

The metacharacter b is an anchor like the caret and the dollar sign. It matches at a position that is called a “word boundary”. This match is zero-length.
There are three different positions that qualify as word boundaries:
- Before the first character in the string, if the first character is a word character.
- After the last character in the string, if the last character is a word character.
- Between two characters in the string, where one is a word character and the other is not a word character.
Simply put: b allows you to perform a “whole words only” search using a regular expression in the form of bwordb. A “word character” is a character that can be used to form words. All characters that are not “word characters” are “non-word characters”.
Exactly which characters are word characters depends on the regex flavor you’re working with. In most flavors, characters that are matched by the short-hand character class w are the characters that are treated as word characters by word boundaries. Java is an exception. Java supports Unicode for b but not for w.
Most flavors, except the ones discussed below, have only one metacharacter that matches both before a word and after a word. This is because any position between characters can never be both at the start and at the end of a word. Using only one operator makes things easier for you.
Since digits are considered to be word characters, b4b can be used to match a 4 that is not part of a larger number. This regex does not match 44 sheets of a4. So saying “b matches before and after an alphanumeric sequence” is more exact than saying “before and after a word”.
B is the negated version of b. B matches at every position where b does not. Effectively, B matches at any position between two word characters as well as at any position between two non-word characters.
Looking Inside The Regex Engine
Let’s see what happens when we apply the regex bisb to the string This island is beautiful. The engine starts with the first token b at the first character T. Since this token is zero-length, the position before the character is inspected. b matches here, because the T is a word character and the character before it is the void before the start of the string. The engine continues with the next token: the literal i. The engine does not advance to the next character in the string, because the previous regex token was zero-length. i does not match T, so the engine retries the first token at the next character position.
b cannot match at the position between the T and the h. It cannot match between the h and the i either, and neither between the i and the s.
The next character in the string is a space. b matches here because the space is not a word character, and the preceding character is. Again, the engine continues with the i which does not match with the space.
Advancing a character and restarting with the first regex token, b matches between the space and the second i in the string. Continuing, the regex engine finds that i matches i and s matches s. Now, the engine tries to match the second b at the position before the l. This fails because this position is between two word characters. The engine reverts to the start of the regex and advances one character to the s in island. Again, the b fails to match and continues to do so until the second space is reached. It matches there, but matching the i fails.
But b matches at the position before the third i in the string. The engine continues, and finds that i matches i and s matches s. The last token in the regex, b, also matches at the position before the third space in the string because the space is not a word character, and the character before it is.
The engine has successfully matched the word is in our string, skipping the two earlier occurrences of the characters i and s. If we had used the regular expression is, it would have matched the is in This.
Tcl Word Boundaries
Word boundaries, as described above, are supported by most regular expression flavors. Notable exceptions are the POSIX and XML Schema flavors, which don’t support word boundaries at all. Tcl uses a different syntax.
In Tcl, b matches a backspace character, just like x08 in most regex flavors (including Tcl’s). B matches a single backslash character in Tcl, just like \ in all other regex flavors (and Tcl too).
Tcl uses the letter “y” instead of the letter “b” to match word boundaries. y matches at any word boundary position, while Y matches at any position that is not a word boundary. These Tcl regex tokens match exactly the same as b and B in Perl-style regex flavors. They don’t discriminate between the start and the end of a word.
Tcl has two more word boundary tokens that do discriminate between the start and end of a word. m matches only at the start of a word. That is, it matches at any position that has a non-word character to the left of it, and a word character to the right of it. It also matches at the start of the string if the first character in the string is a word character. M matches only at the end of a word. It matches at any position that has a word character to the left of it, and a non-word character to the right of it. It also matches at the end of the string if the last character in the string is a word character.
The only regex engine that supports Tcl-style word boundaries (besides Tcl itself) is the JGsoft engine. In PowerGREP and EditPad Pro, b and B are Perl-style word boundaries, while y, Y, m and M are Tcl-style word boundaries.
In most situations, the lack of m and M tokens is not a problem. ywordy finds “whole words only” occurrences of “word” just like mwordM would. Mwordm could never match anywhere, since M never matches at a position followed by a word character, and m never at a position preceded by one. If your regular expression needs to match characters before or after y, you can easily specify in the regex whether these characters should be word characters or non-word characters. If you want to match any word, yw+y gives the same result as m.+M. Using w instead of the dot automatically restricts the first y to the start of a word, and the second y to the end of a word. Note that y.+y would not work. This regex matches each word, and also each sequence of non-word characters between the words in your subject string. That said, if your flavor supports m and M, the regex engine could apply mw+M slightly faster than yw+y, depending on its internal optimizations.
If your regex flavor supports lookahead and lookbehind, you can use (?<!w)(?=w) to emulate Tcl’s m and (?<=w)(?!w) to emulate M. Though quite a bit more verbose, these lookaround constructs match exactly the same as Tcl’s word boundaries.
If your flavor has lookahead but not lookbehind, and also has Perl-style word boundaries, you can use b(?=w) to emulate Tcl’s m and b(?!w) to emulate M. b matches at the start or end of a word, and the lookahead checks if the next character is part of a word or not. If it is we’re at the start of a word. Otherwise, we’re at the end of a word.
GNU Word Boundaries
The GNU extensions to POSIX regular expressions add support for the b and B word boundaries, as described above. GNU also uses its own syntax for start-of-word and end-of-word boundaries. < matches at the start of a word, like Tcl’s m. > matches at the end of a word, like Tcl’s M.
Boost also treats < and > as word boundaries when using the ECMAScript, extended, egrep, or awk grammar.
POSIX Word Boundaries
The POSIX standard defines [[:<:]] as a start-of-word boundary, and [[:>:]] as an end-of-word boundary. Though the syntax is borrowed from POSIX bracket expressions, these tokens are word boundaries that have nothing to do with and cannot be used inside character classes. Tcl and GNU also support POSIX word boundaries. PCRE supports POSIX word boundaries starting with version 8.34. Boost supports them in all its grammars.
Regex Boundaries and Delimiters—Standard and Advanced
![]()
Although this page starts with the regex word boundary b, it aims to go far beyond: it will also introduce less-known boundaries, as well as explain how to make your own—DIY Boundaries.
Jumping Points
For easy navigation, here are some jumping points to various sections of the page:
✽ Boundaries vs. Anchors
✽ Word Boundary: b
✽ Not-a-word-boundary: B
✽ Left- and Right-of-Word Boundaries
✽ Making Your Own Boundaries
✽ DIY Boundary Workshop: «real word boundary»
✽ DIY Boundary: between a letter and a digit
✽ Double Negative Delimiter: Character, or Beginning of String
(direct link)
Boundaries vs. Anchors
Why are ^ and $ called anchors while b is called a boundary?
These tokens have one thing in common: they are assertions about the engine’s current position in the string. Therefore, none of them consume characters.
Anchors assert that the current position in the string matches a certain position: the beginning, the end, or in the case of G the position immediately following the last match.
In contrast, boundaries make assertions about what can be matched to the left and right of the current position.
The distinction is blurry. Typically, you would translate ^ as something like «assert that the current position is the beginning of the string». But if you were in a mood to play with logic, you could say:
Imagine that a string is a space between two walls—one to the left and one to the right. All the positions in the string are within that space. Then we could translate the ^ anchor as:
Assert that immediately to the left of the current position, we can find the left wall, while to the right of the current position we cannot find the left wall.
Yep, in that light, our anchor is a boundary—we look left and right. We’ll keep anchors and boundaries on separate pages because there’s a lot of ground to cover, but just keep that in mind.
(direct link)
Word Boundary: b
The word boundary b matches positions where one side is a word character (usually a letter, digit or underscore—but see below for variations across engines) and the other side is not a word character (for instance, it may be the beginning of the string or a space character).
The regex bcatb would therefore match cat in a black cat, but it wouldn’t match it in catatonic, tomcat or certificate. Removing one of the boundaries, bcat would match cat in catfish, and catb would match cat in tomcat, but not vice-versa. Both, of course, would match cat on its own.
Word boundaries are useful when you want to match a sequence of letters (or digits) on their own, or to ensure that they occur at the beginning or the end of a sequence of characters.
Be aware, though, that bcatb will not match cat in _cat or in cat25 because there is no boundary between an underscore and a letter, nor between a letter and a digit: these all belong to what regex defines as word characters. If you want to create a «real word boundary» (where a word is only allowed to have letters), see the recipe below in the section on DYI boundaries.
(direct link)
Difference between Engines
As you can see on the regex cheat sheet, b behaves differently depending on the engine:
✽ In PCRE (PHP, R…) with the Unicode mode turned off, JavaScript and Python 2.7, it matches where only one side is an ASCII letter, digit or underscore.
✽ In PCRE (PHP, R…) with the Unicode mode turned on, .NET, Java, Perl, Python 3 and Ruby, it matches a position where only one side is a Unicode letter, digit or underscore.
(direct link)
Not-a-word-boundary: B
B matches all positions where b doesn’t match. Therefore, it matches:
✽ When neither side is a word character, for instance at any position in the string $=(@-%++) (including the beginning and end of the string)
✽ When both sides are a word character, for instance between the H and the i in Hi!
This may not seem very useful, but sometimes B is just what you want. For instance,
✽ BcatB will find cat fully surrounded by word characters, as in certificate, but neither on its own nor at the beginning or end of words.
✽ catB will find cat both in certificate and catfish, but neither in tomcat nor on its own.
✽ Bcat will find cat both in certificate and tomcat, but neither in catfish nor on its own.
✽ Bcat|catB will find cat in embedded situation, e.g. in certificate, catfish or tomcat, but not on its own.
Difference between Engines
In all engines that support it, B matches positions that are not matched by b. Since b behaves differently in various engines, see b engine variations a few paragraphs above.
(direct link)
Left- and Right-of-Word Boundaries
The PCRE (PHP, R, …) version 8.34+ and MySQL engines support the POSIX character classes for the beginning-of-word boundary [[:<:]] and the end-of-word boundary [[:>:]]
✽ [[:<:]]cat matches cat in the word on its own as well as in catfish, but neither in tomcat nor in certificate.
✽ cat[[:<:]] never matches as a word cannot start in the middle of a word.
✽ cat[[:>:]] matches cat in the word on its own as well as in tomcat, but neither in catfish nor in certificate.
✽ [[:>:]]cat never matches as a word cannot end in the middle of a word.
For MySQL, the definition of a word character is an ASCII letter, digit or underscore—and this set of characters drives the interpretation of these «start of word» and «end of word» boundaries.
PCRE offers these boundaries as a convenience for occasions when someone might want to paste POSIX regex into a PCRE-powered language (or, more likely, switch the regex library used by an old C program), but the engine makes the following substitutions before starting the match:
✽ The start of word boundary [[:<:]] is converted to b(?=w)
✽ The end of word boundary [[:>:]] is converted to b(?<=w)
Therefore, the «start of word» and «end of word» boundaries derive their meaning from the b boundary. In non-Unicode mode, it matches a position where only one side is an ASCII letter, digit or underscore. In Unicode mode, it matches a position where only one side is a Unicode letter, digit or underscore.
Other Engines
I’ve never yet encountered a situation where I wished I had one of these boundaries. Most likely, if it ever arises, I automatically solve it by using lookarounds. If you ever want to use these specific boundaries in a language that doesn’t support them, one solution among several is to copy the patterns (from two paragraphs above) that PCRE uses to convert the boundaries to regular syntax.
(direct link)
Making Your Own Boundaries
Finding a boundary between a word character and a non-word character is convenient, and we can thank b for that. But there are many other cases where we could use a boundary for which regex does not provide explicit syntax. For instance, how do you match the position between a letter and a digit? We’ll make this exact boundary further down, but let’s get there at a comfortable pace.
Delimiters
As a first example, let’s look at a line in an email reply:
> and then she told him she wouldn’t settle for less than a Hawaiian pizza, and
Let’s say we want a boundary that finds the position between the > and an ASCII letter.
As a first approach, we could use a lookbehind. Assuming we’re in multi-line mode, where the anchor ^ matches at the beginning of any line, the lookbehind (?<=^> ) asserts that what precedes the current position is the beginning of the string, then a «greater-than» symbol > and a space.
Therefore, something like (?<=^> )w+ would find the first word of the line. This works, but I would not call (?<=^> ) a boundary. Whereas a boundary asserts that there is a difference between what lies to the left and what lies to the right, our lookbehind only looks in one direction. If we used it on its own, it would match after the space character > in > >>>: it doesn’t care about what follows. It is what I would call a delimiter, rather than a boundary.
Delimiters are very useful, and they are a major source of business for regex lookarounds. For instance, .*?(?=END) would match an entire line up to—but not including—the word END: the lookahead (?=END) serves as an ending delimiter. Likewise, (?<=START) serves as a beginning delimiter in (?<=START).*, which matches an entire line after—but not including—the word START.
Further down, we will look at a useful technique: double-negative delimiters.
Boundaries: Look Left and Right
To finish our boundary for the position following the start of an email reply line and preceding a letter, we also need to look to the right. We do that by adding a lookahead after the lookbehind:
(?<=^> )(?=[a-zA-Z])
After asserting that what precedes the current position is a «greater than» and a space, we assert that what follows is a letter. Note that the order of the lookahead and the lookbehind do not matter, as they do not consume any characters: they look to the left and to the right with our feet firmly planted in the same spot in the string. Therefore, the reverse-order boundary
(?=[a-zA-Z])(?<=^> )
works equally well.
After either of these patterns, we can confidently use any regex meta-character—such as the dot—and be sure that it will match a letter: they are true boundaries.
(direct link)
Generalizing the idea: home-made word boundary
We can use this technique to construct any boundary we like. The coming sections will show some examples in detail, but to whet our appetite, how would you build a word boundary if your regex engine didn’t support b?
When it matches on the left of word characters, a word boundary is able to check that what follows is a word character but what precedes is not. In lookaround terms, this is (?=w)(?<!w).
When it matches on the right of word characters, a word boundary is able to check that what precedes is a word character but what follows is not. In lookaround terms, this is (?<=w)(?!w)
A word boundary must match either of these positions. Grouping them together inside an alternation, our homemade word boundary becomes:
(?:(?=w)(?<!w)|(?<=w)(?!w))
Yes, b is a bit shorter.
(direct link)
DIY Boundary Workshop: «real word boundary»
With some variations depending on the engine, regex usually defines a word character as a letter, digit or underscore. A word boundary bdetects a position where one side is such a character, and the other is not.
In the everyday world, most people would probably say that in the English language, a word character is a letter. Others might allow for hyphens. In some situations, it might therefore be useful to have a «real word boundary» that detects the edge between an ASCII letter and a non-letter. How do we do that?
As a start, with lookarounds you can make a left-side and a right-side boundary:
(?i)(?<=^|[^a-z])cat(?=$|[^a-z])
The left side asserts that what precedes is either the beginning of the string or a character that is a non-letter. The right side asserts that what follows is either the end of the string or a non-letter.
Your next step could be to combine the two to form a boundary that can be popped on either side:
(?i)(?<=^|[^a-z])(?=[a-z])|(?<=[a-z])(?=$|[^a-z])
On the left side, of the alternation, we have our earlier left boundary, and we add a lookahead to check that what follows is a letter. On the right side of the alternation, we have our earlier right boundary, and we add a lookbehind to check that what precedes us is a letter.
Needless to say, if you need to paste this wherever you want a «real word boundary», this is a bit heavy. With engines that support pre-defined subroutines—Perl, PCRE (PHP, R, …)—you can define the boundary once and for all, then use it wherever you like by referring to its name:
(?x) # free-spacing mode
(?(DEFINE) # Define some subroutines
(?<alphaB> # Define "alphaB" boundary
# This boundary matches when
# only one side is a letter
(?i)(?<=^|[^a-z])(?=[a-z])|(?<=[a-z])(?=$|[^a-z])
) # End alphaB definition
) # End DEFINE
# The actual regex matching starts here
# We can use our "alphaB" boundary wherever we like
(?&alphaB)cat(?&alphaB)
This would work really well as a component of a large parsing regex.
(direct link)
DIY Boundary: between a letter and a digit
Once we have this recipe, producing boundaries is simple. For instance, with minor tweaks, we can produce a boundary that matches between ASCII letters and digits. I called this pre-defined boundary by the descriptive name A1.
(?x) # free-spacing mode
(?(DEFINE) # Define some subroutines
(?<A1> # Define "A1" boundary
# This boundary matches when
# one side is a letter and
# the other is a number
(?i)(?<=^|d)(?=[a-z])|(?<=[a-z])(?=$|d)
) # End A1 definition
) # End DEFINE
# The actual regex matching starts here
# We can use our "A1" boundary wherever we like
(?&A1)cat(?&A1)
If your engine doesn’t support pre-defined subroutines, you would have to paste this monster in your regex:
(?:(?i)(?<=^|d)(?=[a-z])|(?<=[a-z])(?=$|d))
(direct link)
Double Negative Delimiter: Character, or Edge of String
In this section I would like to introduce you to a useful family of delimiters that use a fiendish technique: double negative delimiters.
Consider the string 0# 1 #2 #3# 4# #5. In this string, we want to match 0, 3 and 5, i.e. digits where each side is either a hash or one of the edges of the string.
One first thought might be to use a capture group: (?:^|#)(d)(?:$|#). This exactly performs the task specified in the previous paragraph—first matching either the beginning of the string or a hash, then a digit, then either the end of the string or a hash. The desired digits are captured to Group 1.
To get rid of the capture group, you will probably think of using lookarounds: (?<=^|#)d(?=$|#). This is nearly exactly the same as the first regex, except that the sides are no longer matched, but just checked with a lookbehind and a lookahead. This works in .NET, PCRE (C, PHP, R, …), Java and Ruby (or Python with the regex module), but not in other engines as traditional lookbehind must have a fixed width (see Lookbehind: Fixed-Width / Constrained Width / Infinite Width).
In Perl, you can get around this problem with (?:^|#K)d(?=$|#), where we match the left-side hash (if any) then drop it with the K. This would also work in PCRE and Ruby.
But here is the solution I would like to introduce you to:
(?<![^#])d(?![^#])
This is a bit of a brain twister. On the left side, the negative lookbehind (?<![^#]) asserts that what precedes the current position is not one character that is not a hash. Flipping the double negative back to a positive assertion, this says that if there is a character behind us, it must be a hash. What is allowed behind us is therefore either a hash character or «not a character» (the beginning of the string).
Why the double negative? Isn’t that the same as the positive lookbehind (?<=#)? Well, no: this positive lookbehind requires a hash character—whereas we also want to allow the absence of any character on the left.
The negative lookahead at the end of the string follows the same principle: (?![^#]) asserts that what follows is not a character that is not a hash—i.e., if it is a character, it must be a hash.
Limitation
This technique works for single-line strings. As soon as you move to multiple lines, 0# no longer matches at the beginning of lines 2 and beyond. That is because there is a character before the 0: the n, and it is not a hash. Likewise, #5 no longer matches at the end of any line but the last, because there is now a line break character—not a hash—after the 5.
Extension
To get your eyes accustomed to the technique, let’s apply it to other tasks.
To match A, B or E in A0 1B1 2C D3 4E, i.e capital letters that have either a digit or a string-end on each side, you can use this pattern:
(?<!D)[A-Z](?!D)
To match A, C or F in A -B- C -D -E F, i.e capital letters that have either a space or a string-end on each side, you can use this pattern:
(?<!S)[A-Z](?!S)
Finally, an unlikely example: to match the tilde, hash or colon in ~A ? 2! _#4 @5 6:, i.e special characters that have either a word character or a string-end on each side, you can use this pattern:
(?<!W)[~#:@?!](?!W)
![]()
Everything You’ve Wanted to know about Capture Groups
Summary: in this tutorial, you’ll learn how to use the word boundary in regular expressions.
The (b) is an anchor like the caret (^) and the dollar sign ($). It matches a position that is called a “word boundary”. The word boundary match is zero-length.
The following three positions are qualified as word boundaries:
- Before the first character in a string if the first character is a word character.
- After the last character in a string if the last character is a word character.
- Between two characters in a string if one is a word character and the other is not.
Simply put, the word boundary b allows you to carry the match the whole word using a regular expression in the following form:
Code language: JavaScript (javascript)
bwordb
For example, in the string Hello, JS! the following positions qualify as a word boundary:
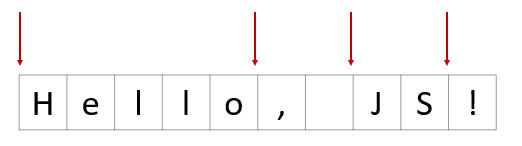
The following example returns 'JS' because 'Hello, JS!' matches the regular expression /bJSb/:
Code language: JavaScript (javascript)
console.log('Hello, JS!'.match(/bJSb/)); // true
Output:
Code language: JavaScript (javascript)
["JS"]
However, the 'Hello, JScript' doesn’t match /bJSb/:
console.log('Hello, JSscript!'.match(/bJSb/)); // nullCode language: JavaScript (javascript)
Note that without b, the /JS/ matches both 'Hello, JS' and 'Hello, JScript':
Code language: JavaScript (javascript)
console.log('Hello, JSscript!'.match(/JS/)); // ["JS"] console.log('Hello, JS!'.match(/JS/)); // ["JS"]
It’s possible to use the word boundary with digits.
For example, the regular expression bddddb matches a 4-digit number surrounded by characters different from w:
Code language: JavaScript (javascript)
console.log('ES 2015'.match(/bddddb/));
Output:
Code language: JavaScript (javascript)
["2015"]
The following example uses the word boundary to find the time that has the format hh:mm e.g., 09:15:
Code language: JavaScript (javascript)
let str = 'I start coding JS at 05:30 AM'; let re = /bdd:ddb/; let result = str.match(re); console.log(result);
Output:
Code language: JavaScript (javascript)
["05:30"]
It’s important to note that the b doesn’t work for non-Latin alphabets.
As you have seen so far, the patterns dddd and dd has been used to match a four-digit or a two-digit number.
It’ll be easier and more flexible if you use quantifiers that will be covered in the quantifiers tutorial. Basically, you can use d{4} instead of dddd, which is much shorter.
Summary
- The
banchor matches a word boundary position.
Was this tutorial helpful ?
Summary: in this tutorial, you’ll learn how to construct regular expressions that match word boundary positions in a string.
Introduction to the Python regex word boundary
A string has the following positions that qualify as word boundaries:
- Before the first character in the string if the first character is a word character (
w). - Between two characters in the string if the first character is a word character (
w) and the other is not (W– inverse character set of the word characterw). - After the last character in a string if the last character is the word character (
w)
The following picture shows the word boundary positions in the string "PYTHON 3!":
In this example, the "PYTHON 3!" string has four word boundary positions:
- Before the letter P (criteria #1)
- After the letter N (criteria #2)
- Before the digit 3 (criteria #2)
- After the digit 3 (criteria #2)
Regular expressions use the b to represent a word boundary. For example, you can use the b to match the whole word using the following pattern:
r'bwordb'Code language: JavaScript (javascript)The following example matches the word Python in a string:
import re
s = 'CPython is the implementation of Python in C'
matches = re.finditer('Python', s)
for match in matches:
print(match.group())Code language: JavaScript (javascript)It returns two matches, one in the word CPython and another in the word Python.
Python
PythonHowever, if you use the word boundary b, the program returns one match:
import re
s = 'CPython is the implementation of Python in C'
matches = re.finditer(r'bPythonb', s)
for match in matches:
print(match.group())
Code language: JavaScript (javascript)Output:
<re.Match object; span=(33, 39), match='Python'>Code language: HTML, XML (xml)In this example, the 'bPythonb' pattern match the whole word Python in the string 'CPython is the implementation of Python in C'.
Summary
- The
brepresents a word boundary in a string. - Use the
r'bwordb'pattern uses the b to match the wholeword
Did you find this tutorial helpful ?
2.6. Match Whole Words
Problem
Create a regex that matches cat in My cat is brown, but not in category or bobcat. Create another
regex that matches cat in staccato, but not in any of the three
previous subject strings.
Solution
Word boundaries
bcatb
| Regex options: None |
| Regex flavors: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Nonboundaries
BcatB
| Regex options: None |
| Regex flavors: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Discussion
Word boundaries
The regular expression token ‹b› is
called a word boundary. It matches at the start
or the end of a word. By itself, it results in a zero-length match.
‹b› is an
anchor, just like the tokens introduced in the
previous section.
Strictly speaking, ‹b› matches in these three positions:
-
Before the first character in the subject, if the first
character is a word character -
After the last character in the subject, if the last
character is a word character -
Between two characters in the subject, where one is a word
character and the other is not a word character
To run a “whole words only” search using a regular expression,
simply place the word between two word boundaries, as we did with
‹bcatb›. The first
‹b› requires the
‹c› to occur at the very
start of the string, or after a nonword character. The second ‹b› requires the ‹t› to occur at the very end of
the string, or before a nonword character.
Line break characters are nonword characters. ‹b› will match after a line break if the line break is immediately followed by a word character. …