
I am learning pandas for data cleaning. I am reading one excel file like below.

What I am looking to do is to rename column names like, First Cost Q3 2020, First Cost Q4 2020, First Cost Q1 2021 and so on. There are other column names «AUFC», «First Cost Growth %» and many more. And I also have to make the same like «First Cost».
I am new to pandas and not getting idea How can I rename columns like this. Can any one guide me?
asked Jul 20, 2021 at 11:52
![]()
2
You can rename a column name by using:
df.rename(columns = {'Q3 2020':'First Cost Q3 2020'}, inplace = True)
To update all column names, you can do this:
df.columns = ['First Cost Q3 2020', 'First Cost Q4 2020', 'First Cost Q1 2021']
answered Jul 20, 2021 at 12:06
![]()
Try via columns attribute and map() method:
df.columns=df.columns.map(' '.join)
Now If you print df or df.columns you will get your expected output
answered Jul 20, 2021 at 12:10
![]()
Anurag DabasAnurag Dabas
23.7k9 gold badges20 silver badges39 bronze badges
Simpliest way is to assign the list of desired column names as below (it must be all columns):
df.columns = ['First Cost Q3 2020', 'First Cost Q4 2020', etc].
If Pandas reads this excel as a multilevel columns you will need some more work. Let us know if this is the case
answered Jul 20, 2021 at 12:00
![]()
IoaTzimasIoaTzimas
10.5k2 gold badges11 silver badges29 bronze badges
1
You can read the excel file with multiindex columns by adding parameter header=[0,1] as follows (described better here):
df = pd.read_excel(your_path,
header=[0,1],
sheetname=your_sheet_name)
And then later merge the multiindex as described here:
df.columns = df.columns.map(' '.join).str.strip(' ')
answered Jul 20, 2021 at 12:02
![]()
RafaRafa
5564 silver badges12 bronze badges
In this tutorial, you’ll learn how to save your Pandas DataFrame or DataFrames to Excel files. Being able to save data to this ubiquitous data format is an important skill in many organizations. In this tutorial, you’ll learn how to save a simple DataFrame to Excel, but also how to customize your options to create the report you want!
By the end of this tutorial, you’ll have learned:
- How to save a Pandas DataFrame to Excel
- How to customize the sheet name of your DataFrame in Excel
- How to customize the index and column names when writing to Excel
- How to write multiple DataFrames to Excel in Pandas
- Whether to merge cells or freeze panes when writing to Excel in Pandas
- How to format missing values and infinity values when writing Pandas to Excel
Let’s get started!
The Quick Answer: Use Pandas to_excel
To write a Pandas DataFrame to an Excel file, you can apply the .to_excel() method to the DataFrame, as shown below:
# Saving a Pandas DataFrame to an Excel File
# Without a Sheet Name
df.to_excel(file_name)
# With a Sheet Name
df.to_excel(file_name, sheet_name='My Sheet')
# Without an Index
df.to_excel(file_name, index=False)Understanding the Pandas to_excel Function
Before diving into any specifics, let’s take a look at the different parameters that the method offers. The method provides a ton of different options, allowing you to customize the output of your DataFrame in many different ways. Let’s take a look:
# The many parameters of the .to_excel() function
df.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)Let’s break down what each of these parameters does:
| Parameter | Description | Available Options |
|---|---|---|
excel_writer= |
The path of the ExcelWriter to use | path-like, file-like, or ExcelWriter object |
sheet_name= |
The name of the sheet to use | String representing name, default ‘Sheet1’ |
na_rep= |
How to represent missing data | String, default '' |
float_format= |
Allows you to pass in a format string to format floating point values | String |
columns= |
The columns to use when writing to the file | List of strings. If blank, all will be written |
header= |
Accepts either a boolean or a list of values. If a boolean, will either include the header or not. If a list of values is provided, aliases will be used for the column names. | Boolean or list of values |
index= |
Whether to include an index column or not. | Boolean |
index_label= |
Column labels to use for the index. | String or list of strings. |
startrow= |
The upper left cell to start the DataFrame on. | Integer, default 0 |
startcol= |
The upper left column to start the DataFrame on | Integer, default 0 |
engine= |
The engine to use to write. | openpyxl or xlsxwriter |
merge_cells= |
Whether to write multi-index cells or hierarchical rows as merged cells | Boolean, default True |
encoding= |
The encoding of the resulting file. | String |
inf_rep= |
How to represent infinity values (as Excel doesn’t have a representation) | String, default 'inf' |
verbose= |
Whether to display more information in the error logs. | Boolean, default True |
freeze_panes= |
Allows you to pass in a tuple of the row, column to start freezing panes on | Tuple of integers with length 2 |
storage_options= |
Extra options that allow you to save to a particular storage connection | Dictionary |
.to_excel() methodHow to Save a Pandas DataFrame to Excel
The easiest way to save a Pandas DataFrame to an Excel file is by passing a path to the .to_excel() method. This will save the DataFrame to an Excel file at that path, overwriting an Excel file if it exists already.
Let’s take a look at how this works:
# Saving a Pandas DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx')Running the code as shown above will save the file with all other default parameters. This returns the following image:
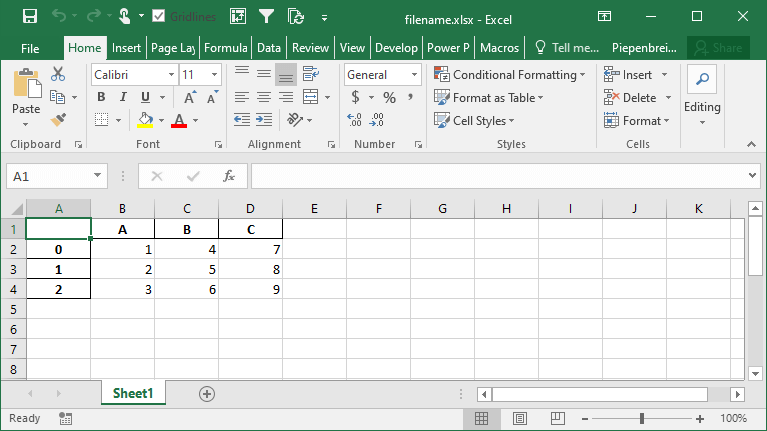
You can specify a sheetname by using the sheet_name= parameter. By default, Pandas will use 'sheet1'.
# Specifying a Sheet Name When Saving to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Your Sheet')This returns the following workbook:
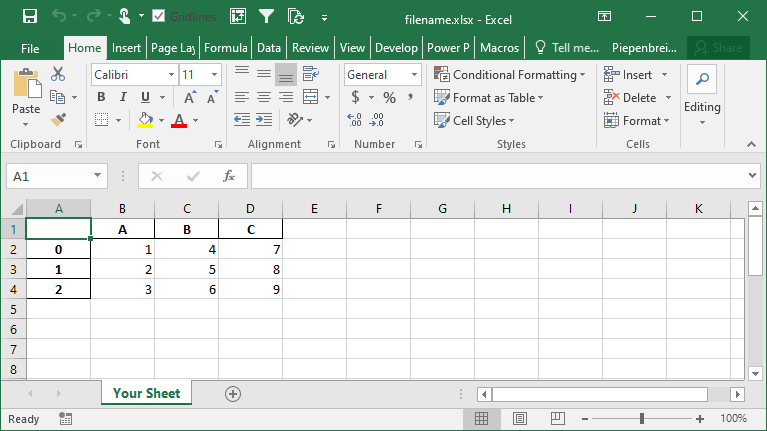
In the following section, you’ll learn how to customize whether to include an index column or not.
How to Include an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will include the index when saving a Pandas Dataframe to an Excel file. This can be helpful when the index is a meaningful index (such as a date and time). However, in many cases, the index will simply represent the values from 0 through to the end of the records.
If you don’t want to include the index in your Excel file, you can use the index= parameter, as shown below:
# How to exclude the index when saving a DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index=False)This returns the following Excel file:
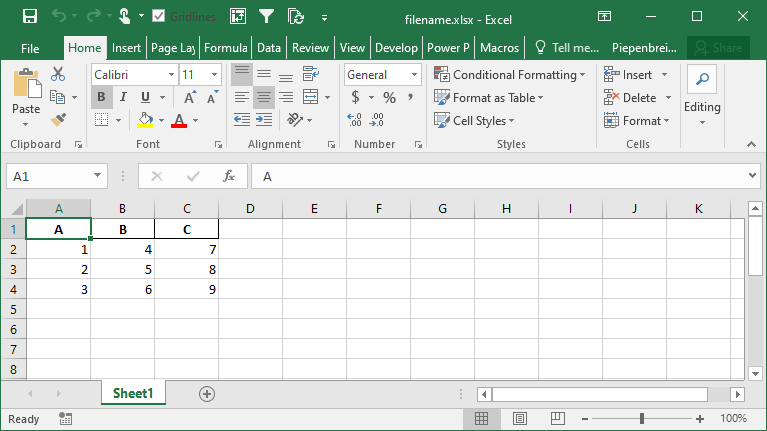
In the following section, you’ll learn how to rename an index when saving a Pandas DataFrame to an Excel file.
How to Rename an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will not named the index of your DataFrame. This, however, can be confusing and can lead to poorer results when trying to manipulate the data in Excel, either by filtering or by pivoting the data. Because of this, it can be helpful to provide a name or names for your indices.
Pandas makes this easy by using the index_label= parameter. This parameter accepts either a single string (for a single index) or a list of strings (for a multi-index). Check out below how you can use this parameter:
# Providing a name for your Pandas index
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index_label='Your Index')This returns the following sheet:
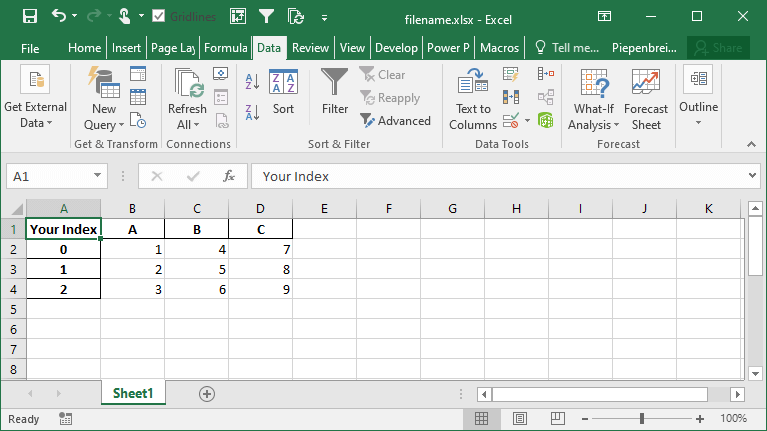
How to Save Multiple DataFrames to Different Sheets in Excel
One of the tasks you may encounter quite frequently is the need to save multi Pandas DataFrames to the same Excel file, but in different sheets. This is where Pandas makes it a less intuitive. If you were to simply write the following code, the second command would overwrite the first command:
# The wrong way to save multiple DataFrames to the same workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Sheet1')
df.to_excel('filename.xlsx', sheet_name='Sheet2')Instead, we need to use a Pandas Excel Writer to manage opening and saving our workbook. This can be done easily by using a context manager, as shown below:
# The Correct Way to Save Multiple DataFrames to the Same Workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
with pd.ExcelWriter('filename.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1')
df.to_excel(writer, sheet_name='Sheet2')This will create multiple sheets in the same workbook. The sheets will be created in the same order as you specify them in the command above.
This returns the following workbook:
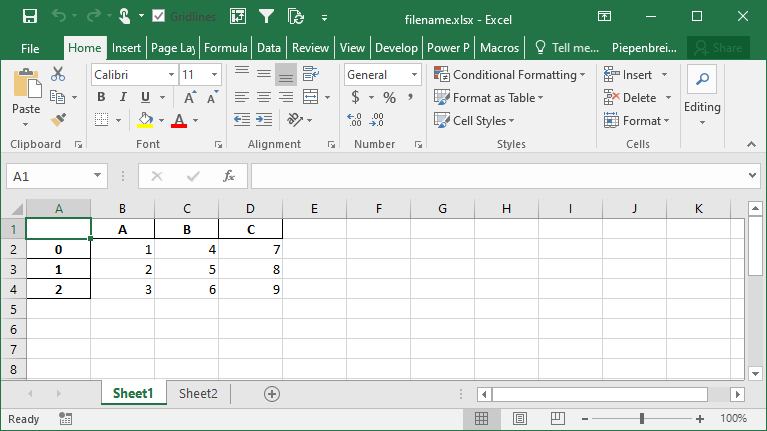
How to Save Only Some Columns when Exporting Pandas DataFrames to Excel
When saving a Pandas DataFrame to an Excel file, you may not always want to save every single column. In many cases, the Excel file will be used for reporting and it may be redundant to save every column. Because of this, you can use the columns= parameter to accomplish this.
Let’s see how we can save only a number of columns from our dataset:
# Saving Only a Subset of Columns to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', columns=['A', 'B'])This returns the following Excel file:
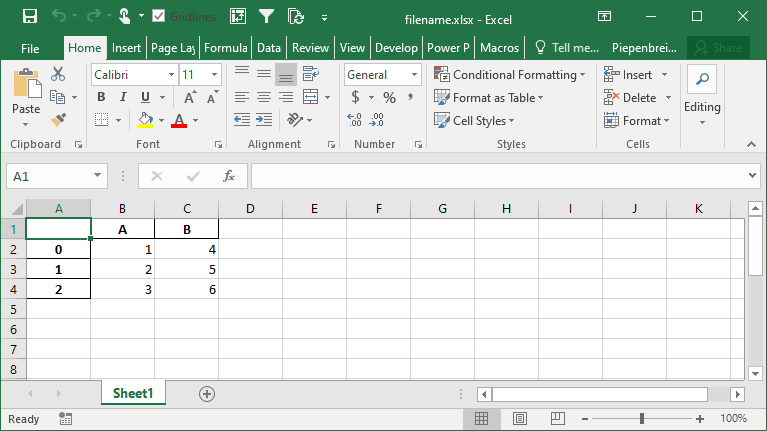
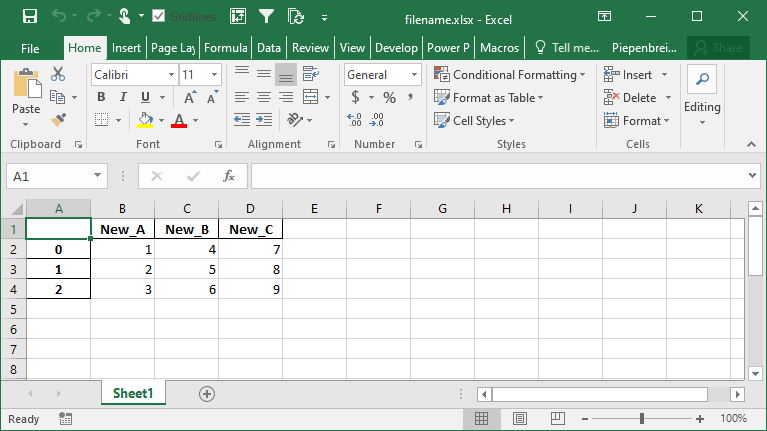
How to Rename Columns when Exporting Pandas DataFrames to Excel
Continuing our discussion about how to handle Pandas DataFrame columns when exporting to Excel, we can also rename our columns in the saved Excel file. The benefit of this is that we can work with aliases in Pandas, which may be easier to write, but then output presentation-ready column names when saving to Excel.
We can accomplish this using the header= parameter. The parameter accepts either a boolean value of a list of values. If a boolean value is passed, you can decide whether to include or a header or not. When a list of strings is provided, then you can modify the column names in the resulting Excel file, as shown below:
# Modifying Column Names when Exporting a Pandas DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', header=['New_A', 'New_B', 'New_C'])This returns the following Excel sheet:
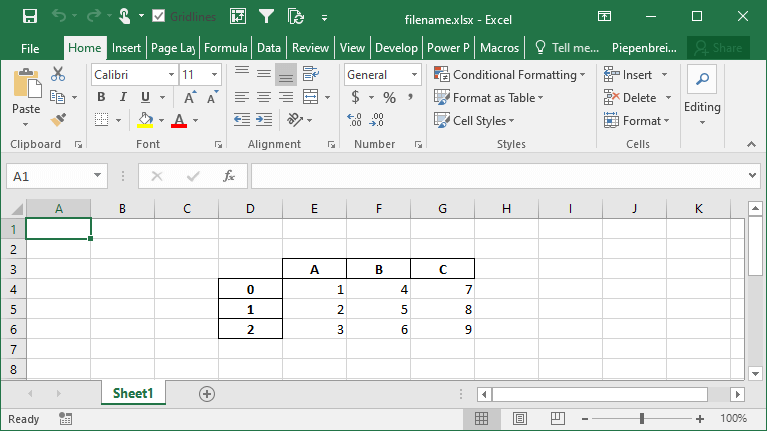
How to Specify Starting Positions when Exporting a Pandas DataFrame to Excel
One of the interesting features that Pandas provides is the ability to modify the starting position of where your DataFrame will be saved on the Excel sheet. This can be helpful if you know you’ll be including different rows above your data or a logo of your company.
Let’s see how we can use the startrow= and startcol= parameters to modify this:
# Changing the Start Row and Column When Saving a DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', startcol=3, startrow=2)This returns the following worksheet:
How to Represent Missing and Infinity Values When Saving Pandas DataFrame to Excel
In this section, you’ll learn how to represent missing data and infinity values when saving a Pandas DataFrame to Excel. Because Excel doesn’t have a way to represent infinity, Pandas will default to the string 'inf' to represent any values of infinity.
In order to modify these behaviors, we can use the na_rep= and inf_rep= parameters to modify the missing and infinity values respectively. Let’s see how we can do this by adding some of these values to our DataFrame:
# Customizing Output of Missing and Infinity Values When Saving to Excel
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', na_rep='NA', inf_rep='INFINITY')This returns the following worksheet:
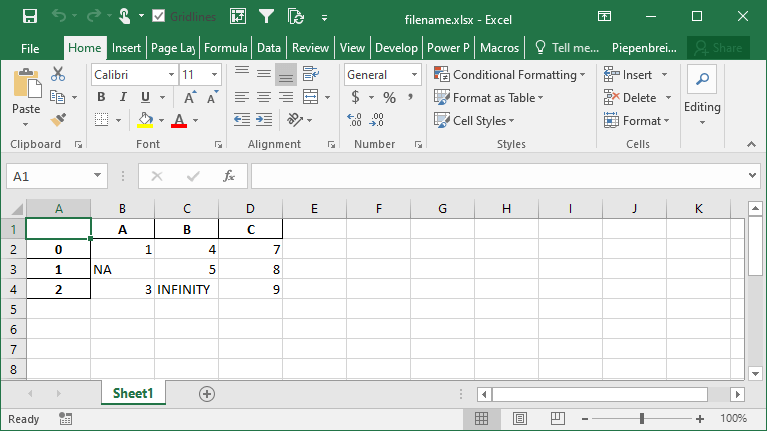
How to Merge Cells when Writing Multi-Index DataFrames to Excel
In this section, you’ll learn how to modify the behavior of multi-index DataFrames when saved to Excel. By default Pandas will set the merge_cells= parameter to True, meaning that the cells will be merged. Let’s see what happens when we set this behavior to False, indicating that the cells should not be merged:
# Modifying Merge Cell Behavior for Multi-Index DataFrames
import pandas as pd
import numpy as np
from random import choice
df = pd.DataFrame.from_dict({
'A': np.random.randint(0, 10, size=50),
'B': [choice(['a', 'b', 'c']) for i in range(50)],
'C': np.random.randint(0, 3, size=50)})
pivot = df.pivot_table(index=['B', 'C'], values='A')
pivot.to_excel('filename.xlsx', merge_cells=False)This returns the Excel worksheet below:
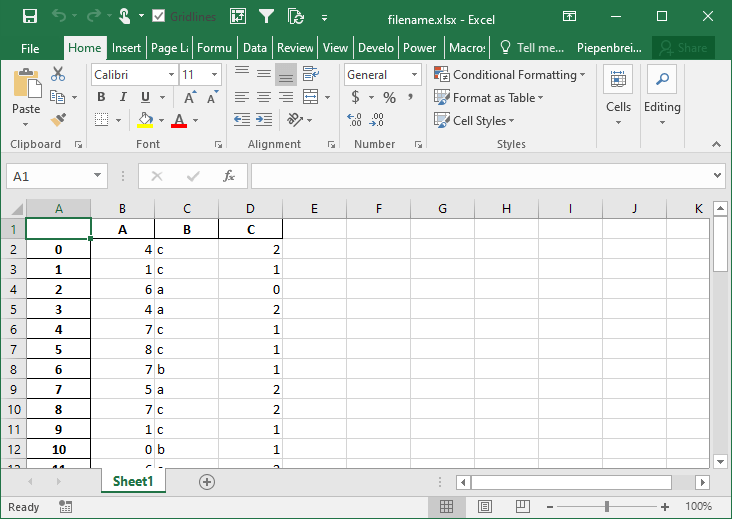
How to Freeze Panes when Saving a Pandas DataFrame to Excel
In this final section, you’ll learn how to freeze panes in your resulting Excel worksheet. This allows you to specify the row and column at which you want Excel to freeze the panes. This can be done using the freeze_panes= parameter. The parameter accepts a tuple of integers (of length 2). The tuple represents the bottommost row and the rightmost column that is to be frozen.
Let’s see how we can use the freeze_panes= parameter to freeze our panes in Excel:
# Freezing Panes in an Excel Workbook Using Pandas
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', freeze_panes=(3,4))This returns the following workbook:
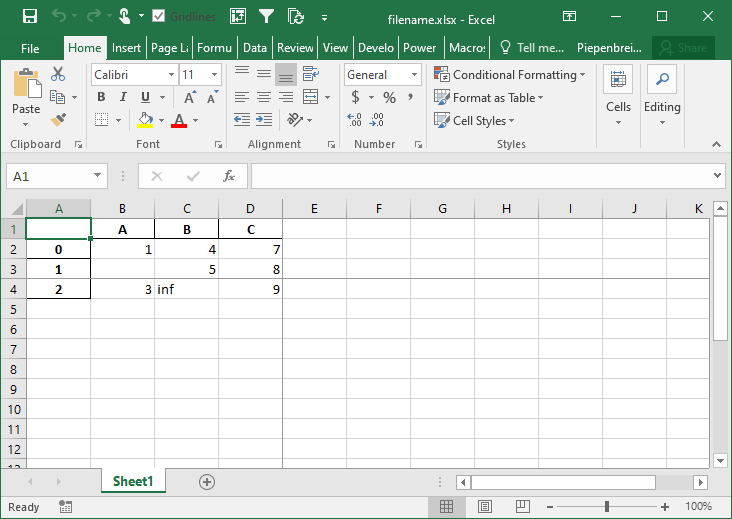
Conclusion
In this tutorial, you learned how to save a Pandas DataFrame to an Excel file using the to_excel method. You first explored all of the different parameters that the function had to offer at a high level. Following that, you learned how to use these parameters to gain control over how the resulting Excel file should be saved. For example, you learned how to specify sheet names, index names, and whether to include the index or not. Then you learned how to include only some columns in the resulting file and how to rename the columns of your DataFrame. You also learned how to modify the starting position of the data and how to freeze panes.
Additional Resources
To learn more about related topics, check out the tutorials below:
- How to Use Pandas to Read Excel Files in Python
- Pandas Dataframe to CSV File – Export Using .to_csv()
- Introduction to Pandas for Data Science
- Official Documentation: Pandas to_excel
Содержание
- Pandas rename column using DataFrame.rename() function
- Install Python Panda Module
- Loading your dataset
- pandas.DataFrame.rename
- Method 1: Using column label
- Method 2: Using axis-style
- Some more examples:
- Pandas rename columns using read_csv with names
- Re-assign column attributes using tolist()
- Define new Column List using Panda DataFrame
- Conclusion
- References
- Rename specific column(s) in pandas
- 7 Answers 7
- How do I rename a specific column in pandas?
- rename with axis=1
- Index.str.replace
- Passing a list to set_axis with axis=1
- How to Rename Columns in Pandas — A Quick Guide
- A short guide on multiple options for renaming columns in a pandas dataframe
- Library Imports and Data Creation
- Renaming Columns When Loading Data
- Renaming All Columns Using .rename()
- Renaming a Specific Column Using .rename()
- Renaming Columns Using Set_axis()
- Using .columns() to Assign a New List of Names
- Using columns.str.replace()
- Summary
Pandas rename column using DataFrame.rename() function
Table of Contents
Pandas is an open source Python library for data analysis. It gives Python the ability to work with spreadsheet-like data for fast data loading, manipulating, aligning, and merging, among other functions.
To give Python these enhanced features, Pandas introduces two new data types to Python:
- Series: It represents single column of the DataFrame
- DataFrame: It represents your entire spreadsheet or rectangular data
A Pandas DataFrame can also be thought of as a dictionary or collection of Series objects.
Install Python Panda Module
It is possible by default panda module is not installed on your Linux environment
So you must first install this module. Since I am using RHEL 8, I will use dnf
Alternatively you can install pip3 and then use pip to install panda module:
Now you can use pip3 to install the panda module: 
Loading your dataset
- When given a data set, we first load it and begin looking at its structure and contents. The simplest way of looking at a data set is to examine and subset specific rows and columns
- Since Pandas is not part of the Python standard library, we have to first tell Python to load (import) the library.
- When working with Pandas functions, it is common practice to give pandas the alias pd
- With the library loaded, we can use the read_csv function to load a CSV data file. To access the read_csv function from Pandas, we use dot notation.
- I have created a sample csv file ( cars.csv ) for this tutorial (separated by comma char), by default the read_csv function will read a comma-separated file:
Output from this script:
pandas.DataFrame.rename
- The rename DataFrame method accepts dictionaries that map the old value to the new value.
- We can use this function to rename single or multiple columns in Python DataFrame
- The rename() method provides an inplace named parameter that is by default False and copies the underlying data.
- We can pass inplace=True to rename the data in place.
Syntax:
The provided values in Syntax are default values unless provided other wise. This will return DataFrame with the renamed axis labels.
Parameters:
mapper: dict-like or function
Dict-like or functions transformations to apply to that axis’ values. Use either mapper and axis to specify the axis to target with mapper, or index and columns.
index: dict-like or function
Alternative to specifying axis (mapper, axis=0 is equivalent to index=mapper).
columns: dict-like or function
Alternative to specifying axis (mapper, axis=1 is equivalent to columns=mapper).
axis: int or str
Axis to target with mapper. Can be either the axis name (‘index’, ‘columns’) or number (0, 1). The default is ‘index’.
copy: bool, default True
Also copy underlying data.
inplace: bool, default False
Whether to return a new DataFrame. If True then value of copy is ignored.
level: int or level name, default None
In case of a MultiIndex, only rename labels in the specified level.
errors: <‘ignore’, ‘raise’>, default ‘ignore’
Method 1: Using column label
Pandas rename single column
The syntax to replace single column within the same file would be:
In this example we will rename Column name «Company» with «Brand»
Execute the script and you can check that our inplace rename for column was successful:
Pandas rename multiple columns
To rename multiple columns inplace we will use below syntax:
We just need to add
- : section within the curl braces for columns to replace the same at multiple places
In this example we replace column name Company with Brand and Car with SUV:
Output from this script confirms the replacement was successful:
Method 2: Using axis-style
DataFrame.rename() also supports an “axis-style” calling convention, where you specify a single mapper and the axis to apply that mapping to.
The syntax to use this method would be:
In this sample python script I will replace two column values from Company to Brand and Car to SUV
Output from this script:
Some more examples:
In this example we will change all headers to Uppercase character using str.upper with rename() function
Output from this script:
Similarly you can use str.lower to transform the Column header format to lowercase
Pandas rename columns using read_csv with names
names parameter in read_csv function is used to define column names. If you pass extra name in this list, it will add another new column with that name with new values.
Use header = 0 to remove the first header from the output
In this example we define a new list new_colums and store the new column name. make sure that length of new list is same as the existing one in your input CSV or List
Output from this script:
Re-assign column attributes using tolist()
- tolist() is used to convert series to list.
- It is possible to reassign the column attributes directly to a Python list.
- This assignment works when the list has the same number of elements as the row and column labels.
- The following code uses the tolist method on each Column object to create a Python list of labels.
- It then modifies a couple values in the list and reassigns the list to the columns attributes:
The output from this script:
Define new Column List using Panda DataFrame
I would not call this as rename instead you can define a new Column List and replace the existing one using columns attribute of the dataframe object. But make sure the length of new column list is same as the one which you are replacing. This is similar to what we did in Method 3 using read_csv with names attribute
The output from this script:
Conclusion
In this tutorial we learned about different methods to rename column values using Python Panda DataFrame function. I have used CSV and read_csv for all the examples but you can also import and type of object to dataframe using pd.DataFrame(var) and then process it to rename the column. You can also replace row values using index property which we will learn in separate chapter.
Lastly I hope this Python tutorial to rename column values using Panda Dataframe was helpful. So, let me know your suggestions and feedback using the comment section.
References
I have used below external references for this tutorial guide
DataFrame.rename()
Didn’t find what you were looking for? Perform a quick search across GoLinuxCloud
If my articles on GoLinuxCloud has helped you, kindly consider buying me a coffee as a token of appreciation.

For any other feedbacks or questions you can either use the comments section or contact me form.
Thank You for your support!!
Источник
Rename specific column(s) in pandas
I’ve got a dataframe called data . How would I rename the only one column header? For example gdp to log(gdp) ?


7 Answers 7
The rename show that it accepts a dict as a param for columns so you just pass a dict with a single entry.
A much faster implementation would be to use list-comprehension if you need to rename a single column.
If the need arises to rename multiple columns, either use conditional expressions like:
Or, construct a mapping using a dictionary and perform the list-comprehension with it’s get operation by setting default value as the old name:
Timings:
How do I rename a specific column in pandas?
From v0.24+, to rename one (or more) columns at a time,
DataFrame.rename() with axis=1 or axis=’columns’ (the axis argument was introduced in v0.21 .
Index.str.replace() for string/regex based replacement.
If you need to rename ALL columns at once,
- DataFrame.set_axis() method with axis=1 . Pass a list-like sequence. Options are available for in-place modification as well.
rename with axis=1
With 0.21+, you can now specify an axis parameter with rename :
(Note that rename is not in-place by default, so you will need to assign the result back.)
This addition has been made to improve consistency with the rest of the API. The new axis argument is analogous to the columns parameter—they do the same thing.
rename also accepts a callback that is called once for each column.
For this specific scenario, you would want to use
Index.str.replace
Similar to replace method of strings in python, pandas Index and Series (object dtype only) define a («vectorized») str.replace method for string and regex-based replacement.
The advantage of this over the other methods is that str.replace supports regex (enabled by default). See the docs for more information.
Passing a list to set_axis with axis=1
Call set_axis with a list of header(s). The list must be equal in length to the columns/index size. set_axis mutates the original DataFrame by default, but you can specify inplace=False to return a modified copy.
Note: In future releases, inplace will default to True .
Method Chaining
Why choose set_axis when we already have an efficient way of assigning columns with df.columns = . ? As shown by Ted Petrou in this answer set_axis is useful when trying to chain methods.
The former is more natural and free flowing syntax.
Источник
How to Rename Columns in Pandas — A Quick Guide
A short guide on multiple options for renaming columns in a pandas dataframe
Ensuring that dataframe columns are appropriately named is essential to understand what data is contained within, especially when we pass our data on to others. In this short article, we will cover a number of ways to rename columns within a pandas dataframe.
But first, what is Pandas? Pandas is a powerful, fast, and commonly used python library for carrying out data analytics. The Pandas name itself stands for “Python Data Analysis Library”. According to Wikipedia, the name originates from the term “panel data”. It allows data to be loaded in from a number file formats (CSV, XLS, XLSX, Pickle, etc.) and stored within table-like structures. These tables (dataframes) can be manipulated, analyzed, and visualized using a variety of functions that are available within pandas
Library Imports and Data Creation
The first steps involve importing the pandas library and creating some dummy data that we can use to illustrate the process of column renaming.
We will create some dummy data to illustrate the various techniques. We can do this by calling upon the .DataFrame() Here we will create three columns with the names A, B, and C.
Renaming Columns When Loading Data
An alternative method for creating the dataframe would be to load the data from an existing file, such as a csv or xlsx file. When we load the data, we can change the names of the columns using the names argument. When we do this, we need to make sure we drop the existing header row by using header=0 .
Renaming All Columns Using .rename()
The first method we will look at is the .rename() function. Here we can pass in a dictionary to the columns keyword argument. The dictionary allows us to provide a mapping between the old column name and the new one that we want.
We will also set the inplace argument to True so that we are making the changes to the dataframe, df, directly as opposed to making a copy of it.
An alternative version of this is to specify the axis, however, it is less readable and may not be clear what this argument is doing compared to using the columns argument.
When we call upon df, we now see that our columns have been renamed from A, B, and C to Z, Y, and X respectively.
Renaming a Specific Column Using .rename()
If we want to rename specific columns, we can use the rename function again. Instead of providing a string for string mapping, we can use df.columns and select a column by providing a column index position in the square brackets. We then map this to a new column name string.
We can also specify a mapping between an existing column name and the new one.
Renaming Columns Using Set_axis()
The next method is set_axis() which is used to set the axis (column: axis=1 or row: axis=0) of a dataframe.
We can use this method to rename the columns by first defining our list of names we want to replace the columns with and setting axis=1 or axis=’columns’ . Note that here the number of names needs to equal the total number of columns.
Using .columns() to Assign a New List of Names
We can rename the columns directly by assigning a new list containing the names that we want to rename the columns to. This is achieved using the df.columns attribute of the dataframe.
This method requires the new list of names to be the same length as the number of columns in the dataframe. Therefore, if we only want to rename one or two columns this is probably not the best approach.
Using columns.str.replace()
The final method we will look at is using str.replace() , which can be used to replace specific characters or entire column names.
In this example, we will replace column 1 with the letter Z.
Summary
There are multiple methods for renaming columns within a pandas dataframe including pd.read_csv, .set_axis, df.rename and df.columns. This illustrates the great flexibility that is available within the pandas python library and makes it easy to ensure that columns within a dataframe are appropriately labeled.
Thanks for reading!
If you have found this article useful, feel free to check out my other articles looking at various aspects of Python and well log data. You can also find my code used in this article and others at GitHub .
If you want to get in touch you can find me on LinkedIn or at my website.
Interested in learning more about python, petrophysics, or well log data petrophysics? Follow me on Medium or on YouTube.
Источник
In this Pandas tutorial, we will go through how to rename columns in a Pandas dataframe. First, we will learn how to rename a single column. Second, we will go on with renaming multiple columns. In the third example, we will also have a quick look at how to rename grouped columns. Finally, we will change the column names to lowercase.
First, however, we are goign to look at a simple code example on how to rename a column in a Pandas dataframe.
How to Rename a Column in Pandas Dataframe
First of all, renaming columns in Pandas dataframe is very simple: to rename a column in a dataframe we can use the rename method:
df.rename(columns={'OldName':'NewName'},
inplace=True)Code language: Python (python)In the code example above, the column “OldName” will be renamed “NewName”. Furthermore, the use of the inplace parameter make this change permanent to the dataframe.
Why Bother with Renaming Variables?
Now, when we are working with a dataset, whether it is big data or a smaller data set, the columns may have a name that needs to be changed. For instance, if we have scraped our data from HTML tables using Pandas read_html the column names may not be suitable for our displaying our data, later. Furthermore, this is at many times part of the pre-processing of our data.

Prerequisites
Now, before we go on and learning how to rename columns, we need to have Python 3.x and Pandas installed. Now, Python and Pandas can be installed by installing a scientific Python distribution, such as Anaconda or ActivePython. On the other hand, Pandas can be installed, as many Python packages, using Pip: pip install pandas. Refer to the blog post about installing Python packages for more information.
If we install Pandas, and we get a message that there is a newer version of Pip, we can upgrade pip using pip, conda, or Anaconda navigator.
How to Rename Columns in Pandas?

So how do you change column names in Pandas? Well, after importing the data, we can change the column names in the Pandas dataframe by either using df.rename(columns={'OldName':'NewName'}, inplace=True or assigning a list the columns method; df.columns = list_of_new_names.
Example Data
In this tutorial, we are going to read an Excel file with Pandas to import data. More information about importing data from Excel files can be found in the Pandas read excel tutorial, previously posted on this blog.
import pandas as pd
xlsx_url = 'https://github.com/marsja/jupyter/blob/master/SimData/play_data.xlsx?raw=true'
df = pd.read_excel(xlsx_url, index_col=0)Code language: Python (python)Now, we used the index_col argument, because the first column in the Excel file we imported is the index column. If we want to get the column names from the Pandas dataframe we can use df.columns:
df.columnsCode language: Python (python)![]()
Now, it is also possible that our data is stored in other formats such as CSV, SPSS, Stata, or SAS. Make sure to check out the post on how to use Pandas read_csv to learn more about importing data from .csv files.
How to Rename a Single Column in Pandas
In the first example, we will learn how to rename a single column in Pandas dataframe. Note, in the code snippet below we use df.rename to change the name of the column “Subject ID” and we use the inplace=True to get the change permanent.
# inplace=True to affect the dataframe
df.rename(columns = {'Subject ID': 'SubID'},
inplace=True)
df.head()Code language: Python (python)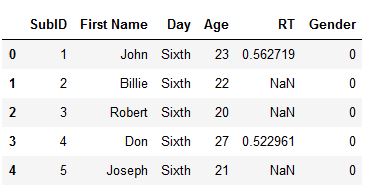
In the next section, we will have a look at how to use Pandas’ rename function to rename multiple columns.
How To Rename Columns in Pandas: Example 1
To rename columns in Pandas dataframe we do as follows:
- Get the column names by using df.columns (if we don’t know the names)
- Use the df.rename, use a dictionary of the columns we want to rename as input.
Here’s a working example on renaming columns in Pandas:
import pandas as pd
xlsx_url = 'https://github.com/marsja/jupyter/blob/master/SimData/play_data.xlsx?raw=true'
df = pd.read_excel(xlsx_url, index_col=0)
print(df.columns)
df.rename(columns = {'RT':'ResponseTime',
'First Name':'Given Name',
'Subject ID':'SubID'},
inplace=True)Code language: Python (python)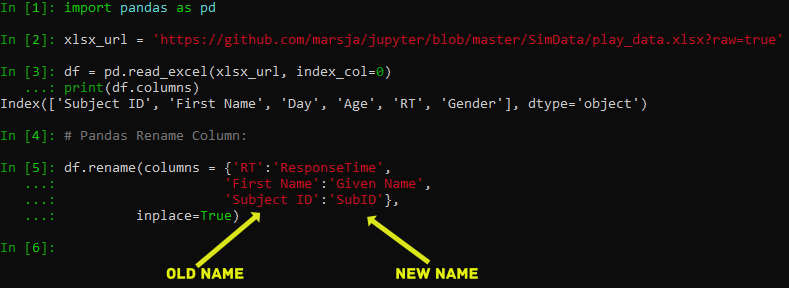
Renaming Columns in Pandas Example 2
Another example of how to rename many columns in Pandas dataframe is to assign a list of new column names to df.columns:
import pandas as pd
xlsx_url = 'https://github.com/marsja/jupyter/blob/master/SimData/play_data.xlsx?raw=true'
df = pd.read_excel(xlsx_url, index_col=0)
# New column names
new_cols = ['SubID', 'Given Name', 'Day', 'Age', 'ResponseTime', 'Gender']
# Renaming the columns
df.columns = new_cols
df.head()Code language: Python (python)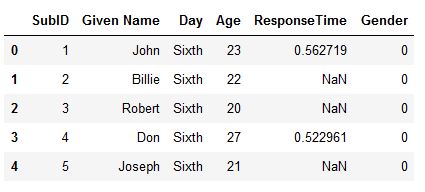
As can be seen in the code above, we imported our data from an Excel file, we created a list with the new column names. Finally, we renamed the columns with df.columns.
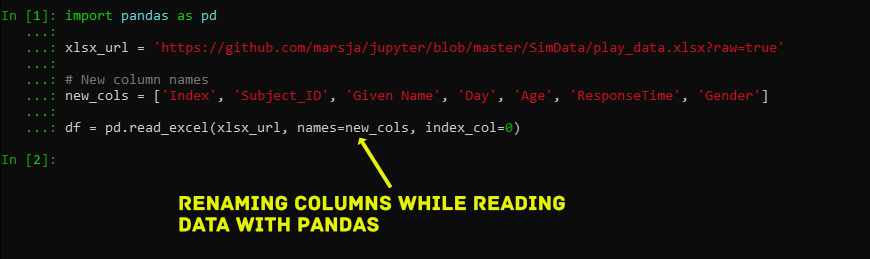
Renaming Columns while Importing Data
In this section, we are going to learn how to rename columns while reading the Excel file. Now, this is also very simple. To accomplish this we create a list before we use the read_excel method. Note, we need to add a column name, in the list, for the index column.
import pandas as pd
xlsx_url = 'https://github.com/marsja/jupyter/blob/master/SimData/play_data.xlsx?raw=true'
# New column names
new_cols = ['Index', 'Subject_ID', 'Given Name', 'Day', 'Age', 'ResponseTime', 'Gender']
df = pd.read_excel(xlsx_url, names=new_cols, index_col=0)
df.columnsCode language: Python (python)![]()
Importantly, when changing the name of the columns while reading the data we need to know the number of columns before we load the data.
In the next example, we are going to learn how to rename grouped columns in Pandas dataframe.
Renaming Grouped Columns in Pandas Dataframe
In this section, we are going to rename grouped columns in Pandas dataframe. First, we are going to use Pandas groupby method (if needed, check the post about Pandas groupby method for more information). Second, we are going rename the grouped columns using Python list comprehension and df.columns, among other dataframe methods.
import pandas as pd
import numpy as np
xlsx_url = 'https://github.com/marsja/jupyter/blob/master/SimData/play_data.xlsx?raw=true'
df = pd.read_excel(xlsx_url, index_col=0)
grouped = df.groupby('Day').agg({'RT':[np.mean, np.median, np.std]})
groupedCode language: Python (python)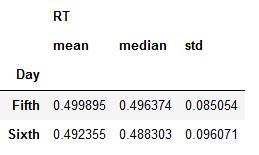
Now, as you can see in the image above, we have a dataframe with multiple indexes. In the next code chunk, however, we are going to rename the grouped dataframe.
grouped.columns = ['_'.join(x) for x in grouped.columns.ravel()]
groupedCode language: Python (python)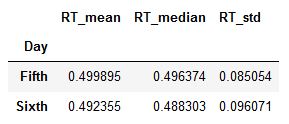
Note, in the code above we also used Pandas ravel method to flatten the output to an ndarray. Now, there are other ways we can change the name of columns in Pandas dataframe. For instance, if we only want to change the column names so that the names are in lower case we can use str.lower.
df.rename(columns=str.lower).head()Code language: Python (python)Importantly, if we want the change to be permanent we need to add the inplace=True argument.
Changing Column Names in Pandas Dataframe to Lowercase
To change all column names to lowercase we can use the following code:
df.rename(columns=str.lower)Code language: Python (python)
Now, this is one way to preprocess data in Python with pandas. In another post, on this blog, we can learn about data cleaning in Python with Pandas and Pyjanitor.
Video Guide: Pandas Rename Column(s)
If you prefer to learn audiovisually, here’s a YouTube Tutorial covering how to change the variable names in Pandas dataframe.
Conclusion
In this post, we have learned all we need to know about renaming columns in Pandas dataframes. First, we learned how to rename a single column. Subsequently, we renamed many columns using two methods; df.rename and df.columns. Third, we renamed the columns while importing the data from an Excel file. In the third example, we learned how to rename grouped dataframes in Pandas. Finally, we also changed the column names to lowercase.
In this tutorial, we will cover various methods to rename columns in pandas dataframe in Python. Renaming or changing the names of columns is one of the most common data wrangling task. If you are not from programming background and worked only in Excel Spreadsheets in the past you might feel it not so easy doing this in Python as you can easily rename columns in MS Excel by just typing in the cell what you want to have. If you are from database background it is similar to ALIAS in SQL. In Python there is a popular data manipulation package called pandas which simplifies doing these kind of data operations.

2 Methods to rename columns in Pandas
In Pandas there are two simple methods to rename name of columns.
First step is to install pandas package if it is not already installed. You can check if the package is installed on your machine by running !pip show pandas statement in Ipython console. If it is not installed, you can install it by using the command !pip install pandas.
Import Dataset for practice
To import dataset, we are using read_csv( ) function from pandas package.
import pandas as pd
df = df = pd.read_csv("https://raw.githubusercontent.com/JackyP/testing/master/datasets/nycflights.csv", usecols=range(1,17))
To see the names of columns in a data frame, write the command below :
df.columns
Index(['year', 'month', 'day', 'dep_time', 'dep_delay', 'arr_time',
'arr_delay', 'carrier', 'tailnum', 'flight', 'origin', 'dest',
'air_time', 'distance', 'hour', 'minute'],
dtype='object')
Method I : rename() function
Suppose you want to replace column name year with years. In the code below it will create a new dataframe named df2 having new column names and same values.
df2 = df.rename(columns={'year':'years'})
If you want to make changes in the same dataset df you can try this option inplace = True
df.rename(columns={'year':'years'}, inplace = True)
By default inplace = False is set, hence you need to specify this option and mark it True.
If you want to rename names of multiple columns, you can specify other columns with comma separator.
df.rename(columns={'year':'years', 'month':'months' }, inplace = True)
Method II : dataframe.columns = [list]
You can also assign the list of new column names to df.columns. See the example below. We are renaming year and month columns here.
df.columns = ['years', 'months', 'day', 'dep_time', 'dep_delay', 'arr_time',
'arr_delay', 'carrier', 'tailnum', 'flight', 'origin', 'dest',
'air_time', 'distance', 'hour', 'minute']
Rename columns having pattern
Suppose you want to rename columns having underscore ‘_’ in their names. You want to get rid of underscore
df.columns = df.columns.str.replace('_' , '')
New column names are as follows. You can observe no underscore in the column names.
Index(['year', 'month', 'day', 'deptime', 'depdelay', 'arrtime', 'arrdelay',
'carrier', 'tailnum', 'flight', 'origin', 'dest', 'airtime', 'distance',
'hour', 'minute'],
dtype='object')
Rename columns by Position
If you want to change the name of column by position (for example renaming first column) you can do it by using the code below. df.columns[0] refers to first column.
df.rename(columns={ df.columns[0]: "Col1" }, inplace = True)
Rename columns in sequence
If you want to change the name of column in sequence of numbers you can do it by iterating via for loop.
df.columns=["Col"+str(i) for i in range(1, 17)]
In the code below df.shape[1] returns no. of columns in the dataframe. We need to add 1 here as range(1,17) returns 1, 2, 3 through 16 (excluding 17).
df.columns=["Col"+str(i) for i in range(1, df.shape[1] + 1)]
Add prefix / suffix in column names
In case you want to add some text before or after existing column names, you can do it by using add_prefix( ) and add_suffix( ) functions.
df = df.add_prefix('V_')
df = df.add_suffix('_V')
How to access columns having space in names
For demonstration purpose we can add space in some column names by using df.columns = df.columns.str.replace('_' , ' '). You can access the column using the syntax df[«columnname»]
df["arr delay"]
How to change row names
With the use of index option, you can rename rows (or index). In the code below, we are altering row names 0 and 1 to ‘First’ and ‘Second’ in dataframe df. By creating dictionary and taking previous row names as keys and new row names as values.
df.rename(index={0:'First',1:'Second'}, inplace=True)