
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки
или
выборочное среднее
(sample average, mean) представляет собой
среднее
арифметическое
всех значений
выборки
.
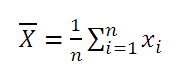
В MS EXCEL для вычисления
среднего выборки
можно использовать функцию
СРЗНАЧ()
. В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения
выборки
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) точечной оценкой
математического ожидания
случайной величины (см.
ниже
), т.е.
среднего значения
исходного распределения, из которого взята
выборка
.
Примечание
: О вычислении
доверительных интервалов
при оценке
математического ожидания
можно прочитать, например, в статье
Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
.
Некоторые свойства
среднего арифметического
:
-
Сумма всех отклонений от
среднего значения
равна 0:
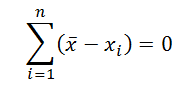
-
Если к каждому из значений x
i
прибавить одну и туже константу
с
, то
среднее арифметическое
увеличится на такую же константу; -
Если каждое из значений x
i
умножить на одну и туже константу
с
, то
среднее арифметическое
умножится на такую же константу.
Математическое ожидание
Среднее значение
можно вычислить не только для выборки, но для случайной величины, если известно ее
распределение
. В этом случае
среднее значение
имеет специальное название —
Математическое ожидание.
Математическое ожидание
характеризует «центральное» или среднее значение случайной величины.
Примечание
: В англоязычной литературе имеется множество терминов для обозначения
математического ожидания
: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет
дискретное распределение
, то
математическое ожидание
вычисляется по формуле:
где x
i
– значение, которое может принимать случайная величина, а р(x
i
) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет
непрерывное распределение
, то
математическое ожидание
вычисляется по формуле:
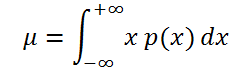
где р(x) –
плотность вероятности
(именно
плотность вероятности
, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL,
Математическое ожидание
можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие
статьи про распределения
). Например, для
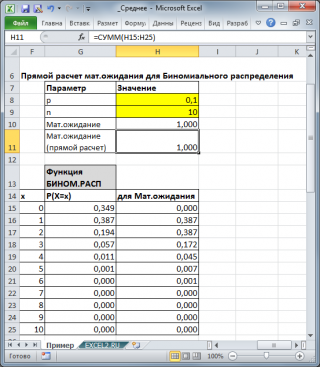
Биномиального распределения
среднее значение
равно произведению его параметров: n*p (см.
файл примера
).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[X+a]=E[X]+a
E[a]=a
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ
: Про другие показатели распределения —
Дисперсию
и
Стандартное отклонение,
можно прочитать в статье
Дисперсия и стандартное отклонение в MS EXCEL
.
На чтение 6 мин Просмотров 8к.
Содержание
- Выборочное среднее
- Математическое ожидание
- Примеры методов анализа числовых рядов в Excel
- Формула расчета линейного коэффициента вариации в Excel
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
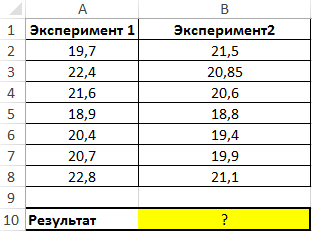
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
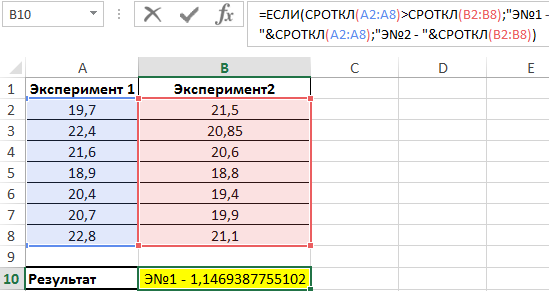
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
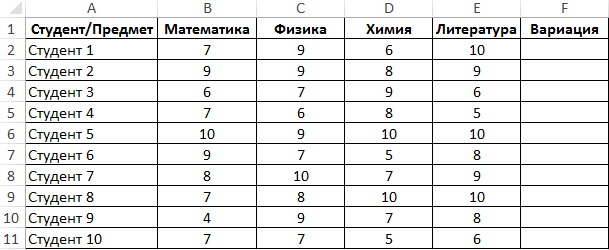
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
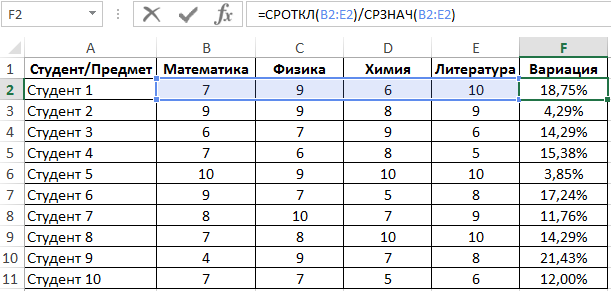
Для определения числа неуспешных студентов по указанному критерию используем функцию:
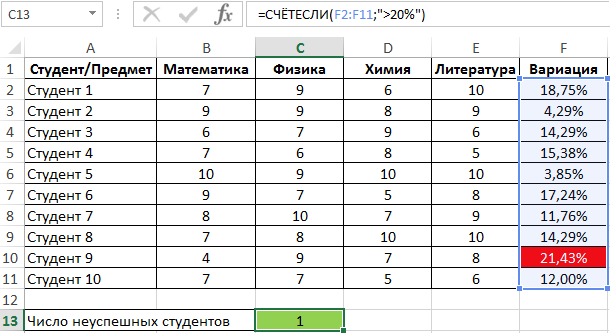
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
Среднее арифметическое значение — самый известный статистический показатель. В этой заметке рассмотрим его смысл, формулы расчета и свойства.
Средняя арифметическая как оценка математического ожидания
Теория вероятностей занимается изучением случайных величин. Для этого строятся различные характеристики, описывающие их поведение. Одной из основных характеристик случайной величины является математическое ожидание, являющееся своего рода центром, вокруг которого группируются остальные значения.
Формула матожидания имеет следующий вид:
![]()
где M(X) – математическое ожидание
xi – это случайные величины
pi – их вероятности.
То есть, математическое ожидание случайной величины — это взвешенная сумма значений случайной величины, где веса равны соответствующим вероятностям.
Математическое ожидание суммы выпавших очков при бросании двух игральных костей равно 7. Это легко подсчитать, зная вероятности. А как рассчитать матожидание, если вероятности не известны? Есть только результат наблюдений. В дело вступает статистика, которая позволяет получить приблизительное значение матожидания по фактическим данным наблюдений.
Математическая статистика предоставляет несколько вариантов оценки математического ожидания. Основное среди них – среднее арифметическое.
Среднее арифметическое значение рассчитывается по формуле, которая известна любому школьнику.
![]()
где xi – значения переменной,
n – количество значений.
Среднее арифметическое – это соотношение суммы значений некоторого показателя с количеством таких значений (наблюдений).
Свойства средней арифметической (математического ожидания)
Теперь рассмотрим свойства средней арифметической, которые часто используются при алгебраических манипуляциях. Правильней будет вновь вернутся к термину математического ожидания, т.к. именно его свойства приводят в учебниках.
Матожидание в русскоязычной литературе обычно обозначают как M(X), в иностранных учебниках можно увидеть E(X). Встречается обозначение греческой буквой μ (читается «мю»). Для удобства предлагаю вариант M(X).
Итак, свойство 1. Если имеются переменные X, Y, Z, то математическое ожидание их суммы равно сумме их математических ожиданий.
M(X+Y+Z) = M(X) + M(Y) + M(Z)
Допустим, среднее время, затрачиваемое на мойку автомобиля M(X) равно 20 минут, а на подкачку колес M(Y) – 5 минут. Тогда общее среднее арифметическое время на мойку и подкачку составит M(X+Y) = M(X) + M(Y) = 20 + 5 = 25 минут.
Свойство 2. Если переменную (т.е. каждое значение переменной) умножить на постоянную величину (a), то математическое ожидание такой величины равно произведению матожидания переменной и этой константы.
M(aX) = aM(X)
К примеру, среднее время мойки одной машины M(X) 20 минут. Тогда среднее время мойки двух машин составит M(aX) = aM(X) = 2*20 = 40 минут.
Свойство 3. Математическое ожидание постоянной величины (а) есть сама эта величина (а).
M(a) = a
Если установленная стоимость мойки легкового автомобиля равна 100 рублей, то средняя стоимость мойки нескольких автомобилей также равна 100 рублей.
Свойство 4. Математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий.
M(XY) = M(X)M(Y)
Автомойка за день в среднем обслуживает 50 автомобилей (X). Средний чек – 100 рублей (Y). Тогда средняя выручка автомойки в день M(XY) равна произведению среднего количества M(X) на средний тариф M(Y), т.е. 50*100 = 500 рублей.
Среднее арифметическое чисел в Excel рассчитывают с помощью функции СРЗНАЧ. Выглядит примерно так.

У этой формулы есть замечательное свойство. Если в диапазоне, по которому рассчитывается формула, присутствуют пустые ячейки (не нулевые, а именно пустые), то они исключается из расчета.
Вызвать функцию можно разными способами. Например, воспользоваться командой автосуммы во вкладке Главная:

После вызова формулы нужно указать диапазон данных, по которому рассчитывается среднее значение.
Есть и стандартный способ для всех функций. Нужно нажать на кнопку fx в начале строки формул. Затем либо с помощью поиска, либо просто по списку выбрать функцию СРЗНАЧ (в категории «Статистические»).

Средняя арифметическая взвешенная
Рассмотрим следующую простую задачу. Между пунктами А и Б расстояние S, которые автомобиль проехал со скоростью 50 км/ч. В обратную сторону – со скоростью 100 км/ч.

Какова была средняя скорость движения из А в Б и обратно? Большинство людей ответят 75 км/ч (среднее из 50 и 100) и это неправильный ответ. Средняя скорость – это все пройденное расстояние, деленное на все потраченное время. В нашем случае все расстояние – это S + S = 2*S (туда и обратно), все время складывается из времени из А в Б и из Б в А. Зная скорость и расстояние, время найти элементарно. Исходная формула для нахождения средней скорости имеет вид:

Теперь преобразуем формулу до удобного вида.

Подставим значения.
![]()
Правильный ответ: средняя скорость автомобиля составила 66,7 км/ч.
Средняя скорость – это на самом деле среднее расстояние в единицу времени. Поэтому для расчета средней скорости (среднего расстояния в единицу времени) используется средняя арифметическая взвешенная по следующей формуле.
![]()
где x – анализируемый показатель; f – вес.
Аналогичным образом по формуле средневзвешенной средней рассчитывается средняя цена (средняя стоимость на единицу продукции), средний процент и т.д. То есть если средняя считается по другим усредненным значениям, нужно применить среднюю взвешенную, а не простую.
Формула средневзвешенного значение в Excel
Обычная функция среднего значения в Excel СРЗНАЧ, к сожалению, считает только среднюю простую. Готовой формулы для среднего взвешенного значения в Excel нет. Однако расчет несложно сделать подручными средствами.
Самый понятный вариант создать дополнительный столбец. Выглядит примерно так.

Имеется возможность сократить количество расчетов. Есть функция СУММПРОИЗВ. С ее помощью можно рассчитать числитель одним действием. Разделить на сумму весов можно в этой же ячейке. Вся формула для расчета среднего взвешенного значения в Excel выглядит так:
=СУММПРОИЗВ(B3:B5;C3:C5)/СУММ(C3:C5)
Интерпретация средней взвешенной такая же, как и у средней простой. Средняя простая – это частный случай взвешенной, когда все веса равны 1.
Физический смысл средней арифметической
Представим, что имеется спица, на которой в разных местах нанизаны грузики различной массы.

Как отыскать центр тяжести? Центр тяжести – это такая точка, за которую можно ухватиться, и спица при этом останется в горизонтальном положении и не будет переворачиваться под действием силы тяжести. Она должна быть в центре всех масс, чтобы силы слева равнялись силам справа. Для нахождения точки равновесия следует рассчитать среднее арифметическое взвешенное расстояний от начала спицы до каждого грузика. Весами будут являться массы грузиков (mi), что в прямом смысле слова соответствует понятию веса. Таким образом, среднее арифметическое расстояние – это центр равновесия системы, когда силы с одной стороны точки уравновешивают силы с другой стороны.
И последнее. В русском языке так сложилось, что под словом «средний» обычно понимают именно среднее арифметическое. То есть моду и медиану как-то не принято называть средним значением. А вот на английском языке слово «средний» (average) может трактоваться и как среднее арифметическое (mean), и как мода (mode), и как медиана (median). Так что при чтении иностранной литературы следует быть бдительным.
Поделиться в социальных сетях:

1 .
.
Выборочная оценка математического
ожидания – выборочное среднее![]()
в Excel
вычисляется с помощью
функция СРЗНАЧ,
при этом
реализуется формула
 .
.
2 .
.
Оценка дисперсии – несмещенная
(исправленная) выборочная дисперсия![]() может быть получена с помощью функцииДИСП.
может быть получена с помощью функцииДИСП.
В Excel
реализована формула
 .
.
3.
Несмещенное выборочное средние
квадратические отклонения (стандартное
отклонение)
![]() вычисляется
вычисляется
с помощью функции
СТАНДОТКЛОН.
Вычисления
в Excel
выполнены по формуле
 .
.
4 .
.
Выборочная (смещенная) оценка дисперсии

вычисляется с помощью
функция ДИСПР.
Результат
вычисления выборочных оценок
![]() ,
,
![]() ,
,
![]() и
и![]()
показан на рис.1.

… … … …
… … …

Рис.
1. Фрагмент листа Excel
с исходными данными и выборочными
оценками параметров.
2. Описательная статистика.
Выполните
процедуру Описательная
статистика.
В
главном меню Excel
выбрать: Данные
→ Анализ данных → Описательная статистика
→ ОК.
В
появившемся окне Описательная
статистика
ввести:
Входной
интервал –
100 случайных чисел в ячейках $A$3:
$A$102;
Группирование
— по столбцам;
Выходной
интервал –
адрес ячейки, с которой начинается
таблица Описательная
статистика – например,
$D$8;
Итоговая
статистика
– поставить галочку. ОК.
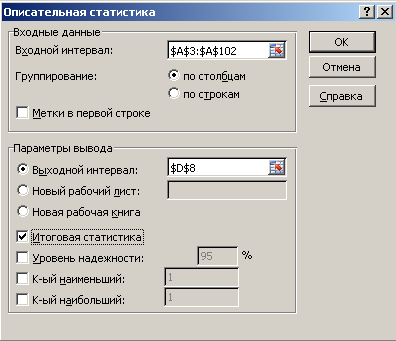
Рис.
2. Диалоговое окно Описательная
статистика
с заполненными полями ввода.
На
листе Excel
появится таблица – Столбец
1. В
таблице даются все необходимые параметры,
кроме моды Mo(X).

Рис.
3. Таблица Описательная
статистика
Таблица содержит
описательные статистики, в частности:
Среднее
– оценка математического ожидания
![]() ;
;
Стандартное
отклонение
– оценка среднего квадратического
отклонения![]() ;
;
Дисперсия
– выборочная исправленная дисперсия
![]() ;
;
Эксцесс
и Асимметричность
– оценки эксцесса и асимметрии;
Медиана
– оценка
медианы;
Мода
– оценка
моды, #Н/Д – нет данных (наиболее часто
встречающееся значение случайной
величины в выборке).
Приблизительное
равенство нулю оценок эксцесса и
асимметрии, и приблизительное равенство
оценки среднего оценке медианы дает
предварительное основание выбрать в
качестве основной гипотезы H0
распределения элементов генеральной
совокупности — нормальный закон.
Интервал
– размах выборки;
Минимум
– минимальное значение случайной
величины в выборке ![]() ;
;
Максимум
– максимальное значение случайной
величины в выборке ![]() .
.
Результаты
процедуры Описательная
статистика
потребуются в дальнейшем при построении
теоретического закона распределения.
3. Построение гистограммы
В
главном меню Excel
выбрать Данные
→ Анализ данных → Гистограмма → ОК.
Далее
необходимо заполнить поля ввода в
диалоговом окне Гистограмма.
Входной
интервал:
100 случайных чисел в ячейках $A$3:
$A$102;
Интервал
карманов:
не
заполнять;
Выходной
интервал:
адрес ячейки, с которой начинается вывод
результатов процедуры Гистограмма;
Вывод
графика –
поставьте галочку.
Если
поле ввода Интервал
карманов не
заполняется, то процедура вычисляет
число интервалов группировки k
и границы интервалов автоматически по
формуле.
![]() ,
,
где,
скобки
![]() означают – округление до целой части
означают – округление до целой части
числа в меньшую сторону.
В
рассматриваемом варианте n
= 100,
следовательно, k
= 11.
Действительно:

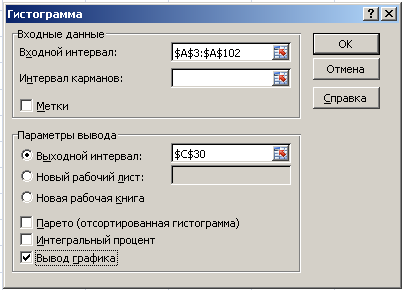
Рис.
4. Диалоговое окно Гистограмма.
В
результате выполнения процедуры
Гистограмма
появляется таблица, содержащая границы
xi
интервалов
группировки (столбец – Карман)
и частоту попадания случайных величин
выборки mi
в i–ый
интервал (столбец
–
Частота).
Справа от таблицы
– график гистограммы.
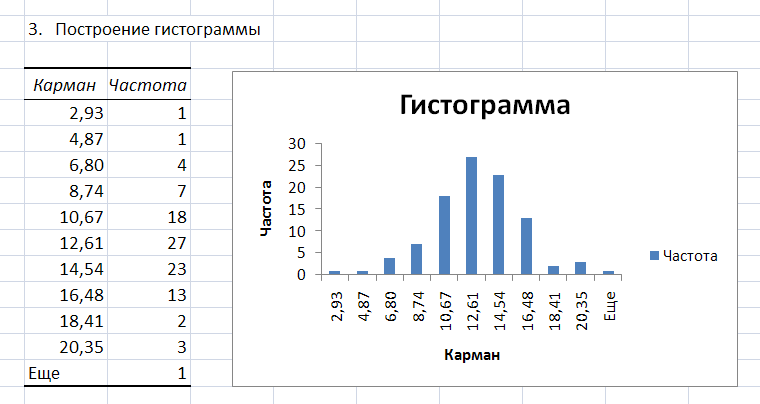
Рис.
5. Фрагмент листа Excel
с результатами процедуры Гистограмма.
По
виду гистограммы можно предположить
(принять гипотезу) о том, что выборка
случайных чисел подчиняется нормальному
закону распределения.
Далее,
для того чтобы убедиться в правильности
выбранной гипотезы (по крайней мере
визуально) надо, первое – построить
график гипотетического нормального
закона распределения, выбрав в качестве
параметров (математического ожидания
и среднего квадратического отклонении)
их оценки (среднее и стандартное
отклонение), и совместить график
гипотетического распределения с графиком
гистограммы.
И,
второе – используя критерий согласия
Пирсона установить справедливость
выбранной гипотезы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Среднее и Математическое ожидание в EXCEL
- Выборочное среднее
- Математическое ожидание
- Свойства математического ожидания
- Основные статистики в EXCEL
- Равномерное непрерывное распределение в EXCEL
- Математическое ожидание и дисперсия
- Генерация случайных чисел
- Оценка среднего и стандартного отклонения
Среднее и Математическое ожидание в EXCEL
history 4 октября 2016 г.
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:
где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
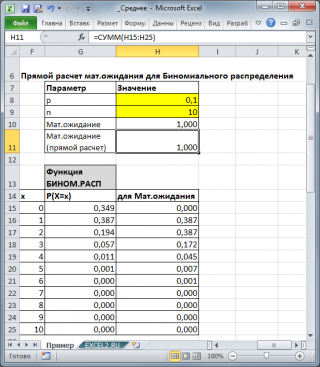
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Источник
Основные статистики в EXCEL
События, характеризующие данные, могут носить случайный характер и появляться с разной вероятностью.
Вероятность события p есть отношение числа благоприятных исходов m к числу всех возможных исходов n этогособытия: p=m/n. Например, вероятность появления туза в наугад выбранной карте из колоды в 52 карты равна 4/52=0.0769, так как m=4, а n=52.
Если известно соответствие между появлениями (величинами) x1, x2, …, xn случайного события (переменной) X и соответствующими вероятностями их реализации p1, p2, …, pn, то говорят, что известен закон распределения случайной величины F(x). Большинство встречающихся на практике распределений вероятностей реализовано в Excel.
Распределения вероятностей имеют числовые характеристики.
Функции Excel для вычисления числовых характеристик распределения вероятностей. Они входят в группу Статистические. При вычислении функций в качестве случайных величин используйте следующие значения:

Математическое ожидание случайной величины (среднее арифметическое), характеризующее центр распределения вероятностей, вычисляется функцией СРЗНАЧ. СРЗНАЧ(A1:A7) = 9.
Дисперсия, характеризует разброс случайной величины относительно центра распределения вероятностей и вычисляется функцией ДИСПР. ДИСПР(A1:A7) = 4.857.
Среднеквадратичное отклонение есть квадратный корень из дисперсии, характеризует разброс случайной величины в единицах случайной величины и вычисляется функцией СТАНДОТКЛОНП. СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль случайной величины с законом распределения F(x) есть значение случайной величины x при заданной вероятности p., т.е. есть решение уравнения F(x)=p. Медиана есть квантиль с вероятностью p=0.5.
Excel, вместо квантилей содержит функции вычисления х для определенных уровней р: квартили (кварта – четверть), децили (дециль – десятая часть), персентили (персент – процент). Различают нижний квартиль с вероятностью p=0.25 и верхний квартиль с вероятностью p=0.75. Децили это квантили с вероятностью 0.1, 0.2, …, 0.9.
Функцию КВАРТИЛЬ используют, чтобы разбить данные на группы. В качестве второго аргумента указывают уровень (четверть), для которого нужно вернуть решение: 0 – минимальное значение распределения, 1 – первый, нижний квартиль, 2 – медиана, 3 – третий, верхний квартиль, 4 – максимальное значение. Например, КВАРТИЛЬ(A1:A7;3) = 10, т.е. 75% всех значений меньше 10, КВАРТИЛЬ(A1:A7;2) = 9.
Функция ПЕРСЕНТИЛЬ вычисляет квантиль указанного уровня вероятности и используется для определения порога приемлемости значений. В качестве второго аргумента указывают уровень 0.1, 0.2, …, 0.9. ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений меньше 11.8.
Excel содержит инструмент Ранг и персентиль, который на основе набора данных формирует выходную таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. См. справку по F1. Ниже приведен пример установки надстройки Пактет анализа
Распределения вероятностей, реализованные в Excel.
Каждый закон распределения описывает процессы разной вероятностной природы и характеризуется специфическими параметрами:
— равномерное распределение – n случайных чисел выпадает с одной и той же вероятностью p=1/n; характеризуется нижней и верхней границей; примером является появление чисел 1, 2, …, 6 при бросании игральной кости (p=1/6);
— биномиальное распределение моделирует взаимосвязь числа успешных испытаний m и вероятностей успеха каждого испытания p при общем количестве испытаний n — функции БИНОМРАСП и КРИТБИНОМ;
— нормальное (гауссово) распределение описывает процессы, в которых на результат воздействует большое число независимых случайных факторов, среди которых нет сильно выделяющихся – функции НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР и НОРМАЛИЗАЦИЯ;
— распределение Пуассона, предсказывает число случайных событий на определенном отрезке времени или на определенном пространстве, позволяет аппроксимировать биномиальное распределение – функция ПУАССОН;
— экспоненциальное (показательное) распределение, моделирует временные задержки между событиями, описывает процессы в задачах массового обслуживания и в задачах с «временем жизни» — ЭКСПРАСП;
— распределение хи-квадрат, связано с нормальным, возвращает одностороннюю вероятность распределения и используется для сравнения предполагаемых и наблюдаемых значений – функция ХИ2РАСП;
— распределение Стьюдента, связано с нормальным, возвращает вероятность для t-распределения Стьюдента и используется для проверки гипотез при малом объеме выборки – функция СТЬЮДРАСП;
— F-распределение (Фишера), связано с нормальным и может быть использовано в F-тесте, который сравнивает степени разброса двух множеств данных – fраспобр;
— гамма-распределение используется для изучения случайных величин, имеющих асимметричное распределение, в теории очередей – функция ГАММАРАСП;
— а также другие распределения – функции БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП, ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное распределениехарактеризуется числом успешных испытаний m, вероятностью успеха каждого испытания p и общим количеством испытаний n. Классическим примером использования биномиального распределения является выборочный контроль качества больших партий товара, изделий в торговле, на производстве, когда сплошная проверка невозможна. Из партии выбирают n образцов и регистрируют число бракованных m. Бракованными могут быть 1, 2, … , n образцов, но вероятности реального числа бракованных будут различными. Если контрольная вероятность брака ниже допустимой вероятности, то можно гарантировать достаточное качество всей партии.
В Excel функция БИНОМРАСП вычисляет вероятность отдельного значения распределения по заданным m, n и р, а функция КРИТБИНОМ – случайное число по заданной вероятности. Обычно функция КРИТБИНОМ используется для определения наибольшего допустимого числа брака.
В качестве примера построим график плотности вероятности биномиального распределения для n=10 (1, 2, …, 10) и p=0.2. Введите исходные данные, как показано на рисунке:
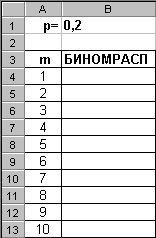
Далее в ячейку В4 введите статистическую функцию БИНОМРАСП и заполните ее параметры как показано на рисунке:
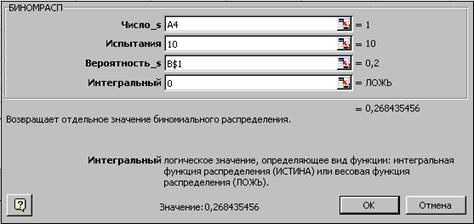
Здесь параметр Число_s есть число успешных испытаний m, Испытания – число независимых испытаний n, Вероятность_s – вероятность успеха каждого испытания p. Параметр Интегральный равен 0, если требуется получить плотность распределения (вероятность для значения m), и равен 1, если требуется получить вероятность с накоплением (вероятность того, что число успешных испытаний не меньше значения аргумента Число_s).
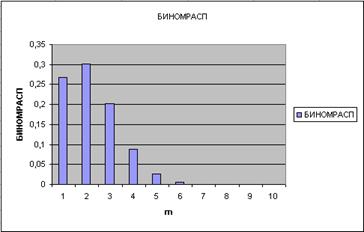
Формулу из В4 размножьте в ячейки В5:В13. Ниже показан результат:

В колонке В вычислены вероятности успешных испытаний m=1, 2, …, 10. Теперь по диапазону В4:В13 постройте график или гистограмму биномиальной функции плотности распределения – результат на рисунке. Поэкспериментируйте, изменяя значение вероятности в ячейке В1: 0.3, 0.4, 0.8, проследите за изменениями формы графика.
Для иллюстрации функции КРИТБИНОМ используем предыдущий пример – необходимо найти число m, для которого вероятность интегрального распределения больше или равна 0.75. Вызовите функцию КРИТБИНОМ и заполните параметры. Вы должны получить значение 3. Это означает, что при вероятности интегрального распределения >= 0.75 будет не менее трех (m>=3) успешных испытаний.

Нормальное распределениехарактеризуется средним арифметическим (математическим ожиданием) m и стандартным (среднеквадратичным) отклонением r. Дисперсия равна r 2 . Краткое обозначение распределения N(m,r 2 ). График нормального распределения симметричен относительно центра распределения (точки m), чем меньше r, тем больше вероятность появления случайной величины. В пределы [m-r,m+r] нормально распределенная случайная величина попадает с вероятностью 0,683 в пределы [m-2r,m+2r] — с вероятностью 0,955 и т.д.
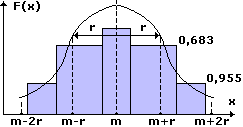
При m=0 и r=1 нормальное распределение называется стандартным или нормированным – N(0,1).
Нормальное распределение имеет очень широкий круг приложений. В качестве примера построим график плотности вероятностей нормального распределения при m=15 и r=1,5 в диапазоне [m-3r,m+3r] c шагом 0,5. Результат показан на рисунке.
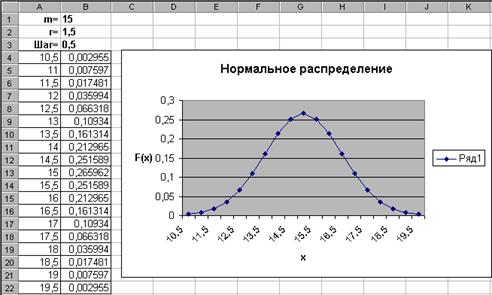
Выполните следующие действия:
— в ячейку А4 введите формулу =B1-3*B2, в ячейку А5 формулу =A4+B$3 и размножьте ее по ячейку А22;
— в ячейку В4 введите функцию НОРМРАСП из группы Статистические – параметры заполните как на рисунке;
— размножьте формулу из ячейки В4 по ячейку В22 и по диапазону В4:В22 постройте график; на 2-ом шаге мастера диаграмм в закладке Ряд введите подписи к оси х из диапазона А4:А22.
Источник
Равномерное непрерывное распределение в EXCEL
history 8 ноября 2016 г.
Рассмотрим равномерное непрерывное распределение. Вычислим математическое ожидание и дисперсию. Сгенерируем случайные значения с помощью функции MS EXCEL СЛЧИС() и надстройки Пакет Анализа, произведем оценку среднего значения и стандартного отклонения.
Равномерно распределенная на отрезке [a; b] случайная величина имеет плотность распределения (вероятности) : 
Функция распределения определяется следующим образом:
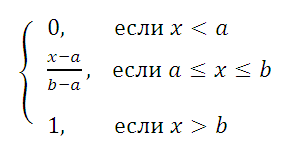
Равномерное непрерывное распределение (англ. Continuous uniform d istribution или Rectangular distribution ) часто встречается на практике.
Пример1. Например, известно, что гейзер извергается каждые 50 минут. Найти вероятность, того что турист увидит извержение, если будет ждать у гейзера 20 минут. В соответствии с вышеуказанными формулами вероятность увидеть извержение в течение времени наблюдения равна 20/50=0,4, т.е. 40%.
Пример2. Симметричный волчок после раскручивания падает набок. Вертикальная ось волчка после падения указывает на определенный угол от 0 до 360 градусов. Найти вероятность, того что ось волчка укажет на сектор от 90 до 180 градусов. Вероятность равна (180-90)/(360-0)=0,25.
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения . 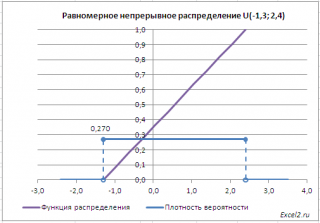
Математическое ожидание и дисперсия
Математическое ожидание для равномерного непрерывного распределения вычисляется по формуле =(a+b)/2.
Генерация случайных чисел
Случайные числа, имеющие равномерное непрерывное распределение на отрезке [0; 1), можно сгенерировать с помощью функции MS EXCEL СЛЧИС() . В функции нельзя задать нижнюю и верхнюю границу интервала, но записав формулу =СЛЧИС()*(b-a)+a можно сгенерировать равномерно распределенные числа на любом интервале [a; b).
Примечание : Чтобы сгенерировать случайные числа, имеющие равномерное дискретное распределение , воспользуйтесь функцией СЛУЧМЕЖДУ() .
Сгенерировать случайные числа, извлеченные из непрерывного равномерного распределения, можно также с помощью надстройки Пакет анализа .
Сгенерируем массив из 50 чисел из диапазона [3,3; 7,5). Для этого в окне Генерация случайных чисел установим следующие параметры (см. файл примера лист Генерация ):
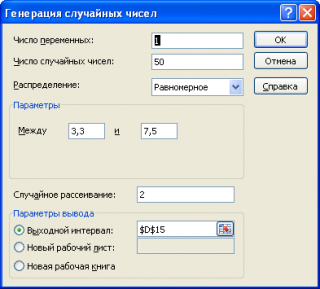
Как видно из рисунка выше, в поле Случайное рассеивание установлен необязательный параметр равный 2. Параметр Случайное рассеивание может принимать значение от 1 до 32767. Если установить этот параметр, то MS EXCEL будет каждый раз генерировать один и тот же массив чисел, соответствующий этот значению. Этот подход удобен для генерации одинаковых массивов, например, на различных компьютерах.
Оценка среднего и стандартного отклонения
Нижнюю и верхнюю границу интервала возьмем [3,3; 7,5) и разместим их в ячейках B4:B5 . Сгенерируем 50 чисел ( выборку ) и поместим их в диапазоне С14:С63 .
Математическое ожидание этого распределения =(B4+B5)/2 и равно 5,4. Стандартное отклонение распределения равно =КОРЕНЬ(((B5-B4)^2)/12)=1,21
Чтобы оценить математическое ожидание воспользуемся значениями выборки =СУММ(C14:C63)/СЧЁТ(C14:C63) .
Оценить стандартное отклонение можно с помощью формулы =СТАНДОТКЛОН.В(C14:C63) в MS EXCEL 2010 или =СТАНДОТКЛОН(C14:C63) для более ранних версий.
Чтобы оценить дисперсию используйте формулу =ДИСП.В(C14:C63) в MS EXCEL 2010 или =ДИСП(C14:C63) для более ранних версий. Также можно использовать формулу =СТАНДОТКЛОН.В(C14:C63)^2 .
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Источник