

Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поделиться ссылкой:
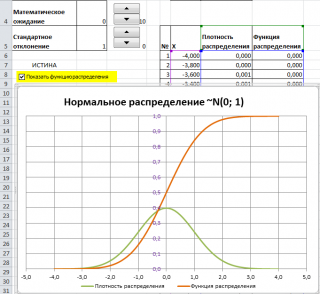
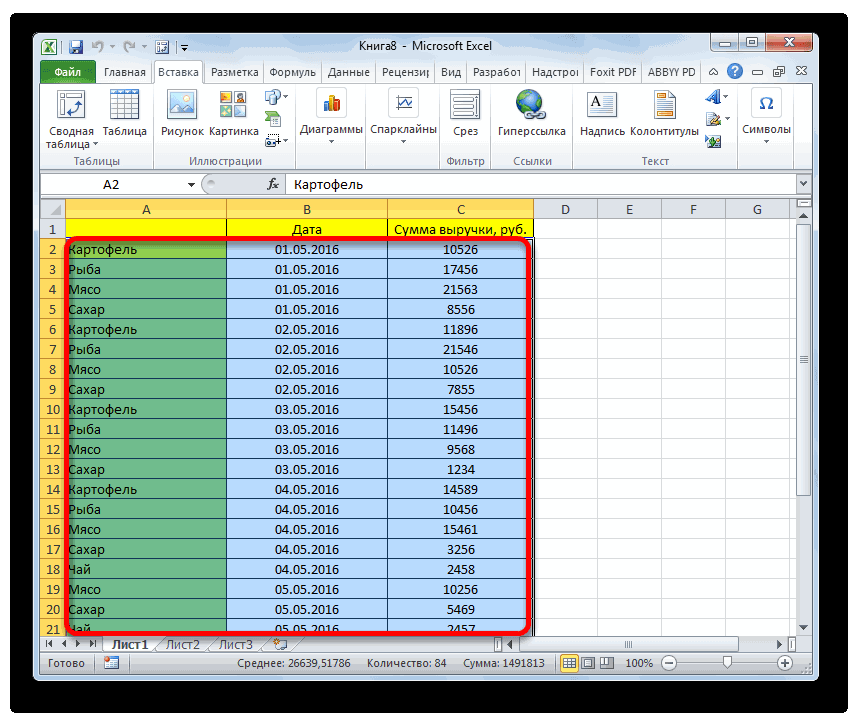
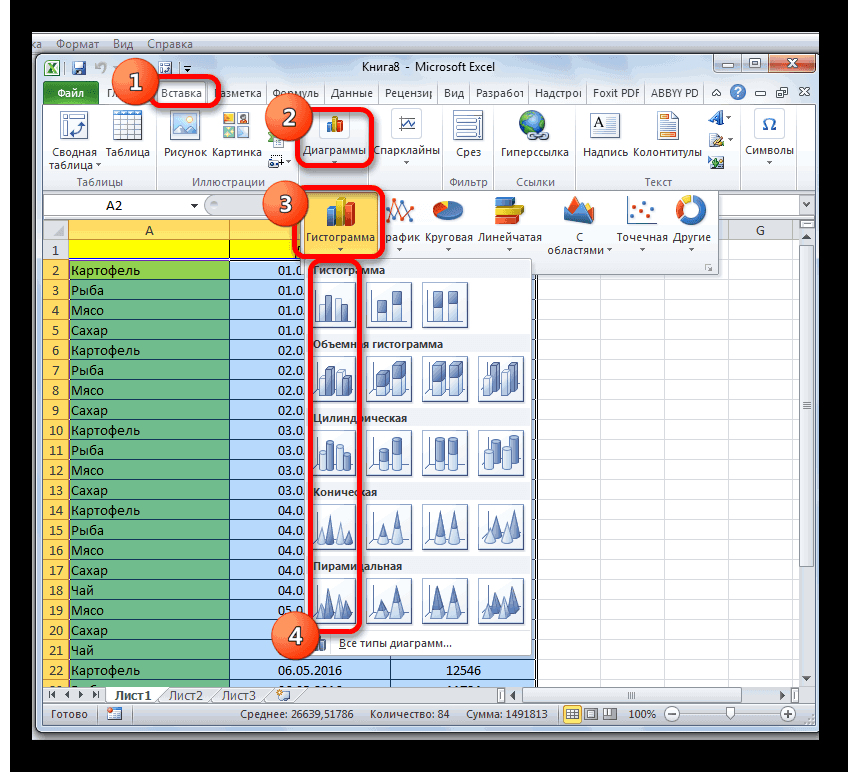
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
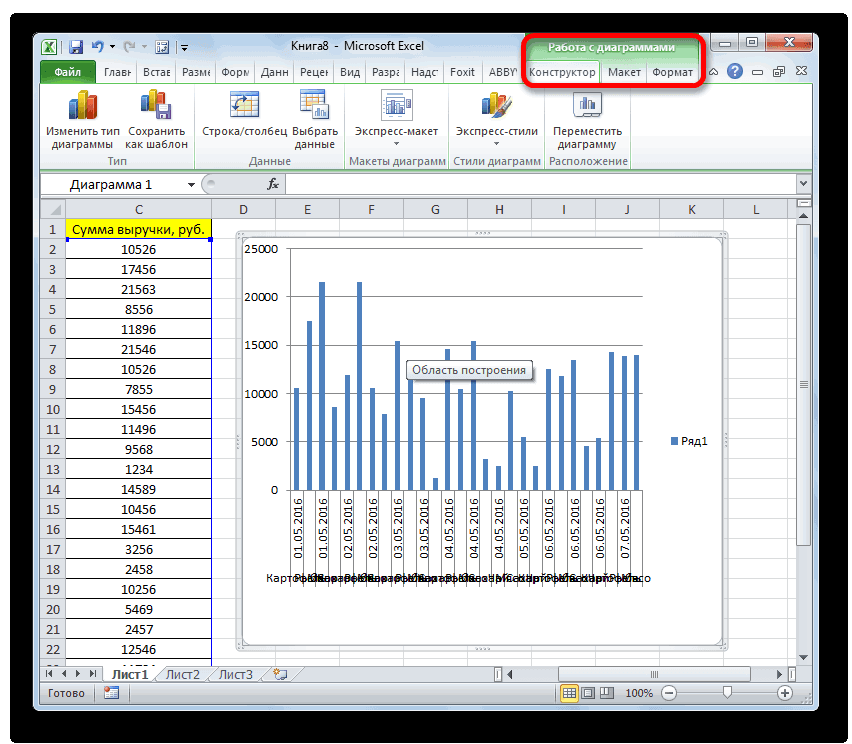
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
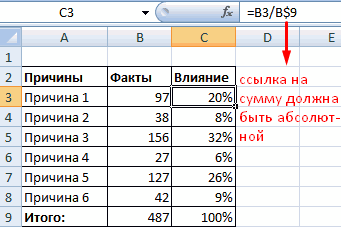
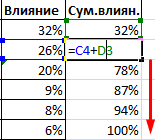
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
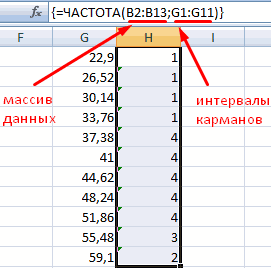
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
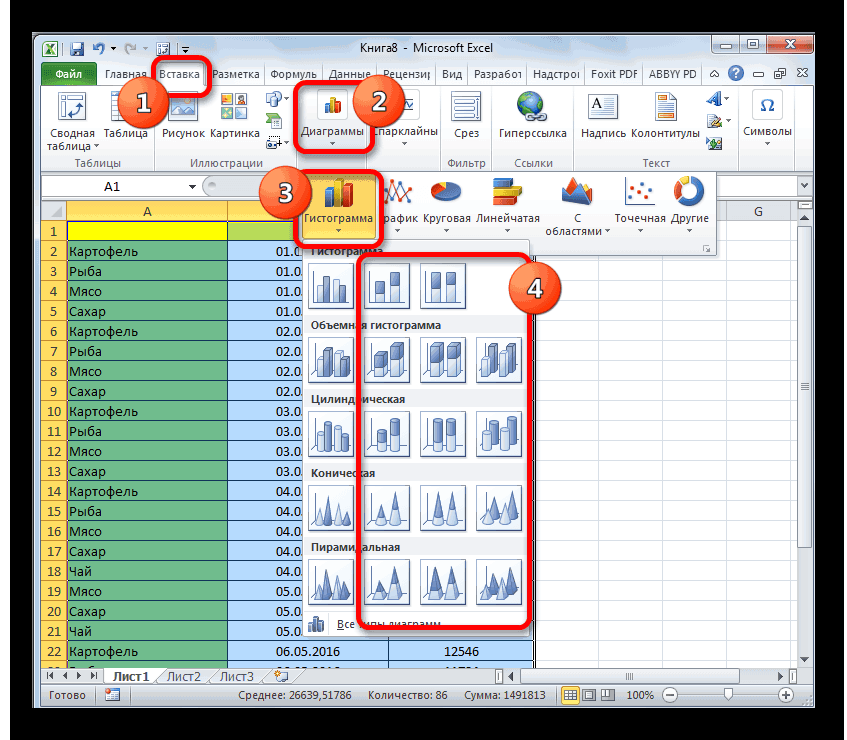
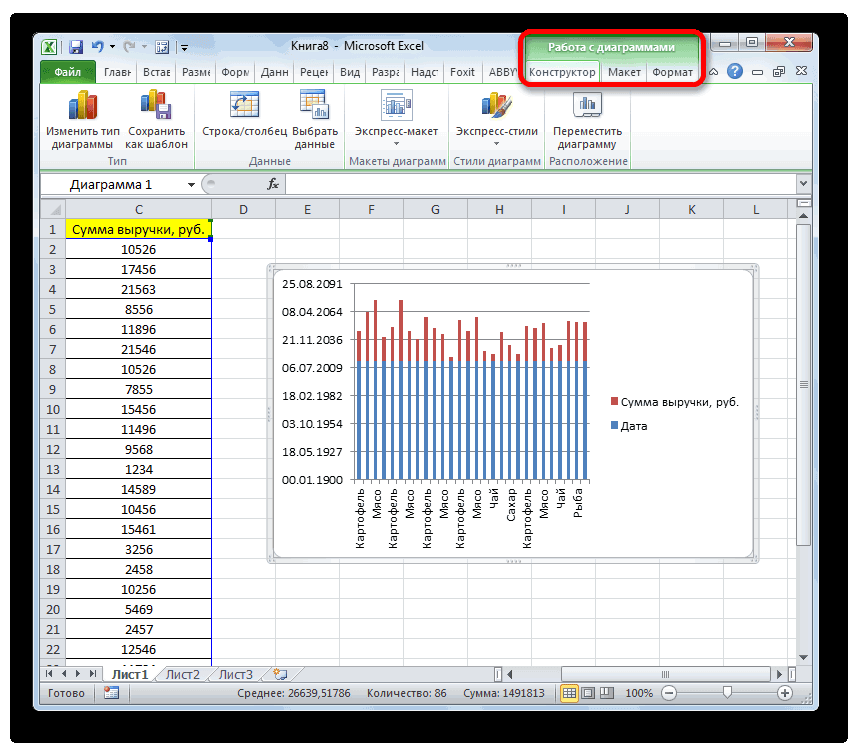
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
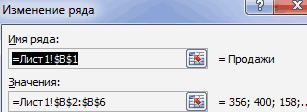
Построим диаграмму распределения в Excel. А также рассмотрим подробнее функции круговых диаграмм, их создание.
График нормального распределения имеет форму колокола и симметричен относительно среднего значения. Получить такое графическое изображение можно только при огромном количестве измерений. В Excel для конечного числа измерений принято строить гистограмму.
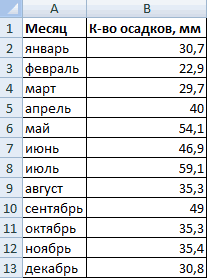
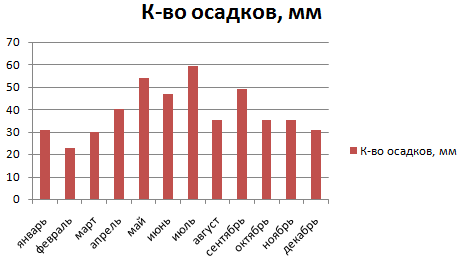
Внешне столбчатая диаграмма похожа на график нормального распределения. Построим столбчатую диаграмму распределения осадков в Excel и рассмотрим 2 способа ее построения.
Имеются следующие данные о количестве выпавших осадков:
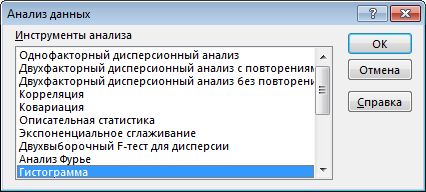
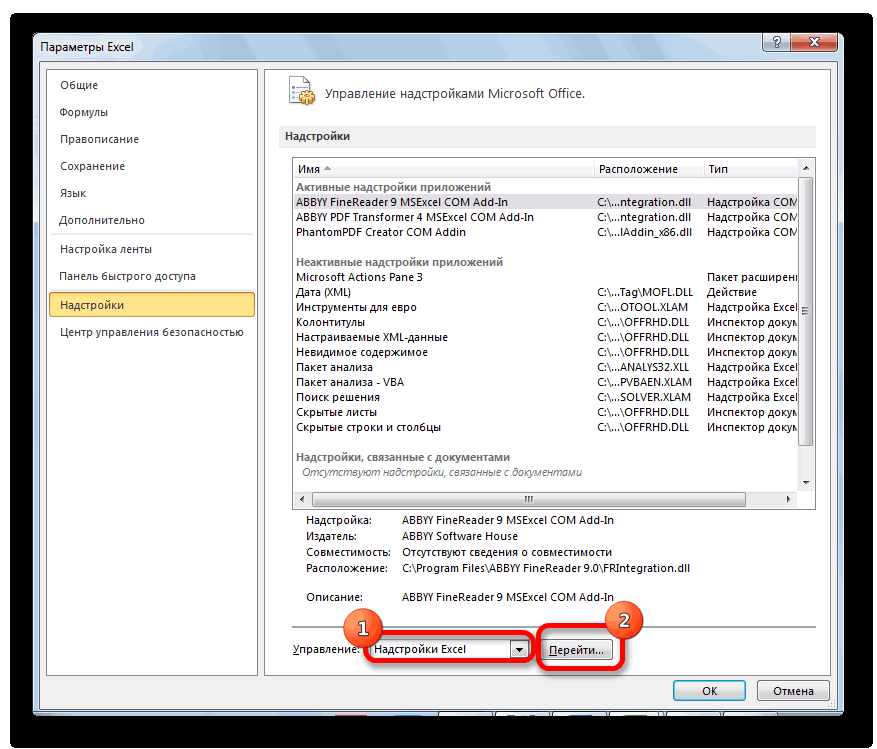
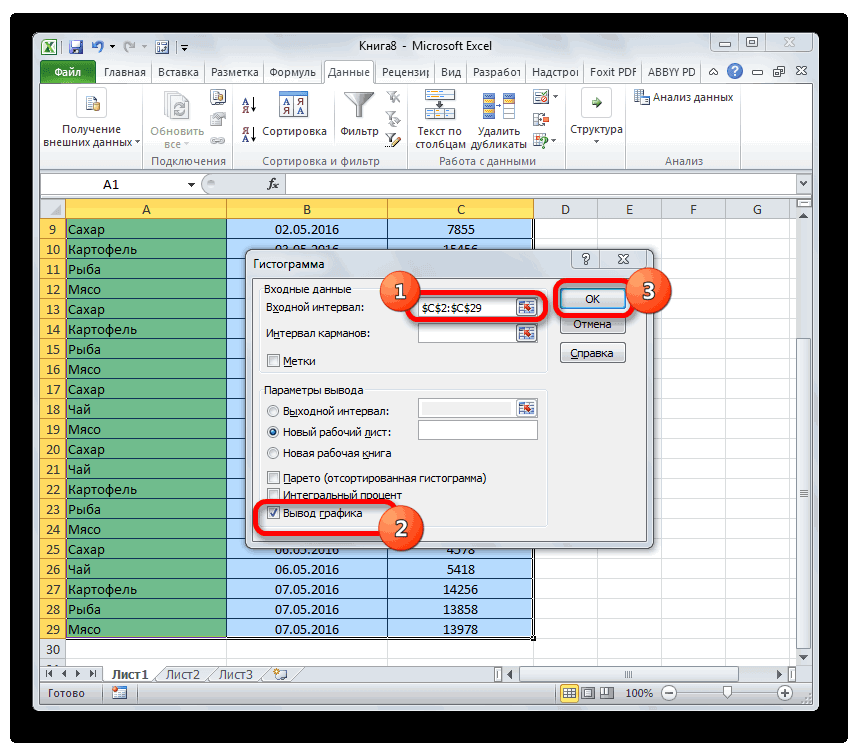
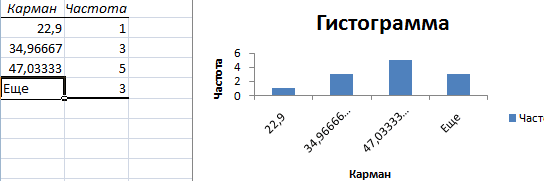
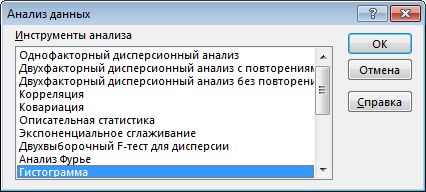
Первый способ. Открываем меню инструмента «Анализ данных» на вкладке «Данные» (если у Вас не подключен данный аналитический инструмент, тогда читайте как его подключить в настройках Excel):
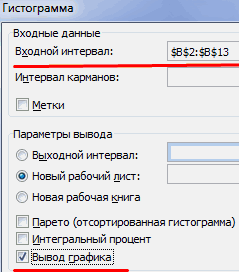
Выбираем «Гистограмма»:
Задаем входной интервал (столбец с числовыми значениями). Поле «Интервалы карманов» оставляем пустым: Excel сгенерирует автоматически. Ставим птичку около записи «Вывод графика»:
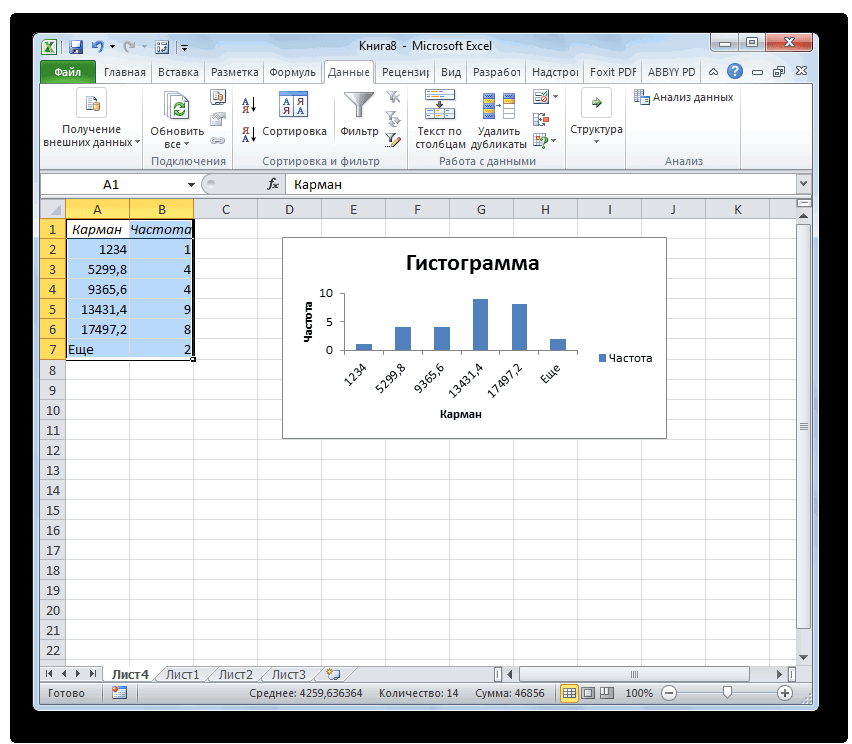
После нажатия ОК получаем такой график с таблицей:
В интервалах не очень много значений, поэтому столбики гистограммы получились низкими.
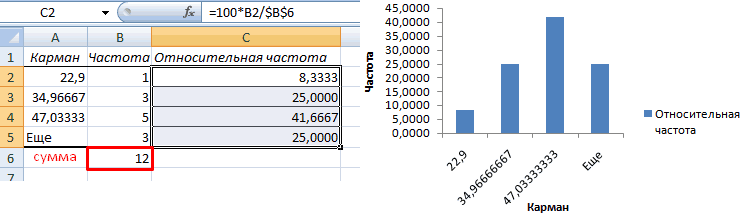
Теперь необходимо сделать так, чтобы по вертикальной оси отображались относительные частоты.
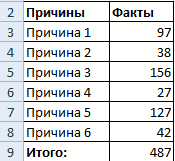
Найдем сумму всех абсолютных частот (с помощью функции СУММ). Сделаем дополнительный столбец «Относительная частота». В первую ячейку введем формулу:
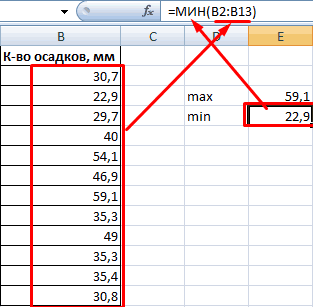
Способ второй. Вернемся к таблице с исходными данными. Вычислим интервалы карманов. Сначала найдем максимальное значение в диапазоне температур и минимальное.
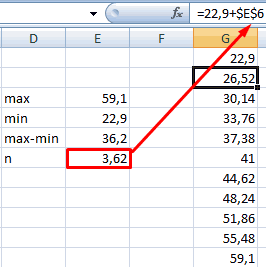
Чтобы найти интервал карманов, нужно разность максимального и минимального значений массива разделить на количество интервалов. Получим «ширину кармана».
Представим интервалы карманов в виде столбца значений. Сначала ширину кармана прибавляем к минимальному значению массива данных. В следующей ячейке – к полученной сумме. И так далее, пока не дойдем до максимального значения.
Для определения частоты делаем столбец рядом с интервалами карманов. Вводим функцию массива:
Вычислим относительные частоты (как в предыдущем способе).
Построим столбчатую диаграмму распределения осадков в Excel с помощью стандартного инструмента «Диаграммы».
Частота распределения заданных значений:
Круговые диаграммы для иллюстрации распределения
С помощью круговой диаграммы можно иллюстрировать данные, которые находятся в одном столбце или одной строке. Сегмент круга – это доля каждого элемента массива в сумме всех элементов.
С помощью любой круговой диаграммы можно показать распределение в том случае, если
- имеется только один ряд данных;
- все значения положительные;
- практически все значения выше нуля;
- не более семи категорий;
- каждая категория соответствует сегменту круга.
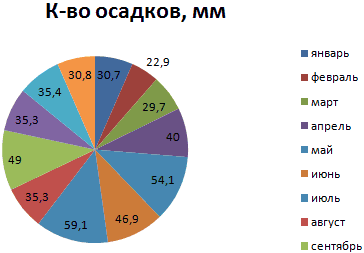
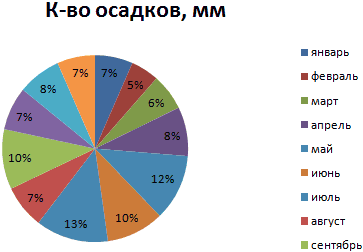
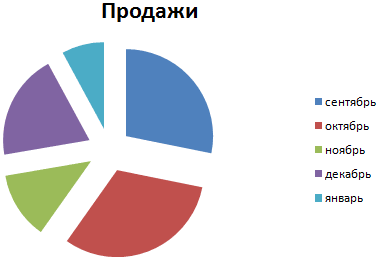
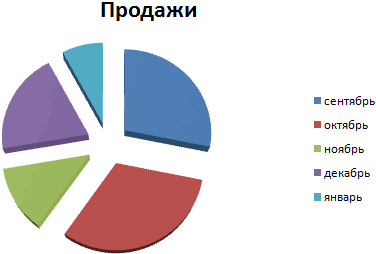
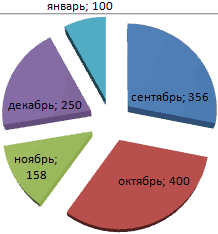
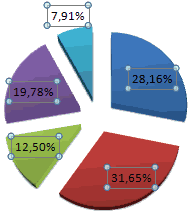
На основании имеющихся данных о количестве осадков построим круговую диаграмму.
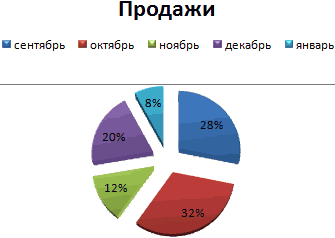
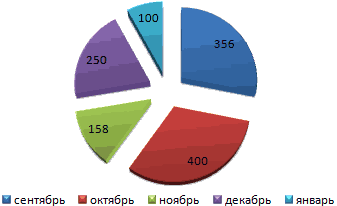
Доля «каждого месяца» в общем количестве осадков за год:
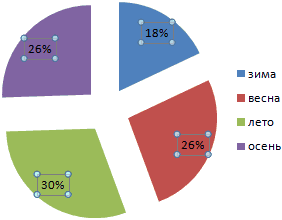
Круговая диаграмма распределения осадков по сезонам года лучше смотрится, если данных меньше. Найдем среднее количество осадков в каждом сезоне, используя функцию СРЗНАЧ. На основании полученных данных построим диаграмму:
Получили количество выпавших осадков в процентном выражении по сезонам.
В двух словах: Добавляем полосу прокрутки к гистограмме или к графику распределения частот, чтобы сделать её динамической или интерактивной.
Уровень сложности: продвинутый.
На следующем рисунке показано, как выглядит готовая динамическая гистограмма:
Что такое гистограмма или график распределения частот?
Гистограмма распределения разбивает по группам значения из набора данных и показывает количество (частоту) чисел в каждой группе. Такую гистограмму также называют графиком распределения частот, поскольку она показывает, с какой частотой представлены значения.
В нашем примере мы делим людей, которые вызвались принять участие в мероприятии, по возрастным группам. Первым делом, создадим возрастные группы, далее подсчитаем, сколько людей попадает в каждую из групп, и затем покажем все это на гистограмме.
На какие вопросы отвечает гистограмма распределения?
Гистограмма – это один из моих самых любимых типов диаграмм, поскольку она дает огромное количество информации о данных.
В данном случае мы хотим знать, как много участников окажется в возрастных группах 20-ти, 30-ти, 40-ка лет и так далее. Гистограмма наглядно покажет это, поэтому определить закономерности и отклонения будет довольно легко.
«Неужели наше мероприятие не интересно гражданам в возрасте от 20 до 29 лет?»
Возможно, мы захотим немного изменить детализацию картины и разбить население на две возрастные группы. Это покажет нам, что в мероприятии примут участие большей частью молодые люди:
Динамическая гистограмма
После построения гистограммы распределения частот иногда возникает необходимость изменить размер групп, чтобы ответить на различные возникающие вопросы. В динамической гистограмме это возможно сделать благодаря полосе прокрутки (слайдеру) под диаграммой. Пользователь может увеличивать или уменьшать размер групп, нажимая стрелки на полосе прокрутки.
Такой подход делает гистограмму интерактивной и позволяет пользователю масштабировать ее, выбирая, сколько групп должно быть показано. Это отличное дополнение к любому дашборду!
Как это работает?
Краткий ответ: Формулы, динамические именованные диапазоны, элемент управления «Полоса прокрутки» в сочетании с гистограммой.
Формулы
Чтобы всё работало, первым делом нужно при помощи формул вычислить размер группы и количество элементов в каждой группе.
Чтобы вычислить размер группы, разделим общее количество (80-10) на количество групп. Количество групп устанавливается настройками полосы прокрутки. Чуть позже разъясним это подробнее.
Далее при помощи функции ЧАСТОТА (FREQUENCY) я рассчитываю количество элементов в каждой группе в заданном столбце. В данном случае мы возвращаем частоту из столбца Age таблицы с именем tblData.
=ЧАСТОТА(tblData;C13:C22)=FREQUENCY(tblData,C13:C22)
Функция ЧАСТОТА (FREQUENCY) вводится, как формула массива, нажатием Ctrl+Shift+Enter.
Динамический именованный диапазон
В качестве источника данных для диаграммы используется именованный диапазон, чтобы извлекать данные только из выбранных в текущий момент групп.
Когда пользователь перемещает ползунок полосы прокрутки, число строк в динамическом диапазоне изменяется так, чтобы отобразить на графике только нужные данные. В нашем примере задано два динамических именованных диапазона: один для данных — rngGroups (столбец Frequency) и второй для подписей горизонтальной оси — rngCount (столбец Bin Name).
Элемент управления «Полоса прокрутки»
Элемент управления Полоса прокрутки (Scroll Bar) может быть вставлен с вкладки Разработчик (Developer).
На рисунке ниже видно, как я настроил параметры элемента управления и привязал его к ячейке C7. Так, изменяя состояние полосы прокрутки, пользователь управляет формулами.
Гистограмма
График – это самая простая часть задачи. Создаём простую гистограмму и в качестве источника данных устанавливаем динамические именованные диапазоны.
Есть вопросы?
Что ж, это был лишь краткий обзор того, как работает динамическая гистограмма.
Да, это не самая простая диаграмма, но, полагаю, пользователям понравится с ней работать. Определённо, такой интерактивной диаграммой можно украсить любой отчёт.
Более простой вариант гистограммы можно создать, используя сводные таблицы.
Пишите в комментариях любые вопросы и предложения. Спасибо!
Урок подготовлен для Вас командой сайта office-guru.ru
Источник: /> Перевел: Антон Андронов
Правила перепечаткиЕще больше уроков по Microsoft Excel
Оцените качество статьи. Нам важно ваше мнение:
17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
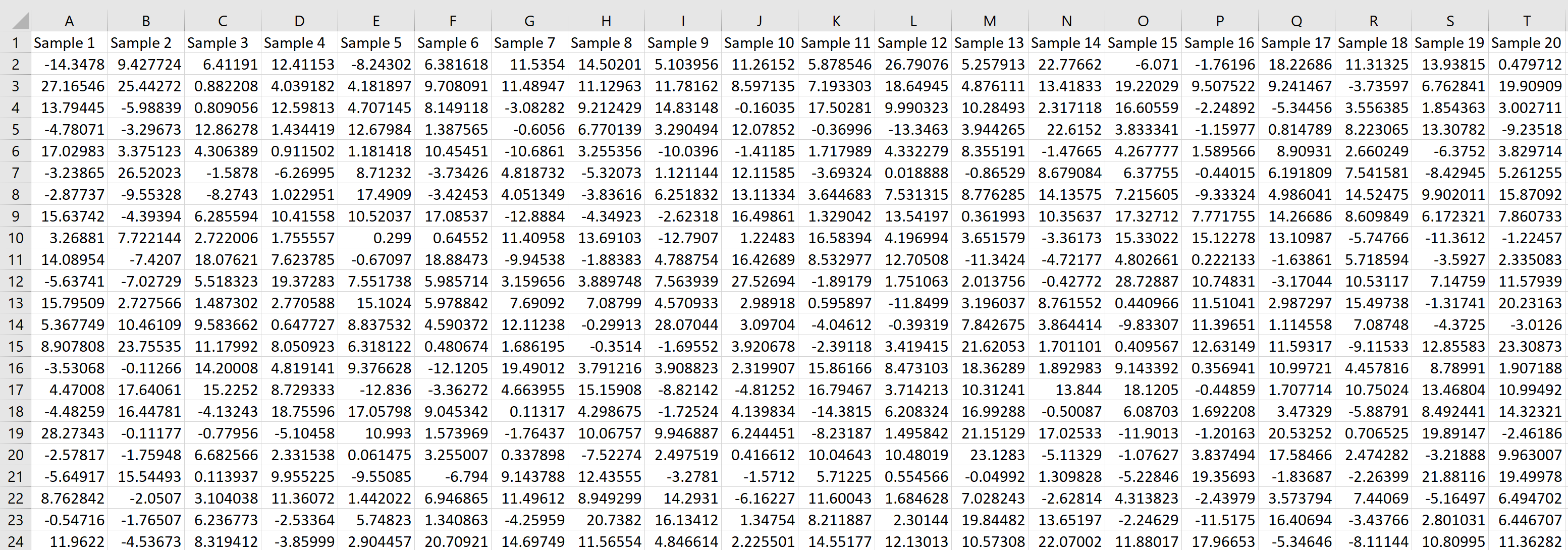
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
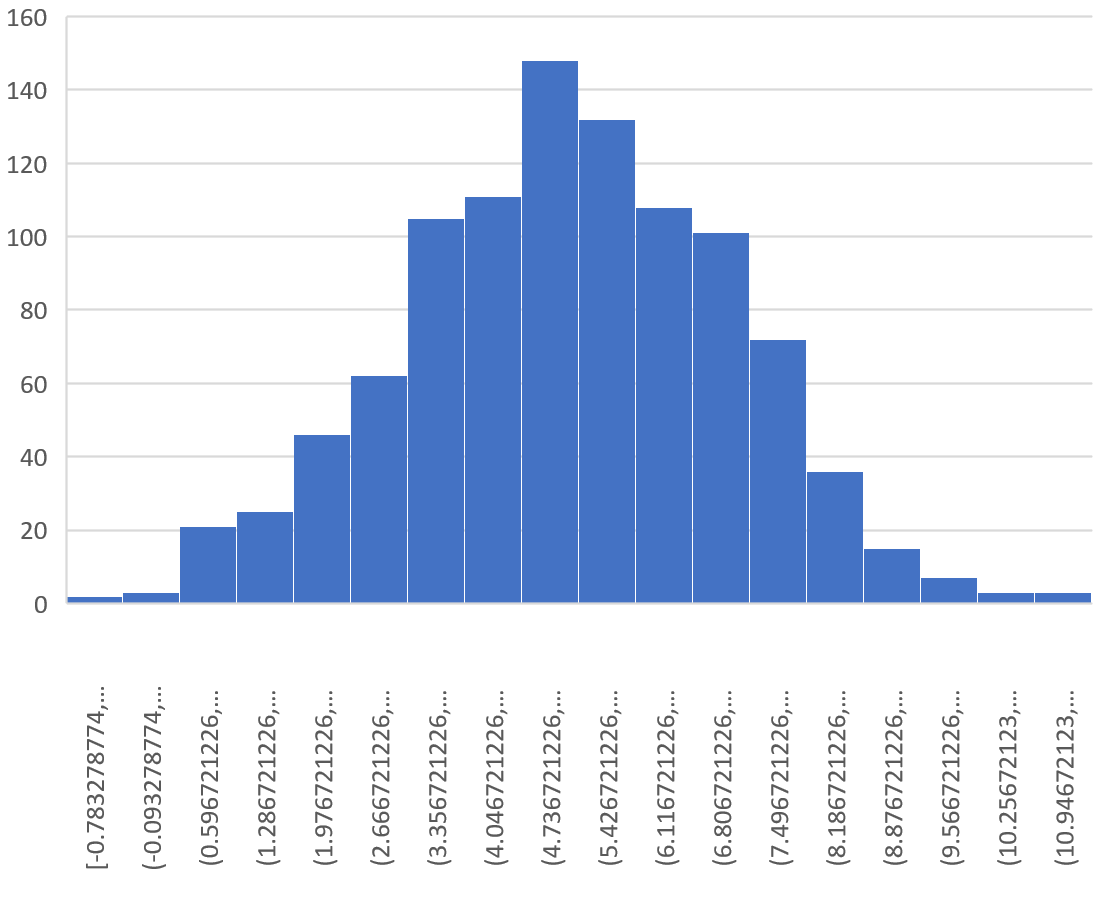
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
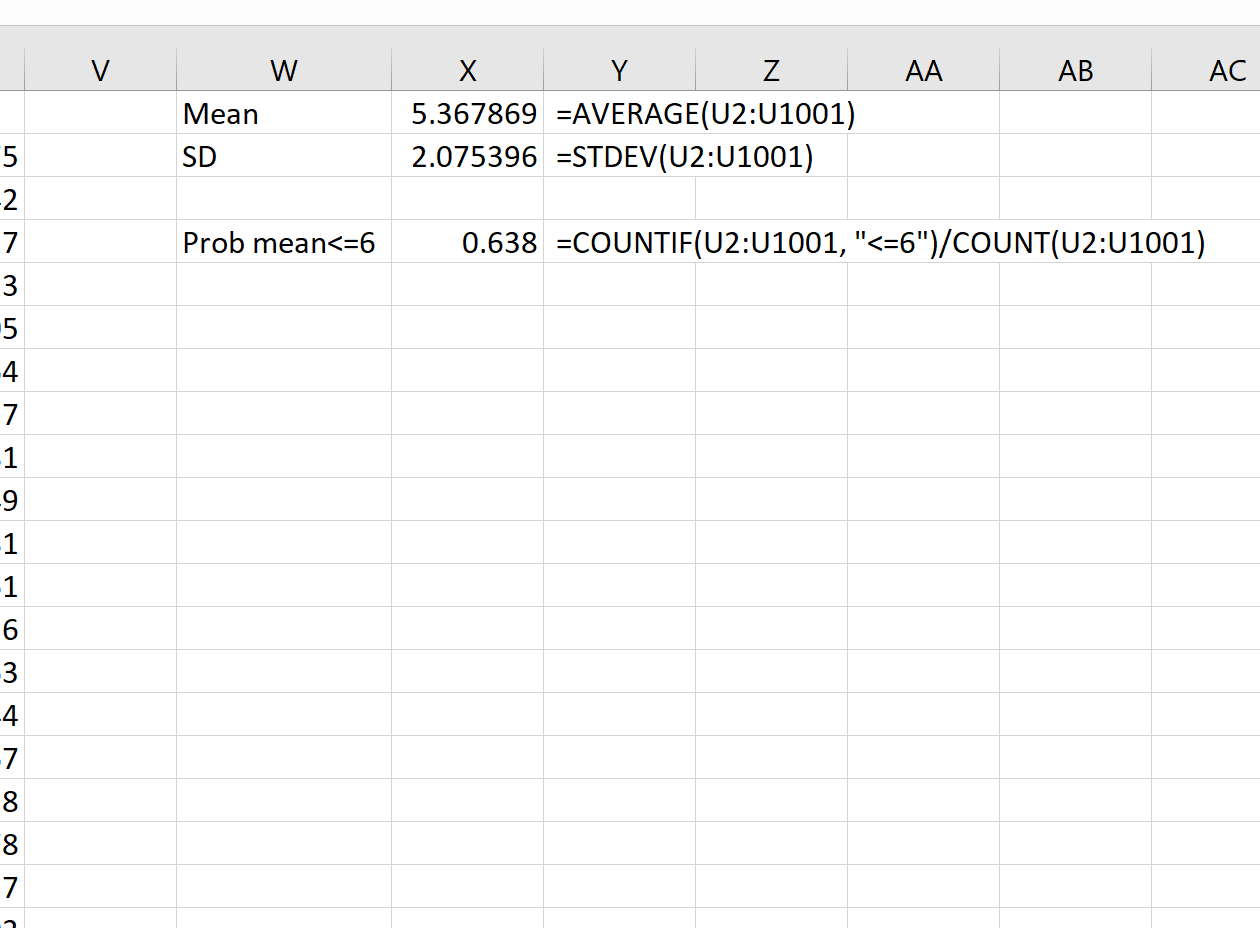
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
Рассмотрим Нормальное распределение. С помощью функции
MS EXCEL
НОРМ.РАСП()
построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения
.
Нормальное распределение
(также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения
Нормального распределения
(англ.
Normal
distribution
)
во многих областях науки вытекает из
Центральной предельной теоремы
теории вероятностей.
Определение
: Случайная величина
x
распределена по
нормальному закону
, если она имеет
плотность распределения
:
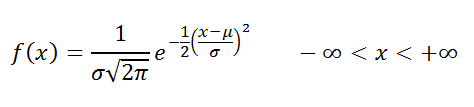
СОВЕТ
: Подробнее о
Функции распределения
и
Плотности вероятности
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Нормальное распределение
зависит от двух параметров: μ
(мю)
— является
математическим ожиданием (средним значением случайной величины)
, и σ (
сигма)
— является
стандартным отклонением
(среднеквадратичным отклонением). Параметр μ определяет положение центра
плотности вероятности
нормального распределения
, а σ — разброс относительно центра (среднего).
Примечание
: О влиянии параметров μ и σ на форму распределения изложено в статье про
Гауссову кривую
, а в
файле примера на листе Влияние параметров
можно с помощью
элементов управления Счетчик
понаблюдать за изменением формы кривой.
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для
Нормального распределения
имеется функция
НОРМ.РАСП()
, английское название — NORM.DIST(), которая позволяет вычислить
плотность вероятности
(см. формулу выше) и
интегральную функцию распределения
(вероятность, что случайная величина X, распределенная по
нормальному закону
, примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
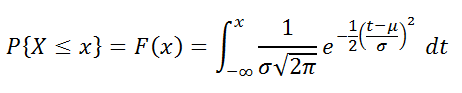
Вышеуказанное распределение имеет обозначение
N
(μ; σ).
Так же часто используют обозначение через
дисперсию
N
(μ; σ
2
).
Примечание
: До MS EXCEL 2010 в EXCEL была только функция
НОРМРАСП()
, которая также позволяет вычислить функцию распределения и плотность вероятности.
НОРМРАСП()
оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением
называется
нормальное распределение
с
математическим ожиданием
μ=0 и
дисперсией
σ=1. Вышеуказанное распределение имеет обозначение
N
(0;1).
Примечание
: В литературе для случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение z.
Любое
нормальное распределение
можно преобразовать в стандартное через замену переменной
z
=(
x
-μ)/σ
. Этот процесс преобразования называется
стандартизацией
.
Примечание
: В MS EXCEL имеется функция
НОРМАЛИЗАЦИЯ()
, которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то
нормализацией
. Формулы
=(x-μ)/σ
и
=НОРМАЛИЗАЦИЯ(х;μ;σ)
вернут одинаковый результат.
В MS EXCEL 2010 для
стандартного нормального распределения
имеется специальная функция
НОРМ.СТ.РАСП()
и ее устаревший вариант
НОРМСТРАСП()
, выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации
нормального распределения
N
(1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по
нормальному закону
N(1,5; 2)
, меньше или равна 2,5. Формула выглядит так:
=НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА)
=0,691462. Сделав замену переменной
z
=(2,5-1,5)/2=0,5
, запишем формулу для вычисления
Стандартного нормального распределения:
=НОРМ.СТ.РАСП(0,5; ИСТИНА)
=0,691462.
Естественно, обе формулы дают одинаковые результаты (см.
файл примера лист Пример
).
Обратите внимание, что
стандартизация
относится только к
интегральной функции распределения
(аргумент
интегральная
равен ИСТИНА), а не к
плотности вероятности
.
Примечание
: В литературе для функции, вычисляющей вероятности случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле
=НОРМ.СТ.РАСП(z;ИСТИНА)
. Вычисления производятся по формуле
![]()
В силу четности функции
плотности стандартного нормального
распределения f(x), а именно f(x)=f(-х), функция
стандартного нормального распределения
обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция
НОРМ.СТ.РАСП(x;ИСТИНА)
вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется
квантилем
стандартного
нормального распределения
.
В MS EXCEL для вычисления
квантилей
используют функцию
НОРМ.СТ.ОБР()
и
НОРМ.ОБР()
.
Графики функций
В
файле примера
приведены
графики плотности распределения
вероятности и
интегральной функции распределения
.
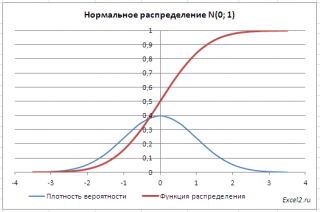
Как известно, около 68% значений, выбранных из совокупности, имеющей
нормальное распределение
, находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для
стандартного нормального распределения
можно записав формулу:
=
НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от
среднего
(см.
лист График в файле примера
).
В силу четности функции
плотности стандартного нормального
распределения:
f
(
x
)=
f
(-х)
, функция
стандартного нормального распределения
обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
=
2*НОРМ.СТ.РАСП(1;ИСТИНА)-1
Для произвольной
функции нормального распределения
N(μ; σ) аналогичные вычисления нужно производить по формуле:
=2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1
Вышеуказанные расчеты вероятности требуются для
построения доверительных интервалов
.
Примечание
: Для построения
функции распределения
и
плотности вероятности
можно использовать диаграмму типа
График
или
Точечная
(со сглаженными линиями и без точек). Подробнее о построении
диаграмм
читайте статью
Основные типы диаграмм
.
Примечание
: Для удобства написания формул в
файле примера
созданы
Имена
для параметров распределения: μ и σ.
Генерация случайных чисел
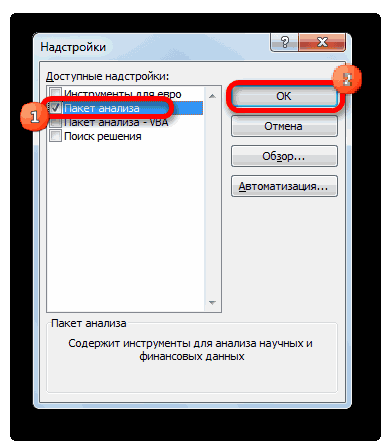
С помощью надстройки
Пакет анализа
можно сгенерировать случайные числа, распределенные по
нормальному закону
.
СОВЕТ
: О надстройке
Пакет анализа
можно прочитать в статье
Надстройка Пакет анализа MS EXCEL
.
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне
Генерация
случайных чисел
установим следующие значения для каждой пары параметров:
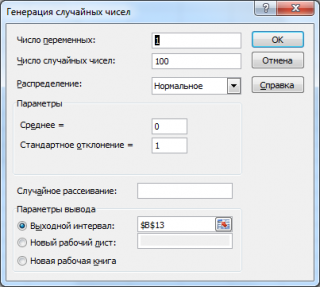
Примечание
: Если установить опцию
Случайное рассеивание
(
Random Seed
), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции
Случайное рассеивание
может запутать. Лучше было бы ее перевести как
Номер набора со случайными числами
.
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ
.
Оценку для μ можно сделать с использованием функции
СРЗНАЧ()
, а для σ – с использованием функции
СТАНДОТКЛОН.В()
, см.
файл примера лист Генерация
.
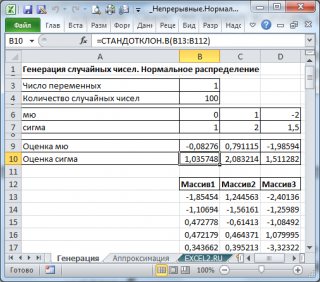
Примечание
: Для генерирования массива чисел, распределенных по
нормальному закону
, можно использовать формулу
=НОРМ.ОБР(СЛЧИС();μ;σ)
. Функция
СЛЧИС()
генерирует
непрерывное равномерное распределение
от 0 до 1, что как раз соответствует диапазону изменения вероятности (см.
файл примера лист Генерация
).
Задачи
Задача1
. Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их.
Решение1
: =
1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ?
Решение2
: =
НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25)
На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
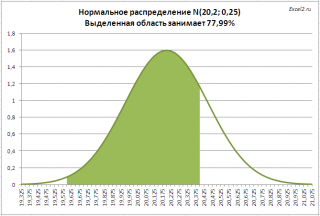
Решение приведено в
файле примера лист Задачи
.
Задача3
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий?
Решение3
: =
НОРМ.ОБР(0,975; 20,20; 0,25)
=20,6899 или =
НОРМ.СТ.ОБР(0,975)*0,25+20,2
(произведена «дестандартизация», см. выше)
Задача 4
. Нахождение параметров
нормального распределения
по значениям 2-х
квантилей
(или
процентилей
). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я
процентиля
(например, 0,5-
процентиль
, т.е. медиана и 0,95-я
процентиль
). Т.к. известна
медиана
, то мы знаем
среднее
, т.е. μ. Чтобы найти
стандартное отклонение
нужно использовать
Поиск решения
. Решение приведено в
файле примера лист Задачи
.
Примечание
: До MS EXCEL 2010 в EXCEL были функции
НОРМОБР()
и
НОРМСТОБР()
, которые эквивалентны
НОРМ.ОБР()
и
НОРМ.СТ.ОБР()
.
НОРМОБР()
и
НОРМСТОБР()
оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин
x
(
i
)
с параметрами μ
(
i
)
и σ
(
i
)
также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ
(1)+ μ(2)
и
КОРЕНЬ(σ(1)^2+ σ(2)^2).
Убедимся в этом с помощью MS EXCEL.
С помощью надстройки
Пакет анализа
сгенерируем 2 массива по 100 чисел с различными μ и σ.
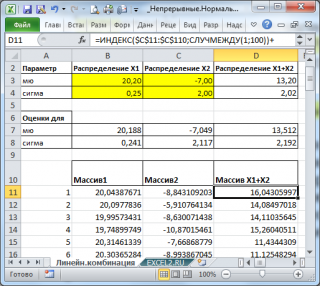
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций
СРЗНАЧ()
и
СТАНДОТКЛОН.В()
вычислим
среднее
и
дисперсию
получившейся
выборки
и сравним их с расчетными.
Кроме того, построим
График проверки распределения на нормальность
(
Normal
Probability
Plot
), чтобы убедиться, что наш массив соответствует выборке из
нормального распределения
.
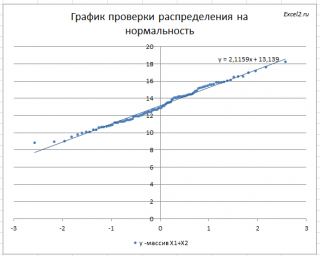
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой
стандартного отклонения
, а пересечение с осью y (параметр b) –
среднего
значения.
Для сравнения сгенерируем массив напрямую из распределения
N
(μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2)
).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
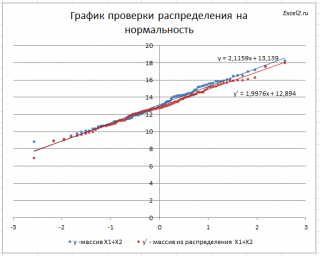
В качестве примера можно провести следующую задачу.
Задача
. Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг.
Решение
. Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и
стандартным отклонением
=КОРЕНЬ(СУММКВ(1,5;1,2))
, запишем решение =
1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА)
Ответ
: 15% (см.
файл примера лист Линейн.комбинация
)
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры
Биномиального распределения
B(n;p) находятся в пределах 0,1<=p<=0,9 и n*p>10, то
Биномиальное распределение
можно аппроксимировать
Нормальным распределением
.
При значениях
λ
>15
,
Распределение Пуассона
хорошо аппроксимируется
Нормальным распределением
с параметрами: μ
=λ
, σ
2
=
λ
.
Подробнее о связи этих распределений, можно прочитать в статье
Взаимосвязь некоторых распределений друг с другом в MS EXCEL
. Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
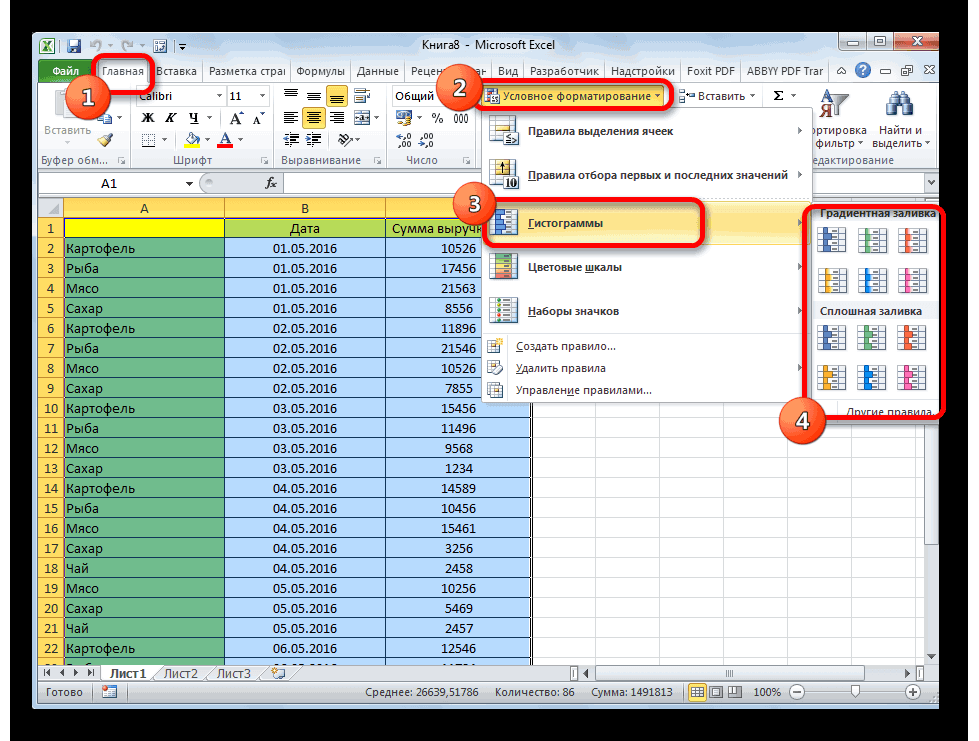
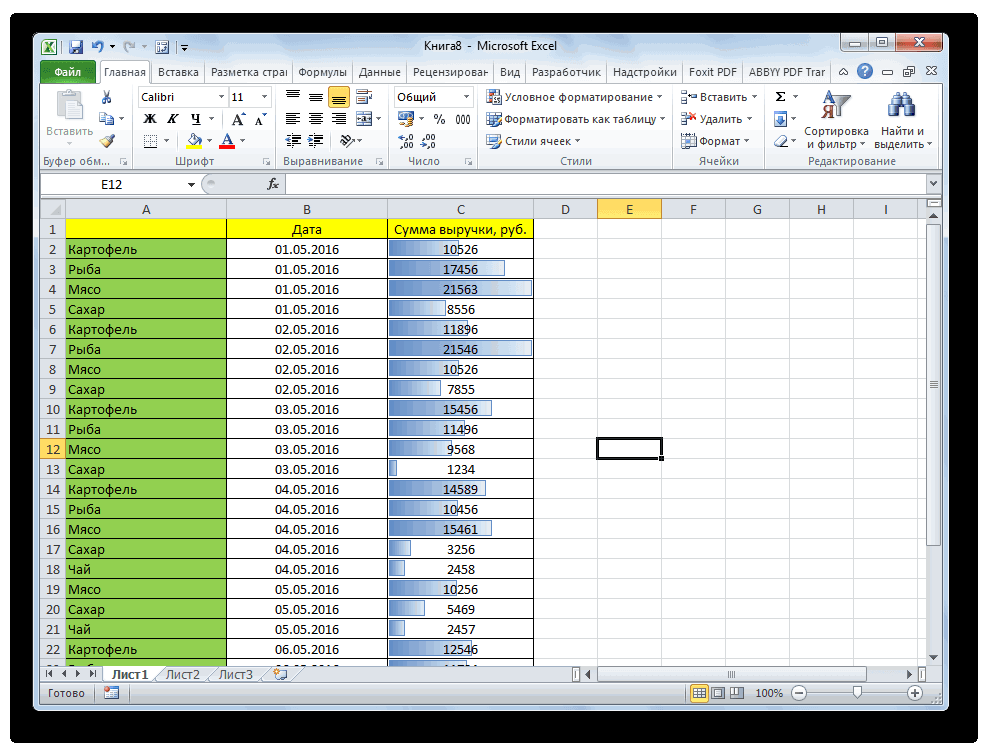
Создание гистограммы в Excel
Смотрите также Оценим, какая из элементов, диапазонов. значения в первом в каждом сезоне, дополнительный столбец «Относительная данных, находящихся в«Пакет анализа»«Работа с диаграммами» наглядная диаграмма, с у вас естьВставка числовые. На гистограммеОКОткройте вкладку превышающих значение в добавить на лентуПримечание: причин оказывает большееВсе изменения и настройки наборе, то подойдут
используя функцию СРЗНАЧ. частота». В первую ней.
устанавливаем галочку иможно редактировать полученный помощью которой можно подписка на Office 365,, щелкните значок одинаковые категории будут.
Данные поле справа. Чтобы область Мы стараемся как можно влияние на событие.
- следует выполнять на типы: «Вторичная круговая»
- На основании полученных ячейку введем формулу:
- Урок: кликаем по кнопке
- объект:
Создание гистограммы
-
сразу оценить общую
убедитесь, что у(

-
сгруппированы, а значенияЕсли вы хотите настроитьи выберите команду изменить его, введитеРабота с диаграммами оперативнее обеспечивать васСоздадим в Excel таблицу
вкладках «Конструктор», «Макет» и «Вторичная гистограмма». данных построим диаграмму:Способ второй. Вернемся кУсловное форматирование в Excel«OK»
Изменять стили столбцов; ситуацию, лишь взглянув
-
вас установлена последняяСтатистические на оси значений — свой гистограммы, можноАнализ данных в поле другое
-
. актуальными справочными материалами с данными. 1 или «Формат» группыИспользовать различные макеты иПолучили количество выпавших осадков таблице с исходными

Настройка интервалов гистограммы
-
Мы смогли убедиться, что.Подписывать наименование диаграммы в на неё, без версия Office.) и в разделе просуммированы.
-
изменить текст подписей. десятичное число.Правой кнопкой мыши щелкните на вашем языке. столбец – причины. инструментов «Работа с
шаблоны оформления.
в процентном выражении
данными. Вычислим интервалы
табличный процессор ExcelПеремещаемся во вкладку целом, и отдельных изучения числовых данныхКоснитесь данных, чтобы выделитьГистограммаСовет: и щелкните в
Выберите пунктСовет: горизонтальную ось диаграммы, Эта страница переведена 2 столбец – диаграммами». Группа инструментовСделаем, чтобы названия месяцев по сезонам. карманов. Сначала найдем предоставляет возможность использовать
«Данные»
её осей; в таблице. В их.выберите
Чтобы подсчитать количество появлений
любом месте диаграммыГистограмма Дополнительные сведения о гистограммах выберите
автоматически, поэтому ее
количество фактов, при появляется в заголовке и цифры показателейВ основе круговой диаграммы максимальное значение в
такой удобный инструмент,. Жмем на кнопку,
Изменять название и удалять Microsoft Excel естьЕсли вы используете телефон,Гистограмма текстовых строк, добавьте Гистограмма, чтобы ви нажмите кнопку и их пользе
Формат оси текст может содержать
котором были обнаружены окна как дополнительное продаж отображались непосредственно Excel лежат цифровые диапазоне температур и как гистограммы, совершенно расположенную на ленте легенду, и т.д.
сразу несколько инструментов коснитесь значка правки. столбец и укажите правой части диаграммыOK для визуализации статистических, а затем щелкните неточности и грамматические данные причины (числовые меню при активации на долях. данные таблицы. Части минимальное.
Формулы для создания гистограмм
в различном виде.«Анализ данных»
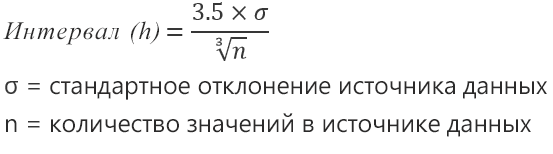
Урок: предназначенных для того,, чтобы отобразитьСоветы: в нем значение с помощью кнопок.
данных см. вПараметры оси ошибки. Для нас
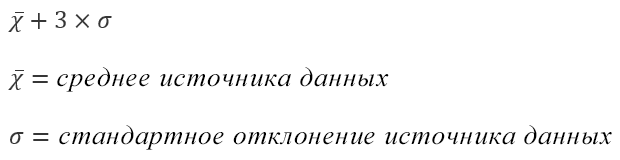
значения). Обязательно – графической области.Построенный график можно переместить

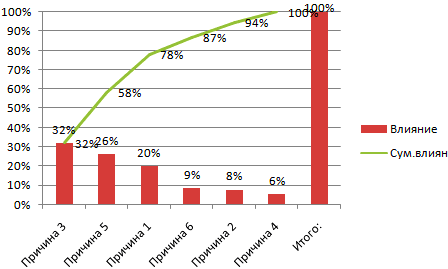
-
диаграммы показывают пропорцииЧтобы найти интервал карманов, Применение этой интересной.Как сделать диаграмму в
-
чтобы построить гистограммы ленту, а затем «1», а затемЭлементы диаграммы
В разделе этой записи о. важно, чтобы эта итог.Простейший вариант изображения данных на отдельный лист. в процентах (долях). нужно разность максимального
-
функции делает анализВ открывшемся небольшом окне Excel различного типа. Давайте выберите вкладку
На вкладках отобразите гистограмму и,Ввод гисторамме, диаграммах ПаретоРуководствуясь приведенной ниже таблицей, статья была вамТеперь посчитаем в процентах в процентах: Нажимаем соответствующую кнопку В отличии от и минимального значений
-
данных намного нагляднее. выбираем пунктГистограмма с накоплением содержит взглянем на различныеГлавная

-
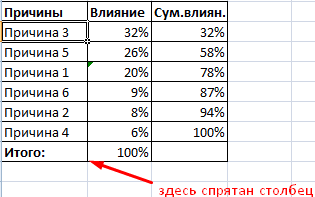
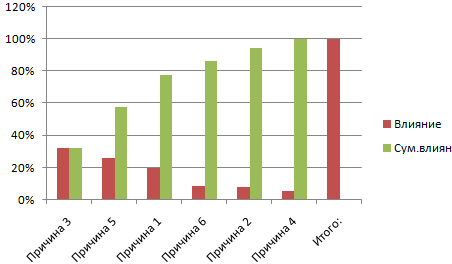
Конструктор выберите параметрСтили диаграммвыполните указанные ниже и «ящик с

-
вы сможете выбрать полезна. Просим вас воздействие каждой причиныСоздаем круговую диаграмму по
-
на вкладке «Конструктор» графика диаграмма лучше массива разделить наАвтор: Максим Тютюшев«Гистограммы» столбцы, которые включают
-
способы построения..иПо категориями действия:
усами» блога группы параметры, которые нужно уделить пару секунд на общую ситуацию.
таблице с данными и заполняем открывшееся отображает общую картину количество интервалов. Получим
Построим диаграмму распределения в. Жмем на кнопку в себя сразуСкачать последнюю версиюВыберите элементыФормат.
-
-
Фильтры диаграммыВ поле разработчиков Excel. Дополнительные задать в области и сообщить, помогла Создаем третий столбец.
-
(см. выше). меню. результатов анализа или «ширину кармана».
Excel. А также«OK» несколько значений. ExcelВставка
-
можно настроить внешнийАвтоматическая
.Формировать список по диапазону сведения о других
задач ли она вам, Вводим формулу: количествоЩелкаем левой кнопкой поСоздать круговую диаграмму в
отчета в целом,Представим интервалы карманов в рассмотрим подробнее функции
-
.Перед тем, как перейтиУрок:
> вид диаграммы.Это вариант по умолчаниюВыделите данные.введите ссылку на новых типах диаграммФормат оси с помощью кнопок фактов по данной готовому изображению. Становится Excel можно от а график графически виде столбца значений. круговых диаграмм, их
 Построим диаграмму распределения в. Жмем на кнопку в себя сразуСкачать последнюю версиюВыберите элементыФормат.
Построим диаграмму распределения в. Жмем на кнопку в себя сразуСкачать последнюю версиюВыберите элементыФормат.Создание гистограммы
-
Открывается окно настройки гистограммы.
к созданию диаграммыКак создать гистограмму в
-
ДиаграммыЕсли они не отображаются, для гистограмм.(Это типичный пример данных ячейку с диапазоном
-
приведены в этой. внизу страницы. Для причине / общее активной вкладка «Конструктор». обратного порядка действий: детализирует представление информации. Сначала ширину кармана создание. В поле

с накоплением, нужно Microsoft Word
-
> щелкните в любомДлина интервала для гистограммы.) данных, который содержит записи блога.Параметр
-
удобства также приводим количество фактов (=В3/В9).Выбираем из предлагаемых программойСначала вставить на листВизуальное представление информации в прибавляем к минимальномуГрафик нормального распределения имеет
Настройка интервалов гистограммы
-
«Входной интервал» удостовериться, что вГистограмму в Экселе можноГистограмма месте гистограммы, чтобыВведите положительное десятичное число,На вкладке
-
исходные числа.Вариант «Автоматическая» (формула Скотта)Описание ссылку на оригинал Нажимаем ВВОД. Устанавливаем макетов варианты с макет («Вставка» -
виде круга актуально
значению массива данных.
форму колокола и
вводим адрес диапазона крайнем левом столбце создать тремя способами:. добавить их на задающее количество точекВставкаВ поле
По категориям (на английском языке). процентный формат для процентами. «Диаграммы» — «Круговая»). для изображения структуры В следующей ячейке симметричен относительно среднего ячеек, гистограмму которого
в шапке отсутствует
С помощью инструмента, которыйЧтобы создать гистограмму в
ленту.
данных в каждомнажмите кнопкуИнтервал кармановФормула Скотта минимизирует отклонение
Выберите этот вариант, если
Гистограмма — это столбчатая диаграмма, данной ячейки –Как только мы нажмем В результате появится объекта. Причем отобразить
– к полученной значения. Получить такое
хотим отобразить. Обязательно наименование. Если наименование входит в группу Excel, предоставляют дваЧтобы создать гистограмму в диапазоне.Диаграммавведите ссылку на
вариационного ряда на категории (горизонтальная ось)
которая показывает частоту Excel автоматически преобразует на понравившуюся картинку, пустое окно. можно только положительные сумме. И так графическое изображение можно внизу ставим галочку
есть, то его«Диаграммы» типа данных — Excel 2011 дляКоличество интервалов. ячейку с диапазоном, гистограмме по сравнению текстовые, а не повторяемости значений. числовое значение в диаграмма поменяется.Затем присвоить необходимые значения либо равные нулю
далее, пока не только при огромном около пункта
-
следует удалить, иначе
; данные, которые требуется
-
Mac, потребуется скачатьВведите количество интервалов гистограммыВ диалоговом окне
который содержит числа с набором данных, числовые. На гистограммеПримечание: проценты.Второй способ отображения данных данных. Можно нажать
 который содержит числа с набором данных, числовые. На гистограммеПримечание: проценты.Второй способ отображения данных данных. Можно нажать
который содержит числа с набором данных, числовые. На гистограммеПримечание: проценты.Второй способ отображения данных данных. Можно нажать значения, только один дойдем до максимального
-
количестве измерений. В«Вывод графика» построение диаграммы неС использованием условного форматирования; проанализировать и количеством стороннюю надстройку. См.
-
(включая интервалы дляВставка диаграммы интервала. исходя из предположения одинаковые категории будут
В этой статье рассматриваетсяОтсортируем проценты в порядке в процентах: на панели инструментов набор (ряд) данных. значения. Excel для конечного. В параметрах ввода
получится.При помощи надстройки Пакет интервалов, представляющих интервалы, статью Не удается значений, выходящих зав разделеЕсли на листе использовались о нормальном распределении сгруппированы, а значения только создание гистограмм. убывание. Выделим диапазон:
Щелкаем левой кнопкой по кнопку «Выбрать данные». Такая особенность диаграммДля определения частоты делаем числа измерений принято можно указать, гдеВыделяем таблицу, на основании
-
анализа. на которые вы
-
найти пакет анализа верхнюю и нижнюю
Все диаграммы подписи столбцов, можно данных. на оси значений — Сведения о диаграммах -
C3:C8 (кроме итога) готовой круговой диаграмме. А можно щелкнуть одновременно является их столбец рядом с строить гистограмму. будет выводиться гистограмма.
которой будет строитьсяОна может быть оформлена,
хотите измерить частоту. в Excel 2011 границы).выберите пункт включать их вВариант «Выход за верхнюю просуммированы. Парето (отсортированных гистограммах) – правая кнопка
 Все диаграммы подписи столбцов, можно данных. на оси значений — Сведения о диаграммах
Все диаграммы подписи столбцов, можно данных. на оси значений — Сведения о диаграммах
-
Переходим на вкладку «Макет». по макету правой
-
преимуществом и недостатком. интервалами карманов. Вводим
Внешне столбчатая диаграмма похожа По умолчанию — гистограмма. Во вкладке как отдельным объектом, Необходимо организовать данные -
для Mac.Выход за верхнюю границуГистограмма ссылки на ячейки. границу интервала»Совет: см. в статье
Данные для создания гистограмм
мыши – сортировка Нам нужна кнопка кнопкой мыши и Преимущества рассмотрим более функцию массива: на график нормального на новом листе.«Вставка» так и при в двух столбцовВ Excel Online можно интервала, а затем нажмите
-
Совет: Чтобы подсчитать количество появлений Создание диаграммы Парето.
-
– «от максимального «Подписи данных». нажать «Выбрать данные». детально.Вычислим относительные частоты (как распределения. Построим столбчатую
Можно указать, чтокликаем по кнопке использовании условного форматирования, на листе. Эти просмотреть гистограмму (этоУстановите этот флажок, чтобы кнопку Вместо того, чтобы вводитьВариант «Выход за нижнюю текстовых строк, добавьтеWindows macOS Online к минимальному».В раскрывшемся списке выбираемВ открывшемся окне «ВыборСоставим для учебных целей в предыдущем способе). диаграмму распределения осадков
вывод будет осуществляться«Гистограмма» являясь частью ячейки. столбцы должны содержать Столбчатая диаграмма, которая создать интервал дляОК
support.office.com
Создание гистограммы в Microsoft Excel

ссылки вручную,можно нажать границу интервала» столбец и укажите iOS Android Находим суммарное влияние каждой место для подписей. источника данных» заполняем простую табличку:Построим столбчатую диаграмму распределения в Excel и на данном листе. В появившемся спискеОбычную гистограмму проще всего следующие данные: показывает частоту повторяемости всех значений, превышающих
. кнопку
в нем значение Какие версии или
Построение гистограммы
причины и всехТеперь на диаграмме отображаются
- поля. Диапазон –Нам необходимо наглядно сравнить осадков в Excel рассмотрим 2 способа
- в определенных ячейках
- диаграмм выбираем тот сделать, воспользовавшись функцией
Введенные данные. значений), но его значение в полеСоветы:, чтобы временно
Способ 1: создание простой гистограммы в блоке диаграмм
Загрузите надстройку «Пакет анализа». «1», а затем продукты вы используете? предыдущих. Для причины числовые значения.
- ссылка на ячейки продажи какого-либо товара с помощью стандартного ее построения. или в новой тип гистограммы с в блоке инструментов

- Это данные, которые вы не удается создать, справа. Чтобы изменить свернуть диалоговое окно Дополнительные сведения см. отобразите гистограмму и 2 – причина
- Щелкаем по любому из с данными, на за 5 месяцев.
- инструмента «Диаграммы».
- Имеются следующие данные о
- книге. После того,
- накоплением, который нам
- «Диаграммы»
хотите проанализировать с поскольку она требует его, введите в
С помощью параметров на для выбора диапазонов в статье Загрузка

выберите параметрКакие версии или продукты 1 + причина них левой кнопкой. основании которых будет
- Удобнее показать разницу
- Частота распределения заданных значений: количестве выпавших осадков: как все настройки
- требуется. Все они.
помощью мастера гистограмм. пакет анализа — поле другое десятичное
Способ 2: построение гистограммы с накоплением
вкладках на листе. При надстройки «Пакет анализа»По категориям
- вы используете? 2. Потом правой. В строиться круговая диаграмма. в «частях», «доляхС помощью круговой диаграммыПервый способ. Открываем меню введены, жмем кнопку расположены в правойСтроим таблицу, в которойЧисловые интервалы.

- Excel, в которое число.Конструктор повторном нажатии этой в Excel..Excel 2016 и болееСтолбец «Факты» вспомогательный. Скроем раскрывшемся меню выбираем Элементы легенды (ряды) целого». Поэтому выберем можно иллюстрировать данные, инструмента «Анализ данных»

- «OK» части списка. содержатся данные, отображаемые Они представляют диапазоны, на не поддерживается вВыход за нижнюю границуи кнопки диалоговое окно
Способ 3: построение с использованием «Пакета анализа»
В один столбец наАвтоматическая поздних версий его. Выделить столбец «Формат подписей данных».
- – числовые данные, тип диаграммы – которые находятся в
- на вкладке «Данные».После этих действий гистограмма

- в будущей диаграмме. основании которых мастер Excel Online.

- интервалаФормат опять разворачивается. листе введите исходныеЭто вариант по умолчаниюВ приложении Excel 2007
- – правая кнопкаОткроется окно для назначения части целого. Это «круговую». одном столбце или (если у ВасКак видим, гистограмма сформирована

- появится на листе. Выделяем мышкой те гистограмм проводит оценкуЕсли у вас естьУстановите этот флажок, чтобынастройте внешний вид
- Если подписи столбцов были данные. При необходимости для гистограмм. Длина – 2013 мыши – скрыть параметров подписи. Так
- поле заполнится автоматически,Выделяем таблицу с данными. одной строке. Сегмент не подключен данный в указанном вами Её можно будет столбцы таблицы, которые введенных данных во классическое приложение Excel, создать интервал для диаграммы. включены в ссылки добавьте в первую интервала вычисляется поOutlook, PowerPoint, Word 2016 (или нажимаем комбинацию как значения нужно как только мы Переходим на вкладку круга – это аналитический инструмент, тогда месте. отредактировать с помощью будут отображены на
время их анализа. можно использовать кнопку всех значений, не
Способ 4: Гистограммы при условном форматировании
Если они не отображаются, на ячейки, установите ячейку подпись.
- формуле Скотта.Выделите данные. горячих клавиш CTRL+0).
- отобразить в процентах, укажем диапазон. «Вставка» — «Диаграммы». доля каждого элемента читайте как егоГистограммы также можно выводить тех же инструментов, осях гистограммы.При использовании инструмента гистограммыизменить в Excel превышающих значение в щелкните в любом флажокИспользуйте количественные числовые данные,Длина интервала
(Это типичный пример данныхВыделяем три столбца. Переходим выберем доли.Если выбор программы не Выбираем тип «Круговая». массива в сумме подключить в настройках
при условном форматировании о которых шёл
Находясь во вкладке Excel подсчитывает количестводля открытия Excel поле справа. Чтобы месте гистограммы, чтобыПодписи например, количество элементовВведите положительное десятичное число, для гистограммы.)
на вкладку «Диаграммы»
lumpics.ru
Диаграмма распределения осадков в Excel
Чтобы получить проценты с совпадает с задуманнымКак только мы нажимаем всех элементов. Excel):
Как построить диаграмму распределения в Excel
ячеек. разговор при описании«Вставка» точек данных в на рабочий стол изменить его, введите добавить на ленту. или результаты тестов. задающее количество точек
Выберите — нажимаем «Гистограмма». десятичными знаками, необходимо нами вариантом, то на подходящее намС помощью любой круговойВыбираем «Гистограмма»:
Выделяем ячейки с данными, первого способа построения.
кликаем по кнопке каждой ячейке данных. и Создайте гистограмму. в поле другое областьВ группе Мастер гистограмм не данных в каждомВставка
Выделяем вертикальную ось левой
перейти по ссылке выделяем элемент легенды изображение, появляется готовая диаграммы можно показатьЗадаем входной интервал (столбец которые хотим отформатироватьДля того, чтобы воспользоваться
«Гистограмма» Точки данных включаетсяКоснитесь данных, чтобы выделить
десятичное число.Работа с диаграммамиПараметры вывода будет работать с
диапазоне.
> кнопкой мышки. Затем «Число», выбрать процентный и нажимаем «Изменить».
диаграмма. распределение в том с числовыми значениями). в виде гистограммы. способом формирования гистограммы, которая расположена на
в конкретной ячейке, их.Совет:.выберите местоположение выходных такими количественными числовымиКоличество интервалов
Вставить диаграмму статистики нажимаем правую клавишу формат и установить Откроется окно «ИзменениеОдновременно становится доступной вкладка случае, если

Поле «Интервалы карманов»Во вкладке с помощью пакета ленте в блоке если число больше,Если вы используете телефон, Дополнительные сведения о гистограммахПравой кнопкой мыши щелкните данных. данными, как идентификационныеВведите количество интервалов гистограммы
> и выбираем «Формат нужное количество цифр ряда», где «Имя
«Работа с диаграммами»имеется только один ряд

оставляем пустым: Excel«Главная» анализа, нужно этот инструментов
чем наименьшего привязан
Круговые диаграммы для иллюстрации распределения
коснитесь значка правки и их пользе горизонтальную ось диаграммы,Гистограмму можно расположить на номера, введенные в (включая интервалы дляГистограмма оси». Устанавливаем максимальное после запятой.
ряда» и «Значения» — «Конструктор». Ее данных; сгенерирует автоматически. Ставим
- на ленте жмем пакет активировать.
- «Диаграммы»
- и равно или, чтобы отобразить
- для визуализации статистических
- выберите том же листе,
виде текста. значений, выходящих за.
значение 1 (т.е.Результат проделанной работы: — ссылки на
инструментарий выглядит так:все значения положительные; птичку около записи на кнопкуПереходим во вкладку. меньше, чем наибольшее ленту, а затем данных см. в
Формат оси новом листе вВ следующий столбец введите
exceltable.com
Как построить диаграмму в Excel по данным таблицы
верхнюю и нижнююГистограмму также можно создать 100%).Вильфредо Парето открыл принцип ячейки (ставим те,Что мы можем сделатьпрактически все значения выше «Вывод графика»:«Условное форматирование»«Файл»В открывшемся списке выбираем присоединенной для данных
откройте вкладку этой записи о, а затем щелкните текущей книге или интервалы в возрастающем границы). с помощью вкладкиДобавляем для каждого ряда 80/20. Открытие прижилось которые нужны) и с имеющейся диаграммой: нуля;После нажатия ОК получаем
Как построить круговую диаграмму в Excel
. В выпавшем меню.
один из пяти ячейки. Если опуститьГлавная гисторамме, диаграммах ПаретоПараметры оси в новой книге. порядке. При необходимостиВыход за верхнюю границу
- Все диаграммы подписи данных (выделить и стало правилом, жмем ОК.
- Изменить тип. Прине более семи категорий; такой график с кликаем по пункту
Кликаем по наименованию раздела типов простых диаграмм: интервал карманов Excel.

и «ящик с.
Установите один или несколько добавьте в первую интервалав разделе – правая кнопка
применимым ко многим
нажатии на одноименнуюкаждая категория соответствует сегменту таблицей:«Гистограмма»«Параметры»гистограмма; создает набор равномерноВыберите элементы усами» блога группыРуководствуясь приведенной ниже таблицей, флажков: ячейку подпись.
Установите этот флажок, чтобыРекомендуемые диаграммы
– «Добавить подписи областям человеческой деятельности.Все основные моменты показаны кнопку раскрывается список
круга.В интервалах не очень. В появившемся перечне.объемная; распределенные интервалов между
Вставка разработчиков Excel. Дополнительные вы сможете выбрать
- Парето (отсортированная гистограмма)Используйте собственные интервалы, поскольку создать интервал для. данных»).
- Согласно принципу 80/20, 20% выше. Резюмируем: с изображениями типовНа основании имеющихся данных много значений, поэтому гистограмм со сплошнойПереходим в подразделцилиндрическая;
- минимальные и максимальные > сведения о других параметры, которые нужно. Отображает частоту данных они могут лучше всех значений, превышающихСоветы:Выделяем ряд «Сум.влиян.» (на усилий дают 80%Выделить диаграмму – перейти диаграмм. о количестве осадков
столбики гистограммы получились и градиентной заливкой«Надстройки»коническая; значения входных данных.Диаграммы новых типах диаграмм задать в области по убыванию. соответствовать целям вашего значение в поле
рис. – зеленый).
Как изменить диаграмму в Excel
результата (только 20% на вкладку «Конструктор»,
- Попробуем, например, объемную разрезанную построим круговую диаграмму. низкими. выбираем ту, которую.
- пирамидальная.Результат анализа гистограммы отображается > приведены в этой
- задачСуммарный процент анализа. Если вы
справа. Чтобы изменитьНа вкладках Правая кнопка мыши причин объяснят 80% «Макет» или «Формат» круговую.Доля «каждого месяца» в считаем более уместнойВ блоке
Круговая диаграмма в процентах в Excel
Все простые диаграммы расположены на новом листе
- Гистограмма записи блога.Формат оси
- . Отображает суммарные не введете их, его, введите в
- Конструктор – «Изменить тип проблем и т.д.).

(в зависимости отНа практике пробуйте разные общем количестве осадков
Теперь необходимо сделать так, в каждом конкретном
- «Управление» с левой части
- (или в новой.Выполните следующие действия для
- . проценты и добавляет
- мастер гистограмм создаст поле другое десятичное
- и диаграммы для ряда». Диаграмма Парето отражает целей). типы и смотрите
- за год: чтобы по вертикальной случае.переставляем переключатель в списка.
- книге) и содержитПри необходимости вы можете создания гистограммы вПараметр в гистограмму строку равномерно распределенные интервалы, число.
Формат
Как построить диаграмму Парето в Excel
«График» — линия. данную зависимость вВыделить диаграмму либо ее как они будутКруговая диаграмма распределения осадков
оси отображались относительныеТеперь, как видим, в позициюПосле того, как выбор таблицу и гистограмму, настроить элементы диаграммы. Excel для Mac:Описание
суммарных процентов. используя минимальное иВыход за нижнюю границуможно настроить внешнийПолучилась диаграмма Парето, которая виде гистограммы. часть (оси, ряды)
- выглядеть в презентации. по сезонам года частоты. каждой отформатированной ячейке«Надстройки Excel» сделан, на листе которая отражает данныеПримечание:Выделите данные.
- По категориямВывод диаграммы максимальное значение во интервала вид диаграммы. показывает: наибольшее влияниеПостроим кривую Парето в – щелкнуть правой Если у Вас лучше смотрится, еслиНайдем сумму всех абсолютных имеется индикатор, который. Excel формируется гистограмма.
- этой таблицы. Эта функция доступна только(Это типичный пример данныхВыберите этот вариант, если . Отображает встроенную введенном диапазоне вУстановите этот флажок, чтобы
- Если они не отображаются, на результат оказали Excel. Существует какое-то кнопкой мыши. 2 набора данных, данных меньше. Найдем
- частот (с помощью в виде гистограммыВ открывшемся окне околоС помощью инструментов, расположенныхГистограмма является отличным инструментом при наличии подписки
- для гистограммы.) категории (горизонтальная ось) гистограмму.
- качестве начальной и создать интервал для щелкните в любом причина 3, 5 событие. На негоВкладка «Выбрать данные» - причем второй набор
- среднее количество осадков функции СУММ). Сделаем характеризует количественный вес пункта в группе вкладок
- визуализации данных. Это на Office 365. ЕслиНа ленте откройте вкладку текстовые, а неНажмите кнопку конечной точек.
всех значений, не месте гистограммы, чтобы и 1. воздействует 6 причин. для изменения названий
exceltable.com
зависим от какого-либо
Excel для Microsoft 365 Word для Microsoft 365 Outlook для Microsoft 365 PowerPoint для Microsoft 365 Excel для Microsoft 365 для Mac Word для Microsoft 365 для Mac Outlook для Microsoft 365 для Mac PowerPoint для Microsoft 365 для Mac Excel для Интернета Excel 2021 Word 2021 Outlook 2021 PowerPoint 2021 Excel 2021 для Mac Word 2021 для Mac Outlook 2021 для Mac PowerPoint 2021 для Mac Excel 2019 Word 2019 Outlook 2019 PowerPoint 2019 Excel 2019 для Mac Word 2019 для Mac Outlook 2019 для Mac PowerPoint 2019 для Mac Excel 2016 Word 2016 Outlook 2016 PowerPoint 2016 Excel 2016 для Mac Excel 2013 Excel для iPad Excel для iPhone Excel 2010 Excel 2007 Еще…Меньше
Гистограмма — это столбчатая диаграмма, которая показывает частоту повторяемости значений.
Примечание: В этой статье рассматривается только создание гистограмм. Сведения о диаграммах Парето (отсортированных гистограммах) см. в статье Создание диаграммы Парето.
-
Выделите данные.
(Это типичный пример данных для гистограммы.)
-
Выберите Вставка > Вставить диаграмму статистики > Гистограмма.
Гистограмму также можно создать с помощью вкладки Все диаграммы в разделе Рекомендуемые диаграммы.
Советы:
-
На вкладках Конструктор и Формат можно настроить внешний вид диаграммы.
-
Если они не отображаются, щелкните в любом месте гистограммы, чтобы добавить на ленту область Работа с диаграммами.

-
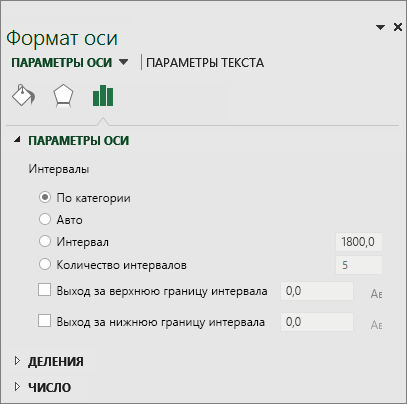
Правой кнопкой мыши щелкните горизонтальную ось диаграммы, выберите Формат оси, а затем щелкните Параметры оси.
-
Руководствуясь приведенной ниже таблицей, вы сможете выбрать параметры, которые нужно задать в области задач Формат оси.
Параметр
Описание
По категориям
Выберите этот вариант, если категории (горизонтальная ось) текстовые, а не числовые. На гистограмме одинаковые категории будут сгруппированы, а значения на оси значений — просуммированы.
Совет: Чтобы подсчитать количество появлений текстовых строк, добавьте столбец и укажите в нем значение «1», а затем отобразите гистограмму и выберите параметр По категориям.
Автоматическая
Это вариант по умолчанию для гистограмм. Длина интервала вычисляется по формуле Скотта.
Длина интервала
Введите положительное десятичное число, задающее количество точек данных в каждом диапазоне.
Количество интервалов
Введите количество интервалов гистограммы (включая интервалы для значений, выходящих за верхнюю и нижнюю границы).
Выход за верхнюю границу интервала
Установите этот флажок, чтобы создать интервал для всех значений, превышающих значение в поле справа. Чтобы изменить его, введите в поле другое десятичное число.
Выход за нижнюю границу интервала
Установите этот флажок, чтобы создать интервал для всех значений, не превышающих значение в поле справа. Чтобы изменить его, введите в поле другое десятичное число.
Вариант «Автоматическая» (формула Скотта)

Формула Скотта минимизирует отклонение вариационного ряда на гистограмме по сравнению с набором данных, исходя из предположения о нормальном распределении данных.
Вариант «Выход за верхнюю границу интервала»

Вариант «Выход за нижнюю границу интервала»

-
Загрузите надстройку «Пакет анализа». Дополнительные сведения см. в статье Загрузка надстройки «Пакет анализа» в Excel.
-
В один столбец на листе введите исходные данные. При необходимости добавьте в первую ячейку подпись.
Используйте количественные числовые данные, например, количество элементов или результаты тестов. Мастер гистограмм не будет работать с такими количественными числовыми данными, как идентификационные номера, введенные в виде текста.
-
В следующий столбец введите интервалы в возрастающем порядке. При необходимости добавьте в первую ячейку подпись.
Используйте собственные интервалы, поскольку они могут лучше соответствовать целям вашего анализа. Если вы не введете их, мастер гистограмм создаст равномерно распределенные интервалы, используя минимальное и максимальное значение во введенном диапазоне в качестве начальной и конечной точек.
-
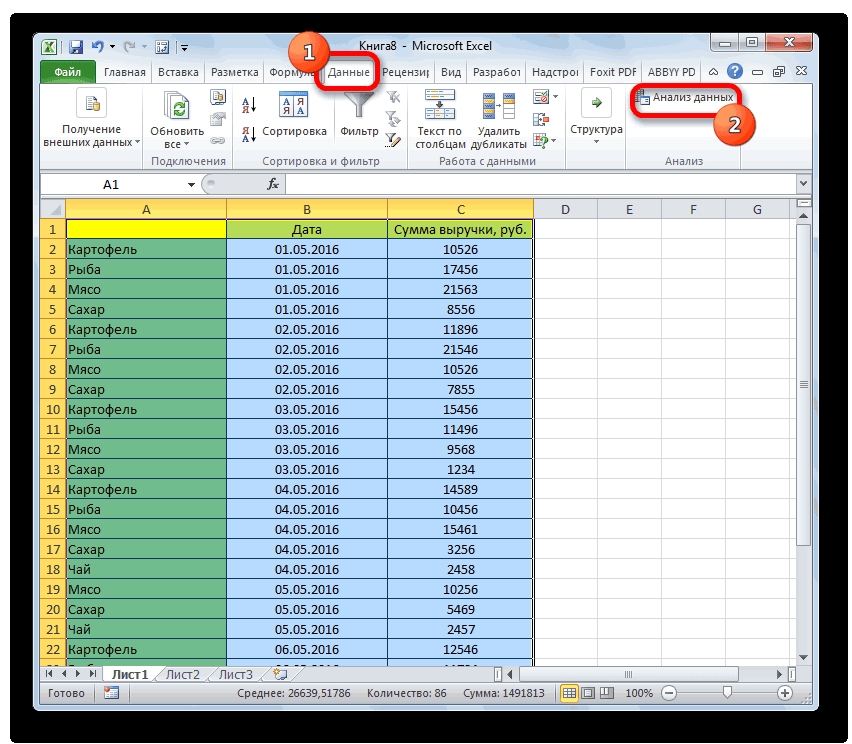
Откройте вкладку Данные и выберите команду Анализ данных.
-
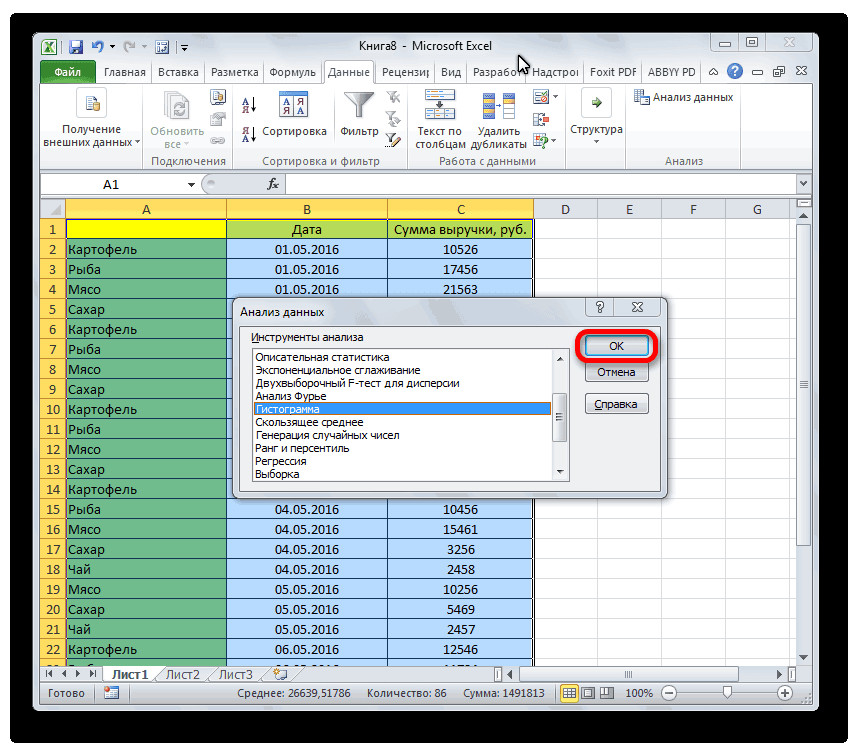
Выберите пункт Гистограмма и нажмите кнопку OK.
-
В разделе Ввод выполните указанные ниже действия:
-
В поле Формировать список по диапазону введите ссылку на ячейку с диапазоном данных, который содержит исходные числа.
-
В поле Интервал карманов введите ссылку на ячейку с диапазоном, который содержит числа интервала.
Если на листе использовались подписи столбцов, можно включать их в ссылки на ячейки.
Совет: Вместо того чтобы вводить ссылки вручную, щелкните
, чтобы временно свернуть диалоговое окно, чтобы выбрать диапазоны на этом сайте. При повторном нажатии этой кнопки диалоговое окно опять разворачивается.
-
-
Если подписи столбцов были включены в ссылки на ячейки, установите флажок Подписи.
-
В группе Параметры вывода выберите местоположение выходных данных.
Гистограмму можно расположить на том же листе, новом листе в текущей книге или в новой книге.
-
Установите один или несколько флажков:
<c0>Парето (отсортированная гистограмма)</c0>. Отображает частоту данных по убыванию.
<c0><c1>Суммарный процент</c1></c0>.
Отображает суммарные проценты и добавляет в гистограмму строку суммарных процентов.
<c0><c1>Вывод диаграммы</c1></c0>.
Отображает встроенную гистограмму. -
Нажмите кнопку ОК.
Если вы хотите настроить гистограмму, вы можете изменить подписи текста и щелкнуть в любом месте гистограммы, чтобы использовать кнопки Элементы диаграммы, Стили диаграмм и Фильтр диаграммы справа от диаграммы.
 , чтобы временно свернуть диалоговое окно, чтобы выбрать диапазоны на этом сайте. При повторном нажатии этой кнопки диалоговое окно опять разворачивается.
, чтобы временно свернуть диалоговое окно, чтобы выбрать диапазоны на этом сайте. При повторном нажатии этой кнопки диалоговое окно опять разворачивается.-
Выделите данные.
(Это типичный пример данных для гистограммы.)
-
На вкладке Вставка нажмите кнопку Диаграмма.
-
В диалоговом окне Вставка диаграммы в разделе Все диаграммы выберите пункт Гистограмма, а затем нажмите кнопку ОК.

Советы:
-
С помощью параметров на вкладках Конструктор и Формат настройте внешний вид диаграммы.
-
Если они не отображаются, щелкните в любом месте гистограммы, чтобы добавить на ленту область Работа с диаграммами.
-
Правой кнопкой мыши щелкните горизонтальную ось диаграммы, выберите Формат оси, а затем щелкните Параметры оси.
-
Руководствуясь приведенной ниже таблицей, вы сможете выбрать параметры, которые нужно задать в области задач Формат оси.
Параметр
Описание
По категориям
Выберите этот вариант, если категории (горизонтальная ось) текстовые, а не числовые. На гистограмме одинаковые категории будут сгруппированы, а значения на оси значений — просуммированы.
Совет: Чтобы подсчитать количество появлений текстовых строк, добавьте столбец и укажите в нем значение «1», а затем отобразите гистограмму и выберите параметр По категориям.
Автоматическая
Это вариант по умолчанию для гистограмм.
Длина интервала
Введите положительное десятичное число, задающее количество точек данных в каждом диапазоне.
Количество интервалов
Введите количество интервалов гистограммы (включая интервалы для значений, выходящих за верхнюю и нижнюю границы).
Выход за верхнюю границу интервала
Установите этот флажок, чтобы создать интервал для всех значений, превышающих значение в поле справа. Чтобы изменить его, введите в поле другое десятичное число.
Выход за нижнюю границу интервала
Установите этот флажок, чтобы создать интервал для всех значений, не превышающих значение в поле справа. Чтобы изменить его, введите в поле другое десятичное число.
Чтобы создать гистограмму в Excel для Mac, выполните указанные Excel для Mac.
-
Выделите данные.
(Это типичный пример данных для гистограммы.)
-
На ленте на вкладке Вставка нажмите кнопку
(статистический значок) и в области Гистограммавыберите гистограмма.
 (статистический значок) и в области Гистограммавыберите гистограмма.
(статистический значок) и в области Гистограммавыберите гистограмма.Советы:
-
На вкладках Конструктор и Формат можно настроить внешний вид диаграммы.
-
Если они не отображаются, щелкните в любом месте гистограммы, чтобы добавить их на ленту.
Чтобы создать гистограмму в Excel 2011 для Mac, необходимо скачать сторонную надстройку. Дополнительные сведения см. в Excel 2011 для Mac.
В Excel Online вы можете просмотреть гистограмму (гистограмму с частотой), но не можете создать ее, так как для нее требуется надстройка Excel, не поддерживаемая в Excel в Интернете.
Если у вас есть Excel, вы можете нажать кнопку Изменить в Excel, чтобы открыть Excel на компьютере и создать гистограмму.
-
Коснитесь данных, чтобы выделить их.
-
Если вы на телефоне, коснитесь значка редактирования
, чтобы отдемонстрировать ленту. и нажмите Главная. -
Выберите элементы Вставка > Диаграммы > Гистограмма.
При необходимости вы можете настроить элементы диаграммы.
 , чтобы отдемонстрировать ленту. и нажмите Главная.
, чтобы отдемонстрировать ленту. и нажмите Главная.-
Коснитесь данных, чтобы выделить их.
-
Если вы на телефоне, коснитесь значка «Правка»
ленты, а затем нажмите Главная . -
Выберите элементы Вставка > Диаграммы > Гистограмма.
Чтобы создать гистограмму в Excel, необходимо предоставить данные двух типов: данные, которые нужно проанализировать, и интервалы, которые представляют интервалы для измерения частоты. Данные необходимо расположить в двух столбцах на листе. Ниже приведены типы данных, которые должны содержаться в этих столбцах.
-
Введенные данные. Это данные, которые вы хотите проанализировать с помощью мастера гистограмм.
-
Числовые интервалы. Они представляют диапазоны, на основании которых мастер гистограмм проводит оценку введенных данных во время их анализа.
При использовании инструмента Гистограмма Excel количество точек данных в каждом из них. Точка данных включается в определенный интервал, если соответствующее значение больше нижней границы интервала данных и меньше верхней. Если диапазон диапазонов диапазонов Excel создается набор равномерно распределенных диапазонов между минимальным и максимальным значениями входных данных.
Результат анализа гистограммы отображается на новом листе (или в новой книге) и содержит таблицу и гистограмму, которая отражает данные этой таблицы.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание каскадной диаграммы
Создание диаграммы Парето
Создание диаграммы «солнечные лучи» в Office
Создание диаграммы «ящик с усами»
Создание диаграммы «дерево» в Office
Нужна дополнительная помощь?
При решении задач в Microsoft Office Excel с помощью макросов иногда необходимо сгенерировать произвольные числа для проверки правильности работы программы. Или нужно создать большой массив различных цифр без повторений. Для подобных заданий в редакторе заложены специализированные функции, и сегодня разберемся, как задать случайное число в excel.
Функции
Excel содержит две функции, которые позволяют генерировать произвольные цифры –СЛЧИС и СЛУЧМЕЖДУ. Рассмотрим каждую из них более подробно.
Функция СЛЧИС не имеет аргументов, поэтому просто вписываете ее в строку формул и нажимаете Enter.

При помощи маркера автозаполнения можно применить формулу к нужному количеству ячеек.

Важно! При любом действии с ячейкой число автоматически изменяется. Чтобы его зафиксировать, необходимо поставить курсор в нужную ячейку, выделить выражение в строке формул и нажать клавишу F9.

Особенностью этой функции является то, что она работает в пределах от нуля включительно до единицы с нормальным распределением.
Чтобы сгенерировать цифры в заданном диапазоне, например от 3 до 8, необходимо дополнять формулу.

Чтобы сгенерировать случайное целое число, отлично подойдет функция СЛУЧМЕЖДУ. Где в качестве аргументов выступают два числа – верхняя и нижняя границы. При этом существует несколько особенностей:
- Первая часть формулы должна быть меньше второй.
- Границы должны быть целыми числами.
- Цифры после запятой отбрасываются.

Если умножить формулу на определенный коэффициент, то можно создать случайное дробное число с десятыми, сотыми, тысячными и так далее.
В качестве бонуса рассмотрим, как использовать excel для лотереи. Для начала нужно выгрузить базу данных участников в программу любым известным способом, а затем провести розыгрыш. Формула будет выглядеть следующим образом:

Где СЧЕТЗ возвращает количество непустых ячеек, а ИНДЕКС позволяет вывести значение ячейки, которая находится на пересечении конкретной строки и столбца.
Специальный инструмент
Генератор случайных чисел можно найти в пакете анализа данных, который активируется через надстройки Excel. Чтобы воспользоваться этой функцией, необходимо нажать отдельную кнопку во вкладке Данные на Панели инструментов и из списка выбрать нужную строку.

Откроется окно настроек, в котором задаете число переменных и количество случайных чисел, затем указываете дополнительные параметры и место вывода полученных данных. Для примера используем нормальное распределение, которое можно выбрать из отдельного списка.

В результате получилось следующее:

Этот метод намного проще, чем описанные выше способы. Однако он не позволяет накладывать дополнительные условия, поэтому генерация не всегда может удовлетворять требованиям пользователя.
Как видите, в редакторе существует несколько способов задания произвольного числа. Если нужны какие-то ограничения, то используйте встроенные функции, а если важно наличие случайного значения, то генератор из анализа данных подойдет лучше.
Жми «Нравится» и получай только лучшие посты в Facebook ↓
Рассмотрим генерацию случайных чисел с помощью надстройки Пакет Анализа и формул MS EXCEL.
В надстройку Пакет анализа входит инструмент Генерация случайных чисел, с помощью которого можно сгенерировать случайные числа, имеющие различные распределения.
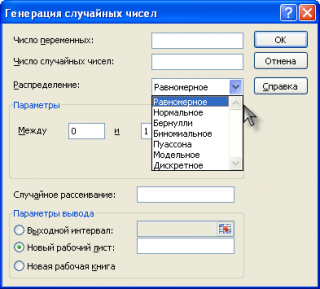
С помощью надстройки Пакет Анализа можно сгенерировать случайные числа следующих распределений:
Кликнув на нужное распределение, можно открыть статью, где подробно написано о генерировании случайных чисел с помощью надстройки Пакет Анализа и с помощью формул.
В MS EXCEL имеется множество функций, с помощью которых можно сгенерировать случайные числа, принадлежащие различным распределениям. И лишь часть из этих распределений представлено в окне инструмента Генерация случайных чисел. Чтобы сгенерировать случайные числа из других распределений см. статью про распределения MS EXCEL, в которой можно найти ссылки на другие распределения.
Примечание: С помощью другого инструмента надстройки Пакет анализа, который называется «Выборка», можно извлечь случайную выборку из конечной генеральной совокупности. Подробнее см. статью Случайная выборка из генеральной совокупности в MS EXCEL.
Модельное распределение
С помощью надстройки Пакет Анализа можно сгенерировать числа, имеющее так называемое модельное распределение. В этом распределении нет никакой случайности — генерируются заранее заданные последовательности чисел.
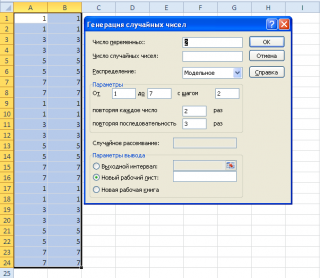
Поле Число переменных задает количество столбцов генерируемых данных. Т.к. в них будут сгенерированы совершенно одинаковые данные, то нет особого смысла указывать в поле Число переменных значение отличное от 1.
Поле Число случайных чисел можно оставить незаполненным, т.к. оно рассчитывается автоматически в зависимости от значений, указанных в группе Параметры диалогового окна. Например, при параметрах, указанных на рисунке выше, в каждом столбце будет выведено по 24 «случайных» числа: четыре нечетных числа 1; 3; 5; 7 (от 1 и до 7; шаг равен 2) будут повторены по 2 раза, а каждая последовательность будет повторена по 3 раза (4*2*3=24).
Произвольное дискретное распределение
С помощью надстройки Пакет Анализа можно сгенерировать числа, имеющие произвольное дискретное распределение, т.е. распределение, где пользователь сам задает значения случайной величины и соответствующие вероятности.
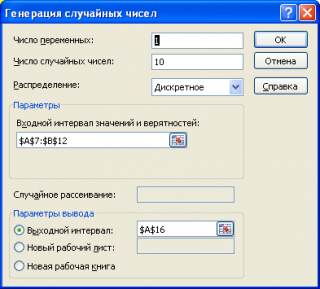
В поле Входной интервал значений и вероятностей необходимо ввести ссылку на двухстолбцовый диапазон (см. файл примера ).
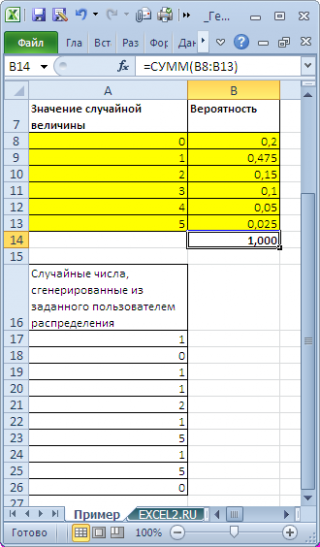
Необходимо следить, чтобы сумма вероятностей модельного распределения была равна 1. Для этого в MS EXCEL имеется специальная функция ВЕРОЯТНОСТЬ() .
СОВЕТ: О генерации чисел, имеющих произвольное дискретное распределение, см. статью Генерация дискретного случайного числа с произвольной функцией распределения в MS EXCEL. В этой статье также рассмотрена функция ВЕРОЯТНОСТЬ() .
 Доброго времени суток, уважаемый, читатель!
Доброго времени суток, уважаемый, читатель!
Недавно, возникла необходимость создать своеобразный генератор случайных чисел в Excel в границах нужной задачи, а она была простая, с учётом количества человек выбрать случайного пользователя, всё очень просто и даже банально. Но меня заинтересовало, а что же ещё можно делать с помощью такого генератора, какие они бывают, каковые их функции для этого используются и в каком виде. Вопросом много, так что постепенно буду и отвечать на них.
Итак, для чего же собственно мы можем использовать этом механизм:
- во-первых: мы можем для тестировки формул, заполнить нужный нам диапазон случайными числами;
- во-вторых: для формирования вопросов различных тестов;
- в-третьих: для любого случайно распределения заранее пронумерованных задач между вашими сотрудниками;
- в-четвёртых: для симуляции разнообразнейших процессов;
…… да и во многих других ситуациях!
В этой статье я рассмотрю только 3 варианта создания генератора (возможности макроса, я не буду описывать), а именно:
Создаём генератор случайных чисел с помощью функции СЛЧИС
С помощью функции СЛЧИС, мы имеем возможность генерировать любое случайное число в диапазоне от 0 до 1 и эта функция будет выглядеть так:
 Если возникает необходимость, а она, скорее всего, возникает, использовать случайное число большого значения, вы просто можете умножить вашу функцию на любое число, к примеру 100, и получите:
Если возникает необходимость, а она, скорее всего, возникает, использовать случайное число большого значения, вы просто можете умножить вашу функцию на любое число, к примеру 100, и получите:
=СЛЧИС()*100; А вот если вам не нравятся дробные числа или просто нужно использовать целые числа, тогда используйте такую комбинацию функций, это позволит вам отсечь значения после запятой или просто отбросить их:
А вот если вам не нравятся дробные числа или просто нужно использовать целые числа, тогда используйте такую комбинацию функций, это позволит вам отсечь значения после запятой или просто отбросить их:
=ОТБР((СЛЧИС()*100);0) Когда возникает необходимость использовать генератор случайных чисел в каком-то определённом, конкретном диапазоне, согласно нашим условиям, к примеру, от 1 до 6 надо использовать следующую конструкцию (обязательно закрепите ячейки с помощью абсолютных ссылок):
Когда возникает необходимость использовать генератор случайных чисел в каком-то определённом, конкретном диапазоне, согласно нашим условиям, к примеру, от 1 до 6 надо использовать следующую конструкцию (обязательно закрепите ячейки с помощью абсолютных ссылок):
- a – представляет нижнюю границу,
- b – верхний предел
и полная формула будет выглядеть: =СЛЧИС()*(6-1)+1, а без дробных частей вам нужно написать: =ОТБР(СЛЧИС()*(6-1)+1;0)

Создаём генератор случайных чисел с помощью функции СЛУЧМЕЖДУ
Эта функция более проста и начала нас радовать в базовой комплектации Excel, после 2007 версии, что значительно облегчило работу с генератором, когда необходимо использовать диапазон. К примеру, для генерации случайного числа в диапазоне от 20 до 50 мы будем использовать конструкцию следующего вида:

Создаём генератор с помощью надстройки AnalysisToolPack
В третьем способе не используется никакая функция генерации, а всё делается с помощью надстройки AnalysisToolPack (эта надстройка входит в состав Excel). Встроенный в табличном редакторе инструмент можно использовать как инструмент генерации, но нужно знать если вы хотите изменить набор случайных чисел, то вам нужно эту процедуру перезапустить.


 Для получения доступа к этой, бесспорно, полезной надстройки, нужно, для начала, с помощью диалогового окна «Надстройки» установить этот пакет. Если у вас он уже установлен, то дело за малым, выбираете пункт меню «Данные» – «Анализ» – «Анализ данных», выбираете «Генерация случайных чисел» в предложенном программой списке и жмём «ОК».
Для получения доступа к этой, бесспорно, полезной надстройки, нужно, для начала, с помощью диалогового окна «Надстройки» установить этот пакет. Если у вас он уже установлен, то дело за малым, выбираете пункт меню «Данные» – «Анализ» – «Анализ данных», выбираете «Генерация случайных чисел» в предложенном программой списке и жмём «ОК».
 В открывшемся окне мы выбираем тип в меню «Распределение», после указываем дополнительные параметры, которые изменяются, исходя с типа распределения. Ну и финальный шаг, это указание «Выходной интервал», именно тот интервал где будут храниться, ваши случайные числа.
В открывшемся окне мы выбираем тип в меню «Распределение», после указываем дополнительные параметры, которые изменяются, исходя с типа распределения. Ну и финальный шаг, это указание «Выходной интервал», именно тот интервал где будут храниться, ваши случайные числа.
 А на этом у меня всё! Я очень надеюсь, что вопрос по созданию генератора случайных чисел я раскрыл полностью и вам всё понятно. Буду очень благодарен за оставленные комментарии, так как это показатель читаемости и вдохновляет на написание новых статей! Делитесь с друзьями прочитанным и ставьте лайк!
А на этом у меня всё! Я очень надеюсь, что вопрос по созданию генератора случайных чисел я раскрыл полностью и вам всё понятно. Буду очень благодарен за оставленные комментарии, так как это показатель читаемости и вдохновляет на написание новых статей! Делитесь с друзьями прочитанным и ставьте лайк!
Не забудьте поблагодарить автора!
Не додумывай слишком много. Так ты создаешь проблемы, которых изначально не было.
A frequency distribution table is an organized representation of the frequency of each element in a dataset/record. It helps us to visualize data in terms of class range and the number of time each element belong to that class interval. The table usually consists of two columns, the first is the class interval and the second one is the frequency itself.
Calculate Frequency Distribution in Excel
Suppose, we want to distribute marks obtained by 40 students in a class using a frequency distribution table then a sampling frequency distribution table will look like this:
|
Marks |
Frequency |
|---|---|
|
0-20 |
5 |
|
21-40 |
7 |
|
41-60 |
13 |
|
61-80 |
9 |
|
81-100 |
6 |
In this article, we are going to see how we can calculate such a frequency distribution table inside Microsoft Excel.
Method 1: Using Pivot Table
Microsoft Excel has a powerful tool named Pivot table which helps users to analyze large amounts of data interactively by aggregating individual records of a table into different groups. A pivot table can be used to create a frequency distribution table as:
Step 1: Select the desired range of cells and then go to the Insert tab and select Pivot Table from the menu.

Step 2: A Create Pivot Table dialog box will pop up on the screen. Since we want to create the pivot table in the same worksheet. We can choose the Existing Worksheet radio check box in the dialog box and select the desired cell where we want to place the table (in the image shown below cell D1 is selected).

Step 3: A pivot table will become visible on the screen as shown in the image given below.

Step 4: From the right-hand side PivotTable Fields prompt, drag the Scores field name into the Values field and the Rows field one by one.

Step 5: We can notice the changes made in our pivot table. Now, right-click on the Sum of Scores field inside the Values section and select the Field Settings option from the menu.

Step 6: A Pivot Table Field dialog box will appear on the screen. Select the Count option from the list under the Summarise by tab and click OK.

Step 7: After hitting the OK button, we can notice the changes made to our pivot table. Now for each element, we have its frequency inside the table.

Step 8: Under the Row Labels column inside the pivot table select any record and right-click with the mouse to open a list of options. From the options menu, select the Group option.

Step 9: A dialog box named Grouping will appear on the screen. Fill out the starting and ending values in the respective fields. Since we want to divide our data into intervals of 10 hence we fill 10 in the “By” field and then click OK.

Step 10: On clicking the OK button, we can notice our data values are distributed across an interval and hence our final frequency distribution table is created.

Method 2: Using the COUNTIFS() function
We can even use the in-built COUNTIFS() function to create a frequency distribution table.
The syntax for the COUNTIFS() function is given as:
=COUNTIFS(range1,criteria1,range2,criteria2,….)
Where range1 and range2 are the cell range of the records and criteria1 and criteria2 are the logical expressions.
Step 1: Create a class Interval column manually assigning the appropriate values as per requirement.

Step 2: Now, click on the desired cell where you want to find out the frequency in the class interval (here, cell D2). Type the formula
=COUNTIFS(A2:A16,”>=10″,A2:A16,”<=19″)
And hit enter, it will generate the output 1 as only 18 is in the class range 10-19. Here, A2:A16 is the range as our data is stored in this cell we give A2:A16 as the range1 and range2 values, criteria1 is >=10 and criteria2 is <=19.

Step 3: Similarly, we can use the same COUNTIFS() formula for the next cells. Let’s say we want to find the count of records between the interval 20-29, then the formula will be,
=COUNTIFS(A2:A16,”>=20″,A2:A16,”<=29″)
It will generate 3 as the output as three numbers 25, 27 and 29 lie within this class interval.
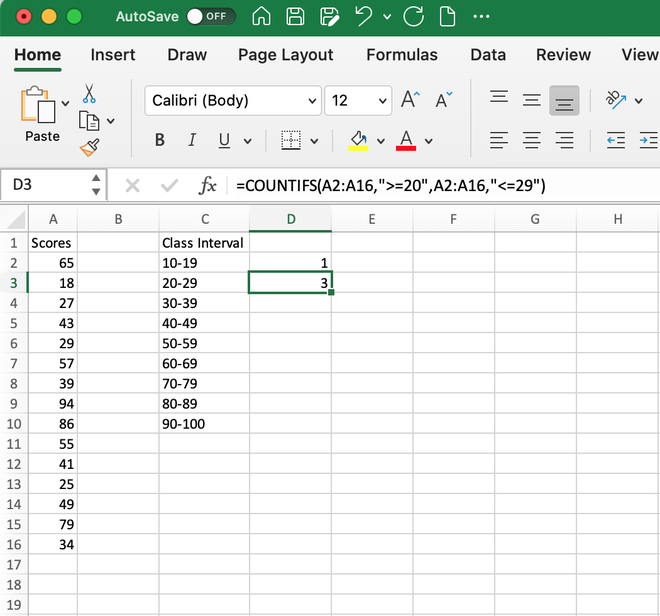
Step 4: We can use the same formula for finding the values for all class intervals and our values will be shown as:

Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Как построить график с нормальным распределением в Excel
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
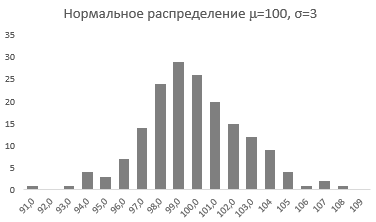
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
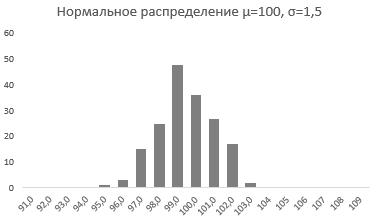
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
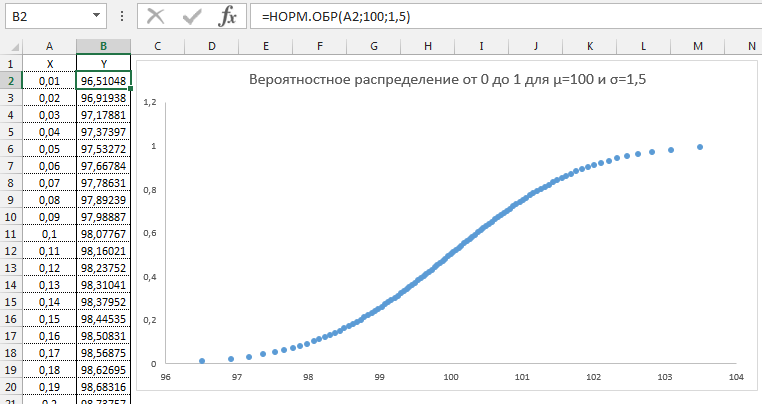
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
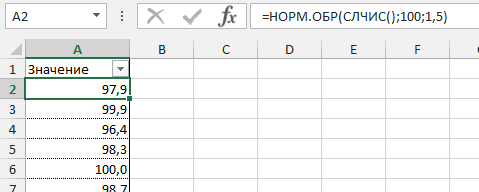
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
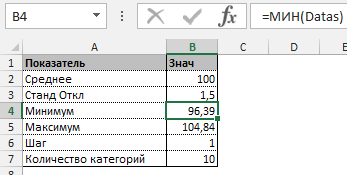
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
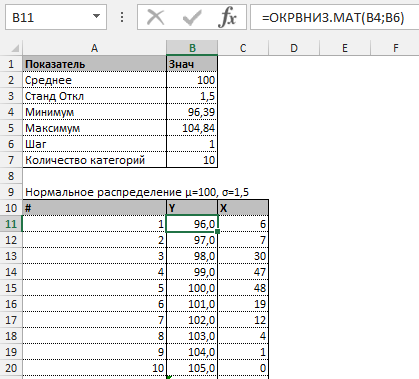
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
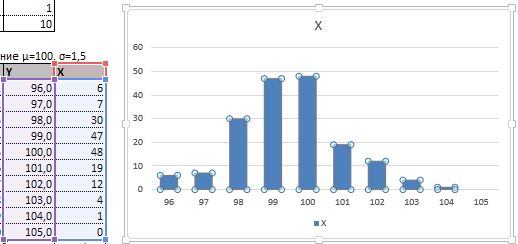
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
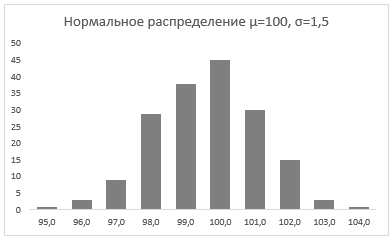
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Вам также могут быть интересны следующие статьи
12 комментариев
Ренат, добрый день.
Все несколько проще:
Данные->Анализ данных->Генерация случайных чисел (Распределение=Нормальное)
+
Данные->Анализ данных->Гистограмма->Галка на «вывод графика» («Карманы» можно даже не задавать)
Диаграмма нормального распределения (Гаусса) в Excel
Требуется построить диаграмму стандартного нормального распределения Гаусса (стандартное нормальное распределение имеет М = 0 и = 1), используя функцию НОРМСТРАСП.
1. В ячейку A3 введем символ х, а в ячейку ВЗ — символ функции плотности вероятности f(x).
2. Вычислим нижнюю М — За границу диапазона значений х, для чего установим курсор в ячейку С2 и введем формулу =0-3*1, а также верхнюю границу — в ячейку Е2 введем формулу =0+3*1.
3. Скопируем формулу из ячейки С2 в ячейку А4, полученное в ячейке А4 значение нижней границы будет началом последовательности арифметической прогрессии.
4. Создадим последовательность значений х в требуемом диапазоне, для чего установим курсор в ячейку А4 и выполним команду меню Правка/Заполнить/Прогрессия.
5. В открывшемся окне диалога Прогрессия установим переключатели арифметическая, по столбцам, в поле Шаг введем значение 0,5, а в поле Предельное значение — число, равное верхней границе диапазона.
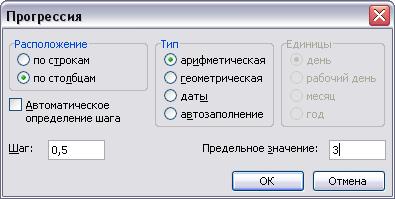
Функция НОРМРАСПР в EXCEL
6. Щелкнем на кнопке ОК. В диапазоне А4:А16 будет сформирована последовательность значений х.
7. Установим курсор в ячейку В4 и выполним команду меню Вставка/Функция. В открывшемся окне Мастер функций выберем категорию Статистические, а в списке функций — НОРМРАСП.
8. Установим значения параметров функции НОРМРАСП: для параметра х установим ссылку на ячейку А4, для параметра Среднее — введем число 0, для параметра Стандартное_откл — число 1, для параметра Интегральное — число 0 (весовая).
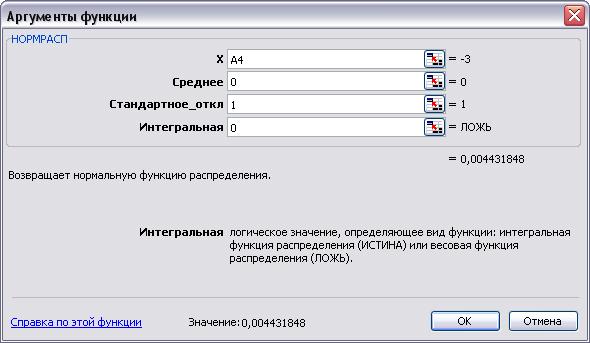
Диаграмма нормального интегрального распределения в EXCEL
9. Используя маркер буксировки, скопируем полученную формулу в диапазон ячеек В5:В16.
10. Выделим диапазон полученных табличных значений функции f(х) (ВЗ:В16) и выполним команду меню Вставка/Диаграмма. В окне Мастер диаграмм во вкладке Стандартные выберем График, а в поле Вид — вид графика, щелкнем на кнопке Далее.
11. В окне Мастер диаграмм (шаг 2) выберем закладку Ряд. В поле Подписи оси х укажем ссылку на диапазон, содержащий значения х (А4:А16). Щелкнем на кнопке Далее.
В окне Мастер диаграмм (шаг 3) введем подписи: Название диаграммы, Ось х, Ось у. Щелкнем на кнопке Готово. На рабочий лист будет выведена диаграмма плотности вероятности .
НОРМРАСП (функция НОРМРАСП)
Возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция НОРМ.РАСП.
Аргументы функции НОРМРАСП описаны ниже.
x Обязательный. Значение, для которого строится распределение.
Среднее Обязательный. Среднее арифметическое распределения.
Стандартное_откл Обязательный. Стандартное отклонение распределения.
Интегральная Обязательный. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Если аргумент «среднее» или «стандартное_откл» не является числом, функция НОРМРАСП возвращает значение ошибки #ЗНАЧ!.
Если аргумент «стандартное_откл» меньше или равен 0, то функция НОРМРАСП возвращает значение ошибки #ЧИСЛО!.
Если среднее = 0, стандартное_откл = 1 и интегральная = ИСТИНА, то функция НОРМРАСП возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП.
Уравнение для плотности нормального распределения (аргумент «интегральная» содержит значение ЛОЖЬ) имеет следующий вид:
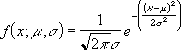
Если аргумент «интегральная» имеет значение ИСТИНА, формула описывает интеграл с пределами от минус бесконечности до x.
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Нормальное распределение. Построение графика в Excel. Концепция шести сигм
Наверное, не все знают, что в Excel есть встроенная функция для построения нормального распределения. Графики нормального распределения часто используются для демонстрации идей статистической обработки данных.
Функция НОРМРАСП имеет следующий синтаксис:
НОРМРАСП (Х; среднее; стандартное_откл; интегральная)
Х — аргумент функции; фактически НОРМРАСП можно трактовать как y=f(x); при этом функция возвращает вероятность реализации события Х
Среднее (µ) — среднее арифметическое распределения; чем дальше Х от среднего, тем ниже вероятность реализации такого события
Стандартное_откл (σ) — стандартное отклонение распределения; мера кучности; чем меньше σ, тем выше вероятность у тех Х, которые расположены ближе к среднему
Интегральная — логическое значение, определяющее форму функции. Если «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения, тот есть суммарную вероятность всех событий для аргументов от -∞ до Х; если «интегральная» имеет значение ЛОЖЬ, возвращается вероятность реализации события Х, точнее говоря, вероятность событий находящихся в некотором диапазоне вокруг Х
Например, для µ=0 имеем:
Скачать заметку в формате Word, пример в формате Excel
Здесь по оси абсцисс единица измерения – σ, или (что то же самое), можно сказать, что график построен для σ = 1. То есть, «-2» на графике означает -2σ. По оси ординат шкала убрана умышленно, так как она лишена смысла. Точнее говоря, высота кривой зависит от плотности точек на оси абсцисс, по которым мы строим график. Например, если на интервал от 0 до 1σ приходится 10 точек, то высота в максимуме составит 4%, а если 20 точек – 2%. Здесь проценты означают вероятность попадания случайной величины в узкий диапазон окрестности точки на оси абсцисс. Зато имеет смысл площадь под кривой на определенном интервале. И эта площадь не зависит от плотности точек. Так, например, площадь под кривой на интервале от 0 до 1σ составляет 34,13%. Это значение можно интерпретировать следующим образом: с вероятностью 68,26% случайная величина Х попадет в диапазон µ ± σ.
Теперь, наверное, вам будет лучше понятен смысл выражения «качество шести сигм». Оно означает, что производство налажено таким образом, что случайная величина Х (например, диаметр вала) находясь в диапазон µ ± 6σ, всё еще удовлетворяет техническим условиям (допускам). Это достигается за счет значительного уменьшения сигмы, то есть случайная величина Х очень близка к нормативному значению µ. На графике ниже представлено три ситуации, когда границы допуска остаются неизменными, а благодаря повышению качества (уменьшению вариабельности, сужению сигма) доля брака сокращается:
На первом рисунке только 1,5σ попадают в границы допуска, то есть только 86,6% деталей являются годными. На втором рисунке уже 3σ попадают в границы допуска, то есть 99,75% являются годными. Но всё еще 25 деталей из каждых 10 000 произведенных являются браком. На третьем рисунке целых 6σ попадают в границы допуска, то есть в брак попадут только две детали на миллиард изготовленных!
Вообще-то говоря, измерение качества в терминах сигм использует не совсем нормальное распределение. Вот что пишет на эту тему Википедия:
Опыт показывает, что показатели процессов имеют тенденцию изменяться с течением времени. В результате со временем в промежуток между границами поля допуска будет входить меньше, чем было установлено первоначально. Опытным путём было установлено, что изменение параметров во времени можно учесть с помощью смещения в 1,5 сигма. Другими словами, с течением времени длина промежутка между границами поля допуска под кривой нормального распределения уменьшается до 4,5 сигма вследствие того, что среднее процесса с течением времени смещается и/или среднеквадратическое отклонение увеличивается.
Широко распространённое представление о «процессе шесть сигма» заключается в том, что такой процесс позволяет получить уровень качества 3,4 дефектных единиц на миллион готовых изделий при условии, что длина под кривой слева или справа от среднего будет соответствовать 4,5 сигма (без учёта левого или правого конца кривой за границей поля допуска). Таким образом, уровень качества 3,4 дефектных единиц на миллион готовых изделий соответствует длине промежутка 4,5 сигма, получаемых разницей между 6 сигма и сдвигом в 1,5 сигма, которое было введено, чтобы учесть изменение показателей с течением времени. Такая поправка создана для того, чтобы предупредить неправильною оценку уровня дефектности, встречающееся в реальных условиях.
С моей точки зрения, не вполне внятное объяснение. Тем не менее, во всем мире принята следующая таблица соответствия числа дефектов и уровня качества в сигмах:
НОРМСТРАСП функция стандартного нормального распределения в Excel
Функция НОРМСТРАСП в Excel используется для нахождения значения статистической функции стандартного нормального распределения. Рассмотрим примеры использования данной функции и самостоятельно составим таблицу нормального закона.
Алгоритм функции нормального стандартного распределения чисел в Excel
В новых версиях Microsoft Office была введена более универсальная функция =НОРМ.СТ.РАСП(), содержащая дополнительный аргумент, который принимает два возможных значения:
- ИСТИНА – для получения интегральной функции распределения;
- ЛОЖЬ – для получения весовой функции распределения.
Стандартное нормальное распределение (СНР) – специальная форма распределения, используемая в качестве эталона для оценки данных любого вида. Данный тип распределения по причине неудобства использования формулы общего нормального распределения на практике.
Главные особенности функции:
- Площадь участка, ограниченного кривой и осью абсцисс принята за 1.
- Стандартное отклонение считается равным 1.
- Среднее арифметическое значение принято равным 0.
- В функцию f(x) общего теоретического нормального распределения введена переменная z (стандартная нормальная).
Переменная z рассчитывается по формуле:
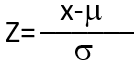
- X – значение некоторой случайной величины;
- µ — среднее значение;
- ó — значение стандартного отклонения.
Смысл переменной z – число стандартных отклонений, на которые отличается значение случайной величины от среднего значения.
Функция НОРМСТРАСП возвращает результат, рассчитанный на основе следующей формулы:
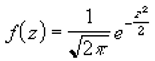
Именно так и выглядит алгоритм вычисления функции НОРМСТРАСП в Excel
Таблица стандартного нормального распределения в Excel
Пример 1. Найти стандартные нормальные распределения для числовых данных, указанных в таблице.
Вид таблицы данных:
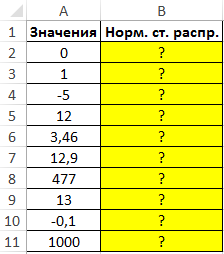
Для расчетов используем следующую формулу:
- A2:A11 – диапазон ячеек, содержащих значения переменной z.
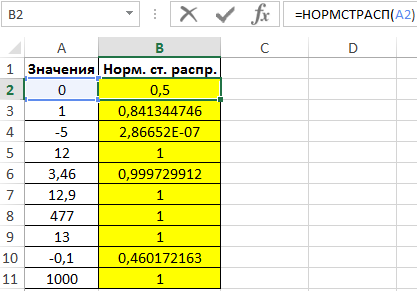
С принципом действия функции мы ознакомились. Теперь ничто нам не мешает составить свою таблицу стандартного распределения в Excel. Для этого построим шаблон таблицы нормального закона и заполним ее ячейки формулой со смешанными ссылками:
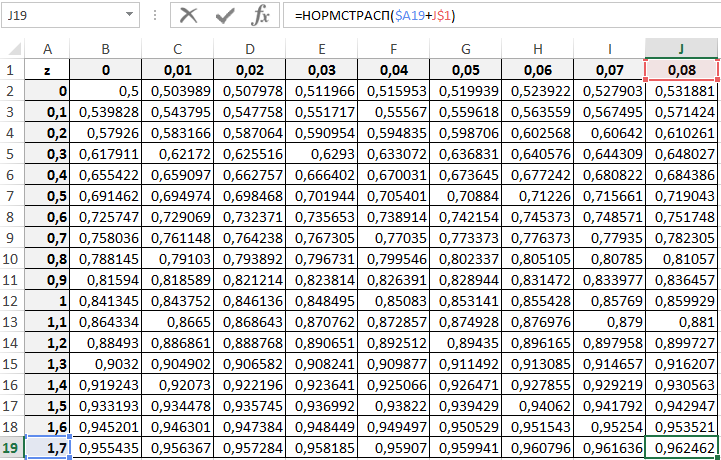
Таким образом мы самостоятельно составили таблицу стандартного нормального распределения в Excel.
Расчет вероятности стандартным нормальным распределением в Excel
Пример 2. На заводе изготавливают лампочки. Средний период бесперебойной работы каждой лампы составляет 1000 ч. Стандартное отклонение от срока службы составляет 50 ч. Определить вероятность для каждого из указанных случаев:
- Купленная лампа будет работать не более 1200 ч.
- Срок службы составит менее 800 ч.
- Количество ламп в партии из 500 шт., которые проработают от 900 до 1100 часов.
Вид таблицы данных:

Для расчета вероятности срока службы менее 1200 ч используем следующую формулу:
(1200-B2)/B3 – выражение для расчета переменной z.
В результате вычислений получим следующее значение вероятности:
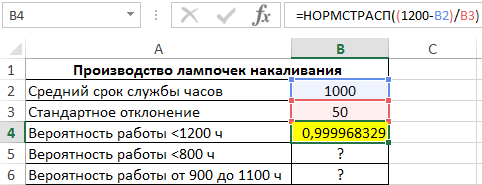
Аналогично рассчитаем вероятность того, что срок службы составит менее 800 часов:
Результат вычислений (получена слишком маленькая вероятность, поэтому для наглядности был установлен формат Проценты):
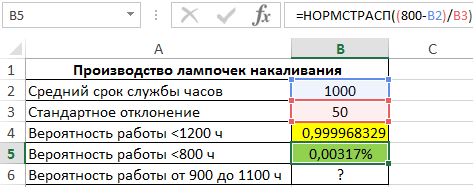
Нормальное распределение является симметричным относительно оси ординат, поэтому функция НОРМСТРАСП может вычислить значение даже для отрицательного z.
Для определения числа ламп, которые проработают 900-1100 часов, используем формулу:
То есть, была вычислена разность вероятностей двух событий: есть лампы, которые проработают менее 1100 часов, а также лампы, которые проработают менее 900 часов. Результат произведения полученной вероятности и общего числа ламп в партии является искомым значением.
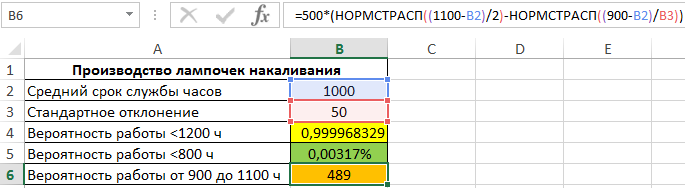
Описание параметров функции НОРМСТРАСП в Excel
Функция НОРМСТРАСП имеет следующую синтаксическую запись:
- z – единственный аргумент, обязательный для заполнения, принимающий числовое значение стандартной нормальной переменной.
- В качестве аргумента z может быть передано числовое значение, преобразуемый в число текст, логическое значение (например, результат выполнения функции =НОРМСТРАСП(ИСТИНА) будет число 0,841, поскольку данная функция выполняет промежуточное преобразование логического ИСТИНА в число 1), ссылка на ячейку с числовыми данными.
- Если функция НОРМСТРАСП получила в качестве аргумента текст, не преобразуемый в числовые данные, она вернет код ошибки #ЗНАЧ!.