

46
•щелкните по пиктограмме Σ;
•поставьтекурсормышивячейкуЕ8 и, зажавлевую клавишу, протащитедоЕ13;
•нажмите клавишу Enter.
3.2.6. Сохранить файл с именем Стипендия
4. Отчет по работе
Распечатка табл.18, 20.
Литература: [1], C.167-175.
1. Цель работы
Изучение возможностей электронных таблиц при создании систем анализа и принятия решения
2. Основные теоретические положения
При реализации в электронных таблицах систем, принимающих решения, можно выделить два взаимосвязанных этапа:
1.Организация исходных данных в таблице.
2.Создание решающих правил.
Рассмотрим оба этапа на примере создания в электронной таблице системы диагностики заболеваний. Разработка решающих правил опирается на знания экспертов в данной области, создающих базу знаний о болезнях и их характеристиках.
Для простоты изложения рассмотрим экспертную систему для диагностики всего четырех болезней, база знаний которой представлена в табл.23. Каждая болезнь характеризуется набором признаков. Степень важности всех признаков задается весовыми факторами.
Когда приходит очередной пациент, сведения о признаках его болезни вводятся в базу данных (табл.24). Если у пациента присутствует указанный симптом, в столбец ответов вводится 1, иначе – 0.
Если введен ответ “Да” (т.е. единица), то весовой фактор симптома сохранится. Если ответ был “Нет” – весовой фактор обнуляется.
Решающее правило в системах диагностики будет следующим:
1)Подсчитывается сумма весовых факторов для каждой болезни.
2)Определяется, какое заболевание “набрало” наибольшее количество баллов. Это заболевание и будет наиболее вероятным.
Впримере, приведенном в табл.24, наибольшее количество баллов “набрало” воспаление легких – 50 значит, скорее всего, у пациента именно эта болезнь.

|
47 |
|||||||||||
|
Таблица 23 |
|||||||||||
|
База знаний |
Весовой фактор |
||||||||||
|
№ п/п |
Болезни |
Симптомы |
|||||||||
|
1 |
Воспаление |
Высокая температура, |
10 |
||||||||
|
легких |
кашель, |
10 |
|||||||||
|
боль в груди, |
5 |
||||||||||
|
хрип в груди |
25 |
||||||||||
|
2 |
Фарингит |
Высокая температура, |
5 |
||||||||
|
боль в горле, |
15 |
||||||||||
|
краснота в горле, |
5 |
||||||||||
|
потеря голоса |
25 |
||||||||||
|
3 |
Грипп |
Высокая температура, |
10 |
||||||||
|
кашель, |
10 |
||||||||||
|
насморк, |
25 |
||||||||||
|
боль в горле |
5 |
||||||||||
|
4 |
Ангина |
Высокая температура, |
10 |
||||||||
|
боль в горле, |
10 |
||||||||||
|
краснота в горле, |
25 |
||||||||||
|
боль в суставах |
5 |
||||||||||
|
Таблица 24 |
|||||||||||
|
БАЗА ЗНАНИЙ |
БАЗА |
ДАННЫХ |
|||||||||
|
№ |
Болезни |
Симптомы |
Весовой |
Ответ |
Весовой |
||||||
|
фактор |
|||||||||||
|
п/п |
фактор |
ответа |
|||||||||
|
Воспа- |
Высокая температура |
10 |
1 |
10 |
|||||||
|
Кашель |
10 |
1 |
10 |
||||||||
|
1 |
ление |
||||||||||
|
Боль в груди |
5 |
1 |
5 |
||||||||
|
легких |
|||||||||||
|
Хрип в груди |
25 |
1 |
25 |
||||||||
|
Сумма весовых факторов ответов |
50 |
||||||||||
|
Фарин- |
Высокая температура |
5 |
1 |
5 |
|||||||
|
2 |
Боль в горле |
15 |
0 |
0 |
|||||||
|
гит |
Краснота в горле |
5 |
0 |
0 |
|||||||
|
Потеря голоса |
25 |
0 |
0 |
||||||||
|
Сумма весовых факторов ответов |
5 |
||||||||||
|
Высокая температура |
10 |
1 |
10 |
||||||||
|
3 |
Грипп |
Кашель |
10 |
1 |
10 |
||||||
|
Насморк |
25 |
0 |
0 |
||||||||
|
Боль в горле |
5 |
1 |
5 |
||||||||
|
Сумма весовых факторов ответов |
25 |
||||||||||
|
Высокая температура |
10 |
1 |
10 |
||||||||
|
4 |
Ангина |
Боль в горле |
10 |
0 |
0 |
||||||
|
Краснота в горле |
25 |
0 |
0 |
||||||||
|
Боль в суставах |
5 |
0 |
0 |
||||||||
|
Сумма весовых факторов ответов |
10 |

48
3. Порядок выполнения работы
Задание 1. Создать систему диагностики заболеваний для двух пациентов согласно табл.24.
Задание 2. Построить диаграммы по созданной таблице.
Реализация системы диагностики заболеваний в режиме показа вычислений представлена в табл.25, в режиме показа формул – в табл.26.
3.1.1. Ввод заголовков
Введите заголовок – заполните ячейки А1:G4 согласно табл.25.
3.1.2. Ввод симптомов заболеваний Поскольку многие симптомы болезней повторяются, нет смысла вводить их
повторно. Поэтому сначала в ячейки А5:А8 вводим симптомы первой болезни
(воспаление легких): Высокая температура, кашель, боль в груди, хрип в груди. Для следующей болезни (фарингит), опускаем повторяющийся симптом (температура) и вводим новые симптомы в ячейки А9:А11. Аналогичным образом заполняем ячейки А12:А13 только новыми симптомами для оставшихся болезней.
3.1.3. Ввод весовых факторов болезней Заполняем ячейки В5:Е13 согласно табл. 25. (Если весовой фактор для
симптома в столбце А отсутствует, вводим 0.)
3.1.4. Ввод данных о симптомах болезней двух пациентах
Вводим сведения о симптомах болезней двух пациентов в ячейки F5:G13 (по табл. 25).
3.1.5. Вычисление весовых факторов болезней для первого пациента Для диагностики заболеваний нужно подсчитать весовой фактор каждого
ответа, затем суммарный фактор для каждой болезни (табл. 25).
Для вычисления весового фактора каждого ответа можно перемножить введенный ответ (0 или 1) на весовой фактор симптома. Тогда, если ответ был положительный (введена 1), весовой фактор ответа сохранится. Если ответ был отрицательным (введен 0), то при умножении на весовой фактор симптома в результате будет 0. После этого нужно просуммировать полученные весовые факторы ответов. Таким образом, для каждой болезни ищем сумму произведений столбца симптомов на столбец сведений о пациенте.
В Excel существует специальная операция СУММПРОИЗВ (категория
Математические).
1) Ввести решающее правило для первого пациента:
а) Ввод заголовков в строках 15, 16 (см. табл. 25) б) Ввод комментариев в ячейки А17:А19
в) Вычисление суммарного весового фактора первой болезни (воспаление легких):
•активизировать ячейку В17;
•щелкнуть по пиктограмме fx Мастера функций;
•в первом окне Мастера функций в списке Категорий выбрать
Математические;

|
49 |
|||||||
|
Таблица 25 |
|||||||
|
A |
B |
C |
D |
E |
F |
G |
|
|
1 |
СИСТЕМА ДИАГНОСТИКИ ЗАБОЛЕВАНИЙ |
||||||
|
2 |
БАЗА ЗНАНИЙ |
БАЗА ДАННЫХ |
|||||
|
3 |
Симптомы |
Названия болезней |
Пациенты |
||||
|
Воспа- |
Фарин- |
1-вый |
2-ой |
||||
|
4 |
ление |
гит |
Грипп |
Ангина |
пациент |
пациент |
|
|
легких |
|||||||
|
5 |
Высокая |
10 |
5 |
10 |
10 |
1 |
1 |
|
температура |
|||||||
|
6 |
Кашель |
10 |
0 |
10 |
0 |
1 |
0 |
|
7 |
Боль в груди |
5 |
0 |
0 |
0 |
1 |
0 |
|
8 |
Хрип в груди |
25 |
0 |
0 |
0 |
1 |
0 |
|
9 |
Боль в горле |
0 |
15 |
5 |
10 |
0 |
1 |
|
10 |
Краснота в горле |
0 |
5 |
0 |
25 |
0 |
1 |
|
11 |
Потеря голоса |
0 |
25 |
0 |
0 |
0 |
0 |
|
12 |
Насморк |
0 |
0 |
25 |
0 |
0 |
0 |
|
13 |
Боль в суставах |
0 |
0 |
0 |
5 |
0 |
1 |
|
14 |
|||||||
|
15 |
О Б Р А Б |
О Т К А |
О Т В |
Е Т О В |
|||
|
16 |
|||||||
|
ДЛЯ ПЕРВОГО ПАЦИЕНТА |
|||||||
|
17 |
Сумма весовых |
50 |
5 |
20 |
10 |
||
|
факторов болезни |
|||||||
|
18 |
Максимальная |
50 |
|||||
|
сумма |
|||||||
|
Воспа- |
|||||||
|
Диагноз |
ление |
0 |
0 |
0 |
|||
|
19 |
легких |
||||||
|
20 |
ДЛЯ |
ВТОРОГО |
ПАЦИЕНТА |
||||
|
Сумма весовых |
10 |
25 |
15 |
50 |
|||
|
21 |
факторов болезни |
||||||
|
Максимальная |
50 |
||||||
|
22 |
сумма |
||||||
|
23 |
Диагноз |
0 |
0 |
0 |
Ангина |
•в списке функций выбрать СУММПРОИЗВ (рис.20);
•в первое поле Массив 1 ввести адрес первого массива (столбец симптомов воспаления легких) В5:В13;
•щелкнуть мышью по окну Массив 2;
•ввести в поле Массив 2 адрес второго массива (столбца сведений о первом пациенте) F5:F13;
•щелкнуть по ОК.

50
Рис. 20 В ячейке В17 появится вычисленное значение суммарного весового фактора
воспаления легких для первого пациента — 50, а в строке показа формул – формула =СУММПРОИЗВ(В5:В13;F5:F13). В режиме показа формул таблица «Система диагностики заболевания» показана в табл. 26)
2) Подготовка формулы в В11 для копирования
Чтобы использовать формулу для копирования в ячейки С17:Е17, нужно запреить изменение адреса сведений о первом пациенте – используем абсолютный адрес для столбца F. Для этого следует изменить в В17 формулу на =СУММПРОИЗВ(В5:В13;$F5:$F13).
3) Ввод формул в ячейки С17:Е17
Скопировать формулу из В17 в ячейки С17:Е17 (проверить формулы по табл.26).
3.1.6. Вычисление максимального весового фактора для первого пациента Выполнить команды:
•активизировать ячейку В18;
•щелкнуть по пиктограмме fx;
•в первом окне Мастера функций выбрать категорию Статистические,
функцию МАКС;
•во втором окне указать адрес В17:Е17;
•щелкнуть по ОК.
Вячейке В18 появится число 50, в строке показа формул =МАКС(В17:Е17).
3.1.7. Ввод решающего правила для первого пациента Будем принимать решение следующим образом. Если вычисленный
максимальный фактор совпал с суммарным весовым фактором конкретной болезни, значит, наиболее вероятна именно эта болезнь.
Очевидно, что для реализации решающего правила удобно использовать функцию ЕСЛИ.
1) Ввод формулы для первой болезни
![]()
51

52
Выполнить команды:
•активизировать ячейку В19;
•щелкнуть по пиктограмме fx;
•в первом окне Мастера функций выбрать категорию Логические, функцию ЕСЛИ;
•в поле Логическое выражение ввести В17=В18;
•щелкнуть левой клавишей по второму полю (или нажать клавишу ТАВ);
•в окне поля Значение, если истина ввести адрес ячейки В4, где хранится название первой болезни;
•перейти в поле Значение, если ложь;
•ввести в это поле 0 (так как, если максимальный весовой фактор не совпал с суммарным весовым фактором воспаления легких, в столбце “Воспаление легких” не нужно ничего печатать).
•щелкнуть по ОК.
Вячейке В19 появится сообщение «Воспаление легких» (так как максимальный весовой фактор 50 совпал с суммарным весовым фактором этой болезни). В строке показа формул — формула =ЕСЛИ(В17=В18;В4;0).
2) Подготовка формул для копирования Чтобы скопировать формулу в ячейки С19:Е19, нужно запретить изменять
адрес ячейки максимального весового фактора В18. Получаем в В19 формулу
=ЕСЛИ(В17=$В18;В4;0).
3) Скопировать формулу в ячейки С19:Е19.
3.1.8. Ввод решающего правила для второго пациента Осуществляется аналогично правилам для первого пациента, так же, как пп.
3.1.6, 3.1.7, только будем использовать столбец ответов G5:G13. Очевидно, что можно скопировать решающее правило для первого пациента.
1) Копирование правил:
•зажав левую клавишу мыши, выделить ячейки А16:Е19;
• щелкнуть по пиктограмме  (копировать);
(копировать);
|
• |
поставить указатель мыши на ячейку А20 (указать начало области вставки); |
|
|
• |
щелкнуть по пиктограмме |
(вставить). |
2) Корректировка решающих правил для второго пациента:
а) Коррекция заголовка
•щелкнуть по ячейке А20 (в строке показа формул появится заголовок “Для первого пациента”);
•щелкнуть по строке показа формул;
•исправить “первого” на “второго”; б) Коррекция формул для вычисления сумм весовых факторов
•щелкните по ячейке В21 (в строке показа формул появится формула
=СУММПРОИЗВ(В5:В13; $F5:$F13);
•щелкнуть по строке показа формул;
•исправить $F5:$F13 на $G5:$G13;
•нажать клавишу Enter;
53
•скопировать формулу в ячейки В21:Е21.
в) Коррекция формулы для вычисления максимального весового фактора
проводится в ячейке В22 (см. таб.26).
г) Коррекция формул для постановки диагноза проводится в ячейках В23:Е23. Адрес ячейки $В18 исправляется на $В22.
3.2. Выполнение задания 2. Построение диаграмм Необходимо построить две диаграммы:
а) Вероятность болезней для первого пациента (выделяем блоки ячеек В4:Е4 – название болезней и В17:Е17 – суммарные весовые факторы болезней); б) Вероятность болезней для двух пациентов (выделяем блоки ячеек В4:Е4;В17:Е17 и В21:Е21).
Особенности построения и редактирования диаграмм см. в работе 2.
|
4. Отчет по работе |
|
|
Распечатка табл.27 и диаграммы п.3.7. |
|
|
Литература: |
[4], c.30-51. |
Работа 8. Решение задач оптимизации в Excel 1. Цель работы
Научиться использовать режим Поиск решения для оптимизации управленческих и экономических задач.
2.Основные теоретические положения
2.1.Решение оптимизационных задач
Табличный процессор Excel обладает возможностью производить поиск решения в таких оптимизационных задачах, как планирование выпуска продукции с достижением максимальной прибыли (или минимальных издержек), оптимальное составление портфеля заказов или плана перевозок продукции с минимальными затратами и т.д. Для этого используем режим Поиск решения. Эта процедура не ориентирована на решение каких-то конкретных задач, но обладает возможностью изменения и перебора значений указанных элементов двумерных массивов при соблюдении широких ограничений, введенных пользователем. Целью пользователя является грамотная постановка задачи и использование высокого быстродействия процессора Excel при переборе параметров.
Исходные данные для режима Поиск решения должны быть представлены в виде таблицы, которая содержит данные и формулы, отражающие зависимость между данными. Рассмотрим задачу планирования перевозок (транспортную задачу).
Транспортная задача
Фирме необходимо организовать перевозку продукции с трех складов в пять магазинов. Сведения о наличии продукции на складах, о потребности в
54
этой продукции магазинов и о стоимости перевозки единицы продукции с каждого склада во все магазины приведены в табл.27.
Таблица 27
|
Склады |
Магазины |
||||||
|
М1 |
М2 |
М3 |
М4 |
М5 |
|||
|
№ склада |
Запас |
Стоимость |
перевозок |
||||
|
S1 |
15 |
1 |
0 |
3 |
4 |
2 |
|
|
S2 |
25 |
5 |
1 |
2 |
3 |
3 |
|
|
S3 |
20 |
4 |
8 |
1 |
4 |
3 |
|
|
Потребности магазинов |
|||||||
|
20 |
12 |
5 |
8 |
15 |
Для правильной формулировки системы ограничений необходимо построить математическую модель задачи.
2.2. Построение математической модели задачи
Обозначим:
Хij – количество продукции, отправляемой со склада i в магазин j: Cij – стоимость перевозки единицы продукции со склада i в магазин j. Математическая модель будет состоять из ряда ограничений:
а) исходя из физического смысла задачи, Хij ≥ 0; Cij ≥ 0;
б) ограничения по предложению (со склада нельзя вывезти продукции больше, чем там имеется):
|
X11+X12+X13+X14+X15≤15 |
(1) |
||||||
|
X21+X22+X23+X24+X25≤25 |
|||||||
|
+ |
+ |
+ |
+ |
X35 |
≤20 |
||
|
X31 |
X32 |
X33 |
X34 |
в) ограничение по спросу (следует завезти в магазин не меньше продукции, чем ему требуется):
|
X 11 + X 21 + X 31 ≥ 20 |
|||
|
+ X 22 |
+ X 32 ≥ 12 |
||
|
X 12 |
|||
|
+ X 23 |
+ X 33 ≥ 5 |
||
|
X 13 |
|||
|
+ X 24 |
+ X 34 ≥ 8 |
||
|
X 14 |
|||
|
+ X 25 |
+ X 35 ≥ 15 |
||
|
X 15 |
|||
|
Общая стоимость перевозок (целевая функция) равна: |
|||
|
3 |
5 |
+3 X13+4 X14+2 X15+ |
|
|
Z =∑ ∑CijXij =1 X11+0 X12 |
|||
|
i=1 |
j=1 |
+5X21+1 X22+2 X23+4 X24+3 X25+
+4X31+8 X32+1 X33+4 X34+3 X35
Необходимо определить такие неотрицательные значения переменных Xij, которые удовлетворяют ограничениям (1) и (2) и обращают в минимум целевую функцию Z (3).
3. Порядок выполнения работы
55
Задание 1. Создать ЭТ с начальным планом перевозок. Задание 2. Оптимизировать решение.
3.1. Выполнение задания 1. Разработка ЭТ с начальным планом перевозок. ЭТ приведена в табл.28 – режим вычислений и табл.29 – режим показа
формул.
3.1.1. Подготовка блока ячеек с исходными данными В ячейки В4:В7 поместить сведения о наличии продукции на складах. В
ячейки С9:G9 – сведения о потребностях магазинов. В ячейки С5:G7 ввести данные о стоимости перевозок единицы продукции со складов в магазины.
3.1.2. Построение начального плана перевозок Считаем, что с каждого склада в каждый магазин везут одну единицу
продукции (ячейки С11:G13 заполнить единицами).
3.1.3. Вычисление количества перевозимой продукции а) В ячейку В11 ввести формулу для вычисления количества продукции,
вывозимой с 1-го склада =СУММ(С11:G11).
Таблица 28
|
A |
B |
C |
D |
E |
F |
G |
||||
|
1 |
ОПТИМИЗАЦИЯ |
ПЛАНА ПЕРЕВОЗОК |
||||||||
|
2 |
Склады |
Магазины |
||||||||
|
3 |
1 -й |
2 -й |
3 -й |
4 -й |
5-й |
|||||
|
4 |
Номер |
Запас |
Стоимость перевозок |
|||||||
|
5 |
1 |
15 |
1 |
0 |
3 |
4 |
2 |
|||
|
6 |
2 |
25 |
5 |
1 |
2 |
3 |
3 |
|||
|
7 |
3 |
20 |
4 |
8 |
1 |
4 |
3 |
|||
|
8 |
Потребности магазинов |
|||||||||
|
9 |
20 |
12 |
5 |
8 |
15 |
|||||
|
10 |
Всего вывозится |
План перевозок |
||||||||
|
11 |
1 |
5 |
1 |
1 |
1 |
1 |
1 |
|||
|
12 |
2 |
5 |
1 |
1 |
1 |
1 |
1 |
|||
|
13 |
3 |
5 |
1 |
1 |
1 |
1 |
1 |
|||
|
14 |
Завоз |
в магазины |
||||||||
|
15 |
3 |
3 |
3 |
3 |
3 |
|||||
|
Стоимость |
перевозок |
в |
||||||||
|
16 |
каждый магазин |
10 |
9 |
6 |
11 |
8 |
||||
|
17 |
Целевая |
44 |
||||||||
|
функция |
Аналогично в ячейки В12, В13 ввести формулы для вычисления количества продукции, вывозимой со второго и третьего складов (очевидно, что достаточно ввести формулу в ячейку В11 и скопировать ее в В12:В13):
=СУММ(С12:G12); =СУММ(С13:G13).
Формулы см. в табл. 29.

56

57
Для начального плана перевозок все суммы равны 5.
б) В ячейку С15 ввести формулу для вычисления количества продукции, которую везем в первый магазин =СУММ(С11:С13).
Аналогично в ячейки D15:G15 следует ввести формулы для вычисления количества продукции, которую везем во 2-й, 3-й, 4-й, 5-й магазины.
|
в ячейку D15 |
= СУММ (D11:D13); |
|
в ячейку E15 |
=СУММ (E11:E13); |
|
в ячейку F15 |
=СУММ (F11:F13); |
|
в ячейку G15 |
=СУММ (G11:G13). |
Поэтому формулу из С15 скопировать в D15:G15.
3.1.4. Определение стоимости перевозок в каждый из магазинов Для определения стоимости перевозок в 1-й магазин, т.е. величины
Z1=X11C11+ X12C12+ X13C13,
ввести в ячейку С16 формулу =СУММПРОИЗВ(С5:С7;С11:С13).
В ячейку D16 следует ввести формулу для вычисления стоимости перевозок во
второй магазин Z2=X12C12+ X22C22+ X32C32: =СУММПРОИЗВ(D5:D7;D11:D13).
Аналогично в ячейки Е16:G16 нужно ввести формулы для вычисления стоимости перевозок в остальные магазины:
вячейку Е16 =СУММПРОИЗВ(Е5:Е7;Е11:Е13);
вячейку F16 =СУММПРОИЗВ(F5:F7;F11:F13);
вячейку G16 =СУММПРОИЗВ(G5:G7;G11:G13).
Для этого скопируем формулу из С16 в ячейки D16:G16.
3.1.5. Определение общей стоимости перевозок (целевой функции ЦФ) Общая стоимость перевозок
Z=Z1 +Z2 +Z3 +Z4+Z5 . (4)
Для ее вычисления ввести в ячейку В17 формулу =СУММ(С16:G16). Для нашего начального плана целевая функция равна 44.
3.2. Выполнение задания 2. Улучшение (оптимизация) плана перевозок. Используем режим Поиск решения Excel.
1)После выполнения команд Сервис, Поиск решения открывается диалоговое окно Поиск решения (рис.21).
2)Ввести данные:
|
Установить целевую ячейку |
В17; |
|
|
Равной |
минимальному значению; |
Изменяя ячейки C11:G13.
Для ввода ограничений щелкнуть по кнопке Добавить. Появится окно Добавление ограничений (рис.22). Ввести первое ограничение. Для этого заполнить поля:
Ссылка на ячейку: C11:G13;
В среднем поле выбираем знак неравенства ≥
Ограничение: 0 , щелкнуть по кнопке Добавить.
Аналогичным образом ввести следующие ограничения.
С11: G13 = целые;

58
В11:В13 ≤ B5:В7;
С15:G15 ≥ C9:G9 .
После ввода каждого ограничения щелкнуть по кнопке Добавить, после ввода последнего – по кнопке ОК.
Рис. 21
Рис. 22 3) Для запуска режима Поиск решения щелкнуть по кнопке Выполнить.
Появится окно Результаты поиска решения (рис.23). Щелкнуть по кнопке ОК. В результате улучшения плана получим оптимальный план (табл.30) стоимости перевозок с целевой функцией (стоимостью перевозок) Z=121.
Рис. 23
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
ТЕХНОЛОГИЯ РАЗРАБОТКИ ЭКСПЕРТНЫХ СИСТЕМ В ТАБЛИЧНОМ СРЕДЕ
Рис. 3. Фрагмент базы знаний ЭС фондовой биржи
Механизм вывода заключений должен содержать процедурные знания о том, как эффективно использовать проблемные знания, что находятся в базе знаний. Если принципиально понятным является то, как знания предметной области может быть занесен в базы знаний электронной таблицы, то далеко не ясно, каким образом сконструировать эффективный механизм вывода. Очевидно, что его структура зависит от того, как организованы и структурированы знания в базе знаний. Также этот механизм должен как можно меньше зависеть от специфики предметной области.
Таблице базы знаний структурировано таким образом, чтобы значение каждого понятия в нижней части таблицы можно было определить, сопоставляя текущие значения понятий верхней части таблицы со значениями, представленными в соответствующих правилах. Взаимосвязь между значениями понятий из верхней части таблицы и значением любого понятия в нижней задается с помощью логических операций конъюнкции и импликации в виде нескольких выражений:
( г ); A 1 & A 2 & . An В , (1)
где г — идентификатор строки, состоящий из обозначения таблицы и обозначения того понятия, значение которого выводится.
Логическое выражение (1) утверждает истинность В , если истинны все утверждения A1, A 2, . An. В противном случае о правдивости В ничего сказать нельзя. Количество выражений (1) с одним и тем же консеквентом (частью продукции справа от знака ) и различными антецедентами (частью продукции слева от знака ) определяется количеством правил вывода утверждение В . Понятно, что, при наличии нескольких правил, консеквентне утверждение может быть получено лишь в том случае, если правила совместимы. На рис. 3 антецеденты (условия) продукций образуются путем сопоставления понятий и правил верхней части таблицы, а консеквенты (післяумови) — понятий и правил нижней. Например, взаимосвязь между значениями понятий из верхней части таблицы базы знаний, показанной на рис. 3, и значением понятия “Процентная ставка” задается совокупностью следующих выражений:
Техпроцесс создания экспертной системы состоит из следующих основных этапов:
— идентификация — определяются классы задач, подлежащих решению, и источники знаний (книги, методики, эксперты, средства автоматизированного получения знаний);
— концептуализация понятий — проводится содержательный анализ предметной области, выявляются ее основные понятия, значения, которых могут приобретать эти понятия, создается база понятий;
— концептуализация знаний — выявляются связи между понятиями, и строится модель предметной области в виде таблиц решений;
— реализация правил — основная операция — занесение ссылок в колонки “Понятия” и “Правила” базы знаний (рис. 3), ссылок на клетки базы понятий (рис. 2) согласно таблиц решений, разработанных на предыдущем этапе;
— реализация механизма вывода заключений — для этого в колонку “Значение” (рис. 3) верхней части каждой таблицы базы знаний заносят условное ссылки на ответы клетки колонок “Факты” и “Выводы” (рис. 2) базы понятий такого содержания: “Если фактическое значение не указано, то брать соответствующее значение из ко лонки Выводы , иначе брать соответствующее значение из колонки Факты ”. Например, в клетки Е4 базы знаний заводится такая фор мула =ЕСЛИ (БП!C 5=0 ; БП!D 5 ; БП!C 5 ) . В нижней части каждой таблицы базы знаний в колонку “Значение” вводят формулу, созданную с использованием функции Импликация .
В целом можно сделать вывод, что при условии создания интерфейса, который позволит автоматизировать наиболее трудоемкие операции создания базы знаний (занесение формул базы знаний во время формирования правил), предложенная технология обеспечивает относительно простой способ разработки продукционных ЭС с достаточно высокими эксплуатационными характеристиками.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Гаврилова Т. А., Червинская К. Г. Извлечение и структурирование знаний для экспертных систем. — М.: Радио и связь, 1992. — 256 с.
Дюк В., Самойленко А. Data mining — С.Пб.: Питер, 2001. — 368 с.
Ус Г. О. Модели представления знаний для систем поддержки принятия решений // Моделирование и информационные системы в экономике. Вып. 63. — К.: КНЭУ, 2000, — С.103-113.
Левин Г., Дранг Д., Эделсон Б. Практическое введение в технологию искусственного интеллекта и экспертных систем с иллюстрациями на Бейсике: Пер. с англ. — М.: Финансы и статистика, 1990. — 235 с.
Н. С. ПИНЧУК, канд. экон. наук, доц.,
Н. С. ОРЛЕНКО, канд. экон. наук, доц.,
Киевский национальный экономический университет
Искусственный интеллект на практике: создаём экспертную систему для приготовления шашлыка

Рассказывает Юрий Дубровских
Экспертные системы — это вычислительные системы, способные в определённой предметной области принимать решения, схожие с решениями экспертов-людей.
Выглядит это примерно так: система задаёт ряд вопросов, причём последующие вопросы зависят от полученных ответов. Затем система делает вывод и показывает всю цепочку рассуждений, которая к нему привела. То есть знания и опыт эксперта тиражируются, а что не менее важно — тиражируется сам ход его рассуждений.
Кроме того, можно применить несколько интересных особенностей. Например, система может сделать не один вывод, а перечислить варианты с разной степенью вероятности. Можно учитывать различные виды нечётких данных — если пользователь не знает ответы на некоторые вопросы или что-то предполагает. Вместо пользователя система может опрашивать датчики или брать информацию из разных источников. Продвинутые системы могут самообучаться, то есть выявлять закономерности во время сеансов работы и генерировать новые знания.
26 июня в 10:00, Минск, Беcплатно
Таким образом, экспертные системы могут применяться для довольно широкого круга задач:
- интерпретация, т. е. описание ситуации по наблюдаемым данным, определение смысла данных;
- диагностика — заключение о нарушениях в системе, составленное на основе наблюдений;
- отладка, исправление неисправностей — составление рекомендаций и выполнение последовательности действий по устранению неисправностей в системе;
- мониторинг — непрерывное сравнение результатов наблюдений с критическими точками плана;
- прогноз — предсказание будущих событий на основе анализа имеющихся данных о прошлом и настоящем;
- проектирование, конструирование — подготовка спецификаций для создания объектов с заранее определёнными свойствами;
- планирование — нахождение плана действий для достижения заранее поставленной цели;
- обучение какой-либо дисциплине или приёмам использования чего-либо;
- управление — решение задач проектирования и планирования, а также интерпретации и диагностики с корректировкой имеющихся планов;
- поддержка принятия решений — помощь в формировании или выборе варианта действий среди множества альтернатив.
Конечно, есть и ограничения. Во-первых, использовать экспертные системы есть смысл только в довольно узких предметных областях, где трудно найти экспертов и легче использовать компьютерную систему. Во-вторых, они не подходят для тех областей, в которых эксперты руководствуются не столько своими знаниями, сколько здравым смыслом, то есть сведениями из общей области знаний, не связанной с конкретным предметом. Также к недостаткам экспертных систем можно отнести то, что они плохо соотносятся с реляционными базами данных, к которым мы все так привыкли.
Тем не менее, в настоящее время существует и используется довольно много экспертных систем в сфере медицины, химии и военного дела. Вот некоторые примеры:
- Система по глобальной онтологии;
- Акинатор — система, которая отгадывает загаданного вами персонажа;
- MYCIN — выбор антимикробной терапии в условиях стационара;
- DENDRAL — химический анализ сложных молекул;
- поговаривают также, что отечественная система «Периметр», предназначенная для ответного удара в случае уничтожения командных пунктов, оснащена экспертной системой (которая и принимает решение о нанесении удара).
Попробуем создать небольшую экспертную систему. Для первого раза возьмём тренировочную предметную область. Хороший способ убедиться, что искусственный интеллект своими руками — это просто.
Не секрет, что в летний сезон в России ожидается резкий рост количества экспертов по приготовлению шашлыка. Думаю, многим знакома ситуация, когда кто-то один готовит шашлык а несколько людей стоят вокруг и дают советы и вообще высказывают своё экспертное мнение. Поведение таких шашлычных экспертов мы и попытаемся сымитировать.
Немного теории
Для начала разберёмся, что нам предстоит сделать.
Итак, экспертная система состоит из нескольких основных компонентов:
- база знаний;
- механизм логического вывода (МЛВ);
- компонента объяснения.
База знаний
База знаний — это, можно сказать, сердце экспертной системы. Знание — это информация вместе со способом её интерпретации, то есть это более высокий уровень информации. Система, обладающая знаниями, может не только выдавать информацию, но и объяснять её смысл и происхождение. Описание способа интерпретации называется метаданными.
Зачастую вся сложность создания экспертной системы заключается в формировании базы знаний. Этим занимаются специально обученные люди — инженеры по знаниям. Совместно с одним или несколькими экспертами они формулируют правила, имеющиеся в предметной области, и заносят их в определённом виде в базу знаний. В промышленных системах количество правил может исчисляться тысячами. При этом связи в предметной области могут быть такими запутанными и даже противоречивыми, что незначительная модификация базы знаний, например изменение порядка следования двух правил, может вызвать кардинальные изменения в работе всей системы.
Отдельная трудность заключается в самом общении с экспертами. Эксперты могут расходиться во мнениях и устраивать принципиальные споры. Кстати, поэтому предпочтительно использовать экспертные системы для тех областей знаний, которые уже устоялись. Кроме того, эксперты могут применять какие-то правила неосознанно или даже намеренно что-то скрывать. Остаётся только пожелать инженерам по знаниям, чтобы они держались.
Получаемая при этом база знаний может быть представлена в различных видах. Это может быть, к примеру, семантическая сеть. Но более классический вариант — набор продукционных правил (продукций). Продукционное правило — это правило вида ЕСЛИ ТО . Формулируя на естественном языке: если мясо жарится долго, оно приготовилось. Где же тут действие, спросите вы. Обо всём по порядку. Посмотрим на структуру правила более пристально.
И условие, и действие содержат в себе некие факты. Факт сам по себе может быть истинным или ложным, а также мы можем не иметь данных о его истинности. Факт может иметь определённую степень уверенности, например мы не знаем, что значит «долго» в контексте приготовления шашлыка, но кажется, что жарится уже довольно давно. Состоит факт из переменной и значения. Значение берётся из множества возможных значений — домена переменной. То есть наше условие «мясо жарится долго» можно переписать в виде: Время жарки = долго, где «время жарки» — переменная, а «долго» — значение. Если все возможные вопросы относительно времени жарки будут иметь ответ только «долго» и «недолго» — это и будет домен этой переменной.
Действие представляет собой присвоение истинности некоторому факту. То есть вместо человеческого «оно приготовилось», в ходе работы правила факт Мясо готово = да помечается как истинный.
Ещё раз посмотрим на то, что получилось из простого предложения эксперта. Из начального Если мясо жарится долго, оно приготовилось получается:
Переменные:
- Время жарки (домен: долго, недолго).
- Мясо готово (домен: да, нет).
Правило:
Если факт «время жарки = долго» — истинный, то факт «мясо готово = да» пометить как истинный.
Конечно, если мясо долго жарится, ещё нельзя уверенно утверждать, что оно готово, может быть, угли холодные. Но в нашем примере мы закроем на это глаза и не будем использовать степень уверенности в фактах.
Так, изучая высказывания экспертов, инженеры по знаниям выделяют имеющиеся в предметной области сущности и формируют правила. Что же с этими правилами происходит дальше?
Механизм логического вывода
После того как база знаний сформирована, можно задавать вопросы системе. Механизм логического вывода обеспечивает поиск ответов на эти вопросы. Вопрос задаёт цель консультации, в общем случае это определение значения какой-либо переменной. В нашем примере мы хотим понять, что же делать с шашлыком, то есть целью консультации будет значение переменной Действие с шашлыком. Возможными вариантами будут ждать, перевернуть или снимать.
На первом шаге механизм находит в базе знаний все правила, в которых переменная-цель присутствует в качестве вывода, не важно, с каким значением. Теперь каждое правило, если они нашлись, по очереди (именно поэтому важен порядок следования правил) проверяются до первого сработавшего. То есть до того, все условия которого окажутся истинными. Для проверки правила берутся все его условия и, опять же, по очереди проверяются — объявляются целью консультации, и алгоритм запускается для них с первого шага.
Не для всех переменных существуют правила, которые их определяют. Некоторые запрашиваются из внешних источников, в простейшем случае — у пользователя. Переменные, которые определяются правилами, называются выводимыми, а определяемые пользователем во время консультации — запрашиваемыми. Тип переменной определяется ещё на этапе формирования базы знаний, и для запрашиваемых должны быть заданы способы определения, например сформулирован вопрос для пользователя. Если пользователь не может ответить или для выводимой переменной не нашлось правил, или ни одно из правил не сработало — переменная остаётся без значения, а пользователь — без установленной истины.
Существуют ещё выводимо-запрашиваемые переменные. Для них существуют и правила вывода, и вопрос пользователю. Сначала механизм логического вывода пытается определить такие переменные с помощью правил, а если не получается — задаёт вопрос.
Компонента объяснения
Ещё одна немаловажная часть экспертной системы. Именно объяснение хода рассуждений и обоснование выводов выгодно отличают экспертную систему от других отраслей искусственного интеллекта.
На этапе формирования базы знаний в качестве метаданных к правилам прилагаются их объяснения на естественном языке. После консультации система может показать все сработавшие правила вместе с этими пояснениями. Комментарии можно также добавлять к отдельным фактам или переменным.
В итоге мы узнаём не только что надо перевернуть шашлык, но и почему нужно это сделать.
Это очень серьёзное преимущество для систем поддержки принятия решений и для других применений экспертных систем. Некоторые промышленные системы в качестве результата дают несколько ответов с пояснениями и степенями вероятности.
Переход к практике
Механизм логического вывода и компонента объяснения не относятся к конкретной экспертной системе. Они используют правила и метаданные базы знаний, но представляют собой скорее оболочку для экспертных систем. Имея такую оболочку, можно конструировать различные системы, создавая только базы знаний. Возможно, потребуются какие-то настройки в механизме логического вывода, но в целом оболочка может использоваться в любой предметной области.
Оболочка экспертной системы
Конечно, существует множество готовых оболочек. Они предоставляют различные возможности и различные способы формирования базы знаний. Однако, я достаточно жаден, чтобы не использовать платные решения и достаточно высокомерен, чтобы из бесплатных ни одно меня не устроило.
Ещё в студенческие годы мне довелось написать оболочку для экспертной системы. Конечно, она далеко не идеальна, ни с точки зрения кода, ни с точки зрения пользовательского интерфейса. Но во-первых, она работает. По крайней мере для небольших задач, как наша, она вполне годится для примера. Во-вторых, как ни странно, та же Википедия называет одним из основных недостатков экспертных систем отсутствие графического пользовательского интерфейса (взаимодействие обычно идёт через терминал). Так что наличие какого бы то ни было интерфейса (который у меня есть) — уже достаточный вклад в отрасль.
Далее я опишу схему данных и основной алгоритм работы механизма логического вывода в собственной оболочке, и дальнейшее создание экспертной системы буду показывать именно в ней. Вам же предлагаю на выбор — поискать оболочки в интернете (например можно взять эту в Википедии, а вот и ссылка на сам проект), воспользоваться моей.
Модель данных можно использовать самую простую, как в теории:
- Domain (Домен):
- Имя.
- Список значений.
В режиме проектирования базы знаний пользователь может завести все эти данные. Затем он переходит в режим консультации. Выбирается цель консультации, и запускается процедура GoConsult . Вот схема её работы:

Как видно, эта процедура вызывает проверку правил DoRule , её тоже рассмотрим подробно:

DoRule в свою очередь вызывает GoConsult , то есть алгоритм получается косвенно-рекурсивным. А в результате мы получаем факт — значение искомой переменной, которое введено пользователем или получено из базы знаний, или отсутствие значения, если истину определить не удалось.
Теперь, когда у нас есть модель данных и алгоритм, можем переходить к самому интересному — проектированию базы знаний.
База знаний
Что ж, начнём записывать в систему свои знания о шашлыке. При этом нужно помнить несколько вещей:
- Согласно алгоритму логического вывода, все условия в правиле объединены через И. Чтобы использовать ИЛИ, нужно создать несколько правил.
- Создать нужно не только подтверждающие что-то правила, но и противоположные. Например, если мы создаём правило ЕСЛИ Время жарки = Долго И Степень поджарки = Поджаристое, ТО Готово = Да, мы должны создать ещё такие правила: ЕСЛИ Время жарки = Только положили ТО Готово = Нет и ЕСЛИ Степень поджарки = Ещё сырое, ТО Готово = Нет.
- Важен порядок правил в базе знаний.
Нужно формализовать свои знания о шашлыке и представить в виде модели базы знаний, то есть выделить домены, переменные и правила. Чтобы было легче сформировать набор правил, да ещё и в нужном порядке, можно составить их графическое представление. У меня получилась довольно дикая, боюсь, понятная только мне схема:

Вершины определяют список переменных и возможных значений, а также какие переменные будут запрашиваемыми, а какие выводимыми. Дуги указывают на некоторые связи, из которых впоследствии получаются правила. Здесь я предположил, что мы будем жарить курицу или свинину, а система может подсказать три действия — ждать, перевернуть, снимать. Исходя из вашего опыта, вы можете сделать другие правила, расширить или переделать эту базу знаний. Вообще говоря, этим база знаний и хороша, что её ещё долго можно расширять, включая новые виды мяса, предполагаемые действия, обстоятельства и так далее. Пока же у меня получилось 27 правил:

В промышленных системах количество правил может исчисляться тысячами. Для нашей тренировочной области пока попробуем чуть меньше. Итак, запустим консультацию и посмотрим, что нам посоветует система.
Я сказал, что жарю свинину минут 10, и система посоветовала подождать ещё, и вот почему:

Когда смотришь на объяснение, как-то даже легче смириться с тем, что надо ещё ждать. Можно поэкспериментировать, запуская консультацию и по-разному отвечая на вопросы. Возможно, в каких-то случаях истина установлена не будет — значит, надо дополнить базу знаний новыми правилами.
Вот и всё, искусственный интеллект — система поддержки принятия решений в узкой предметной области — создан. Конечно, он не учитывает многие факторы, нечёткости и так далее. В базе знаний нет сведений о том, как захватить мир, и в отличие от некоторых промышленных систем, наша не способна анализировать консультации и сама генерировать новые правила. Но с шашлычными экспертами, которые будут кучковаться летом вокруг мангала, она уже вполне может поспорить.
Генерация автоматических тестов: Excel, XML, XSLT, далее — везде
Есть определенная функциональная область приложения: некая экспертная система, анализирующая состояние данных, и выдающая результат — множество рекомендаций на базе набора правил. Компоненты системы покрыты определенным набором юнит-тестов, но основная «магия» заключается в выполнении правил. Набор правил определен заказчиком на стадии проекта, конфигурация выполнена.
Более того, поскольку после первоначальной приемки (это было долго и сложно — потому, что “вручную») в правила экспертной системы регулярно вносятся изменения по требованию заказчика. При этом, очевидно, неплохо — бы проводить регрессионное тестирование системы, чтобы убедиться, что остальные правила все еще работают корректно и никаких побочных эффектов последние изменения не внесли.
Основная сложность заключается даже не в подготовке сценариев — они есть, а в их выполнении. При выполнении сценариев “вручную», примерно 99% времени и усилий уходит на подготовку тестовых данных в приложении. Время исполнения правил экспертной системой и последующего анализа выдаваемого результата — незначительно по сравнению с подготовительной частью. Сложность выполнения тестов, как известно, серьезный негативный фактор, порождающий недоверие со стороны заказчика, и влияющий на развитие системы («Изменишь что-то, а потом тестировать еще прийдется… Ну его. »).
Очевидным техническим решением было бы превратить все сценарии в автоматизированные и запускать их регулярно в рамках тестирования релизов или по мере необходимости. Однако, будем ленивыми, и попробуем найти путь, при котором данные для тестовых сценариев готовятся достаточно просто (в идеале — заказчиком), а автоматические тесты — генерируются на их основе, тоже автоматически.
Под катом будет рассказано об одном подходе, реализующим данную идею — с использованием MS Excel, XML и XSLT преобразований.
Тест — это прежде всего данные
А где проще всего готовить данные, особенно неподготовленному пользователю? В таблицах. Значит, прежде всего — в MS Excel.
Я, лично, электронные таблицы очень не люблю. Но не как таковые (как правило — это эталон юзабилити), а за то, что они насаждают и культивируют в головах непрофессиональных пользователей концепцию «смешивания данных и представления» (и вот уже программисты должны выковыривать данные из бесконечных многоуровневых «простыней», где значение имеет все — и цвет ячейки и шрифт). Но в данном случае — мы о проблеме знаем, и постараемся ее устранить.
Итак, постановка задачи
- обеспечить подготовку данных в MS Excel. Формат должен быть разумным с точки зрения удобства подготовки данных, простым для дальнейшей обработки, доступным для передачи бизнес пользователям (последнее — это факультативно, для начала — сделаем инструмент для себя);
- принять подготовленные данные и преобразовать их в код теста.
Решение
Пара дополнительных вводных:
- Конкретный формат представления данных в Excel пока не ясен и, видимо, будет немного меняться в поисках оптимального представления;
- Код тестового скрипта может со временем меняться (отладка, исправление дефектов, оптимизация).
Известная технология превращения данных в произвольное текстовое представление — шаблонизаторы, и XSLT преобразования, в частности — гибко, просто, удобно, расширяемо. В качестве дополнительного бонуса, использование преобразований открывает путь как к генерации самих тестов (не важно на каком языке программирования), так и к генерации тестовой документации.
Итак, архитектура решения:
- Преобразовать данные из Excel в XML определённого формата
- Преобразовать XML с помощью XSLT в финальный код тестового скрипта на произвольном языке программирования
Этап 1. Ведение данных в Excel
Здесь, честно говоря, я ограничился ведением данных в виде табличных блоков. Фрагмент файла — на картинке.
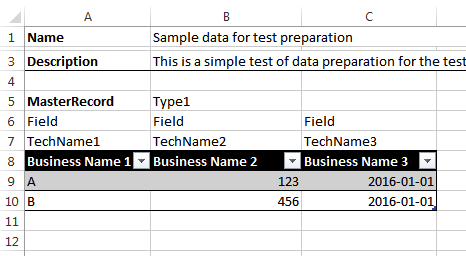
- Блок начинается со строки, содержащей название блока (ячейка “A5″). Оно будет использовано в качестве имени xml-элемента, так что содержание должно соответствовать требованиям. В той же строе может присутствовать необязательный “тип” (ячейка “B5″) — он будет использовано в качестве значения атрибута, так что тоже имеет ограничения.
- Каждая колонка таблицы содержит помимо “официального” названия, представляющего бизнес-термины (строка 8), еще два поля для “типа” (строка 6) и “технического названия” (строка 7). В процессе подготовки данных технические поля можно скрывать, но во время генерации кода использоваться будут именно они.
- Колонок в таблице может быть сколько угодно. Скрипт завершает обработку колонок как только встретит колонку с пустым значением “тип” (колонка D).
- Колонки со “типом”, начинающимся с нижнего подчеркивания — пропускаются.
- Таблица обрабатывается до тех пор, пока не встретиться строка с пустым значением в первой колонке (ячейка “A11”)
- Скрипт останавливается после 3 пустых строк.
Этап 2. Excel -> XML
Преобразование данных с листов Excel в XML — несложная задача. Преобразование производится с помощью кода на VBA. Тут могут быть варианты, но мне так показалось проще и быстрее всего.
Ниже приведу лишь несколько соображений — как сделать финальный инструмент удобнее в поддержке и использовании.
- Код представлен в виде Excel add-in (.xlam) — для упрощения поддержки кода, когда количество файлов с тестовыми данными более 1 и эти файлы создаются/поддерживаются более чем одним человеком. Кроме того — это соответствует подходу разделения кода и данных;
Этап 3. XML -> Code
Эта часть предельно специфична задачам которые решаются, поэтому ограничусь общими замечаниями.
- Начальная итерация начинается по элементам, представляющим листы (различные тестовые сценарии). Здесь можно размещать блоки setup / teardown, утилит;
Финальный комментарий
Через какое-то время файлов с тестовыми данными станет много, а отладка и «полировка» шаблонов генерации тестовых скриптов будет все продолжаться. Поэтому, прийдется предусмотреть возможность «массовой» генерации автотестов из набора исходных Excel файлов.
Заключение
Используя описанный подход можно получить весьма гибкий инструмент для подготовки тестовых данных или полностью работоспособных автотестов.
В нашем проекте удалось довольно быстро создать набор тестовых сценариев для интеграционного тестирования сложной функциональной области — всего на данный момент около 60 файлов, генерируемых примерно в 180 тестовых классов tSQLt (фреймворк для тестирования логики на стороне MS SQL Server). В планах — использовать подход для расширения тестирования этой и других функциональных областей проекта.
Формат пользовательского ввода остается как и раньше, а генерация финальных автотестов можно менять по потребностям.
Код VBA для преобразования Excel файлов в XML и запуска преобразования (вместе с примером Excel и XML) можно взять на GitHub github.com/serhit/TestDataGenerator.
Преобразование XSLT не включено в репозиторий, поскольку оно генерит код для конкретной задачи — у вас все равно будет свой. Буду рад комментариям и pull request’ам.
Проектирование тестов в среде MS Excel и VBA
Если ваши ученики освоили в Excel представление и обработку данных, то можно переходить на качественно новый уровень работы с Excel – автоматизировать свою работу. Язык VBA (Visual Basic for Application) – язык программирования, который подходит для всех приложений Microsoft Office, это один из самых простых в изучении и применении языков, он является версией языка Visual Basic.
Предлагаю задания для создания проектов в виде тестов в среде MS Excel и VBA.
- Откройте Excel.
- Переименуйте Лист1 в Вопросник и составьте таблицу.

Для каждого вопроса создайте пользовательские формы и с помощью их заполните таблицу.
Пользовательские формы могут иметь вид:
UserForm1

UserForm2

- При вызове следующего вопроса закрывается текущая форма, записываются результаты на лист Вопросник, и открывается форма со следующим вопросом.
- В форме с последним вопросом запрограммировано только закрытие формы и запись результатов.
- Спроектируйте на листе Excel Вопросник кнопку вызова форм:

Примечание. Подумайте, как изменится программа, если заполнить таблицу по вертикали.

Темы проектов:
1. Подобрать тест, обработать его, результаты показать через пользовательскую форму.
2. Вопросник по любому предмету, результаты которого обработать в Excel и выдать через пользовательскую форму оценку:

Данная работа является контрольно-обучающим пособием по теме «Практическое применение табличного электронного редактора EXCEL », а именно создание интерактивных тестов.
Работу можно использовать на уроках информатики в 9-11 классах технического профиля, а также для пользователей начинающего уровня.
Microsoft Excel — программа для работы с электронными таблицами, созданная корпорацией Microsoft для Microsoft Windows, Windows NT и Mac OS. Она предоставляет возможности экономико — статистических расчетов, графические инструменты и, за исключением Excel 2008 под Mac OS X, язык макропрограммирования VBA (Visual Basic для приложений). Microsoft Excel входит в состав Microsoft Office и на сегодняшний день Excel является одним из наиболее популярных приложений в мире.
Также в Microsoft Excel можно создавать интерактивные тесты с помощью стандартных функций или макросов.
Создание интерактивных тестов в программе MS Excel.
(инструкция для изучения возможностей и применения MS Excel по созданию интерактивных тестов для учащихся старших классов)
Разработка состоит из трех разделов. В первом – основные сведения по MS Excel – даются лишь самые основные сведения по MS Excel, которые необходимо знать при создании тестов, опытным пользователям можно пропустить этот раздел. Во втором показана возможность создания интерактивного теста с помощью стандартных функций Excel, а в третьем с помощью макросов – набора команд, используемых для автоматического выполнения некоторых операций, что позволяет автоматизировать переход к следующему вопросу теста и возврат к началу теста.
Интерактивные тесты можно применять на различных этапах урока (вводный, текущий, заключительный инструктаж), на различных этапах контроля (входной, текущий, рубежный, итоговый). В моей практике тесты с удовольствием создают сами учащиеся. Наполняют ими свои курсовые проекты. Они привлекают внимание учащихся своим разнообразием, яркостью, возможностью самостоятельно создать мини программу для компьютера, которая не только считает оценку, но и будет применяться на уроках, приобретая практическую значимость для учащихся.
Для создания таких тестов не требуется специального программного обеспечения. Пакет MS Office (Excel в частности) имеется на каждом персональном компьютере. Этим объясняется доступность предлагаемой информации.
Создание интерактивных тестов не требует специальных знаний и умений. Простота изготовления тестов дает возможность пробовать свои силы как опытным, так и начинающим пользователям.
Основные сведения по MS Excel
Для создания теста необходимо знать несколько особенностей программы MS Excel, на которые имеются ссылки в данной разработке.
Перечень команд, которые управляют работой Excel, находится в основном меню (рис.1,1) Здесь Вы найдете команду Вставка, Данные, Сервис.
Пункты основного меню содержат раскрывающийся список команд, открыть который можно щелкнув левой кнопкой мыши на пункте меню. Так Вы найдете команды Проверка (пункта меню Данные), Лист (пункта меню Вставка), Макрос (пункта меню Сервис).
Каждая ячейка Excel имеет уникальный адрес, состоящий из названия столбца и строки (рис.1,2).
Столбцы таблицы Excel обозначаются латинскими буквами (рис.1,3), строки цифрами (рис.1,4). Обратите внимание, если будете вводить формулы с клавиатуры.
Формулы вводим в строку формул (рис.1,5), начиная со знака = (равенства).
Для создания фигуры к тесту воспользуемся панелью инструментов Рисование (находится в нижней части окна Excel), либо пунктом меню Вставка-Рисунок-Автофигуры
Все существующие программы по финансовому анализу рассчитывают различные коэффициенты на основе финансовой отчетности. Среди них есть программы, которые выдают готовое аналитическое заключение. Они используются в основном для проверки надежности внешних контрагентов или для проверки соответствия финансовой устойчивости предприятия нормативам банков.
Эти программы используют за основу отчетность по РСБУ и не проверяют ее качество. Если фирма не подпадает под обязательный аудит и ведет бухгалтерский учет для налоговых целей, то финансовые коэффициенты, посчитанные на основе такой отчетности могут быть не верны – фирма может не начислять резервы по сомнительным долгам, отражать расходы будущих периодов в качестве активов и несвоевременно их списывать, манипулировать переоценками для улучшения показателей отчетности РСБУ.
Для ведения управленческого учета и решения таких задач, как оптимизация оборотного капитала и минимизация кассового разрыва, оптимизация затрат и управление запасами почти нет программ совсем. Эти задачи решаются финансовыми директорами либо вручную в Excel либо с применением QlikView и других систем бизнес анализа, путем построения сложных финансовых моделей и многочасовой работы с таблицами

Другим вариантом является внедрения ERP-систем. Но внедрение ERP стоит дорого и на него надо затратить время, а потом еще вести учет в этой системе – вести там блок казначейство, управление складом, бюджет. Например, для управления запасами существуют прикладные решения, такие как Netstock.Pro, StockM, WA – SCM и другие решения, однако все они предполагают дорогостоящее внедрение и сложную настройку интеграции с существующей ERP системой, в которой ведется бухгалтерский учет и управление складом.
Наиболее популярными инструментами бизнес-анализа являются Qlikview и PowerBI. Это мощные и современные инструменты визуализации данных.
Однако QlikView не имеет экспертной системы бизнес-анализа, которая бы была заранее настроена на решение определенных задач, таких как определение оптимального уровня конкретного запаса, расчет резерва по сомнительным долгам или расчет показателей ликвидности и оборачиваемости. Она не подскажет вам какие формулы и коэффициенты нужно использовать.
В QlikView и PowerBI именно вы, а не база данных, определяете, какие вопросы следует задавать. Вам будет нужно указать какие показатели поделить друг на друга, какие сложить, как именно рассчитать тот или иной коэффициент на основе имеющихся данных.
Что такое экспертная система бизнес-анализа
Экспертная система – это полностью пройденный путь построения бизнес аналитики от проектирования до завершения разработки. Это уже готовое решение, которым можно пользоваться.
Обычно инструменты бизнес-анализа создаются аналитиками, которые не являются бухгалтерами или аудиторами. Аналитики прекрасно знают статистику, корреляции показателей, факторный анализ и другие виды анализа, однако они не знают что нужно искать. Это знают те, кто составляет отчетность и проверяет ее — аудиторы и финансовые директора. Наша экспертная система заранее настроена на поиск и оценку определенных данных, которые действительно важны для финансового директора.
Она создана экспертами с многолетним опытом в области финансового анализа, МСФО и автоматизации учета, в которой все формулы уже определены заранее, однако вы можете их редактировать и изменять, если хотите.
Все финансовые модели уже и настроены на решение таких задач как
- Ускорение оборачиваемости дебиторской задолженности, ABC анализ задолженности и продаж
- Оптимизация размещения свободного остатка денежных средств на депозиты
- Оценка эффективности работы по сбору сомнительных долгов
- Выявление дефицита товарных запасов и неликвидных запасов, поддержание оптимального товарного остатка
- Анализ постоянных и переменных затрат и их оптимизация, ХYZ анализ
- Выявление искажений в бухгалтерском учете
- Прогноз будущих денежных потоков
- Анализ эффективности инвестиционных проектов
Программы способствуют выявлению отгрузок контрагентам с ухудшающейся кредитной динамикой и замедлением скорости оплат, обеспечивают поддержание на складах оптимального остатка запасов и обеспечивают контроль появления неликвидных запасов и мониторинг эффективности работы по сбору сомнительных долгов.
Исходными данными выступают стандартные отчеты 1С, такие как анализ счета и оборотно-сальдовая ведомость. Никакой дополнительной настройки через протоколы обмена данными не требуется. Нужно просто выгрузить в Excel стандартный отчет «Анализ счета» в разрезе требуемой аналитики. Таким образом, весь анализ строится на бухгалтерских проводках. Проводки в отличии от отчетности не позволяют спрятать негативную информацию в агрегированном показателе.
Можно разложить один коэффициент (например, оборачиваемость задолженности) на сотни факторов (например, оборачиваемость задолженности по каждому контрагенту на каждую дату), отслеживать динамику изменения каждого из них и строить прогноз на основе этого.
Программы не содержат макросов и написаны полностью на типовых функциях Excel, что обеспечивает высокий уровень безопасности и защиты данных.

На сайте представлены версии программ с ограничениями по объему данных, которые подходят для небольших компаний (малый бизнес). Снять любые ограничения на объем данных можно за плату от 1000 до 5000 руб., в зависимости от вида программы и объема данных.
При использовании программ нашего сайта дополнительного инструмента интеграции для выгрузки данных 1С в Excel не требуется. Используется стандартный функционал 1С и Excel. Вы также можете использовать встроенные в Excel инструменты Power BI для работы с выгруженными из 1С данными и использовать дополнительные инструменты их визуализации средствами Power BI.
Нашим ноу-хау является преобразование бухгалтерских регистров, таких как оборотно-сальдовые ведомости, в в интерактивные диаграммы Ганта, в которых можно легко делать выборки и формировать их за произвольный период.
На диаграммах маркерами будут отражены все операции, которые являются нетиповыми. Финансовые коэффициенты также отражаются на диаграммах наряду с бухгалтерскими данными. Это сэкономит ваше время на поиск и анализ данных.
Время на прочтение
7 мин
Количество просмотров 14K
Проблема
Есть определенная функциональная область приложения: некая экспертная система, анализирующая состояние данных, и выдающая результат — множество рекомендаций на базе набора правил. Компоненты системы покрыты определенным набором юнит-тестов, но основная «магия» заключается в выполнении правил. Набор правил определен заказчиком на стадии проекта, конфигурация выполнена.
Более того, поскольку после первоначальной приемки (это было долго и сложно — потому, что “вручную») в правила экспертной системы регулярно вносятся изменения по требованию заказчика. При этом, очевидно, неплохо — бы проводить регрессионное тестирование системы, чтобы убедиться, что остальные правила все еще работают корректно и никаких побочных эффектов последние изменения не внесли.
Основная сложность заключается даже не в подготовке сценариев — они есть, а в их выполнении. При выполнении сценариев “вручную», примерно 99% времени и усилий уходит на подготовку тестовых данных в приложении. Время исполнения правил экспертной системой и последующего анализа выдаваемого результата — незначительно по сравнению с подготовительной частью. Сложность выполнения тестов, как известно, серьезный негативный фактор, порождающий недоверие со стороны заказчика, и влияющий на развитие системы («Изменишь что-то, а потом тестировать еще прийдется… Ну его…»).
Очевидным техническим решением было бы превратить все сценарии в автоматизированные и запускать их регулярно в рамках тестирования релизов или по мере необходимости. Однако, будем ленивыми, и попробуем найти путь, при котором данные для тестовых сценариев готовятся достаточно просто (в идеале — заказчиком), а автоматические тесты — генерируются на их основе, тоже автоматически.
Под катом будет рассказано об одном подходе, реализующим данную идею — с использованием MS Excel, XML и XSLT преобразований.
Тест — это прежде всего данные
А где проще всего готовить данные, особенно неподготовленному пользователю? В таблицах. Значит, прежде всего — в MS Excel.
Я, лично, электронные таблицы очень не люблю. Но не как таковые (как правило — это эталон юзабилити), а за то, что они насаждают и культивируют в головах непрофессиональных пользователей концепцию «смешивания данных и представления» (и вот уже программисты должны выковыривать данные из бесконечных многоуровневых «простыней», где значение имеет все — и цвет ячейки и шрифт). Но в данном случае — мы о проблеме знаем, и постараемся ее устранить.
Итак, постановка задачи
- обеспечить подготовку данных в MS Excel. Формат должен быть разумным с точки зрения удобства подготовки данных, простым для дальнейшей обработки, доступным для передачи бизнес пользователям (последнее — это факультативно, для начала — сделаем инструмент для себя);
- принять подготовленные данные и преобразовать их в код теста.
Решение
Пара дополнительных вводных:
- Конкретный формат представления данных в Excel пока не ясен и, видимо, будет немного меняться в поисках оптимального представления;
- Код тестового скрипта может со временем меняться (отладка, исправление дефектов, оптимизация).
Оба пункта приводят к мысли, что исходные данные для теста необходимо предельно оделить и от формата, в котором будет осуществляться ввод, и от процесса обработки и превращения в код автотеста, поскольку обе стороны будут меняться.
Известная технология превращения данных в произвольное текстовое представление — шаблонизаторы, и XSLT преобразования, в частности — гибко, просто, удобно, расширяемо. В качестве дополнительного бонуса, использование преобразований открывает путь как к генерации самих тестов (не важно на каком языке программирования), так и к генерации тестовой документации.
Итак, архитектура решения:
- Преобразовать данные из Excel в XML определённого формата
- Преобразовать XML с помощью XSLT в финальный код тестового скрипта на произвольном языке программирования
Конкретная реализация на обеих этапах может быть специфична задаче. Но некоторые общие принципы, которые, как мне кажется, будут полезны в любом случае, приведены ниже:
Этап 1. Ведение данных в Excel
Здесь, честно говоря, я ограничился ведением данных в виде табличных блоков. Фрагмент файла — на картинке.

- Блок начинается со строки, содержащей название блока (ячейка “A5″). Оно будет использовано в качестве имени xml-элемента, так что содержание должно соответствовать требованиям. В той же строе может присутствовать необязательный “тип” (ячейка “B5″) — он будет использовано в качестве значения атрибута, так что тоже имеет ограничения.
- Каждая колонка таблицы содержит помимо “официального” названия, представляющего бизнес-термины (строка 8), еще два поля для “типа” (строка 6) и “технического названия” (строка 7). В процессе подготовки данных технические поля можно скрывать, но во время генерации кода использоваться будут именно они.
- Колонок в таблице может быть сколько угодно. Скрипт завершает обработку колонок как только встретит колонку с пустым значением “тип” (колонка D).
- Колонки со “типом”, начинающимся с нижнего подчеркивания — пропускаются.
- Таблица обрабатывается до тех пор, пока не встретиться строка с пустым значением в первой колонке (ячейка “A11”)
- Скрипт останавливается после 3 пустых строк.
Этап 2. Excel -> XML
Преобразование данных с листов Excel в XML — несложная задача. Преобразование производится с помощью кода на VBA. Тут могут быть варианты, но мне так показалось проще и быстрее всего.
Ниже приведу лишь несколько соображений — как сделать финальный инструмент удобнее в поддержке и использовании.
- Код представлен в виде Excel add-in (.xlam) — для упрощения поддержки кода, когда количество файлов с тестовыми данными более 1 и эти файлы создаются/поддерживаются более чем одним человеком. Кроме того — это соответствует подходу разделения кода и данных;
- XSLT шаблоны размещаются в одном каталоге с файлом add-in — для упрощения поддержки;
- Генерируемые файлы: промежуточный XML и результирующий файл с кодом, — желательно помещать в тот же каталог, что и файл Excel с исходными данными. Людям создающим тестовые скрипты будет удобнее и быстрее работать с результатами;
- Excel файл может содержать несколько листов с данными для тестов — они используются для организации вариативности данных для теста (например, если тестируется процесс, в котором необходимо проверить реакцию системы на каждом шаге): откопировал лист, поменял часть входных данных и ожидаемых результатов — готово. Все в одном файле;
- Поскольку все листы в рабочей книге Excel должны иметь уникальное имя — эту уникальность можно использовать в качестве части имени тестового скрипта. Такой подход дает гарантированную уникальность имен различных подсценариев в рамках сценария. А если включать в имя тестового скрипта название файла, то достичь уникальности названий скриптов становится еще проще — что особенно важно в случае если тестовые данные готовят несколько человек независимо. Кроме того, стандартный подход к именованию поможет в дальнейшем при анализе результатов теста — от результатов исполнения к исходным данным будет добраться очень просто;
- Данные из всех листов книги сохраняются в один XML файл. Для нас это показалось целесообразным в случае генерации тестовой документации, и некоторых случаях генерации тестовых сценариев;
- При генерации файла с данными для теста удобно оказалось иметь возможность не включать в генерацию отдельные листы с исходными данными (по разным причинам; например, данные для одного из пяти сценариев ещё не готовы — а тесты прогонять пора). Для этого мы используем соглашение: листы, где название начинается с символа нижнего подчёркивания — исключаются из генерации;
- В файле удобно держать лист с деталями сценария по которому создаются тестовые данные («Documentation») — туда можно копировать информацию от заказчика, вносить комментарии, держать базовые данные и константы, на которые ссылаются остальные листы с данными, и так далее. Разумеется, данный лист в генерации не участвует;
- Чтобы иметь возможность влиять на некоторые аспекты генерации финального кода тестовых скриптов, оказалось удобным включать в финальный XML дополнительную информацию «опции генерации», которые не являются тестовыми данными, но могут использоваться шаблоном для включения или исключения участков кода (по аналогии с pragma, define, итп.) Для этого мы используем именованные ячейки, размещённые на негенерируемом листе «Options»;
- Каждая строка тестовых данных должна иметь уникальный идентификатор на уровне XML — это здорово поможет при генерации кода и при обработке кросс-ссылок между строками тестовых данных, которые при этом необходимо формулировать в терминах как раз этих уникальных идентификаторов.
Фрагмент XML который получается из данных в Excel с картинки выше
<MasterRecord type="Type1">
<columns>
<column>
<type>Field</type>
<name>TechName1</name>
<caption>Business Name 1</caption>
</column>
<column>
<type>Field</type>
<name>TechName2</name>
<caption>Business Name 2</caption>
</column>
<column>
<type>Field</type>
<name>TechName3</name>
<caption>Business Name 3</caption>
</column>
</columns>
<row id="Type1_1">
<Field name="TechName1">A</Field>
<Field name="TechName2">123</Field>
<Field name="TechName3">2016-01-01</Field>
</row>
<row id="Type1_2">
<Field name="TechName1">B</Field>
<Field name="TechName2">456</Field>
<Field name="TechName3">2016-01-01</Field>
</row>
</MasterRecord>
Этап 3. XML -> Code
Эта часть предельно специфична задачам которые решаются, поэтому ограничусь общими замечаниями.
- Начальная итерация начинается по элементам, представляющим листы (различные тестовые сценарии). Здесь можно размещать блоки setup / teardown, утилит;
- Итерация по элементам данных внутри элемента сценария должна начинаться с элементов ожидаемых результатов. Так можно логично организовать сгенерированные тесты по принципу «один тест — одна проверка»;
- Желательно явно разделить на уровне шаблонов области, где генерируются данные, выполняется проверяемое действие, и контролируется полученный результат. Это возможно путём использования шаблонов с режимами (mode). Такая структура шаблона позволит в дальнейшем делать другие варианты генерации — просто импортируя этот шаблон и перекрывая в новом шаблоне необходимую область;
- Наряду с кодом, в тот же файл будет удобно включить справку по запуску тестов;
- Очень удобным является выделение кода генерации данных в отдельно вызываемый блок (процедуру) — так чтобы его можно было использовать как в рамках теста, так и независимо, для отладки или просто создания набора тестовых данных.
Финальный комментарий
Через какое-то время файлов с тестовыми данными станет много, а отладка и «полировка» шаблонов генерации тестовых скриптов будет все продолжаться. Поэтому, прийдется предусмотреть возможность «массовой» генерации автотестов из набора исходных Excel файлов.
Заключение
Используя описанный подход можно получить весьма гибкий инструмент для подготовки тестовых данных или полностью работоспособных автотестов.
В нашем проекте удалось довольно быстро создать набор тестовых сценариев для интеграционного тестирования сложной функциональной области — всего на данный момент около 60 файлов, генерируемых примерно в 180 тестовых классов tSQLt (фреймворк для тестирования логики на стороне MS SQL Server). В планах — использовать подход для расширения тестирования этой и других функциональных областей проекта.
Формат пользовательского ввода остается как и раньше, а генерация финальных автотестов можно менять по потребностям.
Код VBA для преобразования Excel файлов в XML и запуска преобразования (вместе с примером Excel и XML) можно взять на GitHub github.com/serhit/TestDataGenerator.
Преобразование XSLT не включено в репозиторий, поскольку оно генерит код для конкретной задачи — у вас все равно будет свой. Буду рад комментариям и pull request’ам.
Happy testing!