом, и хотите вывести дополнительные статистики. После ввода формулы нажатием Ctrl+Shift+Enter, результат должен соответствовать рис. 22.6 (подробнее о десяти статистиках см. Простая линейная регрессия).

Рис. 22.5. Когда требуется дополнительная статистика для одной переменной, выделите диапазон 2*5; функция ЛИНЕЙН вернет 10 значений; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке

Рис. 22.6. Функция ЛИНЕЙН возвращает 10 статистик
В главе 8 было показано, как с помощью формулы преобразовать таблицу в столбец. На рис. 22.7 приведена формула, позволяющая представить результаты работы функции ЛИНЕЙН (которые она возвращает в диапазон 2*5) в вертикальном столбце.
Следующие элементы являются аргументами функции ИНДЕКС:
- аргумент массив: функция ЛИНЕЙН($B$2:$B$12;$A$2:$A$12;ИСТИНА;ИСТИНА) возвращает диапазон из пяти строк и двух столбцов.
- аргумент номер_строки: ОСТАТ(ЧСТРОК(E$1:E1)-1;5)+1 возвращает следующие значения 1,2,3,4,5,1,2,3,4,5 при копировании формулы вдоль столбца от Е1 до Е10.
- аргумент номер_столбца: ЦЕЛОЕ((ЧСТРОК(E$1:E1)-1)/5)+1 возвращает 1,1,1,1,1,2,2,2,2,2 при копировании формулы вдоль столбца от Е1 до Е10.

Рис. 22.7. Преобразование диапазона вывода формулы ЛИНЕЙН из 2*5 в вертикальный
Формула в Е1 не требует ввода с помощью Ctrl+Shift+Enter.
Множественная регрессия
В случае множественной регресии, когда значения y зависят от двух переменных х1 и х2, функция ЛИНЕЙН возвращает 12 статистик (подробнее см. Введение в множественную регрессию и Построение модели множественной регрессии). На рис. 22.8 используются следующие обозначения:
- y = зависимая переменная
- x1 = независимая переменная 1 = баллы за домашнее задание
- x2 = независимая переменная 2 = часов изучал последний столбец тест = гр.
Чтобы выполнить множественную регрессию:
- Выделите диапазон В3:D7 (число столобцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу . Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В13:С23.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В13:С23 до значений х2, наклон сначала указан для х2.

Рис. 22.8. Для двух переменных x1 и х2 функция ЛИНЕЙН выполняет множественную регрессию
Если вас раздражают знаяения ошибки #Н/Д дополните вашу формулу функцией ЕСЛИОШИБКА (рис. 22.9).

Рис. 22.9. Вы можете избавиться от ошибок #Н/Д «обернув» ЛИНЕЙН функцией ЕСЛИОШИБКА
Пример с тремя переменными не должен вызвать затруднений (рис. 22.10).

Рис. 22.10. Множественная регрессия для трех независимых переменных
2 комментария для “Глава 22. Функция массива ЛИНЕЙН”
Добрый день!
У меня следующая ситуация: значения двух независимых переменных x1 и x2 содержаться на разных листах. Перенести их на один лист не получается, потому что наборов данных несколько сотен и делать для каждого набора отдельную вкладку — не вариант. Можно ли как-то обойти требование что x1 и x2 должны содержаться в едином диапазоне?
Функция EXCEL ЛИНЕЙН()
Функция ЛИНЕЙН() специально создана для оценки параметров линейной регрессии, а также для вывода регрессионной статистики (коэффициента детерминации, стандартных ошибок, F -статистики и др.).
Функция ЛИНЕЙН() может использоваться для простой регрессии (в этом случае прогнозируемая переменная Y зависит от одной контролируемой переменной Х) и для множественной регрессии (Y зависит от нескольких Х).
Рассмотрим функцию на примере простой регрессии (оценивается наклон и сдвиг линии регрессии). Использование функции в случае множественной регрессии рассмотрено в соответствующей статье про множественную регрессию .
Функция ЛИНЕЙН() возвращает несколько значений, поэтому для вывода результатов потребуется несколько ячеек. Часто функцию вводят как формулу массива : нажатием клавиш CTRL + SHIFT + ENTER , но, как будет показано ниже, для вывода результатов вычислений это не обязательно.
Функция работает в 2-х режимах. В простейшем случае, когда 4-й аргумент функции опущен или установлен ЛОЖЬ, функция возвращает только 2 значения — это оценки параметров модели: наклона a и сдвига b.
Для того, чтобы вычислить оценки:
- выделите 2 ячейки в одной строке,
- в Строке формул введите, например, = ЛИНЕЙН(C23:C83;B23:B83)
- нажмите CTRL+SHIFT+ENTER.
В левой ячейке будет рассчитано значение наклона , в правой – сдвига .
Примечание : В справке MS EXCEL результат функции ЛИНЕЙН() соответствующий наклону обозначается буквой m, а сдвиг – буквой b.
Примечание : Без формул массива можно обойтись. Для этого нужно использовать функцию ИНДЕКС() , которая выведет нужное значение. Например, чтобы вывести величину сдвига линии регрессии введите формулу = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;2) . Если 4-й аргумент функции опущен или установлен ЛОЖЬ, то функция ЛИНЕЙН() в возвращает массив значений вида 1х2 (т.е. 2 ячейки, расположенные в одной строке). Поэтому, для вывода величины сдвига прямой линии регрессии, первый аргумент функции ИНДЕКС() , который является номером строки, должен быть равен 1, а второй аргумент, номер столбца, должен быть равен 2. Чтобы вывести значение наклона линии регрессии формулу =ЛИНЕЙН(C23:C83;B23:B83) достаточно ввести просто как обычную формулу и нажать ENTER . Конечно, можно использовать и формулу =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;1) .
Теперь о втором, более сложном режиме функции. Этот режим нужно использовать, если требуется вывести дополнительную статистику (4-й аргумент функции должен быть установлен ИСТИНА). В этом случае функция ЛИНЕЙН() возвращает 10 значений в диапазоне 5х2 ячеек (5 строк и 2 столбца). Как и в более простом режиме, в первой строке возвращаются оценки параметров модели: наклона и сдвига .
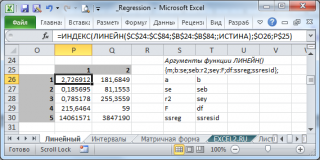
Чтобы ввести функцию как формулу массива выполните следующие действия:
- выделите диапазон 5х2 ячеек (2 столбца и 5 строк),
- в Строке формул введите формулу ЛИНЕЙН($C$23:$C$83;$B$23:$B$83;;ИСТИНА)
- чтобы ввести формулу нажмите одновременно комбинацию клавиш CTRL + SHIFT + ENTER
Примечание : Чтобы обойтись без формул массива нужно использовать функцию ИНДЕКС() , которая выведет нужное значение. Например, чтобы вывести коэффициент детерминации R 2 введите формулу = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;1) . 3 – это номер строки диапазона 5х2, а 1 – это номер столбца. В файле примера на листе Линейный в диапазоне Q 26: R 30 показано как вывести все значения, возвращаемые функцией ЛИНЕЙН() без формул массива .
Итак, установив 4-й аргумент равным ИСТИНА и введя функцию тем или иным способом, функция выведет:
- в строке 1: оценки параметров модели (наклон и сдвиг).
- в строке 2: Стандартные ошибки для наклона и сдвига . Ошибки обозначаются se и seb;
- в строке 3: коэффициент детерминации и стандартную ошибку регрессии . Обозначаются R 2 и SEy;
- в строке 4: значение F-статистики и число степеней свободы . Обозначаются F и df;
- в строке 5: Суммы квадратов SSR, SSE определяющие изменчивость объясненную и необъясненную моделью (см. в статье Простая линейная регрессия разделы про коэффициент детерминации и статью про F-тест ). В справке MS EXCEL SSR, SSE обозначаются как ssreg (Regression Sum of Squares) и ssresid (Residuals Sum of Squares) соответственно.
Примечание : Разобраться в значениях, возвращаемых функцией ЛИНЕЙН() , можно лишь разобравшись в теории линейной регрессии.
В файле примера также приведены формулы, позволяющие сделать расчеты без функции ЛИНЕЙН() – см. диапазон Q 34: R 38 . Альтернативные формулы помогают разобраться в алгоритме расчета вышеуказанных статистических показателей.
5 способов расчета значений линейного тренда в MS Excel
Это первая статья из серии «Как самостоятельно рассчитать прогноз продаж с учетом роста и сезонности», из которой вы узнаете о 5 способах расчета значений линейного тренда в Excel.
Для того, чтобы легче было научиться прогнозировать продажи с учетом роста и сезонности, я разбил 1 большую статью о расчете прогноза на 3 части:
-
- Расчет значений тренда (рассмотрим на примере Линейного тренда в этой статье);
- Расчет сезонности;
- Расчет прогноза;
После изучения данного материала вы сможете выбрать оптимальный способ расчета значений линейного тренда, который будет удобен для решения вашей задачи, а в последствии, и для расчета прогноза наиболее удобным для вас способом.
Линейный тренд хорошо применять для временного ряда, данные которого увеличиваются или убывают с постоянной скоростью.
Рассмотрим линейный тренд на примере расчета прогноза продаж в Excel по месяцам.
Временной ряд продажи по месяцам (см. вложенный файл).
В этом временном ряду у нас есть 2 переменных:
Уравнение линейного тренда y(x)=a+bx, где
y — это объёмы продаж
x — номер периода (порядковый номер месяца)
a – точка пересечения с осью y на графике (минимальный уровень);
b – это значение, на которое увеличивается следующее значение временного ряда;
1-й способ расчета значений линейного тренда в Excel с помощью графика
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044Для прогнозирования нам необходимо рассчитать значения линейного тренда, как для анализируемых значений, так и для будущих периодов.
При расчете значений линейного тренде нам будут известны:
- Время — значение по оси Х;
- Значение «a» и «b» уравнения линейного тренда y(x)=a+bx;
Рассчитываем значения тренда для каждого периода времени от 1 до 25, а также для будущих периодов с 26 месяца до 36.
Например, для 26 месяца значение тренда рассчитывается по следующей схеме: в уравнение подставляем x=26 и получаем y=135134*26+4594044=8107551
27-го y=135134*27+4594044=8242686
2-й способ расчета значений линейного тренда в Excel — функция ЛИНЕЙН
1. Рассчитаем коэффициенты линейного тренда с помощью стандартной функции Excel:
=ЛИНЕЙН(известные значения y, известные значения x, константа, статистика)
Для расчета коэффициентов в формулу вводим
известные значения y (объёмы продаж за периоды),
известные значения x (номера периодов),
вместо константы ставим 1,
вместо статистики 0,
Получаем 135135 — значение (b) линейного тренда y=a+bx;
Для того чтобы Excel рассчитал сразу 2 коэффициента (a) и (b) линейного тренда y=a+bx, необходимо
- установить курсор в ячейку с формулой и выделить соседнюю справа, как на рисунке;
- нажимаем клавишу F2, а затем одновременно — клавиши CTRL + SHIFT + ВВОД.
- известные значения y — это объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
- известные значения x — это номера периодов x для известных значений объёмов продаж y;
- новые значения x — это номера периодов, для которых мы хотим рассчитать значения линейного тренда;
- константа — ставим 1, необходимо для того, чтобы значения тренда рассчитывались с учетом коэффицента (a) для линейного тренда y=a+bx;
Получаем 135135, 4594044 — значение (b) и (a) линейного тренда y=a+bx;
2. Рассчитаем значения линейного тренда с помощью полученных коэффициентов . Подставляем в уравнение y=135134*x+4594044 номера периодов — x, для которых хотим рассчитать значения линейного тренда.
2-й способ точнее, чем первый, т.к. коэффициенты тренда мы получаем без округления, а также быстрее.
3-й способ расчета значений линейного тренда в Excel — функция ТЕНДЕНЦИЯ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ТЕНДЕНЦИЯ(известные значения y; известные значения x; новые значения x; конста)
Подставляем в формулу
Для того чтобы рассчитать значения тренда для всего временного диапазона, в «новые значения x» вводим диапазон значений X, выделяем диапазон ячеек равный диапазону со значениями X с формулой в первой ячейке и нажимаем клавишу F2, а затем — клавиши CTRL + SHIFT + ВВОД.
4-й способ расчета значений линейного тренда в Excel — функция ПРЕДСКАЗ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ПРЕДСКАЗ(x; известные значения y; известные значения x)
Вместо X поставляем номер периода, для которого рассчитываем значение тренда.
Вместо «известные значения y» — объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
«известные значения x» — это номера периодов для каждого выделенного объёма продаж.
3-й и 4-й способ расчета значений линейного тренда быстрее, чем 1 и 2-й, однако с его помощью невозможно управлять коэффициентами тренда, как описано в статье «О линейном тренде».
5-й способ расчета значений линейного тренда в Excel — Forecast4AC PRO
2. Заходим в меню программы и нажимаем «Start_Forecast». Значения линейного тренда рассчитаны.
Для расчета прогноза осталось применить к значениям трендов будущих периодов коэффициенты сезонности, и прогноз продаж с учетом роста и сезонности готов.
В следующих статье «Как самостоятельно сделать прогноз продаж с учетом роста и сезонности» мы:
О том, что еще важно знать о линейном тренде, вы можете узнать в статье «Что важно знать о линейном тренде».
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Решение с помощью функции ЛИНЕЙН
ЛИНЕЙН – это статистическая функция Microsoft Excel, позволяющая определять параметры уравнения линейной регрессии . Технология решения задачи следующая.
1.Введите исходные данные в соответствии с рис. 63.
2. Рассчитайте параметры уравнения линейной регрессии .
2.1. Выделите ячейки В24:С28 (5 строк и 2 столбца).
2.2. Щелкните левой кнопкой мыши на панели инструментов на кнопке
или выполните командуВставка,fxФункция, щелкнув поочередно левой кнопкой мыши.2.3. В диалоговом окне Мастер функций — шаг 1 из 2 с помощью левой кнопки мыши установите: Категория ® , Выберете функцию ® (рис. 73).
2.4. Щелкните левой кнопкой мыши на кнопке .
2.5. На вкладке ЛИНЕЙН установите параметры в соответствии с рис. 74.
2.6. Щелкните левой кнопкой мыши на кнопке .
2.7. Нажмите на клавишу , а затем на комбинацию клавиш + + .
Результаты решения выводятся на экран дисплея в следующем виде (рис. 75).
В табл. 15 приведено название показателей, значение которых дано в ячейках Е2:F6 на рис. 75.
Т а б л и ц а 15
Название показателей, выводимых с помощью функции ЛИНЕЙН
В Microsoft Excel также используется статистическая функция ЛГРФПРИБЛ для вычисления параметров уравнения экспоненциальной регрессии . Технология решения аналогична применению функции ЛИНЕЙН.
Решение с помощью надстройки Анализ данных
Анализ данных – это надстройка Microsoft Excel, предназначенная для статистических расчетов. Технология решения следующая.
1.Введите исходные данные в соответствии с рис. 63.
2. Рассчитайте параметры уравнения линейной регрессии .
2.1. Выполните командуСервис,Анализ данных, щелкнув поочередно левой кнопкой мыши.
2.2. В диалоговом окне Анализ данных с помощью левой кнопки мыши установите: Инструменты анализа ® (рис. 76).
2.3. Щелкните левой кнопкой мыши на кнопке .
2.4. На вкладке Регрессия установите параметры в соответствии с рис. 77.
2.5. Щелкните левой кнопкой мыши на кнопке .
Результаты решения выводятся на экран дисплея в следующем виде (рис. 78).
Пояснения к названию отдельных показателей на рис. 78 приведены в табл. 16.
Т а б л и ц а 16
Название показателей, выводимых с помощью надстройки
Анализ данных
III. Задание к расчетно-графической работе по математической статистике на тему «Статистический анализ вариационных рядов распределения (на примере настрига шерсти овец и длины волоса шерсти)»
По 25 овцам имеются данные о настриге шерсти и длины волоса шерсти (табл. 17 и 18).
Т а б л и ц а 17
Настриг шерсти, кг (y)
Т а б л и ц а 18
Длина волоса шерсти, см (x)
С помощью втабличного процессора Microsoft Excel,выполните следующие задания.
1. Постройте интервальные ряды распределения настрига и длины волоса шерсти, отобразите их графически в виде гистограмм, полигонов и кумулят. Для этого используйте надстройку Анализ данных, Мастер функций и Мастер диаграмм.
2. Для анализа рядов распределения рассчитайте средние величины (среднюю арифметическую, моду, медиану), выборочные показатели вариации (дисперсию, среднее квадратическое отклонение, коэффициент вариации) и показатели распределения (коэффициенты асимметрии и эксцесса). Для этого используйте Мастер функций и инструмент Описательная статистика надстройки Анализ данных.
3. С помощью выборочного метода рассчитайте для каждого ряда распределения предельные ошибки выборочной средней, найдите доверительные пределы генеральной средней при уровне вероятности суждения 0,95
4. Проверьте гипотезу соответствия рядов распределения настрига и длины волоса шерсти нормальному закону распределения. Для этого используйте Мастер функций.
5. Используя данные интервального ряда распределения настрига шерсти с помощью дисперсионного анализа рассчитайте достоверность разницы в настриге шерстив зависимости от длины волоса шерсти. Для этого используйте надстройку Анализ данных.
6. С помощью корреляционного анализа определите влияние длины волоса шерсти на настриг шерсти. Для этого постройте линейное уравнение регрессии, рассчитайте коэффициент корреляции и оцените его достоверность с помощью t-критерия Стьюдента и F-критерия Фишера. Для этого используйте надстройку Анализ данных.
По каждому заданию сделайте соответствующие выводы.
План работы
1. Вариационные ряды распределения. Графическое представление данных.
2. Статистические оценки параметров распределения.
3. Интервальные оценки. Доверительные интервалы. Ошибки выбороч- ной средней.
4. Статистические гипотезы
5. Дисперсионный анализ
6. Корреляционный анализ
Образец оформления
Первичные данные по настригу (кг) и длине волоса шерсти (см) овец
Построение графика в Excel и использование функции ЛИНЕЙН
Рассмотрим результаты эксперимента, приведенные в исследованном выше примере.
Исследуем характер зависимости в три этапа:
— Построим график зависимости.
— Построим линию тренда (в данном случае это прямая ).
— Получим числовые характеристики коэффициентов этого уравнения.
Решение
Построение графика зависимости.
1. Выделим интервал А1:В25.
2. Вызовем Мастер диаграмм, нажав соответствующую кнопку на панели инструментов.
3. Используя мышь, выделим область для встроенной диаграммы.
4. На 1 шаге в диалоговом окне Мастера диаграмм интервал А1:В25 должен быть указан, если это не так укажите. Нажмите Шаг>.
5. На 2 шаге выберите тип диаграммы XY-точечная.Нажмите Шаг>.
6. На 3 шаге выберите первый тип автоформата. Нажмите Шаг>
7. На 4 шаге укажите следующие параметры:
8. Отвести 1 столбец для данных по оси Х; отвести 1 строку для текста легенды. Нажмите Шаг>.
9. На 5 шаге в окне «Название диаграммы: » введите заголовок «Линейная аппроксимация»; в окне «Категорий [X]:» введите «x»; в окне «Значений [Y]:» введите «y». Нажмите Закончить.
Построение линии тренда
Для построения линии тренда выполним следующую последовательность действий:
Дважды щелкнем по диаграмме. Диаграмма активизируется.
Щелкните по графику непосредственно в одну из изображенных точек. Сам график активизируется, его окраска изменится.
Вставляем линию тренда, воспользуемся меню Вставка – Линия тренда.
Появиться диалоговое окно «Линия тренда» выберем на вкладке «Тип» (Рис.2) линейный тип и перейдем к вкладке «Параметры».
На вкладке «Параметры» (Рис.3) потребуем показывать уравнение тренда на диаграмме и показывать значение , поставив их в соответствующие клетки. Нажмем кнопку ОК.
На диаграмме появится линия тренда с соответствующим уравнением. Также изменится легенда. При желании текстовое поле с уравнением и значением , а также название координат x и y, можно оттащить в более удобное место, как это сделано на Рис 4.
Для построения квадратичной аппроксимации на четвертом шаге в диалоговом окне «Линия тренда» выберем на вкладке «Тип» (Рис.2) полиномиальный тип степень 2. Результат представлен на рис.5.
Для построения экспоненциальной аппроксимации на четвертом шаге в диалоговом окне «Линия тренда» выберем на вкладке «Тип» (Рис.2) экспоненциальный тип. Результат представлен на рис.6.
Сравнивая результаты, полученные при помощи функции ЛИНЕЙН видим что они полностью совпадают с вычислениями, проведенными выше. Это указывает на то, что вычисления верны.
Примечание: Полученное при построении линии тренда значение коэффициента детерминированности для экспоненциальной зависимости не совпадает с истинным значением (это значение было сосчитано вручную выше) поскольку при вычислении коэффициента детерминированности с помощью функции ЛИНЕЙН используются не истинные значения , а преобразованные значения с дальнейшей линеаризацией.
Получение числовых характеристик зависимости
Для построения числовых характеристик необходимо создать табличную формулу, которая будет занимать 5 строк и 2 столбца. Этот интервал может располагаться в произвольном месте на рабочем листе. В этот интервал требуется ввести функцию ЛИНЕЙН. Для этого выполняем следующую последовательность действий:
— Выделите область A65:B69.
— Вызовите Мастер функций.
— Выберите функцию Линейн.
— Определим аргументы функции.
— В качестве изв_знач_уукажите В1:В25.
— В качестве изв_знач_хукажите А1:А25.
— Третье поле Константаоставьте пустым.
— В четвертом поле статнаберите истина.
— Нажмите кнопку Закончить.
— Установите курсор в строку формул.
— Нажмите комбинацию клавиш Ctrl+Shift+Enter, это обеспечит ввод табличной формулы!
В результате должны заполниться все ячейки интервала A65:B69(см. табл.9).
Поясним назначение некоторых величин, расположенных в табл.9.
Величины, расположенные в ячейках A67 и B67 характеризуют соответственно наклон и сдвиг.
A69 — коэффициент детерминированности.
A70 — F-наблюдаемое значение.
B68 — число степеней свободы.
A69 — регрессионная сумма квадратов.
B69 — остаточная сумма квадратов.
Рассмотрим назначение функции ЛИНЕЙН.
Эта функция использует метод наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Уравнение для прямой линии имеет следующий вид:
где зависимое значение y является функцией независимого значения x. Значения m — это коэффициенты, соответствующие каждой независимой переменной x, а b — это постоянная. Заметим, что y, x и m могут быть векторами.
Функция ЛИНЕЙН возвращает массив . ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y;известные_значения_x;конст; статистика)
Известные_значения_y — это множество значений y, которые уже известны для соотношения .
— Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — это множество значений x, которые уже известны для соотношения .
— Массив известные_значения_x может содержать одно или несколько множеств переменных.
— Если используется только одна переменная, то известные_значения_y и известные_значения_x могут быть массивами любой формы при условии, что они имеют одинаковую размерность.
— Если используется более одной переменной, то известные_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец).
Конст— это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
— Если констимеет значение ИСТИНА или опущена, то b вычисляется обычным образом.
— Если констимеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx .
Статистика— это логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
— Если статистикаимеет значение ИСТИНА, то функция ЛИНЕЙН возвращает дополнительную регрессионную статистику, так что возвращаемый массив будет иметь вид:
— Если статистика имеет значение ЛОЖЬ или опущена, то функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
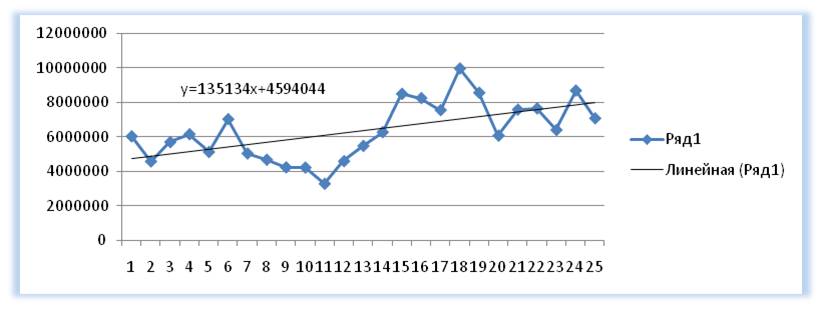 Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044

 или выполните командуВставка,fxФункция, щелкнув поочередно левой кнопкой мыши.
или выполните командуВставка,fxФункция, щелкнув поочередно левой кнопкой мыши.






В этой статье описаны синтаксис формулы и использование функции ЛИНЕЙН в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа в разделе » см .
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
y = m1x1 + m2x2 +. + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив . Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Аргументы функции ЛИНЕЙН описаны ниже.
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив известные_значения_x опущен, то предполагается, что это массив <1;2;3;. >, имеющий такой же размер, что и массив известные_значения_y.
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли возвратить дополнительную регрессионную статистику.
Если аргумент статистика имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: .
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
Стандартные значения ошибок для коэффициентов m1,m2. mn.
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ).
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если это 1, то в примере есть идеальная корреляция — разница между предполагаемыми значениями y и фактическим значением y отсутствует. С другой стороны, если коэффициент определения равен 0, уравнение регрессии не может быть полезным для предсказания значения y. Сведения о том, как вычислена Версия R2, приведены в разделе «Примечания» ниже.
Стандартная ошибка для оценки y.
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными.
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df.
Регрессионная сумма квадратов.
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой (x1,y1) и (x2,y2); наклон будет равен (y2 — y1)/(x2 — x1).
Y-пересечение (b):
Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:
где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
Функции «линейный» и «кривая» ЛИНЕЙН и ЛИНЕЙН могут вычислять подходящую прямую линейную или экспоненциальную кривую, подходящую для данных. Тем не менее, вам нужно решить, какой из двух результатов лучше подходит для ваших данных. Можно вычислить тенденцию (известные_значения_y; известные_значения_x) для прямой линии или рост (известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции без аргумента « Новые_значения_x » возвращают массив значений y, прогнозируемых вдоль данной линии или кривой на реальных точках данных. Затем вы можете сравнить прогнозируемые значения с фактическими значениями. Вы можете попытаться создать диаграмму для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен отношению ssreg/sstotal.
В некоторых случаях один или несколько столбцов X (допускает наличие столбцов Y и X) могут не иметь дополнительного прогнозируемого значения в других столбцах X. Другими словами, удаление одного или нескольких столбцов X может привести к прогнозируемым значениям Y, которые являются одинаково точными. В таком случае эти избыточные столбцы X должны быть опущены в модели регрессии. Это явление называется «коллинеарностй», так как любой избыточный столбец X можно выразить как сумму кратных столбцов X, не являющихся избыточными. Функция ЛИНЕЙН проверяет наличие коллинеарности и удаляет избыточные столбцы X из модели регрессии при их идентификации. Удаленные столбцы X могут быть распознаны в выходных данных ЛИНЕЙН , так как они имеют нулевые коэффициенты в дополнение к значениям 0 SE. Если один или несколько столбцов удалены как избыточные, значение DF будет затронуто, так как DF зависит от количества столбцов X, которые фактически используются для целей прогнозирования. Подробнее о вычислении DF можно найти в разделе Пример 4. Если значение DF изменилось из-за того, что удаляются столбцы с избыточными X, также повлияют значения Сэй и F. Коллинеарность на практике должен быть сравнительно редкой. Тем не менее, если некоторые из столбцов X содержат только значения 0 и 1, в том числе индикаторов того, является ли тема в эксперименте или не входит в состав определенной группы. Если аргумент » Конст » имеет значение истина или опущен, функция ЛИНЕЙН фактически вставляет дополнительный столбец X для всех значений 1, чтобы смоделировать функцию «конст». Если у вас есть столбец с 1 для каждой темы, или 0, если нет, а также есть столбец с 1 для каждой темы, или 0 (если нет), то этот последний столбец является избыточным, так как записи в нем можно получить путем вычитания записи в поле «индикатор» м «. столбец из записи в дополнительном столбце всех значений 1, добавленных функцией ЛИНЕЙН .
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, возвращающие массивы, необходимо вводить как формулы массива.
Примечание: В Excel Online создать формулы массива нельзя.
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Наклон и конст возвращают #DIV/0! Если позиция, которую вы указали, находится перед первым или после последнего элемента в поле, формула возвращает ошибку #ССЫЛКА!. Алгоритмы наклона и перехвата предназначены для поиска только одного ответа, и в этом случае может быть несколько ответов.
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Глава 22. Функция массива ЛИНЕЙН
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику (подробнее см. справку MS Excel).

Рис. 22.1. Четыре аргумента функции ЛИНЕЙН
Скачать заметку в формате Word или pdf, примеры в формате Excel
Линейная регрессия
На рис. 22.2 показан набор данных (он уже анализировался в главе 9, когда мы обсуждали функции НАКЛОН, ОТРЕЗОК, ПРЕДСКАЗ и ТЕНДЕНЦИЯ). Поскольку ЛИНЕЙН является функцией массива и вы хотите, чтобы она вернула два значения, выполните следующие действия:
- Выделите диапазон D2:Е2. Функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y. Это – баллы, которые студенты заработали на последнем тестировании.
- Введите известные значения х. Это количество часов, которые студенты потратили на подготовку к тестам.
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.

Рис. 22.2. Функция ЛИНЕЙН возвращает наклон и отрезок, если массив расположен в горизонтальном диапазоне

Рис. 22.3. Функция массива ЛИНЕЙН заменяет две отдельные функции – НАКЛОН и ОТРЕЗОК
Если вам всё же нужно вывести результаты функции ЛИНЕЙН в вертикальный массив, воспользуйтесь ухищрением (рис. 22.4).

Рис. 22.4. Формулы для вывода результатов в вертикальный массив
Если вы хотите отобразить не только наклон и отрезок, но и дополнительные статистики, выделите диапазон на один столбец больше, чем столбцов с переменными х, и высотой 5 строк. Как показано на рис. 22.5, поскольку у вас лишь одна переменная х, выделите диапазон Е2:F6 (2 столбца по 5 строк). Третьему и четвертому аргументам присвойте значения ИСТИНА: вы хотите, чтобы b считалось обычным образом, и хотите вывести дополнительные статистики. После ввода формулы нажатием Ctrl+Shift+Enter, результат должен соответствовать рис. 22.6 (подробнее о десяти статистиках см. Простая линейная регрессия).

Рис. 22.5. Когда требуется дополнительная статистика для одной переменной, выделите диапазон 2*5; функция ЛИНЕЙН вернет 10 значений; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке

Рис. 22.6. Функция ЛИНЕЙН возвращает 10 статистик
В главе 8 было показано, как с помощью формулы преобразовать таблицу в столбец. На рис. 22.7 приведена формула, позволяющая представить результаты работы функции ЛИНЕЙН (которые она возвращает в диапазон 2*5) в вертикальном столбце.
Следующие элементы являются аргументами функции ИНДЕКС:
- аргумент массив: функция ЛИНЕЙН($B$2:$B$12;$A$2:$A$12;ИСТИНА;ИСТИНА) возвращает диапазон из пяти строк и двух столбцов.
- аргумент номер_строки: ОСТАТ(ЧСТРОК(E$1:E1)-1;5)+1 возвращает следующие значения 1,2,3,4,5,1,2,3,4,5 при копировании формулы вдоль столбца от Е1 до Е10.
- аргумент номер_столбца: ЦЕЛОЕ((ЧСТРОК(E$1:E1)-1)/5)+1 возвращает 1,1,1,1,1,2,2,2,2,2 при копировании формулы вдоль столбца от Е1 до Е10.

Рис. 22.7. Преобразование диапазона вывода формулы ЛИНЕЙН из 2*5 в вертикальный
Формула в Е1 не требует ввода с помощью Ctrl+Shift+Enter.
Множественная регрессия
В случае множественной регресии, когда значения y зависят от двух переменных х1 и х2, функция ЛИНЕЙН возвращает 12 статистик (подробнее см. Введение в множественную регрессию и Построение модели множественной регрессии). На рис. 22.8 используются следующие обозначения:
- y = зависимая переменная
- x1 = независимая переменная 1 = баллы за домашнее задание
- x2 = независимая переменная 2 = часов изучал последний столбец тест = гр.
Чтобы выполнить множественную регрессию:
- Выделите диапазон В3:D7 (число столобцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу <=ЛИНЕЙН(D13:D23;B13:C23;ИСТИНА;ИСТИНА)>. Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В13:С23.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В13:С23 до значений х2, наклон сначала указан для х2.

Рис. 22.8. Для двух переменных x1 и х2 функция ЛИНЕЙН выполняет множественную регрессию
Если вас раздражают знаяения ошибки #Н/Д дополните вашу формулу функцией ЕСЛИОШИБКА (рис. 22.9).

Рис. 22.9. Вы можете избавиться от ошибок #Н/Д «обернув» ЛИНЕЙН функцией ЕСЛИОШИБКА
Пример с тремя переменными не должен вызвать затруднений (рис. 22.10).

Рис. 22.10. Множественная регрессия для трех независимых переменных
Примеры как пользоваться функцией ЛИНЕЙН в Excel
Задача отыскания функциональной зависимости очень важна, поэтому для ее решения в MS Excel введен набор функций, основанных на методе наименьших квадратов. В качестве результата выдаются не только коэффициенты функции, приближающей данные, но и статистические характеристики полученных результатов.
Смысл выходной статистической информации функции ЛИНЕЙН
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, вычисляя прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую.
Общий синтаксис вызова функции ЛИНЕЙН имеет следующий вид:
Для работы с функцией необходимо заполнить как минимум 1 обязательный и при необходимости 3 необязательных аргумента:
- Известные_значения_y − это множество значений y , которые уже известны для соотношения y=mx+b.
- Известные_значения_x − это множество известных значений x . Если этот аргумент опущен, то предполагается, что это массив <1; 2; 3; . >такого же размера, как и известные_значения_y.
- Конст − это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если в функции ЛИНЕЙН аргумент константа имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx.
- Статистика − это логическое значение, которое указывает, требуется ли выдать дополнительную статистику по регрессии.
Примеры использования функции ЛИНЕЙН в Excel
Для решения первой задачи – о соотношении часов подготовки студентов к тесту и результатов теста, как х и у соответственно, – необходимо применить следующий порядок действий (в связи с тем, что ЛИНЕЙН является функцией, которая возвращает массив):
- Выделите диапазон D2:Е2, так как функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y – баллы, которые студенты заработали на последнем тестировании (диапазон ячеек В2:В12).
- Затем введите известные значения х – количество часов, которые студенты потратили на подготовку к тестам (диапазон А2:А12).
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.
Результатом применения функции становится:
Теперь, на примере решения второй задачи, разберем необходимость в отображении не только наклона и отрезка, но и дополнительной статистики. Для примера, на диапазоне А1:В6 выстроим таблицу с соотношением у и х соответствующих сумме заработка студентом денежных средств за период в 5 месяцев. Так как мы имеем лишь одну переменную х, то необходимо выделить диапазон состоящий из двух столбцов и пяти строк. Важно отметить, что в том случае, если переменных х будет больше, то количество столбцов может изменяться соответственно их количеству, однако строк будет всегда 5.
Применительно к решаемой нами задаче, выделим диапазон Е2:F6, затем введем формулу аналогично предыдущей задаче, но в данном случае третьему и четвертому аргументу присвоим значение 1 соответствующее ИСТИНЕ. Для вывода параметров статистики функции ЛИНЕЙН необходимо нажат Ctrl+Shift+Enter, результат должен соответствовать следующему рисунку, на котором представлено обозначение дополнительных статистик:
Вернемся к примеру № 1, касающемуся зависимости между часами подготовки студентов к тесту и баллов за тест. Добавим к условию задачи данные о баллах за домашнее задание — представляющие дополнительную переменную х, что свидетельствует о необходимости применения множественной регрессии.
В случае множественной регрессии, когда значения « y » зависят от двух переменных « х », функция ЛИНЕЙН возвращает 12 статистик. На рисунке с модифицированной таблицей от 1 примера, представленном ниже используются следующие обозначения:
- y = зависимая переменная;
- x1 = независимая переменная 1 = баллы за домашнее задание;
- x2 = независимая переменная 2 = часы подготовки к тесту.
Чтобы выполнить множественную регрессию:
- Выделите диапазон В3:D7 (число столбцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу =ЛИНЕЙН(D14:D24;B14:C24;1;1). Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В14:С24.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В14:С24 до значений х2, наклон сначала указан для х2.
Диапазон D5:D7 содержит ошибку #Н/Д – значащую, что формула не может обнаружить значения для данных ячеек. Визуально наличие ошибки отвлекает от сути решения, поэтому далее предложим вариант избавления от нее. Так, если дополнить формулу содержащую функцию ЛИНЕЙН функцией ЕСЛИОШИБКА, то можно значительно улучшить вид таблицы, результат которой представлен ниже:
Распределение статистик в таблице их значение представлено на следующем рисунке:
В результате мы получили всю необходимую выходную статистическую информацию, которая нас интересует.
Как в Excel ввести формулу массива?
Для расчета прогноза в Excel используется целый ряд формул, которые не будут работать, если их не ввести как формулу массива. Например,
=ЛИНЕЙН() — для расчета коэффициентов линейного тренда y=a+bx
=ТЕНДЕНЦИЯ() — для расчета значений линейного тренда
=ЛГРФПРИБЛ() — для расчета коэффициентов экспоненциального тренда y = b*m^x
=ТРАНСП() — для того чтобы вертикальный диапазон ячеек сделать горизонтальным и наоборот.
Из данной статьи вы узнаете, как в Excel ввести формулу массива.
Принцип ввода формулы массива расскажу на примере 2-х формул =ЛИНЕЙН() и =ТРАНСП().
Для того, чтобы с помощью формулы =ЛИНЕЙН() рассчитать коэффициенты линейного тренда y=a+bx (a) и (b), необходимо:
1. Ввести в формулу данные =ЛИНЕЙН(известные значения y (например, объём продаж по месяцам), известные значения x (номера периодов), константа (коэффициент (a) в формуле y=a+bx, для его расчета ставим «1»), статистика (вводим «0»)) (см. файл с примером).
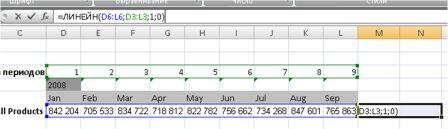
2. Установить курсор в ячейку с формулой и выделить соседнюю справа, как на рисунке:

3. Для ввода формулы массива нажимаем клавишу F2, а затем одновременно — клавиши CTRL + SHIFT + ВВОД.

Коэффициенты линейного тренда y=a+bx (a) и (b) рассчитаны.
2-й пример (см. вложенный файл), в нём мы рассмотрим, как перевернуть диапазон и сделать из горизонтального вертикальный. Для этого воспользуемся функцией =ТРАНСП().
Как она работает:
1. В формулу вводим горизонтальный диапазон, который хотим сделать вертикальным:
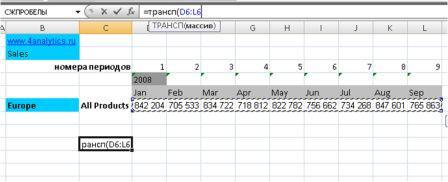
2. Выделяем вертикальный диапазон, равный по количеству ячеек выделенному горизонтальному, вверху диапазона должна быть введена формула =ТРАНСП();
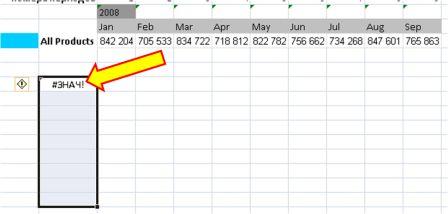
3. Для ввода формулы массива нажимаем клавишу F2, а затем одновременно — клавиши CTRL + SHIFT + ВВОД.
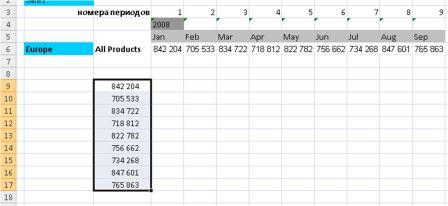
Горизонтальный диапазон стал вертикальным. Теперь, если мы внёсем изменения в горизонтальный диапазон, они тут же отобразятся в вертикальном диапазоне.
Для ввода формулы массива необходимо
- выделить массив — это диапазон ячеек, в которые Excel выведет данные,
- и нажать чудо комбинацию клавиш — F2, а затем одновременно — клавиши CTRL + SHIFT + ВВОД.
Всё просто, попробуйте, и если остались вопросы, задавайте их в комментариях.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Функция MS EXCEL ЛИНЕЙН()
Функция ЛИНЕЙН() специально создана для оценки параметров линейной регрессии, а также для вывода регрессионной статистики (коэффициента детерминации, стандартных ошибок, F-статистики и др.).
Функция ЛИНЕЙН() может использоваться для простой регрессии (в этом случае прогнозируемая переменная Y зависит от одной контролируемой переменной Х) и для множественной регрессии (Y зависит от нескольких Х).
Рассмотрим функцию на примере простой регрессии (оценивается наклон и сдвиг линии регрессии). Использование функции в случае множественной регрессии рассмотрено в соответствующей статье про множественную регрессию.
Функция ЛИНЕЙН() возвращает несколько значений, поэтому для вывода результатов потребуется несколько ячеек. Часто функцию вводят как формулу массива: нажатием клавиш CTRL+SHIFT+ENTER, но, как будет показано ниже, для вывода результатов вычислений это не обязательно.
Функция работает в 2-х режимах. В простейшем случае, когда 4-й аргумент функции опущен или установлен ЛОЖЬ, функция возвращает только 2 значения — это оценки параметров модели: наклона a и сдвига b.
Для того, чтобы вычислить оценки:
- выделите 2 ячейки в одной строке,
- в Строке формул введите, например, = ЛИНЕЙН(C23:C83;B23:B83)
- нажмите CTRL+SHIFT+ENTER.
В левой ячейке будет рассчитано значение наклона, в правой – сдвига.
Примечание: В справке MS EXCEL результат функции ЛИНЕЙН() соответствующий наклону обозначается буквой m, а сдвиг – буквой b.
Примечание: Без формул массива можно обойтись. Для этого нужно использовать функцию ИНДЕКС() , которая выведет нужное значение. Например, чтобы вывести величину сдвига линии регрессии введите формулу = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;2) . Если 4-й аргумент функции опущен или установлен ЛОЖЬ, то функция ЛИНЕЙН() в возвращает массив значений вида 1х2 (т.е. 2 ячейки, расположенные в одной строке). Поэтому, для вывода величины сдвига прямой линии регрессии, первый аргумент функции ИНДЕКС() , который является номером строки, должен быть равен 1, а второй аргумент, номер столбца, должен быть равен 2. Чтобы вывести значение наклона линии регрессии формулу =ЛИНЕЙН(C23:C83;B23:B83) достаточно ввести просто как обычную формулу и нажать ENTER. Конечно, можно использовать и формулу =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;1) .
Теперь о втором, более сложном режиме функции. Этот режим нужно использовать, если требуется вывести дополнительную статистику (4-й аргумент функции должен быть установлен ИСТИНА). В этом случае функция ЛИНЕЙН() возвращает 10 значений в диапазоне 5х2 ячеек (5 строк и 2 столбца). Как и в более простом режиме, в первой строке возвращаются оценки параметров модели: наклона и сдвига.
Аппроксимация опытных данных. Метод наименьших квадратов
Аппроксимация опытных данных – это метод, основанный на замене экспериментально полученных данных аналитической функцией наиболее близко проходящей или совпадающей в узловых точках с исходными значениями (данными полученными в ходе опыта или эксперимента). В настоящее время существует два способа определения аналитической функции:
— с помощью построения интерполяционного многочлена n-степени, который проходит непосредственно через все точки заданного массива данных. В данном случае аппроксимирующая функция представляется в виде: интерполяционного многочлена в форме Лагранжа или интерполяционного многочлена в форме Ньютона.
Рис.1. Аппроксимирующая кривая, построенная по методу наименьших квадратов
— для решения переопределенных систем уравнений, когда количество уравнений превышает количество неизвестных;
— для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений;
— для аппроксимации точечных значений некоторой аппроксимирующей функцией.
— значения расчетной аппроксимирующей функции в узловых точках ,
— заданный массив экспериментальных данных в узловых точках .
Квадратичный критерий обладает рядом «хороших» свойств, таких, как дифференцируемость, обеспечение единственного решения задачи аппроксимации при полиномиальных аппроксимирующих функциях.
В зависимости от условий задачи аппроксимирующая функция представляет собой многочлен степени m
∙ В случае если степень аппроксимирующей функции m=1, то мы аппроксимируем табличную функцию прямой линией (линейная регрессия).
∙ В случае если степень аппроксимирующей функции m=2, то мы аппроксимируем табличную функцию квадратичной параболой (квадратичная аппроксимация).
∙ В случае если степень аппроксимирующей функции m=3, то мы аппроксимируем табличную функцию кубической параболой (кубическая аппроксимация).
В общем случае, когда требуется построить аппроксимирующий многочлен степени m для заданных табличных значений, условие минимума суммы квадратов отклонений по всем узловым точкам переписывается в следующем виде:
Преобразуем полученную линейную систему уравнений: раскроем скобки и перенесем свободные слагаемые в правую часть выражения. В результате полученная система линейных алгебраических выражений будет записываться в следующем виде:
Данная система линейных алгебраических выражений может быть переписана в матричном виде:
Аппроксимация исходных данных линейной зависимостью
В качестве примера, рассмотрим методику определения аппроксимирующей функции, которая задана в виде линейной зависимости. В соответствии с методом наименьших квадратов условие минимума суммы квадратов отклонений записывается в следующем виде:
Необходимым условием существования минимума функции является равенству нулю ее частных производных по неизвестным переменным. В результате получаем следующую систему уравнений:
Решаем полученную систему линейных уравнений. Коэффициенты аппроксимирующей функции в аналитическом виде определяются следующим образом (метод Крамера):
Данные коэффициенты обеспечивают построение линейной аппроксимирующей функции в соответствии с критерием минимизации суммы квадратов аппроксимирующей функции от заданных табличных значений (экспериментальные данные).
Алгоритм реализации метода наименьших квадратов
2.3. Решение системы линейных уравнений с целью определения неизвестных коэффициентов аппроксимирующего многочлена степени m.
2.4.Определение суммы квадратов отклонений аппроксимирующего многочлена от исходных значений по всем узловым точкам
Найденное значение суммы квадратов отклонений является минимально-возможным.
Аппроксимация с помощью других функций
Следует отметить, что при аппроксимации исходных данных в соответствии с методом наименьших квадратов в качестве аппроксимирующей функции иногда используют логарифмическую функцию, экспоненциальную функцию и степенную функцию.
Поиск неизвестных коэффициентов осуществляется по методу наименьших квадратов в соответствии со следующей системой уравнений.
Решаем полученную систему линейных уравнений. Коэффициенты аппроксимирующей функции в аналитическом виде определяются следующим образом:
Для применения метода наименьших квадратов экспоненциальная функция линеаризуется:
Поиск неизвестных коэффициентов осуществляется по методу наименьших квадратов в соответствии со следующей системой уравнений.
Решаем полученную систему линейных уравнений. Коэффициенты аппроксимирующей функции в аналитическом виде определяются следующим образом:
Для применения метода наименьших квадратов степенная функция линеаризуется:
Поиск неизвестных коэффициентов осуществляется по методу наименьших квадратов в соответствии со следующей системой уравнений.
Решаем полученную систему линейных уравнений. Коэффициенты аппроксимирующей функции в аналитическом виде определяются следующим образом:
Выбор наилучшей аппроксимирующей функции определяется значением среднеквадратического отклонения. В связи с этим следует по методу наименьших квадратов определить несколько аппроксимирующих функций, а затем по критерию наименьшего среднеквадратического отклонения выбрать наиболее подходящую функцию.
Для того, чтобы добавить Ваш комментарий к статье, пожалуйста, зарегистрируйтесь на сайте.
Моделирование в электроэнергетике — Аппроксимация опытных данных. Метод наименьших квадратов
Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Данные коэффициенты обеспечивают построение линейной аппроксимирующей функции в соответствии с критерием минимизации суммы квадратов аппроксимирующей функции от заданных табличных значений экспериментальные данные. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
На последнем этапе выполним оценкустатистической надежности моделирования спомощью F – критерия Фишера. Для этого выполним проверку нулевой гипотезы Н о статистической не значимости полученного уравнения регрессиипо условию:
Оцифровка и тарирование графиков
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2023 Excel 2023 for Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Больше. Основные параметры
Тогда средняя ошибка аппроксимации равна
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | ||
| Рязанская | ||
| Смоленская | ||
| Тверская | ||
| Тульская | ||
| Ярославская |
Эмпирические коэффициенты регрессии b , b1 будем определять с помощью инструмента «Регрессия» надстройки «Анализ данных» табличного процессораMS Excel.
Алгоритм определения коэффициентов состоит в следующем.
1. Вводимисходные данные в табличный процессор MS Excel.
4. Заполняем соответствующие позиции окна Регрессия (рисунок 4).
5. Нажимаем кнопку ОК окна Регрессия и получаем протокол решения задачи (рисунок 5)
Из рисунка 5 видно, что эмпирические коэффициенты регрессии соответственно равны
Тогда уравнение парной линейной регрессии, связывающая величину ежемесячной пенсии у с величиной прожиточного минимумахимеет вид
На следующем этапе, в соответствии с заданием необходимо определить степень связи объясняющей переменной х с зависимой переменной у, используя коэффициент эластичности. Коэффициент эластичности для модели парной линейной регрессии определяется в виде:
Следовательно, при изменении прожиточного минимума на 1% величина ежемесячной пенсии изменяется на 0,000758%.
Далее определяем среднюю ошибку аппроксимации по зависимости
Для этого исходную таблицу 1 дополняем двумя колонками, в которых определяем значения, рассчитанные с использованием зависимости (3.2) и значения разности .
Таблица 3.2. Расчет средней ошибки аппроксимации.
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | 0,032 | |
| Рязанская | 0,045 | |
| Смоленская | 0,021 | |
| Тверская | 0,012 | |
| Тульская | 0,028 | |
| Ярославская | 0,017 | |
| S=0,155 |
Тогда средняя ошибка аппроксимации равна
Из практики известно, что значение средней ошибки аппроксимации не должно превышать (12…15)%
На последнем этапе выполним оценкустатистической надежности моделирования спомощью F – критерия Фишера. Для этого выполним проверку нулевой гипотезы Н о статистической не значимости полученного уравнения регрессиипо условию:
если при заданном уровне значимости a = 0,05 теоретическое (расчетное) значение F-критерия больше его критического значения Fкрит (табличного), то нулевая гипотеза отвергается, и полученное уравнение регрессии принимается значимым.
Из рисунка 5 следует, что Fрасч = 0,0058. Критическое значение F-критерия определяем с помощью использования статистической функции FРАСПОБР (рисунок 6). Входными параметрами функции является уровень значимости (вероятность) и число степеней свободы 1 и 2. Для модели парной регрессии число степеней свободы соответственно равно 1 (одна объясняющая переменная) и n-2 = 6-2=4.
Из рисунка 6 видно, что критическое значение F-критерия равно 7,71.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.

Полиномиальная линия тренда используется для описания попеременно возрастающих и убывающих данных. Степень полинома подбирают таким образом, чтобы она была на единицу больше количества экстремумов (максимумов и минимумов) кривой.
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | ||
| Рязанская | ||
| Смоленская | ||
| Тверская | ||
| Тульская | ||
| Ярославская |
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
Тренд как модель
Если же построить модель, описывающую это явление, то получается довольно простой и очень удобный инструмент для прогнозирования не требующий каких-либо сложных вычислений или временных затрат на проверку значимости или адекватности влияющих факторов.
Итак, что же собой представляет тренд как модель? Это совокупность расчетных коэффициентов уравнения, которые выражают регрессионную зависимость показателя (Y) от изменения времени (t). То есть, это точно такая же регрессия, как и те, что мы рассматривали ранее, только влияющим фактором здесь выступает именно показатель времени.
Важно!
Модель линейного тренда
Как и любая другая регрессия, тренд может быть как линейным (степень влияющего фактора t равна 1) так и нелинейным (степень больше или меньше единицы). Так как линейная регрессия является самой простейшей, хотя далеко не всегда самой точной, то рассмотрим более детально именно этот тип тренда.
Чем более выраженная тенденция роста показателя или его падения, тем будет больше коэффициент a 1 . Соответственно, предполагается, что константа a 0 совместно со случайной компонентой Ɛ отражают остальные регрессионные влияния, помимо времени, то есть всех прочих возможных влияющих факторов.
Рассчитать коэффициенты модели можно стандартным Методом наименьших квадратов (МНК). Со всеми этими расчетами Microsoft Excel справляется на ура самостоятельно, при чем, чтобы получить модель линейного тренда либо готовый прогноз существует целых пять способов, которые мы по отдельности разберем ниже.
Графический способ получения линейного тренда
В этом и во всех дальнейших примерах будем использовать один и тот же динамический ряд – уровень ВВП, который вычисляется и фиксируется ежегодно, в нашем случае исследование будет проходить на периоде с 2004-го по 2012-й гг.

Добавим к исходным данным еще один столбец, который назовем t и пометим цифрами по возрастающей порядковые номера всех зафиксированных значений ВВП за указанный период с 2004-го по 2012-й гг. – 9 лет или 9 периодов .


Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда


Построение линейного тренда с помощью формулы ЛИНЕЙН

Суть этого метода сводится к поиску коэффициентов линейного тренда с помощью функции ЛИНЕЙН , затем, подставляя эти влияющие коэффициенты в уравнение, получим прогнозную модель.
Нам потребуется выделить две рядом стоящие ячейки (на скриншоте это ячейки A38 и B38), далее в строке формул вверху (выделено красным на скриншоте выше) вызываем функцию, написав «=ЛИНЕЙН(», после чего эксель выведет подсказки того, что требуется для этой функции, а именно:
- выделяем диапазон с известными значениями описываемого показателя Y (в нашем случае ВВП, на скриншоте диапазон выделен синим) и ставим точку с запятой
- указываем диапазон влияющих факторов X (в нашем случае это показатель t, порядковый номер периодов, на скриншоте выделено зеленым) и ставим точку с запятой
- следующий по порядку требуемый параметр для функции – это определение того нужно ли рассчитывать константу, так как мы изначально рассматриваем модель с константой (коэффициент a 0), то ставим либо «ИСТИНА» либо «1» и точку с запятой
- далее нужно указать требуется ли расчет параметров статистики (в случае, если бы мы рассматривали этот вариант, то изначально пришлось бы выделить диапазон «под формулу» на несколько строк ниже). Указывать необходимость расчета параметров статистики, а именно стандартного значение ошибки для коэффициентов, коэффициента детерминированности, стандартной ошибки для Y, критерия Фишера, степеней свободы и пр. , есть смысл только тогда, когда вы понимаете, что они означают, в этом случае ставим либо «ИСТИНА», либо «1». В случае упрощенного моделирования, которому мы пытаемся научиться, на этом этапе прописывания формулы, ставим «ЛОЖЬ» либо «0» и добавляем после закрывающую скобочку «)»
- чтобы «оживить» формулу, то есть заставить ее работать после прописывания всех необходимых параметров, не достаточно нажать кнопку Enter, необходимо последовательно зажать три клавиши: Ctrl, Shift, Enter

Чтобы получить расчетные значения Y по модели и, соответственно, чтобы получить прогноз, нужно просто подставить формулу в ячейку экселя, а вместо t указать ссылку на ячейку с требуемым номером периода (смотрите на скриншоте ячейку D25 ).
Для сравнения полученной модели с реальными данными, можно построить два графика, где в качестве Х указать порядковый номер периода, а в качестве Y в одном случае – реальный ВВП, а, в другом – расчетный (на скриншоте диаграмма справа).
Построение линейного тренда с помощью инструмента Регрессия в Пакете анализа
В статье , по сути, полностью описан этот метод, единственная же разница в том, что в наших исходных данных только один влияющий фактор Х (номер периода – t ).


Прогнозирование с помощью линейного тренда через функцию ТЕНДЕНЦИЯ
Этот метод отличается от предыдущих тем, что он пропускает необходимые ранее этапы расчета параметров модели и подстановки полученных коэффициентов вручную в качестве формулы в ячейку, чтобы получить прогноз, эта функция как раз и выдает уже готовое рассчитанное прогнозное значение на основе известных исходных данных.

Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.
Прогнозирование с помощью линейного тренда через функцию ПРЕДСКАЗ
Суть данной функции целиком и полностью идентична предыдущей, разница лишь в порядке прописывания исходных данных в формуле и в том, что нет настройки для наличия или отсутствия коэффициента a 0 (то есть функция подразумевает, что этот коэффициент, в любом случае, есть)

Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении.
Подводя итог к статье
Линия тренда в Excel. Процесс построения
Линия тренда — это один из основных инструментов анализа данных
Чтобы сформировать линию тренда , необхдимо совершить три этапа, а именно:
1. Создать таблицу;
2.
3. Выбрать тип линии тренда.
После сбора всей необходимой информации, можно приступить непосредственно к выполнению шагов на пути к получению конечного результата.
Следующее действие построение самой линии тренда . Итак, для этого необходимо вновь выделить график и выбрать вкладку «Макет» на ленте задач. Следом в данном меню нужно нажать на кнопку «Линия тренда » и выбрать «линейное приближение» или же «экспоненциальное приближение».
Линейная аппроксимация . По характеру данная линия прямая, и стандартно применяется в элементарных случаях, когда функция увеличивается или же уменьшается в приблизительном постоянстве.
Логарифмическая аппроксимация. Если величина сначала верно и быстро растет или же наоборот — убывает, а вот затем, спустя значения, стабилизируется, то данная линия тренда подойдет как нельзя кстати.
Полиномиальная аппроксимация . Переменное возрастание и убывание – вот характеристики, что свойственны данной линии. Причем, степень самих полиномов (многочленов) определяется количеством максимумов и минимумом.
Степенная аппроксимация . Характеризует монотонное возрастание и убывание величины, но применение ее невозможно, если данные имеют отрицательные и нулевые значения.
Скользящее среднее . Используется чтобы наглядно показать прямую зависимость одного от другого, путем сглаживания всех точек колебания. Это достигается путем выделения среднего значения между двумя соседними точками. Таким образом, график усредняется, а количество точек сокращается до значения, что было выбрано в меню «Точки» пользователем.
Как используется? Д ля прогнозирования экономический вариантов используется именно полиноминальная линия, степень многочлена которой определяется на основе нескольких принципов: максимизации коэффициента детерминации, а также экономической динамики показателя в период, за который требуется прогноз.
Следуя всем этапам формирования и, разобравшись в особенностях, можно построить всего первичную линию тренда , которая лишь отдаленно соответствует реальным прогнозам. Но вот после настройки параметров можно уже говорить о более реальной картине прогноза.
Линия тренда в Excel. Настройка параметро в функциональной линии
Нажав на кнопку «Линия тренда », выбираем необходимое меню под названием «Дополнительные параметры». В появившемся окне следует нажать на «Формат линии тренда », а после поставить и отметку напротив значения «поместить на диаграмму величину достоверности аппроксимации R^2». После этого закрываем меню, нажав на соответственную кнопку. На самой же диаграмме появляется коэффициент R^2= 0,6442.
После этого отменяем вводимые изменения. Выделив график и нажав на вкладку «Макет», следом нажимаем на «Линию тренда » и наживаем на «Нет». Следом, перейдя в функцию «Формат линии тренда », нажимаем на полиноминальную линию и пытаемся добиться значения R^2= 0,8321, меняя степень.
Чтобы просмотреть формулы или составить другие, отличные от стандартных вариации прогнозов, достаточно не бояться экспериментировать со значениями, а особенно – с полиномами. Таким образом, используя лишь одну программу Excel, можно создать достаточно точный прогноз исходя из вводимых данных.
Уравнением регрессии Y от X называют функциональную зависимость у=f(x) , а ее график – линией регрессии.
Excel позволяет создавать диаграммы и графики довольно приемлемого качества. Excel имеется специальное средство — Мастер диаграмм, под руководством которого пользователь проходит все четыре этапа процесса построения диаграммы или графика.

В Excel 2007 названия осей ставятся во вкладке меню МАКЕТ (рис. 32).
Рис. 32. Настойка названий осей графика в Excel 2007
Для получения математической модели необходимо построить на графике линию тренда. В Excel 2003 и 2007 нужно щелкнуть правой кнопкой мыши на точки графика. Тогда в Excel 2003 появится вкладка с перечнем пунктов, из которых выбираем ДОБАВИТЬ ЛИНИЮ ТРЕНДА (рис. 33).

После нажатия на пункт ДОБАВИТЬ ЛИНИЮ ТРЕНДА появится окно ЛИНИЯ ТРЕНДА (рис. 34). Во вкладке ТИП можно выбрать следующие типы линий: линейная, логарифмическая, экспоненциальная, степенная, полиномиальная, линейная фильтрация.


В Excel 2007 после того, как щелкнем правой кнопкой мыши на точки графика, появится список пунктов меню, из которого ВЫБИРАЕМ ДОБАВИТЬ ЛИНИЮ ТРЕНДА (рис. 36).


Устанавливаем необходимые флажки и нажимаем кнопку ЗАКРЫТЬ .
На графике появится линия тренда, соответствующее ей уравнение и величина достоверности аппроксимации.
Диаграммы и графики используются для анализа числовых данных, например, для оценки зависимости меж-ду двумя видами значений. С этой целью к данным диаграммы или графика можно добавить линию тренда и ее уравнение, прогнозные значения, рассчитанные на несколько периодов вперед или назад.
Предусмотрено несколько вариантов формирования линии трен-да.
Прямая линия тренда (линейный тренд) наилучшим образом подходит для величин, изменяющихся с постоянной скоростью. Приме-няется в случаях, когда точки данных расположены близко к прямой.
Логарифмическая линия тренда соответствует ряду данных, значения которого вначале быстро растут или убывают, а затем постепенно стабилизируются. Может использоваться для положительных и отрицательных данных.
Полиномиальной функцией (до 6-й степени включительно): y= b + c 1 *x + c 2 *x 2 + c 3 *x 3 + . + c 6* x 6
Полиномиальная линия тренда используется для описания попеременно возрастающих и убывающих данных. Степень полинома подбирают таким образом, чтобы она была на единицу больше количества экстремумов (максимумов и минимумов) кривой.
Степенная линия тренда дает хорошие результаты для положительных данных с постоянным ускорением. Для рядов с нулевыми или отрицательными значениями построение указанной линии трен-да невозможно.
где c и b — константы, е — основание натурального логарифма.
Экспоненциальный тренд используется в случае непрерывного возрастания изменения данных. Построение указанного тренда не- возможно, если в множестве значений членов ряда присутствуют нулевые или отрицательные данные.
С использованием линейной фильтрации по формуле: F t = (A t +A (t-1) +⋯+A (t-n+1))/n
Функция ЛИНЕЙН
Для линеаризации в предыдущих примерах мы использовали функцию map() , которая возвращает целые числа. Что делать, если нужна более высокая точность? Можно работать в более мелкой шкале (например миллиметры вместо сантиметров), а можно сделать свой map, который будет считать во float :
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
интерполирующей функцией невозможно описать данные при повторении эксперимента в одних тех же начальных условиях требуется статистическая обработка;. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Знакомое нам всем число π (пи) – это бесконечная десятичная дробь. π = 3,1415926535897932 …. При вычислениях, в которых используется число «пи», принято брать не дробь целиком (но это и невозможно, ведь она бесконечна), а только 2 цифры после запятой.
Табличные зависимости — Аппроксимация табличных зависимостей
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Содержание статьи (кликните для открытия/закрытия)
- Построение графика линейной функции в Excel
- Подготовка расчетной таблицы
- Построение графика функции
- Построение графиков других функций
- Квадратичная функция y=ax2+bx+c
- Кубическая парабола y=ax3
- Гипербола y=k/x
- Построение тригонометрических функций sin(x) и cos(x)
Построение графика зависимости функции является характерной математической задачей. Все, кто хотя бы на уровне школы знаком с математикой, выполняли построение таких зависимостей на бумаге. В графике отображается изменение функции в зависимости от значения аргумента. Современные электронные приложения позволяют осуществить эту процедуру за несколько кликов мышью. Microsoft Excel поможет вам в построении точного графика для любой математической функции. Давайте разберем по шагам, как построить график функции в excel по её формуле
Построение графиков в Excel 2016 значительно улучшилось и стало еще проще чем в предыдущих версиях. Разберем пример построения графика линейной функции y=kx+b на небольшом интервале [-4;4].
Подготовка расчетной таблицы
В таблицу заносим имена постоянных k и b в нашей функции. Это необходимо для быстрого изменения графика без переделки расчетных формул.
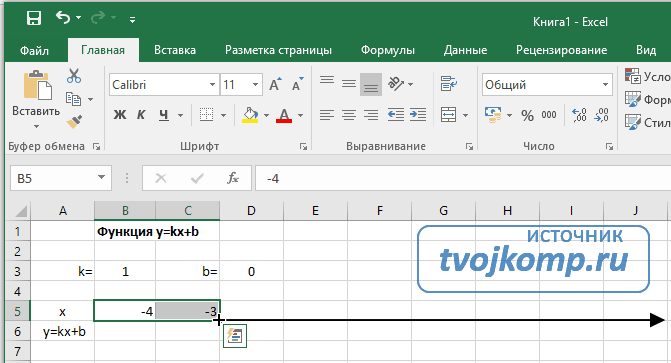
Далее строим таблицу значений линейной функции:
- В ячейки A5 и A6 вводим соответственно обозначения аргумента и саму функцию. Запись в виде формулы будет использована в качестве названия диаграммы.
- Вводим в ячейки B5 и С5 два значения аргумента функции с заданным шагом (в нашем примере шаг равен единице).
- Выделяем эти ячейки.
- Наводим указатель мыши на нижний правый угол выделения. При появлении крестика (смотри рисунок выше), зажимаем левую кнопку мыши и протягиваем вправо до столбца J.
Ячейки автоматически будут заполнены числами, значения которых различаются заданным шагом.

Далее в строку значений функции в ячейку B6 записываем формулу =$B3*B5+$D3
Внимание! Запись формулы начинается со знака равно(=). Адреса ячеек записываются на английской раскладке. Обратите внимание на абсолютные адреса со знаком доллара.
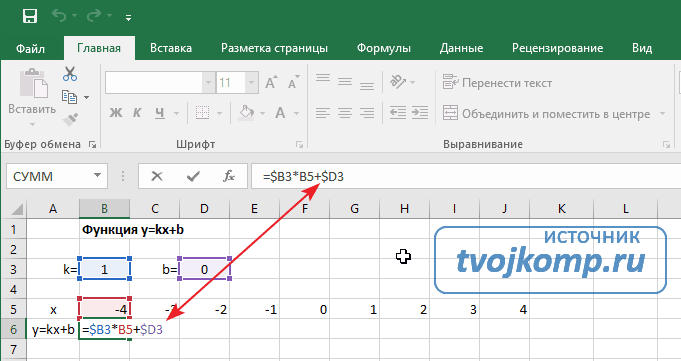
Чтобы завершить ввод формулы нажмите клавишу Enter или галочку слева от строки формул вверху над таблицей.
Копируем эту формулу для всех значений аргумента. Протягиваем вправо рамку от ячейки с формулой до столбца с конечными значениями аргумента функции.
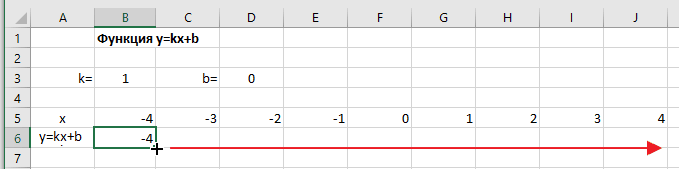
Построение графика функции
Выделяем прямоугольный диапазон ячеек A5:J6.
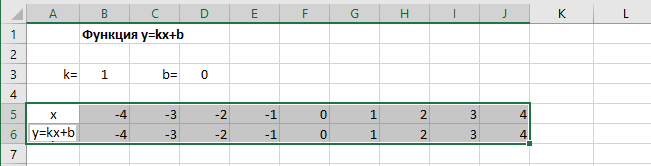
Переходим на вкладку Вставка в ленте инструментов. В разделе Диаграмма выбираем Точечная с гладкими кривыми (см. рисунок ниже).Получим диаграмму.
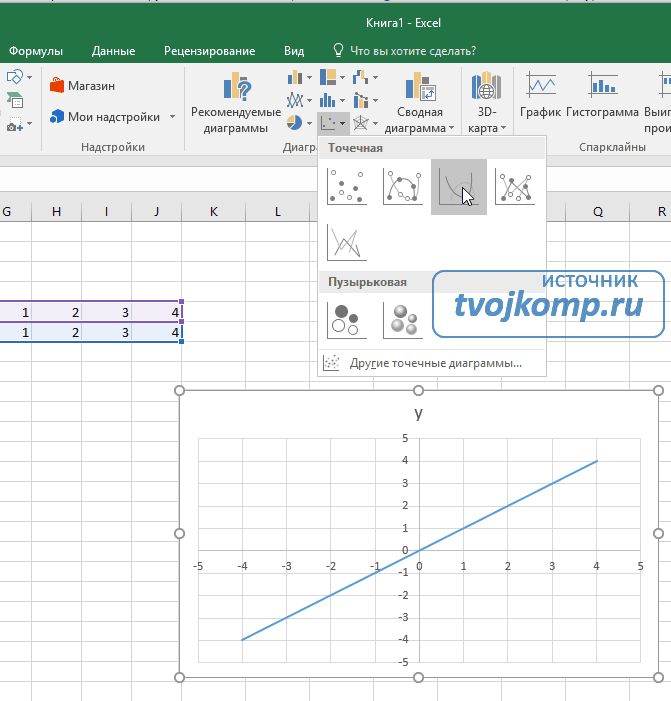
После построения координатная сетка имеет разные по длине единичные отрезки. Изменим ее перетягивая боковые маркеры до получения квадратных клеток.
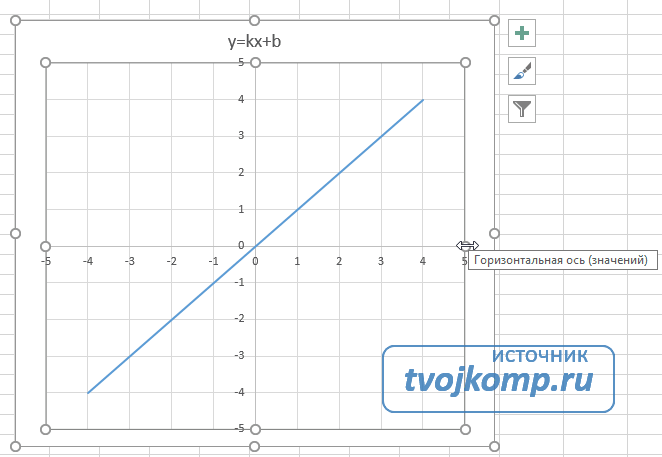
Теперь можно ввести новые значения постоянных k и b для изменения графика. И видим, что при попытке изменить коэффициент график остается неизменным, а меняются значения на оси. Исправляем. Кликните на диаграмме, чтобы ее активировать. Далее на ленте инструментов во вкладке Работа с диаграммами на вкладке Конструктор выбираем Добавить элемент диаграммы — Оси — Дополнительные параметры оси..
В правой части окна появиться боковая панель настроек Формат оси.
- Кликните на раскрывающийся список Параметры оси.
- Выберите Вертикальная ось (значений).
- Кликните зеленый значок диаграммы.
- Задайте интервал значений оси и единицы измерения (обведено красной рамкой). Ставим единицы измерения Максимум и минимум (Желательно симметричные) и одинаковые для вертикальной и горизонтальной осей. Таким образом, мы делаем мельче единичный отрезок и соответственно наблюдаем больший диапазон графика на диаграмме.И главную единицу измерения — значение 1.
- Повторите тоже для горизонтальной оси.
Теперь, если поменять значения K и b , то получим новый график с фиксированной сеткой координат.
Построение графиков других функций
Теперь, когда у нас есть основа в виде таблицы и диаграммы, можно строить графики других функций, внося небольшие корректировки в нашу таблицу.
Квадратичная функция y=ax2+bx+c
Выполните следующие действия:
- В первой строке меняем заголовок
- В третьей строке указываем коэффициенты и их значения
- В ячейку A6 записываем обозначение функции
- В ячейку B6 вписываем формулу =$B3*B5*B5+$D3*B5+$F3
- Копируем её на весь диапазон значений аргумента вправо
Получаем результат
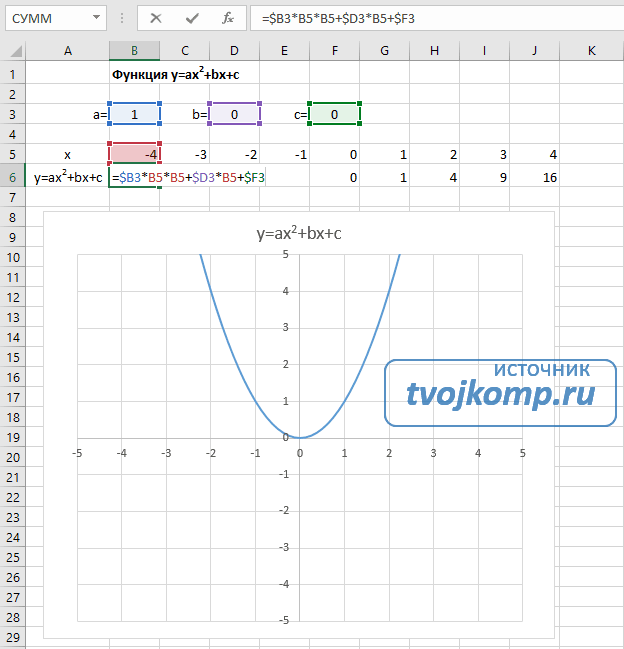
Кубическая парабола y=ax3
Для построения выполните следующие действия:
- В первой строке меняем заголовок
- В третьей строке указываем коэффициенты и их значения
- В ячейку A6 записываем обозначение функции
- В ячейку B6 вписываем формулу =$B3*B5*B5*B5
- Копируем её на весь диапазон значений аргумента вправо
Получаем результат
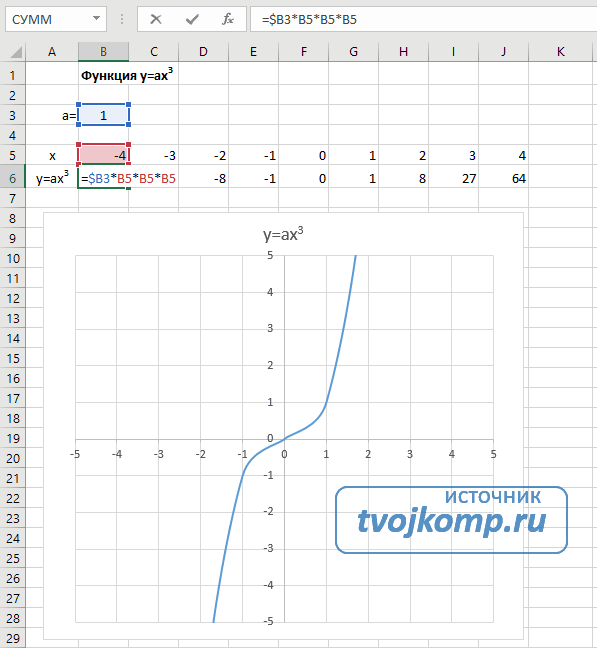
Гипербола y=k/x
Для построения гиперболы заполните таблицу вручную (смотри рисунок ниже). Там где раньше было нулевое значение аргумента оставляем пустую ячейку.
Далее выполните действия:
- В первой строке меняем заголовок.
- В третьей строке указываем коэффициенты и их значения.
- В ячейку A6 записываем обозначение функции.
- В ячейку B6 вписываем формулу =$B3/B5
- Копируем её на весь диапазон значений аргумента вправо.
- Удаляем формулу из ячейки I6.
Для корректного отображения графика нужно поменять для диаграммы диапазон исходных данных, так как в этом примере он больше чем в предыдущих.
- Кликните диаграмму
- На вкладке Работа с диаграммами перейдите в Конструктор и в разделе Данные нажмите Выбрать данные.
- Откроется окно мастера ввода данных
- Выделите мышкой прямоугольный диапазон ячеек A5:P6
- Нажмите ОК в окне мастера.
Получаем результат
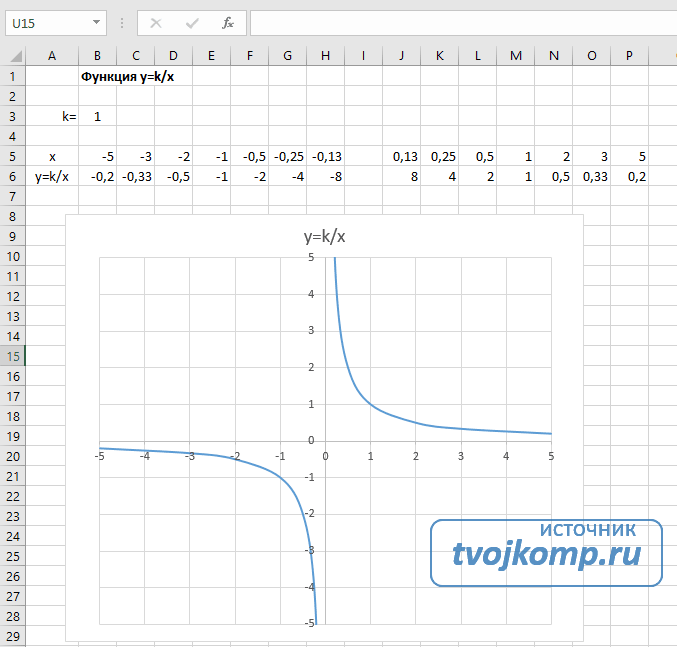
Построение тригонометрических функций sin(x) и cos(x)
Рассмотрим пример построения графика тригонометрической функции y=a*sin(b*x).
Сначала заполните таблицу как на рисунке ниже
В первой строке записано название тригонометрической функции.
В третьей строке прописаны коэффициенты и их значения. Обратите внимание на ячейки, в которые вписаны значения коэффициентов.
В пятой строке таблицы прописываются значения углов в радианах. Эти значения будут использоваться для подписей на графике.
В шестой строке записаны числовые значения углов в радианах. Их можно прописать вручную или используя формулы соответствующего вида =-2*ПИ(); =-3/2*ПИ(); =-ПИ(); =-ПИ()/2; …
В седьмой строке записываются расчетные формулы тригонометрической функции.
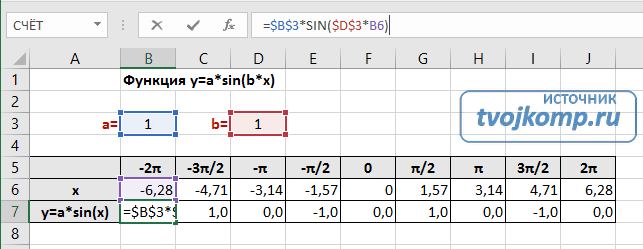
В нашем примере =$B$3*SIN($D$3*B6). Адреса B3 и D3 являются абсолютными. Их значения – коэффициенты a и b, которые по умолчанию устанавливаются равными единице.
После заполнения таблицы приступаем к построению графика.
Выделяем диапазон ячеек А6:J7. В ленте выбираем вкладку Вставка в разделе Диаграммы указываем тип Точечная и вид Точечная с гладкими кривыми и маркерами.
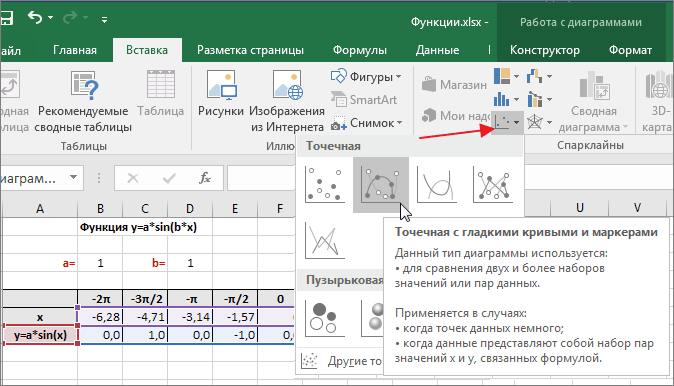
В итоге получим диаграмму.
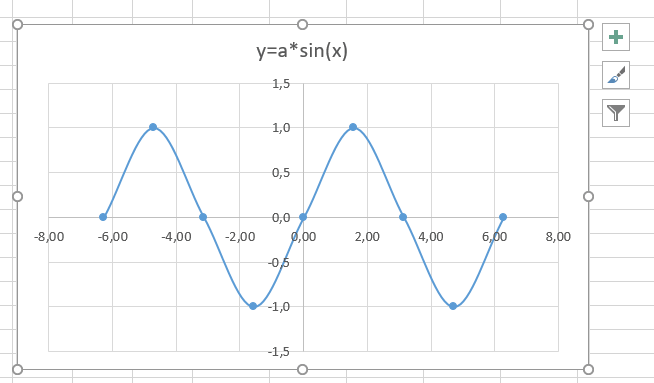
Теперь настроим правильное отображение сетки, так чтобы точки графика лежали на пересечении линий сетки. Выполните последовательность действий Работа с диаграммами –Конструктор – Добавить элемент диаграммы – Сетка и включите три режима отображения линий как на рисунке.
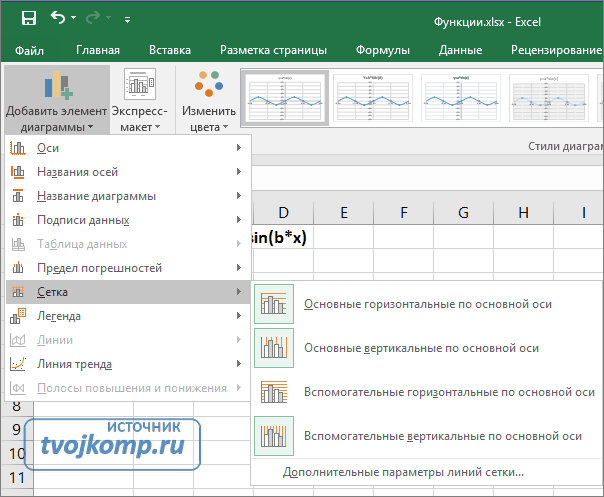
Теперь зайдите в пункт Дополнительные параметры линий сетки. У вас появится боковая панель Формат области построения. Произведем настройки здесь.
Кликните в диаграмме на главную вертикальную ось Y (должна выделится рамкой). В боковой панели настройте формат оси как на рисунке.
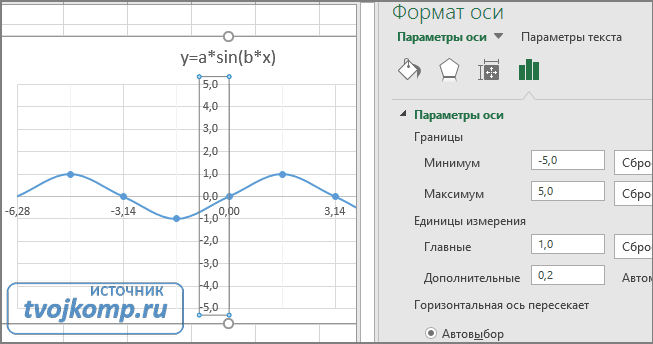
Кликните главную горизонтальную ось Х (должна выделится) и также произведите настройки согласно рисунку.
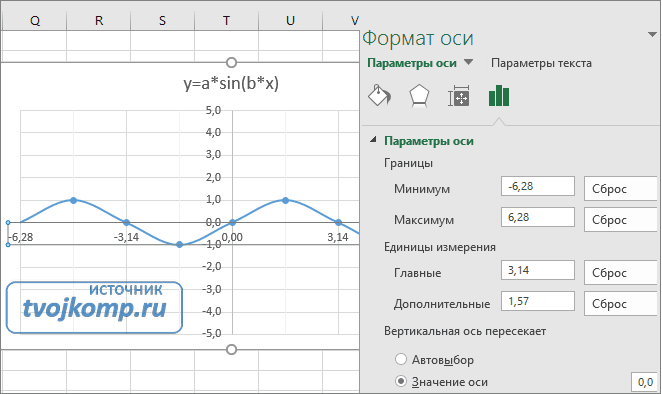
Теперь сделаем подписи данных над точками. Снова выполняем Работа с диаграммами –Конструктор – Добавить элемент диаграммы – Подписи данных – Сверху. У вас подставятся значения числами 1 и 0, но мы заменим их значениями из диапазона B5:J5.
Кликните на любом значении 1 или 0 (рисунок шаг 1) и в параметрах подписи поставьте галочку Значения из ячеек (рисунок шаг 2). Вам будет сразу же предложено указать диапазон с новыми значениями (рисунок шаг 3). Указываем B5:J5.
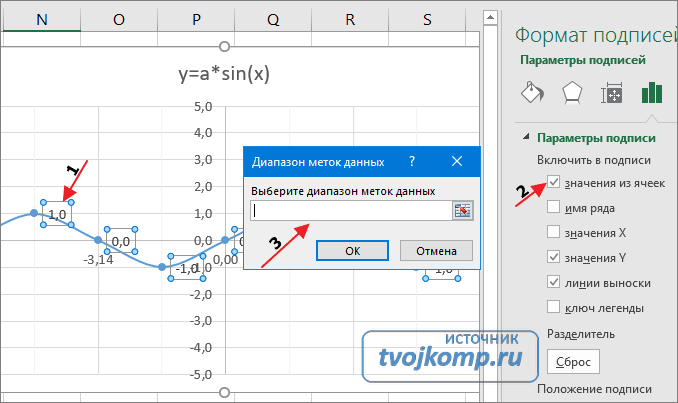
Вот и все. Если сделали правильно, то и график будет замечательным. Вот такой.
Чтобы получить график функции cos(x), замените в расчетной формуле и в названии sin(x) на cos(x).
Аналогичным способом можно строить графики других функций. Главное правильно записать вычислительные формулы и построить таблицу значений функции. Надеюсь, что вам была полезна данная информация.
Дополнительные статьи по теме:
- Знакомство с таблицами в Excel
- Изменение строк и столбцов в Excel
- Работа с ячейками: объединение, изменение, защита…
- Ошибки в формулах: почему excel не считает
- Использования условий в формулах Excel
- Функция CЧЕТЕСЛИМН
- Работа с текстовыми функциями Excel
- Все уроки по Microsoft Excel
Дорогой читатель! Вы посмотрели статью до конца.
Получили вы ответ на свой вопрос? Напишите в комментариях пару слов. Если ответа не нашли, укажите что искали или откройте содержание блога.

ОЧЕНЬ ВАЖНО! Оцени лайком или дизлайком статью!

