
5.4. Find All Except a Specific Word
Problem
You want to use a regular expression to match any complete
word except cat. Catwoman, vindicate, and other words that
merely contain the letters “cat” should be matched—just not cat.
Solution
A negative lookahead can help you rule out specific words, and is
key to this next regex:
b(?!catb)w+
| Regex options: Case insensitive |
| Regex flavors: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Discussion
Although a negated character class (written as ‹[^⋯]›) makes it easy to match anything
except a specific character, you can’t just write ‹[^cat]› to match anything except
the word cat.
‹[^cat]› is a valid regex,
but it matches any character except c, a, or t. Hence, although ‹b[^cat]+b› would avoid matching
the word cat,
it wouldn’t match the word time either, because it contains the
forbidden letter t. The regular expression ‹b[^c][^a][^t]w*› is no good
either, because it would reject any word with c as its first letter, a as its second letter,
or t as its
third. Furthermore, that doesn’t restrict the first three letters to
word characters, and it only matches words with at least three
characters since none of the negated character classes are
optional.
With all that in mind, let’s take another look at how the regular
expression shown at the beginning of this recipe solved the
problem:
b # Assert position at a word boundary. (?! # Not followed by: cat # Match "cat". b # Assert position at a word boundary. ) # End the negative lookahead. w+ ...
I want to use a regular expression to exclude a complete word. I need this for a particular situation which I explain further
Problem
As part of Implementing a vulnerability Waiver Process for infected 3rd party libraries I have a jira transition dialog, which excepts the user to set some values. There are two drop-down fields or as JIRA calls it “Select List (single choice)”. These always present a value None in case nothing is selected.
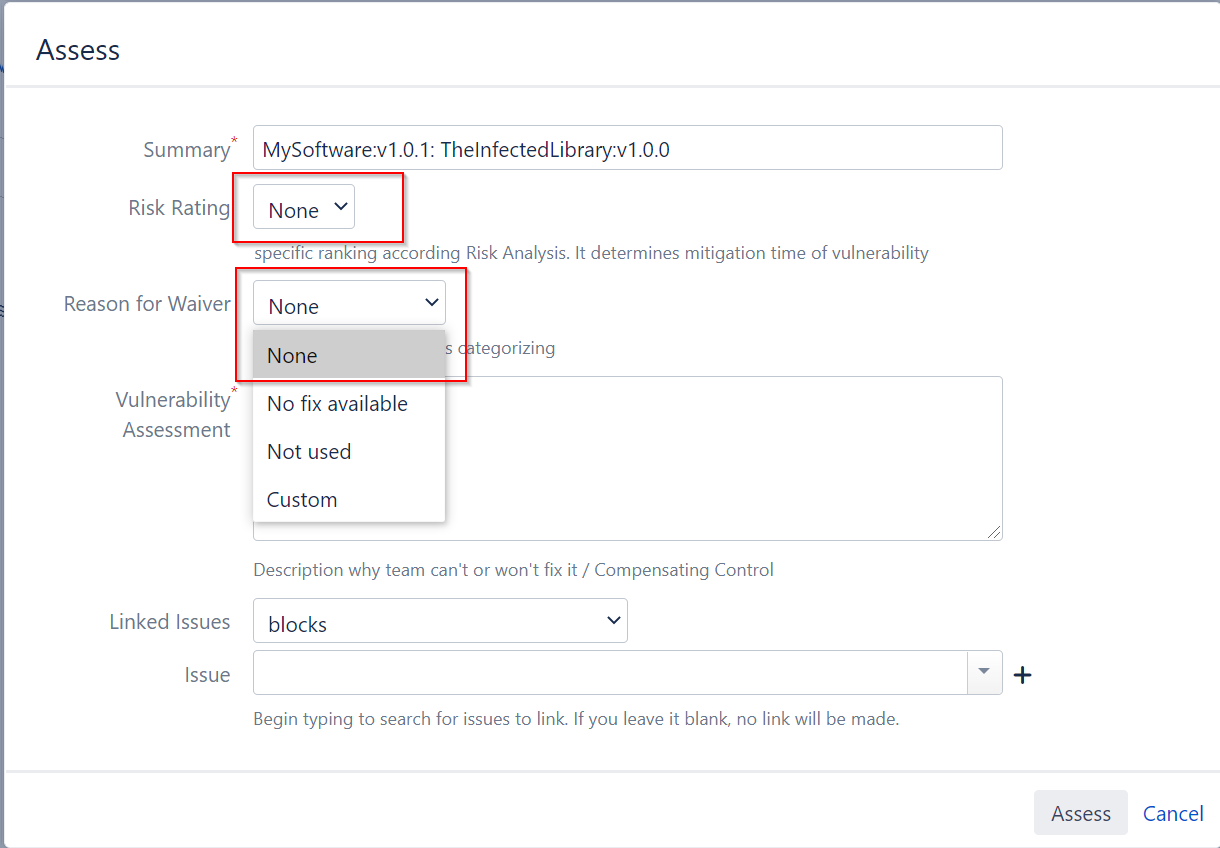
In order to ensure, that when doing a transition to a specific state, a proper value is selected we use jira-validators. These validators support regular expressions, so the question is now, how I ensure that the selected value is not None:
Solution
Some searching in the web I found a solution in the regular-expressions-cookbook — which sample is readable. So the solution is
b(?!Noneb)w+
The result is a proper evaluation of the value in the dialog:
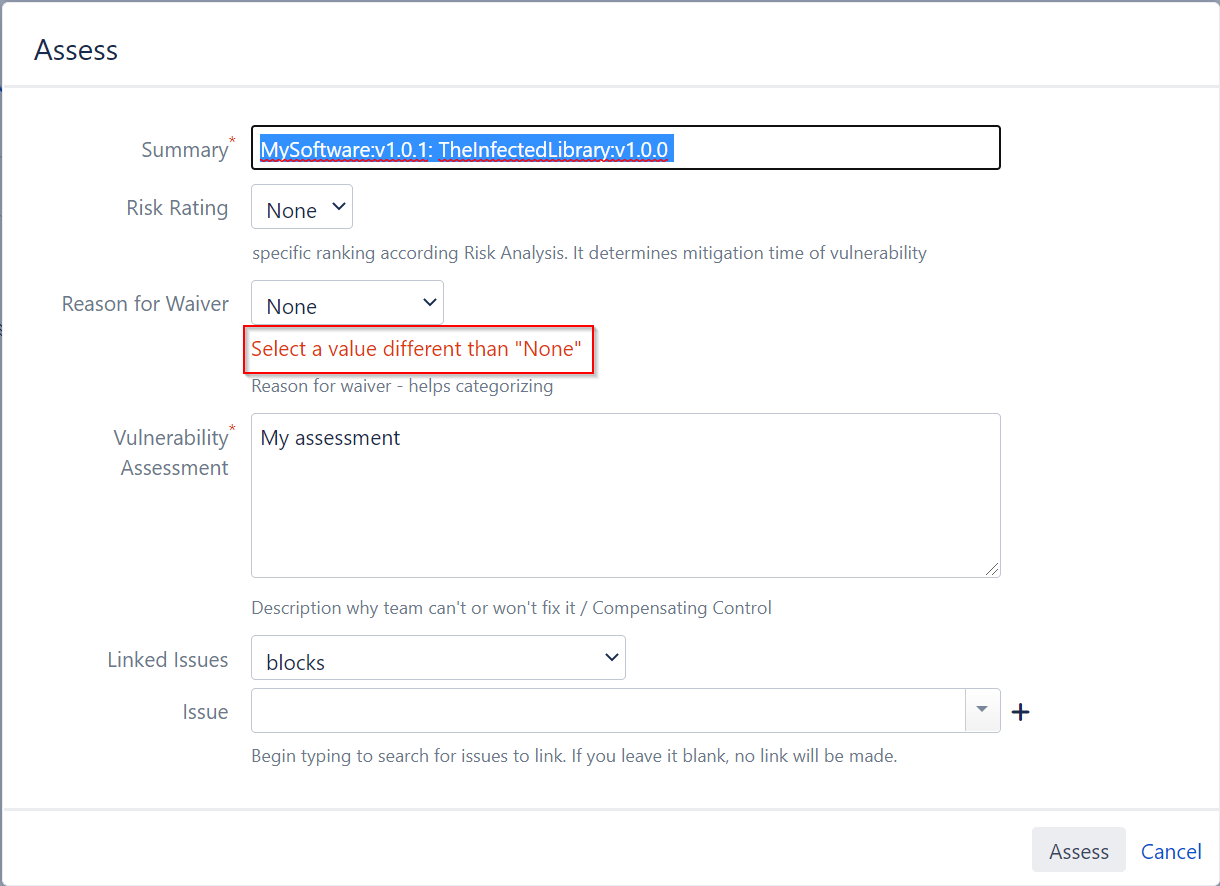
Explain the details
As explained in regular-expressions-cookbook and while looking at the regular-expressions.info you can understand why the above solution works:
-
negate character classes
Typing a caret
^after the opening square bracket negates the character class. The result is that the character class matches any character that is not in the character class.The issue with this is the part highlighted: It matches any character, so using
[^None]ignores anything containingN,o,nande— but we care about the whole word. -
wordboundaries
ballows you to perform a “whole words only” search using a regular expression in the form ofbwordbThe issue with that is that
b[^None]w+bis still looking at the character class thus ignoring any word that containsN,o,nande -
negative lookagead
Similar to positive lookahead, except that negative lookahead only succeeds if the regex inside the lookahead fails to match.
So the final solution using the techniques mentioned above
basserts the position at a word boundary(?!not followed byNonethe word we want to “ignore” i.e. should not matchbasserts the position at a word boundary)ends the negative lookaheadw+still match anything other
Match EVERYTHING except one word
Hello, I would like to match everything except one particular word (let’s say Clide) in a string.
Alice Bob Clide to Alice Clide
The problem is that example I found online don’t match the string at all if it contain the word.
I would still like to match what’s before and after the word except itself.
Is that possible please?
You might use a preg_replace to do so:
Test 1:
$test = preg_replace('/(<.*”>)(.*)(</.*)/s', '<center>$2</center>', '<p style=“text-align:center; others-style:value;”>Content</p>');
var_dump($test);
Output 1:
It would return:
string(24) "<center>Content</center>"
RegEx 1:
The RegEx divides your inputs into three capturing groups, where the first and third groups can be assigned to open/close p tags.
RegEx 2:
You can further expand it, if you wish, with this RegEx for any other tags/quotations/contents that you may want. It would divide any tags with any quotations (» or ” or ‘ or ’) into five groups where the fourth group ($4) is your target content. This type of RegEx may be usually useful for single occurrence non-looping strings, since it uses (.*).
Test 2
$test = preg_replace('/<(.*)("|”|'|’)>(.*)(</.*)/s', '<center>$4</center>', '<p style=“text-align:center; others-style:value;”>Content</p>');
var_dump($test);
RegEx 3
If you may wish to get any specific attributes in style, this RegEx might help:
<(.*)(text-align:)(.*)(center|left|right|justify|inherit|none)(.*)("|”|'|’)>(.*)(</.*)
Test 3
$tags = [
'0' => '<p style=“text-align:center; others-style:value;”>Content</p>',
'1' => '<div style=‘text-align:left; others-style:value;’ class=‘any class’>Any Content That You Wish</div>',
'2' => '<span style='text-align:right; others-style:value;' class='any class'>Any Content That You Wish</span>',
'3' => '<h1 style=“text-align:justify; others-style:value;” class="any class">Any Content That You Wish</h1>',
'4' => '<h2 style=“text-align:inherit; others-style:value;” class=“any class">Any Content That You Wish</h2>',
'5' => '<h3 style=“text-align:none; others-style:value;” class=“any class">Any Content That You Wish</h3>',
'6' => '<h4 style=“others-style:value;” class=“any class">Any Content That You Wish</h4>',
];
var_dump($tag);
$RegEx = '/<(.*)(text-align:)(.*)(center|left|right|justify|inherit|none)(.*)("|”|'|’)>(.*)(</.*)/s';
foreach ($tags as $key => $tag) {
preg_match_all($RegEx, $tag, $matches);
foreach ($matches as $key1 => $match) {
if (sizeof($match[0]) > 0) {
$tags[$key] = preg_replace($RegEx, '<$4>$7</$4>', $tag);
break;
}
}
}
var_dump($tags);
Output 3
It would return:
array(7) {
[0]=>
string(24) "<center>Content</center>"
[1]=>
string(38) "<left>Any Content That You Wish</left>"
[2]=>
string(40) "<right>Any Content That You Wish</right>"
[3]=>
string(44) "<justify>Any Content That You Wish</justify>"
[4]=>
string(44) "<inherit>Any Content That You Wish</inherit>"
[5]=>
string(38) "<none>Any Content That You Wish</none>"
[6]=>
string(86) "<h4 style=“others-style:value;” class=“any class">Any Content That You Wish</h4>"
}
I have this text:
<tag>Value<tag>
and I want to convert it to
<%= Value %>
I was able to do it, using:
Regex.Replace(text, "<tag>(.*?)<tag>", "<%= $1 %>", RegexOptions.Compiled);
However, the text could contain this word «=n» anywhere in the text. for example:
<tag=n>Value<tag>
<tag>Value<tag=n>
<tag>Value=n<tag>
<tag>=nValue<tag>
<tag>Va=nlue<tag>
<ta=ng>Value<tag>
How can I modify my pattern to work?
A simple way out would be to remove =n before passing your string to regex:
Regex.Replace(text.Replace(@"=n", ""), "<tag>([^<]*)<tag>", "<%= $1 %>", RegexOptions.Compiled);
Note that I also replaced the reluctant dot-asterisk .*? with [^<]* to protect your expression from catastrophic backtracking.