
Сколько раз в день вы берете в руки телефон? В среднем, вы разблокируете его 50-100 раз в день. Если бы каждый раз при разблокировке вы учили английские слова, за месяц ваш лексикон бы пополнился тысячами новых слов! Звучит странно? Эта идея классно реализована в приложении Wordbit.
Как построено обучение в Вордбит
Фишка приложения в том, что оно работает при разблокировке экрана и каждый раз показывает новые слова на выбранном языке. Только выполнив упражнение на запоминание слов, вы сможете разблокировать телефон.
Выглядит это так:
После установки приложения вас ждет экскурсия по меню и функционалу. Затем вам нужно выбрать уровень и режим обучения, категории слов. Для пользователей начального уровня слова показываются вместе с картинкой. Это упрощает процесс запоминания.
Для большинства слов есть примеры их употребления в предложениях, формы множественного числа и так далее. Для каждого слово есть озвучка носителем языка. Когда вы будете нажимать на экран, чтобы его разблокировать, прямо по центру будет большая надпись, под ней перевод на русский язык, а в нижней части три цветные иконки: знак вопроса— «Не знаю»; треугольник «Сомневаюсь»; галочка — «Знаю».
Все слова разделены по темам: бизнес, романтика, повседневные фразы, слова, используемые на экзаменах IELTS, TOEFL, SAT, и другие. Есть несколько режимов обучения: флеш-карты, слайды и викторина.
Еще одна полезная функция Вордбит— сортировка слов по мере знания: знаю, сомневаюсь, не знаю. Вы сами помечаете слова, которые знаете лучше или хуже других. То есть, слова, которые вы знаете плохо, будут вам показываться чаще, чем остальные.
Преимущества Wordbit
- Больше 10-ти цветовых тем приложения. Выбирайте ту, что подходит именно вам, ведь пользоваться приложением придется часто!
- Более 30000 слов и выражений в бесплатном доступе.
- Игровой формат обучения.
- Интуитивно понятный и приятный интерфейс.
- Ненавязчивый рекламный контент.
Недостатки
- Нет упражнений по грамматике.
Для кого подойдет
Будет полезно студентам начинающего и продвинутого уровней английского. Отличное образовательное приложение, которое не позволит пропустить уроки!
Wordbit: отзывы пользователей




Добрый день всем!
Сегодня хочу поделиться одним приложением, с помощью которого можно легко и бесплатно учить новые английские слова, идиомы, пословицы, фразы и даже деловой английский. С этим приложением я познакомилась около года назад. Листала приложения на Play Market и нашла его — Word Bit Английский язык.

Максимально простое оформление, отсутствие ненужной информации, легкое управление — сразу меня привлекло.
Для кого подойдет приложение?
Оно подойдет абсолютно всем: как с нулевым знанием языка, так и продвинутому в изучении. Это легко регулируется в настройках.
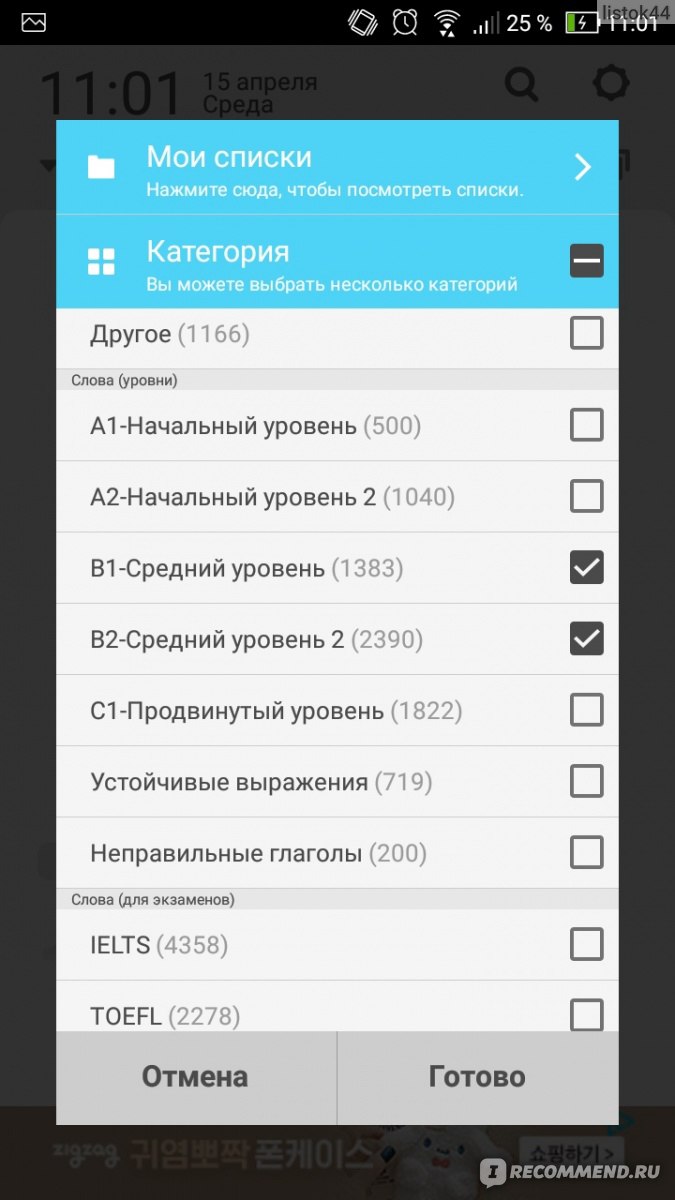
Если понимаете, что уровень для вас низок, просто повысьте его. Можно выбрать несколько сразу.
Принцип работы:
Приложение включается автоматически, как только вы включаете телефон. Нет, не в розетку, а как только у вас загорается экран. За день — это бесчисленное количество раз. Каждый раз появляются новые слова или выражения, уровень и темы, которые вы выбрали.
Таким образом, ваш словарный запас постоянно растет, а обучение происходит как бы между прочим. Мой мозг информацию в таком виде воспринимает лучше, чем зубрешка.
Также на это не нужно специально выделять время.
Какую информацию и в каком виде подучаем:
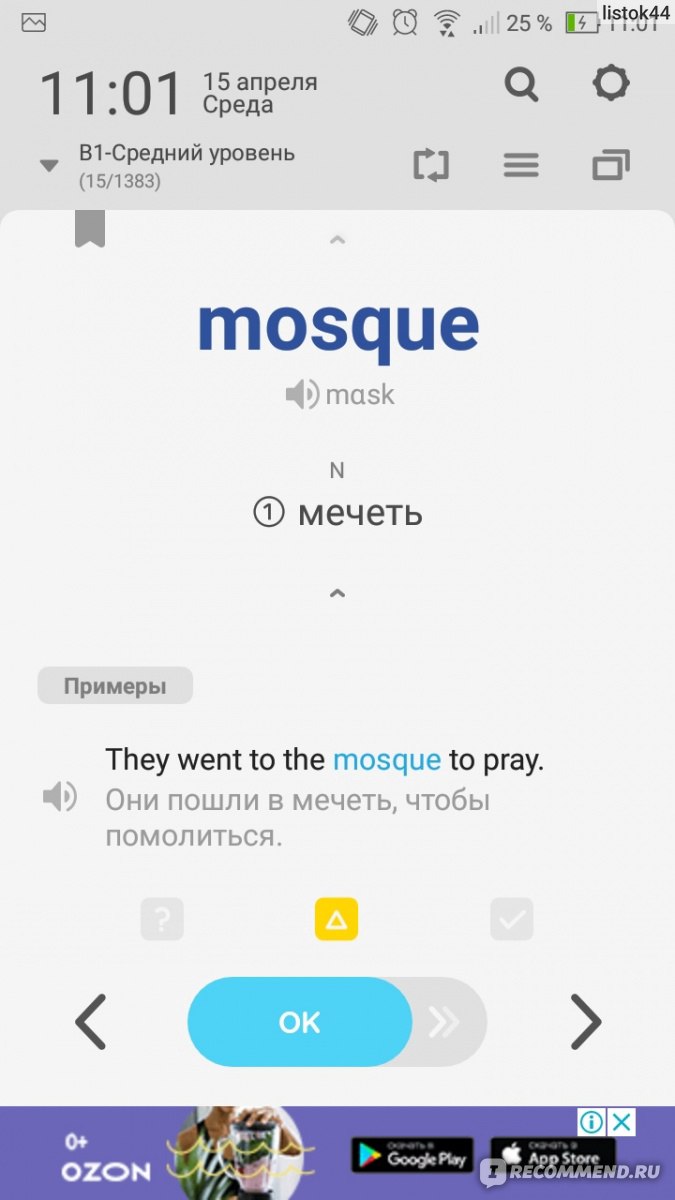
На нашем экране телефона появляется слово, фраза, пословица на английском языке, транскрипция (можно послушать правильное звуковое произношение), все варианты перевода, предложения со словами и их звуковое озвучивание.
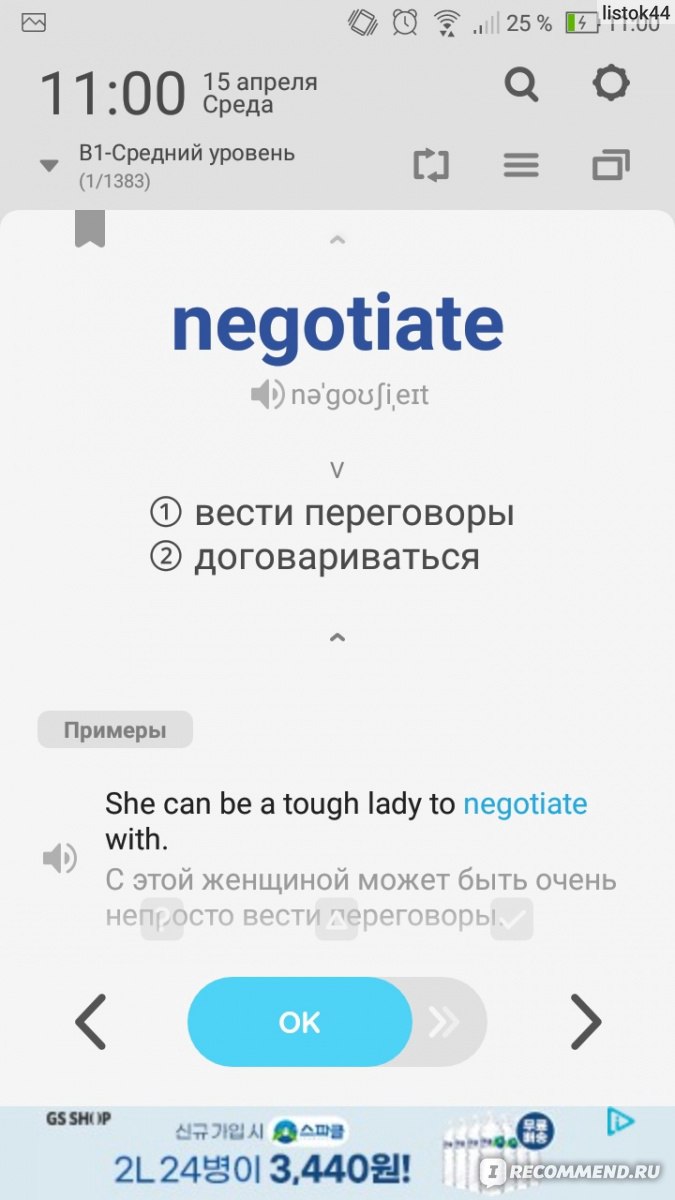
Если это слово вы знаете или выучили, нажимаете ОК, и открывается стартовая страница телефона. Если хотите еще одно слова — нажимаете стрелочку.
Какие темы можно изучить:
В настройках приложения слова также сгруппированы по темам, что удобно, например, для школьников.
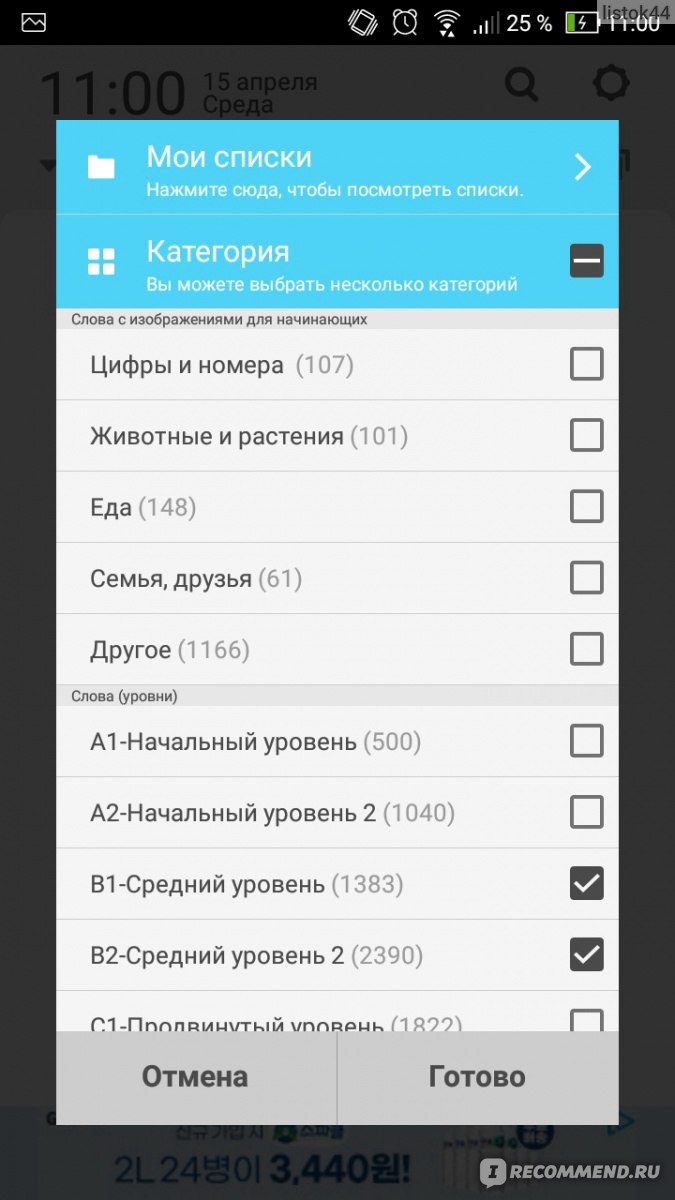
Если вы студент или вам необходимо по работе сдать международный экзамен на знание языка, в настройках необходимо выбрать соответствующие ячейки

Также во многих фирмах приветствуется знание английского языка. Необязательно записываться на дорогие курсы. Школьные знания + лексика из приложения смогут помочь вам получить более престижную должность.
Часто для секретаря достаточно знания нескольких фраз.
Если собираетесь в путешествие — можно подтянуть английский для общения в отеле, магазине, аэропорту.

Есть в приложении и разговорный английский. Что полезно для молодежи, просмотра фильмов без субтитров.
Для деловых людей — подойдет «курс» делового английского.

Принцип работы приложения в изучении и повторении:
Создатели приложения Word Bit предусмотрели функцию повторения. Считаю это актуальным прежде всего для школьников. Откладываешь себе слова и повторяешь их по кругу. Телефон дети не выпускают из рук, слова перед контрольной смогут выучить быстро.
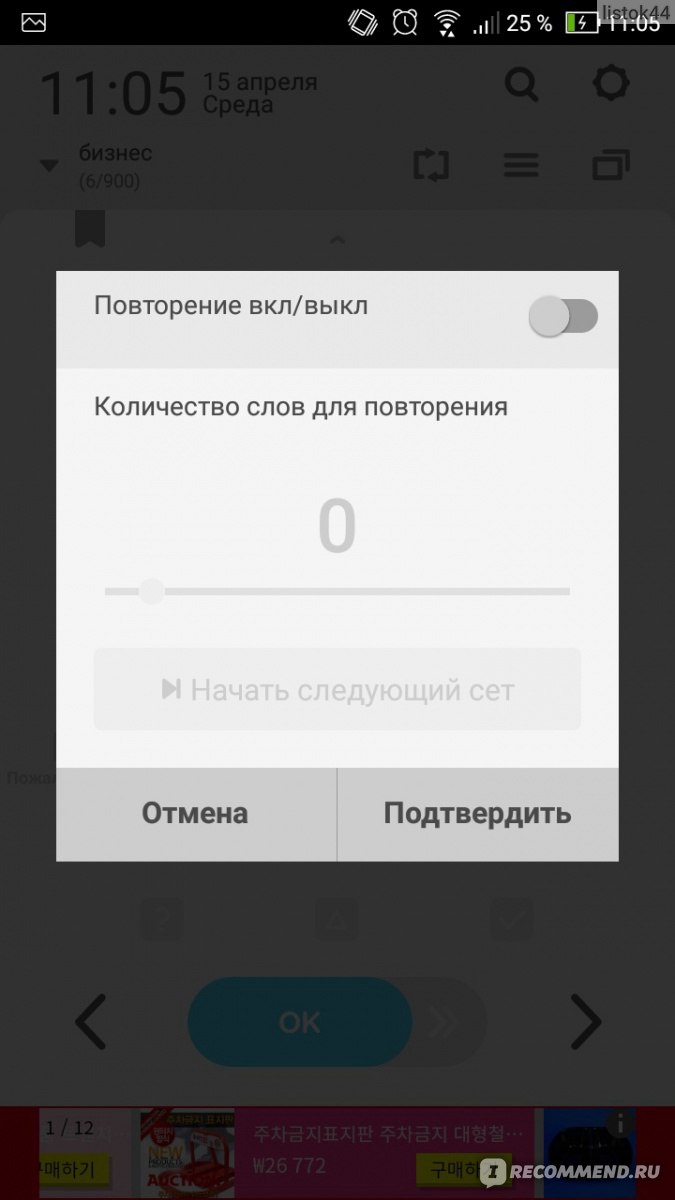
Для себя эту функцию не использую, т.к. пока не вижу в ней необходимости.
Также, если желаете разнообразить свое обучение, можно немного поменять настройки приложения. Привычная подача новых слов будет изменена.
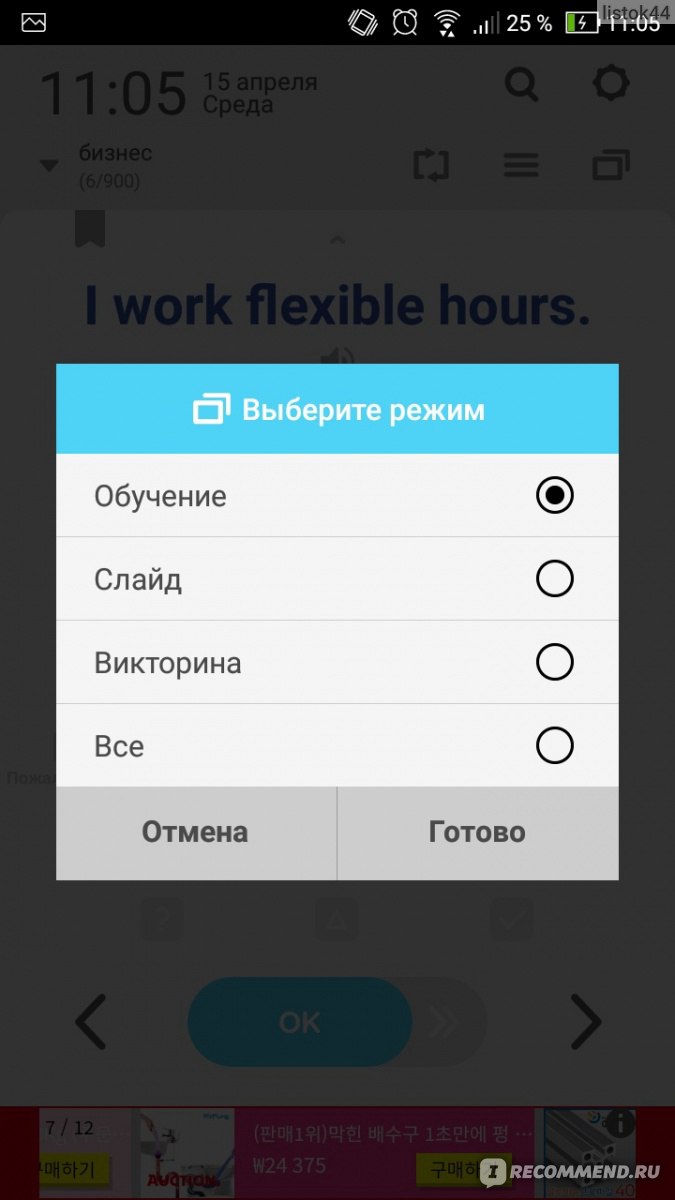
С одной стороны, это плюс. Мозг должен постоянно работать. С другой, бывает трудно перестроиться во время работы, когда приходиться использовать телефон. Мне это мешает. Использую стандарную функцию — обучение.
Приложением я полностью довольна. За время использования приложения и телефона мой словарный запас точно пополнился.
Даже если вы находите отговорки, что у вас нет времени на изучения языка, с приложением Word Bit — вы это исправите. Поверьте, в телефоне мы проводим гораздо больше времени, а одна секунда нашего внимания перед открытием телефона — это наше знание … одного нового английского слова.
Спасибо создателям такой технологии. И главное — бесплатное приложение.
еще немного полезной информации для изучающих иностранные языки:
бесплатный курс по изучению шампанского — теория и практика на английском языке, видео лекции с русскими субтитрами. Возможность получить сертификат
Freerice — онлайн-игра по изучению языков (бесплатно). Возможность своим изучением накормить нуждающихся рисом.
Stepik — онлайн-платформа по изучению (в основном) школьной программы, но есть также много курсов по программированию, языкам (на русском языке) — бесплатно
У нас есть все информационные биты
Это приложение дает вам первую часть программы раннего Educamigos стимуляции чтение битов, содержащие сессий, представленные битами отдельных слов и словосочетаний.
Это приложение завершается второй части программы, которая содержит сессий, представленные битами простых предложений и сложных предложений, которые также могут быть приобретены на Google Play. Google Play Кроме того, вы найдете свою лепту компьютерных программ и математических битов, все на испанском языке, на каталонском и английском языках. Для получения дополнительной информации: www.todoslosbits.com
Биты чтения Educamigos разработаны в соответствии с рекомендациями метода Домана, который широко признанное экспертами как один из наиболее эффективных методов ранней стимуляции. Он основан на том, что научно доказано, что дети, с раннего возраста, имеют огромный потенциал для ассимилировать информацию, поэтому желательно, чтобы воспользоваться первые годы для них, чтобы развиваться как много нейронных сетей за счет ранней стимуляции Впоследствии они обеспечивают повышенную производительность в стадии обучения и обучения.
Это приложение занятия с битами Educamigos содержит 777 слов стимуляции сессий, которые помогают детям распознавать слова, которые они называют их ближе к реальности
Слова представлены Тип печати, красный на белом фоне, так что ребенок способен различать их легко и автоматически произойдет на секунду. Одновременно прослушивании через голосом, отображаемые на экране слова.
Программа может быть использована в двух различных пользователей, сохраняя отдельно информационные сессии проводятся битов каждый. Он также включает в себя автоматическое расписание встреч в целях содействия осуществлению первого до последнего также рекомендации метода.
А также включает в себя инструмент настройки, который позволяет настроить презентацию битов каких-либо преимуществ, со следующими параметрами:
— Изменение цвета слов: красный, черный, зеленый или синий
— Изменение времени экспозиции битов: количество секунд вы хотите
— Изменение шрифта: печати, капитализируются курсивом, Дети
— Запуск в данный момент времени любой из доступных сессий
Вы когда-нибудь задумывались о том, как часто достаете свой андроид смартфон, чтоб проверить время или просто посмотреть на экран?
А если я скажу, что при этом можно заняться очень полезным делом? Если Вам понравилась такая идея, то знакомьтесь с приложением — WordBit для изучения языков. WordBit работает на экране блокировки и будет каждый раз показывать новые слова на выбранном языке.
Приложение не займёт много места и не требует особых характеристик смартфона. После установки Вас ожидает экскурсия по главному меню и функциональным клавишам приложения.
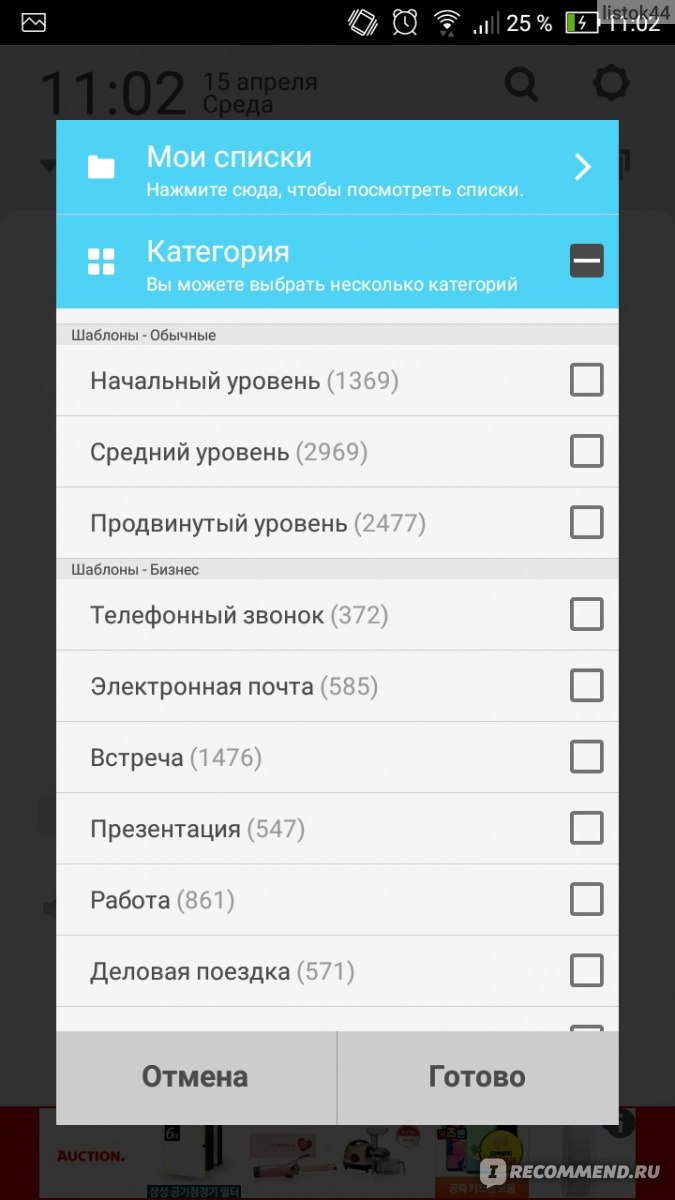
Рассмотрим главный экран. В верхней части отображается дата и время, ниже под этими параметрами можно развернуть всплывающее меню, которое отвечает за настройки отображения слов…
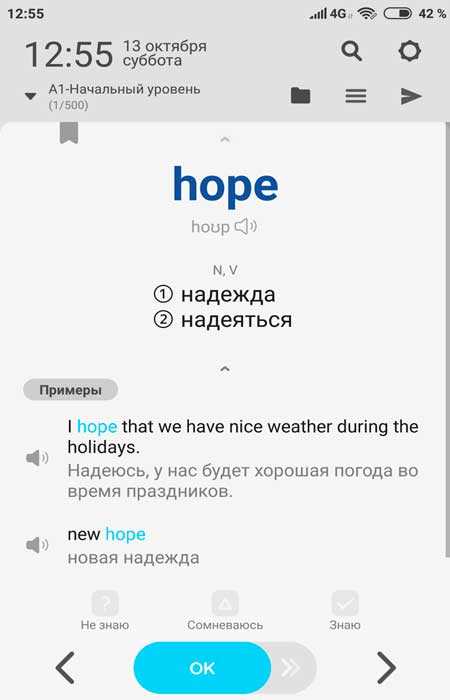
Здесь нужно просто нажать на маленький треугольник в левой части и перед Вами откроется новое окно где расположены различные категории — для экзаменов, бизнес, романтика и так далее. Везде есть определённое количество слов для изучения…
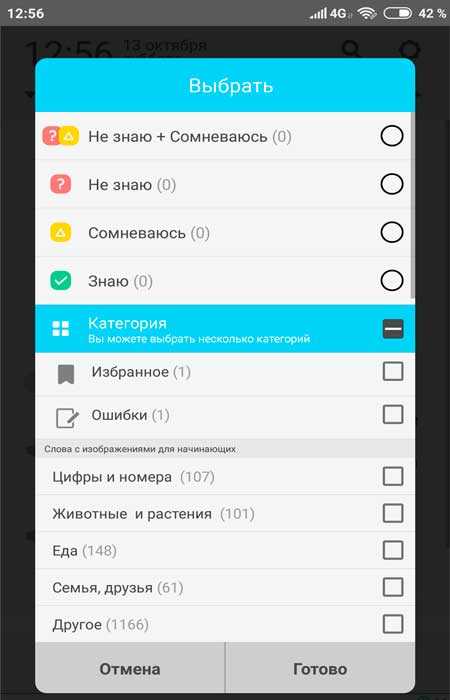
Правее от этой кнопки располагается иконка папки где есть возможность посмотреть Ваш список показанных слов и в случае чего перенести их в другую папку…
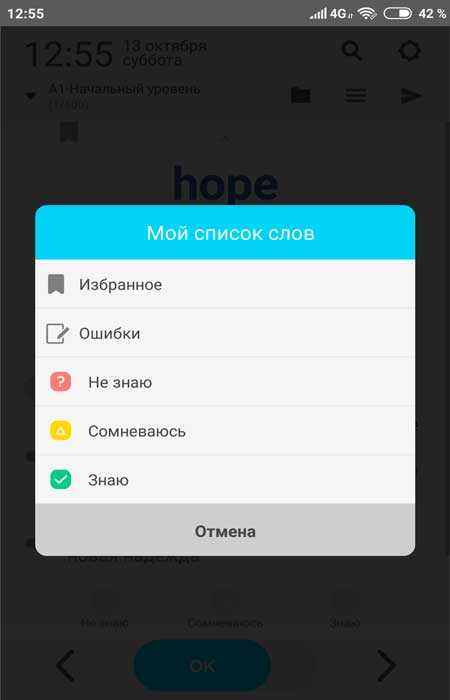
Три полоски в верхней части отвечают абсолютно за все слова представленные в WordBit, а иконка со стрелкой делает скриншот экрана…
Шестеренка сверху отправит Вас в настройки где можно изменить цвет темы, поделиться приложением с друзьями, поставить ему оценку либо временно отключить…
Иконка с лупой отвечает за поиск слов в программе…
…
…
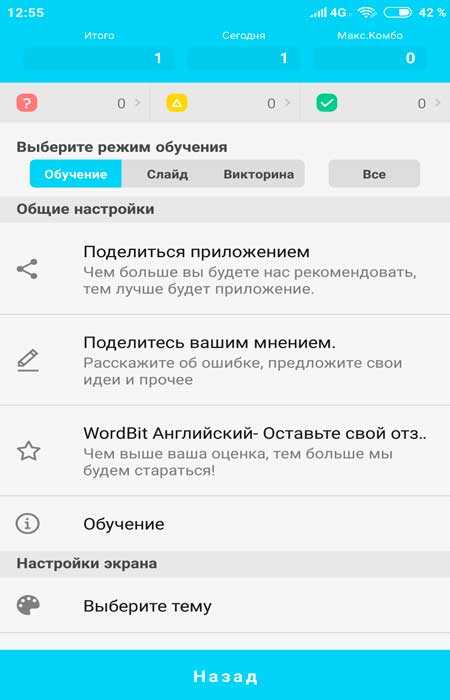
Работа WordBit на экране блокировки
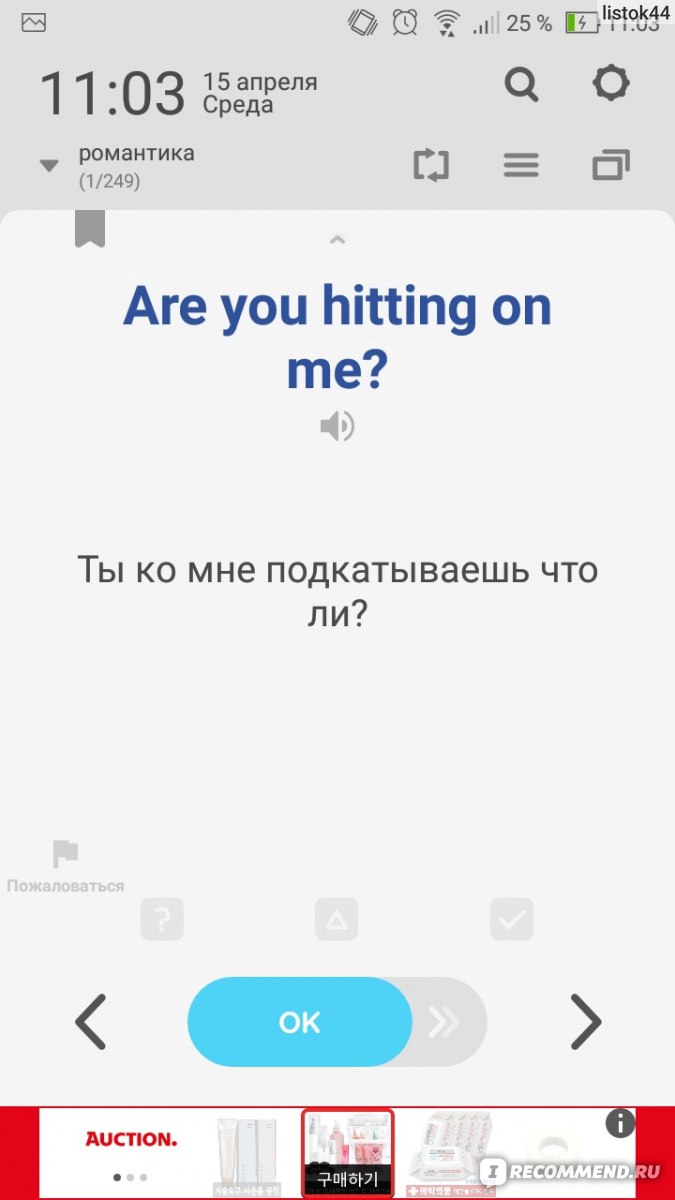
Итак, после того, как Вы настроили своё приложение можно приступить к тому, чтоб пополнить словарный запас. Сейчас каждый раз, когда Вы будете включать смартфон перед Вашими глазами начнет открываться новое окно с иностранными словами для лёгкого и быстрого запоминания их. Прямо по центру будет большая надпись, под ней перевод на русский язык, а в нижней части три цветные иконки:
- Знак вопроса — «Не знаю»
- Треугольник — «Сомневаюсь»
- Галочка — «Знаю»
Первые две категории будут периодически повторяться, а последняя перемещается в корзину.
Также, Вы можете добавить слово в «Избранное» нажав на соответствующую иконку слева от него, а при нажатии на рупор — услышите правильное произношение этого слова.
Для того, чтоб получить доступ к смартфону просто нажмите на кнопку «OK» внизу и проведите вправо.
Краткий итог
Плюсы:
- Большое количество языков в других приложениях разработчиков
- Практически нет рекламы
- Интуитивно удобный интерфейс
Минусы:
- Не обнаружено
Версия Android: 4.2 и выше
Автор: WordBit
Скачать андроид-приложение с помощью QR-кода
 Уверенный пользователь трех домашних ПК с многолетним опытом, «компьютерщик» для всех родственников, соседей и знакомых, в течении 13-ти лет автор более тысячи обзоров интересных и полезных программ для компьютера на собственном софтовом блоге OptimaKomp.RU
Уверенный пользователь трех домашних ПК с многолетним опытом, «компьютерщик» для всех родственников, соседей и знакомых, в течении 13-ти лет автор более тысячи обзоров интересных и полезных программ для компьютера на собственном софтовом блоге OptimaKomp.RU



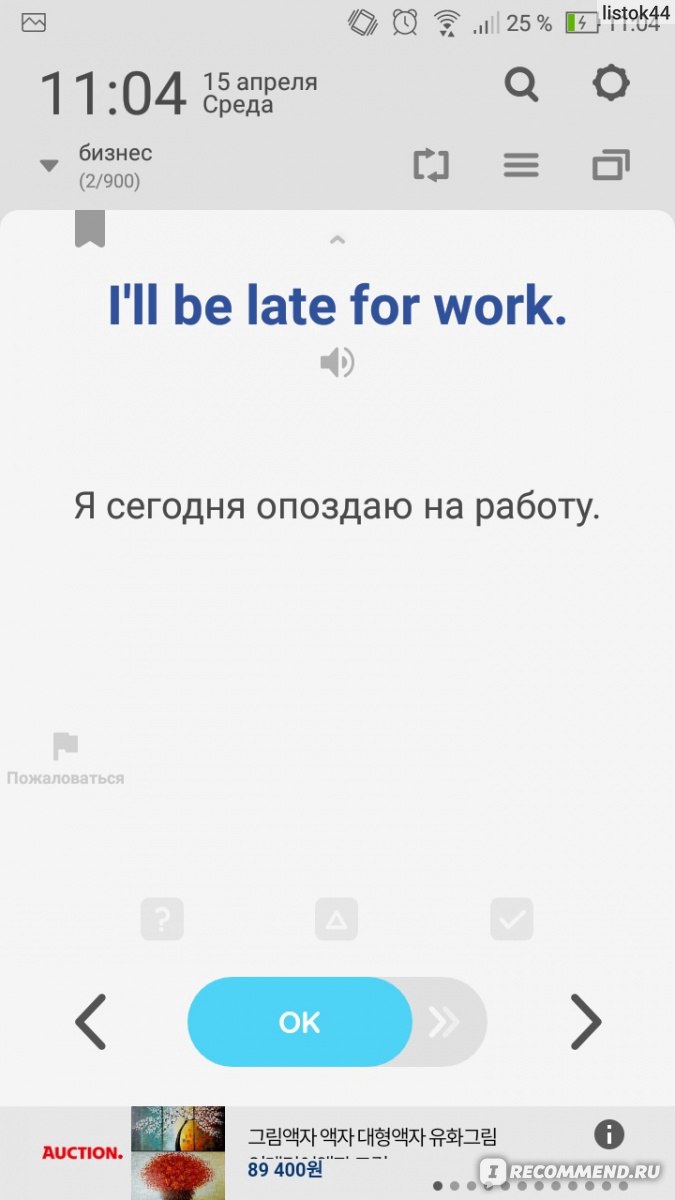
WordBit – приложение, которое поможет изучать английский язык легко и ненавязчиво. Программа отличается от всего, что вы встречали ранее, поскольку вам даже не придется заходить в сервис, чтобы увидеть новый материал для изучения. Каждый раз при разблокировке экрана приложение будет выводить английские слова на ваш дисплей, с вариантами перевода и транскрипцией.
Изучение иностранного языка занятие достаточно сложное и на него нужно время. Многие люди устанавливают десятки приложений по изучению английского, но это, как правило, ни к чему не приводит. Сервис WordBit решил проблему, и теперь освоение новых слов не будет занимать много времени и сил.
Среднестатистический человек в день разблокирует свой телефон несколько сотен раз. Разработчики приложения решили, что это время можно проводить с пользой. Теперь каждый раз, как вы будете брать в руки смартфон, чтобы прочитать сообщение или просто проверить время, на экране будут высвечиваться английские слова или фразы, и вы сможете выделять всего несколько секунд своего времени, чтобы прочитать и запомнить их.
Приложение подойдет и для новичков и для более опытных пользователей. Здесь есть меню настроек, которое поможет установить нужный уровень владения английским, и даже выбрать тематику слов, которые необходимо изучить. В процессе пользования сервисом вы сможете менять эти опции, чтобы не зацикливаться на одной теме, и не заскучать в процессе обучения.
Чтобы вам было проще запоминать слова, программа может их озвучивать и повторять столько раз, сколько вам необходимо для отработки произношения. Также, здесь можно сортировать термины по запоминаемости. То есть, вы самостоятельно выбираете нужные слова, и можете ставить их на повтор на протяжении дня. Таким образом, увидев текст десяток раз за день, вы наверняка запомните его.
Приложение может помочь подготовиться к сдаче экзаменов, причем не только школьных, но и более серьезных, на получение международного уровня. Скачайте сервис WordBit на свой смартфон, и изучайте английский язык весело и легко.
Изменения в последней версии
- Добавленное содержимое доставки — Сегодняшний Шаблон.
- Шаблон которая улучшает навыки письма / разговора, была добавлена. Когда вы знаете полезную шаблон, вы можете легко и эффективно выучить 5 выражений!
| Автор: | |
| ID приложения: | net.wordbit.enru |
| Цена: |
Бесплатно |
| Обновлено: | 2023-04-10 |
| Версия Android: | 4.4 и выше |
| Русский язык: | Есть |
| Украинский язык: | Нет |
Скачать WordBit для Android
Комментарии
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given a text file, extract words from it. In other words, read the content of file word by word. Example :
Input: And in that dream, we were flying. Output: And in that dream, we were flying.
Recommended: Please try your approach on {IDE} first, before moving on to the solution.
Approach : 1) Open the file which contains string. For example, file named “file.txt” contains a string “geeks for geeks”. 2) Create a filestream variable to store file content. 3) Extract and print words from the file stream into a string variable via while loop.
CPP
#include <bits/stdc++.h>
using namespace std;
int main()
{
fstream file;
string word, t, q, filename;
filename = "file.txt";
file.open(filename.c_str());
while (file >> word)
{
cout << word << endl;
}
return 0;
}
Output:
geeks for geeks.
Time Complexity: O(N) // going through the entire file
Auxiliary Space: O(1)
Like Article
Save Article
From Wikipedia, the free encyclopedia
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of words[edit]
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choice[edit]
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architectures[edit]
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressing[edit]
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of two[edit]
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families[edit]
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizes[edit]
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See also[edit]
- Integer (computer science)
Notes[edit]
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is
 . This gives an equivalent of about 9.51 bits for 6 trits.
. This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign

References[edit]
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.