
5.11. Match Complete Lines That Do Not Contain a Word
Problem
You want to match complete lines that do not contain the
word error.
Solution
^(?:(?!berrorb).)*$
| Regex options: Case insensitive, ^ and $ match at line breaks (“dot matches line breaks” must not be set) |
| Regex flavors: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Discussion
In order to match a line that does not contain something, use negative lookahead
(described in Recipe 2.16). Notice that in
this regular expression, a negative lookahead and a dot are repeated
together using a noncapturing group. This is necessary to ensure that
the regex ‹berrorb›
fails at every position in the line. The ‹^› and ‹$› anchors at the edges of the regular expression
make sure you match a complete line, and additionally prevent the group
containing the negative lookahead from limiting it’s tests to only some
part of the line.
The options you apply to this regular expression determine whether
it tries to match the entire subject string or just one line at a time.
With the option to let ^ and $ match at line breaks enabled and the
option to let dot match line breaks disabled, this regular expression
works as described and matches line by line. If you invert the state of
these two options, the regular expression will match any complete string
that does not contain the word “error.”
Caution
Testing a negative lookahead against every position in a line or string is rather inefficient. This solution is intended to be used in situations where one …
The fact that regex doesn’t support inverse matching is not entirely true. You can mimic this behavior by using negative look-arounds:
The regex above will match any string, or line without a line break, not containing the (sub) string ‘hede’.As mentioned, this is not something regex is “good” at (or should do), but still, it is possible.
Explanation
A string is just a list of
characters. Before, and after each character, there’s an empty string. So a list of
characters will have
empty strings. Consider the string
:
1
2
3
4+--+---+--+---+--+---+--+---+--+---+--+---+--+---+--+---+--+
S = |e1| A |e2| B |e3| h |e4| e |e5| d |e6| e |e7| C |e8| D |e9|
+--+---+--+---+--+---+--+---+--+---+--+---+--+---+--+---+--+
index 0 1 2 3 4 5 6 7
where the
‘s are the empty strings. The regex
looks ahead to see if there’s no substring
to be seen, and if that is the case (so something else is seen), then the
(dot) will match any character except a line break. Look-arounds are also called zero-width-assertions because they don’t consume any characters. They only assert/validate something.
So, in my example, every empty string is first validated to see if there’s no
up ahead, before a character is consumed by the
(dot). The regex
will do that only once, so it is wrapped in a group, and repeated zero or more times:
. Finally, the start- and end-of-input are anchored to make sure the entire input is consumed:
As you can see, the input
will fail because on
, the regex
fails (there is
up ahead!).
Jan 18 at 15:49 community-wiki Thanks to Bart Kiers
Я знаю, что можно сопоставить слово, а затем отменить совпадения, используя другие инструменты (например, grep -v). Однако можно ли сопоставить строки, которые не содержат определенного слова, например, «hede», с помощью регулярного выражения?
Входные данные:
hoho
hihi
haha
hede
Код:
grep "<Regex for 'doesn't contain hede'>" input
Желаемый результат:
hoho
hihi
haha
Ответ 1
Понятие о том, что регулярное выражение не поддерживает обратное совпадение, не совсем верно. Вы можете имитировать это поведение, используя негативные образы:
^((?!hede).)*$
Регулярное выражение выше будет соответствовать любой строке или строке без разрыва строки, не, содержащей (под) строку ‘hede’. Как уже упоминалось, это не то, что регулярное выражение «хорошо» (или должно делать), но все же возможно.
И если вам нужно также совместить символы разрыва строки, используйте модификатор DOT-ALL (конечный s в следующем шаблоне ):
/^((?!hede).)*$/s
или используйте его в строке:
/(?s)^((?!hede).)*$/
(где /.../ являются разделителями регулярных выражений, т.е. не являются частью шаблона)
Если модификатор DOT-ALL недоступен, вы можете имитировать такое же поведение с классом символов [sS]:
/^((?!hede)[sS])*$/
Описание
Строка — это всего лишь список символов n. До и после каждого символа есть пустая строка. Таким образом, список символов n будет содержать n+1 пустые строки. Рассмотрим строку "ABhedeCD":
┌──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┐
S = │e1│ A │e2│ B │e3│ h │e4│ e │e5│ d │e6│ e │e7│ C │e8│ D │e9│
└──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┘
index 0 1 2 3 4 5 6 7
где e — это пустые строки. Регулярное выражение (?!hede). смотрит вперед, чтобы увидеть, нет ли подстроки "hede", и если это так (так что что-то еще видно), то . (точка) будет соответствовать любому символу, кроме разрыва строки, Look-arounds также называются утверждениями с нулевой шириной, потому что они не потребляют никаких символов. Они только утверждают/проверяют что-то.
Итак, в моем примере каждая пустая строка сначала проверяется, чтобы увидеть, нет ли "hede" впереди, прежде чем символ будет потребляться . (точка). Регулярное выражение (?!hede). будет делать это только один раз, поэтому оно завернуто в группу и повторяется ноль или более раз: ((?!hede).)*. Наконец, начало и конец ввода привязаны, чтобы убедиться, что весь вход потреблен: ^((?!hede).)*$
Как вы можете видеть, вход "ABhedeCD" завершится с ошибкой, потому что на e3 не выполняется повторное выражение (?!hede) (впереди есть "hede"!).
Ответ 2
Обратите внимание, что решение не начинается с «hede» :
^(?!hede).*$
как правило, намного эффективнее, чем решение не содержит «hede» :
^((?!hede).)*$
Первая проверяет «hede» только на первой позиции входных строк, а не на каждой позиции.
Ответ 3
Если вы просто используете его для grep, вы можете использовать grep -v hede для получения всех строк, которые не содержат hede.
ETA О, перечитав вопрос, grep -v, вероятно, вы подразумеваете под «инструментальными опциями».
Ответ 4
Ответ:
^((?!hede).)*$
Объяснение:
^ начало строки,
( и захватить до 1 (0 или более раз (сопоставление максимально возможной суммы)), (?! Посмотрите вперед, чтобы увидеть, нет ли этого,
hede ваша строка,
) конец ожидания,
. любой символ кроме n, )* end of1 (Примечание: поскольку вы используете квантификатор для этого захвата, только LAST повторение захваченного шаблона будет сохранено в 1) $ перед необязательным n, а конец строки
Ответ 5
Данные ответы совершенно прекрасные, просто академические точки:
Регулярные выражения в значении теоретических компьютерных наук НЕ ДОЛЖНЫ делать это так. Для них это должно было выглядеть примерно так:
^([^h].*$)|(h([^e].*$|$))|(he([^h].*$|$))|(heh([^e].*$|$))|(hehe.+$)
Это соответствует только FULL. Выполнение этого для вспомогательных матчей было бы еще более неудобным.
Ответ 6
Если вы хотите, чтобы тест регулярного выражения завершился неудачей, только если вся строка совпадает, будет работать следующее:
^(?!hede$).*
Например, если вы хотите разрешить все значения, кроме «foo» (то есть «foofoo», «barfoo» и «foobar» пройдут, но «foo» завершится ошибкой), используйте: ^(?!foo$).*
Конечно, если вы проверяете точное равенство, лучшим общим решением в этом случае является проверка на равенство строк, т.е.
myStr !== 'foo'
Вы могли бы даже поставить отрицание вне теста, если вам нужны какие-либо функции регулярных выражений (здесь, нечувствительность к регистру и соответствие диапазона):
!/^[a-f]oo$/i.test(myStr)
Однако решение regex в верхней части этого ответа может быть полезным в ситуациях, когда требуется положительный тест regex (возможно, через API).
Ответ 7
FWIW, поскольку регулярные языки (ака рациональные языки) замкнуты относительно дополнения, всегда можно найти регулярное выражение (aka рациональное выражение), которое отрицает другое выражение. Но это не так много инструментов.
Vcsn поддерживает этот оператор (который он обозначает {c}, postfix).
Сначала вы определяете тип своих выражений: ярлыки — буква (lal_char) для выбора из a в z например (определение алфавита при работе с дополнением, конечно, очень важно), а «значение», рассчитанное для каждого слова, просто логическое: true слово принято, false, отклонено.
В Python:
In [5]: import vcsn
c = vcsn.context('lal_char(a-z), b')
c
Out[5]: {a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z} → 𝔹
то вы вводите свое выражение:
In [6]: e = c.expression('(hede){c}'); e
Out[6]: (hede)^c
преобразуйте это выражение в автомат:
In [7]: a = e.automaton(); a

наконец, преобразуем этот автомат обратно в простое выражение.
In [8]: print(a.expression())
e+h(e+e(e+d))+([^h]+h([^e]+e([^d]+d([^e]+e[^]))))[^]*
где + обычно обозначается | , e обозначает пустое слово, а [^] обычно записывается . (любой символ). Итак, с немного переписыванием ()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*.
Вы можете увидеть этот пример здесь, и попробовать VCSN онлайн там.
Ответ 8
Здесь хорошее объяснение, почему нелегко свести на нет произвольное регулярное выражение. Я должен согласиться с другими ответами, хотя: если это что-то другое, кроме гипотетического вопроса, тогда регулярное выражение здесь не является правильным выбором.
Ответ 9
С отрицательным взглядом регулярное выражение может соответствовать тому, что не содержит определенного шаблона. Об этом отвечает и объясняет Барт Кирс. Отличное объяснение!
Тем не менее, с ответом Барта Кирса, контрольная часть будет проверять от 1 до 4 символов вперед при сопоставлении любого отдельного символа. Мы можем избежать этого и позволить обзорной части проверить весь текст, гарантировать, что нет «hede» , а затем нормальная часть (. *) Может съесть весь текст за один раз.
Вот улучшенное регулярное выражение:
/^(?!.*?hede).*$/
Обратите внимание, что (*?) ленивый квантификатор в отрицательной части обзора необязателен, вместо этого вы можете использовать (*) жадный квантификатор, в зависимости от ваших данных: если «hede» присутствует и в начале половины текста, ленивый квантификатор может быть быстрее; в противном случае, жадный квантор будет быстрее. Однако, если «hede» не присутствует, оба будут равными медленными.
Вот демон-код .
Для получения дополнительной информации о lookahead, посмотрите отличную статью: Освоение Lookahead и Lookbehind.
Кроме того, ознакомьтесь с RegexGen.js, генератором регулярных выражений JavaScript, который помогает создавать сложные регулярные выражения. С помощью RegexGen.js вы можете создать регулярное выражение более читаемым образом:
var _ = regexGen;
var regex = _(
_.startOfLine(),
_.anything().notContains( // match anything that not contains:
_.anything().lazy(), 'hede' // zero or more chars that followed by 'hede',
// i.e., anything contains 'hede'
),
_.endOfLine()
);
Ответ 10
Бенчмарки
Я решил оценить некоторые из представленных опций и сравнить их производительность, а также использовать некоторые новые функции.
Бенчмаркинг в .NET Regex Engine: http://regexhero.net/tester/
Контрольный текст:
Первые 7 строк не должны совпадать, так как они содержат искомое выражение, в то время как нижние 7 строк должны совпадать!
Regex Hero is a real-time online Silverlight Regular Expression Tester.
XRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex HeroRegex HeroRegex HeroRegex HeroRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her Regex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.Regex Hero
egex Hero egex Hero egex Hero egex Hero egex Hero egex Hero Regex Hero is a real-time online Silverlight Regular Expression Tester.
RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her
egex Hero
egex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her is a real-time online Silverlight Regular Expression Tester.
Nobody is a real-time online Silverlight Regular Expression Tester.
Regex Her o egex Hero Regex Hero Reg ex Hero is a real-time online Silverlight Regular Expression Tester.
Результаты:
Результаты — Итерации в секунду в качестве медианы из 3 прогонов — Большее число = лучше
01: ^((?!Regex Hero).)*$ 3.914 // Accepted Answer
02: ^(?:(?!Regex Hero).)*$ 5.034 // With Non-Capturing group
03: ^(?>[^R]+|R(?!egex Hero))*$ 6.137 // Lookahead only on the right first letter
04: ^(?>(?:.*?Regex Hero)?)^.*$ 7.426 // Match the word and check if you're still at linestart
05: ^(?(?=.*?Regex Hero)(?#fail)|.*)$ 7.371 // Logic Branch: Find Regex Hero? match nothing, else anything
P1: ^(?(?=.*?Regex Hero)(*FAIL)|(*ACCEPT)) ????? // Logic Branch in Perl - Quick FAIL
P2: .*?Regex Hero(*COMMIT)(*FAIL)|(*ACCEPT) ????? // Direct COMMIT & FAIL in Perl
Так как .NET не поддерживает действие Глаголы (* FAIL и т.д.), я не смог проверить решения P1 и P2.
Резюме:
Я попытался протестировать большинство предлагаемых решений, некоторые оптимизации возможны для определенных слов.
Например, если первые две буквы строки поиска не совпадают, ответ 03 может быть расширен до
^(?>[^R]+|R+(?!egex Hero))*$, что приводит к небольшому усилению производительности.
Но общее наиболее читаемое и быстродействующее решение, похоже, имеет значение 05, используя условное выражение
или 04 с вероятным квантором. Я думаю, что решения Perl должны быть еще быстрее и более легко читаемыми.
Ответ 11
Не регулярное выражение, но я нашел логичным и полезным использовать последовательные greps с трубкой для устранения шума.
например. искать конфигурационный файл apache без комментариев —
grep -v '#' /opt/lampp/etc/httpd.conf # this gives all the non-comment lines
и
grep -v '#' /opt/lampp/etc/httpd.conf | grep -i dir
Логика последовательного grep (не комментарий) и (соответствует dir)
Ответ 12
при этом вы избегаете проверки взглядов на каждую позицию:
/^(?:[^h]+|h++(?!ede))*+$/
эквивалент (для.net):
^(?>(?:[^h]+|h+(?!ede))*)$
Старый ответ:
/^(?>[^h]+|h+(?!ede))*$/
Ответ 13
Вот как бы я это сделал:
^[^h]*(h(?!ede)[^h]*)*$
Точный и эффективный, чем другие ответы. Он реализует технику эффективности «разворачивания в петлю» Friedl и требует гораздо меньшего возврата.
Ответ 14
Вышеупомянутый (?:(?!hede).)* велик, потому что он может быть привязан.
^(?:(?!hede).)*$ # A line without hede
foo(?:(?!hede).)*bar # foo followed by bar, without hede between them
Но в этом случае достаточно:
^(?!.*hede) # A line without hede
Это упрощение готово к добавлению предложений «И»:
^(?!.*hede)(?=.*foo)(?=.*bar) # A line with foo and bar, but without hede
^(?!.*hede)(?=.*foo).*bar # Same
Ответ 15
Если вы хотите совместить символ, чтобы отменить слово, аналогичное классу отрицательных символов:
Например, строка:
<?
$str="aaa bbb4 aaa bbb7";
?>
Не использовать:
<?
preg_match('/aaa[^bbb]+?bbb7/s', $str, $matches);
?>
Использование:
<?
preg_match('/aaa(?:(?!bbb).)+?bbb7/s', $str, $matches);
?>
Примечание "(?!bbb)." не является ни lookbehind, ни lookahead, он выглядит как текущий, например:
"(?=abc)abcde", "(?!abc)abcde"
Ответ 16
В OP не указывалось или Tag сообщение, указывающее контекст (язык программирования, редактор, инструмент), в котором будет использоваться Regex.
Для меня иногда требуется сделать это, редактируя файл с помощью Textpad.
Textpad поддерживает некоторое Regex, но не поддерживает lookahead или lookbehind, поэтому требуется несколько шагов.
Если я хочу сохранить все строки, что НЕ содержит строку hede, я бы сделал это следующим образом:
1. Найдите/замените весь файл, чтобы добавить уникальный «тег» в начало каждой строки, содержащей любой текст.
Search string:^(.)
Replace string:<@#-unique-#@>1
Replace-all
2. Удалите все строки, содержащие строку
hede(строка замены пуста):
Search string:<@#-unique-#@>.*hede.*n
Replace string:<nothing>
Replace-all
3. На этом этапе все оставшиеся строки NOT содержат строку
hede. Удалите уникальный «тег» со всех строк (строка замены пуста):
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
Теперь у вас есть исходный текст со всеми строками, содержащими строку hede.
Если я ищу Do Something Else только строки, в которых NOT содержит строку hede, я бы сделал это следующим образом:
1. Найдите/замените весь файл, чтобы добавить уникальный «тег» в начало каждой строки, содержащей любой текст.
Search string:^(.)
Replace string:<@#-unique-#@>1
Replace-all
2. Для всех строк, содержащих строку
hede, удалите уникальный «тег» :
Search string:<@#-unique-#@>(.*hede)
Replace string:1
Replace-all
3. На этом этапе все строки, начинающиеся с уникального «тега», NOT содержат строку
hede. Теперь я могу сделать свой Something Else только для этих строк.
4. Когда я закончил, я удаляю уникальный «тег» со всех строк (строка замены пуста):
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
Ответ 17
С момента введения ruby-2.4.1 мы можем использовать новый Absent Operator в регулярных выражениях Rubys
из официального doc
(?~abc) matches: "", "ab", "aab", "cccc", etc.
It doesn't match: "abc", "aabc", "ccccabc", etc.
Таким образом, в вашем случае ^(?~hede)$ выполняется задание для вас
2.4.1 :016 > ["hoho", "hihi", "haha", "hede"].select{|s| /^(?~hede)$/.match(s)}
=> ["hoho", "hihi", "haha"]
Ответ 18
Через глагол PCRE (*SKIP)(*F)
^hede$(*SKIP)(*F)|^.*$
Это полностью пропустит строку, которая содержит точную строку hede и соответствует всем оставшимся строкам.
DEMO
Выполнение частей:
Рассмотрим приведенное выше регулярное выражение, разделив его на две части.
-
Часть перед символом
|. Часть не должна совпадать.^hede$(*SKIP)(*F) -
Часть после символа
|. Часть должна быть сопоставлена .^.*$
ЧАСТЬ 1
Механизм Regex начнет выполнение с первой части.
^hede$(*SKIP)(*F)
Объяснение:
-
^Утверждается, что мы находимся в начале. -
hedeСоответствует строкеhede -
$Указывает, что мы находимся на конце строки.
Таким образом, строка, содержащая строку hede, будет сопоставлена. Как только механизм регулярных выражений увидит следующий (*SKIP)(*F) (Примечание: вы можете написать (*F) как (*FAIL)) глагол, он пропустит и сделает совпадение неудачным. | называется изменением или логическим оператором OR, добавленным рядом с глаголом PCRE, который inturn соответствует всем границам, существующим между каждым символом во всех строках, за исключением того, что строка содержит точную строку hede. См. Демонстрацию здесь. То есть, он пытается сопоставить символы из оставшейся строки. Теперь будет выполняться регулярное выражение во второй части.
ЧАСТЬ 2
^.*$
Объяснение:
-
^Утверждается, что мы находимся в начале. т.е. он соответствует всем путям строк, кроме одного в строкеhede. См. Демонстрацию здесь. -
.*В многострочном режиме.будет соответствовать любому символу, кроме символов новой строки или символа возврата каретки. И*повторит предыдущий символ ноль или более раз. Таким образом,.*будет соответствовать всей строке. См. Демонстрацию здесь.Привет, почему вы добавили. * вместо. +?
Потому что
.*будет соответствовать пустой строке, но.+не будет соответствовать пробелу. Мы хотим сопоставить все строки, кромеhede, может быть возможность пустых строк также на входе. поэтому вы должны использовать.*вместо.+..+повторял предыдущий символ один или несколько раз. См..*соответствует пустой строке здесь. -
$Здесь не требуется завершение привязки линии.
Ответ 19
Поскольку никто другой не дал прямого ответа на заданный вопрос, я сделаю это.
Ответ заключается в том, что с POSIX grep невозможно буквально удовлетворить этот запрос:
grep "Regex for doesn't contain hede" Input
Причина в том, что POSIX grep требуется только для работы с Basic Regular Expressions, которые просто недостаточно эффективны для выполнения этой задачи (они не способны анализировать обычные языки из-за отсутствия чередования и группировки).
Однако GNU grep реализует расширения, которые позволяют это. В частности, | является оператором чередования в реализации GNU BRE, а ( и ) — операторы группировки. Если ваш механизм регулярных выражений поддерживает чередование, отрицательные выражения скобок, группировку и звезду Kleene и способен привязывать к началу и концу строки, все, что вам нужно для этого подхода.
С GNU grep было бы что-то вроде:
grep "^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$" Input
(найденный с Grail и некоторые дальнейшие оптимизации, сделанные вручную).
Вы также можете использовать инструмент, который реализует расширенные регулярные выражения, например egrep, для устранения обратных косых черт:
egrep "^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$" Input
Вот скрипт для его проверки (обратите внимание, что он генерирует файл testinput.txt в текущем каталоге):
#!/bin/bash
REGEX="^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$"
# First four lines as in OP testcase.
cat > testinput.txt <<EOF
hoho
hihi
haha
hede
h
he
ah
head
ahead
ahed
aheda
ahede
hhede
hehede
hedhede
hehehehehehedehehe
hedecidedthat
EOF
diff -s -u <(grep -v hede testinput.txt) <(grep "$REGEX" testinput.txt)
В моей системе он печатает:
Files /dev/fd/63 and /dev/fd/62 are identical
как и ожидалось.
Для тех, кто интересуется деталями, применяемая техника состоит в том, чтобы преобразовать регулярное выражение, которое соответствует слову, в конечный автомат, а затем инвертировать автомат, изменив каждое состояние принятия на непринятие и наоборот, а затем преобразуя полученную FA обратно в регулярное выражение.
Наконец, как все отметили, если ваш механизм регулярных выражений поддерживает негативный взгляд, это значительно упрощает задачу. Например, с GNU grep:
grep -P '^((?!hede).)*$' Input
Обновление: Недавно я нашел отличную библиотеку FormalTheory от Kendall Hopkins, написанную на PHP, которая обеспечивает функциональность, похожую на Grail. Используя это и упроститель, написанный мной, я смог написать онлайн-генератор отрицательных регулярных выражений с учетом входной фразы (только буквенно-цифровые и пробельные символы, которые в настоящее время поддерживаются): http://www.formauri.es/personal/pgimeno/разное/неигровые-регулярное выражение /
Для hede он выводит:
^([^h]|h(h|e(h|dh))*([^eh]|e([^dh]|d[^eh])))*(h(h|e(h|dh))*(ed?)?)?$
что эквивалентно приведенному выше.
Ответ 20
Он может быть более поддерживаемым для двух регулярных выражений в вашем коде, один для первого совпадения, а затем, если он совпадает с run, второе регулярное выражение проверяет наличие случаев, которые вы хотите заблокировать, например, ^.*(hede).*, затем имеет соответствующую логику в ваш код.
Хорошо, я признаю, что на самом деле это не ответ на опубликованный вопрос, и он может также использовать немного больше обработки, чем одно регулярное выражение. Но для разработчиков, которые пришли сюда, чтобы найти быстрое исправление для случая превышения, это решение не следует упускать из виду.
Ответ 21
Язык TXR поддерживает отрицание регулярных выражений.
$ txr -c '@(repeat)
@{nothede /~hede/}
@(do (put-line nothede))
@(end)' Input
Более сложный пример: сопоставьте все строки, которые начинаются с a и заканчиваются на z, но не содержат подстроку hede:
$ txr -c '@(repeat)
@{nothede /a.*z&~.*hede.*/}
@(do (put-line nothede))
@(end)' -
az <- echoed
az
abcz <- echoed
abcz
abhederz <- not echoed; contains hede
ahedez <- not echoed; contains hede
ace <- not echoed; does not end in z
ahedz <- echoed
ahedz
Отрицание регулярных выражений не особенно полезно само по себе, но когда у вас также есть пересечение, вещи становятся интересными, поскольку у вас есть полный набор операций с булевыми множествами: вы можете выразить «множество, которое соответствует этому, за исключением вещей, которые соответствуют этому».
Ответ 22
На мой взгляд, более читаемый вариант верхнего ответа:
^(?!.*hede)
По сути, «сопоставлять в начале строки тогда и только тогда, когда в ней нет слова» хеде «», поэтому требование почти напрямую переводится в регулярное выражение.
Конечно, это может иметь несколько требований отказа:
^(?!.*(hede|hodo|hada))
Детали: Якорь ^ гарантирует, что механизм регулярных выражений не повторяет совпадение в каждом месте строки, что соответствует каждой строке.
Якорь ^ в начале предназначен для обозначения начала строки. Инструмент grep сопоставляет каждую строку по одной за раз, в тех случаях, когда вы работаете с многострочной строкой, вы можете использовать флаг «m»:
/^(?!.*hede)/m # JavaScript syntax
или же
(?m)^(?!.*hede) # Inline flag
Ответ 23
Функция ниже поможет вам получить желаемый результат
<?PHP
function removePrepositions($text){
$propositions=array('/bforb/i','/btheb/i');
if( count($propositions) > 0 ) {
foreach($propositions as $exceptionPhrase) {
$text = preg_replace($exceptionPhrase, '', trim($text));
}
$retval = trim($text);
}
return $retval;
}
?>
Ответ 24
Как использовать контрольные глаголы PCRE backtracking для соответствия строке, не содержащей слова
Вот метод, который я раньше не видел:
/.*hede(*COMMIT)^|/
Как это работает
Сначала он пытается найти «hede» где-то в строке. В случае успеха (*COMMIT) в этот момент указывает движку не только не возвращаться в случае сбоя, но и не пытаться выполнить дальнейшее сопоставление в этом случае. Затем мы пытаемся сопоставить то, что не может совпадать (в данном случае ^).
Если строка не содержит «hede», вторая альтернатива, пустой подшаблон, успешно соответствует теме.
Этот метод не более эффективен, чем негативный взгляд, но я решил, что просто брошу его здесь, если кто-то найдет его отличным и найдет для него использование для других, более интересных приложений.
Ответ 25
Возможно, вы найдете это в Google, пытаясь написать регулярное выражение, которое может соответствовать сегментам строки (в отличие от целых строк), которые не содержат подстроку. Поймайте мне время, чтобы разобраться, поэтому я поделюсь:
Учитывая строку: <span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>
Я хочу сопоставить теги <span> которые не содержат подстроку «bad».
/<span(?:(?!bad).)*?> будет соответствовать <span class="good"> и <span class="ugly">.
Обратите внимание, что есть два набора (слоев) круглых скобок:
- Самый внутренний — для негативного взгляда (это не группа захвата)
- Самый внешний интерпретируемый Ruby как группа захвата, но мы не хотим, чтобы он был группой захвата, поэтому я добавил?: При этом он начинается и больше не интерпретируется как группа захвата.
Демо в Ruby:
s = '<span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>'
s.scan(/<span(?:(?!bad).)*?>/)
# => ["<span class="good">", "<span class="ugly">"]
Ответ 26
Я не понимаю потребности в сложном регулярном выражении или даже взглядах:
/hede|^(.*)$/gm
Не помещайте в группу захвата вещь, которую вы не хотите, но используйте ее для всего остального. Это будет соответствовать всем строкам, которые не содержат «hede».
Ответ 27
Более простым решением является использование неоператора !
Ваш оператор if должен соответствовать «содержит» и не соответствует «исключает».
var contains = /abc/;
var excludes =/hede/;
if(string.match(contains) && !(string.match(excludes))){ //proceed...
Я считаю, что дизайнеры RegEx предполагали использование не операторов.
Ответ 28
С помощью ConyEdit вы можете использовать командную строку cc.gl ! /hede/ для получения строк, которые не содержат соответствия регулярных выражений, или используйте командную строку cc.dl/hede/ для удаления строк, содержащих соответствие регулярных выражений. Они имеют одинаковый результат.
Ответ 29
^ ((?! hede).) * $ — элегантное решение, за исключением того, что оно использует символы, поэтому вы не сможете комбинировать его с другими критериями. Например, скажем, вы хотели проверить отсутствие «хеде» и наличие «хаха». Это решение будет работать, потому что оно не будет потреблять символы:
^ (?!.Bhedeб) (? =.Bhahaб)
Регулярные выражения (их еще называют regexp, или regex) — это механизм для поиска и замены текста. В строке, файле, нескольких файлах… Их используют разработчики в коде приложения, тестировщики в автотестах, да просто при работе в командной строке!
Чем это лучше простого поиска? Тем, что позволяет задать шаблон.
Например, на вход приходит дата рождения в формате ДД.ММ.ГГГГГ. Вам надо передать ее дальше, но уже в формате ГГГГ-ММ-ДД. Как это сделать с помощью простого поиска? Вы же не знаете заранее, какая именно дата будет.

А регулярное выражение позволяет задать шаблон «найди мне цифры в таком-то формате».
Для чего применяют регулярные выражения?
-
Удалить все файлы, начинающиеся на test (чистим за собой тестовые данные)
-
Найти все логи
-
grep-нуть логи
-
Найти все даты
-
…
А еще для замены — например, чтобы изменить формат всех дат в файле. Если дата одна, можно изменить вручную. А если их 200, проще написать регулярку и подменить автоматически. Тем более что регулярные выражения поддерживаются даже простым блокнотом (в Notepad++ они точно есть).

В этой статье я расскажу о том, как применять регулярные выражения для поиска и замены. Разберем все основные варианты.
Содержание
-
Где пощупать
-
Поиск текста
-
Поиск любого символа
-
Поиск по набору символов
-
Перечисление вариантов
-
Метасимволы
-
Спецсимволы
-
Квантификаторы (количество повторений)
-
Позиция внутри строки
-
Использование ссылки назад
-
Просмотр вперед и назад
-
Замена
-
Статьи и книги по теме
-
Итого
Где пощупать
Любое регулярное выражение из статьи вы можете сразу пощупать. Так будет понятнее, о чем речь в статье — вставили пример из статьи, потом поигрались сами, делая шаг влево, шаг вправо. Где тренироваться:
-
Notepad++ (установить Search Mode → Regular expression)
-
Regex101 (мой фаворит в онлайн вариантах)
-
Myregexp
-
Regexr
Инструменты есть, теперь начнём
Поиск текста
Самый простой вариант регэкспа. Работает как простой поиск — ищет точно такую же строку, как вы ввели.
Текст: Море, море, океан
Regex: море
Найдет: Море, море, океан
Выделение курсивом не поможет моментально ухватить суть, что именно нашел regex, а выделить цветом в статье я не могу. Атрибут BACKGROUND-COLOR не сработал, поэтому я буду дублировать регулярки текстом (чтобы можно было скопировать себе) и рисунком, чтобы показать, что именно regex нашел:

Обратите внимание, нашлось именно «море», а не первое «Море». Регулярные выражения регистрозависимые!
Хотя, конечно, есть варианты. В JavaScript можно указать дополнительный флажок i, чтобы не учитывать регистр при поиске. В блокноте (notepad++) тоже есть галка «Match case». Но учтите, что это не функция по умолчанию. И всегда стоит проверить, регистрозависимая ваша реализация поиска, или нет.
А что будет, если у нас несколько вхождений искомого слова?
Текст: Море, море, море, океан
Regex: море
Найдет: Море, море, море, океан

По умолчанию большинство механизмов обработки регэкспа вернет только первое вхождение. В JavaScript есть флаг g (global), с ним можно получить массив, содержащий все вхождения.
А что, если у нас искомое слово не само по себе, это часть слова? Регулярное выражение найдет его:
Текст: Море, 55мореон, океан
Regex: море
Найдет: Море, 55мореон, океан

Это поведение по умолчанию. Для поиска это даже хорошо. Вот, допустим, я помню, что недавно в чате коллега рассказывала какую-то историю про интересный баг в игре. Что-то там связанное с кораблем… Но что именно? Уже не помню. Как найти?
Если поиск работает только по точному совпадению, мне придется перебирать все падежи для слова «корабль». А если он работает по включению, я просто не буду писать окончание, и все равно найду нужный текст:
Regex: корабл
Найдет:
На корабле
И тут корабль
У корабля

Это статический, заранее заданный текст. Но его можно найти и без регулярок. Регулярные выражения особенно хороши, когда мы не знаем точно, что мы ищем. Мы знаем часть слова, или шаблон.
Поиск любого символа
. — найдет любой символ (один).
Текст:
Аня
Ася
Оля
Аля
Валя
Regex: А.я
Результат:
Аня
Ася
ОляАля
Валя

Точка найдет вообще любой символ, включая цифры, спецсисимволы, даже пробелы. Так что кроме нормальных имен, мы найдем и такие значения:
А6я
А&я
А я
Учтите это при поиске! Точка очень удобный символ, но в то же время очень опасный — если используете ее, обязательно тестируйте получившееся регулярное выражение. Найдет ли оно то, что нужно? А лишнее не найдет?
Точку точка тоже найдет!
Regex: file.
Найдет:
file.txt
file1.txt
file2.xls

Но что, если нам надо найти именно точку? Скажем, мы хотим найти все файлы с расширением txt и пишем такой шаблон:
Regex: .txt
Результат:
file.txt
log.txt
file.png1txt.doc
one_txt.jpg
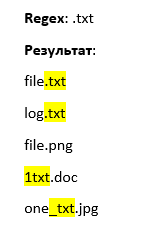
Да, txt файлы мы нашли, но помимо них еще и «мусорные» значения, у которых слово «txt» идет в середине слова. Чтобы отсечь лишнее, мы можем использовать позицию внутри строки (о ней мы поговорим чуть дальше).
Но если мы хотим найти именно точку, то нужно ее заэкранировать — то есть добавить перед ней обратный слеш:
Regex: .txt
Результат:
file.txt
log.txt
file.png
1txt.doc
one_txt.jpg

Также мы будем поступать со всеми спецсимволами. Хотим найти именно такой символ в тексте? Добавляем перед ним обратный слеш.
Правило поиска для точки:
. — любой символ
. — точка

Поиск по набору символов
Допустим, мы хотим найти имена «Алла», «Анна» в списке. Можно попробовать поиск через точку, но кроме нормальных имен, вернется всякая фигня:
Regex: А..а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Если же мы хотим именно Анну да Аллу, вместо точки нужно использовать диапазон допустимых значений. Ставим квадратные скобки, а внутри них перечисляем нужные символы:
Regex: А[нл][нл]а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Вот теперь результат уже лучше! Да, нам все еще может вернуться «Анла», но такие ошибки исправим чуть позже.
Как работают квадратные скобки? Внутри них мы указываем набор допустимых символов. Это может быть перечисление нужных букв, или указание диапазона:
[нл] — только «н» и «л»
[а-я] — все русские буквы в нижнем регистре от «а» до «я» (кроме «ё»)
[А-Я] — все заглавные русские буквы
[А-Яа-яЁё] — все русские буквы
[a-z] — латиница мелким шрифтом
[a-zA-Z] — все английские буквы
[0-9] — любая цифра
[В-Ю] — буквы от «В» до «Ю» (да, диапазон — это не только от А до Я)
[А-ГО-Р] — буквы от «А» до «Г» и от «О» до «Р»
Обратите внимание — если мы перечисляем возможные варианты, мы не ставим между ними разделителей! Ни пробел, ни запятую — ничего.
[абв] — только «а», «б» или «в»
[а б в] — «а», «б», «в», или пробел (что может привести к нежелательному результату)
[а, б, в] — «а», «б», «в», пробел или запятая

Единственный допустимый разделитель — это дефис. Если система видит дефис внутри квадратных скобок — значит, это диапазон:
-
Символ до дефиса — начало диапазона
-
Символ после — конец
Один символ! Не два или десять, а один! Учтите это, если захотите написать что-то типа [1-31]. Нет, это не диапазон от 1 до 31, эта запись читается так:
-
Диапазон от 1 до 3
-
И число 1
Здесь отсутствие разделителей играет злую шутку с нашим сознанием. Ведь кажется, что мы написали диапазон от 1 до 31! Но нет. Поэтому, если вы пишете регулярные выражения, очень важно их тестировать. Не зря же мы тестировщики! Проверьте то, что написали! Особенно, если с помощью регулярного выражения вы пытаетесь что-то удалить =)) Как бы не удалили лишнее…
Указание диапазона вместо точки помогает отсеять заведомо плохие данные:
Regex: А.я или А[а-я]я
Результат для обоих:
Аня
Ася
Аля
Результат для «А.я»:
А6я
А&я
А я
^ внутри [] означает исключение:
[^0-9] — любой символ, кроме цифр
[^ёЁ] — любой символ, кроме буквы «ё»
[^а-в8] — любой символ, кроме букв «а», «б», «в» и цифры 8

Например, мы хотим найти все txt файлы, кроме разбитых на кусочки — заканчивающихся на цифру:
Regex: [^0-9].txt
Результат:
file.txt
log.txt
file_1.txt
1.txt

Так как квадратные скобки являются спецсимволами, то их нельзя найти в тексте без экранирования:
Regex: fruits[0]
Найдет: fruits0
Не найдет: fruits[0]
Это регулярное выражение говорит «найди мне текст «fruits», а потом число 0». Квадратные скобки не экранированы — значит, внутри будет набор допустимых символов.

Если мы хотим найти именно 0-левой элемент массива фруктов, надо записать так:
Regex: fruits[0]
Найдет: fruits[0]
Не найдет: fruits0
А если мы хотим найти все элементы массива фруктов, мы внутри экранированных квадратных скобок ставим неэкранированные!
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[2] = “лимон”;
Не найдет:
cat[0] = “чеширский кот”;
Конечно, «читать» такое регулярное выражение становится немного тяжело, столько разных символов написано…

Без паники! Если вы видите сложное регулярное выражение, то просто разберите его по частям. Помните про основу эффективного тайм-менеджмента? Слона надо есть по частям.
Допустим, после отпуска накопилась гора писем. Смотришь на нее и сразу впадаешь в уныние:
— Ууууууу, я это за день не закончу!

Проблема в том, что груз задачи мешает работать. Мы ведь понимаем, что это надолго. А большую задачу делать не хочется… Поэтому мы ее откладываем, беремся за задачи поменьше. В итоге да, день прошел, а мы не успели закончить.
А если не тратить время на размышления «сколько времени это у меня займет», а сосредоточиться на конкретной задаче (в данном случае — первом письме из стопки, потом втором…), то не успеете оглянуться, как уже всё разгребли!

Разберем по частям регулярное выражение — fruits[[0-9]]
Сначала идет просто текст — «fruits».

Потом обратный слеш. Ага, он что-то экранирует.

Что именно? Квадратную скобку. Значит, это просто квадратная скобка в моем тексте — «fruits[»

Дальше снова квадратная скобка. Она не экранирована — значит, это набор допустимых значений. Ищем закрывающую квадратную скобку.

Нашли. Наш набор: [0-9]. То есть любое число. Но одно. Там не может быть 10, 11 или 325, потому что квадратные скобки без квантификатора (о них мы поговорим чуть позже) заменяют ровно один символ.
Пока получается: fruits[«любое однозназначное число»

Дальше снова обратный слеш. То есть следующий за ним спецсимвол будет просто символом в моем тексте.

А следующий символ — ]
Получается выражение: fruits[«любое однозназначное число»]

Наше выражение найдет значения массива фруктов! Не только нулевое, но и первое, и пятое… Вплоть до девятого:
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[9] = “лимон”;
Не найдет:
fruits[10] = “банан”;
fruits[325] = “ абрикос ”;
Как найти вообще все значения массива, см дальше, в разделе «квантификаторы».
А пока давайте посмотрим, как с помощью диапазонов можно найти все даты.

Какой у даты шаблон? Мы рассмотрим ДД.ММ.ГГГГ:
-
2 цифры дня
-
точка
-
2 цифры месяца
-
точка
-
4 цифры года
Запишем в виде регулярного выражения: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9].
Напомню, что мы не можем записать диапазон [1-31]. Потому что это будет значить не «диапазон от 1 до 31», а «диапазон от 1 до 3, плюс число 1». Поэтому пишем шаблон для каждой цифры отдельно.
В принципе, такое выражение найдет нам даты среди другого текста. Но что, если с помощью регулярки мы проверяем введенную пользователем дату? Подойдет ли такой regexp?
Давайте его протестируем! Как насчет 8888 года или 99 месяца, а?
Regex: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
Найдет:
01.01.1999
05.08.2015
Тоже найдет:
08.08.8888
99.99.2000

Попробуем ограничить:
-
День месяца может быть максимум 31 — первая цифра [0-3]
-
Максимальный месяц 12 — первая цифра [01]
-
Год или 19.., или 20.. — первая цифра [12], а вторая [09]

Вот, уже лучше, явно плохие данные регулярка отсекла. Надо признать, она отсечет довольно много тестовых данных, ведь обычно, когда хотят именно сломать, то фигачат именно «9999» год или «99» месяц…
Однако если мы присмотримся внимательнее к регулярному выражению, то сможем найти в нем дыры:
Regex: [0-3][0-9].[0-1][0-9].[12][09][0-9][0-9]
Не найдет:
08.08.8888
99.99.2000
Но найдет:
33.01.2000
01.19.1999
05.06.2999

Мы не можем с помощью одного диапазона указать допустимые значения. Или мы потеряем 31 число, или пропустим 39. И если мы хотим сделать проверку даты, одних диапазонов будет мало. Нужна возможность перечислить варианты, о которой мы сейчас и поговорим.
Перечисление вариантов
Квадратные скобки [] помогают перечислить варианты для одного символа. Если же мы хотим перечислить слова, то лучше использовать вертикальную черту — |.
Regex: Оля|Олечка|Котик
Найдет:
Оля
Олечка
Котик
Не найдет:
Оленька
Котенка
Можно использовать вертикальную черту и для одного символа. Можно даже внутри слова — тогда вариативную букву берем в круглые скобки
Regex: А(н|л)я
Найдет:
Аня
Аля
Круглые скобки обозначают группу символов. В этой группе у нас или буква «н», или буква «л». Зачем нужны скобки? Показать, где начинается и заканчивается группа. Иначе вертикальная черта применится ко всем символам — мы будем искать или «Ан», или «ля»:
Regex: Ан|ля
Найдет:
Аня
Аля
Оля
Малюля

А если мы хотим именно «Аня» или «Аля», то перечисление используем только для второго символа. Для этого берем его в скобки.
Эти 2 варианта вернут одно и то же:
-
А(н|л)я
-
А[нл]я
Но для замены одной буквы лучше использовать [], так как сравнение с символьным классом выполняется проще, чем обработка группы с проверкой на все её возможные модификаторы.
Давайте вернемся к задаче «проверить введенную пользователем дату с помощью регулярных выражений». Мы пробовали записать для дня диапазон [0-3][0-9], но он пропускает значения 33, 35, 39… Это нехорошо!
Тогда распишем ТЗ подробнее. Та-а-а-ак… Если первая цифра:
-
0 — вторая может от 1 до 9 (даты 00 быть не может)
-
1, 2 — вторая может от 0 до 9
-
3 — вторая только 0 или 1
Составим регулярные выражения на каждый пункт:
-
0[1-9]
-
[12][0-9]
-
3[01]
А теперь осталось их соединить в одно выражение! Получаем: 0[1-9]|[12][0-9]|3[01]

По аналогии разбираем месяц и год. Но это остается вам для домашнего задания =)
Потом, когда распишем регулярки отдельно для дня, месяца и года, собираем все вместе:
(<день>).(<месяц>).(<год>)
Обратите внимание — каждую часть регулярного выражения мы берем в скобки. Зачем? Чтобы показать системе, где заканчивается выбор. Вот смотрите, допустим, что для месяца и года у нас осталось выражение:
[0-1][0-9].[12][09][0-9][0-9]
Подставим то, что написали для дня:
0[1-9]|[12][0-9]|3[01].[0-1][0-9].[12][09][0-9][0-9]
Как читается это выражение?
-
ИЛИ 0[1-9]
-
ИЛИ [12][0-9]
-
ИЛИ 3[01].[0-1][0-9].[12][09][0-9][0-9]
Видите проблему? Число «19» будет считаться корректной датой. Система не знает, что перебор вариантов | закончился на точке после дня. Чтобы она это поняла, нужно взять перебор в скобки. Как в математике, разделяем слагаемые.
Так что запомните — если перебор идет в середине слова, его надо взять в круглые скобки!
Regex: А(нн|лл|лин|нтонин)а
Найдет:
Анна
Алла
Алина
Антонина
Без скобок:
Regex: Анн|лл|лин|нтонина
Найдет:
Анна
Алла
Аннушка
Кукулинка

Итого, если мы хотим указать допустимые значения:
-
Одного символа — используем []
-
Нескольких символов или целого слова — используем |

Метасимволы
Если мы хотим найти число, то пишем диапазон [0-9].
Если букву, то [а-яА-ЯёЁa-zA-Z].
А есть ли другой способ?

Есть! В регулярных выражениях используются специальные метасимволы, которые заменяют собой конкретный диапазон значений:
|
Символ |
Эквивалент |
Пояснение |
|
d |
[0-9] |
Цифровой символ |
|
D |
[^0-9] |
Нецифровой символ |
|
s |
[ fnrtv] |
Пробельный символ |
|
S |
[^ fnrtv] |
Непробельный символ |
|
w |
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания |
|
W |
[^[:word:]] |
Любой символ, кроме буквенного или цифрового символа или знака подчёркивания |
|
. |
Вообще любой символ |
Это самые распространенные символы, которые вы будете использовать чаще всего. Но давайте разберемся с колонкой «эквивалент». Для d все понятно — это просто некие числа. А что такое «пробельные символы»? В них входят:
|
Символ |
Пояснение |
|
Пробел |
|
|
r |
Возврат каретки (Carriage return, CR) |
|
n |
Перевод строки (Line feed, LF) |
|
t |
Табуляция (Tab) |
|
v |
Вертикальная табуляция (vertical tab) |
|
f |
Конец страницы (Form feed) |
|
[b] |
Возврат на 1 символ (Backspace) |
Из них вы чаще всего будете использовать сам пробел и перевод строки — выражение «rn». Напишем текст в несколько строк:
Первая строка
Вторая строка
Для регулярного выражения это:
Первая строкаrnВторая строка
А вот что такое backspace в тексте? Как его можно увидеть вообще? Это же если написать символ и стереть его. В итоге символа нет! Неужели стирание хранится где-то в памяти? Но тогда это было бы ужасно, мы бы вообще ничего не смогли найти — откуда нам знать, сколько раз текст исправляли и в каких местах там теперь есть невидимый символ [b]?

Выдыхаем — этот символ не найдет все места исправления текста. Просто символ backspace — это ASCII символ, который может появляться в тексте (ASCII code 8, или 10 в octal). Вы можете «создать» его, написать в консоли браузера (там используется JavaScript):
console.log("abcbbdef");Результат команды:
adefМы написали «abc», а потом стерли «b» и «с». В итоге пользователь в консоли их не видит, но они есть. Потому что мы прямо в коде прописали символ удаления текста. Не просто удалили текст, а прописали этот символ. Вот такой символ регулярное выражение [b] и найдет.
См также:
What’s the use of the [b] backspace regex? — подробнее об этом символе
Но обычно, когда мы вводим s, мы имеем в виду пробел, табуляцию, или перенос строки.
Ок, с этими эквивалентами разобрались. А что значит [[:word:]]? Это один из способов заменить диапазон. Чтобы запомнить проще было, написали значения на английском, объединив символы в классы. Какие есть классы:
|
Класс символов |
Пояснение |
|
[[:alnum:]] |
Буквы или цифры: [а-яА-ЯёЁa-zA-Z0-9] |
|
[[:alpha:]] |
Только буквы: [а-яА-ЯёЁa-zA-Z] |
|
[[:digit:]] |
Только цифры: [0-9] |
|
[[:graph:]] |
Только отображаемые символы (пробелы, служебные знаки и т. д. не учитываются) |
|
[[:print:]] |
Отображаемые символы и пробелы |
|
[[:space:]] |
Пробельные символы [ fnrtv] |
|
[[:punct:]] |
Знаки пунктуации: ! » # $ % & ‘ ( ) * + , -. / : ; < = > ? @ [ ] ^ _ ` { | } |
|
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания: [а-яА-ЯёЁa-zA-Z0-9_] |
Теперь мы можем переписать регулярку для проверки даты, которая выберет лишь даты формата ДД.ММ.ГГГГГ, отсеяв при этом все остальное:
[0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
↓
dd.dd.dddd
Согласитесь, через метасимволы запись посимпатичнее будет =))
Спецсимволы
Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов:
[ ] / ^ $ . | ? * + ( ) { }
Эти символы нужны, чтобы обозначить диапазон допустимых значений или границу фразы, указать количество повторений, или сделать что-то еще. В разных типах регулярных выражений этот набор различается (см «разновидности регулярных выражений»).
Если вы хотите найти один из этих символов внутри вашего текста, его надо экранировать символом (обратная косая черта).
Regex: 2^2 = 4
Найдет: 2^2 = 4
Можно экранировать целую последовательность символов, заключив её между Q и E (но не во всех разновидностях).
Regex: Q{кто тут?}E
Найдет: {кто тут?}
Квантификаторы (количество повторений)
Усложняем задачу. Есть некий текст, нам нужно вычленить оттуда все email-адреса. Например:
-
test@mail.ru
-
olga31@gmail.com
-
pupsik_99@yandex.ru

Как составляется регулярное выражение? Нужно внимательно изучить данные, которые мы хотим получить на выходе, и составить по ним шаблон. В email два разделителя — собачка «@» и точка «.».

Запишем ТЗ для регулярного выражения:
-
Буквы / цифры / _
-
Потом @
-
Снова буквы / цифры / _
-
Точка
-
Буквы
Так, до собачки у нас явно идет метасимвол «w», туда попадет и просто текст (test), и цифры (olga31), и подчеркивание (pupsik_99). Но есть проблема — мы не знаем, сколько таких символов будет. Это при поиске даты все ясно — 2 цифры, 2 цифры, 4 цифры. А тут может быть как 2, так и 22 символа.
И тут на помощь приходят квантификаторы — так называют специальные символы в регулярных выражениях, которые указывают количество повторений текста.
Символ «+» означает «одно или более повторений», это как раз то, что нам надо! Получаем: w+@

После собачки и снова идет w, и снова от одного повторения. Получаем: w+@w+.
После точки обычно идут именно символы, но для простоты можно снова написано w. И снова несколько символов ждем, не зная точно сколько. Итого получилось выражение, которое найдет нам email любой длины:
Regex: w+@w+.w+
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99_and_slonik_33_and_mikky_87_and_kotik_28@yandex.megatron
Какие есть квантификаторы, кроме знака «+»?
|
Квантификатор |
Число повторений |
|
? |
Ноль или одно |
|
* |
Ноль или более |
|
+ |
Один или более |
Символ * часто используют с точкой — когда нам неважно, какой идет текст до интересующей нас фразы, мы заменяем его на «.*» — любой символ ноль или более раз.
Regex: .*dd.dd.dddd.*
Найдет:
01.01.2000
Приходи на ДР 09.08.2015! Будет весело!
Но будьте осторожны! Если использовать «.*» повсеместно, можно получить много ложноположительных срабатываний:
Regex: .*@.*..*
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99@yandex.ru
Но также найдет:
@yandex.ru
test@.ru
test@mail.

Уж лучше w, и плюсик вместо звездочки.
А вот есть мы хотим найти все лог-файлы, которые нумеруются — log, log1, log2… log133, то * подойдет хорошо:
Regex: logd*.txt
Найдет:
log.txt
log1.txt
log2.txt
log3.txt
log33.txt
log133.txt
А знак вопроса (ноль или одно повторение) поможет нам найти людей с конкретной фамилией — причем всех, и мужчин, и женщин:
Regex: Назина?
Найдет:
Назин
Назина
Если мы хотим применить квантификатор к группе символов или нескольким словам, их нужно взять в скобки:
Regex: (Хихи)*(Хаха)*
Найдет:
ХихиХаха
ХихиХихиХихи
Хихи
Хаха
ХихиХихиХахаХахаХаха
(пустота — да, её такая регулярка тоже найдет)
Квантификаторы применяются к символу или группе в скобках, которые стоят перед ним.
А что, если мне нужно определенное количество повторений? Скажем, я хочу записать регулярное выражение для даты. Пока мы знаем только вариант «перечислить нужный метасимвол нужное количество раз» — dd.dd.dddd.
Ну ладно 2-4 раза повторение идет, а если 10? А если повторить надо фразу? Так и писать ее 10 раз? Не слишком удобно. А использовать * нельзя:
Regex: d*.d*.d*
Найдет:
.0.1999
05.08.20155555555555555
03444.025555.200077777777777777
Чтобы указать конкретное количество повторений, их надо записать внутри фигурных скобок:
|
Квантификатор |
Число повторений |
|
{n} |
Ровно n раз |
|
{m,n} |
От m до n включительно |
|
{m,} |
Не менее m |
|
{,n} |
Не более n |
Таким образом, для проверки даты можно использовать как перечисление d n раз, так и использование квантификатора:
dd.dd.dddd
d{2}.d{2}.d{4}
Обе записи будут валидны. Но вторая читается чуть проще — не надо самому считать повторения, просто смотрим на цифру.
Не забывайте — квантификатор применяется к последнему символу!
Regex: data{2}
Найдет: dataa
Не найдет: datadata
Или группе символов, если они взяты в круглые скобки:
Regex: (data){2}
Найдет: datadata
Не найдет: dataa

Так как фигурные скобки используются в качестве указания количества повторений, то, если вы ищете именно фигурную скобку в тексте, ее надо экранировать:
Regex: x{3}
Найдет: x{3}
Иногда квантификатор находит не совсем то, что нам нужно.
Regex: <.*>
Ожидание:
<req>
<query>Ан</query>
<gender>FEMALE</gender>Реальность:
<req> <query>Ан</query> <gender>FEMALE</gender></req>Мы хотим найти все теги HTML или XML по отдельности, а регулярное выражение возвращает целую строку, внутри которой есть несколько тегов.
Напомню, что в разных реализациях регулярные выражения могут работать немного по разному. Это одно из отличий — в некоторых реализациях квантификаторам соответствует максимально длинная строка из возможных. Такие квантификаторы называют жадными.

Если мы понимаем, что нашли не то, что хотели, можно пойти двумя путями:
-
Учитывать символы, не соответствующие желаемому образцу
-
Определить квантификатор как нежадный (ленивый, англ. lazy) — большинство реализаций позволяют это сделать, добавив после него знак вопроса.
Как учитывать символы? Для примера с тегами можно написать такое регулярное выражение:
<[^>]*>
Оно ищет открывающий тег, внутри которого все, что угодно, кроме закрывающегося тега «>», и только потом тег закрывается. Так мы не даем захватить лишнее. Но учтите, использование ленивых квантификаторов может повлечь за собой обратную проблему — когда выражению соответствует слишком короткая, в частности, пустая строка.
|
Жадный |
Ленивый |
|
* |
*? |
|
+ |
+? |
|
{n,} |
{n,}? |

Есть еще и сверхжадная квантификация, также именуемая ревнивой. Но о ней почитайте в википедии =)
Позиция внутри строки
По умолчанию регулярные выражения ищут «по включению».
Regex: арка
Найдет:
арка
чарка
аркан
баварка
знахарка
Это не всегда то, что нам нужно. Иногда мы хотим найти конкретное слово.

Если мы ищем не одно слово, а некую строку, проблема решается в помощью пробелов:
Regex: Товар №d+ добавлен в корзину в dd:dd
Найдет: Товар №555 добавлен в корзину в 15:30
Не найдет: Товарный чек №555 добавлен в корзину в 15:30

Или так:
Regex: .* арка .*
Найдет: Триумфальная арка была…
Не найдет: Знахарка сегодня…
А что, если у нас не пробел рядом с искомым словом? Это может быть знак препинания: «И вот перед нами арка.», или «…арка:».
Если мы ищем конкретное слово, то можно использовать метасимвол b, обозначающий границу слова. Если поставить метасимвол с обоих концов слова, мы найдем именно это слово:
Regex: bаркаb
Найдет:
арка
Не найдет:
чарка
аркан
баварка
знахарка

Можно ограничить только спереди — «найди все слова, которые начинаются на такое-то значение»:
Regex: bарка
Найдет:
арка
аркан
Не найдет:
чарка
баварка
знахарка
Можно ограничить только сзади — «найди все слова, которые заканчиваются на такое-то значение»:
Regex: аркаb
Найдет:
арка
чарка
баварка
знахарка
Не найдет:
аркан
Если использовать метасимвол B, он найдем нам НЕ-границу слова:
Regex: BакрB
Найдет:
закройка
Не найдет:
акр
акрил
Если мы хотим найти конкретную фразу, а не слово, то используем следующие спецсимволы:
^ — начало текста (строки)
$ — конец текста (строки)
Если использовать их, мы будем уверены, что в наш текст не закралось ничего лишнего:
Regex: ^Я нашел!$
Найдет:
Я нашел!
Не найдет:
Смотри! Я нашел!
Я нашел! Посмотри!
Итого метасимволы, обозначающие позицию строки:
|
Символ |
Значение |
|
b |
граница слова |
|
B |
Не граница слова |
|
^ |
начало текста (строки) |
|
$ |
конец текста (строки) |
Использование ссылки назад
Допустим, при тестировании приложения вы обнаружили забавный баг в тексте — дублирование предлога «на»: «Поздравляем! Вы прошли на на новый уровень». А потом решили проверить, есть ли в коде еще такие ошибки.

Разработчик предоставил файлик со всеми текстами. Как найти повторы? С помощью ссылки назад. Когда мы берем что-то в круглые скобки внутри регулярного выражения, мы создаем группу. Каждой группе присваивается номер, по которому к ней можно обратиться.
Regex: [ ]+(w+)[ ]+1
Текст: Поздравляем! Вы прошли на на новый уровень. Так что что улыбаемся и и машем.

Разберемся, что означает это регулярное выражение:
[ ]+ → один или несколько пробелов, так мы ограничиваем слово. В принципе, тут можно заменить на метасимвол b.
(w+) → любой буквенный или цифровой символ, или знак подчеркивания. Квантификатор «+» означает, что символ должен идти минимум один раз. А то, что мы взяли все это выражение в круглые скобки, говорит о том, что это группа. Зачем она нужна, мы пока не знаем, ведь рядом с ней нет квантификатора. Значит, не для повторения. Но в любом случае, найденный символ или слово — это группа 1.
[ ]+ → снова один или несколько пробелов.
1 → повторение группы 1. Это и есть ссылка назад. Так она записывается в JavaScript-е.
Важно: синтаксис ссылок назад очень зависит от реализации регулярных выражений.
|
ЯП |
Как обозначается ссылка назад |
|
JavaScript vi |
|
|
Perl |
$ |
|
PHP |
$matches[1] |
|
Java Python |
group[1] |
|
C# |
match.Groups[1] |
|
Visual Basic .NET |
match.Groups(1) |
Для чего еще нужна ссылка назад? Например, можно проверить верстку HTML, правильно ли ее составили? Верно ли, что открывающийся тег равен закрывающемуся?

Напишите выражение, которое найдет правильно написанные теги:
<h2>Заголовок 2-ого уровня</h2>
<h3>Заголовок 3-ого уровня</h3>Но не найдет ошибки:
<h2>Заголовок 2-ого уровня</h3>Просмотр вперед и назад
Еще может возникнуть необходимость найти какое-то место в тексте, но не включая найденное слово в выборку. Для этого мы «просматриваем» окружающий текст.
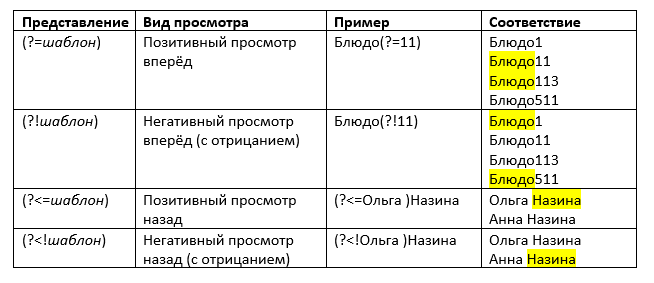
|
Представление |
Вид просмотра |
Пример |
Соответствие |
|
(?=шаблон) |
Позитивный просмотр вперёд |
Блюдо(?=11) |
Блюдо11 Блюдо113
|
|
(?!шаблон) |
Негативный просмотр вперёд (с отрицанием) |
Блюдо(?!11) |
Блюдо1
Блюдо511 |
|
(?<=шаблон) |
Позитивный просмотр назад |
(?<=Ольга )Назина |
Ольга Назина
|
|
(?шаблон) |
Негативный просмотр назад (с отрицанием) |
(см ниже на рисунке) |
Анна Назина |
Замена
Важная функция регулярных выражений — не только найти текст, но и заменить его на другой текст! Простейший вариант замены — слово на слово:
RegEx: Ольга
Замена: Макар
Текст был: Привет, Ольга!
Текст стал: Привет, Макар!
Но что, если у нас в исходном тексте может быть любое имя? Вот что пользователь ввел, то и сохранилось. А нам надо на Макара теперь заменить. Как сделать такую замену? Через знак доллара. Давайте разберемся с ним подробнее.

Знак доллара в замене — обращение к группе в поиске. Ставим знак доллара и номер группы. Группа — это то, что мы взяли в круглые скобки. Нумерация у групп начинается с 1.
RegEx: (Оля) + Маша
Замена: $1
Текст был: Оля + Маша
Текст стал: Оля
Мы искали фразу «Оля + Маша» (круглые скобки не экранированы, значит, в искомом тексте их быть не должно, это просто группа). А замнили ее на первую группу — то, что написано в первых круглых скобках, то есть текст «Оля».
Это работает и когда искомый текст находится внутри другого:
RegEx: (Оля) + Маша
Замена: $1
Текст был: Привет, Оля + Маша!
Текст стал: Привет, Оля!

Можно каждую часть текста взять в круглые скобки, а потом варьировать и менять местами:
RegEx: (Оля) + (Маша)
Замена: $2 — $1
Текст был: Оля + Маша
Текст стал: Маша — Оля
Теперь вернемся к нашей задаче — есть строка приветствия «Привет, кто-то там!», где может быть написано любое имя (даже просто числа вместо имени). Мы это имя хотим заменить на «Макар».
Нам надо оставить текст вокруг имени, поэтому берем его в скобки в регулярном выражении, составляя группы. И переиспользуем в замене:
RegEx: ^(Привет, ).*(!)$
Замена: $1Макар$2
Текст был (или или):
Привет, Ольга!
Привет, 777!
Текст стал:
Привет, Макар!
Давайте разберемся, как работает это регулярное выражение.
^ — начало строки.
Дальше скобка. Она не экранирована — значит, это группа. Группа 1. Поищем для нее закрывающую скобку и посмотрим, что входит в эту группу. Внутри группы текст «Привет, »

После группы идет выражение «.*» — ноль или больше повторений чего угодно. То есть вообще любой текст. Или пустота, она в регулярку тоже входит.

Потом снова открывающаяся скобка. Она не экранирована — ага, значит, это вторая группа. Что внутри? Внутри простой текст — «!».

И потом символ $ — конец строки.
Посмотрим, что у нас в замене.
$1 — значение группы 1. То есть текст «Привет, ».

Макар — просто текст. Обратите внимание, что мы или включает пробел после запятой в группу 1, или ставим его в замене после «$1», иначе на выходе получим «Привет,Макар».

$2 — значение группы 2, то есть текст «!»

Вот и всё!
А что, если нам надо переформатировать даты? Есть даты в формате ДД.ММ.ГГГГ, а нам нужно поменять формат на ГГГГ-ММ-ДД.

Регулярное выражение для поиска у нас уже есть — «d{2}.d{2}.d{4}». Осталось понять, как написать замену. Посмотрим внимательно на ТЗ:
ДД.ММ.ГГГГ
↓
ГГГГ-ММ-ДД
По нему сразу понятно, что нам надо выделить три группы. Получается так: (d{2}).(d{2}).(d{4})
В результате у нас сначала идет год — это третья группа. Пишем: $3

Потом идет дефис, это просто текст: $3-
Потом идет месяц. Это вторая группа, то есть «$2». Получается: $3-$2

Потом снова дефис, просто текст: $3-$2-
И, наконец, день. Это первая группа, $1. Получается: $3-$2-$1

Вот и всё!
RegEx: (d{2}).(d{2}).(d{4})
Замена: $3-$2-$1
Текст был:
05.08.2015
01.01.1999
03.02.2000
Текст стал:
2015-08-05
1999-01-01
2000-02-03

Другой пример — я записываю в блокнот то, что успела сделать за цикл в 12 недель. Называется файлик «done», он очень мотивирует! Если просто вспоминать «что же я сделал?», вспоминается мало. А тут записал и любуешься списком.
Вот пример улучшалок по моему курсу для тестировщиков:
-
Сделала сообщения для бота — чтобы при выкладке новых тем писал их в чат
-
Фолкс — поправила статью «Расширенный поиск», убрала оттуда про пустой ввод при простом поиске, а то путал
-
Обновила кусочек про эффект золушки (переписывала под ютуб)
И таких набирается штук 10-25. За один цикл. А за год сколько? Ух! Вроде небольшие улучшения, а набирается прилично.
Так вот, когда цикл заканчивается, я пишу в блог о своих успехах. Чтобы вставить список в блог, мне надо удалить нумерацию — тогда я сделаю ее силами блоггера и это будет смотреться симпатичнее.

Удаляю с помощью регулярного выражения:
RegEx: d+. (.*)
Замена: $1
Текст был:
1. Раз
2. Два
Текст стал:
Раз
Два
Можно было бы и вручную. Но для списка больше 5 элементов это дико скучно и уныло. А так нажал одну кнопочку в блокноте — и готово!
Так что регулярные выражения могут помочь даже при написании статьи =)
Статьи и книги по теме
Книги
Регулярные выражения 10 минут на урок. Бен Форта — Очень рекомендую! Прям шикарная книга, где все просто, доступно, понятно. Стоит 100 рублей, а пользы море.
Статьи
Вики — https://ru.wikipedia.org/wiki/Регулярные_выражения. Да, именно ее вы будете читать чаще всего. Я сама не помню наизусть все метасимволы. Поэтому, когда использую регулярки, гуглю их, википедия всегда в топе результатов. А сама статья хорошая, с табличками удобными.
Регулярные выражения для новичков — https://tproger.ru/articles/regexp-for-beginners/
Итого
Регулярные выражения — очень полезная вещь для тестировщика. Применений у них много, даже если вы не автоматизатор и не спешите им стать:
-
Найти все нужные файлы в папке.
-
Grep-нуть логи — отсечь все лишнее и найти только ту информацию, которая вам сейчас интересна.
-
Проверить по базе, нет ли явно некорректных записей — не остались ли тестовые данные в продакшене? Не присылает ли смежная система какую-то фигню вместо нормальных данных?
-
Проверить данные чужой системы, если она выгружает их в файл.
-
Выверить файлик текстов для сайта — нет ли там дублирования слов?
-
Подправить текст для статьи.
-
…

Если вы знаете, что в коде вашей программы есть регулярное выражение, вы можете его протестировать. Вы также можете использовать регулярки внутри ваших автотестов. Хотя тут стоит быть осторожным.
Не забывайте о шутке: «У разработчика была одна проблема и он стал решать ее с помощью регулярных выражений. Теперь у него две проблемы». Бывает и так, безусловно. Как и с любым другим кодом.

Поэтому, если вы пишете регулярку, обязательно ее протестируйте! Особенно, если вы ее пишете в паре с командой rm (удаление файлов в linux). Сначала проверьте, правильно ли отрабатывает поиск, а потом уже удаляйте то, что нашли.

Регулярное выражение может не найти то, что вы ожидали. Или найти что-то лишнее. Особенно если у вас идет цепочка регулярок. Думаете, это так легко — правильно написать регулярку? Попробуйте тогда решить задачку от Егора или вот эти кроссворды =)
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Match string not containing string
Given a list of strings (words or other characters), only return the strings that do not match.
Comments
Top Regular Expressions
Cheat Sheet
| Character classes | |
|---|---|
| . | any character except newline |
| w d s | word, digit, whitespace |
| W D S | not word, digit, whitespace |
| [abc] | any of a, b, or c |
| [^abc] | not a, b, or c |
| [a-g] | character between a & g |
| Anchors | |
| ^abc$ | start / end of the string |
| b | word boundary |
| Escaped characters | |
| . * \ | escaped special characters |
| t n r | tab, linefeed, carriage return |
| u00A9 | unicode escaped © |
| Groups & Lookaround | |
| (abc) | capture group |
| 1 | backreference to group #1 |
| (?:abc) | non-capturing group |
| (?=abc) | positive lookahead |
| (?!abc) | negative lookahead |
| Quantifiers & Alternation | |
| a* a+ a? | 0 or more, 1 or more, 0 or 1 |
| a{5} a{2,} | exactly five, two or more |
| a{1,3} | between one & three |
| a+? a{2,}? | match as few as possible |
| ab|cd | match ab or cd |