
17 авг. 2022 г.
читать 2 мин
Одной из наиболее распространенных метрик, используемых для измерения точности прогнозирования модели, является MAPE , что означает среднюю абсолютную ошибку в процентах .
Формула для расчета MAPE выглядит следующим образом:
MAPE = (1/n) * Σ(|факт – прогноз| / |факт|) * 100
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
MAPE обычно используется, потому что его легко интерпретировать и легко объяснить. Например, значение MAPE, равное 11,5%, означает, что средняя разница между прогнозируемым значением и фактическим значением составляет 11,5%.
Чем ниже значение MAPE, тем лучше модель способна прогнозировать значения. Например, модель с MAPE 2% более точна, чем модель с MAPE 10%.
Как рассчитать MAPE в Excel
Чтобы рассчитать MAPE в Excel, мы можем выполнить следующие шаги:
Шаг 1: Введите фактические значения и прогнозируемые значения в два отдельных столбца.
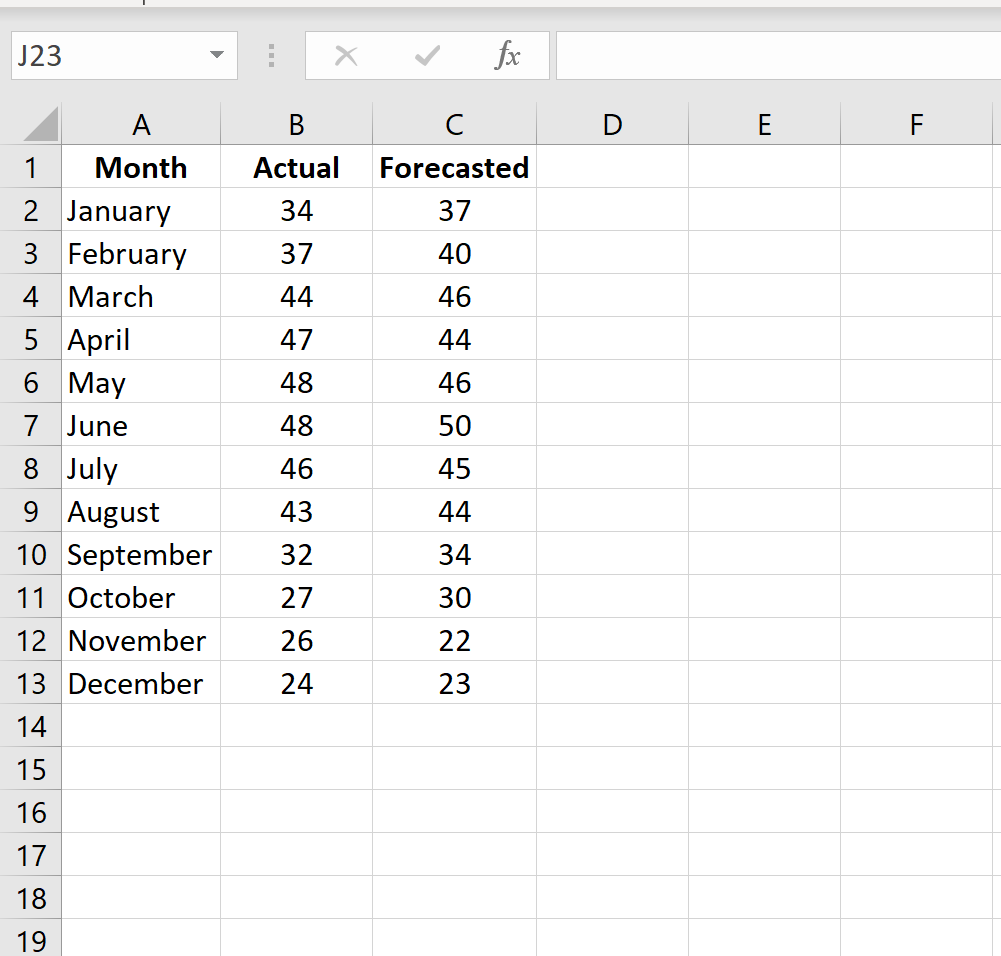
Шаг 2: Рассчитайте абсолютную процентную ошибку для каждой строки.
Напомним, что абсолютная процентная ошибка рассчитывается как: |фактический-прогноз| / |фактическое| * 100. Мы будем использовать эту формулу для расчета абсолютной процентной ошибки для каждой строки.
Столбец D отображает абсолютную процентную ошибку, а столбец E показывает формулу, которую мы использовали:
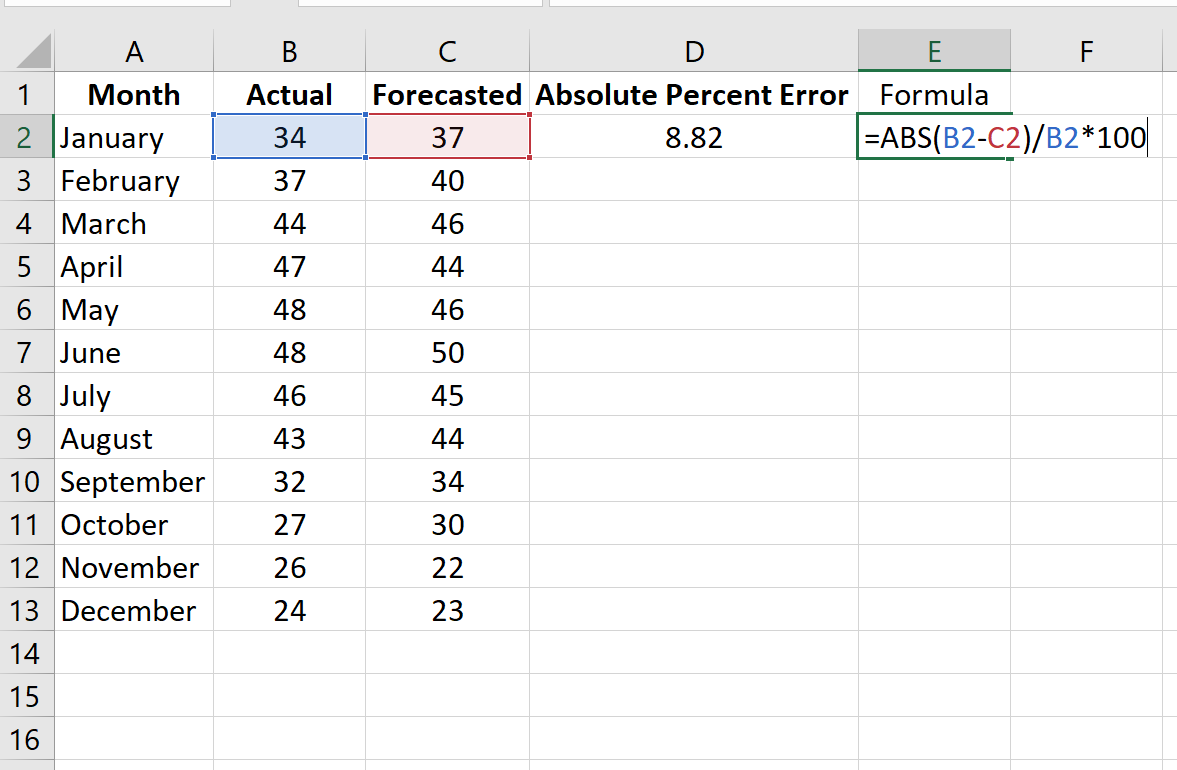
Повторим эту формулу для каждой строки:
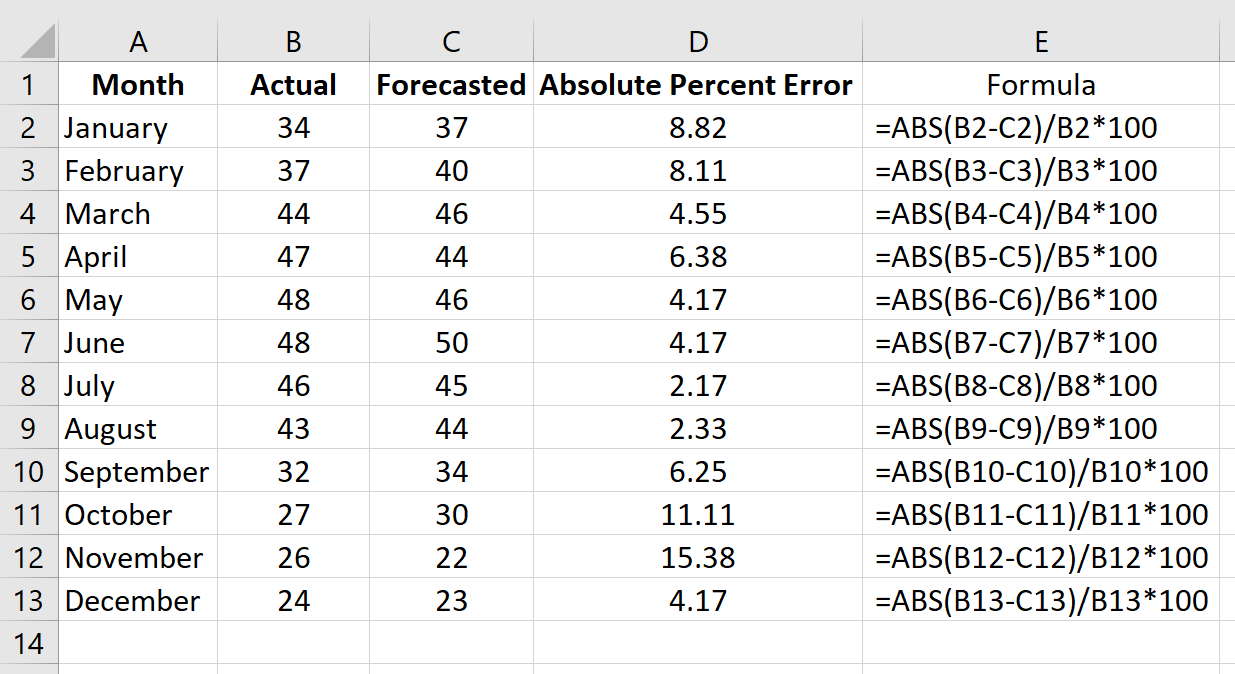
Шаг 3: Рассчитайте среднюю абсолютную ошибку в процентах.
Рассчитайте MAPE, просто найдя среднее значение в столбце D:
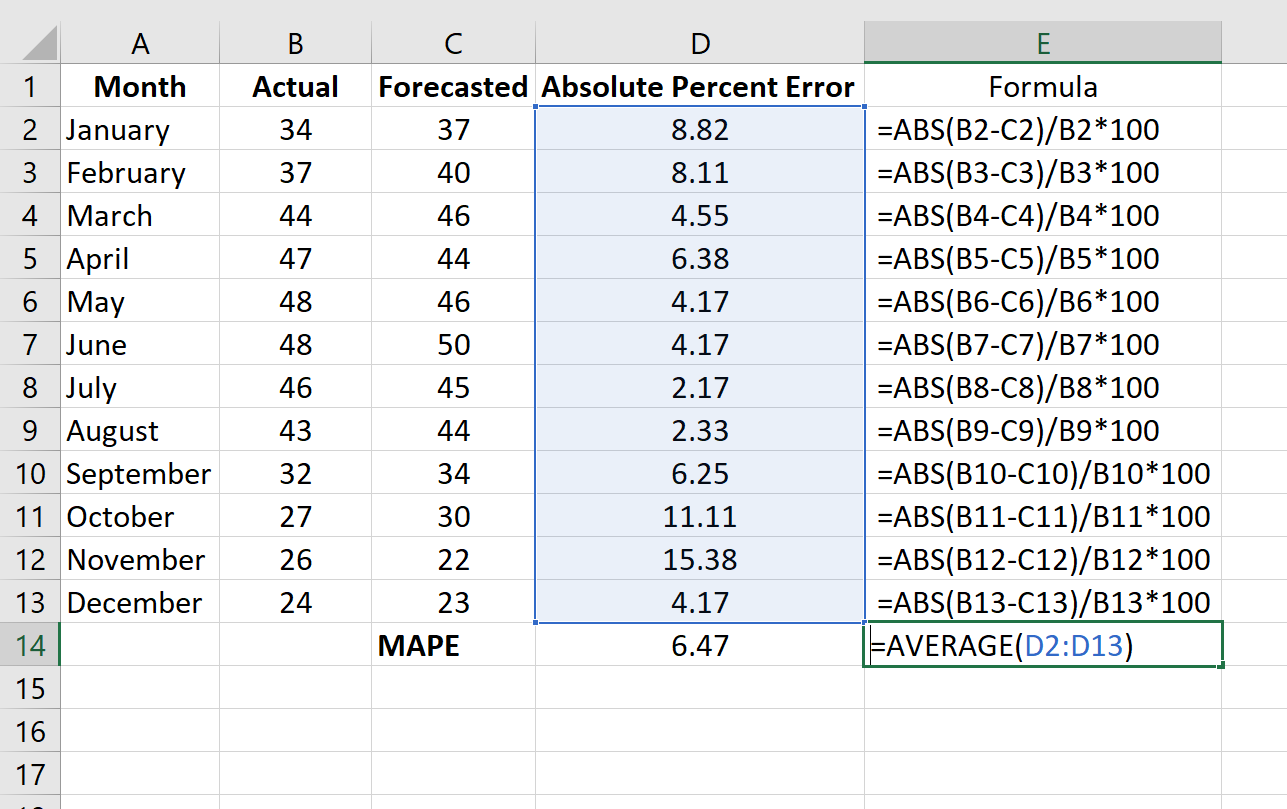
MAPE этой модели оказывается равным 6,47% .
Примечание по использованию MAPE
Хотя MAPE легко вычислить и легко интерпретировать, его использование имеет несколько потенциальных недостатков:
1. Поскольку формула для расчета абсолютной процентной ошибки |фактический-прогноз| / |фактическое| это означает, что он будет неопределенным, если какое-либо из фактических значений равно нулю.
2. MAPE не следует использовать с данными небольшого объема. Например, если фактический спрос на какой-либо товар равен 2, а прогноз равен 1, значение абсолютной процентной ошибки будет |2-1| / |2| = 50%, что создает впечатление, что ошибка прогноза довольно высока, несмотря на то, что прогноз отличается всего на одну единицу.
Другим распространенным способом измерения точности прогнозирования модели является MAD — среднее абсолютное отклонение. О том, как посчитать MAD в Excel, читайте здесь .
Дополнительные ресурсы
Что считается хорошей ценностью для MAPE?
Как рассчитать SMAPE в Excel
Как рассчитать MAE в Excel
One of the most common metrics used to measure the forecasting accuracy of a model is MAPE, which stands for mean absolute percentage error.
The formula to calculate MAPE is as follows:
MAPE = (1/n) * Σ(|actual – forecast| / |actual|) * 100
where:
- Σ – a fancy symbol that means “sum”
- n – sample size
- actual – the actual data value
- forecast – the forecasted data value
MAPE is commonly used because it’s easy to interpret and easy to explain. For example, a MAPE value of 11.5% means that the average difference between the forecasted value and the actual value is 11.5%.
The lower the value for MAPE, the better a model is able to forecast values. For example, a model with a MAPE of 2% is more accurate than a model with a MAPE of 10%.
To calculate MAPE in Excel, we can perform the following steps:
Step 1: Enter the actual values and forecasted values in two separate columns.

Step 2: Calculate the absolute percent error for each row.
Recall that the absolute percent error is calculated as: |actual-forecast| / |actual| * 100. We will use this formula to calculate the absolute percent error for each row.
Column D displays the absolute percent error and Column E shows the formula we used:

We will repeat this formula for each row:

Step 3: Calculate the mean absolute percent error.
Calculate MAPE by simply finding the average of the values in column D:

The MAPE of this model turns out to be 6.47%.
A Note On Using MAPE
Although MAPE is straightforward to calculate and easy to interpret, there are a couple potential drawbacks to using it:
1. Since the formula to calculate absolute percent error is |actual-forecast| / |actual| this means that it will be undefined if any of the actual values are zero.
2. MAPE should not be used with low volume data. For example, if the actual demand for some item is 2 and the forecast is 1, the value for the absolute percent error will be |2-1| / |2| = 50%, which makes it seem like the forecast error is quite high, despite the forecast only being off by one unit.
Another common way to measure the forecasting accuracy of a model is MAD – mean absolute deviation. Read about how to calculate MAD in Excel here.
Additional Resources
What is Considered a Good Value for MAPE?
How to Calculate SMAPE in Excel
How to Calculate MAE in Excel
 MAPE – средняя абсолютная ошибка в процентах используется:
MAPE – средняя абсолютная ошибка в процентах используется:
- Для оценки точности прогноза;
- Показывает на сколько велики ошибки в сравнении со значениями ряда;
- Хороша для сравнения 1-й модели для разных рядов;
- Используется для сравнения разных моделей для одного ряда;
- Оценки экономического эффекта, за счет повышения точности прогноза.
В данной статье мы рассмотрим, как рассчитать MAPE в Excel и как ее использовать.
Формула расчета MAPE:
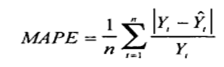
Где:
- Yt – фактический объем продаж за анализируемый период;
- Ŷt — значение прогнозной модели за аналазируемый период;
- n — количество периодов.
Для того, чтобы рассчитать среднюю абсолютную ошибку мы:
- Рассчитываем значение модели прогноза — Ŷt;
- Рассчитываем ошибку прогноза;
- Берем ошибку по модулю;
- Определяем абсолютную ошибку;
- Рассчитываем среднюю абсолютную ошибку в процентах — MAPE.
1. Рассчитаем значение модели прогноза — Ŷt
Возьмем модель с трендом и сезонностью. Рассчитаем значение модели для каждого периода, когда нам известны фактические продажи. Для этого сложившийся тренд за анализируемый период умножим на коэффициент сезонности для соответствующего месяца.
Получили значения прогнозной модели для каждого периода времени:
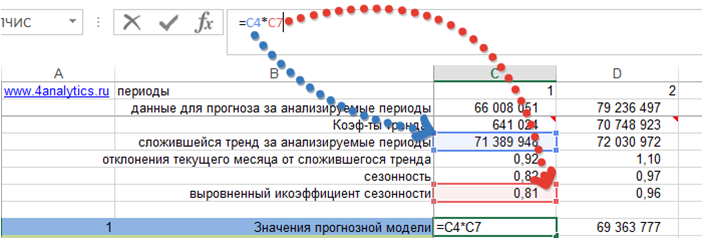
Подробнее о расчете прогноза с помощью тренда и сезонности читайте в статье «Расчет прогноза с помощью тренда и сезонности».
2. Рассчитаем значения ошибки прогноза.
В формуле расчета MAPE – это:
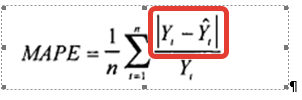
e — Ошибка прогноза — это разность между значениями временного ряда (фактом продаж) и моделью прогноза:
e= Yt — Ŷt
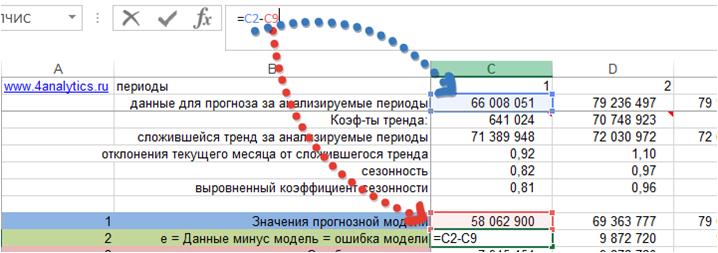
Получили значение ошибки прогноза для каждого момента времени за анализируемый период.
3. Рассчитаем ошибку по модулю.
Для этого воспользуемся функцией Excel =ABC()
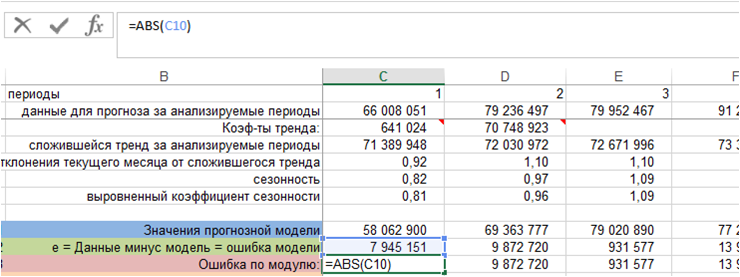
4. Определяем абсолютную ошибку.
Для каждого периода ошибку по модулю делим на фактические значения ряда, т.е. на фактический объем продаж:
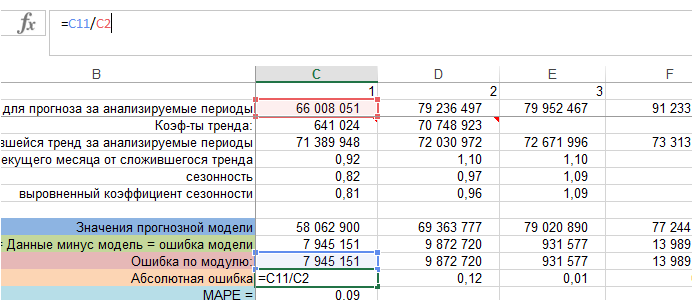
Получили абсолютную ошибку для каждого периода фактических продаж. В формуле MAPE — это:

5. Рассчитаем MAPE – среднюю абсолютную ошибку.
Для этого рассчитаем среднее значение абсолютной ошибки за все периоды:
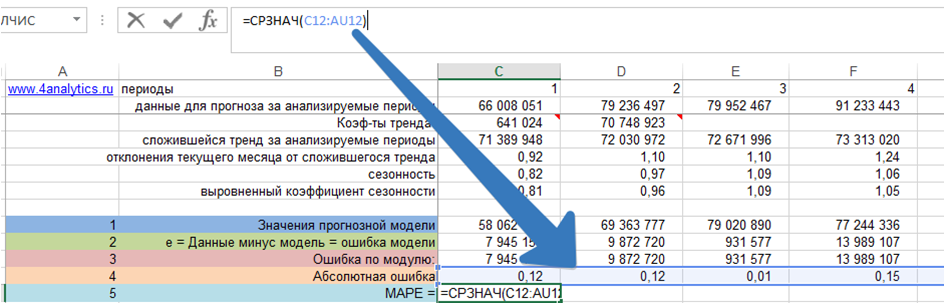
Скачать файл с примером расчета MAPE – средней абсолютной ошибки.
Как рассчитать показатель точность прогноза?
Показатель точность прогноза = 1 –MAPE:

С помощью MAPE вы можете сравнивать различные модели между собой, можете оценивать, как и на сколько модель делает точные прогнозы для разных временных рядов.
А также, что самое главное, можете оценить экономический эффект для компании за счет повышения точности прогноза.
Об этом подробнее можете почитать в нашей статье на сайте http://novoforecast.com/novo-forecast/instruktsiya/item/rost-tochnosti-prognoza-rost-pribyli.html
Если есть вопросы, пожалуйста, пишите в комментариях!
Forecast4AC PRO рассчитает MAPE для каждого временного ряда!
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
In statistics, we often use Forecasting Accuracy which denotes the closeness of a quantity to the actual value of that particular quantity. The actual value is also known as the true value. It basically denotes the degree of closeness or a verification process that is highly used by business professionals to keep track records of their sales and exchanges to maintain the demand and supply mapping every year. There are various methods to calculate Forecasting Accuracy.
So, one of the most common methods used to calculate the Forecasting Accuracy is MAPE which is abbreviated as Mean Absolute Percentage Error. It is an effective and more convenient method because it becomes easier to interpret the accuracy just by seeing the MAPE value. Here, we face a problem of infinite error when the Actual value of any entity becomes zero.
WMAPE or Weighted MAPE abbreviated as Weighted Mean Absolute Percentage Error is also an accuracy prediction technique. Here, the problem of infinite error (divide by zero) is removed since the summation of actual value in the denominator can never be zero. It calculates the error based on weights but in case of MAPE error was calculated based on the average values. So, WMAPE is more reliable and gives efficient accuracy than MAPE.
The formula to calculate WMAPE in Excel is :

In this article we are going to discuss how to calculate WMAPE in Excel using a suitable example.
Example : Consider the dataset shown below :
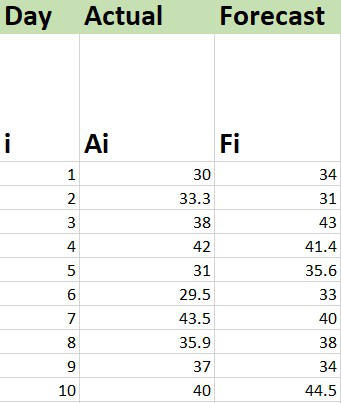
Calculation of WMAPE
The functions needed for formulas in Excel are-
SUM : To calculate the sum of multiple values
ABS : To calculate the absolute value.
The steps are :
1. Insert the data set in the Excel sheet.
2. Calculate the sub part of the formula inside the summation which is also known as Weighted Error.
=ABS(Cell_No_Act-Cell_No_Fore) where ABS : Used to calculate the absolute value Cell_No_Act : Cell number where Actual value is present Cell_No_Fore : Cell number where Forecast value is present
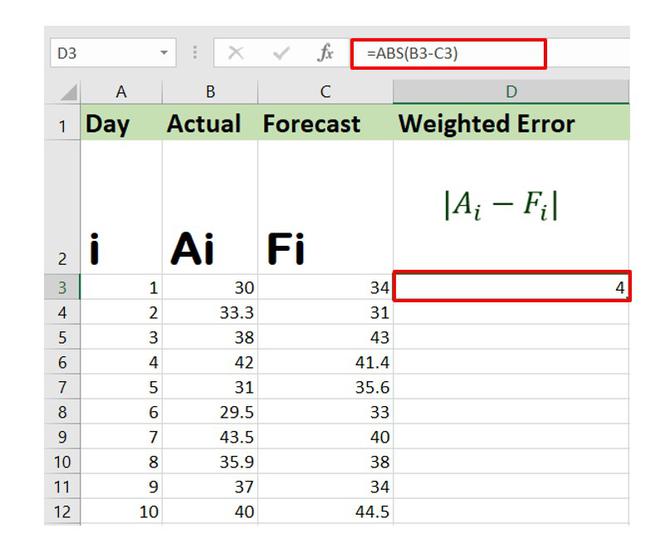
The above formula will calculate the weighted error for the first entry in the data set. Now, you can drag the Auto Fill Options button to get the weighted error for the remaining entries.
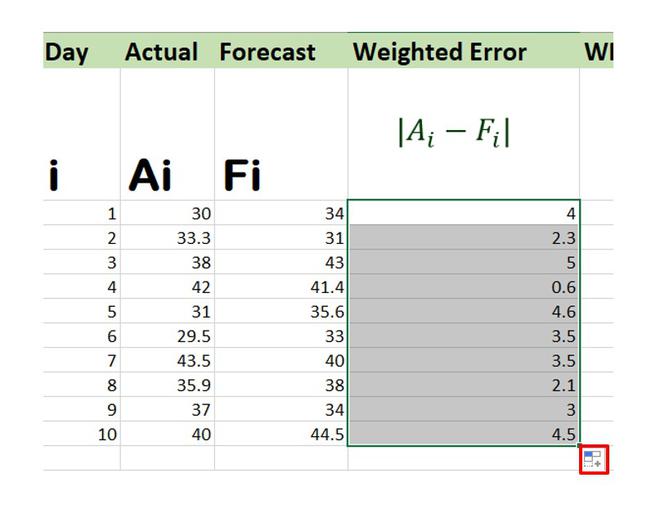
3. Now use the SUM function to find the summation of both weighted errors and the actual values and divide them to get the WMAPE.
The entries of Weighted Error are in the Cell range : D3 to D12
The entries of Actual Value are in the Cell range : B3 to B12

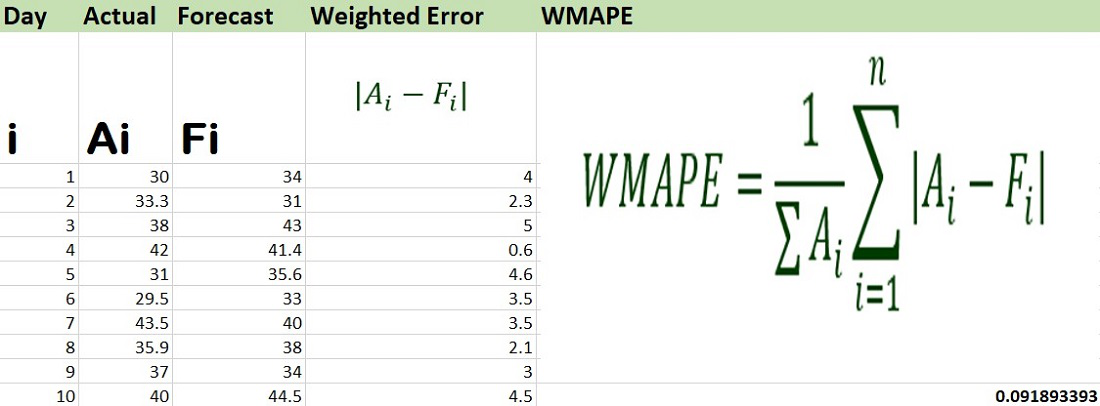
The value of WMAPE is 0.09189 or 9.189% approximately.
One of the most common metrics used to measure the forecasting accuracy of a model is MAPE, which stands for mean absolute percentage error.
The formula to calculate MAPE is as follows:
MAPE = (1/n) * Σ(|actual – forecast| / |actual|) * 100
where:
- Σ – a fancy symbol that means “sum”
- n – sample size
- actual – the actual data value
- forecast – the forecasted data value
MAPE is commonly used because it’s easy to interpret and easy to explain. For example, a MAPE value of 8% means that the average difference between the forecasted value and the actual value is 8%.
However, MAPE performs poorly with low volume data. For example, if the actual demand for some item is 2 and the forecast is 1, the value for the absolute percent error will be |2-1| / |2| = 50%, which makes it seem like the forecast error is quite high, despite the forecast only being off by one unit.
Thus, an alternative to MAPE is Weighted MAPE, which is calculated as:
Weighted MAPE = Σ(|actual – forecast| / |actual|) * 100 * actual / Σ(actual)
By weighting the percentage errors based on volume, we can get a better idea of the true error.
This tutorial explains how to calculate Weighted MAPE in Excel.
To calculate Weighted MAPE in Excel, we can perform the following steps:
Step 1: Enter the actual values and forecasted values in two separate columns.

Step 2: Calculate the weighted error for each row.
Recall that the weighted error is calculated as: |actual-forecast| / |actual| * 100 * actual. We will use this formula to calculate the weighted error for each row.
Column D displays the weighted error and Column E shows the formula we used:

We will repeat this formula for each row:

Step 3: Find the sum of actual values.

Step 4: Calculate the Weighted MAPE.
Lastly, we will calculated the Weighted MAPE by dividing the total weighted errors by the sum of the actual values:

The Weighted MAPE turns out to be 5.92%.
Additional Resources
How to Calculate Mean Absolute Percentage Error (MAPE) in Excel
How to Calculate Mean Squared Error (MSE) in Excel
Have you ever heard of Forecasting Accuracy? Forecasting Accuracy is nothing but the closeness of actual quantity to a particular quantity. Here the actual quantity is often called True Value.
Table of Contents
- How Do You Calculate Mean Absolute Percent Error (MAPE)?
- 1. Insert Actual And Forecasted values in Excel separately
- 2. Find the Absolute Percentage Error
- 3. Calculate the Average Of the Absolute Percentage Error
- Drawback Of Using Mean Absolute Percentage Error (MAPE)
- How Do You Calculate Weighted MAPE (WMAPE)?
- Why We Use Weighted MAPE?
- 1. Insert Actual And Forecasted values separately
- 2. Find Weighted Error
- 3. Calculate the Sum Of Actual Values
- 4. Calculate Weighted MAPE
The concept of Mean Absolute Percentage Error (MAPE) is more focused on Forecasting Accuracy. We can measure the forecasting accuracy by using the MAPE model.
Actually, there are many other proven methods but we prefer this one because it’s easy to solve and explain and last it is more accurate. This method is preferred in Business fields when it comes to maintaining the record of sales and demand and supply.
In this post, we are going to cover How to Calculate Mean Absolute Percentage Error (MAPE) in Excel.
How Do You Calculate Mean Absolute Percent Error (MAPE)?
MAPE = (1/n) * Σ(|actual – forecast| / |actual|) * 100
If you are willing to calculate MAPE then please follow the given steps carefully.
1. Insert Actual And Forecasted values in Excel separately

For calculating MAPE, we are considering working days. Column B indicates the actual values on the other hand Column C indicates Forecasted values.
2. Find the Absolute Percentage Error
Absolute Percentage Error= |actual-forecast| / |actual| * 100
In order to calculate the Absolute Percentage Error, we are using the above formula. We are going to calculate the Absolute Percentage Error for each and every row.

Column D represents the “Absolute Percentage Error” and Column E represents the formula that we have used in the previous column.
3. Calculate the Average Of the Absolute Percentage Error
If you are willing to calculate Mean Absolute Percentage Error then all you need to do is now just find the average of the absolute percentage error.

In my case, the MAPE model has a value of 11.1827.
Drawback Of Using Mean Absolute Percentage Error (MAPE)
Undefined When Actual Value is Zero:- We already know the formula of Absolute Percentage Error is |actual-forecast| / |actual|, it clearly shows that when any of the actual will be zero then we can not define Absolute Percentage Error.
Not Suitable For Low Volume Data:- Suppose, the actual value of any item is 4 and the forecasted value is 2 then the absolute percent error will be |4-2| / |4| = 50%. This represents the forecasting error is too high but we can figure out that it is not the case.
How Do You Calculate Weighted MAPE (WMAPE)?
Why We Use Weighted MAPE?
As we have already discussed that MAPE is not very suitable for Low Volume Data or when sales are very close to 0. thus, we use an alternate that we call Weighted MAPE or often called WMAPE. Again the formula is not too complicated it is very similar to the MAPE.
Weighted MAPE=|actual-forecast| / |actual| * 100 * actual
In order to determine the true error rate, we need to weigh the percentage of errors according to the volume.
1. Insert Actual And Forecasted values separately
As for now, I am using my currently used data that we have already used in MAPE.
2. Find Weighted Error
The next step is to calculate the weighted error for each row by using the formula |actual-forecast| / |actual| * 100 * actual. In my excel sheet, column D shows the weighted error, and column E shows the formula.

3. Calculate the Sum Of Actual Values
Before finding the Weighted MAPE it is necessary to calculate the sum of actual values.

In order to calculate the Weighted MAPE, you need to find the total sum of the Weighted Error and divided it by the sum of the Actual Error.

So, we get a Weighted MAPE of about 10.87
In this tutorial, we discussed “MAPE” and “Weighted MAPE”. We have also seen when we use Mean Absolute Percentage Error and when we use Weighted Mean Absolute Percentage Error In Excel.
Hope you find this post helpful.
history 4 августа 2021 г.
- Группы статей
Сам метод скользящего среднего рассмотрен в статье Скользящее среднее в MS EXCEL, в которой показано как для этого использовать инструмент MS EXCEL Пакет анализа, а также линию тренда и формулы.
В этой статье рассмотрим не сам метод сглаживания, а его применение для прогнозирования. Как было сказано во вводной статье про прогнозирование, метод прогнозирования подбирается в соответствии с процессом, который генерирует значения временного ряда. Поэтому в файле примера используется как стационарные процессы, будем называть их постоянными, т.к. у них среднее и дисперсия постоянные (хотя фактически это белый шум со смещенным средним), и растущий тренд. Для оценки точности прогнозирования рассчитываются ошибки модели, строится интервал прогнозирования (на самом деле не интервал прогнозирования, а некий доверительный интервал на основе вычисленной ошибки). Так же оценивается адекватность модели.
Примечание: Конечно, прогнозировать процессы типа белого шума, бесперспективное занятие, но, во-первых в файле примера демонстрируются характеристики этого процесса (строится диаграмма рассеяния, функция автокорреляции, диаграмма разброса ошибок и пр.), а во-вторых таблицу с исходными значениями можно заменить и все характеристики будут пересчитаны в файле примера автоматически.
Построение исходного и сглаженного ряда
Для построения рядов можно использовать диаграмму типа График или Точечная. Выберем последний тип – Точечная (ниже будет пояснено почему Точечная в данном случае удобнее).
Для исходных рядов нам понадобится 4 столбца с данными (2 «постоянных» процесса, ряд с цикличностью и тренд). В файле примера на листе Исходный и сглаженный ряд это столбцы T:W.
Один из исходных рядов – динамический (столбец U, назовем его «постоянный» процесс с изменениями), т.е. его значения пересчитываются при любом изменении данных листа или после нажатии клавиши F9. Это сделано с помощью формулы =СЛУЧМЕЖДУ($T$10-2*$T$9;$T$10+2*$T$9)
За среднее значение этого ряда взято среднее значение ряда из столбца T =СРЗНАЧ(T13:T111), а диапазон изменения – 2 стандартных отклонения того же ряда =СТАНДОТКЛОН.В(T13:T112).
Такой автоматически генерирующийся ряд удобен для оценки модели – можно получить целый набор прогнозных значений, ошибок и доверительных интервалов. Фактически, конечно, функция СЛУЧМЕЖДУ() генерирует белый шум (с заданным смещением среднего относительно 0).
Примечание: Про функцию СЛУЧМЕЖДУ() можно почитать здесь. Эта функция генерирует непрерывное равномерное распределение, чтобы сгенерировать выборку из нормального или любого другого распределения см. эту статью.
Выбор нужно типа процесса организован с помощью группы переключателей, которая связана с ячейкой I11.

Значения выбранного исходного ряда подставляются в столбце В с помощью формулы =СМЕЩ(T13;;$I$11-1). Подробнее про функцию СМЕЩ() см. здесь.
Сглаженный ряд разместим рядом в столбце С, этот ряд будет формироваться для заданного периода усреднения (ячейка A7) с помощью формулы =ЕСЛИ(A13<$A$7;НД();СРЗНАЧ(СМЕЩ(B13;-$A$7+1;;$A$7)))
Примечание: Про построение сглаженного ряда см. Скользящее среднее в MS EXCEL.
Период усреднения для удобства задается с помощью элемента управления счетчик.
Осталось сформировать данные для линии среднего значений исходного ряда. Для этого понадобится только 2 точки (см. диапазон F43:G44).
Теперь все готово для построения диаграммы.
Примечание: для тех, кто не имеет большого опыта в построении диаграмм MS EXCEL предлагается прочитать эту статью.
Для тренда сглаженный ряд будет выглядеть так: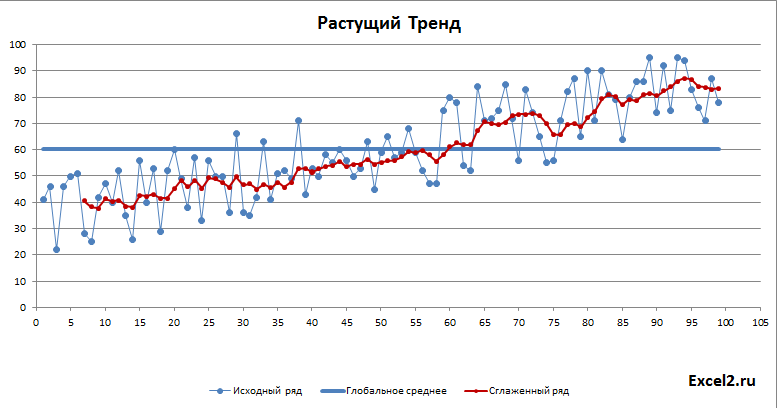
Расчет прогнозного значения
Напомним, что метод скользящего среднего состоит в вычислении средних значений на основе предшествующих значений исследуемого числового ряда. Пусть последнее значение ряда произошло в момент i.
В случае усреднения за 3 периода скользящее среднее в момент i равно:
Yскол.i=(Yi+ Yi-1+ Yi-2)/3
Именно так считает инструмент Пакета Анализа «Скользящее среднее». Понятно, что нас интересует прогноз в будущий момент времени i+1. Положим, что прогнозное значение ряда в момент i+1 равно Yпрогнозн.i+1= Yскол.i
В итоге получаем эквивалентную формулу
Yпрогнозн.i+1=(Yi+ Yi-1+ Yi-2)/3
Для наглядности прогнозное значение на диаграмме изобразим в виде горизонтальной линии зеленого цвета (длина линии ничего не значит). Для этого понадобится только 2 точки (см. диапазон F8:G9).
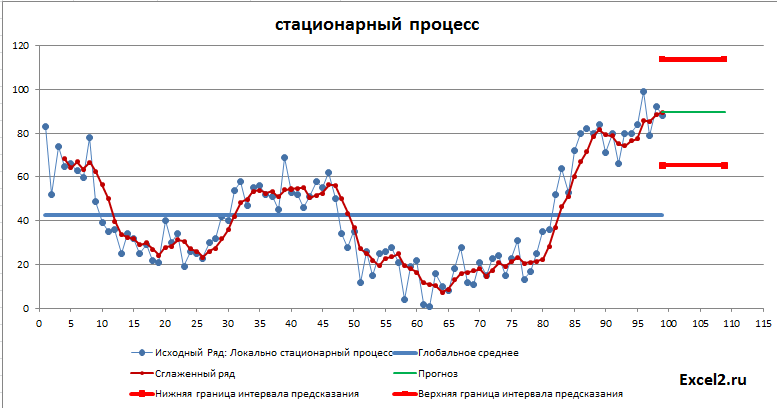
Хотя использование метода скользящего среднего для прогнозирования носит скорее академический, нежели практический интерес, все же покажем как построить что-то типа «интервала предсказания». Для построения интервала воспользуемся ошибкой, которая вычисляется в надстройке Пакет анализа по формуле:
=КОРЕНЬ(СУММКВРАЗН(ИР;СР)/m)
Где m – количество периодов усреднения
ИР — m последних значений Исходного Ряда (ИР)
СР — m последних значений Сглаженного Ряда (СР)
Т.е. данная стандартная ошибка вычисляется по формуле: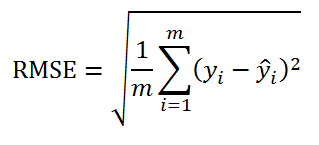
RMSE – это Root Mean Squared Error (среднеквадратическая ошибка).
В файле примера на листе «Прогнозное значение» эта ошибка вычислена по формуле
=КОРЕНЬ(СУММКВРАЗН(СМЕЩ($B$112;-A7;;A7);СМЕЩ($C$112;-A7;;A7))/$A$7)
A7 содержит количество периодов усреднения
СМЕЩ($B$112;-A7;;A7) – это ссылка на диапазон исходного ряда (последние m значений)
СМЕЩ($C$112;-A7;;A7) – это ссылка на диапазон сглаженного ряда
СУММКВРАЗН() вычисляет сумму квадратов разностей
Если вычислить ошибки прогнозирования в отдельном столбце D, то формула для RMSE упростится:
=КОРЕНЬ(СУММКВ(СМЕЩ($D$112;-A7;;A7))/$A$7)
Границы интервала (для заданного уровня значимости альфа) вычисляются как:
Верхняя граница = Yпрогнозн.i+1 + RMSE*tm-1,1-альфа/2
Нижняя граница = Yпрогнозн.i+1 — RMSE*tm-1,1-альфа/2
tm-1,1-альфа/2 — верхний α/2-квантиль распределения Стьюдента с m-1 степенью свободы (это просто число, которое показывает сколько ошибок RMSE нужно, чтобы «интервал предсказания» накрыл прогнозное значение с вероятностью 1-альфа).
Примечание: «Интервал предсказания» вычислен лишь по аналогии с построением доверительного интервала для оценки среднего, для которого у нас была статистическая модель. Для случая скользящего среднего корректность такого построения обосновывается отдельно. В данной статье «Интервал предсказания» построен лишь с целью демонстрации самого процесса построения интервалов предсказания.
Верхний α/2-квантиль вычислим по формуле =СТЬЮДЕНТ.ОБР.2Х(C8;A7-1)
в ячейке С8 находится альфа – уровень значимости (обычно 5%).
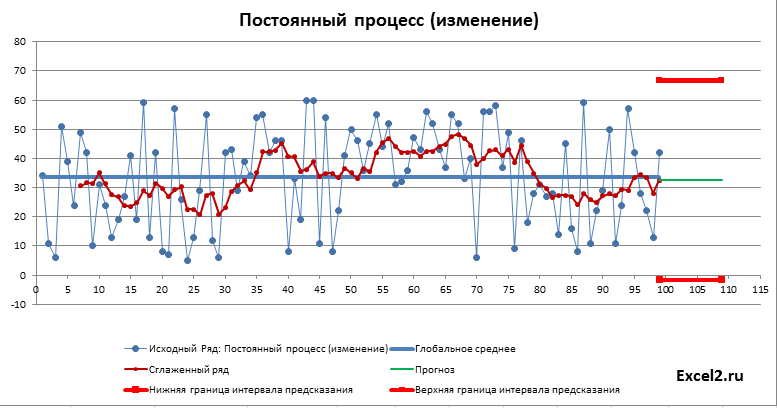
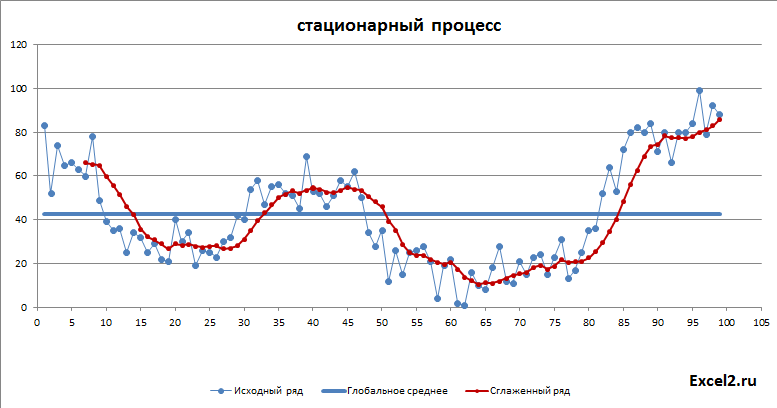
Как видно из диаграммы выше для нашего стационарного процесса (фактически белый шум) прогнозное значение ожидаемо находится около глобального среднего, а доверительный интервал охватывает весь диапазон изменений исходного ряда, т.е. будущее значение этого ряда может появиться на всем интервале, что фактически говорит нам о невозможности предсказания.
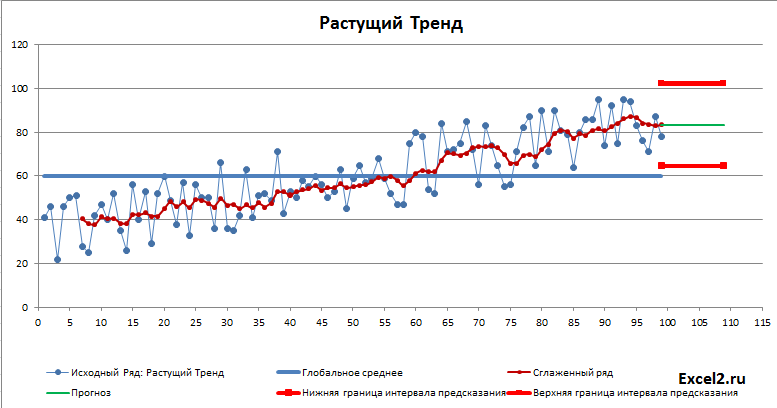
Как и следовало ожидать, для растущего тренда картинка существенно отличается: доверительный интервал уже в 2 раза меньше и прогнозное значение находится вдали от глобального среднего.
Автокорреляция исходного ряда
Исследуем исходный ряд на наличие автокорреляции. Подробно об автокорреляции см. отдельную статью.
Автокорреляция (Autocorrelation, Lagged correlation, Serial correlation) – корреляция значений временного ряда с собственными значениями, сдвинутыми по времени на один или несколько периодов (лагов). Ниже показана диаграмма содержащая исходный ряд и ряд сдвинутый на лаг k=4 (общее количество значений ряда N уменьшится на k, глобальное среднее на диаграмме оставлено как у исходного ряда).
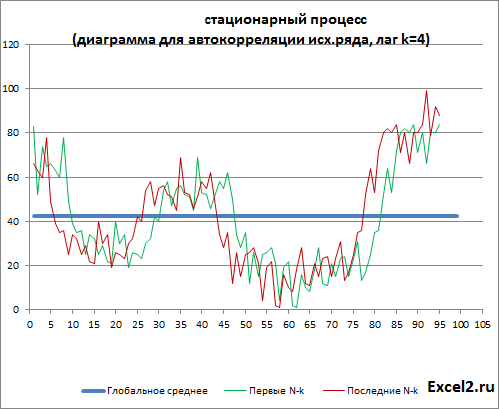
Примечание: Диаграмма построена на листе «Автокорреляция ИР» в файле примера. ИР – Исходный Ряд.
Для оценки автокорреляции используют 3 основных инструмента: график временного ряда (Time Series Plot), диаграмму рассеивания (Lagged Scatterplot) в зависимости от лага и функцию автокорреляции (Autocorelation Function, ACF).
Диаграмма рассеяния используется для отображения возможной взаимосвязи между двумя переменными.
В нашем случае будем исследовать корреляционную зависимость между двумя рядами данных, сдвинутых на лаг k относительно друг друга (см. диаграмму выше).
Для лага k=4 диаграмма рассеяния, очевидно, демонстрирует наличие линейной положительной корреляции.
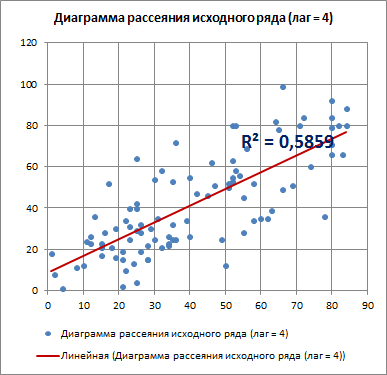
С помощью инструмента диаграммы «Линия тренда» построена линия регрессии и вычислим коэффициент детерминации R2. Ниже мы вычислим R2 с помощью формул, т.к. это просто квадрат коэффициента автокорреляции.
Примечание: Линия тренда подробно описана в разделе Построение линии регрессии статьи про Простую линейную регрессию.
Вычислим коэффициенты автокорреляции для лагов от 1 до 15.
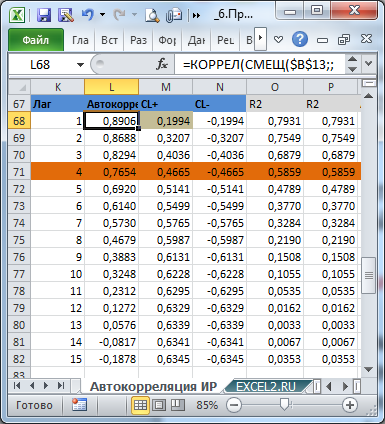
=КОРРЕЛ(СМЕЩ($B$13;;;$B$10-K68);СМЕЩ($B$13;K68;;$B$10-K68))
Два массива в аргументах функции КОРРЕЛ() – это просто 2 ряда, которые сдвинуты на лаг k (ячейка K68) относительно друг друга:
СМЕЩ($B$13;;;$B$10-K68)
СМЕЩ($B$13;K68;;$B$10-K68)
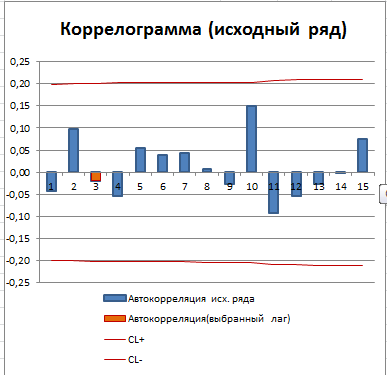
Зависимость коэффициента автокорреляции от лага – это функция автокорреляции (ACF). График ACF – это коррелограмма. Для стационарного процесса (у нас это «постоянный» процесс, фактически белый шум) коррелограмма имеет следующий вид:
Для другого стационарного процесса (с апериодической цикличностью) коррелограмма имеет совершенно другой вид:
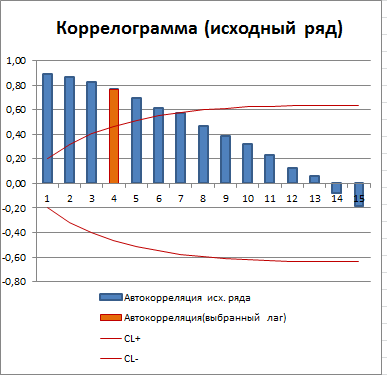
Все коэффициенты автокорреляции, которые выше границ доверительного интервала, являются статистически значимыми (про расчет доверительного интервала для ACF см. статью про Автокорреляцию). Диаграмма рассеяния для выбранного лага (столбец гистограммы, который выделен цветом) также подтверждает отсутствие автокорреляции.
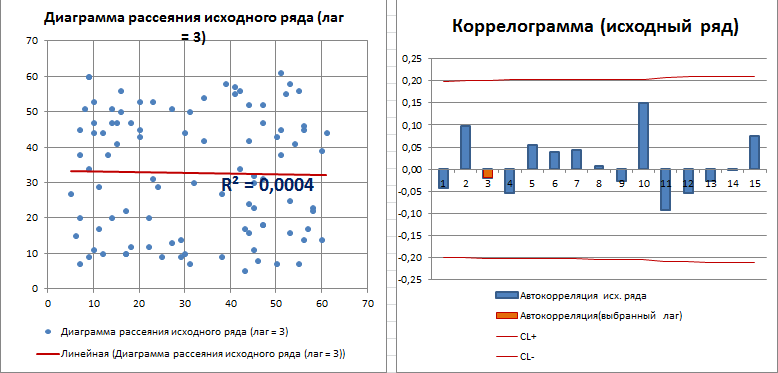
Коэффициент детерминации R2, указанный на диаграмме рассеяния можно рассчитать возведя в квадрат коэффициент корреляции или применив формулу
=КВПИРСОН(СМЕЩ($B$13;;;$B$10-K68);СМЕЩ($B$13;K68;;$B$10-K68))
для тех же массивов, полученных из исходного ряда.
Вычисление ошибок модели
Для прогнозирования значения временного ряда мы использовали модель скользящего среднего с определенным периодом усреднения m. Какое значение является лучшим для прогнозирования?
Критерием оптимальности m является минимизация ошибки модели.
Существует целый ряд формул для вычисления ошибок, но самой лучшей ошибкой для оценки точности модели является среднеквадратичная ошибка (RMSE), вычисленная нами ранее.
Кроме применяются еще несколько других ошибок:
• MAE (Mean Absolute Error, Средняя Абсолютная ошибка). В EXCEL вычисляется по формуле =СРЗНАЧ(ABS(СМЕЩ($D$112;-D10;;D10))). Сначала диапазон ошибок СМЕЩ($D$112;-D10;;D10) в столбце D берется по модулю, затем находится среднее значение. Эта ошибка менее чувствительна к одиночным выбросам, т.к. значения ошибок не возводятся в квадрат.
• MAPE (Mean Absolute Percentage Error, Средняя Абсолютная Процентная Ошибка). В EXCEL вычисляется по формуле =СРЗНАЧ(ABS(СМЕЩ($D$112;-D10;;D10)/СМЕЩ($B$112;-D10;;D10))) Вычисляется практически аналогично MAE, но вместо просто ошибки берется по модулю ее отношение к значению исходного ряда. Получается безразмерная величина. Подходит для исходных рядов с трендом или ярко выраженной сезонностью.
• ME (Mean Error, Средняя ошибка). Эта ошибка показывает имеет ли прогноз смещение. МЕ должна быть около 0. =СРЗНАЧ(СМЕЩ($D$112;-D10;;D10)). ME может быть положительной и отрицательной.
• MPE (Mean Percentage Error, Средняя Процентная ошибка). Вычисляется практически аналогично ME, но вместо просто ошибки берется ее отношение к значению исходного ряда. MPE может быть положительной и отрицательной. =СРЗНАЧ((СМЕЩ($D$112;-D10;;D10)/СМЕЩ($B$112;-D10;;D10)))
Все ошибки вычислены в файле примера на листе Ошибки модели в диапазоне M7:Q11.
Как было сказано выше, для построения «интервала предсказания» прогнозного значения использовалась среднеквадратичная ошибка (RMSE) причем вычисленная не для всего ряда, а лишь на периоде усреднения. Это соответствует формулам MS EXCEL в Пакете анализа. На обоих горизонтах расчета RMSE дает близкие значения, причем в зависимости от лага или значений ряда RMSE вычисленная на периоде усреднения m может давать непредсказуемо либо меньшее либо большее значение по сравнению с RMSE вычисленной для всего ряда (в этом можно убедиться проанализировав RMSE для динамически изменяемого постоянного процесса).
Проверка адекватности модели
На листе Ошибки модели построена диаграмма разброса ошибок и гистограмма ошибок. Эти диаграммы автоматически перестраиваются в зависимости от выбранного лага или типа исходного ряда.
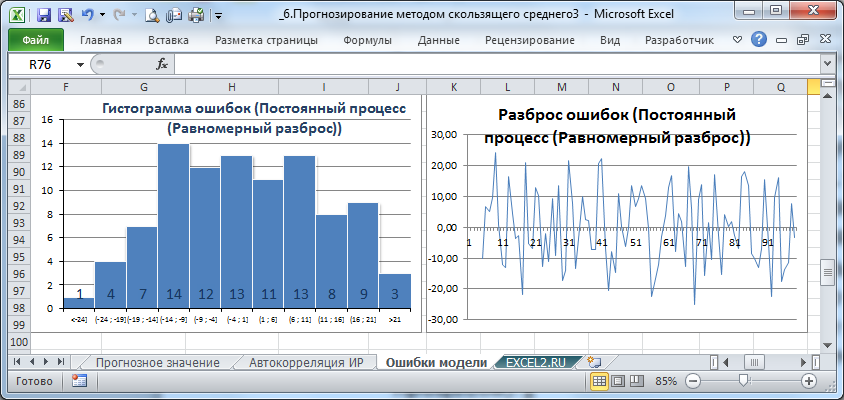
Диаграмму разброса ошибок можно построить на основе диаграммы MS EXCEL типа График. Специальных знаний построения диаграмм практически не требуется. Впрочем, как и для построения Гистограммы. Несколько сложнее построить таблицу исходных данных для гистограммы. Об этом подробно рассказано в статье Гистограмма распределения
Диаграмма разброса ошибок должна демонстрировать колебания ошибок около 0, а гистограмма — типичную выборку из нормального распределения. Проверить распределение ошибок на нормальность можно построить соответствующий график.
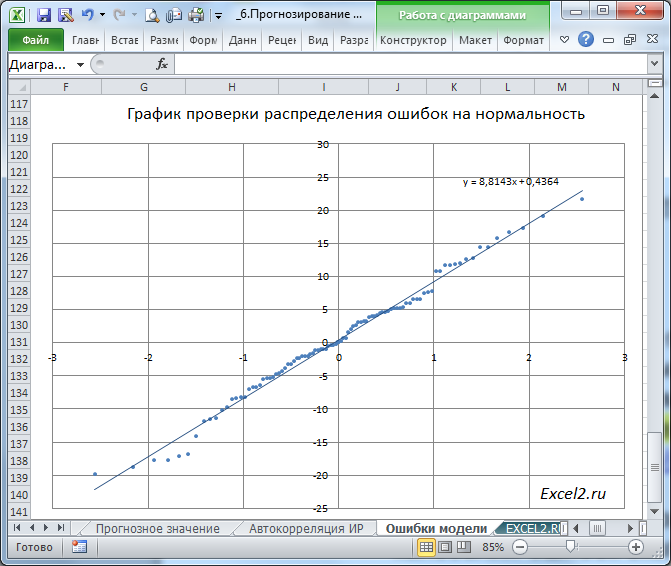
Подробнее о проверке распределения на нормальность см. в этой статье.
В заключение, по аналогии с проверкой исходного ряда на автокорреляцию можно вычислить автокорреляцию ошибок и построить диаграммы рассеяния и коррелограмм.
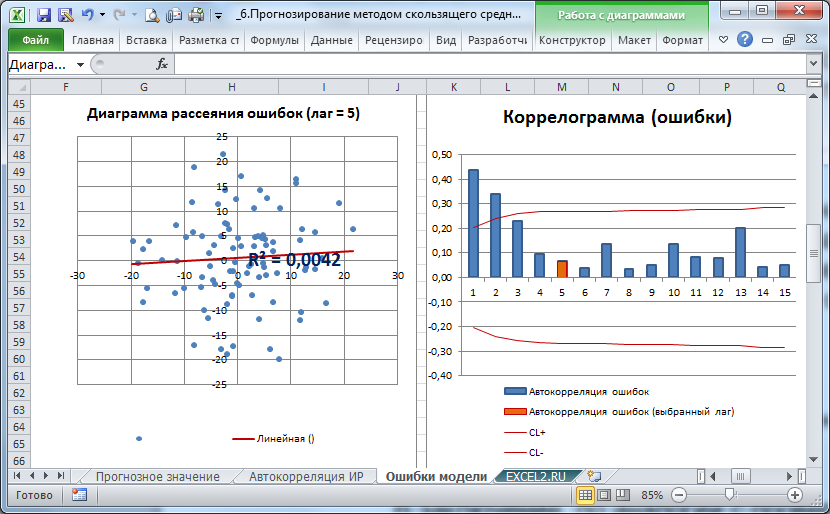
На картинке выше приведены диаграмма рассеяния и коррелограмм для ошибок «постоянного» процесса.
Примечание: На листе «скользящее среднее» объединены все диаграммы, о которых рассказывалось выше в статье.