
1. Replacing all occurrences of one string with another in all files in the current directory:
These are for cases where you know that the directory contains only regular files and that you want to process all non-hidden files. If that is not the case, use the approaches in 2.
All sed solutions in this answer assume GNU sed. If using FreeBSD or macOS, replace -i with -i ''. Also note that the use of the -i switch with any version of sed has certain filesystem security implications and is inadvisable in any script which you plan to distribute in any way.
-
Non recursive, files in this directory only:
sed -i -- 's/foo/bar/g' * perl -i -pe 's/foo/bar/g' ./*
(the perl one will fail for file names ending in | or space)).
-
Recursive, regular files (including hidden ones) in this and all subdirectories
find . -type f -exec sed -i 's/foo/bar/g' {} +If you are using zsh:
sed -i -- 's/foo/bar/g' **/*(D.)(may fail if the list is too big, see
zargsto work around).Bash can’t check directly for regular files, a loop is needed (braces avoid setting the options globally):
( shopt -s globstar dotglob; for file in **; do if [[ -f $file ]] && [[ -w $file ]]; then sed -i -- 's/foo/bar/g' "$file" fi done )The files are selected when they are actual files (-f) and they are writable (-w).
2. Replace only if the file name matches another string / has a specific extension / is of a certain type etc:
-
Non-recursive, files in this directory only:
sed -i -- 's/foo/bar/g' *baz* ## all files whose name contains baz sed -i -- 's/foo/bar/g' *.baz ## files ending in .baz -
Recursive, regular files in this and all subdirectories
find . -type f -name "*baz*" -exec sed -i 's/foo/bar/g' {} +If you are using bash (braces avoid setting the options globally):
( shopt -s globstar dotglob sed -i -- 's/foo/bar/g' **baz* sed -i -- 's/foo/bar/g' **.baz )If you are using zsh:
sed -i -- 's/foo/bar/g' **/*baz*(D.) sed -i -- 's/foo/bar/g' **/*.baz(D.)
The -- serves to tell sed that no more flags will be given in the command line. This is useful to protect against file names starting with -.
-
If a file is of a certain type, for example, executable (see
man findfor more options):find . -type f -executable -exec sed -i 's/foo/bar/g' {} +
zsh:
sed -i -- 's/foo/bar/g' **/*(D*)
3. Replace only if the string is found in a certain context
-
Replace
foowithbaronly if there is abazlater on the same line:sed -i 's/foo(.*baz)/bar1/' file
In sed, using ( ) saves whatever is in the parentheses and you can then access it with 1. There are many variations of this theme, to learn more about such regular expressions, see here.
-
Replace
foowithbaronly iffoois found on the 3d column (field) of the input file (assuming whitespace-separated fields):gawk -i inplace '{gsub(/foo/,"baz",$3); print}' file
(needs gawk 4.1.0 or newer).
-
For a different field just use
$NwhereNis the number of the field of interest. For a different field separator (:in this example) use:gawk -i inplace -F':' '{gsub(/foo/,"baz",$3);print}' file
Another solution using perl:
perl -i -ane '$F[2]=~s/foo/baz/g; $" = " "; print "@Fn"' foo
NOTE: both the awk and perl solutions will affect spacing in the file (remove the leading and trailing blanks, and convert sequences of blanks to one space character in those lines that match). For a different field, use $F[N-1] where N is the field number you want and for a different field separator use (the $"=":" sets the output field separator to :):
perl -i -F':' -ane '$F[2]=~s/foo/baz/g; $"=":";print "@F"' foo
-
Replace
foowithbaronly on the 4th line:sed -i '4s/foo/bar/g' file gawk -i inplace 'NR==4{gsub(/foo/,"baz")};1' file perl -i -pe 's/foo/bar/g if $.==4' file
4. Multiple replace operations: replace with different strings
-
You can combine
sedcommands:sed -i 's/foo/bar/g; s/baz/zab/g; s/Alice/Joan/g' file
Be aware that order matters (sed 's/foo/bar/g; s/bar/baz/g' will substitute foo with baz).
-
or Perl commands
perl -i -pe 's/foo/bar/g; s/baz/zab/g; s/Alice/Joan/g' file -
If you have a large number of patterns, it is easier to save your patterns and their replacements in a
sedscript file:#! /usr/bin/sed -f s/foo/bar/g s/baz/zab/g -
Or, if you have too many pattern pairs for the above to be feasible, you can read pattern pairs from a file (two space separated patterns, $pattern and $replacement, per line):
while read -r pattern replacement; do sed -i "s/$pattern/$replacement/" file done < patterns.txt -
That will be quite slow for long lists of patterns and large data files so you might want to read the patterns and create a
sedscript from them instead. The following assumes a <<!>space<!>> delimiter separates a list of MATCH<<!>space<!>>REPLACE pairs occurring one-per-line in the filepatterns.txt:sed 's| *([^ ]*) *([^ ]*).*|s/1/2/g|' <patterns.txt | sed -f- ./editfile >outfile
The above format is largely arbitrary and, for example, doesn’t allow for a <<!>space<!>> in either of MATCH or REPLACE. The method is very general though: basically, if you can create an output stream which looks like a sed script, then you can source that stream as a sed script by specifying sed‘s script file as -stdin.
-
You can combine and concatenate multiple scripts in similar fashion:
SOME_PIPELINE | sed -e'#some expression script' -f./script_file -f- -e'#more inline expressions' ./actual_edit_file >./outfile
A POSIX sed will concatenate all scripts into one in the order they appear on the command-line. None of these need end in a newline.
-
grepcan work the same way:sed -e'#generate a pattern list' <in | grep -f- ./grepped_file -
When working with fixed-strings as patterns, it is good practice to escape regular expression metacharacters. You can do this rather easily:
sed 's/[]$&^*./[]/\&/g s| *([^ ]*) *([^ ]*).*|s/1/2/g| ' <patterns.txt | sed -f- ./editfile >outfile
5. Multiple replace operations: replace multiple patterns with the same string
-
Replace any of
foo,barorbazwithfoobarsed -Ei 's/foo|bar|baz/foobar/g' file -
or
perl -i -pe 's/foo|bar|baz/foobar/g' file
6. Replace File paths in multiple files
Another use case of using different delimiter:
sed -i 's|path/to/foo|path/to/bar|g' *
If you manage to take a deeper glimpse inside the ecosystem of the Linux operating system environment, you will discover that its built-in commands are sufficient enough to solve most of our computing problems.
One such problem is the need to find and replace text, word, or string in a file especially when you are in a server environment. A solution to this problem lets you handle nagging issues like updating the “/etc/apt/sources.list” file after a successful Linux system upgrade.
Creating the Test Text File in Linux
Create a text file with a name like “test.txt” and populate it with some text, word, or string characters. Let this file be on the same path as your terminal instance.
$ nano test.txt OR $ vi test.txt
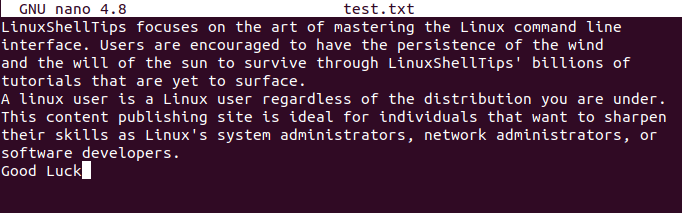
We will be using the cat command to flexible note the changes on our created test file.
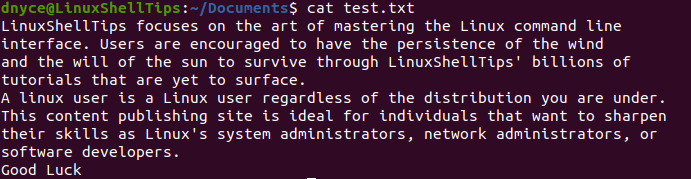
$ cat test.txt
Using Sed to Find and Replace Text, Word, or String in a File
The power of this stream editor is in its easiness in accomplishing basic input streams transformation. The sed command offers a quick, easy, and timeless approach in finding and replacing targeted text, words, or string patterns in a file.
Find and Replace the First Occurrences of Text, Word, or String in File
From our created test file, we are going to update all the instances of the word “LinuxShellTips” with the alternative “this site”. The syntax of the sed command we will be using to accomplish this simple task is as follows:
$ sed -i 's/[THE_OLD_TERM]/[THE_NEW_TERM]/' [TARGETED_FILE]
With reference to the above sed command usage and syntax, we can replace our test file’s “LinuxShellTips” term with “this site” term as follows:
$ sed -i 's/LinuxShellTips/this site/' test.txt
We can now use the cat command to preview the above-proposed changes to our test file to note if any substantial edits took place.
$ cat test.txt
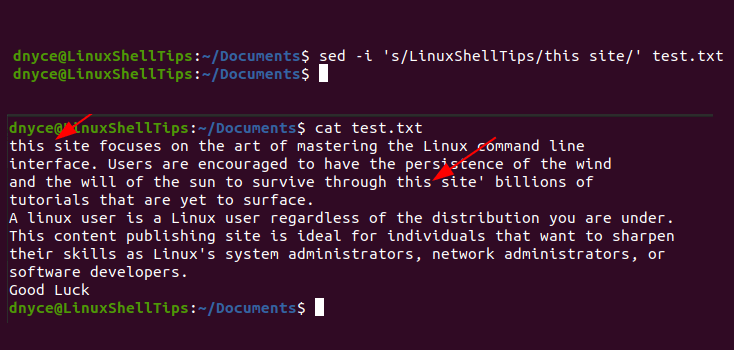
As you can see, the first two occurrences of the word “LinuxShellTips” have been replaced with the phrase “this site”.
Find and Replace All Occurrences of Text, Word, or String in File
Despite the above command having replaced all the targeted word patterns in our test file, its usage tends to be selective in most circumstances. The command works best for small files because, in big files, only the first few occurrences of a targeted word pattern might benefit from its ‘find and replace’ prowess.
To find and replace all occurrences of a word pattern in any editable file, you should adhere to the following sed command syntax.
$ sed -i 's/[THE_OLD_TERM]/[THE_NEW_TERM]/g' [TARGETED_FILE]
As you have noted, the 'g' in the above find & replace command syntax acts as a global variable so that all the global occurrences of a term in a targeted file are considered.
$ sed -i 's/this site/LinuxShellTips/g' test.txt
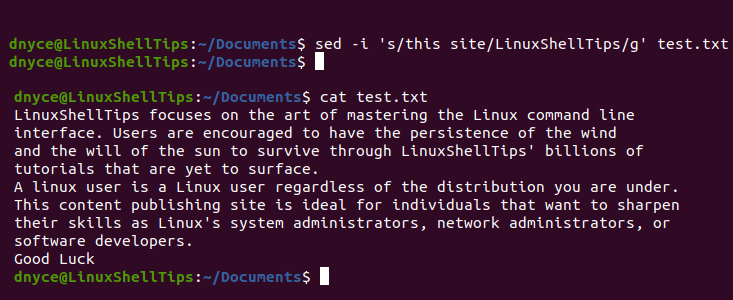
The above command finds all the global occurrences of the term “this site” and replaces it with the term “LinuxShellTips”.
Using Awk to Find and Replace Text, Word, or String in File
If you are familiar with the awk command-line utility, then you know that its powerful scripting language metrics make it a pro at text processing. Linux system administrators and professional users find this tool effective in data extraction and reporting.
The awk command syntax for a simple find-and-replace operation looks like the following snippet:
$ awk '{gsub("[THE_OLD_TERM]","[THE_NEW_TERM]"); print}' [TARGETED_FILE]
In the above syntax, awk will substitute THE_OLD_TERM from THE_NEW_TERM in the TARGETED_FILE and print the resulting file content on the system terminal.
Let us take a practical approach:
$ awk '{gsub("Linux","ubuntu"); print}' test.txt
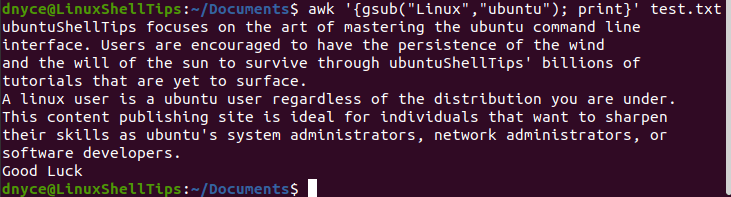
With the dynamic functionalities of both sed and awk command tools, you should now find, replace, and overwrite text, word, or string patterns in a targeted file. These tools give a system user the needed flexibility while on a command-line interface.
What’s the simplest way to do a find and replace for a given input string, say abc, and replace with another string, say XYZ in file /tmp/file.txt?
I am writting an app and using IronPython to execute commands through SSH — but I don’t know Unix that well and don’t know what to look for.
I have heard that Bash, apart from being a command line interface, can be a very powerful scripting language. So, if this is true, I assume you can perform actions like these.
Can I do it with bash, and what’s the simplest (one line) script to achieve my goal?
![]()
tripleee
172k32 gold badges264 silver badges311 bronze badges
asked Feb 8, 2009 at 11:57
![]()
The easiest way is to use sed (or perl):
sed -i -e 's/abc/XYZ/g' /tmp/file.txt
Which will invoke sed to do an in-place edit due to the -i option. This can be called from bash.
If you really really want to use just bash, then the following can work:
while IFS='' read -r a; do
echo "${a//abc/XYZ}"
done < /tmp/file.txt > /tmp/file.txt.t
mv /tmp/file.txt{.t,}
This loops over each line, doing a substitution, and writing to a temporary file (don’t want to clobber the input). The move at the end just moves temporary to the original name. (For robustness and security, the temporary file name should not be static or predictable, but let’s not go there.)
For Mac users:
sed -i '' 's/abc/XYZ/g' /tmp/file.txt
(See the comment below why)
![]()
answered Feb 8, 2009 at 12:20
![]()
johnnyjohnny
12.9k2 gold badges17 silver badges8 bronze badges
9
File manipulation isn’t normally done by Bash, but by programs invoked by Bash, e.g.:
perl -pi -e 's/abc/XYZ/g' /tmp/file.txt
The -i flag tells it to do an in-place replacement.
See man perlrun for more details, including how to take a backup of the original file.
![]()
John Kugelman
345k67 gold badges523 silver badges571 bronze badges
answered Feb 8, 2009 at 12:10
![]()
AlnitakAlnitak
333k70 gold badges404 silver badges492 bronze badges
3
I was surprised when I stumbled over this…
There is a replace command which ships with the "mysql-server" package, so if you have installed it try it out:
# replace string abc to XYZ in files
replace "abc" "XYZ" -- file.txt file2.txt file3.txt
# or pipe an echo to replace
echo "abcdef" |replace "abc" "XYZ"
See man replace for more on this.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Apr 9, 2013 at 15:35
![]()
rayrorayro
8036 silver badges2 bronze badges
7
This is an old post but for anyone wanting to use variables as @centurian said the single quotes mean nothing will be expanded.
A simple way to get variables in is to do string concatenation since this is done by juxtaposition in bash the following should work:
sed -i -e "s/$var1/$var2/g" /tmp/file.txt
![]()
John Kugelman
345k67 gold badges523 silver badges571 bronze badges
answered Dec 7, 2015 at 12:48
![]()
zcourtszcourts
4,7536 gold badges47 silver badges74 bronze badges
2
Bash, like other shells, is just a tool for coordinating other commands. Typically you would try to use standard UNIX commands, but you can of course use Bash to invoke anything, including your own compiled programs, other shell scripts, Python and Perl scripts etc.
In this case, there are a couple of ways to do it.
If you want to read a file, and write it to another file, doing search/replace as you go, use sed:
sed 's/abc/XYZ/g' <infile >outfile
If you want to edit the file in place (as if opening the file in an editor, editing it, then saving it) supply instructions to the line editor ‘ex’
echo "%s/abc/XYZ/g
w
q
" | ex file
Example is like vi without the fullscreen mode. You can give it the same commands you would at vi‘s : prompt.
![]()
P i
28.4k36 gold badges155 silver badges256 bronze badges
answered Feb 8, 2009 at 12:13
![]()
slimslim
39.7k12 gold badges94 silver badges126 bronze badges
4
I found this thread among others and I agree it contains the most complete answers so I’m adding mine too:
-
sedandedare so useful…by hand.
Look at this code from @Johnny:sed -i -e 's/abc/XYZ/g' /tmp/file.txt -
When my restriction is to use it in a shell script, no variable can be used inside in place of «abc» or «XYZ». The BashFAQ seems to agree with what I understand at least. So, I can’t use:
x='abc' y='XYZ' sed -i -e 's/$x/$y/g' /tmp/file.txt #or, sed -i -e "s/$x/$y/g" /tmp/file.txtbut, what can we do? As, @Johnny said use a
while read...but, unfortunately that’s not the end of the story. The following worked well with me:#edit user's virtual domain result= #if nullglob is set then, unset it temporarily is_nullglob=$( shopt -s | egrep -i '*nullglob' ) if [[ is_nullglob ]]; then shopt -u nullglob fi while IFS= read -r line; do line="${line//'<servername>'/$server}" line="${line//'<serveralias>'/$alias}" line="${line//'<user>'/$user}" line="${line//'<group>'/$group}" result="$result""$line"'n' done < $tmp echo -e $result > $tmp #if nullglob was set then, re-enable it if [[ is_nullglob ]]; then shopt -s nullglob fi #move user's virtual domain to Apache 2 domain directory ...... -
As one can see if
nullglobis set then, it behaves strangely when there is a string containing a*as in:<VirtualHost *:80> ServerName www.example.comwhich becomes
<VirtualHost ServerName www.example.comthere is no ending angle bracket and Apache2 can’t even load.
-
This kind of parsing should be slower than one-hit search and replace but, as you already saw, there are four variables for four different search patterns working out of one parse cycle.
The most suitable solution I can think of with the given assumptions of the problem.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Feb 7, 2013 at 14:48
![]()
centuriancenturian
1,23013 silver badges24 bronze badges
1
You can use sed:
sed -i 's/abc/XYZ/gi' /tmp/file.txt
You can use find and sed if you don’t know your filename:
find ./ -type f -exec sed -i 's/abc/XYZ/gi' {} ;
Find and replace in all Python files:
find ./ -iname "*.py" -type f -exec sed -i 's/abc/XYZ/gi' {} ;
answered Jan 14, 2017 at 9:45
![]()
MadvinMadvin
7489 silver badges14 bronze badges
1
If the file you are working on is not so big, and temporarily storing it in a variable is no problem, then you can use Bash string substitution on the whole file at once — there’s no need to go over it line by line:
file_contents=$(</tmp/file.txt)
echo "${file_contents//abc/XYZ}" > /tmp/file.txt
The whole file contents will be treated as one long string, including linebreaks.
XYZ can be a variable eg $replacement, and one advantage of not using sed here is that you need not be concerned that the search or replace string might contain the sed pattern delimiter character (usually, but not necessarily, /). A disadvantage is not being able to use regular expressions or any of sed’s more sophisticated operations.
answered Apr 15, 2017 at 2:09
![]()
johnraffjohnraff
3172 silver badges5 bronze badges
2
You may also use the ed command to do in-file search and replace:
# delete all lines matching foobar
ed -s test.txt <<< $'g/foobar/dnw'
See more in «Editing files via scripts with ed«.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Jun 14, 2009 at 16:37
1
To edit text in the file non-interactively, you need in-place text editor such as vim.
Here is simple example how to use it from the command line:
vim -esnc '%s/foo/bar/g|:wq' file.txt
This is equivalent to @slim answer of ex editor which is basically the same thing.
Here are few ex practical examples.
Replacing text foo with bar in the file:
ex -s +%s/foo/bar/ge -cwq file.txt
Removing trailing whitespaces for multiple files:
ex +'bufdo!%s/s+$//e' -cxa *.txt
Troubleshooting (when terminal is stuck):
- Add
-V1param to show verbose messages. - Force quit by:
-cwq!.
See also:
- How to edit files non-interactively (e.g. in pipeline)? at Vi SE
answered May 11, 2015 at 20:21
![]()
kenorbkenorb
152k85 gold badges671 silver badges732 bronze badges
2
Try the following shell command:
find ./ -type f -name "file*.txt" | xargs sed -i -e 's/abc/xyz/g'
![]()
kenorb
152k85 gold badges671 silver badges732 bronze badges
answered May 31, 2016 at 23:55
![]()
J AjayJ Ajay
3193 silver badges3 bronze badges
2
You can use python within the bash script too. I didn’t have much success with some of the top answers here, and found this to work without the need for loops:
#!/bin/bash
python
filetosearch = '/home/ubuntu/ip_table.txt'
texttoreplace = 'tcp443'
texttoinsert = 'udp1194'
s = open(filetosearch).read()
s = s.replace(texttoreplace, texttoinsert)
f = open(filetosearch, 'w')
f.write(s)
f.close()
quit()
answered May 3, 2016 at 18:44
![]()
Simplest way to replace multiple text in a file using sed command
Command —
sed -i ‘s#a/b/c#D/E#g;s#/x/y/z#D:/X#g;’ filename
In the above command s#a/b/c#D/E#g where I am replacing a/b/c with D/E and then after the ; we again doing the same thing
answered Jul 1, 2021 at 4:17
![]()
You can use rpl command. For example you want to change domain name in whole php project.
rpl -ivRpd -x'.php' 'old.domain.name' 'new.domain.name' ./path_to_your_project_folder/
This is not clear bash of cause, but it’s a very quick and usefull. 
answered Feb 12, 2015 at 8:34
![]()
zalexzalex
7096 silver badges14 bronze badges
For MAC users in case you don’t read the comments
As mentioned by @Austin, if you get the Invalid command code error
For the in-place replacements BSD sed requires a file extension after the -i flag to save to a backup file with given extension.
sed -i '.bak' 's/find/replace' /file.txt
You can use '' empty string if you want to skip backup.
sed -i '' 's/find/replace' /file.txt
All merit to @Austin
answered Nov 25, 2021 at 20:11
![]()
SzekelygobeSzekelygobe
2,1991 gold badge22 silver badges24 bronze badges
Open file using vim editor. In command mode
:%s/abc/xyz/g
This is the simplest
answered Dec 6, 2022 at 21:36
![]()
flash flash
8910 bronze badges
In case of doing changes in multiple files together we can do in a single line as:-
user_name='whoami'
for file in file1.txt file2.txt file3.txt; do sed -i -e 's/default_user/${user_name}/g' $file; done
Added if in case could be useful.
answered Feb 2, 2022 at 14:13
![]()
Время на прочтение
9 мин
Количество просмотров 522K
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.
Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.

Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
$ sed options file
По умолчанию sed применяет указанные при вызове правила, выраженные в виде набора команд, к STDIN. Это позволяет передавать данные непосредственно sed.
Например, так:
$ echo "This is a test" | sed 's/test/another test/'Вот что получится при выполнении этой команды.

Простой пример вызова sed
В данном случае sed заменяет слово «test» в строке, переданной для обработки, словами «another test». Для оформления правила обработки текста, заключённого в кавычки, используются прямые слэши. В нашем случае применена команда вида s/pattern1/pattern2/. Буква «s» — это сокращение слова «substitute», то есть — перед нами команда замены. Sed, выполняя эту команду, просмотрит переданный текст и заменит найденные в нём фрагменты (о том — какие именно, поговорим ниже), соответствующие pattern1, на pattern2.
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
$ sed 's/test/another test' ./myfile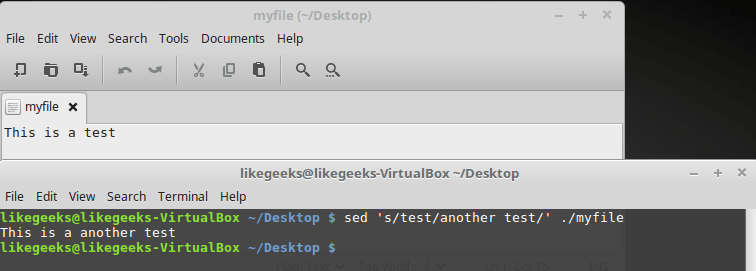
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Sed не меняет данные в обрабатываемом файле. Редактор читает файл, обрабатывает прочитанное, и отправляет то, что получилось, в STDOUT. Для того, чтобы убедиться в том, что исходный файл не изменился, достаточно, после того, как он был передан sed, открыть его. При необходимости вывод sed можно перенаправить в файл, возможно — перезаписать старый файл. Если вы знакомы с одним из предыдущих материалов этой серии, где речь идёт о перенаправлении потоков ввода и вывода, вы вполне сможете это сделать.
Выполнение наборов команд при вызове sed
Для выполнения нескольких действий с данными, используйте ключ -e при вызове sed. Например, вот как организовать замену двух фрагментов текста:
$ sed -e 's/This/That/; s/test/another test/' ./myfile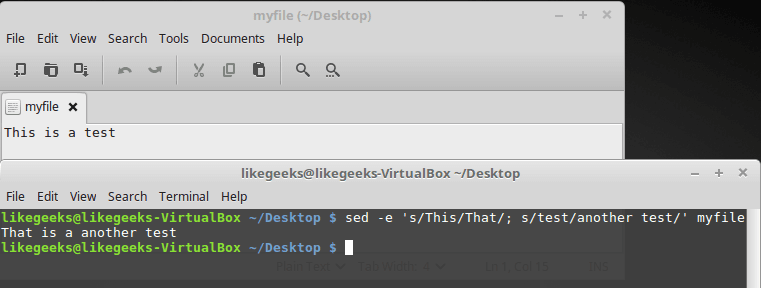
Использование ключа -e при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
$ sed -e '
> s/This/That/
> s/test/another test/' ./myfileВот что получится после того, как команда, представленная в таком виде, будет выполнена.
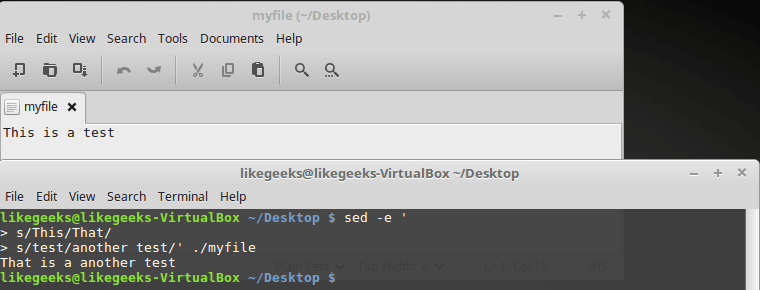
Другой способ работы с sed
Чтение команд из файла
Если имеется множество команд sed, с помощью которых надо обработать текст, обычно удобнее всего предварительно записать их в файл. Для того, чтобы указать sed файл, содержащий команды, используют ключ -f:
Вот содержимое файла mycommands:
s/This/That/
s/test/another test/Вызовем sed, передав редактору файл с командами и файл для обработки:
$ sed -f mycommands myfileРезультат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
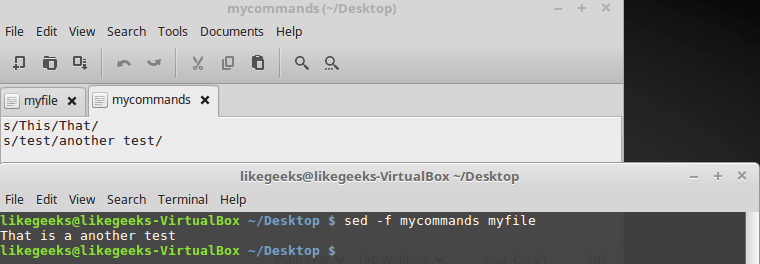
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
$ sed 's/test/another test/' myfileВот что содержится в файле, и что будет получено после его обработки sed.
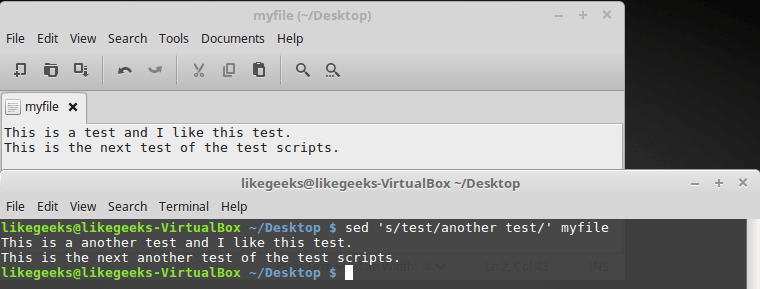
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
s/pattern/replacement/flagsВыполнение этой команды можно модифицировать несколькими способами.
- При передаче номера учитывается порядковый номер вхождения шаблона в строку, заменено будет именно это вхождение.
- Флаг
gуказывает на то, что нужно обработать все вхождения шаблона, имеющиеся в строке. - Флаг
pуказывает на то, что нужно вывести содержимое исходной строки. - Флаг вида
w fileуказывает команде на то, что нужно записать результаты обработки текста в файл.
Рассмотрим использование первого варианта команды замены, с указанием позиции заменяемого вхождения искомого фрагмента:
$ sed 's/test/another test/2' myfile
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g:
$ sed 's/test/another test/g' myfileКак видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.

Глобальная замена
Флаг команды замены p позволяет выводить строки, в которых найдены совпадения, при этом ключ -n, указанный при вызове sed, подавляет обычный вывод:
$ sed -n 's/test/another test/p' myfileКак результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
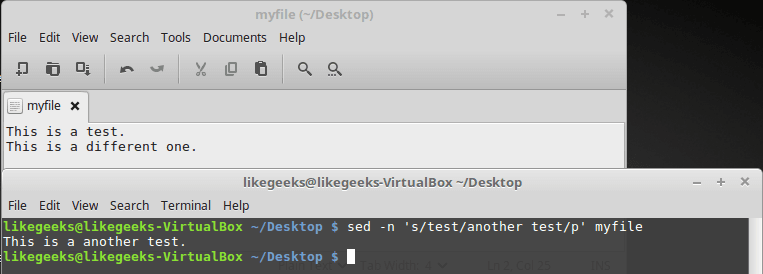
Использование флага команды замены p
Воспользуемся флагом w, который позволяет сохранить результаты обработки текста в файл:
$ sed 's/test/another test/w output' myfile
Сохранение результатов обработки текста в файл
Хорошо видно, что в ходе работы команды данные выводятся в STDOUT, при этом обработанные строки записываются в файл, имя которого указано после w.
Символы-разделители
Представьте, что нужно заменить /bin/bash на /bin/csh в файле /etc/passwd. Задача не такая уж и сложная:
$ sed 's//bin/bash//bin/csh/' /etc/passwdОднако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s:
$ sed 's!/bin/bash!/bin/csh!' /etc/passwdВ данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
- Задать ограничение на номера обрабатываемых строк.
- Указать фильтр, соответствующие которому строки нужно обработать.
Рассмотрим первый подход. Тут допустимо два варианта. Первый, рассмотренный ниже, предусматривает указание номера одной строки, которую нужно обработать:
$ sed '2s/test/another test/' myfile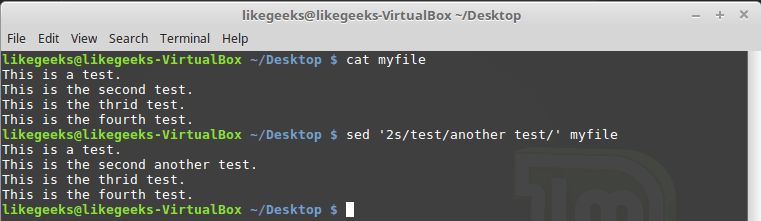
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
$ sed '2,3s/test/another test/' myfile
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
$ sed '2,$s/test/another test/' myfile
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
$ sed '/likegeeks/s/bash/csh/' /etc/passwd
По аналогии с тем, что было рассмотрено выше, шаблон передаётся перед именем команды s.

Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Утилита sed годится не только для замены одних последовательностей символов в строках на другие. С её помощью, а именно, используя команду d, можно удалять строки из текстового потока.
Вызов команды выглядит так:
$ sed '3d' myfileМы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
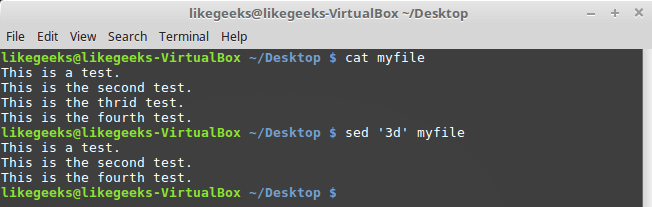
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
$ sed '2,3d' myfile
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
$ sed '3,$d' myfile
Удаление строк до конца файла
Строки можно удалять и по шаблону:
$ sed '/test/d' myfile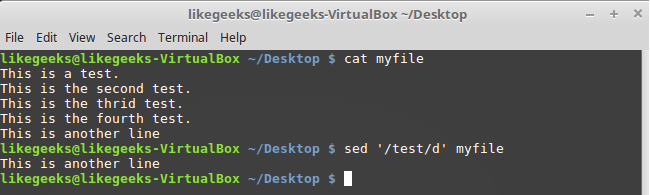
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
$ sed '/second/,/fourth/d' myfile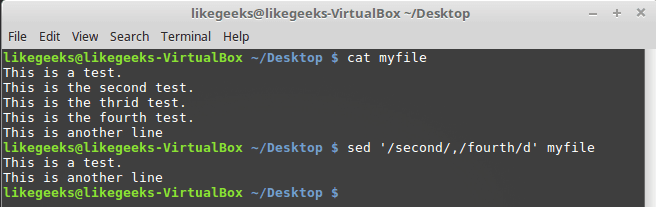
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a:
- Команда
iдобавляет новую строку перед заданной. - Команда
aдобавляет новую строку после заданной.
Рассмотрим пример использования команды i:
$ echo "Another test" | sed 'iFirst test '
Команда i
Теперь взглянем на команду a:
$ echo "Another test" | sed 'aFirst test '
Команда a
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Тут нам поможет указание номера опорной строки в потоке, или шаблона. Учтите, что адресация строк в виде диапазона тут не подойдёт. Вызовем команду i, указав номер строки, перед которой надо вставить новую строку:
$ sed '2iThis is the inserted line.' myfile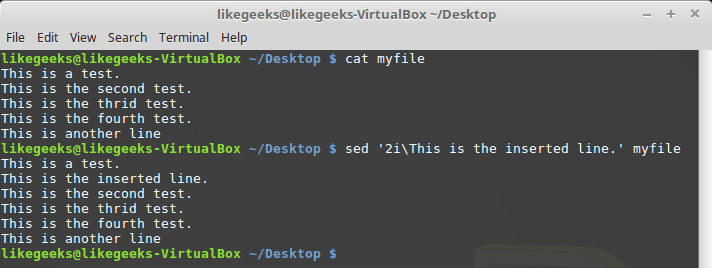
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a:
$ sed '2aThis is the appended line.' myfile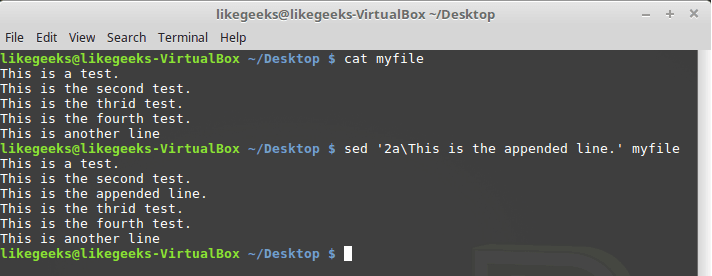
Команда a с указанием номера опорной строки
Обратите внимание на разницу в работе команд i и a. Первая вставляет новую строку до указанной, вторая — после.
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
$ sed '3cThis is a modified line.' myfile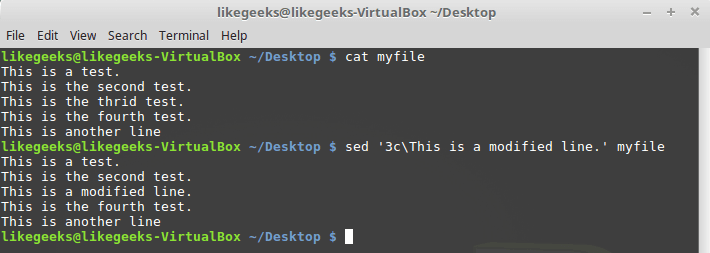
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
$ sed '/This is/c This is a changed line of text.' myfile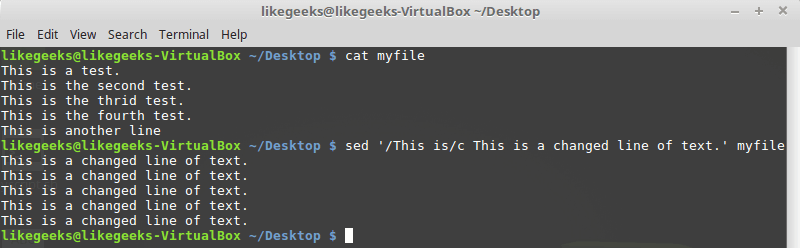
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
$ sed 'y/123/567/' myfile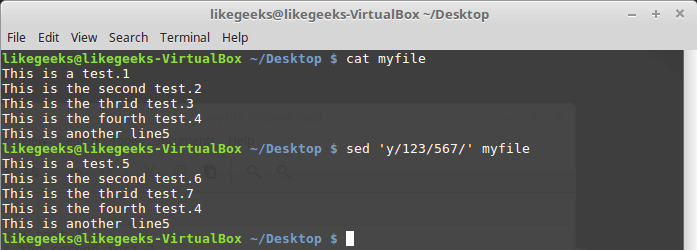
Замена символов
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Если вызвать sed, использовав команду =, утилита выведет номера строк в потоке данных:
$ sed '=' myfile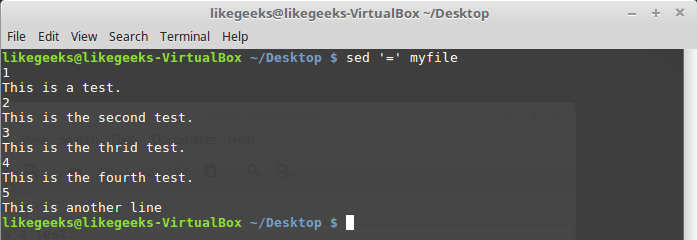
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Если передать этой команде шаблон и воспользоваться ключом sed -n, выведены будут только номера строк, соответствующих шаблону:
$ sed -n '/test/=' myfile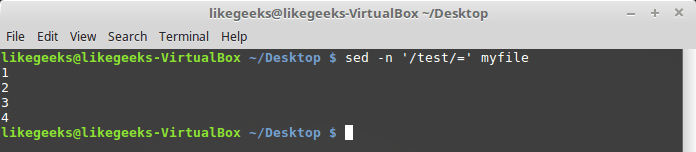
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Выше мы рассматривали приёмы вставки данных в поток, указывая то, что надо вставить, прямо при вызове sed. В качестве источника данных можно воспользоваться и файлом. Для этого служит команда r, которая позволяет вставлять в поток данные из указанного файла. При её вызове можно указать номер строки, после которой надо вставить содержимое файла, или шаблон.
Рассмотрим пример:
$ sed '3r newfile' myfile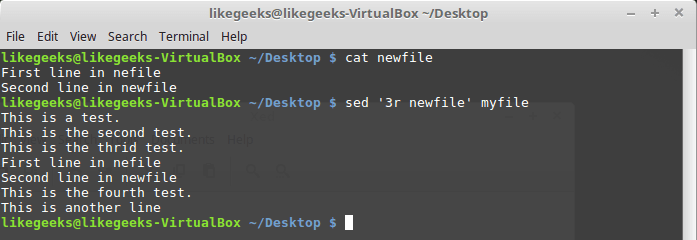
Вставка в поток содержимого файла
Тут содержимое файла newfile было вставлено после третьей строки файла myfile.
Вот что произойдёт, если применить при вызове команды r шаблон:
$ sed '/test/r newfile' myfile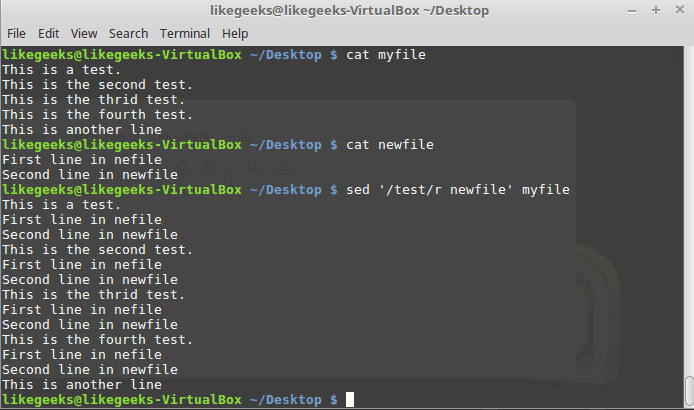
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Представим себе такую задачу. Есть файл, в котором имеется некая последовательность символов, сама по себе бессмысленная, которую надо заменить на данные, взятые из другого файла. А именно, пусть это будет файл newfile, в котором роль указателя места заполнения играет последовательность символов DATA. Данные, которые нужно подставить вместо DATA, хранятся в файле data.
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
$ Sed '/DATA>/ {
r newfile
d}' myfile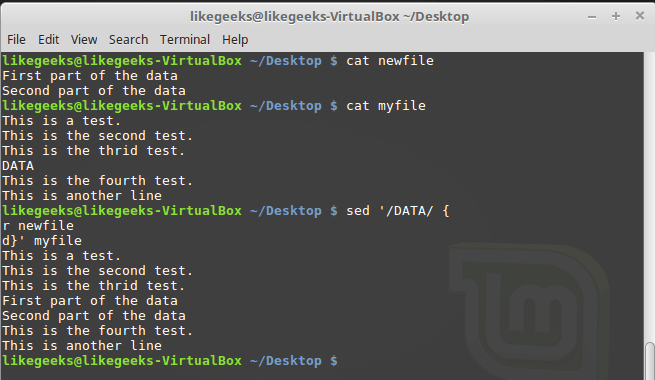
Замена указателя места заполнения на реальные данные
Как видите, вместо заполнителя DATA sed добавил в выходной поток две строки из файла data.
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.