
When you’re ready to print, just click this button:
Make Print-Friendly
Created by carlita
Can you answer these questions about famous classical composers? Was it one of the three B’s? A composer of the classical era or the romantic era? Test your classical music knowledge with this printable word find puzzle…
Instructions: Look at the hints and/or questions and then search for the composer or musical term in the puzzle. Only the last names are present in the word search for composers’ names.
E
V
K
Y
G
I
R
U
N
M
G
R
C
T
I
I
C
A
T
K
W
Z
V
G
X
X
V
H
W
V
Q
M
B
T
U
S
I
D
M
U
Y
Q
Y
O
U
X
B
A
S
B
Q
N
S
N
U
K
N
A
A
B
N
Y
P
P
T
I
X
I
V
N
Y
U
R
Y
U
Q
E
L
R
P
R
W
V
V
O
B
K
V
J
S
M
F
V
S
M
H
A
Z
L
A
N
E
M
P
H
L
S
K
O
S
A
M
U
I
E
R
B
A
F
H
B
Y
D
R
H
C
N
S
S
M
L
T
G
V
K
A
N
E
E
E
T
C
A
Z
S
D
I
S
R
J
R
G
B
T
B
N
E
S
T
R
A
Z
O
M
E
O
K
K
M
L
U
G
E
K
E
W
B
N
F
K
Q
A
O
D
I
V
S
A
B
S
M
T
X
N
M
U
S
I
F
B
S
E
S
W
I
G
S
C
Z
K
E
K
E
K
C
D
W
S
Y
G
M
W
Z
B
B
Show words that are in the puzzle
Show questions/hints
Words
-
Famous composer of the classical era born in Salzburg and wrote the Magic Flute
Mozart -
German composer known for his 5th Symphony and Für Elise
Beethoven -
This Austrian composer is known for his many waltzes including the Blue Danube
Strauss -
Born in Brooklyn, this 20th century musician composed the music for Porgy and Bess and wrote Rhapsody in Blue
Gershwin -
Known for the Ride of the Valkyries and the ‘Ring’ operas
Wagner -
J. S. Bach was a well-known composer of this musical era
Baroque -
Claude _____ was a French impressionist composer known for La Mer (The Sea)
Debussy -
Composer of the Rite of Spring and the Firebird suite
Stravinsky -
This Hungarian composer was also known for being a virtuoso pianist
Liszt -
Czech composer of the 19th century, known for the opera The Bartered Bride and the symphonic work Má vlast (or «The Moldau»)
Smetana
![]()
![]()
- Teacher Essentials
- Featured Articles
- Report Card Comments
- Needs Improvement Comments
- Teacher’s Lounge
- New Teachers
- Our Bloggers
- Article Library
- Lesson Plans
- Featured Lessons
- Every-Day Edits
- Lesson Library
- Emergency Sub Plans
- Character Education
- Lesson of the Day
- 5-Minute Lessons
- Learning Games
- Lesson Planning
- Standards
- Subjects Center
- Teaching Grammar
- Admin
- Featured Articles
- Hot Topics
- Leadership Resources
- Parent Newsletter Resources
- Advice from School Leaders
- Programs, Strategies and Events
- Principal Toolbox
- Administrator’s Desk
- Interview Questions
- Professional Learning Communities
- Teachers Observing Teachers
- Tech
- Featured Articles
- Article Library
- Tech Lesson Plans
- Science, Math & Reading Games
- WebQuests
- Tech in the Classroom
- Tech Tools
- Web Site Reviews
- Creating a WebQuest
- Digital Citizenship
- PD
- Featured PD Courses
- Online PD
- Classroom Management
- Responsive Classroom
- School Climate
- Dr. Ken Shore: Classroom Problem Solver
- Professional Development Resources
- Graduate Degrees For Teachers
- Worksheets & Printables
- Worksheet Library
- Highlights for Children
- Venn Diagram Templates
- Reading Games
- Word Search Puzzles
- Math Crossword Puzzles
- Friday Fun
- Geography A to Z
- Holidays & Special Days
- Internet Scavenger Hunts
- Student Certificates
- Tools & Templates
WHAT’S NEW
Lesson Plans
- General Archive
- By Subject
- The Arts
- Health & Safety
- History
- Interdisciplinary
- Language Arts
- Lesson of the Day
- Math
- PE & Sports
- Science
- Social Science
- Special Ed & Guidance
- Special Themes
- Top LP Features
- Article Archive
- User Submitted LPs
- Box Cars Math Games
- Every Day Edits
- Five Minute Fillers
- Holiday Lessons
- Learning Games
- Lesson of the Day
- News for Kids
- ShowBiz Science
- Student Engagers
- Work Sheet Library
- More LP Features
- Calculator Lessons
- Coloring Calendars
- Friday Fun Lessons
- Math Machine
- Month of Fun
- Reading Machine
- Tech Lessons
- Writing Bug
- Work Sheet Library
- All Work Sheets
- Critical Thinking Work Sheets
- Animals A to Z
- Backpacktivities
- Coloring Calendars
- EveryDay Edits
- Geography A to Z
- Hunt the Fact Monster
- Internet Scavenger Hunts
- It All Adds Up Math Puzzles
- Make Your Own Work Sheets
- Math Cross Puzzles
- Mystery State
- Math Practice 4 You
- News for Kids
- Phonics Word Search Puzzles
- Readers Theater Scripts
- Sudoku Puzzles
- Vocabulous!
- Word Search Puzzles
- Writing Bug
- Back to School
- Back to School Archive
- Icebreaker Activities
- Preparing for the First Day
- Ideas for All Year
- The Homework Dilemma
- First Year Teachers
- Don’t Forget the Substitute
- More Great Ideas for the New School Year
- Early Childhood
- Best Books for Educators
- Templates
- Assessments
- Award Certificates
- Bulletin Board Resources
- Calendars
- Classroom Organizers
- Clip Art
- Graphic Organizers
- Newsletters
- Parent Teacher Communications
- More Templates
![]()
EW Lesson Plans

EW Professional Development
EW Worksheets

Chatter
Trending
125 Report Card Comments
It’s report card time and you face the prospect of writing constructive, insightful, and original comments on a couple dozen report cards or more. Here are 125 positive report card comments for you to use and adapt!
Struggling Students? Check out our Needs Improvement Report Card Comments for even more comments! 
You’ve reached the end of another grading period, and what could be more daunting than the task of composing insightful, original, and unique comments about every child in your class? The following positive statements will help you tailor your comments to specific children and highlight their strengths.
You can also use our statements to indicate a need for improvement. Turn the words around a bit, and you will transform each into a goal for a child to work toward. Sam cooperates consistently with others becomes Sam needs to cooperate more consistently with others, and Sally uses vivid language in writing may instead read With practice, Sally will learn to use vivid language in her writing. Make Jan seeks new challenges into a request for parental support by changing it to read Please encourage Jan to seek new challenges.
Whether you are tweaking statements from this page or creating original ones, check out our Report Card Thesaurus [see bottom of the page] that contains a list of appropriate adjectives and adverbs. There you will find the right words to keep your comments fresh and accurate.
We have organized our 125 report card comments by category. Read the entire list or click one of the category links below to jump to that list.
AttitudeBehaviorCharacterCommunication SkillsGroup WorkInterests and TalentsParticipationSocial SkillsTime ManagementWork Habits
Attitude
The student:
is an enthusiastic learner who seems to enjoy school.
exhibits a positive outlook and attitude in the classroom.
appears well rested and ready for each day’s activities.
shows enthusiasm for classroom activities.
shows initiative and looks for new ways to get involved.
uses instincts to deal with matters independently and in a positive way.
strives to reach their full potential.
is committed to doing their best.
seeks new challenges.
takes responsibility for their learning.
Behavior
The student:
cooperates consistently with the teacher and other students.
transitions easily between classroom activities without distraction.
is courteous and shows good manners in the classroom.
follows classroom rules.
conducts themselves with maturity.
responds appropriately when corrected.
remains focused on the activity at hand.
resists the urge to be distracted by other students.
is kind and helpful to everyone in the classroom.
sets an example of excellence in behavior and cooperation.
Character
The student:
shows respect for teachers and peers.
treats school property and the belongings of others with care and respect.
is honest and trustworthy in dealings with others.
displays good citizenship by assisting other students.
joins in school community projects.
is concerned about the feelings of peers.
faithfully performs classroom tasks.
can be depended on to do what they are asked to do.
seeks responsibilities and follows through.
is thoughtful in interactions with others.
is kind, respectful and helpful when interacting with his/her peers
is respectful of other students in our classroom and the school community
demonstrates responsibility daily by caring for the materials in our classroom carefully and thoughtfully
takes his/her classroom jobs seriously and demonstrates responsibility when completing them
is always honest and can be counted on to recount information when asked
is considerate when interacting with his/her teachers
demonstrates his/her manners on a daily basis and is always respectful
has incredible self-discipline and always gets his/her work done in a timely manner
can be counted on to be one of the first students to begin working on the task that is given
perseveres when faced with difficulty by asking questions and trying his/her best
does not give up when facing a task that is difficult and always does his/her best
is such a caring boy/girl and demonstrates concern for his/her peers
demonstrates his/her caring nature when helping his/her peers when they need the assistance
is a model citizen in our classroom
is demonstrates his/her citizenship in our classroom by helping to keep it clean and taking care of the materials in it
can always be counted on to cooperate with his/her peers
is able to cooperate and work well with any of the other students in the class
is exceptionally organized and takes care of his/her things
is always enthusiastic when completing his/her work
is agreeable and polite when working with others
is thoughtful and kind in his/her interactions with others
is creative when problem solving
is very hardworking and always completes all of his/her work
is patient and kind when working with his/her peers who need extra assistance
trustworthy and can always be counted on to step in and help where needed
Communication Skills
The student:
has a well-developed vocabulary.
chooses words with care.
expresses ideas clearly, both verbally and through writing.
has a vibrant imagination and excels in creative writing.
has found their voice through poetry writing.
uses vivid language in writing.
writes clearly and with purpose.
writes with depth and insight.
can make a logical and persuasive argument.
listens to the comments and ideas of others without interrupting.
Group Work
The student:
offers constructive suggestions to peers to enhance their work.
accepts the recommendations of peers and acts on them when appropriate.
is sensitive to the thoughts and opinions of others in the group.
takes on various roles in the work group as needed or assigned.
welcomes leadership roles in groups.
shows fairness in distributing group tasks.
plans and carries out group activities carefully.
works democratically with peers.
encourages other members of the group.
helps to keep the work group focused and on task.
Interests and Talents
The student:
has a well-developed sense of humor.
holds many varied interests.
has a keen interest that has been shared with the class.
displays and talks about personal items from home when they relate to topics of study.
provides background knowledge about topics of particular interest to them.
has an impressive understanding and depth of knowledge about their interests.
seeks additional information independently about classroom topics that pique interest.
reads extensively for enjoyment.
frequently discusses concepts about which they have read.
is a gifted performer.
is a talented artist.
has a flair for dramatic reading and acting.
enjoys sharing their musical talent with the class.
Participation
The student:
listens attentively to the responses of others.
follows directions.
takes an active role in discussions.
enhances group discussion through insightful comments.
shares personal experiences and opinions with peers.
responds to what has been read or discussed in class and as homework.
asks for clarification when needed.
regularly volunteers to assist in classroom activities.
remains an active learner throughout the school day.
Social Skills
The student:
makes friends quickly in the classroom.
is well-liked by classmates.
handles disagreements with peers appropriately.
treats other students with fairness and understanding.
is a valued member of the class.
has compassion for peers and others.
seems comfortable in new situations.
enjoys conversation with friends during free periods.
chooses to spend free time with friends.
Time Management
The student:
tackles classroom assignments, tasks, and group work in an organized manner.
uses class time wisely.
arrives on time for school (and/or class) every day.
is well-prepared for class each day.
works at an appropriate pace, neither too quickly or slowly.
completes assignments in the time allotted.
paces work on long-term assignments.
sets achievable goals with respect to time.
completes make-up work in a timely fashion.
Work Habits
The student:
is a conscientious, hard-working student.
works independently.
is a self-motivated student.
consistently completes homework assignments.
puts forth their best effort into homework assignments.
exceeds expectations with the quality of their work.
readily grasps new concepts and ideas.
generates neat and careful work.
checks work thoroughly before submitting it.
stays on task with little supervision.
displays self-discipline.
avoids careless errors through attention to detail.
uses free minutes of class time constructively.
creates impressive home projects.
Related: Needs Improvement Report Card Comments for even more comments!
Student Certificates!
Recognize positive attitudes and achievements with personalized student award certificates!
Report Card Thesaurus
Looking for some great adverbs and adjectives to bring to life the comments that you put on report cards? Go beyond the stale and repetitive With this list, your notes will always be creative and unique.
Adjectives
attentive, capable, careful, cheerful, confident, cooperative, courteous, creative, dynamic, eager, energetic, generous, hard-working, helpful, honest, imaginative, independent, industrious, motivated, organized, outgoing, pleasant, polite, resourceful, sincere, unique
Adverbs
always, commonly, consistently, daily, frequently, monthly, never, occasionally, often, rarely, regularly, typically, usually, weekly
Copyright© 2022 Education World

Back to Geography Lesson Plan
Where Did Foods Originate?
(Foods of the New World and Old World)
Subjects
Arts & Humanities
—Language Arts
Educational Technology
Science
—Agriculture
Social Studies
—Economics
—Geography
—History
—-U.S. History
—-World History
—Regions/Cultures
Grade
K-2
3-5
6-8
9-12
Advanced
Brief Description
Students explore how New World explorers helped change the Old World’s diet (and vice versa).
Objectives
Students will
learn about changes that occurred in the New World and Old World as a result of early exploration.
use library and Internet sources to research food origins. (Older students only.)
create a bulletin-board map illustrating the many foods that were shared as a result of exploration.
Keywords
Columbus, explorers, origin, food, timeline, plants, map, New World, Old World, colonies, colonial, crops, media literacy, products, consumer
Materials Needed:
library and/or Internet access (older students only)
outline map of the world (You might print the map on a transparency; then use an overhead projector to project and trace a large outline map of the world onto white paper on a bulletin board.)
magazines (optional)
Lesson Plan
The early explorers to the Americas were exposed to many things they had never seen before. Besides strange people and animals, they were exposed to many foods that were unknown in the Old World. In this lesson, you might post an outline map of the continents on a bulletin board. Have students use library and/or Internet resources (provided below) to research some of the edible items the first explorers saw for the first time in the New World. On the bulletin board, draw an arrow from the New World (the Americas) to the Old World (Europe, Asia, Africa) and post around it drawings or images (from magazines or clip art) of products discovered in the New World and taken back to the Old World.
Soon, the explorers would introduce plants/foods from the Old World to the Americas. You might draw a second arrow on the board — from the Old World to the New World — and post appropriate drawings or images around it.
Adapt the Lesson for Younger Students
Younger students will not have the ability to research foods that originated in the New and Old World. You might adapt the lesson by sharing some of the food items in the Food Lists section below. Have students collect or draw pictures of those items for the bulletin board display.
Resources
In addition to library resources, students might use the following Internet sites as they research the geographic origins of some foods:
Curry, Spice, and All Things Nice: Food Origins
The Food Timeline
Native Foods of the Americas
A Harvest Gathered: Food in the New World
We Are What We Eat Timeline (Note: This resource is an archived resource; the original page is no longer live and updated.)
Food Lists Our research uncovered the Old and New World foods below. Students might find many of those and add them to the bulletin board display. Notice that some items appear on both lists — beans, for example. There are many varieties of beans, some with New World origins and others with their origins in the Old World. In our research, we found sources that indicate onions originated in the New and sources that indicate onions originated in the Old World. Students might create a special question mark symbol to post next to any item for which contradictory sources can be found
Note: The Food Timeline is a resource that documents many Old World products. This resource sets up a number of contradictions. For example:
Many sources note that tomatoes originated in the New World; The Food Timeline indicates that tomatoes were introduced to the New World in 1781.
The Food Timeline indicates that strawberries and raspberries were available in the 1st century in Europe; other sources identify them as New World commodities.
Foods That Originated in the New World: artichokes, avocados, beans (kidney and lima), black walnuts, blueberries, cacao (cocoa/chocolate), cashews, cassava, chestnuts, corn (maize), crab apples, cranberries, gourds, hickory nuts, onions, papayas, peanuts, pecans, peppers (bell peppers, chili peppers), pineapples, plums, potatoes, pumpkins, raspberries, squash, strawberries, sunflowers, sweet potatoes, tobacco, tomatoes, turkey, vanilla, wild cherries, wild rice.
Foods That Originated in the Old World: apples, bananas, beans (some varieties), beets, broccoli, carrots, cattle (beef), cauliflower, celery, cheese, cherries, chickens, chickpeas, cinnamon, coffee, cows, cucumbers, eggplant, garlic, ginger, grapes, honey (honey bees), lemons, lettuce, limes, mangos, oats, okra, olives, onions, oranges, pasta, peaches, pears, peas, pigs, radishes, rice, sheep, spinach, tea, watermelon, wheat, yams.
Extension Activities
Home-school connection. Have students and their parents search their food cupboards at home; ask each student to bring in two food items whose origin can be traced to a specific place (foreign if possible, domestic if not). Labels from those products will be sufficient, especially if the products are in breakable containers. Place those labels/items around a world map; use yarn to connect each label to the location of its origin on the map.
Media literacy. Because students will research many sources, have them list the sources for the information they find about each food item. Have them place an asterisk or checkmark next to the food item each time they find that item in a different source. If students find a food in multiple sources, they might consider it «verified»; those foods they find in only one source might require additional research to verify.
Assessment
Invite students to agree or disagree with the following statement:The early explorers were surprised by many of the foods they saw in the New World.
Have students write a paragraph in support of their opinion.
Lesson Plan Source
Education World
Submitted By
Gary Hopkins
National Standards
LANGUAGE ARTS: EnglishGRADES K — 12NL-ENG.K-12.2 Reading for UnderstandingNL-ENG.K-12.8 Developing Research SkillsNL-ENG.K-12.9 Multicultural UnderstandingNL-ENG.K-12.12 Applying Language Skills
SOCIAL SCIENCES: EconomicsGRADES K — 4NSS-EC.K-4.1 Productive ResourcesNSS-EC.K-4.6 Gain from TradeGRADES 5 — 8NSS-EC.5-8.1 Productive ResourcesNSS-EC.5-8.6 Gain from TradeGRADES 9 — 12NSS-EC.9-12.1 Productive ResourcesNSS-EC.9-12.6 Gain from Trade
SOCIAL SCIENCES: GeographyGRADES K — 12NSS-G.K-12.1 The World in Spatial TermsNSS-G.K-12.2 Places and Regions
SOCIAL SCIENCES: U.S. HistoryGRADES K — 4NSS-USH.K-4.1 Living and Working together in Families and Communities, Now and Long AgoNSS-USH.K-4.3 The History of the United States: Democratic Principles and Values and the People from Many Cultures Who Contributed to Its Cultural, Economic, and Political HeritageNSS-USH.K-4.4 The History of Peoples of Many Cultures Around the WorldGRADES 5 — 12NSS-USH.5-12.1 Era 1: Three Worlds Meet (Beginnings to 1620)NSS-USH.5-12.2 Era 2: Colonization and Settlement (1585-1763)NSS-WH.5-12.6 Global Expansion and Encounter, 1450-1770
TECHNOLOGYGRADES K — 12NT.K-12.1 Basic Operations and ConceptsNT.K-12.5 Technology Research Tools
Find many more great geography lesson ideas and resources in Education World’s Geography Center.
Click here to return to this week’s World of Learning lesson plan page.
Updated 10/11/12
50 «Needs Improvement» Report Card Comments

Having a tough time finding the right words to come up with «areas for improvement» comments on your students’ report cards? Check out our helpful suggestions to find just the right one!
The following statements will help you tailor your comments to specific children and highlight their areas for improvement.
Be sure to check out our 125 Report Card Comments for positive comments!
Needs Improvement- all topics
is a hard worker, but has difficulty staying on task.
has a difficult time staying on task and completing his/her work.
needs to be more respectful and courteous to his/her classmates.
needs to listen to directions fully so that he/she can learn to work more independently.
is not demonstrating responsibility and needs to be consistently reminded of how to perform daily classroom tasks.
works well alone, but needs to learn how to work better cooperatively with peers.
does not have a positive attitude about school and the work that needs to be completed.
struggles with completing his/her work in a timely manner.
gives up easily when something is difficult and needs extensive encouragement to attempt the task.
gets along with his/her classmates well, but is very disruptive during full group instruction.
has a difficult time using the materials in the classroom in a respectful and appropriate manner.
has a difficult time concentrating and gets distracted easily.
is having a difficult time with math. Going over _____ at home would help considerably.
is having a very difficult time understanding math concepts for his/her grade level. He/she would benefit from extra assistance.
could benefit from spending time reading with an adult every day.
is enthusiastic, but is not understanding ____. Additional work on these topics would be incredibly helpful.
is having difficulty concentrating during math lessons and is not learning the material that is being taught because of that.
understands math concepts when using manipulatives, but is having a difficult time learning to ____ without them.
is a very enthusiastic reader. He/she needs to continue to work on _____ to make him/her a better reader.
needs to practice reading at home every day to help make him/her a stronger reader.
needs to practice his/her sight words so that he/she knows them on sight and can spell them.
needs to work on his/her spelling. Practicing at home would be very beneficial.
can read words fluently, but has a difficult time with comprehension. Reading with ______ every day would be helpful.
could benefit from working on his/her handwriting. Slowing down and taking more time would help with this.
is having difficulty writing stories. Encouraging him/her to tell stories at home would help with this.
has a difficult time knowing when it is appropriate to share his/her thoughts. We are working on learning when it is a good time to share and when it is a good time to listen.
needs to work on his/her time management skills. _______is able to complete his/her work, but spends too much time on other tasks and rarely completes his/her work.
needs reminders about the daily classroom routine. Talking through the classroom routine at home would be helpful.
is having a difficult time remembering the difference between short and long vowel sounds. Practicing these at home would be very helpful.
is struggling with reading. He/she does not seem to enjoy it and does not want to do it. Choosing books that he/she like and reading them with him/her at home will help build a love of reading.
frequently turns in incomplete homework or does not hand in any homework. Encouraging _______to complete his/her homework would be very helpful.
does not take pride in his/her work. We are working to help him/her feel good about what he/she accomplishes.
does not actively participate in small group activities. Active participation would be beneficial.
has a difficult time remembering to go back and check his/her work. Because of this, there are often spelling and grammar mistakes in his/her work.
does not much effort into his/her writing. As a result, his/her work is often messy and incomplete.
is struggling to understand new concepts in science. Paying closer attention to the class discussions and the readings that we are doing would be beneficial.
is reading significantly below grade level. Intervention is required.
does not write a clear beginning, middle and end when writing a story. We are working to identify the parts of the stories that he/she is writing.
is struggling to use new reading strategies to help him/her read higher level books.
is wonderful at writing creative stories, but needs to work on writing nonfiction and using facts.
has a difficult time understanding how to solve word problems.
needs to slow down and go back and check his/her work to make sure that all answers are correct.
is not completing math work that is on grade level. Intervention is required.
is struggling to understand place value.
is very enthusiastic about math, but struggles to understand basic concepts.
has a difficult time remembering the value of different coins and how to count them. Practicing this at home would be helpful.
would benefit from practicing math facts at home.
is very engaged during whole group math instruction, but struggles to work independently.
is able to correctly answer word problems, but is unable to explain how he/she got the answer.
is having a difficult time comparing numbers.
Related: 125 Report Card Comments for positive comments!
Student Award Certificates!
Recognize positive attitudes and achievements with personalized student award certificates!
Copyright© 2020 Education World

75 Mill St. Colchester, CT 06415
Receive timely lesson ideas and PD tips
Sitemap



Sign up for our free weekly newsletter and receive
top education news, lesson ideas, teaching tips and more!
No thanks, I don’t need to stay current on what works in education!
COPYRIGHT 1996-2016 BY EDUCATION WORLD, INC. ALL RIGHTS RESERVED.
Introduction
Question Answering is a popular application of NLP. Transformer models trained on big datasets have dramatically improved the state-of-the-art results on Question Answering.
The question answering task can be formulated in many ways. The most common application is an extractive question answering on a small context. The SQuAD dataset is a popular dataset where given a passage and a question, the model selects the word(s) representing the answer. This is illustrated in Fig 1 below.
However, most practical applications of question answering involve very long texts like a full website or many documents in the database. Question Answering with voice assistants like Google Home/Alexa involves searching through a massive set of documents on the web to get the right answer.
In this blog, we build a search and question answering application using Haystack. This application searches through Physics, Biology and Chemistry textbooks from Grades 10, 11 and 12 to answer user questions. The code is made publicly available on Github here. You can also use the Colab notebook here to test the model out.
Search and Ranking
So, how do we retrieve answers from a massive database?
We break the process of Question Answering into two steps:
- Search and Ranking: Retrieving likely passages from our database that may have the answer
- Reading Comprehension: Finding the answer among the retrieved passages
This process is also illustrated in Fig 2 below.
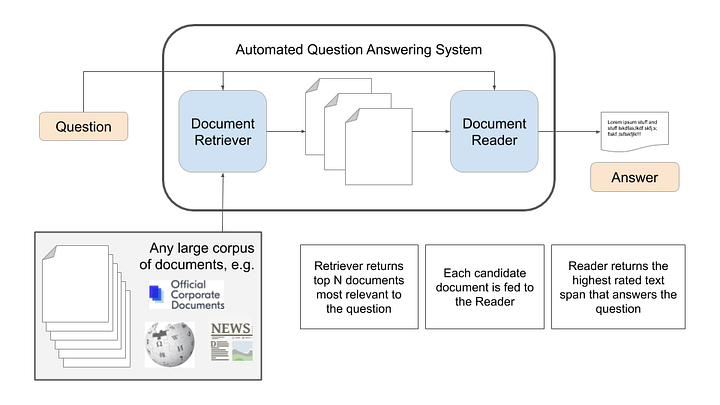
The search and ranking process usually involves indexing the data into a database like ElasticSearch or FAISS. These databases have implemented algorithms for very fast search across millions of records. The search can be done using the words in the query using TFIDF or BM25, or the search can be done considering the semantic meaning of the text by embedding the text or a combination of these can also be used. In our code, we use a TFIDF based retriever from Haystack. The entire database is uploaded to an ElasticSearch database and the search is done using a TFIDF Retriever which sorts results by score. To learn about different types of searches, please check out this blog by Haystack.
The top-k passages from the retriever are then sent to a Question-Answering model to get possible answers. In this blog, we try 2 models — 1. BERT model trained on SQuAD dataset and 2. A Roberta model trained on the SQuAD dataset. The reader in Haystack helps load these models and get the top K answers by running these models on the retrieved passages from the search.
Building our Question-Answering Application
We download PDF files from the NCERT website. There are about 130 PDF chapters spanning 2500 pages. We have created a combined PDF which is available on google drive here. If using Colab upload this PDF to your environment.
We use the HayStack PDF converter to read the PDF to a text file
converter = PDFToTextConverter(remove_numeric_tables=True, valid_languages=["en"])
doc_pdf = converter.convert(file_path="/content/converter_merged.pdf", meta=None)[0]
Then we split the document into many smaller documents using the PreProcessor class in Haystack.
preprocessor = PreProcessor(
clean_empty_lines=True,
clean_whitespace=True,
clean_header_footer=False,
split_by="word",
split_length=100,
split_respect_sentence_boundary=True)
dict1 = preprocessor.process([doc_pdf])
Each document is about 100 words long. The pre-processor creates 10K documents.
Next, we index these documents to an ElasticSearch database and initialize a TFIDF retriever.
retriever = TfidfRetriever(document_store=document_store)
document_store.write_documents(dict1)
The retriever will run a search against the documents in the ElasticSearch database and rank the results.
Next, we initialize the Question-Answering pipeline. We can load any Question Answering model on the HuggingFace hub using the FARM or Transformer Reader.
reader = TransformersReader(model_name_or_path="deepset/bert-large-uncased-whole-word-masking-squad2", tokenizer="bert-base-uncased", use_gpu=-1)
Finally, we combine the retriever and ranker into a pipeline to run them together.
from haystack.pipelines import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, retriever)
That’s all! We are now ready to test our pipeline.

Testing the Pipeline
To test the pipeline, we run our questions through it setting our preferences for top_k results from retriever and reader.
prediction = pipe.run(query="What is ohm's law?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}}
When we ask the pipeline to explain Ohm’s law, the top results are quite relevant.

Next, we ask about hydropower generation.
prediction = pipe.run(query="What is hydro power generation?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}}

We have tested the pipeline on many questions and it performs quite well. It is fun to read on a new topic in the source PDFs and ask a question related to it. Often, I find that the paragraph I read was in the top 3 results.
My experimentation suggested mostly similar results from BERT and Roberta with Roberta being slightly better.
Please use the code on Colab or Github to run your own STEM questions through the model.
Conclusion
This blog shows how question answering can be used for many practical applications involving long texts like a database with PDFs, or through a website containing many articles. We use Haystack here to build a relatively simple application. Haystack has many levers to adjust and fine-tune to further improve performance. I hope you pull down the code and run your own experiments. Please share your experience in the comments below.
At Deep Learning Analytics, we are extremely passionate about using Machine Learning to solve real-world problems. We have helped many businesses deploy innovative AI-based solutions. Contact us through our website here if you see an opportunity to collaborate.
References
![]()
Download Article
![]()
Download Article
Making a word search for your kids on a rainy day, your students to help them learn vocabulary, or simply for a bored friend can be a fun activity. You can get as creative as you like—just follow these steps to learn how to create your own word search.
-

1
Decide on the theme of your word search. Picking a theme for the words you want to put in your word search will make the word search seem more professional. If you are making this word search for a child, picking a theme will make the puzzle more understandable. Some example themes include: country names, animals, states, flowers, types of food, etc.
- If you do not want to a have a theme for your word search, you don’t have to. It is up to you what you decide to put into your word search.
- If you are making the word search as a gift, you could personalize the word search for the person you are making it for by using themes like, ‘names of relatives’ or ‘favorite things.’
-
2
Select the words you want to use. If you decided to go with a theme, pick words that match that theme. The number of words you choose depends on the size of your grid. Using shorter words will allow you to include more words in your puzzle. Word searches generally have 10-20 words. If you are making a very large puzzle, you could have more than that.
- Examples of words for the theme ‘animals’: dog, cat, monkey, elephant, fox, sloth, horse, jellyfish, donkey, lion, tiger, bear (oh my!), giraffe, panda, cow, chinchilla, meerkat, dolphin, pig, coyote, etc.
Advertisement
-
3
Look up the spelling of words. Do this particularly if you are using more obscure words or the names of foreign countries. Misspelling words will lead to confusion (and someone potentially giving up on your puzzle.)



Advertisement
-
1
Leave space at the top of your page. You will want to add a title to your word search once you have drawn your grid. If you have a theme, you can title your word search accordingly. If you don’t have a theme, simply write ‘Word Search’ across the top of your page.
- You can also make your grid on the computer. To make a grid in versions of word prior to Word 2007: Select ‘View’ at the top of the page. Select ‘Toolbars’ and make sure the ‘Drawing’ toolbar is selected. Click on ‘Draw’ (it looks like an ‘A’ with a cube and a cylinder). Click ‘Draw’ and then click ‘Grid’. A grid option box will pop up—make sure you select ‘Snap to Grid’ and then select any other options you would like for your grid. Click ‘OK’ and make your grid.
- To make a grid in Word 2007: Click ‘Page Layout’ at the top of the page and click the ‘Align’ list within the ‘Arrange’ grouping. Click ‘Grid settings’ and make sure ‘Snap to Grid’ is selected. Select any other options you want for your grid. Click ‘ok’ and draw your grid.
-
2
Draw a grid by hand. It is easiest to make word searches when using graph paper, although you do not have to use graph paper. The standard word search box is 10 squares by 10 squares. Draw a square that is 10 centimeter (3.9 in) by 10 centimeter (3.9 in) and then make a line at each centimeter across the box. Mark each centimeter going down the box as well.
- You do not need to use a 10×10 grid. You can make your grid as big or as small as you like, just remember that you need to be able to draw small squares within your grid. You can make your grid into the shape of a letter (perhaps the letter of the person’s name who you are making it for?) or into an interesting shape.
-
3
Use a ruler to draw lines. Use a pencil to draw the lines evenly and straightly. You need to create small, evenly-sized squares within your grid. The squares can be as big or as small as you like.
- If you are giving the word search to a child, you might consider making the squares larger. Making larger squares will make the puzzle a bit easier because each individual square and letter will be easier to see. To make your puzzle harder, make smaller, closer together squares.



Advertisement
-
1
Make a list of your words. Place the list next to your grid. You can label your words #1, #2 etc. if you want to. Write your words out clearly so that the person doing the word search knows exactly which word he or she is looking for.
-
2
Write all of your words into your grid. Put one letter in each box. You can write them backward, forward, diagonally, and vertically. Try to evenly distribute the words throughout the grid. Get creative with your placements. Make sure to write all of the words that you have listed next to the grid so that they are actually in the puzzle. It would be very confusing to be looking for a word in the word search that isn’t actually there.
- Depending on who you are giving the puzzle to, you may wish to make your letters larger or smaller. If you want your puzzle to be a little less challenging, like if you are giving it to a child, you might consider writing your letters larger. If you want your puzzle to be more challenging, make your letters smaller.
-
3
Create an answer key. Once you have finished writing in all the words, make a photocopy of it and highlight all of the hidden words. This will serve as your answer key so whoever does your puzzle will be able to see if they got everything right (or can get help if they are stuck on one word) without the confusion of the extra, random letters.
-
4
Fill in the rest of the blank squares. Once you have written all of your chosen words into the puzzle, fill the still empty squares with random letters. Doing this distracts the person from finding the words in the search.
- Make sure that you do not accidentally make other words out of your extra letters, especially other words that fit into your theme. This will be very confusing for the person doing the puzzle.
-
5
Make copies. Only do this if you are planning on giving your word search to more than one person.





Advertisement
Add New Question
-
Question
Why do I not use lowercase letters?

Uppercase makes the letters clearer and easier to see.
-
Question
How do I make a crossword?
Rene Teboe
Community Answer
Websites like puzzle-maker.com let you make word searches and crossword puzzles by just typing in the words and clues you want.
-
Question
How do I find a word in a word search?
Look at the beginning letter, then go line by line down the word search until you find the first letter. When you find one, look at the letters surrounding it to see if there is the next letter of the word. If there aren’t any of the next letters there, carry on until you find the word.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Write all the letters in capitals so that it doesn’t give away any clues.
-
Make the letters easy to read.
-
If you do not want to take the time to make your word search by hand or in a document on your computer, there are many websites where you can make your own word search online. Type ‘make a word search’ into your search engine and you are guaranteed to find many websites that will generate word searches for you.
Thanks for submitting a tip for review!
Advertisement
Things You’ll Need
- Pen or Pencil
- Paper
- Eraser
- Ruler
About This Article
Article SummaryX
After you’ve decided what words you want in your word search, use a ruler to draw a grid on a piece of graph paper. Fill in your word search by writing your words in the grid, but make sure to spread them out and vary writing them so words are written vertically, diagonally, backwards, and forward. Once you’ve added all of your words, add other letters in the blank squares. Finally, write out a list of your words next to the grid so the person doing the word search knows what they’re looking for. If you want to learn how to make your word search on the computer, keep reading!
Did this summary help you?
Thanks to all authors for creating a page that has been read 141,332 times.
Did this article help you?
![]()

7.0 Overview
In January 2011, IBM shocked the world by beating two former Jeopardy! champions with its Watson DeepQA system. The Watson victory was a prominent feature in press reports and the subject of a popular book (Baker, 2013).
This chapter starts by explaining how the IBM Watson system worked. Though it was far from a human-level natural language processing system, it was an amazing accomplishment and is a great example available of how clever programming can make a system appear to be intelligent when nothing could be further from the truth.
Following the discussion of Watson will be a discussion of question-answering research that has taken place since Watson and a description of how AI researchers have attacked the problem of question answering. Question answering research can be divided into five research categories:
(1) Text-to-SQL
Corporations and other organizations have massive amounts of data stored in relational databases. Text-to-SQL systems translate natural language requests for information into SQL commands.
(2) Knowledge Base QA
Knowledge bases store factual information. KB-QA systems translate take natural language factual questions as input and retrieve facts from KBs in response.
(3) Text QA
Text QA systems take natural language questions as input and search document collections such as Wikipedia to find answers. In 2018, both Microsoft and Alibaba announced they had built systems that matched human performance on a standardized reading comprehension test. However, as will be explained below, this reading comprehension test is susceptible to clever Watson-like tricks, and the systems that do well on this and similar tests use these tricks and really don’t understand language like people understand language.
(4) Task-oriented personal assistants and social chatbots
Like KB-QA and text-QA systems, personal assistants (e.g. Alexa and Siri) respond to natural language questions. Additionally, they respond to commands and also keep track of the dialogue state in an effort to provide responses that make sense given the history of the dialogue. Academic research on these types of systems is termed Conversational QA (Zaib et al, 2021).
(5) Commonsense reasoning QA
As will be discussed below, many questions can be answered without requiring any high-level reasoning. Commonsense QA datasets are designed with questions that are difficult to answer without knowledge of the real world and the ability to reason about that knowledge.
This chapter will discuss Text-to-SQL systems, KB-QA, and Text-QA. The chatbots chapter will discuss task-oriented personal assistants and social chatbots.
7.1 IBM’s Watson question answering system
Jeopardy! is a popular question-answering TV show in which a contestant picks one of six categories. Then all three contestants are presented with a question from that category. The first contestant to hit a buzzer is given the opportunity to answer the question. (Actually, the question is given in the form of an answer and the answer must be given in the form of a question). There is a significant penalty for wrong answers. All questions must be answered from “memory”. And no access to the internet is allowed.
PIQUANT: Watson’s question answering predecessor
IBM’s Watson question answering system was developed as a follow-on to research on a question-answering system named PIQUANT that was funded by government research grants and that performed well in conference competitions between 1999 and 2005 (Ferrucci, 2012). The PIQUANT system was oriented toward answering simple factual questions of the type that can be answered using a knowledge base.
The IBM Watson question answering project was kicked off in April 2007 and culminated with the stunning victory in January 2011. The team first considered building on PIQUANT. However, after analyzing the performance of prior Jeopardy! winners, the team determined that Watson would need to buzz in for at least 70% of the questions and get 85% correct. As a baseline, they tested the PIQUANT system and found that when it buzzed in 70% of the time, it only got 16% correct.
The basic approach of PIQUANT was to first determine the knowledge base category of the question. A specialized set of handcrafted information extraction rules were created for each high-level category (e.g. people, organizations, and animals) that found the correct instance of the type. This was possible because of the constrained domain of the conference tasks.
That approach doesn’t work for Jeopardy! or for open-domain question answering (i.e. not restricted to a small subject area) in general because there are just too many possible entity types. For example, the YAGO ontology has 350,000 entity types (i.e. classes). Developing 350,000 separate algorithms would be a big effort.
Documents stored in the IBM Watson system
The Jeopardy! rules do not allow contestants to access the internet, so part of the challenge was to collect and organize a huge body of information. Wikipedia was the primary information source as more than 95.47% of Jeopardy! questions can be answered with Wikipedia titles. The IBM Watson team (Carroll et al, 2012) cited this example:
TENNIS: The first U.S. men’s national singles championship, played right here in 1881, evolved into this New York City tournament. (Answer: US Open)
This clue contains 3 facts about the US Open (1st US men’s championship, first played in 1881, now played in New York City) that are all found in the Wikipedia article titled “US Open (tennis)”. The IBM Watson team noted that Wikipedia articles are also key resources when an entity is mentioned in the question (answer). For example:
Aleksander Kwasniewski became the president of this country in 1995. (Answer: Poland)
The second sentence of Kwasniewski’s Wikipedia article says:
He served as the President of Poland from 1995-2005.
The IBM team then analyzed the 4.53% of questions that couldn’t be answered via Wikipedia titles and found several types of questions. Many questions involved dictionary definitions so they incorporated a modified version of Wiktionary (a crowd-sourced dictionary) which, like Wikipedia, was already title-oriented. Other common sources of questions included Bible quotes, song lyrics, quotes, and book and movie plots and they created title-oriented documents for these categories.
For example, for song lyrics, they created one set of documents with the artist as the title and the lyrics in the article and another set with the song title as the title. As will be explained below, the IBM Watson system used many different strategies for matching questions to documents. Nearly all matching algorithms were lexically-oriented. In other words, the matching algorithms matched words in the questions to words in the documents rather than extracting the meaning of the question into a canonical meaning representation, extracting the meaning of the document into a canonical meaning representation, and matching on the meanings rather than the words.
Since there are many different word combinations for expressing most facts and since each Wikipedia and/or Wiktionary article typically has only a single lexical form for each fact, the team augmented popular articles and definitions with other text found on the web and news wire articles in the hope of capturing other lexical forms of important facts and increasing the likelihood of matching question words or synonyms to documents words or synonyms. These document acquisition methodologies expanded the initial Wikipedia-based knowledge-base from 13 to 59 GB and improved Jeopardy! performance by 11.4%.
Information extraction in IBM Watson
Identifying entities and relations in questions and linking them to Wikipedia titles and other stored documents was a key capability for the IBM Watson DeepQA system.
It used an open-source natural language processing framework that was developed from 2001 to 2006 by IBM named the Unstructured Information Management Architecture (UIMA). UIMA includes tools for language identification, language-specific segmentation, POS tagging, text indexing, sentence boundary detection, tokenization, stemming, regular expressions, and entity detection.
The IBM Watson DeepQA system also used a parsing and representational system named slot grammars (McCord et al, 2012) that captures both surface linguistic information (e.g. POS), morphological information (e.g. tense and number), logical argument structure (subject, object, complement), and dependency information. English, German, French, Spanish, Italian, and Portuguese implementations of the parser were used.
The DeepQA system automatically extracted a set of entities and relations from Wikipedia and used them to create a lexicon that could drive recognition of entities and relations in Jeopardy! questions. To learn lexical entries (i.e. words or phrases) that can be used to identify Wikipedia entities, DeepQA didn’t simply rely on keyword matching to Wikipedia titles. In addition to keywords, they used link information (i.e. words in Wikipedia articles that are hyperlinked to the entity article) to match different surface forms (i.e. words and phrases) to each entity in Wikipedia.
The extracted lexicon included 1.4 million proper noun phrasal entries extracted from Wikipedia, phrasal medical entries extracted from the Unified Medical Language System, and numerous entity and type synonyms extracted using the relationships between Wikipedia, YAGO, and WordNet.
To learn a set of relations and a lexicon to identify each relation, the IBM Watson DeepQA system used Wikipedia infoboxes which frequently contain relations. For example, in describing the IBM Watson relation extraction process, the IBM Watson authors (Wang et al, 2011) note that the infobox in the article for Albert Einstein lists his “alma mater” as “University of Zurich”. Then the first sentence in the article mentioning “alma mater” and “University of Zurich” says
Einstein was awarded a PhD by the University of Zurich
Sentences like this were then used as training sentences for their relations. Classifiers were automatically trained for over 7000 relations based on this type of analysis of Wikipedia text. The IBM Watson team also defined 30 handcrafted patterns to identify common relations with high confidence. An example pattern to identify the authorOf relationship was
[Author] [WriteVerb] [Work]
They also developed a “true case” algorithm to account for the fact that clues are presented in all upper case. This algorithm was trained on thousands of same phrases to transform the upper case clues into mixed case clues and thereby provide algorithms (e.g. NER) with additional information.
How IBM Watson interpreted the questions
When the IBM Watson DeepQA system read a Jeopardy! question, it extracted four key pieces of Jeopardy!-specific information:
Focus: The focus was determined by a set of handcrafted rules such as
A noun phrase with determiner “this” or “these”.
This rule would pick up the correct focus in question such as
THEATRE: A new play based on this Sir Arthur Conan Doyle canine classic opened on the London stage in 2007.
If none of the rules matched, the question (answer) was treated as if it didn’t have a focus.
Lexical answer types (LATs): The DeepQA interprets each question as having one or more Lexical Answer Types (LATs). A LAT is often the Focus of the question. It can also be a class. For example, “dog” would be a LAT in the question
Marmaduke is this breed of dog.
The set of LATs can also include the answer category. For example, “capital” will be a LAT for questions in the category
FOLLOW THE LEADER TO THE CAPITAL
You can think of the LAT as a type of concept. For example, a clue might indicate the response is a type of dog. In this case, “dog” would be the LAT. Here also, we can run into a word matching problem. A clue might reference the concept associated with the word “dog” by many different words and phrases, including “dog,” “canine,” and “man’s best friend.”
Fortunately, there are ontologies that provide this type of mapping. An open-source ontology named YAGO is available online that maps words to concepts, and the IBM Watson team used YAGO to map the LAT word(s) onto YAGO concepts. There is also an open-source mapping from Wikipedia to YAGO named DBPedia, and DeepQA used this to map possible answers to YAGO concepts.
YAGO also contains hierarchical information about concepts. For example, YAGO lists an animal hierarchy (animal->mammal->dog). When the entity and LAT were both available in YAGO, DeepQA used conventionally coded hierarchical rules to determine if the entity matched the LAT concept exactly or matched a subtype or supertype in the YAGO concept hierarchy.
Certain LATs (e.g., countries, US presidents) have a finite list, and the list instances often are matched to the entities in candidate answer documents using Wikipedia lists.
See the IBM Watson team paper on this topic (Lally et al, 2012) for information on how DeepQA determines the LATs.
Question Classification: Factoid questions are the most common type of Jeopardy! question. However, the IBM team found 12 other question categories (e.g. Definition, Multiple-Choice, Puzzle, Common Bonds, Fill-in-the-Blanks, Abbreviation). They developed a separate set of handcrafted rules for recognizing the question class and applied different answering techniques for each type.
Question Sections (QSections): These are annotations placed by the IBM Watson system on the query text that indicate special treatment is required. For example, a phrase like
…this 4-letter word…
is marked as a LEXICAL CONSTRAINT which indicates that it should be used to select the answer but should not be part of the answer. Like Question Classes, these are identified by a set of handcrafted rules.
Using the parsing information discussed earlier, the entities and relations are also extracted from the question.
How IBM Watson identified the candidate answers
The next step is to identify Wikipedia and other documents that contain candidate answers. Consider, for example, the following clue (Carroll et al, 2012b).
MOVIE-ING: Robert Redford and Paul Newman starred in this depression-era grifter flick.
(Answer: The Sting)
Both the focus and LAT are “flick” and two relations are extracted:
actorIn (Robert Redford; flickflick : focus)
actorIn (Paul Newman; flick : focus)
Four types of document searches are performed:
Titled document search: Titled documents (e.g. Wikipedia and Wiktionary) are searched for “Robert Redford”, “Paul Newman”, “star”, “depression”, “era”, “grifter”, and “flick” and rated by several criteria. For example, documents with both the Redford and Newman names are weighted the highest. Documents with the focus word “flick” are weighted next highest. The 50 long documents (e.g. Wikipedia) and 5 short documents (e.g. Wiktionary) that are rated highest are considered candidates. The document titles become the candidate answers.
Passage search: Untitled documents (e.g. news articles) are searched using the same terms in two stages to identify one- or two-sentence passages that contain candidate answers.
First, articles are found for which the words in the headline is contained in the clue. The ten highest-rated candidate passages are retrieved.
Second, all other articles are searched using two different search engines with very different algorithms. The documents are rated based on the similarity of the words in the passage to the words in the query and other factors such as whether the sentence is close to the beginning of the article. Similarity includes exact word matches plus synonym and/or thesaurus matches.
The five highest-rated passages for each search engine are considered candidate documents. For each candidate document, a variety of lexically-oriented techniques are used to extract the candidate answer (Ferrucci et al, 2012).
Structured databases: One might think that simply looking up answers in structured databases such as IMDB (Internet Movie Database) and/or a knowledge base (DBPedia was the knowledge base used by DeepQA) would provide an answer to most factoid questions. The difficulty is that this requires matching the words in the names used in the query to the words in the names in these structured data sources. Moreover, it relies on the words identifying the relations discovered matching the words defining the relations in these data sources. Said another way, the relations might match, but if the words used to express the relation in the question and database are different, the system won’t see the match. As a result, while this technique was found to be effective for some types of relations, especially the ones extracted with handcrafted rules such as actorIn, it was generally a less effective strategy than Title Document Search and Passage Search.
PRISMATIC knowledge base: The IBM Watson team created its own knowledge base named PRISMATIC (Fan et al, 2012). The facts in PRISMATIC are extracted from encyclopedias, dictionaries, news articles, and other sources. The facts include commonsense knowledge such as “scientists publish papers” that can be used to help interpret questions. DeepQA used PRISMATIC as another source of candidate answers.
How IBM Watson scores the candidate answers on LAT match
One of the most important steps in scoring each candidate answer is to determine the likelihood that it matches the LAT. To accomplish this, the IBM watson system canonicalizes entity references using several different techniques including:
- The NER detector from PIQUANT which is used for 100 common named entity types.
- Entity linking by matching the entity mention string to strings in Wikipedia articles that have hyperlinks. Different ways of mentioning the entity in Wikipedia are all linked back to the same Wikipedia page thereby providing a means of canonicalizing the lexical variation in entity references.
- Word co-occurrence algorithms using Wikipedia disambiguation pages and other unstructured and structured resources.
Next, the canonicalized entity reference is matched to the LAT. However, the LAT is just a word or string of words and it also needs to be canonicalized by finding its underlying concept in an ontology. IBM Watson system uses the YAGO ontology and uses WordNet / YAGO links to map words in the mention string to concepts in YAGO. The LAT mention string is looked up in WordNet. In some cases, there are multiple word senses.
The IBM Watson team (Kalyanpur et al, 2012) offered the example of the word “star”. This has two WordNet word senses. The higher ranked word sense is the astronomy sense. The lower-ranked word sense is the movies sense. As a result, the LAT will be associated with two concepts. It will be associated with the astronomy sense with a 75% probability and the movie star sense with a 25% probability. However, if the candidate answer has a named entity that is a movie star, the match will still occur.
The relative probabilities are then adjusted by determining which word senses have more instances in DBPedia and are therefore presumed to be more popular. The IBM Watson system uses several methods to assess each candidate answer against each LAT (Murdoch et al, 2012). Some of these methods are:
Wikipedia Lookup: The type of the entity concept extracted from the candidate answer is looked up in YAGO and compared with the YAGO LAT concept. For example, if the candidate answer matches a link to a Wikipedia title, the entity is looked up in DBPedia which has a cross-reference to YAGO types. Wikipedia articles are also commonly tagged with categories. These categories are matched against the LAT.
Taxonomic Reasoning: When the entity and LAT can both be found in YAGO, it is possible to do taxonomic reasoning and determine if the entity matches the LAT concept exactly or matches a subtype or supertype in the YAGO concept hierarchy.
Gender: A special algorithm is used to compare LAT’s that specify a gender (e.g. “he”) to an entity in the candidate answer.
Closed LATs: Certain LATs (e.g. countries, US presidents) have a finite list and the list instances are matched to the candidate entity.
WordNet: The lexical unit hierarchy is checked for matches between the LAT and candidate answers.
Wikipedia Lists: Wikipedia contains many lists. These lists are stored and matched against question text starting with “List of…”.
Each method also assigns a confidence rating to the type match.
Additional evidence used by IBM Watson
Additional evidence is also gathered for each candidate answer. For example, each candidate answer is merged into the question, and searches are performed looking for text passages that contain some or all the question words in any order. Over 50 separate scoring algorithms are used to create a set of scores that are then used as features in a machine learning algorithm. Some examples:
- The found passages are scored by several different scorers that analyze things like how many question words are matched and how well the word orders match.
- There are multiple temporal answer scorers that determine if the dates for the candidate answer are consistent with the dates in the question. If the question asks about the 1900s, someone who lived in the 1800s is not a plausible answer. Temporal references are normalized and matched against DBPedia which has dates (e.g. birth/death dates of people) and durations of events. Temporal data is also extracted into a DeepQA knowledge base that contains the number of times a date range was mentioned for an entity and this knowledge base is used to score time period references in candidate answers.
- Similarly, location scorers assess the geographic compatibility between the question and candidate answer. Longitude/latitude specifications in a query are normalized using regular expressions and matched against location data stored in DBPedia and Freebase.
- Other scorers check handcrafted rules such as an entity can’t be both a country and a person. There are over 200 such rules.
How IBM Watson computed the final scores
Candidate answers are ultimately scored by applying a logistic regression algorithm (with regularization) to rank candidate answers according to a set of 550 features (Gondek et al, 2012). The classifier is trained to compare each pair of candidate answers and identify the best answer. This produces a ranking of the answers.
A supervised learning algorithm was trained on 25,000 Jeopardy! questions with 5.7 million question-answer pairs (including both correct and incorrect answers). The answer produced by the IBM Watson system is the candidate response with the high rank (converted into a question).
Summary of IBM Watson question answering
The IBM Watson system is an amazing feat of engineering. The result is a system that appears to understand complex English questions. Under the hood, what is really occurring is a massive set of mostly handcrafted rules that extract entities and relations, a set of rules for keyword matches between words in the questions and words in the stored documents and databases, and a massive set of handcrafted rules for identifying the most likely entity answer from a large set of candidate answers.
There is no attempt by the IBM Watson system to understand a question by producing a meaning representation of the question and matching that meaning representation to the meaning representations of documents and knowledge bases. As David Ferrucci, the IBM Watson team leader, said (Ferrucci, 2012),
“DeepQA does not assume that it ever completely understands the question…”
Most of the system is based on brute force lexical matching of questions to documents. The rules used to match the time frame and location specified in the question to the time frame and location specified in the candidate answers and to match the entities and relations in the question to the candidate answers could be considered a form of reasoning if one stretches the definition. However, clever programming is a more apt description of the entire system.
7.2 Text-to-SQL
One of the major early areas of focus of both academic research and commercial system was in the area of natural language interfaces to SQL databases. In the 1970s and 1980s, before business intelligence software revolutionized the way knowledge workers interact with databases, it was thought that natural language interfaces had huge potential for bridging the gap between non-technical business people and the information in structured databases.
Starting in the 1980s, several commercial text-to-SQL systems were created with varying degrees of success. All of these commercial systems used symbolic NLP techniques. Most current research uses machine learning. Both will be discussed below.
7.2.1 Text-to-SQL challenges
Text-to-SQL systems face four major challenges:
(1) Schema encoding
Text-to-SQL systems need to translate natural language into a representation that capture the database schema semantics, i.e. the database tables, columns, and the relationships between the tables. If the text-to-SQL system requires significant manual effort for each new database, the implementation cost can be a barrier to the use of the text-to-SQL system.
(2) Schema linking
Text-to-SQL systems need to correctly interpret references to the tables and columns of the database in the query. Here also, manual effort to create the lexical entries for each new databases is a barrier to use.
(3) Multi-table schemas
Most real-world databases have multiple tables and text-to-SQL systems need to generate SQL that includes joins to link these tables. Text-to-SQL systems developed for single-table databases won’t have this capability.
(4) Syntactically correct but semantically incorrect queries
Many queries contain syntactically correct SQL and, when run against the database, will produce output. However, the output can be meaningless. One example, is SQL with many-to-one-to-many joins. For example, a database may have a table of payments by customer and another table of orders by customer. However, SQL that merges the data from these two tables will generate incorrect data. The data will look like it shows payments for specific orders but that information is not actually contained in the tables.
7.2.2 Datasets for training text-to-SQL systems
Many datasets are available for research on natural language interfaces to databases. These datasets include a SQL database and include questions and correct SQL broken down into training and test sets. Most of these datasets contain databases with a single table. These include
- ATIS (Hemphill et al, 1990), a flight database
- Restaurants (Tang and Mooney, 2000), a database of restaurant locations and food types
- GeoQuery (Zelle and Mooney, 1996), a database of states, cities, and other places
- Academic (Li and Jagadish, 2014), a database of academic publications
- Scholar (Iyer et al, 2017), another database of academic publications
- Yelp, a dataset of Yelp data
- IMDB, a movie database
- Advising (Finegan-Dollak et al, 2017), a database of course information
More recently, researchers have developed datasets that cross a wide range of topics. These include
- WikiSQL (Zhong et al, 2017), a database of questions and answers from a wide range of Wikipedia articles so topic identification is important. Each question references a single table so there is no need for joins. The WikiSQL leaderboard can be found here.
- Spider (Yu et al, 2018), a database of questions and answers cover a wide range of databases extracted from college database classes. Many questions require joins between tables. The Spider leaderboard can be found here.
More importantly, the articles/databases in these last two datasets are not present in the training sets. This forces the system to learn generalized patterns, not ones that are specific to the training data.
7.2.3 Symbolic NLP approaches
The first text-to-SQL system was developed in 1960 by MIT researcher Bert Green (who became my Ph.D. thesis advisor 18 years later). Green and colleagues wrote a computer program (Green et al, 1961) that could answer questions about the 1959 baseball season like:
Who did the Red Sox lose to on July 5? Where did each team play on July 7? What teams won 10 games in July? Did every team play at least once in each park?
Similarly, the LUNAR system (Woods et al, 1972) allowed geologists to ask questions such as:
Give me all lunar samples with magnetite. In which samples has apatite been identified? What is the specific activity of A126 in soil? Analyses of strontium in plagioclase. What are the plag analyses for breccias? What is the average concentration of olivine in breccias? What is the average age of the basalts? What is the average potassiudrubidium ratio in basalts? In which breccias is the average concentration of titanium greater than 6 percent?
In 1971, the LUNAR system was put to a test by actual geologists. Of 111 moon rock questions posed by geologists, 78% were answered correctly. In 1978, Stanford Research Institute developed a system named LADDER (Hendrix et al, 1978) that retrieved Navy ship data.
In 1981, Wendy Lehnert and I (Shwartz, 1982; Lehnert and Shwartz, 1983) developed a natural language interface to oil company well data where one could ask questions like
Show me a map of all tight wells drilled before May I, 1980 but since May I, 1970 by texaco that show oil deeper than 2000, were themselves deeper than 5000, are now operated by shell, are wildcat wells where the operator reported a drilling problem, and have mechanical logs, drill stem tests, and a commercial oil analysis, that were drilled within the area defined by latitude 30 deg 20 min 30 sec to 31:20:30 and 80-81. scale 2000 feet.
These systems all used semantic parsing. Semantic parsers have hand-coded rules that translate natural language queries into a very narrow frame-based meaning representation that only has slots for the information necessary to create a computer program to retrieve the data. These slots primarily fell into three categories:
- A list of fields and/or calculations to be retrieved
- A set of filters that restricted the information
- A set of sorts that defined how the output should be sorted
For example, the EasyTalk commercial text-to-SQL system (Shwartz, 1987) would translate inputs such as
Show me the customer, city, and dollar amount of Q1 sales of men’s blue shirts in the western region sorted by state.
This would result in a frame-based representation:
Display:
customer_name customer_city customer_state sales_$
Filters:
transaction_date >= ‘1/1/1983’ transaction date <= ‘3/31/1983’ product_id in (‘23423’, ‘23424’, ‘24356’) region = ‘west’
Sorts:
customer_state
In order to parse natural language inputs into this frame-based representation, the EasyTalk system used a hand-coded lexicon. A lexicon contains entries for individual words and tokens, phrases, and/or patterns.
So, for example, the word “customer” by itself and the phrase “customer name” both map to the customer_name field. The token “Q1” maps to a transaction date filter. And so on.
From this internal representation, it is a simple matter to generate SQL or some other database query language to retrieve and display the requested data. For example, the Display elements become the SELECT parameters, the Filters become the WHERE clause, and so on.
It was also a simple matter to create paraphrases of the information in order to confirm with the user that the system correctly understood the request. Early natural language interfaces to databases had hand-coded lexicons some of which enabled inferences such as inferring from
Who owes me for over 60 days?
that an outstanding balance is being requested.
However, the amount of hand-coding for each new database and the required expertise made widespread development of this type of interface impractical.
In 1983, Barbara Grosz at the Stanford Research Institute, developed a framework for TEAM a “transportable” natural language database interface. General domain-independent language patterns for identifying the columns to be retrieved and the filters to be applied were hand-coded. File, record, and field names were retrieved directly from the database and users could enter synonyms for these items. The result was a model for a system that could be applied to any database. The domain specifics were just synonyms of field names that didn’t require special linguistics expertise.
That same general idea was adopted by my EasyTalk system and by several other commercial companies. I started one of those other companies where we produced the Esperant system. Another commercial product is EasyAsk which is a text-to-SQL system that evolved from early research at Dartmouth College (Harris, 1978). Microsoft developed PowerBI Q&A. Tableau offers Ask Data. And there are many more.
Some of these commercial systems improved on the transportability idea via additional mechanisms such as reading description fields and automatically creating lexicon entries based on those fields. For example, a product description field might contain “blue men’s medium long-sleeved shirt”. From that description, the EasyTalk system would automatically generate patterns that would match “blue shirt”, “men’s long-sleeved blue shirt”, and so on.
The market need for text-to-SQL systems diminished with the advent of graphical business intelligence tools in the early 1990s. The problem was that, as user interface pioneer Ben Schneiderman pointed out (Schneiderman, 1993), people would rather use a reliable and predictable user interface than an intelligent but unreliable one.
A group of University of Washington researchers (Popescu et al, 2003) argued that, to guarantee reliability, natural language inputs had to be restricted to those that contain unambiguous references to database elements.
Commercial natural language interfaces to databasestext-to-SQL system are far from 100% reliable unless users impose their own constraints on the allowable natural language inputs by learning what questions they can ask.
Interestingly, less than 100% reliability has more recently become acceptable as evidenced by the widespread popularity of chatbots which also require users to either learn what they ask or accept much less than 100% reliable responses.
My own efforts moved in the direction of graphical interfaces with the development of Esperant which was one of the leading business intelligence products of the early and mid-1990s. In addition to accepting free-form natural language input, Esperant led the user through a set of menu-based choices that led to the construction of a natural language sentence that was guaranteed to produce a 100% reliable answer. For queries that required information from multiple tables, Esperant would gray out choices that would lead to incorrect joins.
7.2.4 Machine learning text-to-SQL approaches
Researchers have been studying the use of machine learning to create natural language interfaces for over 20 years (e.g. Wong and Mooney, 2006; Zettlemoyer and Collins, 2007).
For example, Zettlemoyer and Collins trained a system to learn a lexicon and grammar for translating English queries into database retrieval requests. They started with a dataset of queries annotated with the formal meaning representation for each query. An example query (Zelle and Mooney, 1996) was
What is the capital of the state with the largest population?
The meaning representation for that query was
answer(C, (capital(S,C), largest(P, (state(S), population(S,P)))))
The system used a set of handcrafted features and a supervised learning algorithm to learn a lexicon and grammar based on a set of lexical features in the queries. One significant limitation of this approach was the degree of effort required to create the dataset of annotated queries for each database.
The approach has also been used only for relatively small databases such as Geobase which contains 800 facts (e.g. population, neighboring states, area, capital city, major cities, major rivers, and elevation) about US states.
More recently, sequence-to-sequence neural networks have been used for this task. Dong and Lapata (2016) used an attention-based encoder-decoder model to translate from natural language questions to any arbitrary meaning representation or logical form with a formal grammar. They demonstrated its efficacy on several databases including Geobase.
Salesforce (Zhong et al, 2017) and UC Berkeley (Xu et al, 2017) researchers applied a seq2seq model directly to the problem of generating SQL from natural language inputs. They created the WikiSQL dataset. Their model generates a SQL query that gets the correct answer about 70% of the time. However, they can only do this for a single table (i.e. no joins) and the questions are limited to those that contain a column name.
More recently, researchers have created schemes that enable a system to learn information about the database schema and relate it to the question. Allen Institute researchers (Bogin et al, 2019) used a graph neural network to learn the schema information and used an encoder-decoder to convert text to SQL. They used the Spider dataset and their system was able to create joins and complex SQL constructs including subqueries.
Microsoft researchers (Wang et al, 2020) increased performance on the Spider dataset by creating a system named RAT-SQL using relation-aware self-attention in which they encode the schema foreign key information and the questions in a common format. This allows using a transformer architecture to jointly learn questions and database schema, to generate SQL that contains joins, and to restrict the generated SQL to syntactically correct SQL (but not necessarily semantically correct).
As of June 2022, the leading system with published data on the
dataset was PICARD (Scholak et al, 2021). At each step of the decoding process, pre-trained language models can produce 10,000+ sub-word tokens, some of which are grammatically incorrect. PICARD rejects these inadmissable subword tokens at each step of the generation process.
7.2.5 Text-to-SQL summary
In many NLP sub-disciplines, machine learning approaches are outpacing symbolic approaches. The opposite is true for text-to-SQL systems. Commercial systems using symbolic NLP have long been able to produce joins (i.e. answer natural language queries involving more than one table) and recognize the column name if an unordered subset of a column value (e.g. “blue shirts”) is used in the question. These capabilities are created using automated tools and do not require manual coding and have been available for 35 years (Shwartz, 1987).
Additionally, symbolic text-to-SQL systems have the ability to generate SQL that is both syntactically AND semantically correct. Machine learning researchers have not yet begun to study this issue.
7.3 Knowledge base QA
Recall that knowledge bases (KBs) like Wikidata store facts like (Obama, BornIn, Hawaii). Queries against KBs like Freebase are considered open domain because of the high breadth of stored knowledge and queries against Wikipedia and other text sources have even a higher breadth of stored knowledge. In constrast, closed domain QA systems operate in a single domain such as restaurants or movies.
Queries against KBs offer the opportunity to develop a single system that can answer a broad range of questions against a wide variety of topics. The two primary approaches to KBQA that will be discussed are semantic parsing and information retrieval.
7.3.1 Semantic parsing
One approach is to perform a syntactic and semantic analysis of the question to parse it into a meaning representation in which the entities are not yet linked to the KB. Then the entities are mapped to entities in the KB and the meaning representation is converted to a logical that can be executed as a KB query. For example, two Temple University researchers (Cai and Yates, 2013) studied learning algorithms for the more than 2000 relations in the Freebase KB. KB’s contain simple facts that can be used to answer a wide variety of simple questions such as:
What are the neighborhoods in New York City?
How many countries use the rupee?
Question (1) asks about the relation “neighborhoods” and the entity “New York City”. Question (2) asks about the relation “countries_used” and the entity “rupee”. However, if we strip out the relation and entity terms, the questions are much more generic:
What are the <relation> in <entity>?
How many <relation> the <entity>?
One can think of the learning problem as one of trying to learn all the different general forms of queries like (3) and (4) and learning to recognize the words used to identify the relations and entities in the KB.
The Temple researchers reasoned that a supervised learning algorithm on its own would require an enormous dataset that contained annotated questions most combinations of question type, relation, and entity. They tested this idea by using a supervised learning algorithm against a training dataset that had one set of relations and entities and found that the system could not answer a single question from a dataset of questions with a different set of entities and relations.
Instead, they used a supervised algorithm to essentially learn the different query types and a separate algorithm to learn the different ways of expressing the KB relations and entities in natural language texts. Their approach to learning words that reference relations and entities was quite clever and borrows techniques from the discipline of schema matching.
7.3.2 Information retrieval
Information retrieval approaches do not produce an intermediate logical form and instead map directly from the question to the structure of the KB. They typically try to match a representation of the query to multiple candidate subgraphs from the KB. For simple queries that match a single KB fact, the answer is the best-matching candidate subgraph. For complex queries, an intermediate logical reasoning step is required (see next section).
Early information retrieval approaches relied on handcrafted rules. For example, University of Washington researchers (Fader et al, 2014) developed an open question answering system named OQA for simultaneously querying a set of KBs. Rather than learning to map natural language questions for logical forms, ten handcrafted regular expression templates were used. An example of one of the ten templates is:
Template: Who/What RVrel NParg (?x, rel, arg) Example Question: Who invented papyrus? Example Query: (?x, invented, papyrus)
RV stands for relational verbs identified by an open information extraction system. NP stands for noun phrase. The resulting query is then used to search the four KBs for matching triples. If this were the end of the story, the resulting system wouldn’t be very successful because the relation words used in the question might not match the relation words used in the KB. For example, a KB might contain the fact
(papyrus, was invented by, ancient egyptians)
which does not match the query
(?x, invented, papyrus)
Because of the dependence on surface lexical forms, the system needs the following query rewrite operator:
(?x, invented, ?y) (?y, was invented by, ?x)
The system learned 74 million rewrite operators by searching the KBs for pairs of triples in which the two entities match. For example, these two triples were found:
(papyrus, was invented by, ancient egyptians) (ancient egyptians, invented, papyrus)
Because the relations “invented” and “was born to” were found with at least 10 other entity pairs, this rewrite rule was learned:
(?x, invented, ?y) (?y, was invented by, ?x)
The system also learned 5 million paraphrase rules applied directly to the lexical forms of question by analyzing 23 million sets of sentences that were listed as synonymous in a large crowdsourced dataset of questions and answers formerly named WikiAnswers. An example lexical rewrite rule is:
What is the latin name for …? What is …’s scientific name?
The Open QA system was also able to process queries asking for lists and counts instead of just individual facts and could handle conjunctions (ANDs and ORs).
The advantage of this approach is that it does not require handcrafted KBs and/or annotated datasets and is, therefore, more likely to be applicable to many different types of KBs, specialized vocabularies, and languages other than English.
A more recent version of this open domain question answering system is available for public use at openie.allenai.org. Open QA techniques are lexically-based. Words, phrases, and synonyms in questions are matched to words, phrases, and synonyms in knowledge base entries and there is no real understanding of the meaning of the questions.
More recently, information retrieval approaches to KBQA have relied on deep learning. Some systems, termed memory networks, learn embeddings for both the questions and KB facts and match the similarity of the embeddings to find the best match for a question either directly (Bordes et al, 2015) or using an attention mechanism (Sukhbaatar et al, 2015).
A group of Facebook researchers (Weston et al, 2015) developed memory networks to compensate for the fact that RNN networks (including LSTMs) do not have a distinct memory other than what is compressed and encoded into the system weights. As a result, RNNs are known to have difficulty in performing tasks that would require memory in people. For example, RNNs cannot perform memorization, the simple copying task of outputting the same input sequence they have just read (Zaremba & Sutskever, 2015). To remedy this deficiency, they developed a neural network augmented with an explicit memory. A memory network processes each question in four steps:
- Input Module: Converts the question string to an input feature representation.
- Memory Module: The memory is updated given the new question string.
- Output Module: A set of output features are computed given the new input feature representation and the current state of the memory.
- Response Module: The output features are decoded to produce an answer.
For example, Bordes et al (2015) used a memory network to answer questions against the WebQuestions dataset (Berant et al, 2013).
Both the KB itself and the training questions were processed by the input module. Each question in the training set was converted into a set of input features composed of a bag-of-ngrams representation of words in the questions. A vector was created of all the words in all the training questions plus all the n-grams (i.e. phrases) for all the aliases of all the Freebase entities.
For each question, the vector contained a 1 if the word or n-gram was present in the question and a 0 if not present. Each fact in the subset of the Freebase KB used was also loaded into a vector representation. In this case, the vector had an entry for each entity, and each relationship in the subset of the KB that is part of the fact triple. Two embedding matrices are learned, one for the words and n-grams in the questions and one for the entities and relationships that make up the facts. At each step of the learning process, the following occurs:
- A question along with the answer fact are sampled
- An incorrect answer fact is randomly retrieved
- A stochastic gradient descent step adjusts the weights according to a cost function that requires that correct facts are preferred over incorrect facts.
- The output module finds the best match between a new question and an existing fact during both training and test.
7.3.3 Complex KBQA
The KBQA approaches just discussed are applicable only to questions that can be answered by finding a single relation in the KB. For example, the question
What films has Harrison Ford acted in?
can be answered by a single relation in a movie KB that has an acted_films relation. But many KB questions cannot be answered by directly matching a single relation to the query.
Complex KBQA involves questions that require one or more of the following:
- Multi-hop questions that require accessing two or more different KB relations
- Questions that require simple logical reasoning
- Questions that require numerical operations such as counting or ranking for superlative or comparative questions
- Questions that require parsing constraints such as time constraints (e.g. “in the 1800s”) and/or constraints on entities (e.g. “former CEO Lewin”)
Complex queries make semantic parsing more difficult because the logical forms are more complex. Moreover, if supervised learning is contemplated, logical form labeling becomes more difficult, more expensive, and requires higher-skilled annotators.
Complex queries also make IR approaches difficult because it is no longer possible to assume that the entities and relation in the query correspond to a single fact in the KB. If supervised learning is contemplated, it is often helpful to annotate the learning path but this is far more difficult and expensive with complex queries.
7.3.3.1 Multi-hop KBQA
A question like
What films has Harrison Ford acted in that were produced by George Lucas?
would require accessing two relations (e.g. acted_films and produced_films) and taking the intersection of the results. Knowledge base question answering systems perform poorly on questions that require multiple relations. Performance degrades by approximately 50% when four KB relations are required to produce an answer versus when only one KB relation is required (Sorokin and Gurevych, 2018). These systems also cannot handle questions that require reasoning based on time. For example, consider the question
Which actress was married to Luc Besson while starring in one of his movies?
Researchers have recently developed several datasets of questions that require multiple relations to answer (e.g. Bao et al, 2016; Abujabal et al, 2017) and the use of time-based reasoning. Research is still at the early stages of these more complex questions datasets but some progress has been made (e.g. Zhang et al, 2017; Saxena et al, 2020).
7.3.3.2 Simple logical reasoning
Researchers have also studied how to perform simple types of reasoning on a KB in order to answer simple questions for which there is no fact stored in the KB. For example, suppose the question is
Is Lebron James an athlete?
and the KB does not contain this fact directly. Suppose further that the KB only has the fact
Lebron James is a basketball player
and in the knowledge base ontology the concept athlete has the sub-concept of basketball player. Then when the search finds the fact that Lebron James is a basketball player, it’s an easy inference to make use of this hierarchical information and conclude that Lebron James is also an athlete. Of course, this type of inference only works for hierarchical relationships.
CMU researchers (Sun et al, 2018) explored supplementing knowledge bases with entity-linked text. Their approach was to extract entities and relations from this text and use them to enhance the knowledge base prior to answering the question from the knowledge base.
He et al (2021) explored using a pair of networks: A student network that finds the correct answer and a teacher network that learns reasoning rules.
For more in-depth overviews of complex KBQA, see Lan et al (2021) and Fu et al (2020).
7.4 Text question answering
As discussed above, KB’s are both limited in scope and limited in completeness and are hard to keep up-to-date. There is far more information available in text data sources such as Wikipedia. While structured KB’s are easier to query than text documents, by nature they provide far less coverage than text documents.
7.4.1 Closed domain question answering
Early research into answering queries from text documents focused on building systems that could perform reading comprehension tests. Reading comprehension research is focused on building systems capable of answering questions in reading comprehension settings like those commonly found in school settings. A block of text is presented. A question is asked about the text. The answer can be found in the text and no external knowledge is required. Perhaps the most prominent reading comprehension dataset is the Stanford Question Answering Dataset (SQuAD) (Rajpurkar et al, 2016). SQuAD is large enough to support machine learning with 107,000 crowdsourced questions based on passages from 536 Wikipedia articles. An example is shown below:
Passage: In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity. The main forms of precipitation include drizzle, rain, sleet, snow, graupel and hail… Precipitation forms as smaller droplets coalesce via collision with other rain drops or ice crystals within a cloud. Short, intense periods of rain in scattered locations are called “showers”.
Question: What causes precipitation to fall? (Answer: gravity)
Question: Where do water droplets collide with ice crystals to form precipitation? (Answer: “within a cloud”)
Figure 7.1. A SQuAD example.
Since the answer can always be found in the text, it is considered a closed-domain dataset.
A later version (SQuAD 2.0) added 50,000 questions that could not be answered from the passage for which the correct response was “not answerable”.
The development of large datasets like SQuAD and CNN/Daily Mail has enabled the application of neural networks to these tasks.
Most reading comprehension systems use the encoder-decoder architecture that was originally developed for machine translation. The encoder learns word embeddings of both the question and the text. The decoder uses a hard-coded or learned attention mechanism to find the portion of text that is most like the query (Hermann et al, 2015; D. Chen et al, 2016; Kadlec et al, 2016; Xiong et al, 2017; Seo et al, 2017; W. Wang et al, 2018). The limitation of the end-to-end learning approach is that these systems cannot generalize outside their training domains.
One of the main contributions of research on SQuAD and similar datasets that require finding the answer in a body of text is the development of systems that can zero in on the exact text string that answers the question.
AI systems now perform at a level that is actually better than human-level performance on the SQuAD 2.0 dataset. At first blush, it appears that AI systems that can perform at human levels are really reading and understanding these passages.
However, it turns out this is not really the case. When the answer is contained in a span of words in the document, human-level understanding is not required. Systems can become quite proficient just by learning how to locate the sentence and to match and align the lexical units in the sentence to those in the question.
This can be done by several techniques including direct lexical matching, use of syntactic cues, and use of word similarities based on the word embeddings associated with each word in the passage, question, and alternate answers.
If one looks closely at the example in Figure 7.1, one can see that answers can be obtained by surface-level analysis rather than true understanding. The correct sentence can be identified by matching the words “precipitation” and “fall” for the first question and the words “water”, “droplets”, “collide” (“collision”), “ice”, “crystals”, and “precipitation,” in the passage.
A similar dataset was created by Google DeepMind researchers by extracting news articles from CNN and The Daily Mail (Hermann et al, 2015). Both publishers provide bullet-point summaries of their articles. The researchers simply deleted an entity reference from a summary to create a question. For example:
Passage: The BBC producer allegedly struck by Jeremy Clarkson will not press charges against the “Top Gear” host, his lawyer said Friday. Clarkson, who hosted one of the most-watched television shows in the world, was dropped by the BBC Wednesday after an internal investigation by the British broadcaster found he had subjected producer Oisin Tymon “to an unprovoked physical and verbal attack.” . . .
Question: Producer X will not press charges against Jeremy Clarkson, his lawyer says.
Answer: Oisin Tymon
Researchers studying this dataset concluded that most questions systems could answer most questions by finding the single most relevant sentence in the passage.
This greatly restricts the number of possible entities in the answer – often to just one entity (D. Chen et al, 2016). Therefore, the task doesn’t really require understanding the passage. It merely requires finding the sentence that most closely matches the question. Finding the sentence can again be accomplished via word matching, syntactic cues, and/or similarities based on word embeddings.
A different Stanford Research effort (D. Chen et al, 2016) studied a random 100-question sample of the CNN/Daily Mail dataset and concluded that most answerable questions (25% were deemed unanswerable even by people) could be answered by finding the single most relevant sentence in the passage thereby greatly restricting the number of possible entities in the answer – often to just one entity.
Therefore, the task doesn’t really require understanding the passage. It merely requires finding the sentence that most closely matches the question.
Finding the sentence can be accomplished via lexical matching, syntactic cues, and/or similarities based on word embeddings.
Another set of Stanford University researchers (Jia and Liang, 2017) did some experiments to determine whether the systems scoring highest on the SQUAD dataset were really engaging in human-like natural language understanding. They added a syntactically correct but irrelevant and factually incorrect sentence to each passage. For example, here is an original SQUAD passage:
Passage: Peyton Manning became the first quarterback ever to lead two different teams to multiple Super Bowls. He is also the oldest quarterback ever to play in a Super Bowl at age 39. The past record was held by John Elway, who led the Broncos to victory in Super Bowl XXXIII at age 38 and is currently Denver’s Executive Vice President of Football Operations and General Manager.
Question: What is the name of the quarterback who was 38 in Super Bowl XXXIII?
Answer: John Elway
The Stanford researchers added this sentence to the passage:
Quarterback Jeff Dean had jersey number 37 in Champ Bowl XXXIV
(Jeff Dean wasn’t a quarterback. He was actually the head of Google AI research.) They found that this added sentence caused performance to decrease by over 50% and led the system to give answers like “Jeff Dean” to the question. They concluded that these systems are just learning very superficial rules (e.g. taking the last entity mentioned) and not exhibiting deep understanding and/or reasoning at all.
See Liu et al (2021) for a review of reading comprehension research.
7.4.2 Open-domain question answering
Open domain question answering (ODQA) involves answering questions using Wikipedia or some other unstructured text source. Answering questions by searching Wikipedia or the entire web can provide answers to a much wider range of questions than answering questions using KB’s (see above). Additionally, the information is often more up-to-date (though conflicting information can be a problem).
ODQA researchers often use queries from the KBQA datasets such as WebQuestions from RC datasets like SQuAD and Natural Questions (Kwiatkowski et al, 2019). However, rather than answering the questions from a specific KB or from a provided RC passage, questions are answered by searching text sources such as Wikipedia and the internet.
7.4.2.1 Information retrieval + reading comprehension
Early research broke the ODQA task into having two components:
- Information retrieval: Identifying the document or passage most likely to contain the answer.
- Reading comprehension: Searching the document or passage for the text span that contains the answer.
For example, a group of Facebook researchers (D. Chen et al, 2017) created the DrQA system using Wikipedia as their unstructured text source. The questions were taken from the SQuAD dataset but no passages were provided. They also used only Wikipedia as a text source and did not rely on information redundancy like IBM’s Watson system which used info from many different sources.
The first step was for the Information Retrieval module was to search Wikipedia and find the five best articles. The system compared the bag of words vector that makes up the question to the bag of words vector that makes up each article to find the five best articles.
The second step was for the reading comprehension system (the document reader) to try and find the answer in each of the five articles using techniques like those discussed in the RC section above. When the document reader is given the top 5 articles returned by the information retrieval module, accuracy was 27.1%. That is far worse than the 70.0% performance achieved by the document reader on its own when applied to the closed domain SQuAD 1.1 dataset where a single paragraph is provided.
It was also tested on an open domain version of the WebQuestions dataset where it produced 19.5% accuracy and on the WikiMovies dataset (Miller et al, 2016) where it achieved 34.3%. These low accuracy results are a good indication of how much harder it is to retrieve answers by searching all of Wikipedia than searching a single paragraph.
A group of Facebook researchers (Raison et al, 2018) developed the Weaver system as a better document reader. Their system uses very similar features to the DrQA document reader features. However, instead of encoding the question and context words separately, they use every combination of words composed of one word from the question and one from the context. These encodings are learned via multiple BiLSTMs stacked on top of each other plus a memory network.
Their system achieved an exact match accuracy of 74.4% of the original SQuAD dataset (paragraphs provided) compared to 70.0% for DrQA. It achieved 42.3% against the full Wikipedia vs. 27.1% for DrQA. It also achieved 23.7% on open domain WebQuestions (vs 20.7% for DrQA) and 43.9% on WikiMovies (vs 34.3% for DrQA).
A group of IBM researchers (S. Wang et al, 2018) looked to improve on the accuracy of these systems by using evidence-based re-ranking techniques reminiscent of (but quite different than) those used by the IBM Watson system. They were able to achieve 42.3% exact match accuracy on Quasar-T (compared to 51.5% human performance), 57.0% on SearchQA (compared to 43.9% human performance), and 44.6% on TriviaQA (human performance not measured).
7.4.2.2 Pre-trained language models + external knowledge sources
More recently, researchers have achieved state-of-the-art resulting using using pre-trained language models augmented by external knowledge sources. Building on the success of earlier systems for retrieval augmented generation (Guu et al, 2020; Piktus et al, 2021; Borgeaud et al, 2022), Meta AI researchers (Izacard et al, 2022) created Atlas. This system used an external knowledge source, Wikipedia, to help it answer questions and check facts:

Atlas has two components, a pre-trained language model and a retriever module. The language model was trained using a T5 (Raffel et al, 2020) encoder-decoder text-to-text network. It was pre-trained on Wikipedia articles using a self-supervised algorithm that used masked language modeling. For each span of text in each document, three words were masked, and the system was trained to generate the three words.
The retriever module was trained with a dual-encoder architecture with one encoder for the question and one encoder for the documents. It was trained simultaneously with the language model and the language model provided the supervision during the training. More specifically, during the language model training, the question is concatenated with each document. If the language model finds a document to be helpful in recovering the masked tokens, then the retriever’s objective function will rank the document higher and use that objective function to create similar encodings for queries and highly ranked documents.
When performing the question answering task, the model first retrieves the most relevant documents based on the similarity between the encoding of the question and each document. Then the documents plus the question are fed to the language model which generates the output.
With only 64 fine-tuning examples, the Atlas model achieved state of the art results as of August, 2022 for few-shot question answering on several few-shot benchmarks. On the NaturalQuestions benchmark, it achieved an accuracy of 42.4% and outperformed the PaLM language model (Chowdhery et al, 2022) by 3 percentage points despite having only 11 billion parameters compared to the 540 billion parameters in the PaLM model.
Using the full dataset for fine-tuning, Atlas achieved an accuracy of 64.0% which was 8.1 points better that the previous state of the art.
7.5 Question answering summary
This chapter discussed the inner workings of several question answering systems. First up was the IBM Watson system that beat the Jeopardy! champions. This was an amazing accomplishment. The IBM Watson system answered questions using primarily lexically-oriented techniques such as keyword matching. It could perform temporal reasoning using a set of handcrafted rules for comparing time periods or intervals.
This chapter also discussed the question answering systems developed out of research efforts that followed the IBM Watson system. These question answering techniques have greatly expanded the state of the art.
Knowledge base question answering techniques have improved to the point where entities and relationships in questions can be reliably extracted and matched to knowledge bases.
Reading comprehension techniques enable pinpointing the answer to a short span of text rather than just retrieving relevant documents.
In the decade following IBM’s Jeopardy! win, amazing progress has been made. Rather than relying on handcrafted rules, today’s question answering systems now employ deep learning models that use external knowledge sources.
Chatbots >
© aiperspectives.com, 2020. Unauthorized use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given with appropriate and specific direction to the original content.
SHARE THIS
Page load link