
|
Распределение объемов груза на месяц с заданной частотой |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |




Создадим модель для нахождения наилучшего распределения ресурсов, при котором минимизируются затраты, понесенные за несколько периодов (Allocation Problem). Расчет будем проводить с помощью надстройки Поиск решения.
Задача оптимального распределения ресурсов (распределительная задача) заключается в отыскании наилучшего распределения ресурсов, при котором либо максимизируется результат, либо минимизируются затраты. Задача, в которой минимизируются затраты, понесенные в одном периоде решена в статье
Поиск решения MS EXCEL (1.2). Распределение ресурсов (ограничение по количеству оборудования)
, и имеет смысл предварительно познакомиться с изложенным там материалом. В этой статье мы решим аналогичную задачу, но для случая работы оборудования в нескольких периодах (пример с сайта
www.solver.com
).
Вводная статья про
Поиск решения
в MS EXCEL 2010
находится здесь
.
Задача
Предприятие выпускает монопродукт (только один вид изделия и ничего более) и ему необходимо выполнить заказ клиента. Выпуск продукции осуществляется в течение 5 дней. Отгрузка заказа ежедневная. На предприятии 3 типа оборудования. Каждый тип оборудования выпускает один и тот же продукт. Производительность каждого типа оборудования разная. Каждый тип оборудования имеет постоянную и переменную часть расходов. Переменная часть расходов пропорциональна количеству произведенных изделий. Имеется ограниченное количество единиц оборудования каждого типа (но общее количество оборудования избыточно для выполнения заказа). Требуется минимизировать расходы на оборудование при условии выполнения заказа.
Создание модели
На рисунке ниже приведена модель, созданная для решения задачи (см.
файл примера
).
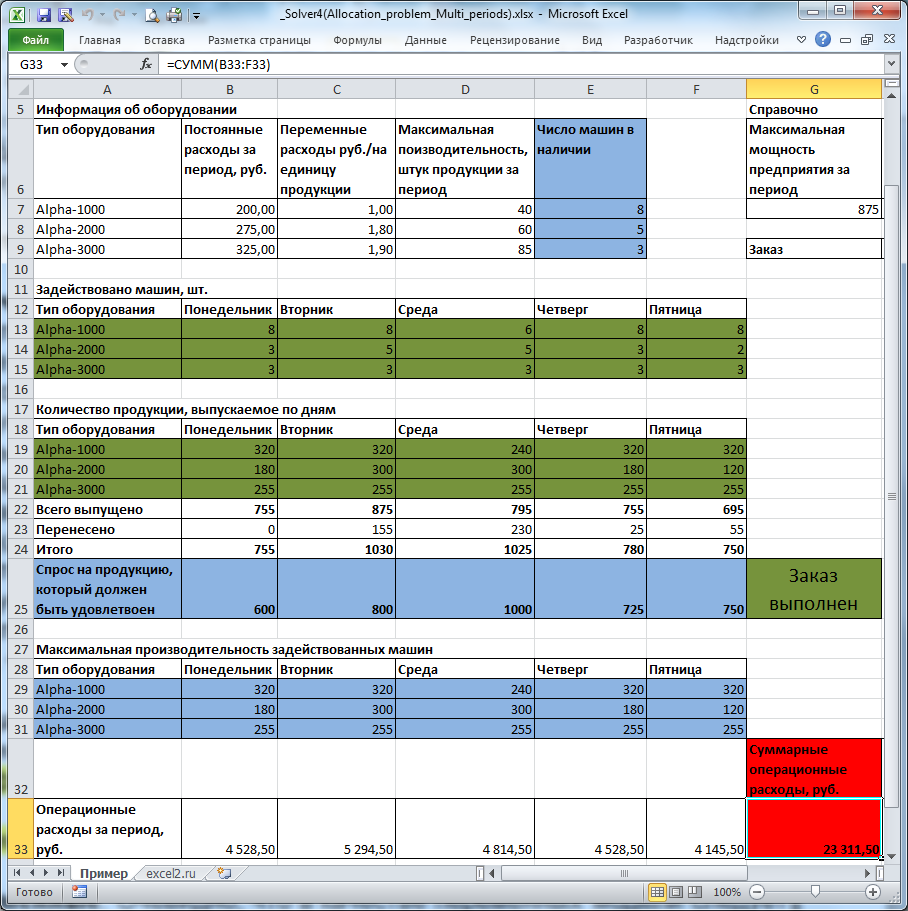
Предприятие несет расходы в зависимости от типа оборудования: использование оборудования типа Alpha-3000 самое дорогое в эксплуатации, но оно и самое производительное. Оборудование типа Alpha-1000 самое дешевое в эксплуатации, но оно и менее производительное. Задача
Поиска решения
выбрать наиболее дешевое оборудование, так чтобы заказ был выполнен (мощностей Alpha-1000 не хватит для выполнения заказа). Казалось бы, решение очевидно (взять по максимуму дешевое оборудование, остальную производительность обеспечить более дорогим). Однако, если учесть, что из-за низкой производительности дешевых машин приходится их брать больше, неся существенные постоянные расходы, то решение уже не кажется очевидным.
Переменные (выделено зеленым)
. В качестве переменных модели следует взять количество задействованных единиц оборудования каждого типа и суммарное количество продукции, выпущенное на каждом типе оборудования (производительность задается не для каждой единицы, а для типа в целом). Для наглядности диапазонам ячеек, содержащих переменные, присвоены
имена
Машин_Задействовано
и
Продукции_выпущено.
Ограничения (выделено синим)
. Количество задействованных машин должно быть целым числом. Количество задействованных машин каждого типа должно быть не больше, чем имеется в наличии (используются
именованные диапазоны
Alpha
XXXX
_Задействовано
и
Alpha
XXXX
_в_наличии
). Всего должно быть выпущено продукции не меньше чем величина заказа (используется
именованный диапазон
Продукции выпущено_Итого
). В день возможно производить больше продукции, чем требуется в день заказа, излишек переносится на следующий день. Также необходимо ограничить производительность задействованного оборудования. Производительность задается не для каждой единицы, а для типа в целом (используются
именованные диапазоны
Продукции выпущено
и
Макс_производительность_задейств_машин
).
Целевая функция (выделено красным)
. Целевая функция – это сумма операционных расходов за 5 дней. Операционные расходы, понесенные за день, задается формулой
=СУММПРОИЗВ(B19:B21; Расходы_переменные)+ СУММПРОИЗВ(B13:B15; Расходы_постоянные)
B19:B21
– количество продукции, выпущенной в определенный день.
B13:B15
— количество задействованных машин в определенный день.
Это суммарные операционные расходы (переменная и постоянные части). Сумма операционных расходов за 5 дней должна быть минимизирована.
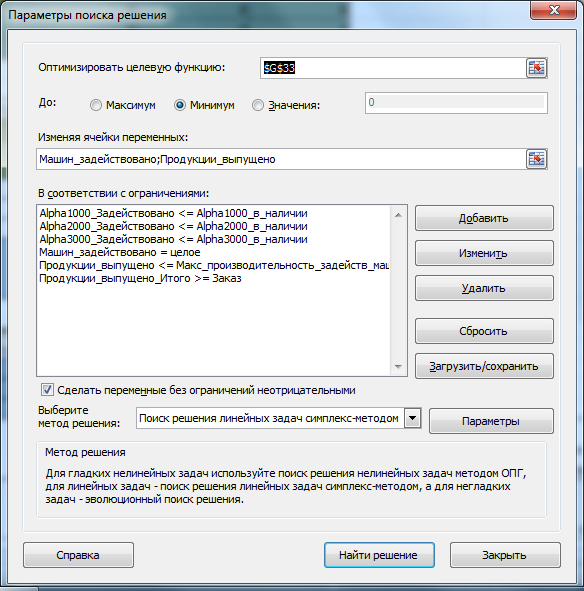
Убедитесь, что метод решения соответствует линейной задаче. Параметры
Поиска решения
были выбраны следующие:
Теперь в диалоговом окне можно нажать кнопку
Найти решение
.
Результаты расчетов
Поиск решения
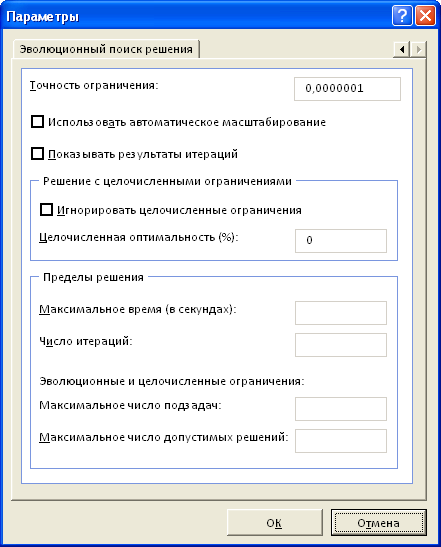
подберет оптимальный набор единиц оборудования по типам и их производительность, при котором операционные расходы будут минимальные, а заказ выполнен. В нашей задаче было установлено целочисленное ограничение, что существенно усложняет задачу поиска и, соответственно, сказывается на скорости расчета. Как показано на рисунке выше,
Целочисленная оптимальность
была выбрана 0% (
Целочисленная оптимальность
(Integer Optimality) позволяет
Поиску решения
остановить поиск, в случае, если он найдет целочисленное решение, в пределах указанного процента от оптимального). В нашем случае (0%), требуется найти лучшее из известных
Поиску решения
решений. Поиск в этом случае занял 8 секунд, результат 23 311,50. Установив
Целочисленную оптимальность
1%, поиск займет 0,2 сек, результат 23 370,50 (отличие на 0,3%). Это информация к размышлению: стоит ли увеличение точности на 0,3% уменьшения скорости расчетов более чем на порядок? Решать Вам. В любом случае, первые расчеты модели лучше проводить при
Целочисленной оптимальности
не равной 0%.
Существует
множество задач, решение которых может
быть существенно облегченно с помощью
инструмента Поиск
решений.
Но для этого следует начать с организации
рабочего листа в соответствии с пригодной
для поиска решений моделью, для чего
нужно хорошо понимать взаимосвязи между
переменными и формулами. Хотя постановка
задачи обычно представляет основную
сложность, время и усилия, затраченные
на подготовку модели, вполне оправданы,
поскольку полученные результаты могут
уберечь от излишней траты ресурсов, при
неправильном планирование, помогут
увеличить прибыль за счет оптимального
управление финансами или выявить
наилучшее соотношение объемов
производства, запасов и наименований
продукции.
За
своей сущностью задача
оптимизации –
это математическая модель определенного
процесса производства продукции, его
распределение, хранение, переработки,
транспортирования, покупки или продажи,
выполнение комплекса сервисных услуг
и т.д. Это обычная математическая задача
типа: Дано/Найти/При условии, но
которая имеет множество возможных
решений. Таким образом, задача оптимизации
– задача выбора з множества возможных
вариантов наилучшего, оптимального.
Решение
такой задачи называют планом или программой,
например, говорят – план производства
или программа реконструкции. Другими
словами это те неизвестные которые нам
надо найти, например, количество
продукции которое даст максимальную
прибыль. Задача оптимизации – поиск
экстремума, то есть, максимального или
минимального значения определенной
функции, которую называют целевой
функцией,
например, это может быть функция прибыли
– выручка минус затраты. Так как и всё
в мире ограничено (время, деньги, природные
и человеческие ресурсы), в задачах
оптимизации всегда есть
определенные ограничения,
например, количество метала, рабочих и
станков на предприятии по изготовлению
деталей.
Далее рассмотрен пример
оформления очень простой задачи
оптимизации, но с помощью его можно
легко понять организации о построение
таблицы для эффективности решений
практический проблем оптимизации.
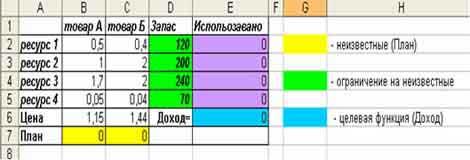
Имеем классическую
задачу когда фирма производит два вида
продукции (товар А и товар Б) по определенной
цене, на их производство требуется 4
вида ресурсов (ресурс 1, ресурс 2, ресурс
3, ресурс 4), которые есть в наличие на
фирме в определенном количестве (Запас),
также имеется информация сколько нужно
каждого ресурса на производство единицы
продукции, соответственно товара А и
товара Б. Нужно найти, то количество
товара А и товара Б, которое
максимизирует доход (выручку) (см. рис.).
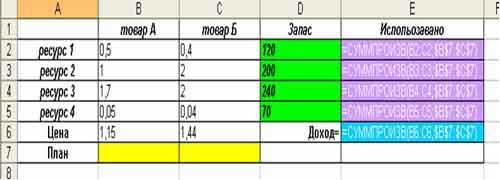
Далее
нам надо сделать взаимосвязи между
ограничениями, планом и целевой функцией.
Для этого мы строим дополнительный
столбец (Использовано), в котором вводим
формулуСУММПРОИЗВ(Норма;
План). Норма — это затраты определенного
ресурса на производство единицы продукции
товара А и Б, а План – количество
продукции, которое мы ищем. В ячейки
Доход вводим формулу СУММПРОИЗВ(Цена;
План). Таким образом мы заполнили
формулами столбец Использовано и ячейку
Доход. Так как план это переменные от
которых зависит количество использованных
ресурсов и доход, то ячейки с формулами
напрямую зависят от данных, которые там
появятся в результате поиска решений.
С
выше сказанного можно сделать следующие
выводы, что каждая задача оптимизации
обязательно должна иметь три компоненты:
-
неизвестные (что
ищем, то есть, план); -
ограничение на
неизвестные (область поиска); -
целевая
функция (цель,
для которой ищем экстремум).
Мощным
средством анализа данных Excel является
надстройка Solver
(Поиск решения).
С ее помощью можно определить, при каких
значениях указанных влияющих ячеек
формула в целевой ячейке принимает
нужное значение (минимальное, максимальное
или равное какой-либо величине). Для
процедуры поиска решения можно задать
ограничения, причем не обязательно,
чтобы при этом использовались те же
влияющие ячейки. Для расчета заданного
значения применяются различные
математические методы поиска. Вы можете
установить режим, в котором полученные
значения переменных автоматически
заносятся в таблицу. Кроме того, результаты
работы программы могут быть оформлены
в виде отчета.
Программа Поиск решений
(в оригинале Excel Solver) – дополнительная
надстройка табличного процессора MS
Excel, которая предназначена для решения
определенных систем уравнений, линейных
та нелинейных задач оптимизации,
используется с 1991 года.
Размер задачи,
которую можно решить с помощью базовой
версии этой программы, ограничивается
такими предельными показателями:
-
количество
неизвестных (decision variable) – 200; -
количество
формульных ограничений (explicit constraint) на
неизвестные – 100; -
количество
предельных условий (simple constraint) на
неизвестные – 400.
Разработчик
программы Solver компания Frontline System уже
давно специализируется на разработке
мощных и удобных способов оптимизации,
встроенных в среду популярных табличных
процессоров разнообразных фирм-производителей
(MS Excel Solver, Adobe Quattro Pro, Lotus 1-2-3).
Высокая
эффективность их применения объясняется
интеграциею программы оптимизации и
табличного бизнес-документа. Благодаря
мировой популярности табличного
процессора MS Excel встроенная в его
среду программа Solver есть наиболее
распространенным инструментом для
поиска оптимальных решений в сфере
современного бизнеса.
По
умолчанию в Excel надстройка Поиск решения
отключена. Чтобы активизировать ее
в Excel
2007,
щелкните значок Кнопка
Microsoft Office ,
щелкните Параметры
Excel,
а затем выберите категорию Надстройки.
В поле Управлениевыберите
значение Надстройки
Excel и
нажмите кнопку Перейти.
В поле Доступные
надстройки установите
флажок рядом с пунктом Поиск
решения и
нажмите кнопку ОК.
В Excel
2003 и
ниже выберите команду Сервис/Надстройки,
в появившемся диалоговом окне Надстройки
установите флажок Поиск
решения и
щелкните на кнопке ОК. Если вслед за
этим на экране появится диалоговое окно
с предложением подтвердить ваши
намерения, щелкните на кнопке Да.
(Возможно, вам понадобится установочный
компакт-диск Office).
Процедура
поиска решения
1. Создайте
таблицу с
формулами, которые устанавливают связи
между ячейками.
2.
Выделите целевую ячейку, которая должна
принять необходимое значение, и выберите
команду:
— В Excel
2007 Данные/Анализ/Поиск
решения;

—
В Excel
2003 и
ниже Tools >Solver
(Сервис > Поиск решения). Поле Set Target
Cell (Установить целевую ячейку) открывшегося
диалогового окна надстройки Solver (Поиск
решения) будет содержать адрес целевой
ячейки.
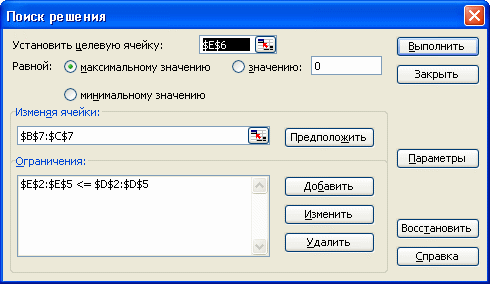
3. Установите переключатели
Equal To (Равной), задающие значение целевой
ячейки, — Мах (максимальному значению),
Min (минимальному значению) или Value of
(значению). В последнем случае введите
значение в поле справа.
4. Укажите в
поле By Changing Cells (Изменяя ячейки), в каких
ячейках программа должна изменять
значения в поисках оптимального
результата.
5. Создайте ограничения в
списке Subject to the Constraints (Ограничения). Для
этого щелкните на кнопке Add (Добавить)
и в диалоговом окне Add Constraint (Добавление
ограничения) определите ограничение.
6. Щелкните на
кнопке на кнопке Options (Параметры), и в
появившемся окне установите переключатель
Неотрицательные значения (если переменные
должны быть позитивными числами),
Линейная модель (если задача, которую
вы решаете, относится к линейным моделям)
7.
Щелкнув на кнопке Solver (Выполнить),
запустите процесс поиска решения.
8. Когда появится
диалоговое окно Solver Results (Результаты
поиска решения), выберите переключатель
Keep Solve Solution (Сохранить найденное решение)
или Restore Original Values (Восстановить исходные
значения).
9. Щелкните на кнопке ОК.
Параметры
средства Поиск решения
Максимальное
время —
служит для ограничения времени,
отпущенного на поиск решения задачи. В
этом поле можно ввести время в секундах,
не превышающее 32 767 (примерно девять
часов); значение 100, используемое по
умолчанию, вполне приемлемо для решения
большинства простых задач.
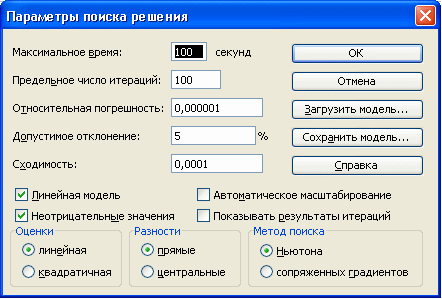
Предельное
число итераций —
управляет временем решения задачи путем
ограничения числа вычислительных циклов
(итераций).
Относительная
погрешность —
определяет точность вычислений. Чем
меньше значение этого параметра, тем
выше точность вычислений.
Допустимое
отклонение —
предназначен для задания допуска на
отклонение от оптимального решения,
если множество значений влияющей ячейки
ограничено множеством целых чисел. Чем
больше значение допуска, тем меньше
времени требуется на поиск
решения.
Сходимость —
применяется только к нелинейным задачам.
Когда относительное изменение значения
в целевой ячейке за последние пять
итераций становится меньше числа,
указанного в поле Сходимость, поиск
прекращается.
Линейная
модель —
служит для ускорения поиска решения
путем применения к задаче оптимизации
линейной модели. Нелинейные модели
предполагают использование нелинейных
функций, фактора роста и экспоненциального
сглаживания, что замедляет
вычисления.
Неотрицательные
значения —
позволяет установить нулевую нижнюю
границу для тех влияющих ячеек, для
которых не было задано соответствующее
ограничение в диалоговом окне Добавить
ограничение.
Автоматическое
масштабирование —
используется, когда числа в изменяемых
ячейках и в целевой ячейке существенно
различаются.
Показывать
результаты итераций —
приостанавливает поиск решения для
просмотра результатов отдельных
итераций.
Загрузить
модель —
после щелчка на этой кнопке отрывается
одноименное диалоговое окно, в котором
можно ввести ссылку на диапазон ячеек,
содержащих модель оптимизации.
Сохранить
модель —
служит для отображения на экране
одноименного диалогового окна, в
котором
можно ввести ссылку на диапазон ячеек,
предназначенный для хранения модели
оптимизации.
Оценка
линейная —
выберите этот переключатель для работы
с линейной моделью.
Оценка
квадратичная —
выберите этот переключатель для работы
с нелинейной моделью.
Разности
прямые —
используется в большинстве задач, где
скорость изменения ограничений
относительно невысока. Увеличивает
скорость работы средства Поиск
решения.
Разности
центральные —
используется для функций, имеющих
разрывную производную. Данный способ
требует больше вычислений, однако его
применение может быть оправданным, если
выдано сообщение о том, что получить
более точное решение не удается.
Метод
поиска Ньютона —
требует больше памяти, но выполняет
меньше итераций, чем в методе сопряженных
градиентов.
Метод
поиска сопряженных градиентов —
реализует метод сопряженных градиентов,
для которого требуется меньше памяти,
но выполняется больше итераций, чем в
методе Ньютона. Данный метод следует
использовать, если задача достаточно
большая и необходимо экономить память
или если итерации дают слишком малое
отличие в последовательных приближениях.
Соседние файлы в папке Excel
- #
- #
- #
- #
- #
- #
В сегодняшнем видеоуроке мы с вами рассмотрим решение очень популярной задачи о распределении ресурсов. С помощью инструмента Поиск решений, пакета Microsoft Excel, мы имеем возможность решать различные виды оптимизационных задач. Начнем с рассмотрения простейшей из них.
Предприятие производит 3 вида продукции (изделия А, Б и В) и реализует их на рынке, каждое по своим ценам:
– изделие А по цене 560 у.е. за единицу;
– изделие Б по цене 280 у.е. за единицу;
– изделие В по цене 430 у.е. за единицу.
При этом, на выпуск каждого изделия расходуется 5 видов ресурсов. Нормы расходования каждого ресурса на выпуск единицы изделий приведены в таблице:

Следует учесть, что возможный объем производимой продукции ограничен имеющимися запасами производственных ресурсов на складе (последняя колонка таблицы).
Нам необходимо разработать такой оптимальный план производства, чтобы полученный доход был максимальным.
В общем случае, номенклатура выпускаемых изделий и количество потребляемых ресурсов могут быть произвольными. Таким образом, мы имеем в чистом виде задачу линейного программирования. Традиционным методом решения таких задач является симплекс-метод. Мы же используем для этих целей современные информационные технологии. Но прежде чем искать решение сформулированной задачи, составим ее математическую модель. Для этого введем следующие условные обозначения: пусть х1, х2, х3 – соответственно, объем выпуска продукции А, Б и В в натуральных единицах измерения. Тогда, совокупный доход, который следует максимизировать, запишется в виде:
F = 560×1 + 280×2 + 430×3 → max (целевая функция)
Система ограничений, в соответствии с имеющимися запасами ресурсов, выглядит так:
120×1 + 46×2 + 98×3 <= 52000
85×1 + 110×2 <= 35000
155×1 + 75×3 <= 36000
12×1 + 26×2 + 18×3 <= 18000
38×1 + 66×2 + 150×3 <= 49000
Каждое из приведенных ограничений характеризует расходование ресурса 1, ресурса 2 и т.д.
Поскольку по условию задачи выпуск продукции не может быть отрицательным, в нашу экономико-математическую модель следует добавить условие не отрицательности:
x1, x2, x3 >= 0
Таким образом, мы получили математическое представление задачи оптимального программирования. Далее разместим исходные данные, представленные выше, на рабочем листе Microsoft Excel следующим образом, рис. 1.
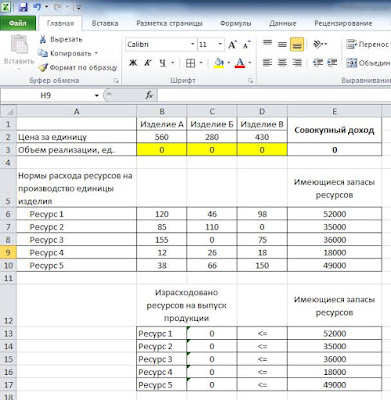
Рис. 1. Ввод исходных данных на рабочий лист
В ячейках, отмеченных желтым цветом, содержится искомый план выпуска и реализации продукции каждого вида (неизвестные переменные х1, х2, х3, значения которых нужно найти).
При этом, в некоторых ячейках рабочего листа, в соответствии с разработанной экономико-математической моделью, введены формулы, рис 2.

Рис. 2. Расположение формул на рабочем листе
Как видим, в ячейке Е3 рассчитывается совокупный доход, полученный от реализации всех изделий: цена изделия каждого вида умножается на его объем реализации. Пока объем выпуска и реализации изделий равняется нулю, совокупный доход также равен нулю.
Также, в ячейках С13:С17 рассчитываются объемы ресурсов, необходимых для производства изделий каждого вида. Для этого нормы расходов ресурсов умножаются на соответствующие объемы выпуска продукции. Пока объем выпуска и реализации изделий равняется нулю, величина расходования ресурсов каждого вида также равняется нулю.
Как только в ячейках B3:D3 мы начинаем увеличивать объемы выпуска и реализации продукции (выделены серым цветом), сразу же начинает увеличиваться совокупный доход в ячейке Е3. Также, растут объемы расходования ресурсов, ячейки С13:С17. При этом, объемы расходования ресурсов не должны превысить имеющихся запасов, то есть, значения ячеек С13:С17 не должны превышать значений ячеек Е13:Е17.
Для нахождения оптимального плана производства воспользуемся встроенным инструментом Microsoft Excel – «Поиском решений». Он располагается справа на вкладке «Данные». Общий вид окна Поиска решения показан на рис. 3.

Рис. 3. Настройка целевой функции, изменяемых ячеек и ограничений
В качестве целевой функции должна использоваться ячейка с формулой, значение которой требуется улучшить (увеличить или уменьшить). В нашей задаче такой ячейкой является совокупный доход, ячейка Е3.
В поле изменяемых ячеек мы сообщаем «Поиску решений», какими ячейками он может управлять, пытаясь увеличить совокупный доход. В нашем случае, это объемы реализации продукции, отмеченные на рис. 4 желтым цветом, то есть ячейки B3:D3.

Рис. 4. Оптимальный план выпуска продукции
Пытаясь найти оптимальный план выпуска продукции, «Поиск решений» должен принимать во внимание ограничения нашей задачи:
– во-первых, объем выпуска продукции не может быть отрицательным, то есть B3:D3 >= 0;
– во-вторых, объем выпуска каждого изделия измеряется в количестве единиц и не может быть дробным, то есть B3:D3 = целое;
– в-третьих, объемы израсходованных ресурсов, ячейки С13:С17, не могут превышать из имеющегося объема, ячейки Е13:Е17. То есть С13:С17 <= Е13:Е17.
Добавление указанных ограничений в окно «Поиска решений» осуществляется с помощью кнопки «Добавить», рис. 3.
После указания всех необходимых параметров нажимаем кнопку «Найти решение». На рабочем листе Excel отобразится найденный оптимальный план выпуска продукции, рис. 4, о чем свидетельствует появившееся окно результатов поиска решений, в котором следует нажать кнопку «ОК».
Как видно из рис. 4, предлагается произвести 136 единиц изделия А, 213 единиц изделия Б и 198 единиц изделия В. При этом, доход от реализации составит 220940 у.е.
Сравнивая между собой значения ячеек С13:С17 и Е13:Е17 можно сделать вывод, что ресурс 2, ресурс 3 и ресурс 5 будут использованы почти в полном объеме, а ресурса 1 и ресурса 4 у нас в избытке.
В нашем видеоуроке мы подробно остановимся на всех этапах решения данной задачи:
Определив один раз параметры окна Поиска решений, впоследствии можно многократно их использовать для различных исходных данных.
Надеюсь, моя подсказка помогла вам в работе.
Введение
Планирование ресурсов может быть одним из самых сложных аспектов управления проектами, особенно если вы просите сделать это для нескольких проектных групп в рамках всей организации в течение длительного периода времени. Если у вас есть Microsoft Project Server, вы можете довольно легко распределить ресурсы, потому что Microsoft Project Server может просматривать все проекты в вашей организации и сообщать вам, где выделен конкретный ресурс. Однако стандартная версия Microsoft не позволяет вам этого делать, и в этот момент легче обратиться к расписанию проекта в Microsoft Project или где-либо еще и создать документацию по распределению ресурсов в Excel. Эта статья проведет вас через все, что вам нужно для создания документации по ресурсам в Microsoft Excel.

При работе над распределением ресурсов может показаться, что вы решаете очень большую головоломку.
Составьте список
Первый шаг — составить список всех ресурсов, за распределение которых вы будете отвечать. Если это для одного проекта или небольшого отдела, вы, вероятно, можете сделать это самостоятельно, но если вы распределяете ресурсы для большого отдела, где сотрудники работают над сотнями проектов, вам может потребоваться проработать отдел поддержки, чтобы убедиться, что у вас есть полный список имен. Попросите кого-нибудь просмотреть список. Вы не хотите начинать перемещать людей и корректировать сроки проекта только для того, чтобы узнать, что есть другие люди, которые могли бы заполнить некоторые из дыр.
Фактор поддержки
В некоторых компаниях сотрудники, которые работают над проектами, также выполняют значительный объем вспомогательной работы. Процент вспомогательной работы, которую выполняют сотрудники, варьируется от компании к компании и от сотрудника к сотруднику. Важно понимать, какой процент вспомогательной работы вам необходимо учесть в цифрах для каждого сотрудника в течение среднего рабочего дня или рабочей недели в течение периода, на который вы выделяете ресурсы. И если вы не тот человек, который достаточно знаком с рабочей нагрузкой сотрудников, убедитесь, что вы получили эту информацию от кого-то, кто это знает. Если вы сделаете предположение, и оно окажется неверным, это сильно ухудшит ваши цифры, что может причинить много боли.
Что делать, если проект идет плохо
Знайте продолжительность, на которую вы выделяете
В качестве пояснения всегда проверяйте продолжительность, на которую вас просят выделить ресурсы. Прогнозировать, где будут люди в ближайшем будущем, проще, но чем дальше по дороге вас просят посмотреть, тем больше риск, что вы ошибетесь, и если вам не нужно указывать число там, вы можете серьезно подумать о том, чтобы не делать этого.
Соберите графики проекта
Прогноз, который вы делаете как часть распределения ресурсов, становится намного более точным, если у вас есть полные расписания проекта в качестве входных данных. Даже если проект еще не начался формально, вы сможете составить простой высокоуровневый график проекта, в котором будут указаны все известные задачи, которые необходимо будет выполнить. Однако на этом этапе разработка, скорее всего, будет просто большим отрезком времени без деталей, поскольку структурная декомпозиция работ, которая детализирует все задачи, еще не была построена. Но вы все равно должны уметь объединять имена людей, выполняющих работу по разработке, вместе с именами людей, связанных со всеми другими задачами. После рассмотрения бизнес-кейса и беседы с коммерческим лицом, запросившим проект, вы:Я получу очень общее представление о сложности проекта и смогу прогнозировать продолжительность каждой из задач, исходя из этого. Если проект уже находится в стадии разработки и есть иерархическая структура работ, в которой перечислены все задачи, связанные с разработкой, тогда у вас будет еще более подробная информация о том, кто, над чем и когда будет работать.

Выравнивание ресурсов — это критически важный заключительный шаг в работе над распределением ресурсов, поскольку он помогает предприятиям понять, когда увеличивать или уменьшать масштаб своей рабочей силы, и помогает руководителям проектов составлять реалистичные графики проектов.
Чемпионы по лидерству и управлению проектами
Создайте электронную таблицу распределения ресурсов
Шаги по направлению всей собранной вами информации в электронную таблицу распределения ресурсов в Excel следующие:
- Откройте новую книгу в Excel и создайте новые листы для каждого ресурса, для которого нужно делать прогноз.
- На первом листе, начиная с нескольких строк вниз, начните вставлять названия проектов, над которыми будет работать человек, в первый столбец, при этом каждый проект будет помещен в свою строку.
- В пустой строке непосредственно над тем местом, где вы ввели свой первый проект, перейдите ко второй ячейке в строке и начните вводить либо отдельные дни, либо однонедельные диапазоны дат в течение периода, на который вам необходимо выделить ресурсы в этой строке. В конечном итоге это зависит от того, насколько детализированным вы или ваш начальник хотите добиться.
- Откройте расписание проекта для первого проекта в вашем списке и отфильтруйте только те задачи, с которыми был связан ресурс, который вы просматриваете. Найдите продолжительность первой задачи, в которой был задействован ресурс, и перейдите к создаваемой вами электронной таблице распределения ресурсов. Перейдите к ячейкам в этой строке проекта, которые совпадают с этим дневным или однонедельным диапазоном, а затем введите количество часов, в течение которых этот ресурс вкладывается за этот период времени. Повторите этот шаг для всех задач во всех проектах для всех сотрудников.
- Введите формулу внизу каждого столбца дневного или однонедельного диапазона дат, которая суммирует общее количество наших в этом столбце с учетом необходимой поддержки для этого ресурса.
- Просмотрите итоги. Если вы использовали единичные стандартные рабочие дни, то любые дни, когда кажется, что сотрудник потратит более восьми часов, являются красным флажком и требуют внимания. Это совершенно нормально, когда вы собираетесь суммировать числа, и это действительно подчеркивает, как большинство организаций перераспределяют свои ресурсы и даже не осознают этого, пока не пройдут подобное упражнение.
- Выровняйте свои ресурсы. Здесь вы выполняете упражнение: либо перекладываете работу на других людей, либо увеличиваете продолжительность задачи, чтобы все были распределены соответствующим образом.
© 2017 Макс Далтон

Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поделиться ссылкой:
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
Построим диаграмму распределения в Excel. А также рассмотрим подробнее функции круговых диаграмм, их создание.
График нормального распределения имеет форму колокола и симметричен относительно среднего значения. Получить такое графическое изображение можно только при огромном количестве измерений. В Excel для конечного числа измерений принято строить гистограмму.
Внешне столбчатая диаграмма похожа на график нормального распределения. Построим столбчатую диаграмму распределения осадков в Excel и рассмотрим 2 способа ее построения.
Имеются следующие данные о количестве выпавших осадков:
Первый способ. Открываем меню инструмента «Анализ данных» на вкладке «Данные» (если у Вас не подключен данный аналитический инструмент, тогда читайте как его подключить в настройках Excel):
Выбираем «Гистограмма»:
Задаем входной интервал (столбец с числовыми значениями). Поле «Интервалы карманов» оставляем пустым: Excel сгенерирует автоматически. Ставим птичку около записи «Вывод графика»:
После нажатия ОК получаем такой график с таблицей:
В интервалах не очень много значений, поэтому столбики гистограммы получились низкими.
Теперь необходимо сделать так, чтобы по вертикальной оси отображались относительные частоты.
Найдем сумму всех абсолютных частот (с помощью функции СУММ). Сделаем дополнительный столбец «Относительная частота». В первую ячейку введем формулу:
Способ второй. Вернемся к таблице с исходными данными. Вычислим интервалы карманов. Сначала найдем максимальное значение в диапазоне температур и минимальное.
Чтобы найти интервал карманов, нужно разность максимального и минимального значений массива разделить на количество интервалов. Получим «ширину кармана».
Представим интервалы карманов в виде столбца значений. Сначала ширину кармана прибавляем к минимальному значению массива данных. В следующей ячейке – к полученной сумме. И так далее, пока не дойдем до максимального значения.
Для определения частоты делаем столбец рядом с интервалами карманов. Вводим функцию массива:
Вычислим относительные частоты (как в предыдущем способе).
Построим столбчатую диаграмму распределения осадков в Excel с помощью стандартного инструмента «Диаграммы».
Частота распределения заданных значений:
Круговые диаграммы для иллюстрации распределения
С помощью круговой диаграммы можно иллюстрировать данные, которые находятся в одном столбце или одной строке. Сегмент круга – это доля каждого элемента массива в сумме всех элементов.
С помощью любой круговой диаграммы можно показать распределение в том случае, если
- имеется только один ряд данных;
- все значения положительные;
- практически все значения выше нуля;
- не более семи категорий;
- каждая категория соответствует сегменту круга.
На основании имеющихся данных о количестве осадков построим круговую диаграмму.
Доля «каждого месяца» в общем количестве осадков за год:
Круговая диаграмма распределения осадков по сезонам года лучше смотрится, если данных меньше. Найдем среднее количество осадков в каждом сезоне, используя функцию СРЗНАЧ. На основании полученных данных построим диаграмму:
Получили количество выпавших осадков в процентном выражении по сезонам.
В двух словах: Добавляем полосу прокрутки к гистограмме или к графику распределения частот, чтобы сделать её динамической или интерактивной.
Уровень сложности: продвинутый.
На следующем рисунке показано, как выглядит готовая динамическая гистограмма:
Что такое гистограмма или график распределения частот?
Гистограмма распределения разбивает по группам значения из набора данных и показывает количество (частоту) чисел в каждой группе. Такую гистограмму также называют графиком распределения частот, поскольку она показывает, с какой частотой представлены значения.
В нашем примере мы делим людей, которые вызвались принять участие в мероприятии, по возрастным группам. Первым делом, создадим возрастные группы, далее подсчитаем, сколько людей попадает в каждую из групп, и затем покажем все это на гистограмме.
На какие вопросы отвечает гистограмма распределения?
Гистограмма – это один из моих самых любимых типов диаграмм, поскольку она дает огромное количество информации о данных.
В данном случае мы хотим знать, как много участников окажется в возрастных группах 20-ти, 30-ти, 40-ка лет и так далее. Гистограмма наглядно покажет это, поэтому определить закономерности и отклонения будет довольно легко.
«Неужели наше мероприятие не интересно гражданам в возрасте от 20 до 29 лет?»
Возможно, мы захотим немного изменить детализацию картины и разбить население на две возрастные группы. Это покажет нам, что в мероприятии примут участие большей частью молодые люди:
Динамическая гистограмма
После построения гистограммы распределения частот иногда возникает необходимость изменить размер групп, чтобы ответить на различные возникающие вопросы. В динамической гистограмме это возможно сделать благодаря полосе прокрутки (слайдеру) под диаграммой. Пользователь может увеличивать или уменьшать размер групп, нажимая стрелки на полосе прокрутки.
Такой подход делает гистограмму интерактивной и позволяет пользователю масштабировать ее, выбирая, сколько групп должно быть показано. Это отличное дополнение к любому дашборду!
Как это работает?
Краткий ответ: Формулы, динамические именованные диапазоны, элемент управления «Полоса прокрутки» в сочетании с гистограммой.
Формулы
Чтобы всё работало, первым делом нужно при помощи формул вычислить размер группы и количество элементов в каждой группе.
Чтобы вычислить размер группы, разделим общее количество (80-10) на количество групп. Количество групп устанавливается настройками полосы прокрутки. Чуть позже разъясним это подробнее.
Далее при помощи функции ЧАСТОТА (FREQUENCY) я рассчитываю количество элементов в каждой группе в заданном столбце. В данном случае мы возвращаем частоту из столбца Age таблицы с именем tblData.
=ЧАСТОТА(tblData;C13:C22)=FREQUENCY(tblData,C13:C22)
Функция ЧАСТОТА (FREQUENCY) вводится, как формула массива, нажатием Ctrl+Shift+Enter.
Динамический именованный диапазон
В качестве источника данных для диаграммы используется именованный диапазон, чтобы извлекать данные только из выбранных в текущий момент групп.
Когда пользователь перемещает ползунок полосы прокрутки, число строк в динамическом диапазоне изменяется так, чтобы отобразить на графике только нужные данные. В нашем примере задано два динамических именованных диапазона: один для данных — rngGroups (столбец Frequency) и второй для подписей горизонтальной оси — rngCount (столбец Bin Name).
Элемент управления «Полоса прокрутки»
Элемент управления Полоса прокрутки (Scroll Bar) может быть вставлен с вкладки Разработчик (Developer).
На рисунке ниже видно, как я настроил параметры элемента управления и привязал его к ячейке C7. Так, изменяя состояние полосы прокрутки, пользователь управляет формулами.
Гистограмма
График – это самая простая часть задачи. Создаём простую гистограмму и в качестве источника данных устанавливаем динамические именованные диапазоны.
Есть вопросы?
Что ж, это был лишь краткий обзор того, как работает динамическая гистограмма.
Да, это не самая простая диаграмма, но, полагаю, пользователям понравится с ней работать. Определённо, такой интерактивной диаграммой можно украсить любой отчёт.
Более простой вариант гистограммы можно создать, используя сводные таблицы.
Пишите в комментариях любые вопросы и предложения. Спасибо!
Урок подготовлен для Вас командой сайта office-guru.ru
Источник: /> Перевел: Антон Андронов
Правила перепечаткиЕще больше уроков по Microsoft Excel
Оцените качество статьи. Нам важно ваше мнение:
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html