
Press J to jump to the feed. Press question mark to learn the rest of the keyboard shortcuts
Log In
Found the internet!
Feeds
HomePopular
Topics
ValheimGenshin ImpactMinecraftPokimaneHalo InfiniteCall of Duty: WarzonePath of ExileHollow Knight: SilksongEscape from TarkovWatch Dogs: Legion
NFLNBAMegan AndersonAtlanta HawksLos Angeles LakersBoston CelticsArsenal F.C.Philadelphia 76ersPremier LeagueUFC
GameStopModernaPfizerJohnson & JohnsonAstraZenecaWalgreensBest BuyNovavaxSpaceXTesla
CardanoDogecoinAlgorandBitcoinLitecoinBasic Attention TokenBitcoin Cash
The Real Housewives of AtlantaThe BachelorSister Wives90 Day FianceWife SwapThe Amazing Race AustraliaMarried at First SightThe Real Housewives of DallasMy 600-lb LifeLast Week Tonight with John Oliver
Kim KardashianDoja CatIggy AzaleaAnya Taylor-JoyJamie Lee CurtisNatalie PortmanHenry CavillMillie Bobby BrownTom HiddlestonKeanu Reeves
Animals and PetsAnimeArtCars and Motor VehiclesCrafts and DIYCulture, Race, and EthnicityEthics and PhilosophyFashionFood and DrinkHistoryHobbiesLawLearning and EducationMilitaryMoviesMusicPlacePodcasts and StreamersPoliticsProgrammingReading, Writing, and LiteratureReligion and SpiritualityScienceTabletop GamesTechnologyTravel
Create an account to follow your favorite communities and start taking part in conversations.
Sorry, for some reason reddit can’t be reached.
A regular expression that matches everything after a specific character (like colon, word, question mark, etc.) in a string.
Can be used to replace or remove everything in the text that starts with a certain character.
Note that don’t forget to replace the FOO as displayed below.
/FOO(.*)/g
Matches:
- FOOAbcdefg
- FOO1234567
- FOOABCDEFG
Non-matches:
- FOAbcdefg
- AFOObcdefg
- 1234567FOO
See Also:
- Regex To Match Anything After The First Space In A String
- Regex To Match The First Word After A Specific Word
I am trying to extract text after the word «tasks» in the below table. Only where Field contains «tasks» do I want the value «.0.» or «.1.». I have tried various different Regular Expressions using the RegEx tool but unable to output a value in a new field (it is coming out null or blank). Thanks in advance!
We can use Regex to get all words after the nth word in a sentence in Google Sheets.
For that, there is a built-in function called REGEXREPLACE. Another option is the QUERY, SPLIT, and SUBSTITUTE combo. We will try that too.
Actually, I was about to write another tutorial to explain a formula that I have offered to one of my readers via comment reply. It was about comma-separated values.
As part of that formula, I wanted to extract all the words after the first word.
Since that’s a complex formula, I thought to write this tutorial to explain that specific part.
As mentioned above, to get all the words after the nth word in a sentence, we will use REGEXREPLACE instead of another related function called REGEXEXTRACT.
The reason is like this.
We will replace the first n words and non-word characters, such as a space with blanks.
The rest of the sentence part will be the result we wish to get as the formula output.
Let’s quickly try our non-regex formula to get all words after the nth word in a sentence. The regex formula follows.
Without Using RE2 Regular Expression
To test, we may use the following dummy text in cell A1.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus posuere efficitur sapien, eu euismod lacus vulputate vitae.
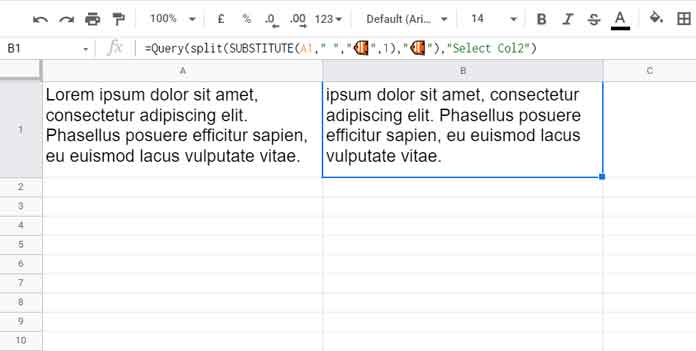
=Query(split(SUBSTITUTE(A1," ","🐠",1),"🐠"),"Select Col2")The above formula extracts all the words after the first word from the dummy text in cell A1.
Replace the number 1 in the formula with the number 5 to get all the words after the fifth word in the sentence.
Formula Explanation:
We have used the SUBSTITUTE formula to replace the first occurrence of the space character with the fish character.
We then split the sentence into two based on the said delimiter.
That will create two-column data. The QUERY is to return the data from the second column, and that is what we want.
Does the above non-regex formula that returns all words after the nth word in a sentence will work in an array?
Yes, it will! Here is an example.
=ArrayFormula(Query(split(SUBSTITUTE(A1:A100," ","🐠",1),"🐠"),"Select Col2"))In the above, you can see a cell range in use (A1:A100) instead of the cell reference (A1).
In addition to that, as you may already know, I have included the ARRAYFORMULA function to expand the result.
Note:- Use TRIM(A1:A1000) or TRIM(A1) if you doubt the words in your sentence are separated by multiple spaces intentionally or due to typo. In the following REGEX, it’s not required.
That being said, let’s go to the regular expression based formula.
We can use the below regular expression for the same in the REGEXREPLACE function.
Regular Expression and Formula Options
Expression:
^(w*W*){2}Elements:
^ – Asserts position at the beginning of text or line.
w – Matches word characters (underscore and alphanumeric characters [0-9A-Za-z_]).
* – Capture preceding token between 0 and unlimited times.
W – Matches ‘not word’ characters (not underscore and alphanumeric characters [^0-9A-Za-z_]).
{n} – Matches the preceding token exactly n times.
Note:- Please refer this GitHub page for RE2 syntax reference.
The above is the regex regular expression that we can use to get all the words after the nth word in a sentence in Google Sheets.
How to use the above regular expression in a Google Sheets formula?
Here you go!
=REGEXREPLACE(A1,"^(w*W*){3}","")Array Formula to Get All Words after the Nth Word in a Sentence in Google Sheets
The above formula will support cell range that means capable of returning an array result.
Here is an example for you to understand the array use of the above regular expression in Google Sheets.
=ArrayFormula(REGEXREPLACE(A1:A,"^(w*W*){2}",""))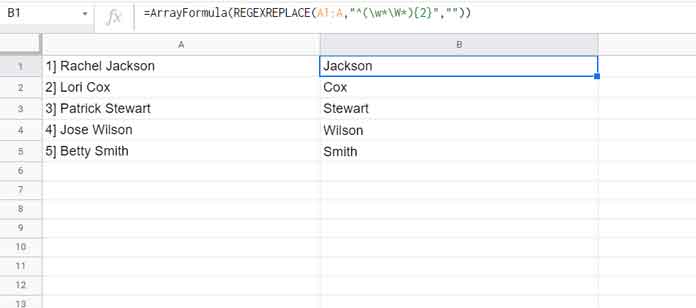
In the list of names from column A, the above REGEXREPLACE array formula returns the last name.
It replaces the first two words, i.e., the serial number and first name, with blank.
That’s all. Thanks for the stay. Enjoy!
Related Resources:
- How to Split Number from Text When No Delimiter Present in Google Sheets.
- Insert Delimiter into a Text After N or Every N Character in Google Sheets.
- Substitute Nth Match of a Delimiter from the End of a String.
- Extract Last N Values from a Delimiter Separated String in Google Sheets.
- How to Match | Extract Nth Word in a Line in Google Sheets.
- Split a Text after Every Nth Word in Google Sheets.
17
Friday
Feb 2017
One of the frequently asked questions about REGEXP in Oracle SQL are like “How to extract string after specific character?”. Let’s look at the following simple example:
Requirement : Extract everything after dot from string ‘123abc.xyz456‘ i.e. output should be ‘xyz456‘.
SQL> WITH data AS
2 (
3 SELECT '123abc.xyz456' str FROM dual
4 )
5 SELECT str,
6 REGEXP_SUBSTR(str, '[^.]+$') new_str
7 FROM data;
STR NEW_STR
------------- -------------
123abc.xyz456 xyz456
How it works :
- [^.] negated character class to match anything except for a dot
- + quantifier to match one or more of these
- $ anchor to restrict matches to the end of the string
Hope it helps!