
I want to use a regular expression to exclude a complete word. I need this for a particular situation which I explain further
Problem
As part of Implementing a vulnerability Waiver Process for infected 3rd party libraries I have a jira transition dialog, which excepts the user to set some values. There are two drop-down fields or as JIRA calls it “Select List (single choice)”. These always present a value None in case nothing is selected.
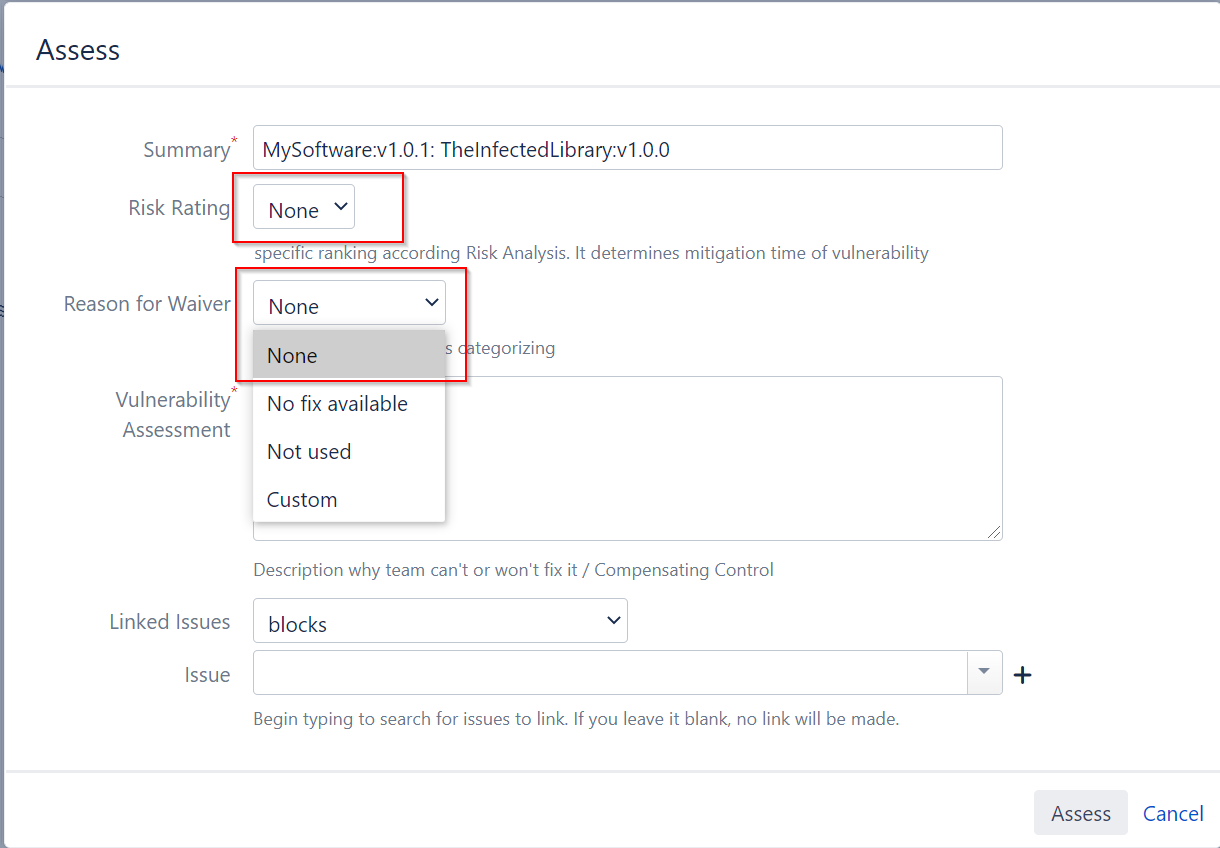
In order to ensure, that when doing a transition to a specific state, a proper value is selected we use jira-validators. These validators support regular expressions, so the question is now, how I ensure that the selected value is not None:
Solution
Some searching in the web I found a solution in the regular-expressions-cookbook — which sample is readable. So the solution is
b(?!Noneb)w+
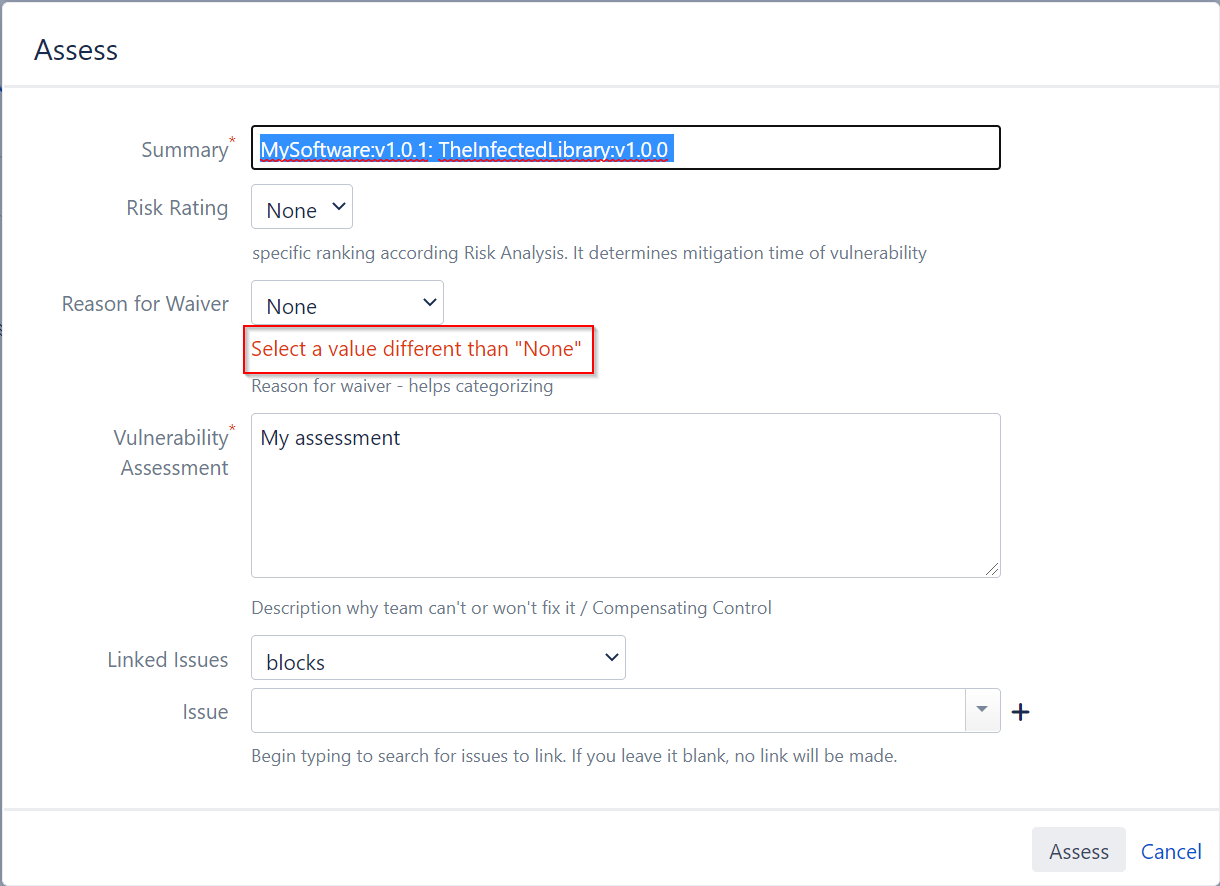
The result is a proper evaluation of the value in the dialog:
Explain the details
As explained in regular-expressions-cookbook and while looking at the regular-expressions.info you can understand why the above solution works:
-
negate character classes
Typing a caret
^after the opening square bracket negates the character class. The result is that the character class matches any character that is not in the character class.The issue with this is the part highlighted: It matches any character, so using
[^None]ignores anything containingN,o,nande— but we care about the whole word. -
wordboundaries
ballows you to perform a “whole words only” search using a regular expression in the form ofbwordbThe issue with that is that
b[^None]w+bis still looking at the character class thus ignoring any word that containsN,o,nande -
negative lookagead
Similar to positive lookahead, except that negative lookahead only succeeds if the regex inside the lookahead fails to match.
So the final solution using the techniques mentioned above
basserts the position at a word boundary(?!not followed byNonethe word we want to “ignore” i.e. should not matchbasserts the position at a word boundary)ends the negative lookaheadw+still match anything other
5.4. Find All Except a Specific Word
Problem
You want to use a regular expression to match any complete
word except cat. Catwoman, vindicate, and other words that
merely contain the letters “cat” should be matched—just not cat.
Solution
A negative lookahead can help you rule out specific words, and is
key to this next regex:
b(?!catb)w+
| Regex options: Case insensitive |
| Regex flavors: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Discussion
Although a negated character class (written as ‹[^⋯]›) makes it easy to match anything
except a specific character, you can’t just write ‹[^cat]› to match anything except
the word cat.
‹[^cat]› is a valid regex,
but it matches any character except c, a, or t. Hence, although ‹b[^cat]+b› would avoid matching
the word cat,
it wouldn’t match the word time either, because it contains the
forbidden letter t. The regular expression ‹b[^c][^a][^t]w*› is no good
either, because it would reject any word with c as its first letter, a as its second letter,
or t as its
third. Furthermore, that doesn’t restrict the first three letters to
word characters, and it only matches words with at least three
characters since none of the negated character classes are
optional.
With all that in mind, let’s take another look at how the regular
expression shown at the beginning of this recipe solved the
problem:
b # Assert position at a word boundary. (?! # Not followed by: cat # Match "cat". b # Assert position at a word boundary. ) # End the negative lookahead. w+ ...
If you want to exclude a certain word/string in a search pattern, a good way to do this is regular expression assertion function. It is indispensable if you want to match something not followed by something else.
A Simple Example
String str = "programcreek"; Pattern p = Pattern.compile(".*program(?=creek).*"); Matcher m = p.matcher(str); if(m.matches()){ System.out.println("Match!"); }else{ System.out.println("No"); }
1. Look Ahead
In the example above, if you want to find «programcreek», but not «programriver». You can use the pattern:
programcreek matches
programriver doesn’t match
?= is positive lookahead and ?! is negative lookahead.
2. Look Behind
Lookbehind is similar. We can use ?<= for positive look behind and ?<! for negative lookbehind.
programcreek matches
softwarecreek doesn’t match
The Data Suite use the whole power of Regular Expressions to exclude elements from your results. That makes it easy for you to handle your millions of files and folders.
You do not have to take care about large and lower case because we implemented it case insensitive. In addition, the filter is always evaluated as a full match that means we will handle the ^$ for you.
Take care about the following signs:
| RegEx | Description |
|---|---|
| The backslash is the escape indicator. You have to escape some characters in your pattern: . (dot) — (dash) (backslash) $ (dollar) |
|
| . | Matches any single character |
| [] [0-3a-c] |
Matches a single character that is contained within the brackets. Matches only a single character of 0123abc. |
| [^] | Matches a single character that is not contained within the brackets. |
| * | Matches the preceding element zero or more times. |
| .* | Combination of this: Matches any single character zero or more times. |
| (RegEx)|(RegEx) | Combine two or more pattern with a logic or. Please use brakets for each pattern to separate them from each other. |
For more details, please refer to a documentation of Regular Expression. There are also a lot of RegEx-Tester out there. If you are not familiar with Regular Expression, please give them a try. You can also contact our support team.
Exclude Path
If you add a path to the exclude you can do it in two ways:
- with escaping (\\YourServer\YourShare\Folder\)
- without escaping (//YourServer/YourShare/Folder/)
A folder must end always with a slash, otherwise, it will be interpreted as a file!
We added some best practice examples as default filters:

| Pattern | Description |
|---|---|
.*\~snapshot\ |
Exclude all folders that are named ~snapshot (e.g. NetApp is using this folders to store the snapshots (backups) of all files in it.) |
.*\~snapshot |
Exclude all files that are named ~snapshot |
.*\.svn\ |
Exclude all folders that are named .svn (e.g. Subversion is using these folders to store synchronization information in it.) |
.*/archive/.*.txt.*\archive\.*.txt |
Exclude all txt files in all folders which named archive and its subfolders |
.*\archive\[^\]*.txt |
Exclude all txt files in the archive folder but not in the subfolders |
- Remove From My Forums
-
Question
-
Currently i am using one regex for accepting some records from a file. That regex is ^[a-zA-Z0-9| ].*$. This regex accepts record starting with alphanumerics or blank space.
I want to modify this regex such that, previous conditions should be there and regex should not accept record starting with word ‘bbb’.
Which regex should be used?-
Edited by
Tuesday, March 9, 2010 4:27 PM
-
Moved by
OmegaManModerator
Thursday, August 26, 2010 2:51 PM
Regex question (From:Visual C# Language)
-
Edited by
Answers
-
The pattern you have does not accurately match the description you provided. You want to allow alphanumerics or spaces, yet you’ve used the «or» pipe symbol within a character class. By doing so you are actually allowing the «|» character to be a valid match. To «or» things correctly you should use a group: ([A-Z]| ) but in your case this isn’t needed. Simply remove the «|» from the character class and it will work as you originally intended:
^[a-zA-Z0-9 ].*$
To answer to your question you can use a negative look-around to prevent matches that start with the word «sample.» This would be:^(?!sample)[a-zA-Z0-9 ].*$
Bear in mind that you can shorten your pattern by using the w metacharacter which matches alphanumeric characters. The new pattern would be:
^(?!sample)[w ].*$
EDIT: you changed the word «sample» to «bbb» in your recent edit. Switch those words in the patterns given above.
Document my code? Why do you think it’s called «code»?
-
Edited by
Ahmad Mageed
Tuesday, March 9, 2010 4:35 PM
moved patterns to code block, forum was adding unintended spaces -
Marked as answer by
kkkkkkkkkkkkkkkkkkkkkkkkkkkkkk
Wednesday, March 10, 2010 8:22 AM
-
Edited by
-
Using the pattern I mentioned earlier here’s a snippet to demonstrate:
string[] inputs = { "abc1132456 1456621", "bbb1246661 164992" }; string pattern = @"^(?!bbb)[w ].*$"; foreach (string input in inputs) { Console.WriteLine("{0}: {1}", Regex.IsMatch(input, pattern), input); }
Document my code? Why do you think it’s called «code»?
-
Marked as answer by
kkkkkkkkkkkkkkkkkkkkkkkkkkkkkk
Wednesday, March 10, 2010 8:22 AM
-
Marked as answer by
-
-
Marked as answer by
kkkkkkkkkkkkkkkkkkkkkkkkkkkkkk
Wednesday, March 10, 2010 8:22 AM
-
Marked as answer by