
Функция ПИРСОН (вводить следует PEARSON на английском) предназначена для вычисления коэффициента корреляции Пирсона r. Данную функцию используют в работе в том случае, когда необходимо отразить степень линейной зависимости между двумя массивами данных. В Excel имеется несколько функций с помощью которых можно получить такой же результат, однако универсальность и простота функции Пирсон делают выбор в ее пользу.
Как работает функция ПИРСОН в Excel?
Рассмотрим пример расчета корреляции Пирсона между двумя массивами данных при помощи функции PEARSON в MS EXCEL. Первый массив представляет собой значения температур, второй давление в определенный летний период. Пример заполненной таблицы изображен на рисунке:
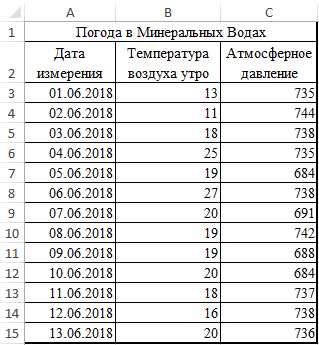
Задача следующая: необходимо определить взаимосвязь между температурой и давлением за июнь месяц.
Пример решения с функцией ПИРСОН при анализе в Excel
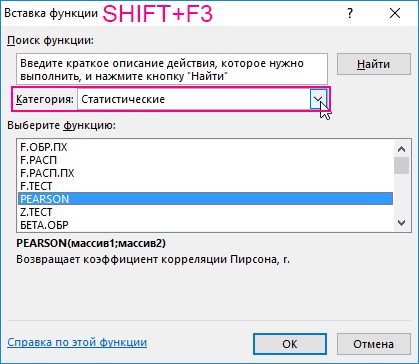
- Выберем ячейку С17 в которой должен будет посчитаться критерий Пирсона как результат и нажмем кнопку мастер функций «fx» или комбинацию горячих клавиш (SHIFT+F3). Откроется мастер функций, в поле Категория необходимо выбрать «Статистические». В списке статистических функций выбрать PEARSON и нажать Ok:
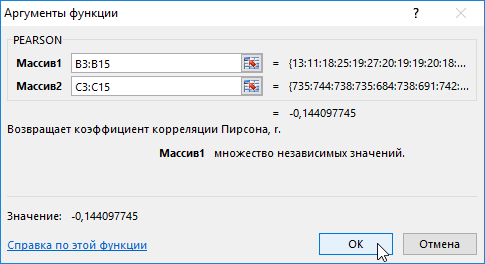
- В меню аргументов выбрать Массив 1, в примере это утренняя температура воздуха, а затем массив 2 – атмосферное давление.
- В результате в ячейке С17 получим коэффициент корреляции Пирсона. В нашем случае он отрицательный и приблизительно равен -0,14.
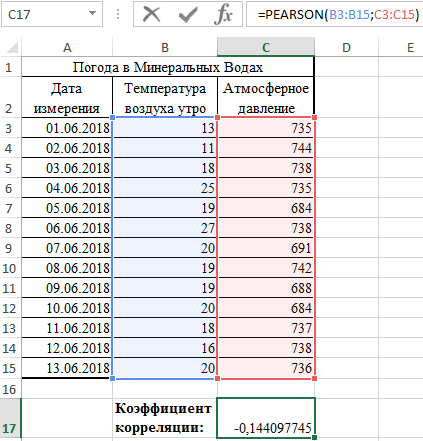
Данный показатель -0,14 по Пирсону, который вернула функция, говорит об неблагоприятной зависимости температуры и давления в раннее время суток.
Функция ПИРСОН пошаговая инструкция
Коэффициент корреляции является самым удобным показателем сопряженности количественных признаков.
Задача: Определить линейный коэффициент корреляции Пирсона.
Пример решения:
- В таблице приведены данные для группы курящих людей. Первый массив х — представляет собой возраст курящего, второй массив y представляет собой количество сигарет, выкуренных в день.
- Выберем ячейку В4 в которой должен будет посчитаться результат и нажмем кнопку мастер функций fx (SHIFT+F3).
- В группе Статистические выберем функцию PEARSON.
- Выделим Массив 1 – возраст курящего, затем Массив 2 – число сигарет, выкуренных в день.
- Нажмем кнопку ОК и увидим критерий нормального распределения Пирсона в ячейке В4.


Таким образом, по результату вычисления статистическим выводом эксперимента выявлена отрицательная зависимость между возрастом и количеством выкуренных сигарет в день.
Корреляционный анализ по Пирсону в Excel
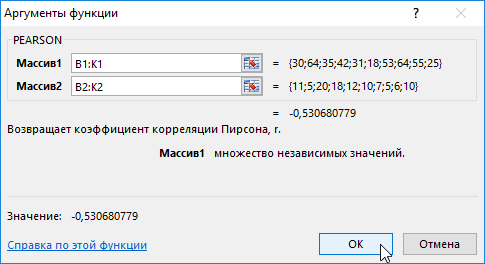
Задача: школьникам были даны тесты на наглядное и вербальное мышление. Измерялось среднее время решения заданий теста в секундах. Психолога интересует вопрос: существует ли взаимосвязь между временем решения этих задач?
Пример решения: представим исходные данные в виде таблицы:
- Переходим курсором в ячейку F2. Откроем мастер функций fx (SHIFT+F3) или вводим вручную.
- Выберем функцию PEARSON.
- Выделим мышкой Массив1, затем Массив 2.
- Нажмем ОК и в ячейке F2 получим критерий согласия Пирсона.
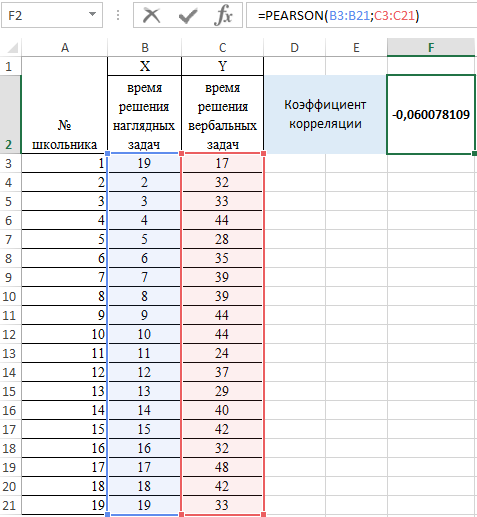
Интерпретация результата вычисления по Пирсону
Величина коэффициента линейной корреляции Пирсона не может превышать +1 и быть меньше чем -1. Эти два числа +1 и -1 – являются границами для коэффициента корреляции. Когда при расчете получается величина большая +1 или меньшая -1 – следовательно, произошла ошибка в вычислениях.
Если коэффициент корреляции по модулю оказывается близким к 1, то это соответствует высокому уровню связи между переменными.
Скачать примеры функции ПИРСОН для корреляции в Excel
Если же получен знак минус, то большей величине одного признака соответствует меньшая величина другого. Иначе говоря, при наличии знака минус, увеличению одной переменной (признака, значения) соответствует уменьшение другой переменной. Такая зависимость носит название обратно пропорциональной зависимости. Эти положения очень важно четко усвоить для правильной интерпретации полученной корреляционной зависимости.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции PEARSON в Microsoft Excel.
Описание
Возвращает коэффициент корреляции Пирсона (r) — безразмерный индекс в интервале от -1,0 до 1,0 включительно, который отражает степень линейной зависимости между двумя множествами данных.
Синтаксис
PEARSON(массив1;массив2)
Аргументы функции PEARSON описаны ниже.
-
Массив1 Обязательный. Множество независимых значений.
-
Массив2 Обязательный. Множество зависимых значений.
Замечания
-
Аргументы должны быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Если массив1 или массив2 пуст, либо число точек данных в этих массивах не совпадает, функция PEARSON возвращает значение ошибки #Н/Д.
-
Коэффициента корреляции Пирсона (r) вычисляется по следующей формуле:

где x и y — выборочные средние значения СРЗНАЧ(массив1) и СРЗНАЧ(массив2).
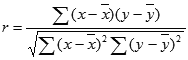
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Независимые значения |
Зависимые значения |
|
|
9 |
10 |
|
|
7 |
6 |
|
|
5 |
1 |
|
|
3 |
5 |
|
|
1 |
3 |
|
|
Формула |
Описание (результат) |
Результат |
|
=PEARSON(A3:A7;B3:B7) |
Коэффициент корреляции Пирсона для приведенных выше данных (0,699379) |
0,699379 |
Нужна дополнительная помощь?
Рассмотрим применение в
MS
EXCEL
критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая
выборка
) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной
выборкой
. Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием
критериев согласия
.
Нулевой гипотезой
, обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение
критерия согласия Пирсона Х
2
(хи-квадрат)
в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем —
применение критерияв случае сложных гипотез
, когда задается только форма распределения, а параметры этого распределения и значение
статистики
Х
2
оцениваются/рассчитываются на основании одной и той же
выборки
.
Примечание
: Применение
критерия согласия Пирсона
Х
2
в отношении сложных гипотез см. статью
Проверка сложных гипотез критерием хи-квадрат Пирсона в MS EXCEL
.
Примечание
: В англоязычной литературе процедура применения
критерия согласия Пирсона
Х
2
имеет название
The chi-square goodness of fit test
.
Напомним процедуру проверки гипотез:
-
на основе
выборки
вычисляется значение
статистики
, которая соответствует типу проверяемой гипотезы. Например, дляпроверки гипотезы о равенстве среднего μ некоторому заданному значению μ
0
используется
t
-статистика
(еслистандартное отклонение
не известно);
-
при условии истинности
нулевой гипотезы
, распределение этой
статистики
известно и может быть использовано для вычисления вероятностей (например, для
t
-статистики
этораспределение Стьюдента
);
-
вычисленное на основе
выборки
значение
статистики
сравнивается с критическим для заданногоуровня значимости
значением (
α-квантилем
);
нулевую гипотезу
отвергают, если значение
статистики
больше критического (или если вероятность получить это значение
статистики
(p-значение
) меньше
уровня значимости
, что является эквивалентным подходом).
Проведем
проверку гипотез
для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
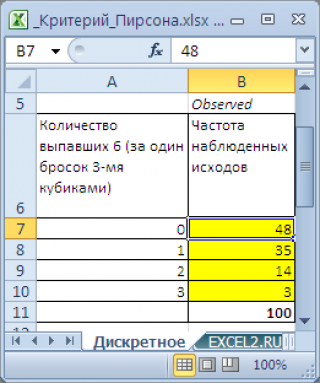
Примечание
: Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется
биномиальному закону
. Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке
А7
содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание
: Расчеты приведены в
файле примера на листе Дискретное
.
Для сравнения
наблюденных
(Observed) и
теоретических частот
(Expected) удобно пользоваться
гистограммой
.
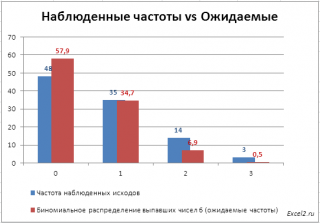
При значительном отклонении наблюденных частот от теоретического распределения,
нулевая гипотеза
о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от
биномиального распределения
.
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим
критерий согласия Пирсона Х
2
, чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения
гистограмм
, использовать математически корректное утверждение.
Используем тот факт, что в силу
закона больших чисел
наблюденная частота (Observed) с ростом объема
выборки
n стремится к вероятности, соответствующей теоретическому закону (в нашем случае,
биномиальному закону
). В нашем случае объем выборки n равен 100.
Введем
тестовую
статистику
, которую обозначим Х
2
:
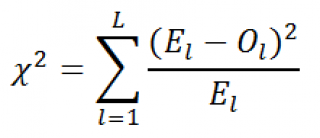
где O
l
– это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E
l
– это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Примечание
: Вышеуказанная
статистика
является частным случаем
статистики
используемой для вычисления
критерия независимости хи-квадрат
(см. статью
Критерий независимости хи-квадрат в MS EXCEL
).
Как видно из формулы, эта
статистика
является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим
биномиальный закон
), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение
статистики
Х
2
(
статистика
Х
2
вычислена на основе случайной
выборки
, поэтому она является случайной величиной и, следовательно, имеет свое
распределение вероятностей
).
Из многомерного аналога
интегральной теоремы Муавра-Лапласа
известно, что при n—>∞ наша случайная величина Х
2
асимптотически
распределена по закону Х
2
с L — 1 степенями свободы.
Итак, если вычисленное значение
статистики
Х
2
(сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть
нулевую гипотезу
. Как и при проверке
параметрических гипотез
, предельное значение задается через
уровень значимости
. Если вероятность того, что статистика Х
2
примет значение меньше или равное вычисленному (
p
-значение
), будет меньше
уровня значимости
, то
нулевую гипотезу
можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х
2
примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание
: Функция
ХИ2.ТЕСТ()
специально создана для проверки связи между двумя категориальными переменными (см.
статью про критерий независимости
).
Вероятность 0,000045 существенно меньше обычного
уровня значимости
0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (
нулевая гипотеза
о его честности отвергается).
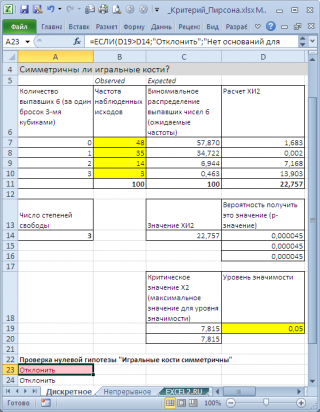
При применении
критерия Х
2
необходимо следить за тем, чтобы объем
выборки
n был достаточно большой, иначе будет неправомочна аппроксимация
Х
2
-распределением
распределения
статистики Х
2
. Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы
Х
2
-распределения
.
Для того чтобы улучшить качество применения
критерия Х
2
(
увеличить его мощность
), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество
степеней свободы
), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Примечание
: Рассмотренный выше пример является частным случаем применения
критерия независимости хи-квадрат
(chi-square test), который позволяет определить есть ли связь между двумя категориальными переменными (см. статью
Критерий независимости хи-квадрат в MS EXCEL
).
СОВЕТ
: О проверке других видов гипотез см. статью
Проверка статистических гипотез в MS EXCEL
.
Непрерывный случай
Критерий согласия Пирсона
Х
2
можно применить так же в случае
непрерывного распределения
.
Рассмотрим некую
выборку
, состоящую из 200 значений.
Нулевая гипотеза
утверждает, что
выборка
сделана из
стандартного нормального распределения
.
Примечание
: Cлучайные величины в
файле примера на листе Непрерывное
сгенерированы с помощью формулы
=НОРМ.СТ.ОБР(СЛЧИС())
. Поэтому, новые значения
выборки
генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных
нормальному распределению
можно визуально оценить
с помощью графика проверки на нормальность (normal probability plot)
.
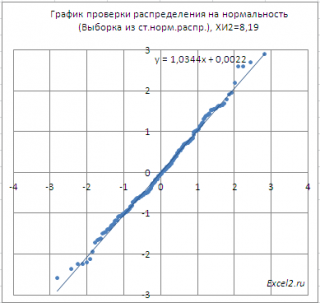
Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в
дискретном случае
для
проверки гипотезы
применим
Критерий согласия Пирсона Х
2
.
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5
стандартных отклонений
. Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции
ЧАСТОТА()
, а теоретические – с помощью функции
НОРМ.СТ.РАСП()
.
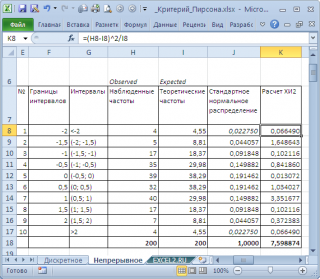
Примечание
: Как и для
дискретного случая
, необходимо следить, чтобы
выборка
была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х
2
и сравним ее с критическим значением для заданного
уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше
критического значения
–
нулевая гипотеза
не отвергается.
Ниже приведена
диаграмма
, на которой
выборка
приняла маловероятное значение и на основании
критерия
согласия Пирсона Х
2
нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы
=НОРМ.СТ.ОБР(СЛЧИС())
, обеспечивающей
выборку
из
стандартного нормального распределения
).
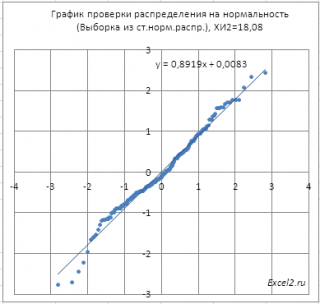
Нулевая гипотеза
отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем
выборку
из
непрерывного равномерного распределения
U(-3; 3). В этом случае, даже из графика очевидно, что
нулевая гипотеза
должна быть отклонена.
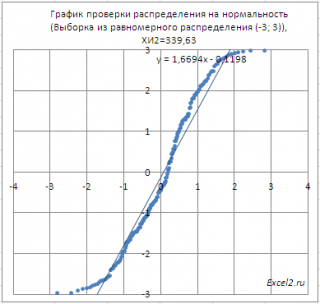
Критерий
согласия Пирсона Х
2
также подтверждает, что
нулевая гипотеза
должна быть отклонена.
Для того, чтобы рассчитать коэффициент корреляции Пирсона в Excell необходимо сделать следующие шаги:
1.Вносим значения для двух переменных в таблицу (Например Переменная 1 и Переменная 2)
2. Ставим курсор в пустую ячейку
3. На панеле инструментов нажимаем кнопку fx (вставить формулу)
4. В открывшемся окне «Мастер функций» в поле «Категории» выбираем Полный алфавитный перечень
5. Затем в поле «Выберите функцию» находим функцию ПИРСОН
5.1. Нажимаем Ок
6. В открывшемся окне «Аргументы функции» в поле Массив1 вносим номера ячеек, содержащие значения Переменной 1, в поле Массив2 вносим номера ячеек, содержащие значения Переменной2.
7. Нажимаем Ок
8. Смотрим получившийся результат
Correlations are important in many areas of science. Although correlation doesn’t equal causation, it’s often the first step to understanding the true relationship between two variables and can give a valuable hint that there is a causal relationship somewhere.
Learning to calculate a correlation is crucial, and you can easily find the “r value” in Excel using either built-in functions or by working through the calculation in pieces using the more basic functions of the program. The simplest way is using the built-in function, but understanding the calculation is helpful if you ever need to use a different program to find it.
What Is Pearson’s Correlation Coefficient?
Pearson’s correlation coefficient is a simple way of calculating the degree of correlation between two variables, returning a value (called r) ranging from −1 to 1. A perfect correlation (r = 1) between two variables would be where an increase in one variable by a certain amount leads to a correspondingly-sized increase in the other, or vice-versa.
A perfect negative correlation (r = −1) is basically the same, except an increase in one variable leads to a correspondingly-sized decrease in the other. Finally, no correlation whatsoever means there is no relationship at all between two things.
In practice, you’ll almost never see a perfect correlation, and most values will be some decimal value between −1 and 1. So when you find the Pearson r in Excel, the result will usually be some decimal value, where the magnitude of the number tells you the strength of the correlation between your variables.
Pearson Correlation in Excel
The easiest method for finding the Pearson correlation in Excel is using the built-in “Pearson” function or (equivalently) the “Correl” function. The function has a simple syntax: PEARSON(array 1, array 2).
In short, you just need two arrays of values (i.e. columns of results, for example, age and blood pressure arranged so there is a row for each individual patient) that are equal in length, then type “=PEARSON(” into an empty cell, followed by the range of values for the first array, a comma, then the range of values for the second. Then you close out the brackets, hit “Enter” and it will return the r value.
As always, you can highlight the values you want to search for correlations with your mouse or by navigating to the relevant cells with the arrow keys on your keyboard.
You can also use the “Correl” function, which performs the same calculation as “Pearson” and on versions of Excel from 2003 onward, leads to the exact same result. However, if you have an older version of Excel, you should use the “Correl” function because there can be rounding errors with “Pearson.”
Finding Pearson’s r “By Hand”
You can also calculate the r value in Excel in the more traditional method but with the help of the automatic calculations from the program. First, put the values for your variables (which can be referred to as x and y for clarity) in two columns, then create three more columns: xy, x2 and y2. Now multiply each value in the x column by the y column in the xy column (using the cell numbers in the calculation so you can drag it down for the rest of the column), square the x values for the next column, and square the y values for the final one.
Create a “sum” row underneath your data, and take the sum of all the values for each column. You can then use the formula to calculate your r value:
Here, n is the number of pairs of values you have. You can follow this through in pieces: Take the number of pairs of values, multiply it by the sum of your xy column, and then subtract the product of the sums of the x and y values.
Then, multiply the sum of your x2 column by n, subtract the sum of your x column squared, do the same thing for y and multiply these together, then take the square root of the whole thing. Finally, divide the first result by the second to get your r value.