
ЭЛЕМЕНТЫ ТЕОРИИ ПОГРЕШНОСТЕЙ
АБСОЛЮТНАЯ И ОТНОСИТЕЛЬНАЯ ПОГРЕШНОСТИ
Пусть 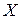 – точное значение,
– точное значение, 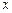 – приближенное значение некоторого числа.
– приближенное значение некоторого числа.
Абсолютная погрешность приближенного числа равна модулю разности между его точным и приближенным значениями:
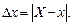
Довольно часто точное значение 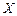 неизвестно, поэтому вместо абсолютной погрешности используют понятие границы абсолютной погрешности:
неизвестно, поэтому вместо абсолютной погрешности используют понятие границы абсолютной погрешности:
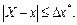
Число 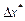 называется предельной абсолютной погрешностью, оно равно или превышает значение абсолютной погрешности.
называется предельной абсолютной погрешностью, оно равно или превышает значение абсолютной погрешности.
Основной характеристикой точности числа является относительная погрешность.
Относительная погрешность – это отношение абсолютной погрешности к приближенному значению числа:
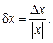
 Результат действий над приближенными числами представляет собой приближенное число. Погрешность результата выражается через погрешности первоначальных данных по правилам:
Результат действий над приближенными числами представляет собой приближенное число. Погрешность результата выражается через погрешности первоначальных данных по правилам:
1. 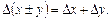
2. 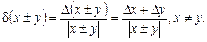
3. 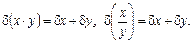
4. 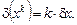
Общая формула для оценки предельной абсолютной погрешности функции нескольких переменных 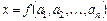 имеет вид:
имеет вид:
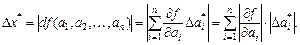
где 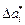 –предельная абсолютная погрешность числа
–предельная абсолютная погрешность числа 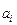 .
.
Пример: Известно, что 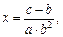 где
где 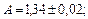
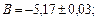
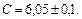
Найти , 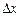 ,
, 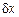 ,
, 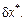
Для оценки предельной абсолютной погрешности воспользуемся формулой:
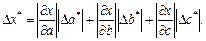
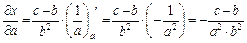
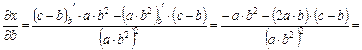
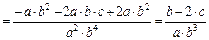
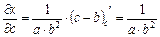
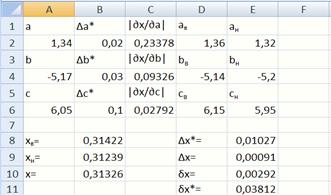
Рис. 1. Вид экрана для вычисления абсолютной и относительной погрешностей
Исходные данные вводятся в блок А1:B6 (рис. 1). В ячейки С1:С6вводятся формулы для вычисления частных производных искомой функции. В ячейку Е8записывается формула 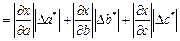 . Модуль вводится с использованием функции =abs().
. Модуль вводится с использованием функции =abs().
В ячейках D1:E6рассчитываются верхние и нижние оценки значений переменных по формулам  (аналогично для других переменных).
(аналогично для других переменных).
В ячейках B8:B10вычисляются верхняя и нижняя оценки значений функции и само значение функции отличие вычисляемых функций в используемом наборе аргументов.
В ячейку Е9записывается формула для вычисления абсолютной погрешности 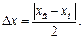 Найденная абсолютная погрешность не должна превышать значение предельной абсолютной погрешности, т.е.
Найденная абсолютная погрешность не должна превышать значение предельной абсолютной погрешности, т.е. 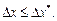
В ячейку Е10записывается формула для вычисления относительной погрешности
Предельную относительную погрешность заданной функции 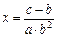 вычислим следующим образом:
вычислим следующим образом:
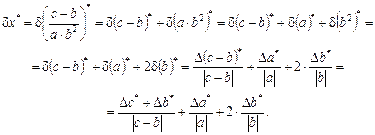
Полученную формулу записывают в ячейку Е11. Найденная относительная погрешность не должна превышать значение предельной относительной погрешности, т.е. 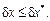
Задания для самостоятельного выполнения.
Из таблицы 1 приложения взять исходные данные своего варианта. Вариант определяется по порядковому номеру в списке группы. Вычислить частные производные, верхнюю и нижнюю оценки значений функции и само значение функции, изменить формулу вычисления предельной относительной погрешности. Все остальные ячейки пересчитаются автоматически.
Контрольные вопросы
1. Как записать основные математические функции в Excel.
2. Сформулируйте определение абсолютной и относительной погрешностей.
3. Запишите формулы для вычисления предельной абсолютной и предельной относительной погрешностей.
4. Основные правила вычисления абсолютной и относительной погрешностей.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Только сон приблежает студента к концу лекции. А чужой храп его отдаляет. 8833 —  | 7547 —
| 7547 —  или читать все.
или читать все.
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
С использованием встроенных функций Excel расчет доверительного интервала проводится следующим образом.
1) Рассчитывается среднее значение
=СРЗНАЧ(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется среднее.
2) Рассчитывается стандартное отклонение
=СТАНДОТКЛОНП(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется стандартное отклонение.
3) Рассчитывается абсолютная погрешность
=ДОВЕРИТ(альфа ;станд_откл;размер)
альфа — уровень значимости используемый для вычисления уровня надежности.
(  , т.е.
, т.е.  означает надежности
означает надежности  );
);
станд_откл — стандартное отклонение, предполагается известным;
размер — размер выборки.
Задание: Обработать заданный набор экспериментальных данных методом Стьюдента, построить экспериментальные кривые методом наименьших квадратов.
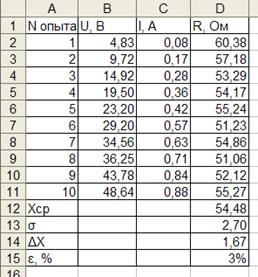
Предположим, в ходе эксперимента по измерению электросопротивления были получены следующие данные:

Используя для определения сопротивления закон Ома 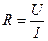 произведем обработку данной серии экспериментальных данных.
произведем обработку данной серии экспериментальных данных.
| Используемуе формулы |
 |
| Результат расчета |
 |
Для построения графика используем мастер диаграмм.
Полученные экспериментальные данные следует аппроксимировать. Для выполнения этой процедуры в Excel предусмотрен мастер, добавляющий линию тренда, производящий аппроксимацию и сглаживание.
В меню «Диаграмма» выберите пункт «Добавить линию тренда…».

В результате, должен получиться следующий график.
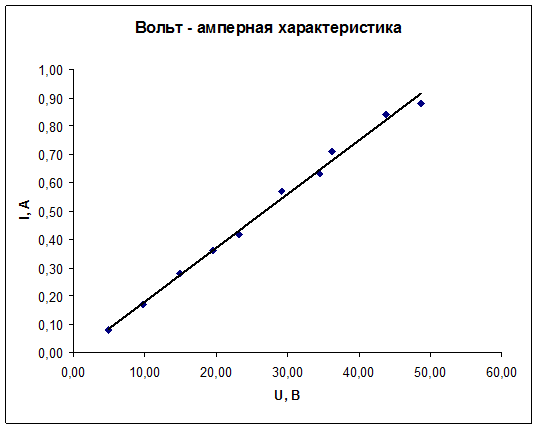
Задание 1.
Просчитать погрешность измерений и построить график ее распределения.
| Задание 1 | Задание 2 | Задание 3 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 4 | Задание 5 | Задание 6 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
| Задание 7 | Задание 8 | Задание 9 |
| № опыта | № опыта | № опыта |
| 10,3 | 13,55 | 12,65 |
| 10,277 | 13,527 | 12,627 |
| 10,325 | 13,575 | 12,675 |
| 10,285 | 13,535 | 12,635 |
| 10,297 | 13,547 | 12,647 |
| 10,31 | 13,56 | 12,66 |
| 10,35 | 13,6 | 12,7 |
| 10,35 | 13,6 | 12,7 |
| 10,29 | 13,54 | 12,64 |
| 10,38 | 13,63 | 12,73 |
| Задание 10 | Задание 11 | Задание 12 |
| № опыта | №опыта | № опыта |
| 26,65 | 24,65 | 18,3 |
| 26,627 | 24,627 | 18,277 |
| 26,675 | 24,675 | 18,325 |
| 26,635 | 24,635 | 18,285 |
| 26,647 | 24,647 | 18,297 |
| 26,66 | 24,66 | 18,31 |
| 26,7 | 24,7 | 18,35 |
| 26,7 | 24,7 | 18,35 |
| 26,64 | 24,64 | 18,29 |
| 26,73 | 24,73 | 18,38 |
| Задание 13 | Задание 14 | Задание 15 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 16 | Задание 17 | Задание 18 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
Задание 2.
Определить является ли 3-е измерение промахом.
Доброго дня, друзья.
Так как в после прошлого поста несколько человек заинтересовались моей таблицей, решил поделиться с вами еще одной своей таблицей.
Есть у нас лаборатория, и мы постоянно сверяем результаты наших исследований с результатами контрагентов. По нормативным документам нужно придерживаться определенных пределов расхождений в результатах.
Чтобы постоянно не открывать таблицу с значениями пределов воспроизведения, селал себе такую таблчку.
Чтобы было понятно, Результаты испытаний записываются в виде X±Δ
где X – результат анализа;
±Δ – погрешность результатов анализа, в нашем случае воспроизводимость..
То есть для первого испытания на медь для Пробы 1 результат у нас (H7) 1,30±0,12, а у контрагентов (ячейка C7) 4,81±0,12. А разница между результатами 4,81-1,30=3,51
Мы не входим в предел воспроизведения, ячейка M7 окрасилась в красный и сразу видим, что и один из нас хочет другого немного обмануть)) Если бы ячейка стала зеленой, то все норм.
Вот чтобы такие расчеты постоянно не делать, была создана данная таблица.
Данные вычисления могут быть полезны чтобы узнать и в других областях, где нужно узнать, вписываемся мы в пределы или нет.
Вот так выглядит рабочая таблица на странице Данные:
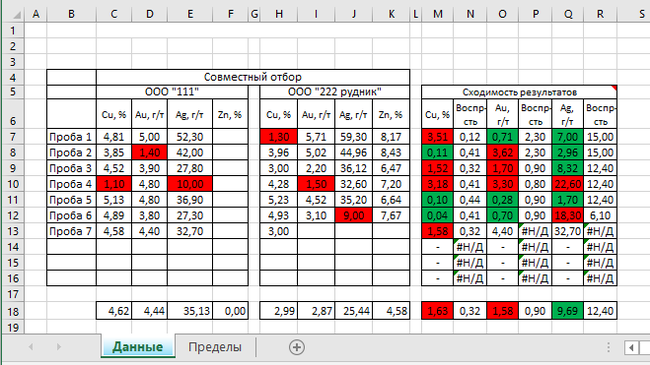
Левая табличка разделена на две чати — наши данные при отгрузке продукта и данные контрагента при приемке продкта. В правой табличке, соответственно производятся все вычисления и ячейка окрашивается в определенный цвет при выполнении и невыполнении условий.
Также имеется вторая табличка на странице Пределы, где расписаны пределы по диапазонам:
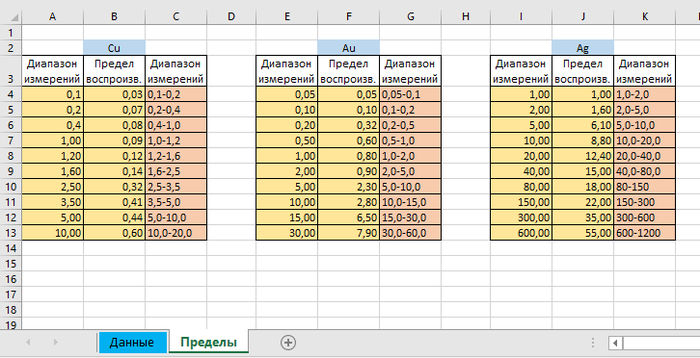
Вычисления производятся по желтым ячейкам, а розовые для информации. Первый и третий столбци по сути одно и то же.
Итак погнали. Что тут творится вообще ))
Буду объяснять для пробы 1, результаты Cu, ячейки M7 и N7. Остальное аналогично
Сперва вычислим раницу между нашими результатами испытаний. Нам нужны только абсолютные значения, так как разность может быть отрицательной. В M7 ввоим формулу:
В N7 вводим следующую формулу:
Тут остановимся, разберем формулу по частям:
Берем значение из ячейки H7 (это наш результат) и ищем на странице Пределы в массиве для Cu пределы значений, куда входит наш результат. Находим, что походит диапазон 1,2-1,6
Ищем номер строки значениея из ячейки H7 в таблице на листе Пределы. В предыдущей формуле мы нашли, что значение относится к пределам 1,2-1,6 и теперь легком можем найти номер строки, где он находится.
Так, номер строки нашли, и нам надо узнать значение погрешности или воспроизведения. Тут нам поможет функция ИНДЕКС, который возвращает значение на пересечении указанных номеров строки и столбца в массиве.Номер строки мы узнали из предыдущей формулы, номер столбца, где нужно искать результат укажем вручную:
Тут Пределы!$B$4:$C$13 это массив где мы делаем поиск
ПОИСКПОЗ(ВПР(Данные!H7;Пределы!$A$4:$C$13;3;ИСТИНА);Пределы!$C$4:$C$13;0) — номер строки.
И единичка в конце — номер столбца.
Теперь мы узнали, что наш результат должен быть 1,30±0,12
А разница результатов двух предприятий 3,51. Это означает, что мы не входим в предел воспроизведения.
Чтобы визуально сразу увидеть это, окрасим эту ячейку в красный. Делается это через меню Условное форматирование
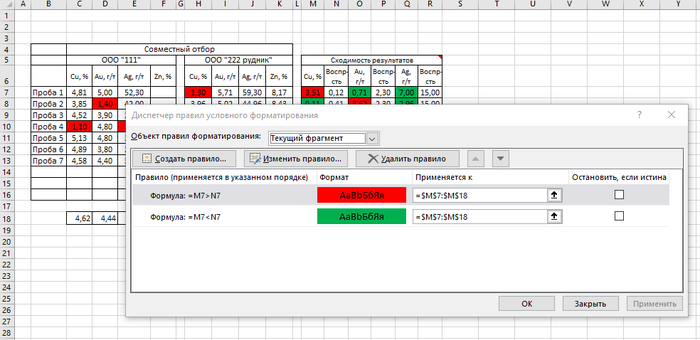
Выбираем в меню Условное форматирование — Правила выделения ячеек — Больше (Меньше) и задаем форматирование — окрасить ячейку в красный или зеленый цвет.
Также у нас есть ограничение в поставке продукта. Качество должно быть не менее определенного значения. Чтобы тоже сразу наглядно это увидеть, я через Условное форматирование выбрал пункт Между.. и задал нужные значения
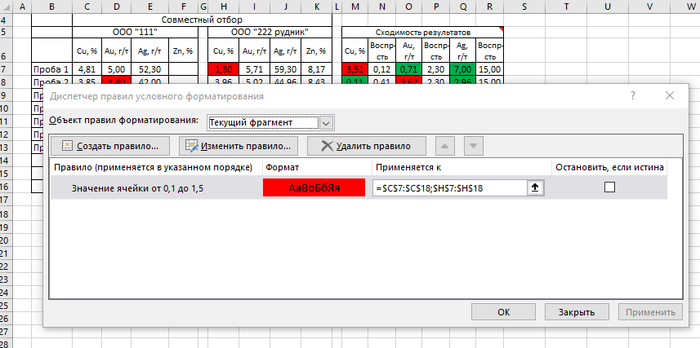
Если отгрузим товар с качеством по меди меньше 1,5%, то ячейка окрашивается в красный цвет.
Спасибо что дочитали, надеюсь кому-нибудь пригодится данная таблица или формулы.
С использованием встроенных функций
Excel расчет доверительного
интервала проводится следующим образом.
1) Рассчитывается среднее значение
=СРЗНАЧ(число1; число2;
…)
число1, число2,
… — аргументы, для которых вычисляется
среднее.
2) Рассчитывается стандартное отклонение
=СТАНДОТКЛОНП(число1; число2;
…)
число1, число2,
… — аргументы, для которых вычисляется
стандартное отклонение.
3) Рассчитывается абсолютная погрешность
=ДОВЕРИТ(альфа ;станд_откл;размер)
альфа —
уровень значимости используемый для
вычисления уровня надежности.
(![]() ,
,
т.е.
![]()
означает надежности![]() );
);
станд_откл
— стандартное отклонение, предполагается
известным;
размер — размер выборки.
Лабораторная работа
1
Тема: Обработка прямых
измерений в Excel (2 часа ).
Задание:
Обработать заданный набор экспериментальных
данных методом Стьюдента, построить
экспериментальные кривые методом
наименьших квадратов.
|
Пример |
Используемуе |
|
|
|

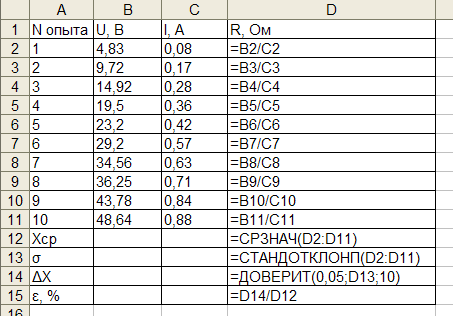
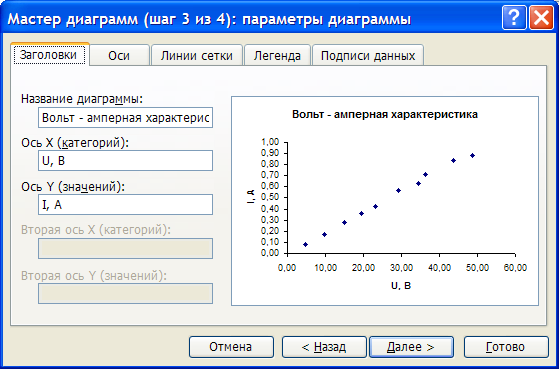
Для построения графика используем
мастер диаграмм.




Расчет
погрешности при косвенных измерениях
При измерении
величины косвенным методом предполагается,
что известна математическая модель
![]()
связывающая искомую
величину
![]()
с величинами
![]() ,
,
измеряемыми непосредственно. Далее
предполагается, выполнена обработка
всех прямых измерений, т. е. определены
доверительные интервалы для величин
![]() :
:
![]()
Погрешность величины у
определяется по формуле:

где
![]() .
.
Расчет косвенной
погрешности в Maple
Рассмотрим расчет погрешности на примере
функции одной переменной
![]() ,
,
где
![]()

Таким образом, найден доверительный
интервал величины
![]() .
.
В случае, если определяемая в косвенном
измерении величина, является функцией
нескольких переменных, рекомендуем:
-
вычисление погрешности оформить в виде
процедуры
>dy:=proc(y, dx) ……код
процедуры
…… end proc
Код процедуры учащийся должен составить
самостоятельно на основе примера,
рассмотренного выше.
-
параметр dx считать массивом из N
переменных -
для определения списка аргументов и
их количества величины y
можно использовать операторы op() и
nops():

-
Лабораторная работа 2 Тема: Обработка косвенных измерений в Maple (4 часа).
Задание:
Написать программу нахождения погрешности
косвенного измерения в среде Maple.
Выполнение задания
1. Ввести выборку значений измеряемых
величин в матричном виде
2. Определить размерность выборки
3. Задать уровень значимости и определить
степень доверия:
4. Вычислить среднее значение выборки
измеряемой величины:
a) с помощью операций
суммирования
б) с помощью встроенных функций
5. Вычислить значения среднеквадратичного
отклонения.
а) с помощью операций суммирования
,
в) с помощью встроенных функций
6. Вычислить доверительный интервал:
а) Задать коэффициент Стьюдента для
данных размерности выборки и степени
доверия:
.
б) Вычислить абсолютную случайную
погрешность
.
в) Вычислить верхнюю и нижнюю границы
доверительного интервала.
.
7. Учесть приборные погрешности:
а) Задать приборные погрешности
.
б) Вычислить абсолютную случайную
погрешность с учетом приборных
погрешностей
.
8. Представить результат:
а) Абсолютная погрешность:
,
б) Относительная погрешность:
,
в) Верхняя и нижняя границы доверительного
интервала.
.
Примечание. Вычисления провести:
а) в обычном виде,
(См. Дов_инт_01)
б) с помощью операций суммирования,
(См. Дов_инт_02)
в) с помощью встроенных функций.
(См. Дов_инт_03)
2. Вычисление косвенных погрешностей
Выполнение задания
1. Провести аналитические вычисления:
а) Ввести выражение для исследуемой
функции:
,
б) Получить выражение для среднего
значения величины исследуемой функции:
,
в) Получить выражение косвенной
погрешности исследуемой функции в общем
виде и для значения :
,
,
1. Провести численные вычисления:
а) Ввести численные значения постоянных,
б) Ввести средние значения и доверительные
интервалы переменных,
в) Вычислить относительные погрешности
переменных,
г) Вычислить среднее значение исследуемой
функции:
,
г) Вычислить косвенную погрешность
(абсолютную погрешность) исследуемой
функции
,
г) Вычислить относительную погрешность
исследуемой функции
,
в) Вычислить верхнюю и нижнюю границы
доверительного интервала исследуемой
функции:
.
(См. Косв_погр).
3. Построение графиков. Полиномиальная
регрессия
Выполнение задания
1. Ввод выборок значений величин :
2. Вычислить верхнюю и нижнюю границы
доверительного величины Y:
.
3. Полиномиальная регрессия:
а) Задать степень полинома k:
б) Задать число точек данных:
.
в) Задать регрессионную зависимость:
.
г) Определить коэффициенты уравнения
регрессии
:
,
.
4. Построить графики:
а) точечных график данных,
б) кривую регрессии,
в) доверительные интервалы величины Y.
(См. Постр_граф).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Примечание: Следующие процедуры применяются к Office 2013 и более поздним версиям. Ищете инструкции по Office 2010?
Добавление и удаление отрезков ошибок
-
Щелкните в любом месте диаграммы.
-
Нажмите кнопку «Элементы диаграммы
 рядом с диаграммой, а затем установите флажок «Панели ошибок «. (Снимите флажок, чтобы удалить отрезки ошибок.)
рядом с диаграммой, а затем установите флажок «Панели ошибок «. (Снимите флажок, чтобы удалить отрезки ошибок.) -
Чтобы изменить отображаемую сумму ошибки, щелкните стрелку рядом с полосами ошибок и выберите нужный вариант.
-
Выберите предопределенный параметр планок погрешностей, такой как Стандартная погрешность, Относительное отклонение или Стандартное отклонение.
-
Выберите пункт Дополнительные параметры, чтобы задать собственные величины пределов погрешностей, а затем выберите нужные параметры в разделе Вертикальный предел погрешностей или Горизонтальный предел погрешностей. Здесь также можно изменить направление и стиль концов пределов погрешностей или создать собственные пределы погрешностей.
-
 рядом с диаграммой, а затем установите флажок «Панели ошибок «. (Снимите флажок, чтобы удалить отрезки ошибок.)
рядом с диаграммой, а затем установите флажок «Панели ошибок «. (Снимите флажок, чтобы удалить отрезки ошибок.)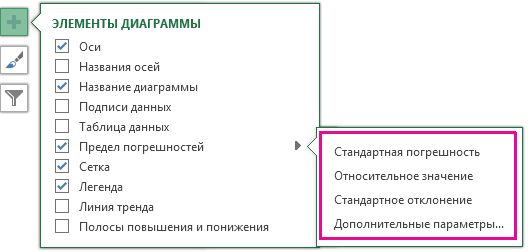
Примечание: Направление планок погрешностей зависит от типа диаграммы. Для точечных диаграмм могут отображаются и горизонтальные, и вертикальные планки погрешностей. Чтобы удалить планки погрешностей, выделите их и нажмите клавишу DELETE.
Формулы для расчета величины погрешности
Пользователи часто спрашивают, как в Excel вычисляется величина погрешности. Для вычисления стандартной погрешности и стандартного отклонения, которые отображаются на диаграмме, используются указанные ниже формулы.
|
Параметр |
Используемое уравнение |
|---|---|
|
Стандартная погрешность |
Где s = номер ряда; i = номер точки в ряду s; m = номер ряда для точки y на диаграмме; n = число точек в каждом ряду; yis = значение данных ряда s и i-й точки; ny = суммарное число значений данных во всех рядах. |
|
Стандартное отклонение |
Где s = номер ряда; i = номер точки в ряду s; m = номер ряда для точки y на диаграмме; n = число точек в каждом ряду; yis = значение данных ряда s и i-й точки; ny = суммарное число значений данных во всех рядах; M = среднее арифметическое. |
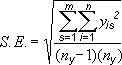
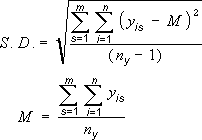
Добавление, изменение и удаление отрезков ошибок на диаграмме в Office 2010
В Excel можно отобразить столбцы ошибок, использующие стандартную сумму ошибок, процент от значения (5 %) или стандартное отклонение.
Стандартные ошибки и стандартное отклонение используют следующие уравнения для вычисления сумм ошибок, отображаемых на диаграмме.
|
Параметр |
Используемое уравнение |
Где |
|---|---|---|
|
Стандартная погрешность |
|
s = номер ряда; i = номер точки в ряду s; m = номер ряда для точки y на диаграмме; n = число точек в каждом ряду; yis = значение данных ряда s и i-й точки; ny = суммарное число значений данных во всех рядах. |
|
Стандартное отклонение |
|
s = номер ряда; i = номер точки в ряду s; m = номер ряда для точки y на диаграмме; n = число точек в каждом ряду; yis = значение данных ряда s и i-й точки; ny = суммарное число значений данных во всех рядах; M = среднее арифметическое. |
-
На двухмерной диаграмме, линейчатой диаграмме, столбце, линии, хи (точечной) или пузырьковой диаграмме выполните одно из следующих действий:
-
Чтобы добавить гистограммы во все ряды данных на диаграмме, щелкните область диаграммы.
-
Чтобы добавить панели ошибок в выбранную точку данных или ряд данных, щелкните нужные точки данных или ряды данных или выполните следующие действия, чтобы выбрать ее из списка элементов диаграммы:
-
Щелкните в любом месте диаграммы.
Будут отображены средства Работа с диаграммами, включающие вкладки Конструктор, Макет и Формат.
-
На вкладке Формат в группе Текущий фрагмент щелкните стрелку рядом с полем Элементы диаграммы, а затем выберите нужный элемент диаграммы.
-
-
-
На вкладке «Макет » в группе «Анализ » щелкните » Панели ошибок».
-
Выполните одно из указанных ниже действий.
-
Выберите предопределенный параметр панели ошибок, например «Панели ошибок со стандартной ошибкой«, «Отрезки ошибок с процентом» или «Отрезки ошибок» со стандартным отклонением.
-
Щелкните «Дополнительные параметры панели ошибок», а затем в разделе «Вертикальные полосы ошибок» или «Горизонтальные панели ошибок» выберите нужные параметры отображения и количества ошибок.
Примечание: Направление гистограммы зависит от типа диаграммы. Для точечных диаграмм по умолчанию отображаются горизонтальные и вертикальные полосы ошибок. Вы можете удалить один из этих столбцов ошибок, выбрав их и нажав клавишу DELETE.
-

-
На двухстрочной области, линейчатой диаграмме, столбце, линии, хи (точечной) или пузырьковой диаграмме щелкните отрезки ошибок, точку данных или ряд данных с полосами ошибок, которые вы хотите изменить, или выполните следующие действия, чтобы выбрать их из списка элементов диаграммы:
-
Щелкните в любом месте диаграммы.
Будут отображены средства Работа с диаграммами, включающие вкладки Конструктор, Макет и Формат.
-
На вкладке Формат в группе Текущий фрагмент щелкните стрелку рядом с полем Элементы диаграммы, а затем выберите нужный элемент диаграммы.
-
-
На вкладке «Макет » в группе «Анализ » щелкните » Панели ошибок» и выберите пункт «Дополнительные параметры панели ошибок».
-
В разделе «Отображение» щелкните направление и стиль конца панели ошибок, которые вы хотите использовать.
-
На двухстрочной области, линейчатой диаграмме, столбце, линии, хи (точечной) или пузырьковой диаграмме щелкните отрезки ошибок, точку данных или ряд данных с полосами ошибок, которые вы хотите изменить, или выполните следующие действия, чтобы выбрать их из списка элементов диаграммы:
-
Щелкните в любом месте диаграммы.
Будут отображены средства Работа с диаграммами, включающие вкладки Конструктор, Макет и Формат.
-
На вкладке Формат в группе Текущий фрагмент щелкните стрелку рядом с полем Элементы диаграммы, а затем выберите нужный элемент диаграммы.
-
-
На вкладке «Макет » в группе «Анализ » щелкните » Панели ошибок» и выберите пункт «Дополнительные параметры панели ошибок».
-
В разделе «Сумма ошибки» выполните одно или несколько из следующих действий:
-
Чтобы использовать другой метод для определения количества ошибок, щелкните нужный метод и укажите сумму ошибки.
-
Чтобы определить количество ошибок с помощью пользовательских значений, нажмите кнопку «Пользовательский» и выполните следующие действия.
-
Нажмите кнопку «Указать значение».
-
В полях «Положительное значение ошибки» и «Отрицательное значение ошибки» укажите диапазон листа, который вы хотите использовать в качестве значений количества ошибок, или введите значения, которые вы хотите использовать, разделив их запятыми. Например, введите 0.4, 0.3, 0.8.
Совет: Чтобы указать диапазон листа, можно нажать кнопку «Свернуть
«, а затем выбрать данные, которые нужно использовать на листе. Снова нажмите кнопку «Свернуть диалоговое окно», чтобы вернуться к диалоговом окне.Примечание: В Microsoft Office Word 2007 или Microsoft Office PowerPoint 2007 диалоговом окне «Настраиваемые панели ошибок» кнопка «Свернуть диалоговое окно» может не отображаться, а введите только значения количества ошибок, которые вы хотите использовать.
-
-
 «, а затем выбрать данные, которые нужно использовать на листе. Снова нажмите кнопку «Свернуть диалоговое окно», чтобы вернуться к диалоговом окне.
«, а затем выбрать данные, которые нужно использовать на листе. Снова нажмите кнопку «Свернуть диалоговое окно», чтобы вернуться к диалоговом окне.-
На двухстрочной области, панели, столбце, линии, хи (точечной) или пузырьковой диаграмме щелкните гистограмму, точку данных или ряд данных с отрезками ошибок, которые нужно удалить, или выполните следующие действия, чтобы выбрать их из списка элементов диаграммы:
-
Щелкните в любом месте диаграммы.
Будут отображены средства Работа с диаграммами, включающие вкладки Конструктор, Макет и Формат.
-
На вкладке Формат в группе Текущий фрагмент щелкните стрелку рядом с полем Элементы диаграммы, а затем выберите нужный элемент диаграммы.
-
-
Выполните одно из указанных ниже действий.
-
На вкладке « Макет» в группе «Анализ » щелкните » Панели ошибок» и выберите пункт » Нет».
-
Нажмите клавишу DELETE.
-
Совет: Вы можете удалить полосы ошибок сразу после их добавления на диаграмму, нажав кнопку «Отменить» на панели быстрого доступа или нажав клавиши CTRL+Z.
Выполните одно из следующих действий:
Выражение погрешности в виде процентной доли, стандартного отклонения или стандартной ошибки
-
На диаграмме выберите ряд данных, к которому нужно добавить панели ошибок.
Например, щелкните одну из линий графика. Будут выделены все маркер данных этого ряд данных.
-
На вкладке «Деиговка диаграммыn» нажмите кнопку «Добавить элемент диаграммы».
-
Наведите указатель мыши на панели ошибок и выполните одно из следующих действий:
|
Команда |
Действие |
|---|---|
|
Стандартная погрешность |
Применение стандартной ошибки с использованием следующей формулы:
s — номер ряда; |
|
Процентный |
Применение процентной доли значения к каждой точке данных в ряду данных |
|
Стандартное отклонение |
Применение кратного стандартного отклонения с использованием следующей формулы:
s — номер ряда; |
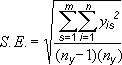
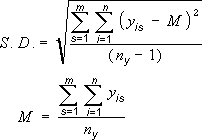
Выражение погрешностей в виде пользовательских значений
-
На диаграмме выберите ряд данных, к которому нужно добавить панели ошибок.
-
На вкладке «Конструктор диаграммы » нажмите кнопку «Добавить элемент диаграммы» и выберите пункт «Дополнительные параметры гистограммы».
-
В области «Формат гистограмм» на вкладке «Параметры панели ошибок» в разделе «Сумма ошибки» нажмите кнопку «Настраиваемое» и выберите команду «Указать значение».
-
В разделе Величина погрешности выберите пункт Настраиваемая, а затем — пункт Укажите значение.
-
В полях Положительное значение ошибки и Отрицательное значение ошибки введите нужные значения для каждой точки данных, разделенные точкой с запятой (например, 0,4; 0,3; 0,8), и нажмите кнопку ОК.
Примечание: Значения погрешностей можно также задать в виде диапазона ячеек из той же книги Excel. Чтобы указать диапазон ячеек, в диалоговом окне Настраиваемые планки погрешностей очистите содержимое поля Положительное значение ошибки или Отрицательное значение ошибки и укажите нужный диапазон ячеек.
Добавление полос повышения и понижения
-
На диаграмме выберите ряд данных, в который нужно добавить отрезки вверх и вниз.
-
На вкладке «Конструктор диаграмм » нажмите кнопку «Добавить элемент диаграммы», наведите указатель мыши на полосы вверх и вниз, а затем щелкните «Стрелки вверх /вниз».
В зависимости от типа диаграммы, некоторые параметры могут быть недоступны.
Содержание
- 0.1 Добавление планки погрешности к ряду данных
- 0.2 Нестандартное использование планок погрешностей в Excel
- 1 Настройка округления как на экране
- 1.1 Включение настройки точности как на экране в современных версиях Excel
- 1.2 Включение настройки точности как на экране в Excel 2007 и Excel 2003
- 1.3 Помогла ли вам эта статья?
- 2 Как же быть?
- 2.1 Какими бывают погрешности
- 2.2 Когда это бывает?
- 3 Наносим линии погрешностей
Ряды данных диаграмм могут включать планки погрешностей, которые предоставляют дополнительную информацию о данных. К примеру, вы можете использовать планки погрешностей для отображения количества ошибок или неопределенностей для каждой точки ряда данных.
На рисунке отображен график Excel с планками погрешностей, которые указывают на диапазон ошибок для каждой точки. В данном случае погрешность основана на процентах – плюс/минус 10 процентов. Планка для первой точки ряда данных (значение 100) находится в пределах от 90 до 110.
Добавление планки погрешности к ряду данных
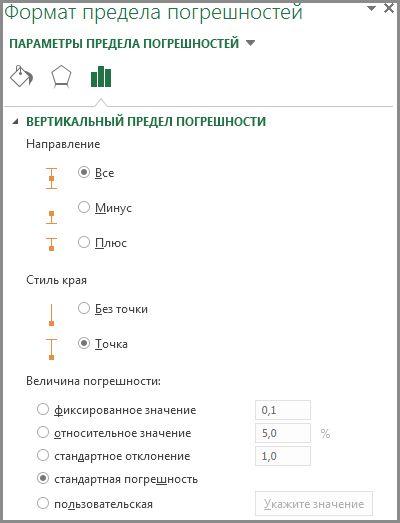
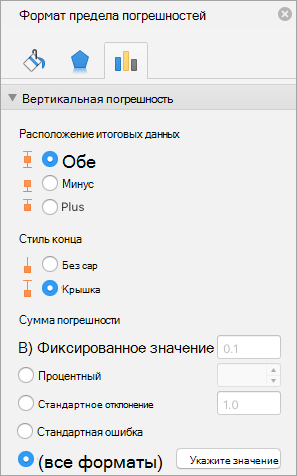
Чтобы добавить планку погрешности, выделите ряд данных на диаграмме, перейдите по вкладке Работа с диаграммами –> Конструктор в группу Макеты диаграмм, щелкните по кнопке Добавить элемент диаграммы -> Предел погрешностей –> Дополнительные параметры предела погрешностей. К ряду данных будут добавлены планки погрешностей с фиксированным значением (по умолчанию равно 1), слева экрана появится диалоговое окно Формат предела погрешностей.
Если у вас точечная или пузырьковая диаграмма, вы можете определять значения планок погрешностей как для вертикальных, так и для горизонтальных пределов. Чтобы переключиться между ними, необходимо в диалоговом окне Формат предела погрешностей щелкнуть по треугольнику рядом с полем Параметры предела погрешностей и выбрать соответствующий.
Сперва необходимо определиться с направлением планок погрешностей: выше, ниже или в обе стороны от точки ряда данных. Для горизонтальных пределов погрешностей доступны те же опции, только в горизонтальном направлении. Далее определяемся со стилем края, будет ли она ограничиваться чертой на конце планки, либо нет. И выбираем одну из пяти вариантов величины погрешности:
Фиксированное значение: Планка погрешности будет смещена на, указанную вами, фиксированную величину от точки ряда данных. Каждая планка будет одинаковой высоты (или ширины для горизонтальных планок).
Относительное значение: Планка погрешности будет смещена от точки ряда данных на заданных процент от значения точки. К примеру, если вы задали относительное значение равным 5%, а точка ряда данных равна 100, предел погрешности будет находиться в диапазоне от 95 до 105. Т.е. в зависимости от значения точки ряда данных, предел погрешности будет различаться.
Стандартное отклонение: Планки погрешностей будут центрированы по невидимой линии, которая представляет среднее значение ряда данных, выше или ниже на то значение, которое было указано в поле. Для этой опции величина планки погрешностей не зависит от значения точки ряда данных и всегда параллельна оси.
Стандартная погрешность: Размер планки погрешности задается в единицах среднеквадратичной ошибки, которую Excel вычисляет для ряда данных.
Пользовательская: Планки погрешностей определяются значениями диапазона данных, который вы указали. Обычно они содержат формулы.
В Excel 2013 пределы погрешностей можно добавить еще одним способом. Выберите ряд данных и щелкните по иконке справа от диаграммы в виде плюсика. В появившемся справа, выпадающем меню Элементы диаграммы, поставьте галочку напротив поля Предел погрешностей. При необходимости можете задать уточняющие параметры, нажав по стрелке рядом с полем.
Нестандартное использование планок погрешностей в Excel
На самом деле, за все свое знакомство с Excel, я ни разу не воспользовался планками погрешностей по их прямому назначению. Более того, ни разу не встречал людей, которые бы ими пользовались. Если уж дальше развивать эту тему, скажу, что их используют как угодно, но только не так, как задумывалось изначально.
Наиболее распространенный способ использования планок погрешностей в Excel – в виде целевых значений. К примеру, у вас есть пять KPI (показателей эффективности) со своими целевыми значениями и вы хотите отобразить текущее и целевое значение на одном графике. Строим гистограмму с двумя рядами данных.
Меняем тип диаграммы для целевого ряда данных на точечный, чтобы была возможность строить горизонтальные планки погрешностей. Для этого щелкаем правой кнопкой по целевому ряду данных, из выпадающего меню выбираем Изменить тип диаграммы для ряда. В появившемся диалоговом окне, меняем тип диаграммы на точечный. Далее к нему добавляем планки погрешностей, любым из описанных выше способов. Удаляем вертикальные пределы. Форматируем планку и точку ряда данных по нашему усмотрению. Получаем диаграмму с пятью фактическими и целевыми значениями.
Данный подход применялся в одной из предыдущих статей, когда мы с вами распределяли показатели на дашборде.
Скачать файл с примерами использования планок погрешностей.
Производя различные вычисления в Excel, пользователи не всегда задумываются о том, что значения, выводящиеся в ячейках, иногда не совпадают с теми, которые программа использует для расчетов. Особенно это касается дробных величин. Например, если у вас установлено числовое форматирование, которое выводит числа с двумя десятичными знаками, то это ещё не значит, что Эксель так данные и считает. Нет, по умолчанию эта программа производит подсчет до 14 знаков после запятой, даже если в ячейку выводится всего два знака. Данный факт иногда может привести к неприятным последствиям. Для решения этой проблемы следует установить настройку точности округления как на экране.
Настройка округления как на экране
Но прежде, чем производить изменение настройки, нужно выяснить, действительно ли вам нужно включать точность как на экране. Ведь в некоторых случаях, когда используется большое количество чисел с десятичными знаками, при расчете возможен кумулятивный эффект, что снизит общую точность вычислений. Поэтому без лишней надобности этой настройкой лучше не злоупотреблять.
Включать точность как на экране, нужно в ситуациях следующего плана. Например, у вас стоит задача сложить два числа 4,41 и 4,34, но обязательным условиям является то, чтобы на листе отображался только один десятичный знак после запятой. После того, как мы произвели соответствующее форматирование ячеек, на листе стали отображаться значения 4,4 и 4,3, но при их сложении программа выводит в качестве результата в ячейку не число 4,7, а значение 4,8.
Это как раз связано с тем, что реально для расчета Эксель продолжает брать числа 4,41 и 4,34. После проведения вычисления получается результат 4,75. Но, так как мы задали в форматировании отображение чисел только с одним десятичным знаком, то производится округление и в ячейку выводится число 4,8. Поэтому создается видимость того, что программа допустила ошибку (хотя это и не так). Но на распечатанном листе такое выражение 4,4+4,3=8,8 будет ошибкой. Поэтому в данном случае вполне рациональным выходом будет включить настройку точности как на экране. Тогда Эксель будет производить расчет не учитывая те числа, которые программа держит в памяти, а согласно отображаемым в ячейке значениям.

Для того, чтобы узнать настоящее значение числа, которое берет для расчета Эксель, нужно выделить ячейку, где оно содержится. После этого в строке формул отобразится его значение, которое сохраняется в памяти Excel.

Урок: Округление чисел в Excel
Включение настройки точности как на экране в современных версиях Excel
Теперь давайте выясним, как включить точность как на экране. Сначала рассмотрим, как это сделать на примере программы Microsoft Excel 2010 и ее более поздних версий. У них этот компонент включается одинаково. А потом узнаем, как запустить точность как на экране в Excel 2007 и в Excel 2003.
- Перемещаемся во вкладку «Файл».
- В открывшемся окне кликаем по кнопке «Параметры».
- Запускается дополнительное окно параметров. Перемещаемся в нем в раздел «Дополнительно», наименование которого значится в перечне в левой части окна.
- После того, как перешли в раздел «Дополнительно» перемещаемся в правую часть окна, в которой расположены различные настройки программы. Находим блок настроек «При пересчете этой книги». Устанавливаем галочку около параметра «Задать точность как на экране».
- После этого появляется диалоговое окно, в котором говорится, что точность вычислений будет понижена. Жмем на кнопку «OK».

После этого в программе Excel 2010 и выше будет включен режим «точность как на экране».
Для отключения данного режима нужно снять галочку в окне параметров около настройки «Задать точность как на экране», потом щелкнуть по кнопке «OK» внизу окна.
Включение настройки точности как на экране в Excel 2007 и Excel 2003
Теперь давайте вкратце рассмотрим, как включается режим точности как на экране в Excel 2007 и в Excel 2003. Данные версии хотя и считаются уже устаревшими, но, тем не менее, их используют относительно немало пользователей.
Прежде всего, рассмотрим, как включить режим в Excel 2007.
- Жмем на символ Microsoft Office в левом верхнем углу окна. В появившемся списке выбираем пункт «Параметры Excel».
- В открывшемся окне выбираем пункт «Дополнительно». В правой части окна в группе настроек «При пересчете этой книги» устанавливаем галочку около параметра «Задать точность как на экране».
Режим точности как на экране будет включен.
В версии Excel 2003 процедура включения нужного нам режима отличается ещё больше.
- В горизонтальном меню кликаем по пункту «Сервис». В открывшемся списке выбираем позицию «Параметры».
- Запускается окно параметров. В нем переходим во вкладку «Вычисления». Далее устанавливаем галочку около пункта «Точность как на экране» и жмем на кнопку «OK» внизу окна.
Как видим, установить режим точности как на экране в Excel довольно несложно вне зависимости от версии программы. Главное определить, стоит ли в конкретном случае запускать данный режим или все-таки нет.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Некоторые статистические данные могут отображаться на диаграммах, даже без создания отдельных рядов. Многие (но не все) диаграммы позволяют дополнить ряд (ряды) данных полосами погрешностей. Полосы погрешностей отображают дополнительную информацию о данных. Например, их можно использовать для изображения ошибки или неопределенности, связанной с каждой точкой данных.
Например (рис. 1) полосы погрешностей могут изображать диапазоны ошибок измерения каждой точки данных. В этом примере полосы погрешностей выражены в процентах: значение плюс-минус 10% от значения.
Рис. 1. График с полосами погрешностей, выраженных в процентах
Скачать заметку в формате Word или pdf, примеры в формате Excel2013 или Excel2007
Полосы погрешностей поддерживаются рядами следующих типов двухмерных диаграмм:
- диаграммы с областями;
- линейчатые диаграммы;
- гистограммы;
- графики;
- точечные диаграммы;
- пузырьковые диаграммы.
Поскольку точечные и пузырьковые диаграммы имеют две оси значений, полосы погрешностей в них можно выводить как для оси х, так и для оси у (а также для обеих осей).
Добавление полос погрешностей в ряд
Для добавления полос погрешностей выделите ряд данных диаграммы, и пройдите по меню Конструктор – Добавить элемент диаграммы – Предел погрешностей и выберите одну из опций: Стандартная погрешность, Процент или Стандартное отклонение (рис. 2). Если выбрать опцию Дополнительные параметры предела погрешностей, откроется диалоговое окно Формат предела погрешностей (рис. 3). В этом окне, помимо трех упомянутых, можно также задать еще две опции предела погрешностей: Фиксированное значение и пользовательское. На рисунке 3 показ выбор, соответствующий пределу погрешностей, изображенному на рис. 1 – относительное значение 10%.
Рис. 2. Добавление предела погрешностей
Рис. 3. Формат предела погрешностей
Остановимся подробнее на формате полос погрешностей. Полосы могут выводиться над точкой, под точкой или в обоих направлениях от точки данных (область Направление меню Формат предела погрешностей, см. рис. 3). Окончание полосы может быть в виде планки или без оной.
Возможно использование пяти типов предела погрешностей:
- Фиксированное значение. Полосы погрешностей откладываются от каждой точки данных на заданную пользователем фиксированную величину. Все полосы погрешностей имеют одинаковую высоту. Обратите внимание: ошибка выражается не в процентах от значения, а в единицах самого значения (по оси y).
- Относительное значение. Полосы погрешностей откладываются от каждой точки данных на величину, определяемую в процентах от значения точки. Например, если задать в поле ввода значение 5%, а значение точки равно 100, то полоса погрешности будет выведена от 95 до 105. Таким образом, длина полосы погрешности зависит от значения точки.
- Стандартное отклонение. Полосы погрешностей откладываются на величину стандартного отклонения (другое название — среднеквадратическое отклонение), равного корню от суммы квадратов отклонений, деленному на квадратный корень от объема выборки. Для обозначения стандартного отклонения обычно используется символ σ (сигма):где – среднее значение по выборке. Все полосы погрешностей имеют одинаковую высоту и откладываются от среднего значения вверх и вниз на заданное (не обязательно целое) число σ. Обратите внимание: расположение полос погрешностей одинаковое для всех точек на диаграмме, поскольку они откладываются не от конкретной точки, а от среднего всех точек. Пример ниже.
- Стандартная погрешность. Как сообщает справка Excel, полосы погрешностей откладываются от каждой точки на величину: , где ny – число значений в ряду. При этом не сообщается, рассчитанные значения откладываются по обе стороны от точки, или вычисленное значение нужно поделить пополам и только половину отложить в каждую сторону от точки. У меня, кстати, не получилось подтвердить приведенную формулу. Более того, при уменьшении целого ряда значений у, стандартная погрешность только росла… Обратите внимание: размер полос погрешностей одинаковый для всех точек, а вот откладываются полосы погрешностей от каждой отдельной точки (а не от среднего значения по всем точкам)
- Пользовательская. Полосы погрешностей определяются значениями, хранящимися в заданном пользователем диапазоне. Обычно диапазон содержит формулы. Об этом подробнее ниже.
Метод стандартного отклонения проиллюстрирован на рис. 3. Здесь на точечную диаграмму нанесена полоса погрешностей по оси у. В отличие от других типов полос погрешностей полоса типа стандартное отклонение выводится относительно среднего арифметического значения всех точек данных. В примере, показанном на рис. 3, среднее ста точек равно 40, а стандартное отклонение — 10. Поэтому полоса погрешностей выводится вокруг среднего плюс-минус отклонение: 40±10. Благодаря полосе погрешности из диаграммы ясно видно, что большинство точек данных (теоретически 68,2%) отличаются от среднего не более чем на величину стандартного отклонения σ.
На рис. 4 показана точечная диаграмма с полосами погрешностей как по оси у, так и по оси х. Оба набора полос погрешностей выводят для каждого значения соответствующие ошибки — плюс-минус 10%. Полосы погрешностей по осям х и у независимы друг от друга. Для них могут быть установлены разные параметры.
Рис. 4. Точечная диаграмма с полосами погрешностей по осям х и у
Форматирование и модификация полос погрешностей
Для изменения формата полос погрешностей дважды щелкните на любой из них. Появится диалоговое окно Формат предела погрешностей. Во вкладке Заливка и границы можно изменить практически любые параметры планки погрешности (рис. 5).
Рис. 5. Вкладке Заливка и границы диалогового окна Формат предела погрешностей
Делая активной горизонтальную или вертикальную планку погрешности можно в диалоговом окне Формат предела погрешностей выбирать вкладку для параметров X-погрешности или Y-погрешности. В диаграммах, отличных от точечных и пузырьковых, вкладка Х-погрешности отсутствует.
Пользовательские полосы погрешностей
Переключатель пользовательская применяется для создания полос погрешностей, величина которых задастся в ячейках рабочего листа. В большинстве случаев сначала нужно создать формулы, вычисляющие погрешности на основе исходных данных. Затем ячейки с формулами должны быть определены как диапазон (диапазоны), используемый полосами погрешностей.
На рис. 6 показан график, отображающий объемы ежемесячных продаж. Полосы погрешностей изображают изменение объемов продаж по сравнению с предыдущим годом. Если полоса погрешности расположена над точкой данных, то в этом месяце прошлого года объем продаж был выше, а если под точкой — ниже. Такое использование полос погрешностей фактически является альтернативой выводу дополнительного ряда данных.
Рис. 6. Пределы погрешностей изображают объемы продаж в эти же месяцы прошлого года
Столбец D содержит простую формулу, вычисляющую разность данных столбцов В и С. Диапазон D2:D13 используется в качестве диапазона «+», ассоциированного с переключателем пользовательская. Выбран режим вывода Плюс.
Для построения диаграммы выделяем диапазон А1:В13 и вставляем стандартный график с маркерами. Далее добавляем предел погрешности (как на рис. 2). В качестве величины погрешности устанавливаем тип Пользовательская. Жамкаем кнопку Укажите значения, и для Положительное значение ошибки задаем диапазон D2:D13. Поле Отрицательное значение ошибки оставляем пустым.
Заметка написана с использованием материалов книги Джона Уокенбаха Диаграммы в Excel; книга была написана для Excel2003; более поздние издания мне не известны.
В современных версиях наряду с термином полосы погрешностей используются термины планки погрешности и пределы погрешностей. Я буду использовать все эти термины как синонимы.
Недавно я впервые приобрел для дома лицензионную версию MS Excel. Во-первых, очень хотелось поюзать новинки от MS. Во-вторых, MS предлагает вполне бюджетный вариант – Microsoft Office Home and Student 2013 по цене от 2800 руб. (есть Excel, Word, PowerPoint, OneNote + 7ГБ места в облаке!). Так что изложение и иллюстрации основаны на Excel2013.
Такая структура данных была сформирована путем задания в ячейках А1:А100 формулы =НОРМ.ОБР(СЛЧИС();40;10), где СЛЧИС() – вероятность от 0 до 1, 40 –среднее, 10 – стандартное отклонение
Как построить график в Excel с учетом погрешностей? Подобная задача нередко возникает у студента при обработке результатов лабораторных работ. Результаты представляют собой, как правило, два массива данных (в общем случае Х и Y). Пусть, для примера, имеется следующая экспериментальная зависимость:
| Х | 2,0 | 4,0 | 5,0 | 7,0 | 9,0 | 11,0 | 15,0 |
| У | 3,2 | 4,2 | 9,0 | 14,8 | 23,0 | 15,2 | 12,8 |
Требуется представить эту зависимость Y от Х графически. Получится примерно то, что представлено на рисунке.
Например, в ходе лабораторной работы студент измерял зависимость силы тока в одной из ветвей электрической цепи (в Амперах) от напряжения на том или ином ее элементе (в Вольтах). Необходимо отложить данные на графике с учетом погрешностей.
Надо сказать, что сделать построение вручную, как ни парадоксально, в данном случае даже немного проще, чем с использованием, казалось бы, такой мощной и удобной программы, как Excel. Дело в том, что, на самом деле, график, приведенный на предыдущем рисунке… построен неверно.
Почему? Ведь, вроде бы, ничего сложного нет. Нажимаем в Excel кнопку «Мастер диаграмм», Выбираем тип диаграммы – точечная. Затем нажимаем «Далее», задаем массивы для X и Y, затем опять «Далее»… — и вскоре получится то, что приведено на предыдущем рисунке.
Вроде бы, все правильно. Да только график построен строго по точкам. Видно, что зависимость немонотонная, с достаточно острым максимумом – что не всегда имеет место в реальности. Ибо в реальности подавляющее большинство зависимостей могут быть более плавными.
Конечно, здесь надо смотреть, какие конкретно показатели анализируются. Если это, к примеру, динамика биржевого курса ценных бумаг; или – динамика поступления платежей от покупателей, равно как и другой аналогичный экономический показатель, то, конечно, можно с уверенностью сказать, что график вовсе не обязан быть плавным. В самом деле, очень многие экономические показатели меняются, как правило, скачкообразно.
А вот если анализировать данные, скажем, из области психологии, физики, биологии (отчасти), а также из ряда иных отраслей, то там графики экспериментальных зависимостей, за немногим исключением, зачастую являются достаточно плавными (хотя, все относительно, конечно).
Но, вроде бы, и здесь нет никаких проблем: следует провести линию тренда, которых Excel предлагает несколько типов. Так, можно выбрать линейный, степенной, экспоненциальный и т.д. тренд.
Можно… На примере выбранных нами данных, выбор показал, что наиболее близким для выбранной совокупности данных является параболический тренд. Отобразим его на рисунке.
Вроде бы, то, что проведено черной линией (тренд), уже гораздо ближе к истине. Правда, совсем ненамного. Фактически, проведенный тренд достаточно хорошо соответствует исходным данным только для 3, 4 и 7-й точек. Для остальных точек имеются существенные расхождения, причем ошибка доходит до 80%.
Ясно, что построенный тренд, в силу его высокой погрешности, в данном случае никак нельзя принять в качестве качественного графика, отражающего ход зависимости, выявленной экспериментально. Однако, и первоначально построенную (синюю) линию, вероятно, также нельзя принять в качестве такового, ибо, повторимся, она вообще не учитывает погрешностей.
Как же быть?
Конечно, есть возможность провести интерполяцию и уже с ее учетом определить функцию, которая будет наиболее плавной (с учетом погрешностей) и построить ее в качестве графика. Однако, это – задача достаточно сложная, представляющая собой предмет отдельного разговора. Скажем, в том же MatLab, конечно, существуют подобные функции, при помощи которых можно это реализовать.
Однако, тогда, в любом случае, придется писать программу (в MatLab это будет проще, в Excel – посложнее, ибо там придется программировать вручную готовые функции, которые уже имеются в MatLab). А для студента, которому требуется обработать данные лабораторной или (реже) контрольной работы, это может являться сложной, отдельной задачей. В самом деле, вместо анализа результатов он вынужден вначале думать, каким образом построить эти результаты, а потом программировать. Добро, если лабораторная работа проходит на старшем курсе. Однако, зачастую, студент делает их, начиная с самого начала своего обучения, т.е. когда опыта математической обработки, не говоря уже об умении строить интерполяционные многочлены, нет вообще.
Какими бывают погрешности
Погрешности бывают, в общем случае, относительные (в процентах) и абсолютные (выраженные в единицах измеряемой величины). Кроме того, они могут иметь постоянное значение или переменное.
Надо сказать, что старые версии программы Excel не позволяют просто так нанести погрешность на график. А вот, начиная, по крайней мере, с версии Excel 2007, это можно сделать достаточно просто. Вот пример, как наносятся погрешности в Excel.
Да, все вроде бы, замечательно. Но только график, приведенный на сайте (по указанной ссылке), также построен, строго говоря, неверно. Дело в том, следует повторить, что график должен представлять собой, по возможности, плавную линию. Которая где-то пройдет через середину интервала погрешности, а где-то, быть может, через один из его краев. Так вот, стандартные средства Excel даже самых новых версий не позволяют построить такой график автоматически. Тем более, если идет речь о том, что каждая экспериментальная точка может иметь, вообще говоря, разную погрешность.
Когда это бывает?
Например, в случае, когда разные экспериментальные точки были получены на базе исследований, проведенных разными методами.
Например, взять эксперименты по измерению зависимости внутреннего трения (т.е. степени перехода механической энергии в тепловую при упругих деформациях) материалов от частоты упругой деформации.
- Если частота равна нулю (т.е. происходит равномерная деформация материала), то необходимо применять установки для растяжения/сжатия, способные измерить работу, затраченную на нагрев материала в процессе деформации.
- Если говорить о частоте, когда ее значения лежат в пределах 10 Гц… 1000 Гц, то такие измерения проводятся при помощи совсем других установок, например, с использованием так называемых крутильных маятников (т.е. когда образец совершает вынужденные крутильные колебания заданной частоты).
- Если вести речь о диапазоне частот 20 кГц… 200 кГц то здесь необходимо применять ультразвуковые установки.
- Наконец, исследования при гиперзвуковых частотах (более 109 Гц) проводятся при помощи оптических, пьезоэлектрических методов.
Таким образом, даже ориентировочное рассмотрение выявило, что существуют, как минимум, четыре основных диапазона частот, для каждого из которых может быть применен какой-либо свой метод исследования, кардинально отличающийся от других. Соответственно, у каждого из методов может быть свое значение погрешности (относительной или абсолютной).
Как построить плавный график в Excel с учетом погрешностей?
Итак, как построить нормальный, правильный график? Который, с одной стороны, был бы, по возможности, плавным (т.е. содержал бы поменьше нестабильных, немонотонных участков — в пределах погрешности, конечно), а с другой – лежал бы в рамках допустимых погрешностей.
Рассмотрим самый сложный, общий случай – разных погрешностей для каждой из экспериментальных точек и покажем, как можно применить Excel для того, чтобы построить корректный график зависимости.
Пусть погрешности экспериментальных точек равны следующим значениям:
±10%; ±7%; ±5%; ±12%; ±20%; ±17%; ±23%.
Ясно, что как относительная, так и абсолютная погрешности данных будут разными для каждой из экспериментальных точек. Однако, для каждой из них можно определить минимальное и максимальное значения (через интервал которых и должен пройти график). Проведем такой расчет (благо, при помощи Excel это сделать очень легко и быстро):
| Х | 2,0 | 4,0 | 5,0 | 7,0 | 9,0 | 11,0 | 15,0 |
| Y | 3,2 | 4,2 | 9,0 | 14,8 | 23,0 | 15,2 | 12,8 |
| Относительная погрешность (для Y), % | 10 | 7 | 5 | 12 | 20 | 17 | 23 |
| Минимальное значение Y | 2,9 | 3,9 | 8,6 | 13,0 | 18,4 | 12,6 | 9,9 |
| Максимальное значение Y | 3,5 | 4,5 | 9,5 | 16,5 | 27,6 | 17,8 | 15,8 |
Минимальные и максимальные значения Y образуют допустимый интервал (диапазон), в котором может находиться график. Отложим этот диапазон на рисунке.
Нижняя граница диапазона показана зеленой линией, верхняя – черной. Толстая черная линия – это ранее нанесенные тренд. Четко видно, что тренд (даже, повторимся, оптимальный, выбранный из предлагаемого программой Excel перечня) только в двух (из семи) экспериментальных точках проходит в пределах допустимой области. Следовательно, необходимо отказаться от него. Удалим его с рисунка.
Итак, построена допустимая область. Искомый график зависимости должен лежать внутри нее, при этом имея, по возможности, наиболее плавный вид.
Его построение (если расчет оптимального интерполяционного многочлена вызывает сложность) проще провести вручную. Т.е. на бумаге полученный рисунок и уже на нем нанести график. Но, вполне возможно это сделать и при помощи компьютера – чтобы вообще не возиться с пишущими принадлежностями, причем сделать это можно очень быстро.
Для этого удобнее всего использовать программу Inkscape. Она является совершенно бесплатной, если у Вас она еще не установлена, можете скачать ее с официального сервера.
Устанавливаем ее, затем открываем. Копируем рисунок (отметим, лучше это сделать не из Word, а из первоисточника, т.е. из Excel).
Затем, как обычно, нажимаем кнопку «Вставить», размещаем рисунок примерно по центру рабочей области. Если ее размеры не совпадают с рисунком, нужно ее настроить, для чего нажимаем «Файл», «Свойства документа» и там устанавливаем альбомную ориентацию и указываем требуемые размеры (параметры «Ширина» и «Высота»). Примерно вот что должно получиться в итоге.
Так как Excel создает диаграммы в векторном виде, они без проблем редактируются в Incscape. Таким образом, наша задача – вручную таким образом исправить синюю линию, чтобы она стала как можно более плавной.
Нажав клавишу F2, затем, удерживая «Shift», кликаем мышкой по элементам синей кривой так, чтобы на ней появились серые узлы. Когда они появятся на каждом из ее участков, это означает, что мы выделили ее ВСЮ в режиме редактирования узлов.
Затем нажимаем в меню пункт «Контур», «Упростить». Число узлов значительно снизится, останутся лишь основные. Кстати, если кликнуть по каждому узлу в отдельности, его можно будет стереть путем нажатия клавиши «Delete». Но, это будет достаточно долго, поэтому проще использовать команду «Упростить».
Затем, удерживая левую кнопку мыши на соответствующем узле, двигаем его в ту или иную сторону. Так повторяем с другими узлами (при необходимости скорректировать кривизну линии в конкретном узле, можно также двигать рычаги каждого из них).
В итоге линия принимает вид, показанный на рисунке.
Для наглядности (чтобы можно было помнить, где проходила линия графика, построенная в Excel), экспериментальные точки, в виде синих ромбиков, оставлены.
Вставить рисунок из Incscape в Word достаточно просто – как обычно: нажимаем «Правка», «Выделить все» (как уже говорилось, рабочая область должна быть подогнана к размерам рисунка; впрочем, можно и рисунок, путем его деформаций, подогнать к размерам рабочей области программы Inkscape), затем – «Скопировать».
Проверяем, что рисунок выделился, как полагается. Тогда переходим в Word и выполняем вставку из буфера обмена, как обычно, путем нажатия кнопки «Вставить» на панели инструментов. Но, учтите, что, к сожалению, исправить в Excel измененную диаграмму уже не получится (она вставится, как рисунок). Поэтому все, что необходимо сделать на диаграмме в Excel, надо делать заранее, ДО ТОГО, т.е. до преобразования ее в Inkscape. Вместе с тем, при желании, полученный рисунок можно вновь скопировать в Inkscape провести, если нужно, дальнейшее его редактирование.
Таким образом, мы получили сглаженный, более плавный график, чем тот, который был построен автоматически в Excel. Даже не взяв в руки карандаш или иной пишущий инструмент: использовались лишь некоторые клавиши и мышь.
Наносим линии погрешностей
Что же касается линий погрешностей, то их можно провести, используя соответствующие возможности Excel (если он у Вас, как минимум, версии 2007 г.). Правда, так как величина погрешности в нашем примере для каждой из точек – разная, то возможности Excel по построению погрешностей здесь помогут мало.
Так что, в данном случае, можно начертить их вручную (т.е. нарисовать мышкой соответствующие вертикальные линии, проходящие через каждую экспериментальную точку).
Однако, это, на наш взгляд, утомительно. Поэтому, если совсем не хочется возиться с ручным рисованием, выход вполне есть – их можно выполнить, нарисовав соответствующее (в данном случае 7) дополнительных графиков. Повторимся, это следует сделать ДО того, как преобразовывать диаграмму в Inkscape.
Итак, заходим на вкладку «Диаграмма». Нажимаем в панели инструментов «Диаграмма», «Исходные данные». Выбираем вкладку «Ряд», затем нажимаем «Добавить».
Далее, жмем кнопку с красной стрелочкой – там, где значения Х. Переходим на Лист, на котором находятся данные, по которым построена эта диаграмма и указываем, к примеру, четвертое значение Х (равное 7). Затем (внимание!), удерживая клавишу «Ctrl», кликаем вновь мышкой по тому же самому значению Х (т.е. по Х, равном 7). В итоге в строке, где задается адрес диапазона значений Х, адрес ячейки, в которой расположена цифра 7, должен присутствовать ДВАЖДЫ, через точку с запятой. Убедившись в этом, нажимаем, как обычно, красную стрелочку.
Теперь выбираем значения Y. После нажатия красной стрелочки, перейдя на нужный Лист, кликаем на минимальное значения Y, соответствующее Х, равному 7. Затем, удерживая клавишу «Ctrl», кликаем максимальное значение Y. В итоге, через точку с запятой в адресной строке должны появиться адреса двух ячеек, соответствующие минимальному и максимальному значению Y (для Х=7).
Наконец, переходим на диаграмму, дважды кликаем мышкой на получившемся вертикальном отрезке с маркерами, зайдя, тем самым, в свойства только что построенного отрезка. Там устанавливаем вид маркера в виде знака минус («-»). Потом устанавливаем, к примеру, черные цвета линий и маркера и нажимаем «ОК». Результат наших действий приведен на рисунке.
Видим, что для точки Х=7 появилась линия погрешности. Кстати, ширину этой линии можно, при желании, изменять — путем изменения размера маркера.
Поступая таким же образом со всеми остальными точками, можно вскоре построить линии погрешностей для каждой из них (кому не хочется выполнять эту нудную работу, если точек много, можно написать несложный макрос — пишется один раз; правда, некоторым студентам, например, учашимся на младших курсах, это, возможно, будет затруднительно, поэтому проще будет сделать так, как говориось выше). А линии, ограничивающие диапазоны минимальных и максимальных значений (зеленую и черную, соответственно) можно, кстати, потом удалить, если они не нужны. Тогда график примет полностью стандартный вид.
Его можно потом перенести в Inkscape и придать графику (синяя линия) более плавный вид.
С уважением к Вам.
Как построить график в Excel с учетом погрешностей? Подобная задача нередко возникает у студента при обработке результатов лабораторных работ. Результаты представляют собой, как правило, два массива данных (в общем случае Х и Y). Пусть, для примера, имеется следующая экспериментальная зависимость:
| Х | 2,0 | 4,0 | 5,0 | 7,0 | 9,0 | 11,0 | 15,0 |
| У | 3,2 | 4,2 | 9,0 | 14,8 | 23,0 | 15,2 | 12,8 |
Требуется представить эту зависимость Y от Х графически. Получится примерно то, что представлено на рисунке.
Например, в ходе лабораторной работы студент измерял зависимость силы тока в одной из ветвей электрической цепи (в Амперах) от напряжения на том или ином ее элементе (в Вольтах). Необходимо отложить данные на графике с учетом погрешностей.
Надо сказать, что сделать построение вручную, как ни парадоксально, в данном случае даже немного проще, чем с использованием, казалось бы, такой мощной и удобной программы, как Excel . Дело в том, что, на самом деле, график, приведенный на предыдущем рисунке… построен неверно.
Почему? Ведь, вроде бы, ничего сложного нет. Нажимаем в Excel кнопку « Мастер диаграмм », Выбираем тип диаграммы – точечная . Затем нажимаем « Далее », задаем массивы для X и Y, затем опять « Далее »… — и вскоре получится то, что приведено на предыдущем рисунке.
Вроде бы, все правильно. Да только график построен строго по точкам. Видно, что зависимость немонотонная, с достаточно острым максимумом – что не всегда имеет место в реальности. Ибо в реальности подавляющее большинство зависимостей могут быть более плавными.
Конечно, здесь надо смотреть, какие конкретно показатели анализируются. Если это, к примеру, динамика биржевого курса ценных бумаг; или – динамика поступления платежей от покупателей, равно как и другой аналогичный экономический показатель, то, конечно, можно с уверенностью сказать, что график вовсе не обязан быть плавным. В самом деле, очень многие экономические показатели меняются, как правило, скачкообразно.
А вот если анализировать данные, скажем, из области психологии, физики, биологии (отчасти), а также из ряда иных отраслей, то там графики экспериментальных зависимостей, за немногим исключением, зачастую являются достаточно плавными (хотя, все относительно, конечно) .
Но, вроде бы, и здесь нет никаких проблем: следует провести линию тренда, которых Excel предлагает несколько типов. Так, можно выбрать линейный, степенной, экспоненциальный и т.д. тренд.
Можно… На примере выбранных нами данных, выбор показал, что наиболее близким для выбранной совокупности данных является параболический тренд. Отобразим его на рисунке.
Вроде бы, то, что проведено черной линией (тренд), уже гораздо ближе к истине. Правда, совсем ненамного. Фактически, проведенный тренд достаточно хорошо соответствует исходным данным только для 3, 4 и 7-й точек. Для остальных точек имеются существенные расхождения, причем ошибка доходит до 80%.
Ясно, что построенный тренд, в силу его высокой погрешности, в данном случае никак нельзя принять в качестве качественного графика, отражающего ход зависимости, выявленной экспериментально. Однако, и первоначально построенную (синюю) линию, вероятно, также нельзя принять в качестве такового, ибо, повторимся, она вообще не учитывает погрешностей.
Как же быть?
Конечно, есть возможность провести интерполяцию и уже с ее учетом определить функцию, которая будет наиболее плавной (с учетом погрешностей) и построить ее в качестве графика. Однако, это – задача достаточно сложная, представляющая собой предмет отдельного разговора. Скажем, в том же MatLab , конечно, существуют подобные функции, при помощи которых можно это реализовать.
Однако, тогда, в любом случае, придется писать программу (в MatLab это будет проще, в Excel – посложнее, ибо там придется программировать вручную готовые функции, которые уже имеются в MatLab ). А для студента, которому требуется обработать данные лабораторной или (реже) контрольной работы, это может являться сложной, отдельной задачей. В самом деле, вместо анализа результатов он вынужден вначале думать, каким образом построить эти результаты, а потом программировать. Добро, если лабораторная работа проходит на старшем курсе. Однако, зачастую, студент делает их, начиная с самого начала своего обучения, т.е. когда опыта математической обработки, не говоря уже об умении строить интерполяционные многочлены, нет вообще.
Какими бывают погрешности
Погрешности бывают, в общем случае, относительные (в процентах) и абсолютные (выраженные в единицах измеряемой величины). Кроме того, они могут иметь постоянное значение или переменное.
Надо сказать, что старые версии программы Excel не позволяют просто так нанести погрешность на график. А вот, начиная, по крайней мере, с версии Excel 2007 , это можно сделать достаточно просто. Вот пример, как наносятся погрешности в Excel.
Да, все вроде бы, замечательно. Но только график, приведенный на сайте (по указанной ссылке), также построен, строго говоря, неверно. Дело в том, следует повторить, что график должен представлять собой, по возможности, плавную линию. Которая где-то пройдет через середину интервала погрешности, а где-то, быть может, через один из его краев. Так вот, стандартные средства Excel даже самых новых версий не позволяют построить такой график автоматически. Тем более, если идет речь о том, что каждая экспериментальная точка может иметь, вообще говоря, разную погрешность.
Когда это бывает?
Например, в случае, когда разные экспериментальные точки были получены на базе исследований, проведенных разными методами.
Например, взять эксперименты по измерению зависимости внутреннего трения (т.е. степени перехода механической энергии в тепловую при упругих деформациях) материалов от частоты упругой деформации.
- Если частота равна нулю (т.е. происходит равномерная деформация материала), то необходимо применять установки для растяжения/сжатия, способные измерить работу, затраченную на нагрев материала в процессе деформации.
- Если говорить о частоте, когда ее значения лежат в пределах 10 Гц… 1000 Гц, то такие измерения проводятся при помощи совсем других установок, например, с использованием так называемых крутильных маятников (т.е. когда образец совершает вынужденные крутильные колебания заданной частоты).
- Если вести речь о диапазоне частот 20 кГц… 200 кГц то здесь необходимо применять ультразвуковые установки.
- Наконец, исследования при гиперзвуковых частотах (более 10 9 Гц) проводятся при помощи оптических, пьезоэлектрических методов.
Таким образом, даже ориентировочное рассмотрение выявило, что существуют, как минимум, четыре основных диапазона частот, для каждого из которых может быть применен какой-либо свой метод исследования, кардинально отличающийся от других. Соответственно, у каждого из методов может быть свое значение погрешности (относительной или абсолютной).
Как построить плавный график в Excel с учетом погрешностей?
Итак, как построить нормальный, правильный график? Который, с одной стороны, был бы, по возможности, плавным (т.е. содержал бы поменьше нестабильных, немонотонных участков — в пределах погрешности, конечно), а с другой – лежал бы в рамках допустимых погрешностей.
Рассмотрим самый сложный, общий случай – разных погрешностей для каждой из экспериментальных точек и покажем, как можно применить Excel для того, чтобы построить корректный график зависимости.
Пусть погрешности экспериментальных точек равны следующим значениям:
Ясно, что как относительная, так и абсолютная погрешности данных будут разными для каждой из экспериментальных точек. Однако, для каждой из них можно определить минимальное и максимальное значения (через интервал которых и должен пройти график). Проведем такой расчет (благо, при помощи Excel это сделать очень легко и быстро):
| Х | 2,0 | 4,0 | 5,0 | 7,0 | 9,0 | 11,0 | 15,0 |
| Y | 3,2 | 4,2 | 9,0 | 14,8 | 23,0 | 15,2 | 12,8 |
| Относительная погрешность (для Y), % | 10 | 7 | 5 | 12 | 20 | 17 | 23 |
| Минимальное значение Y | 2,9 | 3,9 | 8,6 | 13,0 | 18,4 | 12,6 | 9,9 |
| Максимальное значение Y | 3,5 | 4,5 | 9,5 | 16,5 | 27,6 | 17,8 | 15,8 |
Минимальные и максимальные значения Y образуют допустимый интервал (диапазон), в котором может находиться график. Отложим этот диапазон на рисунке.
Нижняя граница диапазона показана зеленой линией, верхняя – черной. Толстая черная линия – это ранее нанесенные тренд. Четко видно, что тренд (даже, повторимся, оптимальный, выбранный из предлагаемого программой Excel перечня) только в двух (из семи) экспериментальных точках проходит в пределах допустимой области. Следовательно, необходимо отказаться от него. Удалим его с рисунка.
Итак, построена допустимая область. Искомый график зависимости должен лежать внутри нее, при этом имея, по возможности, наиболее плавный вид.
Его построение (если расчет оптимального интерполяционного многочлена вызывает сложность) проще провести вручную. Т.е. распечатать на бумаге полученный рисунок и уже на нем нанести график. Но, вполне возможно это сделать и при помощи компьютера – чтобы вообще не возиться с пишущими принадлежностями, причем сделать это можно очень быстро.
Для этого удобнее всего использовать программу Inkscape. Она является совершенно бесплатной, если у Вас она еще не установлена, можете скачать ее с официального сервера. https://inkscape.org/ru/download/
Устанавливаем ее, затем открываем. Копируем рисунок (отметим, лучше это сделать не из Word, а из первоисточника, т.е. из Excel).
Затем, как обычно, нажимаем кнопку «Вставить», размещаем рисунок примерно по центру рабочей области. Если ее размеры не совпадают с рисунком, нужно ее настроить, для чего нажимаем « Файл », « Свойства документа » и там устанавливаем альбомную ориентацию и указываем требуемые размеры (параметры «Ширина» и « Высота »). Примерно вот что должно получиться в итоге.

Так как Excel создает диаграммы в векторном виде, они без проблем редактируются в Incscape. Таким образом, наша задача – вручную таким образом исправить синюю линию, чтобы она стала как можно более плавной.
Нажав клавишу F2 , затем, удерживая « Shift », кликаем мышкой по элементам синей кривой так, чтобы на ней появились серые узлы. Когда они появятся на каждом из ее участков, это означает, что мы выделили ее ВСЮ в режиме редактирования узлов.
Затем нажимаем в меню пункт « Контур », « Упростить ». Число узлов значительно снизится, останутся лишь основные. Кстати, если кликнуть по каждому узлу в отдельности, его можно будет стереть путем нажатия клавиши « Delete ». Но, это будет достаточно долго, поэтому проще использовать команду » Упростить «.
Затем, удерживая левую кнопку мыши на соответствующем узле, двигаем его в ту или иную сторону. Так повторяем с другими узлами (при необходимости скорректировать кривизну линии в конкретном узле, можно также двигать рычаги каждого из них).
В итоге линия принимает вид, показанный на рисунке.
Для наглядности (чтобы можно было помнить, где проходила линия графика, построенная в Excel), экспериментальные точки, в виде синих ромбиков, оставлены.
Вставить рисунок из Incscape в Word достаточно просто – как обычно: нажимаем « Правка », « Выделить все » (как уже говорилось, рабочая область должна быть подогнана к размерам рисунка; впрочем, можно и рисунок, путем его деформаций, подогнать к размерам рабочей области программы Inkscape) , затем – « Скопировать ».
Проверяем, что рисунок выделился, как полагается. Тогда переходим в Word и выполняем вставку из буфера обмена, как обычно, путем нажатия кнопки « Вставить » на панели инструментов. Но, учтите, что, к сожалению, исправить в Excel измененную диаграмму уже не получится (она вставится, как рисунок) . Поэтому все, что необходимо сделать на диаграмме в Excel, надо делать заранее, ДО ТОГО, т.е. до преобразования ее в Inkscape. Вместе с тем, при желании, полученный рисунок можно вновь скопировать в Inkscape провести, если нужно, дальнейшее его редактирование.
Таким образом, мы получили сглаженный, более плавный график, чем тот, который был построен автоматически в Excel. Даже не взяв в руки карандаш или иной пишущий инструмент: использовались лишь некоторые клавиши и мышь.
Наносим линии погрешностей
Что же касается линий погрешностей, то их можно провести, используя соответствующие возможности Excel (если он у Вас, как минимум, версии 2007 г.) . Правда, так как величина погрешности в нашем примере для каждой из точек – разная, то возможности Excel по построению погрешностей здесь помогут мало.
Так что, в данном случае, можно начертить их вручную (т.е. нарисовать мышкой соответствующие вертикальные линии, проходящие через каждую экспериментальную точку).
Однако, это, на наш взгляд, утомительно. Поэтому, если совсем не хочется возиться с ручным рисованием, выход вполне есть – их можно выполнить, нарисовав соответствующее (в данном случае 7) дополнительных графиков. Повторимся, это следует сделать ДО того, как преобразовывать диаграмму в Inkscape.
Итак, заходим на вкладку « Диаграмма ». Нажимаем в панели инструментов « Диаграмма », « Исходные данные ». Выбираем вкладку « Ряд », затем нажимаем «Добавить».
Далее, жмем кнопку с красной стрелочкой – там, где значения Х. Переходим на Лист, на котором находятся данные, по которым построена эта диаграмма и указываем, к примеру, четвертое значение Х (равное 7). Затем (внимание!), удерживая клавишу « Ctrl », кликаем вновь мышкой по тому же самому значению Х (т.е. по Х, равном 7). В итоге в строке, где задается адрес диапазона значений Х, адрес ячейки, в которой расположена цифра 7, должен присутствовать ДВАЖДЫ , через точку с запятой. Убедившись в этом, нажимаем, как обычно, красную стрелочку.
Теперь выбираем значения Y. После нажатия красной стрелочки, перейдя на нужный Лист, кликаем на минимальное значения Y, соответствующее Х, равному 7. Затем, удерживая клавишу « Ctrl », кликаем максимальное значение Y. В итоге, через точку с запятой в адресной строке должны появиться адреса двух ячеек, соответствующие минимальному и максимальному значению Y (для Х=7).
Наконец, переходим на диаграмму, дважды кликаем мышкой на получившемся вертикальном отрезке с маркерами, зайдя, тем самым, в свойства только что построенного отрезка. Там устанавливаем вид маркера в виде знака минус (« — »). Потом устанавливаем, к примеру, черные цвета линий и маркера и нажимаем « ОК ». Результат наших действий приведен на рисунке.
Видим, что для точки Х=7 появилась линия погрешности. Кстати, ширину этой линии можно, при желании, изменять — путем изменения размера маркера.
Поступая таким же образом со всеми остальными точками, можно вскоре построить линии погрешностей для каждой из них (кому не хочется выполнять эту нудную работу, если точек много, можно написать несложный макрос — пишется один раз; правда, некоторым студентам, например, учашимся на младших курсах, это, возможно, будет затруднительно, поэтому проще будет сделать так, как говориось выше) . А линии, ограничивающие диапазоны минимальных и максимальных значений (зеленую и черную, соответственно) можно, кстати, потом удалить, если они не нужны. Тогда график примет полностью стандартный вид.
Его можно потом перенести в Inkscape и придать графику (синяя линия) более плавный вид.
Расчет случайной погрешности средствами Excel
С использованием встроенных функций Excel расчет доверительного интервала проводится следующим образом.
1) Рассчитывается среднее значение
=СРЗНАЧ(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется среднее.
2) Рассчитывается стандартное отклонение
=СТАНДОТКЛОНП(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется стандартное отклонение.
3) Рассчитывается абсолютная погрешность
=ДОВЕРИТ(альфа ;станд_откл;размер)
альфа — уровень значимости используемый для вычисления уровня надежности.
( , т.е. означает надежности );
станд_откл — стандартное отклонение, предполагается известным;
размер — размер выборки.
Задание: Обработать заданный набор экспериментальных данных методом Стьюдента, построить экспериментальные кривые методом наименьших квадратов.
Предположим, в ходе эксперимента по измерению электросопротивления были получены следующие данные:

Используя для определения сопротивления закон Ома произведем обработку данной серии экспериментальных данных.
| Используемуе формулы |
 |
| Результат расчета |
 |
Для построения графика используем мастер диаграмм.
Полученные экспериментальные данные следует аппроксимировать. Для выполнения этой процедуры в Excel предусмотрен мастер, добавляющий линию тренда, производящий аппроксимацию и сглаживание.
В меню «Диаграмма» выберите пункт «Добавить линию тренда…».

В результате, должен получиться следующий график.
Задание 1.
Просчитать погрешность измерений и построить график ее распределения.
| Задание 1 | Задание 2 | Задание 3 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 4 | Задание 5 | Задание 6 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
| Задание 7 | Задание 8 | Задание 9 |
| № опыта | № опыта | № опыта |
| 10,3 | 13,55 | 12,65 |
| 10,277 | 13,527 | 12,627 |
| 10,325 | 13,575 | 12,675 |
| 10,285 | 13,535 | 12,635 |
| 10,297 | 13,547 | 12,647 |
| 10,31 | 13,56 | 12,66 |
| 10,35 | 13,6 | 12,7 |
| 10,35 | 13,6 | 12,7 |
| 10,29 | 13,54 | 12,64 |
| 10,38 | 13,63 | 12,73 |
| Задание 10 | Задание 11 | Задание 12 |
| № опыта | №опыта | № опыта |
| 26,65 | 24,65 | 18,3 |
| 26,627 | 24,627 | 18,277 |
| 26,675 | 24,675 | 18,325 |
| 26,635 | 24,635 | 18,285 |
| 26,647 | 24,647 | 18,297 |
| 26,66 | 24,66 | 18,31 |
| 26,7 | 24,7 | 18,35 |
| 26,7 | 24,7 | 18,35 |
| 26,64 | 24,64 | 18,29 |
| 26,73 | 24,73 | 18,38 |
| Задание 13 | Задание 14 | Задание 15 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 16 | Задание 17 | Задание 18 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
Задание 2.
Определить является ли 3-е измерение промахом.
Often in statistics, we’re interested in estimating a population parameter using a sample.
For example, we might want to know the mean height of students at a particular school. If the school has 1,000 total students, it might take too long to measure every student so instead we could take a simple random sample of 50 students and calculate the mean height of students in this sample.
And while the mean height of students in the sample might be a good estimate of the true population mean, there is no guarantee that the sample mean is exactly equal to the population mean. In other words, there exists some uncertainty.
One way to account for uncertainty is create a confidence interval, which is a range of values that we believe contains the true population parameter.
For example, if the mean height of students in the sample is 67 inches, our confidence interval for the true mean height of all students in the population might be [65 inches, 69 inches], which means we’re confident that the true mean height of students in the population is between 65 and 69 inches.
A confidence interval is composed of two parts:
Point estimate – often this is a sample mean or sample proportion.
Margin of error – a number that represents the uncertainty of the point estimate.
The formula to create a confidence interval is:
Confidence Interval = point estimate +/- margin of error
Margin of Error Formula
If you’re creating a confidence interval for a population mean, then the formula for the margin of error is:
Margin of error: Z * σ / √n
Where:
Z: Z-score
σ: Population standard deviation
n: Sample size
Note: If the population standard deviation is unknown, then you can replace Z with tn-1, which is the t critical-value that comes from the t distribution table with n-1 degrees of freedom.
And if you’re creating a confidence interval for a population proportion, then the formula for the margin of error is:
Margin of error: Z * √(p*(1-p)) / n)
Where:
Z: Z-score
p: Sample proportion
n: Sample size
Note that the Z-score you’ll use for this calculation is dependent on you chosen confidence level. The following table shows the Z-scores associated with common confidence levels:
| Confidence Level | Z-score |
|---|---|
| 80% | 1.282 |
| 85% | 1.44 |
| 90% | 1.645 |
| 95% | 1.96 |
| 99% | 2.576 |
Next, we’ll walk through two examples of how to calculate the margin of error in Excel.
Example 1: Margin of Error for a Population Mean
Suppose we want to find the mean height of a certain plant. It is known that the population standard deviation, σ, is 2 inches. We collect a random sample of 100 plants and find that the sample mean is 14 inches. Find a 95% confidence interval for the true mean height of this certain plant.
Since we’re finding a confidence interval for the mean height, the formula we will use for the margin of error is: Z * σ / √n
The following image shows how to calculate the margin of error for this confidence interval:

The margin of error turns out to be 0.392.

Thus, the confidence interval for the true mean height of plants would be 14 +/ 0.392 = [13.608, 14.392].
Example 2: Margin of Error for a Population Proportion
Suppose we want to know what percentage of individuals in a certain city support a candidate named Bob. In a simple random sample of 200 individuals, 120 said they supported Bob (i.e. 60% support him). Find a 99% confidence interval for the true percentage of people in the entire city who support Bob.
Since we’re finding a confidence interval for the mean height, the formula we will use for the margin of error is: Z * √(p*(1-p)) / n)
The following image shows how to calculate the margin of error for this confidence interval:

The margin of error turns out to be 0.089.

Thus, the confidence interval for the true percentage of individuals in this city that support Bob is 0.6 +/- 0.089 = [ 0.511, 0.689].
Notes on Finding the Appropriate Z-Score or t-Score
If you’re finding the confidence interval for a population mean and you’re unsure of whether or not to use a Z-Score or a t-Score for the margin of error calculation, refer to this helpful diagram to help you decide:

Also, if you don’t have a helpful table that shows you which Z-Score or t-Score to use based on your confidence interval, you can always use the following commands in Excel to find the correct Z-Score or t-Score to use:
To find Z-Score: =NORM.INV(probability, 0, 1)
For example, to find the Z-Score associated with a 95% confidence level, you’d type =NORM.INV(.975, 0, 1), which turns out to be 1.96.
To find t-Score: =T.INV(probability, degrees of freedom)
For example, to find the t-Score associated with a 90% confidence level and 12 degrees of freedom, you’d type =T.INV(.95, 12), which turns out to be 1.78.