
Регулярные выражения (их еще называют regexp, или regex) — это механизм для поиска и замены текста. В строке, файле, нескольких файлах… Их используют разработчики в коде приложения, тестировщики в автотестах, да просто при работе в командной строке!
Чем это лучше простого поиска? Тем, что позволяет задать шаблон.
Например, на вход приходит дата рождения в формате ДД.ММ.ГГГГГ. Вам надо передать ее дальше, но уже в формате ГГГГ-ММ-ДД. Как это сделать с помощью простого поиска? Вы же не знаете заранее, какая именно дата будет.

А регулярное выражение позволяет задать шаблон «найди мне цифры в таком-то формате».
Для чего применяют регулярные выражения?
-
Удалить все файлы, начинающиеся на test (чистим за собой тестовые данные)
-
Найти все логи
-
grep-нуть логи
-
Найти все даты
-
…
А еще для замены — например, чтобы изменить формат всех дат в файле. Если дата одна, можно изменить вручную. А если их 200, проще написать регулярку и подменить автоматически. Тем более что регулярные выражения поддерживаются даже простым блокнотом (в Notepad++ они точно есть).

В этой статье я расскажу о том, как применять регулярные выражения для поиска и замены. Разберем все основные варианты.
Содержание
-
Где пощупать
-
Поиск текста
-
Поиск любого символа
-
Поиск по набору символов
-
Перечисление вариантов
-
Метасимволы
-
Спецсимволы
-
Квантификаторы (количество повторений)
-
Позиция внутри строки
-
Использование ссылки назад
-
Просмотр вперед и назад
-
Замена
-
Статьи и книги по теме
-
Итого
Где пощупать
Любое регулярное выражение из статьи вы можете сразу пощупать. Так будет понятнее, о чем речь в статье — вставили пример из статьи, потом поигрались сами, делая шаг влево, шаг вправо. Где тренироваться:
-
Notepad++ (установить Search Mode → Regular expression)
-
Regex101 (мой фаворит в онлайн вариантах)
-
Myregexp
-
Regexr
Инструменты есть, теперь начнём
Поиск текста
Самый простой вариант регэкспа. Работает как простой поиск — ищет точно такую же строку, как вы ввели.
Текст: Море, море, океан
Regex: море
Найдет: Море, море, океан
Выделение курсивом не поможет моментально ухватить суть, что именно нашел regex, а выделить цветом в статье я не могу. Атрибут BACKGROUND-COLOR не сработал, поэтому я буду дублировать регулярки текстом (чтобы можно было скопировать себе) и рисунком, чтобы показать, что именно regex нашел:

Обратите внимание, нашлось именно «море», а не первое «Море». Регулярные выражения регистрозависимые!
Хотя, конечно, есть варианты. В JavaScript можно указать дополнительный флажок i, чтобы не учитывать регистр при поиске. В блокноте (notepad++) тоже есть галка «Match case». Но учтите, что это не функция по умолчанию. И всегда стоит проверить, регистрозависимая ваша реализация поиска, или нет.
А что будет, если у нас несколько вхождений искомого слова?
Текст: Море, море, море, океан
Regex: море
Найдет: Море, море, море, океан

По умолчанию большинство механизмов обработки регэкспа вернет только первое вхождение. В JavaScript есть флаг g (global), с ним можно получить массив, содержащий все вхождения.
А что, если у нас искомое слово не само по себе, это часть слова? Регулярное выражение найдет его:
Текст: Море, 55мореон, океан
Regex: море
Найдет: Море, 55мореон, океан

Это поведение по умолчанию. Для поиска это даже хорошо. Вот, допустим, я помню, что недавно в чате коллега рассказывала какую-то историю про интересный баг в игре. Что-то там связанное с кораблем… Но что именно? Уже не помню. Как найти?
Если поиск работает только по точному совпадению, мне придется перебирать все падежи для слова «корабль». А если он работает по включению, я просто не буду писать окончание, и все равно найду нужный текст:
Regex: корабл
Найдет:
На корабле
И тут корабль
У корабля

Это статический, заранее заданный текст. Но его можно найти и без регулярок. Регулярные выражения особенно хороши, когда мы не знаем точно, что мы ищем. Мы знаем часть слова, или шаблон.
Поиск любого символа
. — найдет любой символ (один).
Текст:
Аня
Ася
Оля
Аля
Валя
Regex: А.я
Результат:
Аня
Ася
ОляАля
Валя

Точка найдет вообще любой символ, включая цифры, спецсисимволы, даже пробелы. Так что кроме нормальных имен, мы найдем и такие значения:
А6я
А&я
А я
Учтите это при поиске! Точка очень удобный символ, но в то же время очень опасный — если используете ее, обязательно тестируйте получившееся регулярное выражение. Найдет ли оно то, что нужно? А лишнее не найдет?
Точку точка тоже найдет!
Regex: file.
Найдет:
file.txt
file1.txt
file2.xls

Но что, если нам надо найти именно точку? Скажем, мы хотим найти все файлы с расширением txt и пишем такой шаблон:
Regex: .txt
Результат:
file.txt
log.txt
file.png1txt.doc
one_txt.jpg
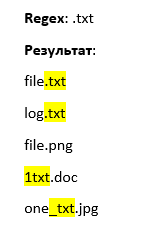
Да, txt файлы мы нашли, но помимо них еще и «мусорные» значения, у которых слово «txt» идет в середине слова. Чтобы отсечь лишнее, мы можем использовать позицию внутри строки (о ней мы поговорим чуть дальше).
Но если мы хотим найти именно точку, то нужно ее заэкранировать — то есть добавить перед ней обратный слеш:
Regex: .txt
Результат:
file.txt
log.txt
file.png
1txt.doc
one_txt.jpg

Также мы будем поступать со всеми спецсимволами. Хотим найти именно такой символ в тексте? Добавляем перед ним обратный слеш.
Правило поиска для точки:
. — любой символ
. — точка

Поиск по набору символов
Допустим, мы хотим найти имена «Алла», «Анна» в списке. Можно попробовать поиск через точку, но кроме нормальных имен, вернется всякая фигня:
Regex: А..а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Если же мы хотим именно Анну да Аллу, вместо точки нужно использовать диапазон допустимых значений. Ставим квадратные скобки, а внутри них перечисляем нужные символы:
Regex: А[нл][нл]а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Вот теперь результат уже лучше! Да, нам все еще может вернуться «Анла», но такие ошибки исправим чуть позже.
Как работают квадратные скобки? Внутри них мы указываем набор допустимых символов. Это может быть перечисление нужных букв, или указание диапазона:
[нл] — только «н» и «л»
[а-я] — все русские буквы в нижнем регистре от «а» до «я» (кроме «ё»)
[А-Я] — все заглавные русские буквы
[А-Яа-яЁё] — все русские буквы
[a-z] — латиница мелким шрифтом
[a-zA-Z] — все английские буквы
[0-9] — любая цифра
[В-Ю] — буквы от «В» до «Ю» (да, диапазон — это не только от А до Я)
[А-ГО-Р] — буквы от «А» до «Г» и от «О» до «Р»
Обратите внимание — если мы перечисляем возможные варианты, мы не ставим между ними разделителей! Ни пробел, ни запятую — ничего.
[абв] — только «а», «б» или «в»
[а б в] — «а», «б», «в», или пробел (что может привести к нежелательному результату)
[а, б, в] — «а», «б», «в», пробел или запятая

Единственный допустимый разделитель — это дефис. Если система видит дефис внутри квадратных скобок — значит, это диапазон:
-
Символ до дефиса — начало диапазона
-
Символ после — конец
Один символ! Не два или десять, а один! Учтите это, если захотите написать что-то типа [1-31]. Нет, это не диапазон от 1 до 31, эта запись читается так:
-
Диапазон от 1 до 3
-
И число 1
Здесь отсутствие разделителей играет злую шутку с нашим сознанием. Ведь кажется, что мы написали диапазон от 1 до 31! Но нет. Поэтому, если вы пишете регулярные выражения, очень важно их тестировать. Не зря же мы тестировщики! Проверьте то, что написали! Особенно, если с помощью регулярного выражения вы пытаетесь что-то удалить =)) Как бы не удалили лишнее…
Указание диапазона вместо точки помогает отсеять заведомо плохие данные:
Regex: А.я или А[а-я]я
Результат для обоих:
Аня
Ася
Аля
Результат для «А.я»:
А6я
А&я
А я
^ внутри [] означает исключение:
[^0-9] — любой символ, кроме цифр
[^ёЁ] — любой символ, кроме буквы «ё»
[^а-в8] — любой символ, кроме букв «а», «б», «в» и цифры 8

Например, мы хотим найти все txt файлы, кроме разбитых на кусочки — заканчивающихся на цифру:
Regex: [^0-9].txt
Результат:
file.txt
log.txt
file_1.txt
1.txt

Так как квадратные скобки являются спецсимволами, то их нельзя найти в тексте без экранирования:
Regex: fruits[0]
Найдет: fruits0
Не найдет: fruits[0]
Это регулярное выражение говорит «найди мне текст «fruits», а потом число 0». Квадратные скобки не экранированы — значит, внутри будет набор допустимых символов.

Если мы хотим найти именно 0-левой элемент массива фруктов, надо записать так:
Regex: fruits[0]
Найдет: fruits[0]
Не найдет: fruits0
А если мы хотим найти все элементы массива фруктов, мы внутри экранированных квадратных скобок ставим неэкранированные!
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[2] = “лимон”;
Не найдет:
cat[0] = “чеширский кот”;
Конечно, «читать» такое регулярное выражение становится немного тяжело, столько разных символов написано…

Без паники! Если вы видите сложное регулярное выражение, то просто разберите его по частям. Помните про основу эффективного тайм-менеджмента? Слона надо есть по частям.
Допустим, после отпуска накопилась гора писем. Смотришь на нее и сразу впадаешь в уныние:
— Ууууууу, я это за день не закончу!

Проблема в том, что груз задачи мешает работать. Мы ведь понимаем, что это надолго. А большую задачу делать не хочется… Поэтому мы ее откладываем, беремся за задачи поменьше. В итоге да, день прошел, а мы не успели закончить.
А если не тратить время на размышления «сколько времени это у меня займет», а сосредоточиться на конкретной задаче (в данном случае — первом письме из стопки, потом втором…), то не успеете оглянуться, как уже всё разгребли!

Разберем по частям регулярное выражение — fruits[[0-9]]
Сначала идет просто текст — «fruits».

Потом обратный слеш. Ага, он что-то экранирует.

Что именно? Квадратную скобку. Значит, это просто квадратная скобка в моем тексте — «fruits[»

Дальше снова квадратная скобка. Она не экранирована — значит, это набор допустимых значений. Ищем закрывающую квадратную скобку.

Нашли. Наш набор: [0-9]. То есть любое число. Но одно. Там не может быть 10, 11 или 325, потому что квадратные скобки без квантификатора (о них мы поговорим чуть позже) заменяют ровно один символ.
Пока получается: fruits[«любое однозназначное число»

Дальше снова обратный слеш. То есть следующий за ним спецсимвол будет просто символом в моем тексте.

А следующий символ — ]
Получается выражение: fruits[«любое однозназначное число»]

Наше выражение найдет значения массива фруктов! Не только нулевое, но и первое, и пятое… Вплоть до девятого:
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[9] = “лимон”;
Не найдет:
fruits[10] = “банан”;
fruits[325] = “ абрикос ”;
Как найти вообще все значения массива, см дальше, в разделе «квантификаторы».
А пока давайте посмотрим, как с помощью диапазонов можно найти все даты.

Какой у даты шаблон? Мы рассмотрим ДД.ММ.ГГГГ:
-
2 цифры дня
-
точка
-
2 цифры месяца
-
точка
-
4 цифры года
Запишем в виде регулярного выражения: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9].
Напомню, что мы не можем записать диапазон [1-31]. Потому что это будет значить не «диапазон от 1 до 31», а «диапазон от 1 до 3, плюс число 1». Поэтому пишем шаблон для каждой цифры отдельно.
В принципе, такое выражение найдет нам даты среди другого текста. Но что, если с помощью регулярки мы проверяем введенную пользователем дату? Подойдет ли такой regexp?
Давайте его протестируем! Как насчет 8888 года или 99 месяца, а?
Regex: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
Найдет:
01.01.1999
05.08.2015
Тоже найдет:
08.08.8888
99.99.2000

Попробуем ограничить:
-
День месяца может быть максимум 31 — первая цифра [0-3]
-
Максимальный месяц 12 — первая цифра [01]
-
Год или 19.., или 20.. — первая цифра [12], а вторая [09]

Вот, уже лучше, явно плохие данные регулярка отсекла. Надо признать, она отсечет довольно много тестовых данных, ведь обычно, когда хотят именно сломать, то фигачат именно «9999» год или «99» месяц…
Однако если мы присмотримся внимательнее к регулярному выражению, то сможем найти в нем дыры:
Regex: [0-3][0-9].[0-1][0-9].[12][09][0-9][0-9]
Не найдет:
08.08.8888
99.99.2000
Но найдет:
33.01.2000
01.19.1999
05.06.2999

Мы не можем с помощью одного диапазона указать допустимые значения. Или мы потеряем 31 число, или пропустим 39. И если мы хотим сделать проверку даты, одних диапазонов будет мало. Нужна возможность перечислить варианты, о которой мы сейчас и поговорим.
Перечисление вариантов
Квадратные скобки [] помогают перечислить варианты для одного символа. Если же мы хотим перечислить слова, то лучше использовать вертикальную черту — |.
Regex: Оля|Олечка|Котик
Найдет:
Оля
Олечка
Котик
Не найдет:
Оленька
Котенка
Можно использовать вертикальную черту и для одного символа. Можно даже внутри слова — тогда вариативную букву берем в круглые скобки
Regex: А(н|л)я
Найдет:
Аня
Аля
Круглые скобки обозначают группу символов. В этой группе у нас или буква «н», или буква «л». Зачем нужны скобки? Показать, где начинается и заканчивается группа. Иначе вертикальная черта применится ко всем символам — мы будем искать или «Ан», или «ля»:
Regex: Ан|ля
Найдет:
Аня
Аля
Оля
Малюля

А если мы хотим именно «Аня» или «Аля», то перечисление используем только для второго символа. Для этого берем его в скобки.
Эти 2 варианта вернут одно и то же:
-
А(н|л)я
-
А[нл]я
Но для замены одной буквы лучше использовать [], так как сравнение с символьным классом выполняется проще, чем обработка группы с проверкой на все её возможные модификаторы.
Давайте вернемся к задаче «проверить введенную пользователем дату с помощью регулярных выражений». Мы пробовали записать для дня диапазон [0-3][0-9], но он пропускает значения 33, 35, 39… Это нехорошо!
Тогда распишем ТЗ подробнее. Та-а-а-ак… Если первая цифра:
-
0 — вторая может от 1 до 9 (даты 00 быть не может)
-
1, 2 — вторая может от 0 до 9
-
3 — вторая только 0 или 1
Составим регулярные выражения на каждый пункт:
-
0[1-9]
-
[12][0-9]
-
3[01]
А теперь осталось их соединить в одно выражение! Получаем: 0[1-9]|[12][0-9]|3[01]

По аналогии разбираем месяц и год. Но это остается вам для домашнего задания =)
Потом, когда распишем регулярки отдельно для дня, месяца и года, собираем все вместе:
(<день>).(<месяц>).(<год>)
Обратите внимание — каждую часть регулярного выражения мы берем в скобки. Зачем? Чтобы показать системе, где заканчивается выбор. Вот смотрите, допустим, что для месяца и года у нас осталось выражение:
[0-1][0-9].[12][09][0-9][0-9]
Подставим то, что написали для дня:
0[1-9]|[12][0-9]|3[01].[0-1][0-9].[12][09][0-9][0-9]
Как читается это выражение?
-
ИЛИ 0[1-9]
-
ИЛИ [12][0-9]
-
ИЛИ 3[01].[0-1][0-9].[12][09][0-9][0-9]
Видите проблему? Число «19» будет считаться корректной датой. Система не знает, что перебор вариантов | закончился на точке после дня. Чтобы она это поняла, нужно взять перебор в скобки. Как в математике, разделяем слагаемые.
Так что запомните — если перебор идет в середине слова, его надо взять в круглые скобки!
Regex: А(нн|лл|лин|нтонин)а
Найдет:
Анна
Алла
Алина
Антонина
Без скобок:
Regex: Анн|лл|лин|нтонина
Найдет:
Анна
Алла
Аннушка
Кукулинка

Итого, если мы хотим указать допустимые значения:
-
Одного символа — используем []
-
Нескольких символов или целого слова — используем |

Метасимволы
Если мы хотим найти число, то пишем диапазон [0-9].
Если букву, то [а-яА-ЯёЁa-zA-Z].
А есть ли другой способ?

Есть! В регулярных выражениях используются специальные метасимволы, которые заменяют собой конкретный диапазон значений:
|
Символ |
Эквивалент |
Пояснение |
|
d |
[0-9] |
Цифровой символ |
|
D |
[^0-9] |
Нецифровой символ |
|
s |
[ fnrtv] |
Пробельный символ |
|
S |
[^ fnrtv] |
Непробельный символ |
|
w |
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания |
|
W |
[^[:word:]] |
Любой символ, кроме буквенного или цифрового символа или знака подчёркивания |
|
. |
Вообще любой символ |
Это самые распространенные символы, которые вы будете использовать чаще всего. Но давайте разберемся с колонкой «эквивалент». Для d все понятно — это просто некие числа. А что такое «пробельные символы»? В них входят:
|
Символ |
Пояснение |
|
Пробел |
|
|
r |
Возврат каретки (Carriage return, CR) |
|
n |
Перевод строки (Line feed, LF) |
|
t |
Табуляция (Tab) |
|
v |
Вертикальная табуляция (vertical tab) |
|
f |
Конец страницы (Form feed) |
|
[b] |
Возврат на 1 символ (Backspace) |
Из них вы чаще всего будете использовать сам пробел и перевод строки — выражение «rn». Напишем текст в несколько строк:
Первая строка
Вторая строка
Для регулярного выражения это:
Первая строкаrnВторая строка
А вот что такое backspace в тексте? Как его можно увидеть вообще? Это же если написать символ и стереть его. В итоге символа нет! Неужели стирание хранится где-то в памяти? Но тогда это было бы ужасно, мы бы вообще ничего не смогли найти — откуда нам знать, сколько раз текст исправляли и в каких местах там теперь есть невидимый символ [b]?

Выдыхаем — этот символ не найдет все места исправления текста. Просто символ backspace — это ASCII символ, который может появляться в тексте (ASCII code 8, или 10 в octal). Вы можете «создать» его, написать в консоли браузера (там используется JavaScript):
console.log("abcbbdef");Результат команды:
adefМы написали «abc», а потом стерли «b» и «с». В итоге пользователь в консоли их не видит, но они есть. Потому что мы прямо в коде прописали символ удаления текста. Не просто удалили текст, а прописали этот символ. Вот такой символ регулярное выражение [b] и найдет.
См также:
What’s the use of the [b] backspace regex? — подробнее об этом символе
Но обычно, когда мы вводим s, мы имеем в виду пробел, табуляцию, или перенос строки.
Ок, с этими эквивалентами разобрались. А что значит [[:word:]]? Это один из способов заменить диапазон. Чтобы запомнить проще было, написали значения на английском, объединив символы в классы. Какие есть классы:
|
Класс символов |
Пояснение |
|
[[:alnum:]] |
Буквы или цифры: [а-яА-ЯёЁa-zA-Z0-9] |
|
[[:alpha:]] |
Только буквы: [а-яА-ЯёЁa-zA-Z] |
|
[[:digit:]] |
Только цифры: [0-9] |
|
[[:graph:]] |
Только отображаемые символы (пробелы, служебные знаки и т. д. не учитываются) |
|
[[:print:]] |
Отображаемые символы и пробелы |
|
[[:space:]] |
Пробельные символы [ fnrtv] |
|
[[:punct:]] |
Знаки пунктуации: ! » # $ % & ‘ ( ) * + , -. / : ; < = > ? @ [ ] ^ _ ` { | } |
|
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания: [а-яА-ЯёЁa-zA-Z0-9_] |
Теперь мы можем переписать регулярку для проверки даты, которая выберет лишь даты формата ДД.ММ.ГГГГГ, отсеяв при этом все остальное:
[0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
↓
dd.dd.dddd
Согласитесь, через метасимволы запись посимпатичнее будет =))
Спецсимволы
Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов:
[ ] / ^ $ . | ? * + ( ) { }
Эти символы нужны, чтобы обозначить диапазон допустимых значений или границу фразы, указать количество повторений, или сделать что-то еще. В разных типах регулярных выражений этот набор различается (см «разновидности регулярных выражений»).
Если вы хотите найти один из этих символов внутри вашего текста, его надо экранировать символом (обратная косая черта).
Regex: 2^2 = 4
Найдет: 2^2 = 4
Можно экранировать целую последовательность символов, заключив её между Q и E (но не во всех разновидностях).
Regex: Q{кто тут?}E
Найдет: {кто тут?}
Квантификаторы (количество повторений)
Усложняем задачу. Есть некий текст, нам нужно вычленить оттуда все email-адреса. Например:
-
test@mail.ru
-
olga31@gmail.com
-
pupsik_99@yandex.ru

Как составляется регулярное выражение? Нужно внимательно изучить данные, которые мы хотим получить на выходе, и составить по ним шаблон. В email два разделителя — собачка «@» и точка «.».

Запишем ТЗ для регулярного выражения:
-
Буквы / цифры / _
-
Потом @
-
Снова буквы / цифры / _
-
Точка
-
Буквы
Так, до собачки у нас явно идет метасимвол «w», туда попадет и просто текст (test), и цифры (olga31), и подчеркивание (pupsik_99). Но есть проблема — мы не знаем, сколько таких символов будет. Это при поиске даты все ясно — 2 цифры, 2 цифры, 4 цифры. А тут может быть как 2, так и 22 символа.
И тут на помощь приходят квантификаторы — так называют специальные символы в регулярных выражениях, которые указывают количество повторений текста.
Символ «+» означает «одно или более повторений», это как раз то, что нам надо! Получаем: w+@

После собачки и снова идет w, и снова от одного повторения. Получаем: w+@w+.
После точки обычно идут именно символы, но для простоты можно снова написано w. И снова несколько символов ждем, не зная точно сколько. Итого получилось выражение, которое найдет нам email любой длины:
Regex: w+@w+.w+
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99_and_slonik_33_and_mikky_87_and_kotik_28@yandex.megatron
Какие есть квантификаторы, кроме знака «+»?
|
Квантификатор |
Число повторений |
|
? |
Ноль или одно |
|
* |
Ноль или более |
|
+ |
Один или более |
Символ * часто используют с точкой — когда нам неважно, какой идет текст до интересующей нас фразы, мы заменяем его на «.*» — любой символ ноль или более раз.
Regex: .*dd.dd.dddd.*
Найдет:
01.01.2000
Приходи на ДР 09.08.2015! Будет весело!
Но будьте осторожны! Если использовать «.*» повсеместно, можно получить много ложноположительных срабатываний:
Regex: .*@.*..*
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99@yandex.ru
Но также найдет:
@yandex.ru
test@.ru
test@mail.

Уж лучше w, и плюсик вместо звездочки.
А вот есть мы хотим найти все лог-файлы, которые нумеруются — log, log1, log2… log133, то * подойдет хорошо:
Regex: logd*.txt
Найдет:
log.txt
log1.txt
log2.txt
log3.txt
log33.txt
log133.txt
А знак вопроса (ноль или одно повторение) поможет нам найти людей с конкретной фамилией — причем всех, и мужчин, и женщин:
Regex: Назина?
Найдет:
Назин
Назина
Если мы хотим применить квантификатор к группе символов или нескольким словам, их нужно взять в скобки:
Regex: (Хихи)*(Хаха)*
Найдет:
ХихиХаха
ХихиХихиХихи
Хихи
Хаха
ХихиХихиХахаХахаХаха
(пустота — да, её такая регулярка тоже найдет)
Квантификаторы применяются к символу или группе в скобках, которые стоят перед ним.
А что, если мне нужно определенное количество повторений? Скажем, я хочу записать регулярное выражение для даты. Пока мы знаем только вариант «перечислить нужный метасимвол нужное количество раз» — dd.dd.dddd.
Ну ладно 2-4 раза повторение идет, а если 10? А если повторить надо фразу? Так и писать ее 10 раз? Не слишком удобно. А использовать * нельзя:
Regex: d*.d*.d*
Найдет:
.0.1999
05.08.20155555555555555
03444.025555.200077777777777777
Чтобы указать конкретное количество повторений, их надо записать внутри фигурных скобок:
|
Квантификатор |
Число повторений |
|
{n} |
Ровно n раз |
|
{m,n} |
От m до n включительно |
|
{m,} |
Не менее m |
|
{,n} |
Не более n |
Таким образом, для проверки даты можно использовать как перечисление d n раз, так и использование квантификатора:
dd.dd.dddd
d{2}.d{2}.d{4}
Обе записи будут валидны. Но вторая читается чуть проще — не надо самому считать повторения, просто смотрим на цифру.
Не забывайте — квантификатор применяется к последнему символу!
Regex: data{2}
Найдет: dataa
Не найдет: datadata
Или группе символов, если они взяты в круглые скобки:
Regex: (data){2}
Найдет: datadata
Не найдет: dataa

Так как фигурные скобки используются в качестве указания количества повторений, то, если вы ищете именно фигурную скобку в тексте, ее надо экранировать:
Regex: x{3}
Найдет: x{3}
Иногда квантификатор находит не совсем то, что нам нужно.
Regex: <.*>
Ожидание:
<req>
<query>Ан</query>
<gender>FEMALE</gender>Реальность:
<req> <query>Ан</query> <gender>FEMALE</gender></req>Мы хотим найти все теги HTML или XML по отдельности, а регулярное выражение возвращает целую строку, внутри которой есть несколько тегов.
Напомню, что в разных реализациях регулярные выражения могут работать немного по разному. Это одно из отличий — в некоторых реализациях квантификаторам соответствует максимально длинная строка из возможных. Такие квантификаторы называют жадными.

Если мы понимаем, что нашли не то, что хотели, можно пойти двумя путями:
-
Учитывать символы, не соответствующие желаемому образцу
-
Определить квантификатор как нежадный (ленивый, англ. lazy) — большинство реализаций позволяют это сделать, добавив после него знак вопроса.
Как учитывать символы? Для примера с тегами можно написать такое регулярное выражение:
<[^>]*>
Оно ищет открывающий тег, внутри которого все, что угодно, кроме закрывающегося тега «>», и только потом тег закрывается. Так мы не даем захватить лишнее. Но учтите, использование ленивых квантификаторов может повлечь за собой обратную проблему — когда выражению соответствует слишком короткая, в частности, пустая строка.
|
Жадный |
Ленивый |
|
* |
*? |
|
+ |
+? |
|
{n,} |
{n,}? |

Есть еще и сверхжадная квантификация, также именуемая ревнивой. Но о ней почитайте в википедии =)
Позиция внутри строки
По умолчанию регулярные выражения ищут «по включению».
Regex: арка
Найдет:
арка
чарка
аркан
баварка
знахарка
Это не всегда то, что нам нужно. Иногда мы хотим найти конкретное слово.

Если мы ищем не одно слово, а некую строку, проблема решается в помощью пробелов:
Regex: Товар №d+ добавлен в корзину в dd:dd
Найдет: Товар №555 добавлен в корзину в 15:30
Не найдет: Товарный чек №555 добавлен в корзину в 15:30

Или так:
Regex: .* арка .*
Найдет: Триумфальная арка была…
Не найдет: Знахарка сегодня…
А что, если у нас не пробел рядом с искомым словом? Это может быть знак препинания: «И вот перед нами арка.», или «…арка:».
Если мы ищем конкретное слово, то можно использовать метасимвол b, обозначающий границу слова. Если поставить метасимвол с обоих концов слова, мы найдем именно это слово:
Regex: bаркаb
Найдет:
арка
Не найдет:
чарка
аркан
баварка
знахарка

Можно ограничить только спереди — «найди все слова, которые начинаются на такое-то значение»:
Regex: bарка
Найдет:
арка
аркан
Не найдет:
чарка
баварка
знахарка
Можно ограничить только сзади — «найди все слова, которые заканчиваются на такое-то значение»:
Regex: аркаb
Найдет:
арка
чарка
баварка
знахарка
Не найдет:
аркан
Если использовать метасимвол B, он найдем нам НЕ-границу слова:
Regex: BакрB
Найдет:
закройка
Не найдет:
акр
акрил
Если мы хотим найти конкретную фразу, а не слово, то используем следующие спецсимволы:
^ — начало текста (строки)
$ — конец текста (строки)
Если использовать их, мы будем уверены, что в наш текст не закралось ничего лишнего:
Regex: ^Я нашел!$
Найдет:
Я нашел!
Не найдет:
Смотри! Я нашел!
Я нашел! Посмотри!
Итого метасимволы, обозначающие позицию строки:
|
Символ |
Значение |
|
b |
граница слова |
|
B |
Не граница слова |
|
^ |
начало текста (строки) |
|
$ |
конец текста (строки) |
Использование ссылки назад
Допустим, при тестировании приложения вы обнаружили забавный баг в тексте — дублирование предлога «на»: «Поздравляем! Вы прошли на на новый уровень». А потом решили проверить, есть ли в коде еще такие ошибки.

Разработчик предоставил файлик со всеми текстами. Как найти повторы? С помощью ссылки назад. Когда мы берем что-то в круглые скобки внутри регулярного выражения, мы создаем группу. Каждой группе присваивается номер, по которому к ней можно обратиться.
Regex: [ ]+(w+)[ ]+1
Текст: Поздравляем! Вы прошли на на новый уровень. Так что что улыбаемся и и машем.

Разберемся, что означает это регулярное выражение:
[ ]+ → один или несколько пробелов, так мы ограничиваем слово. В принципе, тут можно заменить на метасимвол b.
(w+) → любой буквенный или цифровой символ, или знак подчеркивания. Квантификатор «+» означает, что символ должен идти минимум один раз. А то, что мы взяли все это выражение в круглые скобки, говорит о том, что это группа. Зачем она нужна, мы пока не знаем, ведь рядом с ней нет квантификатора. Значит, не для повторения. Но в любом случае, найденный символ или слово — это группа 1.
[ ]+ → снова один или несколько пробелов.
1 → повторение группы 1. Это и есть ссылка назад. Так она записывается в JavaScript-е.
Важно: синтаксис ссылок назад очень зависит от реализации регулярных выражений.
|
ЯП |
Как обозначается ссылка назад |
|
JavaScript vi |
|
|
Perl |
$ |
|
PHP |
$matches[1] |
|
Java Python |
group[1] |
|
C# |
match.Groups[1] |
|
Visual Basic .NET |
match.Groups(1) |
Для чего еще нужна ссылка назад? Например, можно проверить верстку HTML, правильно ли ее составили? Верно ли, что открывающийся тег равен закрывающемуся?

Напишите выражение, которое найдет правильно написанные теги:
<h2>Заголовок 2-ого уровня</h2>
<h3>Заголовок 3-ого уровня</h3>Но не найдет ошибки:
<h2>Заголовок 2-ого уровня</h3>Просмотр вперед и назад
Еще может возникнуть необходимость найти какое-то место в тексте, но не включая найденное слово в выборку. Для этого мы «просматриваем» окружающий текст.
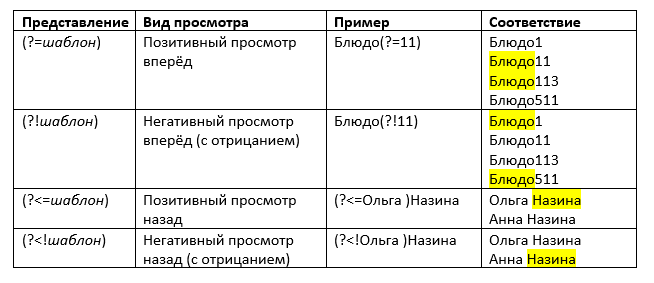
|
Представление |
Вид просмотра |
Пример |
Соответствие |
|
(?=шаблон) |
Позитивный просмотр вперёд |
Блюдо(?=11) |
Блюдо11 Блюдо113
|
|
(?!шаблон) |
Негативный просмотр вперёд (с отрицанием) |
Блюдо(?!11) |
Блюдо1
Блюдо511 |
|
(?<=шаблон) |
Позитивный просмотр назад |
(?<=Ольга )Назина |
Ольга Назина
|
|
(?шаблон) |
Негативный просмотр назад (с отрицанием) |
(см ниже на рисунке) |
Анна Назина |
Замена
Важная функция регулярных выражений — не только найти текст, но и заменить его на другой текст! Простейший вариант замены — слово на слово:
RegEx: Ольга
Замена: Макар
Текст был: Привет, Ольга!
Текст стал: Привет, Макар!
Но что, если у нас в исходном тексте может быть любое имя? Вот что пользователь ввел, то и сохранилось. А нам надо на Макара теперь заменить. Как сделать такую замену? Через знак доллара. Давайте разберемся с ним подробнее.

Знак доллара в замене — обращение к группе в поиске. Ставим знак доллара и номер группы. Группа — это то, что мы взяли в круглые скобки. Нумерация у групп начинается с 1.
RegEx: (Оля) + Маша
Замена: $1
Текст был: Оля + Маша
Текст стал: Оля
Мы искали фразу «Оля + Маша» (круглые скобки не экранированы, значит, в искомом тексте их быть не должно, это просто группа). А замнили ее на первую группу — то, что написано в первых круглых скобках, то есть текст «Оля».
Это работает и когда искомый текст находится внутри другого:
RegEx: (Оля) + Маша
Замена: $1
Текст был: Привет, Оля + Маша!
Текст стал: Привет, Оля!

Можно каждую часть текста взять в круглые скобки, а потом варьировать и менять местами:
RegEx: (Оля) + (Маша)
Замена: $2 — $1
Текст был: Оля + Маша
Текст стал: Маша — Оля
Теперь вернемся к нашей задаче — есть строка приветствия «Привет, кто-то там!», где может быть написано любое имя (даже просто числа вместо имени). Мы это имя хотим заменить на «Макар».
Нам надо оставить текст вокруг имени, поэтому берем его в скобки в регулярном выражении, составляя группы. И переиспользуем в замене:
RegEx: ^(Привет, ).*(!)$
Замена: $1Макар$2
Текст был (или или):
Привет, Ольга!
Привет, 777!
Текст стал:
Привет, Макар!
Давайте разберемся, как работает это регулярное выражение.
^ — начало строки.
Дальше скобка. Она не экранирована — значит, это группа. Группа 1. Поищем для нее закрывающую скобку и посмотрим, что входит в эту группу. Внутри группы текст «Привет, »

После группы идет выражение «.*» — ноль или больше повторений чего угодно. То есть вообще любой текст. Или пустота, она в регулярку тоже входит.

Потом снова открывающаяся скобка. Она не экранирована — ага, значит, это вторая группа. Что внутри? Внутри простой текст — «!».

И потом символ $ — конец строки.
Посмотрим, что у нас в замене.
$1 — значение группы 1. То есть текст «Привет, ».

Макар — просто текст. Обратите внимание, что мы или включает пробел после запятой в группу 1, или ставим его в замене после «$1», иначе на выходе получим «Привет,Макар».

$2 — значение группы 2, то есть текст «!»

Вот и всё!
А что, если нам надо переформатировать даты? Есть даты в формате ДД.ММ.ГГГГ, а нам нужно поменять формат на ГГГГ-ММ-ДД.

Регулярное выражение для поиска у нас уже есть — «d{2}.d{2}.d{4}». Осталось понять, как написать замену. Посмотрим внимательно на ТЗ:
ДД.ММ.ГГГГ
↓
ГГГГ-ММ-ДД
По нему сразу понятно, что нам надо выделить три группы. Получается так: (d{2}).(d{2}).(d{4})
В результате у нас сначала идет год — это третья группа. Пишем: $3

Потом идет дефис, это просто текст: $3-
Потом идет месяц. Это вторая группа, то есть «$2». Получается: $3-$2

Потом снова дефис, просто текст: $3-$2-
И, наконец, день. Это первая группа, $1. Получается: $3-$2-$1

Вот и всё!
RegEx: (d{2}).(d{2}).(d{4})
Замена: $3-$2-$1
Текст был:
05.08.2015
01.01.1999
03.02.2000
Текст стал:
2015-08-05
1999-01-01
2000-02-03

Другой пример — я записываю в блокнот то, что успела сделать за цикл в 12 недель. Называется файлик «done», он очень мотивирует! Если просто вспоминать «что же я сделал?», вспоминается мало. А тут записал и любуешься списком.
Вот пример улучшалок по моему курсу для тестировщиков:
-
Сделала сообщения для бота — чтобы при выкладке новых тем писал их в чат
-
Фолкс — поправила статью «Расширенный поиск», убрала оттуда про пустой ввод при простом поиске, а то путал
-
Обновила кусочек про эффект золушки (переписывала под ютуб)
И таких набирается штук 10-25. За один цикл. А за год сколько? Ух! Вроде небольшие улучшения, а набирается прилично.
Так вот, когда цикл заканчивается, я пишу в блог о своих успехах. Чтобы вставить список в блог, мне надо удалить нумерацию — тогда я сделаю ее силами блоггера и это будет смотреться симпатичнее.

Удаляю с помощью регулярного выражения:
RegEx: d+. (.*)
Замена: $1
Текст был:
1. Раз
2. Два
Текст стал:
Раз
Два
Можно было бы и вручную. Но для списка больше 5 элементов это дико скучно и уныло. А так нажал одну кнопочку в блокноте — и готово!
Так что регулярные выражения могут помочь даже при написании статьи =)
Статьи и книги по теме
Книги
Регулярные выражения 10 минут на урок. Бен Форта — Очень рекомендую! Прям шикарная книга, где все просто, доступно, понятно. Стоит 100 рублей, а пользы море.
Статьи
Вики — https://ru.wikipedia.org/wiki/Регулярные_выражения. Да, именно ее вы будете читать чаще всего. Я сама не помню наизусть все метасимволы. Поэтому, когда использую регулярки, гуглю их, википедия всегда в топе результатов. А сама статья хорошая, с табличками удобными.
Регулярные выражения для новичков — https://tproger.ru/articles/regexp-for-beginners/
Итого
Регулярные выражения — очень полезная вещь для тестировщика. Применений у них много, даже если вы не автоматизатор и не спешите им стать:
-
Найти все нужные файлы в папке.
-
Grep-нуть логи — отсечь все лишнее и найти только ту информацию, которая вам сейчас интересна.
-
Проверить по базе, нет ли явно некорректных записей — не остались ли тестовые данные в продакшене? Не присылает ли смежная система какую-то фигню вместо нормальных данных?
-
Проверить данные чужой системы, если она выгружает их в файл.
-
Выверить файлик текстов для сайта — нет ли там дублирования слов?
-
Подправить текст для статьи.
-
…

Если вы знаете, что в коде вашей программы есть регулярное выражение, вы можете его протестировать. Вы также можете использовать регулярки внутри ваших автотестов. Хотя тут стоит быть осторожным.
Не забывайте о шутке: «У разработчика была одна проблема и он стал решать ее с помощью регулярных выражений. Теперь у него две проблемы». Бывает и так, безусловно. Как и с любым другим кодом.

Поэтому, если вы пишете регулярку, обязательно ее протестируйте! Особенно, если вы ее пишете в паре с командой rm (удаление файлов в linux). Сначала проверьте, правильно ли отрабатывает поиск, а потом уже удаляйте то, что нашли.

Регулярное выражение может не найти то, что вы ожидали. Или найти что-то лишнее. Особенно если у вас идет цепочка регулярок. Думаете, это так легко — правильно написать регулярку? Попробуйте тогда решить задачку от Егора или вот эти кроссворды =)
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
A Regular Expression – or regex for short– is a syntax that allows you to match strings with specific patterns. Think of it as a suped-up text search shortcut, but a regular expression adds the ability to use quantifiers, pattern collections, special characters, and capture groups to create extremely advanced search patterns.
Regex can be used any time you need to query string-based data, such as:
- Analyzing command line output
- Parsing user input
- Examining server or program logs
- Handling text files with a consistent syntax, like a CSV
- Reading configuration files
- Searching and refactoring code
While doing all of these is theoretically possible without regex, when regexes hit the scene they act as a superpower for doing all of these tasks.
In this guide we’ll cover:
- What does a regex look like?
- How to read and write a regex
- What’s a «quantifier»?
- What’s a «pattern collection»?
- What’s a «regex token»?
- How to use a regex
- What’s a «regex flag»?
- What’s a «regex group»?
Download our Regex Cheat Sheet
What does a regex look like?
In its simplest form, a regex in usage might look something like this:

This screenshot is of the regex101 website. All future screenshots will utilize this website for visual reference.
In the «Test» example the letters test formed the search pattern, same as a simple search.
These regexes are not always so simple, however. Here’s a regex that matches 3 numbers, followed by a «-«, followed by 3 numbers, followed by another «-«, finally ended by 4 numbers.
You know, like a phone number:
^(?:d{3}-){2}d{4}$
Enter fullscreen mode
Exit fullscreen mode

This regex may look complicated, but two things to keep in mind:
- We’ll teach you how to read and write these in this article
- This is a fairly complex way of writing this regex.
In fact, most regexes can be written in multiple ways, just like other forms of programming. For example, the above can be rewritten into a longer but slightly more readable version:
^[0-9]{3}-[0-9]{3}-[0-9]{4}$
Enter fullscreen mode
Exit fullscreen mode
Most languages provide a built-in method for searching and replacing strings using regex. However, each language may have a different set of syntaxes based on what the language dictates.
In this article, we’ll focus on the ECMAScript variant of Regex, which is used in JavaScript and shares a lot of commonalities with other languages’ implementations of regex as well.
How to read (and write) regexes
Quantifiers
Regex quantifiers check to see how many times you should search for a character.
Here is a list of all quantifiers:
-
a|b— Match either «a» or «b -
?— Zero or one -
+— one or more -
*— zero or more -
{N}— Exactly N number of times (where N is a number) -
{N,}— N or more number of times (where N is a number) -
{N,M}— Between N and M number of times (where N and M are numbers and N < M) -
*?— Zero or more, but stop after first match
For example, the following regex:
Hello|Goodbye
Enter fullscreen mode
Exit fullscreen mode
Matches both the string «Hello» and «Goodbye».
Meanwhile:
Hey?
Enter fullscreen mode
Exit fullscreen mode
Will track «y» zero to one time, so will match up with «He» and «Hey».
Alternatively:
Hello{1,3}
Enter fullscreen mode
Exit fullscreen mode
Will match «Hello», «Helloo», «Hellooo», but not «Helloooo», as it is looking for the letter «o» between 1 and 3 times.
These can even be combined with one another:
He?llo{2}
Enter fullscreen mode
Exit fullscreen mode
Here we’re looking for strings with zero-to-one instances of «e» and the letter «o» times 2, so this will match «Helloo» and «Hlloo».
Greedy matching
One of the regex quantifiers we touched on in the previous list was the + symbol. This symbol matches one or more characters. This means that:
Hi+
Enter fullscreen mode
Exit fullscreen mode
Will match everything from «Hi» to «Hiiiiiiiiiiiiiiii». This is because all quantifiers are considered «greedy» by default.
However, if you change it to be «lazy» using a question mark symbol (?) to the following, the behavior changes.
Hi+?
Enter fullscreen mode
Exit fullscreen mode
Now, the i matcher will try to match as few times as possible. Since the + icon means «one or more», it will only match one «i». This means that if we input the string «Hiiiiiiiiiii», only «Hi» will be matched.
While this isn’t particularly useful on its own, when combined with broader matches like the the . symbol, it becomes extremely important as we’ll cover in the next section. The . symbol is used in regex to find «any character».
Now if you use:
H.*llo
Enter fullscreen mode
Exit fullscreen mode
You can match everything from «Hillo» to «Hello» to «Hellollollo».

However, what if you want to only match «Hello» from the final example?
Well, simply make the search lazy with a ? and it’ll work as we want:
H.*?llo
Enter fullscreen mode
Exit fullscreen mode

Pattern collections
Pattern collections allow you to search for a collection of characters to match against. For example, using the following regex:
My favorite vowel is [aeiou]
Enter fullscreen mode
Exit fullscreen mode
You could match the following strings:
My favorite vowel is a
My favorite vowel is e
My favorite vowel is i
My favorite vowel is o
My favorite vowel is u
Enter fullscreen mode
Exit fullscreen mode
But nothing else.
Here’s a list of the most common pattern collections:
-
[A-Z]— Match any uppercase character from «A» to «Z» -
[a-z]— Match any lowercase character from «a» to «z» -
[0-9]— Match any number -
[asdf]— Match any character that’s either «a», «s», «d», or «f» -
[^asdf]— Match any character that’s not any of the following: «a», «s», «d», or «f»
You can even combine these together:
-
[0-9A-Z]— Match any character that’s either a number or a capital letter from «A» to «Z» -
[^a-z]— Match any non-lowercase letter
General tokens
Not every character is so easily identifiable. While keys like «a» to «z» make sense to match using regex, what about the newline character?
The «newline» character is the character that you input whenever you press «Enter» to add a new line.
-
.— Any character -
n— Newline character -
t— Tab character -
s— Any whitespace character (includingt,nand a few others) -
S— Any non-whitespace character -
w— Any word character (Uppercase and lowercase Latin alphabet, numbers 0-9, and_) -
W— Any non-word character (the inverse of thewtoken) -
b— Word boundary: The boundaries betweenwandW, but matches in-between characters -
B— Non-word boundary: The inverse ofb -
^— The start of a line -
$— The end of a line -
\— The literal character «»
So if you wanted to remove every character that starts a new word you could use something like the following regex:
s.
Enter fullscreen mode
Exit fullscreen mode
And replace the results with an empty string. Doing this, the following:
Hello world how are you
Enter fullscreen mode
Exit fullscreen mode
Becomes:
Helloorldowreou
Enter fullscreen mode
Exit fullscreen mode

Combining with collections
These tokens aren’t just useful on their own, though! Let’s say that we want to remove any uppercase letter or whitespace character. Sure, we could write
[A-Z]|s
Enter fullscreen mode
Exit fullscreen mode
But we can actually merge these together and place our s token into the collection:
[A-Zs]
Enter fullscreen mode
Exit fullscreen mode
![We're using a regex /[A-Zs]/ to look for uppercase letters and whitespaces in the string "Hello World how are you"](https://res.cloudinary.com/practicaldev/image/fetch/s--vcHTOoua--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://d2h1bfu6zrdxog.cloudfront.net/wp-content/uploads/2022/04/img_625491ecd9758.png)
Word boundaries
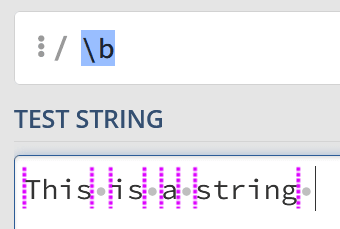
In our list of tokens, we mentioned b to match word boundaries. I thought I’d take a second to explain how it acts a bit differently from others.
Given a string like «This is a string», you might expect the whitespace characters to be matched – however, this isn’t the case. Instead, it matches between the letters and the whitespace:
This can be tricky to get your head around, but it’s unusual to simply match against a word boundary. Instead, you might have something like the following to match full words:
bw+b
Enter fullscreen mode
Exit fullscreen mode
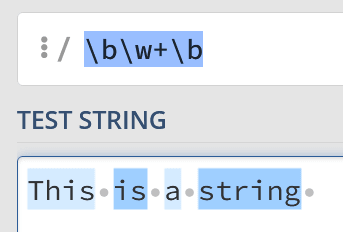
You can interpret that regex statement like this:
«A word boundary. Then, one or more ‘word’ characters. Finally, another word boundary».
Start and end line
Two more tokens that we touched on are ^ and $. These mark off the start of a line and end of a line, respectively.
So, if you want to find the first word, you might do something like this:
^w+
Enter fullscreen mode
Exit fullscreen mode
To match one or more «word» characters, but only immediately after the line starts. Remember, a «word» character is any character that’s an uppercase or lowercase Latin alphabet letters, numbers 0-9, and _.

Likewise, if you want to find the last word your regex might look something like this:
w+$
Enter fullscreen mode
Exit fullscreen mode

However, just because these tokens typically end a line doesn’t mean that they can’t have characters after them.
For example, what if we wanted to find every whitespace character between newlines to act as a basic JavaScript minifier?
Well, we can say «Find all whitespace characters after the end of a line» using the following regex:
$s+
Enter fullscreen mode
Exit fullscreen mode
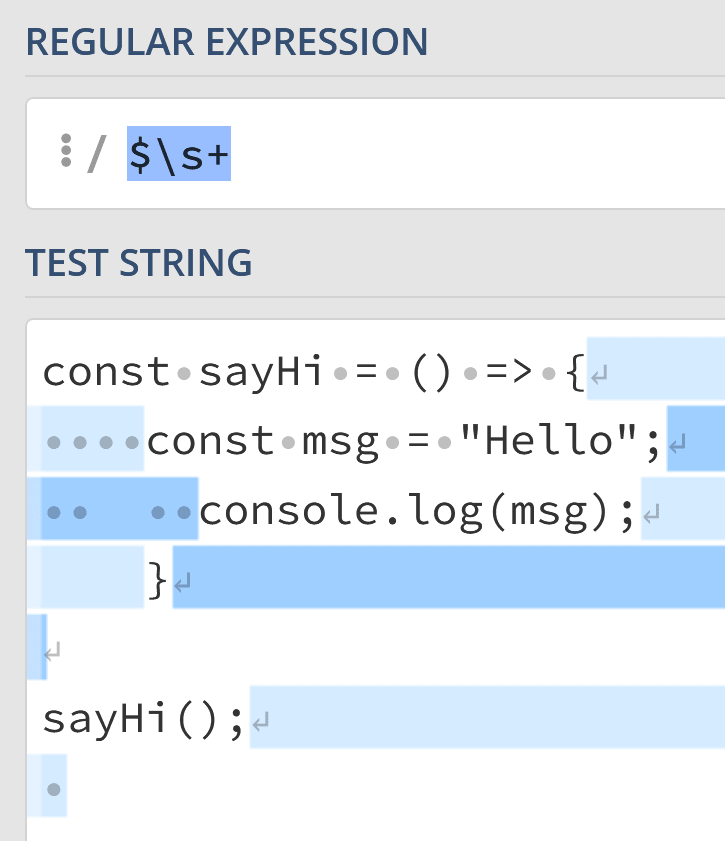
Character escaping
While tokens are super helpful, they can introduce some complexity when trying to match strings that actually contain tokens. For example, say you have the following string in a blog post:
"The newline character is 'n'"
Enter fullscreen mode
Exit fullscreen mode
Or want to find every instance of this blog post’s usage of the «n» string. Well, you can escape characters using . This means that your regex might look something like this:
\n
Enter fullscreen mode
Exit fullscreen mode
How to use a regex
Regular expressions aren’t simply useful for finding strings, however. You’re also able to use them in other methods to help modify or otherwise work with strings.
While many languages have similar methods, let’s use JavaScript as an example.
Creating and searching using regex
First, let’s look at how regex strings are constructed.
In JavaScript (along with many other languages), we place our regex inside of // blocks. The regex searching for a lowercase letter looks like this:
/[a-z]/
Enter fullscreen mode
Exit fullscreen mode
This syntax then generates a RegExp object which we can use with built-in methods, like exec, to match against strings.
/[a-z]/.exec("a"); // Returns ["a"]
/[a-z]/.exec("0"); // Returns null
Enter fullscreen mode
Exit fullscreen mode
We can then use this truthiness to determine if a regex matched, like we’re doing in line #3 of this example:
Run the associated code sample in a code sandbox
We can also alternatively call a RegExp constructor with the string we want to convert into a regex:
const regex = new RegExp("[a-z]"); // Same as /[a-z]/
Enter fullscreen mode
Exit fullscreen mode
Replacing strings with regex
You can also use a regex to search and replace a file’s contents as well. Say you wanted to replace any greeting with a message of «goodbye». While you could do something like this:
function youSayHelloISayGoodbye(str) {
str = str.replace("Hello", "Goodbye");
str = str.replace("Hi", "Goodbye");
str = str.replace("Hey", "Goodbye"); str = str.replace("hello", "Goodbye");
str = str.replace("hi", "Goodbye");
str = str.replace("hey", "Goodbye");
return str;
}
Enter fullscreen mode
Exit fullscreen mode
There’s an easier alternative, using a regex:
function youSayHelloISayGoodbye(str) {
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye");
return str;
}
Enter fullscreen mode
Exit fullscreen mode
Run the associated code sample in a code sandbox
However, something you might notice is that if you run youSayHelloISayGoodbye with «Hello, Hi there»: it won’t match more than a single input:

If the regex /[Hh]ello|[Hh]i|[Hh]ey/ is used on the string «Hello, Hi there», it will only match «Hello» by default.
Here, we should expect to see both «Hello» and «Hi» matched, but we don’t.
This is because we need to utilize a Regex «flag» to match more than once.
Flags
A regex flag is a modifier to an existing regex. These flags are always appended after the last forward slash in a regex definition.
Here’s a shortlist of some of the flags available to you.
-
g— Global, match more than once -
m— Force $ and ^ to match each newline individually -
i— Make the regex case insensitive
This means that we could rewrite the following regex:
/[Hh]ello|[Hh]i|[Hh]ey/
Enter fullscreen mode
Exit fullscreen mode
To use the case insensitive flag instead:
/Hello|Hi|Hey/i
Enter fullscreen mode
Exit fullscreen mode
With this flag, this regex will now match:
Hello
HEY
Hi
HeLLo
Enter fullscreen mode
Exit fullscreen mode
Or any other case-modified variant.
Global regex flag with string replacing
As we mentioned before, if you do a regex replace without any flags it will only replace the first result:
let str = "Hello, hi there!";
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye");
console.log(str); // Will output "Goodbye, hi there"
Enter fullscreen mode
Exit fullscreen mode
However, if you pass the global flag, you’ll match every instance of the greetings matched by the regex:
let str = "Hello, hi there!";
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/g, "Goodbye");
console.log(str); // Will output "Goodbye, Goodbye there"
Enter fullscreen mode
Exit fullscreen mode
A note about JavaScript’s global flag
When using a global JavaScript regex, you might run into some strange behavior when running the exec command more than once.
In particular, if you run exec with a global regex, it will return null every other time:
 This is because, as MDN explains:
This is because, as MDN explains:
JavaScript RegExp objects are stateful when they have the global or sticky flags set… They store a lastIndex from the previous match. Using this internally, exec() can be used to iterate over multiple matches in a string of text…
The exec command attempts to start looking through the lastIndex moving forward. Because lastIndex is set to the length of the string, it will attempt to match "" – an empty string – against your regex until it is reset by another exec command again. While this feature can be useful in specific niche circumstances, it’s often confusing for new users.
To solve this problem, we can simply assign lastIndex to 0 before running each exec command:

Groups
When searching with a regex, it can be helpful to search for more than one matched item at a time. This is where «groups» come into play. Groups allow you to search for more than a single item at a time.
Here, we can see matching against both Testing 123 and Tests 123 without duplicating the «123» matcher in the regex.
/(Testing|tests) 123/ig
Enter fullscreen mode
Exit fullscreen mode
 Groups are defined by parentheses; there are two different types of groups—capture groups and non-capturing groups:
Groups are defined by parentheses; there are two different types of groups—capture groups and non-capturing groups:
-
(...)— Group matching any three characters -
(?:...)— Non-capturing group matching any three characters
The difference between these two typically comes up in the conversation when «replace» is part of the equation.
For example, using the regex above, we can use the following JavaScript to replace the text with «Testing 234» and «tests 234»:
const regex = /(Testing|tests) 123/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 234');
console.log(str); // Testing 234nTests 234"
Enter fullscreen mode
Exit fullscreen mode
We’re using $1 to refer to the first capture group, (Testing|tests). We can also match more than a single group, like both (Testing|tests) and (123):
const regex = /(Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 #$2');
console.log(str); // Testing #123nTests #123"
Enter fullscreen mode
Exit fullscreen mode
However, this is only true for capture groups. If we change:
/(Testing|tests) (123)/ig
Enter fullscreen mode
Exit fullscreen mode
To become:
/(?:Testing|tests) (123)/ig;
Enter fullscreen mode
Exit fullscreen mode
Then there is only one captured group – (123) – and instead, the same code from above will output something different:
const regex = /(?:Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1');
console.log(str); // "123n123"
Enter fullscreen mode
Exit fullscreen mode
Run the associated code sample in a code sandbox
Named capture groups
While capture groups are awesome, it can easily get confusing when there are more than a few capture groups. The difference between $3 and $5 isn’t always obvious at a glance.
To help solve for this problem, regexes have a concept called «named capture groups»
-
(?<name>...)— Named capture group called «name» matching any three characters
You can use them in a regex like so to create a group called «num» that matches three numbers:
/Testing (?<num>d{3})/
Enter fullscreen mode
Exit fullscreen mode
Then, you can use it in a replacement like so:
const regex = /Testing (?<num>d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"
Enter fullscreen mode
Exit fullscreen mode
Named back reference
Sometimes it can be useful to reference a named capture group inside of a query itself. This is where «back references» can come into play.
-
k<name>Reference named capture group «name» in a search query
Say you want to match:
Hello there James. James, how are you doing?
Enter fullscreen mode
Exit fullscreen mode
But not:
Hello there James. Frank, how are you doing?
Enter fullscreen mode
Exit fullscreen mode
While you could write a regex that repeats the word «James» like the following:
/.*James. James,.*/
Enter fullscreen mode
Exit fullscreen mode
A better alternative might look something like this:
/.*(?<name>James). k<name>,.*/
Enter fullscreen mode
Exit fullscreen mode
Now, instead of having two names hardcoded, you only have one.
Run the associated code sample in a code sandbox
Lookahead and lookbehind groups
Lookahead and behind groups are extremely powerful and often misunderstood.
There are four different types of lookahead and behinds:
-
(?!)— negative lookahead -
(?=)— positive lookahead -
(?<=)— positive lookbehind -
(?<!)— negative lookbehind
Lookahead works like it sounds like: It either looks to see that something is after the lookahead group or is not after the lookahead group, depending on if it’s positive or negative.
As such, using the negative lookahead like so:
/B(?!A)/
Enter fullscreen mode
Exit fullscreen mode
Will allow you to match BC but not BA.

You can even combine these with ^ and $ tokens to try to match full strings. For example, the following regex will match any string that does not start with «Test»
/^(?!Test).*$/gm
Enter fullscreen mode
Exit fullscreen mode

Likewise, we can switch this to a positive lookahead to enforce that our string must start with «Test»
/^(?=Test).*$/gm
Enter fullscreen mode
Exit fullscreen mode

Putting it all together
Regexes are extremely powerful and can be used in a myriad of string manipulations. Knowing them can help you refactor codebases, script quick language changes, and more!
Let’s go back to our initial phone number regex and try to understand it again:
^(?:d{3}-){2}d{4}$
Enter fullscreen mode
Exit fullscreen mode
Remember that this regex is looking to match phone numbers such as:
555-555-5555
Enter fullscreen mode
Exit fullscreen mode
Here this regex is:
- Using
^and$to define the start and end of a regex line. - Using a non-capturing group to find three digits then a dash
- Repeating this group twice, to match
555-555-
- Repeating this group twice, to match
- Finding the last 4 digits of the phone number
Hopefully, this article has been a helpful introduction to regexes for you. If you’d like to see quick definitions of useful regexes, check out our cheat sheet.
Download our Regex Cheat Sheet
![]()
Хочешь проверить свои знания по JS?
Подпишись на наш канал с тестами по JS в Telegram!
Решать задачи
×

Регулярное выражение (или regex) — это синтаксис, позволяющий находить строки, соответствующие определенным шаблонам. Это что-то вроде функционала поиска в тексте, только regex позволяют использовать квантификаторы, специальные символы и группы захвата для создания по-настоящему продвинутых шаблонов поиска.
Regex можно использовать во всех случаях, когда вам нужно запросить строковые данные. Примеры юзкейсов:
- анализ вывода командной строки
- парсинг пользовательского ввода
- проверка логов сервера или программы
- управление текстовыми файлами с последовательным синтаксисом, такими, как CSV
- чтение файлов конфигурации
- поиск в коде и рефакторинг кода
Теоретически, делать все это можно и без regex, но использование регулярок дает вам суперсилу в решении подобных задач.
Как выглядят регулярные выражения?
В простейшей форме regex может выглядеть так:

От редакции Techrocks. О сайте regex101 и других сайтах для изучения regex можно почитать в статье «Как, наконец, выучить Regex?».
В примере «Test» буквы test образуют шаблон, как при обычном поиске. Но регулярные выражения далеко не всегда столь просты. Вот regex, означающий «3 цифры, за которыми следует дефис, за которым идут 3 цифры, после которых идет еще дефис, а в конце идут 4 цифры».
Т.е. это формат записи телефонного номера:
^(?:d{3}-){2}d{4}$

Это регулярное выражение может показаться сложным, но, во-первых, к концу этой статьи вы научитесь читать подобные шаблоны, а во-вторых, это действительно сложный способ написания шаблона.
Фактически, большинство регулярных выражений можно написать по-разному. Например, выражение, приведенное выше, можно переписать более длинно, но при этом более читабельно:
^[0-9]{3}-[0-9]{3}-[0-9]{4}$
Большинство языков программирования предоставляют встроенные методы для поиска и замены строк с использованием regex. Но при этом в каждом языке может быть собственный синтаксис регулярок.
В этой статье мы остановимся на варианте regex в ECMAScript, который используется в JavaScript и имеет много общего с реализациями регулярных выражений в других языках.
Как читать (и писать) регулярные выражения
Квантификаторы
В регулярных выражениях квантификаторы указывают, сколько раз должен встретиться символ. Вот список квантификаторов:
a|b— или a, или b?— ноль или один+— один или больше*— ноль или больше{N}— ровно N раз (здесь N — число){N,}— N или больше раз (N — число){N,M}— от N до M раз (N и M — числа, при этом N < M)*?— ноль или больше, но после первого совпадения поиск нужно прекратить
Например, следующее регулярное выражение соответствует и строке «Hello», и строке «Goodbye»:
Hello|Goodbye
В то время как
Hey?
может означать как отсутствие y, так и одно вхождение y, и таким образом весь шаблон может соответствовать и «He», и «Hey».
Еще пример:
Hello{1,3}
Этот шаблон соответствует «Hello», «Hellooo», но не «Helloooo», потому что буква «о» может встречаться от 1 до 3 раз.
Квантификаторы можно комбинировать:
He?llo{2}
Здесь мы ищем строки, в которых «e» нет или встречается 1 раз, а «o» встречается ровно 2 раза. Таким образом, этот шаблон соответствует словам «Helloo» и «Hlloo».
Жадное соответствие
В списке квантификаторов в предыдущем разделе мы познакомились со значением символа +. Этот квантификатор означает один или больше символов. Таким образом, шаблон
Hi+
будет соответствовать как «Hi», так и «Hiiiiiiiiiiiiiiii». Это потому, что все квантификаторы по умолчанию «жадные».
Но вы можете сменить их поведение на «ленивое» при помощи символа ?.
Hi+?
Теперь шаблон будет соответствовать как можно меньшему числу «i». Символ + означает «один или больше», что в «ленивом» варианте превращается в «один». То есть, в строке «Hiiiiiiiiiii» шаблон совпадет только с «Hi».
Само по себе это не слишком полезно, но в сочетании с таким символом, как точка, становится важным.
Точка в регулярных выражениях используется для поиска любого символа.
Например, следующий шаблон соответствует и «Hillo», и «Hello», и «Hellollollo»:
H.*llo

Но что если в строке «Hellollollo» вам нужно совпадение только с «Hello»?
Нужно просто сделать поиск ленивым:
H.*?llo

Наборы
Квадратные скобки позволяют искать совпадение по целому набору символов, указанному в скобках. Например, шаблон
My favorite vowel is [aeiou]
совпадет со строками:
My favorite vowel is a My favorite vowel is e My favorite vowel is i My favorite vowel is o My favorite vowel is u
И ни с чем другим. [aeiou] — это набор, в регулярном выражении означающий «любой из указанных символов».
Вот список самых распространенных наборов:
[A-Z]— совпадает с любой буквой в верхнем регистре, от «A» до «Z»[a-z]— совпадает с любой буквой в нижнем регистре, от «a» до «z»[0-9]-любая цифра[asdf]— совпадает с «a», «s», «d» или «f»[^asdf]— совпадает с любым символом кроме «a», «s», «d» или «f»
Эти наборы можно комбинировать:
[0-9A-Z]— любой символ, являющийся либо цифрой, либо буквой от A до Z[^a-z]— любой символ, не являющийся буквой латинского алфавита в нижнем регистре
Символьные классы
Не каждый символ можно так легко идентифицировать. Скажем, найти буквы с использованием regex легко, а как насчет символа новой строки?
Примечание. Символ новой строки — это символ, который вы вводите, когда нажимаете Enter и переходите на новую строку.
.— любой символn— символ новой строкиt— символ табуляцииs— пробельный символ (включая t, n и некоторые другие)S— не-пробельный символw— любой «словообразующий» символ (буквы латинского алфавита в верхнем и нижнем регистре, цифры 0-9 и символ подчеркивания_)W— любой «несловообразующий» символ (класс символов, обратный классу w)b— граница слова, разделяетwиW, т. е. словообразующие и несловообразующие символы. Граница слова соответствует позиции, где за символом слова не следует другой символ слова.B— несловообразующая граница (класс, обратныйb). Несловообразующая граница соответствует позиции, в которой предыдущий и следующий символы являются символами одного типа: либо оба должны быть словообразующими символами, либо несловообразующими. Начало и конец строки считаются несловообразующими символами.^— начало строки$— конец строки\— символ «» в буквальном значении
Допустим, вы хотите удалить каждый символ, с которого начинается новое слово в строке. Вы можете использовать следующее регулярное выражение для поиска этих символов:
s.
А затем найденные символы можно заменить пустой строкой. Таким образом строка
Hello world how are you
превратится в
Helloorldowreou

Комбинирование наборов
Символьные классы сами по себе не слишком полезны, но их можно сочетать с наборами. Допустим, мы хотим удалить из строки любую букву в верхнем регистре или пробельный символ. Это можно написать так:
[A-Z]|s
Но s можно поместить и внутрь набора:
[A-Zs]

Границы слова
В списке символьных классов вы видели символ b, означающий границу слова. На нем стоит остановиться отдельно, потому что этот токен работает не как остальные.
Допустим, у вас есть строка «This is a string». Вы можете предположить, что символ границы слова соответствует пробелам между словами, но это не так. Он соответствует тому, что находится между буквой и пробелом.

Это может быть трудно понять. Но обычно никто и не ищет сами границы слов. Вместо этого можно написать, например, выражение для поиска целых слов:
bw+b

Это регулярное выражение интерпретируется следующим образом: «Граница слова, за которой следует один или больше словообразующих символов, за которыми следует другая граница слова».
Начало и конец строки
Еще два важных токена — ^ и $. Они означают начало и конец строки соответственно.
То есть, если вы хотите найти первое слово в строке, вы можете написать следующее выражение:
^w+
Оно соответствует одному или большему числу словообразующих символов, но только если они идут непосредственно в начале строки. Помните, что словообразующий символ это любая буква латинского алфавита в любом регистре, а также любая цифра и символ подчеркивания.

Аналогично, если вы хотите найти последнее слово в строке, ваше регулярное выражение может выглядеть так:
w+$

Но то, что символ $ обычно заканчивает строку, не означает, что после него не может идти других символов.
Допустим, мы хотим найти каждый пробельный символ между новыми строками для создания базового минификатора JavaScript-кода.
Мы можем написать следующее выражение, чтобы найти все пробелы после конца строки:
$s+

Экранирование символов
Хотя токены символьных классов очень полезны, иногда с ними возникают сложности. Например, когда нужно написать шаблон для поиска таких токенов в тексте.
Допустим, у вас есть строка в тексте статьи:
"Символ новой строки - 'n'"
Или вы хотите найти вообще все упоминания «n» в тексте. Тогда в шаблоне символ n нужно «экранировать»: поставить перед ним обратную косую черту:
\n
Как использовать regex
Ценность регулярных выражений не только в том, что они позволяют находить строки. Вы также можете использовать их для модификации строк и других действий с ними.
В разных языках программирования есть похожие методы для работы с regex. Мы используем JavaScript в качестве примера.
Создание регулярных выражений и поиск с их помощью
Для начала давайте посмотрим, как строятся регулярные выражения.
В JavaScript (и в некоторых других языках) мы помещаем regex в блоки //. Регулярное выражение для поиска буквы в нижнем регистре будет выглядеть так:
/[a-z]/
Этот синтаксис генерирует объект RegExp, который можно использовать со встроенными методами типа exec для поиска соответствий в строках.
/[a-z]/.exec("a"); // Возвращает ["a"]
/[a-z]/.exec("0"); // Возвращает null
Затем мы можем использовать это истиноподобие для определения, есть ли совпадение с regex (как в строке 3 примера, доступного по ссылке ниже).
Запустить код в песочнице.
Или мы можем вызвать конструктор RegExp со строкой, которую хотим конвертировать в регулярное выражение:
const regex = new RegExp("[a-z]"); // То же самое, что /[a-z]/
Замена строк при помощи регулярных выражений
Вы можете использовать regex для поиска и замены содержимого файлов. Скажем, вы хотите заменить любое приветствие на прощание. Можно сделать это так:
function youSayHelloISayGoodbye(str) {
str = str.replace("Hello", "Goodbye");
str = str.replace("Hi", "Goodbye");
str = str.replace("Hey", "Goodbye"); str = str.replace("hello", "Goodbye");
str = str.replace("hi", "Goodbye");
str = str.replace("hey", "Goodbye");
return str;
}
Но можно и проще, с использованием regex:
function youSayHelloISayGoodbye(str) {
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye");
return str;
}
Запустить код в песочнице
Но вы можете заметить, что при запуске youSayHelloISayGoodbye с «Hello, Hi there» регулярное выражение совпадает не больше, чем с одним вхождением:

Регулярное выражение /[Hh]ello|[Hh]i|[Hh]ey/, примененное к строке «Hello, Hi there», по умолчанию совпадет только с «Hello».
Мы ожидаем, что оно совпадет и с «Hello», и с «Hi», но этого не происходит.
Чтобы регулярное выражение «отловило» больше одного совпадения, нужно использовать особый флаг.
Флаги в regex
Флаг — это модификатор существующего регулярного выражения. При определении regex флаги всегда добавляются после замыкающего слэша.
Вот небольшой список доступных флагов:
g— глобально, больше одного совпаденияm— заставляет$и^соответствовать каждой новой строчке отдельноi— делает regex нечувствительным к регистру
Мы можем взять наше регулярное выражение:
/[Hh]ello|[Hh]i|[Hh]ey/
и переписать его, применив флаг нечувствительности к регистру:
/Hello|Hi|Hey/i
Это регулярное выражение будет соответствовать следующим словам:
Hello HEY Hi HeLLo
Также оно будет соответствовать любому другому варианту чередования заглавных и строчных букв.
Флаг глобального поиска для замены строк
Как уже говорилось, если вы производите замену при помощи regex без всяких флагов, заменен будет только первый результат поиска:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye"); console.log(str); // В выводе будет "Goodbye, hi there"
Но если вы добавите флаг глобального поиска, будут найдены все соответствия шаблону:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/g, "Goodbye"); console.log(str); // В выводе будет "Goodbye, Goodbye there"
Использование флага глобального поиска в JavaScript
При использовании глобального поиска в JavaScript regex вы можете столкнуться со странным поведением.
Если вы многократно запустите exec с глобальным поиском, команда будет через раз возвращать null.

Как объясняет MDN,
«Объекты RegExp в JavaScript, когда у них установлены флаги global или sticky, являются stateful-объектами… Они хранят lastIndex из предыдущего сопоставления. Благодаря этому exec() может применяться для итерации по нескольким сопоставлениям в строке текста…»
Команда exec пытается начать поиск по lastIndex, продвигаясь вперед. Поскольку lastIndex имеет значение длины строки, exec будет пытаться сопоставить с вашим регулярным выражением "" — пустую строку, пока она не будет сброшена новой командой exec. Хотя эта особенность может быть полезна в определенных обстоятельствах, она часто сбивает с толку новичков.
Чтобы решить эту проблему, мы можем просто назначать значение 0 для lastIndex перед каждым запуском команды exec:

Группы в regex
При поиске совпадения с шаблоном может быть полезно искать больше одного сопоставляемого элемента за раз. Тут в игру вступают группы.
В примере ниже мы видим совпадение и с «Testing 123», и с «Tests 123» без дублирования «123» в выражении.
/(Testing|tests) 123/ig

Группы определяются при помощи скобок. Бывают они двух видов: группы захвата и незахватывающие группы (capture groups и non-capturing groups):
(…)— группа, соответствующая любым 3 символам(?:…)— незахватывающая группа, соответствующая любым 3 символам
Разница между этими группами ощутима тогда, когда речь идет о замене символов.
Например, используя приведенное выше выражение, при помощи JavaScript можно заменить текст с «Testing 234» и «tests 234»:
const regex = /(Testing|tests) 123/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 234'); console.log(str); // Testing 234nTests 234"
Мы используем $1 для обращения к первой группе захвата, (Testing|tests). Мы также можем сопоставить больше одной группы, скажем, сопоставлять одновременно (Testing|tests) и (123):
const regex = /(Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 #$2'); console.log(str); // Testing #123nTests #123"
Но это работает только с группами захвата.
Давайте заменим вот это:
/(Testing|tests) (123)/ig
на это:
/(?:Testing|tests) (123)/ig;
Теперь у нас только одна группа захвата — (123), и код, который мы использовали ранее, произведет другой результат:
const regex = /(?:Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1'); console.log(str); // "123n123"
Запустить код в песочнице
Именованные группы захвата
Хотя группы захвата — отличная вещь, в них легко запутаться, когда их у вас несколько. Разница между $3 и $5 не всегда очевидна.
Для решения этой проблемы в регулярных выражениях есть концепция «именованных групп захвата».
(?<name>...) — здесь именованная группа с именем «name» соответствует любым 3 символам.
Например, можно создать группу с именем «num», которая будет соответствовать 3 цифрам:
Затем вы можете использовать эту группу для замены:
const regex = /Testing (?<num>d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"
Именованные обратные ссылки
Иногда бывает полезно сослаться на именованную группу захвата внутри самого запроса. В этом вам помогут «обратные ссылки».
k<name> — ссылка на именованную группу захвата «name» в поисковом запросе.
Скажем, вы хотите, чтобы выш шаблон совпадал со строкой
Hello there James. James, how are you doing?
но не со строкой
Hello there James. Frank, how are you doing?
Вы можете написать regex, где повторяется слово «James»:
/.*James. James,.*/
Но лучше написать так:
/.*(?<name>James). k<name>,.*/
Теперь имя жестко прописано только в одном месте.
Запустить код в песочнице.
Опережающие и ретроспективные группы
Опережающие (lookahead) и ретроспективные (lookbehind) группы — очень мощный инструмент, который часто понимают превратно.
Есть четыре разных типа опережающих и ретроспективных проверок:
(?!)— негативная опережающая проверка(?=)— позитивная опережающая проверка(?<=)— позитивная ретроспективная проверка(?<!)— негативная ретроспективная проверка
Суть lookahead — проверить, что за группой стоит или не стоит определенный шаблон (позитивная и негативная проверка).
Пример негативной опережающей проверки:
/B(?!A)/
Это выражение читается как «найди B, за которым НЕ следует A». Оно соответствует «В» в «BC», но не в «BA».

Это можно комбинировать с символами начала и конца строки, чтобы искать соответствия для целых строк. Например, следующее выражение соответствует любой строке, которая НЕ начинается с «Test»:
/^(?!Test).*$/gm

Мы можем изменить негативную опережающую проверку на позитивную и таким образом найти строки, которые начинаются с «Test»:
/^(?=Test).*$/gm

Итоги
Регулярные выражения — невероятно мощный инструмент, который можно использовать для всевозможных манипуляций со строками. Знание regex поможет вам проводить рефакторинг кодовых баз, вносить быстрые правки в скрипты и т. д.
Давайте вернемся к нашему regex, соответствующему номеру телефона. Попробуйте теперь прочитать это выражение:
^(?:d{3}-){2}d{4}$
Оно служит для поиска телефонных номеров:
555-555-5555
Здесь:
^и$используются для обозначения начала и конца строки- Незахватывающая группа нужна для поиска трех цифр, за которыми следует дефис.
- Эта группа повторяется дважды для соответствия
555-555-
- Эта группа повторяется дважды для соответствия
- Дальше мы ищем последние 4 цифры телефонного номера.
Надеюсь, эта статья дала вам начальное представление о regex.
Перевод статьи «The Complete Guide to Regular Expressions (Regex)».
CHARACTER CLASSES OR CHARACTER SETS
With a “character class”, also called “character set”, you can tell the regex engine to match only one out of several characters. Simply place the characters you want to match between square brackets. If you want to match an a or an e, use [ae]. You could use this in gr[ae]y to match either gray or grey. Very useful if you do not know whether the document you are searching through is written in American or British English.
A character class matches only a single character. gr[ae]y will not match graay, graey or any such thing. The order of the characters inside a character class does not matter. The results are identical.
You can use a hyphen inside a character class to specify a range of characters. [0-9] matches a single digit between 0 and 9. You can use more than one range. [0-9a-fA-F] matches a single hexadecimal digit, case insensitively. You can combine ranges and single characters. [0-9a-fxA-FX] matches a hexadecimal digit or the letter X. Again, the order of the characters and the ranges does not matter.
THE DOT MATCHES (ALMOST) ANY CHARACTER
In regular expressions, the dot or period is one of the most commonly used metacharacters. Unfortunately, it is also the most commonly misused metacharacter.
The dot matches a single character, without caring what that character is. The only exception are newline characters. In all regex flavors discussed in this tutorial, the dot will not match a newline character by default. So by default, the dot is short for the negated character class [^n] (UNIX regex flavors) or [^rn] (Windows regex flavors).
This exception exists mostly because of historic reasons. The first tools that used regular expressions were line-based. They would read a file line by line, and apply the regular expression separately to each line. The effect is that with these tools, the string could never contain newlines, so the dot could never match them.
Modern tools and languages can apply regular expressions to very large strings or even entire files. All regex flavors discussed here have an option to make the dot match all characters, including newlines. In RegexBuddy, EditPad Pro or PowerGREP, you simply tick the checkbox labeled “dot matches newline”.
In Perl, the mode where the dot also matches newlines is called “single-line mode”. This is a bit unfortunate, because it is easy to mix up this term with “multi-line mode”. Multi-line mode only affects anchors, and single-line mode only affects the dot. You can activate single-line mode by adding an s after the regex code, like this: m/^regex$/s;.
Other languages and regex libraries have adopted Perl’s terminology. When using the regex classes of the .NET framework, you activate this mode by specifying RegexOptions.Singleline, such as in Regex.Match(«string», «regex», RegexOptions.Singleline).
In all programming languages and regex libraries I know, activating single-line mode has no effect other than making the dot match newlines. So if you expose this option to your users, please give it a clearer label like was done in RegexBuddy, EditPad Pro and PowerGREP.
JavaScript and VBScript do not have an option to make the dot match line break characters. In those languages, you can use a character class such as [sS] to match any character. This character matches a character that is either a whitespace character (including line break characters), or a character that is not a whitespace character. Since all characters are either whitespace or non-whitespace, this character class matches any character.
Use The Dot Sparingly
The dot is a very powerful regex metacharacter. It allows you to be lazy. Put in a dot, and everything will match just fine when you test the regex on valid data. The problem is that the regex will also match in cases where it should not match. If you are new to regular expressions, some of these cases may not be so obvious at first.
I will illustrate this with a simple example. Let’s say we want to match a date in mm/dd/yy format, but we want to leave the user the choice of date separators. The quick solution is dd.dd.dd. Seems fine at first. It will match a date like 02/12/03 just fine. Trouble is: 02512703 is also considered a valid date by this regular expression. In this match, the first dot matched 5, and the second matched 7. Obviously not what we intended.
dd[- /.]dd[- /.]dd is a better solution. This regex allows a dash, space, dot and forward slash as date separators. Remember that the dot is not a metacharacter inside a character class, so we do not need to escape it with a backslash.
This regex is still far from perfect. It matches 99/99/99 as a valid date. [0-1]d[- /.][0-3]d[- /.]dd is a step ahead, though it will still match 19/39/99. How perfect you want your regex to be depends on what you want to do with it. If you are validating user input, it has to be perfect. If you are parsing data files from a known source that generates its files in the same way every time, our last attempt is probably more than sufficient to parse the data without errors. You can find a better regex to match dates in the example section.
Use Negated Character Sets Instead of the Dot
I will explain this in depth when I present you the repeat operators star and plus, but the warning is important enough to mention it here as well. I will illustrate with an example.
Suppose you want to match a double-quoted string. Sounds easy. We can have any number of any character between the double quotes, so «.*» seems to do the trick just fine. The dot matches any character, and the star allows the dot to be repeated any number of times, including zero. If you test this regex on Put a «string» between double quotes, it will match «string» just fine. Now go ahead and test it on Houston, we have a problem with «string one» and «string two». Please respond.
Ouch. The regex matches «string one» and «string two». Definitely not what we intended. The reason for this is that the star is greedy.
In the date-matching example, we improved our regex by replacing the dot with a character class. Here, we will do the same. Our original definition of a double-quoted string was faulty. We do not want any number of any character between the quotes. We want any number of characters that are not double quotes or newlines between the quotes. So the proper regex is «[^»rn]*».
Start of String and End of String Anchors
Thus far, I have explained literal characters and character classes. In both cases, putting one in a regex will cause the regex engine to try to match a single character.
Anchors are a different breed. They do not match any character at all. Instead, they match a position before, after or between characters. They can be used to “anchor” the regex match at a certain position. The caret ^ matches the position before the first character in the string. Applying ^a to abc matches a. ^b will not match abc at all, because the b cannot be matched right after the start of the string, matched by ^. See below for the inside view of the regex engine.
Similarly, $ matches right after the last character in the string. c$ matches c in abc, while a$ does not match at all.
Useful Applications
When using regular expressions in a programming language to validate user input, using anchors is very important. If you use the code if ($input =~ m/d+/) in a Perl script to see if the user entered an integer number, it will accept the input even if the user entered qsdf4ghjk, because d+ matches the 4. The correct regex to use is ^d+$. Because “start of string” must be matched before the match of d+, and “end of string” must be matched right after it, the entire string must consist of digits for ^d+$ to be able to match.
It is easy for the user to accidentally type in a space. When Perl reads from a line from a text file, the line break will also be stored in the variable. So before validating input, it is good practice to trim leading and trailing whitespace. ^s+ matches leading whitespace and s+$ matches trailing whitespace. In Perl, you could use $input =~ s/^s+|s+$//g. Handy use of alternation and /g allows us to do this in a single line of code.
Using ^ and $ as Start of Line and End of Line Anchors
If you have a string consisting of multiple lines, like first linensecond line (where n indicates a line break), it is often desirable to work with lines, rather than the entire string. Therefore, all the regex engines discussed in this tutorial have the option to expand the meaning of both anchors. ^ can then match at the start of the string (before the f in the above string), as well as after each line break (between n and s). Likewise, $ will still match at the end of the string (after the last e), and also before every line break (between e and n).
In text editors like EditPad Pro or GNU Emacs, and regex tools like PowerGREP, the caret and dollar always match at the start and end of each line. This makes sense because those applications are designed to work with entire files, rather than short strings.
In all programming languages and libraries discussed on this website , except Ruby, you have to explicitly activate this extended functionality. It is traditionally called “multi-line mode”. In Perl, you do this by adding an m after the regex code, like this: m/^regex$/m;. In .NET, the anchors match before and after newlines when you specify RegexOptions.Multiline, such as in Regex.Match(«string», «regex», RegexOptions.Multiline).
Permanent Start of String and End of String Anchors
A only ever matches at the start of the string. Likewise, Z only ever matches at the end of the string. These two tokens never match at line breaks. This is true in all regex flavors discussed in this tutorial, even when you turn on “multiline mode”. In EditPad Pro and PowerGREP, where the caret and dollar always match at the start and end of lines, A and Z only match at the start and the end of the entire file.
JavaScript, POSIX and XML do not support A and Z. You’re stuck with using the caret and dollar for this purpose.
The GNU extensions to POSIX regular expressions use ` (backtick) to match the start of the string, and ‘ (single quote) to match the end of the string.
Zero-Length Matches
We saw that the anchors match at a position, rather than matching a character. This means that when a regex only consists of one or more anchors, it can result in a zero-length match. Depending on the situation, this can be very useful or undesirable. Using ^d*$ to test if the user entered a number (notice the use of the star instead of the plus), would cause the script to accept an empty string as a valid input. See below.
However, matching only a position can be very useful. In email, for example, it is common to prepend a “greater than” symbol and a space to each line of the quoted message. In VB.NET, we can easily do this with Dim Quoted as String = Regex.Replace(Original, «^», «> «, RegexOptions.Multiline). We are using multi-line mode, so the regex ^ matches at the start of the quoted message, and after each newline. The Regex.Replace method will remove the regex match from the string, and insert the replacement string (greater than symbol and a space). Since the match does not include any characters, nothing is deleted. However, the match does include a starting position, and the replacement string is inserted there, just like we want it.
Strings Ending with a Line Break
Even though Z and $ only match at the end of the string (when the option for the caret and dollar to match at embedded line breaks is off), there is one exception. If the string ends with a line break, then Z and $ will match at the position before that line break, rather than at the very end of the string. This “enhancement” was introduced by Perl, and is copied by many regex flavors, including Java, .NET and PCRE. In Perl, when reading a line from a file, the resulting string will end with a line break. Reading a line from a file with the text “joe” results in the string joen. When applied to this string, both ^[a-z]+$ and A[a-z]+Z will match joe.
If you only want a match at the absolute very end of the string, use z (lower case z instead of upper case Z). A[a-z]+z does not match joen. z matches after the line break, which is not matched by the character class.
Looking Inside the Regex Engine
Let’s see what happens when we try to match ^4$ to 749n486n4 (where n represents a newline character) in multi-line mode. As usual, the regex engine starts at the first character: 7. The first token in the regular expression is ^. Since this token is a zero-width token, the engine does not try to match it with the character, but rather with the position before the character that the regex engine has reached so far. ^ indeed matches the position before 7. The engine then advances to the next regex token: 4. Since the previous token was zero-width, the regex engine does not advance to the next character in the string. It remains at 7. 4 is a literal character, which does not match 7. There are no other permutations of the regex, so the engine starts again with the first regex token, at the next character: 4. This time, ^ cannot match at the position before the 4. This position is preceded by a character, and that character is not a newline. The engine continues at 9, and fails again. The next attempt, at n, also fails. Again, the position before n is preceded by a character, 9, and that character is not a newline.
Then, the regex engine arrives at the second 4 in the string. The ^ can match at the position before the 4, because it is preceded by a newline character. Again, the regex engine advances to the next regex token, 4, but does not advance the character position in the string. 4 matches 4, and the engine advances both the regex token and the string character. Now the engine attempts to match $ at the position before (indeed: before) the 8. The dollar cannot match here, because this position is followed by a character, and that character is not a newline.
Yet again, the engine must try to match the first token again. Previously, it was successfully matched at the second 4, so the engine continues at the next character, 8, where the caret does not match. Same at the six and the newline.
Finally, the regex engine tries to match the first token at the third 4 in the string. With success. After that, the engine successfully matches 4 with 4. The current regex token is advanced to $, and the current character is advanced to the very last position in the string: the void after the string. No regex token that needs a character to match can match here. Not even a negated character class. However, we are trying to match a dollar sign, and the mighty dollar is a strange beast. It is zero-width, so it will try to match the position before the current character. It does not matter that this “character” is the void after the string. In fact, the dollar will check the current character. It must be either a newline, or the void after the string, for $ to match the position before the current character. Since that is the case after the example, the dollar matches successfully.
Since $ was the last token in the regex, the engine has found a successful match: the last 4 in the string.
Another Inside Look
Earlier I mentioned that ^d*$ would successfully match an empty string. Let’s see why.
There is only one “character” position in an empty string: the void after the string. The first token in the regex is ^. It matches the position before the void after the string, because it is preceded by the void before the string. The next token is d*. As we will see later, one of the star’s effects is that it makes the d, in this case, optional. The engine will try to match d with the void after the string. That fails, but the star turns the failure of the d into a zero-width success. The engine will proceed with the next regex token, without advancing the position in the string. So the engine arrives at $, and the void after the string. We already saw that those match. At this point, the entire regex has matched the empty string, and the engine reports success.
Caution for Programmers
A regular expression such as $ all by itself can indeed match after the string. If you would query the engine for the character position, it would return the length of the string if string indices are zero-based, or the length+1 if string indices are one-based in your programming language. If you would query the engine for the length of the match, it would return zero.
What you have to watch out for is that String[Regex.MatchPosition] may cause an access violation or segmentation fault, because MatchPosition can point to the void after the string. This can also happen with ^ and ^$ if the last character in the string is a newline.
Word Boundaries
The metacharacter b is an anchor like the caret and the dollar sign. It matches at a position that is called a “word boundary”. This match is zero-length.
There are three different positions that qualify as word boundaries:
- Before the first character in the string, if the first character is a word character.
- After the last character in the string, if the last character is a word character.
- Between two characters in the string, where one is a word character and the other is not a word character.
Simply put: b allows you to perform a “whole words only” search using a regular expression in the form of bwordb. A “word character” is a character that can be used to form words. All characters that are not “word characters” are “non-word characters”.
In all flavors, the characters [a-zA-Z0-9_] are word characters. These are also matched by the short-hand character class w. Flavors showing “ascii” for word boundaries in the flavor comparison recognize only these as word characters. Flavors showing “YES” also recognize letters and digits from other languages or all of Unicode as word characters. Notice that Java supports Unicode for b but not for w. Python offers flags to control which characters are word characters (affecting both b and w).
In Perl and the other regex flavors discussed in this tutorial, there is only one metacharacter that matches both before a word and after a word. This is because any position between characters can never be both at the start and at the end of a word. Using only one operator makes things easier for you.
Since digits are considered to be word characters, b4b can be used to match a 4 that is not part of a larger number. This regex will not match 44 sheets of a4. So saying “b matches before and after an alphanumeric sequence” is more exact than saying “before and after a word”.
Negated Word Boundary
B is the negated version of b. B matches at every position where b does not. Effectively, B matches at any position between two word characters as well as at any position between two non-word characters.
Looking Inside the Regex Engine
Let’s see what happens when we apply the regex bisb to the string This island is beautiful. The engine starts with the first token b at the first character T. Since this token is zero-length, the position before the character is inspected. b matches here, because the T is a word character and the character before it is the void before the start of the string. The engine continues with the next token: the literal i. The engine does not advance to the next character in the string, because the previous regex token was zero-width. i does not match T, so the engine retries the first token at the next character position.
b cannot match at the position between the T and the h. It cannot match between the h and the i either, and neither between the i and the s.
The next character in the string is a space. b matches here because the space is not a word character, and the preceding character is. Again, the engine continues with the i which does not match with the space.
Advancing a character and restarting with the first regex token, b matches between the space and the second i in the string. Continuing, the regex engine finds that i matches i and s matches s. Now, the engine tries to match the second b at the position before the l. This fails because this position is between two word characters. The engine reverts to the start of the regex and advances one character to the s in island. Again, the b fails to match and continues to do so until the second space is reached. It matches there, but matching the i fails.
But b matches at the position before the third i in the string. The engine continues, and finds that i matches i and s matches s. The last token in the regex, b, also matches at the position before the third space in the string because the space is not a word character, and the character before it is.
The engine has successfully matched the word is in our string, skipping the two earlier occurrences of the characters i and s. If we had used the regular expression is, it would have matched the is in This.
Tcl Word Boundaries
Word boundaries, as described above, are supported by most regular expression flavors. Notable exceptions are the POSIX and XML Schema flavors, which don’t support word boundaries at all. Tcl uses a different syntax.
In Tcl, b matches a backspace character, just like x08 in most regex flavors (including Tcl’s). B matches a single backslash character in Tcl, just like \ in all other regex flavors (and Tcl too).
Tcl uses the letter “y” instead of the letter “b” to match word boundaries. y matches at any word boundary position, while Y matches at any position that is not a word boundary. These Tcl regex tokens match exactly the same as b and B in Perl-style regex flavors. They don’t discriminate between the start and the end of a word.
Tcl has two more word boundary tokens that do discriminate between the start and end of a word. m matches only at the start of a word. That is, it matches at any position that has a non-word character to the left of it, and a word character to the right of it. It also matches at the start of the string if the first character in the string is a word character. M matches only at the end of a word. It matches at any position that has a word character to the left of it, and a non-word character to the right of it. It also matches at the end of the string if the last character in the string is a word character.
The only regex engine that supports Tcl-style word boundaries (besides Tcl itself) is the JGsoft engine. In PowerGREP and EditPad Pro, b and B are Perl-style word boundaries, and y, Y, m and M are Tcl-style word boundaries.
In most situations, the lack of m and M tokens is not a problem. ywordy finds “whole words only” occurrences of “word” just like mwordM would. Mwordm could never match anywhere, since M never matches at a position followed by a word character, and m never at a position preceded by one. If your regular expression needs to match characters before or after y, you can easily specify in the regex whether these characters should be word characters or non-word characters. E.g. if you want to match any word, yw+y will give the same result as m.+M. Using w instead of the dot automatically restricts the first y to the start of a word, and the second y to the end of a word. Note that y.+y would not work. This regex matches each word, and also each sequence of non-word characters between the words in your subject string. That said, if your flavor supports m and M, the regex engine could apply mw+M slightly faster than yw+y, depending on its internal optimizations.
If your regex flavor supports lookahead and lookbehind, you can use (?<!w)(?=w) to emulate Tcl’s m and (?<=w)(?!w) to emulate M. Though quite a bit more verbose, these lookaround constructs match exactly the same as Tcl’s word boundaries.
If your flavor has lookahead but not lookbehind, and also has Perl-style word boundaries, you can use b(?=w) to emulate Tcl’s m and b(?!w) to emulate M. b matches at the start or end of a word, and the lookahead checks if the next character is part of a word or not. If it is we’re at the start of a word. Otherwise, we’re at the end of a word.
GNU Word Boundaries
The GNU extensions to POSIX regular expressions add support for the b and B word boundaries, as described above. GNU also uses it’s own syntax for start-of-word and end-of-word boundaries. < matches at the start of a word, like Tcl’s m. > matches at the end of a word, like Tcl’s M.
Alternation with The Vertical Bar or Pipe Symbol
I already explained how you can use character classes to match a single character out of several possible characters. Alternation is similar. You can use alternation to match a single regular expression out of several possible regular expressions.
If you want to search for the literal text cat or dog, separate both options with a vertical bar or pipe symbol: cat|dog. If you want more options, simply expand the list: cat|dog|mouse|fish.
The alternation operator has the lowest precedence of all regex operators. That is, it tells the regex engine to match either everything to the left of the vertical bar, or everything to the right of the vertical bar. If you want to limit the reach of the alternation, you will need to use round brackets for grouping. If we want to improve the first example to match whole words only, we would need to use b(cat|dog)b. This tells the regex engine to find a word boundary, then either “cat” or “dog”, and then another word boundary. If we had omitted the round brackets, the regex engine would have searched for “a word boundary followed by cat”, or, “dog” followed by a word boundary.
Remember That The Regex Engine Is Eager
I already explained that the regex engine is eager. It will stop searching as soon as it finds a valid match. The consequence is that in certain situations, the order of the alternatives matters. Suppose you want to use a regex to match a list of function names in a programming language: Get, GetValue, Set or SetValue. The obvious solution is Get|GetValue|Set|SetValue. Let’s see how this works out when the string is SetValue.
The regex engine starts at the first token in the regex, G, and at the first character in the string, S. The match fails. However, the regex engine studied the entire regular expression before starting. So it knows that this regular expression uses alternation, and that the entire regex has not failed yet. So it continues with the second option, being the second G in the regex. The match fails again. The next token is the first S in the regex. The match succeeds, and the engine continues with the next character in the string, as well as the next token in the regex. The next token in the regex is the e after the S that just successfully matched. e matches e. The next token, t matches t.
At this point, the third option in the alternation has been successfully matched. Because the regex engine is eager, it considers the entire alternation to have been successfully matched as soon as one of the options has. In this example, there are no other tokens in the regex outside the alternation, so the entire regex has successfully matched Set in SetValue.
Contrary to what we intended, the regex did not match the entire string. There are several solutions. One option is to take into account that the regex engine is eager, and change the order of the options. If we use GetValue|Get|SetValue|Set, SetValue will be attempted before Set, and the engine will match the entire string. We could also combine the four options into two and use the question mark to make part of them optional: Get(Value)?|Set(Value)?. Because the question mark is greedy, SetValue will be attempted before Set.
The best option is probably to express the fact that we only want to match complete words. We do not want to match Set or SetValue if the string is SetValueFunction. So the solution is b(Get|GetValue|Set|SetValue)b or b(Get(Value)?|Set(Value)?)b. Since all options have the same end, we can optimize this further to b(Get|Set)(Value)?b.
All regex flavors discussed on this website work this way, except one: the POSIX standard mandates that the longest match be returned, regardless if the regex engine is implemented using an NFA or DFA algorithm.
Optional Items
The question mark makes the preceding token in the regular expression optional. E.g.: colou?r matches both colour and color.
You can make several tokens optional by grouping them together using round brackets, and placing the question mark after the closing bracket. E.g.: Nov(ember)? will match Nov and November.
You can write a regular expression that matches many alternatives by including more than one question mark. Feb(ruary)? 23(rd)? matches February 23rd, February 23, Feb 23rd and Feb 23.
Important Regex Concept: Greediness
With the question mark, I have introduced the first metacharacter that is greedy. The question mark gives the regex engine two choices: try to match the part the question mark applies to, or do not try to match it. The engine will always try to match that part. Only if this causes the entire regular expression to fail, will the engine try ignoring the part the question mark applies to.
The effect is that if you apply the regex Feb 23(rd)? to the string Today is Feb 23rd, 2003, the match will always be Feb 23rd and not Feb 23. You can make the question mark lazy (i.e. turn off the greediness) by putting a second question mark after the first.
I will say a lot more about greediness when discussing the other repetition operators.
Looking Inside The Regex Engine
Let’s apply the regular expression colou?r to the string The colonel likes the color green.
The first token in the regex is the literal c. The first position where it matches successfully is the c in colonel. The engine continues, and finds that o matches o, l matches l and another o matches o. Then the engine checks whether u matches n. This fails. However, the question mark tells the regex engine that failing to match u is acceptable. Therefore, the engine will skip ahead to the next regex token: r. But this fails to match n as well. Now, the engine can only conclude that the entire regular expression cannot be matched starting at the c in colonel. Therefore, the engine starts again trying to match c to the first o in colonel.
After a series of failures, c will match with the c in color, and o, l and o match the following characters. Now the engine checks whether u matches r. This fails. Again: no problem. The question mark allows the engine to continue with r. This matches r and the engine reports that the regex successfully matched color in our string.
Repetition with Star and Plus
I already introduced one repetition operator or quantifier: the question mark. It tells the engine to attempt to match the preceding token zero times or once, in effect making it optional.
The asterisk or star tells the engine to attempt to match the preceding token zero or more times. The plus tells the engine to attempt to match the preceding token once or more. <[A-Za-z][A-Za-z0-9]*> matches an HTML tag without any attributes. The sharp brackets are literals. The first character class matches a letter. The second character class matches a letter or digit. The star repeats the second character class. Because we used the star, it’s OK if the second character class matches nothing. So our regex will match a tag like <B>. When matching <HTML>, the first character class will match H. The star will cause the second character class to be repeated three times, matching T, M and L with each step.
I could also have used <[A-Za-z0-9]+>. I did not, because this regex would match <1>, which is not a valid HTML tag. But this regex may be sufficient if you know the string you are searching through does not contain any such invalid tags.
Limiting Repetition
Modern regex flavors, like those discussed in this tutorial, have an additional repetition operator that allows you to specify how many times a token can be repeated. The syntax is {min,max}, where min is a positive integer number indicating the minimum number of matches, and max is an integer equal to or greater than min indicating the maximum number of matches. If the comma is present but max is omitted, the maximum number of matches is infinite. So {0,} is the same as *, and {1,} is the same as +. Omitting both the comma and max tells the engine to repeat the token exactly min times.
You could use b[1-9][0-9]{3}b to match a number between 1000 and 9999. b[1-9][0-9]{2,4}b matches a number between 100 and 99999. Notice the use of the word boundaries.
Watch Out for The Greediness!
Suppose you want to use a regex to match an HTML tag. You know that the input will be a valid HTML file, so the regular expression does not need to exclude any invalid use of sharp brackets. If it sits between sharp brackets, it is an HTML tag.
Most people new to regular expressions will attempt to use <.+>. They will be surprised when they test it on a string like This is a <EM>first</EM> test. You might expect the regex to match <EM> and when continuing after that match, </EM>.
But it does not. The regex will match <EM>first</EM>. Obviously not what we wanted. The reason is that the plus is greedy. That is, the plus causes the regex engine to repeat the preceding token as often as possible. Only if that causes the entire regex to fail, will the regex engine backtrack. That is, it will go back to the plus, make it give up the last iteration, and proceed with the remainder of the regex. Let’s take a look inside the regex engine to see in detail how this works and why this causes our regex to fail. After that, I will present you with two possible solutions.
Like the plus, the star and the repetition using curly braces are greedy.
Looking Inside The Regex Engine
The first token in the regex is <. This is a literal. As we already know, the first place where it will match is the first < in the string. The next token is the dot, which matches any character except newlines. The dot is repeated by the plus. The plus is greedy. Therefore, the engine will repeat the dot as many times as it can. The dot matches E, so the regex continues to try to match the dot with the next character. M is matched, and the dot is repeated once more. The next character is the >. You should see the problem by now. The dot matches the >, and the engine continues repeating the dot. The dot will match all remaining characters in the string. The dot fails when the engine has reached the void after the end of the string. Only at this point does the regex engine continue with the next token: >.
So far, <.+ has matched <EM>first</EM> test and the engine has arrived at the end of the string. > cannot match here. The engine remembers that the plus has repeated the dot more often than is required. (Remember that the plus requires the dot to match only once.) Rather than admitting failure, the engine will backtrack. It will reduce the repetition of the plus by one, and then continue trying the remainder of the regex.
So the match of .+ is reduced to EM>first</EM> tes. The next token in the regex is still >. But now the next character in the string is the last t. Again, these cannot match, causing the engine to backtrack further. The total match so far is reduced to <EM>first</EM> te. But > still cannot match. So the engine continues backtracking until the match of .+ is reduced to EM>first</EM. Now, > can match the next character in the string. The last token in the regex has been matched. The engine reports that <EM>first</EM> has been successfully matched.
Remember that the regex engine is eager to return a match. It will not continue backtracking further to see if there is another possible match. It will report the first valid match it finds. Because of greediness, this is the leftmost longest match.
Laziness Instead of Greediness
The quick fix to this problem is to make the plus lazy instead of greedy. Lazy quantifiers are sometimes also called “ungreedy” or “reluctant”. You can do that by putting a question mark behind the plus in the regex. You can do the same with the star, the curly braces and the question mark itself. So our example becomes <.+?>. Let’s have another look inside the regex engine.
Again, < matches the first < in the string. The next token is the dot, this time repeated by a lazy plus. This tells the regex engine to repeat the dot as few times as possible. The minimum is one. So the engine matches the dot with E. The requirement has been met, and the engine continues with > and M. This fails. Again, the engine will backtrack. But this time, the backtracking will force the lazy plus to expand rather than reduce its reach. So the match of .+ is expanded to EM, and the engine tries again to continue with >. Now, > is matched successfully. The last token in the regex has been matched. The engine reports that <EM> has been successfully matched. That’s more like it.
An Alternative to Laziness
In this case, there is a better option than making the plus lazy. We can use a greedy plus and a negated character class: <[^>]+>. The reason why this is better is because of the backtracking. When using the lazy plus, the engine has to backtrack for each character in the HTML tag that it is trying to match. When using the negated character class, no backtracking occurs at all when the string contains valid HTML code. Backtracking slows down the regex engine. You will not notice the difference when doing a single search in a text editor. But you will save plenty of CPU cycles when using such a regex repeatedly in a tight loop in a script that you are writing, or perhaps in a custom syntax coloring scheme for EditPad Pro.
Finally, remember that this tutorial only talks about regex-directed engines. Text-directed engines do not backtrack. They do not get the speed penalty, but they also do not support lazy repetition operators.
Repeating Q…E Escape Sequences
The Q…E sequence escapes a string of characters, matching them as literal characters. The escaped characters are treated as individual characters. If you place a quantifier after the E, it will only be applied to the last character. E.g. if you apply Q*d+*E+ to *d+**d+*, the match will be *d+**. Only the asterisk is repeated. Java 4 and 5 have a bug that causes the whole Q..E sequence to be repeated, yielding the whole subject string as the match. This was fixed in Java 6.
Use Round Brackets for Grouping
By placing part of a regular expression inside round brackets or parentheses, you can group that part of the regular expression together. This allows you to apply a regex operator, e.g. a repetition operator, to the entire group. I have already used round brackets for this purpose in previous topics throughout this tutorial.
Note that only round brackets can be used for grouping. Square brackets define a character class, and curly braces are used by a special repetition operator.
Round Brackets Create a Backreference
Besides grouping part of a regular expression together, round brackets also create a “backreference”. A backreference stores the part of the string matched by the part of the regular expression inside the parentheses.
That is, unless you use non-capturing parentheses. Remembering part of the regex match in a backreference, slows down the regex engine because it has more work to do. If you do not use the backreference, you can speed things up by using non-capturing parentheses, at the expense of making your regular expression slightly harder to read.
The regex Set(Value)? matches Set or SetValue. In the first case, the first backreference will be empty, because it did not match anything. In the second case, the first backreference will contain Value.
If you do not use the backreference, you can optimize this regular expression into Set(?:Value)?. The question mark and the colon after the opening round bracket are the special syntax that you can use to tell the regex engine that this pair of brackets should not create a backreference. Note the question mark after the opening bracket is unrelated to the question mark at the end of the regex. That question mark is the regex operator that makes the previous token optional. This operator cannot appear after an opening round bracket, because an opening bracket by itself is not a valid regex token. Therefore, there is no confusion between the question mark as an operator to make a token optional, and the question mark as a character to change the properties of a pair of round brackets. The colon indicates that the change we want to make is to turn off capturing the backreference.
How to Use Backreferences
Backreferences allow you to reuse part of the regex match. You can reuse it inside the regular expression (see below), or afterwards. What you can do with it afterwards, depends on the tool or programming language you are using. The most common usage is in search-and-replace operations. The replacement text will use a special syntax to allow text matched by capturing groups to be reinserted. This syntax differs greatly between various tools and languages, far more than the regex syntax does. Please check the replacement text reference for details.
Using Backreferences in The Regular Expression
Backreferences can not only be used after a match has been found, but also during the match. Suppose you want to match a pair of opening and closing HTML tags, and the text in between. By putting the opening tag into a backreference, we can reuse the name of the tag for the closing tag. Here’s how: <([A-Z][A-Z0-9]*)b[^>]*>.*?</1> . This regex contains only one pair of parentheses, which capture the string matched by [A-Z][A-Z0-9]* into the first backreference. This backreference is reused with 1 (backslash one). The / before it is simply the forward slash in the closing HTML tag that we are trying to match.
To figure out the number of a particular backreference, scan the regular expression from left to right and count the opening round brackets. The first bracket starts backreference number one, the second number two, etc. Non-capturing parentheses are not counted. This fact means that non-capturing parentheses have another benefit: you can insert them into a regular expression without changing the numbers assigned to the backreferences. This can be very useful when modifying a complex regular expression.
You can reuse the same backreference more than once. ([a-c])x1x1 will match axaxa, bxbxb and cxcxc.
Looking Inside The Regex Engine
Let’s see how the regex engine applies the above regex to the string Testing <B><I>bold italic</I></B> text. The first token in the regex is the literal <. The regex engine will traverse the string until it can match at the first < in the string. The next token is [A-Z]. The regex engine also takes note that it is now inside the first pair of capturing parentheses. [A-Z] matches B. The engine advances to [A-Z0-9] and >. This match fails. However, because of the star, that’s perfectly fine. The position in the string remains at >. The position in the regex is advanced to [^>].
This step crosses the closing bracket of the first pair of capturing parentheses. This prompts the regex engine to store what was matched inside them into the first backreference. In this case, B is stored.
After storing the backreference, the engine proceeds with the match attempt. [^>] does not match >. Again, because of another star, this is not a problem. The position in the string remains at >, and position in the regex is advanced to >. These obviously match. The next token is a dot, repeated by a lazy star. Because of the laziness, the regex engine will initially skip this token, taking note that it should backtrack in case the remainder of the regex fails.
The engine has now arrived at the second < in the regex, and the second < in the string. These match. The next token is /. This does not match I, and the engine is forced to backtrack to the dot. The dot matches the second < in the string. The star is still lazy, so the engine again takes note of the available backtracking position and advances to < and I. These do not match, so the engine again backtracks.
The backtracking continues until the dot has consumed <I>bold italic. At this point, < matches the third < in the string, and the next token is / which matches /. The next token is 1. Note that the token is the backreference, and not B. The engine does not substitute the backreference in the regular expression. Every time the engine arrives at the backreference, it will read the value that was stored. This means that if the engine had backtracked beyond the first pair of capturing parentheses before arriving the second time at 1, the new value stored in the first backreference would be used. But this did not happen here, so B it is. This fails to match at I, so the engine backtracks again, and the dot consumes the third < in the string.
Backtracking continues again until the dot has consumed <I>bold italic</I>. At this point, < matches < and / matches /. The engine arrives again at 1. The backreference still holds B. B matches B. The last token in the regex, > matches >. A complete match has been found: <B><I>bold italic</I></B>.
Backtracking Into Capturing Groups
You may have wondered about the word boundary b in the <([A-Z][A-Z0-9]*)b[^>]*>.*?</1> mentioned above. This is to make sure the regex won’t match incorrectly paired tags such as <boo>bold</b>. You may think that cannot happen because the capturing group matches boo which causes 1 to try to match the same, and fail. That is indeed what happens. But then the regex engine backtracks.
Let’s take the regex <([A-Z][A-Z0-9]*)[^>]*>.*?</1> without the word boundary and look inside the regex engine at the point where 1 fails the first time. First, .*? continues to expand until it has reached the end of the string, and </1> has failed to match each time .*? matched one more character.
Then the regex engine backtracks into the capturing group. [A-Z0-9]* has matched oo, but would just as happily match o or nothing at all. When backtracking, [A-Z0-9]* is forced to give up one character. The regex engine continues, exiting the capturing group a second time. Since [A-Z][A-Z0-9]* has now matched bo, that is what is stored into the capturing group, overwriting boo that was stored before. [^>]* matches the second o in the opening tag. >.*?</ matches >bold<. 1 fails again.
The regex engine does all the same backtracking once more, until [A-Z0-9]* is forced to give up another character, causing it to match nothing, which the star allows. The capturing group now stores just b. [^>]* now matches oo. >.*?</ once again matches >bold<. 1 now succeeds, as does > and an overall match is found. But not the one we wanted.
There are several solutions to this. One is to use the word boundary. When [A-Z0-9]* backtracks the first time, reducing the capturing group to bo, b fails to match between o and o. This forces [A-Z0-9]* to backtrack again immediately. The capturing group is reduced to b and the word boundary fails between b and o. There are no further backtracking positions, so the whole match attempt fails.
The reason we need the word boundary is that we’re using [^>]* to skip over any attributes in the tag. If your paired tags never have any attributes, you can leave that out, and use <([A-Z][A-Z0-9]*)>.*?</1>. Each time [A-Z0-9]* backtracks, the > that follows it will fail to match, quickly ending the match attempt.
If you didn’t expect the regex engine to backtrack into capturing groups, you can use an atomic group. The regex engine always backtracks into capturing groups, and never captures atomic groups. You can put the capturing group inside an atomic group to get an atomic capturing group: (?>(atomic capture)). In this case, we can put the whole opening tag into the atomic group: (?><([A-Z][A-Z0-9]*)[^>]*>).*?</1>. The tutorial section on atomic grouping has all the details.
Backreferences to Failed Groups
The previous section applies to all regex flavors, except those few that don’t support capturing groups at all. Flavors behave differently when you start doing things that don’t fit the “match the text matched by a previous capturing group” job description.
There is a difference between a backreference to a capturing group that matched nothing, and one to a capturing group that did not participate in the match at all. The regex (q?)b1 will match b. q? is optional and matches nothing, causing (q?) to successfully match and capture nothing. b matches b and 1 successfully matches the nothing captured by the group.
The regex (q)?b1 however will fail to match b. (q) fails to match at all, so the group never gets to capture anything at all. Because the whole group is optional, the engine does proceed to match b. However, the engine now arrives at 1 which references a group that did not participate in the match attempt at all. This causes the backreference to fail to match at all, mimicking the result of the group. Since there’s no ? making 1 optional, the overall match attempt fails.
The only exception is JavaScript. According to the official ECMA standard, a backreference to a non-participating capturing group must successfully match nothing just like a backreference to a participating group that captured nothing does. In other words, in JavaScript, (q?)b1 and (q)?b1 both match b.
Forward References and Invalid References
Modern flavors, notably JGsoft, .NET, Java, Perl, PCRE and Ruby allow forward references. That is: you can use a backreference to a group that appears later in the regex. Forward references are obviously only useful if they’re inside a repeated group. Then there can be situations in which the regex engine evaluates the backreference after the group has already matched. Before the group is attempted, the backreference will fail like a backreference to a failed group does.
If forward references are supported, the regex (2two|(one))+ will match oneonetwo. At the start of the string, 2 fails. Trying the other alternative, one is matched by the second capturing group, and subsequently by the first group. The first group is then repeated. This time, 2 matches one as captured by the second group. two then matches two. With two repetitions of the first group, the regex has matched the whole subject string.
A nested reference is a backreference inside the capturing group that it references, e.g. (1two|(one))+. This regex will give exactly the same behavior with flavors that support forward references. Some flavors that don’t support forward references do support nested references. This includes JavaScript.
With all other flavors, using a backreference before its group in the regular expression is the same as using a backreference to a group that doesn’t exist at all. All flavors discussed in this tutorial, except JavaScript and Ruby, treat backreferences to undefined groups as an error. In JavaScript and Ruby, they always result in a zero-width match. For Ruby this is a potential pitfall. In Ruby, (a)(b)?2 will fail to match a, because 2 references a non-participating group. But (a)(b)?7 will match a. For JavaScript this is logical, as backreferences to non-participating groups do the same. Both regexes will match a.
Repetition and Backreferences
As I mentioned in the above inside look, the regex engine does not permanently substitute backreferences in the regular expression. It will use the last match saved into the backreference each time it needs to be used. If a new match is found by capturing parentheses, the previously saved match is overwritten. There is a clear difference between ([abc]+) and ([abc])+. Though both successfully match cab, the first regex will put cab into the first backreference, while the second regex will only store b. That is because in the second regex, the plus caused the pair of parentheses to repeat three times. The first time, c was stored. The second time a and the third time b. Each time, the previous value was overwritten, so b remains.
This also means that ([abc]+)=1 will match cab=cab, and that ([abc])+=1 will not. The reason is that when the engine arrives at 1, it holds b which fails to match c. Obvious when you look at a simple example like this one, but a common cause of difficulty with regular expressions nonetheless. When using backreferences, always double check that you are really capturing what you want.
Useful Example: Checking for Doubled Words
When editing text, doubled words such as “the the” easily creep in. Using the regex b(w+)s+1b in your text editor, you can easily find them. To delete the second word, simply type in 1 as the replacement text and click the Replace button.
Parentheses and Backreferences Cannot Be Used Inside Character Classes
Round brackets cannot be used inside character classes, at least not as metacharacters. When you put a round bracket in a character class, it is treated as a literal character. So the regex [(a)b] matches a, b, ( and ).
Backreferences also cannot be used inside a character class. The 1 in regex like (a)[1b] will be interpreted as an octal escape in most regex flavors. So this regex will match an a followed by either x01 or a b.
Named Capturing Groups
All modern regular expression engines support capturing groups, which are numbered from left to right, starting with one. The numbers can then be used in backreferences to match the same text again in the regular expression, or to use part of the regex match for further processing. In a complex regular expression with many capturing groups, the numbering can get a little confusing.
Named Capture with Python, PCRE and PHP
Python’s regex module was the first to offer a solution: named capture. By assigning a name to a capturing group, you can easily reference it by name. (?P<name>group) captures the match of group into the backreference “name”. You can reference the contents of the group with the numbered backreference 1 or the named backreference (?P=name).
The open source PCRE library has followed Python’s example, and offers named capture using the same syntax. The PHP preg functions offer the same functionality, since they are based on PCRE.
Python’s sub() function allows you to reference a named group as 1 or g<name>. This does not work in PHP. In PHP, you can use double-quoted string interpolation with the $regs parameter you passed to pcre_match(): $regs[‘name’].
Named Capture with .NET’s System.Text.RegularExpressions
The regular expression classes of the .NET framework also support named capture. Unfortunately, the Microsoft developers decided to invent their own syntax, rather than follow the one pioneered by Python. Currently, no other regex flavor supports Microsoft’s version of named capture.
Here is an example with two capturing groups in .NET style: (?<first>group)(?’second’group). As you can see, .NET offers two syntaxes to create a capturing group: one using sharp brackets, and the other using single quotes. The first syntax is preferable in strings, where single quotes may need to be escaped. The second syntax is preferable in ASP code, where the sharp brackets are used for HTML tags. You can use the pointy bracket flavor and the quoted flavors interchangeably.
To reference a capturing group inside the regex, use k<name> or k’name’. Again, you can use the two syntactic variations interchangeably.
When doing a search-and-replace, you can reference the named group with the familiar dollar sign syntax: ${name}. Simply use a name instead of a number between the curly braces.
Multiple Groups with The Same Name
The .NET framework allows multiple groups in the regular expression to have the same name. If you do so, both groups will store their matches in the same Group object. You won’t be able to distinguish which group captured the text. This can be useful in regular expressions with multiple alternatives to match the same thing. E.g. if you want to match “a” followed by a digit 0..5, or “b” followed by a digit 4..7, and you only care about the digit, you could use the regex a(?’digit'[0-5])|b(?’digit'[4-7]). The group named “digit” will then give you the digit 0..7 that was matched, regardless of the letter.
Python and PCRE do not allow multiple groups to use the same name. Doing so will give a regex compilation error.
Names and Numbers for Capturing Groups
Here is where things get a bit ugly. Python and PCRE treat named capturing groups just like unnamed capturing groups, and number both kinds from left to right, starting with one. The regex (a)(?P<x>b)(c)(?P<y>d) matches abcd as expected. If you do a search-and-replace with this regex and the replacement 1234, you will get abcd. All four groups were numbered from left to right, from one till four. Easy and logical.
Things are quite a bit more complicated with the .NET framework. The regex (a)(?<x>b)(c)(?<y>d) again matches abcd. However, if you do a search-and-replace with $1$2$3$4 as the replacement, you will get acbd. Probably not what you expected.
The .NET framework does number named capturing groups from left to right, but numbers them after all the unnamed groups have been numbered. So the unnamed groups (a) and (c) get numbered first, from left to right, starting at one. Then the named groups (?<x>b) and (?<y>d) get their numbers, continuing from the unnamed groups, in this case: three.
To make things simple, when using .NET’s regex support, just assume that named groups do not get numbered at all, and reference them by name exclusively. To keep things compatible across regex flavors, I strongly recommend that you do not mix named and unnamed capturing groups at all. Either give a group a name, or make it non-capturing as in (?:nocapture). Non-capturing groups are more efficient, since the regex engine does not need to keep track of their matches.
Best of Both Worlds
The JGsoft regex engine supports both .NET-style and Python-style named capture. Python-style named groups are numbered along unnamed ones, like Python does. .NET-style named groups are numbered afterwards, like .NET does. You can mix both styles in the same regex. The JGsoft engine allows multiple groups to use the same name, regardless of the syntax used.
In PowerGREP, named capturing groups play a special roles. Groups with the same name are shared between all regular expressions and replacement texts in the same PowerGREP action. This allows captured by a named capturing group in one part of the action to be referenced in a later part of the action. Because of this, PowerGREP does not allow numbered references to named capturing groups at all. When mixing named and numbered groups in a regex, the numbered groups are still numbered following the Python and .NET rules, like the JGsoft flavor always does.
Regular Expression Advanced Syntax Reference
|
Grouping and Backreferences |
||
|
Syntax |
Description |
Example |
| (regex) | Round brackets group the regex between them. They capture the text matched by the regex inside them that can be reused in a backreference, and they allow you to apply regex operators to the entire grouped regex. | (abc){3} matches abcabcabc. First group matches abc. |
| (?:regex) | Non-capturing parentheses group the regex so you can apply regex operators, but do not capture anything and do not create backreferences. | (?:abc){3} matches abcabcabc. No groups. |
| 1 through 9 | Substituted with the text matched between the 1st through 9th pair of capturing parentheses. Some regex flavors allow more than 9 backreferences. | (abc|def)=1 matches abc=abc or def=def, but not abc=def or def=abc. |
|
Modifiers |
||
|
Syntax |
Description |
Example |
| (?i) | Turn on case insensitivity for the remainder of the regular expression. (Older regex flavors may turn it on for the entire regex.) | te(?i)st matches teST but not TEST. |
| (?-i) | Turn off case insensitivity for the remainder of the regular expression. | (?i)te(?-i)st matches TEst but not TEST. |
| (?s) | Turn on “dot matches newline” for the remainder of the regular expression. (Older regex flavors may turn it on for the entire regex.) | |
| (?-s) | Turn off “dot matches newline” for the remainder of the regular expression. | |
| (?m) | Caret and dollar match after and before newlines for the remainder of the regular expression. (Older regex flavors may apply this to the entire regex.) | |
| (?-m) | Caret and dollar only match at the start and end of the string for the remainder of the regular expression. | |
| (?x) | Turn on free-spacing mode to ignore whitespace between regex tokens, and allow # comments. | |
| (?-x) | Turn off free-spacing mode. | |
| (?i-sm) | Turns on the option “i” and turns off “s” and “m” for the remainder of the regular expression. (Older regex flavors may apply this to the entire regex.) | |
| (?i-sm:regex) | Matches the regex inside the span with the option “i” turned on and “m” and “s” turned off. | (?i:te)st matches TEst but not TEST. |
|
Atomic Grouping and Possessive Quantifiers |
||
|
Syntax |
Description |
Example |
| (?>regex) | Atomic groups prevent the regex engine from backtracking back into the group (forcing the group to discard part of its match) after a match has been found for the group. Backtracking can occur inside the group before it has matched completely, and the engine can backtrack past the entire group, discarding its match entirely. Eliminating needless backtracking provides a speed increase. Atomic grouping is often indispensable when nesting quantifiers to prevent a catastrophic amount of backtracking as the engine needlessly tries pointless permutations of the nested quantifiers. | x(?>w+)x is more efficient than xw+x if the second x cannot be matched. |
| ?+, *+, ++ and {m,n}+ | Possessive quantifiers are a limited yet syntactically cleaner alternative to atomic grouping. Only available in a few regex flavors. They behave as normal greedy quantifiers, except that they will not give up part of their match for backtracking. | x++ is identical to (?>x+) |
|
Lookaround |
||
|
Syntax |
Description |
Example |
| (?=regex) | Zero-width positive lookahead. Matches at a position where the pattern inside the lookahead can be matched. Matches only the position. It does not consume any characters or expand the match. In a pattern like one(?=two)three, both two and three have to match at the position where the match of one ends. | t(?=s) matches the second t in streets. |
| (?!regex) | Zero-width negative lookahead. Identical to positive lookahead, except that the overall match will only succeed if the regex inside the lookahead fails to match. | t(?!s) matches the first t in streets. |
| (?<=regex) | Zero-width positive lookbehind. Matches at a position if the pattern inside the lookahead can be matched ending at that position (i.e. to the left of that position). Depending on the regex flavor you’re using, you may not be able to use quantifiers and/or alternation inside lookbehind. | (?<=s)t matches the first t in streets. |
| (?<!regex) | Zero-width negative lookbehind. Matches at a position if the pattern inside the lookahead cannot be matched ending at that position. | (?<!s)t matches the second t in streets. |
|
Continuing from The Previous Match |
||
|
Syntax |
Description |
Example |
| G | Matches at the position where the previous match ended, or the position where the current match attempt started (depending on the tool or regex flavor). Matches at the start of the string during the first match attempt. | G[a-z] first matches a, then matches b and then fails to match in ab_cd. |
|
Conditionals |
||
|
Syntax |
Description |
Example |
| (?(?=regex)then|else) | If the lookahead succeeds, the “then” part must match for the overall regex to match. If the lookahead fails, the “else” part must match for the overall regex to match. Not just positive lookahead, but all four lookarounds can be used. Note that the lookahead is zero-width, so the “then” and “else” parts need to match and consume the part of the text matched by the lookahead as well. | (?(?<=a)b|c) matches the second b and the first c in babxcac |
| (?(1)then|else) | If the first capturing group took part in the match attempt thus far, the “then” part must match for the overall regex to match. If the first capturing group did not take part in the match, the “else” part must match for the overall regex to match. | (a)?(?(1)b|c) matches ab, the first c and the second c in babxcac |
|
Comments |
||
|
Syntax |
Description |
Example |
| (?#comment) | Everything between (?# and ) is ignored by the regex engine. | a(?#foobar)b matches ab |
Sample Regular Expressions
Below, you will find many example patterns that you can use for and adapt to your own purposes. Key techniques used in crafting each regex are explained, with links to the corresponding pages in the tutorial where these concepts and techniques are explained in great detail.
If you are new to regular expressions, you can take a look at these examples to see what is possible. Regular expressions are very powerful. They do take some time to learn. But you will earn back that time quickly when using regular expressions to automate searching or editing tasks in EditPad Pro or PowerGREP, or when writing scripts or applications in a variety of languages.
RegexBuddy offers the fastest way to get up to speed with regular expressions. RegexBuddy will analyze any regular expression and present it to you in a clearly to understand, detailed outline. The outline links to RegexBuddy’s regex tutorial (the same one you find on this website), where you can always get in-depth information with a single click.
Oh, and you definitely do not need to be a programmer to take advantage of regular expressions!
Grabbing HTML Tags
<TAGb[^>]*>(.*?)</TAG> matches the opening and closing pair of a specific HTML tag. Anything between the tags is captured into the first backreference. The question mark in the regex makes the star lazy, to make sure it stops before the first closing tag rather than before the last, like a greedy star would do. This regex will not properly match tags nested inside themselves, like in <TAG>one<TAG>two</TAG>one</TAG>.
<([A-Z][A-Z0-9]*)b[^>]*>(.*?)</1> will match the opening and closing pair of any HTML tag. Be sure to turn off case sensitivity. The key in this solution is the use of the backreference 1 in the regex. Anything between the tags is captured into the second backreference. This solution will also not match tags nested in themselves.
Trimming Whitespace
You can easily trim unnecessary whitespace from the start and the end of a string or the lines in a text file by doing a regex search-and-replace. Search for ^[ t]+ and replace with nothing to delete leading whitespace (spaces and tabs). Search for [ t]+$ to trim trailing whitespace. Do both by combining the regular expressions into ^[ t]+|[ t]+$ . Instead of [ t] which matches a space or a tab, you can expand the character class into [ trn] if you also want to strip line breaks. Or you can use the shorthand s instead.
IP Addresses
Matching an IP address is another good example of a trade-off between regex complexity and exactness. bd{1,3}.d{1,3}.d{1,3}.d{1,3}b will match any IP address just fine, but will also match 999.999.999.999 as if it were a valid IP address. Whether this is a problem depends on the files or data you intend to apply the regex to. To restrict all 4 numbers in the IP address to 0..255, you can use this complex beast: b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)b (everything on a single line). The long regex stores each of the 4 numbers of the IP address into a capturing group. You can use these groups to further process the IP number.
If you don’t need access to the individual numbers, you can shorten the regex with a quantifier to: b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)b . Similarly, you can shorten the quick regex to b(?:d{1,3}.){3}d{1,3}b
More Detailed Examples
Numeric Ranges. Since regular expressions work with text rather than numbers, matching specific numeric ranges requires a bit of extra care.
Matching a Floating Point Number. Also illustrates the common mistake of making everything in a regular expression optional.
Matching an Email Address. There’s a lot of controversy about what is a proper regex to match email addresses. It’s a perfect example showing that you need to know exactly what you’re trying to match (and what not), and that there’s always a trade-off between regex complexity and accuracy.
Matching Valid Dates. A regular expression that matches 31-12-1999 but not 31-13-1999.
Finding or Verifying Credit Card Numbers. Validate credit card numbers entered on your order form. Find credit card numbers in documents for a security audit.
Matching Complete Lines. Shows how to match complete lines in a text file rather than just the part of the line that satisfies a certain requirement. Also shows how to match lines in which a particular regex does not match.
Removing Duplicate Lines or Items. Illustrates simple yet clever use of capturing parentheses or backreferences.
Regex Examples for Processing Source Code. How to match common programming language syntax such as comments, strings, numbers, etc.
Two Words Near Each Other. Shows how to use a regular expression to emulate the “near” operator that some tools have.
Common Pitfalls
Catastrophic Backtracking. If your regular expression seems to take forever, or simply crashes your application, it has likely contracted a case of catastrophic backtracking. The solution is usually to be more specific about what you want to match, so the number of matches the engine has to try doesn’t rise exponentially.
Making Everything Optional. If all the parts in your regex are optional, it will match a zero-width string anywhere. Your regex will need to express the facts that different parts are optional depending on which parts are present.
Repeating a Capturing Group vs. Capturing a Repeated Group. Repeating a capturing group will capture only the last iteration of the group. Capture a repeated group if you want to capture all iterations.
Mixing Unicode and 8-bit Character Codes. Using 8-bit character codes like x80 with a Unicode engine and subject string may give unexpected results.
Matching Numeric Ranges with a Regular Expression
Since regular expressions deal with text rather than with numbers, matching a number in a given range takes a little extra care. You can’t just write [0-255] to match a number between 0 and 255. Though a valid regex, it matches something entirely different. [0-255] is a character class with three elements: the character range 0-2, the character 5 and the character 5 (again). This character class matches a single digit 0, 1, 2 or 5, just like [0125].
Since regular expressions work with text, a regular expression engine treats 0 as a single character, and 255 as three characters. To match all characters from 0 to 255, we’ll need a regex that matches between one and three characters.
The regex [0-9] matches single-digit numbers 0 to 9. [1-9][0-9] matches double-digit numbers 10 to 99. That’s the easy part.
Matching the three-digit numbers is a little more complicated, since we need to exclude numbers 256 through 999. 1[0-9][0-9] takes care of 100 to 199. 2[0-4][0-9] matches 200 through 249. Finally, 25[0-5] adds 250 till 255.
As you can see, you need to split up the numeric range in ranges with the same number of digits, and each of those ranges that allow the same variation for each digit. In the 3-digit range in our example, numbers starting with 1 allow all 10 digits for the following two digits, while numbers starting with 2 restrict the digits that are allowed to follow.
Putting this all together using alternation we get: [0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]. This matches the numbers we want, with one caveat: regular expression searches usually allow partial matches, so our regex would match 123 in 12345. There are two solutions to this.
If you’re searching for these numbers in a larger document or input string, use word boundaries to require a non-word character (or no character at all) to precede and to follow any valid match. The regex then becomes b([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])b. Since the alternation operator has the lowest precedence of all, the round brackets are required to group the alternatives together. This way the regex engine will try to match the first word boundary, then try all the alternatives, and then try to match the second word boundary after the numbers it matched. Regular expression engines consider all alphanumeric characters, as well as the underscore, as word characters.
If you’re using the regular expression to validate input, you’ll probably want to check that the entire input consists of a valid number. To do this, use anchors instead of word boundaries: ^([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])$.
Here are a few more common ranges that you may want to match:
- 000..255: ^([01][0-9][0-9]|2[0-4][0-9]|25[0-5])$
- 0 or 000..255: ^([01]?[0-9]?[0-9]|2[0-4][0-9]|25[0-5])$
- 0 or 000..127: ^(0?[0-9]?[0-9]|1[0-1][0-9]|12[0-7])$
- 0..999: ^([0-9]|[1-9][0-9]|[1-9][0-9][0-9])$
- 000..999: ^[0-9]{3}$
- 0 or 000..999: ^[0-9]{1,3}$
- 1..999: ^([1-9]|[1-9][0-9]|[1-9][0-9][0-9])$
- 001..999: ^(00[1-9]|0[1-9][0-9]|[1-9][0-9][0-9])$
- 1 or 001..999: ^(0{0,2}[1-9]|0?[1-9][0-9]|[1-9][0-9][0-9])$
- 0 or 00..59: ^[0-5]?[0-9]$
- 0 or 000..366: ^(0?[0-9]?[0-9]|[1-2][0-9][0-9]|3[0-5][0-9]|36[0-6])$
Matching Floating Point Numbers with a Regular Expression
In this example, I will show you how you can avoid a common mistake often made by people inexperienced with regular expressions. As an example, we will try to build a regular expression that can match any floating point number. Our regex should also match integers, and floating point numbers where the integer part is not given (i.e. zero). We will not try to match numbers with an exponent, such as 1.5e8 (150 million in scientific notation).
At first thought, the following regex seems to do the trick: [-+]?[0-9]*.?[0-9]*. This defines a floating point number as an optional sign, followed by an optional series of digits (integer part), followed by an optional dot, followed by another optional series of digits (fraction part).
Spelling out the regex in words makes it obvious: everything in this regular expression is optional. This regular expression will consider a sign by itself or a dot by itself as a valid floating point number. In fact, it will even consider an empty string as a valid floating point number. This regular expression can cause serious trouble if it is used in a scripting language like Perl or PHP to verify user input.
Not escaping the dot is also a common mistake. A dot that is not escaped will match any character, including a dot. If we had not escaped the dot, 4.4 would be considered a floating point number, and 4X4 too.
When creating a regular expression, it is more important to consider what it should not match, than what it should. The above regex will indeed match a proper floating point number, because the regex engine is greedy. But it will also match many things we do not want, which we have to exclude.
Here is a better attempt: [-+]?([0-9]*.[0-9]+|[0-9]+). This regular expression will match an optional sign, that is either followed by zero or more digits followed by a dot and one or more digits (a floating point number with optional integer part), or followed by one or more digits (an integer).
This is a far better definition. Any match will include at least one digit, because there is no way around the [0-9]+ part. We have successfully excluded the matches we do not want: those without digits.
We can optimize this regular expression as: [-+]?[0-9]*.?[0-9]+.
If you also want to match numbers with exponents, you can use: [-+]?[0-9]*.?[0-9]+([eE][-+]?[0-9]+)? . Notice how I made the entire exponent part optional by grouping it together, rather than making each element in the exponent optional.
Finally, if you want to validate if a particular string holds a floating point number, rather than finding a floating point number within longer text, you’ll have to anchor your regex: ^[-+]?[0-9]*.?[0-9]+$ or ^[-+]?[0-9]*.?[0-9]+([eE][-+]?[0-9]+)?$. You can find additional variations of these regexes in RegexBuddy’s library.
How to Find or Validate an Email Address
The regular expression I receive the most feedback, not to mention “bug” reports on, is the one you’ll find right on this site’s home page: b[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,4}b. This regular expression, I claim, matches any email address. Most of the feedback I get refutes that claim by showing one email address that this regex doesn’t match. Usually, the “bug” report also includes a suggestion to make the regex “perfect”.
As I explain below, my claim only holds true when one accepts my definition of what a valid email address really is, and what it’s not. If you want to use a different definition, you’ll have to adapt the regex. Matching a valid email address is a perfect example showing that (1) before writing a regex, you have to know exactly what you’re trying to match, and what not; and (2) there’s often a trade-off between what’s exact, and what’s practical.
The virtue of my regular expression above is that it matches 99% of the email addresses in use today. All the email address it matches can be handled by 99% of all email software out there. If you’re looking for a quick solution, you only need to read the next paragraph. If you want to know all the trade-offs and get plenty of alternatives to choose from, read on.
If you want to use the regular expression above, there’s two things you need to understand. First, long regexes make it difficult to nicely format paragraphs. So I didn’t include a-z in any of the three character classes. This regex is intended to be used with your regex engine’s “case insensitive” option turned on. (You’d be surprised how many “bug” reports I get about that.) Second, the above regex is delimited with word boundaries, which makes it suitable for extracting email addresses from files or larger blocks of text. If you want to check whether the user typed in a valid email address, replace the word boundaries with start-of-string and end-of-string anchors, like this: ^[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,4}$.
The previous paragraph also applies to all following examples. You may need to change word boundaries into start/end-of-string anchors, or vice versa. And you will need to turn on the case insensitive matching option.
Trade-Offs in Validating Email Addresses
Yes, there are a whole bunch of email addresses that my pet regex doesn’t match. The most frequently quoted example are addresses on the .museum top level domain, which is longer than the 4 letters my regex allows for the top level domain. I accept this trade-off because the number of people using .museum email addresses is extremely low. I’ve never had a complaint that the order forms or newsletter subscription forms on the JGsoft websites refused a .museum address (which they would, since they use the above regex to validate the email address).
To include .museum, you could use ^[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,6}$. However, then there’s another trade-off. This regex will match john@mail.office. It’s far more likely that John forgot to type in the .com top level domain rather than having just created a new .office top level domain without ICANN’s permission.
This shows another trade-off: do you want the regex to check if the top level domain exists? My regex doesn’t. Any combination of two to four letters will do, which covers all existing and planned top level domains except .museum. But it will match addresses with invalid top-level domains like asdf@asdf.asdf. By not being overly strict about the top-level domain, I don’t have to update the regex each time a new top-level domain is created, whether it’s a country code or generic domain.
^[A-Z0-9._%+-]+@[A-Z0-9.-]+.(?:[A-Z]{2}|com|org|net|edu|gov|mil|biz|info|mobi|name|aero|asia|jobs|museum)$could be used to allow any two-letter country code top level domain, and only specific generic top level domains. By the time you read this, the list might already be out of date. If you use this regular expression, I recommend you store it in a global constant in your application, so you only have to update it in one place. You could list all country codes in the same manner, even though there are almost 200 of them.
Email addresses can be on servers on a subdomain, e.g. john@server.department.company.com. All of the above regexes will match this email address, because I included a dot in the character class after the @ symbol. However, the above regexes will also match john@aol…com which is not valid due to the consecutive dots. You can exclude such matches by replacing [A-Z0-9.-]+. with (?:[A-Z0-9-]+.)+ in any of the above regexes. I removed the dot from the character class and instead repeated the character class and the following literal dot. E.g. b[A-Z0-9._%+-]+@(?:[A-Z0-9-]+.)+[A-Z]{2,4}b will match john@server.department.company.com but not john@aol…com.
Another trade-off is that my regex only allows English letters, digits and a few special symbols. The main reason is that I don’t trust all my email software to be able to handle much else. Even though John.O’Hara@theoharas.com is a syntactically valid email address, there’s a risk that some software will misinterpret the apostrophe as a delimiting quote. E.g. blindly inserting this email address into a SQL will cause it to fail if strings are delimited with single quotes. And of course, it’s been many years already that domain names can include non-English characters. Most software and even domain name registrars, however, still stick to the 37 characters they’re used to.
The conclusion is that to decide which regular expression to use, whether you’re trying to match an email address or something else that’s vaguely defined, you need to start with considering all the trade-offs. How bad is it to match something that’s not valid? How bad is it not to match something that is valid? How complex can your regular expression be? How expensive would it be if you had to change the regular expression later? Different answers to these questions will require a different regular expression as the solution. My email regex does what I want, but it may not do what you want.
Regexes Don’t Send Email
Don’t go overboard in trying to eliminate invalid email addresses with your regular expression. If you have to accept .museum domains, allowing any 6-letter top level domain is often better than spelling out a list of all current domains. The reason is that you don’t really know whether an address is valid until you try to send an email to it. And even that might not be enough. Even if the email arrives in a mailbox, that doesn’t mean somebody still reads that mailbox.
The same principle applies in many situations. When trying to match a valid date, it’s often easier to use a bit of arithmetic to check for leap years, rather than trying to do it in a regex. Use a regular expression to find potential matches or check if the input uses the proper syntax, and do the actual validation on the potential matches returned by the regular expression. Regular expressions are a powerful tool, but they’re far from a panacea.
The Official Standard: RFC 2822
Maybe you’re wondering why there’s no “official” fool-proof regex to match email addresses. Well, there is an official definition, but it’s hardly fool-proof.
The official standard is known as RFC 2822. It describes the syntax that valid email addresses must adhere to. You can (but you shouldn’t–read on) implement it with this regular expression:
(?:[a-z0-9!#$%&’*+/=?^_`{|}~-]+(?:.[a-z0-9!#$%&’*+/=?^_`{|}~-]+)*|»(?:[x01-x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|\[x01-x09x0bx0cx0e-x7f])*»)@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|\[x01-x09x0bx0cx0e-x7f])+)])
This regex has two parts: the part before the @, and the part after the @. There are two alternatives for the part before the @: it can either consist of a series of letters, digits and certain symbols, including one or more dots. However, dots may not appear consecutively or at the start or end of the email address. The other alternative requires the part before the @ to be enclosed in double quotes, allowing any string of ASCII characters between the quotes. Whitespace characters, double quotes and backslashes must be escaped with backslashes.
The part after the @ also has two alternatives. It can either be a fully qualified domain name (e.g. regular-expressions.info), or it can be a literal Internet address between square brackets. The literal Internet address can either be an IP address, or a domain-specific routing address.
The reason you shouldn’t use this regex is that it only checks the basic syntax of email addresses. john@aol.com.nospam would be considered a valid email address according to RFC 2822. Obviously, this email address won’t work, since there’s no “nospam” top-level domain. It also doesn’t guarantee your email software will be able to handle it. Not all applications support the syntax using double quotes or square brackets. In fact, RFC 2822 itself marks the notation using square brackets as obsolete.
We get a more practical implementation of RFC 2822 if we omit the syntax using double quotes and square brackets. It will still match 99.99% of all email addresses in actual use today.
[a-z0-9!#$%&’*+/=?^_`{|}~-]+(?:.[a-z0-9!#$%&’*+/=?^_`{|}~-]+)*@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?
A further change you could make is to allow any two-letter country code top level domain, and only specific generic top level domains. This regex filters dummy email addresses like asdf@adsf.adsf. You will need to update it as new top-level domains are added.
[a-z0-9!#$%&’*+/=?^_`{|}~-]+(?:.[a-z0-9!#$%&’*+/=?^_`{|}~-]+)*@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+(?:[A-Z]{2}|com|org|net|edu|gov|mil|biz|info|mobi|name|aero|asia|jobs|museum)b
So even when following official standards, there are still trade-offs to be made. Don’t blindly copy regular expressions from online libraries or discussion forums. Always test them on your own data and with your own applications.
Regular Expression Matching a Valid Date
^(19|20)dd[- /.](0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])$ matches a date in yyyy-mm-dd format from between 1900-01-01 and 2099-12-31, with a choice of four separators. The anchors make sure the entire variable is a date, and not a piece of text containing a date. The year is matched by (19|20)dd. I used alternation to allow the first two digits to be 19 or 20. The round brackets are mandatory. Had I omitted them, the regex engine would go looking for 19 or the remainder of the regular expression, which matches a date between 2000-01-01 and 2099-12-31. Round brackets are the only way to stop the vertical bar from splitting up the entire regular expression into two options.
The month is matched by 0[1-9]|1[012], again enclosed by round brackets to keep the two options together. By using character classes, the first option matches a number between 01 and 09, and the second matches 10, 11 or 12.
The last part of the regex consists of three options. The first matches the numbers 01 through 09, the second 10 through 29, and the third matches 30 or 31.
Smart use of alternation allows us to exclude invalid dates such as 2000-00-00 that could not have been excluded without using alternation. To be really perfectionist, you would have to split up the month into various options to take into account the length of the month. The above regex still matches 2003-02-31, which is not a valid date. Making leading zeros optional could be another enhancement.
If you want to require the delimiters to be consistent, you could use a backreference. ^(19|20)dd([- /.])(0[1-9]|1[012])2(0[1-9]|[12][0-9]|3[01])$ will match 1999-01-01 but not 1999/01-01.
Again, how complex you want to make your regular expression depends on the data you are using it on, and how big a problem it is if an unwanted match slips through. If you are validating the user’s input of a date in a script, it is probably easier to do certain checks outside of the regex. For example, excluding February 29th when the year is not a leap year is far easier to do in a scripting language. It is far easier to check if a year is divisible by 4 (and not divisible by 100 unless divisible by 400) using simple arithmetic than using regular expressions.
Here is how you could check a valid date in Perl. I also added round brackets to capture the year into a backreference.
sub isvaliddate {
my $input = shift;
if ($input =~ m!^((?:19|20)dd)[- /.](0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])$!) {
# At this point, $1 holds the year, $2 the month and $3 the day of the date entered
if ($3 == 31 and ($2 == 4 or $2 == 6 or $2 == 9 or $2 == 11)) {
return 0; # 31st of a month with 30 days
} elsif ($3 >= 30 and $2 == 2) {
return 0; # February 30th or 31st
} elsif ($2 == 2 and $3 == 29 and not ($1 % 4 == 0 and ($1 % 100 != 0 or $1 % 400 == 0))) {
return 0; # February 29th outside a leap year
} else {
return 1; # Valid date
}
} else {
return 0; # Not a date
}
}
To match a date in mm/dd/yyyy format, rearrange the regular expression to ^(0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])[- /.](19|20)dd$ . For dd-mm-yyyy format, use ^(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20)dd$ . You can find additional variations of these regexes in RegexBuddy’s library.
Finding or Verifying Credit Card Numbers
With a few simple regular expressions, you can easily verify whether your customer entered a valid credit card number on your order form. You can even determine the type of credit card being used. Each card issuer has its own range of card numbers, identified by the first 4 digits.
You can use a slightly different regular expression to find credit card numbers, or number sequences that might be credit card numbers, within larger documents. This can be very useful to prove in a security audit that you’re not improperly exposing your clients’ financial details.
We’ll start with the order form.
Stripping Spaces and Dashes
The first step is to remove all non-digits from the card number entered by the customer. Physical credit cards have spaces within the card number to group the digits, making it easier for humans to read or type in. So your order form should accept card numbers with spaces or dashes in them.
To remove all non-digits from the card number, simply use the “replace all” function in your scripting language to search for the regex [^0-9]+ and replace it with nothing. If you only want to replace spaces and dashes, you could use [ -]+. If this regex looks odd, remember that in a character class, the hyphen is a literal when it occurs right before the closing bracket (or right after the opening bracket or negating caret).
If you’re wondering what the plus is for: that’s for performance. If the input has consecutive non-digits, e.g. 1===2, then the regex will match the three equals signs at once, and delete them in one replacement. Without the plus, three replacements would be required. In this case, the savings are only a few microseconds. But it’s a good habit to keep regex efficiency in the back of your mind. Though the savings are minimal here, so is the effort of typing the extra plus.
Validating Credit Card Numbers on Your Order Form
Validating credit card numbers is the ideal job for regular expressions. They’re just a sequence of 13 to 16 digits, with a few specific digits at the start that identify the card issuer. You can use the specific regular expressions below to alert customers when they try to use a kind of card you don’t accept, or to route orders using different cards to different processors. All these regexes were taken from RegexBuddy’s library.
- Visa: ^4[0-9]{12}(?:[0-9]{3})?$ All Visa card numbers start with a 4. New cards have 16 digits. Old cards have 13.
- MasterCard: ^5[1-5][0-9]{14}$ All MasterCard numbers start with the numbers 51 through 55. All have 16 digits.
- American Express: ^3[47][0-9]{13}$ American Express card numbers start with 34 or 37 and have 15 digits.
- Diners Club: ^3(?:0[0-5]|[68][0-9])[0-9]{11}$ Diners Club card numbers begin with 300 through 305, 36 or 38. All have 14 digits. There are Diners Club cards that begin with 5 and have 16 digits. These are a joint venture between Diners Club and MasterCard, and should be processed like a MasterCard.
- Discover: ^6(?:011|5[0-9]{2})[0-9]{12}$ Discover card numbers begin with 6011 or 65. All have 16 digits.
- JCB: ^(?:2131|1800|35d{3})d{11}$ JCB cards beginning with 2131 or 1800 have 15 digits. JCB cards beginning with 35 have 16 digits.
If you just want to check whether the card number looks valid, without determining the brand, you can combine the above six regexes into ^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6(?:011|5[0-9][0-9])[0-9]{12}|3[47][0-9]{13}|3(?:0[0-5]|[68][0-9])[0-9]{11}|(?:2131|1800|35d{3})d{11})$. You’ll see I’ve simply alternated all the regexes, and used a non-capturing group to put the anchors outside the alternation. You can easily delete the card types you don’t accept from the list.
These regular expressions will easily catch numbers that are invalid because the customer entered too many or too few digits. They won’t catch numbers with incorrect digits. For that, you need to follow the Luhn algorithm, which cannot be done with a regex. And of course, even if the number is mathematically valid, that doesn’t mean a card with this number was issued or if there’s money in the account. The benefit or the regular expression is that you can put it in a bit of JavaScript to instantly check for obvious errors, instead of making the customer wait 30 seconds for your credit card processor to fail the order. And if your card processor charges for failed transactions, you’ll really want to implement both the regex and the Luhn validation.
Finding Credit Card Numbers in Documents
With two simple modifications, you could use any of the above regexes to find card numbers in larger documents. Simply replace the caret and dollar with a word boundary, e.g.: b4[0-9]{12}(?:[0-9]{3})?b.
If you’re planning to search a large document server, a simpler regular expression will speed up the search. Unless your company uses 16-digit numbers for other purposes, you’ll have few false positives. The regex bd{13,16}b will find any sequence of 13 to 16 digits.
When searching a hard disk full of files, you can’t strip out spaces and dashes first like you can when validating a single card number. To find card numbers with spaces or dashes in them, use b(?:d[ -]*?){13,16}b. This regex allows any amount of spaces and dashes anywhere in the number. This is really the only way. Visa and MasterCard put digits in sets of 4, while Amex and Discover use groups of 4, 5 and 6 digits. People typing in the numbers may have different ideas yet.
Deleting Duplicate Lines From a File
If you have a file in which all lines are sorted (alphabetically or otherwise), you can easily delete (consecutive) duplicate lines. Simply open the file in your favorite text editor, and do a search-and-replace searching for ^(.*)(r?n1)+$ and replacing with 1. For this to work, the anchors need to match before and after line breaks (and not just at the start and the end of the file or string), and the dot must not match newlines.
Here is how this works. The caret will match only at the start of a line. So the regex engine will only attempt to match the remainder of the regex there. The dot and star combination simply matches an entire line, whatever its contents, if any. The round brackets store the matched line into the first backreference.
Next we will match the line separator. I put the question mark into r?n to make this regex work with both Windows (rn) and UNIX (n) text files. So up to this point we matched a line and the following line break.
Now we need to check if this combination is followed by a duplicate of that same line. We do this simply with 1. This is the first backreference which holds the line we matched. The backreference will match that very same text.
If the backreference fails to match, the regex match and the backreference are discarded, and the regex engine tries again at the start of the next line. If the backreference succeeds, the plus symbol in the regular expression will try to match additional copies of the line. Finally, the dollar symbol forces the regex engine to check if the text matched by the backreference is a complete line. We already know the text matched by the backreference is preceded by a line break (matched by r?n). Therefore, we now check if it is also followed by a line break or if it is at the end of the file using the dollar sign.
The entire match becomes linenline (or linenlinenline etc.). Because we are doing a search and replace, the line, its duplicates, and the line breaks in between them, are all deleted from the file. Since we want to keep the original line, but not the duplicates, we use 1 as the replacement text to put the original line back in.
Removing Duplicate Items From a String
We can generalize the above example to afterseparator(item)(separator1)+beforeseparator, where afterseparator and beforeseparator are zero-width. So if you want to remove consecutive duplicates from a comma-delimited list, you could use (?<=,|^)([^,]*)(,1)+(?=,|$).
The positive lookbehind (?<=,|^) forces the regex engine to start matching at the start of the string or after a comma. ([^,]*) captures the item. (,1)+ matches consecutive duplicate items. Finally, the positive lookahead (?=,|$) checks if the duplicate items are complete items by checking for a comma or the end of the string.
Example Regexes to Match Common Programming Language Constructs
Regular expressions are very useful to manipulate source code in a text editor or in a regex-based text processing tool. Most programming languages use similar constructs like keywords, comments and strings. But often there are subtle differences that make it tricky to use the correct regex. When picking a regex from the list of examples below, be sure to read the description with each regex to make sure you are picking the correct one.
Unless otherwise indicated, all examples below assume that the dot does not match newlines and that the caret and dollar do match at embedded line breaks. In many programming languages, this means that single line mode must be off, and multi line mode must be on.
When used by themselves, these regular expressions may not have the intended result. If a comment appears inside a string, the comment regex will consider the text inside the string as a comment. The string regex will also match strings inside comments. The solution is to use more than one regular expression, like in this pseudo-code:
GlobalStartPosition := 0; while GlobalStartPosition < LengthOfText do GlobalMatchPosition := LengthOfText; MatchedRegEx := NULL; foreach RegEx in RegExList do RegEx.StartPosition := GlobalStartPosition; if RegEx.Match and RegEx.MatchPosition < GlobalMatchPosition then MatchedRegEx := RegEx; GlobalMatchPosition := RegEx.MatchPosition; endif endforeach if MatchedRegEx <> NULL then // At this point, MatchedRegEx indicates which regex matched // and you can do whatever processing you want depending on // which regex actually matched. endif GlobalStartPosition := GlobalMatchPosition; endwhile
If you put a regex matching a comment and a regex matching a string in RegExList, then you can be sure that the comment regex will not match comments inside strings, and vice versa.
An alternative solution is to combine regexes: (comment)|(string). The alternation has the same effect as the code snipped above. Using backreferences, you can figure out which part of the regex actually matched. The drawback of this solution is that the combined regular expression quickly becomes difficult to read or maintain.
Comments
#.*$ matches a single-line comment starting with a # and continuing until the end of the line. Similarly, //.*$ matches a single-line comment starting with //.
If the comment must appear at the start of the line, use ^#.*$ . If only whitespace is allowed between the start of the line and the comment, use ^s*#.*$ . Compiler directives or pragmas in C can be matched this way. Note that in this last example, any leading whitespace will be part of the regex match. Use capturing parentheses to separate the whitespace and the comment.
/*.*?*/ matches a C-style multi-line comment if you turn on the option for the dot to match newlines. The general syntax is begin.*?end. C-style comments do not allow nesting. If the “begin” part appears inside the comment, it is ignored. As soon as the “end” part if found, the comment is closed.
If your programming language allows nested comments, there is no straightforward way to match them using a regular expression, since regular expressions cannot count. Additional logic is required.
Strings
«[^»rn]*» matches a single-line string that does not allow the quote character to appear inside the string. Using the negated character class is more efficient than using a lazy dot. «[^»]*»allows the string to span across multiple lines.
«[^»\rn]*(?:\.[^»\rn]*)*» matches a single-line string in which the quote character can appear if it is escaped by a backslash. Though this regular expression may seem more complicated than it needs to be, it is much faster than simpler solutions which can cause a whole lot of backtracking in case a double quote appears somewhere all by itself rather than part of a string. «[^»\]*(?:\.[^»\]*)*»allows the string to span multiple lines.
You can adapt the above regexes to match any sequence delimited by two (possibly different) characters. If we use b for the starting character, e and the end, and x as the escape character, the version without escape becomes b[^ern]*e, and the version with escape becomes b[^exrn]*(?:x.[^exrn]*)*e.
Numbers
bd+b matches a positive integer number. Do not forget the word boundaries! [-+]?bd+b allows for a sign.
b0[xX][0-9a-fA-F]+bmatches a C-style hexadecimal number.
((b[0-9]+)?.)?[0-9]+b matches an integer number as well as a floating point number with optional integer part. (b[0-9]+.([0-9]+b)?|.[0-9]+b)matches a floating point number with optional integer as well as optional fractional part, but does not match an integer number.
((b[0-9]+)?.)?b[0-9]+([eE][-+]?[0-9]+)?bmatches a number in scientific notation. The mantissa can be an integer or floating point number with optional integer part. The exponent is optional.
b[0-9]+(.[0-9]+)?(e[+-]?[0-9]+)?balso matches a number in scientific notation. The difference with the previous example is that if the mantissa is a floating point number, the integer part is mandatory.
If you read through the floating point number example, you will notice that the above regexes are different from what is used there. The above regexes are more stringent. They use word boundaries to exclude numbers that are part of other things like identifiers. You can prepend [-+]? to all of the above regexes to include an optional sign in the regex. I did not do so above because in programming languages, the + and – are usually considered operators rather than signs.
Reserved Words or Keywords
Matching reserved words is easy. Simply use alternation to string them together: b(first|second|third|etc)b Again, do not forget the word boundaries.
Find Two Words Near Each Other
Some search tools that use boolean operators also have a special operator called “near”. Searching for “term1 near term2” finds all occurrences of term1 and term2 that occur within a certain “distance” from each other. The distance is a number of words. The actual number depends on the search tool, and is often configurable.
You can easily perform the same task with the proper regular expression.
Emulating “near” with a Regular Expression
With regular expressions you can describe almost any text pattern, including a pattern that matches two words near each other. This pattern is relatively simple, consisting of three parts: the first word, a certain number of unspecified words, and the second word. An unspecified word can be matched with the shorthand character class w+. The spaces and other characters between the words can be matched with W+ (uppercase W this time).
The complete regular expression becomes bword1W+(?:w+W+){1,6}?word2b . The quantifier {1,6}? makes the regex require at least one word between “word1” and “word2”, and allow at most six words.
If the words may also occur in reverse order, we need to specify the opposite pattern as well: b(?:word1W+(?:w+W+){1,6}?word2|word2W+(?:w+W+){1,6}?word1)b
If you want to find any pair of two words out of a list of words, you can use: b(word1|word2|word3)(?:W+w+){1,6}?W+(word1|word2|word3)b. This regex will also find a word near itself, e.g. it will match word2 near word2.
Matching Whole Lines of Text
Often, you want to match complete lines in a text file rather than just the part of the line that satisfies a certain requirement. This is useful if you want to delete entire lines in a search-and-replace in a text editor, or collect entire lines in an information retrieval tool.
To keep this example simple, let’s say we want to match lines containing the word “John”. The regex John makes it easy enough to locate those lines. But the software will only indicate John as the match, not the entire line containing the word.
The solution is fairly simple. To specify that we need an entire line, we will use the caret and dollar sign and turn on the option to make them match at embedded newlines. In software aimed at working with text files like EditPad Pro and PowerGREP, the anchors always match at embedded newlines. To match the parts of the line before and after the match of our original regular expression John, we simply use the dot and the star. Be sure to turn off the option for the dot to match newlines.
The resulting regex is: ^.*John.*$. You can use the same method to expand the match of any regular expression to an entire line, or a block of complete lines. In some cases, such as when using alternation, you will need to group the original regex together using round brackets.
Finding Lines Containing or Not Containing Certain Words
If a line can meet any out of series of requirements, simply use alternation in the regular expression. ^.*b(one|two|three)b.*$ matches a complete line of text that contains any of the words “one”, “two” or “three”. The first backreference will contain the word the line actually contains. If it contains more than one of the words, then the last (rightmost) word will be captured into the first backreference. This is because the star is greedy. If we make the first star lazy, like in ^.*?b(one|two|three)b.*$, then the backreference will contain the first (leftmost) word.
If a line must satisfy all of multiple requirements, we need to use lookahead. ^(?=.*?boneb)(?=.*?btwob)(?=.*?bthreeb).*$ matches a complete line of text that contains all of the words “one”, “two” and “three”. Again, the anchors must match at the start and end of a line and the dot must not match line breaks. Because of the caret, and the fact that lookahead is zero-width, all of the three lookaheads are attempted at the start of the each line. Each lookahead will match any piece of text on a single line (.*?) followed by one of the words. All three must match successfully for the entire regex to match. Note that instead of words like bwordb, you can put any regular expression, no matter how complex, inside the lookahead. Finally, .*$ causes the regex to actually match the line, after the lookaheads have determined it meets the requirements.
If your condition is that a line should not contain something, use negative lookahead. ^((?!regexp).)*$ matches a complete line that does not match regexp. Notice that unlike before, when using positive lookahead, I repeated both the negative lookahead and the dot together. For the positive lookahead, we only need to find one location where it can match. But the negative lookahead must be tested at each and every character position in the line. We must test that regexp fails everywhere, not just somewhere.
Finally, you can combine multiple positive and negative requirements as follows: ^(?=.*?bmust-haveb)(?=.*?bmandatoryb)((?!avoid|illegal).)*$ . When checking multiple positive requirements, the .* at the end of the regular expression full of zero-width assertions made sure that we actually matched something. Since the negative requirement must match the entire line, it is easy to replace the .* with the negative test.