
This java example shows how to read the contents of a file word by word.
Source: (ReadWords.java)
import java.util.Scanner; import java.io.*; public class ReadWords { public static void main(String[] args) throws IOException { File file = new File("words.txt"); Scanner input = new Scanner(file); int count = 0; while (input.hasNext()) { String word = input.next(); System.out.println(word); count = count + 1; } System.out.println("Word count: " + count); } }
Output:
$ cat words.txt The cat in the hat $ java ReadWords The cat in the hat Word count: 5
I need to write a program that rads the text of a text file and returns the amount of times a specific word shows up. I cant figure out how to write a program that reads the text file word by word, ive only managed to write a file that reads line by line. How would i make it so it reads word by word?
import java.io.*;
import java.util.Scanner;
public class main
{
public static void main (String [] args)
{
Scanner scan = new Scanner(System.in);
System.out.println("Name of file: ");
String filename= scan.nextLine();
int count =0;
try
{
FileReader file = new FileReader(filename);
BufferedReader reader = new BufferedReader(file);
String a = "";
int linecount = 0;
String line;
System.out.println("What word are you looking for: ");
String a1 = scan.nextLine();
while((line = reader.readLine()) != null)
{
linecount++;
if(line.equalsIgnoreCase("that"));
count++;
}
reader.close();
}
catch(IOException e)
{
System.out.println("File Not found");
}
System.out.println("the word that appears " + count + " many times");
}
}
posted 14 years ago
-

-

Number of slices to send:
Optional ‘thank-you’ note:
-
-




Hi A beginner question.
I have a text file not in text format (.txt) but it does contain text and numbers.
I would like to know How to read a file line by line and store each word or number into an arraylist, then output them on a new file?
e.g. my text file call ( colorsANDnumbers.data )
Red 2 Blue 3 Yellow 4 Green 5
2 Red 3 Blue 4 Yellow 5 Green
Is that possible to be done with just one arraylist?
regards
Gaz 
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
[edit]Add code tags. CR[/edit]
Marshal

Posts: 77646
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Please use the CODE button; I have edited that post so you can see how much better it looks.
Please don’t simply give out code like that. Since it is pretty standard code, which could have been copied from the Java Tutorials, I think I shall let it stand. But (look at the Beginners’ Forum contents page), where we explain that people learn a lot better if they work out things for themselves.
It doesn’t actually work in its present condition, and I can see a potentially serious error, which I shall let you find for yourself  . I shall also leave you to work out what people would do in Java5 or Java6.
. I shall also leave you to work out what people would do in Java5 or Java6.
*************************************************************************************************
Yes, you can put those entries into a single List<String>, but is that really appropriate? I suggest you go through the different interfaces in the Collections Framework and you might find something more appropriate for keeping colours and numbers.

Skill verified by Jeanne Boyarsky")
Gary kwlai
Greenhorn
Posts: 12
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Impressive 
I have few things not quite understand from the code, what does line 21 and 34 actually doing??, because I have not cover WInputStreamReader and Iterator yet.
Also almost every codes thesedays has Try and Catch in them… are those required? does it prevent the program from crashing or halt when there is an error?
regards
Gaz
Bijj shar
Greenhorn
Posts: 13
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Ritchie-
Thanks for letting me know to use Code Button. What error you are seeing in present condition please explain and user has asked about read and write data in file and he is reading data from existing file why you are giving him suggestion out of box.
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Gary Lai wrote:Also almost every codes thesedays has Try and Catch in them… are those required? does it prevent the program from crashing or halt when there is an error?
regards
If the API throws any kind of exception that inherets from java.lang.Exception the compiler will force you to surround the code with a try/catch block. This allows you to catch any exceptions that are thrown and deal with them. Some API’s throw RuntimeExceptions which don’t require try/catch blocks but if they throw an exception, the application will just die.
Campbell Ritchie
Marshal
Posts: 77646
posted 14 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
You are using the wrong classes for reading; you ought to use FileReader and BufferedReader because it is a text file. DataInputStreams are not designed for text files.
You are opening several Readers; I may be mistaken, but are you actually closing them? If you leave the Reader open, you may suffer a memory leak. That was what worried me. Anyway, when I tried your code, I couldn’t get it to work; I got what appears to be a FileNotFoundException.
I would simply use the Scanner and Formatter classes for text files; they are much easier to use. Since they «consume» their Exceptions, you can get away without the try-catch.
posted 11 years ago
-
1
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
 1
1Hi this is not reading word by word. This is how it’s done:
Scanner input = new Scanner(new File(«liron.txt»));
while(input.hasNext()) {
String word = input.next();
}
lowercase baba
Posts: 13086



posted 11 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Liron Meir wrote:Hi this is not reading word by word. This is how it’s done:
Given that the question, and the last reply, was almost three years ago, i doubt the original poster is still waiting for an answer, or is terribly worried about it anymore.
There are only two hard things in computer science: cache invalidation, naming things, and off-by-one errors
Liron Meir
Greenhorn
Posts: 2
posted 11 years ago
-
1
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Yes, but if someone is looking for a solution to read word by word, this is not it.
Campbell Ritchie
Marshal
Posts: 77646
posted 11 years ago
-
-
Number of slices to send:
Optional ‘thank-you’ note:
-
-
Welcome to the Ranch 
That is what I was hinting at when I mentioned Scanner. We prefer not to give the full solution and it says the following on this forum’s title page:
We’re all here to learn, so when responding to others, please focus on helping them discover their own solutions, instead of simply providing answers.

There are multiple ways of writing and reading a text file. this is required while dealing with many applications. There are several ways to read a plain text file in Java e.g. you can use FileReader, BufferedReader, or Scanner to read a text file. Every utility provides something special e.g. BufferedReader provides buffering of data for fast reading, and Scanner provides parsing ability.
Methods:
- Using BufferedReader class
- Using Scanner class
- Using File Reader class
- Reading the whole file in a List
- Read a text file as String
We can also use both BufferReader and Scanner to read a text file line by line in Java. Then Java SE 8 introduces another Stream class java.util.stream.Stream which provides a lazy and more efficient way to read a file.
Tip Note: Practices of writing good code like flushing/closing streams, Exception-Handling etc, have been avoided for better understanding of codes by beginners as well.
Let us discuss each of the above methods to a deeper depth and most importantly by implementing them via a clean java program.
Method 1: Using BufferedReader class
This method reads text from a character-input stream. It does buffer for efficient reading of characters, arrays, and lines. The buffer size may be specified, or the default size may be used. The default is large enough for most purposes. In general, each read request made of a Reader causes a corresponding read request to be made of the underlying character or byte stream. It is therefore advisable to wrap a BufferedReader around any Reader whose read() operations may be costly, such as FileReaders and InputStreamReaders as shown below as follows:
BufferedReader in = new BufferedReader(Reader in, int size);
Example:
Java
import java.io.*;
public class GFG {
public static void main(String[] args) throws Exception
{
File file = new File(
"C:\Users\pankaj\Desktop\test.txt");
BufferedReader br
= new BufferedReader(new FileReader(file));
String st;
while ((st = br.readLine()) != null)
System.out.println(st);
}
}
Output:
If you want to code refer to GeeksforGeeks
Method 2: Using FileReader class
Convenience class for reading character files. The constructors of this class assume that the default character encoding and the default byte-buffer size are appropriate.
Constructors defined in this class are as follows:
- FileReader(File file): Creates a new FileReader, given the File to read from
- FileReader(FileDescriptor fd): Creates a new FileReader, given the FileDescriptor to read from
- FileReader(String fileName): Creates a new FileReader, given the name of the file to read from
Example:
Java
import java.io.*;
public class GFG {
public static void main(String[] args) throws Exception
{
FileReader fr = new FileReader(
"C:\Users\pankaj\Desktop\test.txt");
int i;
while ((i = fr.read()) != -1)
System.out.print((char)i);
}
}
Output:
If you want to code refer to GeeksforGeeks
Method 3: Using Scanner class
A simple text scanner that can parse primitive types and strings using regular expressions. A Scanner breaks its input into tokens using a delimiter pattern, which by default matches whitespace. The resulting tokens may then be converted into values of different types using the various next methods.
Example 1: With using loops
Java
import java.io.File;
import java.util.Scanner;
public class ReadFromFileUsingScanner
{
public static void main(String[] args) throws Exception
{
File file = new File("C:\Users\pankaj\Desktop\test.txt");
Scanner sc = new Scanner(file);
while (sc.hasNextLine())
System.out.println(sc.nextLine());
}
}
Output:
If you want to code refer to GeeksforGeeks
Example 2: Without using loops
Java
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class ReadingEntireFileWithoutLoop
{
public static void main(String[] args)
throws FileNotFoundException
{
File file = new File("C:\Users\pankaj\Desktop\test.txt");
Scanner sc = new Scanner(file);
sc.useDelimiter("\Z");
System.out.println(sc.next());
}
}
Output:
If you want to code refer to GeeksforGeeks
Method 4: Reading the whole file in a List
Read all lines from a file. This method ensures that the file is closed when all bytes have been read or an I/O error, or other runtime exception, is thrown. Bytes from the file are decoded into characters using the specified charset.
Syntax:
public static List readAllLines(Path path,Charset cs)throws IOException
This method recognizes the following as line terminators:
u000D followed by u000A, CARRIAGE RETURN followed by LINE FEED u000A, LINE FEED u000D, CARRIAGE RETURN
Example
Java
import java.util.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.io.*;
public class ReadFileIntoList
{
public static List<String> readFileInList(String fileName)
{
List<String> lines = Collections.emptyList();
try
{
lines =
Files.readAllLines(Paths.get(fileName), StandardCharsets.UTF_8);
}
catch (IOException e)
{
e.printStackTrace();
}
return lines;
}
public static void main(String[] args)
{
List l = readFileInList("C:\Users\pankaj\Desktop\test.java");
Iterator<String> itr = l.iterator();
while (itr.hasNext())
System.out.println(itr.next());
}
}
Output:
If you want to code refer to GeeksforGeeks
Method 5: Read a text file as String
Example
Java
package io;
import java.nio.file.*;;
public class ReadTextAsString {
public static String readFileAsString(String fileName)throws Exception
{
String data = "";
data = new String(Files.readAllBytes(Paths.get(fileName)));
return data;
}
public static void main(String[] args) throws Exception
{
String data = readFileAsString("C:\Users\pankaj\Desktop\test.java");
System.out.println(data);
}
}
Output:
If you want to code refer to GeeksforGeeks
This article is contributed by Pankaj Kumar. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks. Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
-
October 21st, 2011, 10:28 AM
#1
Junior Member
Reading a text file word by word
Hi all, new to Java programming. Got into it, cause a friend also has been doing it, but he’s been doing it for a while, so is really good. Anyways.
So what I want to do it, read a specific .txt file, then go through that, and split it into words. If that makes sense.
What I want the program to do, is, go through a file, and identify and count how many palindromes are inside the file. So I have been able to do the palindrome part of it. But I am just confused as to how you go about reading the text, word for word, then testing it out.
And help will be appreciated, and not in a rush, this is just a hobby, that I am really enjoying
-
Related threads:
-
October 21st, 2011, 11:00 AM
#2
Re: Reading a text file word by word
Here is the first hit after googling «java file io»: Lesson: Basic I/O (The Java� Tutorials > Essential Classes)
But this sounds like a job for the Scanner class. The API is your new best friend: Java Platform SE 6
-
October 21st, 2011, 12:23 PM
#3
Junior Member
Re: Reading a text file word by word
OK, hi again. I ended up figuring out how to do it. But I have a new problem. When I run the program, I want it to only find single word palindromes. At the moment, when I do it, it is also getting multiple word palindromes. So, in a text file I have, it has, for example «avid diva». It is coming up that each of these are palindromes. And I want it too be only one word palindromes, for example «otto». Any help again is appreciated. Here is what I currently have
import java.io.*; public class PalindromDetector { public static void main(String[] args) { try { FileInputStream fstream = new FileInputStream("C:/Test1.txt"); DataInputStream in = new DataInputStream(fstream); BufferedReader br = new BufferedReader(new InputStreamReader(in)); String strLine = null; while ((strLine = br.readLine()) != null) { String reverse = new StringBuffer(strLine).reverse(). toString(); int i,j,counter=0; String m[]=strLine.split(" "); String[] word=reverse.split(" "); System.out.println("The palindrome words are:"); for(i=0;i<m.length;i++) { for(j=word.length-1;j>=0;j--) { if(m[i].equalsIgnoreCase(word[j])) { System.out.println(m[i]); counter++; break; } } } System.out.println("Number of palindromes:"+counter); } } catch(IOException e){} } }Dunno what I have done. Obviously something silly. I’m sure what I have done is supposed to be harder that what I am supposed to have done
-
October 21st, 2011, 02:06 PM
#4
Re: Reading a text file word by word
Instead of taking the file one line at a time, why don’t you take it one word at a time, since that’s what you really care about?




Here I will show you how to parse a docx file and map it to a Java object (POJO). You can download the final code from this example here: https://github.com/e-reznik/DocxJavaMapper-example.
Technical Background
Docx is a new standard document format, first introduced in 2007 with the release of Microsoft Office 2007. It stores documents as a set of individual folders and files in a zip archive, unlike the old doc format, that uses binary files. Docx files can be opened by Microsoft Word 2007 and later, and by some open source office products, like LibreOffice and OpenOffice. To simply view the contents of a docx, change its extension to .zip and view the resulting archive using any file archiver.
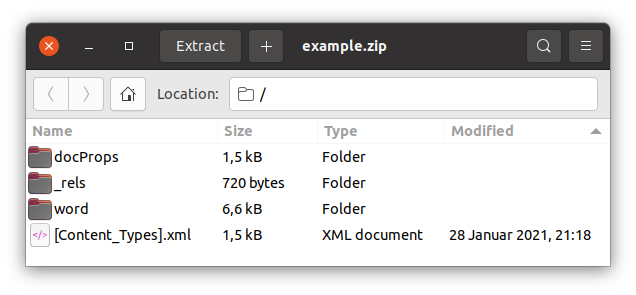
The main content is located in the file document.xml in the folder word. It contains the actual text and some styling information of the entire document. This is the file we will be focusing on in this tutorial.
Detailed information about the structure of a docx can be found at http://officeopenxml.com/anatomyofOOXML.php.
First, we will extract the docx archive. Next, we will read and map the file word/document.xml to a Java object, which can be used for further processing.
Creating an example docx file
We need to create a simple docx that we will be using throughout this tutorial. I created a short text with some simple formatting:

Extracting document.xml
We need to locate and extract the contents of document.xml. As already mentioned, a docx can be handled like a regular zip file. For reading entries from a zip file, Java provides us with the class ZipFile.
We create a new instance and pass our docx file as a parameter to the constructor. To the method public ZipEntry getEntry(String name) we pass the entry that we want to read. In our case, it’s document.xml which is in the folder word. Finally, we return the input stream of that specific entry, so that we can read its contents.
public static InputStream getStreamToDocumentXml(File docx) throws IOException {
ZipFile zipFile = new ZipFile(docx);
ZipEntry zipEntry = zipFile.getEntry("word/document.xml");
return zipFile.getInputStream(zipEntry);
}
We can call that method and save its return value as an InputStream.
String fileName = "example.docx"; InputStream inputStream = Unzipper.getStreamToDocumentXml(new File(fileName));
Viewing and interpreting the results
For testing purposes, we can return the content of the document.xml as a string.
String text = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))
.lines()
.collect(Collectors.joining("n"));
System.out.println(text);
This is the result xml. Can you find and interpret our example text (see above)?
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <w:document xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" mc:Ignorable="w14 wp14"><w:body><w:p><w:pPr><w:pStyle w:val="Normal"/><w:bidi w:val="0"/><w:jc w:val="left"/><w:rPr><w:color w:val="2A6099"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr></w:pPr><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:u w:val="single"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>This</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> is my </w:t></w:r><w:r><w:rPr><w:b/><w:bCs/><w:i/><w:iCs/><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>example</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> text.</w:t></w:r></w:p><w:sectPr><w:type w:val="nextPage"/><w:pgSz w:w="11906" w:h="16838"/><w:pgMar w:left="1134" w:right="1134" w:header="0" w:top="1134" w:footer="0" w:bottom="1134" w:gutter="0"/><w:pgNumType w:fmt="decimal"/><w:formProt w:val="false"/><w:textDirection w:val="lrTb"/><w:docGrid w:type="default" w:linePitch="100" w:charSpace="0"/></w:sectPr></w:body></w:document>
The document.xml follows a specific structure displayed below. This illustration only shows the elements, that are relevant in this example.
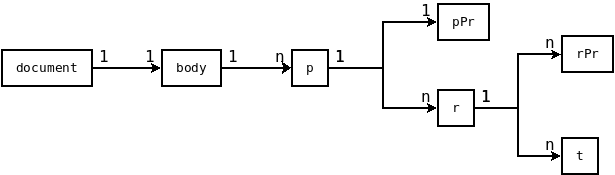
More information about the xml structure in that file can be found at http://officeopenxml.com/WPcontentOverview.php.
Mapping contents to a Java object
Now, that we can read the contents of a docx, we should be able to parse and map it to a POJO. Doing so, we will need to use some tools and create some POJOs in order to map our xml file.
Setting up required tools
- Maven
- build automation tool
- JAXB
- tool for mapping xml documents and Java objects
- I will use the Eclipse Implementation of JAXB
- Lombok
- Reduces boilerplate code
You can simply copy the required dependencies in your pom.xml:
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>3.0.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
Creating POJOs
In order to be able to map the document.xml to our Java object, we need to create some classes, following the structure of our file.
Every document has 1 node document, which itself has 1 node body. We only need getters in order to access its contents later. The fields can be private. Using the annotations from Lombok and JAXB, the POJO (or DTO) for our document element would look like:
@Getter
@FieldDefaults(level = AccessLevel.PRIVATE)
@XmlRootElement(name = "document")
@XmlAccessorType(XmlAccessType.FIELD)
public class DJMDocument {
@XmlElement(name = "body")
DJMBody body;
}
1 body can have multiple paragraphs, that’s why we need to map the paragraphs to a list. The setter is private, because we only need it internally, inside of the class itself. The POJO for the body looks like:
@FieldDefaults(level = AccessLevel.PRIVATE)
public class DJMBody {
List<BodyElement> bodyElements;
@XmlElements({
@XmlElement(name = "p", type = DJMParagraph.class)
})
public List<BodyElement> getBodyElements() {
return bodyElements;
}
private void setBodyElements(List<BodyElement> bodyElements) {
this.bodyElements = bodyElements;
}
}
Similarly, we need to create a class for every element that we want to map to. I will not go too much into detail here. As already mentioned, you can find the complete example project in my GitHub account.
Checking the results
After successfully creating all required classes, we want to check whether we can get the actual text of our docx. The following method iterates through the document, finds all the runs, appends their texts to a StringBuffer and returns it:
public static String getTextFromDocument(DJMDocument djmDocument){
StringBuilder stringBuilder = new StringBuilder();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
stringBuilder.append(dJMRun.getText());
}
}
}
}
return stringBuilder.toString();
}
Executing that method, we receive our text from the document:
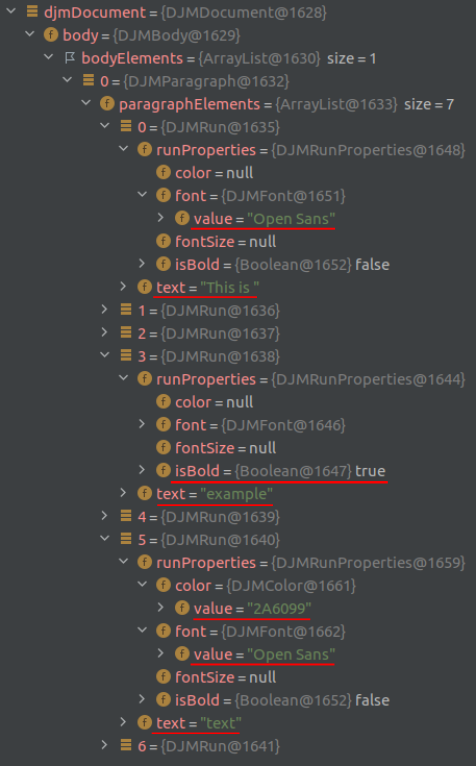
But how can we get the text formattings, like colors, fonts etc.? Using a debugger, we can take a look at our newly created document object during runtime. Unsurprisingly, we can find all the attributes that we set in your docx: Besides the actual text, we can see the font, color and if a particular word is bold.
If we slightly change our method, we can find all bold words in our text, and put them into a list:
public static List<String> getBoldWords(DJMDocument djmDocument) {
List<String> boldWords = new ArrayList<>();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
boolean isBold = dJMRun.getRunProperties().isBold();
if (isBold) {
String text = dJMRun.getText();
boldWords.add(text);
}
}
}
}
}
return boldWords;
}
After executing that method, we correctly get:
Next Steps…
The final code used in this tutorial can be found here: https://github.com/e-reznik/DocxJavaMapper-example. You can clone that project, play around on your machine and try to extends it with more elements, like images, tables, lists etc.
A more advanced project with more mapped elements can be found here: https://github.com/e-reznik/DocxJavaMapper.
You can also check out one of my other projects, where I create a pdf from a docx, using this approach: https://github.com/e-reznik/Docx2PDF.
In this article we will be discussing about ways and techniques to read word documents in Java using Apache POI library. The word document may contain images, tables or plain text. Apart from this a standard word file has header and footers too. Here in the following examples we will be parsing a word document by reading its different paragraph, runs, images, tables along with headers and footers. We will also take a look into identifying different styles associated with the paragraphs such as font-size, font-family, font-color etc.

Maven Dependencies
Following is the poi maven depedency required to read word documents. For latest artifacts visit here
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.16</version>
</dependency>
</dependencies>
Reading Complete Text from Word Document
The class XWPFDocument has many methods defined to read and extract .docx file contents. getText() can be used to read all the texts in a .docx word document. Following is an example.
TextReader.java
public class TextReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); XWPFWordExtractor extractor = new XWPFWordExtractor(xdoc); System.out.println(extractor.getText()); } catch(Exception ex) { ex.printStackTrace(); } } }
Reading Headers and Foooters of Word Document
Apache POI provides inbuilt methods to read headers and footers of a word document. Following is an example that reads and prints header and footer of a word document. The example .docx file is available in the source which can be downloaded at the end of thos article.
HeaderFooter.java
public class HeaderFooterReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); XWPFHeaderFooterPolicy policy = new XWPFHeaderFooterPolicy(xdoc); XWPFHeader header = policy.getDefaultHeader(); if (header != null) { System.out.println(header.getText()); } XWPFFooter footer = policy.getDefaultFooter(); if (footer != null) { System.out.println(footer.getText()); } } catch (Exception ex) { ex.printStackTrace(); } } }
Output
This is Header
This is footer
Other Interesting Posts Java 8 Lambda Expression Java 8 Stream Operations Java 8 Datetime Conversions Random Password Generator in Java
Read Each Paragraph of a Word Document
Among the many methods defined in XWPFDocument class, we can use getParagraphs() to read a .docx word document paragraph wise.This method returns a list of all the paragraphs(XWPFParagraph) of a word document. Again the XWPFParagraph has many utils method defined to extract information related to any paragraph such as text alignment, style associated with the paragrpahs.
To have more control over the text reading of a word document,each paragraph is again divided into multiple runs. Run defines a region of text with a common set of properties.Following is an example to read paragraphs from a .docx word document.
ParagraphReader.java
public class ParagraphReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); List paragraphList = xdoc.getParagraphs(); for (XWPFParagraph paragraph : paragraphList) { System.out.println(paragraph.getText()); System.out.println(paragraph.getAlignment()); System.out.print(paragraph.getRuns().size()); System.out.println(paragraph.getStyle()); // Returns numbering format for this paragraph, eg bullet or lowerLetter. System.out.println(paragraph.getNumFmt()); System.out.println(paragraph.getAlignment()); System.out.println(paragraph.isWordWrapped()); System.out.println("********************************************************************"); } } catch (Exception ex) { ex.printStackTrace(); } } }
Reading Tables from Word Document
Following is an example to read tables present in a word document. It will print all the text rows wise.
TableReader.java
public class TableReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); Iterator bodyElementIterator = xdoc.getBodyElementsIterator(); while (bodyElementIterator.hasNext()) { IBodyElement element = bodyElementIterator.next(); if ("TABLE".equalsIgnoreCase(element.getElementType().name())) { List tableList = element.getBody().getTables(); for (XWPFTable table : tableList) { System.out.println("Total Number of Rows of Table:" + table.getNumberOfRows()); for (int i = 0; i < table.getRows().size(); i++) { for (int j = 0; j < table.getRow(i).getTableCells().size(); j++) { System.out.println(table.getRow(i).getCell(j).getText()); } } } } } } catch (Exception ex) { ex.printStackTrace(); } } }
Reading Styles from Word Document
Styles are associated with runs of a paragraph. There are many methods available in the XWPFRun class to identify the styles associated with the text.There are methods to identify boldness, highlighted words, capitalized words etc.
StyleReader.java
public class StyleReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); List paragraphList = xdoc.getParagraphs(); for (XWPFParagraph paragraph : paragraphList) { for (XWPFRun rn : paragraph.getRuns()) { System.out.println(rn.isBold()); System.out.println(rn.isHighlighted()); System.out.println(rn.isCapitalized()); System.out.println(rn.getFontSize()); } System.out.println("********************************************************************"); } } catch (Exception ex) { ex.printStackTrace(); } } }
Reading Image from Word Document
Following is an example to read image files from a word document.
public class ImageReader { public static void main(String[] args) { try { FileInputStream fis = new FileInputStream("test.docx"); XWPFDocument xdoc = new XWPFDocument(OPCPackage.open(fis)); List pic = xdoc.getAllPictures(); if (!pic.isEmpty()) { System.out.print(pic.get(0).getPictureType()); System.out.print(pic.get(0).getData()); } } catch (Exception ex) { ex.printStackTrace(); } } }
Conclusion
I hope this article served you that you were looking for. If you have anything that you want to add or share then please share it below in the comment section.
Download source
Эта статья является продолжением знакомства с возможностями библиотеки Apache POI. В прошлой статье мы научились создавать новые Word документы на Java, а сегодня рассмотрим простой пример считывания данных с файлов в формате docx.
Считывание Word документа с помощью Apache POI
Давайте рассмотрим краткие теоретические сведения по работе с библиотекой, колонтитулами и параграфами. Считанный в память docx документ представляет собой экземпляр класса XWPFDocument, который мы будем разбирать на составляющие. Для этого нам понадобятся специальные классы:
- Отдельные классы
XWPFHeaderиXWPFFooter— для работы (считывания/создания) верхнего и нижнего колонтитулов. Доступ к ним можно получить через специальный класс-поставщикXWPFHeaderFooterPolicy. - Класс
XWPFParagraph— для работы с параграфами. - Класс
XWPFWordExtractor— для парсинга содержимого всей страницы docx документа
Apache POI содержит множество других полезных классов для работы с таблицами и медиа объектами внутри Word документа, но в этой ознакомительной статье мы ограничимся лишь с разбором колонтитулов и парсингом текстовой информации.
Пример чтения документа Word в формате docx с помощью Apache POI
Теперь добавим в проект библиотеку Apache POI для работы с Word именно в docx формате. Я использую maven, поэтому просто добавлю в проект еще одну зависимость
|
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi—ooxml</artifactId> <version>3.11</version> </dependency> |
Если вы используете gradle или хотите вручную добавить библиотеку в проект, то найти ее можно здесь.
Парсить/считывать я буду docx документ, полученный в предыдущей статье — Создание Word файла. Вы можете использовать свой файл. Содержимое моего документа следующее:

Теперь напишем простой класс для считывания данных из колонтитулов и параграфов документа:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
package ua.com.prologistic.excel; import org.apache.poi.openxml4j.opc.OPCPackage; import org.apache.poi.xwpf.model.XWPFHeaderFooterPolicy; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.apache.poi.xwpf.usermodel.XWPFFooter; import org.apache.poi.xwpf.usermodel.XWPFHeader; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import java.io.FileInputStream; import java.util.List; public class WordReader { public static void main(String[] args) { try (FileInputStream fileInputStream = new FileInputStream(«F:/Apache POI Word Test.docx»)) { // открываем файл и считываем его содержимое в объект XWPFDocument XWPFDocument docxFile = new XWPFDocument(OPCPackage.open(fileInputStream)); XWPFHeaderFooterPolicy headerFooterPolicy = new XWPFHeaderFooterPolicy(docxFile); // считываем верхний колонтитул (херед документа) XWPFHeader docHeader = headerFooterPolicy.getDefaultHeader(); System.out.println(docHeader.getText()); // печатаем содержимое всех параграфов документа в консоль List<XWPFParagraph> paragraphs = docxFile.getParagraphs(); for (XWPFParagraph p : paragraphs) { System.out.println(p.getText()); } // считываем нижний колонтитул (футер документа) XWPFFooter docFooter = headerFooterPolicy.getDefaultFooter(); System.out.println(docFooter.getText()); /*System.out.println(«_____________________________________»); // печатаем все содержимое Word файла XWPFWordExtractor extractor = new XWPFWordExtractor(docxFile); System.out.println(extractor.getText());*/ } catch (Exception ex) { ex.printStackTrace(); } } } |
Запустим и смотрим в консоль:
|
Верхний колонтитул — создано с помощью Apache POI на Java :) Prologistic.com.ua — новые статьи по Java и Android каждую неделю. Подписывайтесь! Просто нижний колонтитул |
Начинающие Java программисты, обратите внимание, что мы использовали конструкцию try-with-resources — особенность Java 7. Подробнее читайте в специальном разделе Особенности Java 7.
Другой способ считать содержимое Word файла
Приведенный выше пример сначала парсит отдельные части документа, а потом печатает в консоль их содержимое. А как быть, если мы просто хотим посмотреть все содержимое файла сразу? Для этого в Apache POI есть специальный класс XWPFWordExtractor, с помощью которого мы в 2 строчки сделаем то, что нам нужно.
Просто раскомментируйте код в листинге выше и еще раз запустите проект. В консоле просто продублируется вывод на экран.
Подробнее о библиотеке Apache POI читайте здесь, а также посмотрите пример чтения Excel файла, а также создания Excel (xls) документа все помощью Apache POI.
Подписывайтесь на новые статьи по Java и Android.