
Модель данных позволяет интегрировать данные из нескольких таблиц, эффективно создавая реляционный источник данных в книге Excel. В Excel модели данных используются прозрачно, предоставляя табличные данные, используемые в сводных таблицах и сводных диаграммах. Модель данных визуализируются как коллекция таблиц в списке полей, и в большинстве раз вы даже не узнаете, что она существует.
Прежде чем приступить к работе с моделью данных, необходимо получить некоторые данные. Для этого мы будем использовать интерфейс Get & Transform (Power Query), поэтому вам может потребоваться выполнить шаг назад и посмотреть видео, или следуйте нашему руководству по обучению по get & Transform и Power Pivot.
Где есть Power Pivot?
-
Excel 2016 & Excel для Microsoft 365 — Power Pivot включен в ленту.
-
Excel 2013 — Power Pivot входит в Office профессиональный плюс Excel 2013, но не включен по умолчанию. Дополнительные сведения о запуске надстройки Power Pivot для Excel 2013.
-
Excel 2010 — скачайте надстройку Power Pivot, а затем установите надстройку Power Pivot.
Где находится get & Transform (Power Query)?
-
Excel 2016 & Excel для Microsoft 365 . Get & Transform (Power Query) интегрировано с Excel на вкладке «Данные«.
-
Excel 2013 — Power Query — это надстройка, которая входит в Excel, но ее необходимо активировать. Перейдите к разделу «Параметры >» > надстроек, а затем в раскрывающемся списке «Управление» в нижней части панели выберите com-надстройки > Go. Проверьте microsoft Power Query Excel, а затем ОК, чтобы активировать его. На Power Query будет добавлена вкладка Power Query.
-
Excel 2010 — скачивание и установка Power Query надстройки.. После активации на ленту Power Query вкладки.
Начало работы
Сначала необходимо получить некоторые данные.
-
В Excel 2016 и Excel для Microsoft 365 используйте data >Get & Transform Data > Get Data > Get Data to import data from any number of external data sources, such as a text file, Excel workbook, website, Microsoft Access, SQL Server, or another relational database that contains multiple related tables.
В Excel 2013 и 2010 перейдите к Power Query >получения внешних данных и выберите источник данных.
-
Excel предложит выбрать таблицу. Если вы хотите получить несколько таблиц из одного источника данных, установите флажок «Включить выбор нескольких таблиц «. При выборе нескольких таблиц Excel автоматически создает модель данных.
Примечание: В этих примерах мы используем книгу Excel с вымышленными сведениями о классах и оценках учащихся. Вы можете скачать пример книги модели данных учащихся и следовать инструкциям. Вы также можете скачать версию с готовой моделью данных..

-
Выберите одну или несколько таблиц и нажмите кнопку «Загрузить «.
Если необходимо изменить исходные данные, можно выбрать параметр «Изменить «. Дополнительные сведения см. в статье «Общие сведения Редактор запросов (Power Query)».
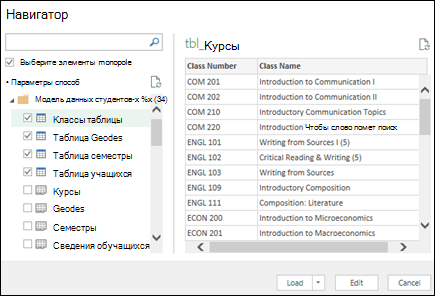
Теперь у вас есть модель данных, которая содержит все импортированные таблицы, и они будут отображаться в списке полей сводной таблицы.
Примечания:
-
Модели создаются неявно, когда вы импортируете в Excel несколько таблиц одновременно.
-
Модели создаются явно, если вы импортируете данные с помощью надстройки Power Pivot. В надстройке модель представлена в макете с вкладками, аналогичном Excel, где каждая вкладка содержит табличные данные. Дополнительные сведения об импорте данных с помощью надстройки Power Pivotсм. в статье «Получение данных с помощью SQL Server данных».
-
Модель может содержать одну таблицу. Чтобы создать модель на основе только одной таблицы, выберите таблицу и нажмите кнопку Добавить в модель данных в Power Pivot. Это может понадобиться в том случае, если вы хотите использовать функции Power Pivot, например отфильтрованные наборы данных, вычисляемые столбцы, вычисляемые поля, ключевые показатели эффективности и иерархии.
-
Связи между таблицами могут создаваться автоматически при импорте связанных таблиц, у которых есть связи по первичному и внешнему ключу. Excel обычно может использовать импортированные данные о связях в качестве основы для связей между таблицами в модели данных.
-
Советы по сокращению размера модели данных см. в статье «Создание модели данных, оптимизированной для памяти, с помощью Excel и Power Pivot».
-
Дополнительные сведения см. в руководстве по импорту данных в Excel и созданию модели данных.
Создание связей между таблицами
Следующим шагом является создание связей между таблицами, чтобы вы могли извлекать данные из любой из них. Каждая таблица должна иметь первичный ключ или уникальный идентификатор поля, например идентификатор учащегося или номер класса. Самый простой способ — перетащить эти поля, чтобы подключить их в представлении схемы Power Pivot.
-
Перейдите в power Pivot > Manage.
-
На вкладке « Главная» выберите » Представление схемы».
-
Будут отображены все импортированные таблицы, и может потребоваться некоторое время, чтобы изменить их размер в зависимости от количества полей в каждой из них.
-
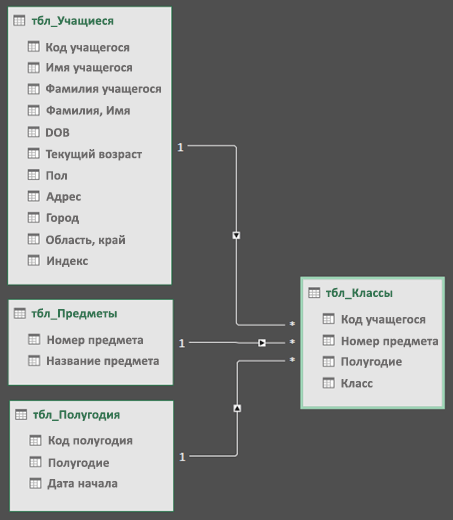
Затем перетащите поле первичного ключа из одной таблицы в следующую. В следующем примере показано представление схемы таблиц учащихся.
Мы создали следующие ссылки:
-
tbl_Students | Идентификатор учащегося > tbl_Grades | Идентификатор учащегося
Другими словами, перетащите поле «Идентификатор учащегося» из таблицы «Учащиеся» в поле «Идентификатор учащегося» в таблице «Оценки».
-
tbl_Semesters | Идентификаторы > tbl_Grades | Семестр
-
tbl_Classes | Номер класса > tbl_Grades | Номер класса
Примечания:
-
Имена полей не обязательно должны совпадать для создания связи, но они должны быть одинаковыми типами данных.
-
Соединители в представлении схемы имеют «1» с одной стороны, а «*» — с другой. Это означает, что между таблицами существует связь «один ко многим», которая определяет, как данные используются в сводных таблицах. См. дополнительные сведения о связях между таблицами в модели данных.
-
Соединители указывают только на наличие связи между таблицами. На самом деле они не показывают, какие поля связаны друг с другом. Чтобы просмотреть ссылки, перейдите в раздел Power Pivot > Manage > Design > Relationships > Управление связями. В Excel можно перейти к разделу «>данных».
-
Создание сводной таблицы или сводной диаграммы с помощью модели данных
Книга Excel может содержать только одну модель данных, но эта модель может содержать несколько таблиц, которые можно многократно использовать в книге. Вы можете добавить дополнительные таблицы в существующую модель данных в любое время.
-
В Power Pivotперейдите к разделу » Управление».
-
На вкладке « Главная» выберите сводную таблицу.
-
Выберите место размещения сводной таблицы: новый лист или текущее расположение.
-
Нажмите кнопку «ОК», и Excel добавит пустую сводную таблицу с областью списка полей справа.
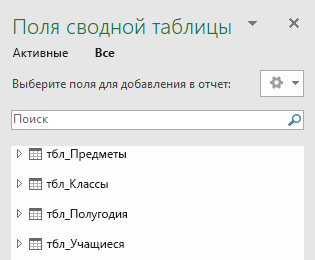
Затем создайте сводную таблицу или сводную диаграмму. Если вы уже создали связи между таблицами, можно использовать любое из их полей в сводной таблице. Мы уже создали связи в образце книги модели данных учащихся.
Добавление имеющихся несвязанных данных в модель данных
Предположим, вы импортировали или скопировали много данных, которые вы хотите использовать в модели, но не добавили их в модель данных. Принудительно отправить новые данные в модель очень просто.
-
Начните с выбора любой ячейки в данных, которые необходимо добавить в модель. Это может быть любой диапазон данных, но лучше всего использовать данные, отформатированные в виде таблицы Excel .
-
Добавьте данные одним из следующих способов.
-
Щелкните Power Pivot > Добавить в модель данных.
-
Выберите Вставка > Сводная таблица и установите флажок Добавить эти данные в модель данных в диалоговом окне «Создание сводной таблицы».
Диапазон или таблица будут добавлены в модель как связанная таблица. Дополнительные сведения о работе со связанными таблицами в модели см. в статье Добавление данных с помощью связанных таблиц Excel в Power Pivot.
Добавление данных в таблицу Power Pivot данных
В Power Pivot невозможно добавить строку в таблицу, введя текст непосредственно в новой строке, как это можно сделать на листе Excel. Но можно добавить строки , скопируйте и вставьте или обновите исходные данные и обновите модель Power Pivot.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Ознакомьтесь & по преобразованию и обучению Power Pivot
Общие сведения о редакторе запросов (Power Query)
Создание модели данных, оптимизированной для памяти, с помощью Excel и Power Pivot
Руководство. Импорт данных в Excel и создание модели данных
Определение источников данных, используемых в модели данных книги
Связи между таблицами в модели данных

Excel может анализировать данные из многих источников. Но используете ли вы модель данных, чтобы облегчить себе жизнь? В этом посте вы узнаете, как создать сводную таблицу с использованием двух таблиц с помощью функции модели данных в Excel.
Оглавление
- Что такое модель данных
- Простая задача
- Преимущества модели данных
- Добавить данные в модель данных
- Создание отношений между данными
- Использование модели данных
Содержание
- Что такое модель данных
- Простая задача
- Преимущества модели данных
- Добавить данные в модель данных
- Создание отношений между данными
- Использование модели данных
- Анализировать в Excel – Модель данных отсутствует в Excel – Сообщество Microsoft Power BI
Что такое модель данных
Модель данных Excel позволяет загружать данные (например, таблицы) в память Excel. Он сохраняется в памяти, где вы его не видите. Затем вы можете указать Excel связать данные друг с другом с помощью общего столбца. Часть «Модель» модели данных относится к тому, как все таблицы соотносятся друг с другом.
Старая школа Excel Pro, используйте формулы для создания огромной таблицы, содержащей все данные для анализа. Им нужна эта большая таблица, чтобы сводные таблицы могли служить источником единой таблицы. Тем не менее, создавая отношения, вы избавляетесь от необходимости использовать формулы ВПР, СУММЕСЛИ, ИНДЕКС-ПОИСКПОЗ. Другими словами, вам не нужно собирать все столбцы в одной таблице. Через отношения модель данных может получить доступ ко всей необходимой информации. Даже если он находится в нескольких местах или за таблицами. После создания модели данных Excel сохраняет данные в своей памяти. И, имея его в своей памяти, вы можете получить доступ к данным по-новому. Например, вы можете начать использовать несколько таблиц в одной сводной таблице.
Простая задача
Представьте, что ваш босс хочет иметь представление о продажах, но также хочет знать пол продавца. Ниже представлен набор данных, содержащий одну таблицу с продажами на человека и другую таблицу, содержащую продавцов и их пол. Чтобы проанализировать ваши данные, используйте формулу ПРОСМОТР и составьте большую таблицу, содержащую всю информацию. На следующем этапе вы можете использовать сводную таблицу для суммирования данных по полу.

Преимущества модели данных
Метод And before отлично подходит, когда вы работаете с очень небольшим количеством данных. Тем не менее, у использования функции модели данных в Excel есть преимущества. Вот некоторые преимущества:
- Проверка и обновление формул может быть произвольной при работе с большим количеством таблиц. В конце концов, вам нужно убедиться, что все формулы заполнены до нужной ячейки. И после добавления новых столбцов формулы LOOKUP также необходимо расширить. Модель данных требует совсем немного времени при настройке , чтобы связать таблицу. При настройке используется общий столбец. Однако столбцы, которые вы добавляете позже, автоматически добавляются в модель данных.
- Работа с большими объемами данных часто приводит к очень медленной работе листа из-за вычислений.. Однако модель данных корректно обрабатывает большие объемы данных , не замедляя работу вашей компьютерной системы.
- Excel 2016 имеет ограничение в 1,048,576 строк. Однако количество строк, которые вы можете добавить в память модели данных, практически не ограничено . В 64-битной среде нет жестких ограничений на размер файла. Размер книги ограничен только доступной памятью и системными ресурсами.
- Если ваши данные находятся только в вашей модели данных, вы значительно сэкономите на размере файла .
Добавить данные в модель данных
Теперь вы узнаете, как добавлять таблицы в модель данных. Для начала убедитесь, что ваши данные находятся в таблице. Используя Power Query, вы можете легко загружать таблицы в модель данных.
- Щелкните вкладку Данные -> Щелкните ячейку в нужной таблице для импорта
- Выберите Из таблицы/диапазона

На главной вкладке редактора Power Query
- Выберите Close & Load -> затем Закрыть и загрузить в…

- Выберите Только создать соединение .
- Обязательно установите флажок Добавить эти данные в модель данных

Это добавляет данные в модель данных. Обязательно выполните эти действия для обеих таблиц .
Создание отношений между данными
После добавления данных в модель данных вы можете связать общие столбцы друг с другом. Чтобы создать связи между таблицами:
- Перейдите на вкладку Данные -> выберите Управление моделью данных

Откроется экран Power Pivot.
- Щелкните Представление диаграммы. Это дает вам обзор всех таблиц в модели данных.
- Затем свяжите общий столбец “Продавец” в первая таблица, со столбцом «Продавец» во второй таблице. Вы можете сделать это, щелкнув и перетащив один столбец на другой. Должна появиться связь.

Примечание : Когда вы устанавливаете связь между двумя столбцами, обычно в одном из столбцов указываются уникальные значения. Это называется отношением один-ко-многим . Наличие дубликатов с обеих сторон может привести к ошибке. Для сложных вычислений могут существовать отношения многие-ко-многим (например, в Power BI). Однако это слишком сложная задача, чтобы описать ее в этой статье. Если вас интересуют эти темы, обязательно исследуйте «Отношения« многие ко многим ».
Использование модели данных
Теперь мы подошли к самому интересному.. Чтобы использовать модель данных в сводной таблице, выполните следующие действия:
- Перейдите на вкладку Вставить -> нажмите Pivot Таблица
Появится всплывающий экран «Создать сводную таблицу». Поскольку у вас есть модель данных, теперь вы можете выбрать использование ее в качестве источника данных.
- Нажмите Использовать модель данных этой книги

Теперь в полях сводной таблицы вы увидите все возможные источники данных для вашей сводной таблицы. Желтый значок базы данных в правом нижнем углу отмеченных таблиц показывает, что она является частью модели данных Excel.

Поскольку две таблицы связаны друг с другом, вы можете использовать поля из обеих таблиц в одной сводной таблице! Прочтите предыдущее предложение еще раз. Разве это не потрясающе ?? В примере ниже используются поля «Продажи» и «Продавец» из таблицы ProductSales, а поле «Пол» – из другой таблицы. И цифры по-прежнему верны!

Используя модель данных, вы можете анализировать данные из нескольких таблиц одновременно . И все это без использования формул ПРОСМОТР, СУММЕСЛИ или ИНДЕКС ПОИСКПОЗ для выравнивания исходной таблицы. Тем не менее, анализируемые данные также могут поступать из базы данных, текстового файла или облачного хранилища. Возможности безграничны.
Чтобы еще больше свести к минимуму использование формул LOOKUP, обратите внимание на Power Query. На моем сайте есть несколько статей об этом. Например, вы можете прочитать, как использовать Power Query для создания уникальных комбинаций или для преобразования столбцов с накоплением .
Я произвел некоторые преобразования и добавил еще несколько столбцов в свою модель данных.
Теперь мне нужно экспортировать эти данные в файл CSV из модели данных, как мне сделать это, Рик? У меня 7,5 миллионов записей.
Ответ
Привет, Рик! – Спасибо, что поделились!
У меня к вам вопрос, надеюсь, вы сможете ответить:
У меня есть файл CSV с 2 мил. строки (записи GL с транзакциями за каждый день). Я использую Power Query для подключения к файлу и добавления в Datamodel.
Если я ничего не сделаю, Datamodel должен обработать 2 миллиона. строк.
Если я сделаю группировку с агрегированием суммы в месяц в Power Query, тогда будет только 80 тысяч строк.
Будет ли это преимуществом, сделайте это быстрее в модели данных , чтобы использовать PowerQuery для такого агрегирования?
Ответ
Привет, Рик, спасибо за ответ. На данный момент я только пытаюсь создать информационный список. Хотя я понял это; когда я объединяю их в Power Query, он определяет уникальный ключ цветового кода и дает мне то, что я ищу. Большое спасибо!
Ответ
У меня есть 5 списков в Sharepoint на основе производственных частей, которые я хочу использовать в модели данных (сначала попробуйте это).
Я только начинаю с двух из них: «Основные части» и «Цветовые коды».. Я подтвердил, что столбец «Цветовой код» в списке «Цветовые коды» уникален (2000 уникальных кодов). В списке «Основные детали» около 1800 номеров деталей. Объединение происходит по «Цветовому коду», который есть в каждом списке. Когда я пытаюсь извлечь описание цвета из списка цветовых кодов, я получаю сообщение о том, что отчет сводной таблицы не помещается на листе – он пытается назначить каждый цветовой код каждому отдельному номеру детали, как будто нет реляционной связи между Столбцы цветового кода в каждом списке, но они явно есть в моей модели данных. Какие-либо предложения? На первом этапе кажется очевидным, что…
Ответ
Привет, Рик,
Ваша статья ясна, проста и легка для понимания.
Я прочитал много статей о модели данных и Power Pivot, но ваша статья действительно проста.
У меня к вам вопрос.
Я создал панель мониторинга в формате xlsb и вставил множество срезов, сводных таблиц и графики.
Две таблицы, из которых берутся данные, состоят из 200 тыс. строк, но они всегда растут неделя за неделей.
Каждую неделю мне приходится преобразовывать данные в таблицы, потому что источники таких данные разные (SAP, Coupa), и, кроме того, я вношу в них некоторые дополнительные изменения.
Теперь я заметил, что время загрузки модели данных слишком сильно увеличивается, и я ищу способ сделать запросы быстрее.
Я сохранил файл как xlsb. Я также удалил исходные данные (изначально я помещал таблицы в тот же файл, что и панель мониторинга на разных листах): после обновления исходных данных и обновления панели мониторинга я использую для удаления листов, на которых были исходные данные, чтобы уменьшить размер файла. На данный момент размер файла составляет 20 МБ (xlsb).
Основная проблема – время для загрузки модели данных. Все еще слишком много.
Я еще не использовал power query/pivot, потому что эта панель инструментов используется многими пользователями, и, если я хорошо помню, всем им следует активировать эту функцию, чтобы панель работала нормально. Это может быть очень сложно управлять.
Я уже пытался не использовать функции.
Исходный источник данных с множеством столбцов и все функции в нем сохранены в другом файле. Затем я помещаю в тот же файл, где находится панель управления, но на другом листе, только те столбцы, которые мне действительно нужны для работы.
Как сказано выше, после обновления сводных таблиц и графиков я удаляю исходные данные (сохраненные в другом файле Excel).
Итак, есть ли у вас предложения, чтобы ускорить запросы?
Спасибо,
Майкл
Ответить
Привет, Рик. Спасибо за то, что уделили время написанию этого.
Итак, я в основном застрял на том факте, что у меня есть рабочая книга, которая добавляет и вычисляет столбцы и меры.
Теперь … я хочу используйте эту модель данных в ДРУГОМ файле excel. Соединение должно обновляться автоматически, поскольку оба файла находятся на Sharepoint.
Мой вопрос заключается в том, могу ли я использовать вычисляемые столбцы и проводить измерения из одной «пустой» книги (модель данных) в другой книге, поэтому я можно создать там новую сводную таблицу.
Есть шансы?
Спасибо,
Сантьяго из Перу
Ответ
Привет, Рик,
Надеюсь, ты поможешь с моим вопросом. У меня есть данные, которые повторяются через годы. Я отметил это стрелкой на картинке. Вот ссылки на файл Excel.
https://www.dropbox.com/scl/fi/1xxmqyb9a0vwpj00mfkgj/Sample.xlsx?dl=0&rlkey=n2zc09cvc7gzxgv0p3g9kwi70
https://www.dropbox.com/s/hpcmtf6q1rfehwl/Capture.PNG?dl=0
https://www.dropbox.com/s/418zg5uupy6g3wj/Capture2.PNG? dl = 0
Стоимость печати должна быть указана только за один год, а не за три года. Все остальные данные верны: гонорар тренера, гонорар эксперта, плата за номер и плата за питание и питание.
Спасибо,
K
Ответить
У меня есть информационная панель, заполненная сводными таблицами, которые заполняются моделью данных. Я хочу включить срезы для фильтрации данных. Если я затем отправлю файл кому-то, у кого нет доступа к исходному источнику данных, будут ли срезы работать для этого человека? Или они получат ошибку, потому что Excel и модель данных больше не могут найти источник данных? (Я знаю, что они не могут обновить модель данных, я просто беспокоюсь о просмотре того, что я уже заполнил, прежде чем отправлять им)
Ответ
не работает для меня! В модели данных все дублируется между двумя таблицами! Итак, у меня есть 99 единичных строк в таблице 1 и 99 уникальных строк в таблице 2, так что есть отображение 1-1. Таблица первая. Я переместил один столбец из таблицы 1 в таблицу 2 и попытался объединить два, используя модель данных, и все, что он делает, повторяет 99 полей из таблицы 2 под ключом в таблице 1 – vlookups намного проще. Кроме того, у меня возникают всевозможные проблемы с памятью, поэтому он не так хорош, как vlookups для больших наборов данных.
Ответ
Так что в основном Excel становится больше похожим на Access?
Ответить
Это было моей мыслью, когда я узнал больше об этом инструменте, особенно после того, как увидел Отношения.
Ответ
Спасибо, отличная информация
Ответ
Одна важная вещь, которая мне нравится в моделях данных, – это дополнительные функции, которые вы можете использовать в сводных таблицах, особенно «Уникальные счетчики».
Ответ
Анализировать в Excel – Модель данных отсутствует в Excel – Сообщество Microsoft Power BI
Привет всем –
I Я пытаюсь использовать «Анализировать в Excel», чтобы перенести мою модель данных Power BI в Microsoft Excel для создания отчетов для моих клиентов (которые предпочитают работать в Excel). Я успешно сохранил файл Excel с подключением pbiazure из службы Power BI и построил сводную таблицу. Однако, когда я пытаюсь щелкнуть «Управление моделью данных» в Excel, чтобы увидеть взаимосвязи (которые, как я ожидаю, будут такими же, как для рабочего стола Power BI), модель данных не отображается и остается пустой.
Кто-нибудь знает, почему это так? В случае, если он напрямую подключен к набору данных в службе Power BI, я предполагаю, что он сможет отображать и редактировать модель данных непосредственно в Excel..
Может ли кто-нибудь пролить свет на то, почему отображается пустой экран без модели данных?
Привет, @ sviswan2!
Параметр «Управление моделью данных» в Excel будет отображать модель данных только при подключении источника данных в Excel. Модель данных создается автоматически при одновременном импорте двух или более таблиц из базы данных. Когда вы импортируете одну таблицу, вы можете выбрать «добавить эти данные в модель данных». См. Эту статью: Advanced Excel – модель данных
В этом выпуске «Анализировать в Excel» просто цитирует набор данных из службы power bi, а не как единый источник данных, этот набор данных взят из вашего. pbix, который включает отношения и т. д., поэтому он не будет использоваться в качестве единственного источника данных для добавления в модель данных в Excel.
Другими словами, сам набор данных был моделью, вы Вы можете управлять им на своем рабочем столе power bi, а не в Excel, чтобы воссоздать модель.
С уважением,
Инцзе Ли
Если этот пост помогает, то, пожалуйста, рассмотрите вариант “Принять его” как решение, которое поможет другим участникам быстрее его найти.
Привет @ v-yingjl –
Спасибо за пояснение, которое немного помогает понять. Поэтому, пожалуйста, поясните следующее:
1) Если модель данных не импортирована, будут ли работать все отношения между данными, которые я настроил в файле рабочего стола, когда я использую его как «Анализировать в Excel “?
2) Если я хочу добавить какую-либо связь или меру, я должен сначала сделать это на рабочем столе Power BI, опубликовать в службе, а затем он должен появиться в моем файле Excel?
спасибо!
Привет @ sviswan2,
- Да, «Анализировать в excel» цитирует набор данных в сервисе power bi, отношения сохранятся.
- Если вы хотите добавить взаимосвязь или меру, у вас есть сделать это сначала на рабочем столе power bi, затем опубликовать в сервисе и повторно использовать «Анализировать в Excel», хотя вы не можете видеть взаимосвязь и конкретную формулу меры, вы можете видеть только поля таблицы и значение меры в excel.
С уважением,
Инцзе Ли
Если этот пост поможет, пожалуйста, примите его как решение чтобы помочь другим участникам найти его быстрее.
Привет @ sviswan2,
Анализировать в Excel позволяет взаимодействовать с набором данных из Power BI, но он имеет только соединение с набором данных, он не имеет данных из модели.
Вот ссылка: https://docs.microsoft.com/en-us/power-bi/collaborate-share/service-analyze-in-excel
“Вы можете сохранить книгу Excel вы создаете с помощью набора данных Power BI, как и любую другую книгу. Однако вы не можете публиковать или импортировать книгу обратно в Power BI, потому что вы можете публиковать или импортировать в Power BI только те книги, которые имеют данные в таблицах или имеют модель данных.. Поскольку новая книга просто подключается к набору данных в Power BI , публикация или импорт в Power BI будет происходить по кругу “.
Преимущества сводной по Модели Данных
При построении сводной таблицы в Excel в первом же диалоговом окне, где нас просят задать исходный диапазон и выбрать место для вставки сводной, есть внизу неприметная, но очень важная галочка — Добавить эти данные в Модель Данных (Add this data to Data Model) и, чуть выше, переключатель Использовать модель данных этой книги (Use Data Model of this workbook):

К сожалению, очень многие даже давно знакомые со сводными таблицами и успешно применяющие их в работе пользователи, порой не очень понимают смысл этих опций и никогда их не используют. И зря. Ведь создание сводной по Модели Данных даёт нам несколько очень важных преимуществ по сравнению с классической сводной таблицей Excel.
Однако, перед тем, как рассматривать эти «плюшки» вблизи, давайте сначала разберёмся с тем, что такое, собственно, эта Модель Данных?
Что такое Модель Данных
Модель Данных (сокращенно — МД или DM=Data Model) — это специальная область внутри файла Excel, куда можно где можно хранить табличные данные — одну или несколько таблиц связанных, при желании, между собой. По сути, это маленькая база данных (OLAP-куб), встроенная внутрь книги Excel. По сравнению с классическим хранением данных в виде обычных (или умных) таблиц на листах самого Excel, у Модели Данных есть несколько серьезных преимуществ:
- Размер таблиц может достигать 2 млрд. строк, а на лист Excel вмещается чуть больше 1 млн.
- Не смотря на гигантские размеры, обработка таких таблиц (фильтрация, сортировка, вычисления по ним, построение сводных и т.д.) выполняются очень быстро — гораздо быстрее, чем в самом Excel.
- С данными в Модели можно производить дополнительные (при желании — весьма сложные) вычисления с помощью встроенного языка DAX.
- Вся информация, загруженная в Модель Данных, очень сильно сжимается с помощью специального встроенного архиватора и весьма умеренно увеличивает размер исходного Excel-файла.
Управлением Моделью и вычислениями по ней занимается специальная встроенная в Microsoft Excel надстройка — Power Pivot, о которой я уже писал. Чтобы её включить, на вкладке Разработчик нажмите кнопку Надстройки COM (Developer — COM Add-ins) и поставьте соответствующую галочку:

Если вкладки Разработчик (Developer) у вас на ленте не видно, то включить её можно через Файл — Параметры — Настройка ленты (File — Options — Customize Ribbon). Если же в показанном выше окне в списке COM-надстроек у вас нет Power Pivot, то значит она не входит в вашу версию Microsoft Office 
На появившейся вкладке Power Pivot будет большая салатового цвета кнопка Управление (Manage), нажатие на которую и откроет поверх Excel окно Power Pivot, где мы и увидим содержимое Модели Данных текущей книги:

Важное замечание по ходу: книга Excel может содержать только одну Модель Данных.
Грузим таблицы в Модель Данных
Для загрузки данных в Модель сначала превращаем таблицу в динамическую «умную» сочетанием клавиш Ctrl+T и даём ей понятное имя на вкладке Конструктор (Design). Это обязательный этап.
Затем можно использовать любой из трех способов, на выбор:
- Жмём кнопку Добавить в модель (Add to Data Model) на вкладке Power Pivot на вкладке Главная (Home).
- Выбираем команды Вставка — Сводная таблица (Insert — Pivot Table) и включаем флажок Добавить эти данные в Модель данных (Add this data to Data Model). В этом случае по загруженным в Модель данным сразу строится ещё и сводная таблица.
- На вкладке Данные (Data) жмём на кнопку Из таблицы/диапазона (From Table/Range), чтобы загрузить нашу таблицу в редактор Power Query. Этот путь самый долгий, но, при желании, здесь можно произвести дополнительную зачистку данных, правки и всяческие трансформации, в которых Power Query очень силён.
Затем причёсанные данные выгружаются в Модель командой Главная — Закрыть и загрузить — Закрыть и загрузить в… (Home — Close&Load — Close&Load to…). В открывшемся окне выбираем вариант Только создать подключение (Only create connection) и, главное, ставим галочку Добавить эти данные в Модель данных (Add this data to Data Model).
Строим сводную по Модели Данных
Чтобы построить сводную Модели Данных можно использовать любой из трёх подходов:
- Нажать кнопку Сводная таблица (Pivot Table) в окне Power Pivot.
- Выбрать в Excel команды Вставка — Сводная таблица и переключиться в режим Использовать модель данных этой книги (Insert — Pivot Table — Use this workbook’s Data Model).
- Выбираем команды Вставка — Сводная таблица (Insert — Pivot Table) и включаем флажок Добавить эти данные в Модель данных (Add this data to Data Model). Текущая «умная» таблица будет загружена в Модель и по всей Модели будет построена сводная таблица.
Теперь, когда мы разобрались с тем, как загружать данные в Модель Данных и строить по ним сводную, давайте изучем те выгоды и преимущества, которые нам это даёт.
Преимущество 1. Связи между таблицами без помощи формул
Обычная сводная может быть построена только по данным из одной исходной таблицы. Если же у вас их несколько, например, продажи, прайс, справочник по клиентам, реестр договоров и т.д., то сначала придется собирать данные из всех таблиц в одну с помощью функций типа ВПР (VLOOKUP), ИНДЕКС (INDEX), ПОИСКПОЗ (MATCH), СУММЕСЛИМН (SUMIFS) и им подобных. Это долго, муторно и вгоняет ваш Excel в «задумчивость» при большом количестве данных.
В случае сводной по Модели Данных всё гораздо проще. Достаточно один раз настроить связи между таблицами в окне Power Pivot — и дело в шляпе. Для этого на вкладке Power Pivot жмём кнопку Управление (Manage) и затем в появившемся окне — кнопку Представление диаграммы (Diagram View). Останется перетащить общие (ключевые) названия столбцов (поля) между таблицами, чтобы создать связи:

После этого в сводной по Модели Данных можно закидывать в области сводной (строки, столбцы, фильтры, значения) любые поля из любых связанных таблиц — всё будет связываться и подсчитываться уже автоматически:

Преимущество 2. Подсчёт количества уникальных значений
Обычная сводная таблица даёт нам возможность выбрать одну из нескольких встроенных функций расчёта: сумму, среднее, количество, минимум, максимум и т.д. В сводной по Модели Данных к этому стандартному списку добавляется весьма полезная функция подсчёта количества уникальных (неповторяющихся значений). С её помощью, например, можно легко посчитать количество уникальных наименований товаров (ассортимент), который мы продаём в каждом городе.
Щёлкаем правой кнопкой мыши по полю — команда Параметры полей значений и на вкладке Операция выбираем Число разных элементов (Distinct count):

Преимущество 3. Свои формулы на языке DAX
Иногда в сводных таблицах приходится выполнять различные дополнительные вычисления. В обычных сводных это делается с помощью вычисляемых полей и объектов, а сводной по Модели Данных для этого используются меры на специальном языке DAX (DAX = Data Analysis Expressions).
Для создания меры выберите на вкладке Power Pivot команду Меры — Создать меру (Measures — New measure) или просто щёлкните правой кнопкой мыши по таблице в списке полей сводной и выберите Добавить меру (Add measure) в контекстном меню:

В открывшемся окне задаём:

- Имя таблицы, где созданная мера будет храниться.
- Название меры — любое понятное вам имя для нового поля.
- Описание — по желанию.
- Формула — самое главное, т.к. здесь мы либо вручную вписываем, либо жмём на кнопку fx и выбираем из списка функцию DAX, которая должна вычислять результат, когда мы потом забросим нашу меру в область Значений.
- В нижней части окна можно сразу задать для меры числовой формат в списке Категория.
Язык DAX не всегда прост для понимания, т.к. оперирует не отдельными значениями, а целыми столбцами и таблицами, т.е. требует некоторой перестройки мышления после классических формул Excel. Однако же, оно того стоит, ибо мощь его возможностей при обработке больших объемов данных трудно переоценить.
Преимущество 4. Свои иерархии полей
Часто при создании типовых отчётов приходится забрасывать в сводные таблицы одни и те же комбинации полей в заданной последовательности, например Год-Квартал-Месяц-День, или Категория-Товар, или Страна-Город-Клиент и т.п. В сводной по Модели Данных эта проблема легко решается созданием собственных иерархий — пользовательских наборов полей.
В окне Power Pivot переключитесь в режим диаграммы кнопкой Представление диаграммы на вкладке Главная (Home — Diagram View), выделите с Ctrl нужные поля и щёлкните по ним правой кнопкой мыши. В контекстном меню будет команда Создать иерархию (Create hierarchy):

Созданную иерархию можно переименовать и перетащить в неё мышью требуемые поля, чтобы потом в одно движение забрасывать их в сводную:

Преимущество 5. Свои наборы элементов
Продолжая идею предыдущего пункта, в сводной по Модели Данных можно создавать ещё и свои наборы элементов для каждого поля. Например, из всего списка городов можно легко сделать набор только из тех, которые входят в зону вашей ответственности. Или собрать в специальный набор только своих клиентов, свои товары и т.п.
Для этого на вкладке Анализ сводной таблицы в выпадающем списке Поля, элементы и наборы есть соответствующие команды (Analyze — Fields, Items & Sets — Create set based on row/column items):

В открывшемся окне можно выборочно удалить, добавить или поменять положение любых элементов и сохранить получившийся набор под новым именем:

Все созданные наборы будут отображаться в панели полей сводной таблицы в отдельной папке, откуда их можно свободно перетаскивать в области строк и столбцов любой новой сводной таблицы:

Преимущество 6. Выборочное скрытие таблиц и столбцов
Это хоть и небольшое, но весьма приятное в некоторых случаях преимущество. Щёлкнув правой кнопкой мыши по названию поля или по ярлычку таблицы в окне Power Pivot, можно выбрать команду Скрыть из набора клиентских средств (Hide from Client Tools):

Скрытый столбец или таблица пропадут из панели со списком полей сводной таблицы. Очень удобно, если вам требуется скрыть от пользователя некоторые вспомогательные столбцы (например, расчетные или столбцы с ключевыми значениями для создания связей) или даже целые таблицы.
Преимущество 7. Продвинутый drill-down
Если в обычной сводной таблице сделать двойной щелчок левой кнопкой мыши по любой ячейке в области значений, то Excel выводит на отдельном листе копию фрагмента исходных данных, которые участвовали в расчёте этой ячейки. Это очень удобная штука, официально называющаяся Drill-down (на русском обычно говорят «провалиться»).
В сводной по Модели Данных этот удобный инструмент работает более тонко. Встав на любую интересующую нас ячейку с результатом, можно щёлкнуть по всплывающему рядом значку с лупой (он называется Экспресс-тенденции) и выбрать затем любое интересующее вас поле в любой связанной таблице:

После этого текущее значение (Модель = Explorer) уйдет в область фильтра, а сводная будет построена уже по офисам:

Само-собой, такую процедуру можно повторять многократно, последовательно углубляясь в ваши данные в интересующем вас направлении.
Преимущество 8. Преобразование сводной в функции кубов
Если выделить любую ячейку в сводной по Модели Данных и выбрать затем на вкладке Анализ сводной таблицы команду Средства OLAP — Преобразовать в формулы (Analyze — OLAP Tools — Convert to formulas), то вся сводная будет автоматически преобразована в формулы. Теперь значения полей в области строк-столбцов и результаты в области значений будут извлекаться из Модели Данных с помощью специальных функций кубов: КУБЗНАЧЕНИЕ и КУБЭЛЕМЕНТ:

Технически, это означает, что теперь мы имеем дело не со сводной, а с несколькими ячейками с формулами, т.е. спокойно можем делать с нашим отчетом любые преобразования недоступные в сводных, например, вставлять в середину отчета новые строки или столбцы, делать внутри сводной любые доп.вычисления, оформлять их любым желаемым образом и т.д.
При этом связь с исходными данными, само-собой, остается и в будущем эти формулы будут обновляться при изменении источников. Красота!
Ссылки по теме
- План-факт анализ в сводной таблице с Power Pivot и Power Query
- Сводная по таблице с многострочной шапкой
- Создание базы данных в Excel с помощью Power Pivot
Время на прочтение
9 мин
Количество просмотров 12K

К старту курса о машинном и глубоком обучении делимся переводом статьи, автор которой показывает на практике, как модель машинного обучения может использоваться через Excel. Зачем это нужно? Компании больше и больше вкладывают в исследования и разработку моделей прогнозов; по мнению автора оригинала статьи, разработчика и основателя компании PyXLL доступ к ML-моделям через Excel открывает новые горизонты. Вы сможете показать модель пользователям Excel, у которых нет опыта программирования или широких знаний в области статистики. При желании можно создавать инструменты разработки и тренировки моделей полностью в Excel, например строить графы в TensorFlow. Весь исходный код из статьи доступен на GitHub.
Надстройка Excel PyXLL встраивает Python в Excel и позволяет расширять возможности Excel через Python. С помощью этой надстройки мы можем добавлять новые функции, макросы, меню и в целом перенести преимущества экосистемы Python и машинное обучение прямо в Excel. К концу статьи мы построим модель классификации животных.
Python для Machine Learning
Python хорошо подходит для машинного обучения, у него большой массив поддерживаемых пакетов, упрощающих программирование и сокращающих время разработки. ML и DL очень хорошо поддерживаются несколькими пакетами, поэтому Python — идеальный выбор. Посмотрим на распространённые пакеты для ML на Python.
Scikit-Learn
Пакет scikit-learn — это лаконичный и последовательный интерфейс к общим алгоритмам ML, упрощая введение ML в производственные системы. Библиотека сочетает высокую производительность, де-факто она отраслевой стандарт машинного обучения на Python. В статье мы будем работать именно с ней.
TensorFlow
TensorFlow от Google. Эта библиотека с открытым исходным кодом для расчёта графов потоков данных оптимизирована для целей ML. Она была разработана, чтобы удовлетворять высоким требованиям обучения нейронных сетей в среде Google и является преемницей DistBelief — основанной на нейронных сетях системы глубокого обучения, применяется в пограничных областях исследований Google.
Впрочем, TensorFlow не строго научна и достаточно обобщена, чтобы применяться в различных прикладных задачах. Ключевая особенность TensorFlow — многослойная система узлов, которая быстро тренирует сети искусственного интеллекта на больших наборах данных. В Google это даёт возможность распознавать голос и находить объекты на изображениях.
Keras
Keras — написанная на Python Open Source библиотека для нейронных сетей. Она способна работать поверх TensorFlow, Microsoft Cognitive Toolkit или Theano и имеет архитектуру, которая позволяет быстро проводить эксперименты с глубоким обучением и сосредоточена на модульности, расширяемости и удобстве пользователя. Из документации следует, что работать с Keras можно, когда вам нужна библиотека глубокого обучения, которая:
-
Обладая перечисленными выше преимуществами, позволяет просто и быстро прототипировать решения.
-
Поддерживает свёрточные и рекуррентные нейронные сети, а также их комбинирование.
-
Без проблем работает на CPU и GPU.
PyTorch
PyTorch — это научный вычислительный пакет на Python, он работает в двух направлениях:
-
Как замена NumPy с возможностью задействовать графические процессоры.
-
Как платформа исследования Deep Learning с максимумом гибкости и скорости.
Деревья решений
Деревья решений — техника машинного обучения для решения задач регрессии и классификации. Дерево делит набор данных на множество наборов по признакам так, что одно дерево владеет одним подмножеством данных. Конечные узлы дерева — листья — содержат прогнозы и используются в новых запросах к натренированной модели. Пример ниже поможет понять, как это работает. Предположим, мы имеем набор данных со множеством признаков животных: млекопитающих, птиц, рептилий, насекомых, моллюсков и амфибий. Интуитивно разделить этот набор можно так:
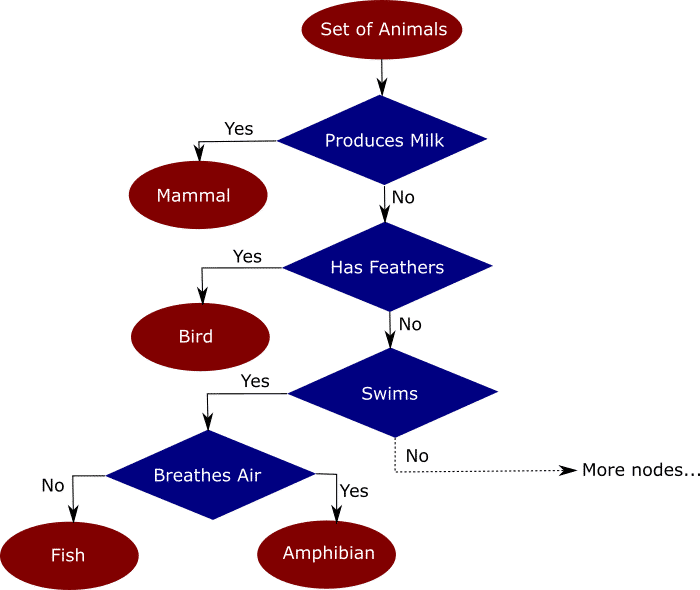
Распределение данных по деревьям на основе признака упрощает классификацию новых данных, точность которой зависит от того, насколько точно деревья отражают действительность. В незаконченное дерево на рисунке выше я заложил мои знания и интуитивные представления о животных. Модель выясняет, как распределить признаки по новым данным — это и называется машинным обучением.
Алгоритм быстро анализирует большой объём данных, чего вручную сделать невозможно. В работе деревьев решений множество аспектов, от математики до логики их построения. Мы не будем касаться этих деталей, но построим модель и я покажу, как работать с ней в Excel.
Тренировка модели
Натренируем модель классифицировать животных при помощи деревьев решений. Воспользуемся для этого набором данных UCI Zoo Data Set из 101 животного, в наборе 17 логических признаков и один признак, который мы будем прогнозировать.
Для загрузки данных воспользуемся pandas, а для построения дерева — scikit-learn. Загрузим данные во фрейм Pandas, разделим на признаки и целевой класс, то есть класс животного. Затем разделим данные на тренировочный и тестовый наборы. Scikit-Learn использует тренировочный набор для обучения деревьев, а тестовый резервируется для проверки точности модели.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
# Read the input csv file
dataset = pd.read_csv("zoo.csv")
# Drop the animal names since this is not a good feature to split the data on
dataset = dataset.drop("animal_name", axis=1)
# Split the data into features and target
features = dataset.drop("class", axis=1)
targets = dataset["class"]
# Split the data into a training and a testing set
train_features, test_features, train_targets, test_targets =
train_test_split(features, targets, train_size=0.75)Начинается самое интересное: при помощи классификатора дерева решений в scikit-learn обучим модель на тренировочных данных. Чтобы модель не переобучилась и могла работать, настроим несколько параметров. Максимальная глубина дерева будет равна 5. Поэкспериментируйте со значениями, чтобы увидеть влияние глубины на результаты.
# Train the model
tree = DecisionTreeClassifier(criterion="entropy", max_depth=5)
tree = tree.fit(train_features, train_targets)Эти две строки строят и обучают модель. Чтобы проверить её точность, подадим на вход данные, которых она не видела.
# Predict the classes of new, unseen data
prediction = tree.predict(test_features)
# Check the accuracy
score = tree.score(test_features, test_targets)
print("The prediction accuracy is: {:0.2f}%".format(score * 100))Воспользуемся моделью и выполним прогноз на новых данных:
# Try predicting based on some features
features = {
"hair": 0,
"feathers": 1,
"eggs": 1,
"milk": 0,
"airbone": 1,
"aquatic": 0,
"predator": 0,
"toothed": 1,
"backbone": 1,
"breathes": 1,
"venomous": 0,
"fins": 0,
"legs": 1,
"tail": 1,
"domestic": 0,
"catsize": 0
}
features = pd.DataFrame([features], columns=train_features.columns)
prediction = tree.predict(features)[0]
print("Best guess is {}".format(prediction])Вызовем модель из Excel
Теперь загрузим модель в Excel, который хорошо подходит для интерактивных данных. Он работает почти везде, вы сможете показать модель незнакомым с разработкой людям, это даёт массу преимуществ в бизнесе, особенно когда модель применяется как часть пакетной системы или системы реального времени. Возможность вызывать модель интерактивно может оказаться по-настоящему полезной, когда нужно понять поведение системы.
К счастью, наша модель написана на Python и перенести её в Excel просто. В PyXLL есть всё необходимое, чтобы писать на Python в Excel. Нужно только добавить несколько декораторов @xl_func из модуля pyxll и настроить надстройку PyXLL для загрузки модуля с моделью. Если вы не знакомы с PyXLL, посмотрите введение в PyXLL в руководстве пользователя.
Построим дерево решений
Начнём с функции. Пользователь вызовет её, чтобы получить объект дерева, а затем этот объект для прогнозирования пройдёт через последовательность функций. Снова построим дерево, но пример будет сложнее: сохраним натренированную при помощи pickle и затем вместо того, чтобы каждый раз её создавать, загрузим её в Excel и настроим параметры, это будет интересно!
from pyxll import xl_func
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import os
@xl_func("float, int, int: object")
def ml_get_zoo_tree(train_size=0.75, max_depth=5, random_state=245245):
# Load the zoo data
dataset = pd.read_csv(os.path.join(os.path.dirname(__file__), "zoo.csv"))
# Drop the animal names since this is not a good feature to split the data on
dataset = dataset.drop("animal_name", axis=1)
# Split the data into a training and a testing set
features = dataset.drop("class", axis=1)
targets = dataset["class"]
train_features, test_features, train_targets, test_targets =
train_test_split(features, targets, train_size=train_size, random_state=random_state)
# Train the model
tree = DecisionTreeClassifier(criterion="entropy", max_depth=max_depth)
tree = tree.fit(train_features, train_targets)
# Add the feature names to the tree for use in predict function
tree._feature_names = features.columns
return treeКод выше совпадает с кодом, который мы видели ранее, за исключением декоратора @xl_func, который сообщает дополнению PyXLL о том, какая функция Python должна стать пользовательской функцией Excel.
Строка float, int, int: object — это сигнатура функции. Она необязательна, но без этой сигнатуры пользователь сможет передавать в функцию свои типы, например, строки и это может привести к сбою. Возвращаемый тип object означает, что классификатор идёт через Excel как объект Python, функция возвращает дескриптор, который возможно передать другим функциям Python.
Код нужно добавить в список модулей конфигурационного файла pyxll.cfg, также необходима надстройка PyXLL, если вы не установили её.
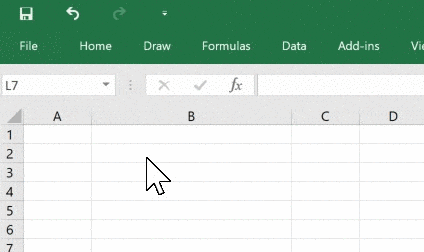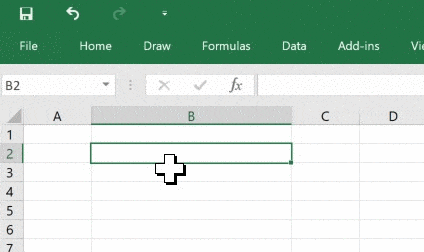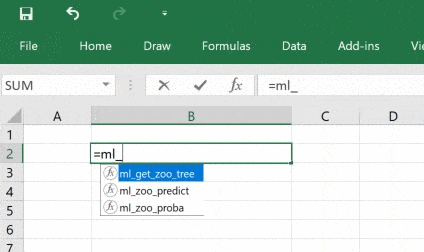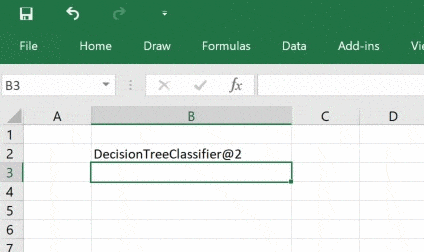
Все аргументы функции имеют значение по умолчанию, поэтому необязательны, но при желании со входными данными можно экспериментировать.
Прогнозируем класс животного
Теперь всё, что нужно для работы с моделью — ещё одна функция для передачи входных данных и получения прогноза. Используем тот же код, что и раньше, но обернём его декоратором @xl_func.
_zoo_classifications = {
1: "mammal",
2: "bird",
3: "reptile",
4: "fish",
5: "amphibian",
6: "insect",
7: "mollusc"
}
@xl_func("object tree, dict features: var")
def ml_zoo_predict(tree, features):
# Convert the features dictionary into a DataFrame with a single row
features = pd.DataFrame([features], columns=tree._feature_names)
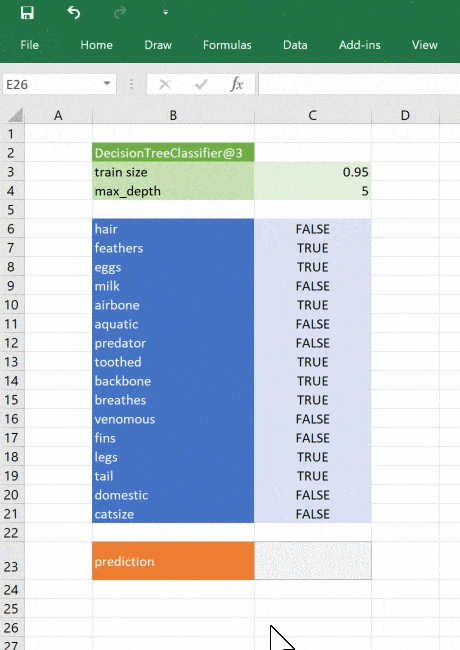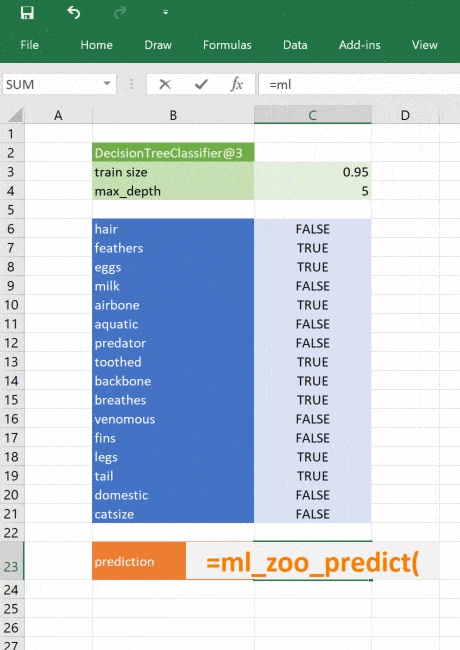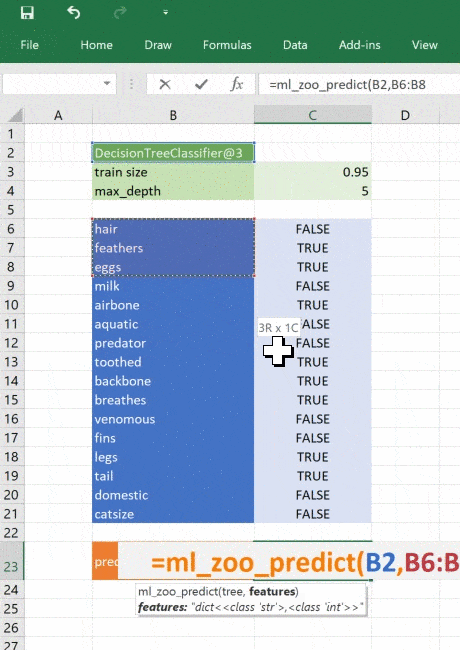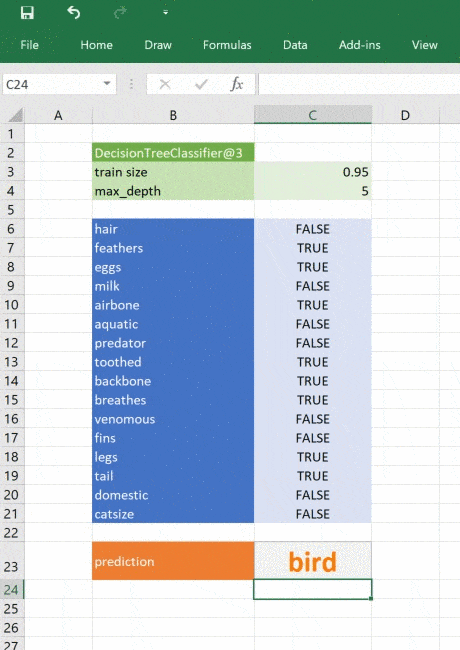
# Get the prediction from the model
prediction = tree.predict(features)[0]
return _zoo_classifications[prediction]Модель возвращает целое число — спрогнозированный класс. Словарь _zoo_classifications содержит эти числа и понятные человеку названия классов.
Эта функция берёт объект дерева из ml_get_zoo_tree и список пар ключ-значение, переданных в неё как словарь. В словаре сопоставлены имена признаков, с которыми мы работали при конструировании дерева, и входные признаки. Их сопоставление таково, что при вызове tree.predict признаки упорядочены правильно.
Это простой пример, натренированный на минимуме данных, но принцип применим к любой сложной модели. При помощи Python вы можете исследовать, разрабатывать и строить модель, чтобы получить ценные инсайты и быстрые прогнозы на реальных данных.
Небольшое дополнение
Чёрно-белые листы с цифрами нравятся всем, но иногда мне нравится добавлять небольшие детали ради привлекательности таблицы. PyXLL позволяет получить доступ к объектной модели Excel с помощью функции xl_app. Объектная модель Excel точно совпадает с той, что применяется в VBA. Функция ниже создаёт на листе объект изображения и загружает его.
from pyxll import xl_app
def show_image_in_excel(classification, figname="prediction_image"):
"""Plot a figure in Excel"""
# Show the figure in Excel as a Picture object on the same sheet
# the function is being called from.
xl = xl_app()
sheet = xl.ActiveSheet
# if a picture with the same figname already exists then get the position
# and size from the old picture and delete it.
for old_picture in sheet.Pictures():
if old_picture.Name == figname:
height = old_picture.Height
width = old_picture.Width
top = old_picture.Top
left = old_picture.Left
old_picture.Delete()
break
else:
# otherwise create a new image
top_left = sheet.Cells(1, 1)
top = top_left.Top
left = top_left.Left
width, height = 100, 100
# insert the picture
filename = os.path.join(os.path.dirname(__file__), "images", _zoo_classifications[classification] + ".jpg")
picture = sheet.Shapes.AddPicture(Filename=filename,
LinkToFile=0, # msoFalse
SaveWithDocument=-1, # msoTrue
Left=left,
Top=top,
Width=width,
Height=height)
# set the name of the new picture so we can find it next time
picture.Name = fignameВызов ml_zoo_predict обновляет изображение в Excel при каждом изменении прогноза. Функция обновляет Excel, поэтому вызывать её нужно после вычислений, именно этим занимается async_call из pyxll, а ниже вы видите новую версию ml_zoo_predict:
from pyxll import xl_func, async_call
@xl_func("object tree, dict features: var")
def ml_zoo_predict(tree, features):
# Convert the features dictionary into a DataFrame with a single row
features = pd.DataFrame([features], columns=tree._feature_names)
# Get the prediction from the model
prediction = tree.predict(features)[0]
# Update the image in Excel
async_call(show_image_in_excel, prediction)
return _zoo_classifications[prediction]Изображение обновляется при изменении прогноза:
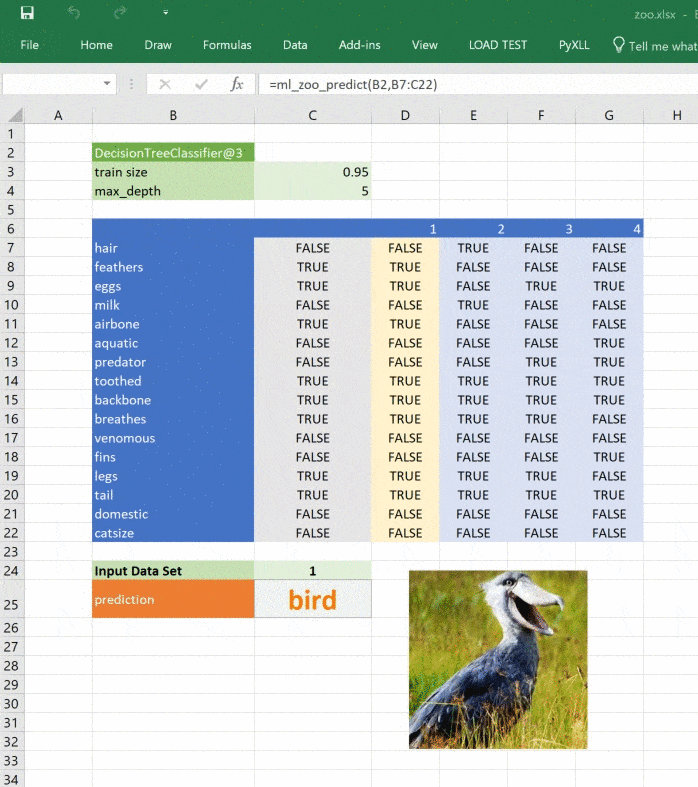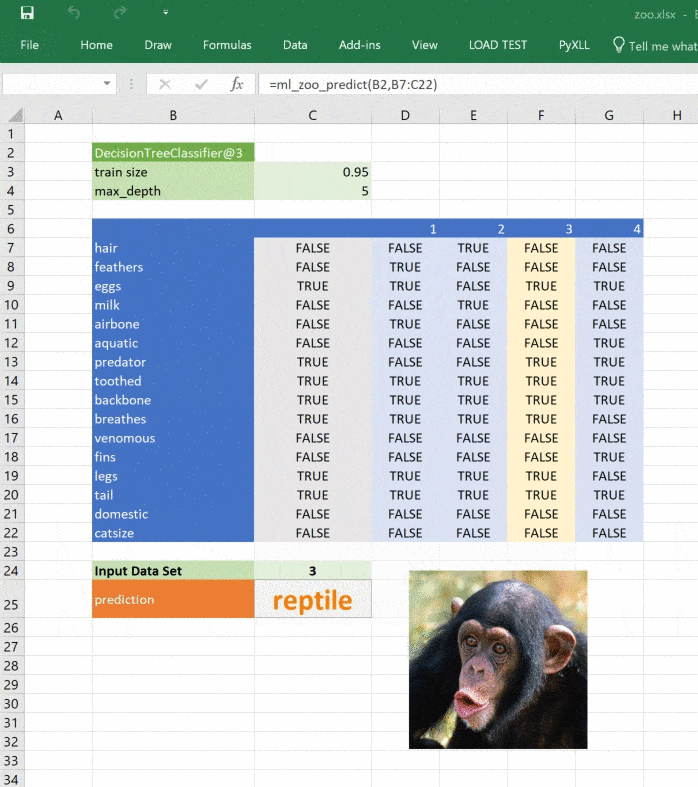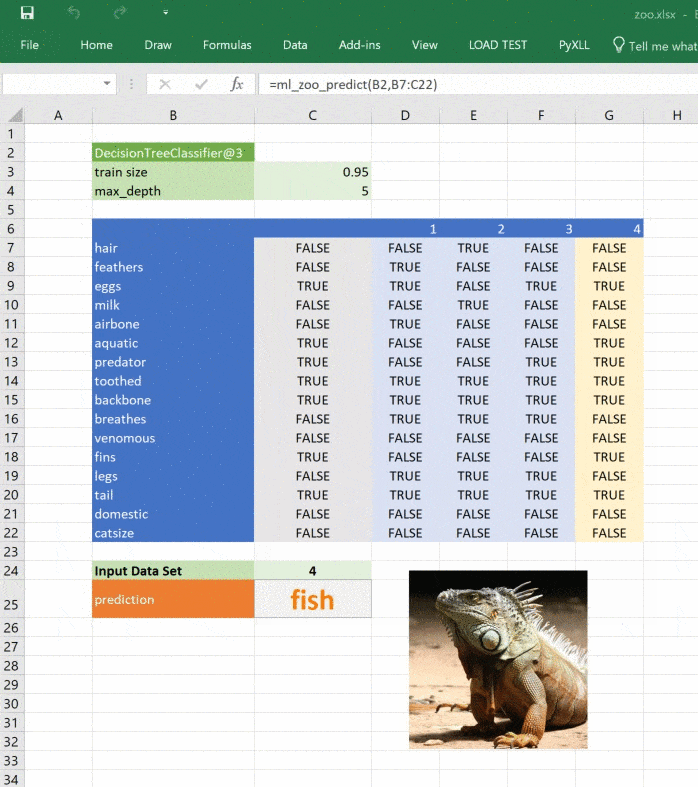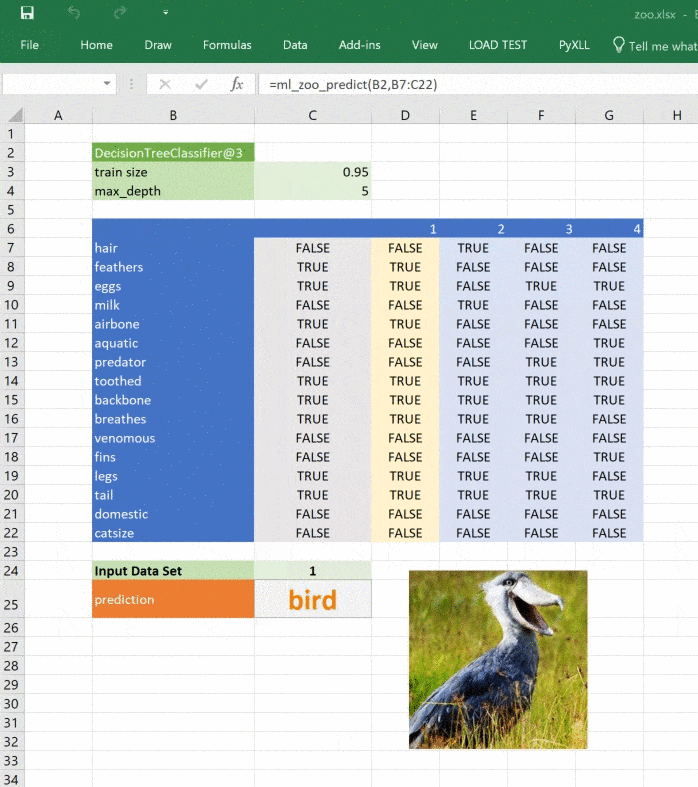
Этот материал — яркое напоминание о том, что Excel может справляться с задачами машинного обучения, а область ML сложна, но её сложность преодолима и если вы хотите изменить карьеру или вывести ваши навыки на новый уровень, то можете обратить внимание на наши курсы по Machine Learning, аналитике данных или присмотреться к флагманскому курсу Data Science. Также вы можете узнать, как начать или продолжить развитие в других направлениях:

Data Science и Machine Learning
-
Профессия Data Scientist
-
Профессия Data Analyst
-
Курс «Математика для Data Science»
-
Курс «Математика и Machine Learning для Data Science»
-
Курс по Data Engineering
-
Курс «Machine Learning и Deep Learning»
-
Курс по Machine Learning
Python, веб-разработка
-
Профессия Fullstack-разработчик на Python
-
Курс «Python для веб-разработки»
-
Профессия Frontend-разработчик
-
Профессия Веб-разработчик
Мобильная разработка
-
Профессия iOS-разработчик
-
Профессия Android-разработчик
Java и C#
-
Профессия Java-разработчик
-
Профессия QA-инженер на JAVA
-
Профессия C#-разработчик
-
Профессия Разработчик игр на Unity
От основ — в глубину
-
Курс «Алгоритмы и структуры данных»
-
Профессия C++ разработчик
-
Профессия Этичный хакер
А также:
-
Курс по DevOps
Финансовая модель — это функциональный инструмент, который поможет оперативно просчитать влияние различных факторов и изменений на результаты работы и финансовое состояние организации. За счёт формул и уравнений расчётов после изменения исходных данных все зависимые характеристики, будут пересчитаны программой автоматически.
Для финансового моделирования наиболее удобен и доступен формат Excel. Использовать его могут как бухгалтеры, так и руководители различных уровней.
Набор показателей для финансовой модели зависит от специфики деятельности организации. Основных групп, как правило, четыре:
- активы — имущество, принадлежащее организации;
- пассивы — обязательства;
- финансовые потоки — различные денежные поступления и платежи;
- доходы и расходы.
Результаты расчётов можно представить в виде баланса, отчётов о доходах и расходах и о движении денежных средств (по состоянию на определённую дату).
Алгоритм построения финансовой модели
Начните финансовое моделирование в Excel с создания простой модели. Из внешних параметров можно, например, взять стоимость продукции и спрос на неё. Например, в качестве внутренних показателей можно взять размер выручки и затрат. На первом этапе количество элементов может быть минимальным, а особой точностью можно пренебречь. Основная цель — установить рабочие взаимосвязи для автоматического пересчёта. Далее модель можно развивать, детализировать и усложнять.
Рассмотрим пример простого моделирования в Excel с небольшим количеством ключевых переменных. Для каждой таблицы необходимо отвести отдельную страницу.
1. Задаём исходные параметры
Попробуем спрогнозировать выручку. За основу можно взять план реализации товаров или услуг за год. Размер выручки на первом этапе можно округлить или указать приблизительные данные (рисунок 1).
Рисунок 1 — План реализации услуг (тыс.руб.)

Выручка рассчитывается как сумма услуг.
2. Определяем переменные затраты
В качестве переменных введём затраты на заработную плату сотрудникам. Допустим, она зависит от объёма реализованных услуг и составляет 25% от выручки. Зарплата рассчитывается помесячно как произведение коэффициента 0,25 (25/100) и плана продаж на конкретный месяц.
Расходы на аренду и управление внесём как фиксированные значения.
Например, чтобы посчитать зарплату за январь, берём план реализации на январь и умножаем на коэффициент
151 * 0,25 = 38 тыс. руб.
В Excel прописываем формулу: fx = 0,25*название страницы с таблицей по плану реализации!B8
Общий размер планируемых затрат будет равен сумме зарплаты, аренды и управленческих расходов (рисунок 2).
Рисунок 2 — План затрат

3. Составляем план доходов и расходов
Обратите внимание на строки «операционные доходы» и «операционные расходы» (рисунок 3). Чтобы их заполнить, потребуется прописать ссылки на соответствующие ячейки функциональных планов.
Рисунок 3 — План доходов и расходов, тыс. руб.

Так, операционные доходы будут равны суммам от услуг 1-4. Например, чтобы рассчитать операционный доход за январь, складываем 15+30+46+60. Получаем 151 тыс. руб.
В формулу прописываем: fх =СУММ(B5:B8)
Числовые значения по услугам прописываем ссылками на ячейки таблицы «План реализации услуг».
Графа «Итого» считается как сумма ячеек с B4 по M4
fх =СУММ(B4:M4)
Аналогично рассчитываются операционные расходы. Данные синхронизируем с таблицей «План затрат».
Операционная прибыль рассчитывается как разность операционные доходы — операционные расходы.
Например, операционная прибыль за январь равна: 151 — 96 = 55 тыс. руб.
Рентабельность рассчитывается как отношение операционной прибыли к операционному доходу помноженное на 100.
За январь получаем: 55/151*100 = 36,69%
fх = B13/B4*100
Обратите внимание, что итоговая рентабельность рассчитывается не как сумма за предыдущие месяцы, а как отношение итоговой операционной прибыли к итоговому операционному доходу.
Прибыль нарастающим итогом — это прибыли (убытки) за прошлый и текущий отчётные периоды. В январе мы берём данные операционной прибыли, равные 55 тысячам рублей. В феврале прибавляем 58 тысяч. Получаем 113 тысяч рублей. В марте прибавляем ещё 64 тысячи. Получаем 176 тысяч. И так суммируем по каждому месяцу.
В нашем финансовом плане прибыль нарастающим итогом за февраль будет прописываться формулой: fх=B15+C13
4. Составляем план движения денежных средств
Допустим, что в организации осуществляется только операционная деятельность, без капитальных вложений и заёмных средств. Также для упрощения исключим дебиторскую задолженность, допустив что время оплаты и время оказания услуг совпадают.
Платежи по заработной плате и аренде происходят в месяце, следующем за месяцем их начисления, а управленческие расходы — в месяц их осуществления (рисунок 4).
Рисунок 4 — План движения денежных средств, тыс. руб.

Платежи по операционной деятельности рассчитываются, как сумма зарплата + аренда + управленческие расходы.
Сальдо по операционной деятельности — это разность поступлений по операционной деятельности и платежей по операционной деятельности.
Сальдо операционной деятельности за январь будет равно: 151 — 38 = 113 тысяч рублей.
Сальдо на конец периода рассчитывается как сумма сальдо на начало периода и сальдо по операционной деятельности. Если принять сальдо на начало января равное 10 тысячам рублей, сальдо на конец периода будет равно 123 тысячам рублей.
5. Делаем прогнозный баланс
На основании плана доходов и расходов и плана движения денежных средств можно построить прогнозный баланс. Начальные остатки нужно взять из баланса предыдущего периода. Допустим, что все они равны 10 тысячам рублей (рисунок 5).
Рисунок 5 — Прогнозный баланс, тыс. руб.

В графу «денежные средства» подставляем значение сальдо на конец периода предыдущего месяца. Так, денежные средства за февраль = 123 тысячам рублей.
Активы будут равны сумме: денежные средства + основные средства + дебиторская задолженность.
Кредиторская задолженность рассчитывается: кредиторская задолженность предыдущего периода + планируемые затраты на заработную плату и аренду предыдущего месяца — планируемы движения денежных средств по зарплате и аренде предыдущего месяца.
Так, кредиторская задолженность на 1 февраля составит 58 тысяч рублей
0+38+20-0-0.
Капитал = капитал за предыдущий период + операционная прибыль предыдущего периода.
Капитал на 1 февраля составляет 65 тысяч рублей. 10+55.
Пассив — это сумма капитала и кредиторской задолженности
Обратите внимание, что дебиторская задолженность будет рассчитываться как дебиторская задолженность за предыдущую дату + отгрузка периода — поступление денежных средств.
Далее финансовую модель можно детализировать. Например, разбить по видам управленческие расходы, расписать зарплаты по сотрудникам, детализировать план продаж.
Финансовую модель можно корректировать, заменять плановые данные фактическими, отслеживать риски и контролировать финансовые результаты.
Узнайте больше о финансовом моделировании в Excel и прогнозировании финансового состояния бизнеса на семинаре в Учебном центре «Финконт».